
Abstract
Path planning is a leading topic in the field of the wheeled robot (WR). Three basic characteristic path planning should have when the WR is traveling toward the goal: (1) obtain information about the given working space conditions, (2) location of itself, and (3) optimize the decision to reach the target. The current research paper focuses on obtaining an efficient and robust technique to guide the WR. Teaching–learning-based optimization technique is the centerpiece of the present research work. Fitness function has been presented to optimize the path planning and reaching target. Parameters selected for the proposed technique are (1) distance between robot, start point, goal, and obstacles and (2) turning angle while avoiding obstacles. The technique is examined in various environments with the different level of difficulties. The WR efficiently reaches the target by avoiding collision with the obstacles. In addition, the proposed technique is compared with the previously used technique. The obtained simulated results justified that the teaching–learning-based optimization technique selects better travel path and have shorter travel length.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
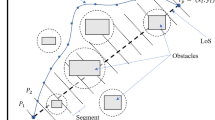
To obtain an efficacious path planning, researchers put the deep attention on navigational strategies. Path planning is defined as obtaining an optimal path to guide the WR from the start point to the target by avoiding collision with the obstacles. Path planning becomes a broad topic for researchers. Figure 1 describes the wheeled robot embedded with an efficient and robust technique gives us optimum, shortest, and collision-free path planning. Algabri et al. [1] have used particle swarm optimization (PSO) to optimize the fuzzy logic controller by adjusting the membership function automatically. Real Khepera III platform was the main focus, and the proposed technique was compared with it. Liu et al. [2] outlined the genetic fuzzy controller. Authors implemented a genetic algorithm so that enhanced parameters of membership function and scaling factor can be obtained. The neuro-fuzzy technique has been proposed in [3] for the path planning of autonomous mobile robot (AMR). Weighing factor is determined to minimize the count of fuzzy rules. Korkmaz and Durdu [4] have concluded that A* and PRM technique is efficient in terms of travel length and elapsed time, respectively. Lu and Gong [5] experimented in an unknown environment with AMR embedded with PSO. They implemented PSO to obtain the best path, but it lacks in modifying the control parameters. Li and Chen [6] have carefully used a five-order polynomial to design smooth trajectory based on PSO and adaptive neural network control. Parhi et al. [7] have simulated and experimented the theory to find the behavior of swarm intelligence techniques. Using the proposed technique, authors try to obtain the optimized path for autonomous wheeled robot.

Result of best technique on implementation in the wheeled robot
2 Kinematics of Wheeled Robot
Kinematics defines the geometry of motion. It describes the initial conditions and portrays the positions of the WR. Steering of the WR is retrieved by utilizing various conditions, which are listed below in equations. Different property of wheels should be attained; these are (1) non-deformable, (2) pure rolling (v = 0 at contact points), and (3) no slip, skid, or slide. a is the radius of wheels; x is the distance between powered wheels. R is the point which is used to estimate the position and motion of the WR. It is pointed at the intersection of the axis of the powered wheel and a straight line passing through the center of mass of the system. Figure 2 describes the schematic diagram of the WR in (X0, Y0) plane. (XN, YN, α) is the location and the orientation of the WR. The axes (X0, Y0) indicate inertial global reference frame with origin O. α is the angular difference between the global and reference frames. The global reference frame is denoted by point R on the robot chassis specified by coordinates (X, Y). Center of mass is represented by C.

Schematic diagram of wheeled robot in X0–Y0 plane
Description of kinematic model is shown by following equations:
where \(W_{\text{l}}\) = velocity of the left wheel, \(W_{\text{r}}\) = velocity of the right wheel, and \(b\) = track width between two wheels.
Following conditions are used for the orientation of the WR:
-
1.
\(W_{\text{l}}\) = \(W_{\text{r}}\), Robot travel straight.
-
2.
\(W_{\text{l}}\) < \(W_{\text{r}}\), Robot turns left.
-
3.
\(W_{\text{l}}\) > \(W_{\text{r}}\), Robot turns right.
3 Navigational Algorithm
Teaching–learning-based optimization technique is the centerpiece of this research paper. It is applied to optimize the path planning for an autonomous, obtain a shortest and collision-free path. TLBO is a nature-based technique that depends upon the teaching and learning skill of teacher and learner, respectively. The ability of the teacher to teach decides the strength of optimized result because at last teacher (best learner) is described as the best solution. TLBO optimizes the problem for two times in a single run, one after teacher phase and second after the learner phase. This process optimizes the path planning of the robot better than other optimization technique [9] and provides the shortest and collision-free path.
Rao et al. [8] have proposed TLBO, and in this paper, it is inserted in path planning. Researchers observed the behavior of learning the skill of learner from teachers and other learner and proposed this technique. Implemented technique mainly contains two phases: One is teacher phase described in Fig. 3a, and second is the learner phase described in Fig. 3b. Teacher phase represents the first optimization of skill of leaner, in which learner observed and grabs the knowledge of the teacher. In the second phase, i.e., learner phase, learners interact among themselves and further optimize their skills. Figure 4 shows the steps for obtaining the optimized path.

Representation of different phases

Steps to obtain an optimized path
Fitness function of TLBO:
Optimization of any technique very much depends upon its selected fitness function. Therefore, the fitness function of any technique should be decided precisely. TLBO mainly revolves around the ability to gain knowledge by the learner, and it decreases the path length by optimizing the turning angle of the WR. Therefore, two fitness functions which are picked for TLBO technique are:
-
(1)
The distance between wheeled robot, start point, target, and obstacles:
The command given to the WR is to move in Euclidean distance. TLBO embedded WR always follows the same path to reach the target until any obstacles come in between its path. When such things occur, the WR takes a turn with the sufficient and optimum angle and again follows the same shortest path.
where \(f_{1}\) is the first fitness function of the proposed technique. Coordinate of the start point in ith iteration is \(\left( {m\left( i \right), n\left( i \right)} \right)\), and coordinate of the target is given by \(\left( {{\text{Tarm,}} \,{\text{Tarn}}} \right)\).
-
(2)
Turning angle while avoiding obstacles:
Turning angle should not be too less that; it fails to avoid the collision. In addition, it should not be too large that it increases the path length. It should be selected after many iterations so that it satisfies the need of the problem. Optimality of the solution depends upon the optimality of the turning angle, and it is represented as follow:
where \(f_{2}\) is the second fitness function of the proposed technique. \({\text{optimum}}\left( i \right)\) is the best turning angle when the WR comes in front of obstacles. \(\left( {x\left( i \right), y\left( i \right)} \right)\) is the coordinate of the WR at ith iteration.
4 Simulation Results
MATLAB graphical user interphase (GUI) has been taken into consideration to obtain the simulation results. Three different types of environments have been considered to find out the stableness of the proposed technique. Environments have one obstacle, two obstacles, and multi-obstacles which have been preferred as shown in Figs. 5, 6, and 7. The complexity of the environment is gradually increased to retrieve the strength of TLBO technique. In each environment, WR embedded with TLBO technique is reaching the target by avoiding the obstacles. In every environment, sufficient numbers of iterations are carried out, and it is about 10–30, and sometimes it reaches up to 40, depending upon the complexity of the environments. A sufficient number of iterations results in optimum path selection by avoiding the collision with the obstacles. Figure 5 makes evident that WR reached the target by avoiding the single pentagon-shaped obstacle. In the process, 12 iterations were carried out to obtain the optimized result. Sometimes the WR reached the target without avoiding collision with the obstacle, reached the target, avoided the obstacle, but the travel length is high. Finally, after 12 iterations, following result has been obtained which is optimum. In Fig. 6, WR is simulated in the environment having two obstacles, one having pentagon shape and other triangular shape. The complexity of this environment is in more than the previous environment because of the shape and number of obstacles. As the complexity is increased, subsequently the number of iterations to obtain the optimum result has been increased. 23 iterations were carried out, and different problems arise in each run. Different results have been gathered, and the optimum result is selected as shown in Fig. 6. Now, the complexity of the environment is tossed to the top, so that the stability, effectuality, robustness, and efficiency of the technique can be gathered. Multiple obstacles having different shape increased the difficulty to the peak. After 28 iterations, we picked the best result which is completing all the need of the WR as shown in Fig. 7. So finally, it can be understood from the results (Figs. 5, 6, and 7) the selected technique is robust and efficient enough to successfully work in any environment.

Application of TLBO technique in environment having one obstacle

Application of TLBO technique in environment having two obstacles

Application of TLBO technique in environment having many obstacles
5 Comparison with Previously Opted Technique
Performing simulation experiment of any technique in the various environment is not enough to claim that it is best. It should give some evident that it is better by comparing it with previously implemented techniques. The current technique is compared with previously opted technique to find out the response in the environment selected by them. To get the best possible result, the previously designed environment is replicated. In addition, during replication, it is strictly taken care to obtain the best possible result. Deepak and Parhi [9] observed the result as shown in Fig. 8a after implementing PSO technique. Figure 8b is describing the best result which is obtained by embedding the TLBO technique. It took more number of iteration to improve the result. At last, the result we obtained is far better than the previously used technique. Table 1 is sufficient to find out the best technique. Travel length in the current technique is lesser than the travel length obtained in previously opted technique. It is effortlessly winning the race of obtaining the shortest travel length.

a Route selected by PSO technique [9]. b Route selected by currently proposed TLBO technique
6 Conclusion
The current paper is making evident of the shortest path length after selecting TLBO technique. The current technique is demonstrated in the various environment by gradually increasing the difficulty. Every time the current technique comes out as the winner with the optimum and best possible result. The technique is extremely robust and efficient that irrespective of the complexity of the environment, it provides the best possible results. The current technique is compared with the previously opted technique, and the result is favorable. TLBO reached the target by traveling the shortest path. Finally, it can be accepted the TLBO technique can work in any environment and give the optimized result. It is also better than the previously opted technique in their selected environment. Future studies could investigate the mutation of TLBO with different algorithms to obtain more efficient results.
References
Algabri, M., Ramdane, H., Mathkour, H., Al-Mutib, K., Alsulaiman, M.: Optimization of fuzzy logic controller using PSO for mobile robot navigation in an unknown environment. Appl. Mech. Mater. 541, 1053–1061 (2014)
Liu, Q., Lu, Y.G., Xie, C.X.: Optimal genetic fuzzy obstacle avoidance controller of autonomous mobile robot based on ultrasonic sensors. In: IEEE International Conference on Robotics and Biomimetics ROBIO’06, pp. 125–129. IEEE Press, Kunming, China (2006)
Tahboub, K.K., Al-Din, M.S.: A neuro-fuzzy reasoning system for mobile robot navigation. JJMIE 3(1), 77–88 (2009)
Korkmaz, M., Durdu, A.: Comparison of optimal path planning algorithms. In: 14th IEEE International Conference on Advanced Trends in Radio Electronics Telecommunications and Computer Engineering (TCSET), pp. 255–258. IEEE Press, Lviv-Slavske, Ukraine (2018)
Lu, L., Gong, D.: Robot path planning in unknown environments using particle swarm optimization. In: Fourth IEEE International Conference on Natural Computation ICNC’08, pp. 422–426. IEEE Press, Jinan, China (2008)
Li, Y., Chen, X.: A new stochastic PSO technique for neural network training. In: International Symposium on Neural Networks 2006. LNCS, vol. 3971, pp. 564–569. Springer, Berlin, Heidelberg (2006)
Parhi, D.R., Pothal, J.K., Singh, M.K.: Navigation of multiple mobile robots using swarm intelligence. In: World Congress on Nature & Biologically Inspired Computing NaBIC, pp. 1145–1149. IEEE Press, Coimbatore, India (2009)
Rao, R.V., Savsani, V.J., Vakharia, D.P.: Teaching–learning-based optimization: a novel method for constrained mechanical design optimization problems. Comput. Aided Des. 43(3), 303–315 (2011)
Deepak, B.B.V.L., Parhi, D.R.: PSO based path planner of an autonomous mobile robot. Open Comput. Sci. 2(2), 152–168 (2012)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Kashyap, A.K., Pandey, A. (2020). Optimized Path Planning for Three-Wheeled Autonomous Robot Using Teaching–Learning-Based Optimization Technique. In: Li, L., Pratihar, D., Chakrabarty, S., Mishra, P. (eds) Advances in Materials and Manufacturing Engineering. Lecture Notes in Mechanical Engineering. Springer, Singapore. https://doi.org/10.1007/978-981-15-1307-7_5
Download citation
DOI: https://doi.org/10.1007/978-981-15-1307-7_5
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-1306-0
Online ISBN: 978-981-15-1307-7
eBook Packages: EngineeringEngineering (R0)