
Abstract
Classical estimators and preliminary test estimators (PTEs) of the powers of model parameter and the two measures of reliability, namely\(R\left( t \right) = P(X > t)\) and \(P = P(X > Y)\) of Kumaraswamy-G distribution, are developed under progressive type-II censoring. The preliminary test confidence intervals (PTCIs) are also developed based on uniformly minimum variance unbiased estimators (UMVUEs) and maximum likelihood estimators (MLEs). Merits of PTEs and PTCIs are established. Simulation results are presented, and real-life data set is also analysed.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Life-testing experiments are usually time-consuming and expensive in nature. To reduce the cost and time of experimentation, various types of censoring schemes are used. The two most common adopted censoring schemes in the literature are type-I and type-II censoring schemes. But these censoring schemes do not allow intermediate removal of the experimental units other than the final termination point. Therefore, to overcome this restriction, a more general censoring scheme known as progressive censoring scheme is considered. Progressive type-II censoring scheme was first discussed by Cohen [14]. Further, Balakrishnan and Aggarwala [2] and Rastogi and Tripathi [26] provide elaborate treatment on the issue. Recently, the progressive censoring scheme has received considerable attention in life-testing and reliability studies. The progressive type-II censoring scheme can briefly be described as follows: Let us assume that \(n\) units are placed on test at time zero. Immediately following the first failure, \(R_{1 }\) surviving units are removed from the test at random. Similarly, after the second failure, \(R_{2 }\) of the surviving units are removed at random. The process continues until at the time of mth failure, the remaining \(R_{m} = n - R_{1} - R_{2} - \ldots - R_{m - 1} - m\) units are removed from the test. In this censoring scheme, failure times of \(m\) units are completely observed.
The reliability function \(R\left( t \right)\) is defined as the probability of failure-free operation until time t. Thus, if the random variable \(X\) denotes the lifetime of an item or a system, then \(R\left( t \right) = P(X > t)\). Another measure of reliability under stress strength set-up is the probability \(P = P(X > Y)\), which represents the reliability of an item or a system of random strength \(X\) subject to random stress \(Y\). For a brief review of the literature related to inferential procedures of \(R\left( t \right)\) and \(P\), one may refer to Bartholomew [5, 6], Johnson [17], Kelly et al. [18] and Chaturvedi and Kumari [9]. Awad and Gharraf [1] provided a simulation study which compared minimum variance unbiased, the maximum likelihood and Bayes estimators for P(Y < X) when Y and X were two independent but not identically distributed Burr random variables. Chaturvedi and Rani [11] obtained the classical as well as Bayesian estimates of reliability in respect of generalized Maxwell failure distribution, and Chaturvedi and Surinder [12] obtained the estimates of reliability functions in respect of exponential distribution under type-I and type-II censoring schemes. The classical as well as Bayesian estimates in respect of negative binomial distribution were obtained by Chaturvedi and Tomer [13]. Estimates of the reliability function for the four-parameter exponentiated generalized lomax distribution were obtained by Chaturvedi and Pathak [10].
In many situations, we come across cases in which there may exist some prior information on the parameters, the usage of which may lead to improved inferential results. It is well known that the estimators with the prior information (called the restricted estimator) perform better than the estimators with no prior information (called the unrestricted estimator). However, when the prior information is doubtful (or not sure), one may combine the restricted and unrestricted estimators to obtain an estimator with better performance, which leads to the PTEs. The preliminary test approach was first discussed by Bancroft [4]. Saleh and Kibria [29] combined the preliminary test and ridge regression approach to estimate regression parameter in a multiple regression model. Kibria [19] considered the shrinkage preliminary test ridge regression estimators (SPTRRE) based on Wald (W), the likelihood ratio (LR) and the Lagrangian multiplier (LM) and further derived the bias and risk functions of the proposed estimators. Saleh [28] discussed the preliminary test and related shrinkage estimation technique. Belaghi et al. [7] proposed the confidence intervals based on preliminary test estimator, Thompson shrinkage estimator and Bayes estimator for the scale parameter in respect of the Burr type-XII distribution. Belaghi et al. [8] defined the Bayes and empirical Bayes preliminary test estimators on the basis of record-breaking observations in the Burr type-XII model.
Motivated by the work of Kumaraswamy [20,21,22], Cordeiro and De Castro [16] proposed Kumaraswamy-G distribution. Nadarajah et al. [24] recommended Kumaraswamy-G distribution as a reliability model, and Tamandi and Nadarajah [30] developed estimation procedures for the parameters based on complete samples.
In the present paper, the ambit of our work dovetailing with Kumaraswamy-G distribution is multi-pronged. In Sect. 2, the estimators (point as well as interval) are obtained for the powers of parameter, R(t) and P for Kumaraswamy-G distribution besides developing testing procedures. In Sect. 3, we propose the PTEs, and in Sect. 4, the PTCIs are developed by us. In Sect. 5, we provide simulated results and also present analysis of real-life data. Lastly, Sect. 6 summarizes findings and conclusions.
2 The Kumaraswamy-G Distribution and Related Inferential Procedures
A random variable (rv) \(X\) is said to follow Kumaraswamy-G distribution if its probability density function (pdf) and cumulative density function (cdf) are given, respectively, by
and
where G(x) is the baseline cdf, g(x) is the pdf of G(x). \(\sigma\) and \(\gamma\) are the shape parameters of this distribution. Under progressive type-II censoring, let us denote the \(m\) failure time by \(X_{i;m,n} , i = 1,2, \ldots ,m .\)
Denoting by \(c = n \left( {n - R_{1} - 1} \right)\left( {n - R_{1} - R_{2} - 2} \right) \ldots \left( {n - R_{1} - R_{2} - \ldots - R_{m - 1} - m + 1} \right)\), from (2.1) and (2.2), the joint pdf of \(X_{i;m,n} , i = 1,2, \ldots ,m\) is given by,
The following theorem establishes the relationship between Kumaraswamy-G distribution and exponential distribution.
Theorem 1
The rv \(Y = - \log \left( {1 - G^{\gamma } \left( X \right)} \right)\)follows exponential distribution with mean life 1/σ.
Proof
Let us make the transformation
or,
Making substitutions from (2.4) and (2.5) in (2.1), we get the pdf of Y to be
and the theorem follows.
Let us consider the transformations
Then \(Z_{j}^{'} s \left( {j = 1,2, \ldots ,m} \right)\) follow exponential distribution with mean life 1/\(\sigma\). Since,
Applying Theorem 1 and additive property of exponential distribution, \(S_{m}\) follows gamma distribution with pdf
Utilizing (2.6), it follows from (2.3) that
The following theorem provides the UMVUE of \(\sigma^{p}\)(p ≠ 0)
Theorem 2
For (p ≠ 0), the UMVUE of \(\sigma^{p}\) is given by
Proof
It follows from (2.6) and factorization theorem that \(S_{m}\) is sufficient for σ. Moreover, since the distribution of \(S_{m}\) belongs to exponential family, it is also complete, the theorem now follows from Lehmann–Scheffe’s theorem and the fact that
The proof of following theorem is a direct consequence of (2.7).
Theorem 3
For (p ≠ 0), the MLE of \(\sigma^{p}\) is given by
Lemma 1
The UMVUE of sampled pdf vide (2.1) at a specified point ‘x’ is given by
Proof
Equation (2.1) may be written as
Applying Theorem 2 and a result due to Chaturvedi and Tomer [13], it follows from (2.8) that
and the desired result is obtained on simplification.
Lemma 2
The MLE of sampled pdf vide (2.1) at a specified point ‘x’ is given by
Proof
The result follows from (2.1) in conjunction with Theorem 3 and invariance property of MLEs.
Theorem 4
The UMVUE of \(R\left( t \right)\) is given by
Proof
We have
Thus,
Therefore, from Lemma 1,
on substituting
and solving the integral, the desired result follows.
Theorem 5
The MLE of \(R\left( t \right)\) is given by
Proof
The proof follows on similar lines as in previous theorem.
Suppose \(X\) and \(Y\) are two independent rvs with parameters \(\left( {\sigma_{1} ,\gamma_{1} } \right)\, {\text{and}}\, \left( {\sigma_{2} ,\gamma_{2} } \right)\), respectively. Then, the UMVUE of \(P\) is given by following theorem.
Theorem 6
The UMVUE of \(P\)is given by
where
Proof
Let the pdf of \(X\) and \(Y\) are given by \(f_{1} \left( {x;\sigma_{1} ,\gamma_{1} } \right) \,{\text{and}} \,f_{2} \left( {y;\sigma_{2} ,\gamma_{2} } \right)\), respectively
and
Suppose that \(n\) units are put on test. Let \(X_{i:m:n} ;i = 1,2, \ldots ,m\) be \(m\) observed failure times from \(X\) and \(Y_{j:l:n} ;j = 1,2, \ldots ,l\) be \(l\) observed failure times from \(Y\).
We denote by \(T_{l} = \mathop \sum \limits_{j = 1}^{l} - \left( {R_{j}^{*} + 1} \right)\log \left( {1 - H^{{\gamma_{2} }} \left( {y_{j} } \right)} \right)\) where \(R_{j}^{*}\) is the censoring scheme for second sample.
From the arguments similar to those used for Theorem 4,
where
On substituting
and taking different values of c, we get the desired result on solving the integral.
Corollary 1
When \(X\)and \(Y\)belong to same family of distributions, i.e. \(G\left( . \right) = H\left( . \right)\), the UMVUE of \(P\)is given by
where
Corollary 2
When \(G\left( . \right) = H\left( . \right)\)and \(\gamma\)1 = \(\gamma\)2, the UMVUE of \(P\)is given by
Theorem 7
The MLE of \(P\)when \(G\left( . \right) = H\left( . \right)\)and \(\gamma_{1}\) = \(\gamma_{2}\) = \(\gamma\)(say) is given by
Proof
We have
On substituting \(H^{{\gamma_{2} }} \left( y \right) = v\), we get
When \(G\left( . \right) = H\left( . \right),\) we get
Using the condition that \(\gamma_{1}\) = \(\gamma_{2}\) = \(\gamma\) (say), we get the desired result on solving the integral.
In the following theorem, we derive critical region for the hypotheses regarding σ.
Theorem 8
Let the null hypothesis be \(H_{0} :\sigma = \sigma_{0}\)against the alternative \(H_{1} :\sigma \ne \sigma_{0}\). Then, the critical region is given by
where, \(\alpha\)is the level of significance
Proof
We know that
The critical region is then given by
or
In what follows, we obtain the critical region for the hypotheses related to \(R\left( t \right)\).
Theorem 9
Let the null hypothesis be \(H_{0} :R\left( t \right) = R_{0} \left( t \right)\)against the alternative \(H_{1} :R\left( t \right) \ne R_{0} \left( t \right)\). Then, the critical region comes out to be,
Proof
From (2.2), we know that,
Therefore, \(H_{0} :R\left( t \right) = R_{0} \left( t \right)\) against the alternative \(H_{1} :R\left( t \right) \ne R_{0} \left( t \right)\) is equivalent to\(H_{0} :\sigma = \sigma_{0}\) against the alternative \(H_{1} :\sigma \ne \sigma_{0}\)
Thus, the theorem follows from Theorem 8.
The following theorem provides critical region for hypotheses regarding \(P\).
Theorem 10
Let us take the null hypothesis \(H_{0} :P = P_{0}\)against the alternative \(H_{1} :P \ne P_{0}\). Then, the critical region turns out to be,
\({\text{where}}\, k = \frac{{P_{0} }}{{1 - P_{0} }}\)
Proof
We know that
\(P = P_{0}\) gives \(\sigma_{2} = k \sigma_{1}\)
Therefore, \(H_{0}\) is equivalent to
As we know that,
Therefore,
The critical region for testing \(H_{0} :P = P_{0}\) is given by,
The theorem follows using (2.9) and (2.10)
The following three theorems provide confidence intervals for σ, R(t) and P, respectively. The proofs of these theorems emanate as a direct consequence of Theorems 8, 9 and 10, respectively.
Theorem 11
The \(100\left( {1 - \alpha } \right)\%\) confidence interval for σ is given by
Theorem 12
The \(100\left( {1 - \alpha } \right)\%\) confidence interval for \(R\left( t \right)\) comes out to be
Theorem 13
The \(100\left( {1 - \alpha } \right)\%\) confidence interval for \(P\) turns out to be
3 Proposed Preliminary Test Estimators
The prior information for the parameter σ can be expressed in the form of the null hypothesis discussed in Theorem 8.
Let us suppose
and I(A) is the Indicator function of the set
The PTEs of \(\sigma^{p}\) based on UMVUE and MLE are then given, respectively, by
and
where \(\hat{\sigma }_{U }^{p} \,{\text{and}} \,\hat{\sigma }_{\text{ML}}^{p}\) are as defined in Theorems 2 and 3, respectively.
Let us suppose
\(\delta = \frac{\sigma }{{\sigma_{o} }}\) where \(\sigma_{o}\) is the true value of \(\sigma\)
The bias of the PTE given at (3.1) is
where \(H_{\varPsi } \left( . \right)\) denotes the \(cdf\) of \(\chi^{2}\) distribution with Ψ degrees of freedom
The mean sum of squares due to error (MSE) of the PTE given at (3.1) comes out to be
The bias of the PTE given at (3.2) is
The MSE of PTE given at (3.2) comes out to be
The prior information for \(R\left( t \right)\) can be expressed in the form of the null hypothesis discussed in Theorem 9. Accordingly, the PTEs of \(R\left( t \right)\) based on MLE and UMVUE are given, respectively, by
where \(R_{0} \left( t \right) = \left[ {1 - G^{\gamma } \left( t \right)} \right]^{{\sigma_{0} }} , {\text{under}}\,H_{0}\)
and
where \(\hat{R}_{U} \left( t \right)\) and \(\hat{R}_{\text{ML}} \left( t \right)\) are as defined in Theorems 4 and 5, respectively.
The bias of the PTE given at (3.3) is
where
The MSE of PTE given at (3.3) is
where
The bias of the PTE given at (3.4) is
where
The MSE of PTE given at (3.4) is
where
and
The prior information for \(P\) can be expressed in the form of the null hypothesis discussed in Theorem 10.
Let I(B) be indicator function of the set
where
The PTEs of \(P\) based on MLE and UMVUE are then given, respectively, by
and
where \(\hat{P}_{U}\) and \(\hat{P}_{\text{ML}}\) are as defined in Theorems 6 and 7, respectively.
Now, we derive bias and MSE expressions of PTEs of \(P\) based on MLE and UMVUE.
We know that,
We make use of the approach given by Constantine [15] to obtain the \({\text{pdf}}\) of \(\hat{Q}\) by transformation into two new independent random variables \(r > 0\) and \(\theta \in \left( {0,\frac{\pi }{2}} \right)\) such that \(\hat{\sigma }_{1ML} = \frac{{\sigma_{1} r{ \sin }^{2} \theta }}{m}\) and \(\hat{\sigma }_{2ML} = \frac{{\sigma_{2} r{ \cos }^{2} \theta }}{l}\).
Putting \(\varphi = { \sin }^{2} \theta \,{\text{and}}\, \rho = \frac{{\sigma_{1} }}{{\sigma_{2} }}\), the \({\text{pdf}}\) of \(\hat{Q} = \left[ {1 + \rho \left( {\frac{l}{m}} \right)\left( {\frac{\varphi }{1 - \varphi }} \right)} \right]^{ - 1}\) is given by,
When \(\varepsilon = 1,\) using (3.8), we get
When \(\varepsilon \ne 1,\) on substituting \(\varepsilon + q\left( {1 - \varepsilon } \right) = \omega ,\) (3.8) gives
where \(\varphi_{5 }\) which is obtained by putting c = 1 in the expression of \(E\left( {\hat{Q}^{c} } \right)\) is as follows
Further,
using (3.10) and (3.11) in (3.7), the bias of PTE of \(P\) based on MLE is:
and the MSE of PTE of \(P\) based on MLE is:
where
Let us define
\(\varphi_{10} = \mathop \sum \limits_{i = 0}^{l - 2} \frac{{\left( { - 1} \right)^{i} \left( {l - 1} \right)!\left( {m - 1} \right)!}}{{\left( {l - i - 2} \right)!\left( {m + i} \right)!}}\left( {\frac{{l\sigma_{1} }}{{m\sigma_{2} }}} \right)^{i + 1} \mathop \int \limits_{{C_{3} }}^{{C_{4} }} \upsilon^{i + 1} \emptyset_{1} \left( \upsilon \right){\text{d}}\upsilon ,\) where \(\emptyset_{1} \left( \cdot \right)\) is the pdf of \(f -\) distribution with (2m, 2l) degrees of freedom.
\(\varphi_{11} = \mathop \sum \limits_{i = 0}^{m - 1} \frac{{\left( { - 1} \right)^{i} \left( {l - 1} \right)!\left( {m - 1} \right)!}}{{\left( {l + i - 1} \right)!\left( {m - i - 1} \right)!}}\left( {\frac{{m\sigma_{2} }}{{l\sigma_{1} }}} \right)^{i} \mathop \int \limits_{{C_{3} }}^{{C_{4} }} \upsilon^{i} \emptyset_{2} \left( \upsilon \right){\text{d}}\upsilon\), where \(\emptyset_{2} \left( \cdot \right)\) is the of \(f -\) distribution with (2l, 2m) degrees of freedom.
The bias of PTE of \(P\) based on UMVUE is:
where \(v = \frac{{S_{m} }}{{H_{l} }} and P\left( B \right) = \left\{ {F_{2m,2l} \left( {C_{4} } \right) - F_{2m,2l} \left( {C_{3} } \right)} \right\}\).
To obtain \({\text{MSE}}\left( {\hat{P}_{{\text{PT}}\_U} } \right)\), consider
where \(a_{i} = \frac{{\left( { - 1} \right)^{i} \left( {l - 1} \right)!\left( {m - 1} \right)!}}{{\left( {l - i - 2} \right)!\left( {m + i} \right)!}}, b_{i} = \frac{{\left( { - 1} \right)^{i} \left( {l - 1} \right)!\left( {m - 1} \right)!}}{{\left( {l + i - 1} \right)!\left( {m - i - 1} \right)!}}\)
We obtain the \({\text{pdf}}\) of \(v\) as:
For c > 0,
Substituting \(r = \left( {1 + \rho v} \right)^{ - 1} ,\) we get on simplification
where
and \(\varPsi = \frac{1}{1 + \rho }\).
Similarly, we can obtain
where
let us denote
Further, using (3.13) and (3.14) in (3.12), we get the expression of \(E\left( {\hat{P}_{U}^{2} } \right) as,\)
Thus, \({\text{Var}}\left( {\hat{P}_{U} } \right) = \varphi_{14} - P^{2}\) and \({\text{Va}}r\left( {\hat{P}_{U} I\left( B \right)} \right) = \left\{ {\begin{array}{*{20}c} {\varphi_{12} - \varphi_{10}^{2} ;v \le 1} \\ {\varphi_{13} - \varphi_{11}^{2} ;v > 1} \\ \end{array} } \right.\),
Finally, we obtain the MSE of PTE of \(P\) based on UMVUE as:
4 Preliminary Test Confidence Intervals
In this section, we derive the preliminary test confidence intervals (PTCIs) for \(\sigma , R\left( t \right)\, {\text{and}}\, P\) based on their UMVUEs and MLEs. After introducing the PTCIs, subsequently the coverage probability is obtained.
From Theorems 2 and 3, we know that
and
Using Theorem 11 and Eqs. (4.1) and (4.2), \(100\left( {1 - \alpha } \right)\%\) equal tail CIs for σ based on UMVUE and MLE are as follows
and
Therefore, the PTCIs of σ based on UMVUE and MLE are as follows
and
where \(\hat{\sigma }_{{\text{PT}}\_U} \,{\text{and}}\, \hat{\sigma }_{{\text{PT}}\_{\text{ML}}}\) are as defined in (3.1) and (3.2), respectively.
Next we derive the PTCI for R(t),
From Theorem 4, we can write
From Theorem 5, we can write
Using Theorem 12 and Eqs. (4.3) and (4.4), \(100\left( {1 - \alpha } \right)\%\) equal tail CIs for \(R\left( t \right)\) based on its UMVUE and MLE may be written as
and
Therefore, the PTCIs of \(R\left( t \right)\) based on UMVUE and MLE are as follows:
and
where \(\hat{R}_{{\text{PT}}\_{\text{ML}}} \left( t \right) \,{\text{and}}\, \hat{R}_{{\text{PT}}\_U} \left( t \right)\) are as defined in (3.3) and (3.4), respectively.
Now, we derive the confidence intervals for \(P\)
From Theorem 6, we can write
From Theorem 7, we can write
Using Theorem 12 and Eqs. (4.5) in (4.6), we can write \(100\left( {1 - \alpha } \right)\)\(\%\) equal tail CIs for \(P\) based on UMVUE and MLE as
and
Therefore, PTCIs for \(P\) based on UMVUE and MLE are defined as follows:
and
where \(\hat{P}_{{\text{PT}}\_{\text{ML}}} \,{\text{and}}\, \hat{P}_{{\text{PT}}\_U}\) are as defined in (3.5) and (3.6), respectively.
Now we obtain the coverage probability of PTCI of σ based on its UMVUE.Let us suppose that, \(\delta = \frac{{{\sigma }}}{{{{\sigma }}_{0} }}, {\text{where}} \,{{\sigma }}_{0} {\text{is }}\,{\text{the }}\,{\text{true }}\,{\text{value}}\,{\text{of}}\, {{\sigma }}\). We know that \(T = 2{{\sigma }}S_{m} \sim \chi_{2m}^{2}\)
where \(A_{1} = \frac{{\chi_{2m}^{2} \left( {\frac{\alpha }{2}} \right)}}{{2\left( {m - 1} \right)}} \,{\text{and}}\, A_{2} = \frac{{\chi_{2m}^{2} \left( {1 - \frac{\alpha }{2}} \right)}}{{2\left( {m - 1} \right)}}\)
or,
Let us denote \(P\left\{ {{{\delta }}\chi_{2m}^{2} \left( {\frac{\alpha }{2}} \right) \le T \le {{\delta }}\chi_{2m}^{2} \left( {1 - \frac{\alpha }{2}} \right)} \right\}I_{{A_{1} A_{2} }} \left( {{\delta }} \right)\) by \(A\), where I(.) is an indicator function. Considering all possible cases of \({{\delta }}\), we may write
Similarly, coverage probability for other PTCI may be obtained.
5 Numerical Findings
In this section, we have tried to judge the performance of preliminary test estimators based on progressive type-II censored data. Five progressive censoring schemes are considered which can be seen in Table 1.
We consider Kumaraswamy distribution [22] as a particular case of Kw-G distributions. A rv \(X\) is said to follow the Kumaraswamy distribution, if its pdf and cdf are given by
and
For simulation studies, different progressively censored samples are generated using the algorithm proposed by Balakrishnan and Sandhu [3] which involves the following steps
-
1.
Generate \(m\) independent and identically (iid) random numbers \(\left( {u_{1} ,u_{2} , \ldots ,u_{m} } \right)\) from uniform distribution \(U\left( {0,1} \right).\)
-
2.
Set \(z_{i} = - \log \left( {1 - u_{i} } \right),\) so that \(z_{i} 's\) are iid standard exponential variates.
-
3.
Given censoring scheme \(R = \left( {R_{1} ,R_{2} , \ldots ,R_{m} } \right)\),
set \(y_{1} = z_{1} /m\) and \(y_{i} = y_{i - 1} + \frac{{z_{i} }}{{\left( {n - \mathop \sum \nolimits_{j = 1}^{i - 1} R_{j} - i + 1} \right)}}, i = 2, \ldots ,m\)
-
4.
Now, \(\left( {y_{1} ,y_{2} , \ldots ,y_{m} } \right)\) is a progressive type-II censored sample from standard exponential distribution.
-
5.
Set \(w_{i} = 1 - \exp \left( { - y_{i} } \right),\) so that \(w_{i} 's\) form a progressive type-II censored sample from \(U\left( {0,1} \right).\)
-
6.
Set \(x_{i} = F^{ - 1} \left( {w_{i} } \right)\), where \(F\left( . \right)\) is the cdf of Kumaraswamy distribution as defined in (5.2).
Now \(\left( {x_{1} ,x_{2} , \ldots ,x_{m} } \right)\) is a progressive type-II censored sample from the said distribution with censoring scheme \(R = \left( {R_{1} ,R_{2} , \ldots ,R_{m} } \right).\)
For a particular set of sample size, parameter value and progressive censoring scheme, we have generated 1000 progressively censored sample. For each case, UMVUE and MLE of parameter, \(R\left( t \right)\) and \(P\) are computed. Finally, mean square error (MSE) of all the estimators is obtained on the basis of estimates from all 1000 simulations.
The estimates of σ along with their MSEs for different censoring schemes are presented in Table 2. Here, it is assumed for the sake of illustration that the true value of σ is 2.5. From Table 2, it can be seen that the MSE of preliminary test estimators is less than that of the classical estimators. Further, the preliminary test estimates are closer to the true value of \(\sigma\) than the classical estimates.
In Table 3, the estimates of \(R\left( t \right)\) and their MSEs are obtained for different values of time t under different censoring schemes. It can be observed that the MSE of preliminary test estimators is less than that of the classical estimators. Further, the preliminary test estimates are closer to the true value of \(R\left( t \right)\) than the classical estimates.
Similarly, the estimates of \(P\) and their MSEs for different combination of \(\left( {m, l} \right)\) and (σ1, σ2) are obtained and presented in Table 4. Similar findings as in the above cases may be drawn here. Therefore, it can be concluded that the preliminary test estimators of \(\sigma , R\left( t \right) \,{\text{and}} \,P\) perform better that the classical estimators since the MSE of preliminary test estimators is less than that of classical estimators in all the cases under simulated data set.
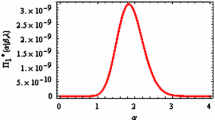
Finally, the coverage probability (CP) of PTCI of σ is plotted against \(\delta\), which can be seen in Fig. 1. It may be seen that for fixed values of \(n, m\) and \(\alpha\) = 0.15, the CP, as a function of \(\delta\), decreases monotonically. It then increases and crosses the line \(1 - \alpha\) and decreases again. It increases and decreases again until reaching a minimum value. Finally, it increases and tends to line \(1 - \alpha\) when δ becomes large. Further, it is observed that for small values of \(m\), the domination interval is wider than for large values of m. Therefore, we may conclude that for some \(\delta\) in specific interval, the CP of PTCI of σ is more than that of equal tail confidence interval.

Coverage probability of PTCI of σ
Let us now consider the real data set used by Proschan [25], Rasouli and Balakrisnan [27] and Kumari et al. [23]. The data represent the intervals between failure (in hours) of the air conditioning system of a fleet of 13 Boeing 750 jet airplanes. It was observed by Proschan [25] that the failure time distribution of the air conditioning system for each of the plane can be well approximated by exponential distribution. For the present study, failure times of plane ‘7913’ are taken which are as follows:3, 5, 5, 13, 14, 15, 22, 22, 23, 30, 36, 39, 44, 46, 50, 72, 79, 88, 97, 102, 139, 188, 197, 210
This data set is transformed to a new data set with range of unit interval by using the transformation,
The transformed data set is as follows,0.0142, 0.0237, 0.0237, 0.0616, 0.0664, 0.0711, 0.1043, 0.1043, 0.1090, 0.1422, 0.1706, 0.1848, 0.2085, 0.2180, 0.2370, 0.3412, 0.3744, 0.4171, 0.4597, 0.4834, 0.6588, 0.8910, 0.9336, 0.9953
It has been seen by Kumari et al. [23] that this data set is a good fit for the distribution under consideration. Further, the ML estimates for the complete data set are \(\left( {\hat{\sigma }, \hat{\gamma }} \right) = \left( {1.0854,0.6054} \right)\).
Let us suppose that out of this data set, the failure time of only 15 units is completely observed, rest all being progressively censored. Then, from Theorem 3, we find that for \(p = 1\), \(\hat{\sigma }_{\text{ML}} = 1.19862\)
Consider the hypothesis,
The computed test statistic is \(2\sigma_{0} S_{m} = 37.54319\) which does not fall in the critical region; therefore, we do not reject the null hypothesis at 5% level of significance which indicates that \(\hat{\sigma }_{{\text{PT}}\_{\text{ML}}} = 1.5\). Further, the estimated value of \(\delta = \frac{{\sigma_{0} }}{{\hat{\sigma }_{\text{ML}} }} = 1.25144\) which falls in the range of (0.422468, 2.367046) which means that the coverage probability of PTCI of σ is more than that of the equal tail CI.
6 Conclusions
In this paper, we have obtained estimators (point as well as interval) for the powers of parameter, \(R\left( t \right)\, {\text{and}}\)\(P\) for Kumaraswamy-G distribution under progressive type-II censoring scheme. The PTEs and PTCIs for parameter \(R\left( t \right)\) and \(P\) for the said distribution are further developed. The bias and MSE of all the PTEs are obtained. It is shown from the numerical analysis that the proposed PTEs perform better than the classical estimators whenever the true value of parameter is close to the prior guessed value. From the analysis of real-life data set, it can be inferred that the PTCI of the parameter has greater coverage probability than that of the equal tail confidence interval in the neighbourhood of null hypothesis. Thus, one can construct the PTEs and PTCIs which are superior to their classical counterparts whenever some prior information is available.
References
Awad AM, Gharraf MK (1986) Estimation of P(Y < X) in the Burr case: a comparative study. Commun Stat Sim Comput 15(2):389–403
Balakrishnan N, Aggarwala R (2000) Progressive censoring: theory, methods and applications. Birkhauser, Boston. https://doi.org/10.1007/978-1-4612-1334-5
Balakrishnan N, Sandhu RA (1995) A simple simulation algorithm for generating progressive type-II censored samples. Am Stat 49(2):229–230
Bancroft TA (1944) On Biases in estimation due to the use of preliminary tests of significance. Ann Math Stat 15(2):190–204
Bartholomew DJ (1957) A problem in life testing. J Am Stat Assoc 52:350–355
Bartholomew DJ (1963) The sampling distribution of an estimate arising in life testing. Technometrics 5:361–374
Belaghi RA, Arashi M, Tabatabaey SMM (2014) Improved confidence intervals for the scale parameter of Burr XII model based on record values. Comput Stat 29(5):1153–1173
Belaghi RA, Arashi M, Tabatabaey SMM (2015) On the construction of preliminary test estimator based on record values for the burr XII model. Commun Stat Theory Methods 44(1):1–23
Chaturvedi A, Kumari T (2015) Estimation and testing procedures for the reliability functions of a family of lifetime distributions. https://interstat.statjournals.net/YEAR/2015/articles/1504001.pdf
Chaturvedi A, Pathak A (2014) Estimation of the reliability function for four-parameter exponentiated generalized lomax distribution. Int J Sci Eng Res 5(1):1171–1180
Chaturvedi A, Rani U (1998) Classical and Bayesian reliability estimation of the generalized Maxwell failure distribution. J Stat Res 32:113–120
Chaturvedi A, Surinder K (1999) Further remarks on estimating the reliability function of exponential distribution under type I and type II censorings. Braz J Probab Stat 13:29–39
Chaturvedi A, Tomer SK (2002) Classical and Bayesian reliability estimation of the negative binomial distribution. J Appl Stat Sci 11:33–43
Cohen AC (1963) Progressively censored sample in life testing. Technometrics 5:327–339
Constantine K, Karson M, TSE SK (1986) Estimation of P(Y < X) in the gamma case. Commun Stat Simul Comput 15(2):365–388
Cordeiro GM, De Castro M (2011) A new family of generalized distributions. J Stat Comput Simul 81(7):883–898
Johnson NL (1975) Letter to the editor. Technometrics 17:393
Kelly GD, Kelly JA, Schucany WR (1976) Efficient estimation of P(Y < X) in the exponential case. Technometrics 18:359–360
Kibria BMG (2004) Performance of the shrinkage preliminary tests ridge regression estimators based on the conflicting of W, LR and LM tests. J Stat Comput Simul 74(11):793–810
Kumaraswamy P (1976) Sinepower probability density function. J Hydrol 31:181–184
Kumaraswamy P (1978) Extended sinepower probability density function. J Hydrol 37:81–89
Kumaraswamy P (1980) A generalized probability density function for double-bounded random processes. J Hydrol 46:79–88
Kumari T, Chaturvedi A, Pathak A (2018) Estimation and testing procedures for the Reliability functions of Kumaraswamy-G distributions and a characterization based on Records. J Stat Theory Pract 13:22
Nadarajah S, Cordeiro GM, Ortega EMM (2012) General results for the Kumaraswamy-G distributions. J Stat Comput Simul 82:951–979
Proschan F (1963) Theoretical explanation of observed decreasing failure rate. Tecnometrics 15:375–383
Rastogi MK, Tripathi YM (2014) Parameter and reliability estimation for an exponentiated half-logistic distribution under progressive type-II censoring. J Stat Comput Simul 84(8):1711–1727
Rasouli A, Balakrishnan N (2010) Exact likelihood inference for two exponential population under joint progressive type-II censoring. Commun Stat Theory Methods 39:2172–2191
Saleh AKME (2006) Theory of preliminary test and Stein-type estimation with applications. Wiley, Hoboken
Saleh AKME, Kibria BMG (1993) Performance of some new preliminary test ridge regression estimators and their properties. Commun Stat Theory Methods 22(10):2747–2764
Tamandi M, Nadarajah S (2016) On the estimation of parameters of Kumaraswamy-G distributions. Commun Stat Sim Comput 45:3811–3821
Acknowledgements
The valuable comments from the anonymous reviewers have helped in coming out with the improved version of the paper (in terms of both contents and presentation) and are gratefully acknowledged.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Chaturvedi, A., Bhatnagar, A. Development of Preliminary Test Estimators and Preliminary Test Confidence Intervals for Measures of Reliability of Kumaraswamy-G Distributions Based on Progressive Type-II Censoring. J Stat Theory Pract 14, 52 (2020). https://doi.org/10.1007/s42519-020-00119-2
Published:
DOI: https://doi.org/10.1007/s42519-020-00119-2