
Abstract
The rapid advancement in the field of deep learning and high performance computing has highly augmented the scope of video-based vehicle counting system. In this paper, the authors deploy several state-of-the-art object detection and tracking algorithms to detect and track different classes of vehicles in their regions of interest (ROI). The goal of correctly detecting and tracking vehicles’ in their ROI is to obtain an accurate vehicle count. Multiple combinations of object detection models coupled with different tracking systems are applied to access the best vehicle counting framework. The models’ addresses challenges associated to different weather conditions, occlusion and low-light settings and efficiently extracts vehicle information and trajectories through its computationally rich training and feedback cycles. The automatic vehicle counts resulting from all the model combinations are validated and compared against the manually counted ground truths of over 9 h’ traffic video data obtained from the Louisiana Department of Transportation and Development. Experimental results demonstrate that the combination of CenterNet and Deep SORT, and YOLOv4 and Deep SORT produced the best overall counting percentage for all vehicles.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Accurate estimation of the number of vehicles on the road is an important endeavor in intelligent transportation system (ITS). An effective measure of on-road vehicles can have a plethora of application in transportation sciences including traffic management, signal control and on-street parking (Asha and Narasimhadhan 2018; Khan et al. 2019; Li et al. 2016). Technically, most vehicle counting methods are characterized into either hardware or software-based systems (Lin and Sun 2018). Inductive-loop detectors and piezoelectric sensors are the two most extensively used hardware systems till date. Although they have higher accuracies than software based systems, they are intrusive and expensive to maintain. On the other hand, software based system thats use video cameras and run on computer vision algorithms present an inexpensive and non-intrusive approach to obtain vehicle counts. Similarly, with increasing computing capabilities and recent successes in object detection and tracking technology, they manifest a tremendous potential to surrogate hardware based systems. Part of the reason to make such a claim is due to the rapid advancement in the field of deep learning and high performance computing, which has fueled an era of ITS within the multi-disciplinary arena of transportation sciences.
This study is motivated by the need to present a robust vision-based counting system that addresses the challenging real-world vehicle counting problem. The visual understanding of objects in an image sequence must face many challenges, perhaps customary to every counting task such as difference in scales and perspectives, occlusions, illumination effects and many more (Ciampi et al. 2018). To address these challenges, several deep learning based techniques are proposed to accurately detect and count the number of vehicles in different environmental conditions. Out of all the problems associated to counting, one that stands out the most would be the occlusion in traffic videos. They appear quite frequently on most urban roads that experience some form of congestion. This leads to ambiguity in vehicle counting which could likely undermine the quality of traffic studies that rely on vision-based counting schemes to estimate traffic flows or volumes (Pang et al. 2007). One of the objectives of this paper is to propose a counting system that is robust to occlusion problem and can provide a resolve in accurately counting vehicles that experience multi-vehicle occlusion.
Passenger cars occupy the greatest proportion of on-road vehicles and most often than not they get occluded by trucks when they are either too near or distant to traffic cameras. Therefore, the scope of this study is limited to counting cars and trucks only. We focus on real-time vehicle tracking and counting using state-of-the-art object detection and tracking algorithms. The rest of the paper is outlined as follows: Sect. “Related Works” briefly reviews related works in the field of vehicle counting. Section “Data” contains data description. Section “Methodology” describes the proposed methodology including different object detection and tracking algorithms. Section “Results” includes empirical results, and Sect. “Conclusion” details the conclusions of this study.
Related Works
Vision-based vehicle counting is an interesting computer vision problem tackled by different techniques. As per the taxonomy accepted in (Zhang et al. 2017), the counting approach could be broadly classified into five main categories: counting by frame-differencing (Cucchiara et al. 2000; Tsai and Yeh 2013), counting by detection (Toropov et al. 2015; Zheng and Peng 2012), motion based counting (Chen et al. 2010; Chen et al. 2012; Mo and Zhang 2010; SuganyaDevi et al. 2012), counting by density estimation (Lempitsky and Zisserman 2010) and deep learning based counting (Arteta et al. 2016; Hsieh et al. 2017; Onoro-Rubio and López-Sastre 2016; Sindagi and Patel 2018; Zhang et al. 2015, 2016; Zhao et al. 2016). The first three counting methods are environmental sensitive and generally don’t perform very well in occluded environments or videos with low frame rates. While counting by density estimation follows a supervised approach, they perform poorly in videos that have larger perspective and contain oversized vehicles. Density estimation based methods are also limited in their scope of detection and lack object tracking capabilities. Finally, out of all these counting approaches, deep learning based counting techniques have had the greatest developments in recent years. The advancement in their built architectures have significantly improved the vehicle counting performance. In this study, we mainly focus on studying counting methods that are founded on deep learning based architectures.
(Awang and Azmi 2018) proposed a deep learning based technique that tabulates the number of vehicles based on the layer skipping-strategy within a convolutional neural network (CNN). Prior to performing counts, their approach classifies the vehicle into different classes based on their distinct features. (Dai et al. 2019) deployed a video based vehicle counting technique using a three-step strategy of object detection, tracking and trajectory analysis. Their method uses a trajectory counting algorithm that accurately computes the number of vehicles in their respective categories and tracks vehicle routes to obtain traffic flow information. Similarly, a deep neural network is trained to detect and count the number of cars in (Mundhenk et al. 2016). This approach integrates residual learning alongside inception-style layers to count cars in a single look. Lately, it has been demonstrated that single-look techniques have the potential to excel at both speed and accuracy (Redmon et al. 2016) requirements useful for object recognition and localization. This could also, prove beneficial to process image frames at much faster rates that can accurately produce vehicle counts in real-time conditions. (Liu et al. 2017) deliberate counting as a computer vision problem and present an adaptive real-time vehicle counting algorithm that takes robust detection and counting approach in an urban setting.
Although video-based counting systems have emerged as an active research area, there are issues with detection and re-identification of vehicles, while they cross each other in separate road lanes. To counter this problem, (Bui et al. 2020) successfully deployed state-of-the-art YOLO and SORT algorithms to perform vehicle detection and tracking, respectively. To further improve their video-based vehicle counter, they followed a distinguished region tracking paradigm that works well for intricate vehicle movement scenarios. Similarly, (Chakraborty et al. 2018) used semi-supervised techniques to obtain vehicle trajectories which is a precursor to obtaining an accurate counting framework. Generally, most object counting literature (Arteta et al. 2016; Onoro-Rubio and López-Sastre 2016; Zhang et al. 2016; Zhao et al. 2016) approximates the object densities, maps them and computes densities over the entire image space to obtain vehicle counts. However, the accuracy of these methods drop whenever a video has a larger perspective or if a large bus or truck appears. The FCN-rLSTM network proposed in (Zhang et al. 2017) tackles problems associated to larger perspective videos by approximating vehicle density maps and performing vehicle counts by integrating fully convolutional neural networks (FCN) with long short term memory networks (LSTM) in a residual learning environment. This approach leverages the capabilities of FCN based pixel wise estimation and the strengths of LSTM to learn difficult time-based vehicle dynamics. The counting accuracy is thus, improved by putting the time-based correlation into perspective.
Data
Traffic images and video feeds were the two kinds of dataset used in this study. These datasets were obtained from the cameras located at six different roadways over a 7-day period. The cameras were installed across different roadways in New Orleans and maintained by the Louisiana Department of Transportation and Development (La DOTD). To train and generate robust models, datasets pertaining to different weather conditions were collected. To incorporate that, video feeds were recorded at the start of every hour for one minute and followed the same loop for the entire 24 h in a day. This recording was further continued for 1 week at all the six roadways. Traffic images and videos consist of daylight, nighttime and rain. To train all the models used in this study, altogether 11,101 images were manually annotated for different classes of vehicles viz. cars and trucks. A total of 29,242 cars were annotated, where 24,901, 2793, and 1548 annotations were performed for daylight, nighttime and rainy conditions. Similarly, for trucks, altogether 3042 instances of annotations were completed for day (2590), night (297) and rain (155) settings.
Figure 1 shows all the six different cameras maintained by La DOTD and their respective camera views. Similarly, any vehicle that travelled across those green and blue polygons were counted and appended in the north and southbound directions, respectively.

Camera locations
Methodology
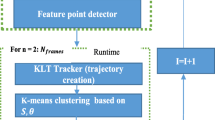
The study compares the combination of different object detectors and trackers for performing vehicle counts. As shown from Fig. 2, the proposed vehicle counting framework initiates by manually annotating traffic images. This is followed by training several object detection models which can then be used to detect different classes of vehicles. All the object detection models are trained on NVIDIA GTX 1080Ti GPU.

Detection-tracking based vehicle counting framework
After obtaining detection results for each video frame, different tracking algorithms are used for multi-object tracking. In this study, we used both online and offline tracking algorithms. Although offline tracking algorithms yield better results, the advantage of using online trackers could be realized in applications that involve online traffic control scenarios. Similarly, based on the detection outcomes, each vehicle is counted only once as per their trajectory matching function’ intrinsic to every object tracking algorithm. The green and blue polygons drawn on the cameras (see Fig. 1) assigns the entrance and exit zones for every vehicles’ trajectory and computes the number of vehicles passing through the north and southbound directions, respectively. Altogether, four different state-of-the-art object detectors and trackers were used making a total of 16 different detector-tracker combinations. Upon obtaining vehicle counts, all these detector-tracker combinations were further analyzed and had their performance capabilities compared based off different environmental conditions. The object detectors and tracking algorithms used in this study are further explained in detail in the subsequent sections.
A. Object Detectors
CenterNet
With the advancement in deep learning, object detection algorithms have significantly improved. In this study, the authors implemented an object detection framework called CenterNet (Duan et al. 2019) which discovers visual patterns within each section of a cropped image at lower computational costs. Instead of detecting objects as a pair of key points, CenterNet detects them as a triplet thereby, increasing both precision and recall values. The framework builds up on the drawbacks encountered by CornerNet (Law and Deng 2018) which uses a pair of corner-keypoints to perform object detection. However, CornerNet fails at constructing a more global outlook of an object, which CenterNet does by having an additional keypoint to obtain a more central information of an image. CenterNet functions on the intuition that if a detected bounding box has a higher Intersection over Union (IoU) with the ground-truth box, then the likelihoods of that central keypoint to be in its central region and be labelled in the same class is high. Hence, the knowledge of having a triplet instead of a pair increases CenterNet’s superiority over CornerNet or any other anchor-based detection approaches. Despite using a triplet, CenterNet is still a single-stage detector but partly receives the functionalities of RoI pooling. Figure 3 shows the architecture of CenterNet, where it uses a CNN backbone that performs cascade corner pooling and center pooling to yield two corner and a center keypoint heatmap. Here, cascade corner pooling enables the original corner pooling module to receive internal information, whereas center pooling helps center keypoints to attain further identifiable visual pattern within objects that would enable it to perceive the central part of the region. Likewise, analogous to CornerNet, a pair of detected corners and familiar embeddings are used to predict a bounding box. Then after, the final bounding boxes are determined using the detected center keypoints. In this study, CenterNet was trained on NVIDIA GTX 1080Ti GPU which took approximately 22 h. A constant learning rate of 0.000025 was used throughout the training.

Architecture of CenterNet
Detectron2
Detectron2 (Wu et al. 2019), is a platform for object detection and segmentation algorithms, that builds up on the Mask R-CNN benchmark. Fueled by the PyTorch deep learning framework, it includes features such as panoptic segmentation (Kirillov et al. 2019), dense-pose (Alp Güler et al. 2018), Cascade R-CNN (Cai and Vasconcelos 2018), rotated bounding boxes, etc. To perform object detection and segmentation, Detectron2 requires images and its annotated database to follow annotation format as followed by the COCO dataset. The annotation consists of every individual object present in all images of the training database. Detectron2 supports implementation to multiple object detection algorithms using different backbone network architectures such as ResNET {50, 101, 152}, FPN, VGG16, etc. Hence, it can be used as a library to support a multitude of projects on top of it. In this study, Resnet-50 with Feature Pyramid Network is used.
YOLOv4
You Only Look Once (YOLO) is the state-of-the-art object detection algorithm. Unlike traditional object detection systems, YOLO investigates the image only once and detects if there are any objects in it. Out of all the earlier versions of YOLO, YOLOv4 is the latest and most advanced iteration till date (Bochkovskiy et al. 2020). It has the fastest operating speed for use in production systems and for optimization in parallel computations. Some of the new techniques adopted in YOLOv4 are: (1) Weighted-Residual-Connections (Shen et al. 2016), (2) Cross-Stage-Partial-Connections (Wang et al. 2020), (3) Cross iteration batch normalization (Yao et al. 2020), (4) Self-adversial-training (Chou et al. 2018), (5) Mish-activation (Misra 2019), etc. To obtain higher values for precision, YOLOv4 uses a Dense Block, a deeper and more complex network. Similarly, the backbone of its feature extractor uses CSPDarknet-53, which deploys the CSP connections alongside Darkenet-53 from the earlier YOLOv3. In addition to CSPDarknet-53, the architecture of YOLOv4 comprises of SPP additional module, PANet path-aggregation neck and YOLOv3 anchor-based head. The SPP block is stacked over CSPDarknet53 to increase the receptive field that could discretize the most remarkable context features and makes sure that there is no drop in its network operation speed. Similarly, PANet is used for parameter aggregation from several levels of backbone in place of Feature Pyramid Network (FPN) that is used in YOLOv3. YOLOv4 models took approximately 24 h to train and shared the same hardware resources with CenterNet. A batch-size of 64 and the optimizer weight decay of 0.0005 is used. Similarly, the initial learning rate of 0.01 is used and the momentum is set to 0.9 throughout the training process. The inference time for CenterNet was approximately 340 ms per image.
EfficientDet
EfficientDet is a state-of-the-art object detection algorithm that basically follows single-stage detectors pattern (Tan et al. 2020). The architecture of EfficientDet is shown in Fig. 4. Here, the ImageNet-pretrained EfficientNets has been deployed as the network’s backbone. Similarly, to obtain an easier and quicker multi-scale fusion of features, a weighted bi-directional feature pyramid network (BiFPN) has been proposed. BiFPN here, serves as the feature network and receives approximately 3–7 features from the backbone network and continually performs top-down and bottom-up bidirectional fusion of features. These synthesized features are transferred to a class and box network to achieve vehicle class and bounding box predictions correspondingly. Also, all the vehicle class and box network weights are jointly shared across every feature level. Similarly, to achieve higher accuracy, a new compound scaling method is proposed for EfficientDet. This compound scaling approach scales up the overall dimensions of width, depth, backbone resolution, BiFPN along with box and class prediction networks. Although, the primary goal of EfficientDet was to perform object detection, it could also be deployed to perform tasks such as semantic segmentation. Training an EfficientDet model took approximately 36 h on an NVIDIA GTX 1080Ti GPU. Similarly, the learning rate is steadily increased from 0 to 0.16, while the momentum and weight decay is set to 0.9 and 0.00004, respectively, during training.

Architecture of EfficientDet (Tan et al. 2020)
B. Object Tracker
IOU Tracker
IOU tracker is built on the assumption that every object is tracked on a per-frame basis such that there are none or very few gaps present in between detections (Bochinski et al. 2018). Similarly, IOU assumes that there is a greater overlap value for intersection over union while obtaining object detections in successive frames. Equation (1) measures the Intersection over Union which forms the basis for this approach:
IOU tracker specifically tracks objects by assigning detection with the highest IOU value (Eq. 1) to the last detection in the earlier frame if a specific threshold value is satisfied. In cases, where any detection was not assigned to an existing track, then it begins with a new one. Likewise, any track that was devoid of an assigned detection will end. Since, we aim to track vehicles in this study, the IOU performance could be further enhanced by canceling tracks that don’t meet a certain threshold time length and where no detected vehicle exceeded the required IOU threshold. It is important to note that IOU tracker is heavily reliant on how accurately vehicles are recognized by object detection models, so special focus should be laid out on effectively training object detection algorithms. IOU’s ability to handle frame rates of over 50,000 fps in conjunction to its low computational cost makes it an incredibly powerful object tracker.
Similarly, Kalman-IOU (KIOU) tracking has been further explored. The Kalman filter’s ability of performing predictions allows users to skip frames while still keeping track of the object. Skipping frames allows the detector to speed-up the process as in a tracking-by-detection task, smaller number of frames wedges lower computational requirement. Using an appropriate object detector with Kalman-IOU tracker, and configuring the frames to skip two-thirds of frames per second could enable the tracker to run in real-time. Likewise, this feature could also improve the performance of Kalman-IOU tracker compared to the original IOU tracker.
SORT
Simple Online and Realtime Tracking (SORT) is an implementation of tracking-by-detection framework, where the main objective is to detect objects each frame and associate them for online and real-time tracking application (Bewley et al. 2016). Methods such as Kalman Filter and Hungarian algorithm are used for tracking. The characteristic feature of SORT is that it only uses detection information from the previous and current frames, enabling it to competently perform online and real-time tracking. In SORT, after a detection is linked to the target object, the detected bounding box is utilized to update the state of target object, where the components of velocity are solved through Kalman filter (Kalman 1960).
Feature Based Object Tracker
In Feature-based object tracking, there is the usage of appearance information to track objects in respective traffic scenes. This method is useful in tracking vehicles in occluded settings. The system extracts object features from one frame and then matches appearance information with successive frames based on the measure of similarity. Feature-based object tracking consists of both feature extraction and feature correspondence. The feature points are extracted from the objects in an image using various statistical approaches. Feature correspondence is considered an arduous task, since a feature point in one image may have analogous points in other images which could perhaps, pose ambiguity problems in feature correspondence. To undermine ambiguity, most contemporary algorithms use exhaustive search along with correlation over larger pixels of image neighborhood. Likewise, the minimum value of cosine distance is also useful at computing any resemblance between some of the characteristic features which is useful for object tracking. In the current study, a feature-based object tracker called Deep SORT is deployed. Some of the features of this tracking algorithm is explained in detail as follows.
Deep SORT
The Simple Online and Realtime Tracking with a Deep Association metric (Deep SORT) enables multiple object tracking by integrating appearance information with its tracking components (Wojke et al. 2017). A combination of Kalman Filter and Hungarian algorithm is used for tracking. Here, Kalman filtering is performed in image space, while Hungarian technique facilitates frame-by-frame data association using an association metric that computes bounding box overlap. To obtain motion and appearance information, a trained convolutional neural network (CNN) is applied. By integrating CNN, the tracker achieves greater robustness against object misses and occlusions while preserving the trackers ability to quickly implement to online and realtime scenarios intact. The CNN architecture of the system is shown in Table 1. A wide residual network with two convolutional layers followed by six residual blocks is applied. In dense layer 10, a global feature map of dimensionality 128 is calculated. Finally, batch and ℓ2 normalization features over the unit hypersphere accesses compatibility with cosine arrival metric. Overall, Deep SORT is a highly versatile tracker and can match performance capabilities with other state-of-the-art tracking algorithms as seen from the MOT16 benchmark for Multi-object Tracking (Milan et al. 2016).
Results
This section evaluates the performance of different combinations of object detectors and trackers. The main goal of this study is to identify the best performing object detector-tracker combination. For comparative analysis, the models are tested on a total of 546 video clips of length 1 min each comprising of over 9 h’ total video length. Figure 1 shows all the camera views with manually generated green and blue polygons that record the number of vehicles passing through them in both north and southbound directions, respectively. The vehicle counts are evaluated based on four different categories: (1) overall count of all vehicles, (2) total count of cars only, (3) total count of trucks only, and (4) overall vehicle counts for different times of the day (i.e., daylight, nighttime, rain). To establish ground truth, all the vehicles are manually counted from the existing 9 h’ video test data. The performance is assessed by expressing the automatic counts obtained from different model combinations over the ground truth value expressed in per hundredth or percentage.
To examine the performance of object detectors, heat maps showing False Negatives (FN), False Positives (FP) and True Positives (TP) are plotted in Fig. 5 for all the object detectors used in the study. The models were tested on altogether six camera views at different times of the day. The left, center and right columns show the heat maps generated for CenterNet, YOLOv4 and EfficientDet, respectively. For all these respective object detectors, the first column represents FN, the second column designates FP and the third column denotes TP. The detection is classified as False Negative (FN) if the detector fails at detecting the vehicle despite it being present at that spot. Therefore, the column showing FN should necessarily not have brighter intensity of colors around those sections of the roadway. Almost all object detectors have performed well at detecting FN in most camera views except for CenterNet’s 5th camera view, where it generates heat maps in its south bounds as well. This is largely because certain camera views had insufficient number of traffic images used for training and could have possibly experienced heavy congestion at those sites. For instance, heat maps closer to the camera in night views are mostly produced when the heavy gross vehicles such as buses and trucks remain congested at those spots for a very long time.

Heat maps generated for different object detectors
Similarly, the detection is classified as False Positive (FP) if the detector erroneously detects a vehicle at a spot with no vehicles present. As observed from the heat maps, the FP columns for object detectors are generally clean with a few camera views in EfficientDet generating incorrect classifications. The camera view with flyovers or overpass roads caused the model to misclassify some of the detections. Sometimes, camera movements and conditions such as rain sticking on the camera lens and pitch darkness also cause such misclassifications. Ideally, we do not aim at seeing intense heat maps for both false negatives and false positives. However, if we have higher false positives but obtain lower false negatives, then the model might have been too confident which is not very ideal. Finally, True Positive (TP) is the one that correctly detects vehicle when there are any actual vehicles present on the roadways. Most object detection models generated correct true positives except for a few camera views, where the vehicles are either too distant or encounters lowlight or nighttime conditions, where only the vehicles’ headlights were visible.
Figure 6 shows the overall count percentage for all vehicles. As seen from the figure, the overall count percentage for some of the model combinations exceed over 100 percent, while a couple combinations obtain counting results below 45 percent of the actual counts. Any model combination that either over-counts or under-counts the actual number of vehicles are considered faulty match, while the ones that perform counts in the order closer to 100 percent are termed an optimal match. The best performing model combinations that obtained a more accurate count estimate for all vehicles were YOLOv4 and Deep SORT, and CenterNet and Deep SORT. Thus, both these model combinations can be considered an optimal match.

Performance of model combination for all vehicles count
Similarly, Figs. 7, 8 compare the performance of different model combinations for counting cars and trucks, respectively. From Fig. 7, it can be observed that CenterNet and IOU, CenterNet and SORT, EfficientDet and Deep SORT, and YOLOv4 and Deep SORT obtained the best counting results. These detector-tracker combinations performed well in both north and southbound directions, respectively. Occlusion issues created a hindrance in correctly locating cars which would often be obstructed by larger vehicles whenever they are too close to the camera. Likewise, in Fig. 8, the truck counter performance is assessed. Out of all the model combinations, only EfficientDet and Deep SORT obtained acceptable counting performance in both north and southbound directions. Although, the combination of CenterNet and KIOU, and EfficientDet and SORT separately obtained accurate counting results, their scope was limited to only either North or Southbound directions, respectively. Most of the other model combinations didn’t accurately count trucks due to the presence of other heavy gross vehicles (HGV) such as buses, trailers, and multi-axle single units. These HGVs often confused the models and were assigned as trucks that generated an over-estimate of truck counts. Exaggerating the actual number of vehicle counts (either trucks or cars) could be attributed to that fact that some of the detectors produced multiple bounding boxes for the same vehicle while traversing the video scene. This impelled the tracker to confuse the same vehicle as different ones and assign them with newer values every time a bounding box re-appears.

Performance of model combination for car counts only

Performance of model combination for truck counts only
Likewise, Table 2 illustrates the performance comparison of models at different times of the day and rainy conditions. The counting results show that the best performing model combinations were YOLOv4 and Deep SORT, and CenterNet and Deep SORT, analogous to the comparison chart, as shown in Fig. 6. Vehicle counting accuracies largely depends on the precision of object detection models. However, it is evident from Table 2 that the models didn’t achieve optimal results for the most part. The reasons could be partly attributed to the inferior camera quality, unstable camera views due to the wind blowing on highways, and the presence of fog or mist on camera lens. During daylight, nighttime and rainy conditions, EfficientDet’s combination with SORT and KIOU failed miserably at counting the number of vehicles. EfficientDet mainly suffered with its detection capability. For model combinations that recorded count percentage over 100 typically had both detector and tracker at fault. Object detectors generated multiple bounding boxes for the same vehicle that resulted in over-counting of the number of vehicles. Also, some of the trackers did not perform ideally at predicting vehicle trajectories and assigned them as separate vehicles at certain occasions.
Conclusion
In this study, a detection-tracking framework is applied to automatically count the number of vehicles on roadways. The state-of-the-art detector-tracker model combinations have been further refined to achieve significant improvements in vehicle counting results although there are still many shortcomings which the authors aim to address in the future study. Occlusion and lower visibility created identity switches and same vehicles were detected multiple times which caused the model to sometimes over-exaggerate the number of vehicles. Although, conditions such as inferior camera quality, occlusion and low light conditions proved tricky in accurately detecting different classes of vehicles, certain combinations of detector-tracker framework functioned fine for challenging conditions as well. Deep learning based object detection models coupled with both online and offline multi-object tracking systems could integrate real-time object detections in conjunction to tracking vehicle movement trajectories. This outline was accepted which in turn facilitated accurate vehicle counts. Moreover, we experimented with the detector-tracker ability to correctly detect different classes of vehicles, estimate vehicles’ speed, direction and its trajectory information to identify some of the best performing models which could be further fine-tuned to remain robust at counting vehicles in different directions and environmental conditions. The figures and tables present a systematic representation of what model combinations perform well at obtaining vehicle counts in different conditions. Overall, for counting all vehicles on the roadway, experimental results from this study prove that YOLOv4 and Deep SORT, and CenterNet and Deep SORT were the most ideal combinations.
References
Alp Güler R, Neverova N, Kokkinos I (2018) Densepose: Dense human pose estimation in the wild. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp 7297–7306
Arteta C, Lempitsky V, Zisserman A (2016) Counting in the wild. In: European conference on computer vision, Springer, pp 483–498
Asha C, Narasimhadhan A (2018) Vehicle counting for traffic management system using YOLO and correlation filter. In: 2018 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), IEEE, pp 1–6
Awang S, Azmi NMAN (2018) Vehicle counting system based on vehicle type classification using deep learning method. In: IT Convergence and Security 2017. Springer, pp 52–59
Bewley A, Ge Z, Ott L, Ramos F, Upcroft B (2016) Simple online and realtime tracking. In: 2016 IEEE International Conference on Image Processing (ICIP), IEEE, pp 3464–3468
Bochinski E, Senst T, Sikora T (2018) Extending IOU based multi-object tracking by visual information. In: 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), IEEE, pp 1–6
Bochkovskiy A, Wang C-Y, Liao H-YM (2020) YOLOv4: optimal speed and accuracy of object detection arXiv preprint arXiv:200410934
Bui N, Yi H, Cho J (2020) A vehicle counts by class framework using distinguished regions tracking at multiple intersections. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp 578–579
Cai Z, Vasconcelos N (2018) Cascade r-cnn: Delving into high quality object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 6154–6162
Chakraborty P, Sharma A, Hegde C (2018) Freeway traffic incident detection from cameras: a semi-supervised learning approach. In: 2018 21st International Conference on Intelligent Transportation Systems (ITSC), IEEE, pp 1840–1845
Chen Y-L, Wu B-F, Huang H-Y, Fan C-J (2010) A real-time vision system for nighttime vehicle detection and traffic surveillance. IEEE Trans Industr Electron 58:2030–2044
Chen Z, Ellis T, Velastin SA (2012) Vehicle detection, tracking and classification in urban traffic. In: 2012 15th International IEEE Conference on Intelligent Transportation Systems, IEEE, pp 951–956
Chou C-J, Chien J-T, Chen H-T (2018) Self adversarial training for human pose estimation. In: 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), IEEE, pp 17–30
Ciampi L, Amato G, Falchi F, Gennaro C, Rabitti F (2018) Counting Vehicles with Cameras. In: SEBD
Cucchiara R, Grana C, Piccardi M, Prati A (2000) Statistic and knowledge-based moving object detection in traffic scenes. In: ITSC2000. 2000 IEEE Intelligent Transportation Systems. Proceedings (Cat. No. 00TH8493), IEEE, pp 27–32
Dai Z, Song H, Wang X, Fang Y, Yun X, Zhang Z, Li H (2019) Video-based vehicle counting framework. IEEE Access 7:64460–64470
Duan K, Bai S, Xie L, Qi H, Huang Q, Tian Q (2019) Centernet: keypoint triplets for object detection. In: Proceedings of the IEEE International Conference on Computer Vision, pp 6569–6578
Hsieh M-R, Lin Y-L, Hsu WH (2017) Drone-based object counting by spatially regularized regional proposal network. In: Proceedings of the IEEE International Conference on Computer Vision, pp 4145–4153
Kalman RE (1960) A new approach to linear filtering and prediction problems
Khan G, Farooq MA, Tariq Z, Khan MUG (2019) Deep-Learning Based Vehicle Count and Free Parking Slot Detection System. In: 2019 22nd International Multitopic Conference (INMIC), IEEE, pp 1–7
Kirillov A, He K, Girshick R, Rother C, Dollár P (2019) Panoptic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 9404–9413
Law H, Deng J (2018) Cornernet: detecting objects as paired keypoints. In: Proceedings of the European Conference on Computer Vision (ECCV), pp 734–750
Lempitsky V, Zisserman A (2010) Learning to count objects in images. In: Advances in neural information processing systems, pp 1324–1332
Li Z, Shahidehpour M, Bahramirad S, Khodaei A (2016) Optimizing traffic signal settings in smart cities. IEEE Trans Smart Grid 8:2382–2393
Lin J-P, Sun M-T (2018) A YOLO-based traffic counting system. In: 2018 Conference on Technologies and Applications of Artificial Intelligence (TAAI), IEEE, pp 82–85
Liu F, Zeng Z, Jiang R (2017) A video-based real-time adaptive vehicle-counting system for urban roads. PLoS ONE 12:e0186098
Milan A, Leal-Taixé L, Reid I, Roth S, Schindler K (2016) MOT16: a benchmark for multi-object tracking arXiv preprint arXiv:160300831
Misra D (2019) Mish: a self regularized non-monotonic neural activation function arXiv preprint arXiv:190808681
Mo G, Zhang S (2010) Vehicles detection in traffic flow. In: 2010 Sixth International Conference on Natural Computation, IEEE, pp 751–754
Mundhenk TN, Konjevod G, Sakla WA, Boakye K (2016) A large contextual dataset for classification, detection and counting of cars with deep learning. In: European Conference on Computer Vision, Springer, pp 785–800
Onoro-Rubio D, López-Sastre RJ (2016) Towards perspective-free object counting with deep learning. In: European Conference on Computer Vision, Springer, pp 615–629
Pang CCC, Lam WWL, Yung NHC (2007) A method for vehicle count in the presence of multiple-vehicle occlusions in traffic images. IEEE Trans Intell Transp Syst 8:441–459
Redmon J, Divvala S, Girshick R, Farhadi A (2016) You only look once: Unified, real-time object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 779–788
Shen F, Gan R, Zeng G (2016) Weighted residuals for very deep networks. In: 2016 3rd International Conference on Systems and Informatics (ICSAI), IEEE, pp 936–941
Sindagi VA, Patel VM (2018) A survey of recent advances in cnn-based single image crowd counting and density estimation. Pattern Recogn Lett 107:3–16
SuganyaDevi K, Malmurugan N, Sivakumar R (2012) Efficient foreground extraction based on optical flow and smed for road traffic analysis. Int J Cyber-Security Digital Forensics (IJCSDF) 1:177–182
Tan M, Pang R, Le QV (2020) Efficientdet: scalable and efficient object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp 10781–10790
Toropov E, Gui L, Zhang S, Kottur S, Moura JM (2015) Traffic flow from a low frame rate city camera. In: 2015 IEEE International Conference on Image Processing (ICIP), IEEE, pp 3802–3806
Tsai C-M, Yeh Z-M (2013) Intelligent moving objects detection via adaptive frame differencing method. In: Asian Conference on Intelligent Information and Database Systems, 2013. Springer, pp 1–11
Wang C-Y, Mark Liao H-Y, Wu Y-H, Chen P-Y, Hsieh J-W, Yeh I-H (2020) CSPNet: a new backbone that can enhance learning capability of cnn. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pp 390–391
Wojke N, Bewley A, Paulus D (2017) Simple online and realtime tracking with a deep association metric. In: 2017 IEEE international conference on image processing (ICIP), IEEE, pp 3645–3649
Wu Y, Kirillov A, Massa F, Lo W-Y, Girshick R (2019) Detectron2
Yao Z, Cao Y, Zheng S, Huang G, Lin S (2020) Cross-iteration batch normalization arXiv preprint arXiv:200205712
Zhang C, Li H, Wang X, Yang X (2015) Cross-scene crowd counting via deep convolutional neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 833–841
Zhang Y, Zhou D, Chen S, Gao S, Ma Y (2016) Single-image crowd counting via multi-column convolutional neural network. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 589–597
Zhang S, Wu G, Costeira JP, Moura JM (2017) Fcn-rlstm: deep spatio-temporal neural networks for vehicle counting in city cameras. In: Proceedings of the IEEE international conference on computer vision, pp 3667–3676
Zhao Z, Li H, Zhao R, Wang X (2016) Crossing-line crowd counting with two-phase deep neural networks. In: European Conference on Computer Vision, Springer, pp 712–726
Zheng Y, Peng S (2012) Model based vehicle localization for urban traffic surveillance using image gradient based matching. In: 2012 15th International IEEE Conference on Intelligent Transportation Systems, IEEE, pp 945–950
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Mandal, V., Adu-Gyamfi, Y. Object Detection and Tracking Algorithms for Vehicle Counting: A Comparative Analysis. J. Big Data Anal. Transp. 2, 251–261 (2020). https://doi.org/10.1007/s42421-020-00025-w
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s42421-020-00025-w