
Abstract
A new semi-supervised clustering framework for uncertain multi-view data is proposed inspired by the theory of three-way decisions, which is an alternative formulation different from the ones used in the existing studies. A cluster is represented by three regions such as the core region, fringe region and trivial region. The three-way representation intuitively shows which objects are fringe to the cluster. The proposed method is an iterative processing which includes two parts: (1) the three-way spectral clustering algorithm which is devised to obtain the three-way representation result; and (2) the active learning strategy which is designed to obtain the prior supervision information from the fringe regions, and the pairwise constraints information is used to adjust the similarity matrix between objects. Experimental results show that the proposed method can cluster multi-view data effectively and is better in performances than the compared single-view clusterings and other semi-supervised clustering approaches.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
In some applications such as computer video, social computing, and multimedia area, objects are usually represented in several different ways. This kind of data is termed as the multi-view data. Multi-view clustering, which is also one kind of multi-view learning, has attracted more and more attentions [1,2,3, 12, 19]. In the existing methods, spectral clustering [4, 13] is a popular one for multi-view data because it represents multi-view data via graph structure and makes it possible to handle complex data such as high-dimensional and heterogeneous as well as it can easily use the pairwise constraint information provided by users. Therefore, some scholars research on spectral clustering for multi-view data [5, 8, 17].
Generally speaking, there are two types of typical prior supervised information, namely, class labels and pairwise constraints [5, 6, 16]. In practice, it is difficult to obtain the independent class labels, yet it could be relatively easy to ensure correlated or uncorrelated information among data objects. Therefore, pairwise constraints describe two objects whether they should be assigned to the same class or the different classes. However, choosing the supervised information is random in most of existing methods, and it does not produce positive effect on improving the clustering result when the algorithm itself can find the prior information or there are amounts of noises in the prior information. Therefore, the active learning method is introduced to optimize the selection of the constraints for semi-supervised clustering [15, 18, 28].
Most of the existing researches on the topic has focused on selecting an initial set of pairwise constraints before performing semi-supervised clustering. This is not suitable if we wish to iteratively improve the clustering model by actively querying users. In fact, many clustering approaches are based on iterative framework. Obviously, it is much better in each iteration that we determine objects with the most important information toward improving the current clustering result and form queries accordingly than just choosing the information randomly. The responses to the queries (i.e., constraints) are then used to update the clustering. This process repeats until we reach the stop conditions. Such an iterative framework is widely used in active learning for semi-supervised clustering.
In this paper, we focus on how to improve the quality of clustering for multi-view data with the aid of pairwise constraints. Therefore, we propose a semi-supervised clustering framework based on active learning by using three-way decisions. In order to further choosing the supervision information during the iterative processing, we introduce the idea of three-way decisions into this work, inspired by the three-way decisions theory as suggested by Yao [21, 22]. Three-way decisions extend binary-decisions in order to overcome some drawbacks of binary-decisions. The basic ideas of three-way decisions have been widely used in real-world decision-making problems, such as decision making [23], email spam filtering [29], three-way investment decisions [9] and many others [25]. Interval sets provide an ideal mechanism to represent soft clustering. Lingras and Yan [10] introduced interval sets to represent clusters. Lingras and West [11] proposed an interval set clustering method with rough k-means for mining clusters of web visitors. Yao et al. [20] represented each cluster by an interval set instead of a single set as the representation of a cluster. Inspired by these results, we have introduced a framework of three-way cluster analysis [26, 27].
In our work, a three-way representation for a cluster is presented, where a cluster is represented by three regions, i.e., the core region, fringe region and trivial region, instead of two regions as the other existing methods. Objects in the core region are typical elements of the cluster, objects in the fringe region are fringe elements of the cluster, and objects in the trivial region do not belong to the cluster definitely. A cluster is therefore more realistically characterized by a set of core objects and a set of boundary objects. The three-way representation intuitively shows which objects are fringe to the cluster. Thus, we can reduce the search space to the fringe regions when selecting the pairwise constraints. The basic idea of the work is to propose an iterative processing, in which a three-way clustering algorithm is devised to obtain the three-way clustering result and an active learning strategy is designed to obtain the prior supervision information from the fringe regions.
The remainder of this paper is organized as follows. Section 2 introduces some basic concepts. Section 3 describes the proposed framework, the three-way spectral clustering algorithm and the active learning strategy. Section 4 reports the results of comparative experiments and conclusions are provided in Sect. 5.
2 Preliminaries
In this section, some basic concepts of multi-view and semi-supervised clustering are introduced.
2.1 Multi-view Data
In the multi-view setting, an object (data point) \(\mathbf x \) is described with several different disjoint sets of features. Let \(X=\{\mathbf{x }_{1}, \cdots ,\mathbf{x }_{i}, \cdots , \mathbf{x }_{N}\}\) be a universe with N objects. There are H numbers of views to describe the objects, and \(X^{(1)}, X^{(2)}, \cdots , X^{(h)}, \cdots , X^{(H)}\) be the data matrix of each view respectively.
For h-th view, \(X^{(h)} \in \mathbb {R}^{N \times d^{(h)}}\), and \( d^{(h)}\) is the feature dimension of the h-th view. \(X^{(h)}=\{\mathbf{x }_{1}^{(h)}, \mathbf{x }_{2}^{(h)}, \cdots , \mathbf{x }_{i}^{(h)}, \cdots , \mathbf{x }_{N}^{(h)}\}\), where \(\mathbf{x }_{i}^{(h)}=(x_{i,h}^{1}, x_{i,h}^{2}, \cdots , x_{i,h}^{j}, \cdots , x_{i,h}^{d^{(h)}})\) is its i-th object, and \(x_{i,h}^{j}\) is the j-th feature of i-th object in the h-th view.
2.2 Pairwise Constraints
Pairwise constraints is one kind of typical prior information for semi-supervised clustering. Wagstaff and Cardie [14] introduce must-link (positive association) and cannot-link (negative association) to reflect the constraint relations between the data points.
For the universe \(X=\{\mathbf{x }_{1}, \cdots ,\mathbf{x }_{i}, \cdots , \mathbf{x }_{N}\}\), let \(Y=\{y_1, \cdots ,y_i, \cdots , y_N\}\) be the class labels of objects respectively. Must-link constraint requires that the two points must belong to the same cluster, and this relation is denoted by \(ML=\{(\mathbf{x }_{i},\mathbf x _{j})~|~ y_{i}=y_{j}, ~for ~ i\ne j, \mathbf x _{i},\mathbf x _{j}\in X, y_{i},y_{j}\in Y\}\). Cannot-link constraint requires that the two points must belong to different clusters, and this relation is denoted by \(CL=\{(\mathbf x _{p},\mathbf x _{q})~|~y_{p}\ne y_{q}, ~for ~ p\ne q,~\mathbf x _{p},\mathbf x _{q}\in X, y_{p},y_{q}\in Y\}\). Klein et al. [7] found that must-link constraint has the transitivity properties on objects, namely, for \(\mathbf x _{i},\mathbf x _{j},\mathbf x _{k}\in X\),
In fact, simply using the constraint information in the algorithm may cause a deflection problem of the singular points during the clustering process. The so-called deflection of singular points is that the points belonging to ML are assigned to CL or the points belonging to CL are assigned to ML. Therefore, it is not always true that there are more pairwise constraints the better the clustering result is. We hope to obtain the best possible result with fewer constraints which is just the purpose of active learning.
2.3 Representation of Three-Way Clustering
The purpose of clustering is to divide the N objects of a universe X into some clusters. If there are K clusters, the family of clusters, \(\mathbf C \), is represented as \(\mathbf C =\{C_1, \cdots , C_k, \cdots , C_K\}\). A cluster is usually represented by a single set in the existing works, namely, \(C_k = \{ \mathbf x _{1}, \cdots , \mathbf x _{i}, \cdots , \mathbf x _{|C_{k}|} \}\), and it is abbreviated as C by removing the subscript when there is no ambiguity. From the view of making decisions, the representation of a single set means that, the objects in the set belong to this cluster definitely, the objects not in the set do not belong to this cluster definitely. This is a typical result of two-way decisions. For hard clustering, one object just belong to one cluster; for soft clustering, one object might belong to more than one cluster. However, this representation cannot show which objects might belong to this cluster, and it cannot show the degree of the object influence on the form of the cluster intuitively. Thus, the use of three regions to represent a cluster is more appropriate than the use of a crisp set, which also directly leads to three-way decisions based interpretation of clustering.
In contrast to the general crisp representation of a cluster, we represent a three-way cluster C as a pair of sets:
Here, \(Co(C) \subseteq X\) and \(Fr(C) \subseteq X\). Let \(Tr(C)= X-Co(C)-Fr(C)\). Then, Co(C), Fr(C) and Tr(C) naturally form the three regions of a cluster as Core Region, Fringe Region and Trivial Region respectively. That is:
If \(\mathbf x \in CoreRegion(C) \), the object \(\mathbf x \) belongs to the cluster C definitely; if \(\mathbf x \in FringeRegion(C)\), the object \(\mathbf {x}\) might belong to C; if \(\mathbf {x} \in TrivialRegion(C)\), the object \(\mathbf {x}\) does not belong to C definitely.
These subsets have the following properties.
If \(Fr(C) = \emptyset \), the representation of C in Eq. (2) turns into \(C = Co(C )\); it is a single set and \(Tr(C)= X- Co(C)\). This is a representation of two-way decisions. In other words, the representation of a single set is a special case of the representation of three-way cluster.
Furthermore, according to Eq. (4), we know that it is enough to represent a cluster expediently by the core region and the fringe region.
In another way, we can define a cluster by the following properties:
Property (i) implies that a cluster cannot be empty. This makes sure that a cluster is physically meaningful. Property (ii) states that any object of X must definitely belong to or might belong to a cluster, which ensures that every object is properly clustered.
With respect to the family of clusters, \(\mathbf C \), we have the following family of clusters formulated by three-way decisions as:
Obviously, we have the following family of clusters formulated by two-way decisions as:
3 The Proposed Semi-supervised Clustering Method
In this section, a semi-supervised three-way clustering framework for multi-view data is proposed. The three-way spectral clustering algorithm and the active learning strategy are described.
3.1 The Framework
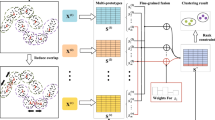
The proposed semi-supervised three-way clustering framework for multi-view data (or SS-TWC, for short) is shown in Fig. 1, which is an iterative processing. In short, the framework consists of two parts, i.e., the three-way clustering and the active learning. The main goal of Part 1 is to produce the clustering result in three-way representation. In other words, the other clustering algorithm also works as long as we alter it to adopt to the three-way representation. The task of Part 2 is to choose some objects (points) to query experts. The responses to the queries (i.e., constraints) are then used to update the clustering in Part 1.

SS-TWC: semi-supervised three-way clustering framework for multi-view data
In this paper, the spectral clustering approach is used to produce the three-way clustering in Part 1. The framework of three-way spectral clustering algorithm is described in Algorithm 1 in Subsect. 3.2. The algorithm computes on the multiple views \(X^{(1)},X^{(2)},\cdots ,X^{(H)}\), to find a low-dimensional feature space E of original data points by calculating eigenvectors of fused Laplacian matrix L. In order to obtain more accurate partitions, uncertain objects are assigned to the fringe region of corresponding cluster. For these uncertain objects, they can get further decision when information is sufficient.
In Part 2, the SS-TWC uses the active learning method to learn dynamically objects with most important information toward improving the current clustering result. The framework of active learning algorithm is described in Algorithm 2 in Subsect. 3.3. In each iteration, the active learning measures uncertain objects in fringe regions with a certain strategy. The produced pairwise constraints information is applied to adjust the similarity matrix between data points in Algorithm 1, which makes objects being more compact in one cluster and more discrete in different clusters.
We need to note that the final result of clustering can be expressed by two-way or three-way representation according to the user demands. In the framework, the result of the first iteration is in three-way representation, and the fringe regions reduce after processing iterations. In each iteration, we query experts to acquire the prior information by choosing the objects from fringe regions. The algorithm obtains the two-way clustering result finally when the iteration is going on until the fringe regions are empty, which is the results in our experiments. The algorithm also can obtain the three-way clustering result finally, if it stops when the clustering result is stable or the iterative times q reaches the maximum number Q.
3.2 The Three-Way Spectral Clustering
First, we need to map the data set \(X=\{\mathbf{x }_{1}, \cdots ,\mathbf{x }_{i}, \cdots , \mathbf{x }_{N}\}\) to a similarity matrix W. We refer to the concept of k-nearest neighbors in consideration of the nearer neighbors contribute more to the classified information than the more distant ones.
In spectral clustering, the Gaussian kernel function is widely used as the similarity measure. However, it is difficult to determine the optimal value of the kernel parameter, which reflects the neighborhood of the data points. In addition, with a fixed kernel parameter, the similarity between two objects is only determined by their Euclidean distance. Inspired by the idea of local scaling parameter can be determined by shared nearest neighbors [24], we proposed an adaptive parameter based on shared neighbors instead of traditional kernel parameter.
Let \(N(\mathbf{x })=\{\mathbf{x }_{s}|dist(\mathbf{x },\mathbf{x }_{s})\le r, \mathbf x _{s}\in kNN(\mathbf{x })\}\) contains objects that are members of neighborhood of \(\mathbf {x}\) with the neighbor radius r, where \(dist(\mathbf {x},\mathbf {x}_{s})\) describes the Euclidean distance between \(\mathbf x \) and \(\mathbf x _{s}\), \(kNN(\mathbf x )\) denotes k neighbor points of \(\mathbf x \). The neighbor radius r of object \(\mathbf x \) is defined as \(r=\frac{1}{k}\sum _{s=1}^{k} dist(\mathbf x ,\mathbf {x}_{s})\), such that \(\mathbf {x}_{s}\in kNN(\mathbf {x})\). Neighbor radius of each object can be confirmed by its k neighbor points. In addition, the number of points in the join neighborhood of two objects indicates their closeness. Therefore, a similarity function that considers global distribution and local consistency is given by:
where \(r_{i}\) and \(r_{j}\) are the neighbor radius of \(\mathbf x _{i}\) and \(\mathbf {x}_{j}\) respectively, \(\left| N(\mathbf {x}_{i})\bigcap N(\mathbf {x}_{j}) \right| \) is the number of objects in the join neighborhood of \(\mathbf {x}_{i}\) and \(\mathbf {x}_{j}\).
We adopt graphs \(G^{(1)}, \cdots , G^{(H)}\) to describe the multiple views \(X^{(1)}, \cdots , X^{(H)}\) respectively. \(G^{(h)}=(V^{(h)},E^{(h)},W^{(h)})\), where \(W^{(h)}\) represents the similarity relationship among data points of h-th view. \(L^{(h)}\) denotes the normalized graph Laplacian matrix of \(G^{(h)}\) and is defined as:
where \(D^{(h)}\in \mathbb {R}^{N\times N}\) denotes the degree matrix of graph \(G^{(h)}\) whose i-th diagonal element is \(d_{i}^{(h)}=\sum _{j=1}^{N} w_{ij}^{(h)}\).
The objective function of the normalized spectral clustering is defined as:
Due to G is the identical matrix of all views, Eq. 10 can be converted to:

In fact, the three-way spectral clustering algorithm (see Algorithm 1) implements the initial clustering and the iterative clustering. In the initial processing, i.e. the iteration times be 1, the constraint set \(R=\emptyset \). That means there is no prior information and the spectral clustering is a unsupervised learning for multi-view data. In the iterative clustering processing, i.e. the iteration times more than 1, pairwise constraints information produced by the active learning algorithm (see Algorithm 2) are added to the constraint set R. The similarity matrixes of spectral clustering are adjusted by the following formula:
Based on the idea of three-way decisions, the proposed framework assigns the current uncertain objects to the corresponding fringe region. First, for the objects need to be divided, the proposed algorithm finds the neighborhood \(N(\mathbf {x}_{i})\) with neighbor radius \(r_{i}\). Then, it calculates the proportion of the objects in \(N(\mathbf x _i)\) belong to each cluster; and it assigns \(\mathbf {x}_{i}\) to the corresponding core region or fringe region. The proportion that objects in \(N(\mathbf {x}_{i})\) belong to \(C_{k}\) is given by:
Naturally, we have the three-way decision rules as follows.
where \(\alpha \) and \(\beta \) are the three-way decision thresholds.
3.3 The Active Learning to Acquire Pairwise Constraints
In this work, we consider active learning of constraints in the iterative framework. The search space is reduced to the fringe regions in the proposed method. In the current iteration, we need to decide which objects have the most important information toward improving the current clustering result and form queries accordingly. The responses to the queries (i.e., constraints) are then used to update the similarity matrix by using Eq. 12.
Specifically, we define the uncertainty in terms of the concept of entropy, which is a classic measure of uncertainty. In the h-th view, \(w_{ij}^{(h)}\) denotes similarity between points \(\mathbf {x}_{i}^{(h)}\) and \(\mathbf {x}_{j}^{(h)}\), the probability of \(\mathbf {x}^{(h)}\) belongs to different core regions \(Co(C_{k})(1\leqslant k\leqslant K)\) is defined as:
where \(\left| Co(C_{k}) \right| \) is the cardinality of \(Co(C_{k})\).
Then, the maximum entropy of \(\mathbf {x}\) among H views is calculated by the following formula.
An object with the bigger entropy will have more classification information to help decision-making. Thus, the object with most important information is selected by the following formula.
where U denotes the set of unlabeled data.
In order to reduce the cost of queries, we first sort the K probabilities, \(p^{(h)}(\mathbf {x^*}~|~Co(C_{k}))\) for \(1\le k \le K\), in descending order. Then, we begin query the core of the cluster from the higher one until a must-link constraint satisfied.

4 Experimental Results
In this section, we validate the proposed method on some real-world datasets. Table 1 gives the summary information about the datasets. SensITFootnote 1 uses two sensors to classify three types of vehicle. We randomly sample 100 data for each class, and then conduct experiments on 2 views and 3 classes. ReutersFootnote 2 contains feature characteristics of documents originally written in five different languages, and their translations over a common set of 6 categories. We use documents originally in English as the first view and their French and German translations as the second and the third view respectively. We randomly sample 1200 documents from this text collection, with each of the 6 clusters having 200 documents. CoraFootnote 3 and CiteSeerFootnote 4 collect kinds of scientific publications, with the first view being the textual content of documents and the second view being citation links between documents.
We compare the proposed SS-TWC method with some representative multi-view clustering strategies.
-
Best Single View(BSV): running the proposed semi-supervised spectral clustering on each input view, and then reporting the results of the view that achieves the best performance.
-
Feature Concatenation(FeatCon): concatenating the features of all views to form a single representation, and then applying the proposed semi-supervised spectral clustering on the concatenated view.
-
AMVNMF: the adaptive multi-view semi-supervised nonnegative matrix factorization, it is an iterative multi-view semi-supervised clustering algorithm from the reference [16].
-
SS-TWC(R): the method is similar with the SS-TWC except it obtains equivalent constraint information by using the random strategy instead of the active learning strategy in Algorithm 2.
The quality of the final clustering is evaluated by the traditional indices such as the accuracy (AC) and normalized mutual information (NMI). To ensure the objectivity of the experimental results, the results of AMVNMF are from the reference [16] and the other methods are programmed in C++. Each test runs 10 times, the average values of AC and the NMI are recorded in Table 2. The k, the number of neighbors, is set to be the 5% of the universe in the tests.
Obviously, the SS-TWC outperforms the other compared methods on the four datasets. Unlike the BSV and FeatCon, the SS-TWC profits from the correlative and complementary information among multiple views. Compared to the AMVNMF, the proposed SS-TWC has the benefit of processing the uncertainty in multi-view data by using the three-way decisions. In addition, the compared results between the SS-TWC and the SS-TWC(R) show that the proposed strategy of selecting pairwise constraints dynamically is much effective. In short, the proposed method work well in dealing with multi-view data.
5 Conclusions
In many scenarios, more than one view can be provided to describe the data due to the fact that data may be collected from different sources or be represented by different kind of feature sets for different tasks. Clustering multi-view data is an important problem. In this paper, we proposed a semi-supervised three-way clustering framework for multi-view data. The framework is an iterative processing, which consists of two parts, i.e., the three-way clustering and the active learning. The main goal of three-way clustering is to produce the clustering result in three-way representation, in which the objects in fringe regions intuitively gives the clue to query. Thus, the task of the active learning is to choose some objects (points) from fringe regions to query experts, and the responses to the queries (i.e., constraints) are then used to update the clustering result in iterations. The spectral clustering and the active learning strategies are used to implement the framework. The experimental results show that the proposed method achieves better performance in both the accuracy and the NMI than the compared methods. However, we need further work to improve the time complexity though the cost for computing has reduced little by constructing kNN graph. To consider the different contribution of different view is another direction for future research.
References
Blum, A., Mitchell, T.: Combining labeled and unlabeled data with co-training. In: Proceeding of the Eleventh Annual Conference on Computational Learning Theory, pp. 92–100. ACM (1998)
Bickel, S., Scheffer, T.: Multi-view clustering. In: ICDM, vol. 4, pp. 19–26 (2004)
Chaudhuri, K., Kakade, S.M., Livescu, K., Sridharan, K.: Multi-view clustering via canonical correlation analysis. In: Proceedings of the 26th Annual International Conference on Machine Learning, pp. 129–136. ACM (2009)
Chen, W., Feng, G.: Spectral clustering: a semi-supervised approach. Neurocomputing 77(1), 229–242 (2012)
Ding, S., Jia, H., Zhang, L., Jin, F.: Research of semi-supervised spectral clustering algorithm based on pairwise constraints. Neural Comput. Appl. 24(1), 211–219 (2014)
Grira, N., Crucianu, M., Boujemaa, N.: Unsupervised and semi-supervised clustering: a brief survey (2005)
Klein, D., Kamvar, S.D., Manning, C.D.: From instrance-level constraints to space-level constraints: making the most of prior knowledge in data clustering. Stanford (2002)
Li, Y., Nie, F., Huang, H., Huang, J.: Large-scale multi-view spectral clustering via bipartite graph. In: AAAI, pp. 2750–2756 (2015)
Liang, D., Liu, D.: Systematic studies on three-way decisions with interval-valued decision-theoretic rough sets. Inf. Sci. 276, 186–203 (2014)
Lingras, P., Yan, R.: Interval clustering using fuzzy and rough set theory. In: Proceedings 2004 IEEE Annual Meeting, Fuzzy Information, Banff, Alberta, pp. 780–784 (2004)
Lingras, P., West, C.: Interval set clustering of web users with rough k-means. J. Intell. Inf. Syst. 23(1), 5–16 (2004)
Liu, J., Wang, C., Guo, J., Han, J.: Multi-view clustering via joint nonnegative matrix factorization. In: Proceeding of the 2013 SIAM International Conference on Data Mining, pp. 252–260. Society for Industrial and Applied Mathematics (2013)
Luxburg, U.: A tutorial on spectral clustering. Stat. Comput. 17(4), 395–416 (2007)
Wagstaff, K., Cardie, C.: Clustering with instance-level constraints. In: AAAI/IAAI, vol. 1097 (2000)
Wang, W., Zhou, Z.H.: On multi-view active learning and the combination with semi-supervised learning. In: Proceedings of the 25th International Conference on Machine Learning, pp. 1152–1159. ACM (2008)
Wang, J., Wang, X., Tian, F., Liu, C.H., Yu, H., Liu, Y.: Adaptive multi-view semi-supervised nonnegative matrix factorization. In: Hirose, A., Ozawa, S., Doya, K., Ikeda, K., Lee, M., Liu, D. (eds.) ICONIP 2016. LNCS, vol. 9948, pp. 435–444. Springer, Cham (2016). doi:10.1007/978-3-319-46672-9_49
Xia, T., Tao, D., Mei, T., Zhang, Y.: Multiview spectral embedding. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 40(6), 1438–1446 (2010)
Xiong, S., Azimi, J., Fern, X.Z.: Active learning of constraints for semi-supervised clustering. IEEE Trans. Knowl. Data Eng. 26(1), 43–54 (2014)
Xu, C., Tao, D., Xu, C.: A survey on multi-view learning. arXiv preprint arXiv:1304.5634 (2013)
Yao, Y., Lingras, P., Wang, R., Miao, D.: Interval set cluster analysis: a re-formulation. In: Sakai, H., Chakraborty, M.K., Hassanien, A.E., Ślęzak, D., Zhu, W. (eds.) RSFDGrC 2009. LNCS, vol. 5908, pp. 398–405. Springer, Heidelberg (2009). doi:10.1007/978-3-642-10646-0_48
Yao, Y.: An outline of a theory of three-way decisions. In: Yao, J.T., Yang, Y., Słowiński, R., Greco, S., Li, H., Mitra, S., Polkowski, L. (eds.) RSCTC 2012. LNCS, vol. 7413, pp. 1–17. Springer, Heidelberg (2012). doi:10.1007/978-3-642-32115-3_1
Yao, Y.: Three-way decisions and cognitive computing. Cogn. Comput. 8(4), 543–554 (2016)
Yao, J., Azam, N.: Web-based medical decision support systems for three-way medical decision making with game-theoretic rough sets. IEEE Trans. Fuzzy Syst. 23(1), 3–15 (2015)
Ye, X., Sakurai, T.: Robust similairty measure for spectral clustering based on shared neighbors. ETRI J. 38(3), 540–550 (2016)
Yu, H., Wang, G.Y., Li, T.R., Liang, J.Y., Miao, D.Q., Yao, Y.Y.: Three-Way Decisions: Methods and Practices for Complex Problem Solving. Science Press, Beijing (2015). (in Chinese)
Yu, H., Zhang, C., Wang, G.: A tree-based incremental overlapping clustering method using the three-way decision theory. Knowl.-Based Syst. 91, 189–203 (2016)
Yu, H., et al.: Methods and practices of three-way decisions for complex problem solving. In: Ciucci, D., Wang, G., Mitra, S., Wu, W.-Z. (eds.) RSKT 2015. LNCS, vol. 9436, pp. 255–265. Springer, Cham (2015). doi:10.1007/978-3-319-25754-9_23
Zhang, X., Zhao, D.Y., Wei, S., Xiao, W.X.: Active semi-supervised clustering based on multi-view learning. In: WRI Global Congress on Intelligent Systems, GCIS 2009, vol. 3, pp. 495–499. IEEE (2009)
Zhou, B., Yao, Y., Luo, J.: Cost-sensitive three-way email spam fitering. J. Intell. Inf. Syst. 42(1), 19–45 (2014)
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China under Grant Nos. 61379114 & 61533020.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Yu, H., Wang, X., Wang, G. (2017). A Semi-supervised Three-Way Clustering Framework for Multi-view Data. In: Polkowski, L., et al. Rough Sets. IJCRS 2017. Lecture Notes in Computer Science(), vol 10314. Springer, Cham. https://doi.org/10.1007/978-3-319-60840-2_23
Download citation
DOI: https://doi.org/10.1007/978-3-319-60840-2_23
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-60839-6
Online ISBN: 978-3-319-60840-2
eBook Packages: Computer ScienceComputer Science (R0)