
Abstract
Goodness-of-fit procedures are introduced for testing the validity of compound models. New tests that utilize the Laplace transform as well as classical tests based on the distribution function are investigated. A major area of application of compound laws is in insurance, to model total claims resulting from specific claim frequencies and individual claim sizes. Monte Carlo simulations are used to compare the different test procedures under a variety of specifications for these two components of total claims. A detailed application to an insurance dataset is presented.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Consider the random sum of random variables,
where N is a count random variable with probability mass function \(p^N\) and the \(U_k\)’s form a sequence of independently and identically distributed (iid) non-negative continuous random variables having a distribution function (DF) \(F^U\), and independent of N.
Such “compound” random variables defined in (1) come up in many practical applications and have different interpretations depending on the context. Our focus here is to consider this compound variable X as the total amount of claim associated with a non-life insurance portfolio over a fixed time period. The random variable N represents the claim frequency while the \(U_k\)’s represent the individual claim sizes. The final objective of practitioners is to identify the components of this quantity defined in (1), i.e. identify the distribution of the claim frequency N and that of the individual claim sizes U. We will work under the assumption that the correspondence between X and the DF ’s for N and \(U_k\)’s within model (1) as being unique and demonstrate that it works in many practical situations, although there may be few exceptions in theory. We note that incomplete data situations, such as these where one has only observations on the total claims X, arise in practice when an insurance company keeps track of only aggregated data by the month, the quarter, or the year. The methodology can also be useful to a reinsurance company, which has only access to partial information on X, and would like to better understand the underlying risk and improve the rate-making. Model (1) is also useful in the banking industry which has only access to data on annualized operational risk. As pointed out in Chaudhury [6], the data available to assess operational risk are typically incomplete as banks often report aggregate losses, often discarding small losses. Such loss of information also occurs when data are merged say after the acquisition of another banking operation.
Assume we observe aggregated claim sizes \(X_1,\ldots ,X_n\), and we wish to assess the conformity of a given compound model in the composite situation whereby the DF ’s involved depend on unknown parameters. Specifically we write \(p^N:=p^N(\cdot ; \vartheta _N)\) and \(F^U:=F^U(\cdot ; \vartheta _U)\), for the component DF ’s with the parameter vector \(\vartheta =(\vartheta _N,\vartheta _U)\) treated as unknown. If \(F^X\) denotes the DF of the compound r.v. X, we wish to test the composite null hypothesis
where \(\Theta \) denotes an appropriate parameter space.
Two types of nonparametric goodness-of-fit (GOF) tests are considered. The first type is based on a dissimilarity measure between the population DF and the empirical DF of the available data; see e.g. D’Agostino and Stephens [9], or Thas [37] for reviews on the subject of DF-based GOF tests. Since the random variable X typically has a point mass at 0 corresponding to \(N=0\), the standard Kolmogorov-Smirnov (KS) and Cramèr-von Mises (CvM) GOF tests need some corresponding modifications. Although these procedures are originally meant to handle continuous data, extensions have been proposed to assess the adequacy for discrete, grouped, or mixed data, see for instance Schmid [30], Walsh [39], Noether [27], Slakter [31], Conover [8], Gleser [16], and Dimitrova et al. [10] for the KS GOF test. Regarding the CvM criterion, the reader is referred to the works of Choulakian et al. [7], Henze [19], Spinelli and Stephens [33], Spinelli [32] and Lockhart et al. [24]. We propose modified estimators of the KS and CvM test statistics that take care of the point mass at 0 and also address the lack of closed form expression for the DF of X.
A second group of procedures we employ here measure the model discrepancy in terms of the distance between the population Laplace transform (LT) and the empirical LT. Statistical tests involving this approach work directly with transform-based statistics, thus avoiding LT inversion which is often complex and costly. These methods are quite convenient in cases where the DF is complicated while the LT is readily available. Such methods are relatively new but since their introduction, they have been used in various estimation and testing problems; see for instance Henze [18], Henze and Klar [20], Henze and Meintanis [21], Meintanis and Iliopoulos [25], Besbeas and Morgan [4], Ghosh and Beran [14], Milošević and Obradović [26], and Allison et al. [2].
The test statistics involved in these procedures lead to non-standard asymptotic distributions for which finding critical values requires sophisticated numerical methods. Moreover, due to the fact that the parameters of the null distribution have to be estimated a priori, the tests are not distribution free. We overcome these difficulties using a parametric bootstrap approach, which has gained popularity in approximating the null distribution in goodness-of-fit testing.
The paper is organized as follows. Section 2 provides a brief background on compound distributions and reviews moment-based estimation of the parameters. Section 3 details the goodness-of-fit testing procedures tailored to the distribution of aggregated claim sizes. Section 4 reports the results of a Monte Carlo simulation study conducted to compare of the GOF tests in terms of power. Section 5 presents an application of our GOF procedures to a real dataset from the insurance industry. We conclude with discussion in Sect. 6. Asymptotic results are contained in the Appendix.
2 Preliminaries
2.1 Compound Distribution
Recall that \(X=\sum _{k=1}^{N}U_i\), where N is a counting rv with probability mass function \(p^N\) and the \(U_k\)’s are iid non-negative continuous random variables with DF \(F^U\), and independent of N. Given the fact that N can take the value zero with probability \(p^{N}(0)\), the DF of X is given by
where \(F^{X|N>0}\) denotes the DF of X provided that \(N>0\). Note that the conditional probability distribution of \(X|N>0\) is continuous. The Laplace transform (LT) of X, defined as \(L^{X}(t):={\mathbb {E}}(e^{-tX})\), may be expressed as
where \(G^N(t):={\mathbb {E}}(t^{N})\) denotes the probability generating function of N and \(L^{U}\) is the LT of the claim size distribution.
We let the distribution of the claim sizes be quite general (apart from its parametric form), but model the claim frequency via a counting distribution from the broad class viz. Katz family. Recall that the distribution of N belongs to the Katz family [23], written \(N\sim \text {KF}(a,b)\), if the probability mass function satisfies the recursive equation
A characterization is given in Sundt and Jewell [35]. Prominent members of this family (5) include
-
1.
The binomial \(N\sim \text {Bin}(\alpha ,p)\) (\(\alpha \in {\mathbb {N}}\), \(0<p<1\)) which satisfies (5) with \(a = -p/(1-p)\) and \(b = (\alpha +1)p/(1-p)\).
-
2.
The Poisson \(N\sim \text {Pois}(\lambda )\) (\(\lambda >0\)) which satisfies (5) with \(a=0\) and \(b=\lambda \).
-
3.
The negative binomial \(N\sim \text {Neg-Bin}(\alpha ,p)\) (\(\alpha >0\), \(0<p<1\)) with probability mass function
$$\begin{aligned} p^{N}(k)=\frac{\Gamma (\alpha +k)}{\Gamma (\alpha )\Gamma (k+1)}p^{\alpha }(1-p)^{k},\text { for }k\ge 0, \end{aligned}$$(6)which satisfies (5) with \(a = 1-p\) and \(b = (\alpha -1)(1-p)\).
These discrete distributions are commonly used to model claim frequencies and this choice seems quite general and justified.
Throughout this paper, we will denote by \(n_0\le n\) the number of zeros and by \(X_1^{+},\ldots ,X_{n-n_0}^{+}\) the nonzero values within the sample \(X_1,\ldots ,X_n\).
2.2 Moments Based Estimation for Aggregate Claims
The Method of Moments estimator is obtained by matching the empirical moments with the theoretical moments of the parametric model. If \(N\sim \text {KF}(a,b)\), then the moments of X may be expressed in terms of the moments of U via the recursive relations
provided in De Pril [29, Equation 3]. Solving the system (7) for \(\vartheta _N= (a,b)\) and \(\vartheta _U\) yields the Method of Moments Estimators (MMEs).
Denote by \({\bar{X}}=n^{-1}\sum _{i=1}^{n}X_i\) and \(m_{k}=n^{-1}\sum _{i=1}^{n}\left( X_i-{\bar{X}}\right) ^{k}\) the sample mean and the sample centered moments of order \(k\ge 2\), respectively. The following examples provide expressions for the MMEs in the geometric-exponential, Poisson-exponential, and Poisson-gamma cases:
Example 1
-
1.
(geometric-exponential): Assume that the claim sizes follow an exponential distribution, \(U\sim \text {Exp}(\theta )\), and that the claim frequency is geometric \(N\sim \text {Neg-Bin}(1,p)\). Thus, we have that \(a=1-p\), \(b=0\), in the Katz family parametrization in (5). Substituting in (7) and solving yields the parameters estimates
$$\begin{aligned} {\widehat{\theta }}=\frac{m_2-{\bar{X}}^{2}}{2{{\bar{X}}}}\text { and }{\widehat{p}}=\frac{{\widehat{\theta }}}{{\widehat{\theta }}+{{\bar{X}}}}. \end{aligned}$$(8) -
2.
(Poisson-exponential): Assume a Poisson frequency for \(N\sim \text {Pois}(\lambda )\), with claim size following an exponential distribution \(U\sim Exp(\theta )\), with density
$$\begin{aligned} f^U(x)=\frac{1}{\theta } e^{-x/\theta },\text { for }x\ge 0. \end{aligned}$$(9)The Poisson distribution with parameter \(\lambda \) corresponds to \(a=0\), \(b=\lambda \) in the Katz family parametrization in (5), while for the exponential distribution with parameter \(\theta \) we have, \({\mathbb {E}}(U)=\theta \), and \({\mathbb {E}}\left( U^{2}\right) =2\theta ^{2}\). Substituting in (7) and solving yields the parameter estimates
$$\begin{aligned} {\widehat{\theta }}=\frac{m_2}{2{{\bar{X}}}}\text { and }{\widehat{\lambda }}=\frac{2{\bar{X}}^{2}}{m_2}. \end{aligned}$$(10) -
3.
(Poisson-gamma): Assume that the claim sizes follow a gamma distribution, \(U\sim \text {gamma}(r, \theta )\), with density
$$\begin{aligned} f^U(x)=\frac{e^{-x/\theta }x^{r-1}}{\theta ^{r}\Gamma (r)},\text { for }x\ge 0. \end{aligned}$$(11)Let the claim frequency be Poisson distributed \(N\sim \text {Pois}(\lambda )\). We have that \(a=0\), \(b=\lambda \), \({\mathbb {E}}(U)=r\theta \), \({\mathbb {E}}\left( U^{2}\right) =r(r+1)\theta ^{2}\), and \({\mathbb {E}}\left( U^{3}\right) =r(r+1)(r+2)\theta ^{3}\). Substituting in (7) and solving yields the parameters estimates
$$\begin{aligned} {\widehat{r}}=\frac{2m_2^{2}-m_3{\bar{X}}}{m_3{\bar{X}}-m_2^{2}}\ \text {, }{\widehat{\theta }}=\frac{m_2}{{{\bar{X}}}({\widehat{r}}+1)},\ \text { and }{\widehat{\lambda }}=\frac{{\bar{X}}}{{\widehat{r}}{\widehat{\theta }}}. \end{aligned}$$(12)
Remark 21
The estimates of the parameters in Examples (8) and (12) may turn out to be negative due to the lack of fit of the model. The partial Method of Moments presented below often resolves this difficulty.
The “partial Method of Moments" idea is as follows: whenever the data consist of one or more \(X_i\) that take the value zero, i.e. \(n_0>0\), consider adding to the system of equations (7), an additional estimation equation corresponding to the probability of this event. If \(N\sim \text {Bin}(\alpha ,p)\) or \(N\sim \text {Neg-Bin}(\alpha ,p)\), it is given by
and when \(N\sim \text {Pois}(\lambda )\), it is
This probability that \(N=0\) is estimated by \({\widehat{p}}^{N}(0)=n_0/n\). The parameters of the claim sizes distribution follow from the other MME equations. The resulting estimates are referred to as partial Method of Moments Estimators (partial-MMEs) in the remainder. The following example provides the expressions of the partial-MMEs in the geometric-exponential, Poisson-gamma and Poisson-inverse Gaussian cases.
Example 2
-
1.
Assume that the claim frequency is geometric \(N\sim \text {Neg-Bin}(1,p)\), then \(b=0\) and \(a=1-p\), and p is estimated via
$$\begin{aligned} {\widehat{p}} = \frac{n_0}{n}, \end{aligned}$$and if the claim sizes are exponentially distributed \(U\sim \text {Exp}(\theta )\), then \(\theta \) is estimated via
$$\begin{aligned} {\widehat{\theta }}=\frac{{\widehat{p}}{\bar{X}}}{1-{\widehat{p}}}. \end{aligned}$$Hence, the partial-MME cannot be negative in the geometric-exponential case.
-
2.
Assume that the claim frequency is Poisson distributed \(N\sim \text {Pois}(\lambda )\), then \(a=0\) and \(b=\lambda \), and \(\lambda \) is estimated via
$$\begin{aligned} {\widehat{\lambda }} = -\log \left( \frac{n_0}{n}\right) , \end{aligned}$$and if the claim sizes are gamma distributed \(U\sim \text {Gamma}(r,\theta )\), then using (7), the Gamma parameters are estimated via
$$\begin{aligned} {\widehat{r}}=\frac{{\bar{X}}^{2}}{{\widehat{\lambda }}m_2-{\bar{X}}^{2}}\text { and }{\widehat{\theta }}=\frac{{\bar{X}}}{{\widehat{\lambda }}{\widehat{r}}}. \end{aligned}$$(15)These estimators do not involve the third order moment anymore, and if \(\lambda \) is in a reasonable range (\(\lambda > \frac{{\bar{X}}^{2}}{m_2}\)) , their values will be non-negative.
-
3.
Assume that the claim frequency is Poisson distributed \(N\sim \text {Pois}(\lambda )\), then \(a=0\) and \(b=\lambda \), and \(\lambda \) is estimated via
$$\begin{aligned} {\widehat{\lambda }} = -\log \left( \frac{n_0}{n}\right) . \end{aligned}$$Let the claim sizes be inverse-Gaussian distributed \(U\sim \text {IG}(\mu , \phi )\), with density
$$\begin{aligned} f^U(x)=\left( \frac{1}{2\pi x^3\phi }\right) ^{1/2}\exp \left[ -\frac{(x-\mu )^2}{2\mu ^2\phi x}\right] ,\text { }x>0. \end{aligned}$$(16)Substituting in (7) and solving yields the parameter estimates
$$\begin{aligned} {\widehat{\mu }}=\frac{{\bar{X}}}{{\widehat{\lambda }}}\text { and }{\widehat{\phi }}=\frac{{\widehat{\lambda }} m_{2}-{\bar{X}}^2}{{\bar{X}}}. \end{aligned}$$(17)
3 Goodness-of-Fit Tests for Aggregate Claims
3.1 Tests Based on the Distribution Function
As already mentioned, a DF-based GOF test compares the population DF \(F^X_0(x;\vartheta )={\mathbb {P}}_0(X\le x\big |\vartheta ), \ x\in {\mathbb {R}}\), to its empirical counterpart, the empirical DF, defined by
Note that the empirical DF may be rewritten as
where \(F_n^{X|N>0}\) denotes the empirical DF of X given that \(N>0\), which can be estimated via
We estimate the population DF as \({\widehat{F}}_0^{X}(x):=F^{X}_0(x;{\widehat{\vartheta }})\) where \({\widehat{\vartheta }}={\widehat{\vartheta }}(X_1,\ldots X_n)\) is some asymptotically efficient estimator. As we assumed that the distribution of N belongs to the Katz family, the population DF may be approximated via the so-called Panjer algorithm, see [28] for more details.
3.1.1 Kolmogorov-Smirnov Test for Compound Distributions
The Kolmogorov-Smirnov GOF test employs the distance
Denote by \(X^{+}_{1:n-n_0},\ldots ,X^{+}_{n-n_0:n-n_0}\), the order statistics associated with the sample \(X_1^{+},\ldots ,X_{n-n_0}^{+}\), and define the intervals \(I_i=[X_{i:n-n_0}^{+},X_{i+1:n-n_0}^{+})\) for \(i=0,\ldots ,n-n_0\), with the convention \(X_{0:n-n_0}=0\) and \(X_{n-n_0+1:n-n_0}=\infty \) . Then for \(x\in I_i\),
so that
Considering successively the intervals \(I_i\), we estimate the KS distance (20) by
where
3.1.2 Cramér-von Mises Test for Compound Distributions
The Cramér-von Mises GOF test uses the criterion
Given the mixed nature of the distribution of X, the probability measure follows from differentiation in (3) with
where \(\delta _0(x)\) denotes the Dirac measure at 0. Reinserting (22) into the integral (21) yields
Because the non-negative data points \(X_1^{+},\ldots ,X_{n-n_0}^{+}\) are assumed to be distributed as \(F^{X|N>0}_0\) under the null hypothesis, we can write the integral in (23) as
By expanding the square and applying the change of variable \(u = F^{X|N>0}(x)\), the integral (24) may be rewritten as
Finally combining (23), (24) and (25) allows to estimate the CvM statistics as
where \({{\widehat{F}}}^{X|N>0}_0(x):=F^{X|N>0}_0(x;{{\widehat{\vartheta }}})\) and \({\widehat{p}}^{N}_0(0):=p^{N}_0(0;{\widehat{\vartheta }}_N)\) is the parametric estimator of the probability that \(N=0\) under the null hypothesis.
3.2 Tests Based on the Laplace Transform
LT-based GOF tests are based on a distance between the LT \(L_0^X(t;\vartheta ):={\mathbb {E}}_0(e^{-t X}|\vartheta ), \ t>0\), (we often write \(L_0^X(t)\) for simplicity) corresponding to the null hypothesis, and its empirical counterpart, the empirical LT, given by
Typically, such a test statistic is expressed as an integrated distance between \(L^X_n(t)\) and \(L_0^X(t)\) involving a weight function \(w(t)>0,\text { }t\ge 0\). The main motivation of the LT approach lies in tractability of the LT \(L_0^X(\cdot )\), given by (4). Two approaches are described in Sects. 3.2.1 and 3.2.2.
3.2.1 \(L^{2}\) Dissimilarity Measure
An obvious choice is to consider the discrepancy between the theoretical and empirical Laplace transform
and integrate \(\mathrm {SE}_n^2(\cdot )\) against the weight function w(t) as
where \({{\widehat{L}}}_0^X(t)= L_0^X(t;{{\widehat{\vartheta }}})\). Choosing the exponential weight function \(w(t)=e^{-\beta t}, \ \beta >0\), allows us to write the test statistic in (28) as
Depending on the hypothesized LT, numerical integration may be required for the evaluation. A classical work-around in LT-based GOF testing to avoid numerical integration is to define a dissimilarity measure relying on a differential equation which we discuss next. The issue of the choice of the weight parameter \(\beta \) is postponed to Sect. 4.
3.2.2 Dissimilarity Measure Based on a Differential Equation
If under the null hypothesis, \(N\sim \text {KF}(a,b)\) then the LT of X satisfies a differential equation. Start by noting that
where \(\mathrm{{d}}f(t)\) denotes the first derivative of the function f with respect to t. Differentiating with respect to t on both sides of (4) yields
and reinserting (30) into (31) leads to the following differential equation
Equation (32) motivates us to define a dissimilarity measure as
where
The corresponding test statistic (analogous to (28)) is defined by
with rejection for large values of \(T_{n,w}\).
Letting \(w(t)=e^{-\beta t}, \ \beta >0\) and by straightforward computations we have from (34),
where

The exponential weight function \(e^{-\beta t}, \ \beta >0\), allows us to derive tractable formulas when the claim sizes distribution is gamma or inverse Gaussian as shown in the following example.
Example 3
First note that \(K_\beta ^{(0)}(x)=(x+\beta )^{-1}\).
-
1.
Let U be gamma distributed \(\text {Gamma}(r,\theta )\) with LT given by \(L^{U}_0(t)=\left( 1+\theta t\right) ^{-r}\). We have that
$$\begin{aligned} K_\beta ^{(1)}(x)=a\frac{(x+\beta +\theta )}{r\theta (x+\beta )^{2}}-\frac{e^{(x+\beta )/\theta }\theta ^{r}}{r(x+\beta )^{r+2}}\Gamma _{u}\left( r+2;\frac{x+\beta }{\theta }\right) \end{aligned}$$and
$$\begin{aligned} K_\beta ^{(2)}(x)= & {} \frac{e^{(x+\beta )/\theta }\theta ^{2r}}{r^{2}(x+\beta )^{2r+3}}\Gamma _u\left( 2r+3;\frac{x+\beta }{\theta }\right) -2a\frac{e^{(x+\beta )/\theta }\theta ^{r}}{r^{2}(x+\beta )^{r+3}}\Gamma _u\left( r+3;\frac{x+\beta }{\theta }\right) \\+ & {} a^{2}\frac{(x^{2}+2\theta x+2\theta ^{2})}{(r\theta )^{2}(x+\beta )^{3}}, \end{aligned}$$where \(\Gamma _u(r;x)=\int _{x}^{+\infty }y^{r-1}e^{-y}\text {d}y\) denotes the upper incomplete gamma function.
-
2.
Let U be inverse Gaussian distributed \(\text {IG}(\mu ,\phi )\) with LT given by \(L^{U}_0(t)=\exp \left( \frac{1-\sqrt{1+\phi \mu ^{2}t}}{\mu \phi }\right) \). Denote by \(c=\sqrt{2}\frac{x+\beta -\mu }{\mu \sqrt{\phi (x+\beta )}}\) and \(d=\sqrt{2}\frac{x+\beta -2\mu }{\mu \sqrt{\phi (x+\beta )}}\). We have that
$$\begin{aligned} K_\beta ^{(1)}(x)= & {} a\frac{\sqrt{\phi }e^{\frac{(x+\beta )}{2\mu ^{2}\phi }}}{(x+\beta )^{3/2}}\left\{ \frac{e^{-\frac{(x+\beta )}{2\mu ^{2}\phi }}\sqrt{x+\beta }}{\mu \sqrt{\phi }}+\frac{1}{\sqrt{2}}\mathrm{{erfc}}\left( \sqrt{2}\frac{x+\beta }{\mu ^{2}\phi }\right) \right\} \\+ & {} \frac{e^{c^{2}}}{\mu ^{2}\sqrt{(x+\beta )\phi }}\left\{ \frac{\mu ^{2}\phi }{x+\beta }\left[ \frac{c}{\sqrt{2}}e^{-c^{2}}+\frac{1}{\sqrt{2}}\mathrm{{erfc}}\left( c\right) \right] \right. \\+ & {} \left. \frac{2\mu ^{2}\sqrt{\phi }}{(x+\beta )^{3/2}}e^{-c^{2}}+\frac{\mu ^{2}}{(x+\beta )^{2}\sqrt{2}}\mathrm{{erfc}}(c)\right\} \end{aligned}$$and
$$\begin{aligned} K_\beta ^{(2)}(x)= & {} \frac{2^{3}e^{d^{2}}}{(x+\beta )^{3}\sqrt{\phi (x+\beta )}}\left( \frac{1}{\sqrt{2}}\mathrm{{erfc}}(d)+ \frac{3\sqrt{\phi (x+\beta )}}{2} e^{-d^{2}}\right. \\+ & {} \left. \frac{3\phi (x+\beta )}{4}\left\{ \frac{d}{\sqrt{2}}e^{-d^{2}}+\frac{1}{\sqrt{2}}\mathrm{{erfc}}(d)+\frac{\sqrt{\phi (x+\beta )}}{2}\frac{d^{2}+4}{2}e^{-d^{2}}\right\} \right) \\- & {} 2ae^{c^{2}}\left( \frac{1}{\sqrt{2}}\mathrm{{erfc}}(c)+3\sqrt{\phi x}e^{-c^{2}}\right. \\+ & {} \left. 3\phi x \left\{ \frac{c}{\sqrt{2}}e^{-c^{2}}+\frac{1}{\sqrt{2}}\mathrm{{erfc}}(c) \right\} +[\phi (x+\beta )]^{3/2}\frac{c^{2}+4}{2}e^{-c^{2}} \right) \\+ & {} a^{2}\left( \frac{1}{\mu ^{2}(x+\beta )}+\frac{2\phi }{(x+\beta )^2}\right) , \end{aligned}$$where \(\mathrm{{erfc}}(x)=\frac{2}{\sqrt{\pi }}\int _{x}^{+\infty }e^{-t^2}\text {d}t\) denotes the complementary error function.
Asymptotic results including the limit distribution of the LT-based test statistic \(S_{n,w}\) under the null hypothesis are given in the Appendix. This distribution, as well as the limit distributions corresponding to the other LT- or DF-based tests considered here, is extremely complicated. Therefore, in the next section, we resort to resampling techniques in order to obtain critical values and actually carry out the tests.
4 Simulation study
This section presents the result of a Monte Carlo experiment designed to assess the power of the GOF procedures. In the first subsection, we investigate the impact of the choice of the parameter \(\beta \) in the weight function on the performance of the LT-based GOF procedures. In the second subsection, the DF- and LT-based GOF tests are compared in terms of power. Parametric bootstrap resampling is used to approximate the distribution of the test statistic under the null hypothesis. This type of resampling has been set on a firm theoretical basis, see e.g., Stute et al. [34], Henze [19], and Genest and Rémillard [13], and is typically called upon when the asymptotic null distribution of any given test is too complicated to apply in practice. For the sake of completeness, the parametric bootstrap principle is recalled hereafter. Say we wish to assess the fit of an iid sample \(X_1,\ldots , X_n\) of aggregated claim data to a parametric model characterized by its DF \(F_0^X(x,\vartheta )\). The parameter of the model is inferred as \({\widehat{\vartheta }} ={\widehat{\vartheta }}(X_1,\ldots , X_n)\) and the test statistic \(\text {TS}\in \{\text {CM}_n,\text {KS}_n,S_{n,w},T_{n,w}\}\) is computed. Bootstrap samples are then drawn from \(F_0^X(x,{\widehat{\vartheta }})\). We compute the test statistic for each one of the samples and the critical values follow from quantile estimation. The steps of the parametric bootstrap routine are given in Algorithm 1 where \(B\in {\mathbb {N}}\) denotes the number of bootstrap samples and \(\alpha \in (0,1)\) is the confidence level of the GOF test.

In the sequel, we study the probability of rejection of a sample generated by a fixed model \(F^X\) when the model tested is \(F_0^{X}(x, \vartheta )\). It requires to generate \(M\in {\mathbb {N}}\) samples \(X_{k,1},\ldots , X_{k,n},\text { }k=1,\ldots ,M\) drawn from \(F^X\) and apply Algorithm 1. The warp-speed strategy suggested by Giacomini et al. [15] allows us to reduce the running time required for our experiment. The idea is to generate only one bootstrap sample from \(F_0^{X}\) for each Monte Carlo sample simulated from \(F^X\). The parametric bootstrap routine augmented by the warp-speed strategy is provided in Algorithm 2.

4.1 Investigation of the Impact of the Weight Function
The goal of this subsection is to investigate the role of the weight parameter \(\beta \) in LT-based procedures and prompt the discussion for the choice of good values of this parameter. It is well known from Tauberian theorems, see for instance Feller [12, Chapter XIII.5] that the tail behavior of a probability distribution concentrated on the positive half-line is reflected by the behavior of the Laplace transform at 0 and vice-versa. It is especially true in our context, that for \(\mathrm{{SE}}_n(t)\) we have
Choosing small values of \(\beta \) leads to capturing a difference in the atom of probability at 0, while choosing a large \(\beta \) allows to detect variations in the right tail. Note also that opting for the partial-MME method will make the \(\mathrm{{SE}}_n(t)\) distance tend toward 0 for large values of t.
For further scrutiny on the role of the weight function and the weight parameter \(\beta \), we consider the discrepancy SE(t) in (27) and take the Taylor series expansion of the exponential function figuring in the empirical Laplace transform therein. This leads to
where \({{\widehat{\mu }}}_k = n^{-1}\sum _{k=1}^{n}X_i^k\text {, }k\ge 1\), denote the empirical moments of the sample \(X_1,\ldots , X_n\) and \(\widehat{{\mathbb {E}}}_0(X^k):={\mathbb {E}}_0(X^k;{{\widehat{\vartheta }}})\) is the estimate of the corresponding expectation of the aggregated claim size under \(H_0\) obtained by replacing \(\vartheta \) by \({{\widehat{\vartheta }}}\). Integrating (37) term-by-term against the exponential weight function \(w(t) = e^{-\beta t}\) yields
Thus, the weight function tunes how the difference between the empirical and theoretical moments enter the test statistic \(S_{n,w}\). Namely, lowering the value of \(\beta \) allows one to take into account higher order moments. This analysis holds too for the \(\text {DE}_n(t)\) distance with
where \((Q_k)_{k\ge 1}\) is a sequence of polynomials satisfying \({\mathbb {E}}_0\left[ Q_k(X)\right] = 0,\text { for }k\ge 1\). The polynomial \(Q_k(x)\) is of order k in x and its coefficients may be expressed in terms of the parameters of the model specified under \(H_0\). For instance, if a compound Poisson-exponential \(\text {Pois}(\lambda )-\exp (\theta )\) is assumed under \(H_0\) then we have that
Integrating (39) term-by-term against the exponential weight function \(w(t) = e^{-\beta t}\) yields
The value of \(\beta \) is calibrated to select the moments that will influence the test decision. We note also that with moment estimation, \(\widehat{{\mathbb {E}}}_0(X^k)={{\widehat{\mu }}}_k, \ k=1,2\), so that the corresponding terms in (38) and (41) vanish when choosing the Method of Moments estimator.
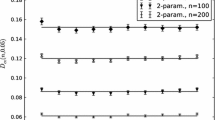
A Monte Carlo experiment is further conducted to gain insight on how to choose \(\beta \) to optimize the performance of the Laplace transform GOF procedures. We test the adequacy of a compound Poisson-exponential model \(\text {Pois}({\lambda })-\mathrm{{Exp}}({\theta })\) to data coming from a Poisson-gamma model \(\text {Pois}(\lambda = 1)-\text {gamma}(r,\theta = 1)\). The probability of rejection is computed when varying the value the shape parameter \(r\in \{0.5, 0.75, 1, 2, 4\}\) for both of the Laplace transform-based procedures as well as the two available inference methods (MME and partial-MME). We set the sample size to \(n = 100\) and use Algorithm 2 with \(M = 10,000\) Monte Carlo runs. Figure 1 displays the level (when \(r=1\)) of the test for \(\beta \) ranging from \(10^{-13}\) to \(10^{3}\).

Level of the LT-based GOF test depending on the distance between Laplace transform and inference techniques used: (dotted) \(S_{n,\beta }\) and MME ; (dashed) \(S_{n,\beta }\) and partial-MME; (solid) \(T_{n,\beta }\) and MME ; (dotdash) \(T_{n,\beta }\) and partial-MME

Power of the LT-based GOF test for the different combinations of distances and inference techniques: (dotted) \(S_{n,\beta }\) and MME ; (dashed) \(S_{n,\beta }\) and partial-MME; (solid) \(T_{n,\beta }\) and MME ; (dotdash) \(T_{n,\beta }\) and partial-MME
The probability of rejection (expected to be around \(5\%\)) is too high when using the \(T_{n,\beta }(t)\) statistic and too low when using the \(S_{n,\beta }\) when \(\beta < 10^{-7}\). The sampling error on the parameter estimates might explain this fact as the variance is higher for large integrated distance. Figure 2 displays the power (when \(r\ne 1\)) of the tests. The power of the test always decreases with \(\beta \) which reflects that the distance between the Laplace transforms vanishes as t approaches 0. Two behaviors may be observed on Fig. 2 depending on the value of r. When \(r<1\), the rejection probability increases before reaching a maximum and decreasing. When \(r>1\), the power admits a plateau before decreasing. It is common in the goodness-of-fit testing literature to opt for the values of \(\beta \) that fare well in the majority of the cases. In this connection, we note that there exist data-driven selection methods to determine proper values of the parameter \(\beta \) in LT-based goodness-of-fit tests, such as those proposed recently by Allison and Santana [1] and Tenreiro [36]. However, given the computing time associated with the test statistic, we decided not to implement such search methods here and employ in the comparative study below the values \(\beta = 10^{-3}, 10^{-2}\) when using the \(S_{n,\beta }\) and \(\beta =0.1, 1\) when using the \(S_{n,\beta }\), which performed well in our preliminary study.
4.2 Comparison of the GOF Procedures
In this subsection, we compare the GOF procedures in terms of probability of rejection when the input samples differ from the model stated under the null hypothesis.
Test 1
In this first test, we generate samples from a Poisson-Weibull model \(\text {Pois}(\lambda = 1)-\text {Weibull}(r,\theta = 1)\) and test with our GOF method the adequacy of a Poisson-exponential, Poisson-gamma and Poisson-inverse Gaussian model. The Weibull distribution \(\text {Weibull}(r,\theta )\) admits a probability density function given by
We set the sample size to 100 and use the partial-MME to infer the parameters in the model specified in \(\text {H}_0\). Figure 3 displays the powers computed via our parametric bootstrap routine with 10, 000 Monte Carlo runs changing the shape parameter r in the claim sizes distribution. The Poisson-Weibull coincides with the Poisson-exponential and Poisson-gamma models when the shape parameter is set to 1 so the power tends toward \(5\%\) on Figs. 3a and b as r gets closer to 1. The GOF procedures do well when testing for a Poisson-exponential with very high power as r gets farther from 1, see Fig. 3a. The results are a bit disappointing when testing for a Poisson-gamma distribution, the DF-based procedures achieve greater power in this case, see Fig. 3b. The procedures associated with the \(S_{n,\beta }\) distance outperform greatly the other methods when testing for a Poisson-inverse Gaussian model.

Power of the various GOF tests in Test 1: (dotted) Cramér-von Mises ; (dash) Kolmogorov-Smirnov; (solid) \(S_{n,\beta }, \beta = 10^{-3}\) ; (dotdash) \(S_{n,\beta }, \beta = 10^{-2}\);(two dash) \(T_{n,\beta }, \beta = 0.1\) ; (long dash) \(T_{n,\beta }, \beta = 1\)
Test 2
In this second test, samples are generated from zero-modified Poisson-exponential \(\text {zmpois}(\lambda = 5, p_0)-\exp (\theta = 1)\) and mixed Poisson-exponential \(\text {mpois}(p, \lambda _1 = 1, \lambda _2 = 5)-\exp (\theta = 1)\) and we assess the adequacy of a Poisson-exponential model. The probability mass function of the zero-modified Poisson distribution \(\text {zmpois}(\lambda , p_0)\) is given by
and the probability mass function of the mixed Poisson distribution \(\text {mpois}(p, \lambda _1, \lambda _2)\) is given by
The Poisson-exponential under \(\text {H}_0\) is fitted using the MME based on samples of size 100. Figure 4 displays the probability of rejection are computed via our parametric bootstrap routine with 10, 000 Monte Carlo runs letting the parameter p vary in the alternative claim frequency distributions. The GOF procedures all detect reasonably well the modification at 0, see Fig. 4a. The Laplace transform-based techniques outperform the DF-based one in the mixed Poisson example, see Fig. 4b. The probability of rejection computed remain relatively small. The shape of the power is on the low side when p is close to 0 or 1 which makes sense since the Mixed Poisson distribution is then very close to a Poisson distribution. The downfall at 0.5 indicates that a balanced mixture of two Poisson random variables may be approximated well by one Poisson random variable.

Power of the various GOF tests in Test 2: (dotted) Cramer-von Mises ; (dash) Kolmogorov-Smirnov; (solid) \(S_{n,\beta }, \beta = 10^{-3}\) ; (dotdash) \(S_{n,\beta }, \beta = 10^{-2}\); (two dash) \(T_{n,\beta }, \beta = 0.1\) ; (long dash) \(T_{n,\beta }, \beta = 1\)
Other cases have been studied, the simulation data may be found in the online supplements [17]. The main conclusion is that none of the procedures stands out in all and every case. This conclusion is corroborated by analytic methods which lead to the conclusion that any given goodness-of-fit test has nontrivial power only towards a given direction away from the null hypothesis; see Janssen [22], and Escanciano [11]. Therefore, we suggest, in a practical situation, to apply all the procedures to see if they lead to the same conclusion.
5 An Application to Insurance Data
We illustrate our inference and goodness-of-fit procedures on an actuarial dataset called itamtplcost accessible from the R package CASdatasets (see also the book of Charpentier [5]). This dataset contains losses (in excess of 500, 000 euros) of an Italian Motor-TPL company since 1997. It comprises two variables Date and UltimateCost, and 457 observations. Table 1 shows the first 5 observations of the dataset itamtplcost. We start by looking at the individual claim data before applying our methods to the monthly aggregated data, in the hope that they lead to similar inference and conclusions.

Quantile-Quantile Plots
Figure 5 displays the exponential and Pareto Quantile-Quantile plots. A linear relationship is observed between the lower order quantiles on Fig. 5a and between the higher order quantiles on Fig. 5b. This, in turn, suggests the use of a splicing model with an exponential-type distribution to model the small claims and a Pareto-type distribution to fit the larger losses. The claim sizes distribution tested in the sequel are the exponential, gamma and inverse Gaussian distributions. Due to the heavy tail of the data, these distributions are not likely to result in a good fit. Hence, we decided to conduct the analysis over the whole dataset and then on the smaller claims only. The small claims are defined on the basis of a threshold. The cut-off point between small and large claims is the upper order statistic that minimizes the asymptotic mean squared error of the Hill estimator, as it is a standard procedure in extreme value theory; see for instance the case study in the book by Beirlant et al. [3, Chapter 6]. Figure 6 displays the mean-excess plot and the Hill plot of the loss data. The threshold is set at 1, 766, 751 euros (corresponding to the vertical line on Figs. 6a and b). A statistical summary over the whole dataset and the small claims is provided in Table 2. We note the swift decrease in variance when considering the small claims solely. The quartiles are stable while the mean in the small claims subset decreases to get closer to the median. Table 3 reports the Method of Moments estimators of the parameters of the exponential, gamma and inverse Gaussian distribution. Figure 7 displays the histograms of the claim sizes, on which are superposed the densities of the exponential, gamma and inverse Gaussian distributions with the parameters provided in Table 3. Table 4 reports the value of the AIC as well as the outcome of the KS and CvM GOF test for the exponential, gamma and inverse Gaussian distributions. On the basis of these results, it seems that the gamma is the single distribution that provides a better fit for both of the datasets. We note how the rejection when using the KS GOF test is a close call when testing the gamma and inverse Gaussian model for the small claims. In order to apply our method, the original data need to be processed so as to consider claim amounts aggregated monthly. For each time period, we collect the claim frequency as well as the sums of the incurred claims. Table 5 provides an overview of the processed data. Table 6 reports the estimated parameters of the Poisson and geometric distributions accompanied by the Akaike information criterion and the \(\chi ^{2}\) distance. The Poisson is better suited than the geometric distribution in view of the lower \(\chi ^{2}\) distance and AIC values.

Mean-Excess plot and Hill plot

Histograms of the data along with the density of the exponential (solid), gamma (dotted) and inverse Gaussian (dashed) distributions
Table 7 gives the partial-MMEs for the Poisson-exponential, Poisson-gamma, Poisson-inverse Gaussian and geometric-exponential compound models. We note that these values are very different from the values estimated via the individual claim sizes and frequency data given in Tables 3 and 6. Tables 8, 9 and 10 provide a summary of the GOF procedures applied on the data. The critical values are computed using Algorithm 1 with 10, 000 bootstrap loops. The Poisson-gamma and Poisson-Inverse Gaussian models cannot be discarded according to all the methods. The exponential claim sizes are discarded for all the methods except when using the \(S_{n,\beta }\) test statistic based on the Laplace transform, see Table 8.
6 Conclusion and Perspectives
Several goodness-of-fit tests for compound distributions were investigated, both classical as well as tests based on the Laplace transform. In either case, the test criteria were tailored to specific versions of the null hypothesis that are popular in applications. The message drawn from a detailed Monte Carlo study is that all criteria respect the nominal level of the test and at the same time have reasonable power against some interesting alternatives, with the Laplace transform-based test having a certain edge in terms of power. The real-data application shows the potential of the suggested methods for practitioners in order to also identify the components of an aggregate claim probability distribution, namely the claim frequency and the claim size distribution, when the only available data are the aggregated losses.
There are clearly several possible directions in which the current results can be extended. For instance, one can explore alternate estimation methods for the parameters, go outside the Katz family for counting models, or consider situations where multivariate data are available on the compound variable X.
References
Allison J, Santana L (2015) On a data-dependent choice of the tuning parameter appearing in certain goodness-of-fit tests. J Stat Comput Simul 85(16):3276–3288. https://doi.org/10.1080/00949655.2014.968781
Allison JS, Santana L, Smit N, Visagie IJH (2017) An ‘apples to apples’ comparison of various tests for exponentiality. Comput Stat. 32(4):1241–1283. https://doi.org/10.1007/s00180-017-0733-3
Beirlant J, Goegebeur Y, Segers J, Teugels J (2006) Statistics of extremes: theory and applications. Wiley
Besbeas P, Morgan BJT (2004) Efficient and robust estimation for the one-sided stable distribution of index 1/2. Stat Probab Lett 66(3):251–257. https://doi.org/10.1016/j.spl.2003.10.013
Charpentier A (2014) Computational actuarial science with R. CRC Press, Boca Raton
Chaudhury M (2010) A review of the key issues in operational risk capital modeling. J Oper Risk 5(3):37
Choulakian V, Lockhart R, Stephens M (1994) Cramér-von Mises statistics for discrete distributions. Can J Stat 22(1):125–137
Conover W (1972) A Kolmogorov goodness-of-fit test for discontinuous distributions. J Am Stat Assoc 67(339):591–596
D’Agostino RB, Stephens RB (1986) Goodness-of-Fit Techniques, vol. 68. Statistics, textbooks and monograph
Dimitrova DS, Kaishev V, Tan S (2017) Computing the Kolmogorov-Smirnov distribution when the underlying cdf is purely discrete, mixed or continuous. Available at http://openaccess.city.ac.uk/18541/
Escanciano J (2009) On the lack of power of omnibus specification tests. Economet Theor 25:162–194
Feller W (2008) An introduction to probability theory and its applications, vol 2. Wiley, New York
Genest C, Rémillard B (2008) Validity of the parametric bootstrap for goodness-of-fit testing in semiparametric models. Ann Inst Henri Poincaré Probab Stat 44(6):1096–1127
Ghosh S, Beran J (2006) On estimating the cumulant generating function of linear processes. Ann Inst Stat Math 58(1):53–71. https://doi.org/10.1007/s10463-005-0009-5
Giacomini R, Politis D, White H (2013) A warp-speed method for conducting Monte Carlo experiments involving bootstrap. Economet Theor 29(3):567–589
Gleser L (1985) Exact power of goodness-of-fit tests of Kolmogorov type for discontinuous distributions. J Am Stat Assoc 80(392):954–958
Goffard PO (2019) Online accompaniment for "Goodness-of-fit tests for compound distributions with applications in insurance". Available at https://github.com/LaGauffre/Online_accoompaniement_GOF_Test_Compound_Distribution
Henze N (1992) A new flexible class of omnibus tests for exponentiality. Commun Stat Theor Methods 22(1):115–133. https://doi.org/10.1080/03610929308831009
Henze N (1996) Empirical-distribution-function goodness-of-fit tests for discrete models. Can J Stat 24(1):81–93
Henze N, Klar B (2002) Goodness-of-fit tests for the inverse Gaussian distribution based on the empirical laplace transform. Ann Inst Stat Math 54(2):425–444. https://doi.org/10.1023/A:1022442506681
Henze N, Meintanis SG (2002) Tests of fit for exponentiality based on the empirical Laplace transform. Statistics 36(2):147–161. https://doi.org/10.1080/02331880212042
Janssen A (2000) Global power function of goodness-of-fit tests. Ann Stat 28:239–253
Katz L (1965) Unified treatment of a broad class of discrete probability distributions. in: Classical and Contagious Discrete Distributions, Pergamon Press, Oxford
Lockhart R, Spinelli J, Stephens M (2007) Cramér-von Mises statistics for discrete distributions with unknown parameters. Canad J Stat 35(1):125–133
Meintanis S, Iliopoulos G (2003) Tests of fit for the Rayleigh distribution based on the empirical Laplace transform. Ann Inst Stat Math 55(1):137–151. https://doi.org/10.1007/BF02530490
Milošević B, Obradović M (2016) New class of exponentiality tests based on u-empirical laplace transform. Stat Pap 57(4):977–990. https://doi.org/10.1007/s00362-016-0818-z
Noether G (1963) Note on the Kolmogorov statistic in the discrete case. Metrika 7(1):115–116
Panjer HH (1981) Recursive evaluation of a family of compound distributions. ASTIN Bull 12(1):22–26. https://doi.org/10.1017/S0515036100006796
Pril ND (1986) Moments of a class of compound distributions. Scand Actuar J 2:117–120. https://doi.org/10.1080/03461238.1986.10413800
Schmid P (1958) On the Kolmogorov and Smirnov limit theorems for discontinuous distribution functions. Ann Math Stat 29(4):1011–1027
Slakter MJ (1965) A comparison of the Pearson chi-square and Kolmogorov goodness-of-fit tests with respect to validity. J Am Stat Assoc 60(311):854–858
Spinelli J (2001) Testing fit for the grouped exponential distribution. Can J Stat 29(3):451–458
Spinelli J, Stephens M (1997) Cramér-von Mises tests of fit for the Poisson distribution. Can J Stat 25(2):257–268
Stute W, Manteiga WG, Quindimil MP (1993) Bootstrap based goodness-of-fit-tests. Metrika 40(1):243–256
Sundt B, Jewell WS (1981) Further results on recursive evaluation of compound distributions. ASTIN Bull 12(1):27–39
Tenreiro C (2019) On the automatic selection of the tuning parameter appearing in certain families of goodness-of-fit tests. J Stat Comput Simul 89(10):1780–1797. https://doi.org/10.1080/00949655.2019.1598409
Thas O (2010) Comparing distributions. Springer
van der Vaart AW, Wellner JA (1996) Weak convergence. In: Weak Convergence and Empirical Processes, pp. 16–28. Springer New York. https://doi.org/10.1007/978-1-4757-2545-2_3
Walsh JE (1963) Bounded probability properties of Kolmogorov-Smirnov and similar statistics for discrete data. Ann Inst Stat Math 15(1):153–158
Acknowledgements
The authors thank an anonymous referee for helpful comments and suggestions that helped improve the original manuscript. This work was initiated while Pierre-Olivier Goffard and Simos Meintanis were visiting the department of Statistics and Applied Probability at UC Santa Barbara. The authors are grateful for the warm welcome they received there. Pierre-Olivier Goffard’s work is conducted within the Research Chair DIALog under the aegis of the Risk Foundation, an initiative by CNP Assurances.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the topical collection “Advances in Probability and Statistics: an Issue in Memory of Theophilos Cacoullos” guest edited by Narayanaswamy Balakrishnan, Charalambos #. Charalambides, Tasos Christofides, Markos Koutras, and Simos Meintanis.
Appendix: Consistency and Limit Null Distribution
Appendix: Consistency and Limit Null Distribution
In this section, we discuss the consistency and limiting distribution of the LT-based test statistics under the null hypothesis \(H_0\). We focus our attention on the test criterion \(S_{n,w}\) defined in (28), but note that similar results may be obtained for the test statistic \(T_{n,w}\). We begin with the consistency of the test based on \(S_{n,w}\) under the following assumptions:
-
(A.1)
The estimator satisfies \({{\widehat{\vartheta }}}\rightarrow {\widetilde{\vartheta }}\), a.s., as \(n\rightarrow \infty \), for some \({\widetilde{\vartheta }} \in \Theta \), with \({\widetilde{\vartheta }}\equiv \vartheta _0\) when the null hypothesis \(H_0\) is true, with \(\vartheta _0\) being the true value.
-
(A.2)
The LT \(L^X_0(\cdot ;\vartheta )\) is continuous in \( \vartheta \).
-
(A.3)
The weight function satisfies,
-
(i)
\(w(t)>0, \forall t>0\), except for a set of measure zero,
-
(ii)
\(\int _0^\infty w(t) \mathrm{{d}} t<\infty \).
-
(i)
Theorem 1
Let \(L^X(t)\) denote the LT of X. Then if assumptions (A.1) to (A.3) are satisfied,
a.s., as \(n\rightarrow \infty \).
Proof
: Clearly the strong consistency of the empirical Laplace transform and the continuity of \(L_0(\cdot ;\vartheta )\) imply that
a.s., as \(n\rightarrow \infty \). Then since SE\(^2_n(t)\le 4\), the result follows by Lebesgue’s dominated convergence theorem. \(\square \)
The right-hand side of (45) is positive unless \(L^X(t)=L^X_0(t;\widetilde{\vartheta })\), for all \(t>0\). However, by the uniqueness of the LT, the last identity holds true only under the null hypothesis \(H_0\), in which case \({\widetilde{\vartheta }} \equiv \vartheta _0\), thus implying the strong consistency of the test that rejects \(H_0\) for large values of \(S_{n,w}\).
We continue with the limit distribution of the test statistic \(S_{n,w}\) under the null hypothesis \(H_0\). For simplicity, we assume that \(\vartheta \) is a scalar parameter. To this end assume that
-
(A.4)
The estimator \({{\widehat{\vartheta }}}:={{\widehat{\vartheta }}}_n\) satisfies the Bahadur representation
$$\begin{aligned} {{\widehat{\vartheta }}}_n-\vartheta _0=\frac{1}{n}\sum _{j=1}^n \ell (X_j;\vartheta _0)+o_P(1) \end{aligned}$$where \(\ell (\cdot ;\cdot )\) are such that \({\mathbb {E}}(\ell (X;\vartheta _0))=0\) and \({\mathbb {E}}(\ell ^2(X;\vartheta _0))<\infty \).
-
(A.5)
The LT \(L_0^X(t;\vartheta )\) is twice differentiable with respect to \(\vartheta \) with a continuous second derivative in the neighborhood of the true value \(\vartheta _0\).
-
(A.6)
The weight function is such that
and
for all \(\vartheta ^*\) in a neighborhood of \(\vartheta _0\).
Theorem 2
Under assumptions (A.1) to (A.6) we have under \(H_0\),
as \(n\rightarrow \infty \), where Z(t) is the zero-mean Gaussian process with covariance kernel \(K(s,t;\vartheta _0)={\mathbb {E}}(Y(t;\vartheta _0)Y(s;\vartheta _0))\) with
The covariance kernel is specified by
Proof
: Along the proof we will write \(Z^{(1)}_n\approx Z^{(2)}_n\) if the two random processes \((Z^{(k)}_n(t), k=1,2)\), satisfy \(Z^{(1)}_n(t)-Z^{(2)}_n(t)=\varepsilon _n(t)\), and the remainder \(\varepsilon _n(t)\) is such that it has no effect on the limit null distribution of the test statistic \(S_{n,w}\).
With this understanding using assumption (A.5) and the second part of (A.6), a two-term Taylor expansion yields
where
In turn, using assumption (A.4) and the first part of (A.6) in (46) leads to
where
The result now follows by applying the Central Limit Theorem in Hilbert spaces, (see e.g. van der Vaart and Wellner [38], p. 50) on the process \(Z^{**}_n(t)\) given in (47). \(\square \)
Now the limit distribution of the test statistic follows from Theorem 2 and the Continuous Mapping theorem. Specifically we have
where Z(t) is the process defined in Theorem 2. The distribution of \(Z_w\) is the same as that of \(\sum _{j=1}^\infty \lambda _j N^2_j\), where \(\lambda _1,\lambda _2, . . .\), are the eigenvalues corresponding to the integral operator
i.e. the solutions of the equation \(Ag(s)=\lambda g(s)\), and where \(N_j, \ j\ge 1\), are iid standard normal variates.
Remark 71
The assumptions (A.1)–(A.3) made in order to prove consistency, as well as those pertaining to the limit null distribution, (A.4)–(A.6), are standard in the context of testing goodness-of-fit based on the empirical LT; see for instance Henze [18], Henze and Klar [20], and Henze and Meintanis [21].
Rights and permissions
About this article

Cite this article
Goffard, PO., Jammalamadaka, S.R. & Meintanis, S.G. Goodness-of-Fit Procedures for Compound Distributions with an Application to Insurance. J Stat Theory Pract 16, 52 (2022). https://doi.org/10.1007/s42519-022-00276-6
Accepted:
Published:
DOI: https://doi.org/10.1007/s42519-022-00276-6