
Abstract
In order to work with mathematical content in computer systems, it is necessary to represent it in formal languages. Ideally, these are supported by tools that verify the correctness of the content, allow computing with it, and produce human-readable documents. These goals are challenging to combine and state-of-the-art tools typically have to make difficult compromises.
In this paper we discuss languages that have been created for this purpose, including logical languages of proof assistants and other formal systems, semi-formal languages, intermediate languages for exchanging mathematical knowledge, and language frameworks that allow building customized languages.
We evaluate their advantages based on our experience in designing and applying languages and tools for formalizing mathematics. We reach the conclusion that no existing language is truly good enough yet and derive ideas for possible future improvements.
C. Kaliszyk—Supported by ERC starting grant no. 714034 SMART.
F. Rabe—Supported by DFG grant RA-1872/3-1 OAF and EU grant Horizon 2020 ERI 676541 OpenDreamKit.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others



1 Introduction
Today’s formal systems can verify advanced theorems in mathematics [Hal14], such as the Kepler conjecture [Hal12] or the Feit–Thompson theorem [GAA+13], as well as certify important computer systems, such as the CompCert C compiler [Ler09] and the seL4 microkernel [KAE+14]. All these systems and projects use advanced logical languages that are computer-understandable but hard for humans to write and read.
Computer science commonly defines and implements such formal languages for mathematical content that define syntax and semantics and offer strong automation support. However, non-trivial and expensive transformation steps are needed to formalize human-near natural language texts in them.
This is in contrast to standard approaches to writing mathematics or specifying computer systems, which use natural language with interspersed syntactically unrestricted formulas, e.g., as written in
 . While interpreting this natural language is very difficult for computers (arguably AI-complete), it is extremely effective for humans in a way that formal languages have so far not been able to capture. In fact, in 2007, Wiedijk claimed
[Wie07], citing four representative statements, that no existing formal system was sufficient to naturally express basic mathematical content. Despite the progress made since then, his critique still applies.
. While interpreting this natural language is very difficult for computers (arguably AI-complete), it is extremely effective for humans in a way that formal languages have so far not been able to capture. In fact, in 2007, Wiedijk claimed
[Wie07], citing four representative statements, that no existing formal system was sufficient to naturally express basic mathematical content. Despite the progress made since then, his critique still applies.
We give an introduction to the objectives and main approaches in Sect. 2. Then Sects. 3 and 4 describe the main approaches: formal system and intermediate languages in more detail. Sections 5 and 6 describe closely related orthogonal aspects: language frameworks and interchange libraries. We evaluate our findings and conclude in Sect. 7.
2 Overview
2.1 Objectives
Thus, a big picture goal of the field is a tighter integration of (i) natural language mathematical content such as textbooks or software specifications, and (ii) formalization of such content in logics and theorem proving systems. We can identify the following overarching objectives:
A Universal Formal Language for Mathematical Content that Supports Complex Structuring Mechanisms. We want a language that combines the universality of natural mathematical languages with the automation support of formal logics and programming languages. It should be closer to mathematics than these formal languages in regards to abstract syntax, notations, and type system. This is critical not only for generality but also to appeal to mathematicians at all because, as Wiedijk observes, most mathematicians do not like to read (or write) code [Wie07]. On the other hand, it should be fully formal including automation support for type, module, and proof systems of formal languages that have proved critical for large scale applications.
A Comprehensive Standard Library of Mathematical Concepts. The language must allow for building a standard library of mathematical concepts. In order to allow for semantics-aware machine support, it should be more formal than existing informal libraries such as induced by Wikipedia or PlanetMath by including formal types, notations, and properties. On the other hand, in order to achieve generality and support interoperability, it should not be committed to a particular logic like all the major formal libraries are. This combination of advantages would allow it to serve as a standard library, i.e., a central community resource to be used, e.g., to cross-link between existing libraries in a star-shaped network or to provide a basis for projects like FAbstracts [Hal17].
Practical Workflows that Integrate Natural and Formal Languages. Such a language and standard library would enable substantially better tool support for working researchers in mathematical sciences: Being structurally similar to both natural and formal languages, they could serve as an interface language for tools of either kind. This would allow enriching existing workflows such as
 -based authoring or proof-assistant–based verification. For example, researchers could easily formalize conjectures and their proof outlines in a general language as a first and cheap formalization step, before or instead of a full verification of the proof. This would avoid hindering practicians as today’s all-or-nothing approach of formalization in proof assistants tends to do
[KR16]. It is critical for success here to retain existing workflows instead of trying to develop a single be-all-end-all tool that no one would adopt. Therefore, any major project in this direction must aim at developing concrete improvements to the current ecosystem.
-based authoring or proof-assistant–based verification. For example, researchers could easily formalize conjectures and their proof outlines in a general language as a first and cheap formalization step, before or instead of a full verification of the proof. This would avoid hindering practicians as today’s all-or-nothing approach of formalization in proof assistants tends to do
[KR16]. It is critical for success here to retain existing workflows instead of trying to develop a single be-all-end-all tool that no one would adopt. Therefore, any major project in this direction must aim at developing concrete improvements to the current ecosystem.
2.2 Approaches
The most successful formal languages for mathematical content have been developed in the areas of formal logic where they occur most prominently as the input languages of proof assistants as well as in computer algebra where they occur as programming languages fitted to mathematical algorithms. These combine formal foundations with complex structuring mechanisms, especially type, module, proof, and computation systems, which have proved critical to achieve efficient large scale tool support. Importantly, these fix not only the syntax but also the semantics of, e.g., proofs and computations On the contrary, in natural language, these are not spelled out at all, let alone explicated as a primitive feature—instead, they are emergent features driven by conventions and flexibly adaptable to different contexts. Consequently, formalization is usually a non-structure-preserving transformation that is often prohibitively expensive and creates an entry barrier for casual users. For example, the mathematician Kevin Buzzard admonishes computer scientists to build more human-near languages “so users can at least read sentences they understand and try to learn to write these sentences”.
Between the extremes of natural and formal languages, a variety of intermediate languages make different trade-offs aiming at combining the universal applicability of natural language with the advantages of formal semantics. A central observation is that
-
existing intermediate languages apply only the formal syntax and (to varying degrees) semantics of formal languages but not their complex structuring mechanisms, and
-
this limitation is not necessarily an inherent feature of the approach but rather a frontier of research.
The following table summarizes the resulting trichotomy and shows how each kind of language satisfies only two out of three essential requirements:
Language properties | Natural | Intermediate | Formal |
|---|---|---|---|
Formal syntax and semantics | – | + | + |
Complex structuring | + | – | + |
Universal applicability | + | + | – |
In the subsequent sections, we discuss the state of the art for these languages in more detail.
3 Formal Languages
Formal languages use a wide variety of foundations and complex structuring mechanisms. This unfortunately means that it is rare for two tools to be compatible with each other. Additionally, all are quite removed from natural language. In the sequel, we discuss the most important complex structuring features.
3.1 Type Systems
Many formal systems use what we call hard type systems, which assign a unique type to each object and are thus easiest to automate. Systems derived from Martin-Löf type theory [ML74] or the calculus of constructions [CH88] usually use the proofs-as-programs correspondence (Curry-Howard [CF58, How80]) that represents mathematical properties as types and proofs as data. These include Agda [Nor05], Coq [Coq15], Lean [dKA+15], Matita [ASTZ06] as well as Nuprl [CAB+86]. Systems derived from Church’s higher-order logic [Chu40] usually use the LCF architecture [Mil72] that uses an abstract type of proved theorems. These include HOL4 [HOL], ProofPower [Art], Isabelle [NPW02], and HOL Light [Har96].
Hard type systems are at odds with natural language as the unique-type property precludes representing mathematical sets and subsets as types and subtypes. In particular, the lack of expressive subtyping in hard type systems is fundamentally at odds with every day mathematics, where sets and subsets are used throughout: hard type system precludes a direct representation of sets as types because they cannot represent the rich (even undecidable) subset relation using subtyping.
Multiple systems have explored compromises. We speak of semi-soft type systems if a hard type system is extended with variants of subtyping. For example, PVS [ORS92] uses predicate subtypes, Lean [dKA+15] and Nurpl [CAB+86] support predicate subtypes and quotient types, and IMPS uses [FGT93] refinement types.
Both hard and semi-soft type systems force users to choose between representing information using the type system (e.g., \(\forall x:\mathbb {N}{.}P(x)\)) or the logical system (e.g., \(\forall x{.} x\in \mathbb {N}\Rightarrow P(x)\)). Problematically, this choice usually has far-reaching consequences, e.g., the type system may be decidable but the logic system undecidable. But from the perspective of mathematics this distinction is artificial, and the fact that the two resulting representations may be entirely incompatible down the road is very awkward.
These problems are avoided in untyped languages. ACL2 [KMM00] is a first-order logic on top of the untyped \(\lambda \)-calculus of Lisp that strongly emphasizes computation. Untyped set theory is used in Isabelle/ZF [PC93], Metamath [Meg07], and the B method [Abr96]. Untyped languages are also common in virtually all computer algebra systems, such as Mathematica [Wol12] or SageMath [S+13].
We speak of soft type systems if unary predicates on the untyped objects mimic types and the type system is an emergent feature of the logical system. These are used most prominently in Mizar [TB85] among proof assistants and GAP [Lin07] among computer algebra systems. Both use the types-as-predicates approach, where the semantics of a type is given by a unary predicate ranging over untyped objects. Both allow declaring functions and dependent types (i.e., predicates \(n+1\) arguments that return a unary predicate after fixing the first n arguments) that have type constraints on the arguments. Soft type systems are generally hardest to automate because type-checking is reduced to undecidable theorem proving. Here Mizar leverages theorem proving: the type checker is guided by user-stated typing rules (called registrations), which are specially marked theorems about typing properties. GAP leverages computation: the typing predicates must be computable properties, which are computed and cached at run-time for every object.
Thus, soft type systems are heuristic, which makes implementations more difficult for the developer and their behavior less predictable for the user. But they are the most human-friendly. A combination of hard and soft type systems, where advanced hard type systems are emergent features built systematically on top of a soft one, could potentially model mathematical content best but has so far received much less systematic attention than the above approaches. But as theorem proving technology becomes more routine, they become more and more attractive.
An example soft type system has been recently developed on top of a hard-typed Isabelle for the Isabelle/Mizar object logic [KP19a], which expresses the largest softly typed proof library in a logical framework. As part of this research, the type system of Mizar has been formalized including its intersection type constructions, various ways to express set-theoretic structures, and declarative proof translations [KP19b] have been investigated. Furthermore, a common foundation for proofs that allows practically combining results between HOL and set theory has been developed [BKP19].
3.2 Module Systems
A key use of modules is to represent structures (also called records or theories); here the abstract definition (e.g., “group”) is represented as a module, and concrete models (e.g., individual groups) are represented as instances of the module. The used module systems vary widely but roughly fall into the following groups.
Firstly, ML-inspired external module systems use a two-layer language where the module language is external to the logical language. These allow for inheritance, refinement, and instantiation (e.g., Coq modules, Isabelle locales, PVS theories, SageMath categories, Axiom categories) as well as more advanced structuring such as parametric modules (e.g., PVS), module expressions (e.g., Isabelle locales, Axiom joins), or morphisms between modules (Isabelle, IMPS). Hard module systems differ greatly from natural language where no two-layer language is fixed.
Secondly, internal module systems use record types to mimic modular structure inside the type system. This is possible in all systems that support record types (e.g., Agda, Coq, Isabelle, Lean, PVS); Mizar’s structures behave similarly. Soft modules are more flexible and thus similar to natural language, but the lack of a concise module system makes modular reasoning like inheritance and refinement more difficult. For example, soft module systems must manually employ extra-logical conventions (e.g., [GGMR09]), and combining modules built with different conventions quickly becomes impractical. This is even worse in the common case where both hard and soft module systems are present in parallel (we have initiated work in this direction in [MRK18]).
Both of the above can be seen as hard module systems in the sense that a module encapsulates a fixed set of declarations that induce selectors that can be applied to the module’s instances. A third group, which we call soft module systems is somewhat hypothetical as it is used much less widely. Here, in analogy to soft tying, modules are treated as unary predicates that range over objects. Inheritance then becomes a special case of implication. This idea is used in the GAP module system, whose soft types (called properties) and soft modules (called categories) are treated very similarly: they are jointly filters, and the run-time system tracks which object satisfies which filters. The main difference between them is that categories can have constructors and thus allow for filters that are satisfied by construction.
Finally, since module systems have mostly been designed as extensions of existing logical languages, both hard and soft module systems fail to capture a number of essential features of natural mathematical language: the identification of isomorphic instances of the same module; the seamless extension of operations across substructures and quotient structures (e.g., \(+\) is first defined on \(\mathbb {N}\), then extended to \(\mathbb {Z}\)); the flexibility of presence and order of fields in a structure (e.g., \((\mathbb {Z},+,*)\) and \((\mathbb {Z},+,0,-,*,1)\) should be the same ring); the context-sensitive meaning of structures (e.g., \(\mathbb {Z}\) should be a ring or a total order, depending on the context); and in many systems also the implicit application of forgetful functors (e.g., a group is not automatically also a monoid).
3.3 Proof Systems
Formal languages shine when using logics implemented in proof assistants to find and check proofs automatically. Tactic-based proof systems (e.g., HOL Light) are optimized for efficiency of proof checking but have an imperative flavor that is very different from natural mathematical language. Declarative proof systems (e.g. Mizar, Isabelle/Isar) were designed to be closer to natural language.
While many current tools support declarative proofs using quite similar languages, all of these are intertwined with the respective logic and therefore not immediately reusable as a universally applicable declarative proof language. In particular, the expressivity of these languages is limited by the strength of the underlying logic, i.e., they can only express the kind of proof steps that can be potentially verified by the tool. Declarative proof languages are conceptually close to natural mathematics but technically tied to specific logics. We discuss logical languages in more detail in Sect. 5.
In computer algebra systems no formal logics are implied and automated reasoning is restricted to computable properties. Additionally, these systems can capture logical properties by user declaration: for example, most systems’ libraries distinguish between groups and commutative groups and allow users to construct a group as commutative even if that property is not proved.
3.4 Computation Systems
The second major application of formal languages stems from computer algebra systems, which use mathematics-customized variants of general purpose programming languages for efficient computation.
Even though mathematics uses mostly pure functions, most systems are based on Turing-complete imperative programming, mostly to reuse existing user knowledge and fast implementations. It is common to use the same language for pure mathematical algorithms and interspersed imperative meta-operations like I/O, logging, memoization, or calling external tools (in particular in SageMath).
Proof assistants take a much more restricted approach to integrate pure computations with a logic. Three main approaches exist. Firstly, normalization in the type theory, in particular \(\beta \)-reduction is a primitive form of computation. It becomes much stronger when combined with (co)inductive types and recursion, and these are primitive features in most complex type theories like Coq. Systems then usually include heuristic termination criteria to check the soundness of the functions, which leads to a trade-off between logical and Turing-completeness. Secondly, certain theorems such as Horn formulas about equality can be interpreted as conditional rewrite rules. Typically, systems require the user to choose which theorems to use and then exhaustively rewrite expressions with them. This is much slower but allows for a much simpler language as computation is relegated to the meta-level. This is the main method used in systems without primitive (co)inductive types such as Isabelle. Thirdly, computation can be supplied by external tools or special kernel modules. This computation can be a part of the, consequently rather big, trusted code base, such as in PVS decision procedures, the usage of SAT solvers is Mizar [Nau14]. This is also the case in Theorema: As the proof assistant is written in the Mathematica computer algebra system, it is in principle possible to use most Mathematica’s algorithms inside Theorema [Win14]. In some cases, a trade-off is possible where computations are run externally and their results are efficiently verified by the prover.

Functionality for intermediate languages (left) market gap for stepwise formalization support (right)
4 Intermediate Languages
Intermediate languages try to capture the advantages of natural languages in a formal language. There is a rather diverse set of such approaches, which we describe in groups below. However, we can identify some general effects that motivate the design of many intermediate languages.
Firstly, an intermediate language can already provide sufficient automation support for some tasks. Thus, it can serve as a more natural and easier-to-use target language for (partial) formalization if the task at hand is supported. For example, search, interactive documents, or dependency management can be realized well in some intermediate languages and even benefit from structural similarity to the human-near natural language formulation. The main counter-examples are verification and computation, which requires a lot more formalization. This is indicated in Fig. 1 (left).
Secondly, an intermediate language can serve as an interface between human-near natural language and a verification- or computation-oriented formal language. This enables stepwise formalization and thus a smoother transition from the informal to the formal realm. It may also allow for a separation of concerns where a domain experts transform content from informal to intermediate in a first step and a formalization transforms from intermediate to formal in a second step. The relative lack of highly successful approaches in this style is indicated in Fig. 1 (right).
Thirdly, the intermediate representation is often not or only barely committed to a particular formal language (e.g., a particular type system, module system, proof system or computation system). During stepwise formalization, this means that the first step only needs to be done once and can then be reused for different second steps targeting different formal languages. Expanding on this, we see that an intermediate language can provide an interoperability layer between formal languages. That can help with the notorious lack of interoperability between formal systems (see also Sect. 6).
4.1 Controlled Natural Language
These approaches combine formal grammars for fragments of natural language with formal languages for formulas. Their goal is to make the surface syntax of a formal language as close to traditional mathematics as possible while retaining a formal grammar that allows for automated parsing. While the languages often look similar to some semi-formal languages discussed below, we classify them differently because they use a formal logic-near language in their kernel.
This method is applied in MathLang [KW08, KWZB14], MathNat [Hum12], in [KN12] within the FMathL project, and Naproche [CFK+09]. Mizar [TB85] is a logical language whose surface syntax has been carefully designed to look like a small fragment of natural language and thus looks similar to controlled natural language systems without being one.
These systems vary in how the semantics of the language is defined and how much implementation support is provided. Both MathLang and Naproche use, effectively, a soft type system on top of set theory to define the semantics. MathLang allows for translating content into proof assistants (Isabelle, Coq) for users to finish and check proofs, and Naproche uses automated first-order theorem provers to discharge proof obligations automatically.
Contrary to the verification/computation-oriented formal languages, where large libraries of formal content (up to \({\sim }10^5\) theorems in the biggest systems) are developed and shared in vibrant communities, none of the controlled natural language systems provides a substantial library. This is a hen-egg problem since large libraries often result from the practical necessities caused by verification and computation. A critical limiting factor of existing controlled natural languages is the lack of scalable automation support and large libraries.
4.2 Semi-formal Languages
These approaches aim at combining unrestricted natural mathematical language and formal language in the same document. Contrary to the controlled natural language approaches discussed above, the interpretation of the natural language parts remains AI-complete.
Flexiformal systems use informal and formal language as alternatives, i.e., content may be written informally or formally. Thus, not all mathematical content is formalized, and all tool support must degrade gracefully when informal and thus uninterpretable content is encountered. The sTeX system
[Koh08] is a
 package for annotating informal mathematical texts with its formal meaning, which then allows for writing (parts of) formulas in formal logical syntax. In addition to pdf, sTeX documents can be processed into OMDoc documents
[Koh06], which makes them available for further machine processing. sTeX provides no type system and only a very simple hard module system. It has been used by the developer to write his introductory computer science lecture notes.
package for annotating informal mathematical texts with its formal meaning, which then allows for writing (parts of) formulas in formal logical syntax. In addition to pdf, sTeX documents can be processed into OMDoc documents
[Koh06], which makes them available for further machine processing. sTeX provides no type system and only a very simple hard module system. It has been used by the developer to write his introductory computer science lecture notes.
Literate programming [Knu84] and approaches inspired by it allow for natural and formal language to appear in parallel. Here, content is described twice: the formal version defines the semantics, and the informal version provides documentation. Contrary to the other approaches mentioned here, this is not a third language in between formal and natural, but a combination of the two. Several formal systems provide mature support for writing content in literate programming style such as Agda, Isabelle (see [Wen11]), and Axiom.
Discourse representation languages [KR93] perform an analysis of the language used in written mathematics and design a fixed set of disambiguation conventions. Ganesalingam [Gan13] proposes a system of types that together with a parsing procedure and the set of disambiguation conventions could be used to parse non-foundational mathematics. Apart from the foundational issues, the approach also has a problem with adaptivity of mathematical texts.
4.3 Interchange Languages
These approaches apply the general principles of formal languages while avoiding a commitment to a particular logic or implementation. A major goal is system interoperability.
Standardized representation languages have been developed in the area of knowledge management such as OpenMath [BCC+04], content MathML [ABC+10], and OMDoc [Koh06]. These prioritize standardizing the syntax using standard machine-friendly representation formats such as XML (where the formal structure of objects is explicit). They do not specify user-friendly surface syntaxes (where the formal structure would have to be inferred through complex parsing and disambiguation) or rigorous semantics. This allows their use as interchange languages (e.g., in the SCIEnce [HR09] and OpenDreamKit [DIK+16] EU projects), as a basis for integrating mathematics with the semantic web (e.g., in the MONET and HELM/MoWGLI FP6 projects), or as markup languages for web browsers (e.g., by the integration of MathML into HTML5).
A different trade-off is made in interchange languages mostly developed for theorem provers. They are restricted to small families of logical languages used in theorem provers. Thus, they are more widely applicable than individual logical languages but less widely than the truly universal standard representation languages. The TPTP [Sut09] family of languages has played a major role in the community: it serves the role of a common language for automated theorem prover inputs and outputs. TPTP was originally restricted to first-order logics, and a few extensions exist [BRS08, SSCB12], which co-evolve with the available theorem provers, thus offering the possibility of problem exchange also between formal proof systems. OpenTheory [Hur09] is restricted to the HOL-based proof assistants. It offers some support for abstracting from the systems’ idiosyncrasies in order to increase portability, and some HOL theories have been manually refactored to make use of this abstraction. The ISO-standardized Common Logic [edi07] has a broader ambition, aiming at interchanging between any knowledge-based systems. But its applicability to mathematics is limited by its focus on first-order logic and a lack of integration with mathematical software.
Overall, interchange languages focus mostly on a universal formal syntax while sacrificing a universal semantics or restrict attention to small families of languages. Neither provides strong support for type/module/proof/computation systems that would be critical to capture the complexity of large scale formal libraries. A partial exception is the second author’s Mmt system, which combines aspects of standard languages [DIK+16, KMP+17] and prover interchange languages [BRS08, HR15, KRS16] with hard type and module systems [RK13]. The OAF project [KR16, KR20] used Mmt to represent large libraries of proof assistants in a standard representation language, including those of Mizar in [IKR11], HOL Light in [KR14], PVS in [KMOR17] (including the NASA library), Coq in [MRS19] (including all available libraries), and Isabelle in [KRW20] (including the Archive of Formal Proofs).
5 Language Frameworks
Language frameworks are formal languages in which the syntax and semantics of other languages can be represented. They are superficially related to parser frameworks but much stronger because they (i) allow specifying not only the syntax but also the semantics of a language, (ii) often offer strong support for context-sensitivity, which is critical in mathematics.
Logical frameworks are language frameworks for building formal language. Examples are Isabelle [Pau94], Dedukti [BCH12], \(\lambda \)Prolog [MN86], or the LF [HHP93] family including Twelf [PS99] and others. Frameworks also exist for building controlled natural languages such as GF [Ran11].
Contrary to the approaches discussed above, these frameworks do not in themselves provide languages for formalizing mathematics. But they are worth discussing in this context for two reasons: Firstly, they allow the rapid prototyping of implementations, which speeds up the feedback loop between language design and applications. Thus, users can experiment with new languages and conduct large case studies in parallel. Secondly, they allow developing scalable applications language-independently such that they are immediately applicable for any language defined in the framework. That is important because evaluating formal languages often requires building (or trying to build) large libraries in them. Such applications include at least parsing and type-checking but can also include meta-reasoning (e.g., Twelf), interactive theorem proving (e.g., Isabelle), or language translation (e.g., GF).
Despite many successes in representing logical languages in logical frameworks (e.g., [CHK+11, KR14, KMOR17, MRS19]), current frameworks cover only unrealistically simple languages compared to the needs for mathematically structured content and do not have good support for, e.g., soft type systems and soft module systems and practical proof systems. Thus, even the representation of the already insufficient languages discussed above is often very difficult or not possible.
Therefore, more flexible logical frameworks were developed recently. Both ELPI [DGST15] and Mmt [Rab17, Rab18] allow users to flexibly change critical algorithms whenever a concrete language definition needs it. That makes them more promising for representing languages designed for mathematical content (and can even allow sharing some functionality across incompatible foundations).
Mmt [Rab13, RK13] is a logic-independent representation and management system for formal logical content that uses logical frameworks to provide a rigorous semantics for OMDoc and OpenMath. It manages all aspects of language design in a coherent framework including language definition, rapid prototyping of tools, and library development. Fully parametric in the choice of formal system, it maximizes the reuse of concepts, formalizations, and tool support. It subsumes in particular logical frameworks such as the LF family [MR19]. The LATIN project [CHK+11] used an Mmt precursor language based on the Twelf module system [RS09] to build a library of common logics of symbolic software systems and proof checkers. It contains close to 1000 modules (theories and morphisms between them), which can be imported into Mmt.
[KRSS20] makes the first steps towards combining the advantages of Mmt and ELPI. [KS19] uses Mmt to extend LF-like logical frameworks with the natural language framework GF.
6 Interchange Libraries
The quest for the best formal language for mathematics is likely to never-ending. Therefore, it is important to investigate how to combine the existing libraries of formalized content. Due to major incompatibilities between the various formal systems, this is an extremely difficult problem, and it would go beyond the scope of this paper to discuss approaches in detail. But we want to mention the idea of interchange libraries because we consider it to be one of the most promising ideas.
An interchange library I is a formalization of mathematics written in an intermediate language with the goal of serving as an interoperability layer between formal systems. The main idea is that all translations from source system S to target system T are split into two steps \(S\rightarrow I\) and \(I\rightarrow T\).
Both steps have characteristic difficulties. The step \(S\rightarrow I\) is usually a partial translation because every formal systems uses idiosyncratic features that cannot be represented in I and optimizations for verification/computation that need not be represented in I. The step \(I\rightarrow T\) tends to be easier, but there is a tricky trade-off in the design of I: the less I commits to a particular formal system, the more systems T can be handled but the more difficult the individual translations \(I\rightarrow T\) become. In practice, a further major logistic problem is that I and the translations via it needs to be built and maintained, which is even harder to organize and fund than for the systems S and T themselves.
The standard content dictionaries written in OpenMath [BCC+04] were the first concerted effort to build an interchange library. 214 dictionaries (including contributed ones) declaring 1578 symbols are maintained by the OpenMath Society. These focus on declaring names for mathematical symbols and describing their semantics verbally and with formal axioms. However, the approach was not widely adopted as little tool support existed for OpenMath itself and for OpenMath-based interoperability. Individual formal systems were also less able to export/import their objects at all.
Recently, the idea was picked up again in the OpenDreamKit project. It uses Mmt (whose language of theories and expressions essentially subsumes OpenMath CDs and objects) to write a formal interchange library (dubbed MitM for Math-in-the-middle) [DIK+16]. MitM is more formal than the OpenMath CDs, in particular employing a hard type and module system. It was used as an interoperability layer for computer algebra systems [KMP+17] and mathematical databases [WKR17, BKR19].
A complementary approach is SMGloM [GIJ+16], a multi-lingual glossary of mathematical concepts. It retains the untyped natural of OpenMath CDs but uses sTeX to obtain tool support for writing the library.
SMGloM and MitM serve similar purposes with different methods that recall the distinctions described in Sect. 2: SMGloM uses mostly natural language, and MitM uses formal language with hard type and module system. The short-comings of these efforts seem to indicate that soft types and modules may be the best trade-off for building an interchange library.
In order to streamline the process of building the translations \(S\rightarrow I\) and \(I\rightarrow T\), the concept of alignments was developed [KKMR16]. An alignment between two symbols c and \(c'\) in different libraries captures that translations should try to translate objects with c to objects with head d. Both exact manual efforts [MRLR17] and machine learning–based heuristic approaches were used to find alignments across formal libraries. The latter includes alignment from six proof assistants [GK19], showing that such alignments allow both conjecturing and more powerful automation [GK15]. The same approach has been used to obtain alignments between informal and formal libraries, which can be used to automatically formalize parts of mathematical texts, both statistically [KUV17] and using deep learning techniques [WKU18]. Similarly, [GC14] automatically obtains alignments between informal libraries.
7 Conclusion
We have presented a survey of languages for formalizing mathematics. The various languages have been designed and implemented for different purposes and have different features, and their many distinguishing features give them characteristic advantages and disadvantages. Natural language that mathematicians are used to lacks formal semantics (and in many cases even formal syntax). But fully formal languages are still very far from natural language. And existing intermediate languages lack complex structuring features and large libraries and scalable tools that would make them directly usable for formalization.
We expect that future research in the domain must continue to experiment with language development aiming at the formal representation of syntax and semantics while preserving natural readability and extensibility and large-scale structuring features. The use of language frameworks will be helpful to rapidly experiment with these novel ideas. We see a lot of potential in the development of a new intermediate language along those lines that could enable partial and stepwise formalization as well as provide an interoperability layer for formal languages. Concretely, we expect this future language to feature at least a combination of soft type and module systems with rigorous development of their hard analogues as emergent features.
References
Ausbrooks, R., et al.: Mathematical Markup Language (MathML) Version 3.0. Technical report, World Wide Web Consortium (2010). http://www.w3.org/TR/MathML3
Abrial, J.: The B-Book: Assigning Programs to Meanings. Cambridge University Press, Cambridge (1996)
Arthan, R.: ProofPower. http://www.lemma-one.com/ProofPower/
Asperti, A., Coen, C.S., Tassi, E., Zacchiroli, S.: Crafting a proof assistant. In: Altenkirch, T., McBride, C. (eds.) TYPES 2006. LNCS, vol. 4502, pp. 18–32. Springer, Heidelberg (2007). https://doi.org/10.1007/978-3-540-74464-1_2
Buswell, S., Caprotti, O., Carlisle, D., Dewar, M., Gaetano, M., Kohlhase, M.: The Open Math Standard, Version 2.0. Technical report, The Open Math Society (2004). http://www.openmath.org/standard/om20
Boespflug, M., Carbonneaux, Q., Hermant, O.: The \(\lambda \varPi \)-calculus modulo as a universal proof language. In: Pichardie, D., Weber, T. (eds.) Proceedings of PxTP2012: Proof Exchange for Theorem Proving, pp. 28–43 (2012)
Brown, C., Kaliszyk, C., Pąk, K.: Higher-order Tarski Grothendieck as a foundation for formal proof. In: Harrison, J., O’Leary, J., Tolmach, A. (eds.) Interactive Theorem Proving. LIPIcs, vol. 141, pp. 9:1–9:16 (2019)
Berčič, K., Kohlhase, M., Rabe, F.: Towards a unified mathematical data infrastructure: database and interface generation. In: Kaliszyk, C., Brady, E., Kohlhase, A., Sacerdoti Coen, C. (eds.) CICM 2019. LNCS (LNAI), vol. 11617, pp. 28–43. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-23250-4_3
Benzmüller, C., Rabe, F., Sutcliffe, G.: THF0 – the core of the TPTP language for higher-order logic. In: Armando, A., Baumgartner, P., Dowek, G. (eds.) IJCAR 2008. LNCS (LNAI), vol. 5195, pp. 491–506. Springer, Heidelberg (2008). https://doi.org/10.1007/978-3-540-71070-7_41
Constable, R., et al.: Implementing Mathematics with the Nuprl Development System. Prentice-Hall, Upper Saddle River (1986)
Curry, H., Feys, R.: Combinatory Logic. North-Holland, Amsterdam (1958)
Cramer, M., Fisseni, B., Koepke, P., Kühlwein, D., Schröder, B., Veldman, J.: The Naproche project controlled natural language proof checking of mathematical texts. In: Fuchs, N.E. (ed.) CNL 2009. LNCS (LNAI), vol. 5972, pp. 170–186. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-14418-9_11
Coquand, T., Huet, G.: The calculus of constructions. Inf. Comput. 76(2/3), 95–120 (1988)
Codescu, M., Horozal, F., Kohlhase, M., Mossakowski, T., Rabe, F.: Project abstract: logic atlas and integrator (LATIN). In: Davenport, J.H., Farmer, W.M., Urban, J., Rabe, F. (eds.) CICM 2011. LNCS (LNAI), vol. 6824, pp. 289–291. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-22673-1_24
Church, A.: A formulation of the simple theory of types. J. Symb. Log. 5(1), 56–68 (1940)
Coq Development Team: The Coq proof assistant: reference manual. Technical report, INRIA (2015)
Dunchev, C., Guidi, F., Sacerdoti Coen, C., Tassi, E.: ELPI: fast, embeddable, \(\lambda \)prolog interpreter. In: Davis, M., Fehnker, A., McIver, A., Voronkov, A. (eds.) LPAR 2015. LNCS, vol. 9450, pp. 460–468. Springer, Heidelberg (2015). https://doi.org/10.1007/978-3-662-48899-7_32
Dehaye, P.-O., et al.: Interoperability in the OpenDreamKit project: the math-in-the-middle approach. In: Kohlhase, M., Johansson, M., Miller, B., de de Moura, L., Tompa, F. (eds.) CICM 2016. LNCS (LNAI), vol. 9791, pp. 117–131. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-42547-4_9
de Moura, L., Kong, S., Avigad, J., van Doorn, F., von Raumer, J.: The lean theorem prover (system description). In: Felty, A.P., Middeldorp, A. (eds.) CADE 2015. LNCS (LNAI), vol. 9195, pp. 378–388. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-21401-6_26
Common Logic editors: Common Logic (CL) – A framework for a family of logic-based languages. Technical Report 24707, ISO/IEC (2007)
Farmer, W., Guttman, J., Thayer, F.: IMPS: an interactive mathematical proof system. J. Autom. Reason. 11(2), 213–248 (1993)
Gonthier, G., et al.: A machine-checked proof of the odd order theorem. In: Blazy, S., Paulin-Mohring, C., Pichardie, D. (eds.) ITP 2013. LNCS, vol. 7998, pp. 163–179. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-39634-2_14
Ganesalingam, M.: The language of mathematics. In: Ganesalingam, M. (ed.) The Language of Mathematics. LNCS, vol. 7805, pp. 17–38. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-37012-0_2
Ginev, D., Corneli, J.: NNexus reloaded. In: Watt, S.M., Davenport, J.H., Sexton, A.P., Sojka, P., Urban, J. (eds.) CICM 2014. LNCS (LNAI), vol. 8543, pp. 423–426. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-08434-3_31
Garillot, F., Gonthier, G., Mahboubi, A., Rideau, L.: Packaging mathematical structures. In: Berghofer, S., Nipkow, T., Urban, C., Wenzel, M. (eds.) TPHOLs 2009. LNCS, vol. 5674, pp. 327–342. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-03359-9_23
Ginev, D., et al.: The SMGloM project and system: towards a terminology and ontology for mathematics. In: Greuel, G.-M., Koch, T., Paule, P., Sommese, A. (eds.) ICMS 2016. LNCS, vol. 9725, pp. 451–457. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-42432-3_58
Gauthier, T., Kaliszyk, C.: Sharing HOL4 and HOL light proof knowledge. In: Davis, M., Fehnker, A., McIver, A., Voronkov, A. (eds.) LPAR 2015. LNCS, vol. 9450, pp. 372–386. Springer, Heidelberg (2015). https://doi.org/10.1007/978-3-662-48899-7_26
Gauthier, T., Kaliszyk, C.: Aligning concepts across proof assistant libraries. J. Symb. Comput. 90, 89–123 (2019)
Hales, T.: Dense Sphere Packings: A Blueprint for Formal Proofs. London Mathematical Society Lecture Note Series, vol. 400. Cambridge University Press (2012)
Hales, T.: Developments in formal proofs. Séminaire Bourbaki, 1086, 2013–2014. arxiv.org/abs/1408.6474
Hales, T.: The formal abstracts project (2017). https://formalabstracts.github.io/
Harrison, J.: HOL light: a tutorial introduction. In: Srivas, M., Camilleri, A. (eds.) FMCAD 1996. LNCS, vol. 1166, pp. 265–269. Springer, Heidelberg (1996). https://doi.org/10.1007/BFb0031814
Harper, R., Honsell, F., Plotkin, G.: A framework for defining logics. J. Assoc. Comput. Mach. 40(1), 143–184 (1993)
HOL4 development team. https://hol-theorem-prover.org/
Howard, W.: The formulas-as-types notion of construction. In: To, H.B. (ed.) Curry: Essays on Combinatory Logic, Lambda-Calculus and Formalism, pp. 479–490. Academic Press, Cambridge (1980)
Horn, P., Roozemond, D.: OpenMath in SCIEnce: SCSCP and POPCORN. In: Carette, J., Dixon, L., Coen, C.S., Watt, S.M. (eds.) CICM 2009. LNCS (LNAI), vol. 5625, pp. 474–479. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-02614-0_38
Horozal, F., Rabe, F.: Formal logic definitions for interchange languages. In: Kerber, M., Carette, J., Kaliszyk, C., Rabe, F., Sorge, V. (eds.) CICM 2015. LNCS (LNAI), vol. 9150, pp. 171–186. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-20615-8_11
Humayoun, M.: Developing system MathNat for automatic formalization of mathematical texts. Ph.D. thesis, Université de Grenoble (2012)
Hurd, J.: OpenTheory: package management for higher order logic theories. In: Dos Reis, G., Théry, L. (eds.) Programming Languages for Mechanized Mathematics Systems, pp. 31–37. ACM (2009)
Iancu, M., Kohlhase, M., Rabe, F.: Translating the Mizar Mathematical Library into OMDoc format. Technical Report KWARC Report-01/11, Jacobs University Bremen (2011)
Klein, G., et al.: Comprehensive formal verification of an OS microkernel. ACM Trans. Comput. Syst. 32(1), 2 (2014)
Kaliszyk, C., Kohlhase, M., Müller, D., Rabe, F.: A standard for aligning mathematical concepts. In: Kohlhase, A., et al. (eds.) Work in Progress at CICM 2016, pp. 229–244. CEUR-WS.org (2016)
Kaufmann, M., Manolios, P., Moore, J.: Computer-Aided Reasoning: An Approach. Kluwer Academic Publishers, Boston (2000)
Kohlhase, M., Müller, D., Owre, S., Rabe, F.: Making PVS accessible to generic services by interpretation in a universal format. In: Ayala-Rincón, M., Muñoz, C.A. (eds.) ITP 2017. LNCS, vol. 10499, pp. 319–335. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-66107-0_21
Kohlhase, M., et al.: Knowledge-based interoperability for mathematical software systems. In: Blömer, J., Kotsireas, I.S., Kutsia, T., Simos, D.E. (eds.) MACIS 2017. LNCS, vol. 10693, pp. 195–210. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-72453-9_14
Kofler, K., Neumaier, A.: DynGenPar – a dynamic generalized parser for common mathematical language. In: Jeuring, J., et al. (eds.) CICM 2012. LNCS (LNAI), vol. 7362, pp. 386–401. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-31374-5_26
Knuth, D.: Literate programming. Comput. J. 27(2), 97–111 (1984)
Kohlhase, M.: OMDoc – An Open Markup Format for Mathematical Documents [version 1.2]. LNCS (LNAI), vol. 4180. Springer, Heidelberg (2006). https://doi.org/10.1007/11826095
Kohlhase, M.: Using
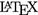 as a semantic markup format. Math. Comput. Sci. 2(2), 279–304 (2008)
as a semantic markup format. Math. Comput. Sci. 2(2), 279–304 (2008)Kaliszyk, C., Pąk, K.: Semantics of Mizar as an Isabelle object logic. J. Autom. Reason. 63(3), 557–595 (2019)
Kaliszyk, C., Pąk, K.: Declarative proof translation (short paper). In: Harrison, J., O’Leary, J., Tolmach, A. (eds.) 10th International Conference on Interactive Theorem Proving (ITP 2019). LIPIcs, vol. 141, pp. 35:1–35:7 (2019)
Kamp, H., Reyle, U.: From Discourse to Logic. Introduction to Modeltheoretic Semantics of Natural Language, Formal Logic and Discourse Representation Theory, Studies in Linguistics and Philosophy, vol. 42. Springer, Heidelberg (1993). https://doi.org/10.1007/978-94-017-1616-1
Kaliszyk, C., Rabe, F.: Towards knowledge management for HOL light. In: Watt, S.M., Davenport, J.H., Sexton, A.P., Sojka, P., Urban, J. (eds.) CICM 2014. LNCS (LNAI), vol. 8543, pp. 357–372. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-08434-3_26
Kohlhase, M., Rabe, F.: QED reloaded: towards a pluralistic formal library of mathematical knowledge. J. Form. Reason. 9(1), 201–234 (2016)
Kohlhase, M., Rabe, F.: Experiences from Exporting Major Proof Assistant Libraries (2020). https://kwarc.info/people/frabe/Research/KR_oafexp_20.pdf
Kaliszyk, C., Rabe, F., Sutcliffe, G.: TH1: the TPTP typed higher-order form with rank-1 polymorphism. In: Fontaine, P., Schulz, S., Urban, J. (eds.) Workshop on Practical Aspects of Automated Reasoning, pp. 41–55 (2016)
Kohlhase, M., Rabe, F., Sacerdoti Coen, C., Schaefer, J.: Logic-independent proof search in logical frameworks (short paper). In: Peltier, N., Sofronie-Stokkermans, V. (ed.) Automated Reasoning, vol. 12166, pp. 395–401. Springer (2020)
Kohlhase, M., Rabe, F., Wenzel, M.: Making Isabelle Content Accessible in Knowledge in Representation Formats (2020). https://kwarc.info/people/frabe/Research/KRW_isabelle_19.pdf
Kohlhase, M., Schaefer, J.: GF + MMT = GLF - from language to semantics through LF. In: Miller, D., Scagnetto, I. (eds.) Logical Frameworks and Meta-Languages: Theory and Practice, pp. 24–39. Open Publishing Association (2019)
Kaliszyk, C., Urban, J., Vyskočil, J.: Automating formalization by statistical and semantic parsing of mathematics. In: Ayala-Rincón, M., Muñoz, C.A. (eds.) ITP 2017. LNCS, vol. 10499, pp. 12–27. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-66107-0_2
Kamareddine, F., Wells, J.: Computerizing mathematical text with MathLang. In: Ayala-Rincón, M., Haeusler, E. (eds.) Logical and Semantic Frameworks, with Applications, pp. 5–30. ENTCS (2008)
Kamareddine, F., Wells, J., Zengler, C., Barendregt, H.: Computerising mathematical text. In: Siekmann, J. (ed.) Computational Logic. Elsevier (2014)
Leroy, X.: Formal verification of a realistic compiler. Commun. ACM 52(7), 107–115 (2009)
Linton, S.: GAP: groups, algorithms, programming. ACM Commun. Comput. Algebr. 41(3), 108–109 (2007)
Megill, N.: Metamath: A Computer Language for Pure Mathematics. Lulu Press, Morrisville (2007)
Milner, R.: Logic for computable functions: descriptions of a machine implementation. ACM SIGPLAN Not. 7, 1–6 (1972)
Martin-Löf, P.: An intuitionistic theory of types: predicative part. In: Proceedings of the ’73 Logic Colloquium, pp. 73–118. North-Holland (1974)
Miller, D.A., Nadathur, G.: Higher-order logic programming. In: Shapiro, E. (ed.) ICLP 1986. LNCS, vol. 225, pp. 448–462. Springer, Heidelberg (1986). https://doi.org/10.1007/3-540-16492-8_94
Müller, D., Rabe, F.: Rapid prototyping formal systems in MMT: case studies. In: Miller, D., Scagnetto, I. (eds.) Logical Frameworks and Meta-languages: Theory and Practice, pp. 40–54 (2019)
Müller, D., Rabe, F., Kohlhase, M.: Theories as types. In: Galmiche, D., Schulz, S., Sebastiani, R. (eds.) IJCAR 2018. LNCS (LNAI), vol. 10900, pp. 575–590. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-94205-6_38
Müller, D., Rothgang, C., Liu, Y., Rabe, F.: Alignment-based translations across formal systems using interface theories. In: Dubois, C., Woltzenlogel Paleo, B. (eds.) Proof eXchange for Theorem Proving, pp. 77–93. Open Publishing Association (2017)
Müller, D., Rabe, F., Sacerdoti Coen, C.: The Coq library as a theory graph. In: Kaliszyk, C., Brady, E., Kohlhase, A., Sacerdoti Coen, C. (eds.) CICM 2019. LNCS (LNAI), vol. 11617, pp. 171–186. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-23250-4_12
Naumowicz, A.: SAT-enhanced Mizar proof checking. In: Watt, S.M., Davenport, J.H., Sexton, A.P., Sojka, P., Urban, J. (eds.) CICM 2014. LNCS (LNAI), vol. 8543, pp. 449–452. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-08434-3_37
Norell, U.: The Agda WiKi (2005). http://wiki.portal.chalmers.se/agda
Nipkow, T., Wenzel, M., Paulson, L.C. (eds.): Isabelle/HOL—A Proof Assistant for Higher-Order Logic. LNCS, vol. 2283. Springer, Heidelberg (2002). https://doi.org/10.1007/3-540-45949-9
Owre, S., Rushby, J.M., Shankar, N.: PVS: a prototype verification system. In: Kapur, D. (ed.) CADE 1992. LNCS, vol. 607, pp. 748–752. Springer, Heidelberg (1992). https://doi.org/10.1007/3-540-55602-8_217
Paulson, L.: Isabelle: A Generic Theorem Prover. LNCS, vol. 828. Springer, Heidelberg (1994). https://doi.org/10.1007/BFb0030541
Paulson, L., Coen, M.: Zermelo-Fraenkel Set Theory. Isabelle distribution, ZF/ZF.thy (1993)
Pfenning, F., Schürmann, C.: System description: Twelf - a meta-logical framework for deductive systems. In: Ganzinger, H. (ed.) Automated Deduction, pp. 202–206 (1999)
Rabe, F.: A logical framework combining model and proof theory. Math. Struct. Comput. Sci. 23(5), 945–1001 (2013)
Rabe, F.: How to identify, translate, and combine logics? J. Log. Comput. 27(6), 1753–1798 (2017)
Rabe, F.: A Modular type reconstruction algorithm. ACM Trans. Comput. Log. 19(4), 1–43 (2018)
Ranta, A.: Grammatical Framework: Programming with Multilingual Grammars. CSLI Publications, Stanford (2011)
Rabe, F., Kohlhase, M.: A scalable module system. Inf. Comput. 230(1), 1–54 (2013)
Rabe, F., Schürmann, C.: A practical module system for LF. In: Cheney, J., Felty, A. (eds.) Proceedings of the Workshop on Logical Frameworks: Meta-Theory and Practice (LFMTP), pp. 40–48. ACM Press (2009)
Stein, W., et al.: Sage Mathematics Software. The Sage Development Team (2013). http://www.sagemath.org
Sutcliffe, G., Schulz, S., Claessen, K., Baumgartner, P.: The TPTP typed first-order form with arithmetic. In: Bjørner, N., Voronkov, A. (eds.) LPAR 2012. LNCS, vol. 7180, pp. 406–419. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-28717-6_32
Sutcliffe, G.: The TPTP problem library and associated infrastructure: the FOF and CNF Parts, v3.5.0. J. Autom. Reason. 43(4), 337–362 (2009)
Trybulec, A., Blair, H.: Computer assisted reasoning with MIZAR. In: Joshi, A. (eds.) Proceedings of the 9th International Joint Conference on Artificial Intelligence, pp. 26–28. Morgan Kaufmann (1985)
Wenzel, M.: Isabelle as document-oriented proof assistant. In: Davenport, J.H., Farmer, W.M., Urban, J., Rabe, F. (eds.) CICM 2011. LNCS (LNAI), vol. 6824, pp. 244–259. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-22673-1_17
Wiedijk, F.: The QED manifesto revisited. In: From Insight to Proof, Festschrift in Honour of Andrzej Trybulec, pp. 121–133 (2007)
Windsteiger, W.: Theorema 2.0: a system for mathematical theory exploration. In: Hong, H., Yap, C. (eds.) ICMS 2014. LNCS, vol. 8592, pp. 49–52. Springer, Heidelberg (2014). https://doi.org/10.1007/978-3-662-44199-2_9
Wiesing, T., Kohlhase, M., Rabe, F.: Virtual theories – a uniform interface to mathematical knowledge bases. In: Blömer, J., Kotsireas, I.S., Kutsia, T., Simos, D.E. (eds.) MACIS 2017. LNCS, vol. 10693, pp. 243–257. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-72453-9_17
Wang, Q., Kaliszyk, C., Urban, J.: First experiments with neural translation of informal to formal mathematics. In: Rabe, F., Farmer, W.M., Passmore, G.O., Youssef, A. (eds.) CICM 2018. LNCS (LNAI), vol. 11006, pp. 255–270. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-96812-4_22
Wolfram. Mathematica (2012)
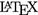 as a semantic markup format. Math. Comput. Sci. 2(2), 279–304 (2008)
as a semantic markup format. Math. Comput. Sci. 2(2), 279–304 (2008)Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Kaliszyk, C., Rabe, F. (2020). A Survey of Languages for Formalizing Mathematics. In: Benzmüller, C., Miller, B. (eds) Intelligent Computer Mathematics. CICM 2020. Lecture Notes in Computer Science(), vol 12236. Springer, Cham. https://doi.org/10.1007/978-3-030-53518-6_9
Download citation
DOI: https://doi.org/10.1007/978-3-030-53518-6_9
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-53517-9
Online ISBN: 978-3-030-53518-6
eBook Packages: Computer ScienceComputer Science (R0)