
Abstract
For biomedical image processing and prediction of skin diseases, deep learning methods are playing a very significant role in better decision making. This paper has proposed an automatic classification system of images containing a skin lesion as malignant or benign. In this method the transfer learning and a pre-trained deep learning network are implemented. In this proposed work transfer learning is applied to VGGNet architecture by replacing the last layer by a softmax layer for the classification of two different lesions (malignant and benign). Fine-tuning, data augmentations, and cross-validations are also added to the method. After evaluating the performances of the proposed method on the testing set of the ISIC dataset the method has achieved a significantly higher classification accuracy rate of 98.02%, the sensitivity of 98.10%, and Specificity of 97.05%.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Among various deadly human diseases skin cancer is one of them which causes death [1]. Most well-known skin cancer types are mainly melanoma and nonmelanoma. Because of melanoma lesions in the last few years the death rate has raised highly. Early-stage detection of this skin lesion is very essential. The curing rate can be possible over 90% if these lesions are detected at a very early stage by the physicians [2]. Visual examination of skin cancer is very hard and inefficient because many more similarities are there among different types of skin lesions [3]. For manually skin disease detection needs intensive human efforts and time. Highly magnifying and illuminated images are required for the improvement of the clarity of the spots [4]. Even for trained medical experts, by only visual investigation it is very difficult to distinguish between melanoma and nonmelanoma. In this aspect, the computer-aided classification system for skin lesion images is an alternative solution [5]. Using digital image processing techniques and artificial intelligence technologies for this automatic system time, endeavor, and human life are saved. Recently, for detection, classification, segmentation, and diagnosis of many skins disease deep learning is providing many computerized automated systems [6]. In this proposed research work, two type classification problems are represented, determining the skin lesions whether it is malignant or benign lesions. Here deep learning methods are used, mainly deep convolutional neural network (DCNN) with transfer learning for two type classification and pre-trained VGG-16 architecture is chosen for implementation. This paper is organized as follows: Sect. 2 describes related work; the method for classification of color skin images is described in Sects. 3 and 4 describes the results and discussion along with some comparative study with other methods; finally, Sect. 5 offers concluding part of the proposed work.
2 Related Work
In early days computer-aided systems used to face some difficulties for classification of dermatological images. The first problem was the data crisis or insufficiency of data [7] and the second challenge was image processing of skin images. For skin images simple dermoscopy devices are mainly used but for other biomedical images microscopy and biopsy are used [8]. The previous approaches [9, 10] used to require extensive preprocessing, segmentation, and feature extraction processes for the classification of the skin images. Current time the researchers are utilizing deep learning in visual tasks [11]. In [12] Codella et al. designed a hybrid model to classify melanoma using a combinational Artificial Neural Network (ANN) model of Support Vector Machine (SVM), deep learning, and sparse coding and accrued high accuracy. Barata et al. [13] had utilized two different models for the melanoma in skin images with the help of global and local features and concluded that better performances of color features than texture features. After applying different machine learning classification methods into melanoma for normal and abnormal cases Ozkan and Koklu et al. [14] achieved the highest accuracy of 92.5% from the ANN model. In [15] Litjens et al. suggested that the convolutional networks are very suitable to learn from features hierarchically and very much applicable for the analysis of biomedical images. For large datasets applications the accuracy for medical image classification is raised by applying deep convolution neural network and Transfer Learning [16]. By combined use of supervised learning and deep learning Premaladha and Ravichandran et al. [17] developed a diagnosis system for skin cancer classification. After applying the median filter and normalized Otsu’s segmentation for normal skin separation an accuracy rate of 92.89% is achieved. Adria Romero et al. [18] proposed a system for classifying a dermoscopy image containing a skin lesion as malignant or benign built around the CNN model and used the transfer learning methods. In [19] Yu et al. proposed a Mask R-CNN and U-net for segmentation analysis of skin specially applied for the ISIC 2017 dataset.
3 Proposed Model of Transfer Learning
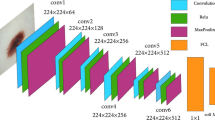
Several layers of neural networks are used to form a Deep Convolution Neural Network (DCNN). This model is very useful for extraction features from different images and classification of images [20]. There are many architectures of DCNN which are LeNet, VGGNet, AlexNet, ZFNet, GoogLeNet, ResNet, Efficient Net, Dense Net, etc. [21]. These architectures are applied for image classification, object detection, image segmentation, and many other complex tasks. VGGNet is one of the well-known and widely used model for DCNN [22]. For this proposed model the DCNN pre-trained VGG-16 architecture is used. In VGG-16 the number 16 means 16 layers that have weights. In Fig. 1 the process flow model of the architecture is described and an illustration of the proposed VGG-16 architecture is displayed in Fig. 2.

Process flow model

Description of proposed VGG-16 model
3.1 Image Augmentation
For better performance of the neural network, a large training dataset is required which gives a good learning experience to the network. Image augmentation techniques are applied to increase virtually the size of training data for good performance of neural network classifiers. Different data augmentation techniques are also applied using multiple ways of combination like rotating the images, flipping the images, and shearing the image.
3.2 Description of the Architecture
For classification of image dataset efficiently Deep Convolutional Neural Network (DCNN) is a most useful model. The proposed architecture of VGG-16 (described in Fig. 2) is used here for the classification of lesions. In the convolution layer for obtaining of feature matrix, a kernel matrix is multiplied with the image matrix. The input size of the RGB image which is provided in the convolution layer is 224 × 224 × 3. In this architecture there are a total of 13 convolution layers. The model contains two convolution layers of size 224 × 224 × 64, then another two layers of size 112 × 112 × 128 also three layers of size 56 × 56 × 256, along with another three layers having size 28 × 28 × 512. Rectified Linear Unit (ReLU) activation function is added to each layer followed by Max Pooling so that all the negative values are not passed to the next layer. A matrix is produced as an output by the pooling layer in the proposed network that is working as the input for a fully connected layer. The last layer is a dense layer followed by another dense layer with Softmax activation which has given the output classes of the images. By the use of flatten() function one matrix is connected to a long vector and linear operations are performed in the dense() layer. Relu() and Softmax are used as an activation function. The dense layers are consists of two dense layer of 4096 units each and one dense layer of Softmax layer of 4 units. ReLU function is used for both the dense layer of 4096 units to stop forwarding negative values through the network.
4 Results and Discussion
In this paper ISIC image dataset of Skin cancer is used to train the model [23]. It contains a binary label that is benign and malignant. 1800 images of benign skin cancer images and 1497 images of malignant images are used. Among these 1440 images for training and 360 for testing of benign are used for this model. Among the malignant images 1197 are used for training and 300 images for testing. After testing the cross-validation is also done using 20% of the total images. Since there are a lot of images, so a lot of processing power is also required for the model. Since the PC where the model is coded has low processing power, therefore Google’s cloud platform is used to execute the model. It is not only providing a virtual RAM but also providing a high-end virtual GPU to run the proposed model. For the implementation of the deep learning network the well-known Keras framework of Python is used for this model. For the evaluation of the performance measure of the proposed methods, three-evaluation measures such as accuracy, sensitivity and specificity are used by the help of the confusion matrix. Some common terminologies are used such as (i) True Positive (TP): Number of images for Malignant correctly classified as Malignant, (ii) True Negative (TN): Number of images of Benign correctly predicted as Benign, (iii) False Positive (FP): Number of images predicted as Benign but it is Malignant, (iv) False Negative (FN): Number of images classified as Malignant but it is Benign. The equations are defined as:
In this paper, the proposed model is achieved with very good results, with an accuracy of 98.02%, a Sensitivity of 98.10% and also Specificity of 97.05% which are significantly better than the others methods of Esteva et al. [24], Pham et al. [25], Hosny et al. [26], Adria Romero Lopez et al. [27], which are mentioned in Table 1. In Fig. 3 some sample images of Malignant and Benign are shown which are collected from the ISIC image data set. Figure 4a depicts the accuracy for both training and validation accuracy of the model for epoch values and Fig. 4b represents the loss for both training and validation.

Sample images of Malignant and Benign skin lesions from the ISIC dataset

a Training accuracy and testing accuracy graph, b training loss and testing loss graph of the model
5 Conclusion
In this paper the deep convolutional model is implemented for two type classification applications, more specifically for Malignant and Benign skin lesion prediction. The image augmentations are applied to overcome the challenges of a crisis of labeled more images for the training of the model. The proposed method is able to classify more than two type lesions only by replacing the last layer to the softmax layer for more than two classifications. The weights of the proposed model are also fine-tuned. With the computation of three performance measures i.e., accuracy, sensitivity, and specificity, and comparing with other existing models, the obtained results of this model are significantly better than others. Along with the accuracy that the loss of the model is found out of 0.0467 is significantly very less. After testing the model with testing data, the minor difference between training and test sets are observed which suggests that the model neither overfits nor underfits. Transfer learning offers very good efficiency to deal with complex image processing problems with a massive number of the images data set.
References
American Cancer Society: Cancer facts and figures 2018. Available: https://www.cancer.org/content/dam/cancer-org/research/cancer-factsand-statistics/annual-cancer-facts-and-figures/2018/cancer-facts-andfigures-2018.pdf
Ballerini L., Fisher R., Aldridge B., Rees J.: A color and texture-based hierarchical K-NN approach to the classification of non-melanoma skin lesions. Color Medical Image Analysis, Lecture Notes in Computational Vision and Biomechanics Volume 6, Editors: (Emre Celebi M. and Gerald Schaefer). Springer, pp. 63–86 (2013)
Codella N., Nguyen Q., Pankanti S., Gutman D., Helba B., Halpern A., Smith J.: Deep learning ensembles for melanoma recognition in dermoscopy images. IBM J. Res. Dev. 61(4/5), 5:1–5:15 (2017)
Kittler, H., Pehamberger, H., Wolff, K., Binder, M.: Diagnostic accuracy of dermoscopy. Lancet Oncol. 3(3), 159165 (2002)
Mishra N., Celebi M.: An overview of melanoma detection in dermoscopy images using image processing and machine learning. (2016). Available from: arXiv:1601.07843
Rajpara, S.M., Botello, A.P., Townend, J., Ormerod, A.D.: Systematic review of dermoscopy and digital dermoscopy/artificial intelligence for the diagnosis of melanoma. Br. J. Dermatol. 161(3), 591–604 (2009)
Masood, A., Al-Jumaily, A.A.: Computer-aided diagnostic support system for skin cancer: a review of techniques and algorithms. Int. J. Biomed. Imaging 323268, 2013 (2013)
Binder, M., et al.: Epi-luminescence microscopy-based classification of pigmented skin lesions using computerized image analysis and an artificial neural network. Melanoma Res. 8, 261–266 (1998)
Burroni, M., et al.: Melanoma computer-aided diagnosis: reliability and feasibility study. Clin. Cancer Res. 10, 1881–1886 (2004)
Schindewolf, T., et al.: Classification of melanocytic lesions with color and texture analysis using digital image processing. Anal. Quant. Cytol. Histol. 15, 1–11 (1993)
Silver, D., et al.: Mastering the game of Go with deep neural networks and tree search. Nature 529, 484–489 (2016)
Codella N., Cai J., Abedini M., Garnavi R., Hapern A., Smith J.: Deep learning, sparse coding, and SVM for melanoma recognition in dermoscopy images. In: Machine Learning in Medical Imaging. Lecture Notes in Computer Science, vol. 9352, pp. 118–126. Springer (2015)
Barata, C., Ruela, M., Francisco, M., Mendonça, T., Marques, J.S.: Two systems for the detection of melanomas in dermoscopy images using texture and color features. IEEE Syst. J. 8(3), 965–979 (2014)
Ozkan, I.A., Koklu, M.: Skin lesion classification using machine learning algorithms. Intell. Syst. Appl. Eng. 5(4), 285–289 (2017)
Litjens, G., Kooi, T., Bejnordi, B., Setio, A., Ciompi, F., Ghafoorian, M., et al.: A survey on deep learning in medical image analysis. Med. Image Anal. 42, 60–88 (2017). https://doi.org/10.1016/j.media.2017.07.005
Shin, H.C., Roth, H.R., Gao, M., Lu, L., Xu, Z., Nogues, I., et al.: Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 35(5), 1285–1298 (2016). https://doi.org/10.1109/TMI.2016.2528162
Premaladha, J., Ravichandran, K.: Novel approaches for diagnosing melanoma skin lesions through supervised and deep learning algorithms. J. Med. Syst. 40(96), 1–12 (2016)
Lopez, A.R., Giro-i-Nieto, X., Burdick, J., Marques, O. et al.: Skin Lesion Classification from Dermoscopic Images using Deep Learning Techniques. IASTED International Conference on Biomedical Engineering, pp. 49–54 (2017)
Yu, L., Chen, H., Dou, Q., Qin, J., Heng, P.A.: Automated melanoma recognition in dermoscopy images via very deep residual networks. IEEE Trans. Med. Imaging 36(4), 994–1004 (2016)
LeCun, Y., Bengio, Y., Hinton, G.: Deep learning. Nature 521, 436–444 (2015). https://doi.org/10.1038/nature14539
Srinivas, S., Sarvadevabhatla, R., Mopuri, K., Prabhu, N., Kruthiventi, S., Babu, R.: A taxonomy of deep convolutional neural nets for computer vision. Front. Robot. AI 2 (2016). Available from: arXiv:1601.06615
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
International Skin Imaging Collaboration: Melanoma Project Website. https://isic-archive.com/
Esteva, A., Kuprel, B., Novoa, R., Ko, J., Swetter, S., Blau, H., et al.: Dermatologist-level classification of skin cancer with deep neural networks. Nature 542, 115–118 (2017). https://doi.org/10.1038/nature21056
Pham, T.C., Luong, C.M., Visani, M., Hoang, V.D.: Deep CNN and data augmentation for skin lesion classification. In: Intelligent Information and Database Systems, Lecture Notes in Computer Science, vol. 10752, pp. 573–582. Springer (2018)
Hosny, K.M., Kassem, M.A., Foaud, M.M.: Classification of skin lesions using transfer learning and augmentation with Alex-net. PLoSONE 14(5), e0217293. https://doi.org/10.1371/journal.pone.0217293
Lopez, A.R., Giro-i-NietO, X., Burdick, J., Marques, O., et al.: Skin Lesion Classification from Dermoscopic Images using Deep Learning Techniques. In: IASTED International Conference on Biomedical Engineering, pp. 49–54 (2017)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 The Editor(s) (if applicable) and The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Samanta, P.K., Rout, N.K. (2021). Skin Lesion Classification Using Deep Convolutional Neural Network and Transfer Learning Approach. In: Banerjee, S., Mandal, J.K. (eds) Advances in Smart Communication Technology and Information Processing. Lecture Notes in Networks and Systems, vol 165. Springer, Singapore. https://doi.org/10.1007/978-981-15-9433-5_32
Download citation
DOI: https://doi.org/10.1007/978-981-15-9433-5_32
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-9432-8
Online ISBN: 978-981-15-9433-5
eBook Packages: EngineeringEngineering (R0)