
Abstract
Supervised and unsupervised prototype based vector quantization frequently are proceeded in the Euclidean space. In the last years, also non-standard metrics became popular. For classification by support vector machines, Hilbert space representations are very successful based on so-called kernel metrics. In this paper we give the mathematical justification that gradient based learning in prototype-based vector quantization is possible by means of kernel metrics instead of the standard Euclidean distance. We will show that an appropriate handling requires differentiable universal kernels defining the kernel metric. This allows a prototype adaptation in the original data space but equipped with a metric determined by the kernel. This approach avoids the Hilbert space representation as known for support vector machines. Moreover, we give prominent examples for differentiable universal kernels based on information theoretic concepts and show exemplary applications.
Access provided by Autonomous University of Puebla. Download to read the full chapter text
Chapter PDF
Similar content being viewed by others
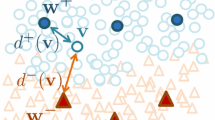


Keywords
- Support Vector Machine
- Vector Quantization
- Reproduce Kernel Hilbert Space
- Nonnegative Matrix Factorization
- Learn Vector Quantization
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
References
Aronszajn, N.: Theory of reproducing kernels. Transactions of the American Mathematical Society 68, 337–404 (1950)
Ben-Hamza, A., Krim, H.: Jensen-Rényi divergence measure: theoretical and computational perspectives. In: Proceedings of the IEEE International Symposium on Information Theory, pp. 257–257 (2003)
Bezdek, J.: A convergence theorem for the fuzyy ISODATA clustering algorithm. IEEE Transactions on Pattern Analysis and Machine Intelligence 2(1), 1–8 (1980)
Bezdek, J.: Pattern Recognition with Fuzzy Objective Function Algorithms. Plenum, New York (1981)
Biehl, M., Bunte, K., Schleif, F.-M., Schneider, P., Villmann, T.: Large margin discriminative visualization by matrix relevance learning. In: Abbass, H., Essam, D., Sarker, R. (eds.) Proc. of the International Joint Conference on Neural Networks (IJCNN), Brisbane, pp. 1873–1880. IEEE Computer Society Press, Los Alamitos (2012)
Biehl, M., Hammer, B., Schleif, F.-M., Schneider, P., Villmann, T.: Stationarity of matrix relevance learning vector quantization. Machine Learning Reports 3(MLR-01-2009), 1–17 (2009) ISSN:1865-3960, http://www.uni-leipzig.de/~compint/mlr/mlr_01_2009.pdf
Blake, C., Merz, C.: UCI repository of machine learning databases. Dep. of Information and Computer Science, University of California, Irvine (1998), http://www.ics.edu/mlearn/MLRepository.html
Chan, A., Vasconcelos, N., Moreno, P.: A family of probabilistic kernels based on information divergence. Technical Report SVCL-TR 2004/01, Statistical Visual Computing Laboratory (SVCL) at Universit of California, San Diego (2004)
Cichocki, A., Amari, S.-I.: Families of alpha- beta- and gamma- divergences: Flexible and robust measures of similarities. Entropy 12, 1532–1568 (2010)
Cichocki, A., Cruces, S., Amari, S.-I.: Generalized alpha-beta divergences and their application to robust nonnegative matrix factorization. Entropy 13, 134–170 (2011)
Crammer, K., Gilad-Bachrach, R., Navot, A., Tishby, A.: Margin analysis of the LVQ algorithm. In: Becker, S., Thrun, S., Obermayer, K. (eds.) Advances in Neural Information Processing (Proc. NIPS 2002), vol. 15, pp. 462–469. MIT Press, Cambridge (2003)
Ferreira, J., Menegatto, V.: Reproducing properties of differentiable Mercer-like kernels. Mathematische Nachrichten 285 (in press, 2012)
Frénay, B., Verleysen, M.: Parameter-free kernel in extreme learning for non-linear support vector regression. Neurocomputing 74(16), 2526–2531 (2011)
Gretton, A., Herbrich, R., Smola, A., Bousquet, O., Schölkopf, B.: Kernel methods for measuring independence. Journal of Machine Learning Research 6, 2075–2129 (2005)
Hammer, B., Strickert, M., Villmann, T.: Supervised neural gas with general similarity measure. Neural Processing Letters 21(1), 21–44 (2005)
Hammer, B., Villmann, T.: Generalized relevance learning vector quantization. Neural Networks 15(8-9), 1059–1068 (2002)
Hein, M., Bousquet, O.: Hilbertian metrics and positive definite kernels on probability measures. Technical report, Max Planck Institute for Biological Cybernetics (2004)
Heskes, T.: Energy functions for self-organizing maps. In: Oja, E., Kaski, S. (eds.) Kohonen Maps, pp. 303–316. Elsevier, Amsterdam (1999)
Hoffmann, T., Schölkopf, B., Smola, A.: Kernel methods in machine learning. The Annals of Statistics 36(3), 1171–1220 (2008)
Kästner, M., Hammer, B., Biehl, M., Villmann, T.: Functional relevance learning in generalized learning vector quantization. Neurocomputing 90(9), 85–95 (2012)
Kohonen, T.: Self-Organizing Maps. Springer Series in Information Sciences, vol. 30. Springer, Heidelberg (1995) (Second Extended Edition 1997)
Kolmogorov, A., Fomin, S.: Reelle Funktionen und Funktionalanalysis. VEB Deutscher Verlag der Wissenschaften, Berlin (1975)
Kulis, B., Sustik, M., Dhillon, I.: Low-rank kernel learning with Bregman matrix divergences. Journal of Machine Learning Research 10, 341–376 (2009)
Kullback, S., Leibler, R.: On information and sufficiency. Annals of Mathematical Statistics 22, 79–86 (1951)
Martin, A., Smith, N., Xing, E., Aguiar, P., Figueiredo, M.: Nonextensive information theoretic kernels on measures. Journal of Machine Learning Research 10, 935–975 (2009)
Martinetz, T.M., Berkovich, S.G., Schulten, K.J.: ’Neural-gas’ network for vector quantization and its application to time-series prediction. IEEE Trans. on Neural Networks 4(4), 558–569 (1993)
Mercer, J.: Functions of positive and negative type and their connection with the theory of integral equations. Philosophical Transactions of the Royal Society, London, A 209, 415–446 (1909)
Micchelli, C., Xu, Y., Zhang, H.: Universal kernels. Journal of Machine Learning Research 7, 26051–22667 (2006)
Mwebaze, E., Schneider, P., Schleif, F.-M., Aduwo, J., Quinn, J., Haase, S., Villmann, T., Biehl, M.: Divergence based classification in learning vector quantization. Neurocomputing 74(9), 1429–1435 (2011)
Nielsen, F., Nock, R.: Sided and symmetrized Bregman centroids. IEEE Transaction on Information Theory 55(6), 2882–2903 (2009)
Österreicher, F., Vajda, I.: A new class of metric divergences on probability spaces and its applicability in statistics. Annals of the Institute of Statistical Mathematics 55(3), 639–653 (2003)
Pekalska, E., Duin, R.: The Dissimilarity Representation for Pattern Recognition: Foundations and Applications. World Scientific (2006)
Principe, J.: Information Theoretic Learning. Springer, Heidelberg (2010)
Qin, A., Suganthan, P.: A novel kernel prototype-based learning algorithm. In: Proceedings of the 17th International Conference on Pattern Recognition (ICPR 2004), vol. 4, pp. 621–624 (2004)
Qin, A.K., Suganthan, P.N.: Kernel neural gas algorithms with application to cluster analysis. In: ICPR (4), pp. 617–620 (2004)
Rényi, A.: On measures of entropy and information. In: Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability. University of California Press (1961)
Rényi, A.: Probability Theory. North-Holland Publishing Company, Amsterdam (1970)
Sato, A., Yamada, K.: Generalized learning vector quantization. In: Touretzky, D.S., Mozer, M.C., Hasselmo, M.E. (eds.) Proceedings of the 1995 Conference Advances in Neural Information Processing Systems, vol. 8, pp. 423–429. MIT Press, Cambridge (1996)
Sato, A.S., Yamada, K.: Generalized learning vector quantization. In: Tesauro, G., Touretzky, D., Leen, T. (eds.) Advances in Neural Information Processing Systems, vol. 7, pp. 423–429. MIT Press (1995)
Schleif, F.-M., Villmann, T., Hammer, B., Schneider, P.: Efficient kernelized prototype based classification. International Journal of Neural Systems 21(6), 443–457 (2011)
Schölkopf, B., Smola, A.: Learning with Kernels. MIT Press (2002)
Schneider, P., Hammer, B., Biehl, M.: Adaptive relevance matrices in learning vector quantization. Neural Computation 21, 3532–3561 (2009)
Scovel, C., Hush, D., Steinwart, I., Theiler, J.: Radial kernels and their reproducing kernel Hilbert spaces. Journal of Complexity 26, 641–660 (2010)
Shannon, C.: A mathematical theory of communication. Bell System Technical Journal 27, 379–432 (1948)
Sriperumbudur, B., Fukumizu, K., Lanckriet, G.: Universality, characteristic kernels, and RKHS embedding of measures. Journal of Machine Learning Research 12, 2389–2410 (2011)
Steinwart, I.: On the influence of the kernel on the consistency of support vector machines. Journal of Machine Learning Research 2, 67–93 (2001)
Villmann, T., Haase, S.: Divergence based vector quantization. Neural Computation 23(5), 1343–1392 (2011)
Villmann, T., Haase, S.: A note on gradient based learning in vector quantization using differentiable kernels for Hilbert and Banach spaces. Machine Learning Reports 6(MLR-02-2012), 1–29 (2012) ISSN:1865-3960, http://www.techfak.uni-bielefeld.de/~fschleif/mlr/mlr_02_2012.pdf ,
Zhang, H., Xu, Y., Zhang, J.: Reproducing kernel banach spaces for machine learning. Journal of Machine Learning Research 10, 2741–2775 (2009)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Villmann, T., Haase, S., Kästner, M. (2013). Gradient Based Learning in Vector Quantization Using Differentiable Kernels. In: Estévez, P., Príncipe, J., Zegers, P. (eds) Advances in Self-Organizing Maps. Advances in Intelligent Systems and Computing, vol 198. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-35230-0_20
Download citation
DOI: https://doi.org/10.1007/978-3-642-35230-0_20
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-35229-4
Online ISBN: 978-3-642-35230-0
eBook Packages: EngineeringEngineering (R0)