
Abstract
Since implicit neural representation methods can be utilized for continuous image representation learning, pixel values can be successfully inferred from a neural network model over a continuous spatial domain. The recent approaches focus on performing super-resolution tasks at arbitrary scales. However, their magnified images are often distorted and their results are inferior compared to single-scale super-resolution methods. This work proposes a novel CrossSR consisting of a base Cross Transformer structure. Benefiting from the global interactions between contexts through a self-attention mechanism of the Cross Transformer, the CrossSR could efficiently exploit cross-scale features. A dynamic position-coding module and a dense MLP operation are employed for continuous image representation to further improve the results. Extensive experimental and ablation studies show that our CrossSR obtained competitive performance compared to state-of-the-art methods, both for lightweight and classical image super-resolution.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others
Keywords
1 Introduction
With the rapid development of deep learning and computer vision [7, 13, 20], image super-resolution has shown a wide range of real-world applications, driving further development in this direction. Image super-resolution is a classical computer vision task, which aims to restore high-resolution images from low-resolution images. Generally, according to the manner of feature extractions, image super-resolution methods can be roughly divided into two categories, i.e., traditional interpolation methods, such as bilinear, bicubic, and deep convolutional neural network-based methods, such as SRCNN [6], DRCN [11], CARN [2], etc. Image super-resolution methods based on CNNs have achieved progressive performance. However, these methods cannot solve the problem of continuous image representation, and additional training is required for each super-resolution scale, which greatly limits the application of CNN-based image super-resolution methods.

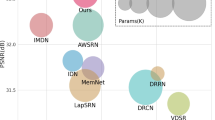
PSNR results v.s the total number of parameters of different methods for image SR (\(\times \)4) on Urban100 [9]. Best viewed in color and by zooming in. (Color figure online)
The LIIF [5] was proposed using implicit image representation for arbitrary scale super-resolution, aiming to solve the continuous image representation in super-resolution. However, the implicit function representation of MLP-based LIIF [5] cannot fully utilize the spatial information of the original image, and the EDSR feature encoding module used in LIIF lacks the ability to mine the cross-scale information and long-range dependence of features, so although LIIF has achieved excellent performance in arbitrary-scale super-resolution methods, there is a certain gap compared with the current state-of-the-art single-scale methods.

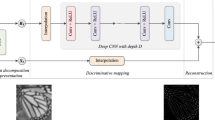
The architecture of CrossSR is in the top, it consists of two modules: a transformer backbone for feature encoding and an continuous image implicit function representation module. CTB is the inner structure of Cross Transformer Blocks, CEL is the structure of Cross-scale Embedding Layer we proposed, the n and n/2 in Conv(n,n/2) are the number of channels for input and output features.
The currently proposed transformer [21] has attracted a lot of buzz through remarkable performance in multiple visual tasks. The transformer is mainly based on a multi-head self-attention mechanism, which could capture long-range and global interaction among image contexts. The representative methods employing transformers for single-scale image super-resolution are SwinIR [14] and ESRT [17], which obtained superior performance than traditional deep neural networks-based methods.
This paper employs a novel framework of Cross Transformer for effective and efficient arbitrary-scale image super-resolution (CrossSR). Specifically, CrossSR consists of a Cross Transformer-based backbone for feature encoding and an image implicit function representation module. The feature encoding module is mainly based on the framework of Cross Transformer [23] with residual aggregation [16]. The Cross Transformer consists of four stages, and each stage contains multiple cross-scale feature embedding layers and multiple Cross Transformer layers. The image implicit function representation module is based on a modification of LIIF [5]. Specifically, it includes a dynamic position encoding module and a dense MLP module. Extensive experiments on several benchmark datasets and comparisons with several state-of-the-art methods on image super-resolution show that our proposed CrossSR achieves competitive performance with less computing complex. The main contributions of our proposed method include the following three aspects:
-
Firstly, a novel image super-resolution network backbone is designed based on a Cross Transformer block [23] combined with a residual feature aggregation [16], and a new cross-scale embedding layer (CEL) is also proposed to reduce the parameters while preserving the performance.
-
A series of new network structures are designed for continuous image representation, including dynamic position coding, and dense MLP, which could significantly increase the performance of super-resolution.
-
The experiments evaluated on several benchmark datasets show the effectiveness and efficiency of our proposed CrossSR, and it obtained competitive performance compared with state-of-the-art methods on image super-resolution.
2 Proposed Method
2.1 Network Architecture
As shown in Fig. 2, our proposed CrossSR framework consists of two modules: a transformer backbone based on Cross Transformer for feature extraction and a continuous function expression module which utilize a dynamic position encoding block (DPB) [23] and a dense multi-layer perception machine (dense MLP) to reconstruct high quality (HQ) images at arbitrary scales.
Transformer Backbone: Convolutional layers operated at early visual processing could lead to more stable optimization and better performance [25]. Given an input image x, we can obtained the shallow feature through a convolutional layer:
where \(L_{shallow}\) is the convolutional layer, \(F_{0}\) is the obtained shallow feature maps.
After that, the deep features \(F_{LR}\) are extracted through some Transformer blocks and a convolutional layer. More specifically, the extraction process of the intermediate features and the final deep features can be represented as follows:
where \(L_{CTB_i}\) denotes the i-th Cross Transformer block (CTB) of total k CTBs, \(L_{Conv}\) is the last convolutional layer, \(Concat(\cdot ,\cdot )\) indicates cascading them on the channel direction. Residual Feature Aggregation structure is designed by cascading the output of the transformer block of each layer and passing through a convolutional layer, thus, the residual features of each layer can be fully utilized [16].

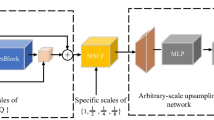
The architecture of Cross Transformer Layer (CTL) is on the left, SDA and LDA are used alternately in each block. The a diagram on the right shows the architecture of DPB. The middle figure b is the structure of the original MLP, and the rightmost figure c is a schematic of part of the structure of the dense MLP. These three structures contain a ReLU activation layer after each linear layer, which is omitted in the figure.
Continuous Function Expression: In the continuous function expression module, a continuous image representation function \(f_\theta \) is parameterized by a dense MLP. The formulation of continuous function expression is as follow:
where \(F_{SR}\) is the high-resolution result that to be predicted, \(v_i\) is the feature vector for reference, and \(\delta _x\) is the pixel coordinate information of the \(F_{SR}\), \(dpb(\cdot )\) means the dynamic position encoding block [23]. The reference feature vector \(v_i\) is extracted from the LR feature map \(F_{LR} \in R^{C\times H\times W}\) in its spacial location \(\delta _{vi}\in R^{H\times W}\) which is close to \(\delta _x \). \(f_\theta \) is the implicit image function simulated by the dense multi-layer perception machine.
Loss Function: For image super-resolution, the \(L_1\) loss is used to optimize the CrossSR as previous work [5, 14, 17, 19] done,
where \(F_{SR}\) is obtained by taking low resolution image as the input of CrossSR, and HR is the corresponding high-quality image of ground-truth.
2.2 Cross Transformer Block
As shown in Fig. 2, CTB is a network structure consisting of multiple groups of small blocks, each of which contains a Cross-scale Embedding Layer (CEL) and a Cross Transformer Layer (CTL). Given the input feature \(F_{i,0}\) of the \(i-th\) CTB, the intermediate features \(F_{i,1}\),\(F_{i,2}\),,,\(F_{i,n}\) can be extracted by n small blocks as:
where \(L_{CEL_{i,j}}(\cdot )\) is the j-th Cross-scale Embedding Layer in the i-th CTB, \(L_{CTL_{i,j}}(\cdot )\) is the j-th Cross Transformer Layer in the i-th CTB.
Cross-scale Embedding Layer(CEL): Although Cross Transformer [23] elaborates a Cross-scale Embedding Layer (CEL), it is still too large to be directly applied in image super-resolution. In order to further reduce the number of parameters and the complex operations, a new CEL is designed based on four convolutional layers with different convolutional kernel sizes. Benefiting from each convolution operation with different kernel size is based on the result of the previous convolution, the subsequent convolutions can obtain a substantial perceptual field with only one small convolution kernel, instead of using a \(32 \times 32\) kernel as large as in Cross Transformer [23]. Moreover, to further reduce the number of complex operations, the dimension of the projection is reduced as the convolution kernel increases. This design could significantly reduce computational effort while achieving excellent image super-resolution results. The output feature of Cross-scale Embedding Layer (CEL) \(F_{cel_{i,j}}\) is formulated as:
Cross Transformer Layer (CTL): Cross Transformer Layer (CTL) [23] is based on the standard multi-head self-attention of the original Transformer layer. The main differences lie in short-distance attention (SDA), long-distance attention (LDA), and dynamic position encoding block (DPB). The structure of Cross Transformer is shown in the Fig. 3. For the input image, the embedded features are firstly cropped into small patches to reduce the amount of operations. For short-distance attention, each \(G\times {G}\)-adjacent pixel point is cropped into a group. For long-distance attention, pixel points with fixed distance I are grouped together, and then these different grouping features X are used as input for long and short distance attention, respectively. The specific attentions are defined as follows:
where \(Q,K,V \in {R^{G^2\times D}}\) represent query, key, value in the self-attention module, respectively. And \(\sqrt{d}\) is a constant normalizer. \(B \in {R^{G^2\times {G^2}}}\) is the position bis matrix. Q, K, V are computed as
where X is the different grouping features for LDA and SDA, \(P_Q,P_K,P_V\) are projection matrices implemented through different linear layers.
Next, a multi-layer perception (MLP) is used for further feature transformations. The LayerNorm (LN) layer is added before the LSDA (LDA or SDA) and the MLP, and both modules are connected using residuals. The whole process is formulated as:
2.3 DPB and Dense MLP
Dynamic Position encoding Block (DPB): Image super-resolution aims to recover the high-frequency details of an image. And a well-designed spatial coding operation allows the network to effectively recover the details in visual scenes [26]. With the four linear layers of DPB, we expand the two-dimensional linear spatial input into a 48-dimensional spatial encoding that can more fully exploit the spatial location information, and such design could effectively reduce structural distortions and artifacts in images. The network structure of DPB is shown in Fig. 3.a, and the location information followed the DPB encoding operation is represented as:
where \(L_1,L_2,L_3\) all consist of three layers: linear layer, layer normalisation, and ReLU. \(L_4\) only consists of one linear layer. Then, the DPB encoded spatial information \(dpb(\delta _x)\) and the original location information \(\delta _x\) are cascaded and input into the dense MLP to predict the high-resolution image as shown in Eq. 4.
Dense MLP: Considering that dense networks have achieved good results in image super-resolution and the fascinating advantages of densenets: they reduce the problem of gradient disappearance, enhance feature propagation, encourage function reuse, and greatly reduce the number of parameters. We design a dense MLP network structure, which connects each layer to each other in a feedforward manner. As shown in Fig. 3.c, for each layer of Dnese MLP, all feature maps of its previous layer are used as input, and its own feature map is used as input of all its subsequent layers.
3 Experiment
3.1 Dataset and Metric
The main dataset we use to train and evaluate our CrossSR is the DIV2K [1] dataset from NTIRE 2017 Challenge. DIV2K consists of 1000 2 K high-resolution images together with the bicubic down-sampled low-resolution images under scale \(\times \)2, \(\times \)3, and \(\times \)4. We maintain its original train validation split, in which we use the 800 images from the train set in training and the 100 images from the validation set for testing. Follows many prior works, we also report our model performance on 4 benchmark datasets: Set5 [4], Set14 [27], B100 [3], Urban100 [9]. The SR results are evaluated by PSNR and SSIM metrics on the Y channel of transformed YCbCr space.
3.2 Implementation Details
As with LIIF, we set the input patch size to \(48\times 48\). We set the number of channels for the lightweight network and the classic image super-resolution task to 72 and 288, respectively. Our models were trained by ADAM optimizer using \(\beta 1=0.9\), \(\beta 2=0.99\) and \(\epsilon =10^{-8}\). The model of the lightweight network was trained for \(10^6\) iterations with a batch size of 16, and the learning rate was initialized to \(1 \times 10^{-4}\) and then reduced to half at \(2 \times 10^5\) iterations. In contrast, the classical network has a batch size of 8 and an initial learning rate of \(5 \times 10^{-5}\). We implemented our models using the PyTorch framework with an RTX3060 GPU.
3.3 Results and Comparison
Table 1 compares the performances of our CrossSR with 8 state-of-the-art light weight SR models. Compared to all given methods, our CrossSR performs best on the four standard benchmark datasets: Set5 [4], Set14 [27], B100 [3], Urban100 [9]. We can find a significant improvement in the results on Urban100. Specifically, a gain of 0.4 dB over EDSR-LIIF [5] on super-resolution for the Urban100 dataset is achieved. This is because Urban100 contains challenging urban scenes that often have cross-scale similarities, as shown in the Fig. 4, and our network can effectively exploit these cross-scale similarities to recover a more realistic image. On other datasets, the gain in PSNR is not as large as the improvement on the Urban100 dataset, but there is still a lot of improvement, all of which is greater than 0.1 dB.
We also compared our method with the state-of-the-art classical image super-resolution methods in Table 2. As can be seen from the data in the table, the results of some current arbitrary-scale methods [5, 8] are somewhat worse than those of single-scale super-resolution [14, 19]. Our CrossSR is an arbitrary-scale method that simultaneously achieves results competitive with state-of-the-art single-scale methods on different data sets in multiple scenarios, demonstrating the effectiveness of our method.
In Table 3, we also compared the performance of some arbitrary-scale image super-resolution models [8, 22] with our CrossSR at different non-integer scales. It can be found that the PSNR results of our model are consistently higher than those of MetaSR and ArbRDN at all scales.

Visualization comparison with liif on dataset Urban at \(\times \)4 SR.
3.4 Ablation Studies
To verify the effectiveness of modified Transformer, DPB and Dense MLP, we conducted ablation experiments in Table 4. Our experiments were performed on the Set5 dataset for x2 lightweight super-resolution.
As can be seen from the data in Table 4, the addition of the modified Transformer improved the test set by 0.05 dB compared to the baseline method, and the addition of DPB and Dense MLP improved it by 0.01 dB and 0.04 dB respectively. This demonstrates the effectiveness of the Transformer backbone, DPB and Dense MLP.
4 Conclusions
In this paper, a novel CrossSR framework has been proposed for image restoration models of arbitrary scale on the basis of Cross Transformer. The model consists of two components: feature extraction and continuous function representation. In particular, a Cross Transformer-based backbone is used for feature extraction, a dynamic position-coding operation is used to incorporate spatial information in continuous image representation fully, and finally, a dense MLP for continuous image fitting. Extensive experiments have shown that CrossSR achieves advanced performance in lightweight and classical image SR tasks, which demonstrated the effectiveness of the proposed CrossSR.
References
Agustsson, E., Timofte, R.: NTIRE 2017 challenge on single image super-resolution: dataset and study. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2017, Honolulu, HI, USA, 21–26 July 2017, pp. 1122–1131. IEEE Computer Society (2017)
Ahn, N., Kang, B., Sohn, K.-A.: Fast, accurate, and lightweight super-resolution with cascading residual network. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11214, pp. 256–272. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01249-6_16
Arbelaez, P., Maire, M., Fowlkes, C., Malik, J.: Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 33(5), 898–916 (2010)
Bevilacqua, M., Roumy, A., Guillemot, C., Alberi-Morel, M.: Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In: Bowden, R., Collomosse, J.P., Mikolajczyk, K. (eds.) British Machine Vision Conference, BMVC 2012, Surrey, UK, 3–7 September 2012, pp. 1–10. BMVA Press (2012)
Chen, Y., Liu, S., Wang, X.: Learning continuous image representation with local implicit image function. In: CVPR, Computer Vision Foundation/IEEE, pp. 8628–8638 (2021)
Dong, C., Loy, C.C., He, K., Tang, X.: Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 38(2), 295–307 (2015)
Hu, F., Lakdawala, S., Hao, Q., Qiu, M.: Low-power, intelligent sensor hardware interface for medical data preprocessing. IEEE Trans. Inf Technol. Biomed. 13(4), 656–663 (2009)
Hu, X., Mu, H., Zhang, X., Wang, Z., Tan, T., Sun, J.: Meta-sr: a magnification-arbitrary network for super-resolution. In: CVPR, Computer Vision Foundation/IEEE, pp. 1575–1584 (2019)
Huang, J., Singh, A., Ahuja, N.: Single image super-resolution from transformed self-exemplars. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015, pp. 5197–5206. IEEE Computer Society (2015)
Hui, Z., Gao, X., Yang, Y., Wang, X.: Lightweight image super-resolution with information multi-distillation network. In: Amsaleg, L., et al., (eds.) Proceedings of the 27th ACM International Conference on Multimedia, MM 2019, Nice, France, 21–25 October 2019, pp. 2024–2032. ACM (2019)
Kim, J., Lee, J.K., Lee, K.M.: Deeply-recursive convolutional network for image super-resolution. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016, pp. 1637–1645. IEEE Computer Society (2016)
Li, W., Zhou, K., Qi, L., Jiang, N., Lu, J., Jia, J.: LAPAR: linearly-assembled pixel-adaptive regression network for single image super-resolution and beyond (2021). CoRR abs/2105.10422
Li, Y., Song, Y., Jia, L., Gao, S., Li, Q., Qiu, M.: Intelligent fault diagnosis by fusing domain adversarial training and maximum mean discrepancy via ensemble learning. IEEE Trans. Ind. Informatics 17(4), 2833–2841 (2021)
Liang, J., Cao, J., Sun, G., Zhang, K., Gool, L.V., Timofte, R.: Swinir: image restoration using swin transformer. In: IEEE/CVF International Conference on Computer Vision Workshops, ICCVW 2021, Montreal, BC, Canada, 11–17 October 2021, pp. 1833–1844. IEEE (2021)
Lim, B., Son, S., Kim, H., Nah, S., Lee, K.M.: Enhanced deep residual networks for single image super-resolution. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2017, Honolulu, HI, USA, 21–26 July 2017, pp. 1132–1140. IEEE Computer Society (2017)
Liu, J., Zhang, W., Tang, Y., Tang, J., Wu, G.: Residual feature aggregation network for image super-resolution. In: CVPR, Computer Vision Foundation/IEEE, pp. 2356–2365 (2020)
Lu, Z., Liu, H., Li, J., Zhang, L.: Efficient transformer for single image super-resolution (2021). CoRR abs/2108.11084
Luo, X., Xie, Y., Zhang, Y., Qu, Y., Li, C., Fu, Y.: LatticeNet: towards lightweight image super-resolution with lattice block. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12367, pp. 272–289. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58542-6_17
Mei, Y., Fan, Y., Zhou, Y.: Image super-resolution with non-local sparse attention. In: CVPR, Computer Vision Foundation/IEEE, pp. 3517–3526 (2021)
Qiu, H., Zheng, Q., Msahli, M., Memmi, G., Qiu, M., Lu, J.: Topological graph convolutional network-based urban traffic flow and density prediction. IEEE Trans. Intell. Transp. Syst. 22(7), 4560–4569 (2021)
Vaswani, A., et al.: Attention is all you need. In: NIPS, pp. 5998–6008 (2017)
Wang, L., Wang, Y., Lin, Z., Yang, J., An, W., Guo, Y.: Learning A single network for scale-arbitrary super-resolution. In: ICCV, pp. 4781–4790. IEEE (2021)
Wang, W., Yao, L., Chen, L., Cai, D., He, X., Liu, W.: Crossformer: a versatile vision transformer based on cross-scale attention (2021). CoRR abs/2108.00154
Wang, Z., Gao, G., Li, J., Yu, Y., Lu, H.: Lightweight image super-resolution with multi-scale feature interaction network. In: 2021 IEEE International Conference on Multimedia and Expo, ICME 2021, Shenzhen, China, 5–9 July 2021, pp. 1–6. IEEE (2021)
Xiao, T., Singh, M., Mintun, E., Darrell, T., Dollár, P., Girshick, R.B.: Early convolutions help transformers see better (2021). CoRR abs/2106.14881
Xu, X., Wang, Z., Shi, H.: Ultrasr: spatial encoding is a missing key for implicit image function-based arbitrary-scale super-resolution (2021). arXiv preprint arXiv:2103.12716
Zeyde, R., Elad, M., Protter, M.: On single image scale-up using sparse-representations. In: Boissonnat, D., et al. (eds.) Curves and Surfaces 2010. LNCS, vol. 6920, pp. 711–730. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-27413-8_47
Zhang, Y., Wang, H., Qin, C., Fu, Y.: Aligned structured sparsity learning for efficient image super-resolution. In: Advances in Neural Information Processing Systems, vol. 34 (2021)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
He, D., Wu, S., Liu, J., Xiao, G. (2022). Cross Transformer Network for Scale-Arbitrary Image Super-Resolution. In: Memmi, G., Yang, B., Kong, L., Zhang, T., Qiu, M. (eds) Knowledge Science, Engineering and Management. KSEM 2022. Lecture Notes in Computer Science(), vol 13369. Springer, Cham. https://doi.org/10.1007/978-3-031-10986-7_51
Download citation
DOI: https://doi.org/10.1007/978-3-031-10986-7_51
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-10985-0
Online ISBN: 978-3-031-10986-7
eBook Packages: Computer ScienceComputer Science (R0)