
Abstract
In this paper, a new kind of multivariate global sensitivity index based on energy distance is proposed. The covariance decomposition based index has been widely used for multivariate global sensitivity analysis. However, it just considers the variance of multivariate model output and ignores the correlation between different outputs. The proposed index considers the whole probability distribution of dynamic output based on characteristic function and contains more information of uncertainty than the covariance decomposition based index. The multivariate probability integral transformation based index is an extension of the popularly used moment-independent sensitivity analysis index. Although it considers the whole probability distribution of dynamic output, it is difficult to estimate the joint cumulative distribution function of dynamic output. The proposed sensitivity index can be easily estimated, especially for models with high dimensional outputs. Compared to the classic sensitivity indices, the proposed sensitivity index can be easily used for dynamic systems and obtain reasonable results. An efficient method based on the idea of the given-data method is used to estimate the proposed sensitivity index with only one set of input-output samples. The numerical and engineering examples are employed to compare the proposed index and the covariance decomposition based index. The results show that the input variables may have different effect on the whole probability distribution and variance of dynamic model output since the proposed index and the covariance decomposition based index measure the effects of input variables on the whole distribution and variance of model output separately.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Uncertainties are often encountered in the practical systems and mathematical models (Iman et al. 2005; Nannapaneni et al. 2016; Xiao et al. 2012), which lead to uncertain performance. Uncertainty analysis has been widely used to help decision makers understand the degree of confidence of the model results so that they can know the degree of confidence in the decision they made and assess the risk (Borgonovo and Peccati 2006). However, most applications of uncertainty analysis do not provide information on how the uncertainty of model output can be apportioned to the uncertainty of model inputs, and therefore, on which factors to devote data collection resources so as to reduce the uncertainty most effectively (Wang 2017; Xiong et al. 2010). Global sensitivity analysis (GSA) has been widely used to apportion the uncertainty of model output to different sources of uncertainty in the model inputs (Saltelli et al. 2008). Thus, GSA can help researchers find the significant or non-significant input factors (Morris 1991), measure the respective contributions of input factors to the uncertainty of model output or detect the interaction effect between different input factors. Then, researchers can reduce the uncertainty of model output effectively through the calibration of the most influential input factors and simplify the model by fixing the non-influential input factors into nominal values. In addition, it can also help researchers obtain a comprehensive insight on the model behavior and structure (Xu et al. 2017). Due to this property, GSA has been widely used in risk assessment and decision making, etc. For example, Saltelli and Tarantola (2002) used GSA on the safety assessment for nuclear waste disposal, Hu and Mahadevan (2016) proposed an enhanced surrogate model-based reliability analysis method based on GSA, Patil and Frey (2004) used GSA for the food safety risk assessment, Borgonovo and Peccati (2006) used GSA techniques in the investment decisions, Lamboni et al. (2009) used GSA for dynamic crop models to help researchers make better decisions in the growing season of crops. More details of GSA can be found in the reviews of other researchers, such as Refs. (Borgonovo and Plischke 2016; Wei et al. 2015).
The traditional GSA methods, such as the nonparametric methods (Helton 1999), variance based methods (Saltelli et al. 2010; Sobol 2001), distribution based methods (Borgonovo 2007; Liu and Homma 2010; Pianosi and Wagener 2015), the relative entropy based method (Liu et al. 2006), the probability distance based method (Greegar and Manohar 2015), etc. focus on the models with scalar output, which can be considered as a random variable. However, many practical models with dynamic output, which can be considered as random process, are widely used in engineering. In these models, time-dependent model outputs are usually considered (in practical, time-dependent output is often discretized, which leads to high dimensional multivariate output). Usually, an appropriate scalar objective function (such as an aggregated statistic like sum, average or maximum value) is selected at first, then GSA is performed on the selected objective function (Saltelli et al. 2000). While if no appropriate scalar objective function can be obtained, then the GSA should be performed on model output at each time moment separately (Lilburne and Tarantola 2009). Although performing GSA on a pre-defined scalar function of the dynamic output can be convenient and useful when the selected scalar function has a meaningful interpretation, it leads to many potential scalar functions, and sometimes it is impossible to find a proper scalar function (Li et al. 2016). On the other hand, conducting GSA on the model output at each instant can give information on how the sensitivity of input variable evolves over time, however, it may lead to redundancy since strong correlation often exists between outputs from one instant to another (Garcia-Cabrejo and Valocchi 2014) and can not get how the input variables affect the whole model output in an entire time interval. As mentioned by Campbell et al. (2006), it may be insufficiently informative to perform GSA on a specific scalar function of the outputs or on the output at each time instant separately. Thus, it is more appropriate to apply GSA on the dynamic model output as a whole.
Similar to the variance based GSA method for models with scalar output, which utilizes the variance to describe the uncertainty of model output, the uncertainty of dynamic output (multivariate output) can be represented by the covariance matrix. Then Gamboa et al. (2013) proposed a set of multivariate global sensitivity indices based on the decomposition of the covariance matrix of model output which are equivalent to the Sobol’ indices (Sobol 1993) in the scalar case. These indices can be considered as the average of all the Sobol’ indices for each output weighted by the variance of the corresponding output, and they do not consider the covariance among different outputs. Based on the idea of the output decomposition method proposed by Campbell et al. (2006), Lamboni et al. (2011) used principal component analysis (PCA) to perform the decomposition of model output and proposed a set of multivariate global sensitivity indices according to the variance based GSA method. These indices can still be considered as averaging all the Sobol’ indices for the principal components weighted by the variance of each principal component. Since the total variance of all the principal components is equal to the total variance of the original model output, these two sets of indices are equivalent if the selected principal components preserve all the variance of the original model output. This has also been pointed out by Garcia-Cabrejo and Valocchi (2014). The PCA based method still misses the covariance among different model outputs.
The multivariate sensitivity analysis methods mentioned above are all based on the variance of the model output, which implicitly assume that the variance is sufficient to describe output variability (Saltelli 2002). However, the variance only provides a summary of the whole distribution and it will result in inevitable loss of information when representing the uncertainty of output with variance alone (Helton and Davis 2003). Thus, a sensitivity index based on the whole distribution of dynamic output is preferable to have a comprehensive assessment of the influence of model inputs on the dynamic output. Based on the density based GSA method for scalar output (Borgonovo 2007), Cui et al. (2010) proposed a multivariate sensitivity index based on the joint probability density function (PDF) of the multivariate output. Although this method can take both the whole distribution and the correlation of the multivariate output into consideration, it suffers the “curse of dimensionality” for calculating the high dimensional integration and the difficulty in estimating the joint PDF of the high dimensional output variables. Later, Li et al. (2016) utilized the joint cumulative distribution function (CDF) to describe the whole uncertainty of multivariate output since the CDF is easier to be estimated than the PDF (Liu and Homma 2009). Then the multivariate global sensitivity index was defined based on the multivariate probability integral transformation (PIT) distribution of the multivariate output. It is recognized that valuable information of the correlation structure is contained in the joint CDF of the multivariate output. In addition, due to the univariate nature of the multivariate PIT, this index can be calculated through a univariate integration. Although the multivariate PIT based method is easier to be implemented than the joint PDF-based method, it still needs to estimate the joint CDF of the multivariate output, which is very difficult in the case of high dimension model outputs. This is often the case when the time-dependent output is discretized, which usually will lead to a very high dimensional model output.
In this work, we propose a new multivariate global sensitivity index which measures the effect of the input uncertainty on the whole probability distribution of the model output, and it takes the correlation among different outputs into consideration. This new sensitivity index is defined based on the energy distance (Rizzo and Székely 2016; Székely and Rizzo 2013), which is used to measure the difference between the unconditional distribution of the multivariate output and the conditional one when a certain input variable is fixed. Compared to the joint PDF based method and the multivariate PIT based method, the new method does not need to estimate the joint PDF or CDF of the multivariate output and can be estimated through a surprisingly simple form of expectation.
The rest of this paper is organized as follows: Section 2 briefly reviews the covariance decomposition based method and the multivariate PIT based method. In Section 3, the energy distance is briefly introduced at first, then the new multivariate global sensitivity index is defined based on the energy distance and the properties of the new sensitivity index are discussed. Section 4 gives the comparison of the proposed sensitivity index with the existent indices and the estimation of the proposed sensitivity index. A numerical example and two engineering examples are employed in Section 5 to show the validity and the benefits of the proposed sensitivity index. Section 6 gives the conclusion.
2 Review of the multivariate global sensitivity analysis methods
Let X i (i = 1 , 2 , … , d) be a set of independent random input variables with PDFs \( {f}_{X_i}\left({x}_i\right) \) (i = 1 , 2 , … , d). The dynamic output is defined as
where Y(t) is the dynamic output and g represents the deterministic model response function. The model output becomes a vector Y = (Y(t 1), Y(t 2), … , Y(t m )) if the \( \mathrm{domain}\kern0.2em \mathcal{T} \) is discrete or more generally a function Y(t) (\( t\in \mathcal{T} \)) \( \mathrm{if}\kern0.2em \mathcal{T} \) is continuous. In practical application, many continuous functions are often discretized for a more convenient calculation and analysis. Here, we will consider the discrete case.
2.1 Covariance decomposition based method
The multivariate sensitivity analysis based on covariance decomposition proposed by Gamboa et al. (2013) is established on the high dimensional model representation (HDMR) (Sobol 1993) of the outputs, i.e.
where
and t r (r = 1 , 2 , … , m, and m is the number of the time instant) is the time instant which indicates different outputs and E(•) denotes the expectation operator.
Take the covariance matrices for both sides of (2), then the following equation can be obtained
Equation (4) denotes that the covariance matrix of multivariate output can be partitioned into the sum of covariance matrices that comes from changes in single, pairs, triplets, etc. of input variables (Garcia-Cabrejo and Valocchi 2014). For the scalar output, this equation becomes the decomposition of the variance, which is used to define the traditional variance based global sensitivity indices. For the case of multivariate output, Gamboa et al. (2013) showed that the covariance matrix C can be projected onto a scalar through multiplication by a matrix M and then taking the trace. They also showed that the matrix M can be taken as the identify matrix, i.e. M = I. Then it leads to
Thus, the multivariate main effect index of input variable X i is defined as
And the multivariate total effect index of X i can be defined as
Since all the elements along diagonal in C are positive, the trace of C is positive. This trace is equal to the sum of variances of all the outputs Y(t r ) (r = 1 , … , m), i.e., the total variance of all the output variables. The trace of C i is the total variance of all the output variables associated with changes in input variable X i . According to the law of total variance, the numerator in (6) can be represented as \( {\sum}_{j=1}^m V\left({g}_i\left({X}_i,{t}_r\right)\right)={\sum}_{j=1}^m V\left( E\left( Y\left({t}_r\right)\left|{X}_i\right.\right)\right)={\sum}_{j=1}^m V\left( Y\left({t}_r\right)\right)- E\left( V\left( Y\left({t}_r\right)\left|{X}_i\right.\right)\right) \). V(Y(t r )|X i ) is the conditional variance of Y(t r ) when X i is fixed at a certain value. E(V(Y(t r )|X i )) denotes the average residual variance of Y(t r ) when X i can be fixed. Thus, \( {\sum}_{j=1}^m V\left( Y\left({t}_r\right)\right)- E\left( V\left( Y\left({t}_r\right)\left|{X}_i\right.\right)\right) \) represents the average reduction of the total variance of all the output variables when X i can be fixed. \( S{1}_i^M \) can be interpreted as the expected percentage reduction in the total variance of output variables when the uncertainty of X i is eliminated. \( {ST}_i^M \) is the summation of all the sensitivity indices related to input variable X 1, thus \( {ST}_i^M \) can measure both the individual effect of X i and the interaction effects between X i and other input variables on the outputs.
According to the definition of \( S{1}_i^M \) in (6), \( S{1}_i^M \) can also be represented as
where \( S{1}_{i,{t}_j}=\frac{V\left( E\left( Y\left({t}_j\right)\left|{X}_i\right.\right)\right)}{V\left( Y\left({t}_j\right)\right)} \) is the main effect index of X i on the single output Y(t j ). Thus, \( S{1}_i^M \) can be regarded as the weighted average of the main effect indices of X i on the single output Y(t j ) (j = 1 , … , m), and the weight of each term is proportional to the variance of each output. Similarly, \( {ST}_i^M \) can also be represented as
where X ~i denotes all the input variables except X i , \( {ST}_{i,{t}_j}=\frac{E\left( V\left( Y\left({t}_j\right)\left|{\mathbf{X}}_{\sim i}\right.\right)\right)}{V\left( Y\left({t}_j\right)\right)} \) is the total effect index of X i on the single output Y(t j ). Thus, \( {ST}_i^M \) is also the weighted average of the total effect indices of X i on the single output Y(t j ) (j = 1 , … , m).
According to the definition, it can be seen that the covariance decomposition based indices mainly concern the variance of model outputs, which may be insufficient for representing the uncertainty of model output. In addition, they also ignore the covariance terms in the covariance matrix, which represent the correlation between different outputs.
2.2 Multivariate probability integral transformation based method
The base of the multivariate sensitivity analysis method proposed by Li et al. (2016) is the multivariate probability integral transformation (PIT) (Genest and Rivest 2001). Let F Y (y 1, y 2, … , y m ) be the joint CDF of the multivariate output Y = (Y(t 1), Y(t 2), … , Y(t m )), then the m-dimensional PIT of Y can be obtained by taking the CDF of Y, i.e., V = F Y (y 1, y 2, … , y m ). The CDF of V, represented by K V (v), is known as the PIT distribution of Y. For the univariate case, K V (v)is a standard uniform distribution. While for the multivariate case, K V (v) is not a standard uniform distribution since it relies on the correlation structure of the joint CDF of Y. Specifically, K V (v) is distributed in [0, 1] for the multivariate case and it can be represented as K V (v) = P(V ≤ F Y (y 1, y 2, … , y m ), where P(•) denotes the probability of event • in the bracket. Since K V (v) is obtained from the joint CDF of the multivariate output Y, it contains valuable information about the joint CDF of Y.
Denote \( {F}_{\mathbf{Y}\left|{X}_i\right.}\left({y}_1,{y}_2,\dots, {y}_m\right) \) as the conditional joint CDF of Y when fixing a input variable X i at a certain value. Then the corresponding conditional PIT distribution is \( {K}_{V\left|{X}_i\right.}(v)= P\Big( V\le {F}_{Y\left|{X}_i\right.}\left({y}_1,{y}_2,\dots, {y}_m\right) \). Thus, the effect of input variable fixed in a certain value on the multivariate output can be measured through the difference between K V (v) and \( {K}_{V\left|{X}_i\right.}(v) \), which can be represented as
Since X i is a random variable with PDF \( {f}_{X_i}\left({x}_i\right) \), the average effect of X i on the multivariate output can be measured through the expectation of s(X i ), i.e.
The final multivariate sensitivity index is defined as
η i represents the normalized average effect of X i on the PIT distribution of Y. Larger value of η i will indicate greater effect of X i on the multivariate output.
It can be seen that the multivariate PIT based index η i focuses on the joint CDF of model output, which contains all the uncertainty information of model output. However, it needs to estimate the joint CDF of model output, which is a difficult task, especially for the cases of high dimensional output. In addition, when the model output becomes a scalar random variable, the index η i is not suitable. Since the PIT distribution of an one-dimensional variable is standard uniform distribution, thus K V (v) is equal to \( {K}_{V\left|{X}_i\right.}(v) \), which leads to that η i is zero.
3 Multivariate global sensitivity analysis based on energy distance
In this section, we will propose a new multivariate sensitivity index which will take the whole distribution of the multivariate output into consideration. Firstly, the energy distance, which is used for the definition of the new index, will be introduced.
3.1 Energy distance
Energy distance is a distance between probability distributions (Rizzo and Székely 2016; Székely and Rizzo 2013), which is analogous to the potential energy between objects in a gravitational space. For two independent random vectors X and Y in ℝ d, the energy distance between them is defined as
where E denotes expectation operator, ‖•‖ denotes the Euclidean norm if the argument is real and the complex norm when the argument is complex, E‖X‖ < ∞, E‖Y‖ < ∞, X ′ denotes an independent and identically distributed (iid) copy of X and Y ′ denotes an iid copy of Y.
A significant advantage of the energy distance is that ε(X, Y) = 0 if and only if X and Y are identically distributed. Thus, the energy distance has been used for testing of equal distributions (Székely and Rizzo 2004; Székely et al. 2007). This advantage of energy distance can be explained with the following proposition (Székely and Rizzo 2013).
Proposition
For d-dimensional independent random vectors X and Y with E‖X‖ + E‖Y‖ < ∞, ϕ X (t) and ϕ Y (t) denote the characteristic functions of X and Y separately, then their energy distance can be represented as
where
with Γ(•) is the complete gamma function. Thus, ε(X, Y) ≥ 0 with equality to zero if and only if X and Y are identically distributed.
The proof of this proposition can be found in (Székely and Rizzo 2005). Equation (14) shows that energy distance is the weighted L 2 distance between characteristic functions, with the weight function w(t) = ‖t‖−(d + 1). The characteristic function is the Fourier transform of the PDF, and it also contains all the information of the distribution of random vectors. Thus, the energy distance measures the difference between the distributions of two random vectors.
Another advantage of energy distance is that it is distribution free, i.e., the estimated value of energy distance does not depend on the distribution form of random vectors, although it can be represented as the form of characteristic function. Due to the form of expectation in (13), the energy distance can be estimated with the following surprisingly simple form. Let \( {\mathbf{x}}_1,\dots, {\mathbf{x}}_{n_1} \) denote the samples of X and \( {\mathbf{y}}_1,\dots, {\mathbf{y}}_{n_2} \) denote the samples of Y, then the energy distance can be estimated as follows (Rizzo and Székely 2016)
where A, B, C are simply the average of the pairwise distance:
Since the value of the energy distance does not has a upper bound, a normalized energy distance \( \overline{\varepsilon}\left(\mathbf{X},\mathbf{Y}\right) \) can be obtained as follows (Rizzo and Székely 2016)
Then \( 0\le \overline{\varepsilon}\left(\mathbf{X},\mathbf{Y}\right)\le 1 \) with \( \overline{\varepsilon}\left(\mathbf{X},\mathbf{Y}\right)=0 \) if and only if X and Y are identically distributed. In the next subsection, the normalized energy distance is applied to define the multivariate global sensitivity index.
3.2 The new sensitivity index
Consider the dynamic model Y(t) = g(X 1 . X 2, … , X d , t) used in Section 2 with the discrete model output Y = (Y(t 1), Y(t 2), … , Y(t m )). Let Y|X i denote the conditional multivariate output when one input variable X i is fixed at a certain value. The effect of the fixed value of X i on the multivariate output can be measured by the energy distance between Y and Y|X i as follows
Then d(X i ) is a function only dependent on X i . Since X i is a random variable with PDF \( {f}_{X_i}\left({x}_i\right) \), the average effect of X i on the multivariate output can be described by the expectation of d(X i ) as follows
Then the multivariate global sensitivity index is defined as follows
ξ i denotes the expected difference between the distributions of the unconditional output Y and the conditional output Y when fixing X i . Larger value of ξ i means that the input variable X i has a greater effect on the multivariate output.
Similarly, the multivariate global sensitivity index for any group of input variables (\( {X}_{i_1},{X}_{i_2},\dots, {X}_{i_p} \)) can also be defined as follows
The properties of the proposed sensitivity index are listed in Table 1.
Proof of property 1
Since
Thus, it can be obtained that
Namely
Proof of property 2 and 3
If Y is independent of X i , then the distribution of Y would be the same with the distribution of Y|X i , thus, it can be obtained that \( \overline{\varepsilon}\left(\mathbf{Y},\mathbf{Y}\left|{X}_i\right.\right)=0 \), i.e., \( {\xi}_i= E\left(\overline{\varepsilon}\left(\mathbf{Y},\mathbf{Y}\left|{X}_i\right.\right)\right)=0 \).
If Y is dependent on X i but independent on X j , then the distribution of Y|(X i , X j ) will be equal to the distribution of Y|X i , thus, \( \overline{\varepsilon}\left(\mathbf{Y},\mathbf{Y}\left|\left({X}_i,{X}_j\right)\right.\right)=\overline{\varepsilon}\left(\mathbf{Y},\mathbf{Y}\left|{X}_i\right.\right) \), i.e., \( {\xi}_{i, j}=\overline{\varepsilon}\left(\mathbf{Y},\mathbf{Y}\left|\left({X}_i,{X}_j\right)\right.\right)=\overline{\varepsilon}\left(\mathbf{Y},\mathbf{Y}\left|{X}_i\right.\right)={\xi}_i \).
4 Discussion and estimation of the proposed sensitivity index
4.1 Discussion of the proposed sensitivity index
The proposed sensitivity index ξ i measures the effect of input variables on the multivariate output through the average energy distance between the unconditional multivariate output and the conditional one. Since the energy distance can be used to measure the difference between the distributions of two random vectors through the weighted L 2 distance between characteristic functions, ξ i can measure the effect of input variables on the whole distribution of the multivariate output. For the covariance decomposition based indices, they just utilize a certain moment (variance) of whole distribution for the multivariate output, which can not represent the whole uncertainty information of multivariate output. In addition, they only use the variances of the multivariate output, but neglect the covariance (correlation) between different outputs. Thus, compared to the covariance decomposition based indices, the proposed index captures more information of the uncertainty of model output and can obtain more reasonable results.
Both ξ i and the multivariate PIT based index measure the effect of input variables on the whole distribution of the multivariate output, the main difference is that ξ i utilizes the weighted L 2 distance between characteristic functions but the PIT based index uses the L 1 distance between the PIT distributions. The multivariate PIT transforms the joint CDF of multivariate output into a univariate function, which may miss some useful information. The characteristic function still contains all the information of model output. Another advantage of ξ i is that it can be easily calculated due to the form of expectation in (13). For the PIT based method, it needs to calculate the joint CDF of the multivariate output, which is quite difficult compared to the proposed method, especially for the cases of high dimensional output. When the time-dependent output is discretized, which will lead to a very high dimension of model outputs, the PIT based method will not be appropriate.
For the special case of scalar variables X and Y, the energy distance can also be represented as follows
where F X (•) and F Y (•) are the CDFs of X and Y, separately. It can be seen that, the energy distance for scalar variables is also the L 2 distance between the CDFs. Thus, for the scalar model output, the proposed sensitivity index can also be represented as the average difference between the unconditional CDF and conditional CDF of model output. This is similar to the sensitivity index proposed by Liu and Homma (Liu and Homma 2010), which used the absolute operator instead of the square operator. As mentioned before, the multivariate PIT based index is not suitable for the special case of scalar model output since the index will always be zero.
4.2 Estimation of the proposed sensitivity index
According to the definition of the proposed index, a direct way to estimate ξ i needs a double loop sampling, which is similar to the method used in Refs.(Borgonovo 2007; Li et al. 2016). However, the double loop sampling method is not efficient enough, especially for the computationally intensive models. Later, Plischke et al. (2013) proposed an efficient method to estimate the distribution based index proposed in (Borgonovo 2007) with just one set of input-output samples, and it also has been developed into a general and consistent method for estimating many sensitivity indices (Borgonovo et al. 2016). In this subsection, this idea is adopted to estimate the proposed index ξ i .
For a certain input X i , suppose the corresponding sample space is [b 1, b 2], and partition the sample space of X i into L successive and non-overlapping subintervals A l = [a l − 1, a l ], where b 1 = a 0 < a 1 < ⋯ < a l < ⋯ < a L = b 2 and l = 1 , 2 , … , L. Then the following theorem can be obtained (The proof similar to that in (Zhai et al. 2014) is given in Appendix).
Theorem 1
Suppose the model Y = g(X, t) is continuous with respect to X. Then, when \( \Delta a=\underset{l}{ \max}\left|{a}_l-{a}_{l-1}\right| \) approaches zero, the following equation can be obtained
where \( {P}_l={\int}_{a_{l-1}}^{a_l}{f}_{X_i}\left({x}_i\right)\mathrm{d}{x}_i={F}_{X_i}\left({a}_l\right)-{F}_{X_i}\left({a}_{l-1}\right) \) and \( {F}_{X_i}\left(\cdot \right) \) is the CDF of X i .
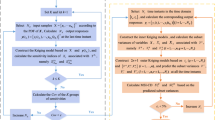
Theorem 1 shows that when the maximum length of intervals Δa approaches zero (the number of intervals approaches infinity), the estimator \( {\widehat{\xi}}_i=\sum_{l=1}^L{P}_l\overline{\varepsilon}\left(\mathbf{Y},\mathbf{Y}\left|{X}_i\in {A}_l\right.\right) \) approaches ξ i . Then based on Theorem 1, the following steps are proposed to estimate the sensitivity indices and the flow chart is shown in Fig. 1.
-
1)
Generate N samples {x 1, … , x N} according to the joint PDF f X (x) of model inputs, and then obtain the corresponding output sample set B = {y 1, … , y N} through running the model Y = g(X, t).
-
2)
Partition the sample space of model input X i into L successive and non-overlapping subintervals A l = [a l − 1, a l ], l = 1 , 2 , … , L.
-
3)
Partition the output samples into L subsets based on the partition of X i , i.e.,

The flow chart for estimating the proposed sensitivity index
Then estimate the energy distance between Y and Y|X i ∈ A l using the sample sets B and B l according to (16) and (17). Denote the estimated value as \( \widehat{\overline{\varepsilon}}\left(\mathbf{Y},\mathbf{Y}\left|{X}_i\in {A}_l\right.\right) \) (l = 1 , 2 , … , L).
-
4)
Estimate ξ i as follows
-
5)
Repeat steps 2) to 4) to estimate the sensitivity index for all the input variables.
For a group of input variables (\( {X}_{i_1},{X}_{i_2},\dots, {X}_{i_p} \)), the procedure above can also be used to estimate the corresponding sensitivity index \( {\xi}_{i_1,{i}_2,\dots, {i}_p} \). The difference is that one needs to partition the joint sample space of (\( {X}_{i_1},{X}_{i_2},\dots, {X}_{i_p} \)) into subspaces. Then partition the output samples based on the partition of (\( {X}_{i_1},{X}_{i_2},\dots, {X}_{i_p} \)).
The same output samples {y 1, … , y N} can be partitioned into different subsets for different X i , thus, one group of samples will be enough to estimate the sensitivity indices for each model input. The sampling process for generating the samples of model input can be realized by many different methods (simple random sampling, Latin hypercube sampling, quasi random sampling, etc.). In this work, the Sobol’ quasi random sequence (Sobol” 1976; Sobol’ et al. 2011) is utilized to generate the samples due to its low discrepancy property. Several partition strategies are available in (Plischke 2012). In this paper, the equiprobability partition (Zhai et al. 2014) is adopted, which is a widely used and effective scheme. The previous studies showed that there exists a tradeoff of selecting the number of subintervals for a given set of input-output samples, it should be guaranteed that both the number of subintervals and the number of samples in each subinterval are enough. A recommended strategy for selecting the number of subintervals is \( L=\left[\sqrt{N}\right] \) (take the integer part of \( \sqrt{N} \), and N is the total sample size) to achieve a balance of number of subintervals and the number of samples in each subinterval (Li and Mahadevan 2016). This strategy is used in this work.
5 Examples
In this section, a numerical example and two engineering examples with high dimensional model output are adopted. Since the estimation of the PIT based method is very difficult in the case with high dimensional model output, only the covariance decomposition method and the proposed method are applied on these example to have a comparison.
5.1 Numerical example
Here, a numerical example with time-dependent output is adopted. The model response function can be represented as
Each value of the time parameter t corresponds to a model output. Here, t lies in the interval [0, 5] and it is discretized into 128 time points equally distributed in [0, 5], which correspond to 128 model outputs. The independent input variables x 1, x 2, x 3 follow normal distribution and their distribution parameters are shown in Table 2.
Figure 2 shows the estimated values of the proposed index for the three input variables with different sample sizes by the proposed method in Section 4.2. It shows that the proposed estimation method can obtain a stable result as the sample size increases.

Values of the proposed index with different sample sizes for the numerical example
Table 3 shows the values of different indices. The results indicate that the importance rankings of the input variables based on the proposed sensitivity index and the covariance decomposition based sensitivity indices are different. For the covariance decomposition based sensitivity indices, the importance ranking is x 2 > x 1 > x 3, while for the proposed sensitivity index, the importance ranking is x 1 > x 2 > x 3. The difference of the importance ranking is caused by the fact that covariance decomposition based sensitivity indices measure the effect of input variables on the variance of the model output and do not consider the correlation between different model outputs, while the proposed sensitivity index measure the effect of input variables on the entire probability distribution (represented by the characteristic function) of the model outputs. Thus, x 2 has the most effect on the variance of the model output and x 1 has the most effect on the entire probability distribution of the model output. This also denotes that the variable having the most effect on the variance of model output may not have the most effect on the entire probability distribution of model outputs. In addition, x 2 has more effect on the variance of model output than x 3, but almost has the same effect on the entire probability distribution of model output with x 3.
5.2 A vibration problem
In this example, a vibration problem used in (Hu and Du 2015) is adopted and it is shown in Fig. 3. The stiffness of spring k 2, damping coefficient c 2, mass m 2, stiffness of spring k 1, and mass m 1 are considered as random input variables, and they are described in Table 4. The amplitude of the vibration of mass m 1 subjected to force f 0 sin(Ωt) is given by

A vibration problem
This equation can be non-dimensionalized using a static deflection of main system, defined by \( {q}_{1\mathrm{st}}=\frac{f_0}{k_1} \). Thus, the non-dimensional displacement of m 1 is considered as the output and can be given as
where
The parameter Ω is the excitation frequency in [8, 28] rad/s. Different values of Ω will lead to different model outputs. In this example, Ω will take the values from 8 rad/s to 28 rad/s with a step size of 0.2 rad/s, which correspond to 101 model outputs.
The estimated values of the proposed sensitivity index through the method proposed in Section 4.2 with different sample sizes are shown in Fig. 4, which indicates that as the sample size increases, the proposed method can converge toward a stable result.

Values of the proposed index with different sample sizes for the vibration problem
The values of different sensitivity indices are shown in Table 5. For both kinds of indices, k 1 is the most important variable, which means that k 1 not only has the most effect on variance of model output but also has the most effect on the entire probability distribution of model output. For the covariance decomposition based indices, m 2 is the second important variable and it almost has the same effect on the variance of model output with k 1, the other variables have little effect on the variance of model output. However, for the proposed sensitivity index, k 2 and m 1 are the second and third important variables separately, and they almost have the same effect on the entire probability distribution of model output, but has less effect on the entire probability distribution of model output than k 1 apparently. m 2 and c 2 have the least effect on the whole probability distribution of model output, and they are just a little less important than m 1 and k 2. The results also show that the relative importance of input variables based on these two kinds of indices may not be the same. Since k 1 is the most important variable based on these two kinds of sensitivity indices, more attention should be paid on k 1 to have a more accurate estimation of the output.
5.3 Automobile front axle
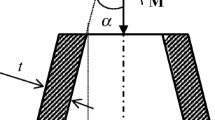
In this example, an automobile front axle beam used in (Shi et al. 2017) is adopted. In the automobile engineering, the front axle beam is used to carry the weight of the front part of the vehicle (Fig. 5(a)). Since the whole front part of the automobile rests on the front axle beam, it must be robust enough in construction to make sure it is reliable. The I-beam is often used in the design of the front axle due to its high bend strength and light weight. Figure 5(b) shows the dangerous cross-section. The maximum normal stress and shear stress are σ = M/W x and τ = T/W ρ separately, where M and T are time-dependent bending moment and torque, i.e., \( M={M}_0\left(\frac{1}{10} \cos \frac{1}{10} z+\frac{1}{10}\right) \) and \( T={T}_0 \sin \frac{1}{3} z \), where M 0 and T 0 are the basic bending moment and torque, z is the time parameter which lies in the interval [0, 10] second. W x and W ρ are section factor and polar section factor which are given as

Diagram of the automobile front axle
The limit state function for checking the strength of front axle can be expressed as:
where σ s is the ultimate stress of yielding. According to the material property of the front axle, the ultimate stress of yielding σ s is 460 MPa. The geometry variables of I-beam a , b , t , h and the basic bending moment M 0 and torque T 0 are independent normal variables with distribution parameters listed in Table 6. The time parameter z will take the values from 0.1 to 10 s with a step size of 0.1 s, which will lead to 100 model outputs.
Fig. 6 shows the estimated values of the proposed sensitivity index through the proposed method with increasing sample sizes. It denotes that the estimated values converge to a stable value as the sample size increases. Table 7 shows the values of different sensitivity indices. For the covariance decomposition based sensitivity indices, T 0 has the most significant effect on the variance of model output and b comes at the second. The other variables has little effect on the variance of model output. For the proposed sensitivity index, h has the most significant effect on the whole probability distribution of model output. The second and third important input variables are M 0 and b separately, and they almost have the same effect on the whole probability distribution of model output. The other variables have the least effect on the whole probability distribution of model output. Based on the results, if one focuses on the variance of model output, more attention should be paid on T 0 and b. While if one is interested in the whole probability distribution of model output, then more attention should be paid on h, M 0 and b.

Values of the proposed index with different sample sizes for the automobile front axle
6 Conclusion
A multivariate global sensitivity index is proposed in this work to measure the effect of input variables on the entire probability distribution of the discretized dynamic output. Compared to the covariance decomposition based indices, which just considers the variance of model output and neglects the correlation between different model outputs, the proposed sensitivity index considers the whole probability distribution of the model output, which contains more information of model output. Compared to the multivariate PIT based method, which needs to estimate the joint CDF of multivariate output and is quite difficult to implement for high dimensional outputs, the proposed sensitivity index can be represented as the form of expectations and can be easily estimated, especially for high dimensional outputs. To estimate the proposed sensitivity index more efficiently, the given-data method is adopted in this work, which just needs one set of input-output sample. The numerical and engineering examples are used to compare the proposed method and the covariance decomposition based method. It can be seen that the input rankings based on these two kinds of sensitivity indices are not necessarily the same. This is caused by the fact that the covariance decomposition based indices consider the effect of input variables on the variance of model output while the proposed index considers the effect of input variables on the whole distribution of model output. Through these two kinds of sensitivity indices, one can easily obtain the input variables which have significant effect on the whole probability distribution of output and the input variables which have the significant effect on the variance of output separately. When the output variable is normally distributed or the response function is a quadratic utility function, variance is sufficient to describe the uncertainty of model output. Otherwise, the whole probability distribution is preferable to have a more comprehensive description of the uncertainty of model output.
References
Borgonovo E (2007) A new uncertainty importance measure. Reliab Eng Syst Saf 92:771–784. doi:10.1016/j.ress.2006.04.015
Borgonovo E, Peccati L (2006) Uncertainty and global sensitivity analysis in the evaluation of investment projects. Int J Prod Econ 104:62–73. doi:10.1016/j.ijpe.2005.05.024
Borgonovo E, Plischke E (2016) Sensitivity analysis: a review of recent advances. Eur J Oper Res 248:869–887. doi:10.1016/j.ejor.2015.06.032
Borgonovo E, Hazen GB, Plischke E (2016) A common rationale for global sensitivity measures and their estimation. Risk Anal 36:1871–1895. doi:10.1111/risa.12555
Campbell K, McKay MD, Williams BJ (2006) Sensitivity analysis when model outputs are functions. Reliab Eng Syst Saf 91:1468–1472. doi:10.1016/j.ress.2005.11.049
Cui L, Lu Z, Zhao X (2010) Importance measures of basic variable under multiple failure modes and their solutions. Sci Sinica Phys Mech Astron 40:1532–1541
Gamboa F, Janon A, Klein T, Lagnoux A (2013) Sensitivity indices for multivariate outputs. C R Math 351:307–310. doi:10.1016/j.crma.2013.04.016
Garcia-Cabrejo O, Valocchi A (2014) Global sensitivity analysis for multivariate output using polynomial chaos expansion. Reliab Eng Syst Saf 126:25–36. doi:10.1016/j.ress.2014.01.005
Genest C, Rivest L-P (2001) On the multivariate probability integral transformation. Stat Probab Lett 53:391–399. doi:10.1016/S0167-7152(01)00047-5
Greegar G, Manohar CS (2015) Global response sensitivity analysis using probability distance measures and generalization of Sobol's analysis. Probab Eng Mech 41:21–33. doi:10.1016/j.probengmech.2015.04.003
Helton JC (1999) Uncertainty and sensitivity analysis in performance assessment for the waste isolation pilot plant. Comput Phys Commun 117:156–180. doi:10.1016/S0010-4655(98)00171-4
Helton JC, Davis FJ (2003) Latin hypercube sampling and the propagation of uncertainty in analyses of complex systems. Reliab Eng Syst Saf 81:23–69. doi:10.1016/S0951-8320(03)00058-9
Hu Z, Du X (2015) Mixed efficient global optimization for time-dependent reliability analysis. J Mech Des 137:051401–051409. doi:10.1115/1.4029520
Hu Z, Mahadevan S (2016) Global sensitivity analysis-enhanced surrogate (GSAS) modeling for reliability analysis. Struct Multidiscip Optim 53:501–521. doi:10.1007/s00158-015-1347-4
Iman RL, Johnson ME, Watson CC (2005) Uncertainty analysis for computer model projections of hurricane losses. Risk Anal 25:1299–1312. doi:10.1111/j.1539-6924.2005.00674.x
Lamboni M, Makowski D, Lehuger S, Gabrielle B, Monod H (2009) Multivariate global sensitivity analysis for dynamic crop models. Field Crop Res 113:312–320. doi:10.1016/j.fcr.2009.06.007
Lamboni M, Monod H, Makowski D (2011) Multivariate sensitivity analysis to measure global contribution of input factors in dynamic models. Reliab Eng Syst Saf 96:450–459. doi:10.1016/j.ress.2010.12.002
Li C, Mahadevan S (2016) An efficient modularized sample-based method to estimate the first-order Sobol′ index. Reliab Eng Syst Saf 153:110–121. doi:10.1016/j.ress.2016.04.012
Li L, Lu Z, Wu D (2016) A new kind of sensitivity index for multivariate output. Reliab Eng Syst Saf 147:123–131. doi:10.1016/j.ress.2015.11.006
Lilburne L, Tarantola S (2009) Sensitivity analysis of spatial models. Int J Geogr Inf Sci 23:151–168. doi:10.1080/13658810802094995
Liu Q, Homma T (2009) A new computational method of a moment-independent uncertainty importance measure. Reliab Eng Syst Saf 94:1205–1211. doi:10.1016/j.ress.2008.10.005
Liu Q, Homma T (2010) A new importance measure for sensitivity analysis. J Nucl Sci Technol 47:53–61. doi:10.1080/18811248.2010.9711927
Liu H, Chen W, Sudjianto A (2006) Relative entropy based method for probabilistic sensitivity analysis in engineering design. J Mech Des 128:326–336. doi:10.1115/1.2159025
Morris MD (1991) Factorial sampling plans for preliminary computational experiments. Technometrics 33:161–174. doi:10.2307/1269043
Nannapaneni S, Hu Z, Mahadevan S (2016) Uncertainty quantification in reliability estimation with limit state surrogates. Struct Multidiscip Optim 54:1509–1526. doi:10.1007/s00158-016-1487-1
Patil SR, Frey HC (2004) Comparison of sensitivity analysis methods based on applications to a food safety risk assessment model. Risk Anal 24:573–585. doi:10.1111/j.0272-4332.2004.00460.x
Pianosi F, Wagener T (2015) A simple and efficient method for global sensitivity analysis based on cumulative distribution functions. Environ Model Softw 67:1–11. doi:10.1016/j.envsoft.2015.01.004
Plischke E (2012) An adaptive correlation ratio method using the cumulative sum of the reordered output. Reliab Eng Syst Saf 107:149–156. doi:10.1016/j.ress.2011.12.007
Plischke E, Borgonovo E, Smith CL (2013) Global sensitivity measures from given data. Eur J Oper Res 226:536–550. doi:10.1016/j.ejor.2012.11.047
Rizzo ML, Székely GJ (2016) Energy distance. Wiley Interdiscip Rev Comput Stat 8:27–38. doi:10.1002/wics.1375
Saltelli A (2002) Sensitivity analysis for importance assessment. Risk Anal 22:579–590
Saltelli A, Tarantola S (2002) On the relative importance of input factors in mathematical models: safety assessment for nuclear waste disposal. J Am Stat Assoc 97:702–709
Saltelli A, Tarantola S, Campolongo F (2000) Sensitivity Anaysis as an ingredient of modeling. Stat Sci 15:377–395. doi:10.1214/ss/1009213004
Saltelli A., Ratto, M., Andres, T. et al. (2008) Global sensitivity analysis. The primer. Wiley, New York
Saltelli A, Annoni P, Azzini I, Campolongo F, Ratto M, Tarantola S (2010) Variance based sensitivity analysis of model output. Design and estimator for the total sensitivity index. Comput Phys Commun 181:259–270. doi:10.1016/j.cpc.2009.09.018
Shi Y, Lu Z, Cheng K, Zhou Y (2017) Temporal and spatial multi-parameter dynamic reliability and global reliability sensitivity analysis based on the extreme value moments. Struct Multidiscip Optim:1–13. doi:10.1007/s00158-017-1651-2
Sobol’ IM (1976) Uniformly distributed sequences with additional uniformity properties. USSR Comput Math Math Phys 16:236–242
Sobol’ IM (1993) Sensitivity analysis for non-linear mathematical models. Math Model Comput Exp 1:407–414
Sobol’ IM (2001) Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates. Math Comput Simul 55:271–280. doi:10.1016/S0378-4754(00)00270-6
Sobol’ IM, Asotsky D, Kreinin A, Kucherenko S (2011) Construction and comparison of high-dimensional Sobol' generators. Wilmott 2011:64–79. doi:10.1002/wilm.10056
Székely GJ, Rizzo ML (2004) Testing for equal distributions in high dimension. InterStat 5:1–6
Székely GJ, Rizzo ML (2005) A new test for multivariate normality. J Multivar Anal 93:58–80. doi:10.1016/j.jmva.2003.12.002
Székely GJ, Rizzo ML (2013) Energy statistics: a class of statistics based on distances. J Stat Plann Infer 143:1249–1272. doi:10.1016/j.jspi.2013.03.018
Székely GJ, Rizzo ML, Bakirov NK (2007) Measuring and testing dependence by correlation of distances. Ann Stat 35:2769–2794
Wang Z (2017) Piecewise point classification for uncertainty propagation with nonlinear limit states. Struct Multidiscip Optim:1–12. doi:10.1007/s00158-017-1664-x
Wei P, Lu Z, Song J (2015) Variable importance analysis: a comprehensive review. Reliab Eng Syst Saf 142:399–432. doi:10.1016/j.ress.2015.05.018
Xiao N-C, Huang H-Z, Wang Z, Liu Y, Zhang X-L (2012) Unified uncertainty analysis by the mean value first order saddlepoint approximation. Struct Multidiscip Optim 46:803–812. doi:10.1007/s00158-012-0794-4
Xiong F, Greene S, Chen W, Xiong Y, Yang S (2010) A new sparse grid based method for uncertainty propagation. Struct Multidiscip Optim 41:335–349. doi:10.1007/s00158-009-0441-x
Xu X, Lu Z, Luo X (2017) A kernel estimate method for characteristic function-based uncertainty importance measure. Appl Math Model 42:58–70. doi:10.1016/j.apm.2016.09.028
Zhai Q, Yang J, Zhao Y (2014) Space-partition method for the variance-based sensitivity analysis: optimal partition scheme and comparative study. Reliab Eng Syst Saf 131:66–82. doi:10.1016/j.ress.2014.06.013
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Grant no. NSFC 51475370) and the fundamental research funds for the central university (Grant no. 3102015BJ (II) CG009). The authors are thankful to the anonymous reviewers for their valuable comments
Author information
Authors and Affiliations
Corresponding author
Appendix. Proof of Theorem 1
Appendix. Proof of Theorem 1
First, rewrite \( {\xi}_i={E}_{X_i}\left( d\left({X}_i\right)\right) \) as follows
According to the mean value theorem, there exists a value λ l ∈ [a l − 1, a l ] such that
Thus, it can be obtained that
When Δa → 0, the interval [a l − 1, a l ] → ξ l . Then based on the definition of Riemann integration, it can be obtained that
Rights and permissions
About this article

Cite this article
Xiao, S., Lu, Z. & Wang, P. Multivariate global sensitivity analysis for dynamic models based on energy distance. Struct Multidisc Optim 57, 279–291 (2018). https://doi.org/10.1007/s00158-017-1753-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00158-017-1753-x