
Abstract
Coordinate measuring machines (CMMs) are massively exploited as measuring tools in the modern manufacturing industry. The performance of these machines, in terms of accuracy, has been considerably improved in recent years by using quasi-static errors compensation. Considering the shorter cycle times required during measurement tasks, CMMs are to be operated at high measuring velocity. In such measuring conditions, dynamic errors have a critical impact on measuring accuracy. Consequently, dynamic errors assessment, modeling, and compensation are needed to improve the overall CMM metrological performances. In this paper, a comprehensive predictive modeling strategy for dynamic error compensation is developed and applied successfully. The main measuring parameters that influence CMM dynamic performance are identified and used in a systematic experimental investigation. The positioning accuracy is then evaluated concerning dynamic conditions using a high-precision laser interferometer. Based on the experimental results, neural network models are built according to a structured modeling procedure inspired by the Taguchi method. Improved statistical analysis tools and performance measurement criteria are used to extract the most appropriate variables and conditions leading to well-founded predictive modeling. The resulting models are implemented on a bridge-type CMM to compensate for both geometric and dynamic errors. The results demonstrate a reduction of more than 80% of dynamic errors. This demonstrates that the compensation of dynamic-induced errors using high-speed measurement is achieved leading to shorter cycle times of measurement tasks while maintaining high accuracy measurements.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Coordinate measuring machines (CMMs), a 3D metrology tool as presented in Fig. 1, are frequently used in modern industrial sectors such as automotive and aerospace industries, manufacturing of consumer goods, and medical products. Given that the current manufacturing trend is toward product miniaturization and batch size reduction, the importance of machines’ flexibility in production is increased. Nowadays, one of the main performance criteria and key performance indicators (KPI) of a production cell is the ability to manufacture parts at high speeds while maintaining high accuracy. In this regard, CMMs are regularly used to control the dimensional accuracy of products on the shop floor as well as in the quality control rooms close to the production line. However, the CMM’s accuracy can also be affected by the usage condition and the part geometry to be measured. In fact, two sources of errors can downgrade the accuracy of multi-axis machines such as CMMs [1, 2]. The first error sources contain quasi-static errors, including geometric errors, errors related to the finite stiffness of the machine’s components, and thermal errors. The second error sources refer to dynamic errors, which are defined as velocity-dependent deformation of CMM components. Dynamic errors are caused due to self-induced and forced part movements and vibrations.

A bridge-type coordinate measuring machine
Quasi-static error compensation has been dealt with in the past two decades; it is currently a widely adopted method and is applied successfully to compensate for quasi-static errors [3,4,5,6,7]. However, controlling dynamic errors remains a challenge in 3D geometric measurement using CMMS. To avoid dynamic errors of CMMs, low to very low operating velocities can be adopted in the measuring procedures. However, this error reduction method is no longer acceptable in industrial sectors considering that the competitive manufacturing markets require increasing production volume and decreasing leading time accordingly. In this regard, it is necessary to find new methods to reduce the effects of dynamic errors through which high productivity can be maintained. In order to take into consideration this crucial issue, research works are presented to compensate for dynamic errors [1, 2, 8,9,10,11,12,13,14,15,16,17,18,19]. Using displacement sensors to analyze the dynamic errors of CMM during fast probing, Weekers and Schellekens [20] concluded that dynamic errors are chiefly caused by unwanted structural deflection in the joints of the machine. However, their model and the calibration process are too complex to be considered a compliant and flexible solution. Chensong et al. [21] directly measured the angular error of the main connecting mechanism during the movement to model the probing errors. Investigating the main factors influencing dynamic errors, Kaichen and Guoxiong [22] suggested that the coordinate position of CMMs is the most important factor in comparison with measurement velocity. Zhang and Jizhu [23], Jinwen and Yanling [24] focused on the deformation analyses of CMM’s crossbeam using finite element analysis (FEA). By analyzing the crossbeam deformation with acceleration, constant speed, and deceleration, a model of beam deformation with respect to loading conditions was developed. However, this method is only useful for error compensation in one direction. Krajewski and Woźniak [25] presented a method of applying a simple master artifact for evaluating the dynamic performance of CMM through the identification and assessment of dynamic error sources. This approach can achieve a quantitative assessment for a specific scanning probe at different scanning speeds. The structural characteristic, deformation, and stress distribution of a CMM are studied by Chan et al. [11] leading to dynamic characteristics of the measuring bed structure using FEA. The geometric accuracy of the CMM is improved using their calibration equipment. Budzyn et al. [17] developed a configuration of a laser interferometer to study the behavior and geometry of a computer numerical controlled (CNC) machine. Based on Bayesian inversion, Jiang et al. [18] proposed a method to compensate for dynamics errors of a self-developed contact probe and improve probe system measurement accuracy.
1.1 Dynamic error analyses
In a CMM without dynamic error compensation, a typical probing (measurement) operation (as shown in Fig. 2) consists of two steps, positioning the probe and measurement. During the positioning step, the probe travels at a high speed to get closer to the probing point and then moves at a slow speed until contact is made with the workpiece. The velocity of the probe is changed for two reasons. The first reason is to allow damping dynamic errors before the measurement is made and thus reduce their impact on the measurement accuracy. Nonetheless, this is not regularly happening in practice. In the case of short approaching distances, CMM will still be accelerating when contacting the measuring part. Particularly, given small measuring elements, approaching distances can usually be short and therefore the CMM is likely to be subjected to disturbing forces during the probing. The second reason is to avoid damage occurring to the probe or the workpiece, although this only concerns touch-trigger probes equipped CMMs. Machine parameters considering the cycle time of a probing operation are positioning distance (PD), positioning velocity (PV), approach distance (AD), and approach velocity (AV). Other parameters such as geometric parameters (coordinate of points to be measured and probing direction), the type of CMM, and its architecture (positioning acceleration and approaching acceleration) can also affect the measurement accuracy and precision.

A typical probing operation in a CMM
The main purpose of this study is to develop an approach to increase the productivity rate of the CMM while maintaining high accuracy, which means a shorter cycle time for measurement tasks. To achieve this, measurement tasks need to be performed at high speeds and short distances. Depending on the type of probing device being used, three scenarios for executing a measurement task are to be discussed as illustrated in Fig. 3. Case 1 reflects the use of a touch trigger probe. During the positioning, the probe will travel most of the distance with a maximum velocity achievable by the machine VM; then, the probe will travel a shorter distance with the maximum limit velocity VL. That will cause no damage to the probe when contact is made with the workpiece. Because of the acceleration change during the motion, the dynamic errors will be very pronounced and will cause inaccuracies in the measurement. In case 2, a non-contact probe is used such as proximity or scanning devices. Given that there is no approaching phase, VM velocity can be adopted. However, using high velocities for probe displacements can cause higher decelerations before the probing and thus will cause dynamic errors in the measurements, which will decrease the machine's accuracy. For this issue, the solution proposed in case 3 suggests that VL is used during probing operations. This solution is not adequate to completely remove the dynamic error effects since the velocity used is not sufficiently low to allow the dumping of errors. In addition, it does not solve the problem concerning the reduction of measurement cycle time. This emphasizes the importance of developing an approach to using high measuring velocities while maintaining high accuracy measurements.

Typical probing operations scenarios
In a practical example, measuring parts using a bridge-type CMM (Fig. 1), acceleration/deceleration in X-direction produces large inertial forces on the machine’s structure due to the mass distribution of machine components. Given that the driving system is located on one side of the bridge and considering the limited stiffness of air bearings, the bridge undergoes rotational motion around the joints of air bearings. The bridge also presents elastic deformation under the pressure of inertial forces. These undesired rotational motions result in positioning and angular errors at the probe as a consequence of Abbe offset in the path of motion [26]. In order to present error compensation strategies, dynamic error attributes are defined and evaluated with respect to measurement parameters. In this regard, an experiment was set and run, in which a typical probing operation (PV = 40 mm/s and AV = 12 mm/s) was executed. Applying a laser interferometer, the evolution of dynamic errors in regard to velocity/acceleration was recorded. Using a laser interferometer enables evaluating the deformation of CMM components under dynamic conditions. It also allows identifying the contribution of each error source in the global dynamic error. Analyzing the results of this experience, as illustrated in Fig. 4, four dynamic error attributes can be identified, namely maximum positioning error (MPE), residual positioning error (RPE), maximum approaching error (MAE), and residual approaching error (RAE). MPE appears just after the positioning acceleration; RPE can be detected after the acceleration dissipation and is characterized by an average of ten consecutive values of the dynamic error before deceleration; MAE is observed immediately after the approaching acceleration; and RAE is detected after some settling time between decelerating probing and is characterized by the dynamic error value in a second before probing.

Definition of dynamic error attributes (positioning velocity [mm/s], acceleration [mm/s2], time [s], dynamic error [µm])
It can be observed that the acceleration peaks occur only in a very short time; in consequence, the corresponding dynamic errors (MPE and MAE) do not have an immediate impact on the accuracy of the measurement seen that the probing has not taken place yet. Thus, RPE and RAE are the attributes to be taken into consideration during the development of error compensation algorithms. In fact, RPE and RAE are applied to both contact and non-contact probes. For these reasons, compensation models will solely be developed for RPE and RAE. In this regard, experimental investigations are carried out to analyze the contribution and the effect of machine parameters such as positioning distance (PD), positioning velocity (PV), approach distance (AD), and approach velocity (AV) on dynamic errors (RPE and RAE) [27]. Using Automated Precision Inc. (API) laser system, error measurements are performed by evaluating dynamic translations and rotations in different directions. The results of this experimental analysis, as illustrated in Table 1 and Fig. 5, reveal that PV and PD are the most affecting factors on RPE with the contribution of 79.1% and 13.6% accordingly, which is strongly sensitive to the acceleration/deceleration. In fact, the increase of the positioning distance (PD) improves the dissipation of the acceleration’s effects. It can also be observed that AV and AD are the most affecting factors on RAD with a contribution of 61.8% and 29.1%, respectively.

Effects of measurement parameters on RPE and RAE [27]
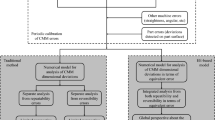
To the best of the authors’ knowledge, there is no approach allowing dynamic error prediction and compensation of measuring machines. In this regard, this article presents an ANN-based approach to predicting the dynamic errors of CMMs in relation to machines’ parameters. More specifically, this article presents a structured and comprehensive approach developed to design an effective model to predict and compensate for dynamic errors in CMMs. The proposed approach evaluates machine parameters and conditions, which have an influence on the dynamic errors to build a prediction model step by step. The modeling procedure is based on a structured and exhaustive experimental investigation to identify possible relationships between dynamic error sources and positioning accuracy. Using experimental orthogonal arrays, statistical analysis, and a multi-criterion assessment, neural networks-based prediction models are developed and evaluated.
2 Dynamic errors compensation method and strategy guidelines
Dynamic errors are by nature nonlinear and stochastic. Deterministic models that are usually used for this kind of application are commonly accurate for only a certain type of error affecting a CMM. In order to obtain the finest solution, an appropriate modeling form, techniques, and variables are to be figured out. Various modeling approaches are available for such tasks, namely the finite element method and the artificial neural networks. The finite element method (FEM), a numerical method for solving problems of engineering and mathematical physics, is a very capable method for modeling complex physical phenomena. However, the approach is very time-consuming to set up by modeling all detailed components of a machine and can’t be implemented as a compensation method for dynamic errors. Nonetheless, it can be used to assess and simulate dynamic errors [12]. Multivariate polynomial regression can also be used as a prediction model. Polynomial regression fits a nonlinear relationship between a series of input values and the corresponding conditional response of output. The biggest advantage of nonlinear regression over other techniques is the broad range of functions that can be fit to represent the process. However, they are highly sensitive to outliers and not suitable for problems where high nonlinearity is present in the data such as dynamic errors. The other type of modeling being considered for the compensation is the artificial neural networks (ANNs). A form of connected calculations, they are computing models inspired by the neural structure of the human brain. The main asset of ANN models over other statistical methods is that the latter considers linear relationships and/or normal distribution, while real data are nonlinear and non-normal. Thus, ANN models can better conform with data acquired from real physical problems. Among various methods presented in neural modeling, the multilayer network technique is one of the most convenient alternatives for this type of application due to its simplicity and flexibility [28, 29].
Including all the variables in a model (classic model) is not always a viable solution; hence, it is recommended to ascertain the ideal combination of variables that result in the optimal model. To this end, a design of experiments is set up as a base for the modeling scheme. The objective is to compare a model involving all the variables (classic model) and assorted models with a reduced number of variables. This process is divided into three main steps as follows:
-
1.
Producing an acceptable number of models, where each model includes a subgroup of explicitly selected variables.
-
2.
Assessing each model's performance in accordance with a precise criterion.
-
3.
Rating the fallout of each modeling variable's contribution to lowering training, validation, and prediction errors using statistical analyses.
The quality assessment of a model depends on the conditions that the model will be applied which are specified as the model success criterion. In this case, the model success criterion should be presented as a predictive modeling criterion to allow the selection of appropriate models. To evaluate continuous-valued estimation models, metrics are often used as the coefficient of determination (R2), average error, sum of squared error (SSE), total squared error (Mallow’s Cp), mean squared error (MSE), median error, average absolute error, and median absolute error. In each of these metrics, the model deviation is first calculated, and the appropriate statistic is then computed. While average errors are used in determining whether the models are biased toward positive or negative errors, average absolute errors are usually used to estimate the magnitude of errors. In this regard, the overall value of the model acceptance criterion along with the entire range of predicted values, by considering scatter plots of actual versus predicted values or actual versus residuals (errors), is evaluated. Most modeling techniques are developed based on the minimization of SSE. It is worth noting that MSE, Cp, and R2 are linear functions of SSE. Considering a fixed number of variables, the combination of variables that minimizes SSE leads to minimizing MSE and Cp and maximizing R2. Among these criteria, R2 does not have a maximum value and shows a gradually increasing trend when the number of variables in the model is increased. Thus, the use of R2 as a variable’s selection criterion can allow some subjectivity. If p variables among q variables are chosen, the residual mean square error is MSEp = SSEp / (n-p-1), where n is the total number of observations. The terms SSEp and n-p both decrease with increasing the number of separate variables p which can result in maximizing MSEp value. In this paper, for each of the chosen dynamic error attributes, we used the criteria to adjust the models’ performance wherein the training residual mean square error (MSEt), the validation residual mean square error (MSEv), in addition to the total residual mean square error (MSEtot) are minimized.
In this study, the orthogonal arrays (also called the Taguchi method [30]) are adopted as an experimental design method [31]. The method has been employed with great success in engineering experiments to study the effect of several control factors (variables). The choice is justified by the advantages that this method offers, among which a reduced number of experiments to be conducted which reduces greatly the experimental costs, the conclusions are legitimate over the entire region spanned by the control factors and their settings, and finally, the analysis of the results is straightforward. The detailed model making can be resumed in six distinct steps as follows:
-
1.
Input data for training and validation of models are gathered. Besides, parameters and conditions that could affect the process are identified and taken into account.
-
2.
The modeling technique and the performance criteria are selected.
-
3.
The proper orthogonal array for the required number of models is set up.
-
4.
Training and validation of models in accordance with the chosen criteria are performed.
-
5.
The effect of each variable on models’ performance is evaluated using analysis of variance (ANOVA).
-
6.
The final model configuration is established and implemented as dynamic errors compensator of the measuring machine.
3 Application of the proposed strategy
This section presents the implementation of a predictive modeling procedure, as described in Sect. 2, to achieve compensation for the designated dynamic error attributes (RPE and RAE). The experience is performed on a bridge-type CMM equipped with a touch-trigger probe as shown in Fig. 6.

Experimental data acquisition set
3.1 Experimental data analysis
The success of constructing an effective compensation model is linked not only to the judicious choice of the relevant modeling technique but also to the data being used for the modeling. The most reliable data are typically those obtained by experimentation through which the real aspects of the physical phenomenon can be modeled. Thus, it is critical to choose appropriate data acquisition equipment, strategy, and variables included in the model. In this article, the data for modeling are solely provided by experimentations. The dynamic error measurements are performed using an Automated Precision Inc. (API) 6/D laser interferometer set. This measurement device allows five simultaneous displacement measurements (linear displacement, horizontal straightness, vertical straightness, yaw, and pitch errors) along with velocity and acceleration measurements. To avoid other environmental elements from disturbing the measurement process, all the experiments are conducted in a controlled environment wherein relative humidity and temperature are set at 43% and 20 °C, respectively. Furthermore, to achieve a higher measurement accuracy, the experiments are only performed after the laser is preheated to a precision standard as determined by the user manual of the device provided by Laser Automated Precision Inc. Setting up the experimental configuration as shown in Fig. 6, dynamic errors are measured while the bridge is moving along the x-guideway. Locating the x-carriage in the middle position along the laser beam at Y = 250 mm, the bridge moves in the x-direction at different speeds and accelerations. Each experiment is repeated three times and their average is used in modeling to reduce the possibility of errors and anomalies during measurement. Four machine parameters PV, PD, AV, and AD are used as input variables. The acceleration is not included among the variables in conformity with the hypothesis stating that there are cumulative effects of velocity and acceleration.
3.2 Artificial neural network modeling
Among miscellaneous ANN models, a multilayer feed-forward neural network is employed as a modeling technique in this article considering its simplicity and flexibility. As illustrated in Fig. 7, a neural network consists of N neurons, for which each neuron is connected to neurons of adjacent layers.

Simple computational elements of the multilayer feed-forward neural network [32]
Let \({I}_{j,l}\) be the input to the jth neuron on layer l; then, the output of this neuron (Oj,l) is given by:
Given that,
where Oi,l-1 is the output of the ith processing neuron of layer l-1, nl-1 is the number of neurons on layer l-1, θj,l is the threshold associated with neuron j of layer l, and \({W}_{i,j,l}\) is the weight of the connection between neuron i on layer l-1 and neuron j on layer l (also called synaptic strengths). The ANN structure shown in Fig. 7 provides a typical and useful example to illustrate the mechanism of a supervised learning process. In response to a pattern presented to the input layer, ANN attempts to produce an associated pattern by its output layer. The hidden layers are employed to filter noises that are present in the input signals so that the task of feature extraction can be performed effectively. Input values in the network are linearly mapped between the range of 0 and 1 resulting network’s output values between 0 and 1, which can be mapped back to the full range. In order to determine the optimized parameters of each neuron, the backpropagation algorithm is used. In fact, ANN training by backpropagation involves three steps, namely feed-forward of input training pattern, calculation and backpropagation of associated errors, and adjustments of the weights. After training, the application of the network involves only the computations of the feed-forward phase. The performance of the network is determined by the mean squared error. Lower MSE corresponds to better learnability and predictability. In this study, the Levenberg–Marquardt algorithm is used as a training function for backpropagation. This method involves an iterative improvement to weight values to minimize the MSE of the training data. The Levenberg–Marquardt algorithm is presented as a combination of two minimization methods, the gradient descent, and the Gauss–Newton method. This algorithm acts more like a gradient descent method when the parameters are far from their optimal value and acts more like the Gauss–Newton method when the parameters are close to their optimal values.
3.3 Modeling design
The practicality of a design of experiments generally depends on the efficiency and precision of experimental equipment, the quality of acquired data, and the data collection method. Full factorial designs are usually used in scientific research as they allow to achieve all possible combinations of variables. However, full factorial design is not always efficient nor a cost-effective approach. In fact, a design of an experiment including lots of variables cannot be easily implemented given the increased number of repetitions involved. This type of design is costly and increases the risk of experimental error leading to erroneous results accordingly. For these reasons, the orthogonal array (OA) design is adopted in this study as an alternative to using full factorial designs. In this regard, the selection of a convenient OA is an important step. OA must contain all the factors and their respective levels. Moreover, OA’s degrees of freedom should be greater than or equal to the total degrees of freedom of the concerned variables. For these reasons and as a matter of resolution and accuracy, an L8 OA [30] was chosen, shown in Table 2, as a design of experiments. The (+) and (-) signs indicate whether the variables are included in the model or not, respectively. All in all, 8 ANNs are to be built with data generated by the experimental OAs.
3.4 Training and validation of the neural models
Before proceeding with the training and validation of models, it is crucial to set up the ANN topology and optimize training performances. The objective is to come close to a relationship between the network parameters and the complexity of variables to be estimated, notably given the variation of the number of variables concerned from one model to the other. Regardless of the hidden layer size, every single model built has to have an average error inferior to 1%. To this end, a [(i) × (2i + 1) × (o)] network structure is adopted where (i) and (o) are the number of inputs and outputs accordingly. Another consideration regarding the choice of this structure is to prevent long training and over-fitting that could affect the model’s accuracy. Given that the starting weights influence the optimal configuration found by ANN, multiple random starting weights are used to avoid getting stuck in a local minimum. It is important to note that during the training stage, the input data are normalized to the range of [-1, 1]. The weights and biases of the network are initialized to small random values to avoid a fast saturation of the activation function.
Levels for each of the variables involved in the experiments are to be determined. Several facts are taken into consideration when the levels of the variables are selected. First, each factor level is selected inside the operating limitation range that is set by the machine manufacturer. In addition, the levels are also limited to represent real measurement conditions to reflect a typical high-frequency production cell. The resulting levels are represented in Table 3.
As it can be deduced from the design of experiments chosen (Table 2), a total of 8 networks with distinct input combinations are to be made. By choosing which examples to present and in which order to present them to the learning system, one can guide training and remarkably increase the speed at which learning can occur [17]. Since the neural network objective functions are non-convex, using the different ordering of training samples would lead to possibly different local minima. For this reason, the data for training are shuffled. A total of 24 samples composed of 18 samples from the L18 and 6 samples randomly picked from the L16 are used for the training of neural networks. The remaining 10 samples of the L16 are used for the validation. The performance of the built models in accordance with the criteria is illustrated in Table 4. The best two among eight networks with random sets of starting weights are selected, and then, the average performance of models is submitted for more analysis. It is worth mentioning that each MSE value is computed using normalized data to allow comparing the models.
4 Analysis of the modeling results
Investigating the modeling results, presented in Table 4, reveals the presence of an important variation in regard to the models’ performance. For all models, the validation MSE values are greater than those of the training. In addition, most of the RAE prediction errors are lower than those of RPE for all models. Only models 1 and 2 for RPE, and models 1 and 7 for RAE matched the data relatively well as it can be figured out from their respective mean square error values. The worst prediction models are those that use AD and AV for the prediction of RPE as well as PD and PV for the prediction of RAE. This is easy to foretell since RPE is heavily affected by PD and PV, the same can be said about RAE with AD and AV, respectively (see Table 2).
To study the impact of variables on the models’ performances, an ANOVA is performed on the results of MSE. In this case, the analysis is based on two statistical indicators. The percent (%) contributions and the average effects of each variable are included in the models. The (%) contribution of a variable indicates the portion of the observed total variation assigned to this variable. Ideally, the sum of the (%) contribution of all involved variables must be 100%; however, this is not possible because of the contribution of some other uncontrolled modeling variables and experimental shortfalls. The main effect graphs, illustrated in Figs. 8 and 9, approximately present the effects of each variable on the modeling performances. Considering the variables' effects on RPE models, Fig. 8 presents the effect of machine parameters on the models’ mean square error for both training and validation. In both graphs, PD and PV have a positive impact on the models’ accuracy with PV dominating. However, AD and AV seem to have an opposite effect on the designed models’ performance, especially in the validation phase. This can be confirmed by the variables' contributions as presented in Tables 5 and 6. The positioning velocity (PV) is the governing variable in reducing the total MSE values with an estimate of 96.35%. It is followed by the positioning distance (PD) with a value of 1.79%. The contribution of the approach distance and velocity (AD and AV) is negligible for the training, validation, and the total MSE value. A negligible error contribution, very close to 0% (0.73%), signifies that no important variables are excluded from the modeling procedure. Thus, the positioning distance and velocity (PD and PV) are the variables to be appropriate for the RPE compensation model. In addition, no interaction has been detected for the RPE.

Effects of control parameters on MSE variations in modeling RPE for both the training and validation data

Effects of control parameters on MSE variations in modeling RAE for training and validation
Considering the variables' effect on RAE models, as illustrated in Fig. 9, the approaching distance and velocity (AD and AV) have a drastic reducing effect on the training and validation MSE values. Further, the positioning distance and velocity (PD and PV) seem to increase the training mean square error values and, in a more pronounced manner, the validation MSE values. These observations are validated by the percent contribution of each variable. In fact, Tables 5 and 6 unveil that the approaching velocity (AV) is the variable that reduces the most the MSE values with nearly 72.03% total contribution. The approaching distance (AD) comes in second place with a total contribution of 24.56%. The contribution of positioning distance and velocity is negligible. The error contribution is below 1% for the training MSE value and around 3% for the validation and total MSE values, which implies that no important variables are omitted in the procedure. Finally, no significant interaction is noticed between the two major variables reducing the MSE values.
The next step of the procedure is the choice of the models that predict the best RPE and RAE. To this end, the threshold of the model accepting criteria at a variable percent contribution of at least 2.5% is set. For both RPE and RAE, one model is selected and compared with the classic model containing all the variables (M1). The best predictive model of RPE (M2) contains PD and PV, as for RAE, the model (M7) containing AD and AV will be considered. As it can be observed in Fig. 10, both models for RPE (M1 and M2) fit well the training data and to a lesser extent the validation data. M2 seems to fit slightly better than M1 as it can be confirmed by the corresponding MSE values and thus will be retained for the final compensation model.

Predicted and measured RPE between the classic and the selected models
Figure 11 illustrates the predicted and measured RAE for the classic model containing all the variables (M1) and the selected model (M7) which includes only two variables. A good distribution of the training and validation data is observed for the prediction models. M7 seems to fit better than M1, which can be explained by the fact that M7 does not include the positioning distance (PD) as a variable that has a contribution of 1.5%. Therefore, M7 is the most appropriate model to be used for the compensation of RAE.

Predicted and measured RAE values for the selected models
Based on the modeling process results, various statistical indicators are estimated to evaluate the performance of each model. Coefficient of determination R2 is commonly applied to training errors. Its main defect is its growth with the addition of input variables to the model, whereas an excess of variables does not always lead to robust models. This is why one is interested in the adjusted coefficient R2adj. Mean square error (MSE) and root mean squared error (RMSE) are indicators based on the standard deviation of prediction errors that measure the extent of residual errors and indicates the concentration of data around the line of best fit. Mean absolute percentage error (MAPE) is a useful measure of forecasting accuracy, which is expressed in percentages and thus easy to interpret. The criteria are expressed mathematically as:
where n, p, \({y}_{i}\), \({\widehat{y}}_{i}\), and \(\overline{y }\) denote, respectively, sample size, number of input process parameters, actual output, estimated output, and the mean of actual output.
The evaluation of the selected models using the proposed statistical performance indicators is summarized in Table 7. As already explained, among the eight (8) generated predictive models, models M2 and M1 represent the best RPE, while models M7 and M1 predict the best RAE. Referring to the results presented in Table 7, it can also be seen that the models R2 and R2adj of M1, M2, and M7for RPE and RAE reach approximately 0.92 and 0.84, respectively. The MAPE of these models is less than 10% inferring small prediction errors in these models. However, considering RPE, the precision of M2 is higher than M1 due to its superior R2 and R2ajust values as well as its inferior error values (MSE, RMSE, and MAPE). The same logic can be observed for RAE for which M7 presents a more precise model with respect to M1. It is worth mentioning that PD and PV as well as AD and AV are the two variables considered in M2 and M7, respectively, whilst all four variables are taken into consideration in M1.
5 Geometric and dynamic error compensation results
In the previous sections, ANN predictive models are developed allowing dynamic error compensation during measurements using CMMs. In order to achieve an exhaustive error compensation method, the prediction models should be integrated into the error compensation algorithm of CMM and their performance needs to be investigated by comparing with the existing compensation model for the geometric errors. In fact, geometric error compensation models, developed by our team, apply laser-interferometer-based measurement [32]. In this regard, the accuracy of CMMs is improved by evaluating and compensating geometric errors based on 3D volumetric error mapping using rigid body kinematics and a homogeneous transformation matrix. It is demonstrated that this ANN-based geometric error compensation approach can improve the machine's accuracy by reducing more than 90% of quasi-static errors [32]. Combining geometric and dynamic errors compensation approaches, the integration architecture is shown in Fig. 12. Both the predicted geometric and dynamic errors are combined before calculating the resulting errors in x, y, and z directions, Ex, Ey, and Ez. The error compensation system operates using the machine parameters as well as the encoder positions X, Y, and Z. When the probe is triggered, the system returns the compensation Δx, Δy, and Δz that must be added to the encoder position so as to improve the machine position accuracy. ANN models provide error components for geometric errors as a function of encoder positions (X, Y, and Z) and dynamic errors as a function of machine parameters (PV, PD, AV, and AD). Volumetric error components are synthesized using the kinematic model of a machine. The compensated position is then used as an input to CMM software for geometric computations and metrological analysis.

The architecture of an integrated compensation model combining geometric and dynamic error compensation models
In order to evaluate the performance of the proposed integrated geometric and dynamic errors compensation procedure, three tests are performed. In each test, the CMM is controlled to move from the reference coordinate system position along X-axis with a travel distance of 400 mm. The machine is controlled to move 40 mm in each step along X-axis. At each position step, its coordinates from the CMM controller are collected and transferred to the computer where the errors are synthesized. The actual and predicted distances are then compared, and the correction of the travel distance is applied. In the first test, the machine travels at the slowest speed to reveal only the geometric errors and will be used as a reference. In the second one, the standard measuring pattern, using positioning and approaching velocities during measurement, is performed using a positioning velocity of 70 mm/s and an approach velocity of 12 mm/s. Given that the measurement is performed in approaching velocity, the second test represents RAE. In the final test, the measurement pattern for a non-contact probe-equipped machine is adopted with a travel velocity of 70 mm/s. Positioning error (RPE) can be evaluated in this test pattern since the measuring is performed in position velocity. The actual and predicted travel distances as well as the residual errors for each test are illustrated for the indicator of each test pattern (geometric error, RPE, and RAE) in Fig. 13. It can be observed in these graphs that the errors exceeded 12 μm for RAE and 16 μm for RPE while the maximum geometric error recorded does not reach 8 μm. The maximum residual error is lower than ± 1 μm for the geometric errors, while it is ± 2 μm for RAE and between 2 and -3 μm for RPE. This demonstrates the proposed compensation procedure is efficient allowing the use of higher velocities while maintaining very good measurement accuracy. Using this errors compensation approach results in raising the productivity of production cells by allowing a higher frequency of measurement operations.

Integrated geometric and dynamic errors compensation model performance
6 Conclusions
To increase productivity, 3D geometrical measurements, using coordinate measuring machines (CMMs), are performed at the highest permissible velocity, which leads to dynamic errors. These errors negatively affect the measurement accuracy during high-speed measuring of parts. In this article, a comprehensive predictive modeling strategy of dynamic errors in CMMs is developed. The proposed approach consists of six distinct steps:
-
1.
Identifying key parameters and conditions that affect CMM dynamic performance and proceeding to experimental investigation to evaluate the effects of these parameters and conditions on the positioning accuracy.
-
2.
Selecting the modeling technique and the performance criteria.
-
3.
Setting up the adequate orthogonal array to fit the modeling procedure specifications.
-
4.
Training and evaluating the developed models.
-
5.
Selecting the best combination of variables to include in the optimal models.
-
6.
Establishing and integrating the selected models in the proposed dynamic errors compensation strategy.
Implemented on a bridge-type CMM equipped with a touch-trigger probe, the proposed approach results in the development of predictive error compensation models presenting good agreement with experimental data with a correlation of more than 95% and 97% for residual positioning error (RPE) and residual approaching error (RAE) of probe, respectively. While employing high traveling velocities, the final integrated models succeeded in reducing the total errors by 80% regardless of the used measurement pattern. The proposed compensation strategy is easy to implement allowing the use of a CMM at its highest productivity while maintaining accuracy. The developed models are able to reduce the dynamic errors from 12 μm to 2 μm using 12 mm/s as approach velocity and from 18 μm to 3 μm using 70 mm/s as positioning velocity.
Although the results of this study are promising, the research can be extended to apply the method to a wider range of machine parameters and different types of measuring machines.
Availability of data and materials
All data, material, and codes used in this paper are available.
Abbreviations
- CMM:
-
Coordinate measuring machine
- ANOVA:
-
Analysis of variance
- ANN:
-
Artificial neural network
- PD:
-
Positioning distance
- PV:
-
Positioning velocity
- AP:
-
Approach distance
- AV:
-
Approach velocity
- MPE:
-
Maximum positioning error
- RPE:
-
Residual positioning error
- MAE:
-
Maximum approaching error
- RAE:
-
Residual approaching error
- % C:
-
Percent contribution
- F-test:
-
Fisher test
- MSEt :
-
Training residual mean square error
- MSEv :
-
Validation residual mean square error
- MSEtot :
-
Total residual mean square error
References
Franco P, Jodar J (2021) Theoretical analysis of straightness errors in Coordinate Measuring Machines (CMM) with three linear axes. Int J Precis Eng Manuf 22:63–72. https://doi.org/10.1007/s12541-019-00264-0
Yuan D, Tao X, Xie C, Zhao H, Ren D, Zhu X (2018) Calibration and compensation of dynamic Abbe errors of a coordinate measuring machine. J Dyn Syst Meas Control 140
Valdés RA, Di Giacomo B, Paziani FT (2005) Synthesization of thermally induced errors in Coordinate Measuring Machines. J Brazilian Soc Mech Sci Eng 27:170–177. https://doi.org/10.1590/S1678-58782005000200009
Tan KK, Huang SN, Lim SY, Leow YP, Liaw HC (2006) Geometrical error modeling and compensation using neural networks. IEEE Trans Syst Man Cybern Part C Appl Rev 36:797–809. https://doi.org/10.1109/TSMCC.2005.855527
Hermann G (2007) Geometric error correction in coordinate measurement. Acta Polytech Hungarica 4:47–62
Kruth J-P, Vanherck P, Van den Bergh C (2001) Compensation of static and transient thermal errors on CMMs. CIRP Ann Manuf Technol 50:377–380. https://doi.org/10.1016/S0007-8506(07)62144-1
Harris JO, Spence AD (2004) Geometric and quasi-static thermal error compensation for a laser digitizer equipped coordinate measuring machine. Int J Mach Tools Manuf 44:65–77. https://doi.org/10.1016/j.ijmachtools.2003.08.002
Gu J, Agapiou JS (2019) Incorporating local offset in the global offset method and optimization process for error compensation in machine tools. Procedia Manuf 34:1051–1059
Franco P, Jodar J (2020) Theoretical analysis of measuring accuracy of three linear axis CMMs from position errors. Int J Precis Eng Manuf 21:2235–2247. https://doi.org/10.1007/s12541-019-00198-7
Wang S-M, Tu R-Q, Gunawan H (2021) In-process error-matching measurement and compensation method for complex mating. Sensors 21. https://doi.org/10.3390/s21227660
Chan T-C, Hong Y-P, Yu J-H (2021) Effect of moving structure on the spatial accuracy and compensation of the coordinate measuring machine. Int J Precis Eng Manuf 22:1551–1561
de Nijs JFC, Lammers MGM, Schellekens PHJ, van der Wolf ACH (1988) Modelling of a coordinate measuring machine for analysis of its dynamic behaviour. CIRP Ann Manuf Technol 37:507–510. https://doi.org/10.1016/S0007-8506(07)61688-6
Yang H, Fei Y (2008) Research on characteristic parameter optimization of fast probing CMM. Zhongguo Jixie Gongcheng/China Mech Eng 19:2428–2432
Hongtao FYZJW, Xiushui M (2004) A review of research on dynamic errors of coordinate measuring machines. Chinese J Sci Instrum S1
Liu C, Sitong X, Chengwei L, Chengyang W, Zhengchun D, Yang J (2020) Dynamic and static error identification and separation method for three-axis CNC machine tools based on feature workpiece cutting. Int J Adv Manuf Technol 107:2227–2238
Grochalski K, Wieczorowski M, Pawlus P, H’Roura J (2020) Thermal sources of errors in surface texture imaging. Materials (Basel) 13:2337
Budzyn G, Rzepka J, Kaluza P (2021) Laser interferometer based instrument for 3D dynamic measurements of CNC machines geometry. Opt Lasers Eng 142:106594
Jiang W-S, Cheng Z-Y, Gong W-C, Yu L, Li R-J, Huang Q-X (2021) A novel dynamic compensation method for a contact probe based on Bayesian inversion. Measurement 186:110143
Lyu H, Kong L (2020) Modeling and simulation of dynamic errors in a coordinate measuring machine with 3-DOF laser interferometer. AOPC 2020 Opt Ultra Precis Manuf Test 11568, International Society for Optics and Photonics, p 115681L
Weekers WG, Schellekens PHJ (1995) Assessment of dynamic errors of CMMs for fast probing. CIRP Ann Manuf Technol 44:469–474. https://doi.org/10.1016/S0007-8506(07)62365-8
Chensong D, Yuhai M, Guoxiong Z (1998) Assessing the dynamic characteristics of CMMS with a laser interferometer. J TianJin Univ 31:621–626
Kaichen S, Guoxiong ZYLSZ (1999) A study of compensation for dynamic errors of CMMS. J Chin Sci Instrum 20:23–25
Zhang Y, Jizhu L (2009) Research on the CMM compensation errors models based on finite element simulations. Technol Test 6:78–80
Jinwen W, Yanling C (2011) The geometric dynamic errors of CMMs in fast scanning-probing. Meas J Int Meas Confed 44:511–517. https://doi.org/10.1016/j.measurement.2010.11.003
Krajewski G, Woźniak A (2014) Simple master artefact for CMM dynamic error identification. Precis Eng 38:64–70. https://doi.org/10.1016/j.precisioneng.2013.07.005
Dong C, Zhang C, Wang B, Zhang G (2002) Prediction and compensation of dynamic errors for coordinate measuring machines. J Manuf Sci Eng Trans ASME 124:509–514. https://doi.org/10.1115/1.1465435
Echerfaoui Y, El Ouafi A, Chebak A (2018) Experimental investigation of dynamic errors in coordinate measuring machines for high speed measurement. Int J Precis Eng Manuf 19:1115–1124. https://doi.org/10.1007/s12541-018-0132-x
Huang SH, Zhang H-C (1994) Artificial neural networks in manufacturing: Concepts, applications, and perspectives. IEEE Trans Components Packag Manuf Technol Part A 17:212–228. https://doi.org/10.1109/95.296402
Meireles MRG, Almeida PEM, Simões MG (2003) A comprehensive review for industrial applicability of artificial neural networks. IEEE Trans Ind Electron 50:585–601. https://doi.org/10.1109/TIE.2003.812470
Montgomery DC (2017) Design and analysis of experiments. John Wiley & Sons
Hedayat AS, Sloane NJA, Stufken J (1999) Orthogonal arrays: Theory and applications. Springer Science & Business Media
Echerfaoui Y, El Ouafi A, Chebak A (2017) Laser interferometer based measurement for positioning error compensation in cartesian multi-axis systems. J Anal Sci Methods Instrum 7:75–92
Funding
This work was supported by the Natural Sciences and Engineering Research Council of Canada (NSERC).
Author information
Authors and Affiliations
Contributions
The authors' contributions are as follows: AEO and YE conceived, planned, and carried out the experiments; AEO, YE, and SSK contributed to the measurement interpretation, visualization, and analyses of results. AEO, YE, and SSK contributed actively to writing the manuscript; all authors provided critical feedback and helped shape the research, analysis, and manuscript.
Corresponding author
Ethics declarations
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent to publish
The publisher has the permission of the authors to publish the given article.
Competing interests
The authors declare that there are no conflicts of interest/competing interests concerning this paper. In this regard, they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Echerfaoui, Y., El Ouafi, A. & Sattarpanah Karganroudi, S. Dynamic errors compensation of high-speed coordinate measuring machines using ANN-based predictive modeling. Int J Adv Manuf Technol 122, 2745–2759 (2022). https://doi.org/10.1007/s00170-022-10007-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00170-022-10007-7