
Abstract
In this paper, a new Leaky-LMS (LLMS) algorithm that modifies and improves the Zero-Attracting Leaky-LMS (ZA-LLMS) algorithm for sparse system identification has been proposed. The proposed algorithm uses the sparsity of the system with the advantages of the variable step-size and l 0 -norm penalty. We compared the performance of our proposed algorithm with the conventional LLMS and ZA-LLMS in terms of the convergence rate and mean-square-deviation (MSD). Additionally, the computational complexity of the proposed algorithm has been derived. Simulations performed in MATLAB showed that the proposed algorithm has superiority over the other algorithms for both types of input signals of additive white Gaussian noise (AWGN) and additive correlated Gaussian noise (ACGN).
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
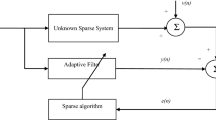
In adaptive filtering technology, the least-mean-square (LMS) algorithm is a commonly used algorithm for system identification (see Fig. 1), noise cancellation or channel equalization models [1]. Although it is a very simple and robust algorithm, its performance deteriorates for some applications which have high correlation, long filter length, sparse signals etc. In the literature, many different LMS-type algorithms were proposed to improve the performance of the standard LMS algorithm.

Block diagram of the system identification process.
Leaky-LMS algorithm was proposed [2, 3] to overcome the issues when the input signal is highly correlated, by using shrinkage in its update equation. Another LMS based algorithm VSSLMS uses a variable step-size in update equation of the standard LMS to increase the convergence speed at the beginning stages of the iterations and decrease MSD at later iterations [4, 5]. In order to improve the performance of the LMS algorithm when the system is sparse (most of the system coefficients are zeroes), ZA-LMS algorithm was proposed in [6].
In [7], the author proposed the ZA-LLMS algorithm which combines the LLMS algorithm and the ZA-LMS algorithm for sparse system identification. A better performance was obtained for AWGN and ACGN input signals. In [8], a high performance algorithm called zero-attracting function-controlled variable step-size LMS (ZAFC-VSSLMS) was proposed by using the advantages of variable step-size and l 0-norm penalty. We were motivated by the inspiration of the combination of these two algorithms. So in this paper we proposed a new algorithm that combines the ZA-LLMS and ZAFC-VSSLMS algorithms. In the next section, a brief review of the LLMS and ZA-LLMS algorithms is provided. We describe the proposed algorithm in Sect. 3 with computational complexity and convergence analysis. In Sect. 4, the simulations are presented and the performance of the algorithm is compared. Conclusions are drawn in the last section.
2 Review of the Related Algorithms
2.1 Leaky-LMS (LLMS) Algorithm
In a system identification process, the desired signal is defined as,
where \( {\mathbf{w}}_{0} = [w_{0 0} , \ldots ,w_{0N - 1} ]^{T} \) are the unknown system coefficients with length N, \( {\mathbf{x}}(n) = [x_{0} , \ldots ,x_{N - 1} ]^{T} \) is the input-tap vector and \( v(n) \) is the additive noise. In addition to being independent of the noise sample \( v(n) \) with zero mean and variance of \( \sigma_{\upsilon }^{2} \), the input data sequence \( {\mathbf{x}}(n) \) and the additive noise sample \( v(n) \) are also assumed to be independent.
The cost function of the LLMS algorithm is given by,
where w(n) is the filter-tap vector at time n, \( \gamma \) is a positive constant called ‘leakage factor’ and \( e(n) \) is the instantaneous error and given by,
The update equation of the LLMS algorithm can be derived by using the gradient method as,
where µ is the step-size parameter of the algorithm.
2.2 Zero-Attracting Leaky-LMS (ZA-LLMS) Algorithm
The cost function of the LLMS algorithm was modified by adding the log-sum penalty of the filter-tap vector as given below:
where \( \gamma^{\prime} \) and \( \xi^{\prime} \) are positive parameters. Taking the gradient of the cost function and subtracting from the previous filter-tap vector iteratively, then the update equation was derived as follows [7]:
where \( \rho = \frac{{\mu \gamma^{\prime}}}{{\xi^{\prime}}} \) is the zero-attracting parameter, \( \xi = \frac{1}{{\xi^{\prime}}} \) and sgn(.) operation is defined as,
3 The Proposed Algorithm
3.1 Derivation of the Proposed Algorithm
An improved sparse LMS-type algorithm was proposed in [8] by exploiting the advantages of variable step-size and recently proposed [9] l 0-norm which gives an approximate value of \( \left\| \cdot \right\|_{0} \). We modify the cost function of that algorithm by adding the weight vector norm penalty as,
where ε is a small positive constant and \( \left\| {{\mathbf{w}}(n)} \right\|_{0} \) denotes the l 0-norm of the weight vector given as,
where λ is a positive parameter. Deriving (8) with respect to w(n) and substituting in the update equation we get,
where \( \rho (n) = \mu (n)\varepsilon \lambda \) is the sparsity aware parameter and depends on the positive constant λ and \( \mu (n) \) which is the variable step-size and given in [6] as
where \( 0 < \alpha < 1,\;\gamma_{s} > 0 \) are some positive constants and \( e(n) \) is a mean value of the error vector. \( \hat{e}_{ms}^{2} (n) \) is the estimated mean-square-error (MSE) and is defined as
where \( \beta \) is a weighting factor given as \( 0 < \beta < 1\;{\text{and}}\;f(n) \) is a control function given below
A summary of the algorithm is given in Table 1.
It is seen that the update equation of the ZA-LLMS algorithm has been modified by changing the constant step-size µ with µ(n) given in [8] and the zero-attractor \( \rho \frac{{\text{sgn} [{\mathbf{w}}(n)]}}{{1 + \xi \left| {{\mathbf{w}}(n)} \right|}} \) with \( \rho (n)\text{sgn} [{\mathbf{w}}(n)]e^{{ - \lambda \left| {{\mathbf{w}}(n)} \right|}} \).
3.2 Computational Complexity
The update equation of the conventional LMS algorithm has O(N) complexity and has been calculated as 2N + 1 multiplications and 2N additions at each iteration [10]. For \( (1 - \mu \gamma ){\mathbf{w}}(n) \) in LLMS N + 1 extra multiplications and one addition are required. In the update equation of the estimated MSE used in the algorithm proposed in [8], 3 multiplications and 2 additions are required additionally to compute the \( \hat{e}_{ms}^{2} (n) \). For update equation of \( \mu (n) \), we need 5 multiplications and one addition. The computational complexity of the zero attractor, \( \rho (n)\text{sgn} [{\mathbf{w}}(n)]e^{{ - \lambda \left| {{\mathbf{w}}(n)} \right|}} \), requires N multiplications for \( \lambda \left| {{\mathbf{w}}(n)} \right| \), N additions for \( e^{{ - \lambda \left| {{\mathbf{w}}(n)} \right|}} \) (taking the first two terms of Taylor series), N multiplications for \( \rho (n)\text{sgn} [{\mathbf{w}}(n)] \), N multiplications for one by one element product of \( \lambda \left| {{\mathbf{w}}(n)} \right| \) by \( \rho (n)\text{sgn} [{\mathbf{w}}(n)] \) and N comparisons for \( \text{sgn} [{\mathbf{w}}(n)] \). So, overall complexity of the zero attractor is 3N multiplications, N additions and N comparisons. The overall computational complexity of the proposed algorithm requires 6N + 10 multiplications, 3N + 4 additions and N comparisons, that is, (O(N) complexity.
4 Simulation Results
In this section, we compare the performance of the proposed algorithm with LLMS and ZA-LLMS algorithms in high-sparse and low-sparse system identification settings. Two different experiments are performed for each of AWGN and ACGN input signals. To increase the reliability of the expected ensemble average, experiments were repeated by 200 independent Monte-Carlo runs. The constant parameters are found by extensive tests of simulations to obtain the optimal performance as follows: For LLMS: µ = 0.002 and γ = 0.001. For ZA-LLMS: µ = 0.002, γ = 0.001, ρ = 0.0005 and ξ = 30. For the proposed algorithm: ρ = 0.0005 and λ = 8.
In the first experiment, all algorithms are compared for 90 % high-sparsity and 50 % low-sparsity of the system with 20 coefficients having in the first part two ‘1’ and 18 ‘0’; in the second part ten ‘1’ and ten ‘0’ for 5000 iterations. Signal-to-noise ratio (SNR) is kept at 10 dB by regulating the variances of the input signal and the additive noise. The performance of the algorithm is compared in terms of convergence speed and \( MSD = E\left\{ {\left\| {{\mathbf{w}}_{0} - {\mathbf{w}}(n)} \right\|^{2} } \right\} \). Figures 2 and 3 give the MSD vs. iteration number of the three algorithms for 90 % sparsity and 50 % sparsity levels respectively. In Fig. 2, the proposed algorithm has a convergence speed of around 1000 iterations and MSD about −37 dB, while the others are close to each other at a convergence speed of 2500 iterations and MSD of −26~28 dB. Figure 3 shows that the proposed algorithm has a convergence speed of 1100 iterations and MSD of −29.9 dB while the other algorithms have convergence speed and MSD about 3000 iterations and −26 dB, respectively. The figures show that, the proposed algorithm has a fairly fast convergence with lower MSD than that of the other algorithms.

Steady state behavior of the LLMS, ZA-LLMS and the proposed algorithm for 90 % sparsity with AWGN.

Steady state behavior of the LLMS, ZA-LLMS and the proposed algorithm for 50 % sparsity with AWGN.
In the second experiment, all conditions are kept as same as in the previous experiment except the input signal type. A correlated signal is created by the AR(1) process as \( x(n) = 0.4x(n - 1) + v_{0} (n) \) and the normalized. Figures 4 and 5 shows that the proposed algorithm has a faster convergence and lower MSD than the other algorithms for 90 % sparsity and 50 % sparsity levels respectively.

Steady state behavior of the LLMS, ZA-LLMS and the proposed algorithm for 90 % sparsity with ACGN.

Steady state behavior of the LLMS, ZA-LLMS and the proposed algorithm for 50 % sparsity with ACGN.
5 Conclusions
In this work, we proposed a modified leaky-LMS algorithm for sparse system identification. It was derived by combining the ZA-LLMS and ZAFC-LMS algorithms. The performance of the proposed algorithm was compared with LLMS and ZA-LLMS algorithms for 90 % and 50 % sparsity levels of the system with AWGN and ACGN input signals in two different experiments performed in MATLAB. Additionally, the computational complexity of the proposed algorithm has been derived. It was shown that the computational complexity of the proposed algorithm is O(N) as same as in other LMS-type algorithms. Besides, the simulations showed that the proposed algorithm has a very high performance with a quite faster convergence and lower MSD than that of the other algorithms. As a future work, it is recommended that the proposed algorithm can be modified for transform domain or be tested for non-stationary systems.
References
Zaknich, A.: Principles of Adaptive Filters and Self-learning Systems. Springer, London (2005)
Mayyas, K.A., Aboulnasr, T.: Leaky-LMS: a detailed analysis. In: Proceedings of IEEE International Symposium on Circuits and Systems, vol. 2, pp. 1255–1258 (1995)
Sowjanya, M., Sahoo, A. K., Kumar, S.: Distributed incremental leaky LMS. In: International Conference on Communications and Signal Processing (ICCSP), pp. 1753–1757 (2015)
Chen, W.Y., Haddad, R.: A variable step size LMS algorithm. In: IEEE Proceedings of 33rd Midwest Symposium on Circuits and Systems, Calgary, vol. 1, pp. 423–426 (1990)
Won, Y.K., Park, R.H., Park, J.H., Lee, B.U.: Variable LMS algorithms using the time constant concept. IEEE Trans. Consum. Electron. 40(4), 1083–1087 (1994)
Chen, Y., Gu, Y., Hero, A. O.: Sparse LMS for system identification. In: IEEE International Conference Acoustic, Speech and Signal Processing, pp. 3125–3128 (2009)
Salman, M.S.: Sparse leaky-LMS algorithm for system identification and its convergence analysis. Int. J. Adapt. Control Sig. Process. 28(10), 1065–1072 (2013)
Turan, C., Salman, M. S.: Zero-attracting function controlled VSSLMS algorithm with analysis. In: Circuits, Systems, and Signal Processing, vol. 34, no. 9, pp. 3071–3080. Springer (2015)
Sing-Long, C.A., Tejos, C.A., Irarrazaval, P.: Evaluation of continuous approximation functions for the l 0 -norm for compressed sensing. In: Proc. Int. Soc. Mag. Reson. Med. 17: 4585 (2009)
Dogancay, K.: Partial-Update Adaptive Filters and Adaptive Signal Processing: Design, Analysis and Implementation. Elsevier, Hungary (2008)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Turan, C., Amirgaliev, Y. (2016). A Robust Leaky-LMS Algorithm for Sparse System Identification. In: Kochetov, Y., Khachay, M., Beresnev, V., Nurminski, E., Pardalos, P. (eds) Discrete Optimization and Operations Research. DOOR 2016. Lecture Notes in Computer Science(), vol 9869. Springer, Cham. https://doi.org/10.1007/978-3-319-44914-2_42
Download citation
DOI: https://doi.org/10.1007/978-3-319-44914-2_42
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-44913-5
Online ISBN: 978-3-319-44914-2
eBook Packages: Computer ScienceComputer Science (R0)