
Abstract
The COVID-19 pandemic is a global emergency that badly impacted the economies of various countries. COVID-19 hits India when the growth rate of the country was at the lowest in the last ten years. To semantically analyze the impact of this pandemic on the economy, it is curial to have an ontology. CIDO ontology is a well-standardized ontology that is specially designed to assess the impact of coronavirus disease and utilize its results for future decision forecasting for the government, industry experts, and professionals in the field of various domains like research, medical advancement, technical innovative adoptions, and so on. However, this ontology does not analyze the impact of the COVID-19 pandemic on the Indian banking sector. On the other side, COVID-19-IBO ontology has been developed to analyze the impact of the COVID-19 pandemic on the Indian banking sector, but this ontology does not reflect complete information of COVID-19 data. Resultantly, users cannot get all the relevant information about the COVID-19 and its impact on the Indian economy. This article aims to extend the CIDO ontology to show the impact of COVID-19 on the Indian economy sector by reusing the concepts from other data sources. We also provide a simplified schema matching approach that detects the overlapping information among the ontologies. The experimental analysis proves that the proposed approach has reasonable results.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
The new business models and the different government regulatory interventions during the COVID-19 pandemic have led to various behavioral and structural changes in peoples’ lives across the globe. These changes cut across the width of the financial landscape thereby posing challenges to the key functions of the banking sector as well. In addition to other challenges, the major technological challenge is the inability to access systems and data because of various constraints. The existing artificial intelligence technologies should be leveraged to their full potential to enable data integration, analysis, and sharing for remote operations. Especially, for financial institutions like the banking sector, artificial intelligence could offer better data integration and sharing through semantic knowledge representation approaches. Many reports containing plenty of data stating the effects of this pandemic on the banking sector are available in the public domain as listed below:
These Web sites offer a static representation of COVID-19 data which is largely unstructured in nature (text, audio, video, image, newspaper, blogs, etc.) creating a major problem for the users to analyze, query, and visualize the data. The data integration task gets highly simplified by the incorporation of knowledge organization systems (taxonomy, vocabulary, ontology) as background knowledge. Storing the knowledge using the semantic data models enhances the inference power also. Ontology is a data model that is very useful to enable knowledge transfer and interoperability between heterogeneous entities due to the following reasons: (i) They simplify the knowledge sharing among the entities of the system; (ii) it is easier to reuse domain knowledge; and (iii) they provide a convenient way to manage and manipulate domain entities and their interrelationships. An ontology consists of a set of axioms (a statement is taken to be true, to act as a premise for further reasoning) that impose constraints or restrictions on sets of classes and relationships allowed among the classes. These axioms offer semantics because by using these axioms, machines can extract additional or hidden information based on data explicitly provided [1]. Web ontology language (OWL) is designed to encode rich knowledge about the entities and their relationships in a machine-understandable manner. OWL is based on the description logic (DL) which is a decidable subset (fragment) of first-order logic (FOL), and it has a model-theoretic semantics.
Various ontologies have been developed in OWL language to semantically analyze the COVID-19 data. CIDO ontology is a well-standardized ontology and specially designed for coronavirus disease [2]. However, this ontology does not analyze the impact of the COVID-19 pandemic on Indian banking sectors. On the other side, COVID-19-IBO ontology has been developed to analyze the impact of the COVID-19 pandemic on the Indian banking sector, but this ontology does not reflect the complete information of COVID-19 [3]. The contributions of this article are as follows:
-
To extend the CIDO ontology to encode the rich knowledge about the impact of COVID-19 on the Indian banking sector
-
To detect the overlapping information by designing a simplified schema matching approach
The rest of the part of this article is organized as follows: Sect. 2 illustrates the available COVID-19 ontologies. Section 3 focuses on the development of the proposed InBan_CIDO ontology. Section 4 shows the proposed schema matching approach, and the last section concludes this article.
2 A Glance on Available COVID-19 Ontologies
Ontology provides a way to encode human intelligence in a machine-understandable manner. For this reason, ontologies are used in every domain specifically in the emergency domain. As COVID-19 pandemic is a global emergency, various countries are badly impacted by it. India is one of the countries that is badly impacted by second wave of this pandemic. Various ontologies are offered to semantically analyze the COVID-19 data. These ontologies are listed below:
-
IDO ontology [4] provides a strong foundation to the other ontologies; therefore, this ontology is extended by various ontologies, namely VIDO, CIDO, IDO-COVID-19. The extended ontologies only import those concepts or entities that are required as per domain.
The coronavirus infectious disease ontology (CIDO) is a community-based ontology that imports COVID-19 pandemic-related concepts from the IDO ontology [2]. CIDO is a more specific standard ontology as compared to IDO and encodes knowledge about the coronavirus disease as well as provides integration, sharing, and analysis of the information. The latest version of CIDO is released in May 2021.
-
Dutta and DeBellis [5] published the COVID-19 ontology for case and patient information (named CODO) on the web as a knowledge graph that gives information about the COVID-19 pandemic as a data model. The CODO ontology’s primary goal is to characterize COVID-19 cases and COVID-19 patient data.
-
Mishra et al. [3] have developed an ontology called COVID-19-IBO ontology that semantically analyzes the impact of COVID-19 on the performance of the Indian banking sector. This is only one ontology that reflects the COVID-19 information as well as its impact on the Indian economy.
Table 1 shows the value of the metrics of the available COVID-19 ontologies. CIDO ontology has the highest number of classes as compared to other ontologies. These classes describe the concept of the domain. Properties (data and object) increase the richness of the ontology. The axioms-imposed restriction on the entities of the ontology provide an ability to semantically infer the information of the imposed queries from the ontology.
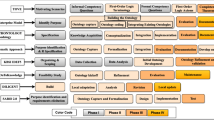
As of now, various methodologies for the development of ontology are proposed [6]. The four most famous ontology methodologies, namely TOVE, Enterprise model approach, METHONTOLOGY, and KBSI IDEF5 are presented in Fig. 1. It is quite clear that developing ontologies is not focused on understanding the engineering process, but it is a matter of craft skill. The selection of the methodologies heavily depends on the application and requirement of the ontology. Therefore, there is no perfect methodology available that can be used universally.

Available methodologies and their steps
There are two ways to create an entity inside the ontology, (a) to reuse concepts from the available ontologies and (b) to create all concepts separately (without reusing concepts). It is good practice to reuse the existing concepts that offer a common understanding of the domain. With the help of IRI, we can reuse the concepts. IRI is internationalized resource identifier which avoids multiple interpretations of entities of ontology.
After studying the literature, we state that available ontologies contain detailed information about the COVID-19 disease. However, they do not have complete (or partial) information about the impact of COVID-19 on the Indian banking sector (the sector which plays a vigorous role in the growth of the Indian economy) along with COVID-19 data. The different COVID-19 ontologies create the heterogeneity problem that needs to resolve in order to achieve interoperability among the available ontologies.
3 InBan_CIDO Ontology
Ontology is a semantic model that represents the reality of a domain in a machine-understandable manner. The basic building block of an ontology is classes, relationships, axioms, and instances [7]. Nowadays, ontologies are used everywhere because of their ability to infer semantic information of the imposed queries. As, literature shows available ontologies are not capable to analyze the impact of COVID-19 on the Indian economy along with COVID-19 detailed information. Therefore, we extend the CIDO ontology to fill this gap. On behalf of the above-listed methodologies, we have selected five phases for the extension of the CIDO ontology (called InBan_CIDO) that will offer complete information about the impact of COVID-19 on the performance of the Indian banking sector along with information on the COVID-19 pandemic. These five phases are scope determination, extraction of the concept, organization of the concept, encoding, and evaluation. The detailed description of these phases is stated below:
-
Scope Determination: The objective of this phase is to determine the scope of the ontology. We use competency questions to fix the scope and boundary of the proposed ontology. Some selected questions are mentioned below that are framed after the discussion with the expert of the domain.
-
(a)
How to the central bank will tackle the situation that arises due to non-collection of debt recovery in the moratorium period during the COVID-19 lock down?
-
(b)
What will be the impact on the balance sheet of banks when the NPA number will be added for the period of COVID-19?
-
(c)
What is the cumulative impact on the banking industry due to the loss of other industries like aviation, tourism, marketing?
-
(d)
How risk assessment and planning should be done for the upcoming COVID-19 wave (if any)?
-
(e)
How effectively the risk assessment and mitigation mechanism worked during the first and second waves?
-
(a)
-
Concept Extraction: This phase aims to extract the concepts or entities from the different sources as per the specified domain. These concepts can be marked as classes, properties (data and object properties), and instances in the further phases. We use the following sources for the development of the InBan_CIDO ontology.
-
(a)
Research articles from various data sources and indexed by Scopus, SCI, etc.
-
(b)
Ontology repositories like OBO library, bio-portal
-
(c)
Ontologies like COVID-19-IBO
-
(d)
Databases provided by WHO and Indian government
-
(e)
Interview with the experts of the domain
-
(a)
We have extensively gone through these data sources and extracted all the entities that are required for the extension of CIDO ontology to fulfill the proposed scope. All the extracted entities are stored in the Excel sheet for further analysis.
-
Concept Organization: This phase aims to organize the extracted concepts in a hierarchical manner. Firstly, we classified the extracted concepts, as classes, properties, and instances based on their characteristics. All the identified concepts are organized in a hierarchal manner (parent–child relationship). For example, a class private bank and a class government bank should become the subclasses of class Bank. We import some concepts inside InBan_CIDO ontology from the other ontologies like COVID-19-IBO. Some imported concepts are mentioned below:
Reused classes |
Current_Challenging_conditions_of_banking_industry, NPA, Loan, Bank, InfectedFamilyMember, Scheduled_Banks, Doubtfull, ETB, Cooperative_Banks, Impact, Commercial_Banks, Financial, Employee, Bankers, Digital_optimization, Loan_repayment, NRE, Detect_probable_defaults_in_early_phase, New_Assets_Quality_Review, IndividualCurrentAccount, Robust_digital_channels, OnHuman, BankingRetailCenters, Contactless_banking_options, High_credit_risk, Private_Sector, Deposit, Policies |
Reused data properties |
ContainedIn, EmployeeID, hasBankingRelationship, has_status, has_temp_of_human, number_of_account, number_of_credit_card, number_of_loans_reported, sanctioned_strength, working_strength, has_date |
Reused object properties |
Return, negative_return, positive_return, hasStatistics, has_cause, has_close, has_gender, has_nationality, has_open, type_of_relationship, via_account, via_card, via_loan, via_insurance, city_wise_statistics |
-
Encoding: We encode the InBan_CIDO ontology by using Protégé 5.5.0 tool [8]. Protégé tool is freely available on the web, and it has a very interactive interface. User can encode the ontology in protégé without having any technical knowledge about any programming language. InBan_CIDO ontology has two types of classes: old classes and new classes. Old classes are those classes that already available in CIDO ontology (CIDO is the base ontology that we have extended). New classes are categorized into two groups:
-
(a)
Classes are imported inside InBan_CIDO from other available ontologies (source ontologies) by using the IRI of that ontology
-
(b)
New classes are added as per need just by creating classes under the thing class
-
(a)
The process of Importing Classes inside InBan_CIDO Ontology: For the reusability purpose, we import some classes in the InBan_CIDO ontology from the COVID-19-IBO ontology. The process to import the classes inside destination ontology is required the IRI of that source ontology where these classes are defined. After getting the IRI of the ontology, we open the Protégé tool and create the name of the class under the thing class (which is a default class) or any other classes as per need, then go to the new entity option (Fig. 2a) and click on specified IRI (Fig. 2b) and write the IRI of the source ontology where that concept defined and then click on the ok option. Now, the IRI of the class will be changed (Fig. 2c). For example, Fig. 2 shows the process to import the class Person in InBan_CIDO ontology from the FOAF ontology which is an upper ontology. The class person of COVID-19-IBO ontology is also imported from FOAF ontology [9].

Process to import the concepts in InBan_CIDO ontology
To define the new classes inside InBan_CIDO ontology, we simply click on active ontology IRI (Fig. 2b) instead of the specified IRI which we did in the case of importing the concepts. Figure 3 shows the screenshot of the InBan_CIDO ontology that has been taken from the plugins OWLViz of Protégé tool. The latest version of InBan_CIDO ontology is available on the bio-portal for public use.

InBan_CIDO ontology
-
Evaluation: Evaluation of an ontology determines the quality, completeness, and correctness of an ontology according to the proposed scope. We have used the OOPs tool [10] to know the available anomalies (pitfall) inside the InBan_CIDO ontology. OOPs detects the pitfall in three categories, namely critical, minor, and Important. The critical pitfall is very serious because it damages the quality of the ontology. Figure 4 shows that there is no critical pitfall in the InBan_CIDO ontology, and all the minor and important pitfalls are removed by extending the ontology.
Fig. 4 
OOPs results of InBan_CIDO ontology

4 A Simplified Schema Matching Approach for COVID-19 Ontologies
The developed InBan_CIDO ontology contains information about the COVID-19 disease as well as information of the impact of COVID-19 on the performance of the Indian banking sector which is imported from COVID-19-IBO ontology. The COVID-19-IBO ontology has also contained information about the COVID19 disease as per need. Therefore, it is required to investigate the overlapping information from the existing COVID-19 ontologies with respect to COVID-19-IBO ontology. Matching systems use the matching algorithm and detect the relationships between the entities of the ontologies [11].
We propose a schema matching approach (SMA-COVID-19) to find out the overlapping information among the developed COVID-19 ontologies. The first step of the SMA-COVID-19 algorithm is to select two ontologies (OS and OT) from the ontology repository and then extract all the labels of the concepts in both ontologies with the help of Id and IRI. The labels of the concepts of source and target ontologies are stored in a n, m dimensional array (a[n] and b[m]) separately where n = number of classes in OS and m = number of classes in OT. The SMA-COVID-19 algorithm picks one label of OS and then matches it with all the labels of OT. The matching between the labels is performed according to the Levenshtein and synonym matchers. If two labels are matched based on synonyms, then a 0.9 similarity value will be assigned to them. The matching result (similarity value between the labels) is stored in the n × m matrix (Avg[n][m]). All the pairs whose similarity value is greater than α (where α is a threshold for the similarity value) are considered to be correspondences.

Experimental configuration and analysis: We have run SMA-COVID-19 in windows server 2012 R2 standard with an Intel Xeon, 2.20 GHz (40 cores) CPU, and 128 GB RAM. The proposed approach is implemented in the Python programming language. During experiments, we have set parameter ∝ = 0.8. We used libraries like Numpy (NumPy is a Python library, supporting large, multi-dimensional arrays and matrices, along with a large number of high-level mathematical functions for these arrays) and pandas (Open source, BSD-licensed library providing high-performance, easy-to-use data structures and data analysis tools for the Python programming language). We have imported the Python library for string matching and fetched a list of words from the nltk library (from nltk.corpus import stopwords).
Figure 5 shows the matching results of available COVID-19 ontologies, namely CODO, VIDO, CIDO, IDO, IDO-COVID-19 with respect to COVID-19-IBO ontology in terms of performance parameters, namely precision, recall, and F-measure. The precision parameter explains the correctness of the algorithm, whereas the Recall parameter measures the completeness of the algorithm. The parameter F-measure is the harmonic mean of precision and recall [12]. The obtained results of these parameters show that the proposed matching algorithm has reasonable performance.

Performance result of SMA-COVID-19 approach
5 Conclusion
We have extended the CIDO ontology by reusing the concepts from other data sources. The developed InBan_CIDO ontology offers accurate and precise knowledge about the impact of COVID-19 on the Indian economy as well as detailed information about the COVID-19 data. To detect the overlapping information, we have provided the SMA-COVID-19 algorithm approach that matches the schema of COVID-19 ontologies. The experimental analysis shows that the proposed approach has reasonable results in terms of precision, recall, and F-measure.
References
Web Ontology Language (OWL). https://en.wikipedia.org/wiki/Web_Ontology_Language
Y. He, H. Yu, E. Ong, Y. Wang, Y. Liu, A. Huffman, B. Smith et al., CIDO, A community-based ontology for coronavirus disease knowledge and data integration, sharing, and analysis. Sci. Data 7(1), 1–5 (2020)
A.K. Mishra, A. Patel, S. Jain, in Impact of Covid-19 Outbreak on Performance of Indian Banking Sector. CEUR Workshop Proceedings, vol. 2786 (2021)
S. Babcock, L.G. Cowell, J. Beverley, B. Smith, The Infectious Disease Ontology in the Age of COVID-19 (2020)
B. Dutta, M. DeBellis, CODO: An Ontology for Collection and Analysis of Covid-19 Data (2020). arXiv preprint arXiv: 2009.01210
D. Jones, T. Bench-Capon, P. Visser, Methodologies for Ontology Development (1998)
A. Patel, S. Jain, A partition-based framework for large scale ontology matching. Recent Pat. Eng. 14(3), 488–501 (2020)
M.A. Musen, The protégé project: a look back and a look forward. AI Matters 1(4), 4–12 (2015)
D.L. Gomes, T.H.B. Barros, in The Bias in Ontologies: An Analysis of the FOAF Ontology. Knowledge Organization at the Interface (Ergon-Verlag, 2020), pp. 236–244
OOPS! Tool. http://oops.linkeddata.es/
A. Patel, S. Jain, A novel approach to discover ontology alignment. Recent Adv. Comput. Sci. Commun. (Formerly: Recent Patents on Computer Science) 14(1), 273–281 (2021)
P. Shvaiko, J. Euzenat, Ontology matching: state of the art and future challenges. IEEE Trans. Knowl. Data Eng. 25(1), 158–176 (2011)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Patel, A., Debnath, N.C. (2022). Development of the InBan_CIDO Ontology by Reusing the Concepts Along with Detecting Overlapping Information. In: Smys, S., Balas, V.E., Palanisamy, R. (eds) Inventive Computation and Information Technologies. Lecture Notes in Networks and Systems, vol 336. Springer, Singapore. https://doi.org/10.1007/978-981-16-6723-7_26
Download citation
DOI: https://doi.org/10.1007/978-981-16-6723-7_26
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-16-6722-0
Online ISBN: 978-981-16-6723-7
eBook Packages: EngineeringEngineering (R0)