
Abstract
It is known that the conventional adaptive filtering algorithms can have good performance for non-sparse systems identification, but unsatisfactory performance for sparse systems identification. The normalized least mean absolute third (NLMAT) algorithm which is based on the high-order error power criterion has a strong anti-jamming capability against the impulsive noise, but reduced estimation performance in case of sparse systems. In this paper, several sparse NLMAT algorithms are proposed by inducing sparse-penalty functions into the standard NLMAT algorithm in order to exploit the system sparsity. Simulation results are given to validate that the proposed sparse algorithms can achieve a substantial performance improvement for a sparse system and robustness to impulsive noise environments.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Adaptive filtering algorithms have received much attention over the past decades and are widely used for diverse applications such as system identification, adaptive beamforming, interference cancelation and channel estimation [15, 19, 30, 35]. The least mean square (LMS) algorithm, introduced by Widrow and Hoff [41], has become one of the most popular methods for adaptive system identification due to its simplicity and low computational complexity. The normalized least mean square (NLMS) was also proposed to further improve the identification performance [34, 41]. There is a trade-off between lower steady-state error and fast convergence rate in LMS and NLMS. However, their major drawbacks are slow convergence and performance degradation with colored input signals or in the presence of heavy-tailed impulsive interferences [33]. Therefore, in order to overcome these limitations, a normalized robust mixed-norm RMN (NRMN) algorithm [26, 27] was presented by using the variable step size instead of the fixed step size of the RMN algorithm [7]. Nevertheless, it needs to know the variance of the white noise and impulsive noise. In the recent years, adaptive filtering algorithms that were based on high-order error power (HOEP) conditions were proposed [13, 28, 39] which can improve the convergence rate performance and mitigate the noise interference effectively. The least mean absolute third (LMAT) algorithm is based on the minimization of the mean of the absolute error value to the third power [12, 13]. The error function is a perfect convex function with respect to the filter coefficients, so there is no local minimum for the LMAT algorithm. The LMAT algorithm often converges faster than the LMS algorithm and is suitable for various noise conditions [23]. To alleviate the dependence of the input signal power effect, a normalized form of LMAT (NLMAT) algorithm is proposed in [43]. The NLMAT algorithm exhibits good stability and can mitigate non-Gaussian impulsive noise.
In many physical scenarios, the unknown systems to be identified exhibit sparse representation, i.e., their impulse response has few nonzero (dominant) coefficients, while most of the coefficients are zero or close to zero. Such systems are encountered in many practical applications such as wireless multipath channels [1], acoustic echo cancelers [4] and digital TV transmission channels [31]. The channel impulse response in an acoustic system is relatively long due to the presence of echoes, but is zero for most of the time. Such a system is said to be sparse, meaning that many of the terms in the impulse response are zero, while only a few terms are nonzero. It is worthy to note that if the a priori knowledge about the system sparsity is properly utilized, the identifying performance can be improved. However, all of the above-mentioned algorithms do not take into account such sparse prior information present in the system and may lose some estimation performance.
Recently, many sparse adaptive filter algorithms that exploit system sparsity have been proposed, notable among them being the proportionate normalized LMS (PNLMS) algorithm [17] and its variants [5, 11, 14, 22]. On the other hand, motivated by the least absolute shrinkage and selection operator (LASSO) [38] and the recent research in compressive sensing [3, 6, 16], an alternative approach to identify sparse systems has been proposed in [10]. The approach applies ℓ1 relaxation, to improve the performance of the LMS algorithm. To achieve further performance improvement, adaptive sparse channel estimation methods using reweighted ℓ1-norm sparse-penalty LMS (RL1-LMS) [36, 37] and non-uniform norm constraint LMS (NNC-LMS) [42] were also proposed. Under the Gaussian noise model assumption, these algorithms exhibit improved performance in comparison with the traditional adaptive filters. Recently, a novel ℓ0-norm approximate method based on the correntropy-induced metric (CIM) [32] is widely used in sparse channel estimation [18, 21, 24, 40]. However, these methods may be unreliable in estimating the system under non-Gaussian impulsive noise environments. In [25], the impulsive noise is modeled as a sparse vector in the time domain and proved useful for a powerline communication application. Fractional adaptive identification algorithms have been applied for parameter estimation in channel equalization, linear and nonlinear control autoregressive moving average model [2, 8, 9, 29]. It is observed that fractional-based identification algorithms outperform standard estimation methods in terms of accuracy, convergence, stability and robustness. The theoretical development for the case in which both sparsity and impulsive noise are present is out of the scope of this paper.
The normalized LMAT algorithm has been successfully validated for system identification under impulsive noise environments [43]. To the best of our knowledge, no paper has reported on sparse NLMAT algorithms. In this paper, we propose sparse NLMAT algorithms based on different sparsity penalty terms to deal with sparse system identification under impulsive noise environment and various noise distributions. The following algorithms that integrate similar approaches presented above are proposed: the zero-attracting NLMAT (ZA-NLMAT), reweighted zero-attracting NLMAT (RZA-NLMAT), reweighted ℓ1-norm NLMAT (RL1-NLMAT), non-uniform norm constraint NLMAT (NNC-NLMAT) and correntropy-induced metric NLMAT (CIM-NLMAT).
The remaining part of the paper is organized as follows. Section 2 reviews the known LMAT and NLMAT algorithms. In Sect. 3, the sparse NLMAT algorithms are derived. In Sect. 4, we compare the proposed algorithms in terms of computational complexity. The performances of the proposed algorithms are demonstrated in Sect. 5. Finally, Sect. 6 concludes the paper.
2 Review of LMAT and Normalized LMAT Algorithm
The general block diagram of sparse system identification using an adaptive filter is shown in Fig. 1.

Block diagram of sparse system identification
The desired response \( d(n) \) of the adaptive filter is calculated as \( d(n) = {\mathbf{h}}^{T} \bar{x}(n) + v(n) \), where superscript T indicates transpose of matrix or vector, \( {\mathbf{h}} \) denotes the weight vector of the unknown system of length L, \( \bar{x}(n) = \left[ {x(n),x(n - 1), \ldots x(n - L + 1)} \right]^{T} \) is the input vector of the system, and \( v(n) \) is the system background noise. The system noise consists of the impulsive noise along with different noise distributions (Gaussian, uniform, Rayleigh and exponential).
2.1 LMAT Algorithm
The objective function of LMAT algorithm is
where \( y(n) = \bar{W}^{T} (n)\bar{x}(n) \) is the output of the adaptive filter, \( e(n) = d(n) - y(n) \) denotes the error signal, and \( \bar{W}(n) = \left[ {w_{1} (n),w_{2} (n), \ldots w_{L} (n)} \right]^{\text{T}} \) is the weight vector of the adaptive filter.
The gradient descent method is used to minimize \( J_{\text{LMAT}} (n) \) which can be expressed as
By substituting Eq. (1) in the above equation, the weight update rule of the LMAT algorithm is given by
where the positive constant \( \mu \) is the step-size parameter.
\( \text{sgn} (x) \) denotes the sign function of \( x \) which is defined as
The drawback of the LMAT algorithm is that its convergence performance is highly dependent on the power of the input signal.
2.2 Normalized LMAT Algorithm
To avoid the limitation of the LMAT algorithm, the NLMAT algorithm [43] is derived by considering the following minimization problem [34]:
where \( \left\| \bullet \right\| \) is the Euclidean norm of a vector.
Derivating Eq. (5) with respect to \( \bar{W}(n + 1) \) and equating to zero yields
The weight update equation for the NLMAT algorithm is given by
where \( \mu \) is a step-size parameter, and \( \delta \) is a small positive constant to prevent division by zero when \( \bar{x}^{T} (n)\bar{x}(n) \) vanishes.
In the presence of impulsive noises, the squared error term \( e^{2} (n) \) in Eq. (7) might degrade the NLMAT algorithm in the convergence performance, and hence, we consider assigning an upper-bound \( e_{\text{up}} \) to \( e^{2} (n) \).
Thus, the NLMAT algorithm is modified as
where \( e_{\text{up}} \) is the upper-bound assigned to \( e^{2} (n) \) in Eq. (7).
The posteriori error \( e_{p} (n) \) is defined as
For convenience, we can neglect the small parameter δ in Eq. (9) and have
Taking the mathematical expectation of both sides of Eq. (10),
Denoting \( \bar{\mu } = \mu e^{2} (n) \) [20], Eq. (11) is rewritten as
By using the Price’s theorem in [12], Eq. (12) can be simplified as
where \( \sigma_{e} (n) \) is the standard deviation of the error e(n).
In steady-state condition, the algorithm is assumed to be converged such that the error e(n) is considerably smaller. Hence,
Thus, substituting Eq. (14) into Eq. (13), we get
The magnitude of the a posteriori error \( E[e_{p} (n)] \) does not exceed that of the priori error \( E[e(n)] \), and then, the following inequality must be satisfied [20]
Finally, by solving Eq. (16), we can obtain the upper-bound of \( {\text{e}}_{\text{up}} \) as
The standard deviation \( \sigma_{e} (n) \) is estimated by the following probabilistic method [7, 26, 27]
where \( T_{w} \) is the diagonal matrix defined as, \( T_{w} = {\text{diag}}[1, \ldots ,1,0, \ldots 0], \) that sets the last \( K \) elements of \( O(n) \) to zero, and forms an unbiased estimate \( \sigma_{e} (n) \) by using the remaining (\( N{}_{w} - K \)) elements.
\( O(n) = {\text{sort}}\left( {\left[ {\left| {e(n)} \right|, \ldots ,\left| {e(n - N_{w} + 1)} \right|} \right]^{T} } \right) \) contains the \( N_{w} \) most recent values of \( e(n) \) arranged in the increasing order of the absolute value.
In general, \( N{}_{w} \) and \( K \) are chosen as \( N_{w} = L \) and \( K \ge 1 + \left\lfloor {L\Pr } \right\rfloor \) where \( \left\lfloor \bullet \right\rfloor \) is the floor operator which rounds a number to the next integer and \( \Pr \) is the probability of the impulsive noise occurrence.
3 Proposed Sparse NLMAT Algorithms
To exploit the system sparsity and robustness against impulsive noise, several sparse NLMAT algorithms are proposed by inducing effective sparsity constraints into the standard NLMAT, namely zero-attracting NLMAT, reweighted zero-attracting NLMAT, reweighted ℓ1-norm (RL1)-NLMAT, non-uniform norm constraint (NNC)-NLMAT and correntropy-induced metric (CIM)-NLMAT.
The update equation of LMAT sparse adaptive filter can be generalized as
3.1 Zero-Attracting NLMAT (ZA-NLMAT)
The cost function of ZA-LMAT filter with ℓ1-norm penalty is given by
The updating equation of ZA-LMAT filter can be written as
where \( \rho_{\mathrm{ZA}} = \mu \lambda_{\mathrm{ZA}} \).
Based on the updated Eq. (7), the NLMAT-based sparse adaptive updated equation can be generalized as
In order to avoid the stability issues of Eq. (22), the modified form can be represented as
Equation (24) corresponds to the updated equation of sparse NLMAT filter.
The update equation of the modified sparse NLMAT algorithm is given by
which is termed as the zero-attracting NLMAT (ZA-NLMAT).
The ZA-NLMAT algorithm based on ℓ1-norm penalty is easy to implement and performs well for the systems that are highly sparse, but struggles as the system sparsity decreases. This behavior comes from the fact that the shrinkage parameter in the ZA-NLMAT cannot distinguish between zero taps and nonzero taps. Since all the taps are forced to zero uniformly, its performance would deteriorate for less sparse systems.
3.2 Reweighted Zero-Attracting NLMAT (RZA-NLMAT)
The cost function of the Reweighted ZA-LMAT algorithm is derived by introducing the log-sum penalty
The ith filter coefficient is then updated as
The RZA-LMAT update equation can be expressed in vector form as
By using \( \lambda_{\mathrm{RZA}} \sum\nolimits_{i = 1}^{L} {\log (1 + \varepsilon_{\mathrm{RZA}} \left| {w_{i} (n)} \right|)} \) as a sparse penalty in Eq. (23), the RZA-NLMAT update equation can be expressed as
where \( \rho_{\mathrm{RZA}} = \mu \lambda_{\mathrm{RZA}} \varepsilon_{\mathrm{RZA}} \) and \( \lambda_{\mathrm{RZA}} > 0 \) is the regularization parameter for RZA-NLMAT.
A logarithmic penalty that resembles the ℓ0-norm which is the exact measure of sparsity is considered in RZA-NLMAT. This makes RZA-NLMAT to exhibit a better performance than the ZA-NLMAT. However, the cost function Eq. (26) is not convex and the convergence analysis is problematic for Eq. (29).
3.3 Reweighted ℓ1-Norm NLMAT (RL1-NLMAT)
Since the complexity of using the ℓ0-norm penalty is high, a term more similar to the ℓ0-norm, i.e., the reweighted ℓ1-norm penalty is used in the proposed RL1-NLMAT algorithm. This penalty term is proportional to the reweighted ℓ1-norm of the coefficient vector.
The cost function of the reweighted ℓ1-norm LMAT algorithm is given by
where \( \lambda_{{{\text{RL}}1}} \) is the parameter associated with the penalty term and the elements of \( \bar{f}(n) \) are set to
with \( \delta_{{{\text{RL}}1}} \) being some positive number, and hence, \( \left[ {\bar{f}(n)} \right]_{i} > 0 \) for \( i =0,1, \ldots\break L - 1. \) Differentiating Eq. (30) with respect to \( \bar{W}(n), \), the update equation of RL1-LMAT is
According to the NLMAT in Eq. (8), the update equation of RL1-NLMAT can be written as
where \( \rho_{{{\text{RL}}1}} = \mu \lambda_{{{\text{RL}}1}} \).
The cost function Eq. (30) is convex unlike the cost function for the RZA-NLMAT. Therefore, the algorithm is guaranteed to converge to the global minimum under some conditions.
3.4 Non-uniform Norm Constraint NLMAT (NNC-NLMAT)
In all the above algorithms, there is no adjustable factor which can effectively adapt the norm penalty itself to the unknown sparse finite impulse response of the system. In order to further improve the performance of sparse system identification, the non-uniform p-norm-like constraint is incorporated into NLMAT algorithm.
Let us consider the cost function of sparse NLMAT with p-norm-like constraint as
where \( \left\| {\bar{W}(n)} \right\|_{p}^{p} = \sum\limits_{i = 1}^{L} {\left| {w_{i} (n)} \right|}^{p} \) is called \( L_{p}^{p} {\text{ - norm}} \) or p-norm like, \( 0 \le p \le 1 \).
The gradient of the cost function \( J(n) \) with respect to \( \bar{W}(n) \) is
Thus, the gradient descent recursion of the filter coefficient vector is
Similar to the sparse algorithms created by using ℓ0-norm and ℓ1-norm, the zero attractor term in Eq. (36) which is produced by the p-norm-like constraint will cause an estimation error for the desired sparsity exploitation. To solve this problem, the non-uniform p-norm-like definition which uses a different value of p for each of the L entries in \( \bar{W}(n) \) is provided,
The new cost function using the non-uniform p-norm-penalty is given as
The corresponding gradient descent recursion equation is
where
and \( \rho_{\text{NNC}} = \mu \lambda_{\text{NNC}} \).
The reweighted zero attraction which is used to reduce the bias is introduced to Eq. (41).
The weight update equation of NNC-LMAT algorithm is written as
where \( \varepsilon_{\text{NNC}} > 0. \)
The weight update equation of NNC-NLMAT algorithm can be written in vector form as
where \( \varvec{F} \) is defined as
3.5 Correntropy-Induced Metric NLMAT (CIM-NLMAT)
Due to the superiority of the correntropy-induced metric (CIM) for approximate the ℓ0-norm, CIM is used as the penalty term in the CIM-NLMAT algorithm. CIM favors sparsity and can be used as a sparsity penalty term in the sparse channel estimation.
The similarity between two random vectors \( \varvec{p} = \left\{ {p_{1} ,p_{2} , \ldots p_{L} } \right\} \) and \( \varvec{q} = \left\{ {q_{1} ,q_{2} , \ldots q_{L} } \right\} \) in kernel space can be measured using CIM which is described as
where
For the Gaussian kernel,
here \( {{e}} = {{p}} - {{q}} \) and \( \sigma \) is the kernel width.
The CIM provides a good approximation for the ℓ0-norm that can be represented as
The Gaussian kernel-based CIM is integrated into the cost function of the LMAT algorithm which is given by
The gradient of the cost function \( J_{\text{CIM}} (n) \) with respect to \( \bar{W}(n) \) is
The weight update equation of CIM-LMAT is expressed as
where \( \rho_{\text{CIM}} = \mu \lambda_{\text{CIM}} > 0 \) is a regularization term which balances the estimation error and sparsity penalty.
Equation (53) can be rewritten in matrix form as
By using \( \lambda_{\text{CIM}} \frac{k(0)}{L}\sum\limits_{i = 1}^{L} {\left( {1 - \exp \left( { - \frac{{\left( {w_{i} (n)} \right)^{2} }}{{2\sigma^{2} }}} \right)} \right)} \) as a sparse penalty in Eq. (23), the CIM-NLMAT update equation is given by
The matrix form of CIM-NLMAT algorithm is expressed as
Pseudocodes for the proposed sparse NLMAT algorithms are summarized in Table 1.
4 Computational Complexity
The numerical complexity of the proposed sparse algorithms in terms of additions, multiplications, divisions, square roots and comparisons per iteration is shown in Table 2.
5 Simulation Results
In this section, the performance of the proposed sparse algorithms is evaluated in the context of system identification using various noise distributions and impulsive noise environment. The unknown system, h, is of length L = 16, and its channel impulse response (CIR) is assumed to be sparse in the time domain. The adaptive filter is also assumed to be of the same length. The proposed algorithms are compared under different sparsity levels S = 1 and S = 4. The active coefficients are uniformly distributed in the interval (− 1, 1), and the position of the nonzero taps in the CIR is randomly chosen. The Gaussian white noise with variance \( \sigma_{x}^{2} = 1 \) is considered as the input signal \( x(n) \). The correlated signal \( \bar{z}(n) \) is obtained using a first-order autoregressive process, AR(1), with a pole 0.5 and is given by \( \bar{z}(n) = 0.5\bar{z}(n - 1) + \bar{x}(n) \). The system background noise consists of impulsive noise combined with different noise distributions such as (1) white Gaussian noise with \( N(0,1) \), (2) uniformly distributed noise within the range (-1, 1), (3) Rayleigh distribution with 1 and (4) an exponential distribution with 2. The impulsive noise is modeled by a Bernoulli–Gaussian (BG) process and is given as \( \xi (n) = a(n)I(n) \), where \( a(n) \) is a white Gaussian signal with \( N\left( {0,\sigma_{a}^{2} } \right) \) and \( I(n) \) is a Bernoulli process described by the probability \( p\left\{ {I(n) = 1} \right\} = \Pr \), \( p\left\{ {I(n) = 0} \right\} = 1 - \Pr , \) where \( Pr \) represents the probability of the impulsive noise occurrence. We choose \( Pr \) = 0.01 and \( \sigma_{a}^{2} = {\raise0.7ex\hbox{${10^{4} }$} \!\mathord{\left/ {\vphantom {{10^{4} } {12}}}\right.\kern-0pt} \!\lower0.7ex\hbox{${12}$}} \).
The mean square deviation (MSD) and excess mean square error (EMSE) are used as the performance metrics to measure the performance of the proposed algorithms which are expressed as
and
\( \varepsilon (n) = \theta^{T} (n)\bar{x}(n), \) where \( \theta (n) = \varvec{h} - \bar{W}(n). \)
The average of 100 independent trials with SNR = 20 dB is used in evaluating the results.
In order to show the effectiveness of the proposed sparse NLMAT algorithms, a comparison with the NRMN algorithms is performed. In Fig. 2, the simulation results for the proposed algorithms are shown for the white Gaussian input and when the background noise consists of only white Gaussian noise for the system with sparsity S = 1. The simulation results shown in Fig. 3 are carried out for the white Gaussian input with background noise consisting of white Gaussian noise and impulsive noise with sparsity level S = 1. It can be seen from Figs. 2 and 3 that the proposed sparse NLMAT algorithms exhibit better performance than NLMAT and NRMN algorithms in terms of MSD for the very sparse system. Moreover, the proposed CIM-NLMAT algorithm achieves lower steady-state error value.

MSD Comparison of the proposed algorithms with white Gaussian noise as the background noise and the Gaussian white input signal for the system with sparsity S = 1. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 5 \times 10^{ - 5} , \)\( \rho_{\mathrm{RZA}} = 3 \times 10^{ - 4} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 1 \times 10^{ - 5} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 1 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 2 \times 10^{ - 3} , \)\( \sigma = 0.05 \)

MSD Comparison of the proposed algorithms with white Gaussian noise and impulsive noise as the background noise and the white Gaussian input signal for the system with sparsity S = 1. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 1 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 4 \times 10^{ - 4} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 1 \times 10^{ - 5} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 1 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 2 \times 10^{ - 3} , \)\( \sigma = 0.05 \)
In Fig. 4, the simulation results for the proposed algorithms are shown for the white Gaussian input, while the background noise has white noise with uniform distribution within the range (−1, 1) and impulsive noise for the system with sparsity S = 1. In Fig. 5, the input is white Gaussian with background noise consisting of Rayleigh distributed noise with 1 and impulsive noise for the system with sparsity S = 1. In Fig. 6, the input is white Gaussian signal and the background noise is composed of an exponential distribution of 2 and impulsive noise for the system with sparsity S = 1.

MSD Comparison of the proposed algorithms when the background noise is composed of white noise with uniform distribution within the range (−1, 1) and impulsive noise and the white Gaussian input signal for the system with sparsity S = 1. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 1 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 4 \times 10^{ - 4} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 1 \times 10^{ - 5} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 1 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 2 \times 10^{ - 3} , \)\( \sigma = 0.05 \)

MSD Comparison of the proposed algorithms with background noise comprising of a Rayleigh distributed noise with 1 and impulsive noise and the input is white Gaussian signal for the system with sparsity S = 1. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 1 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 5 \times 10^{ - 4} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 3 \times 10^{ - 5} , \)\( \delta_{{{\text{RL}}1}} = 0.01 \)\( \rho_{\text{NNC}} = 1 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 2 \times 10^{ - 3} , \)\( \sigma = 0.05 \)

MSD Comparison of the proposed algorithms with background noise comprising of an exponential distribution with 2 and impulsive noise and the white Gaussian input signal for the system with sparsity S = 1. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 1 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 5 \times 10^{ - 4} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 3 \times 10^{ - 5} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 2 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 2 \times 10^{ - 3} , \)\( \sigma = 0.05 \)
It can be easily seen from Figs. 4, 5 and 6 that the proposed sparse NLMAT algorithms provide better performance than NLMAT and NRMN algorithms in terms of MSD for the very sparse system. As shown above, the proposed CIM-NLMAT algorithm achieves lower steady-state error too.
The EMSE values of the proposed algorithms obtained for different noises with uncorrelated input and system sparsity S = 1 are given in Table 3. It is confirmed that the proposed sparse algorithms outperform the NLMAT algorithm in identifying a sparse system.
In the simulations shown in Figs. 7, 8, 9, 10, 11, the input signal is the correlated/colored input and the system sparsity is S = 1. In Fig. 7, the system noise is only white Gaussian noise, while for Fig. 8 is both white Gaussian noise and impulsive noise. The system noise for simulations shown in Fig. 9 consists of white noise with uniform distribution within the range (−1, 1) and impulsive noise. In the case of Fig. 10, the system noise has Rayleigh distributed noise of 1 and impulsive noise, while for Fig. 11 consists of an exponential distribution of 2 and impulsive noise. It is observed from Figs. 7, 8, 9, 10 and 11 that the proposed sparse NLMAT algorithms exhibit better performance than NLMAT and NRMN algorithms in terms of MSD for the very sparse system. Moreover, like for the previous simulations, the proposed CIM-NLMAT algorithm achieves the lowest steady-state error value.

MSD Comparison of the proposed algorithms with white Gaussian noise as the background noise and the input is the correlated signal for the system with sparsity S = 1. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 5 \times 10^{ - 5} , \)\( \rho_{\mathrm{RZA}} = 3 \times 10^{ - 4} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 1 \times 10^{ - 5} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 1 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 2 \times 10^{ - 3} , \)\( \sigma = 0.05 \)

MSD Comparison of the proposed algorithms with white Gaussian noise and impulsive noise as the background noise and the input is the correlated signal for the system with sparsity S = 1. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 1 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 4 \times 10^{ - 4} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 1 \times 10^{ - 5} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 1 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 2 \times 10^{ - 3} , \)\( \sigma = 0.05 \)

MSD Comparison of the proposed algorithms when the background noise is comprised of white noise with uniform distribution within the range (−1, 1) and impulsive noise and the correlated input signal for the system with sparsity S = 1. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 1 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 3 \times 10^{ - 4} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 1 \times 10^{ - 5} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 1 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 2 \times 10^{ - 3} , \)\( \sigma = 0.05 \)

MSD Comparison of the proposed algorithms with background noise comprising of a Rayleigh distributed noise with 1 and impulsive noise and the input is the correlated signal for the system with sparsity S = 1. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 1 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 5 \times 10^{ - 4} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 3 \times 10^{ - 5} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 3 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 1 \times 10^{ - 3} , \)\( \sigma = 0.05 \)

MSD Comparison of the proposed algorithms with background noise comprising of an exponential distribution with 2 and impulsive noise and the input is the correlated signal for the system with sparsity S = 1. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{ZA} = 1 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 5 \times 10^{ - 4} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 3 \times 10^{ - 5} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 2 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 2 \times 10^{ - 3} , \)\( \sigma = 0.05 \)
The EMSE values of the proposed algorithms obtained for different noises with correlated/colored input and system sparsity S = 1 are given in Table 4. It can be easily noticed that the proposed sparse algorithms outperform the NLMAT algorithm in identifying a sparse system.
In Figs. 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, the performance of the proposed algorithms when the system sparsity is changed to S = 4 is shown.

MSD Comparison of the proposed algorithms with white Gaussian noise as the background noise and the Gaussian white input signal for the system with sparsity S = 4. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 1 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 5 \times 10^{ - 3} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 1 \times 10^{ - 4} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 5 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 5 \times 10^{ - 3} , \)\( \sigma = 0.05 \)

MSD Comparison of the proposed algorithms with white Gaussian noise and impulsive noise as the background noise and the white Gaussian input signal for the system with sparsity S = 4. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 5 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 5 \times 10^{ - 3} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 8 \times 10^{ - 5} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 5 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 5 \times 10^{ - 3} , \)\( \sigma = 0.05 \)

MSD Comparison of the proposed algorithms when the background noise is composed of white noise with uniform distribution within the range (−1, 1) and impulsive noise and the white Gaussian input signal for the system with sparsity S = 4. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 1 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 5 \times 10^{ - 3} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 1 \times 10^{ - 4} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 8 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 5 \times 10^{ - 3} , \)\( \sigma = 0.05 \)

MSD Comparison of the proposed algorithms with background noise comprising of a Rayleigh distributed noise with 1 and impulsive noise and the input is white Gaussian signal for the system with sparsity S = 4. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 1 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 5 \times 10^{ - 3} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 1 \times 10^{ - 4} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 5 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 5 \times 10^{ - 3} , \)\( \sigma = 0.05 \)

MSD Comparison of the proposed algorithms with background noise comprising of an exponential distribution with 2 and impulsive noise and the white Gaussian input signal for the system with sparsity S = 4. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 5 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 5 \times 10^{ - 3} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 8 \times 10^{ - 5} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 6 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 5 \times 10^{ - 3} , \)\( \sigma = 0.05 \)

MSD Comparison of the proposed algorithms with white Gaussian noise as the background noise and the input is the correlated signal for the system with sparsity S = 4. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 1 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 5 \times 10^{ - 3} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 1 \times 10^{ - 4} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 5 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 5 \times 10^{ - 3} , \)\( \sigma = 0.05 \)

MSD Comparison of the proposed algorithms with white Gaussian noise and impulsive noise as the background noise and the input is the correlated signal for the system with sparsity S = 4. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 4 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 4 \times 10^{ - 3} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 8 \times 10^{ - 5} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 5 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{CIM} = 5 \times 10^{ - 3} , \)\( \sigma = 0.05 \)

MSD Comparison of the proposed algorithms when the background noise is comprised of white noise with uniform distribution within the range (− 1, 1) and impulsive noise and the correlated input signal for the system with sparsity S = 4. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 3 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 5 \times 10^{ - 3} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 7 \times 10^{ - 5} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 5 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 8 \times 10^{ - 3} , \)\( \sigma = 0.05 \)

MSD Comparison of the proposed algorithms with background noise comprising of a Rayleigh distributed noise with 1 and impulsive noise and the input is the correlated signal for the system with sparsity S = 4. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 2 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 5 \times 10^{ - 3} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 1 \times 10^{ - 4} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 8 \times 10^{ - 3} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 5 \times 10^{ - 3} , \)\( \sigma = 0.05 \)

MSD Comparison of the proposed algorithms with background noise comprising of an exponential distribution with 2 and impulsive noise and the input is the correlated signal for the system with sparsity S = 4. The simulation parameters for sparse NLMAT algorithms are given as \( \mu = 0.8, \)\( \delta = 1 \times 10^{ - 3} , \)\( \rho_{\mathrm{ZA}} = 2 \times 10^{ - 4} , \)\( \rho_{\mathrm{RZA}} = 5 \times 10^{ - 3} , \)\( \varepsilon_{\mathrm{RZA}} = 20, \)\( \rho_{{{\text{RL}}1}} = 2 \times 10^{ - 4} , \)\( \delta_{{{\text{RL}}1}} = 0.01, \)\( \rho_{\text{NNC}} = 1 \times 10^{ - 2} , \)\( \varepsilon_{\text{NNC}} = 20, \)\( \rho_{\text{CIM}} = 5 \times 10^{ - 3} , \)\( \sigma = 0.05 \)
In Fig. 12, the simulation results for the proposed algorithms are shown for the white Gaussian input and when the background noise consists of only white Gaussian noise for the system with sparsity S = 4. The simulation results shown in Fig. 13 are carried out for the white Gaussian input with background noise consisting of white Gaussian noise and impulsive noise with sparsity level S = 4. It can be seen from Figs. 12 and 13 that the proposed sparse NLMAT algorithms exhibit better performance than NLMAT and NRMN algorithms in terms of MSD even after changing the system sparsity to S = 4.
In Fig. 14, the simulation results for the proposed algorithms are shown for the white Gaussian input, while the background noise has white noise with uniform distribution within the range (− 1, 1) and impulsive noise for the system with sparsity S = 4. In Fig. 15, the input is white Gaussian with background noise consisting of Rayleigh distributed noise with 1 and impulsive noise for the system with sparsity S = 4. In Fig. 16, the input is white Gaussian signal and the background noise is composed of an exponential distribution of 2 and impulsive noise for the system with sparsity S = 4.
It can be easily seen from Figs. 14, 15 and 16 that the proposed sparse NLMAT algorithms provide better performance than NLMAT and NRMN algorithms in terms of MSD even after changing the system sparsity to S = 4. As shown above, the proposed CIM-NLMAT algorithm achieves lower steady-state error too.
The EMSE values of the proposed algorithms obtained for different noises with uncorrelated input and system sparsity S = 4 are given in Table 5. It is confirmed that the proposed sparse algorithms outperform the NLMAT algorithm in identifying a sparse system.
In the simulations shown in Figs. 17, 18, 19, 20 and 21, the input signal is the correlated/colored input and the system sparsity is changed to S = 4. In Fig. 17, the system noise is only white Gaussian noise, while for Fig. 18 is both white Gaussian noise and impulsive noise. The system noise for simulations shown in Fig. 19 is comprised of white noise with uniform distribution within the range (− 1, 1) and impulsive noise. In the case of Fig. 20, the system noise has Rayleigh distributed noise of 1 and impulsive noise, while for Fig. 21 consists of an exponential distribution of 2 and impulsive noise. It is observed from Figs. 17, 18, 19, 20 and 21 that the proposed sparse NLMAT algorithms exhibit better performance than NLMAT and NRMN algorithms in terms of MSD even after changing the system sparsity to S = 4. Moreover, like for the previous simulations, the proposed CIM-NLMAT algorithm achieves the lowest steady-state error.
The EMSE values of the proposed algorithms obtained for different noises with correlated/colored input and system sparsity S = 4 are given in Table 6. It can be shown that the proposed sparse algorithms outperform the NLMAT algorithm in identifying a sparse system.
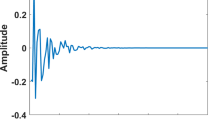
Let us now consider a network echo cancelation (NEC) system with the echo path impulse response of length L = 512 as shown in Fig. 22. This is a sparse impulse response.

Network echo path impulse response
In Fig. 23, the simulation results for the proposed algorithms are shown for the white Gaussian input and when the background noise consists of both white Gaussian noise with SNR = 20 dB, and impulsive noise. It can be seen from Fig. 23 that the proposed sparse NLMAT algorithms exhibit better performance than the NLMAT algorithm for long echo paths with sparse impulse response.

MSD Comparison of the proposed algorithms in a NEC sparse system with white Gaussian noise and impulsive noise as the background noise and the input is white Gaussian signal
In Fig. 24, the input signal is the correlated/colored input and the system noise is comprised of both white Gaussian noise and impulsive noise. It is observed that the proposed sparse NLMAT algorithms exhibit better performance than NLMAT algorithm. Moreover, like for the previous simulations, the proposed CIM-NLMAT algorithm achieves the lowest steady-state error for long echo paths with sparse impulse response.

MSD Comparison of the proposed algorithms in a NEC sparse system with white Gaussian noise and impulsive noise as the background noise and the input is the AR(1) correlated signal
6 Conclusion
The normalized LMAT algorithm based on high-order error power (HOEP) criterion achieves improved performance and mitigates the noise interference effectively, but it does not promote sparsity. Hence, in this paper, we have proposed different sparse normalized LMAT algorithms in the sparse system identification context. From the simulation results, it is verified that our proposed sparse algorithms are capable of exploiting the system sparsity as well as providing robustness to impulsive noise. Moreover, the proposed CIM-NLMAT algorithm exhibits superior performance in the presence of different types of noise. The comparison of the proposed algorithms with the fractional adaptive algorithms will be investigated in a future paper.
References
F. Adachi, E. Kudoh, New direction of broadband wireless technology. Wirel. Commun. Mob. Comput. 7(8), 969–983 (2007). https://doi.org/10.1002/wcm.507
M.S. Aslam, N.I. Chaudhary, M.A.Z. Raja, A sliding-window approximation-based fractional adaptive strategy for Hammerstein nonlinear ARMAX systems. Nonlinear Dyn. 87(1), 519–533 (2017). https://doi.org/10.1007/s11071-016-3058-9
R. Baraniuk, Compressive sensing. IEEE Signal Process. Mag. 24(4), 118–121 (2007). https://doi.org/10.1109/msp.2007.4286571
J. Benesty, T. Gänsler, D.R. Morgan, M.M. Sondhi, S.L. Gay, Advances in Network and Acoustic Echo Cancellation (Springer, Berlin, 2001). https://doi.org/10.1007/978-3-662-04437-7
J. Benesty, S.L. Gay, An improved PNLMS algorithm, in IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Orlando, FL, USA, May 2002, pp. 1881–1884. https://doi.org/10.1109/icassp.2002.5744994
E. Cand‘es, Compressive sampling. Int. Congr. Math. 3, 1433–1452 (2006). https://doi.org/10.4171/022-3/69
J. Chambers, A. Avlonitis, A robust mixed-norm adaptive filter algorithm. IEEE Signal Proc. Lett. 4(2), 46–48 (1997). https://doi.org/10.1109/97.554469
N.I. Chaudhary, M. Ahmed et al., Design of normalized fractional adaptive algorithms for parameter estimation of control autoregressive systems. Appl. Math. Model. 55, 698–715 (2018). https://doi.org/10.1016/j.apm.2017.11.023
N.I. Chaudhary, S. Zubair, M.A.Z. Raja, A new computing approach for power signal modeling using fractional adaptive algorithms. ISA Trans. 68, 189–202 (2017). https://doi.org/10.1016/j.isatra.2017.03.011
Y. Chen, Y. Gu, A.O. HERO III, Sparse LMS for system identification, in IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Taipei, Taiwan, April 2009, pp. 3125–3128. https://doi.org/10.1109/icassp.2009.4960286
Z. Chen, S. Haykin, S.L. Gay, Proportionate Adaptation: New Paradigms in Adaptive Filters, Ch. 8 (Wiley, New York, 2005)
S. Cho, D.K. Sang, Adaptive filters based on the high order error statistics, in IEEE Asia Pacific Conference on Circuits and Systems, Seoul, South Korea, November 1996, pp. 109–112. https://doi.org/10.1109/apcas.1996.569231
S.H. Cho, S.D. Kim, H.P. Moon, J.Y. Na, Least mean absolute third (LMAT) adaptive algorithm: Mean and mean-squared convergence properties, in Proceedings of Sixth Western Pacific Regional Acoustics Conference, Hong Kong, China, November 1997, pp. 305-310
H. Deng, M. Doroslovacki, Improving convergence of the PNLMS algorithm for sparse impulse response identification. IEEE Signal Process. Lett. 12(3), 181–184 (2005). https://doi.org/10.1109/lsp.2004.842262
P.S.R. Diniz, Adaptive Filtering: Algorithms and Practical Implementations, 3rd edn. (Springer: Boston, MA, USA, 2008). ISBN: 978-0-387-31274-3
D.L. Donoho, Compressed sensing. IEEE Trans. Inf. Theory 52(4), 1289–1306 (2006). https://doi.org/10.1109/tit.2006.871582
D.L. Duttweiler, Proportionate normalized least-mean-squares adaptation in echo cancellers. IEEE Trans. Speech Audio Process. 8(5), 508–518 (2000). https://doi.org/10.1109/89.861368
G. Gui, L. Dai, B. Zheng, L. Xu, F. Adachi, Correntropy induced metric penalized sparse RLS algorithm to improve adaptive system identification, in IEEE 83rd Vehicular Technology Conference (VTC Spring), Nanjing, China, May 2016. https://doi.org/10.1109/vtcspring.2016.7504179
S. Haykin, Adaptive Filter Theory, 4th edn. (Prentice-Hall: Upper Saddle River, NJ, USA, 2002). ISBN: 978-0-130-90126-2
J. J. Jeong, S. W. Kim, Exponential normalized sign algorithm for system identification, in International Conference on Information Communications and Signal Processing International Conference (ICICS), Singapore, December 2011, pp. 1–4. https://doi.org/10.1109/icics.2011.6174219
Z. Jin, Y. Li, Y. Wang, An enhanced set-membership PNLMS algorithm with a correntropy induced metric constraint for acoustic channel estimation. Entropy 19(6), 1–14 (2017). https://doi.org/10.3390/e19060281
A.W.H. Khong, P.A. Naylor, Efficient use of sparse adaptive filters, in Proceedings of the 40th Asilomar Conference on Signals, Systems and Computers (ACSSC ‘06), Pacific Grove, CA, USA, 29 Oct.-1 Nov. 2006, pp. 1375–1379. https://doi.org/10.1109/acssc.2006.354982
Y.H. Lee, J.D. Mok, S.D. Kim, S.H. Cho, Performance of least mean absolute third (LMAT) adaptive algorithm in various noise environments. Electron. Lett. 34(3), 241–243 (1998). https://doi.org/10.1049/el:19980181
Y. Li, Z. Jin, Y. Wang, R. Yang, A robust sparse adaptive filtering algorithm with a correntropy induced metric constraint for broadband multi-path channel estimation. Entropy 18(10), 1–14 (2016). https://doi.org/10.3390/e18100380
J. Lin, M. Nassar, B.L. Evans, Impulsive noise mitigation in powerline communications using sparse Bayesian learning. IEEE J. Sel. Areas in Commun. 31(7), 1172–1183 (2013). https://doi.org/10.1109/jsac.2013.130702
D.P. Mandic, E.V. Papoulis, C.G. Boukis, A normalized mixed-norm adaptive filtering algorithm robust under impulsive noise interference, in Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP’03), Hong Kong, China, April 2003, pp. 333–336. https://doi.org/10.1109/icassp.2003.1201686
E.V. Papoulis, T. Stathaki, A normalized robust mixed-norm adaptive algorithm for system identification. IEEE Signal Proc. Lett. 11(1), 56–59 (2004). https://doi.org/10.1109/lsp.2003.819353
S. Pei, C. Tseng, Least mean p-power error criterion for adaptive FIR filters. IEEE J. Sel. Areas Commun. 12(9), 1540–1547 (1994). https://doi.org/10.1109/49.339922
M.A.Z. Raja, N.I. Chaudhary, Two-stage fractional least mean square identification algorithm for parameter estimation of CARMA systems. Sig. Process. 107, 327–339 (2015). https://doi.org/10.1016/j.sigpro.2014.06.015
A.H. Sayed, Fundamentals of Adaptive Filtering (Wiley- NJ, USA, 2003). ISBN: 0-471-46126-1
W.F. Schreiber, Advanced television systems for terrestrial broadcasting: Some problems and some proposed solutions. Proc. IEEE 83(6), 958–981 (1995). https://doi.org/10.1109/5.387095
S. Seth, J.C. Principe, Compressed signal reconstruction using the correntropy induced metric, in Proceedings of IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Las Vegas, USA, 31 March–4 April 2008, pp. 3845–3848. https://doi.org/10.1109/icassp.2008.4518492
M. Shao, C.L. Nikias, Signal processing with fractional lower order moments: Stable processes and their applications. Proc. IEEE 81(7), 986–1010 (1993). https://doi.org/10.1109/5.231338
D.T.M. Slock, On the convergence behavior of the LMS and NLMS algorithms. IEEE Trans. Signal Process. 41(9), 2811–2825 (1993). https://doi.org/10.1109/78.236504
M.M. Sondhi, The history of echo cancellation. IEEE Signal Process. Mag. 23(5), 95–102 (2006). https://doi.org/10.1109/msp.2006.1708416
O. Taheri, S.A. Vorobyov, Sparse channel estimation with Lp-norm and reweighted L1-norm penalized least mean squares, in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, May 2011, pp. 2864–2867. https://doi.org/10.1109/icassp.2011.5947082
O. Taheri, S.A. Vorobyov, Reweighted l1-norm penalized LMS for sparse channel estimation and its analysis. Signal Process. 104(2014), 70–79 (2014). https://doi.org/10.1016/j.sigpro.2014.03.048
R. Tibshirani, Regression shrinkage and selection via the lasso. J. R. Stat. Soc. B 58(1), 267–288 (1996)
E. Walach, B. Widrow, The least mean fourth (LMF) adaptive algorithm and its family. IEEE Trans. Inf. Theory 30(2), 275–283 (1984). https://doi.org/10.1109/tit.1984.1056886
Y. Wang, Y. Li, F. Albu, R. Yang, Sparse channel estimation using correntropy induced metric criterion based SM-NLMS algorithm, in Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), San Francisco, USA, March 2017, pp. 1–6. https://doi.org/10.1109/wcnc.2017.7925628
B. Widrow, S.D. Stearns, Adaptive Signal Processing (Prentice Hall: NJ, USA, 1985). ISBN: 0-13-004029-0
F.Y. Wu, F. Tong, Non-uniform norm constraint LMS algorithm for sparse system identification. IEEE Commun. Lett. 17(2), 385–388 (2013). https://doi.org/10.1109/lcomm.2013.011113.121586
H. Zhao, Y. Yu, S. Gao, Z. He, A new normalized LMAT algorithm and its performance analysis. Signal Process. 105(12), 399–409 (2014). https://doi.org/10.1016/j.sigpro.2014.05.018
Acknowledgements
The work of Felix Albu was supported by a grant from the Romanian National Authority for Scientific research and Innovation, CNCS/CCCDI-UEFISCDI project number PN-III-P4-ID-PCE-2016-0339.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Pogula, R., Kumar, T.K. & Albu, F. Robust Sparse Normalized LMAT Algorithms for Adaptive System Identification Under Impulsive Noise Environments. Circuits Syst Signal Process 38, 5103–5134 (2019). https://doi.org/10.1007/s00034-019-01111-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-019-01111-3