
Abstract
In this paper, discrete-time linear systems with parameter switching in the repetitive mode are considered. A new iterative learning control design method is proposed. This method is based on the construction of an auxiliary 2D model in the form of a discrete repetitive process; the stability of the auxiliary model guarantees the convergence of the learning process. Stability conditions are derived using the divergent method of Lyapunov vector functions. The concept of the average dwell time in pass direction is introduced. An example that demonstrates the capabilities and features of the new method is presented.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
In modern control theory, switched systems are often understood as a class of models of dynamic systems consisting of a finite number of subsystems, of which only one is currently functioning, called the active subsystem, and the choice of the active subsystem is determined by some logical rule. The simplest example is a multi-mode system, in which subsystems are interpreted as separate modes of this system. Subsystems are usually described by an indexed set of differential or difference equations. The class of switched systems has been intensively studied in recent decades and continues to be actively developed nowadays, which is motivated by numerous applications in engineering, physics, biology, economics, and other fields, as well as by theoretical problems still open in this field of research. Like for other classes of control systems, the theory of stability and stabilization is of top priority, where a number of interesting and important results have been established. For an initial acquaintance with these results, in the first place the reader is recommended the monograph [1], the surveys [2, 3], and the recent books [4, 5].
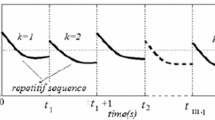
Since the 1960s the theory of the so-called 2D systems began to develop actively. Its appearance was motivated by the problems of image processing and multidimensional electrical circuits, where the Roesser and Fornasini–Marchesini models [6] were constructed and subsequently became the classical 2D models; also, see a rich bibliography in the book [6]. A significant upsurge in the development of the theory of 2D systems was connected with the work of Arimoto [7], who first presented a theoretical justification of iterative learning control (ILC) algorithms for robots performing repetitive operations and revealed the natural 2D nature of the control process. (It includes a dynamic process on each separate repetition, also called pass or trial, and a dynamic process of transition from pass to pass.) 2D models in the form of repetitive processes [6, 8] serve as a natural description of ILC processes. The theory of repetitive processes was successfully applied to the design of ILC algorithms in [9, 10], where experimental results were also obtained. At present, the theory and applications of ILC continue to develop intensively, and numerous publications are devoted to this field of research. For an initial acquaintance, the reader is recommended the surveys [11, 12]. Among the recent works, note [13], where ILC was used for high-precision laser metal deposition and the results of experimental validation were presented. A very important application of ILC algorithms is robotic-assisted stroke rehabilitation. Well-known developments in this area were clinically tested [14, 15].
Switched repetitive processes were considered in [16, 17]. These works were motivated by metal rolling: a metal strip of a finite length is shaped by passing through a set of rolls, so that the output of a previous roll is the input for a next one. In [16], such systems were modeled by linear repetitive processes with switched dynamics. In both papers cited above, special switching rules were analyzed. The final results of these studies were ILC design procedures that can be implemented using calculations based on linear matrix inequalities (LMIs).
Finally, note a number of very recent works [18–21]. The paper [18] dealt with a class of discrete-time switched systems consisting of a linear part and a static nonlinearity satisfying special constraints. More specifically, the definitions of exponential stability and average dwell time were introduced, and sufficient conditions for exponential stability were established using the methods of the general and multiple 2D Lyapunov functions, respectively. The theoretical results obtained therein were applied to ILC design. Next, the authors [19] proposed high-order ILC for linear discrete-time switched systems under different initial conditions on repetitions and the action of disturbances bounded by norm. Linear discrete-time switched systems were also considered in [20], where the initial conditions on repetitions were assumed to be the same. The ILC algorithm constructed therein assumes the availability of the full state vector for the controller and ensures the monotonic convergence of the learning error. In [21], the systems consisting of a continuous linear part with mode switching and a Lipschitz nonlinearity were studied. An adaptive ILC algorithm assuming the availability of the full state vector for the controller was proposed. In all the publications listed, the technique of linear matrix inequalities was effectively used.
In this paper, linear discrete-time switched systems are considered. In contrast to the cited and other known works, only the output vector is assumed to be available for the controller and the ILC algorithm is formed using the error and an estimate of the state vector. The approach proposed below actually extends the earlier results of the authors (see [22–25]) to the class of switched systems. Unlike the well-known counterparts, this approach effectively utilizes the state estimates for improving the performance characteristics of the learning process and opens up the capabilities of nonlinear ILC design with mode switching depending on the accuracy achieved. An illustrative example of a dynamic model of a flexible rotating link operating in a repetitive mode [26] is presented. Switched and non-switched ILC algorithms are obtained and compared with one another.
2 Problem Statement
Consider a discrete-time system in repetitive mode described by the linear state-space model with switching
where an integer T denotes the number of samples over the pass length; on pass k, \({x}_{k}(p)\in {{\mathbb{R}}}^{{n}_{x}}\) is the state vector, \({y}_{k}(p)\in {{\mathbb{R}}}^{{n}_{y}}\) is the pass profile vector (output), and \({u}_{k}(p)\in {{\mathbb{R}}}^{{n}_{u}}\) is the control input; \({\mathcal{F}}=\{({A}_{1},{B}_{1}),({A}_{2},{B}_{2}),\ldots ,({A}_{N},{B}_{N})\}\) is the set of matrix pairs of compatible dimensions.
Following the standard notation of switched systems theory [1], consider a piecewise constant mapping of the set of nonnegative integers \({{\mathbb{Z}}}^{+}\to {\mathcal{F}}\). Such a mapping is defined by a piecewise constant function \(\sigma :\,{{\mathbb{Z}}}^{+}\to {\mathcal{N}}=\{1,\ldots ,N\}\) so that A(k) = Aσ(k) and B(k) = Bσ(k), k = 0, 1, 2….
The function σ can be treated as the switching signal in pass direction. Assume that switchings occur at the beginning of each pass. Define the switching times in pass direction as the pass numbers k1, k2, … on which the pass profile vector of system (2.1) changes mode. Thus, for each pass k the switching signal specifies the index \(\sigma (k)=i\in {\mathcal{N}}\) of the active subsystem whose dynamics are described by the equations
Assume that the switching times are observable and there are no impulse effects: at a switching instant the value of the state vector does not change in jumps and remains constant.
On each pass the output of system (2.1) must track a reference trajectory yref (p), 0 ⩽ p⩽T − 1. This goal can be achieved using iterative learning control. Denote by ek(p) the tracking error of the reference trajectory (the learning error) on pass k:
If the initial conditions on each pass are the same, feedback control will give the same tracking error of the reference trajectory on all passes; moreover, this error may not match the existing accuracy requirements. The problem is to find a sequence of control inputs uk(p), k = 0, 1, …, that will ensure the achievement of a specified tracking accuracy of the reference pass profile in a finite number of passes kfin with preserving this accuracy for all subsequent passes, i.e.,
This problem will be solved using iterative learning control. In accordance with this approach, the control input on a current pass is given by
where Δuk+1(t) is a control update to be designed. The problem stated above will be solved if the control input sequence satisfies the conditions
where u∞(p) is a bounded variable, often called the learned control.
3 Discrete 2D Model
Following [25], the control update law will be designed using the learning error and a state estimate \({\hat{x}}_{k}(p)\) obtained by a full-order observer:
Introduce the estimation error and also the increments of the state estimate and estimation error:
Then the system’s dynamics with this observer can be described by the equations in the increments
where
Denote
and write (3.3) as the standard discrete repetitive process model [6]:
Find the control update law as a feedback in the increments:
If for all 0 ⩽ p⩽T − 1, ∣ek(p)∣ → 0 as k → ∞, then there exists a number kfin for which conditions (2.4) will be satisfied. Therefore, the problem will be solved if there exists a sequence vk(p) such that
provided that the norm of the estimation error is bounded above by a monotonically decreasing function, where \({u}_{\infty }(p)={\mathrm{lim}\,}_{k\to \infty }{u}_{k}(p).\) Obviously, in this case there exists a number kfin starting from which condition (2.4) will hold.
4 Main Results
4.1 Stability Conditions
Denote by Nσ(kf, ks) the number of switchings of the signal σ on an interval (ks, kf) and define the average dwell time as follows.
Definition 1.
A positive number \({\kappa }_{a}\in {{\mathbb{Z}}}^{+}\) is called the average dwell time under the switching signal in pass direction σ if, for some N0 ⩾ 0,
Inequality (4.1) means that on this interval the average number of passes between any two sequential switchings is not smaller than κa.
The solution will be obtained using the theory of stability and dissipativity of repetitive processes [22].
Definition 2.
[22] A discrete repetitive process (3.4), (3.5) is said to be exponentially stable if there exist real numbers κ > 0 and 0 < ϱ < 1 such that
where ϱ does not depend on T.
Note that under condition (4.2) the error norm (see the previous section) is bounded above by a monotonically decreasing function, which in turn ensures the achievement of the given accuracy.
The switched system (3.4), (3.5) is generally nonlinear. A universal stability analysis method for nonlinear systems (Lyapunov’s second method) involves Lyapunov functions. However, the system equations under consideration are not resolved with respect to the total increments of the state variables, and this method becomes inapplicable here. To overcome this difficulty, the authors developed the so-called divergent method of vector Lyapunov functions, in which, unlike the classical version, stability is established based on the properties of the divergence operator (or its discrete counterpart) of these vector functions. In the case under study, introduce a vector Lyapunov function of the form
where V1(xk+1(p)) > 0, xk+1(t) ≠ 0, V2i(ek(p)) > 0, yk(p) ≠ 0, V1(0) = 0, and V2i(0) = 0, \(i\in {\mathcal{N}}.\) Define a counterpart of the divergence operator as
where ΔpV1(ηk+1(p)) = V1(ηk+1(p + 1)) − V1(ηk+1(p)), ΔkV2(ek(p)) = V2(ek+1(p)) − V2(ek(p)).
Theorem 1.
A discrete repetitive process (3.4), (3.5) is exponentially stable under any switching signal in pass direction σ with an average dwell time
and an arbitrary number N0 if there exist a vector function (4.3) and positive scalars c1, c2, and c3 such that
Proof. Consider an interval (0, kf), and let Nσ = Nσ(kf, 0) be the number of switchings on this interval. From inequality (4.8) it follows that
Using (4.6), (4.7), and (4.8), rewrite inequality (4.9) as
which is equivalent to
The left-hand side of (4.11) is positive definite. Hence, \(0<1-\frac{{c}_{3}}{{c}_{2}}<1.\) Denoting \(\lambda =1-\frac{{c}_{3}}{{c}_{2}}\), rewrite (4.11) as
Solving inequality (4.12) in V1(xk+1(p)) gives
Introduce
Then inequality (4.13) implies
Assume that on some pass kn the active mode i is switched to mode j. From condition (4.7) it follows that
where \(\mu =\frac{{c}_{2}}{{c}_{1}}\geqslant 1.\) Solving inequality (4.14) with using (4.15) yields
which is equivalent to
Inequality (4.17) implies
Recall that all passes have the same initial conditions; therefore, V1(ηn+1(0)) = 0. In addition, since yref(p) is bounded for all p, ∣eo(p)∣2 = f(p)⩽Mf. Then the left-hand side of (4.18) can be estimated as
for all k ⩽ kf and p ∈ [0, T]. Due to (4.19), from (4.18) it follows that
for all k ⩽ kf and p ∈ [0, T]. For k = kf and (4.5), inequalities (4.18)–(4.21) finally give
for any kf and p ∈ [0, T], where \({\lambda }_{0}={\mu }^{{\kappa }_{a}^{-1}}={({c}_{2}/{c}_{1})}^{{\kappa }_{a}^{-1}}<1\). The proof of Theorem 1 is complete.
This theorem leads to an important result as follows.
Corollary. A discrete repetitive process (3.4), (3.5) is exponentially stable under an arbitrary switching signal in pass direction σ if there exist a vector function
and positive scalars c1, c2, and c3 such that
4.2 ILC Design Based on Dissipativity Theory
Consider the auxiliary vector
where C1, C2, and D are constant matrices of compatible dimensions. Following [22], introduce an important property of discrete repetitive processes.
Definition 3.
A discrete repetitive process (3.4) is said to be exponentially dissipative with respect to the input vk+1(t) and the output zk+1(t) defined by (4.24) if there exist a vector function (4.3) and positive scalars c1, c2, and c3 such that
where Si is a scalar function such that Si(0, 0) = 0.
In the theory of dissipativity pioneered by Willems, the functions Si and Vi are called a supply rate and a storage function, respectively. Clearly, if for some z sequence (3.5) satisfies the condition Si(zk+1(p), vk+1(p)) ⩽ 0, \(i\in {\mathcal{N}},\) then system (3.4), (3.5) will be exponentially stable under any switching signal in pass direction σ with an average dwell time (4.5); see Theorem 1. Thus, the ILC design problem is to find a stabilizing triplet {V, z, v}. Introduce the notations
Define a block-diagonal matrix Pi = diag[P1P2i] ≻ 0 as the solution of the Riccati inequality
where 0 < σ < 1 is a positive scalar, and Q ≻ 0 and R ≻ 0 are weight matrices. Clearly, if the system of linear matrix inequalities
is solvable in Xi = diag[X1X2i] ≻ 0, then \({P}_{i}={X}_{i}^{-1}\), \(i\in {\mathcal{N}}\).
The next theorem suggests a possible set of stabilizing triplets.
Theorem 2.
A discrete repetitive process (3.4) is exponentially dissipative with respect to the supply rate
with the input vk+1(p) and the output
where \({P}_{i}={X}_{i}^{-1}\), \({X}_{i}={\rm{diag}}[{X}_{1}\,{X}_{2i}]\succ 0 \i\in {\mathcal{N}}\), is the solution of (4.25). The set of control update sequences (3.5) ensuring the exponential stability of system (3.4), (3.5) is given by
where Θ(ζ) is a symmetric matrix function that satisfies the relation
for all \(\zeta \in {{\mathbb{R}}}^{2{n}_{x}+{n}_{y}}\), where
Proof. Choose the components of the vector storage function (4.3) as the quadratic forms
where P1 ≻ 0 and P2 ≻ 0 are the diagonal blocks of the matrix P representing the solution of (4.25). Calculating the counterpart of the divergence operator of (4.3) along the trajectories of (3.4) yields
From (4.31) it follows that (3.4) is exponentially dissipative with respect to the supply rate (4.27) with the input vk+1(p) and the output (4.28). Moreover, from (4.31) it follows that if sequence (3.5) is determined by (4.29), then
and the discrete repetitive process (4.29), (3.4) is exponentially stable under any switching signal in pass direction σ with an average dwell time (4.5); see Theorem 1. The proof of Theorem 2 is complete.
Remark 1. Since the increment of the estimation error \({\tilde{\xi }}_{k+1}(p)\) is not available for the control update design, the matrix Θi always has the form \({\Theta }_{i}(\zeta )={\rm{diag}}[{0}_{{n}_{x}}\,{\Theta }_{i1}(\zeta )]\). In the simplest case, matrix Θi1 can be chosen independent of ζ and then, after the matrix Pi is found, condition (4.30) reduces to a system of linear matrix inequalities, and Theorem 2 gives a linear sequence of control updates. In the general case, Θi(ζ) depends on the variations of the error in pass direction; therefore, the control update coefficients can be decreased upon achieving the required accuracy and, conversely, increased when the error is large. In other words, adaptation to the error value can be introduced in the control update procedure. This approach will guarantee a reasonable compromise between the rate of learning and ILC costs. The simplest solution here is to use piecewise-constant variations of Θ, depending on the accuracy achieved. For discrete repetitive processes without switching, it was discussed in [24].
4.3 Alternative Approach
In a series of cases, it seems interesting to construct non-switched control. Here an alternative approach turns out to be more efficient. Consider a Lyapunov function (4.22) with the components
where P1 ≻ 0 and P2 ≻ 0. Find the control update law as a linear feedback in the increments of the measurable variable and the error:
where K = [K1K2], \(H=[0\,{I}_{{n}_{x}+{n}_{y}}]\). Calculating the divergence operator of (4.22) along the trajectories of (3.4), (4.32) gives
where
Assume that the matrices P ≻ 0 and K satisfy the system of inequalities
where Q ≻ 0 and R ≻ 0 are some matrices, which play the same role as weight matrices in linear-quadratic control design. Due to (4.33), the discrete repetitive process (3.4), (4.32) is exponentially stable under an arbitrary switching signal in pass direction σ; see the corollary of Theorem 1. Using the well-known Schur’s complement lemma, inequalities (4.34) are easily reduced to the following linear matrix inequalities and equation in the variables \(X={\rm{diag}}[{P}_{1}^{-1}\,{P}_{2}^{-1}]\), Y, and Z:
If the inequalities and equation of (4.35) are solvable, then K = [K1K2] = YZ−1, since the matrix Z is nonsingular due to the structure of the matrix H.
5 Example
Consider the model of a single flexible link gantry robot [26] operating in a repetitive mode with a constant repetition period. The dynamics of the gantry robot are described by the state-space equations
where \(x(t)={\left[\theta (t)\alpha (t)\dot{\theta }(t)\dot{\alpha }(t)\right]}^{{\rm{T}}}\) in which θ(t) is the servo angle and α(t) is the flexible link angle;
in which Beq is the viscous friction coefficient of the servo, Ks is the stiffness of the flexible link, Jl is the moment of inertia of the flexible link, and Jeq is the moment of inertia of the servo. The flexible link is moving in the horizontal plane.
The problem is to find an iterative learning control algorithm enabling the output variable y(t) = θ(t) to track a reference trajectory yref(t) with a given accuracy e*. Only the servo angle θ is available for direct measurement.
Select the following nominal values of the parameters for simulation [26]: Beq = 0.004N × m/(rad/s), Ks = 1.3N × m/rad, Jl = 0.0038kg × m2, Jeq = 2.08 × 10−3kg × m2.
Set the length of a repetition period equal to 3 s and the required accuracy to \({e}^{* }=0.5\,{\rm{grad}}=0.00873\,{\rm{rad}}\).
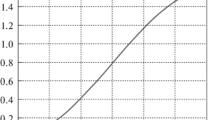
Let the reference trajectory of the output variable (see Fig. 1) be described by

Reference trajectory of servo angle.
Assume that the ILC algorithm is implemented on computer with a sampling rate of Ts = 0.01s. The equivalent discrete model of (5.1), which connects the values of all variables at the time instants 0, Ts, 2Ts, …, has the form
where \(A=\exp ({A}_{0}{T}_{s})\), \(B=\left(\mathop{\int}\nolimits_{0}^{{T}_{s}}\exp ({A}_{0}\tau )d\tau \right){B}_{0},\) and \({N}_{{T}_{f}}\) is the number of samples on the interval [0, Tf].
When the gantry robot begins operation, the first few passes are without load for presetting, and the parameters have their nominal values. After three passes, the gantry robot is loaded: Jl = 0.0076kg × m2, Jeq = 3.3 × 10−3 kg × m2. Based on the physical meaning of the state variables, set the weight matrices Q = diag[10−3I8 106] and R = 0.01. Treating the stepwise change in the gantry robot’s load as a mode switching, use the results of Section 4.3, which are convenient for comparative analysis. Denote by A1 and B1 the matrices of the unloaded gantry robot and by A2 and B2 and the matrices of the loaded one. The switched iterative learning control algorithm is described by
The non-switched algorithm has the form
For assessing the tracking accuracy of the reference trajectory, select the mean-square learning error
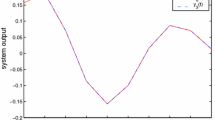
The progressions of the mean-square learning error depending on the number of passes under the switched and non-switched control algorithms are presented in Figs. 2 and 3, respectively.

Mean square learning error depending on number of passes: switched control.

Mean square learning error depending on number of passes: non-switched control.
A direct analysis of these dependencies shows that in the case of switched control, the required accuracy is achieved immediately after the presetting passes; in the case of non-switched control, additional passes in the operating mode are required to achieve the required accuracy, which is obviously undesirable.
6 Conclusions
This paper has proposed a state observer-based iterative learning control design method for switched discrete repetitive processes. As it has been demonstrated by an example, in the case of observable switchings the switched iterative learning control algorithm accelerates the convergence of the learning process. In the authors’ viewpoint, further research in this area can be associated with the development of the theory for switched differential repetitive processes and its application to iterative learning control design problems. Also, an in-depth study is needed for the choice of the nonlinear function Θi(ζ) in the dissipativity-based design procedure (Theorem 2 and Remark 1). Of considerable interest are networked iterative learning control problems, where switching is a natural model of structural changes in the network configuration. The combination of iterative learning control and feedback control is another interesting area for future investigations.
7 Funding
This work was supported by the Russian Foundation for Basic Research, project no. 19-08-00528_a.
References
Liberzon, D. Switching in Systems and Control. (Birkhäuser, Boston, 2003).
Shorten, R., Wirth, F., Mason, O., Wulff, K. & King, C. Stability Criteria for Switched and Hybrid Systems. SIAM Rev. 49, 545–592 (2007).
Lin, H. & Antsaklis, P. J. Stability and Stabilizability of Switched Linear Systems: A Survey of Recent Results. IEEE Trans. Autom. Control 54, 308–321 (2009).
Sun, Z. & Ge, S. S. Stability Theory of Switched Dynamical Systems. (Springer-Verlag, London, 2011).
Alwan, M. S. & Liu, X. Theory of Hybrid Systems: Deterministic and Stochastic. (Springer Nature Singapore, Singapore, 2018).
Rogers, E., Gałkowski, K. & Owens, D. H. Control Systems Theory and Applications for Linear Repetitive Processes. Lecture Notes in Control and Information Sciences 349 (Springer-Verlag, Berlin, 2007).
Arimoto, S., Kawamura, S. & Miyazaki, F. Bettering Operation of Robots by Learning. J. Robotic Syst. 1(no. 2), 123–140 (1984).
Bolder, J. and Oomen, T., Iterative Learning Control: A 2D System Approach, Automatica, 2016, vol. 71, pp. 247–253.
Hladowski, L., Gałkowski, K., Cai, Z., Rogers, E., Freeman, C.T., and Lewin, P.L., Experimentally Supported 2D Systems Based Iterative Learning Control Law Design for Error Convergence and Performance, Control Eng. Practice, 2010, vol. 18, pp. 339–348.
Paszke, W., Rogers, E., Gałkowski, K., and Cai, Z., Robust Finite Frequency Range Iterative Learning Control Design with Experimental Verification, Control Eng. Practice, 2013, vol. 23, pp. 1310–1320.
Bristow, D. A., Tharayil, M. & Alleyne, A. G. A Survey of Iterative Learning Control. IEEE Control Syst. Mag. 26(no. 3), 96–114 (2006).
Ahn, H.-S., Chen, Y. Q. & Moore, K. L. Iterative Learning Control: Brief Survey and Categorization. IEEE Trans. Syst., Man, Cybernet., Part C: Appl. Rev. 37(no. 6), 1099–1121 (2007).
Sammons, P. M., Gegel, M. L., Bristow, D. A. & Landers, R. G. Repetitive Process Control of Additive Manufacturing with Application to Laser Metal Deposition. IEEE Trans. Control Syst. Technol. 27(no. 2), 566–575 (2019).
Freeman, C. T., Rogers, E., Hughes, A.-M., Burridge, J. H. & Meadmore, K. L. Iterative Learning Control in Health Care: Electrical Stimulation and Robotic-Assisted Upper-Limb Stroke Rehabilitation. IEEE Control Syst. Magaz. 32(no. 1), 18–43 (2012).
Meadmore, K.L., Exell, T.A., Hallewell, E., Hughes, A.-M., Freeman, C.T., Kutlu, M., Benson, V., Rogers, E., and Burridge, J.H.The Application of Precisely Controlled Functional Electrical Stimulation to the Shoulder, Elbow and Wrist for Upper Limb Stroke Rehabilitation: a Feasibility Study, J. Neuro Eng. Rehabil., 2014, vol. 11, no. 105.
Bochniak, J., Gałkowski, K. Rogers, E. Multi-machine Operations Modelled and Controlled as Switched Linear Repetitive Processes. Int. J. Control 81, 1549–1567 (2008).
Bochniak, J., Gałkowski, K., Rogers, E., Mehdi, D., Bachelier, O. & Kummert, A. Stabilization of Discrete Linear Repetitive Processes with Switched Dynamics. Multidim. Syst. Sign. Process. 17, 271–295 (2006).
Shao, Z. & Xiang, Z. Iterative Learning Control for Non-linear Switched Discrete-time Systems. IET Control Theory Appl. 11(no. 6), 883–889 (2017).
Shao, Z. and Duan, Z.A High-order Iterative Learning Control for Discrete-time Linear Switched Systems, Proc. 57th Annual Conference of the Society of Instrument and Control Engineers of Japan (SICE), Nara, Japan, 2018, pp. 354–361.
Ouerfelli, H., BenAttia, S. & Salhi, S. Switching-iterative Learning Control Method for Discrete-time Switching System. Int. J. Dynamics Control 6, 1755–1766 (2018).
Shao, Z. & Xiang, Z. Adaptive Iterative Learning Control for Switched Nonlinear Continuous-time Systems. Int. J. Syst. Sci. 50(no. 5), 1028–1038 (2019).
Pakshin, P., Emelianova, J., Emelianov, M., Gałkowski, K. Rogers, E. Dissipativity and Stabilization of Nonlinear Repetitive Processes. Syst. Control Lett. 91, 14–20 (2016).
Pakshin, P., Emelianova, J., Gałkowski, K. Rogers, E. Stabilization of Two-dimensional Nonlinear Systems Described by Fornasini-Marchesini and Roesser Models. SIAM J. Control Optim. 56, 3848–3866 (2018).
Pakshin, P., Emelianova, J., Emelianov, M., Gałkowski, K. & Rogers, E. Passivity Based Stabilization of Repetitive Processes and Iterative Learning Control Design. Syst. Control Lett. 122, 101–108 (2018).
Emelianova, J. P. & Pakshin, P. V. Iterative Learning Control Design Based on State Observer. Autom. Remote Control 80(no. 9), 1561–1573 (2019).
Apkarian, J., Karam, P. & Levis, M. Workbook on Flexible Link Experiment for Matlab/Simulink Users. (Quanser, Markham, 2011).
Author information
Authors and Affiliations
Rights and permissions
About this article

Cite this article
Pakshin, P., Emelianova, J. Iterative Learning Control Design for Switched Systems. Autom Remote Control 81, 1461–1474 (2020). https://doi.org/10.1134/S0005117920080081
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1134/S0005117920080081