
Abstract
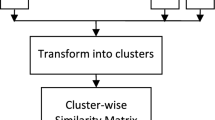
When dealing with multiple clustering solutions, the problem of extrapolating a small number of good different solutions becomes crucial. This problem is faced by the so called Meta Clustering [12], that produces clusters of clustering solutions. Often such groups, called meta-clusters, represent alternative ways of grouping the original data. The next step is to construct a clustering which represents a chosen meta-cluster. In this work, starting from a population of solutions, we build meta-clusters by hierarchical agglomerative approach with respect to an entropy-based similarity measure. The selection of the threshold value is controlled by the user through interactive visualizations. When the meta-cluster is selected, the representative clustering is constructed following two different consensus approaches. The process is illustrated through a synthetic dataset.
Access provided by Autonomous University of Puebla. Download to read the full chapter text
Chapter PDF
Similar content being viewed by others


References
Berman, P., DasGupta, B., Kao, M., Wang, J.: On constructing an optimal consensus clustering from multiple clusterings. Inf. Process. Lett. 104, (4) 137–145 (2007)
Gusfield, D.: Partition-distance: A problem and class of perfect graphs arising in clustering. Information Processing Letters 82, 159–164 (2002)
Amato, R., Ciaramella, A., Deniskina, N., et al.: A Multi-Step Approach to Time Series Analysis and Gene Expression Clustering. Bioinformatics 22, 589–596 (1995)
Jiang, D., Tang, C., Zhang, A.: Cluster Analysis for Gene Expression Data: A Survey. IEEE Transactions on Knowledge and Data Engineering 16, (11) 1370–1386 (2004)
Xui, R., Wunsch, D.: Survey of clustering algorithms. IEEE Transactions on Neural Networks 16(3), 645–678 (2005)
Hu, Y., Hu, Y.P.: Global optimization in clustering using hyperbolic cross points. Pattern Recognition 40(6), 1722–1733 (2007)
Agarwal, P.K., Mustafa, N.H.: k-means projective clustering. In: Proceedings of the Twenty-Third ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, pp. 155–165. ACM Press, New York (2004)
Kaukoranta, T., Franti, P., Nevalainen, O.: Reallocation of GLA codevectors for evading local minima. Electronics Letters 32(17), 1563–1564 (1996)
Valentini, G., Ruffino, F.: Characterization Of Lung Tumor Subtypes Through Gene Expression Cluster Validity Assessment. RAIRO-Inf. Theor. Appl. 40, 163–176 (2006)
Bertoni, A., Valentini, G.: Random projections for assessing gene expression cluster stability. In: Proceedings IEEE International Joint Conference on Neural Networks, vol. 1, pp. 149–154 (2005)
Kuncheva, L.I., Vetrov, D.P.: Evaluation of Stability of k-Means Cluster Ensembles with Respect to Random Initialization. PAMI 28(11), 1798–1808 (2006)
Caruana, R., Elhawary, M., Nguyen, N., Smith, C.: Meta Clustering. In: ICDM, pp. 107–118 (2006)
Bifulco, I., Murino, L., Napolitano, F., Raiconi, G., Tagliaferri, R.: Using Global Optimization to Explore Multiple Solutions of Clustering Problems. In: KES 2008 (2008)
Ciaramella, A., Cocozza, S., Iorio, F., Miele, G., Napolitano, F., Pinelli, M., Raiconi, G., Tagliaferri, R.: Interactive data analysis and clustering of genomic data. Neural Networks 21, 368–378 (2007)
Napolitano, F., Raiconi, G., Tagliaferri, R., Ciaramella, A., Staiano, A., Miele, A.: Clustering and visualization approaches for human cell cycle gene expression data analysis. International Journal Of Approximate Reasoning 47(1), 70–84 (2008)
Barthélemy, J.P., Leclerc, B.: The median procedure for partitions. In: Cox, I.J., Hansen, P., Julesz, B. (eds.) Partitioning Data Sets, American Mathematical Society, Providence, RI, pp. 3–34 (1995)
Gionis, A., Mannila, H., Tsaparas, P.: Clustering aggregation. ACM Trans. Knowl. Discov. Data 1(4), 1 (2007)
Bertolacci, M., Wirth, A.: Are approximation algorithms for consensus clustering worthwhile? In: 7th SIAM International Conference on Data Mining, pp. 437–442 (2007)
Nguyen, N., Caruana, R.: Consensus Clustering. In: Perner, P. (ed.) ICDM 2007. LNCS (LNAI), vol. 4597, pp. 607–612. Springer, Heidelberg (2007)
Topchy, A., Jain, A.K., Punch, W.: Clustering ensembles: models of consensus and weak partitions. IEEE Transactions on Pattern Analysis and Machine Intelligence 27(12), 1866–1881 (2005)
Topchy, A., Minaei-Bidgoli, B., Jain, A.K., Punch, W.F.: Adaptive clustering ensembles. Pattern Recognition. In: Proceedings of the 17th International Conference, vol. 1, pp. 272–275 (2004)
Author information
Authors and Affiliations
Editor information
Rights and permissions
Copyright information
© 2008 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Bifulco, I., Fedullo, C., Napolitano, F., Raiconi, G., Tagliaferri, R. (2008). Robust Clustering by Aggregation and Intersection Methods. In: Lovrek, I., Howlett, R.J., Jain, L.C. (eds) Knowledge-Based Intelligent Information and Engineering Systems. KES 2008. Lecture Notes in Computer Science(), vol 5179. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-85567-5_91
Download citation
DOI: https://doi.org/10.1007/978-3-540-85567-5_91
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-85566-8
Online ISBN: 978-3-540-85567-5
eBook Packages: Computer ScienceComputer Science (R0)