
Abstract
Power quality disturbances are one of the main problems in an electric power system, where deviations in the voltage and current signals can be evidenced. These sudden changes are potential causes of malfunctions and could affect equipment performance at different demand locations. For this reason, a classification strategy is essential to provide relevant information related to the occurrence of the disturbance. Nevertheless, traditional data extraction and detection methods have failed to carry out the classification process with the performance required, in terms of accuracy and efficiency, due to the presence of a non-stationary and non-linear dynamics, specific of these signals. This paper proposes a hybrid approach that involves the implementation of the Hilbert–Huang Transform (HHT) and long short-term memory (LSTM), recurrent neural networks (RNN) to detect and classify power quality disturbances. Nine types of synthetic signals were reproduced and pre-processed taking into account the mathematical models and their specifications established in the IEEE 1159 standard. In order to eliminate the presence of mode mixing, the ensemble empirical decomposition (EEMD) and masking signal methods were implemented. Additionally, based on the successful benefits of LSTM RNNs reported in the literature, associated to the high accuracy rates achieved at learning long short-term dependencies, this classification technique is implemented to analyze the sequences obtained from the HHT. Based on the experimental results, it is possible to show that the ensemble recognition approach using the EEMD yields a better classification accuracy rate (98.85%) compared with the masking signal and the traditional HHT approach.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Nowadays, based on the society’s increasing dependence on electrical devices, concerns about equipment malfunctions due to the presence of power quality disturbances have become an interesting subject for many research studies around the world. As such, disturbances in Power Quality (PQ) are characterized as a change in current, voltage, or frequency wave forms that interfere wit the normal operation of the power system [1, 2]. Recently, the application of this topic has grown, mainly based on the integration of vast amounts of photovoltaic generation, which leads the distribution feeder to shift towards higher voltages and frequency changes. In this context, it has been shown that the use of renewable power generation brings new challenges related to power quality issues, such as voltage and frequency stability.
For many years, Fourier Series-based analysis were enough to study signals in power systems and the notion of Instantaneous Frequency (IF) has scarcely been explored in these kinds of systems. The arrival of new technologies such as distributed generation, nonlinear loads, and electronic devices, created new problems in power quality and this has generated the necessity to develop new methodologies for analyzing signals which have different characteristics to previously studied [1]. Some of the most common strategies used in power systems for signal analysis have been the Fast Fourier Transform (FFT), the Short Time Fourier Transform (STFT), the Wavelet Transform (WT), the S-transform, Wigner-Ville distribution, among others. Most of them with their inherent time limitation or frequency resolutions [2, 3]. In this context, in [4] and [5], the energy distribution of seven power quality events at different decomposition levels (11, and 13, respectively) of wavelet and the time duration of each disturbance have been analyzed. Results have shown a notable improvement during the detection and localization of PQ disturbances. Alternatively, in [6], the S-transform has been implemented to extract the features required for the classification of 11 PQ events. Although, this approach has reported successful results in the presence of noise, one of the main disadvantages lies on its high computational complexity (O(\(N^3\))) [7]. In order to overcome this limitation, several variations of the fast discrete S-transform (FDST) have been proposed in the context of the PQ disturbances recognition [8, 9]. Recently, the Variational Mode Decomposition (VMD) has been proposed as well to separate the band-limited intrinsic mode functions (BLIMFs) from the non-stationary PQ disturbances [10, 11] as an alternative solution to characterize PQ events.
As such, different methods based on the principle of instantaneous frequency were targeted, searching for an accurate and instantaneous disturbance detection. The Hilbert–Huang Transform (HHT) is an alternative method that emerged as an attempt to contribute to this problem in multi-component signals [12]. The disturbance detection method for power systems application needs to analyze harmonic signals and also nonlinear and non-stationary signals. Hilbert–Huang Transform is an adaptive time-frequency analysis method which can deal with these kinds of signals. Compared with FFT, HHT can analyze non-stationary and non-periodic signals [13]. WT is a powerful signal-processing tool that is particularly useful for the analysis of non-stationary signals [14], and WT has always better resolution than STFT [3]. These techniques have been generally used independently and sometimes such as hybrid combinations to obtain a better performance. It is necessary however to continue seeking for solutions to power quality problems to establish a methodology that allows better detection of disturbances in the power system that is undergoing transformation.
HHT comprises the Empirical Mode Decomposition (EMD) and the Hilbert Transform (HT) which makes possible the computation of the Instantaneous Frequency (IF). The notion of IF has not been thoroughly explored in the analysis of electric power systems. Arguably, the reason for this has been that the century-old electric power system has been dominated by large electromechanical generators that produced an excellent voltage quality with an stationary constant frequency. However, due to the sustained integration of Renewable Energy Sources (RESs) and growing electricity demand, electric power systems are incorporating many new components with different properties than those of the past. For example, as the frequency of the voltage generated from RESs in general does not have the same behavior of the traditional power systems, power electronic converters are used as an interface to synchronize Photovoltaic (PV) generation with the electrical network [15, 16]. In this sense, the approach proposed in this paper can help to overcome the analysis difficulties generated by the complexity of the signals acquired in this field.
Based on these considerations, it is important to implement and develop systems which are able not only to characterize the power quality disturbances, but also classify these fluctuations in order to take additional actions to solve the problematic. In this regard, a wide variety of power quality disturbances classifiers have been proposed in the literature. These strategies include Decision trees (DT), Artificial Neural Networks (ANN), Support Vector Machine (SVM), fuzzy logic (FL), among others. These approaches play a crucial role to classify power quality disturbances because their performance depends on both, the features extracted and the classifier implementation. In this sense, the performance could be highly limited by the effectiveness of the disturbance characterization. ANNs have reported successful results in different classification, optimisation, and data clustering tasks [3]. Likewise, back-propagation algorithm has been the most widely implemented strategy for the MultiLayer Perceptron Neural Network (MLPNN) training, being applied recently in the power quality disturbances classification field together with the HHT results [13]. Additional ANNs configurations have been proposed in this area such as the Radial Basis Function (RBF) or the Probabilistic Neural Networks (PNN). These approaches have been implemented in conjunction with the WT and S-transform [6, 14, 17]. Likewise, a special type of single layer feed-forward neural network (SLFN) called an Extreme Learning Machine has been proposed to detect and classify PQ disturbances in real-time [11, 18]. The results associated to these works have exhibited advantages such as a fast learning and a robust outliers detection during the classification process.
Alternatively, SVM has been effectively used for the automatic classification of voltage disturbances [19]. Some variations of SVM have been reported in this field such as Least-Square LS-SVM, Directed Acyclic Graph DAG-SVM, rank Wavelet rank-WSVM, among others [20,21,22]. Additional solutions have involved the implementation of FL classifiers [23], initialized by Decision Trees (DT) [24] or refined by a combination with ANNs [25, 26]. However, for each of the previous approaches, the corresponding feature extraction strategy should be complemented to select scalar features such as maximum, minimum, or mean values. The reason is based on the inability of these classifiers to analyse complete data sequences, which could allow information losses during the process. Likewise, the SVM and DT strategies generate cumulative errors during the iterative classification process. In this context, ANN-based classifiers have been widely implemented through an expeditious learning process [27]. As such, more complex ANN architectures have emerged in deep learning algorithms, capable of learning optimal features from raw input data. From this perspective, in [28], a voltage sag estimation in sparsely monitored power systems is proposed by means of a Convolutional Neural Network (CNN) model. Li et al., on the other hand, proposes to utilize an approach of deep belief network (DBN) for the classification of PQ disturbances [29].
In order to analyze the signal dynamics from the complete time sequences, Recurrent Neural Networks (RNN) have been implemented [30]. Advantages are focused on their inherent capability to automatically learn optimal features from raw input data, reducing time consuming associated to the selection of scalar variables. However, the performance of this approach decreases when the duration of the temporal dependencies is large. In this way, recently it has been proved that deep learning based strategies, such as the use of gated recurrent units (Long Short Term Memory-LSTM-, Gated Recurrent Units-GRU-, among others) have successfully increased the accuracy results in these classification tasks [31]. Based on the promising results reported in the literature, this work aims to improve them by the combination of a HHT analysis with a gated RNN approach.
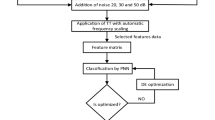
Therefore, in this paper, the classification of power quality disturbances is performed by an hybrid approach that involves a characterization and a classification stage. In the first step, the HHT implementation is carried out, taking into account the concepts of Empirical Mode Decomposition (EMD) and its Intrinsic Mode Functions (IMF). These whole data sequences feed the classifier defined as a Long Short-Term Memory (LSTM) RNN. In this way, the ensemble strategy described in this work allows to use individual advantageous effects to improve the reported results during the automatic classification of power quality disturbances. Experiments were conducted through the analysis of a synthetic database generated with the mathematical models and specifications reported in the IEEE 1159 standard [1]. The results obtained show a superior performance of the proposed approach compared with conventional feature selection and RNN based classification strategies. This paper is organized as follows: Sect. 2 provides the mathematical foundation associated to the HHT and the EMD for disturbances detection, Sect. 3 describes the LSTM RNN architecture implemented for the classification stage, Sect. 4 describes the synthetic data-set generated for the power quality disturbances analysis and Sect. 5 presents the results based on the analysis of the characteristic behavior of instantaneous frequencies, the confusion matrix and the classification accuracy rates. Finally, in Sect. 6, conclusions are drawn and the future work is outlined.
2 Hilbert–Huang Transform (HHT)
The HHT integrates the empirical mode decomposition (EMD) with the Hilbert spectral (HS) analysis methods, developed by Huang et al. [32], specifically used to analyse data with nonlinear and non-stationary dynamics. The EMD can be defined as the decomposition process to represent multi-component non-stationary signals into a sum of sub-signals called Intrinsic Mode Functions (IMF). Subsequently to this procedure, the Hilbert Transform is used to obtain the respective HS [32].
2.1 Empirical Mode Decomposition
According to the EMD approach, any time series can be decomposed into IMFs. The temporal sequences provided contain a set of simple oscillatory modes for certain frequencies [32]. In particular, each IMF must comply with the following specifications:
-
The quantity of crosses by zero and extremes should be the same. It could be different, at most in one.
-
The average maximum and minimum envelopes value must be zero at any point.
-
IMFs have equal numbers of extreme crosses per zero.
-
IMFs have at least two extreme values that could be minimum or maximum.
-
Time scale should be characterized by the time between the extreme values.
In addition, the filtering process implemented to compute the IMFs is performed by following this procedure:
-
1.
Detection of each minimum or maximum value of the primary signal x(t).
-
2.
Calculation of the respective envelopes, based on the connection between maximum and minimum points.
-
3.
Mean value computation based on the upper and the lower envelope m(t).
-
4.
Calculation of the new signal \(d(t)=x(t)-m(t)\).
-
5.
Repetition of the previous steps until the final IMF becomes a zero-mean signal.
-
6.
Definition of the first IMF as the d(t) signal with zero mean.
-
7.
New IMF considers the IMF extracted from the original signal and its corresponding residue.
-
8.
When the residue becomes a monotonous function (with only one minimum and maximum), this process ends. From this point on, a new IMF can not be retrieved from the residue values.
The initial function can be reconstructed using the statement:
with \(C_{i}(t)\) as the IMFs extracted from the initial function and \(r_{n}\) as the residues from the decomposition. When this procedure is completed, the Hilbert transform is calculated for each signal. As such, the respective amplitudes and instantaneous frequencies are obtained (see Fig. 1).

IMF empirical decomposition mode algorithm
2.2 Hilbert Transform
The Hilbert Transform is a special case of the convolution process between x(t) and the function 1/ty [33]:
with this definition, x(t) and y(t) form the complex conjugate pair, so we can have an analytic signal, z(t) using the Euler’s identity, as
where:
The polar coordinate expression further clarifies the local nature of this representation: it is the best local fit of an amplitude and phase varying trigonometric function to x(t) [32]. Theoretically, there are infinite ways of defining the imaginary part, but the Hilbert transform provides a unique way using an analytic function. Considering the previous statements, the instantaneous frequency is calculated by:
It is important to note that the expressions to compute amplitude (Eq. 4) and frequency (Eq. 6) are time dependent, allowing to express amplitude values based on time and frequency (H(\(\omega \),t)) [33]. In order to adequately estimate the instantaneous frequency using the Hilbert transform, the initial time sequence is defined as a purely oscillatory signal with a zero reference level. Based on this concept, x(t) can be represented by a sum of purely oscillatory signals (Empirical Mode Decomposition-EMD-) [33].
2.3 Ensemble Empirical Mode Decomposition method (EEMD)
The EEMD arose as an alternative to eliminate mode mixing, which is one of the biggest problems for the EMD. The EEMD consist of the addition of white Gaussian noise (WGN) to the signal in order to separate the closest IMFs. The ensemble can be described as \({s_n(t)_{n=1}^{N}}=x(t)+{w_n(t)_{n=1}^{N}}\), where x(t) is the original signal, \({w_n(t)_{n=1}^{N}}\sim N(0,\sigma {^{2}}))\) are independent realizations of (WGN), and the averaging is performed across same-index IMFs over the ensemble. Since the added noise is different for each test, the resulting IMF does not show any correlation with the corresponding IMFs from other analysis. Since, the averaging effects of added WGN can be reduced with an increase in the ensemble size N (samples) according to \(\sigma ^{2}/N^{2}\), the EEMD benefits from enhanced local mean estimation in noisy data to yield IMFs that are less prone to mode mixing. If the value of N is adequate, the aggregate noise can be eliminated by the ensemble average of the IMF obtained [34]. The ensemble size of \(N= 1000\) was implemented because the resulting IMFs exhibited less residual noise than the IMFs obtained with the EMD, whose IMFs still contained oscillations. The EEMD process is described in Algorithm 1.

The white noise series included in the process cancel each other out at the final average of the corresponding IMF, plus the average of the IMF remain within the natural dyadic filter limits. Therefore, it significantly reduces the possibility of mode mixing and it preserves the dyadic property [34]. The added white noise effect must decrease according to the following statistical rule (stop criteria):
where N is the number of set elements, \(\varepsilon \) is the added noise amplitude, and \(\varepsilon _{n}\) is the errors’ final standard deviation , which is defined as the difference between the input signal and the corresponding IMFs. It is recommended according to [34], to repeat three times the “sifting” number (N) or set it to 10 as stop criteria.
2.4 Masking Signal
The mode mixing phenomenon can be managed by adding a masking signal, which can impose a controlled artificial mode by mixing it with one of the signal’s components. This operation leaves the other element free of mode mixing [35]. If a masking signal of appropriate frequency and amplitude is added to the original signal, this masking signal will attract just one of the mixed signals. The principle of attraction between the spectral tones of closed space will create a new controlled mixture of artificial mode. This way, one of the mixed signals is originally separated from the mix of modes and comes out as a pure mode (IMF) from the EMD process [35]. Algorithm 2 shows the main stages of this method:

The masking signal selection procedure is detailed in [35], where the Boundary Conditions map presented by Flandrin in [36] has been used . This work presents a guide to choose the masking signal’s frequency and amplitude. It is important to highlight from this work, when selecting this frequency, the relationship principle between the original signal frequency and the the masking signal frequency must considered, which has to be located in the red area of the Boundary Conditions map. While the frequencies proportion must be located in the blue area of the map [35]. The same procedure must be completed for amplitude values.
3 Long Short-Term Memory (LSTM) Recurrent Neural Networks
Recurrent neural networks (RNN) analyses data sequences, in comparison with traditional neural networks, where every input and output is defined as a scalar variable. This type of network has been called recurrent, because it performs the same task for each sequence sample and the output depends on previous calculations. Based on this idea, RNNs are represented as memory units that captures and processes information based on previous calculations [37]. A RNN can be represented as follows (Fig. 2):

Recurrent Neural Network Structure
Where \(x_t\) is the input in the instant t, \(h_t\) is defined as the neural network memory and \(y_{class}\) is the respective output. It is important to point out that in contrast to a traditional neural network, a RNN shares the same parameters for each layer [37]. Several investigations have proposed alternative structures for the memory units of the traditional RNN model in order to improve its performance. Remarkable results have been found with bidirectional, deep and LSTM RNNs.
Specifically, traditional structures for the recurrent neural networks can model the correlations between different segments of the sequences, however, problems arise when handling dependencies for a significant number of samples [38].
LSTM networks overcome this problem, since each network allows to record information for long periods of time. As such, in this paper, LSTM RNNs are implemented based on their inherent advantages during the memory calculation, which combines the previous state, the current memory, and inputs values. In particular, LSTM unit has a chain structure, where its flow chart depicts the specific process of the memory generation (see Fig. 3). This formulation significantly improves the RNNs performance [38].

LSTM neuron model
Each line of the diagram represents a complete vector, from one node’s output to the input of the next. LSTMs are characterized because they have the ability to add or remove module status information structures called gates. Each model has an input gate i, a memory gate, f and an output gate o. First, the input is limited between values of \(-1\) and 1, by means of the activation function \(\tanh \) [38]:
where \(U^g\) and \(V^g\) are the input and output weights of the previous module respectively and \(b^g\) represents the input bias. Thus, the input is multiplied by the output of the input gate defined by a sigmoid function:
The LSTM output module input section is defined by \(g^{\circ }i\). The memory gate output is defined as:
The output gate is represented as:
4 Data-Set Generation
In order to characterize the power system behavior, disturbance signals are usually categorized in terms of their period and their magnitude. In this work, the mathematical models associated to these phenomena, described on IEEE 1159, were taken as reference [1]. Taken into account the parametric equations and the parameter range variations reported for each disturbance model, one hundred variations were generated for each signal (see Table 1) [1].
The disturbance generation is carried out using a sampling frequency of 1kHz. For every mathematical model associated to the PQ disturbances, the parameter A depicts the signal amplitude and it is represented as constant (equal to 1). The parameter \(\alpha \), on the other hand, characterizes the intensity of a sag, swell, or interruption disturbance. Likewise, the step function \(\mu (t)\) represents the duration of the event on the signal. Parameters \(\beta \) and \(\alpha _f\) specify the flicker frequency and the magnitude variation for a range from 5 to 20 Hz and 0.1 to 0.2 per unit, respectively. Finally, the 3rd, 5th, and 7th order harmonic component per unit values ranging from 0.05 to 0.15 per unit are taken into consideration for each disturbance.
5 Classification Results
During the experimental evaluation, the HHT is implemented for each of the synthetic signals, taking into account the instantaneous values for the frequency. Figures 4, 5, 6, 7, 8, 9, 10 and 11 expose the characteristic dynamics for each disturbance in the frequency domain. In order to carry out the classification process for each type of disturbance, the second IMF is analyzed. Although the first IMF provides the base frequency (60 Hz), it is important to highlight the presence of noise, which makes it difficult to ensure an adequate representation of the analyzed disturbance’s real dynamics. As such, the second IMF for each disturbance reduces the noise, providing a more accurate signal characterization. Four random signals A, B, C, and D are presented in order to evidence the instantaneous frequency’s behavior that characterizes each signal.

Instantaneous values of the sags’ frequency

Instantaneous values of the swells’ frequency

Instantaneous values of the harmonics’ frequency

Instantaneous values of the interruptions’ frequency

Instantaneous values of the frequency for high-frequency transients

Instantaneous values of the frequency for low-frequency transients disturbances

Instantaneous values of the sag with harmonics frequency

Instantaneous values of the swell with harmonics frequency
Taking into account the computed frequencies, the classification process using the LSTM recurrent neural networks is carried out. The confusion matrix shown in Fig. 12 provides the percentage of correctly classified signals, represented by green boxes. Likewise, erroneously classified signals are presented in red boxes. The total percentage of correctly (96.86%) and erroneously (3.14%) classified disturbances are shown in blue boxes. Each element located in the the left and bottom sides of the confusion matrix, provide the signal’s output (see Table 2).

Classification results
The instantaneous frequency behavior of each disturbance is analyzed in order to understand the reason why rates below an acceptable percentage were obtained for some kinds of disturbances. It can be seen that different disturbances have similar frequency values in similar ranges which can be the main cause of error. This can be evidenced in the confusion matrix, where only twenty four out of the fifty interruption disturbances were correctly classified, the rest were classified as high frequency transients. While analyzing different disturbances, it was discovered that many presented mode mixing. In order to study the impact of this phenomenon on the classification results, the two electromagnetic phenomena that evidenced the highest amount of mode mixing cases were selected. These signals were the high frequency transients (HFT) and low frequency transients (LFT). To begin with the analysis, the signal samples with mode mixing for each of the analysed disturbances (high and low frequency transients) were selected and their intrinsic functions were obtained by applying the empirical mode decomposition method (see Fig. 13).

Decomposition using standard EMD
As Fig. 13 shows, in the second and third IMF, mode mixing occurs due to the sudden change in frequency. In order to solve this problem the masking signal and EEMD methods are applied to compare and determine which method successfully eliminates mode mixing.
5.1 Ensemble Empirical Mode Decomposition (EEMD) Results
In the EEMD case, the standard deviation parameters, maximum number of sifting, and the number of iterations are established. These values are selected by performing different tests and sequentially alternating their properties. For the standard deviation, the value suggested by Huang [34] of 0.2 was selected. In Fig. 14 the IMF obtained using the EEMD method can be observed.

Decomposition using EEMD
5.2 Masking Signal Results
In this case, a masking signal of the form \(x_{m}=A\sin (2\pi f_{m}t)\) was selected. To obtain the frequency and amplitude values, the Boundary Map [36] technique is applied. The instantaneous frequencies (see Fig. 15) and amplitude of the transformed signal are obtained using the Hilbert transform.

Instantaneous frequencies of the third IMF where mode mixing exists
Based on the obtained instantaneous frequencies, the values calculated from the proposed equations are replaced for the masking signal selection shown in [35]. The corresponding results are summarized in Table 3.
Where estimated F1 and F2 are the frequencies where mode mixing appears, estimated A and B are the amplitude components that present mode mixing. The estimated frequency is the minimum instantaneous frequency detected and \(\Delta f\) is the number of peaks/seconds in the instantaneous frequency graphs. Replacing the equations, the resulting masking signal is:
With the selected masking signal, the characteristic IMFs are calculated (see Fig. 16).

Decomposition using masking signal
In order to compare the three methods, the resulting IMFs are plotted on the same graph as shown in Fig. 17. Likewise, a similar procedure is performed with the low frequency transient signals (LFT). For the implementation of the EEMD method in both scenarios, the parameters remain the same. For the experiments associated to the masking signal method, the values used are described in Table 4. By replacing the equations, the resulting masking signal is represented as:

Comparison of resulting IMF with each method implemented to the HFT. In green, the EEMD is presented, in purple the masking signal, in blue and red the IMF with mode mixing

Comparison of resulting IMF with each method implemented to the LFT. In green the EEMD is presented, in blue the masking signal and in red the IMF with mode mixing
It can be seen that both implemented methods dissipate the mode mixing feature. However, the EEMD has a better performance as it can be seen in Fig. 18, where the masking signal shows difficulties processing low frequency transients since it can not establish a constant behavior.
Another factor to take into account is the parameter selection for each type of model. In the case of the EEMD, it is not required to make a representative change in the number of samples of white noise, the standard deviation, and the number of sifting. For both cases, the values used were the same and the expected results were obtained, since the analyzed signals are synthetic and they do not present significant changes in mode mixing.
For the masking signal, the proposed method in [39] presents a wide range of frequencies where significant changes are observed on a small scale, expanding the samples based on the frequency selection. To choose the amplitude, it must satisfy the restrictions presented in the Boundary map.

Map of boundary conditions. Taken from [36]. The green dot represents the frequency for the LFT signal and the purple dot the frequency for the HFT signal
Based on the map shown in Fig. 19, it can be seen that the selected signals meet the parameters, since they are in the blue band. In order to verify if the elimination of mode mixing has a direct impact in the classification of every disturbance, two case scenarios of classification throughout the LSTM recurrent neural networks are performed. For both scenarios, the classification was carried out implementing the same methodology used with the empirical mode decomposition, the only difference lies in the instantaneous frequencies used for the HFT and LFT. In the first case, the EEMD frequencies for each transient were analyzed and in the second case, the respective masking signal frequencies. Classification results are presented in Fig. 20 (masking signal) and Fig. 21 (EEMD).

Classification results (masking signal)

Classification results (EEMD)
Based on these results, a better classification performance is obtained using the EEMD method (98.85), showing a significant improvement in the transients classification by including the mixing mode reduction (from 48 to 100%). The transients classification rates increase, in turn the global performance from 96.86 to 98.85%. Regarding to the computational time, the feature extraction process takes 9.14 and 4.53 s for the EEMD, and the masking signal, respectively. On the other hand, the classifier takes 54 s analyzing the signal obtained from the EEMD approach, and 54.5 s with the masking signal results.
5.3 Discussion
In order to compare our results with existing methodologies implemented in the PQ disturbance classification field, the Variational Mode Decomposition (VMD) and the Wavelet Transform (WT) are implemented as alternative feature extraction methods. The VMD decomposes the PQ disturbance into various modes using variation calculus. In this case, each obtained function is assumed to have compact frequency support around a central frequency. The WT, on the other hand, uses the mother wavelets to divide the 1-D disturbances signals to ND time series. Likewise, the proposed model is compared with a simple LSTM-based classifier fed with the raw data.
For the VMD implementation, \(\alpha \) is the balancing parameter of the data-fidelity constraint, which is set to 2000. It has been proved that a low value of \(\alpha \) injects high amount of noise in the decomposed modes. To extract features in DWT domain, the signal decomposition is carried out using Morlet as the mother wavelet.
It is noticed that the time complexity of VMD is higher than WT. VMD takes a computational time of approximately 357 s for feature extraction, while WT requires around 100 s. The LSTM-based classification takes around 3673 and 3592 s, for both approaches, respectively. All the experiments carried out in this work are developed on Windows system having 2.50 GHz Core i5 with 8 GB RAM. The accuracy metrics for the approaches, considered in this stage, are summarized in Table 5.
From Table 5, it is noticed that the EEMD feature extraction outperforms the VMD and WT. In addition, it is shown that a single LSTM can not achieve the same performance results compared with the ensemble method proposed in this paper (90.52%, compared with 98.85%, respectively). Regarding our previous work [13], the proposed approach outperforms the results reported (accuracy of 98.85% compared to 94.6%). The main reason relies on the fact that in [13], a different approach is proposed, considering only a fixed number of instantaneous frequency values from the EEMD signal, in contrast with the current strategy where the whole frequency sequence and its internal dependencies are modeled to carry out the classification process.
6 Conclusions
Power disturbances can cause innumerable problems in industrial and residential demand points that can damage equipment, causing economic losses in a variety of ways. For this reason, different strategies have been implemented to detect power disturbances in order to manage and mitigate its effects. Most of the methods reported on the literature show poor results in terms of efficiency, computer load, and performance. As such, the implementation of the Hilbert–Huang transform facilitates the detection procedure of power quality disturbances, providing a better analysis of the signal dynamics. These results are based on the fact that this mathematical tool allows the analysis of non-stationary signals, revealing significant information of the intrinsic decompositions for each disturbance. The EEMD presents satisfactory results obtaining a final classification rate of 98.85 %, which was the highest compared to the rest of the techniques implemented. These results provide evidence that the classification strategy is effective when analyzing the similarity features in the frequency domain between the disturbance signals. Our ongoing work is focused on studying the size of the window used for the selection of the frequencies, as well as its characteristic variables. In addition, it is important to keep analyzing alternative deep learning configurations in order to improve the efficacy of the classification process in real-time events. The adoption of these algorithms, on a large scale, could increase the disturbances classification rates, and in this way improve the quality of the power system.
References
IEEE recommended practice for monitoring electric power quality (2009) IEEE Std 1159-2009 (Revision of IEEE Std 1159-1995) c1–81. https://doi.org/10.1109/IEEESTD.2009.5154067
Shukla S, Mishra S, Singh B (2014) Power quality event classification under noisy conditions using EMD-based de-noising techniques. IEEE Trans Ind Inform 10(2):1044–1054. https://doi.org/10.1109/TII.2013.2289392
Uyar M, Yildirim S, Gencoglu MT (2009) An expert system based on s-transform and neural network for automatic classification of power quality disturbances. Expert Syst Appl 36(3):5962–5975
Gaing Z-L (2004) Wavelet-based neural network for power disturbance recognition and classification. IEEE Trans Power Deliv 19(4):1560–1568
He H, Starzyk JA (2005) A self-organizing learning array system for power quality classification based on wavelet transform. IEEE Trans Power Deliv 21(1):286–295
Mishra S, Bhende C, Panigrahi B (2007) Detection and classification of power quality disturbances using s-transform and probabilistic neural network. IEEE Trans Power Deliv 23(1):280–287
Brown RA, Frayne R (2008) A fast discrete s-transform for biomedical signal processing. In: 30th annual international conference of the IEEE engineering in medicine and biology society. IEEE 2008, pp 2586–2589
Biswal M, Dash PK (2013) Detection and characterization of multiple power quality disturbances with a fast s-transform and decision tree based classifier. Digit Signal Process 23(4):1071–1083
Babu PR, Dash P, Swain S, Sivanagaraju S (2014) A new fast discrete s-transform and decision tree for the classification and monitoring of power quality disturbance waveforms. Int Trans Electr Energy Syst 24(9):1279–1300
Achlerkar PD, Samantaray SR, Manikandan MS (2016) Variational mode decomposition and decision tree based detection and classification of power quality disturbances in grid-connected distributed generation system. IEEE Trans Smart Grid 9(4):3122–3132
Sahani M, Dash P (2018) Variational mode decomposition and weighted online sequential extreme learning machine for power quality event patterns recognition. Neurocomputing 310:10–27
Mandic DP, Rehman Nu, Wu Z, Huang NE (2013) Empirical mode decomposition-based time-frequency analysis of multivariate signals: the power of adaptive data analysis. IEEE Signal Process Mag 30(6):74–86
Rodriguez MA, Sotomonte JF, Cifuentes J, Bueno-López M (2019) Classification of power quality disturbances using Hilbert–Huang transform and a multilayer perceptron neural network model. In: 2019 international conference on smart energy systems and technologies (SEST). IEEE, pp. 1–6
Lin C-H, Tsao M-C (2005) Power quality detection with classification enhancible wavelet-probabilistic network in a power system. IEE Proc Gener Transm Distrib 152(6):969–976
Yue X, Boroyevich D, Lee FC, Chen F, Burgos R, Zhuo F (2018) Beat frequency oscillation analysis for power electronic converters in DC nanogrid based on crossed frequency output impedance matrix model. IEEE Trans Power Electron 33(4):3052–3064
Mozaffari K, Amirabadi M (2019) A highly reliable and efficient class of single-stage high-frequency ac-link converters. IEEE Trans Power Electron 34(9):8435–8452
Jayasree T, Devaraj D, Sukanesh R (2009) Power quality disturbance classification using s-transform and radial basis network. Appl Artif Intell 23(7):680–693
Chakravorti T, Dash PK (2017) Multiclass power quality events classification using variational mode decomposition with fast reduced kernel extreme learning machine-based feature selection. IET Sci Meas Technol 12(1):106–117
Janik P, Lobos T (2006) Automated classification of power-quality disturbances using SVM and RBF networks. IEEE Trans Power Deliv 21(3):1663–1669
Zhang Q-M, Liu H-J (2008) Application of LS-SVM in classification of power quality disturbances. Proc Chin Soc Electr Eng 28(1):106
Li J, Teng Z, Tang Q, Song J (2016) Detection and classification of power quality disturbances using double resolution S-transform and DAG-SVMs. IEEE Trans Instrum Meas 65(10):2302–2312
Liu Z, Cui Y, Li W (2015) A classification method for complex power quality disturbances using EEMD and rank wavelet SVM. IEEE Trans Smart Grid 6(4):1678–1685
Meher SK, Pradhan AK (2010) Fuzzy classifiers for power quality events analysis. Electric power systems Research 80(1):71–76
Samantaray S (2010) Decision tree-initialised fuzzy rule-based approach for power quality events classification. IET Gener Transm Distrib 4(4):538–551
Saikia L, Borah S, Pait S (2010) Detection, and classification of power quality disturbances using wavelet transform, fuzzy logic, and neural network. In: Annual IEEE India conference (INDICON). IEEE 2010, pp 1–5
Kanirajan P, Kumar VS (2015) Wavelet-based power quality disturbances detection and classification using RBFNN and fuzzy logic. Int J Fuzzy Syst 17(4):623–634
Cai K, Cao W, Aarniovuori L, Pang H, Lin Y, Li G (2019) Classification of power quality disturbances using Wigner-Ville distribution and deep convolutional neural networks. IEEE Access 7:119099–119109
Liao H, Milanović JV, Rodrigues M, Shenfield A (2018) Voltage sag estimation in sparsely monitored power systems based on deep learning and system area mapping. IEEE Trans Power Deliv 33(6):3162–3172
Li C, Li Z, Jia N, Qi Z, Wu J (2018) Classification of power-quality disturbances using deep belief network. In: 2018 international conference on wavelet analysis and pattern recognition (ICWAPR). IEEE, pp 231–237
Temurtas F, Gunturkun R, Yumusak N, Temurtas H (2004) Harmonic detection using feed forward and recurrent neural networks for active filters. Electr Power Syst Res 72(1):33–40
Mohan N, Soman K, Vinayakumar R (2017) Deep power: deep learning architectures for power quality disturbances classification. In: 2017 international conference on technological advancements in power and energy (TAP Energy). IEEE, pp 1–6
Huang NE, Shen Z, Long SR, Wu MC, Shih HH, Zheng Q, Yen N-C, Tung CC, Liu HH (1998) The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc R Soc Lond A Math Phys Eng Sci 454(1971):903–995. https://doi.org/10.1098/rspa.1998.0193
Alshahrani S, Abbod M, Taylor G (2016) Detection and classification of power quality disturbances based on Hilbert–Huang transform and feed forward neural networks. In: 2016 51st international universities power engineering conference (UPEC), pp. 1–6. https://doi.org/10.1109/UPEC.2016.8114075
Wu Z, Huang NE (2009) Ensemble empirical mode decomposition: a noise-assisted data analysis method. Adv Adapt Data Anal 1(01):1–41
Gasca-Segura MV, Bueno-López M, Molinas M, Fosso OB (2018) Time-frequency analysis for nonlinear and non-stationary signals using HHT: a mode mixing separation technique. IEEE Latin Am Trans 16(4):1091–1098. https://doi.org/10.1109/TLA.2018.8362142
Rilling G, Flandrin P (2007) One or two frequencies? The empirical mode decomposition answers. IEEE Trans Signal Process 56(1):85–95. https://doi.org/10.1109/TSP.2007.906771
Guridi Mateos G et al (2017) Modelos de redes neuronales recurrentes en clasificación de patentes, B.S. thesis
Cifuentes J, Boulanger P, Pham MT, Prieto F, Moreau R (2019) Gesture classification using lstm recurrent neural networks. In: 41st annual international conference of the IEEE engineering in medicine and biology society (EMBC), vol 2019. IEEE, pp 6864–6867. https://doi.org/10.1109/EMBC.2019.8857592
Fosso OB, Molinas M (2018) EMD mode mixing separation of signals with close spectral proximity in smart grids. In: 2018 IEEE PES innovative smart grid technologies conference Europe (ISGT-Europe), pp 1–6. https://doi.org/10.1109/ISGTEurope.2018.8571816
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This document is a collaborative effort.
Rights and permissions
About this article

Cite this article
Rodriguez, M.A., Sotomonte, J.F., Cifuentes, J. et al. A Classification Method for Power-Quality Disturbances Using Hilbert–Huang Transform and LSTM Recurrent Neural Networks. J. Electr. Eng. Technol. 16, 249–266 (2021). https://doi.org/10.1007/s42835-020-00612-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s42835-020-00612-5