
Abstract
The novel coronavirus disease 2019 (COVID-19) spill has spread rapidly and appeared as a pandemic affecting global public health. Due to the severe challenges faced with the increase of suspected cases, more testing methods are explored. These methods, however, have several disadvantages, such as test complexity and associated problems—sensitivity, reproducibility, and specificity. Hence, many of them need help to achieve satisfactory performance. Motivated by these shortcomings, this work proposes a custom deep neural network framework named “AutoCov22” that detects COVID-19 by exploiting medical images—chest X-ray and CT-scan. First, multiple neural networks extract deep features from the input medical images, including popularly used VGG16, ResNet50, DenseNet121, and InceptionResNetV2. Then, the extracted features are fed to different machine-learning techniques to identify COVID-19 cases. One objective of this work is to quicken COVID-19 detection. Another goal is to reduce the number of falsely detected cases by a significant margin. Comprehensive simulation results achieve a classification accuracy of 99.74%, a precision of 99.69%, and a recall of 98.80% on exercising chest X-ray images. Extended experiment results in accuracy, precision, and recall up to 87.18%, 84.98%, and 85.66%, respectively, in processing CT-scan images. Thus, the AutoCov22 approach demonstrates a promising and plausible best solution over several methods in the state-of-the-art.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
COVID-19 is a new viral disease identified in December 2019. A few days later, it spread rapidly globally on its first appearance. It is incredibly contagious, and its intense effect has infected millions of people and caused a few million causalities within a month. In addition, the number of COVID-19 cases got doubled every three days. For example, more than 115 million people across the globe were found infected by the virus until March 4, 2020. At the same time, nearly 3 million unfortunate deaths are reported. Due to the high spreading rate of COVID-19, the world health organization (WHO) declared the ongoing global pandemic on March 11, 2020 [1,2,3,4,5].
There seems to be no sign that the infections and fatalities will decline, so the situation needs to be regulated [6,7,8]. Respective governments impose Countrywise many prevention mechanisms. Some common recommendations are frequent hand washing in homes and working places, wearing masks and maintaining social distancing in public areas, avoiding public transport, quarantine, using temperate measurement monitoring instruments, etc. Many countries have applied Lockdowns to slow down its rapid spread in the community by restricting people’s movement and disrupting supply chains. Subsequently, paralyzed mobility worldwide is observed, severely impacting the world economy [2,3,4,5, 9]. Despite strict lockdown imposition and quarantine restrictions, the study stated that the cumulative number of cases (both active and deaths) is still massive—the WHO reported 14,246,629 active cases and 592,690 unfortunate deaths worldwide as of July 11, 2020. The status is worried and reported about 4,60,15,562 active cases and 11,94,906 poor deaths till November 2020 [3, 10].
COVID-19 and its variants are the new members of a spectrum of viruses. The virus causes respiratory disorders, e.g., middle east respiratory syndrome (MERS) and severe acute respiratory syndrome (SARS) [11], with common symptoms. Typical symptoms of COVID-19 patients may include dry cough, fever, dyspnea, myalgia, and muscle aches [10, 12, 13]. The best way to slow down and avoid the rapid transmission of the infection is an early screening of the suspected patients and diagnosis, followed by quarantine and successful therapy. A faster and smoother medical recovery is possible when the diagnosis is completed immediately. The reverse transcription–polymerase chain reaction (RT–PCR) is standard clinical practice for COVID-19 infection detection [2, 9]. The method has several disadvantages. The main disadvantage includes the time taken to conclude the decision. In special or critical cases, the RT–PCR results are ready at 24 h; otherwise, the results are available after several days. Other disadvantages may be its complexity and associated problems like specificity, sensitivity, reproducibility, etc. [14]. Despite several limitations, the RT–PCR is preferred, because the method can produce almost 100% accurate results if one conducts a proper test. However, there is a high chance of inaccuracy with new strains. Sometimes, computed tomography (CT) becomes an alternative diagnostic technique, but it is more expensive and not easily accessible. Thus, it is essential to investigate other alternative methods that can detect the virus more accurately and quickly at a possible low cost when curbing the spread of the virus is of utmost importance. This article proposes the AutoCov22, a custom deep neural network framework for accurate COVID-19 detection, and overcomes other limitations by existing methods including [3].
The main contributions of this are listed below.
-
Deep neural network-based architecture for automatic COVID-19 detection using chest X-ray images.
-
Extended scheme to detect COVID-19 using chest CT-Scan images.
-
Reduction of false detection cases through improved accuracy and performance metrics, such as precision and F1-Score.
-
Detailed experimentation by implementing the proposed scheme with many learning networks.
-
Detailed comparative study between the proposed scheme and previous techniques.
The rest of the article is organized as follows. The section “Related Works, Motivation, and Contributions” studies the literature. The section “Proposed Work” presents the proposed COVID-19 detection framework. The section “Experimental Results and Discussion” demonstrates the experimental results. A detailed comparison is discussed in the section “Comparative Study”. The section “Conclusion and Future Scope” concludes the article and paves the way for its future scope.
Related Works, Motivation, and Contributions
Since the declaration of the COVID-19 pandemic, experts have tried to identify significant areas to prevent the spreading of the disease and reduce its impact. Four key areas include (1) prepare and ready, (2) detect, protect, and treat, (3) reduce transmission, and (4) innovate and learn [3, 5, 15]. Concerning the impact of the disease, significant efforts are undertaken. The best way to slow down and avoid the infection’s rapid transmission is through early diagnosis, quarantine, and successful therapy. In clinical practice, RT–PCR-based method is a gold standard for diagnosing COVID-19 disease [3, 16]. However, due to the challenges and disadvantages of the RT–PCR test, as mentioned earlier, and the possibility of newer strains of the virus spreading, there is a slightly higher chance of the existing RT–PCR test giving an error in classification. At this point, a key concern for a country and its government is to reduce false-negative test outcomes. Therefore, there is a need to find alternative techniques to detect the virus more accurately when curbing the spread of the virus is of utmost importance. Artificial Intelligence (AI) technology, including machine and deep learning, is rapidly being applied successfully in many areas, including healthcare systems and computer vision [17,18,19,20]. In the wake of COVID-19, several researchers including [15, 21,22,23,24,25,26,27,28] worldwide are engaged in proving detection approaches using AI technology [5, 19, 29, 30].
Londono et al. [15] presented chest X-ray image-based automatic COVID-19 diagnosis tool. The advantage of the tool is that it can differentiate the images between pneumonia, controls, or COVID-19 groups. Achievements by this model include a classification accuracy of 91.5% and an average recall of 87.4%. Ohata et al. [21] have suggested a diagnosis system based on a set of limited chest X-ray images to detect COVID-19 infections automatically. Their system achieved accuracy and F1-Score in the range of 95.6\(-\)98.5%. Horry et al. [22] presented a convolutional neural network (CNN) model through an initial comparative study of several popular CNN models using the neural ensemble method. They used transfer learning models, including VGG-16, and then created a custom CNN model architecture. The results indicate that the multiple levels of COVID-19 detection can achieve a chest X-ray (CXR) precision of up to 86% and CT scan precision of up to 84%. Oh et al. [23] have discussed the FC-DenseNet103 model, a COVID-19 detection process capable of achieving an accuracy of up to 88.9%. Another COVID-19 detection process—the DeCovNet model, is discussed by Wang et al. [24]. The accuracy of the method is up to 90.1%. The recent X-ray image-based approaches and different deep learning (DL) techniques [3, 16, 31] for COVID-19 detection report a classification accuracy of nearly 80–90%. However, many recent works have achieved an accuracy of over 90%. For example, a deep learning-based chest radiograph classification (DL-CRC) [32] method is used to differentiate between COVID-19 cases from other anomalies (e.g., pneumonia) and common cases with high accuracy. The suggested DL-CRC frame uses data enhancement of the COVID-19 X-ray image algorithm called DARI and detects the disease up to 93.94%. Rajaraman et al. [33] have proposed a custom neural network in which the ImageNet model is trained. With the weighted average of the best pruning model, the accuracy of COVID-19 findings using chest X-ray images is achieved up to 99.01%. Another early detection of COVID-19 cases using X-ray images is discussed in [34]. The obtained accuracies are binary and multiclasses. The accuracy is 98.08% and 87.02%, respectively. Five pre-trained CNN-based models viz. Inception-ResNetV2, ResNet101, InceptionV3, ResNet152, and ResNet50 are evaluated in [25] to detect COVID-19 infections. Performance results suggest that the ResNet50 model achieves the highest accuracy of 96.1% among these CNNs.
X-ray imaging is relatively cost-effective and is commonly helpful by most approaches for COVID-19 detection. CT scans are comparatively costly, and the CT scan-based COVID-19 detection consumes experts’ involvement. Despite this, patients are forced to perform selective testing for only high-risk cases, because CT scans provide much higher image resolution and contrast than standard CXRs [22]. In a word, chest CT is a critical component of the diagnostic procedure for a few selected and suspected patients. Different works have been seen in the literature. Song et al. [35] developed a deep learning-based CT diagnosis system to identify patients with COVID-19. The experimental results accurately discriminate the COVID-19 patients from the bacteria pneumonia patients. This discrimination is with an area under the receiver-operating characteristics curve (AUC), recall (sensitivity), and precision of 0.95, 0.96, and 0.79. However, these recall, and precision becomes 0.93 and 0.86, respectively, when the designed model integrates different classes of CT scans. Congcong et al. [26] proposed the weakly regulated detection process for COVID-19, ResNext+, using a chest-CT scan that only includes labels of volume levels and can estimate the status of the slice. The test results from the public data collection indicate a precision of 81.9% and an F1-Score of 81.4%. Caruso et al. [36] have investigated the chest CT features of patients with COVID-19. The investigation compared the sensitivity as a diagnostic performance parameter between the chest CT and the X-ray images. The parameter is reported to be 97% while using chest CT scans. Other recent contributions include [10, 37,38,39,40,41,42] that use the CT scans and evaluate the parameters like accuracy and precision, which are around 80–85%.
The detailed literature works studied above have a few things in common. The contributions aimed to detect the COVID-19 disease and reduce falsely detected cases. The objectives have been attempted by using the X-ray and CT scan images. Some works have used a custom CNN model, whereas others have used transfer learning. Table 1 summarizes the relative performances of the existing techniques that detect COVID-19 using chest X-ray and CT-Scan images. All these studies report comparative results. However, a more accurate and rapid diagnosis of suspected COVID-19 cases at an early stage plays a crucial role for patients. Further, a missed chance would continue to cause COVID-19 to spread, i.e., a missed diagnosis for some small lesions would heighten the potential risks for the pandemic. Therefore, developing an alternate system for detecting COVID-19 is vital to overcome and improve many existing methods, including [3]. Motivated by these shortcomings, we propose an automatic COVID-19 detection framework named “AutoCov22” to overcome many current limitations.
The main contributions of this article include the following.
-
(1)
Development of a novel learning-based model for COVID-19 detection. The method employs several pre-trained custom CNN models, who undergo training by a transfer learning technique using a large data set of thousands of X-ray images.
-
(2)
Development of an extended detection method for deep learning techniques using CT-Scan images.
-
(3)
Reduction of false prediction on the COVID-19 infection detection through improved performance using a large data set containing thousands of medical images of CXRs and CT scans. These images are from both normal and COVID-19 patients.
-
(4)
Detailed experimentation on the derived data sets provides quantitative results of several metrics such as accuracy, precision, and recall. Experimental results show that the accuracies by the considered networks lie between 87.18 and 99.74%. Other metrics, such as precision and recall are in the range of 84.98\(-\)99.69% and 85.66\(-\)98.80%, respectively.
-
(5)
Establishment of the method’s effectiveness via detailed comparative study with the existing techniques in the state-of-the-art. The study clearly shows the proposed AutoCov22 adequately improves essential performance metrics over the previous works. For example, our method improves accuracy by up to 20%, significantly reducing the false prediction of COVID-19 detection in masses.
Proposed Work
Recently, deep learning (DL) has been extensively and successfully used in medical applications like pneumonia detection, image segmentation, etc. This section proposes a DL-based design methodology to detect the COVID-19 disease. The primary objective of the proposed method is to achieve evaluation metrics, e.g., accuracy at the highest from the COVID-19-induced chest X-rays and CT-scan images. Another goal is to provide an acceptable false detection rate. The section first describes the transfer learning approach used to train various machine learning (ML) models. Next, the proposed COVID-19 detection methodology is detailed.
Transfer Learning Techniques
Transfer learning in machine learning focuses on storing knowledge (by weights) gained while solving a base task and applying it to a related target task. This work applies the transfer learning technique to train different machine learning models for COVID-19 disease detection. These models are trained on a finite data set which consists of medical images: X-ray and CT-scans images. Two major factors have influenced to choice of the transfer learning approach. First, a deep neural network (DNN) or convolutional neural network (CNN) needs a voluminous data set. However, publicly available images are minimal and in hundreds to a few thousand due to patients’ privacy. This amount of data is very fractional concerning total COVID-19 patients worldwide. Second, training a CNN or DNN computationally has become more demanding, because it looks for a suitable pre-trained model and checks its usefulness for data representation and feature extraction. Thus, multiple reasons for using the transfer learning approach include (1) a better performance of a neural network (machine learning model); (2) lower training time; (3) no need to remember a lot of data; and (4) saving time on building complex neural networks from scratch. Therefore, a transfer learning technique is employed when a model is required to carry out a similar task to one for which it has already been pre-trained using a large amount of data.
The proposed COVID-19 detection framework utilizes and analyzes the information contained in the mentioned medical images. This work employs 24 transfer learning models available using the TensorFlow and Keras framework. These pre-trained networks perform differently on the data sets. These networks can classify the images correctly in the input data set achieving state-of-the-art performance. Even some of the networks, e.g., VGG-16, ResNet152, ResNet50, ResNet101, DenseNet121, and DenseNet201, give promising results on input data sets. The neural networks have many layers and massive trainable parameters that help the transfer learning approach decrease the network’s training time and reduce generalization error. Weights in previously used layers are constant and can be used as a base for training and problem-specific adaptation. The similarity in issue structure may be advantageous in both settings, especially if the base task contains significantly more labeled data than the target job of interest. In the end, transfer learning is about relating a new issue to a similar situation in the past. It means the understanding from one model can be ported to the next model resulting in a shortened training process. A transfer learning model can be used in several ways, e.g., Classifier, Integrated Feature Extractor, Standalone Feature Extractor, and Weight Initialization. It may need to be discovered which of the pre-trained models above applications yield the best results on a new computer vision task. Therefore, enormous experimentation is encouraged, providing three possible benefits: higher start, slope, and asymptote while using transfer learning.

COVID-19 Detection Method
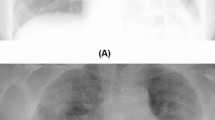
Algorithm 1 describes the algorithmic framework for detecting COVID-19 disease. The key steps involved in the proposed detection approach are described as follows. The first step involves loading the images from the input data set collected from different sources. The images are fed to the convolutional layers of the pre-trained models considered for hierarchical feature extractions. Considering the outstanding performance in image classification, different machine learning classifiers are placed as the front end of the pre-trained models—these classifiers with adequate generalization capability segment the input data set into two subsets. One subset consists of COVID images, and another contains non-COVID images. Collected images have different dimensions, i.e., width W and height H. The pre-trained models are loaded with the weights and measurements of the pictures. Therefore, to achieve the best performance and accuracy by the models, input images to these neural networks must have a uniform dimension. The next step thus involves reshaping the images into \(W\times H\times 3\), e.g., \(300\times 300\times 3\), so that the image size and resized image size match. Figure 1 shows an X-ray image of a COVID patient before and after the reshaping. We develop a preprocessing step that ensures uniform intensity through data normalization throughout a data set. Each pre-trained model is next included and trained in the proposed neural network architecture using the reprocessed data.

Sample X-ray images of a COVID patient

Proposed deep learning architecture for COVID-19 detection
Figure 2 represents a high-level view of the proposed architecture that comprises multiple layers and nodes. The stack of layers begins with the layer of a pre-trained model. The output from the preceding layer is forwarded to the following layer. In this way, the last layer of the pre-trained model delivers its work to the next part for the flattening process of the proposed neural network.
The reshaped images are multi-dimensional and undergo the flattening stage, transforming the combined feature map into a one-dimensional sequence. We flatten the output of the convolutional layer to produce a single extended function vector. With the flattened feature, the combined feature map in the single column is sent to the fully/ultimately linked layer. Therefore, the output from one convolutional layer is input to the successive layers. Thus the result becomes an input to the completely/fully connected convolutional layer. It is fully connected, because each dense layer receives feedback from its previous neurons. The layer includes the commonly used rectified linear activation function (ReLU) defined in Eq. 1 actives a function elementwise where the process outputs on the input directly if it is positive; otherwise, it outputs zero [46]. The ReLU function also derives the node’s activation or output from the summed weighted input of a node. Here, z is an input variable in the fully connected layer:
Overfitting is a significant issue while observing performance in detecting the disease. One can prevent it with a dropout layer that reduces the phenomenon by preventing a layer from seeing the same pattern more than once. 20% of the neurons with complete connections are supplied to the dropout() method. An additional dense layer completes the binary classification with one neuron next to it. The activation function differentiable and bounded in \(\forall z \in \mathbb {R}\) in this layer is a “Sigmoid”. The defined in Eq. 2 has exactly a non-negative derivative on one inflexion point. It does binary classification shooting the threshold to 1; otherwise, 0. The proposed approach uses this threshold to categorize COVID and non-COVID scenarios:
Activation Function, Loss Function, and Optimizer
The compile() function in Algorithm 1 configures the training process model with the optimizer, selected metrics, and loss function. Selected metrics are loss, accuracy, recall, and precision. A model undergoes multiple epochs on a data set. The number of epochs is set to 15, by which 24 models considered in this work achieve their best training performance metrics. Some models preferred the softmax function over the Sigmoid function in the final dense layer [47]. For example, the Softmax activation function works well in the final dense layer for ResNet and EfficientNet models, whereas the Sigmoid function works well for other models. A vector of integers is transformed into a vector of probabilities by the Softmax function. Due to direct proportionality, the relative scale of each value in the vector determines the likelihood of each value. The softmax function is used in a multiclass logistic regression. The sigmoid function is used in two-class logistic regression. Due to the excellent outcomes of our work, we have employed the softmax function for a handful of pre-trained models. Otherwise, in binary classification, the sigmoid function is preferred. Class 0 is a non-COVID class, whereas class 1 is assumed to be COVID. These labels are also interchangeable. So, we adopt the binomial probability distribution. For instance, a prediction made by a network with a single node for its output layer falls under class 1. Equation 3 defines such an activation function:
Due to the many benefits of deep learning applications in natural language processing and computer vision, the Adam optimizer based on a stochastic gradient descent modification is used to facilitate the learning process. The loss function is a binary cross entropy for a binary classification task and is defined in Eq. 4. Here, \(p, q, y, \hat{y}\) are the entropy values. The p and q are the two binary distributions. The pi and qi represent the truth and predicted values of the ith data point. Alternatively, \(p_i\) and \(q_i\) can be represented using the y and \(\hat{y}\), respectively. Our model predicts a model distribution of p, q as we have a binary distribution. Another measure is the learning rate, a hyperparameter for regulating and monitoring how much the model changes each time it is updated in response to the predicted mistake. Small or large values of this pace may lead to a drawn-out training procedure. It could lead to a stalled or inadequate set of weights or an unstable training process. Selecting the learning rate takes time and effort. In our work, a learning rate of 0.0001 works pretty well for all models except the ResNet and Efficient Net models. A learning rate of 0.001 works well for these two models:
Extended COVID-19 Detection Method
The AutoCov22 architecture described in Algorithm 1 is incapable of adequately detecting the COVID-19 disease using CT-Scan images. Because the model overfits pretty quickly over the CT-Scan data set. Hence, we have proposed another version of AutoCov22 that performs exceptionally well on CT-Scan images compared to its current version. This new and extended architecture is exclusively developed for CT-Scan images. The images are all grayscale. The new architecture takes the images with an input dimension of 300\(\times\)300. This is close to the mean size of the images in the CT-Scan data set. Due to the availability of a limited data set size, we use data augmentation techniques to increase the data set size. Every training sample image is given a 0–10 degrees rotation in either a clockwise or anti-clockwise direction. The new architecture consists of 2 convolutional layers. Each layer size is 32\(\times\)32 and uses the ReLU activation function. The size of the convolution kernel is 3\(\times\)3. A max-pooling layer of pool size 2\(\times\)2 follows each convolutional layer. Once all the convolution and pooling operations are accomplished, the resulting image kernel undergoes the flattening to a one-dimension (1-D) vector. A fully connected dense layer follows this with one neuron for binary classification. Like the previous architecture, the Sigmoid activation function and the Adam optimizer with a learning rate of 0.0001 and binary-cross entropy as the loss function are employed in this new architecture. This new detection model is compiled and fits 50 epochs.
Experimental Results and Discussion
We assess our AutoCov22 model’s performance using four standard metrics: accuracy, recall, precision, and F1-Score. The suggested method is tested on a Python environment that supports GPUs. We employ the TensorFlow framework and the Keras package to conduct deep learning activities. We get data from two open-source, freely accessible databases: Kaggle and GitHub.
Data Collection and Annotation
Using the proposed neural networks, two types of data sets: chest X-ray and chest CT scan images, are excersized for COVID-19 detection. Clinicians often use these data sets as a main source of information for COVID-19 diagnosis.
Chest X-Ray Data Set
The first data set is collected from the GitHub database [48]. It contains 6310 images in a total of chest X-rays, of which 1310 are COVID-positive images that include infection areas, and 5000 are COVID-negative images. One important point to note for the second category of X-Ray images, i.e., normal or non-COVID. These images might include other unhealthy conditions caused by chronic obstructive pulmonary (COP) disease, viral or bacterial infections, etc. In light of this, a typical or non-COVID instance may not always indicate a healthy lower respiratory system.
Chest CT-Scan Data Set
To develop a CT-Scan images model, we exercise images from the data set available in another public domain-Kaggle [49]. The size of this data set consists of 2481 chest CT-Scan images. This data set is augmented to increase the number of images input to train the proposed architecture for COVID-19 detection using CT-Scan images.
Inter-dimensional Analysis
The COVID-19 detection using the proposed scheme is like an image classification problem where input images to a neural network must be the same size. The images in the data sets collected from different sources need to undergo preprocessing and resizing of images, because these images are of different sizes.
Image Dimension Constraints
The dimension (width and height) of collected images ranges from the smallest size of 200\(\times\)200 to the most significant extent close to 1000\(\times\)1000. The mean measurement is around 381\(\times\)341. We should consider resizing the minor input variable if the image sizes vary within comparable aspect ratios. For this reason, we chose not to resize anything above 500x500. It means that most images of similar size would require severe adjustments, significantly impacting the training. Maintaining the raw image aspect ratio and resizing them proportionally is generally safer. For this purpose, seven sets of squared and seven sets of rectangular image dimensions are considered. Overall, the input size of the image can impact the training process in many ways. Some include time taken for training, learning, and information loss during resizing.
Resizing the Images
Image resizing or reshaping is a critical preprocessing step, because it impacts the training of a learning model. The model gets trained faster on dimensionally smaller size images when compared to bigger ones. An input image with double the size requires a network to learn from four times as many pixels. There is no set of dimensions that can do wonders. However, training a learning model from a smaller size is preferred over starting with a bigger image. A good strategy is then to increase the image dimension progressively. The proposed architectures are evaluated the input images in two ways. Firstly, we chose a few regularly spaced square sizes from 200\(\times\)200 to 500\(\times\)500. Hence, we began with 200\(\times\)200 and periodically added 50 to the width and height of the current dimension for the next set of experiments. Secondly, we consider seven random rectangular sizes: 370\(\times\)340, 450\(\times\)350, 380\(\times\)420, 381\(\times\)341, 400\(\times\)300, 275\(\times\)375, and 150\(\times\)350. Because it is worth trying to exercise a wide range of preprocessed images in the data set, even better, we can use the learned weights from the small models to initiate training on the larger input models.
Evaluation Metrics
The evaluation of the proposed scheme for detecting COVID-19 disease is conducted by the confusion matrix, classification accuracy, precision, recall (sensitivity), and F1-Score [50].
-
Confusion Matrix is a tabular visualization of the model predictions versus the ground-truth labels in True/False and Positive/Negative.
-
True Positive: When the ground truth and the prediction are true.
-
True Negative: When the ground truth and the prediction are negative.
-
False Positive: The prediction is true when the ground truth is false.
-
False Negative: The prediction is false when the ground truth is true.
The simple truth is that the patient has the disorder, but the forecast tells us what the classification/model tells the patient that the illness is contracted on a data basis.
-
-
Classification Accuracy defined in Eq. 5 is the number of accurate forecasts divided by the total number of projections. It shows how similar the predictions of the fundamental truth are
$$\begin{aligned} \text {Accuracy} =\frac{\text {True Positive + True Negative}}{\text {Total Number of Cases}} \end{aligned}$$(5) -
Precision defined in Eq. 6 is the fraction of the appropriate instances of the samples obtained. This metric is also referred to as the positive predictive value:
$$\begin{aligned} \text {Precision} =\frac{\text {True Positive}}{\text {True Positive + False Positive}} \end{aligned}$$(6) -
Recall or sensitivity defined in Eq. 7 is a proportion of the total number of instances currently detected:
$$\begin{aligned} \text {Recall} = \frac{\text {True Positive}}{\text {True Positive + False Negative}} \end{aligned}$$(7) -
F1-Score defined in Eq. 8 demonstrates the combination of accuracy and recall. The maximum value is 1, which means complete accuracy and reminder, and the lowest possible value is 0:
$$\begin{aligned} \text {F1-Score} = \frac{2 \times \text {Precision} \times Recall}{\text {Precision} + \text {Recall}} \end{aligned}$$(8)

Behaviour of test accuracy metric by all learning models at square shaped \(350\times 350, 450\times 450, 500\times 500\) images

Behaviour of test loss metric by all learning models at square shaped \(350\times 350, 450\times 450, 500\times 500\) images
Results Analysis
We divide the chosen data set into two sets, 70:30 for our studies. It is standard practice to split the data into 70% as training and 30% as testing set. However, researchers may vary this split ratio based on their data set size [51]. These collections serve as testing and training samples, respectively. For instance, in the data set of X-ray images, the training sample set has 4431 images, while the testing sample set contains 1899 images. Different sizes are used for the images. In the processing stages, the images in the data sets of X-ray and CT-Scan images are transformed into 14 data sets to train the learning models completely. Every image is reshaped in the range of 200\(\times\)200 to \(500\times 500\). We consider 24 various pre-trained models for the training process and closely examine the performance of the proposed architecture for COVID-19 identification. The reshaped images are fed to these transfer learning models. These models are studied using two performance metrics: test accuracy and loss. Equation 9 defines the test accuracy metric:

Behaviour of test accuracy metric by all learning models at rectangular shaped \(370\times 340, 450\times 350\) images

Behaviour of test loss metric by all learning models at rectangular shaped \(370\times 340, 450\times 350\) images
The experiments are carried out at multiple epochs (iterations). The proposed model took seven generations to be precise to attain its best accuracy. Most models took between 7 and 15 epochs to achieve their best accuracy. The models that took around seven epochs usually continued performing almost the same for another few epochs before a declining performance. First, the experiments are carried out at some selected image dimensions. Figures 3 and 4 show the behaviour of test accuracy and loss metrics by all learning models trained with square-shaped \(350\times 350, 450\times 450, 500\times 500\) images. In addition to the square-shaped images, the models are trained with rectangular images. Figures 5 and 6 describes the behaviour of test accuracy and test loss metrics by all learning models trained with rectangular shaped \(370\times 340, 450\times 350\) images. One can see that each of these models achieves a test accuracy above 90%. Many models are performing well at image dimensions 450\(\times\)450 and 500\(\times\)500. A model has many features present in the images to learn and for further use in detecting COVID-19 positive or negative images. A few models at the image dimensions 200\(\times\)200 and 250\(\times\)250 are not performing comparatively due to fewer features available for extraction during the training phase.

Behavior of test accuracy metric by best learning models at both square and rectangular shaped images

Behavior of test accuracy metric by DenseNet201, EfficientNetB1, EfficientNetB4, and InceptionV3 learning models at both suqare and rectangular shaped images
The selected dimension sets of input images may provide a tentative behaviour instead of an actual trend. The experiment is then extended to the rest of the image dimensions. Figures 7, 8, 9, and 10 give the test accuracy and loss metrics achieved by best learning models at both square and rectangular-shaped images. The learning models perform well for different dimensions of images. Instead, these models achieve to best test accuracy value at a separate and particular image dimension. We observe the highest test accuracy returned by all the models in Table 2. It is observed that the best-trained model is ResNet152. This model’s accuracy is higher than all other models and is 99.74% with X-ray images. The trend is that most models’ image dimensions perform well in 350 to 500. Most of the learning models in our scheme give accuracy above 98%. Because (1)Most of the images have an aspect ratio that falls under this range, (2) When compared to an image of smaller size, a larger image can contain a lot more information which will be helpful for feature extraction during the training process, and (3) Some rectangular aspect ratios also perform better than most square ones, directly indicating the rectangular shape of most of the images in the data set.

Behavior of test loss metric by best learning models at both square and rectangular shaped images

Behavior of test loss metric by DenseNet201, EfficientNetB1, EfficientNetB4, and InceptionV3 learning models at both suqare and rectangular shaped images

Application of the proposed method on ResNet152 model
Besides several learning models’ test accuracy and loss metrics, we evaluate our proposed scheme for other essential metrics: precision, recall, and F1-Score. The trained model which gives the best result on exercising X-ray images is ResNet152. The proposed scheme with this learning model achieves a precision value of 99.69% and a recall of 98.80%. These achievements are higher than many of the existing models. The performance of the proposed method is assessed at different image qualities. Figure 11 provides insight into the effectiveness of the suggested approach using the ResNet152 model with X-ray images as input. The proposed scheme achieves the best accuracy, precision, and recall by seven epochs. The performance of a set of learning models on X-ray images is very close to the best model. Other learning models have comparatively lower performance than the ResNet group of learning models. The proposed scheme is extended to detect COVID-19 disease by exercising the chest CT-Scan images. Figure 12 shows the nature of performance metrics—accuracy, precision, and recall values of the proposed AutoCov22 architecture using CT-Scan images. The highest accuracy achieved by the architecture is 87.18%, while the precision and F1-Score are 84.98% and 85.66%, respectively. These best metric values are attained before the 50th epoch. However, at a few epochs, the recall metric achieves above 90%.
Comparative Study
The proposed AutoCov22 framework is compared against several state-of-the-art methods on Chest X-ray and CT-Scan data sets. The same training data set and setting are used for these methods. Table 3 shows a comparison study on the accuracy metrics between AutoCov22 and various previous ways with respect to the X-ray image data set. The table gives an idea of our model’s actual and relative improvements (Columns IV and V) by the proposed model on the accuracy metric over the others. A pre-trained model that provides the best accuracy metric in previous works is included in the comparison study.
Chest X-Ray
A deep learning framework in [43] has used six pre-trained models, among which the Xception network can achieve the accuracy of 98% despite a series of preprocessing operations applied to the X-ray data set. In contrast, the Xception network in our model reaches the metric up to 99.26% resulting in 1.26% direct and 1.28% relative improvements. Whether natural or proximate, this improvement significantly reduces falsely detected cases in a country, e.g., Bharat, with a large population. The FCovNet discussed in [44] achieves an accuracy level of 99.10% which is 0.64% less accurate than our best ResNet152 network. When Xception, Resnet50, and InceptionV3 are trained under the FCovNet scheme, these pre-trained models achieve 80.18%, 90.09%, and 95.59%, respectively. These models under the AutoCov22 reach accuracy up to 99.26%, 99.74%, and 99.68%, respectively. In other words, the AutoCov22 is 4.15\(-\)19.56% more accurate than the FCovNet [44]. Madaan et al. [52] presented a CNN based FCovNet model for COVID-19 detection. This model can detect the COVID-19 disease up to 98.44%. Arias-Londo et al. [15] proposed a DNN-based model called COVID-Net to see COVID-19 using chest X-ray images. The model, on average, detects the disease by 87.4% accurately. The maximum accuracy level of this model is 91.5% which is 8.24% lesser than the AutoCov22. Oh et al. [23] discussed a deep convolutional neural network model called FC-DenseNet103 for COVID-19 diagnosis. The model’s detection process results in an accuracy of 88.9%, i.e., 10.84% less accurate than our AutoCov22, establishing a significant improvement towards a precise detection of this disease. The DL-CRC framework [32] is planned to distinguish COVID-19 cases from regular patients. On evaluation, the DL-CRC framework reaches the detection accuracy of up to 93.94%, which is sufficiently lower than many of the pre-trained models used in our AutoCov22 (see Table 2). So far, in the discussion, the AutoCov22 framework outperforms accurate detection and improves detection accuracy by up to 20% over previous works.

Performance of the proposed scheme with CT-Scan images
Besides the accuracy metric, the proposed AutoCOV-19 is compared to other metrics like precision and F1-Score. Figure 13 illustrates the results of different previous methods and our model on these metrics. The red bars represent the models evaluated under the proposed CNN model, i.e., the AutoCov22 framework. In contrast, the blue bars refer to the metrics achieved by previous methods discussed in the state-of-the-art. It can be observed that our COVID-19 detection framework achieves better results. For example, the F1-Score from the best learning network Mobilenet in the automatic detection method for COVID-19 infection discussed in [21] is 98.5%. The best learning model in the AutoCOV-19 is the ResNet152 network which shows the F1-Score is 99.24%. Thus, our AutoCov22 framework plays a significant role in COVID-19 detection and reduces falsely detected cases using CT scans.
Chest CT-Scan
We extend the COVID-19 detection using the CT-Scan. In addition to comparing our method with previous schemes on chest X-rays, we compare our extended AuotCOV-21 with multiple previous methods that appeared in state-of-the-art the test set of CT-Scan images. Table 4 illustrates the result differently concerning the CT-Scan image data set. The performance of the proposed approach is below 90% on exercising the CT-Scan image data set. This performance seems less due to a smaller data set size. With a larger data set size, the issue can be overcome. In that case, the selected learning networks driven by the scheme can be trained and predict the disease more accurately.

Performance comparison of different models with X-ray images
Congcong et al. [26] proposed a deep learning-based detection process ResNext+ for COVID-19 disease using CT-Scans. The method shows a precision of 81.9% and an F1-Score of 81.4%. In contrast, our model gives these as 84.98% and 84.65%, respectively. Compared to this model, AutoCov22 makes 3.09% and 3.25% improvements on these metrics. Ying et al. [35] developed a deep learning-based CT diagnosis system (COVID-19-CT) to identify patients with COVID-19. This model is evaluated on the CT-Scans of 88 patients diagnosed with COVID-19. The evaluation shows a precision of 79%. In contrast, our model provides an accuracy of 87.10% resulting in 8.10% improvements. Yan et al. [10] developed a new deep convolutional neural network (NDCNN) tailored to COVID-19 infections detection for chest CT images. The scheme shows nearly 72.6% precision, which is direct 12.38% less than the AutoCov22, i.e., our model performs 17.05% more and is significant for reducing the falsely detected cases. Horry et al. [22] selected and optimized the VGG19 model for COVID-19 detection using the CT Scan data set. The model on extensive tuning results in accuracy, precision, and F1-Score up to 79%, 83%, and 81%, respectively. This performance is achieved over 70 epochs, while AutoCov22 achieves comparatively better results by 50 epochs. Peng et al. [37] presented COVID-19-CT–CXR, a public database of COVID-19 CXR and CT images. The performance of fine-tuned deep neural networks on the database achieved the highest precision and F1-Score at 81.60% and 79.20%, respectively. Tanvir et al. [38] presented a hybrid neural network that is proposed, named CovTANet, to predict COVID-19 utilizing chest computer tomography (CT) scans. Through multiphase optimization and extensive experimentation, the scheme achieves 85.20% accuracy and 86.68% F1-Score. Although the scheme shows 2.03% more F1-Score but lacks 1.90% accuracy than our AutoCov22. Summarily, the extended AutoCov22 improves accuracy, precision, and F1-Score by 9.50%, 12.38%, and 5.45%, respectively. It can be noticed that Table 4 has no value for a few models, because these models did not measure such variables. Instead, they evaluated other metrics but not in the current work. The table provides the metrics values assessed by the models shown in the table. For example, NDCNN [10] model evaluated the metrics—dice, sensitivity, and precision. The precision is the standard evaluating metric by our and the NDCNN model.
In this abrupt outbreak of COVID-19, there is a need for more experienced specialists, radiologists, and researchers. Consequently, evaluating different detection schemes using chest X-ray and CT Scans is most familiar with the tremendous increase in patients. The experimental results from the existing approaches significantly help specialists, radiologists, and researchers. Since this virus is yet to investigate more for having the full radiologic features and prognosis, any improved result substantially increases towards a complete diagnosis of the disease. Subsequently, our proposed AutoCov22 method outperforms and ensures a promising solution for diagnosing COVID-19 over many existing ways.
Conclusion and Future Scope
To address the rapidly spread global pandemic of COVID-19, we proposed a customized deep learning framework named AutoCov22 for automatic detection of the disease from chest X-ray and CT-Scan images. The proposed AutoCov22 has come out as an alternate, improved, and promising solution that does not detect the COVID-19 disease only but also reduces the progressing number of false-negative cases on the condition. Leveraging the transfer learning networks, we apply a more significant number (twenty-four) of pre-trained deep CNNs. Our experimental results demonstrated that the proposed scheme provides comparative and adequately improved results with different state-of-the-art methods. The results indicate that AutoCov22 outperforms other methods in terms of accuracy of medical diagnosis for chest X-ray and CT-scan images. The proposed work has multiple future scopes. (1) Recently, a new variant of the COVID-19 virus has appeared and needs to be diagnosed by the proposed approach to observe its performance with new variants. (2) Unfortunately, the systematic collection of the extensive data set on CT scans for training is complex due to the emergent nature of the COVID-19 global pandemic and its unavailability in the public domain. It leads to less performance by the proposed approach, because learning models need to be more trained, hence being unable to provide the expected performance. This needs to be improved with a larger data set concerning a large population. (3) The proposed approach has yet to measure the time taken by a learning model for training and predicting the disease. The training and testing time may be computed to see early detection. (4) One needs further study on patients from diverse geographic locations to understand the mutation and evolution of this deadly virus, etc.
Data Availability
All relevant data are within the paper.
References
Wang B, Zhao Y, Chen CLP. Hybrid transfer learning and broad learning system for wearing mask detection in the COVID-19 era. IEEE Trans Instrum Meas. 2021;70:1–12.
Shamsi A, Asgharnezhad H, Jokandan SS, Khosravi A, Kebria PM, Nahavandi D, Nahavandi S, Srinivasan D. An uncertainty-aware transfer learning-based framework for COVID-19 diagnosis. IEEE Trans Neural Netw Learn Syst. 2021;32(4):1408–17.
Bhowmik B, Varna SA, Kumar A, Kumar R. Reducing false prediction on COVID-19 detection using deep learning. In: IEEE International Midwest Symposium on Circuits and Systems (MWSCAS), 2021. p. 404–7.
Zhou J, Zhang X, Zhu Z, Lan X, Fu L, Wang H, Wen H. Cohesive multi-modality feature learning and fusion for COVID-19 patient severity prediction. IEEE Trans Circuits Syst Video Technol. 2022;32(5):2535–49.
Bhowmik BR, Varna SA, Kumar A, Kumar R. Deep neural networks in healthcare systems. In: Machine learning and deep learning in efficacy improvement of healthcare systems. USA: CRC Press, Taylor and Francis; 2021. p. 5–226.
Team CF, Reiner RC, Collins JK, Murray CJ. Forecasting the trajectory of the COVID-19 pandemic into 2023 under plausible variant and intervention scenarios: a global modelling study, 2023.
Angalakuditi H, Bhowmik B. Impact of stress during COVID-19 pandemic. In: 2023 IEEE 9th International Conference on Advanced Computing and Communication Systems (ICACCS), 2023. p. 1–6.
Callaway E, et al. Beyond omicron: what’s next for COVID’s viral evolution. Nature. 2021;600(7888):204–7.
Yamac M, Ahishali M, Degerli A, Kiranyaz S, Chowdhury MEH, Gabbouj M. Convolutional sparse support estimator-based COVID-19 recognition from x-ray images. IEEE Trans Neural Netw Learn Syst. 2021;32(5):1810–20.
Yan Q, Wang B, Gong D, Luo C, Zhao W, Shen J, Ai J, Shi Q, Zhang Y, Jin S, Zhang L, You Z. COVID-19 chest CT image segmentation network by multi-scale fusion and enhancement operations. IEEE Trans Big Data. 2021;7(1):13–24.
Wang R, Lee J-H, Kim J, Xiong F, Hasani LA, Shi Y, Simpson EN, Zhu X, Chen Y-T, Shivshankar P, et al. Sars-cov-2 restructures host chromatin architecture. Nat Microbiol. 2023;8(4):679–94.
Paluru N, Dayal A, Jenssen HB, Sakinis T, Cenkeramaddi LR, Prakash J, Yalavarthy PK. Anam-net: Anamorphic depth embedding-based lightweight CNN for segmentation of anomalies in COVID-19 chest CT images. IEEE Trans Neural Netw Learn Syst. 2021;32(3):932–46.
Vente Cd, Boulogne LH, Venkadesh KV, Sital C, Lessmann N, Jacobs C, Sánchez CI, Ginneken BV. Automated COVID-19 grading with convolutional neural networks in computed tomography scans: a systematic comparison. IEEE Trans Artif Intell. 2022;3(2):129–38.
Fang Y, Zhang H, Xie J, Lin M, Ying L, Pang P, Ji W. Sensitivity of chest CT for COVID-19: comparison to RT-PCR. Radiology. 2020;296(2):E115–7.
Arias-Londoño JD, Gomez-Garcia JA, Moro-Velázquez L, Godino-Llorente JI. Artificial intelligence applied to chest x-ray images for the automatic detection of COVID-19. A thoughtful evaluation approach. IEEE Access. 2020;8:226811–27.
Manjunath TD, Bhowmik B. Quantum machine learning and recent advancements. In: 2023 International Conference on Artificial Intelligence and Smart Communication (AISC), 2023. p. 1–6.
Verma A, Bhowmik B. Automated detection of maize leaf diseases in agricultural cyber-physical systems. In: 2022 30th Mediterranean Conference on Control and Automation (MED), 2022. p. 841–846.
Kumar A, Bhowmik B. Rice cultivation and its disease classification in precision agriculture. IEEE Artif Intell Smart Commun (AISC). 2023;2023:1–6.
Guria M, Bhowmik B. IOT-enabled driver drowsiness detection using machine learning. In: 2022 Seventh International Conference on Parallel, Distributed and Grid Computing (PDGC), 2022. p. 519–524.
Bhowmik BR, Manjunath TD. Quantum learning and its related applications for future. In: Handbook of research on quantum computing for smart environments. Pennsylvania: IGI Global Publishing; 2023. p. 25–47.
Ohata EF, Bezerra GM, das Chagas JVS, Neto AVL, Albuquerque AB, de Albuquerque VHC, Reboucas Filho PP. Automatic detection of COVID-19 infection using chest x-ray images through transfer learning. IEEE/CAA J Autom Sin. 2020;8(1):239–48.
Horry MJ, Chakraborty S, Paul M, Ulhaq A, Pradhan B, Saha M, Shukla N. COVID-19 detection through transfer learning using multimodal imaging data. IEEE Access. 2020;8:149808–24.
Oh Y, Park S, Ye JC. Deep learning COVID-19 features on CXR using limited training data sets. IEEE Trans Med Imaging. 2020;39(8):2688–700.
Wang X, Deng X, Fu Q, Zhou Q, Feng J, Ma H, Liu W, Zheng C. A weakly-supervised framework for COVID-19 classification and lesion localization from chest CT. IEEE Trans Med Imaging. 2020;39(8):2615–25.
Narin A, Kaya C, Pamuk Z. Automatic detection of coronavirus disease (COVID-19) using x-ray images and deep convolutional neural networks. Pattern Anal Appl. 2021;24:1207–20.
Mohammed A, Wang C, Zhao M, Ullah M, Naseem R, Wang H, Pedersen M, Cheikh FA. Weakly-supervised network for detection of COVID-19 in chest CT scans. IEEE Access. 2020;8:155987–6000.
Kranthi Kumar L, Alphonse P. COVID-19 disease diagnosis with light-weight CNN using modified MFCC and enhanced GFCC from human respiratory sounds. Eur Phys J Spec Top. 2022;231(18):3329–46.
Le D-N, Parvathy VS, Gupta D, Khanna A, Rodrigues JJ, Shankar K. IoT enabled depthwise separable convolution neural network with deep support vector machine for COVID-19 diagnosis and classification. Int J Mach Learn Cybern. 2021;12:3235–48.
Bhowmik B, Hazarika P, Kale P, Jain S. AI technology for NOC performance evaluation. IEEE Trans Circuits Syst II Express Briefs. 2021;68(12):3483–7.
Bhowmik BR. Ann-based performance prediction in MoCs. In: Communications in computer and information science. Cham: Springer; 2023. p. 133–44.
Mondal R, Bhowmik B. Decs: a deep neural network framework for cold start problem in recommender systems. In: 2022 IEEE Region 10 Symposium (TENSYMP), 2022. p. 1–6.
Sakib S, Tazrin T, Fouda MM, Fadlullah ZM, Guizani M. Dl-CRC: deep learning-based chest radiograph classification for COVID-19 detection: a novel approach. IEEE Access. 2020;8:171575–89.
Rajaraman S, Siegelman J, Alderson PO, Folio LS, Folio LR, Antani SK. Iteratively pruned deep learning ensembles for COVID-19 detection in chest x-rays. IEEE Access. 2020;8:115041–50.
Ozturk T, Talo M, Yildirim EA, Baloglu UB, Yildirim O, Acharya UR. Automated detection of COVID-19 cases using deep neural networks with x-ray images. Comput Biol Med. 2020;121: 103792.
Song Y, Zheng S, Li L, Zhang X, Zhang X, Huang Z, Chen J, Wang R, Zhao H, Zha Y, Shen J, Chong Y, Yang Y. Deep learning enables accurate diagnosis of novel coronavirus (COVID-19) with CT images. IEEE/ACM Trans Comput Biol Bioinform. 2021;18(6):2775–80.
Caruso D, Zerunian M, Polici M, Pucciarelli F, Polidori T, Rucci C, Guido G, Bracci B, De Dominicis C, Laghi A. Chest CT features of COVID-19 in Rome, Italy. Radiology. 2020;296(2):E79–85.
Peng Y, Tang Y, Lee S, Zhu Y, Summers RM, Lu Z. COVID-19-CT-CXR: a freely accessible and weakly labeled chest x-ray and CT image collection on COVID-19 from biomedical literature. IEEE Trans Big Data. 2021;7(1):3–12.
Mahmud T, Alam MJ, Chowdhury S, Ali SN, Rahman MM, Anowarul-Fattah S, Saquib M. Covtanet: a hybrid tri-level attention-based network for lesion segmentation, diagnosis, and severity prediction of COVID-19 chest CT scans. IEEE Trans Ind Inform. 2021;17(9):6489–98.
Anwar T, Zakir S. Deep learning based diagnosis of COVID-19 using chest CT-scan images. In: 2020 IEEE 23rd International Multitopic Conference (INMIC), 2020. p. 1–5.
Dutta P, Roy T, Anjum N. COVID-19 detection using transfer learning with convolutional neural network. In: 2021 2nd International Conference on Robotics, Electrical and Signal Processing Techniques (ICREST). IEEE, 2021. p. 429–432.
Seum A, Raj AH, Sakib S, Hossain T. A comparative study of CNN transfer learning classification algorithms with segmentation for COVID-19 detection from CT scan images. In: 2020 11th International Conference on Electrical and Computer Engineering (ICECE). IEEE, 2020. p. 234–237.
James RM, Sunyoto A. Detection of CT-scan lungs COVID-19 image using convolutional neural network and clahe. In: 2020 3rd International Conference on Information and Communications Technology (ICOIACT). IEEE, 2020. p. 302–307.
El Gannour O, Hamida S, Cherradi B, Raihani A, Moujahid H. Performance evaluation of transfer learning technique for automatic detection of patients with COVID-19 on x-ray images. In: 2020 IEEE 2nd International Conference on Electronics, Control, Optimization and Computer Science (ICECOCS), 2020. p. 1–6.
Santoso FY, Purnomo HD. A modified deep convolutional network for COVID-19 detection based on chest x-ray images. In: 2020 3rd International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), 2020. p. 700–704.
Nurtiyasari D, Rosadi D. Covid-19 chest x-ray classification using convolutional neural network architectures. In: 2020 3rd International Seminar on Research of Information Technology and Intelligent Systems (ISRITI), 2020. p. 667–671.
Relu activation function for deep learning neural networks available at: https://machinelearningmastery.com/rectified-linear-activation-function-for-deep-learning-neural-networks/.
Bridge J, Meng Y, Zhao Y, Du Y, Zhao M, Sun R, Zheng Y. Introducing the GEV activation function for highly unbalanced data to develop COVID-19 diagnostic models. IEEE J Biomed Health Inform. 2020;24(10):2776–86.
Cohen JP, Morrison P, Dao L, Roth K, Duong TQ, Ghassemi M. Covid-19 image data collection: Prospective predictions are the future, arXiv preprintarXiv:2006.11988, 2020.
Sars-cov-2 CT-scan dataset available at: https://www.kaggle.com/plameneduardo/sarscov2-ctscan-dataset.
Hicks SA, Strümke I, Thambawita V, Hammou M, Riegler MA, Halvorsen P, Parasa S. On evaluation metrics for medical applications of artificial intelligence. Sci Rep. 2022;12(1):5979.
Xu Y, Goodacre R. On splitting training and validation set: a comparative study of cross-validation, bootstrap and systematic sampling for estimating the generalization performance of supervised learning. J Anal Test. 2018;2:249–62.
Madaan V, Roy A, Gupta C, Agrawal P, Sharma A, Bologa C, Prodan R. Xcovnet: Chest x-ray image classification for COVID-19 early detection using convolutional neural networks. New Gener Comput. 2020;39:583–97.
Funding
This work was not funded.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The author declares that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the topical collection “Research Trends in Computational Intelligence” guest edited by Anshul Verma, Pradeepika Verma, Vivek Kumar Singh and S. Karthikeyan.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Bhowmik, B., Varna, S., Kumar, A. et al. AutoCov22: A Customized Deep Learning Framework for COVID-19 Detection. SN COMPUT. SCI. 4, 659 (2023). https://doi.org/10.1007/s42979-023-02094-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42979-023-02094-4