
Abstract
Robust design optimization (RDO) is a popular framework for addressing uncertainties in the design of engineering systems by considering different statistical measures, typically the mean and standard deviation of the system response. RDO can lead to a wide range of different candidate designs, establishing a different compromise between these competing objectives. This work introduces a new robustness measure, termed probability of dominance, for assessing the appropriateness of each candidate design. This measure is defined as the likelihood that a particular design will outperform the rival designs within a candidate set. Furthermore, a multi-stage implementation is introduced to facilitate increased versatility/confidence in the decision-making process by considering the comparison among smaller subsets within the initial larger set of candidate designs. For enhancing the robustness in these comparisons the impact of prediction errors, introduced to address potential differences between the real (i.e. as built) system and the numerical model adopted for it, is also addressed. This extends to proper modeling of the influence of the prediction error, including selection of its probability model, as well as evaluation of its impact on the probability of dominance and on the RDO formulation itself. Two illustrative examples are presented, the first considering the design of a tuned mass damper (TMD) for vibration mitigation of harmonic excitations and the second a topology optimization problem for minimum compliance. Extensive comparisons are presented in these two examples and the discussions demonstrate the power of the proposed approach for assessing the designs’ robustness.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In engineering design, the performance predictions for the system under consideration may involve some level of uncertainty, stemming from the incomplete knowledge about the system itself and its excitation (Schuëller and Jensen 2008; Beck and Taflanidis 2013). Explicitly accounting for these uncertainties is exceptionally important for providing optimal configurations that exhibit a robust performance (Doltsinis 2004; Beck and Santana Gomes 2012). A probability logic approach provides a rational and consistent framework for performing this task (Jaynes 2003), employing probability models to characterize the relative plausibility of the different model parameter values. Within this setting, various formulations have been proposed for addressing the design of engineering systems under uncertainty (Schuëller and Jensen 2008; Doltsinis 2004; Beck and Santana Gomes 2012; Beyer and Sendhoff 2007), one of the more popular ones being Robust Design Optimization (RDO).
Typically, RDO is formulated (Beyer and Sendhoff 2007; Lee and Park 2001) by considering as objectives the mean value as well as the standard deviation of the performance (although different statistical measures can be also used), either within a multi-objective setting (Doltsinis 2004; Marler and Arora 2004) or, and perhaps more commonly, by formulating a single objective through the introduction of an appropriate weight between these two competing objectives (Dunning and Kim 2013; Lee and Park 2001). Different design can then be attained through this problem formulation either by varying the latter weight or by approaching the initial problem as an explicit multi-objective optimization, establishing a different compromise between the mean and standard deviation of the performance. Viewing this as a multi-objective optimization problem, these designs will lay on the region of the objective space defined as the Pareto frontier (Sawaragi et al. 1985). Frequently, this approach will provide designs that are fundamentally different in the design space, but exhibit similar robust traits (i.e. values for mean and variance). Selecting the most suitable design among the candidate set is then a challenging task, as it requires either some measure of appropriateness, or that a design stands out from the rest because of its superior performance (mean value) and robustness (standard deviation), which is, though, not the typical case as the two competing objectives usually conflict with one another.
The final design selection among the set of Pareto-optimal points, can be then viewed as the responsibility of a Decision Maker (DM) (Miettinen 1999). This selection process will typically involve the integration of additional criteria that were not part of the initial objective function formulation incorporating the DM preferences and experience. Normally, the DM preferences are explicitly quantified through adoption of a utility (or valued) function (Keeney and Raiffa 1993) which might entail some a posteriori modification of the problem objective/constraints. An interactive implementation can be also considered, with the DM providing explicit feedback during the solution phase (Reeves and Gonzalez 1989), which is though not the typical case in RDO applications, where the selection of a final design is executed after the Pareto-optimal designs have been generated (employing any desired method). A common preference function in this case (i.e., for RDO) for selecting the final design, especially when no other utility function is available and the DM cannot impose additional preferences a posteriori, is to use some metric between the Pareto-optimal points and a point of interest (Rangavajhala 2007), normally the utopia point, corresponding to the minimum mean and standard deviation treated as single-objectives for each instance (Beyer and Sendhoff 2007). This requires the definition of a proper norm (to quantify distance), and establishing a proper weighting of the two objectives for this purpose is not always straightforward.
This work introduces a new preferences measure, termed probability of dominance, and a multi-stage evaluation approach to aid the DM in assessing the appropriateness of different candidate designs within an RDO setting. This is intended to serve as an additional tool for the designer towards the selection of a preferred robust design, complementing any other preference and utility functions that may exist for the specific application of interest. The probability of dominance compares simultaneously the entire set of candidate designs and examines the favorability of each design for all different model parameter values. It is defined as the likelihood that the performance of a design will outperform all other designs in the set. This likelihood is quantified by considering the probabilistic description of the system uncertainties, explicitly incorporating all information available to the designer for comparing the available designs. A multi-stage implementation is also proposed that facilitates increased versatility in the decision-making process (and ultimately robustness) by considering the comparison among smaller subsets within the initial larger set of candidate designs. It should be stressed that this new preference measure requires a probabilistic definition of the uncertainties influencing the performance of the different designs under consideration, i.e. it is not devised for design selection of just any multi-objective problem.
For enhancing the robustness in the definition of the preference measure, the impact of prediction errors is introduced to address potential differences between the real (i.e. as built) system and the model adopted for it and quantify the incomplete information for the latter model (Weber 1987; Beck and Taflanidis 2013). Since inclusion of this error in the analysis has received little attention within the robust optimization literature, different aspects are examined in detail. This extends to proper modeling of the prediction error influence, including selection of a probability model for it, as well as its impact on the probability of dominance and on the RDO formulation. Two different error models are considered, corresponding to either additive or multiplicative influence of the prediction error, and comparisons are drawn between them. The correlation between the errors for different design configurations is also explored.
In the next section, the RDO formulation is reviewed, while in Section 3 the probability of dominance and the multi-stage formulation are introduced. Section 4 discusses the prediction error and then in Section 5 two illustrative examples are presented. The first one considers the design of a tuned mass damper (TMD) for vibration mitigation under harmonic excitations and the second one is a topology optimization problem of minimum compliance. Extensive comparisons are discussed in these two examples, with some emphasis on the influence of the prediction error on the robustness traits of the obtained solutions.
2 RDO problem formulation
Consider a system that involves some controllable parameters defined henceforth as design variables, and let \( \mathbf{x}=\left[{x}_1\ {x}_2 \dots {x}_{n_x}\right]\in X\subset {\mathbb{R}}^{n_x} \) be the vector of design variables where X denotes the bounded admissible design space. Moreover, let \( \boldsymbol{\uptheta} =\left[{\theta}_1\ {\theta}_2\dots {\theta}_{n_{\theta }}\right]\in \mathtt{\varTheta}\subset {\mathbb{R}}^{n_{\theta }} \) be the vector of uncertain model parameters (random variables) for the system model, where Θ denotes the set of their possible values defining the uncertain space. Α Probability Density Function (PDF) p(θ) - which incorporates our available knowledge about the system into its assumed numerical model - is assigned to these uncertain parameters. In addition, let \( h\left(\mathbf{x},\boldsymbol{\uptheta} \right):{\mathbb{R}}^{n_x \times {n}_{\theta }}\to \mathbb{R} \) be the scalar performance function characterizing the favorability of the system’s behavior for the design selection x and model configuration θ. The simplest case for h(.) is to correspond directly to the model response; nevertheless, in many engineering applications other utility functions can be chosen to characterize the system performance. Initially we will assume that the numerical model provides accurate predictions for the performance of the real system. The existence of errors in these predictions will be addressed later, in Section 4.
Under the influence of the uncertain parameters in θ, h(x,θ) is itself a random variable. For RDO, two different statistical measures of h(x,θ) are typically used to characterize and address the impact of uncertainty in the description of the system-model (Doltsinis 2004). The first one is the mean value for h(x,θ), given by
where E[.] stands for expected value, in this case under probability model p(θ), and the second one the standard deviation of h(x,θ), given by
Furthermore, σ 2(x) corresponds to the variance of h(x,θ).
RDO establishes a compromise between the minimization of the mean value of the performance and the minimization of the spread of this performance around this mean value. The latter directly influences the robustness characteristics of the approach by implicitly providing a measure of response variability in the RDO formulation. These two statistical measures, define the feasible objective space, \( \mathbf{F}\left(\mathbf{x}\right):=\left[\mu \left(\mathbf{x}\right)\ \sigma \left(\mathbf{x}\right)\right]\in F\subset {\mathbb{R}}^2 \), and most often conflict with each other; therefore, the RDO problem can be viewed as a multi-objective minimization of μ(x), and σ(x). A key feature of the objective space F(x) is the utopia point, corresponding to the minimum of μ(x) and σ(x), when each of them is viewed as a separate objective. This point corresponds to the best solution in F, but in general is unattainable. The compromise between μ(x), and σ(x) is typically expressed through the Pareto front, composed (Marler and Arora 2004) of the designs for which no other feasible design exists that will simultaneously improve both competing objectives (in other words, it cannot make one better without making the other worse).
Several different methods have been proposed for formulating/solving the multi-objective RDO problem (Marler and Arora 2004; Kalyanmoy and Gupta 2006). A popular approach for obtaining an approximation to the Pareto front is to employ the weighed sum as objective function, in which a single objective is formed by employing a weighted liner combination of μ(x), and σ(x). This is the approach adopted in this study, leading to the optimization problem
where any constraints are incorporated in the definition of the admissible design space X and the objective function defined as
where w ∈ [0, 1] is the weight parameter and μ n , σ n are normalization constants for the mean and standard deviation respectively. Commonly, μ n and σ n are selected as the minimum mean and standard deviation (Lee and Park 2001), denoted by μ ο and σ ο that can be obtained by solving (4) when considering w = 0 and w = 1 respectively. Τhe point [μ ο σ ο ] is in fact the utopia point (Beyer and Sendhoff 2007). Moreover, the solution to the probabilistic integrals in Eqs. (1) and (2) is challenging to obtain, since often a close form solution does not exist. Thus, different approaches have been proposed for performing the optimization in Eq. (3), mainly differentiated by the methodologies adopted for approximating the aforementioned integrals. The references (Beyer and Sendhoff 2007; Doltsinis 2004) offer a detailed review of these methods in the context of RDO.
Independent of the optimization approach adopted, solution of the multi-objective RDO problem will lead to a set of optimum designs Δ = {x * k , k = 1, …, m} composed of m different designs with corresponding objectives [μ(x k *) σ(x k *)]. Selection of a final design among this set requires the definition of an appropriate utility and preference functions to quantify appropriateness of each considered design. As discussed in the introduction, a common approach within RDO is to use as such preference function the distance in the objective space of each Pareto optimal point from the utopia point, which measures the departure of the established resultant probabilistic performance [μ(x k *) σ(x k *)] from the best (but unachievable) performance [μ ο σ ο ] using some appropriate weighted norm to calculate this distance. In this work a new probabilistic measure is introduced as a potential preference function that rather than looking at such resultant probabilistic measures or having to select an ad-hoc normalization, compares designs directly with one another with respect to the performance measure h(x,θ) over the uncertain parameter space.
3 Probability of dominance
Assume that a finite set of candidate designs Δ = {x k , k = 1,…, m} is provided, where each design is accompanied by their associated performance h(x k ,θ), and model parameters characterized by probability model p(θ). The framework discussed here ultimately provides a preference measure/index for assessing the appropriateness of each design, to aid the decision maker in the selection of a final design among the set members. Note that the approach is completely decoupled from the process of obtaining the set Δ; it simply assumes that some designs have been provided by the decision maker. This may correspond to a finite number of Pareto-optimal solutions for the problem under consideration, or to any desired set of candidate designs. For this purpose the explicit notation * to denote optimal design for x is not used henceforth.
3.1 Formulation for the entire set of candidate designs
The foundation of the method is the introduction of new preference measure, termed probability of dominance. This measure is defined as the likelihood that a candidate design x i outperforms its rival designs within the set Δ under probability model p(θ) for the uncertain model parameters. Based on the total probability theorem this probability of dominance P D is given by
where P D (x i |Δ, θ) stands for the probability of dominance given the model configuration θ and is equal to the probability that the performance for the i th design will outperform all other designs. Dominance is, thus, probabilistically attained when a particular design x i has a better performance h(x,θ) relative to other designs under a specific realization of the uncertain parameters θ.
Assuming that a smaller performance is preferable, one has
In the case that no prediction error is assumed for the model (the case with prediction error will be addressed later) this is also given by
and it finally corresponds to the indicator function
with the notation I(Δ i ,θ) used to symbolize the indicator function for the dominance of design i among the designs in set Δ.
The high-dimensional probability integral in (5) can be readily calculated through stochastic (Monte Carlo) simulation, leading to
where the N samples for θ, with θ j denoting the j th sample, are simulated from p(θ). Since we are ultimately interested in the dominant design, corresponding to a high probability, it is anticipated that this approach will yield satisfactorily results (adequate accuracy) without significant computational burden (necessity to select high values for N). The accuracy of the estimation can be assessed through the coefficient of variation of the estimator whereas variance reduction approaches, such as importance sampling, can be used if that accuracy needs to be improved (Robert and Casella 2004).
The probability of dominance ultimately corresponds to a weighted measure of the hyper-volume of the region over Θ where a particular design has a performance that is the best among the candidate designs, with the weight provided by the relative likelihood p(θ) of the model parameters θ within Θ. This probability P D (x i |Δ) can be then utilized as a preference index for assessing the appropriateness of each design. If no other indicators are used in the decision making process then the final design may be chosen as the dominant design, i.e. the one corresponding to the maximum P D (x i |Δ)
An advantage of this measure is that it is independent of the design process, which allows its application to any arbitrary group of designs. However, a caveat of the approach is the fact that the result depends on the exact designs contained in the set Δ, with the final outcome potentially changing even when non-dominant designs are introduced into (or removed from) the set of candidate designs. This can happen if the new design only dominates (that is, provides better performance) in regions of the uncertain space that the previous best design used to dominate, thus detracting from the favorability of the previously dominant design only (and not of any other designs). This may ultimately switch the preference, without this new design emerging as the new dominant.
3.2 Multi-stage formulation
To circumvent the challenge identified at the end of the previous section, and provide enhanced versatility and robustness in the choice of a most appropriate design, a multi-stage formulation is developed. Rather than looking at the dominance over the entire set Δ, the dominance within d-dimensional subsets of Δ containing d total designs is considered (simplest choice for d is 2). A design is then termed as d-dominant if it is the dominant one within the n d different d-dimensional subsets that include it. To formalize these ideas we will denote S d as the set of d-dimensional subsets of d, S d i as the set of d-dimensional subsets including design x i and will use subscript l to distinguish between the different elements of these sets (so S d l denotes the l th subset of Δ containing d designs). For instance, if Δ = {A, B, C, D}, then S 2 C = {[C A], [C B], [C D]} (thee candidate sets including two designs that have C as a member), S 3 C = {[C A B], [C A D]} (two candidate sets including three designs that have C as a member) whereas S 3 = {[C A B], [C A D], [D A B]} (three candidate sets including three total designs). The probability of dominance over subset S d il is then
where x dli k denotes the k th design within the S d il set. This probability can be evaluated though stochastic simulation as in Eq. (9), employing Eq. (8) to describe the probability function within the integrand. The transformed equations are
with
The design x i is defined to be dominant within the set S d il if it has the largest probability of dominance within the set and it is considered to be d-dominant if it dominates each subset within S d i . The overall preferred design could be taken as the one that is dominant within the lowest possible d-dimensional subsets considered. This does not necessarily mean that the chosen design will be dominant for higher values of d-dimensional subsets, but it exhibits the most robust dominance characteristics for the set Δ. For example, assume that a candidate design exhibits d = 2 dimensional dominance, then if some other design is removed from Δ, the candidate design will still enjoy the dominance property, whereas if an additional design is added, then if the older dominant design outperforms the newly added, it will also preserve its d = 2 dimensional dominance. Note that for certain values of d, it can be the case that no design emerges as dominant. For the example discussed in the first paragraph of this section, this will happen for the two-dimensional (d = 2) comparisons if A dominates B and D, but is dominated by C, whereas C is dominated at least by B. If on the other hand A dominates all B, C, and D (always within the context of individual comparisons) then A is the dominant design for the d = 2 dimensional subsets.
3.3 Quantification of preference within multi-stage implementation
Beyond just the simple notion of absolute dominance discussed above, i.e. which one is the best design, additional information that could be useful to guide the selection process is the relative dominance, i.e. how much better is one design over the next best alternative? To quantify a preference index associated with the relative dominance of a design, we define: (a) the margin of dominance between a particular design x i and the rest of the designs within set S d il as
and (b) the degree of dominance of the design over the d-dimensional subsets as
The margin of dominance corresponds to the difference between the probability of dominance for x i compared to the design among the ones remaining in S d il that has the highest probability of dominance. Positive values for this margin correspond to dominance of x i in subset S d il . The degree of dominance corresponds to the minimum of the margin of dominance for x i among all subsets that include it. A positive value for it corresponds to d-dimensional dominance for x i .
A robust preference towards a design can be then evaluated based on its degree of dominance by adopting a minimum threshold D t ≥ 0; The preferred design will be the one satisfying D d (x) ≥ D t , if one exists. If no design satisfies that condition, then, as discussed above, a larger value of d needs to be considered. More generally the degree of dominance can be used to provide guidance in the selection process; this is established by calculating D d (x) for different values of d and using this information to evaluate the different design choices. In this case, the final selection is made by the designer, with D d (x) serving as a tool aiding this decision. It can be the case that the designer will select a design with negative value D d (x) as long as (i) that value is close to zero (the opposite means that the design is significantly dominated and thus should probably be avoided) and (ii) the design has some other desired attributes (that ultimately guide the preference towards it).
Note that for all the computations required to identify the dominant design [relying on stochastic simulation as described by Eq. (12)] the same sample set θ j can be used. As such, the performance function evaluations (which could be computationally intensive for complex models) used in the estimation of Eq. (12) can be the same ones used for Eq. (9), and the former evaluation merely needs proper comparison of these performance evaluations (not re-computation of the performance). Furthermore, to reduce the overall burden the results from the comparison within the set Δ can be used to guide the priority of comparisons; designs for which P D (x i |Δ) is small are not expected to dominate within any considered d-dimensional set and can be given lower priority in the comparisons. Considering these observations, the computational framework for identifying the dominant design within set Δ = {x i , i = 1,…, m} (i.e. the design with lowest d-dimensional dominance) is the following:
-
Step 1
Generate a set of N samples {θ j} from p(θ) and evaluate the performance for each one to obtain the set {h(x i, θ j); i = 1,…,m j = 1,…,N}, if h(x i, θ j) is not readily available from the optimization stage.
-
Step 2
Calculate the probability of dominance for entire set Δ for each design i = 1,…,m by Eq. (12) utilizing the performance function evaluations from Step 1. Re-order the design based on their dominance P D (x i |Δ) to obtain set {\( {\underset{\bar{\mkern6mu}}{\mathbf{x}}}_c \), c = 1,…,m} and ignore any designs as deemed appropriate.
-
Step 3
Set d = 2 and start the comparison form the smallest possible subset class.
-
Step 4
Set c = 1 and start by considering the most dominant design based on P D (x i |Δ).
-
Step 5
For all subsets in S d c including \( {\underset{\bar{\mkern6mu}}{\mathbf{x}}}_c \) estimate the probability of dominance for all designs included in it \( \left\{{P}_D\left({\underset{\bar{\mkern6mu}}{\mathbf{x}}}_k\Big|{S}_{cl}^d\right);\ l=1,\dots, {n}_d,\ k=1,..,d\right\} \) using approximation in Eq. (12), calculated through the readily available performance function evaluations form Step 1. For the first subset comparisons (when d =2) this corresponds to comparison of a pair of designs and the probability of dominances for the compared designs are complimentary.
-
Step 6
Calculate the margin of dominance with Eq. (14) and the degree of dominance with Eq. (15). If the latter is greater than zero (or the chosen threshold D t ) then \( {\underset{\bar{\mkern6mu}}{\mathbf{x}}}_c \) is the overall dominant design and process can stop. Else set c = c + 1 and go back to Step 5, understanding that a lot of the necessary probabilities \( {P}_D\left({\underset{\bar{\mkern6mu}}{\mathbf{x}}}_k\Big|{S}_{\left(c+1\right)l}^d\right) \) have been already computed (when considering the smaller valued c’s). Perform Step 5 for the new \( {\underset{\bar{\mkern6mu}}{\mathbf{x}}}_c \) only if it could emerge as a dominant one, meaning if it has not yet been dominated by any of the previously considered designs.
-
Step 7
If all designs have been examined i.e. c = m, and no dominant design has been identified for the d-dimensional subsets then set d = d + 1 and go back to Step 4.
Through this approach, the design exhibiting the lowest possible d-dimensional dominance is identified. As will be illustrated later, this frequently (but not necessarily always) corresponds to 2-dimensional dominance and to a design having a large associated value of P D (x i |Δ). This design is guaranteed to outperform all other designs within the considered class of candidate designs. If the more general approach is adopted, i.e. the degree of dominance is evaluated for different values of d rather than the dominant design identified, the same computational approach is utilized with the only difference that the stopping criteria in Steps 6 and 7 for the identification process are ignored; rather, the evaluation is repeated for all desired values of d and all designs. The entire process will be illustrated in the examples considered later.
4 Impact of prediction error on the probability of dominance
The previous analysis assumed no error between the response of the actual system, denoted h s(x) henceforth, and that of its assumed model, h(x,θ) [in other words, it was taken that h s (x) = h(x,θ)]. The notation h s(x) is used to stress the fact that the real system is dependent on the exact design selection x, and its performance is independent of the numerical model assumed and thus of θ (although θ is obviously related to the system properties). This assumption, i.e. h s (x) = h(x,θ), is the reason why the probability P D (x i |S d il , θ) ultimately corresponds to the indicator function I(S d il , θ) in the analysis discussed in Section 3.
In any engineering application, though, the adopted model cannot describe exactly the behavior of the actual system (Beck 2010); a prediction error always exist and its incorporation in probabilistic analysis can have an impact on the design choices as has been shown recently in (Taflanidis and Beck 2010). This error, e, quantifies the difference between h s (x) and h(x,θ) and since it is unknown, it can be probabilistically described by assigning a probability density function p(e) for it, treating it like any other uncertain model parameter. This prediction error can be viewed as describing (a) un-modeled characteristics of the system model or (b) un-modeled uncertainties for θ (Beck 2010; Beck and Taflanidis 2013). In this section, the influence of this error on the probability of dominance will be investigated to enhance the robustness in the selection process of the final design. This will extend to the selection of appropriate probability models for this error, a task that has received limited attention for engineering design application. The two most common models will be considered for the impact of the error, these are either additive or multiplicative influence on h(x,θ). Furthermore, the assumption that e is independent of θ will be utilized (this ultimately means independence between p(θ) – or equivalently h(x,θ) – and e). The latter assumption introduces the largest amount of uncertainty in the problem formulation (Taflanidis and Beck 2010; Jaynes 2003) and is the reason adopted here (establishing a greater robustness), as it assumes the least amount of information imposed upon the problem description.
4.1 Correlation of errors between designs
Before moving forward, the correlation between errors for different design selections needs to be addressed, as this correlation will be important in assessing the probability P D (x i |S d il , θ). This correlation is expected to depend on the distance between x i and x k ; if the two designs are very similar, then any prediction errors for the system numerical model are expected to be the same for both of them since the system models examined (under design configurations x i and x k ) are similar. Note that assuming no correlation introduces the largest amount of uncertainty in the problem formulation, but in this case this is not a reasonable choice. In the examples considered later, an exponential function will be assumed for the correlation coefficient ρ ik between designs i and k given by
where ||x i − x k || v stands for the weighted Euclidean norm with v l weight for each component of vector x, while λ is the assumed decay rate of the exponential function. Exact selection of these terms will be discussed in the examples later. It should be stressed that, even though the use of exponential type of functions to describe correlation is popular in engineering applications (Lophaven et al. 2002), this choice is ultimately ad-hoc, especially due to the dependence on the chosen norm and decay rate λ, and if more information is available for the prediction error and its relationship to the design configuration, some different correlation structure can be adopted (Papadimitriou and Lombaert 2012) (note that this type of information is, though, not available in most practical engineering problems).
For the analysis in this section, a correlation coefficient ρ ik between designs will be utilized, assumed to be defined by the designer through any appropriate method chosen (Papadimitriou and Lombaert 2012), whereas in the examples, the impact of this correlation on the final design choice will be examined using the correlation function in Eq. (16). Next, the different modeling choices for the prediction error and their impact on the probability of dominance are discussed.
4.2 Additive prediction error
The most commonly used assumption for the prediction error is an additive influence [this agrees with the assumption commonly used for Bayesian system identification applications (Beck and Taflanidis 2013)], leading to
The mean for the system model is updated as
where E[e] is taken equal to zero in order to establish unbiased predictions. Similarly, the variance is transformed to
where σ 2 e is the variance of the prediction error and for the second to last equality the independence between e and h(x,θ) was utilized. These equations show that to characterize the statistics of interest, knowledge of only the mean and variance of the error is necessary, while to establish unbiased predictions the mean needs to be zero. This also agrees with modeling intuition: the error in Eq. (17) should be zero mean (the opposite would indicate a consistent bias in the predictions of the numerical model). Thus, the minimum additional information needed to quantify the error statistically is its variance. Based on this information, the probability model for p(e) is chosen as Gaussian with zero mean and variance σ 2 e . This Gaussian model is the probability model that maximizes the entropy, or equivalently, it incorporates the largest amount of uncertainty in the definition of p(e), assuming that only its mean and variance are known (Jaynes 2003), and is the reason why it is chosen.
Therefore, the only remaining question for the complete description of p(e) is: how should its variance be defined? Note that based on Eq. (17) the error in this case (and so its variance) has same units as the performance function. Rather than choosing the variance to be constant in the design space a reasonable assumption is to take the error statistics to be dependent upon the statistic of the system model. If the error is assumed to represent un-modeled uncertainties then σ 2 e should be set as a fraction of the variance of the system model
where γ is a proportionality constant. Note that this constant will typically have a small value since the error is expected to be small, at least if the engineering model predictions are expected to be close to the real system behavior. Through Eq. (20) the error statistics are scaled based on the variability observed for the system model and stemming from the uncertainty in θ; if that variability is small then so will be the error, showing that in fact the error does primarily address un-modeled uncertainties. If, on the other hand, the error is taken to represent also un-modeled characteristics of the system then a more reasonable assumption is to select it proportional to the second moment of the response, scaling the overall magnitude of the response
The latter components in Eq. (21), i.e. γ 2 μ 2(x), can be considered to address the un-modeled characteristics of the real system, with the first component representing the un-modeled uncertainties. Both these assumptions ultimately lead to an error variance that is dependent upon the design configuration σ 2 e = σ 2 e (x). Modeling assumption in Eq. (20) will be referred hereafter as variance proportional and modeling assumption in Eq. (21) as moment-proportional.
Once the error has been defined, the important question is how to incorporate it in the analysis for the probability of dominance? In other words, how is P D (x i |S d il , θ) modified by considering the influence of the prediction error. In this case P D (x i |S d il , θ) is expressed with respect to the real system behavior
and utilizing Eq. (17) to introduce the impact of the prediction error Eq. (22) is transformed to
where the superscript dli is omitted herein for notational simplicity and a subscript is used for e to denote the design configuration that each error term corresponds to. This then leads to
where the different inequalities in the latter expression are examined component-wise.
Considering now the vector
and based on the assumed probability model for each of the error terms, it will follow (Johnson and Wichern 2002) a Gaussian distribution with zero mean and covariance matrix with elements (the k th, and q th entry is presented below)
where a subscript is used to denote the relationship of the error’s standard deviation to the design configuration since such a relationship has been introduced based on Eqs. (20) or (21). For the diagonal elements of the covariance matrix this relationship simplifies to
Since the probability model for the error vector in Eq. (25) is known, the probability in Eq. (24) corresponds to the associated cumulative distribution function (CDF). This eventually leads to
and probability of dominance given by
where F G [Dh d il (θ), 0, Σ d il ] stands for the CDF of the multivariate Gaussian distribution with zero mean, and covariance matrix Σ d il with elements given by Eq. (26) obtained by comparing the error for the i th design to the error of each other element of S d il . This CDF is evaluated at the vector of differences between the performances of each of these designs to the performance of the i th design (recall this vector does not include the i th design), given by
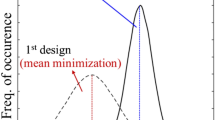
The introduction of the prediction error leads to modification of the initial indicator function, which was imposing a binary distinction for the system performance (either dominates or not), to a preference function. This function is expressed as the likelihood of dominance based on the difference between the performance of the design of interest and the performance of the other designs under consideration given by Eq. (30), as well as the statistics of the prediction error, introduced through the covariance matrix Σ d il . Note that this ultimately corresponds to analytical integration over the prediction error on the initial probabilistic integral of Eq. (22). Figure 1 illustrates this concept for a two-dimensional example (comparison of two designs). It is evident that increasing the prediction error variance (equivalent in this case to increasing β) provides a smoother transition between the two extreme cases, as the amount of uncertainty in the system description increases, reducing the confidence in assessing the real-system dominance when knowing the dominance characteristics for the model.

Likelihood function for comparison of x i against A = {x k } for different values of β 2 = σ 2 ei + σ 2 ek − 2σ ei σ ek ρ ik
Computationally, the probability of dominance with the prediction error can be still evaluated by Monte Carlo simulation as in Eq. (12) substituting P D (x i |S d il , θ j) with F G [Dh d il (θ j), 0, Σ d il ]. The latter multivariate CDF can be estimated by any standard numerical approach. In the example later, the highly efficient algorithm proposed in (Genz 1992) is adopted. For assessing the dominance over the entire set, the approach is same as above and simply needs to utilize Δ instead of S d il .
4.3 Multiplicative prediction error
Modeling prediction errors through a multiplicative assumption is also common in the engineering literature (Taflanidis et al. 2013; Porter et al. 2007), especially for performance function that must take strictly positive values. The relationship between system and model performance in this case is
with e > 0 corresponding to a dimensionless quantity. This modeling assumption for the prediction error addresses both un-modeled uncertainties and un-modeled characteristics in the numerical model since it directly scales the entire performance function (the option of addressing only un-model uncertainties does not exist here). The mean and variance for the real system, respectively, are
where E[e] is taken equal to one in order to establish unbiased predictions and the independence between e and θ was used in the third equality in both relationships above. Similarly to the case of additive prediction error, only the mean and variance of the error are necessary to determine the statistics of interest for the real system behavior. To establish unbiased predictions the mean of the error needs to be one. Since in this case the error e is dimensionless and directly scales the model performance, its variance should be independent of the characteristics of the model and so it is assumed to be σ 2 e = γ 2, with γ having typically a small value (similar justification as for additive error). Note that for the same value of γ there is an equivalence for the statistics of the real-system response between the multiplicative error and the additive error with moment-proportional variance modeled through Eq. (21). This is also consistent with the fact that both of these cases address both (i) un-modeled uncertainties and (ii) un-modeled system characteristics.
Furthermore, taking the log of Eq. (31) we have
which means then that the log(e) has an additive influence on the log of the performance. Based on this observation the common assumption for the multiplicative prediction error probability model is a lognormal distribution. This also agrees with the most appropriate model based on the maximum entropy principle if the available knowledge is assumed to be on the log of error (rather than the error itself) to circumvent the e > 0 constraint. This means that ε = log(e) follows a Gaussian distribution with mean and variance
where the approximation in the second equation is established assuming that σ 2 e is small and the first equality is necessary so that E[e] = 1.
The modification for P D (x i |S d il , θ) is in this case
which is then analyzed in a similar way as for the additive error since ε = log(e) is Gaussian, leading to
where Dl i dl (θ) is the vectors of the difference between the logarithms of the performance
and the covariance matrix Σ d il has elements
where \( {\overline{\rho}}_{ik} \) is the correlation between ε i = log(e i ) and ε k = log(e k ), which can be readily obtained (Law and Kelton 2000) based on the correlation of e i and e k , ρ ik , through
where the assumption that σ e is small was used for the approximation in the second equality.
Thus, the evaluation under the impact of multiplicative error follows exactly the same approach as for the additive error, simply replace the CDF in Eq. (28) with a similar CDF given by Eq. (37).
4.4 Impact of prediction error on the RDO formulation
Beyond the impact on the probability of dominance, the influence of the prediction error on the RDO designs can be also examined. In the objective function of Eq. (4) the statistics of the real system are substituted, leading to
with [μ sn σ sn ] corresponding to the new normalization, selected based on the utopia point for the real system [μ so σ so ]. For multiplicative prediction error or for additive prediction error with moment-proportional scaled variance of Eq. (21) this leads to
with μ so = μ o , σ so ≠ σ o . For the additive error with the scaling of Eq. (20) the new objective function is
with \( {\mu}_{so}={\mu}_o,{\sigma}_{so}=\sqrt{1+{\gamma}^2}{\sigma}_o \), and thus it remains identical to the objective function with respect to the system-model performance of Eq. (4) as long as the objective function is normalized with respect to the new utopia point. Note that as mentioned earlier, the expressions of the additive error with moment scaling and the multiplicative error yield the same model variance.
4.5 Summary for modeling/impact of the prediction error
This section addressed the influence of the model prediction error on the probability of dominance as well as on the RDO formulation. The modeling of this error was also extensively discussed and various reasonable modeling assumptions were presented, the most important being that the adopted numerical model for the system provides unbiased predictions for the expected performance. Additive and multiplicative impact of the error were considered and the assumed probability models were suggested to be (i) Gaussian with zero mean and variance scaled according to the statistics of the numerical model and (ii) lognormal with mean unity and a constant variance (independent of the model statistics). The additive prediction error can possibly be chosen to address only un-modeled uncertainties, with its variance scaled according to the response variance of the assumed numerical model (because of the modeled uncertainties θ). In this case, the formulation of the RDO problem is not impacted at all. The additive error can also be selected to address both un-modeled uncertainties and un-modeled system characteristics, with its variance scaled according to the second moment of the numerical model. This is equivalent to the multiplicative prediction error in terms of how it impacts the statistics of the real system performance and ultimately the RDO formulation.
Lastly, the impact of the modeling error on the probability of dominance can be readily addressed by substituting the indicator function describing the favorability of the design given the system model, with a likelihood function dependent upon the assumed probability model of the error and the model performance.
5 Illustrative examples
The proposed framework is now illustrated with two examples. The first example considers the design of a tuned mass damper (TMD) for vibration mitigation of harmonic excitations and extensive comparisons are established for a variety of different cases. These cases mainly vary in the probability models utilized for p(θ) and the error assumptions. Τhe second example discusses the topology optimization problem for minimum compliance and the discussion (due to space constraints) focuses only on specific cases of interest.
5.1 Design of a robust tuned mass damper
Tuned mass dampers (TMDs) are widely used to mitigate vibrations for a variety of different structural systems (Chang 1999; Karrem and Kline 1993; Kwon and Park 2004). They consist (as seen in Fig. 2) of a secondary mass, m d , connected to the primary mass through a spring with stiffness k s = ω 2 d m s and a dashpot with damping coefficient c d = 2ζ d ω d m d , where ω d represents the damper’s natural frequency and ζ d its damping ratio. Through the proper tuning of these two design variables (stiffness and damping) significant reduction of the response can be achieved for a variety of dynamic environmental excitations.

Schematic of single degree of freedom system with tuned mass damper. The equations of motion are also shown in the figure
The RDO of TMDs has been extensively discussed in the literature (Marano et al. 2008; Mohtat and Dehghan-Niri 2011; Debbarma et al. 2010; Zang et al. 2005). Here the design of a TMD to mitigate the vibrations of a bridge structure, modeled as a single degree of freedom (SDOF) system, under harmonic (monochromatic) excitation is considered, a problem similar to the one discussed in (Zang et al. 2005). Fig. 2 shows the details, a SDOF, with mass m s , stiffness k s = ω 2 s m s , and damping coefficient c s = 2ζ s ω s m s (where ω s represents the natural frequency and ζ s the damping ratio), equipped with a TMD is considered, under the impact of dynamic excitation F f (t). The mass of the damper m d is taken as 0.5 % of the median (i.e., nominal) mass of the structure. The design variables correspond to the damper stiffness and damping coefficient x = [k d c d ]T. The uncertain model parameters correspond to the mass, stiffness, and damping ratio of the structure, θ = [m s k s ζ s ]T. For all of these, independent lognormal distributions are assumed with coefficient of variation γ c and median values 17,500 kg for m s , 3 MN/m for k s and 3 % for ζ s . Two cases are considered for γ c , representing different levels of assumed uncertainty in θ, the first corresponding to 30 % coefficient of variation and the second to 10 % coefficient of variation. These cases will be termed large variability and small variability, respectively.
The performance function is taken as the maximum of the amplification factor, corresponding to the maximum of the dynamic response for a monochromatic excitation over every potential frequency ω. This ultimately leads to (Chang 1999)
where the auxiliary variables φ and β f correspond to the tuning ratio for the damper and the non-dimensional excitation frequency, respectively, while μ = m s /m d is defined as the mass ratio.
The RDO weight parameter w is varied from 0 to 1 with higher emphasis on lower weight values, w = [0, 0.1, 0.2, 0.3, 0.4, 0.6, 1] (this creates a balanced Pareto-front as will be shown later), leading ultimately to seven different designs configurations. The multivariate probabilistic integrals in Eq. (1) and Eq. (2) needed for the objective function are calculated using stochastic simulation, with the required expected values approximated as
where {θ j} is the sample-set used for θ, each element corresponding to a sample from p(θ). The total number of samples to generate the RDO designs is taken as N r = 2000 and an exterior sampling approach is adopted (Spall 2003) using the same set {θ j} over the entire optimization procedure, thus transforming the RDO problem in Eq. (3) into a standard deterministic optimization problem that can be solved by any numerical optimization approach (an exhaustive search is adopted here). The bounds of the design space X are selected as k d = [1 × 104 1.5 × 104] N/m and c d = [100 500] Ns/m.
The following cases are considered for comparison
-
i.
No prediction error, termed as NE
-
ii.
Additive prediction error with variance scaling according to Eq. (20) and γ chosen as 10 %. This case is termed as AE.
-
iii.
Additive prediction error with variance scaling according to Eq. (21) and γ chosen as 5 %. This case is termed as AE t .
-
iv.
Multiplicative prediction error with γ chosen same as in AE t . This case is termed as ME.
As discussed in Section 4, the NE and AE cases and ME and AE t cases lead to identical RDO designs when normalization is established with respect to the utopia point (as was done here). The higher value for γ chosen for AE compared to the value for AE t is selected so that similar values are established for the error variance σ 2 e between AE and AE t .
The results for the optimization are shown in Table 1, and in Figs. 3 and 4. In particular, Table 1 shows for the different weights, the optimal solution for k d and c d as well as the performance μ(x) and σ(x) under that optimal design configuration. For the AE t and ME the variance for the real system σ s (x) is reported (that is, under the influence of the prediction error). For the AE design this information is omitted since it merely corresponds to multiplication of σ(x) by \( \sqrt{1+{\gamma}^2} \). Figure 3 then shows the different optimal solutions in the design space X and Fig. 4 the Pareto-front in the normalized (with respect to utopia point) objective space F. The arrow in this figure represents the closest distance of any design from the utopia point. The closest point corresponds to the w = 0.4 design for all cases considered, and it would have been the preferred design based on this traditional approach for evaluation of appropriateness among RDO design.

Design space along with Pareto optimal designs that compose the set Δ for (a) large variability case, and (b) small variability

Pareto-front for the TMD RDO implementation of the (a) large and (b) small variability cases. Closest design to utopia point indicated with an arrow
Focusing first on the RDO results, it is evident that the uncertainty in the system description has an important impact on the robust design configuration. Different values for w lead to different optimal designs with the higher variability case (larger uncertainty in system description) contributing, as expected, to higher values of the system statistics (mean and standard deviation). The variation of the normalized values for these statistics is, though, smaller for this case (Fig. 4), and same principle applies for the optimal design configurations. This is easy to explain; because of the higher uncertainty in the system description the TMD has smaller comparative efficiency (more challenging to regulate the performance over the entire Θ region of importance) and as such the differences between the performance for different w values becomes smaller. The prediction error has an impact on the optimal design configuration (as seen by the differences in designs between AE t /ME and NE/AE) especially for the small variability case, something that is evident in Figs. 3 and 4. This should be attributed to the fact that for that case the impact of the system uncertainty is smaller (smaller variability in system characteristics), which allows the uncertainty induced by the error to influence more prominently the resultant design/performance.
The probability of dominance is examined next. This further requires definition of the correlation characteristics for the prediction error. The exponential function in Eq. (16) is adopted, with normalization weight v l selected as one over the length of the design domain for each design variable. The decay rate λ is selected so that correlation decrease is equal to ρ o = 5 % when the total change in the weighted distance reaches α = 30 %, leading to
This assumption leads to the following correlation matrices ρ jk between the different designs for the AE design case (due to space constraints the results for AE t /ME are not reported) for the large and small variability cases, respectively
The probability of dominance over Δ as well as the degree of dominance for 3 different values of d, equal to 2,3, and 4 are then calculated and shown in Tables 2, 3, 4 and 5. It is assumed in this case that the decision maker has chosen not to just identify the dominant design (based on the procedure outlined in Section 3.3), but to calculate the degree of dominance for three different d values (2, 3 and 4). Tables 2 and 4 show the results for the NE and AE designs for the large and small variability cases, respectively. Note that even though the designs corresponding to these cases (AE and NE) are the same, the probability of dominance will not be, since the latter design includes a prediction error (that influences this probability). Subsequently, Tables 3 and 5 show the results for the AE t and ME in similar fashion. The results will also be different, in this case, because of the different impact of the prediction error. 10,000 samples were used to calculate the statistics reported in these tables, facilitating a high-accuracy comparison.
Based on the probability of dominance P D (x i |Δ) over the entire set Δ, the design corresponding to w = 0 is deemed as the dominant one for all cases considered. Before making a final selection, the decision maker should additionally look into the margin of dominance to examine additional robustness traits. For the small variability case, this dominance is preserved when looking at lower dimensional subsets. This agreement provides confidence in the design selection since for all subsets considered, i.e. d = 2, 3, or 4, design w = 0 emerges as the more dominant one (degree of dominance for it has positive value), although the margin of dominance is somewhat reduced, dropping to just 15 % for d = 2 dimensional subsets. Aside from the most dominant design w = 0, the design corresponding to w = 0.1 emerges as the second most appropriate design for all cases considered. It is interesting to note that this design would have also been the second preferable one when looking at the entire set Δ. Introduction of the model prediction error has only a small influence on the estimated statistics, with the overall trend corresponding to a relative reduction of the preference, while degrees of dominance trend closer to 0 (note that this trend does not hold for all instances). No significant changes are reported for the degree of preference towards the w = 0 design. This should be attributed to the fact that the main rival design is w = 0.1, which has high correlation to the dominant design w = 0 based on the assumed correlation characteristics for the prediction error [close to 0.8–0.9 based on matrices Eqs. (47) and (48)]. As such, this error has only a small impact on the calculated statistics (see also discussion later in this section). It should be noted that if only the dominant design was to be identified (based on the framework discussed in Section 3.3) then the evaluation of the degree of dominance for all cases would start from the design corresponding to w = 0 and would immediately stop as soon as the positive degree of dominance for it D 2(x 1) was calculated.
For the high variability case, some of these trends change. Similarly, the w = 0 design maintains dominance when looking at the entire set Δ. However, it would not emerge as dominant for some of the cases considered when looking at the lower dimensional subsets. For the NE case, the w = 0.3 design emerges as the dominant one since it exhibits d = 2 dominance, although with a relatively small (degree of dominance 7.4 %). It is interesting to note than when looking at higher values for d, w = 0.3 quickly loses its dominance whereas even when looking at the entire set Δ its associated probability of dominance is rather small (7 %). Another interesting characteristics for the NE case is the fact that no design exhibits dominance for d = 3, 4 dimensional subsets, with all of them having negative values for the degree of dominance. Overall w = 0, w = 1 and w = 0.3 exhibit the highest probability of dominance but w = 0.3 possesses the most favorable degree of dominance based on the proposed multistage approach, focusing on lower d-dimensional dominance. This discussions demonstrate that looking solely at \( {\tilde{P}}_D\left({\mathbf{x}}_i\Big|\Delta \right) \) could not be enough, and investigating the dominance within smaller subsets becomes necessary. Comparisons among S 2 provide the more trustworthy information, since it is equivalent to one-on-one comparisons of the designs. Looking at larger dimensional subsets, conclusive information is not necessarily established for selecting a particular design, though some valuable insight is provided. It is up to the decision maker then to use this insight for selecting the final design.
The introduction of the error in this case has a bigger impact (compared to the low variability case); for AE the statistics change significantly when compared with the NE case, even though the compared designs are identical. This demonstrates the importance of explicitly accounting for the prediction error in the comparisons for the probability of dominance. For AE, the design w = 0.1 exhibits the lower dimensional dominance (d = 2), though with a very small margin (degree of dominance 3 %), whereas two other designs, w = 0.2 and w = 0.1, show good performance (degree of dominance as large as −5 %). For this instance, (dominance by only a small margin) one would be interested in looking at higher values for d before assessing overall robustness, and in this case it is evident that w = 0 exhibits better robustness characteristics. The previous discussion indicates that beyond the degree of dominance being positive, its value should be also taken into account by the designer in assessing the preferences towards different designs. Looking next at the other cases, for the ME and AE t cases the characteristics for dominance also change (compared to the NE case), although with smaller margins. For ME w = 0 emerges as the dominant design, exhibiting both d = 2 and d = 4 dominance (but not d = 3 for which no design emerges as dominant, with w = 0 having the better performance overall). For AE t designs w = 0 and w = 0.1 are practically equal. In this case the decision needs to be based on comparisons of higher order values for d, which tilts the preference towards w = 0. The big impact of the prediction error on the preference towards different designs for the high variability case can be explained based on the inability of the TMD to efficiency suppress vibrations over the entire important Θ region; thus, close performance is established by a few different designs and this is why the different preference for this performance given by the different error-model selections can ultimately shift the dominance towards different designs.
To further examine the influence of the correlation of the error on the results, Table 6 shows the probability of dominance for some of the design-cases considered (AE and ME for small variability case and AE for large variability case) if no such correlation is assumed. Comparison of these results to the results in Table 2 (for AE and large variability), Table 4 (for AE and small variability) and Table 5 (for ME and small variability) shows small differences for the AE case when small variability is assumed for the system description, but large for the other two cases. For the large variability case (AE) the differences are large enough to impact the dominance of the designs over the d = 2 and 3 dimensional subsets; when no correlation is considered for the prediction error the design w = 0 emerges as the dominant design which was not the case before. This discussion shows that the assumed correlation of the prediction error can have an impact on the calculated statistics, so it should be carefully chosen.
It is also interesting to note that in no case examined the design selected through the degree of dominance coincides with the one corresponding to the minimum distance from the utopia point (w = 0.4 as previously shown). In all cases examined and for all different values considered for d the latter design has a rather small associated value for the degree of dominance, and thus would have been avoided through the proposed approach. This demonstrates the utility of the new methodology for offering an alternative preference measure in assessing the robustness characteristics of different proposed designs.
5.2 Robust topology optimization for minimum compliance
Topology optimization searches for the structural configuration (shape and connectivity of the structure), contained within a given design domain X, that for some given boundary and loading conditions provides the most favorable response in terms of some chosen performance measure (Bendsøe and Sigmund 2003). A popular approach to obtain the solution is to discretize the domain into finite elements and select the densities of each element as design variables x e ∈ [0, 1], e = 1,…,N e (typically interpolated between two states: either void or full material), where N e corresponds to the total number of elements. The performance objective is typically taken as the minimization of the compliance c(x) for a given structural domain, subject to a prescribed mass fraction constraint m f such that m X ≤ m f , where m X denotes the domain’s mass fraction, which can be computed as
For a linear elastic material, the compliance is a function of the global displacement U (found through the finite element method) and the global stiffness matrix K (Bendsøe and Sigmund 2003). Here the problem is relaxed by employing the Solid Isotropic Material with Penalization (SIMP) formulation (Rietz 2001), leading to the compliance function given by (Sigmund 2001)
where p p is a penalization factor employed to avoid intermediate densities (i.e. to drive each element towards a particular state: either void or full material), u e is the local displacement vector for a given element, and k o is the element’s stiffness matrix which in turn is a function of the poison ratio ν and the modulus of elasticity E e of the element.
The gradient of the compliance can be analytically obtained (Bendsøe and Sigmund 2003) as
More information on the general topology optimization design problem as well as on different solution strategies may be found in (Bendsøe and Sigmund 2003).
The RDO formulation has been extensively employed for addressing uncertainties within topology optimization applications (Chen et al. 2010; Dunning et al. 2011; Tootkaboni et al. 2012; Dunning and Kim 2013). A problem similar to the one presented by Chen et al. (2010) is adopted here: a rectangular design domain, with length double its height, is subjected to a central point load at the bottom with simply supported conditions (Fig. 5). The design domain is discretized into 100x50 elements (resulting in N e = 5000) and the mass fraction is taken as m f = 0.3 (meaning that 30 % of the domain may be occupied). The uncertain model parameters correspond to (i) the loading conditions, where the component of the load in the horizontal direction F x is assumed to follow a uniform distribution in [−1, 1] and the component of the load in the vertical direction F y a uniform distribution in [0, 2], and (ii) to the Young’s moduli for each element, assumed to follow a lognormal distribution with median 1 and coefficient of variation of 0.2. The performance function is directly taken as the compliance of the structure h(x,θ) = c(x,θ).

Topology optimization RDO problem formulation
The solution to the optimization problem Eq. (3) is obtained with the Method of Moving Asymptotes (MMA) (Svanberg 1987), which is a popular algorithm to solve topology optimization problems. To avoid a solution with intermediate densities, a penalization factor of p p = 3 is employed. In addition, to avoid the problem where a checker-board pattern emerges causing artificial stiffness, a filter with size of 1.2 is employed. More details about the selection of these parameters can be found in (Bendsøe and Sigmund 2003). This solution approach ultimately required the gradient of the objective function, meaning the gradients for the mean and variance of the response. Assuming that the functions c(x,θ)p(θ) and ∂c(x,θ)/∂x i p(θ) are continuous on the domain X × Θ and bounded, while also noting that p(θ) does not depend on x, the differentiation and the expectation operators commute (Spall 2003), leading to the following expressions for the elements of these gradients
All expected values required for the above expressions within the optimization algorithm are obtained through stochastic simulation employing again exterior sampling (as in the TMD optimization case) with total of N r = 2000 samples. Note that for the case corresponding to the multiplicative error or the moment-proportional additive error, the partial derivatives for the system variance, needed in the objective function of Eq. (42) are transformed to
In this example, the value of w was varied from 0 to 1 with equal steps of 0.2, whereas only the following three cases are considered
-
i.
No prediction error, termed as NE
-
ii.
Additive prediction error with variance scaled according to Eq. (20) and γ chosen as 10 %. This case is termed as AE.
-
iii.
Multiplicative prediction error with γ chosen as 5 %. This case is termed as ME.
The resultant optimal solutions were very similar for the NE/AE and ME cases (almost identical topologies), thus the various results are primarily reported for the former only. The optimal topologies for different values of w are shown in Fig. 6 whereas the statistics (mean and standard deviation) in Table 7. 5,000 samples were used for the statistics reported in this table, facilitating, again, a high-accuracy comparison. Figure 7 shows the Pareto-front in the normalized (with respect to utopia point) objective space F for all three design cases considered. The arrow in this figure represents the closest distance of any design from the utopia point. The closest point corresponds to the w = 1 design for all cases, and it would have been the preferred design based on this traditional approach for evaluation of appropriateness among RDO design.

Optimal topologies for different values of w for the NE/AE designs

Pareto-front for the Topology RDO implementation. Closest design to utopia point indicated with an arrow
These results agree with the ones reported by Chen et al. (2010) where asymmetry is observed in the optimum designs due to asymmetric boundary conditions. It is possible to observe that the different designs have a similar statistical response even though they correspond to distinct topologies. In fact, the values for μ and σ between the different designs are so similar that it would be very challenging to select a preferred design from the set solely based on these statistics. The probability of dominance, which in this case corresponds to the probability of having a lower compliance over Θ, provides a rational measure for assessing the appropriateness of the candidate designs. For the correlation of the prediction error needed to calculate this probability (and similar to the TMD example), the exponential function in Eq. (16) is adopted, with normalization weight v l selected as one and decay rate λ selected so that correlation-decay is equal to ρ o = 5 % when the total change in the weighted distance between designs reaches α = 30 % [as described by Eq. (46)]. This assumption leads then to the following correlation matrix ρ jk between the different designs for the AE design case (due to space constraints the results for ME design not reported)
The probability of dominance over Δ as well as the degree of dominance for 2 different values of d (equal to 2 and 3) are shown in Table 8. As in the TMD example, rather than just identifying the dominant design based on the procedure outlined in Section 3.2, the degree of dominance for different d values is reported to facilitate a more thorough comparison.
For the NE case, design w = 0 emerges as the dominant one when looking at the entire set Δ, with that preference also upheld over d = 2 (S 2) subsets and d = 3 (S 3) dimensional subsets. For the d = 3 case actually no design emerges as dominant [values of D 3(x i ) are negative for all of them], though for the w = 0 design the value of D 3(x i ) is very close to zero, and much larger than all other designs, indicating a strong preference for it, especially when combined with the information for dominance over Δ and over the two-dimensional subsets. It is interesting to note that design w = 0.2 is close to being dominant over the two dimensional subsets [value of D 2(x i ) only slightly negative] but has poor performance when looking at the three dimensional subsets or at the entire set Δ. This stresses the importance of looking at different subsets to evaluate the preference toward a specific design, especially when the dominance properties it exhibits have a narrow margin (values close to zero). When incorporating the additive prediction error in the analysis (AE case in Table 8), we see significant differences in the calculated probabilities. This should be attributed to the fact that the compared designs have very similar statistical characteristics (as shown in Table 7), contributing to stronger influence from the prediction error. Design w = 0 still emerges as the preferred one when looking at lower dimensional subsets (d = 2 or 3, nothing though that for d = 3 there is no dominance) but with much smaller margins compared to the NE case, whereas when looking at the entire set Δ it practically ties with the w = 1 design. Changing the probability model for the prediction error to multiplicative influence (ME case), changes its overall impact. Though the prediction error still has a strong influence on the calculated probability of dominance (changes over the NE case) the relative impact as compared to the AE case changes, without, though, a change in the overall preference (w = 0 is still the dominant design with actually increased robustness margins when looking at the lower dimensional subsets). This validates the previous conclusions that the prediction error model may have an impact on the results.
Finally is also interesting to note that, like the TMD example, in no case examined the design selected through the degree of dominance coincides with the one corresponding to the minimum distance from the utopia point (w = 1 in all cases as previously discussed). Though the w = 1 design has competitive values when considering the probability of dominance over the entire set Δ, for some cases it corresponds to rather small values for the probability of dominance for lower values of d, and would have been avoided through the proposed approach. This further demonstrates the utility of the new methodology for assessing the robustness characteristics of different proposed designs.
6 Conclusions
A novel approach for assessing the appropriateness of a set of candidate designs was introduced based upon the definition of a new robustness measure, termed probability of dominance. This measure is defined as the likelihood that a given design will outperform the rival designs within the candidate set. Given that the resultant probability is a function of the exact designs composing the set, a multi-stage approach was also formulated for enhancing robustness of the chosen solution. This approach compares designs within smaller dimensional subsets and searches for the design that dominates within all subsets that include it. For evaluating the relative preference towards a design the degree of dominance is introduced, which is obtained by comparing the probability of dominance for the candidate design against the probability of dominance of all other designs within all different subset that the candidate design belongs to. This degree of dominance can be utilized as a tool to guide the selection of the final design, with absolute dominance corresponding to a positive value for it. For enhancing the robustness in this selection the impact of prediction errors between the real system and the assumed numerical model was additionally investigated. Two different error models were explored; these correspond to either an additive or multiplicative influence, while reasonable assumptions for selecting the error characteristics were discussed in detail. The additive prediction error can be ultimately chosen to address two different sources of modeling uncertainty. It can be selected to address only un-modeled uncertainties, when its variance is scaled according to the response variance of the assumed numerical model. If this assumption is selected, the formulation of the RDO problem is not impacted at all. This error can also be also selected to address both un-modeled uncertainties and un-modeled system characteristics, when its variance is scaled according to the second moment of the numerical model. This in turn is equivalent to the multiplicative prediction error in terms of how it impacts the statistics of the real system performance and ultimately the RDO formulation. In addition, it was shown that when modeling errors are considered, the impact on the probability of dominance corresponds to substitution of the indicator function, describing the favorability of each design, by a likelihood function dependent upon the assumed probability model of the error and the model performance.
Two RDO illustrative examples were presented, the first considering the design of a tuned mass damper (TMD) for vibration mitigation of harmonic excitations, and the second the robust topology optimization for minimum compliance. It was shown in these examples that the new approach provides an alternative to the established popular methodologies for assessing the appropriateness of the candidate designs. Thus, it ultimately equips designers (decision maker) with an additional tool in the search for a preferred design. The results also showed that looking solely at the probability of dominance (over the entire set) does not always lead to the most appropriate choice. Comparison among smaller dimensional subsets can guide decisions better and further facilitate a deeper understanding of the preference toward each design, even when none emerges as dominant. It was also demonstrated that beyond the degree of dominance being positive, its value should also be taken into account by the designer in assessing the preferences for different designs. Small values for the degree of dominance should be carefully examined by the designer when evaluating the different designs. Moreover, it was shown that explicitly including the prediction error in the comparison can have a significant impact on the assessment. In this case, the assumed correlation of the prediction error between different designs needs to be carefully considered. The influence of the prediction error is especially critical when the compared designs have similar statistical performance despite corresponding to different design configurations. In general, the proposed method showed promising results and provided a rational framework for assessing the appropriateness of a set of candidate robust designs.
Abbreviations
- γ :
-
Parameter associated with definition of prediction error variance
- Δ:
-
Set of candidate designs
- ε :
-
Log of error when it is incorporated through a multiplicative formulation
- Θ:
-
Uncertain Space
- θ :
-
uncertain model parameters
- {θ j}:
-
Set of samples from p(θ)
- λ :
-
Decay rate for exponential correlation function
- μ(x):
-
Mean for system model
- μ s (x):
-
Mean for real system
- [μ o σ ο ]:
-
Utopia point (minimum mean and standard deviation) for system model
- [μ s σ s ]:
-
Utopia point (minimum mean and standard deviation) for real system
- v l :
-
Weight for defining norm for exponential correlation
- ρ ik :
-
Correlation function for the prediction errors associated with designs x i and x k
- Σ d il :
-
Covariance matrix for the vector composed of the error for i th design subtracting the errors from each of the designs in S d il
- σ(x):
-
Standard deviation for system model
- σ e :
-
Standard deviation for prediction error
- σ s (x):
-
Standard deviation for real system
- d :
-
Dimension of subsets of Δ under consideration
- D d (x i ):
-
Degree of dominance of design x i against the d-dimensional subsets
- D t :
-
Threshold for acceptable dominance level
- Dh d il (θ):
-
Vector of the different between performance for i th design and the performance of the designs in S d il
- Dl d il (θ):
-
Version of Dh d il (θ) utilizing log of performance
- Ε[.]:
-
Expectation for random variable
- e :
-
Prediction error
- F G [.]:
-
Gaussian cumulative distribution function
- f(x):
-
Objective function
- h(x, θ):
-
Performance function for system model
- h s (x):
-
Performance function for real model
- I(A i , θ):
-
Indicator function for dominance of x i against set A for given θ
- . i :
-
Subscript i. Characteristic associated with the i th design
- M d il :
-
Margin of dominance for design x i within set S d il
- m :
-
Number of designs in Δ
- N :
-
Number of samples for stochastic simulation
- n θ :
-
Dimension of θ
- n x :
-
Dimension of x
- P D (x i |A):
-
Probability of dominance of design x i over set A
- P D (x i |A,θ):
-
Probability of dominance of design x i over set A given the system configuration θ
- \( {\tilde{P}}_D\left({\mathbf{x}}_i\Big|A\right) \) :
-
Probability of dominance of design x i over set A calculated through Monte Carlo simulation
- p(θ):
-
Probability density function for θ
- p(e):
-
Probability model for prediction error
- S d :
-
Set of all possible d-dimensional subsets of Δ
- S d i :
-
Set of d-dimensional subsets of Δ including design x i
- S d il :
-
l th subset of d-dimensional subsets of Δ including design x i
- w :
-
Weight used in the RDO formulation
- X :
-
Admissible design space
- \( \underset{\bar{\mkern6mu}}{\mathbf{x}} \) :
-
Ordered of candidate designs based on probability of dominance P D (x i |Δ)
- x :
-
Design variable vector
- x dli k :
-
k th design within the S d il set
References
Beck JL (2010) Bayesian system identification based on probability logic. Struct Control Health Monit 17(7):825–847
Beck AT, Santana Gomes WJ (2012) A comparison of deterministic, reliability-based and risk-based structural optimization under uncertainty. Probabilistic Eng Mech 12:18–29
Beck JL, Taflanidis A (2013) Prior and posterior robust stochastic predictions for dynamical systems using probability logic. J Uncertain Quantif 3(4):271–288
Bendsøe MP, Sigmund O (2003) Topology optimization: theory, methods, and applications. Springer Verlag, Berlin, Germany
Beyer H-G, Sendhoff B (2007) Robust optimization - a comprehensive survey. Comput Methods Appl Mech Eng 196:3190–3218
Chang CC (1999) Mass dampers and their optimal designs for building vibration control. Eng Struct 21:454–463
Chen S, Chen W, Lee S (2010) Level set based robust shape and topology optimization under random field uncertainties. Struct Multidiscip Optim 41(4):506–534
Debbarma R, Chakraborty S, Kumar Ghosh S (2010) Optimum design of tuned liquid column dampers under stochastic earthquake load considering uncertain bounded system parameters. Int J Mech Sci 52(10):1385–1393
Doltsinis I (2004) Robust design of structures using optimization methods. Comput Methods Appl Mech Eng 193(23–26):2221–2237
Dunning PD, Kim HA (2013) Robust topology optimization: minimization of expected and variance of compliance. AIAA J 51(11):2656–2664
Dunning PD, Kim HA, Mullineux G (2011) Introducing loading uncertainty in topology optimization. AIAA J 49(4):760–768
Genz A (1992) Numerical computation of multivariate normal probabilities. J Comput Graph Stat 1(2):141–149
Jaynes ET (2003) Probability theory: the logic of science. Cambridge University Press, Cambridge, UK
Johnson RA, Wichern DW (2002) Applied multivariate statistical analysis, 5th edn. Hall Prentice, Upper Saddle River
Kalyanmoy D, Gupta H (2006) Introducing robustness in multi-objective optimization. Evol Comput 14(4):463–494
Karrem A, Kline S (1993) Performance of multiple mass dampers under random loading. J Struct Eng ASCE 121(2):348–361
Keeney RL, Raiffa H (1993) Decisions with multiple objectives: preferences and trade-offs. Press Cambridge University, Cambridge
Kwon S-D, Park K-S (2004) Suppression of bridge flutter using tuned mass dampers based on robust performance design. J Wind Eng Ind Aerodyn 92(11):919–934
Law AM, Kelton WD (2000) Simulation modeling and analysis, 3rd edn. Mc.Graw Hill, Boston, MA
Lee K-H, Park G-J (2001) Robust optimization considering tolerances of design variables. Comput Struct 79(1):77–86
Lophaven SN, Nielsen HB, Sondergaard J (2002) Aspects of the MATLAB toolbox DACE. Informatics and mathematical modelling report IMM-REP-2002-13. Technical University of Denmark
Marano GC, Sgobba S, Greco R, Mezzina M (2008) Robust optimum design of tuned mass dampers devices in random vibrations mitigation. J Sound Vib 313(3–5):472–492
Marler RT, Arora JS (2004) Survey of multi-objective optimization methods for engineering. Struct Multidiscip Optim 26:369–395
Miettinen K (1999) Nonlinear multiobjective optimization. Kluwer Academic Publishers, Dordrecht
Mohtat A, Dehghan-Niri E (2011) Generalized framework for robust design of tuned mass damper systems. J Sound Vib 330(5):902–922
Papadimitriou C, Lombaert G (2012) The effect of prediction error correlation on optimal sensor placement in structural dynamics. Mech Syst Signal Process 28:105–127
Porter KA, Kennedy RP, Bachman RE (2007) Creating fragility functions for performance-based earthquake engineering. Earthquake Spectra 23(2):471–489
Rangavajhala S (2007) Decision making in design under uncertainty with multiobjective robust design optimization. Renssealer Polytechnic Institute, Troy, NY
Reeves GR, Gonzalez JJ (1989) A comparison of two interactive MCDM procedures. Eur J Oper Res 41:203–209
Rietz A (2001) Sufficiency of a finite exponent in SIMP (power law) methods. Struct Multidiscip Optim 21(2):159–163
Robert CP, Casella G (2004) Monte Carlo statistical methods, 2nd edn. Springer, New York, NY
Sawaragi Y, Nakamura H, Tanino T (1985) Theory of multiobjective optimization. Academic Press New York, NY
Schuëller GI, Jensen HA (2008) Computational methods in optimization considering uncertainties - an overview. Comput Methods Appl Mech Eng 198(1):2–13
Sigmund O (2001) 99 line topology optimization code written in Matlab. Struct Multidiscip Optim 21(2):120–127
Spall JC (2003) Introduction to stochastic search and optimization. Wiley-Interscience, New York
Svanberg K (1987) The method of moving asymptotes - a new method for structural optimization. Int J Numer Methods Eng 24(2):359–373
Taflanidis AA, Beck JL (2010) Reliability-based design using two-stage stochastic optimization with a treatment of model prediction errors. J Eng Mech 136(12):1460–1473
Taflanidis AA, Vetter C, Loukogeorgaki E (2013) Impact of modeling and excitation uncertainties on operational and structural reliability of tension leg platforms. Appl Ocean Res 43:131–147
Tootkaboni M, Asadpoure A, Guest JK (2012) Topology optimization of continuum structures under uncertainty-a polynomial chaos approach. Comput Methods Appl Mech Eng 201–204:263–275
Weber M (1987) Decision making with incomplete information. Eur J Oper Res 28(1):44–57
Zang C, Friswell MI, Mottershead JE (2005) A review of robust optimal design and its application in dynamics. Comput Struct 83(3–5):315–326
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Medina, J.C., Taflanidis, A. Probabilistic measures for assessing appropriateness of robust design optimization solutions. Struct Multidisc Optim 51, 813–834 (2015). https://doi.org/10.1007/s00158-014-1160-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00158-014-1160-5