
Abstract
In this paper, a well-known nonlinear optimal control problem (OCP) arisen in a variety of biological, chemical, and physical applications is considered. The quadratic form of the nonlinear cost function is endowed with the state and control functions. In this problem, the dynamic constraint of the system is given by a classical diffusion equation. This article is concerned with a generalization of Lagrange functions. Besides, a generalized Lagrange–Jacobi–Gauss–Radau (GLJGR) collocation method is introduced and applied to solve the aforementioned OCP. Based on initial and boundary conditions, the time and space variables, t and x, are clustered with Jacobi–Gauss–Radau points. Then, to solve the OCP, Lagrange multipliers are used and the optimal control problem is reduced to a parameter optimization problem. Numerical results demonstrate its accuracy, efficiency, and versatility of the presented method.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
In order to present OCP solved in this manuscript, firstly, we give an introduction to the OCP and provide an explanation of the functions and parameters defined in this problem. A brief review and history of these equations and spectral and pseudospectral methods are in the following subsections.
1.1 The governing equations
Optimum control problems arise in the minimization of a functional over a set of admissible control functions subject to dynamic constraints on the state and control functions [1, 2]. Regarding that the equations of dynamics in the system are reformed by a partial differential equation—with time and space variables—this OCP is known as an optimal control of a distributed system [1]. The formulation of this optimal control problem is [3]:
subject to
with initial and boundary conditions
In fact, this is a nonlinear quadratic optimal control problem with the dynamic system of the classical diffusion equation.
In Eqs. (1)–(3), y(x, t) is the optimization function that must be calculated so that it and the function of z(x, t) are held in Eqs. (1)–(3) and the value of J is minimized. z(x, t) and y(x, t) are called the state and control functions and usually calculated in such a way that they are smooth and the derivatives and integral in Eqs. (1) and (2) can be calculated analytically or numerically. \(z_0(x)\) is a known real function, \(c_1\) and \(c_2\) are two arbitrary constants, k is a numerical constant that is specified in the problem, and r and R are positive real constants. Here, \(t>0\) and its upper bound is 1. The parameter r is specified in numerical examples as \(r=1\) or \(r=2\).
The purpose of solving this problem is to approximate the control and state functions that minimize the J.
This OCP arises in a variety of biological, chemical, and physical applications; for more details, see Refs. [4,5,6].
1.2 The literature on optimal control problems
Two-dimensional (2D) systems and their beneficial applications in many different industrial fields draw the attention of scientists presently. These applications rise in heat transfer, image processing, seismological and geophysical data processing, distributed systems, restoration of noisy images, earthquake signal processing, water stream heating gas absorption, smart materials, and transmission lines [7,8,9,10]. The miscellaneous chemical, biological, and physical problems are modeled by diffusion processes involving control function mentioned in Eqs. (1)–(3). By the aid of Roesser’s model [10], Attasi’s model [11, 12], Fornasini–Marchesini’s models [13, 14], the state-space models of 2D systems are organized [7]. Remarkable studies have been done in the area of optimal controls, and excellent articles are written hereby [15,16,17,18,19]. Among these studies, numerical techniques have been used to solve optimal control problems [17, 20]. Moreover, Agrawal [1] presented a general formulation and a numerical scheme for fractional optimal control for a class of distributed systems. He used eigenfunctions to develop his method. In other works, Manabe [21], Bode et al. [22] and Rabiee et al. [23] studied fractional-order optimal control problems. Additionally, Mamehrashia and Yousefi [3, 7] and Lotfi et al. [24] employed the Ritz method to solve optimal control problems. With the variational method, Yousefi et al. [25] found the solution of the optimal control of linear systems, approximately. Li et al. [26] considered a continuous-time 2D system and converted it to the discrete-time 2D model. In other works, Wei et al. [27] and Zhang et al. [28] investigated an optimal control problem in continuous-time 2D Roesser’s model. They employed iterative adaptive critic design algorithm and the adaptive dynamic programming method to approximate the solution. Sabeh et al. [29] introduced a pseudo-spectral method for the solution of distributed optimal control problem with the viscous Burgers equation.
1.3 The literature of spectral and pseudospectral methods
The main feature of spectral methods is to use different orthogonal polynomials/functions as trial functions. These polynomials/functions are global and infinitely differentiable. These methods are applied to four types of problems: periodic problems, nonperiodic problems, whole-line problems, and half-line problems. These can be categorized as: Trigonometric polynomials for periodic problems; classical Jacobi, ultraspherical, Chebyshev and Legendre polynomials for non-periodic problems; Hermite polynomials for problems on the whole line; and Laguerre polynomials for problems on the half line [30]. With the truncated series of smooth global functions, spectral methods are giving the solution of a particular problem [31, 32]. These methods, with a relatively limited number of degrees of freedom, provide such an accurate approximation for a smooth solution. Spectral coefficients tend to zero faster than any algebraic power of their index n; see page 2 in [33].
Spectral methods can fall into three categories: Tau, Collocation and Galerkin methods [34].
-
The Tau spectral method is used to approximate numerical solutions of various differential equations. This method considers the solution as an expansion of orthogonal polynomials/functions. Such coefficients, in this expansion, are set to approximate the solution correctly [35].
-
Collocation method helps obtain highly accurate solutions to nonlinear/linear differential equations; see page 2 in [36,37,38,39]. Two common steps in collocation methods are: First, suitable nodes (Gauss/Gauss–Radau/Gauss–Lobatto) are selected to restate a finite or discrete form of the differential equations. Second, a system of algebraic equations from the discretization of the original equation is achieved [40, 41].
-
In the Galerkin spectral method, trial and test functions are chosen the same [42]; This method can result in a highly accurate solution.
It is said that spectral Galerkin methods are similar to Tau methods where in approximation by Tau method, the differential equation is enforced [33].
Furthermore, some other numerical methods like finite difference method (FDM) and finite element method (FEM) need network construction of data and they perform locally. Although spectral methods are continuous and globally performing, they do not require network construction of data [43].
In addition to spectral methods, pseudospectral methods have also attracted researchers recently [44,45,46,47]. As mentioned previously, Sabeh et al. [29] investigated a pseudospectral method to solve the optimal control problem. Pseudospectral methods are also utilized in the solution of other optimal control problems as well [48,49,50,51]. These methods become popular because of their computational feasibility and efficiency. In fact, in standard pseudospectral methods, interpolation operators are used to reduce the cost of computation of the inner product we encounter in some of the spectral methods. For this purpose, a set of distinct interpolation points \(\{x_i\}_{i=0}^{n}\) is considered by which the corresponding Lagrange interpolants are achieved. Besides, when applying collocation points, \(\{x_i\}_{i=0}^{n}\), the residual function is set to vanish on the same set of points. Notwithstanding, the collocation points do not need to be chosen the same as the interpolation nodes. Indeed, just for having the Kronecker delta property, they are considered to be the same: as a consequence, this property helps reduce computational cost noticeably as well. There are such authors who utilized pseudospectral methods for the solution of optimal control as well. William [52] introduced a Jacobi pseudospectral method for solving an optimal control problem. He reported that significant differences in computation time can be seen for different parameters of the Jacobi polynomial. Jacobi pseudospectral method endowed with Lagrange basis is also in [53] to solve a problem defined in semi-infinite domain problem. In another work in [54], a set of nonlinear PDEs was solved by applying this Jacobi pseudospectral method. Garge et al. [50] presented a unified framework for the numerical solution of optimal control problems using collocation at Legendre–Gauss (LG), Legendre–Gauss–Radau (LGR), and Legendre–Gauss–Lobatto (LGL) points and discussed the advantages of each for solving optimal control problems. Chebyshev pseudospectral method was utilized by Fahroo et al. [49] to provide an optimal solution for the optimal control problem.
1.4 The main aim of this paper
To the best of our knowledge, the use of pseudospectral methods for solving optimal control problems has been limited in the literature to either Chebyshev or Legendre methods. Noteworthily, the pseudospectral method based on Jacobi can encompass a wide range of other pseudospectral methods since the Legendre and Chebyshev nodes can be obtained as particular cases of the general Jacobi. Therefore, examining different choices of the parameters in the Jacobi polynomials and a proper selection of the Jacobi parameters will allow us to obtain more accurate real-time solutions to nonlinear optimal control problems. Meanwhile, an arbitrary and not precise selection of nodes may result in poor interpolation characteristics such as the Runge phenomenon; therefore, the nodes in pseudospectral methods are selected as the Gauss–Radau points [52].
In this paper, we present a general formulation and a suitable numerical method called the GLJGR collocation method to solve OCP for a class of distributed systems. Using GLJGR collocation method helps lessen the computational and CPU time. The developed method is exponentially accurate and obtained by a generalization of classical Lagrange polynomials [55]. Additionally, the equation of the dynamics of optimal control problem is reformed as a partial differential equation.
This paper is arranged as follows: In Sect. 2, we present some preliminaries and drive some tools for introducing GL function, GLJGR collocation method, and their relevant derivative matrices. In Sect. 3, we apply the GLJGR collocation method to the solution of the OCP. Section 4 shows numerical examples to demonstrate the effectiveness of the proposed method. Also, a conclusion is given in Sect. 5.
2 Preliminaries, conventions, and notations
In this section, we review some necessary definitions and relevant properties of Jacobi polynomials. In the next step, we introduce generalized Lagrange (GL) functions. Then, we state some theorems on GL functions and develop GLJGR collocation method. Finally, in terms of GLJGR collocation method, we give a formula that expresses the derivative matrix of the mentioned functions.
2.1 Jacobi polynomials
A basic property of the Jacobi polynomials is that they are the eigenfunctions to a singular Sturm–Liouville problem. Jacobi polynomials are defined on \([-1,1]\) and are of high interest recently [56,57,58,59]. The following recurrence relation generates the Jacobi polynomials [60]:
where
The Jacobi polynomials satisfy the following identities:
and its weight function is \(w^{\alpha ,\beta }(x)=(1-x)^{\alpha }(1+x)^{\beta }\).
Moreover, the Jacobi polynomials are orthogonal on \([-1,1]\):
where \(\delta _{m,n}\) is the Kronecker delta function and \(L_{w^{\alpha ,\beta }}^2[-1,1]\) is the weighted space. The inner product and the norm of \(L_{w^{\alpha ,\beta }}^2[-1,1]\) with respect to the weight function are defined as:
It is noted that the set of Jacobi polynomials forms a complete \(L_{w^{\alpha ,\beta }}^2[-1,1]\) system [36].
It is known that the \((n+1)\) points of Gauss–Radau are the n roots of \(P_{n}^{\alpha ,\beta +1}(x)\) over \((-1,1)\) and one particular root as \(-1\) or 1. Similarly, for the interval [a,b] with the shifting parameter u(x), these points are n roots of \(P_{n}^{\alpha ,\beta +1}(u(x))\) over (a, b) and one particular root as a or b on the boundaries, where more details on u(x) are discussed in the following sections.
2.2 Generalized Lagrange (GL) functions
In this section, generally, the GL functions are introduced and the suitable formulas for the first- and second-order derivative matrices of these functions are presented.
Definition 1
Let \(w(x)=\prod _{i=0}^N\big (u(x)-u(x_i)\big )\), then the generalized Lagrange (GL) formula is shown as [55]
where \(\partial _uw(x)=\frac{1}{u'}\partial _xw(x)\), \(\kappa _j=\frac{u'_j}{\partial _x w(x_j)}\), u(x) is a continuous, arbitrary, and sufficiently differentiable function, \(x_i\)s are arbitrary distinct points on domain of u(x) such that \(u'_i\ne 0\) for any \(i=0,\cdots ,N\) and \(u_i \ne u_j\) for all \(i \ne j\).
For simplicity, \(u=u(x)\) and \(u_i=u(x_i)\) are considered.
Theorem 1
Considering the GL functions \(L_j^u(x)\) in Eq. (4), one can exhibit the first-order derivative matrices of GL functions as
where
Proof
As the GL functions defined in Eq. (4), the first-order derivative formula for the case \(k \ne j\) can be achieved as follows:
But, when \(k=j\), with L’Hopital’s rule:
This completes the proof. \(\square \)
Theorem 2
Let \(D^{(1)}\) be the above matrix (first-order derivative matrix of GL functions) and define matrix Q such that \(Q=Diag(u'_0,u'_1,...,u'_N)\), \(Q^{(1)}=Diag(u''_0,u''_1,...,u''_N)\); then, the second-order derivative matrix of GL functions can be formulated as:
Proof
See Ref. [55]. \(\square \)
For simplicity, from now on, \(D^{(1)}\) is considered D.
2.3 Generalized Lagrange–Jacobi–Gauss–Radau (GLJGR) collocation method
It is a well-established fact that a proper choice of collocation points is crucial in terms of accuracy and computational stability of the approximation by Lagrange basis [61]. As an appropriate choice of such collocation points, we can refer to the well-known Gauss–Radau points in which points lie inside (a,b) and one point is clustered near the endpoints [29, 61]. In this sequel, we use Jacobi–Gauss–Radau nodes.
In the case of GLJGR collocation method, w(x) in Eq. (4) can be considered as two approaches: in the first approach, one point is clustered near the end of the interval:
and in the second approach, one point at the beginning of the interval is clustered:
where \(\lambda \) is a real constant. As a matter of simplification, we write
with the following important properties:
Let us speak of the first approach as in Eq. (7). Assuming
then we have:
We can rewrite the formula in Theorem 1 for a Jacobi–Gauss–Radau specific case: It is easy to do this by setting \(w(x)=\lambda (u-u_0)P_{n}^{\alpha ,\beta +1}(u)\) and recalling that \(\{P_{n}^{\alpha ,\beta +1}(u_j)=0\}_{j=0}^{n-1}\). So, by this, the formula in Theorem 1 can be obtained as a Jacobi–Gauss–Radau case, and the entry of the first-order derivative matrix of GL functions will be:
Similar to this fashion, for the second approach shown in Eq. (8), one can write:
Now this is obvious that \(\{P_{n}^{\alpha ,\beta +1}(u_j)=0\}_{j=1}^{n}\). Therefore, by the second approach, the entries of defined matrix D can be filled as:
More specifically, Legendre, Chebyshev, and ultraspherical polynomials can be obtained as special cases from the proposed method. These cases are summarized in the following remark:
Remark 1
We have all the mentioned formulas of GL functions, i.e., D, \(D^{(2)}\) for Gegenbauer (ultraspherical), Legendre, Chebyshev (the first, second, third, and fourth kinds) polynomials by simply setting \(\alpha =\beta \), \(\alpha =\beta =0\), \(\alpha =\beta =-0.5\), \(\alpha =\beta =0.5\), \(\alpha =-0.5\), \(\beta =0.5\), and \(\alpha =0.5\), \(\beta =-0.5\), respectively. These specifications can be named generalized Lagrange–[Gegenbauer, Legendre, Chebyshev (first, second, third, fourth)]–Gauss–Radau for that manner.
2.4 Operational matrix of GL functions
In this subsection, we intend to clarify that when it comes to the collocation method, the operational matrix of derivative for GL functions is equal to transpose of the derivative matrix mentioned in 2.3.
Defining the one-column vectors
for the approximation of a function \(\xi (x)\), one can write
and similarly for the derivative of this function, one can rewrite it as
where \(K\in \mathfrak {R}^{(n+1)\times (n+1)}\) is the operational matrix of derivative where
and in other words,
To prove it, take the jth row
and by collocating the Jacobi–Gauss–Radau nodes (\(\{x_i\}_{i=0}^{n}\)) in this equation, we obtain:
This means that the operational matrix for these functions is
where D is defined in Sect. 2.3. Similarly, for \(\partial _{xx}\xi (x)\), one can also say
where \(D^{(2)}\) is defined in Eq. (6).
3 Numerical method
The main objective of this section is to develop the GLJGR collocation method to solve OCP. In this section, firstly, a promising function approximation method has been presented. Then, GLJGR collocation is implemented so as to accomplish the introduction of the presented numerical method for OCP of interest.
3.1 Function approximation
If \(H=L^2(\eta )\), \(\eta =0\cup (0,1)\times (0,1)\cup 1\), where
\(s\subset H \), s is the set of GL functions product and
where \(V_{nm}\) is a finite-dimensional vector space. For any \(q\in S\), one can find the best approximation of q in space \(V_{nm}\) as \(P_{nm}(x,t)\) such that
where \( \Vert f \Vert _2=\sqrt{\langle f,f\rangle } \) and \(\langle .,.\rangle \) is the inner product. Therefore, for any \(P_{nm}(x,t)\in V_{nm}\), one can write
in which C is a matrix of \(\mathfrak {R}^{(m+1)\times (n+1)}\), and \(c_{ij}\) are the relevant coefficients and calculable. \(L_i^u(x)\) is considered by the first approach mentioned in Sect. 2.3 in which \(u(x)=\frac{2}{R}x-1\), and \(L_j^u(t)\) is based on the second approach and considered as \(u(t)=2t-1\). This can be proved that as n and m increase, the approximate solution tends to the exact solution [3].
3.2 Implementation of GLJGR collocation method for solving the OCP
Now, for the approximation of state and control functions
where
We define residual functions res(x, t) by substituting Eqs. (20) and (21) in Eq. (2)
in terms of Eqs. (17) and (18), one can write
\(A,B\in \mathfrak {R}^{(n+1)\times (m+1)} \), \(D\in \mathfrak {R}^{(n+1)\times (n+1)} \) and \({\hat{D}}\in \mathfrak {R}^{(m+1)\times (m+1)} \) so Eq. (22) can be restated as
and the initial and boundary conditions of the problem are obtained as
and within the assumption of Eqs. (21) and (20)
As 0 and R are the \( t_0 \) and \( x_n \), with the aid of the characteristic of Lagrange polynomials, we write
where B[ : , 0] and B[n, : ] are the first column and \((n+1)\)th row of Matrix B.
Then, with (\(n+1\)) collocation nodes in x space and (\(m+1\)) collocation nodes in t space, a set of algebraic equations is constructed by using Eq. (26) together with the conditions in Eq. (28). (Simplification of Eq. (29) is also used.)
in which \( res(x_i,t_j) \) can be considered as
or
The reason why j starts from 1 (in the second case of Eq. (30)) is that: in both examples we will consider later, for the first case of Eq. (30), we have \(z_0(x_n=R)=0\) and this makes a redundancy with the second case of Eq. (30) at \(j=0\). To avoid this, j starts from 1.
We now describe the method of the selection of points in this paper. In what follows, we have used \(x_i\) and \(t_j\) which are considered as the following statements. Firstly,
which should \(x\in (0,R]\). Therefore, we set \(u(x)=\frac{2x}{R}-1\), and we have:
One can see that this assignment is based on the first approach in Sect. 2.3.
With the same fashion, for variable t we have
that should \(t \in [0,1)\). Therefore, we set \(u(t)=2t-1\), and we have:
Again, one can consider this assignment based on the second approach shown by Eq. (8) in Sect. 2.3.
At the next step, we approximate the integral existing in the OCP. For this, we exploit Gauss–Jacobi quadrature.
For estimating an integral by Gauss–Jacobi quadrature, we do as follows:
where \(v\in [a,b]\) and \(s\in [-1,1]\) , and Eq. (36) is exact when \(degree \big (f(v)\big )\le (2N+1)\) for Gauss–Jacobi quadrature.
\(\{s_i\}_{i=0}^{N}\) are Gauss–Jacobi nodes, and their relevant weights \(\{\varpi \}_{i=0}^{N}\) are [64]
The cost functional J is estimated by a numerical integration method. For this, we applied Gauss–Jacobi quadratures in Eq. (36) for both variables t and x.
where \(\varpi _x^i\), \(\varpi _t^j\), \(\hat{x_i}\), \(\hat{t_j}\) are as follows
From Eq. (38) to Eq. (42) for both variables t and x, we consider 15 Gauss–Jacobi nodes (\(M=N=14\)).

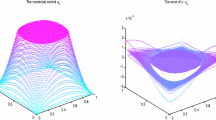
Plots of approximate state and control functions for Example 1.
Thus, on the basis of what we have just discussed, the optimal control problem is reduced to a parameter optimization problem. This can be stated as follows:
\({\hat{\lambda }}=\{\lambda _i\}_{i=0}^{2(n+m)+nm+1}\) are Lagrange multipliers. Therefore, the minimization problem can, under these new conditions
produce a system of \(4(n+m+1)+3nm\) algebraic equations which can be solved by a mathematical software for achieving the unknowns. This system is solved by Newton’s method via ”fsolve” command in Maple. The solution of this system is given by using Maple software.
4 Numerical examples
In this section, the GLJGR collocation method is used to solve two cases of aforementioned OCP in Eq. (1). The aim is to find the state and control functions z(x, t), y(x, t) that minimize the cost function J.
Example 1
Consider the aforementioned OCP with \(c_1=c_2=r=R=k=1\) and initial condition [3, 62]
so the optimal control problem of Eq. (1) would be
subject to
with boundary and initial conditions
Consider the assumptions mentioned in Example 1. With the methodology presented in Sects. 2 and 3, we approximate the function z(x, t) and y(x, t). In Table 1, the presented method is used to solve the OCP of Example 1. This table, by presenting the value of cost functional, simply shows the accuracy of the presented method for the different choices of n and m. The effect of \(\alpha \) and \(\beta \) is shown as well to provide Chebyshev (all four kinds), Legendre cases, and other different cases. As the aim of this paper is to find z(x, t), y(x, t) in order to minimize J, we plot these state and control functions in Fig. 1a, c. Also, the graph of these functions for the different number of bases is illustrated in Fig. 1b, d; they are the surface plots of the state and control functions. The comparison with the Ritz method by Mamehrashi and Yousefi [3] is made in Table 2. These results show that the presented method is accurate and provides such solutions rather faster than the Ritz method. In other words, with \(n=1,m=4\), we obtained such a result that the Ritz method, somehow, provides with \(n=2,m=7\). Similar to what has been concluded in [3], we obtained that the control and state functions initially have distinct values over the x-axis and as time goes by they tend to reach the same value: This phenomenon is representative of a diffusion process.
Example 2
In this example, the \(r=2\), \(c_1=c_2=R=k=1\) and the initial condition is [3, 63]
Therefore, we have
subject to
with boundary and initial conditions
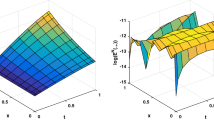
Like Example 1, the method discussed in Sects. 2, 3 is utilized to approximate the solution of Example 2. The cost functional J for the different selection of n, m, \(\alpha \), \(\beta \) is calculated in Table 3. Figure 2a, c shows numerical results for state and control functions, i.e., z(x, t) and y(x, t), respectively. These results are plotted in Fig. 2b, d at \(x=0.5\) in a surface plot. Note that initially the state and control at two different locations differ, but as time progresses, the two values become very close. As said in Example 1, this is because of diffusion. A comparison with the Ritz method [3] is made and reported in Table 4. The results in this table demonstrate that the presented method is accurate and reliable, and these results seem to be reached faster than the Ritz method.

Plots of approximate state and control functions for Example 2
5 Conclusion
In this study, an OCP is investigated. This problem has beneficial applications in many chemical, biological, and physical fields of studies. The goal of this article is to develop an efficient and accurate method to solve this nonlinear OCP. The method is based upon GLJGR collocation method. Firstly, GL functions are introduced so as to satisfy in delta Kronecker function and GLJGR collocation method is described. The advantage of employing this method is that it reduces the computational and CPU time remarkably. As expressed, these functions are a generalization of the classical Lagrange polynomials. The corresponding differentiation matrices of \(D^{(1)}\) and \(D^{(2)}\) can be obtained by simple formulas. The main benefit of the proposed formulas is that these formulas are derivative-free. Additionally, the accuracy of the presented method by GL function has an exponential convergence rate. Secondly, the obtained results compared with those provided by Mamehrashi and Yousefi [3] show the accuracy and reliability of the presented method. This numerical approach is applicable and effective for such kind of nonlinear OCPs and other problems that can be approximated by Gauss–Radau nodes.
References
OP. Agrawal, J. Comput. Nonlin. Dyn. 24:3(2) (2008)
O.P. Agrawal, IFAC Proc. 39(11), 68–72 (2006)
K. Mamehrashi, S.A. Yousefi, Int. J. Control 90(2), 298–306 (2017)
F. Andreu, V. Caselles, J.M. Mazon, S. Moll, Arch. Ration. Mech. Anal. 182, 269–297 (2006)
F. Andreu, V. Caselles, J.M. Mazon, S.J. Moll, Evol. Equat. 7, 113–143 (2007)
N.F. Britton, Reaction-Diffusion Equations and Their Applications to Biology (Academic Press, Cambridge, 1986)
K. Mamehrashi, S.A. Yousefi, Optim. Contr. Appl. Method. 37(4), 765–781 (2016)
F.L. Lewis, Automatica. 28(2), 345–354 (1992)
W. Marszalek, Appl. Math. Model. 8, 11–14 (1984)
R.P.I.E.E.E.T. Roesser, Automat. Contr. 20(1), 1–10 (1975)
S. Attasi, IRIA Rapport Laboria. 30 (1973)
S. Attasi, IRIA Rapport Laboria. 56 (1975)
E. Fornasini, IEEE T. Automat. Contr. 21(4), 484–491 (1976)
E. Fornasini, G. Marchesini, Math. Sys. Theory. 12(1), 59–72 (1978)
A.E. Bryson, Applied Optimal Control: Optimization, Estimation and Control (CRC Press, Boca Raton, 1975)
A.P. Sage, C.C. White, Optimum Systems Control (Prentice Hall, New York, 1977)
O.P. Agrawal, Int. J. Control 50(2), 627–638 (1989)
A. Lotfi, M. Dehghan, S.A. Yousefi, Comput. Math. Appl. 62(3), 1055–1067 (2011)
A.J. Samimi, S.A. Yousefi, A.M. Tehranchian, Appl. Math. Comput. 172(1), 198–209 (2006)
J. Gregory, C. Lin, Constrained optimization in the calculus of variations and optimal control theory. Springer Publishing Company Incorporated (2007)
S. Manabe, Proc. DETC. 3, 609–616 (2003)
HW. Bode, Network analysis and feedback amplifier design (1945)
K. Rabiei, Y. Ordokhani, E. Babolian, Nonlin. Dyn. 88(2), 1013–1026 (2017)
A. Lotfi, S.A. Yousefi, J Optimiz. Theory App. 174(1), 238–255 (2017)
S.A. Yousefi, M. Dehghan, A. Lotfi, Int. J. Comput. Math. 87(5), 1042–1050 (2010)
J. Li, J.S. Tsai, L.S. Shieh, Asian J. Contr. 5(1), 78–87 (2003)
Q.L. Wei, H.G. Zhang, L.L. Cui, Acta Automatica Sinica. 35(6), 682–692 (2009)
H. Zhang, D. Liu, Y. Luo, D. Wang, Adaptive Dynamic Programming for Control: Algorithms and Stability (Springer, London, 2013)
Z. Sabeh, M. Shamsi, M. Dehghan, Math. Methods Appl. Sci. 39(12), 3350–3360 (2016)
E.H. Doha, W.M. Abd-Elhameed, A.H. Bhrawy, Collectanea Mathematica. 64(3), 373–394 (2013)
K. Parand, M. Delkhosh, J. Comput. Appl. Math. 317, 624–642 (2017)
K. Parand, M. Delkhosh, Boletim da Sociedade Paranaense de Matemática. 36(4), 33–54 (2018)
A.H. Bhrawy, M.M. Al-Shomrani, Adv. Differ. E. 2012(1), 8 (2012)
E.H. Doha, A.H. Bhrawy, Appl. Numer. Math. 58(8), 1224–1244 (2008)
E.H. Doha, A.H. Bhrawy, D. Baleanu, S. Ezz-Eldien, Adv. Differ. E. 2014(1), 231 (2014)
A.H. Bhrawy, M.A. Alghamdi, Boundary Value Problem. 2012, 1 (2012)
H.J. Tal-Ezer, Numer. Anal. 23(1), 11–26 (1986)
H.J. Tal-Ezer, Numer. Anal. 26(1), 1–11 (1989)
A.H. Bhrawy, Al-Shomrani, MM. Abstract and Applied Analysis, Hindawi Publishing Corporation. 947230, 2012 (2012)
A.H. Bhrawy, E.H. Doha, M.A. Abdelkawy, R.A. Van Gorder, Appl. Math. Model. 40(3), 1703–1716 (2016)
K. Parand, M. Delkhosh, M. Nikarya, Tbilisi Math. J. 10(1), 31–55 (2017)
J.P. Boyd, Chebyshev and Fourier Spectral Methods, 2nd edn. (Dover, New York, 2000)
K. Parand, M. Hemami, Int. J. Appl. Comput. Math 3(2):1053–1075 (2016)
M.A. Saker, S. Ezz-Eldien, A.H. Bhrawy, Romanian. J. Phys. 2017(62), 105 (2017)
A.H. Bhrawy, M.A. Abdelkawy, F. Mallawi, Boundary Value Problem. 2015(1), 1–20 (2015)
E.H. Doha, A.H. Bhrawy, M.A. Abdelkawy, J. Comput. Nonlin. Dyn. 2015(1), 1–20 (2015)
K. Parand, S. Latifi, M.M. Moayeri, SeMA J. (2017). https://doi.org/10.1007/s40324-017-0138-9
G.E. Mohammad, A. Kazemi, M. Razzaghi, IEEE T. Autom. Control 40(10), 1793–1796 (1995)
F. Fahroo, Michael Ross I. J. Guid. Control D. 25(1):160-166 (2002)
D. Garg, M. Patterson, W.W. Hager, A.V. Rao, D.A. Benson, G.T. Huntington, Automatica. 46(11), 1843–1851 (2010)
M. Shamsi, Oprim. Contr. Appl. Met. 32, 668–680 (2011)
P. J.Williams, Guid. Control D. 27(2):293–296 (2004)
K. Parand, S. Latifi, M. Delkhosh, M.M. Moayeri, Eur. Physical J. Plus. 133(1), 28 (2018)
K. Parand, S. Latifi, M.M. Moayeri, M. Delkhosh, Commun. Theor. Phys. 69(5), 519 (2018)
M. Delkhosh, K. Parand, J. Comput. Sci. 34, 11–32 (2019)
AH. Zaky, M. Math. Method Appl. Sci. 39(7): 1765-1779 (2015)
A.H. Bhrawy, J.F. Alzaidy, M.A. Abdelkawy, A. Biswas, Nonlin. Dyn. 84(3), 1553–1567 (2016)
A.H. Bhrawy, E.H. Doha, S.S. Ezz-Eldien, M.A. Abdelkawy, Comput. Model. Eng. Sci. 104(3), 185–209 (2015)
A.H. Bhrawy, E.H. Doha, D.Baleanu, R.M. Hafez, Math. Method Appl. Sci. 38(14): 3022-3032 (2015)
E.H. Doha, A.H. Bhrawy, M.A. Abdelkawy, R.A. Van Gorder, J. Comput. Phys. 261, 244–255 (2014)
F. Daniele, Polynomial approximation of differential equations, Lecture Notes in Physics. New Series m: Monographs. 8. Springer- Verlag: Berlin (1992)
N. Ozdemir, O.P. Agrawal, D. Karadeniz, B.B. Iskender, Phys. Scr. 2009(T136), 014024 (2009)
M.M. Hasan, X.W. Tangpong, O.P. Agrawal, J. Vib. Control 18(10), 1506–1525 (2012)
J. Shen, T. Tang, L.L. Wang , Spectral methods: algorithms, analysis and applications. Springer Science & Business Media (2011)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Latifi, S., Parand, K. & Delkhosh, M. Generalized Lagrange–Jacobi–Gauss–Radau collocation method for solving a nonlinear optimal control problem with the classical diffusion equation. Eur. Phys. J. Plus 135, 834 (2020). https://doi.org/10.1140/epjp/s13360-020-00847-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjp/s13360-020-00847-1