
Abstract
A (directed) random polymer in d + 1 dimensions is a random walk in d dimensions whose law is transformed by a random potential. The time axis is considered as an additional dimension. The best known and most famous case is the directed polymer in random environment which has a potential given by independent random variables in space and time. Some of the basic questions are open even in 1 + 1 dimensions which is believed to be connected with the KPZ universality class. The main focus of the notes is on the so-called copolymer, first discussed in the physics literature by Garel, Huse, Leibler and Orland in 1989 which models the behavior of a polymer at an interface. Important rigorous results have first been obtained by Sinai and Bolthausen-den Hollander, and have later been developed by many authors. A basic object of interest is a critical line in the parameter space which separates a localized phase from a delocalized one. Particularly interesting is the behavior at the weak disorder limit where the phase transition is characterized by a universal critical tangent whose existence had first been proved in the Bolthausen-den Hollander paper, and whose exact value is still open. This critical tangent is discussed in detail, and new bounds are derived, partly based on large deviation techniques developed by Birkner, Greven, and den Hollander.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
- Copolymers
- Directed polymers
- Large deviation principles
- Localization-delocalization phenomena
- Phase transitions
- Universality
1 Introduction: Random Polymers, Different Models
A very challenging model in probability theory is the “directed polymer” in random environment. We formulate it in d + 1 dimensions: The “polymer” is the sequence \(\left \{\left (n,S_{n}\right )\right \}_{n\in \mathbb{N}_{0}}\) with S 0 = 0, and \(\left \{S_{n}\right \}\) is a random walk on \(\mathbb{Z}^{d}\), e.g. nearest neighbor, symmetric. We write P N for the law of \(\left \{S_{n}\right \}_{0\leq n\leq N}.\) It is the uniform distribution on all nearest-neighbor paths in \(\mathbb{Z}^{d}\), starting in 0, and of length N. This law is transformed by a random Hamiltonian through a “time-space” random field \(\omega = \left \{\omega \left (n,x\right )\right \}_{n\in \mathbb{N}_{0},\ x\in \mathbb{Z}^{d}}\). The law, governing this random field is always denoted by \(\mathbb{P}\). The random Hamiltonian
transforms the path measure P N to a random path measure
with inverse temperature β > 0, where
Occasionally, we will use some slight modifications, for instance attaching the randomness ω to bonds and not to sites, and often, we will pin down the endpoint S N to 0 (which simplifies slightly the proof of the existence of the free energy). Sometimes, we also use β as a parameter inside H, not necessarily as a prefactor.
Some of the standard examples are:
-
The usual directed polymer in random environment which has \(\omega \left (i,x\right )\) i.i.d. in space-time.
-
The pinning model: This has \(\omega \left (i,x\right ) = 0\) for x ≠ 0. So there is a random effect only on the one-dimensional “defect line” \(\left \{\left (n,0\right ): n \in \mathbb{N}_{0}\right \}.\) It is traditional to write the Hamiltonian with two parameters
$$\displaystyle{H_{N}\left (S\right ) =\sum _{ j=1}^{N}\left (\beta \omega _{ j} + h\right )1_{S_{j}=0},}$$β ≥ 0, \(h \in \mathbb{R}\), and one assumes that \(\mathbb{E}\omega _{i} = 0\) and \(\mathop{\mathrm{{\ast}}}\nolimits var\omega _{i} = 1\).
-
The copolymer: This is defined only for d = 1 and it has
$$\displaystyle{\omega \left (i,x\right ) = \left \{\begin{array}{cc} \omega _{i} &\mathrm{if\ }x > 0 \\ -\omega _{i}&\mathrm{if\ }x < 0\end{array} \right.,}$$with ω i i.i.d. It means that at a “time” point i for which ω i > 0, the walk prefers to be on the positive side, and of ω i < 0 the opposite. As the ω i fluctuate wildly, it is not clear what the behavior of the path under \(\hat{P}\) is for typical ω. It is convenient to replace ω i by ω i + h and assume that \(\mathbb{E}\omega _{i} = 0\). \(h \in \mathbb{R}\) is then an additional parameter which is responsible for an asymmetry: If h > 0, then positive S i are stronger preferred if ω i > 0 than negative S i when ω i < 0. This gives the Hamiltonian
$$\displaystyle{H_{\omega,\,\,N}\left (S\right ) =\sum _{ j=1}^{N}\left (\omega _{ j} + h\right )\mathop{\mathrm{{\ast}}}\nolimits sign\left (S_{j}\right ).}$$It is however convenient to take \(\mathop{\mathrm{{\ast}}}\nolimits sign\left (S_{j-1} + S_{j}\right )\) instead of \(\mathop{\mathrm{{\ast}}}\nolimits sign\left (S_{j}\right )\) in order to avoid ties when the random walk hits 0. In this modification, the Hamiltonian is
$$\displaystyle{ H_{\omega,\,\,N}\left (S\right ) =\sum _{ j=0}^{N-1}\left (\omega _{ j} + h\right )\mathop{\mathrm{{\ast}}}\nolimits sign\left (S_{j} + S_{j+1}\right ). }$$(1)In the case of copolymer, one typically takes β in the standard way as a multiplicative parameter.
-
A case which has attracted a lot of attention is when \(\omega \left (i,x\right )\) does not depend on i but only on x. This is closely related to the parabolic Anderson model, and there are hundreds of research papers on this and related models. Work in this framework has be done by Carmona, Molchanov, Sznitman, Sinai, Gärtner, den Hollander, and many others with many difficult and striking results. For this Hamiltonian, also the so-called annealed model is great interest. This refers to transforming the path measure by \(\mathbb{E}\exp \left [-\beta H\right ]\). Early quite spectacular results with ω j given by coin-tossing had been obtained by Donsker and Varadhan, Sznitman, myself, Povel and others. We can’t discuss this case at all in these notes at all, as a half way exhausting presentation would require hundreds of pages. For some of the very deep results, see the monograph by Sznitman [28].
There are many other models, which have been investigated in the literature. The directed polymer is the most difficult one, and despite of a lot of recent progress, many of the key problems are still open.
The basic problems are quite the same for all the models, namely to investigate the localization-delocalization behavior. It turns out that if the disorder ω is strong enough (or β large enough) then it is able to force the path measure into narrow favorable tunnels. For the directed polymer, these tunnels itself are random (determined by ω), but for the pinning and the copolymer, a localization can only happen by the path hanging around the defect line 0. Often, there is a phase transition from localized to delocalized behavior. This is also present for the directed polymer for d ≥ 3, as will shortly be discussed in the next section.
In these notes, we concentrate on the copolymer and present some older and some recent results and techniques. In particular, we discuss the an application of the large deviation method of [3, 4] worked out in [10]. I however also present in Sect. 6 an “elementary” version of the crucial lower bound which is bypassing the use of complicated large deviation techniques. I start with two short chapters on the directed polymer and the pinning model, essentially citing some results from the literature.
2 The Directed Polymer
The first rigorous result on the directed polymer was proved by Imbrie and Spencer in 1988 [22], namely that in d ≥ 3 there is a high-temperature region where the random potential has essentially no influence on the path behavior. Shortly later, I found in [8] a very simple argument for this result. As it is very short, I present the argument here.
Theorem 1
Assume that the \(\omega \left (i,x\right ),\ i \in \mathbb{N},\ x \in \mathbb{Z}^{d}\) are i.i.d. and satisfy \(M\left (\beta \right )\mathop{ =}\limits^{\mathrm{ def}}\mathbb{E}\exp \left [\beta \omega \left (i,x\right )\right ] < \infty \) for all β, and consider the directed polymer as described above. If d ≥ 3 and β > 0 is small enough, then
\(\mathbb{P}\) -almost surely, and
Furthermore, for \(\mathbb{P}\) -almost all ω, \(S_{N}/\sqrt{N}\) under \(\hat{P}_{\beta,N,\omega }\) is asymptotically centered Gaussian with covariance matrix d −1 I d , I d being the identity matrix.
Remark 2
Imbrie and Spencer proved (2) and (3). The CLT was first proved in [8].
Proof
We restrict to (2) and (3). Evidently,
and
is a martingale with respect to the filtration \(\mathcal{F}_{N}\mathop{ =}\limits^{\mathrm{ def}}\sigma \left (\omega \left (i,x\right ): x \in \mathbb{Z}^{d},i \leq N\right ).\) As it is positive, and has expectation 1, it converges almost surely to a nonnegative random variable ζ. The crucial property is that for β small and d ≥ 3, the second moment stays bounded:
If S i ≠ S i ′, we have
and if S i = S i ′
Therefore, if we put
we get
As we assume d ≥ 3, θ N ≤ θ ∞ has an exponential moment, i.e. for some \(\delta \left (d\right ) > 0\) one has
Therefore, if β > 0 is small enough, the martingale \(\left \{M_{N}\right \}\) is L 2-bounded, and therefore converges in L 1 (and also in L 2). So \(\mathbb{E}\zeta = 1\) implying \(\mathbb{P}\left (\zeta > 0\right ) > 0\).
On the other hand, it is evident that the event \(\left \{\zeta > 0\right \}\) is a tail event for the sequence \(\left \{\hat{\mathcal{F}}_{N}\right \},\ \hat{\mathcal{F}}_{N}\mathop{ =}\limits^{\mathrm{ def}}\sigma \left (\omega \left (i,x\right ): x \in \mathbb{Z}^{d},\ i \geq N\right ),\) and so the Kolmogorov 0-1-law implies \(\mathbb{P}\left (\zeta > 0\right ) = 1\). This proves (2).
For (3), write \(S_{n} = \left (S_{n,1},\ldots,S_{n,d}\right ).\) Define for \(i,j \leq d,\ n \in \mathbb{N}\)
As is well known, and easily checked, the sequences \(\left \{Y _{n}^{i,j}\right \}_{n\in \mathbb{N}}\) are martingales under the law of the random walk. From that, it follows that
are \(\left \{\mathcal{F}_{N}\right \}\)-martingales under \(\mathbb{P}\). A computation as done above in the proof of (2) reveals that if β is small enough, the martingales
(with \(Y _{0}^{i,j}\mathop{ =}\limits^{\mathrm{ def}}0\)) are L 2-bounded and therefore converge almost surely. From the Kronecker lemma, one concludes that
almost surely. Together with (2), this proves (3). ■
There are many more recent and deeper results on the topic. Here is an (incomplete) list of results which have been obtained.
-
The directed polymer is said to be in the strong disorder regime if ζ = 0 a.s., and in the weak disorder regime if ζ > 0 a.s. The application of the Kolmogorov 0-1-law above does not depend on the dimension, and therefore ζ = 0 almost surely, or ζ > 0 almost surely. Comets and Yoshida proved in [15] that there exists a critical value β cr, depending on the law of the disorder and the dimension such that the system is in the weak disorder regime for β < β cr and in the strong disorder regime for β > β cr. Furthermore, they proved that β cr = 0 for d = 1, 2, and that a CLT holds always in the weak disorder regime (see [16]).
-
It is not difficult to see that the free energy exists and is self-averaging:
$$\displaystyle{f\left (\beta \right )\mathop{ =}\limits^{\mathrm{ def}}\lim _{N\rightarrow \infty } \frac{1} {N}\log Z_{N,\beta } =\lim _{N\rightarrow \infty } \frac{1} {N}\mathbb{E}\log Z_{N,\beta }}$$Jensen’s inequality shows that
$$\displaystyle{f\left (\beta \right ) \leq f^{\mathrm{ann}}\left (\beta \right )\mathop{ =}\limits^{\mathrm{ def}}\lim _{ N\rightarrow \infty } \frac{1} {N}\log \mathbb{E}Z_{N,\beta } =\log M\left (\beta \right ).}$$The system is called to be in the very strong disorder regime if \(f\left (\beta \right )\neq f^{\mathrm{ann}}\left (\beta \right ).\)
It was proved that for d = 1 in [14], and for d = 2 in [24], that the system is in the very strong disorder regime for any positive β.
-
In the strong disorder regime, one always has a localization property: There exists \(c = c\left (\beta \right ) > 0\) such that for \(\mathbb{P}\)-almost all ω, one has
$$\displaystyle{\liminf _{N\rightarrow \infty } \frac{1} {N}\sum _{n=1}^{N}\hat{P}_{\beta,n-1,\omega }^{\otimes 2}\left (S_{ n}^{\left (1\right )} = S_{ n}^{\left (2\right )}\right ) \geq c.}$$Here \(S_{n}^{\left (1\right )},S_{n}^{\left (2\right )}\) are two independent realizations (“replicas”) of the walk under the measure \(\hat{P}_{\beta,n-1,\omega }\). In other words, two independent replicas share a positive proportion of the time at the same place, in sharp contrast to the behavior of independent standard random walks. The result had first been proved by Carmona and Hu [13] and Comets et al. [17].
-
Whereas the properties in the weak disorder regime in d ≥ 3 are now fully understood, in the strong disorder regime, many of the properties are still completely open even for d = 1. The one-dimensional directed polymer is believed to belong to the so-called KPZ universality class. KPZ stands for Kardar-Parisi-Zhang who investigated (non-rigorously) an ill-posed stochastic PDE which is supposed to describe the directed polymer and many other interface models in an appropriate scaling limit.
Under \(\mathbb{P} \otimes \hat{ P}_{\beta,N,\omega }\), the deviation of S N from the origin is believed to be of order N 2∕3. The random environment is supposed to create random channels which deviate from the origin at this order, and then, for fixed ω, the paths are forced to localize in these channels. There are a number of very special models for which such a behavior has been proved (see [23]). The investigation of the KPZ class has been one of the main research topics in probability theory over the past years, with many deep results. But for the very “simplest” directed polymer with d = 1, given by the ordinary random walk and coin tossing ± 1 random environment, it is not even proved that the deviation of the end point under \(\mathbb{P} \otimes \hat{ P}_{\beta,N,\omega }\) is larger than of order \(\sqrt{n}.\)
3 On the Pinning Model
The pinning polymer model is considerably simpler than the directed polymer. The localization, if present, has to be around 0. This is also true for the copolymer discussed in more details later.
There is a natural generalization of the pinning and the copolymer: One remarks that the Hamiltonian does not at all depend on the exact path at excursions away from 0. Essentially only the lengths of the return times to 0 count. For the copolymer it also matters whether the path is positive or negative on excursions, but the exact path along these excursions is also totally irrelevant. If we write 0 = τ 0 < τ 1 < τ 2 < ⋯ for the sequence of return times and τ for the collection, then τ i −τ i−1 are i.i.d. with
for n even. We generalize this by allowing
with α > 1, and L a slowly varying function. Some of the results don’t depend on such a form but need only that
exists and is > 1. In the case where α > 2, the return times have a finite moment which simplifies things. The more interesting case is with 1 < α < 2. We write τ for the set of return times: \(\tau \mathop{=}\limits^{\mathrm{ def}}\left \{\tau _{0}\mathop{ =}\limits^{\mathrm{ def}}0,\tau _{1},\ldots \right \}.\) It is also interesting to consider transient cases where \(\sum _{n}\rho \left (n\right ) < 1\), but we will always stick to the recurrent case with \(\sum _{n}\rho \left (n\right ) = 1\), and where the τ i < ∞ for all i.
In order to avoid boring periodicity discussions, we assume \(\rho \left (n\right ) > 0\) for all large enough n, although it excludes the application to the standard random walk case presented in the introduction. Evidently, this is a very minor point.
The partition function Z of the pinning model can then be expressed by
We include 1 N ∈ τ for convenience (it is of no real importance). E refers to the distribution of τ.
Consider the so-called quenched free energy
The existence of this limit follows by a simple subadditivity argument which works nicely because we included 1 N ∈ τ :
and so
where \(\theta _{N}\left (\omega \right ) = \left (\omega _{N+1},\omega _{N+2},\ldots \right )\) which has the same distribution as ω. Therefore
From that the existence of the \(f\left (\beta,h\right )\) follows, and one can easily derive lower and upper bounds:
so \(f\left (\beta,h\right ) \geq 0.\)
An upper bound follows from the important annealed bound: By Jensen and Fubini, one has
where \(M\left (\beta \right )\mathop{ =}\limits^{\mathrm{ def}}\mathbb{E}\mathrm{e}^{\beta \omega _{1}}\), which we always assume to be finite for all β. Therefore, \(f\left (\beta,h\right ) \leq h +\log M\left (\beta \right ) < \infty.\)
is called the annealed free energy. The above computation shows
One therefore sees that the annealed partition function and path measure is nothing but the path measure in the absence of disorder and shifted parameter. The model without disorder (and therefore also the annealed model) has a very trivial localization-delocalization transition: If h > 0, then \(f\left (0,h\right ) > 0\) and the paths in the transformed measure spend a positive fraction of the time at 0 as n → ∞, \(h_{c}\left (0\right ) =\inf \left \{\beta: f\left (0,h\right ) > 0\right \} = 0\). In the transient case where \(\sum _{n}\rho \left (n\right ) < 1\), one of course has \(h_{c}\left (0\right ) > 0\) (a fact which has been used in the proof of Theorem 1). If we define
then the above considerations imply \(h_{\mathrm{cr}}\left (\beta \right ) \geq -\log M\left (\beta \right )\) (or \(\geq h_{\mathrm{cr}}\left (0\right ) -\log M\left (\beta \right )\) in case \(h_{\mathrm{cr}}\left (0\right )\neq 0\)).
A question which has attracted considerable attention is about the sharpness of the above inequality. If \(h_{\mathrm{cr}}\left (\beta \right ) > h_{\mathrm{cr}}\left (0\right ) -\log M\left (\beta \right )\) then one says that disorder is relevant, and if one has equality, that disorder is irrelevant.
This question has attracted considerable attention. Here a summary of results which have been obtained for the pinning model.
-
Ken Alexander in [1], and with a different proof Fabio Toninelli in [30], showed that in the case of Gaussian disorder, for α < 3∕2 and β small enough, one has \(h_{\mathrm{cr}}\left (\beta \right ) = h_{\mathrm{cr}}\left (0\right ) -\log M\left (\beta \right )\). Actually, considerably more information is obtained in these papers. For a more general result, not assuming Gaussian disorder, and with an elegant short proof, see [25].
-
For α > 3∕2, disorder is always relevant, and the critical values are always different for β > 0. This was proved in [19].
-
Finally, also the critical case with α = 3∕2 was investigated in [21] with a very sophisticated refinements of the methods in [19].
For the state of art before 2007, see also the excellent monograph by Giacomin [20].
We will see in the next chapters that for the copolymer, the situation is rather different, and disorder is always relevant in the above sense.
4 The Random Copolymer
4.1 The Localization-Delocalization Critical Line
The copolymer is quite a bit more complicated than the pinning model, and a number of important questions are still open. The partition function is
We again assume
In addition, we assume that the distribution of the ω i is symmetric, which simplifies some points. We again also assume
for all β.
We write this in terms of the return times τ i to the origin. As in the case of the pinning model, we allow for essentially arbitrary i.i.d. distributions ρ of τ i −τ i−1. We assume that the renewal sequence is recurrent and that (4) is satisfied. In some situations, we assume more, but generally we make no efforts to achieve the best possible conditions for the results. We can then write the partition function in terms of τ and the signs of the excursions, call them \(\varepsilon _{i}:\)
here E referring to taking the expectation for the \(\tau _{i},\varepsilon _{i}.\) The \(\varepsilon _{n}\) can however trivially be integrated out, and we get
and the existence of the free energy
follows in the same way as in the pinning model. For the model here, we can assume h ≥ 0 as the case with negative h is just symmetric.
One gets a trivial lower bound by restricting to τ 1 = N:
Therefore, by the law of large number for the ω i , and \(\lim _{N\rightarrow \infty } \frac{1} {N}\log \frac{1} {2}\rho \left (N\right ) = 0\), we have
and we call
the excess free energy. There is however a small but important trick by a modification of the Hamiltonian, which has a slightly different finite N free energy: We simply subtract 1 from the \(\varepsilon _{n}\) in (5) which evidently, in the quenched free energy leads to \(\bar{f}\left (\beta,h\right )\). After integrating out the \(\varepsilon _{n}\), we have for this modified partition function
where
By the law of large numbers, we get
The advantage of this modification (called Morita-correction) is that the corresponding annealed free energy (which is different from the annealed free energy for the original Hamiltonian) behaves better.
It is plausible that the path measure of the copolymer is localized if \(f\left (\beta,h\right ) >\beta h\) i.e. \(\bar{f}\left (\beta,h\right ) > 0\) and delocalized if \(\bar{f}\left (\beta,h\right ) = 0.\) We will not really go into a detailed discussion of the path properties under the Gibbs measure. That \(\bar{f}\left (\beta,h\right ) > 0\) implies that the paths, under the Gibbs measure, are strongly localized around the origin has been proved by Biskup and den Hollander [5]. Such a pathwise localization had already been proved by Sinai [27] for the h = 0 case. The path behavior in the case when \(\bar{f}\left (\beta,h\right ) = 0\) is still less clear. Pathwise delocalization has only be proved for large enough h, strictly above the critical value which we introduce shortly.
For the moment, we take the behavior of \(\bar{f}\left (\beta,h\right )\) as the definition of localization and delocalization:
and we call \(\mathcal{L}\) the localized region, and \(\mathcal{D}\) the delocalized one.
Proposition 3
-
a)
For any β > 0, there exists \(h_{\mathrm{cr}}\left (\beta \right ) > 0\) such that \(\left (\beta,h\right ) \in \mathcal{L}\) when \(h < h_{\mathrm{cr}}\left (\beta \right )\) and \(\left (\beta,h\right ) \in \mathcal{D}\) when \(h \geq h_{\mathrm{cr}}\left (\beta \right )\) .
-
b)
\(\lim _{\beta \rightarrow 0}h_{\mathrm{cr}}\left (\beta \right ) = 0\) .
-
c)
The function \(\beta \rightarrow h_{\mathrm{cr}}\left (\beta \right )\) is continuous and increasing in β.
That \(\left (\beta,h\right ) \in \mathcal{D}\) for large enough h follows from the annealed bound, as we will see in a moment. That for a fixed β, \(\left (\beta,h\right ) \in \mathcal{D}\) for small enough h will be a consequence of the bound given in Sect. 4.2. (b) will then also follow. I don’t prove (c) here which is technical but not difficult result. For the standard random walk case with α = 3∕2, a proof is in [9], and the general case is proved in [20].
By Jensen’s inequality, we have
The right hand side is much easier to evaluate than the left hand side:
(It would be \(M\left (-2\beta \right )\), but as we assume symmetry, this is \(M\left (2\beta \right )\)). If we define
then we see that \(f^{\mathrm{\mathrm{ann}}}\left (\beta,h\right ) = 0\) if and only if
and \(f^{\mathrm{\mathrm{ann}}}\left (\beta,h\right ) > 0\) otherwise. Therefore, the corresponding annealed critical value is
above which the annealed free energy is 0. From (10), we get
and so we have proved
Proposition 4
We will later see that in sharp contrast to the situation in the last chapter, the inequality is strict for all β > 0.
For notational convenience we will use f instead of \(\bar{f}\), and one should keep in mind that it is the Morita-corrected free energy.
4.2 The Monthus-Bodineau-Giacomin Lower Bound
Theorem 5
For the copolymer model
(Remark that the bound is given by \(h_{\mathrm{cr}}^{\mathrm{\mathrm{ann}}}\left (\beta /\alpha \right )\) ).
Proof
Let \(k \in \mathbb{N}\) and divide \(\mathbb{N}\) into blocks I j of length k: \(I_{j}\mathop{ =}\limits^{\mathrm{ def}}\left \{\left (j - 1\right )k + 1,jk\right \}.\) We fix some negative x, and we call the interval I j to be good, provided \(\sum _{n\in I_{j}}\omega _{n} \leq kx\). This notion depends on k and x < 0.
By the Cramer theorem, denoting \(\pi \left (k\right )\) to be the \(\mathbb{P}\)-probability that I 1 is good
where
Given N ≥ k, denote by \(\mathcal{J}_{k,x,N}\left (\omega \right )\) the set of the good intervals which are contained in \(\left \{1,\ldots,N - 1\right \}.\) Remark that this set is defined in terms of the environment ω (and k, x, N of course). Depending on \(\mathcal{J}_{k,x,N}\),we fix one specific sequence τ and sequence \(\varepsilon\) of signs (for the “excursions”): τ contains exactly the endpoints of the intervals in \(\mathcal{J}_{k,x,N}\) and N. Remark that because we have taken the intervals to be in \(\left \{1,\ldots,N - 1\right \},\) we have now an odd number of points in τ. The signs \(\varepsilon _{i}\) of the excursions are chosen to be negative for the good intervals and positive otherwise.
If \(M_{N}\mathop{ =}\limits^{\mathrm{ def}}\left \vert \mathcal{J}_{k,x,N}\right \vert\) and l 1, …, l M ≥ 1 are the distances between the good intervals (l 1 left endpoint of the first good interval), and L is the right endpoint of the last good interval, then we get for the above specific chosen τ and \(\varepsilon\), the Hamiltonian as
and the P-probability for this special “path” as
and therefore
By the law of large numbers, we have \(\lim _{N\rightarrow \infty }M_{N}/N =\pi \left (k\right )/k\) almost surely, and therefore
This bound holds for any \(k \in \mathbb{N},\ x \leq 0.\) For k → ∞, the right hand side evidently goes to 0, but we claim that for \(h < \frac{\alpha } {2\beta }\log M\left (\frac{2\beta } {\alpha } \right )\), we can make it positive, by choosing k appropriately.
To prove this, we first observe that by our assumption (4) and (11), we have
and furthermore, inverting the Legendre transform for the rate function I:
Therefore, the rhs of (12) is for k → ∞, by optimizing over x ≤ 0:
As soon as \(h < \frac{\alpha } {2\beta }M\left (\frac{2\beta } {\alpha } \right ),\) the bracket is positive for large k, and therefore, we have proved
■
The proof above is due to Bodineau and Giacomin [6]. The basic idea of the above proof was originally presented in non-rigorous terms in [26], where it was argued that \(h_{\mathrm{cr}}^{\mathrm{\mathrm{ann}}}\left (\beta /\alpha \right )\) is the correct critical line. This conjecture was open for a considerable time. Later, it however became clear that it cannot be correct. It first came out from a fully controlled numerical study [12]. It was first rigorously proved in [7] for large enough α (still α < 2, but not including α = 3∕2), and then \(h_{\mathrm{cr}}\left (\beta \right ) > \frac{\alpha } {2\beta }\log M\left (\frac{2\beta } {\alpha } \right )\) was proved in [10] for all α > 1. I present an elementary self-contained proof in Sect. 6.
4.3 The Proof of the Existence of the Tangent at the Critical Line at the Origin
By the annealed bound in Proposition 4 and the lower bound in Theorem 5 we have squeezed the critical line between two simple curves
The upper bound has tangent 1 at the origin and the lower bound tangent 1∕α. This because we have assumed that the variance of the ω i is 1. It is therefore natural to suspect that the critical line has a tangent at the origin which is between 1∕α and 1.
The proof of the existence of such a tangent turned out to be highly non-trivial. It had first been done in [9] for the standard random walk case (with α = 3∕2) and for more general situations later by Caravenna and Giacomin [11]. More important than just the existence of the tangent is the fact that it is universal in the sense that it depends only on α and not on the exact distribution of the ω i . This had not been proved explicitly in [9], where just the coin tossing distribution for the ω i was used, but as the proof is done via a Brownian approximation, it strongly suggests this universality property. For recent results about this universality property, see [2]. I sketch here the key steps in the original argument in [9].
We first define a continuous model which starts with two Brownian motions, \(\left (\omega _{t}\right )_{t\geq 0}\) for the environment, and \(\left (B_{t}\right )_{t\geq 0}\) for the random walk. We then define the quenched path measure
where \(\Delta _{s}\left (B\right )\) is 1 if B s < 0, and 0 otherwise. It is not difficult to prove that
exists, and is non-random and ≥ 0. The problem is to decide if it is 0 or not. From a scaling \(\left \{\left (B_{s},\omega _{s}\right )\right \}_{s\leq t}\mathop{ =}\limits^{ \mathcal{L}}\left (aB_{s/a^{2}},a\omega _{s/a^{2}}\right )_{s\leq t},\) we get that
and therefore
for all a > 0. Therefore, there is only one parameter left:
In a similar way as in the discrete model (although there are some technical difficulties, see also [20]), one proves that there is a critical value κ such that \(\phi \left (1,h\right ) = 0\) for h > κ, and \(\phi \left (1,h\right ) > 0\) for h ≤ κ. Furthermore, the same type of arguments as in the discrete case (here with α = 3∕2) give the bounds
Theorem 6
For the random walk case (i.e. α = 3∕2) with free energy f, one has
-
a)
$$\displaystyle{\lim _{a\rightarrow 0} \frac{1} {a^{2}}f\left (a\beta,ah\right ) =\phi \left (\beta,h\right ).}$$
-
b)
The critical curve \(h_{\mathrm{cr}}\left (\beta \right )\) satisfies
$$\displaystyle{\lim _{\beta \rightarrow 0}\frac{h_{\mathrm{cr}}\left (\beta \right )} {\beta } =\kappa }$$
As explained above, κ is really the object of interest in the model.
(b) is unfortunately not quite a consequence of (a), unfortunately because the proof of (b) is much more difficult than the proof of (a). (a) gives only a one-sided bound: If r < κ then from (a) we get
and therefore \(f\left (\beta,r\beta \right ) > 0\) for small enough β, implying \(h_{\mathrm{cr}}\left (\beta \right ) \geq r\beta\) for small enough β, i.e.
The other bound in (b) however does not follow from (a). If r > κ, then (a) implies only
but this does not exclude \(f\left (\beta,r\beta \right ) > 0\) for small β. We would like to prove that for r > κ one has \(f\left (\beta,r\beta \right ) = 0\) for small enough β.
In order to get the result about the tangent, we need a better control of \(\beta ^{-2}f\left (\beta,\beta h\right )\) in terms of ϕ than that provided by (a). In fact, in [9] we prove
Theorem 7
Let h > 0, H ≥ 0 and ρ > 0 satisfy \(\left (1+\rho \right )H \leq h.\) Then for small enough β, one has
These estimates are sufficient to prove Theorem 6.
The proof of Theorem 7 is rather tricky and uses a complicated double truncation on the excursion lengths, and cannot be given here in all details.
The arguments are however quite interesting, I think, and are based on a kind of partial quenched versus annealed computations which I just shortly sketch. Readers interested in the details of the argument should also study the paper of Caravenna and Giacomin [11] where essentially the same is proved in a more general setup. They use the same arguments, but in a somewhat streamlined version.
Assume that there is a random Hamiltonian H N which can be split into two parts \(H = H^{\left (I\right )} + H^{\left (II\right )}.\) Then
and therefore
The crucial point will be to choose \(H^{\left (II\right )}\) in such a way that
so that we obtain
For the proof, we stay with the form (7) of the partition function, and the corresponding finite N free energy
In order to make use of the i.i.d. properties of the time lengths between successive returns of the random walk to 0, we drop the final 1 N ∈ τ in the original partition function.
The key idea of the proof is that as β → 0, excursions of length much smaller than 1∕β 2 don’t contribute. Also for the continuous model (13) for fixed β = 1, it turns out that short excursion of the Brownian motion don’t contribute substantially. For the longer excursions, one can apply the convergence of the random walk to Brownian motion. A proof of part (a) of Theorem 6 is relatively straightforward, but as remarked above, not sufficient to proof the existence and identification of the tangent.
The strategy of the proof is first to prove that a quite complicated truncation mechanism with which is cutting out irrelevant excursions does not change the free energy. Then we replace ω i by standard Gaussian ones, and finally go to the Brownian motion, still with the cuts of the excursions, and in the last step finally prove that one can put back the short excursions for the Brownian which had been kept out. So, in the end, we perform four transformation steps, each one with a version of the above explained semi-annealed estimates.
To give an impression of the technical complications, I describe the splitting in the first step. We will need two additional (small) parameters \(0 <\varepsilon <\delta.\) We divide \(\left \{1,\ldots,T\beta ^{-2}\right \}\) into subintervals \(I_{1},I_{2},,\ldots,I_{T/\varepsilon }\) of length \(\varepsilon \beta ^{-2}.\) (We will always assume that T β −2 is integer, and divisible by \(\varepsilon \beta ^{-2}\) to avoid trivial adjustments, and similarly in other situations). We call I j occupied if there is a τ n in I j . We then define a random sequence of natural numbers \(\sigma _{0}\mathop{ =}\limits^{\mathrm{ def}}0 <\sigma _{1} <\sigma _{2} < \cdots \) with the property that the \(I_{\sigma _{i}}\) are occupied. However, we always want to have a gap condition between the σ’s depending on the larger parameter δ:
We also define
For 1 ≤ k ≤ m we put s k = 1 if the excursion ending at the first zero in \(I_{\sigma _{k}}\) is negative, and s k = 0 otherwise. (There is a slight correction needed for s m which we neglect.) We then define
with
and we recall that
with
So, we have the same form. Remark first that there is a trivial rescaling property: If κ > 0 then
We also have
We now use (14) with H T and
Then one finally proves
Lemma 8
For any h,H,ρ there exists δ 0 such that for δ ≤δ 0 there exists \(\varepsilon _{0}\left (\delta \right )\) such that for \(\varepsilon \leq \varepsilon _{0}\left (\delta \right )\) there exists \(\beta _{0}\left (\delta,\varepsilon \right )\) such that for \(\beta \leq \beta _{0}\left (\delta,\varepsilon \right )\)
The proof is too complicated, and probably too boring, to be presented here. This is just the first step, but fortunately, the most complicated one. After finding the suitable \(\varepsilon -\delta\)-truncations, it is possible to replace the coin tossing ω i by Gaussian ones, but again we have to achieve an estimate (15), and afterwards one can switch to the Brownian model with truncations, and in the end, one removes the truncations.
It should also be clear that a proof of part (a) of Theorem 6 is considerably simpler, as one does not really need an estimate as sharp as that in Theorem 7.
Although, we didn’t do it in [9], it is clear that the argument works with general distributions for the ω i , subject to an exponential moment condition \(M\left (\beta \right ) < \infty \) for all β.
5 The Large Deviation Principles by Birkner and Birkner-Greven-den Hollander, and Their Applications to the Copolymer
Considerable progress in the understanding of the copolymer was achieved with ideas originally developed by Birkner in [3]. The setup he had developed there could not be used directly for the polymer problems with the renewal process having only polynomially decaying tails. A bit later, his approach was extended in [4], and in this form, the LDP did in principle apply to the copolymer, but there were still a number of tricky issues to be handled. This has finally be done in [10]. Probably, the most striking application was the proof that the tangent κ of the critical line at the origin is strictly larger than 1∕α, disproving an old conjecture of Cécile Monthus.
I will present later in Sect. 6 an elementary proof of this lower bound, bypassing the somewhat heavy large deviation machinery, but the argument is in its core still the one given in [10], and the elementary proof would probably have been difficult to find without the general setup.Footnote 1
I give here on outline of the general large deviation principles. We first need a couple of definitions
-
\(\mathcal{W}\) is the set of finite length sequences of real numbers. These sequences we call “words”. For \(w \in \mathcal{W},\) \(\ell\left (w\right )\) denotes the length of the word, so that
$$\displaystyle{w = \left (x_{1},\ldots,x_{\ell\left (w\right )}\right ),\ x_{i} \in \mathbb{R},}$$and we set
$$\displaystyle{\sigma \left (w\right )\mathop{ =}\limits^{\mathrm{ def}}\sum _{i=1}^{\ell\left (w\right )}x_{ i}.}$$\(\mathcal{W}\) comes with a naturally defined Borel σ-field \(\mathcal{B}_{\mathcal{W}}\).
-
We define \(\varphi: \mathcal{W}\rightarrow \mathbb{R}^{+}\) by
$$\displaystyle{ \varphi \left (w\right ) = \frac{1} {2}\left (1 +\exp \left [-2\beta h\ell\left (w\right ) - 2\beta \sigma \left (w\right )\right ]\right ),\ \phi \mathop{=}\limits^{\mathrm{ def}}\log \varphi }$$(16)Occasionally, we emphasize the dependence on β, h by writing \(\varphi _{\beta,h}\), ϕ β, h .
-
The concatenation map attaches to a finite or infinite sequence \(\mathbf{w} = \left (w_{1},w_{2},\ldots \right )\) of words the corresponding sequence of real numbers: \(\mathop{\mathrm{{\ast}}}\nolimits co: \mathcal{W}^{\mathbb{N}} \rightarrow \mathbb{R}^{\mathbb{N}}:\) If \(w_{i} = \left (x_{i,1},x_{i,2},\ldots,x_{i,n_{i}}\right )\) then \(\mathop{\mathrm{{\ast}}}\nolimits co\left (w_{1},w_{2},\ldots \right ) = \left (x_{1,1},\ldots,x_{1,n_{1}},x_{2,1},\ldots,x_{2,n_{2}},x_{3,1},\ldots \right ).\) In case of a finite sequence of words, \(\mathop{\mathrm{{\ast}}}\nolimits co\) maps \(\mathcal{W}^{n}\) to \(\mathcal{W}\).
-
\(\mathcal{P}^{\mathrm{inv}}\) denotes the set of stationary probability measures on \(\left (\mathcal{W}^{\mathbb{N}},\mathcal{B}_{\mathcal{W}}^{\otimes \mathbb{N}}\right ).\)
-
For \(Q \in \mathcal{P}^{\mathrm{inv}},\) m Q is the average length of the words under Q. m Q may be infinite. \(\mathcal{P}^{\mathrm{inv,\ fin}}\) is the set of measures in \(\mathcal{P}^{\mathrm{inv}}\) for which m Q is finite.
-
For \(Q \in \mathcal{P}^{\mathrm{inv}}\) \(Q\mathop{\mathrm{{\ast}}}\nolimits co^{-1}\) is a probability measure on \(\mathbb{R}^{\mathbb{N}}\). It is fairly evident that, in general, it will not be stationary. In order to get a stationary measure, one has to do an averaging procedure which requires that m Q < ∞. In this case we define can define a mapping \(\Psi _{Q}: \mathcal{P}^{\mathrm{inv}} \cap \left \{Q: m_{Q} < \infty \right \}\rightarrow \mathcal{P}^{\mathrm{inv}}\left (\mathbb{R}^{\mathbb{N}}\right )\) by
$$\displaystyle{\Psi _{Q} = \frac{1} {m_{Q}}E_{Q}\left (\sum \nolimits _{k=0}^{\tau _{1}-1}\delta _{ \theta ^{\kappa }\mathop{ \mathrm{{\ast}}}\nolimits co\left (Y \right )}\right ).}$$τ 1: the length of the first word of \(Y \in \mathcal{W}^{\mathbb{N}}.\ \theta\) is the shift operation on \(\mathbb{R}^{\mathbb{N}}.\)
Consider now a probability distribution ν on \(\mathbb{R}\), and a sequence \(\boldsymbol{\omega }= \left \{\omega _{n}\right \}\) of i.i.d. random variables distributed according to ν. We write \(\mathbb{P}\) for \(\nu ^{\otimes \mathbb{N}}\). Then consider also a probability measure ρ on \(\mathbb{N}\) and a sequence \(\left \{\zeta _{n}\right \}\) of i.i.d. random variables distributed according to ρ, and write \(\tau _{0}\mathop{ =}\limits^{\mathrm{ def}}0,\ \tau _{n}\mathop{ =}\limits^{\mathrm{ def}}\sum _{i=1}^{n}\tau _{i}.\) As before we write τ for the collection \(\left \{\tau _{i}\right \}\) of the renewal points. We write P for the law governing this renewal sequence. Together with \(\boldsymbol{\omega }\) this defines a sequence of words \(W\left (\left (\boldsymbol{\omega },\tau \right )\right )\mathop{ =}\limits^{\mathrm{ def}}\left \{w_{n}\left (\boldsymbol{\omega },\tau \right )\right \}_{n\geq 1}\) by
Fixing N we consider the periodized sequence of words
and for 0 ≤ n ≤ N − 1 the shifts θ n W N of this sequence. The empirical distribution is then defined by
Evidently, \(L_{N}\left (\boldsymbol{\omega },\tau \right )\) is a random element in \(\mathcal{P}^{\mathrm{inv}}\).
As usual in disordered systems, one has two natural situations to consider. First, the so-called quenched law is the law of \(L_{N}\left (\boldsymbol{\omega },\tau \right )\) for fixed \(\boldsymbol{\omega }\) under the probability measure P for the renewal sequence τ. One then tries to obtain properties of L N in the N → ∞ limit which hold for \(\mathbb{P}\)-almost all \(\boldsymbol{\omega }\). The averaged or annealed law of L N is obtained under the product measure \(\mathbb{P} \otimes P\).
For given ν, ρ we consider the probability q ρ, ν on \(\mathcal{W}\): The distribution of the length of the word is given by ρ, and conditionally on the length \(\left \{\ell= k\right \}\) the distribution of the “letters” is the k-fold product of ν, i.e.
We also need the specific relative entropy \(H\left (Q\vert q_{\rho,\nu }^{\otimes \mathbb{N}}\right )\) for \(Q \in \mathcal{P}^{\mathrm{inv}}\) defined by
where Q N is the marginal of Q on the first N components, and \(I\left (\cdot \vert \cdot \right )\) is the usual relative entropy (or Kullback-Leibler information). The sequence \(N^{-1}I\left (Q_{N}\vert q_{\rho,\nu }^{\otimes N}\right )\) is increasing in N. In particular, it follows that
The quenched LDP by Birkner [3] goes as follows:
Theorem 9 (Birkner)
Assume that ρ has an exponential moment, i.e. that for some α > 0
For \(\mathbb{P}\) -almost all ω, L N satisfies a good LDP with rate function
This LDP is crucial for the application in [10], but it’s direct use is limited, first by the assumption that ρ has an exponential moment, and secondly, by the somewhat complicated definition of the rate function. The condition on \(\Psi _{Q} =\nu ^{\otimes \mathbb{N}}\) makes the application quite difficult.
The LDP was extended in [4] to the case where ρ has polynomial tails. The formulation needs quite some care, mainly as the rate function may be finite for measures Q with m Q = ∞.
Theorem 10 (Birkner, Greven, den Hollander)
Assume that ρ satisfies (4) with 1 < α < ∞. Then, for \(\mathbb{P}\) -almost all ω, L N satisfies a good LDP with a rate function I qu given in the following way. If m Q < ∞, then
If m Q = ∞ then
Here \(\left [Q\right ]_{n}\) is the induced measure under the truncation map \(\mathbf{w} = \left (w_{1},w_{2},\ldots \right ) \in \mathcal{W}^{\mathbb{N}} \rightarrow \left [\mathbf{w}\right ]_{n} = \left (\left [w_{1}\right ]_{n},\left [w_{2}\right ]_{n},\ldots \right ),\) \(\left [w\right ]_{n}\) obtained by truncating the word w at length n.
Remark 11
The averaged version of the above LDP is a standard result in large deviation theory: Under the joint law \(\mathbb{P} \otimes P\), \(\left \{L_{n}\right \}\) satisfies a good LDP with rate function \(H\left (Q\vert \nu _{\rho }^{\otimes \mathbb{N}}\right ).\) This is the standard Donsker-Varadhan “level 3” LDP. See for instance [18]. The nice feature of the Birkner-Greven-den Hollander LDP is that it gives a fairly concrete expression \(\left (\alpha -1\right )m_{Q}H\left (\Psi _{Q}\vert \nu ^{\otimes \mathbb{N}}\right )\) for the difference between the annealed and the quenched situation.
We will not prove these results here. A good outline is given in the introduction of [4]. Roughly, the explanation for the term \(\left (\alpha -1\right )m_{Q}H\left (\Psi _{Q}\vert \nu ^{\otimes \mathbb{N}}\right )\) is like follows. In order to achieve L N ≈ Q in the quenched situation, i.e. with \(\boldsymbol{\omega }\) fixed, one has either \(\Psi _{Q} =\nu ^{\otimes \mathbb{N}},\) in which case \(H\left (\Psi _{Q}\vert \nu ^{\otimes \mathbb{N}}\right ),\) and the probability is just \(\approx \exp \left [-NH\left (Q\vert q_{\rho,\nu }^{\otimes \mathbb{N}}\right )\right ]\), as in the Birkner case, or the renewal process has to first make a big first step to in one (or very few) jumps, in order to reach a portion of the sequence \(\boldsymbol{\omega }\) which looks typically under \(\Psi _{Q}\). Such a jump has to be exponentially long in N, and if the renewal sequence is coming from i.i.d. variables ζ i having an exponential tail, this would cost double exponential, and would not be possible. Therefore, in the Birkner LDP, one just has a rate function which is ∞ in case \(\Psi _{Q}\neq \nu ^{\otimes \mathbb{N}}\). However, in the case of polynomial tails, such an exponential excursion costs only an exponential price, and therefore, it is of the appropriate order for a LDP. At first sight, one may think that for \(\rho \left (n\right ) \approx n^{-\alpha }\) the price should come with a factor α and not α − 1. The reason that the correction is given as \(\left (\alpha -1\right )m_{Q}H\left (\Psi _{Q}\vert \nu ^{\otimes \mathbb{N}}\right )\) is coming from an entropic gain in the relation \(Q \leftrightarrow \Psi _{Q}\). This is somewhat difficult to see in the general picture, but it also appears in the more elementary computation done here in Sect. 6.
Proposition 12
Assume that \(Q \in \mathcal{P}^{\mathrm{inv}}\) satisfies \(I^{\mathrm{qu}}\left (Q\right ) < 0.\) Then there exists a sequence \(\left \{Q_{n}\right \} \subset \mathcal{P}^{\mathrm{inv}}\) which satisfies \(\Psi _{Q_{n}} =\nu ^{\otimes \mathbb{N}}\) which weakly converges to Q and which satisfies
The statement looks at first sight strange, as it claims that the crucial second summand in \(I^{\mathrm{qu}}\left (Q\right )\) is produced by an approximation where it is 0. The proposition is however at the very heart of the application to the copolymer, and we give the details of the proof. The result is not stated exactly in this form in [4], but it comes out from considerations done there.
We come now to the application to the copolymer.
The starting point is to not look first at a fixed end point but investigate what happens with a fixed number N of excursions. We also need an artificial “killing” parameter g ≥ 0. Let
where
Evidently, we have
where \(\overline{Z}_{n}\) is the partition function (7).
Lemma 13
-
a)
$$\displaystyle{s^{\mathrm{qu}}\left (\beta,h,g\right )\mathop{ =}\limits^{\mathrm{ def}}\lim _{ n\rightarrow \infty } \frac{1} {N}\log F_{N} =\lim _{n\rightarrow \infty } \frac{1} {N}\mathbb{E}\log F_{N}}$$
exists, and is a convex function of g which is finite for g > 0. Particularly \(g \rightarrow S^{\mathrm{qu}}\left (\beta,h,g\right )\) is continuous as a function of g on the positive axis, except possibly at g = 0.
-
b)
The free energy of the copolymer given by (6) is given by
$$\displaystyle{f\left (\beta,h\right ) =\inf \left \{g \geq 0: s^{\mathrm{qu}}\left (\beta,h,g\right ) < 0\right \}.}$$ -
c)
\(\left (\beta,h\right ) \in \mathcal{D}\) (see (9) ) if and only if
$$\displaystyle{s^{\mathrm{qu}}\left (\beta,h,0+\right )\mathop{ =}\limits^{\mathrm{ def}}\lim _{ g\downarrow 0}s^{\mathrm{qu}}\left (\beta,h,g\right ) \leq 0.}$$
The proof of the finiteness of \(s^{\mathrm{qu}}\left (\beta,h,g\right )\) for all g > 0 is quite tricky and involves some detailed estimates. From that, the rest of the lemma is quite straightforward. I difficult unsolved problem is the continuity at g = 0 which we expect to be correct but which we had been unable to prove. However, for the discussion of localization and delocalization in terms of the free energy, this is not important.
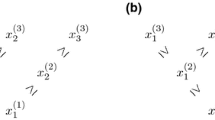
The critical point \(h_{\mathrm{c}}^{\mathrm{qu}}\left (\beta \right )\) is therefore characterized by the following pictures:

The main result in [10] is the following variation formula:
Theorem 14
-
a)
If g > 0 then \(s^{\mathrm{qu}}\left (\beta,h,g\right ) = s_{\mathrm{\mathop{\mathrm{{\ast}}}\nolimits var}}^{\mathrm{qu}}\left (\beta,h,g\right )\) where
$$\displaystyle{s_{\mathrm{\mathop{\mathrm{{\ast}}}\nolimits var}}^{\mathrm{qu}}\left (\beta,h,g\right ) =\sup _{ Q\in \mathcal{P}^{\mathrm{inv},\mathrm{fin}}\cap \mathcal{R}}\left [\int \phi _{\beta,h}\left (w\right )Q\pi _{1}^{-1}\left (dw\right ) - gm_{ Q} - H\left (Q\vert q_{\rho,\nu }^{\mathbb{N}}\right )\right ],}$$where \(\mathcal{R}\mathop{ =}\limits^{\mathrm{ def}}\left \{Q \in \mathcal{P}^{\mathrm{inv}}: \Psi _{Q} =\nu ^{\otimes \mathbb{N}}\right \},\) and where \(\pi _{1}: \mathcal{W}^{\mathbb{N}} \rightarrow \mathcal{W}\) is the projection on the first factor. (Remember that \(\ell\left (w\right )\) is the length of a word w, and \(\sigma \left (w\right ) =\sum _{ i=1}^{\ell\left (w\right )}x_{i}\) when \(w = \left (x_{1},\ldots,x_{\ell\left (w\right )}\right ).\) )
-
b)
\(g \rightarrow s_{\mathrm{\mathop{\mathrm{{\ast}}}\nolimits var}}^{\mathrm{qu}}\left (\beta,h,g\right )\) is convex and continuous on [0,∞) (possibly ∞ at g = 0).
-
c)
At g = 0, we have the alternative variational characterization
$$\displaystyle\begin{array}{rcl} s_{\mathrm{\mathop{\mathrm{{\ast}}}\nolimits var}}^{\mathrm{qu}}\left (\beta,h,0\right )& =& \sup _{ Q\in \mathcal{P}^{\mathrm{inv},\mathrm{fin}}}\Big[\int \phi _{\beta,h}\left (w\right )Q\pi _{1}^{-1}\left (dw\right ) {}\\ & & -H\left (Q\vert q_{\rho,\nu }^{\mathbb{N}}\right ) -\left (\alpha -1\right )m_{ Q}H\left (\Psi _{Q}\vert \nu ^{\otimes \mathbb{N}}\right )\Big]. {}\\ \end{array}$$
Part (a) follows from an application of Theorem 9, given the estimates one has to prove \(s^{\mathrm{qu}}\left (\beta,h,g\right ) < \infty \). As it is, it is not very useful because the set \(\mathcal{R}\) is not very easy to handle. The continuity of \(s_{\mathrm{\mathop{\mathrm{{\ast}}}\nolimits var}}^{\mathrm{qu}}\left (\beta,h,g\right )\) at g = 0 and the alternative description of \(s_{\mathrm{\mathop{\mathrm{{\ast}}}\nolimits var}}^{\mathrm{qu}}\left (\beta,h,0\right )\) in terms of the variational formula from Theorem 10 was the main and most complicated task in [10].
Corollary 15
A consequence of the above corollary is the following result on the behavior of \(h_{\mathrm{c}}^{\mathrm{qu}}\left (\beta \right )\).
Theorem 16
-
a)
\(h_{\mathrm{c}}^{\mathrm{qu}}\left (\beta \right ) > h_{\mathrm{c}}^{\mathrm{ann}}\left (\frac{\beta }{\alpha }\right )\) for all β > 0,α > 1 and \(\kappa \left (\alpha \right ) > 1/\alpha.\) For 1 < α < 2, the lower bound for the slope is
$$\displaystyle{\kappa \left (\alpha \right ) \geq B\left (\alpha \right )/\alpha,}$$where \(B\left (\alpha \right ) > 1.\) (The exact bound is given in Sect. 6 .)
-
b)
\(h_{\mathrm{c}}^{\mathrm{qu}}\left (\beta \right ) < h_{\mathrm{c}}^{\mathrm{ann}}\left (\beta \right )\) for all β,α > 1.
The result in (b) has been proved also by Toninelli [31] using a fractional moment bound. Toninelli’s method also proves \(\kappa \left (\alpha \right ) < 1\) which is unfortunately not (yet) coming out from our bound. Although, at the moment, the LDP method does not prove \(\kappa \left (\alpha \right ) < 1\), I believe that it gives considerable insights, and probably will be improved in the course of time.Footnote 2
We prove part (a) in a completely self-contained way in the next chapter. The argument there is essentially the one given in [10], but bypassing the somewhat heavy large deviation machinery.
Proof of Theorem 16(b)
From (17) it follows that
where Q 1 is the first marginal of Q and \(\left (\Psi _{Q}\right )_{1}\) the marginal of the first component of \(\Psi _{Q}.\) So, we get
The supremum is over probability measures on the set of words. \(\pi \left (q\right )\) is the first marginal of \(\Psi _{q^{\otimes \mathbb{N}}}.\) It is obtained by averaging properly over the marginals measures of q. Actually, as q ρ, ν , conditioned on the length of the words being n, is invariant under the (cyclic) permutation mappings \(\mathbb{R}^{n} \rightarrow \mathbb{R}^{n}\), one can restrict the above supremum to q which have the same invariance property. Then \(\pi \left (q\right ) =\sum _{n}\left (q^{\left (n\right )}\right )_{1}\), where \(q^{\left (n\right )}\) is the restriction of q to words of length n.
We define the measure q ∗ on \(\mathcal{W}\) by
with
which is finite for \(h \geq h_{\mathrm{cr}}^{\mathrm{\mathrm{ann}}}\left (\beta \right ).\) So q ∗ is well defined for these values. Remark that \(z\left (\beta,h_{\mathrm{cr}}^{\mathrm{\mathrm{ann}}}\left (\beta \right )\right ) = 1.\) We use
(Remember that \(\phi =\log \varphi\), (16).) Therefore
At \(h = h_{\mathrm{cr}}^{\mathrm{\mathrm{ann}}}\left (\beta \right ),\) \(\log z\left (\beta,h\right ) = 0\), and one easily sees that the infimum is positive. The first part \(I\left (q\vert q_{\beta,h}^{{\ast}}\right )\) has its infimum at q = q β, h ∗, but it’s evident that the marginal \(\pi \left (q_{\beta,h}^{{\ast}}\right )\neq \nu.\) Therefore
and so it follows that \(h_{\mathrm{cr}}\left (\beta \right ) < h_{\mathrm{cr}}^{\mathrm{\mathrm{ann}}}\left (\beta \right ).\) ■
Remark 17
One of course hopes that this would lead to κ < 1, but unfortunately, it is not true. One can prove that with the bound for \(h_{\mathrm{cr}}\left (\beta \right )\) one obtains from this estimate, say \(h^{{\ast}}\left (\beta \right )\), it holds that
So, although the rather crude estimates (18) are good enough to prove \(h_{\mathrm{cr}}\left (\beta \right ) < h_{\mathrm{cr}}^{\mathrm{\mathrm{ann}}}\left (\beta \right ),\) they are not good enough for \(\kappa \left (\alpha \right ) < 1\).
6 A Proof of a Lower Bound
I give here a self-contained proof of the lower bound of Theorem 16(a). It does not use the variational formula from Theorem 14, but it is very much inspired by it.
For convenience, we take ν coin tossing, i.e. \(E = \left \{-1,1\right \} \subset \mathbb{R},\) and \(\nu \left (1\right ) =\nu \left (-1\right ) = 1/2\). Given \(K \in \mathbb{N}\), we write \(\mathcal{W}_{K}\) for the set of words of length ≤ K.
We make the following assumptions
-
The \(\rho \left (n\right ) > 0\) for all \(n \in \mathbb{N}\) and
$$\displaystyle{\lim _{n\rightarrow \infty }\frac{-\log \rho \left (n\right )} {\log n} =\alpha \in \left (1,\infty \right )}$$ -
μ is a probability measure on \(\mathcal{W}_{K}\) for some \(K \in \mathbb{N}\), and that all words in \(\mathcal{W}_{K}\) have positive weight.
We write m μ for the mean word length under μ:
Proposition 18
If there exists μ such that
then \(f\left (\beta,h\right ) > 0.\)
Remark that \(q_{\rho,\nu }\left (w\right ) > 0\) for all words, as we have assumed that \(\rho \left (n\right ) > 0\) for all n. Therefore, \(I\left (\mu \vert q_{\rho,\nu }\right ) < \infty \).
where
Let \(\mathcal{S}_{K}\) be the set of all finite sentences with words in \(\mathcal{W}_{K}\), i.e. the set of finite length sequences of words in \(\mathcal{W}_{K}\).
We define probability measures Q n on \(\mathcal{S}_{K}\) which have the additional parameter \(n \in \mathbb{N}\). For that, we define probability measures χ n on \(\mathbb{N}\) by
It is readily checked that
(The law χ n is essentially symmetric around n except for the truncation on the negative integers.)
We then define Q n by
We denote the length of a sentence in \(\mathcal{S}_{K}\), in terms of the number of words in it, by σ. This random variable has of course distribution χ n under Q n .
For a word \(\mathbf{x} = \left (x_{1},\ldots,x_{N}\right ),\ x_{i} \in E\), define \(\mathcal{S}_{K}\left (\mathbf{x}\right )\) to be the set of sentences \(\mathbf{w} \in \mathcal{S}_{K}\) with \(\mathop{\mathrm{{\ast}}}\nolimits co\left (\mathbf{w}\right ) = \mathbf{x}\).
Below, we use C for a constant ≥ 1 which may depend on μ, but on nothing else, particularly not on n.
Lemma 19
Given N and two words \(\mathbf{x} = \left (x_{1},\ldots,x_{N}\right ),\) and x ′ which is obtained from x by adding one letter from E at an arbitrary place, one has
Proof
Let
We define a mapping \(f: \mathcal{S}_{K}\left (\mathbf{x}\right ) \rightarrow \mathcal{S}_{K}\left (\mathbf{x}^{{\prime}}\right )\). Let \(\mathbf{w} = \left (w_{1},\ldots,w_{n}\right ) \in \mathcal{S}_{K}\left (\mathbf{x}\right )\) and w j be the word which contains x i . If w j does not contain x i+1, we simply add the word \(\left (y\right )\) to w at the right place, and obtain \(\mathbf{w}^{{\prime}}\in \mathcal{S}_{K}\left (\mathbf{x}^{{\prime}}\right )\). In case w j contains x i and x i+1, and its length is less than K, we replace w j by the word w j ′ which is obtained by adding the letter y at the right place. Again this leads to a \(\mathbf{w}^{{\prime}}\in \mathcal{S}_{K}\left (\mathbf{x}^{{\prime}}\right )\). Finally, if w j contains x i and x i+1 and has maximal length K, we split the word into \(\left (\cdots \,,x_{i}\right )\) and \(\left (x_{i+1},\cdots \,\right )\) and add y to the first one on the right side, and obtain a sentence \(\mathbf{w}^{{\prime}}\in \mathcal{S}_{K}\left (x^{{\prime}}\right ).\) Then we put \(f\left (\mathbf{w}\right ) = \mathbf{w}^{{\prime}}\). f is evidently injective and we have \(Q_{n}\left (\mathbf{w}\right ) \leq CQ_{n}\left (f\left (\mathbf{w}\right )\right )\). Therefore
We can also define a mapping \(f^{{\prime}}: \mathcal{S}_{K}\left (\mathbf{x}^{{\prime}}\right ) \rightarrow \mathcal{S}_{K}\left (\mathbf{x}\right )\) by either shortening one word or deleting on (in case \(\left (y\right )\) is a word in the sentence). This is not injective, but evidently, at maximum two sentences in \(\mathcal{S}_{K}\left (\mathbf{x}^{{\prime}}\right )\) can be mapped to a single sentence in \(\mathcal{S}_{K}\left (\mathbf{x}\right )\). Also, again \(Q_{n}\left (\mathbf{w}^{{\prime}}\right ) \leq CQ_{n}\left (f\left (\mathbf{w}^{{\prime}}\right )\right )\) for some constant C. Therefore,
By adjusting C, the claim follows. ■
We define \(F: \mathcal{S}_{K} \rightarrow \mathbb{R}^{+}\) by
For \(k \in \mathbb{N}\), we also write F k for the restriction of F to \(\mathcal{S}_{K}^{\left (k\right )}\), the sentences in \(\mathcal{S}_{K}\) having exactly k words. Let d H be the Hamming distance on \(\mathcal{S}_{K}^{\left (k\right )}\), i.e.
An immediate corollary of Lemma 19 is
Lemma 20
-
a)
If \(\mathbf{w},\mathbf{w}^{{\prime}}\in \mathcal{S}_{K}^{\left (k\right )}\) then
$$\displaystyle{F_{k}\left (\mathbf{w}\right ) \leq C^{d_{H}\left (\mathbf{w},\mathbf{w}^{{\prime}}\right ) }F_{k}\left (\mathbf{w}^{{\prime}}\right ).}$$ -
b)
If \(\mathbf{w} = \left (w_{1},\ldots,w_{k}\right ),\ \mathbf{w}^{{\prime}} = \left (w_{1},\ldots,w_{k},w_{k+1}\right ),\) then
$$\displaystyle{ \frac{1} {C} \leq \frac{F_{k}\left (\mathbf{w}\right )} {F_{k+1}\left (\mathbf{w}^{{\prime}}\right )} \leq C.}$$
Corollary 21
There exists C > 0, depending only on K,μ, such that
Proof
and so we only have the estimate the first summands.
By one of the basic (end easily proved) concentration inequalities of Talagrand, see [29, Proposition 2.1.1], one has from Lemma 20(a)
where \(\mathop{\mathrm{{\ast}}}\nolimits med\left (\log F_{k}\right )\) is any median of the distribution of logF k under μ ⊗k, and as this inequality also implies \(\left \vert \mathop{\mathrm{{\ast}}}\nolimits med\left (\log F_{k}\right ) -\int \log F_{k}\ d\mu ^{\otimes k}\right \vert \leq C\sqrt{k}\), we can replace the median by the expectation under μ ⊗k which we denote by E k logF k . However, from Lemma 20(b), we get
As we have restricted k to an \(\sqrt{n}\)-neighborhood of n, we can estimate
and the right hand side is again estimated by \(C\exp \left [-t^{2}/Cn\right ],\) by adjusting C. So the claim follows. ■
We fix n (large) and put \(N\mathop{ =}\limits^{\mathrm{ def}}\left [nm_{\mu }\right ]\). For the rest of the proof, N will always be tied to n in this way. Then, consider the event
and
where for a finite sentence w we write \(\ell\left (\mathbf{w}\right )\) for the sum of lengths of the words, \(\lambda \left (\mathbf{w}\right )\) for the number of words in the sentence, and \(\left \Vert \cdot \right \Vert _{\mathrm{\mathop{\mathrm{{\ast}}}\nolimits var}}\) denotes the total variation distance.
Below, we need
The proof of its existence is not difficult, but we don’t really need it. The right hand side stays trivially bounded as F ≤ 1 and \(F\left (\mathbf{w}\right ) \geq Q_{n}\left (\mathbf{w}\right )\). All we need is the limit along an arbitrary subsequence, and we define \(\gamma \left (\mu \right )\) to be the limit along such a subsequence. In all the arguments which follow, we always assume n to belong to this subsequence (if necessary). For notational convenience, we still use n instead. From \(F\left (\mathbf{w}\right ) \geq Q_{n}\left (\mathbf{w}\right )\) we immediately get
but we need a better bound later.
By a local CLT, one immediately sees that
and using the concentration inequality of the corollary, and large deviation estimates for \(n^{-1}\sum \nolimits _{i=1}^{\lambda }\delta _{w_{i}}\), we also have
It is straightforward to give an estimate of the number of elements in A n :
Lemma 22
For fixed μ and n →∞
Proof
This is immediate from \(Q_{n}\left (A_{n}\right ) =\exp \left [o\left (n\right )\right ]\), and from \(Q_{n}\left (\mathbf{w}\right ) =\exp \left [-nh\left (\mu \right ) + o\left (n\right )\right ]\) which follows from \(\left \vert \lambda \left (\mathbf{w}\right ) - n\right \vert \leq n^{3/4}\) and
■
\(X_{n}\mathop{ =}\limits^{\mathrm{ def}}\left \{\mathop{\mathrm{{\ast}}}\nolimits co\left (\mathbf{w}\right ): \mathbf{w} \in A_{n}\right \}\) is a subset of E N. For every x ∈ X n , we write
Lemma 23
There exists a subset \(\hat{X}_{n} \subset X_{n}\) such that
and
uniformly in \(\mathbf{x} \in \hat{ X}_{n}.\)
Proof
If \(\mathbf{x} =\mathop{ \mathrm{{\ast}}}\nolimits co\left (\mathbf{w}\right )\) for some w ∈ A n 0, we have for
that \(Q_{n}\left (\bar{A}_{n}\left (\mathbf{x}\right )\right ) =\exp \left [-\gamma \left (\mu \right )n + o\left (n\right )\right ]\). Therefore
and as \(A_{n}\left (\mathbf{x}\right ) \subset \bar{ A}_{n}\left (\mathbf{x}\right )\), we get
Let \(\varepsilon _{n} \rightarrow 0\) be a sequence of positive numbers such that \(\varepsilon _{n}n \gg o\left (n\right )\) for the various \(o\left (n\right )\)-terms above. Then define
Then
the second inequality by (22), and therefore \(\hat{X}_{n}\mathop{ =}\limits^{\mathrm{ def}}X_{n}\setminus \Gamma \) satisfies
and by construction, we have for any \(\mathbf{x} \in \hat{ X}_{n}\)
On the other hand, for all elements \(\mathbf{w} \in A_{n}\left (\mathbf{x}\right )\), we have
and so the claim follows. ■
The above considerations lead to an estimate of \(\gamma \left (\mu \right )\) which will be important below. To derive this, remark that for \(\mathbf{x} \in \hat{ X}_{n}\), the set of words in \(A_{n}\left (\mathbf{x}\right )\) is in one to one correspondence with a set of sequences \(\mathbf{l} = \left (l_{1},\ldots,l_{\sigma }\right )\) of integers ≤ K, n − n 3∕4 ≤ k ≤ n + n 3∕4, and \(\sum _{i}l_{i} = N\) which defines the sequence of in \(A_{n}\left (\mathbf{x}\right )\) through cutting \(\mathbf{x} = \left (x_{1},\ldots,x_{N}\right )\) into the words \(w_{1} = \left (x_{1},\ldots,x_{l_{1}}\right ),\ w_{2} = \left (x_{l_{1}+1},\ldots,x_{l_{1}+l_{2}}\right ),\ldots\). By an abuse of notation, we use \(A_{n}\left (\mathbf{x}\right )\) also for this sequence of integer. Let ρ μ be the distribution of \(\ell\left (w\right )\) under μ. If \(\mathbf{l} \in A_{n}\left (x\right )\), one has
Therefore,
where
leading to
For \(\mathbf{x} \in \hat{ X}_{n}\), we define \(\xi _{n}\left (\mathbf{x}\right )\) as the partition function obtained through summation over \(\mathbf{l} \in A_{n}\left (\mathbf{x}\right )\), i.e.
By the construction of \(A_{n}\left (\mathbf{x}\right )\), we have for all \(\mathbf{w} \in A_{n}\left (\mathbf{x}\right )\) and \(\mathbf{x} \in \hat{ X}_{n}\)
and therefore
For a fixed sequence \(\mathbf{x} \in E^{\mathbb{N}}\) we construct a lower bound for the partition function. This lower bound will depend on n besides of course on x. We first divide \(\mathbb{N}\) into the intervals
and write x j for the restriction of x to I j viewed as an element in E N. Then we write τ 1 < τ 2 < ⋯ for the successive occurrences of \(\mathbf{x}_{\tau } \in \hat{ X}_{n}\). \(\nu ^{\otimes \mathbb{N}}\)-almost surely, all the τ j are finite and the τ j −τ j−1 are i.i.d. geometrically distributed with success probabilities
For \(T \in \mathbb{N}\), we define
Then we get the lower bound for \(Z_{NT}\left (\mathbf{x}\right ):\)
Therefore
We let first T → ∞ with fixed (large) n. By the law of large numbers, one has for \(\mu ^{\otimes \mathbb{N}}\)-almost all \(\mathbf{x} \in E^{\mathbb{N}}\)
So, the first summand on the right hand side above goes to
and the third summand to
\(o\left (1\right )\) here refers to n → ∞. Hence the first summand can be incorporated into the \(o\left (1\right )\) summand above.
The second summand converges, as T → ∞, to
where η n is geometrically distributed with parameter δ n .
Therefore,
Using (23) \(\gamma \left (\mu \right ) \geq h\left (\mu \right ) - h\left (\rho _{\mu }\right )\) and
we get that the right hand side above is
Therefore, if \(\mu \left (\phi \right ) -\alpha I\left (\mu \vert q_{\rho,\nu }\right ) > 0\) for large enough n. Therefore, we have proved Proposition 18.
Remark 24
-
a)
I would like to emphasize a tricky point in the above argument. At first sight, it appears that the rather trivial estimate (23) makes \(\gamma \left (\mu \right )\) essentially useless. This is however not true as \(\gamma \left (\mu \right )\) appears twice in the estimates above, leading in the end to the crucial fact that γ appears with a factor \(\left (\alpha -1\right )\), in fact for the very same reason, of course, as α − 1 appears in the LDP in Theorem 10. Only after this partial cancellation, we use (23). The fact that \(\gamma \left (\mu \right )\) enters twice, once with the factor − 1 and once with the factor α is due to the equipartition property of Lemma 23 which here is proved through the concentration of measure property in Corollary 21. In the general setup of [3, 4], this was proved via rather complicated arguments from a Shannon-McMillan-Breiman theorem, but here, as we just consider a product measure on the words, a simpler argument works.
-
b)
Without replacing \(\gamma \left (\mu \right )\) by \(h\left (\mu \right ) - h\left (\rho _{\mu }\right )\), the estimate would of course be better as, generally, \(\gamma \left (\mu \right )\neq h\left (\mu \right ) - h\left (\rho _{\mu }\right )\). However, it seems to be difficult to evaluate \(\gamma \left (\mu \right )\) precisely. Even if this could be done, the estimate above would most probably not give a sharp bound for \(h_{\mathrm{cr}}\left (\beta \right )\). The sharp bound is of course encoded in the full large deviation principle given in Corollary 15 above, but there, an exact evaluation seems to be completely hopeless.
The above bound is sufficient to prove a lower bound for \(h_{\mathrm{cr}}\left (\beta \right )\) of Theorem 16(a), which is strictly better than the Bodineau-Giacomin lower bound and also proves that the tangent at the origin is strictly bigger than 1∕α.
It is actually easy to determine what the optimal choice of μ is:
where z is the appropriate norming:
This choice does of course not satisfy the condition that it charges only words in \(\mathcal{W}_{K}\) for some K, but a simple approximation which we leave to the reader shows that if
for this μ, then it is also true for a suitably truncated distribution charging only words in \(\mathcal{W}_{K}\) for some large enough K.
For the above choice of μ, one has
and therefore, we see that if
one has \(h_{\mathrm{cr}}\left (\beta \right ) > h\)
Corollary 25
For all β > 0, one has
Proof
where
Remark that
by the definition of M. An elementary computation shows that
is strictly convex on \(\mathbb{R}^{+}\) for α > 1. Therefore
This proves the claim. ■
We next derive a lower bound for the tangent of \(h_{\mathrm{cr}}\left (\beta \right )\) at the origin. To formulate the result, consider first the integral
where Z is a standard normal random variable. The integral is convergent for 1 < α < 2, and b ≥ 1. For y ∼ 0, the term in the square bracket is of order y, and so the integral converges near 0. At y ∼ ∞, we have
which is bounded in y for b ≥ 1, and as α > 1, the integral converges at y ∼ ∞. For b = 1, one has
and therefore
On the other hand, it is easy to see that
and that \(I_{\alpha }\left (b\right )\) is continuous and strictly decreasing on \(\left (1,\infty \right ).\) Therefore, there exists a unique \(B = B\left (\alpha \right ) > 1\) with \(I_{\alpha }\left (B\left (\alpha \right )\right ) = 0\).
Corollary 26
Proof
We prove only the first case as this disproves a long-standing conjecture by Cécile Monthus for the standard random walk case, i.e. α = 2∕3. We choose \(1 < B < B\left (\alpha \right )\) and show that
for all β > 0 small enough which implies the claim.
By an elementary substitution, we have
where
and for i.i.d. symmetric coin tossing variables ξ i
If \(\rho \left (k\right ) \sim Ak^{-\alpha }\), then a Riemann approximation, together with the CLT for X y , yields
as \(B < B\left (\alpha \right ).\) We therefore conclude that
for small enough β > 0. ■
Remark 27
It should be remarked that the estimate on the tangent at the origin, which is in a way the main relevant object being “universal”, comes out from the improved estimate for the critical line. My feeling is that one is still quite far away from a thorough understanding of this tangent. It could well be that for β ∼ 0, there is some structural behavior which would allow to get the tangent explicitly.
Notes
- 1.
As many people have over years tried without success to disprove the Monthus conjecture, this is quite a safe statement, I believe.
- 2.
A hand waving computation which we have not been able to make rigorous, suggests \(\kappa \left (\alpha \right ) \leq \left (1+\alpha \right )/2\alpha\). The right hand side would be in agreement with numerical studies. Actually, the value has been conjectured to be the true value for the tangent. (Oral communication by G. Giacomin.)
References
K. Alexander, The effect of disorder on polymer depinning transitions. Commun. Math. Phys. 279, 117–146 (2008)
Q. Berger, F. Caravenna, J. Poisat, R. Sun, N. Zygouras, The critical curve of the random pinning and copolymer models at weak coupling. Commun. Math. Phys. 326, 507–530 (2014)
M. Birkner, Conditional large deviations for a sequence of words. Stoch. Proc. Appl. 118, 703–729 (2008)
M. Birkner, A. Greven, F. den Hollander, Quenched large deviation principle for words in a letter sequence. Probab. Theory Relat. Fields 148, 403–456 (2010)
M. Biskup, F. den Hollander, A heteropolymer near a linear interface. Ann. Appl. Probab. 9, 668–687 (1999)
T. Bodineau, G. Giacomin, On the localization transition of random copolymers near selective interfaces. J. Stat. Phys. 117, 801–818 (2004)
T. Bodineau, G. Giacomin, H. Lacoin, F.L. Toninelli, Copolymers at selective interfaces: New bounds on the phase diagram. J. Stat. Phys. 132, 603–626 (2008)
E. Bolthausen, A note on the diffusion of directed polymers in a random environment. Commun. Math. Phys. 123, 529–534 (1989)
E. Bolthausen, F. den Hollander, Localization transition for a polymer near an interface. Ann. Probab. 25, 1334–1366 (1997)
E. Bolthausen, F. den Hollander, A. Opoku, A copolymer near a selective interface: Variational characterization of the free energy. Ann. Probab. 43(2), 875–933 (2015)
F. Caravenna, G. Giacomin, The weak coupling limit of disordered copolymer models. Ann. Probab. 38, 2322–2378 (2010)
F. Caravenna, G. Giacomin, M. Gubinelli, A numerical approach to copolymers at selective interfaces. J. Stat. Phys. 122, 799–832 (2006)
P. Carmona, Y. Hu, On the partition function of a directed polymer in a random environment. Probab. Theory Relat. Fields 124, 431–457 (2002)
F. Comets, V. Vargas, Majorizing multiplicative cascades for directed polymers in random media. ALEA Lat. Am. J. Probab. Math. Stat. 2, 267–277 (2006)
F. Comets, N. Yoshida, Some new results on Brownian directed polymers in random environment. RIMS Kokyuroku 1386, 50–66 (2004)
F. Comets, N. Yoshida, Directed polymers in random environment are diffusive at weak disorder. Ann. Probab. 34, 1746–1770 (2006)
F. Comets, T. Shiga, N. Yoshida, Directed polymers in random environment: Path localization and strong disorder. Bernoulli 9, 705–723 (2003)
A. Dembo, O. Zeitouni, Large Deviations Techniques and Applications, 2nd edn. (Springer, New York, 1998)
B. Derrida, G. Giacomin, H. Lacoin, F.L. Toninelli, Fractional moment bounds and disorder relevance for pinning models. Commun. Math. Phys. 287, 867–887 (2009)
G. Giacomin, Random Polymer Models (Imperial College Press/World Scientific, Singapore, 2007)
G. Giacomin, H. Lacoin, F.L. Toninelli, Marginal relevance of disorder for pinning models. Commun. Pure Appl. Math. 63, 233–265 (2010)
J. Imbrie, T. Spencer, Diffusion of directed polymers in a random environment, J. Stat. Phys. 52, 609–626 (1988)
K. Johannson, Transversal fluctuations for increasing subsequences on the plan. Probab. Theory Relat. Fields 116, 445–456 (2000)
H. Lacoin, New bounds for the free energy of directed polymers in dimension 1+1 and 1+2. Commun. Math. Phys. 294, 471–503 (2010)
H. Lacoin, The martingale approach to disorder irrelevance for pinning models. Electron. Commun. Probab. 15, 418–427 (2010)
C. Monthus, On the localization of random heteropolymers at the interface between two selective solvents. Eur. Phys. J. B 13, 111–130 (2000)
Ya. Sinai, A random walk with random potential. Theory Probab. Appl. 38, 382–385 (1993)
A.-S. Sznitman, Brownian Motion, Obstacles and Random Media. Springer Monographs in Mathematics (Springer, Berlin, 1998)
M. Talagrand, Concentration of measure and isoperimetric inequalities in product spaces. Inst. Hautes Études Sci. Publ. Math. 81, 73–205 (1995)
F.L. Toninelli, A replica-coupling approach to disordered pinning models. Commun. Math. Phys. 280, 389–401 (2008)
F. Toninelli, Disordered pinning models and copolymers: Beyond annealed bounds. Ann. Appl. Probab. 18, 1569–1587 (2008)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this chapter
Cite this chapter
Bolthausen, E. (2015). Random Copolymers. In: Gayrard, V., Kistler, N. (eds) Correlated Random Systems: Five Different Methods. Lecture Notes in Mathematics, vol 2143. Springer, Cham. https://doi.org/10.1007/978-3-319-17674-1_1
Download citation
DOI: https://doi.org/10.1007/978-3-319-17674-1_1
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-17673-4
Online ISBN: 978-3-319-17674-1
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)