
Abstract
Fracture or fault can control several geological or geophysical events and exploration, where the fault associated with mineralization or fluid flow can be used as a source for Self-Potential (SP) anomaly. The 2-D inclined sheet can be used for modeling for fault interpretation using SP data. In this paper, the improved crow search algorithm (ICSA) using Levy flight is proposed for SP data inversion in determining SP model parameters. In order to evaluate ICSA, the ICSA is compared with standard crow search algorithm (CSA) for determining synthetic SP data that contains multiple anomalies with inclined sheet type structures. It was found that CSA is more explorative than ICSA, and both algorithms can estimate the posterior distribution model (PDM) of SP data. Using uncertainty analysis within the applied threshold in the objective function, both algorithms are reliable to determine PDM. Furthermore, ICSA is tested and implemented to both synthetic and field of SP anomalies for providing the posterior distribution model of SP parameters. The experimental results demonstrate that the ICSA is feasible and effective for determining model parameters and its uncertainty of mono- and multi-SP anomalies. Furthermore, estimating both model parameter and its uncertainty are sufficient for validation with previous researchers. Finally, the interpretation of multiple anomalies in SP anomaly crossing the Grindulu Fault in Pacitan, East Java, Indonesia, is analyzed.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Fault or fracture can be used to identify the presence of geyser (Monteiro Santos et al. 2002) and hydrocarbon (Hardman and Booth 1991), causing instability and water seepage from embankments (Sungkono et al. 2014b, 2018), causing seismic hazards (Diambama et al. 2019; Pace et al. 2018), controlling aquifer (Saribudak and Hawkins 2019), etc. The geological fault is connected with mineralization (Biswas et al. 2014; Biswas and Sharma 2016; Mehanee 2015) or associated with water flow through fracture/fault (Monteiro Santos et al. 2002), that also produces the self-potential anomaly (Biswas 2017) which can be used for the inversion process to obtain the characteristic parameters (e.g., depth, the elevation, width, and edges position) from the inclined sheet that formed by this fault.
Analysis of SP data recently classifies into two approaches including signal analysis (Di Maio et al. 2016a, 2017; Mauri et al. 2011), inversion process, and combining signal analysis and inversion approaches (Biswas 2018). The inversion process also divided into two approaches, namely local optimization (LO) and global optimization (GO) (Biswas 2016), where the GO is more robust than LO. The popular global optimizations have successfully inversed SP data to determine the model parameter of their anomalies viz. particle swarm optimization (PSO) (Essa 2020; Monteiro Santos 2010), differential evolution (DE) (Balkaya 2013; Sungkono 2020b), simulated annealing (SA) (Sharma and Biswas 2013), grey wolf optimizer (GWO) (Agarwal et al. 2018), black hole algorithm (BHA) (Sungkono and Warnana 2018), hybrid GWO and PSO (Ramadhani and Sungkono 2019), Genetic-Price algorithm (Di Maio et al. 2016b, 2019) and flower pollination algorithm (FPA) (Sungkono 2020a).
Nevertheless, the significant number of GO has been proposed as an algorithm for SP data inversion, the last three algorithms provide uncertainty analysis and solution estimation (Ramadhani and Sungkono 2019; Sungkono 2020a; Sungkono and Warnana 2018), although both steps are important in inversion process (Fernández-Muñiz et al. 2019). The uncertainty analysis is important to analysis ambiguity for the model parameter in the SP inversion (Biswas and Sharma 2015). Uncertainty analysis and solution appraisal can be solved using random sampling, Bayesian approach, and exploratory GO methods. The last method is more reliable for applying several problems because this method needs lesser time for calculating forward modeling and objective function than others, although the wide search space bounds in the inversion process are used (Ekinci et al. 2020).
Furthermore, based on the No Free Lunch (NFL) theorem (Wolpert and Macready 1997) described that no algorithm could successfully solve all optimization problems. It means that GO algorithms have described above does not guarantee to solve all optimization problems with different type and characteristic. Consequently, several researchers propose to GO algorithm for inversion problems. In this paper, a GO, called crow search algorithm (CSA) is applied for determining the model parameter of SP data and its uncertainty analysis. The diversity of CSA to measure exploration percentage for the algorithm is also evaluated.
2 Self-potential (SP) method
SP method is one of the earliest geophysical methods. This method measures the superposition of multiple source contribution (natural potential) including electrokinetic (streaming), mineralization (geobattery), electrochemical (liquid junction or diffusion), and thermoelectric potentials (Revil and Jardani 2013; Sharma 1997). Consequently, some application of SP method can be known, for example: water seepage in embankment and landslides potential can be identified using potential electrokinetic concepts in SP method (Ikard et al. 2014; Sungkono 2020b; Sungkono and Warnana 2018); exploration of minerals including copper, sulfide, silica, uranium, graphite and copper deposits (Biswas 2017) is associated with mineralization potential; study of geothermal systems using SP data is based on the thermoelectric potential because strong thermal gradients, hot gas emission, and thermal conduction have existed in the subsurface around the geothermal system (Zlotnicki and Nishida 2003); assessment of landfill leachate is based on combining electrokinetic, mineralization and electrochemical potentials (Arora et al. 2007; Giang et al. 2018).
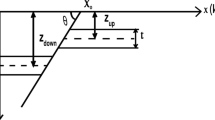
The approach in modeling the SP anomaly can be classified as an idealized anomaly body (horizontal, vertical cylinder, sphere and inclined sheet) and non-ideal body that use the finite element approach. For the geological model that contains fracture or fault, the SP anomaly can be considered as a 2-D inclined sheet (Fig. 1a) which mathematically, the voltage can be described as follow (Biswas and Sharma 2014a, b):
where N is counted anomaly that identified through SP data in x measurement, while \( k = I\rho /\left( {2\pi } \right) \) indicated the polarization parameter (mV), while \( x_{1} \), \( z_{1} \) and \( x_{2} \), \( z_{2} \) show the coordinates of the top and bottom edges of the sheet (Fig. 1a). Equation (1) is used to avoid the ambiguity that formed by the inversion process of SP data in an inclined sheet anomaly. Also, this formula is far more realistic for multiple anomalies of SP data (Biswas and Sharma 2013, 2014a, 2017). Generally, SP anomaly for the inclined sheet which is frequently used for interpretation of SP data is formulated in Eq. (2) as shown in Fig. 1b (Sundararajan et al. 1998). Equation (2) have lower uncertainty than Eq. (1), however, Eq. (1) is better to interpret multiple anomalies of SP data than Eq. (2) (Biswas and Sharma 2014a).
where \( xa,a,h \) and \( \theta \) are x-coordinate as a center of anomaly, half-length of a sheet, depth from the center of the sheet, and inclination counterclockwise in x positive axis, respectively. The other parameters have the same meaning as Eq. (1). According to Eq. (2) we can determine that the geological model is relevant if only \( h \ge a\sin \theta \) (Biswas and Sharma 2014a). The condition must be owned by inclined sheet model parameters.

3 Crow search algorithm (CSA)
3.1 Original CSA
CSA is developed using the intelligent behavior of crow bird (Askarzadeh 2016). This algorithm is based on behavior and characteristic of crows which are: (1) Generally, crow lives as a group; (2) crows have memories for their last current position and nest; (3) crows follow the others clandestinely; (4) crows protect their nest from another intruder with several probabilities.
According to the following characteristic, CSA is being developed and applied for solving several problems. The main characteristic of crow shows that the CSA algorithm uses a distinct population which is N population. Furthermore, for initializing the crow position (for M population) are commenced randomly in the model room with specified approximation \( X_{i} = X_{\hbox{min} } + rand_{i} \times \left( {X_{\hbox{max} } - X_{\hbox{min} } } \right) \), with \( i = 1,2, \ldots ,M \). Then, the objective function calculation for every position of crow is initialized. After the following initialization process, because every crow has a memory for its nest, \( m_{i} \), the initialization parameter is also executed. For every memory in a position of crow is the best last known memories. Mathematically, this memory is analogous to Pbest in the PSO algorithm. This memory parameter is used for a crow to move to a better nest and hunt.
In the iteration process, i crow decides to follow j crow to approach the crow j’s nest. This may cause several probabilities such as: (1) j crow doesn’t know that he is being followed by i crow, so that i crow will approach j’s crow nest; (2) j crow knows that he is being followed by i crow, to protect his nest from intruder, j crow will trick i crow by moving to another position in model. In addition, this probability can be mathematically represented as:
while \( r_{i} \) and \( r_{j} \) denote uniform random number with a value between 0 and 1, \( fl_{i} \) indicates as flight length of crows,\( AP \) is awareness probability from crow \( j \), also \( x\hbox{min} \) and \( x\hbox{max} \) orderly is a lower and upper bond of the model parameter.
After the updated position of the crow, the next step is checking the feasibility of the new position. If the position is feasible, the crow position will be updated otherwise, if the position is not feasible, the crow position will be randomized through the model are. The position that has been checked for feasibility also checked for the objective function. This calculation, however, is required to maintain the memory for each crow. Detailed step of the CSA is shown in Appendix A.
The idealized GO usually provides the proper balance between exploration and exploitation (Fernández-Martínez et al. 2010a; Laby et al. 2016; Sungkono and Warnana 2018). In order to obtain the correct model parameter for optimum global faster. The explorative and exploitative characteristic in CSA is determined by two parameters (\( fl \) and \( AP \)), that have to be tuned firstly. Askarzadeh (2016) suggests that the \( fl \) parameter should be higher than one. Otherwise, Eq. (1) shows that big \( AP \) will cause CSA to be more explorative with a diverse model parameter, but require more iteration to reach optimum global. Contrary, if \( AP \) is lower, the probability of CSA to be exploitative and tend to have better local search; however, the parameter model for the solution is often trapped in a local optimum.
3.2 Improved CSA
In order to make the CSA is usable for estimating the optimum global parameter correctly, in this research use the adaptive AP,\( fl = 2.5 \) and use the Lévy flight for random movement as shown in Eq. (3) (Diaz et al. 2018). This adaptive AP is determined according to the value of objective function, which mathematically can be described as following:
with \( f\left( {X_{i} \left( {iter} \right)} \right) \) is objective function for every crow. Furthermore, the crow position in CSA can be written as follows:
where \( Xbest \) is the best individual, while \( L \) representing step size parameter with Lévy distribution. Furthermore, CSA uses Eq. (5) with AP as shown in Eq. (4) called improved CSA (ICSA), while CSA that uses Eq (3) with constant AP, in this case is 0.1, called CSA.
3.3 Inversion of SP data using CSA or ICSA
The measured data obtained from a fix based method needs to correction process, including reference correction and drift correction (Revil and Jardani 2013). Next, the corrected SP data usually contains unwanted noise that reflects near and far telluric interference. This interference can distort the low amplitude anomaly or long-wave anomaly (Biswas 2017). Moreover, SP noise can be sourced from a strong heterogeneity of the resistivity distribution in the shallow subsurface (Fajriani et al. 2017; Revil and Jardani 2013). Consequently, any SP data needs to be filtered using a moving average (Fajriani et al. 2017) or empirical mode decomposition based (Sungkono and Warnana 2018) before carried out for inversion.
Inversion SP data using CSA or ICSA process is automatically finding model parameter \( X_{i} \) associated with the global minimum of the objective function. The model parameter \( X_{i} \) contains SP data parameters (in Eq. 1) including \( k, \) \( x_{1} \), \( z_{1} \), \( x_{2} \) and \( z_{2} \) for all sources of SP data. It means that for each individual (crow) can be written as \( X_{i} = [k_{1} , \ldots ,k_{N} ,x_{11} , \ldots ,x_{1N} ,z_{11} , \ldots ,z_{1N} ,x_{21} , \ldots ,x_{2N} ,z_{21} , \ldots ,z_{2N} ] \) with \( N \) indicates the number of anomalies. Further, the inversion of SP data uses CSA or ICSA as following flow in Appendix A for minimizing an objective function. The objective function must reflect for fitting between calculated \( V^{c} = [V_{1}^{c} ,V_{2}^{c} , \ldots ,V_{Nd}^{c} ] \) and observed \( V^{o} = [V_{1}^{o} ,V_{2}^{o} , \ldots ,V_{Nd}^{o} ] \) SP response. The objective function for each individual as following (Monteiro Santos 2010)
Equation (6) reflects that the minimum of objective function occurs when the calculated is close to observed SP data. The objective function is used to handle multiple anomalies of SP data (Monteiro Santos 2010).
In geophysics, the inversion process is for estimating the model parameter with the minimum objective function. Another function is providing uncertainty solutions of model parameters. The uncertainty of model parameters is to handle a non-unique solution in the inversion process. Both of this can be achieved by using a posterior distribution model (PDM) (Fernández-Martínez et al. 2010b, 2013, 2019). This PDM can be estimated using Markov Chain Monte Carlo (MCMC) (Sungkono and Santosa 2015) and trade-off objective function from GO (Sungkono 2020a; Sungkono and Warnana 2018).
3.4 ICSA compared to other GO for SP inversion
Several GO methods are successfully applied to multiple SP sources inversion including PSO (Monteiro Santos 2010), very fast simulated annealing (VFSA) (Sharma and Biswas 2013), whale optimization algorithm (WOA) (Abdelazeem et al. 2019), BHA (Sungkono and Warnana 2018), GPA (Di Maio et al. 2019), FPA (Sungkono 2020a), and micro-adaptive differential evolution (\( \mu \) JADE) (Sungkono 2020b). FPA uses Lévy flight and uniforms distribution, VFSA applies Cauchy distribution, while the others utilize uniforms distribution for individual moving. It indicates the FPA algorithm has similarities and differences with ICSA.
ICSA needs a parameter tunning (\( fl \)) and uses Lévy distribution, while CSA involves two tuning parameters (\( fl \) and \( AP \)) and uses uniform random number. Two parameters as unknown are generally more challanging to be adjusted than tuning only one parameter, which is an advantage of ICSA compared with CSA. Furthermore, ICSA is like FPA, which is applied Lévy distribution for movement, and the performances are influenced by a parameter (Sungkono 2020a; Yang 2012). In addition, movement parameter in Eq. (5) if \( r_{j} < AP \)(movement using Lévy distribution) is a similar equation with global pollination in FPA. However, ICSA with \( r_{j} \ge AP \) conditions is different from local pollination in FPA. The difference includes ICSA uses memory parameter, adaptive probability (\( AP \)), and scaling parameter (\( fl_{i} \)). Memory in GO can help speed up global minimum search (Sree Ranjini and Murugan 2017).
Both BHA and \( \mu \) JADE are free tuning parameters for the inversion process, while the other algorithms involve it. The performance of ICSA and WOA is mainly influenced by a parameter, while GPA and VFSA are controlled by two parameters, and PSO is affected by three parameters. Consequently, ICSA and WOA are easier than GPA, VFSA, and PSO for determining parameter tunes. However, WOA sets explorative in the first half iteration, while the others are exploitation, and BHA has more explorative than ICSA. It means that WOA and BHA probably require high iteration than ICSA.
4 Synthetic study
In this section, the CSA and ICSA algorithm is utilized to provide the best model parameter and uncertainty analysis based on SP data. In order to CSA and ICSA algorithm can be used to provide the posterior distribution model, CSA and ICSA parameter is set to have balance characteristic between exploitative and explorative. The exploitative characteristic will tend to make an algorithm to be faster in reaching convergent and have a possibility to be trapped in a local minimum, while explorative characteristic can maintain the algorithm to avoid the local minimum trap. The measurement characteristic of CSA and ICSA is utilizing the dimension-wise diversity approach (Hussain et al. 2019). This characteristic test will be made in synthetic data inversion with a tuning parameter from both CSA and ICSA algorithm.
Before applying both CSA and ICSA in real field data, both algorithms need to be assessed in synthetic data with two anomalies of the inclined sheet of SP data (Table 1). The synthetic data is generated using forward modeling as in Eq. (1) with input “true parameter” in Table 1. This CSA algorithm then compared with the ICSA algorithm. This comparison has an arrangement portion of explorative and objective value from the best individual as the iteration function. Value from objective function as iteration from CSA and ICSA algorithm is displayed as in Fig. 2a, while the percentage of explorative in both algorithms shown in Fig. 2b. However, Fig. 2b shows that the CSA algorithm tends more explorative than the ICSA algorithm (this can be shown from iteration number 50 to end of iteration) with objective function value is identical to each other (Fig. 2a). The percentages of exploration show fluctuations (decrement and increment) and systematically reach to a very low value. It does not always decrease, which means that both CSA and ICSA algorithms can achieve optimum global and may not be trapped in a local minimum. The argument is supported by good fitting curves of observed (synthetic) and calculated from CSA and ICSA of SP data (Fig. 3).

Comparison performances of CSA and ICSA in the SP inversion. a The best objective functions of CSA and ICSA for each iteration; b explorative measurement of CSA and ICSA for each iteration

Comparison synthetic and inverted SP data using CSA and ICSA, where dots represent the synthetic data, while the solid and dashed line into a curve shows the inverted SP anomaly via CSA and ICSA, respectively
Figures 4 and 5 in the arrangement indicated the result of the posterior distribution model, which has been inverted by ICSA and CSA algorithm with the objective function threshold is 0.1. These figures show that median from PDM within the ICSA and CSA is approaching the true parameter, except for x2 on the first anomaly in CSA. Albeit, the correct value of the model parameter of SP data is still in ranges of PDM statistics (interquartile ± median) that have been resulted by both algorithms (Table 1).

Histograms of PDM resulted by CSA inversion. The first anomaly is presented in the upper panel, while the second anomaly is demonstrated in the lower panel. True parameters presented with red dots, while the median of PDM is shown by crosses. True parameters are correctly estimated by the highest frequency of PDM. Furthermore, median of PDM is close to true parameters

Histograms of PDM resulted by ICSA inversion. Other pieces of information are the same in Fig. 4
5 Field studies
Several data from the region have been analyzed by previous researchers and interpreted to investigate the performance of the ICSA algorithm in providing low objective value PDM. Last but not least, the ICSA algorithm is also utilized in interpreting the Grindulu Fault located in Pacitan Region, East Java, Indonesia.
5.1 Pinggirsari SP anomaly, indonesia
Pinggirsari anomaly of Self-Potential is measured for identifying and characterizing fault structure and acquisition in Pinggirsari village, Bandung Regency, West Java, Indonesia (Fajriani et al. 2017). The measurement design of SP data has crossed the fault in the geological map of the area (Fig. 6 upper panel), while cross-section in S–N direction from geological map (Fig. 6 lower panel) is through the fault. SP anomaly is presented in Fig. 7, which is shown that the potential difference of anomaly around 500 m in distances. The observed SP anomaly has been analyzed using two methods namely, Levenberg–Marquardt (LM) (Fajriani et al. 2017), WOA (Gobashy et al. 2019) with the assumption that the anomaly is triggered by fault structure in the subsurface.

Geological map of SP measurement in the Pinggirsari area (Pinggirsari anomaly) (Alzwar et al. 1992) and position of observed SP data (upper panel); cross-section from geological map crossed the fault (lower panel)

ICSA inversion results for tracing fault in the Pinggirsari area (Fajriani et al. 2017). A comparison of measured and calculated data is demonstrated in the upper panel, where dots indicate the measured SP data, while the solid and dashed lines represent the calculated SP data; the subsurface model derived by ICSA (median of PDM) (red) and LM (black) methods are shown in the lower panel
ICSA inversion process of Pinggirsari anomaly uses 200 generations and 100 populations, as shown in Fig. 7. ICSA inversion result shows that calculated SP data is very close to observed SP data, while the LM method also good fitting with observed data except around the 510 meters in distance. Furthermore, in order to obtain the subsurface model, the PDM is revealed by ICSA (0.3 as a threshold of objective functions). The result is presented in Fig. 8. The model parameter and its uncertainty are estimated from median and interquartile of PDM, respectively, which is shown by Table 2 together with that interpretation by several other authors. The other authors generally analyze using Eq. (2), consequently, the results need to convert in Eq. (1) parameters. Table 2 shows that the model parameters revealed by WOA are not relevant. The ICSA and LM approaches are satisfactory with an association of the geological map (Fig. 6), where SP data can identify the near-surface fault (Fig. 6 lower panel).

Histogram of PDM derived by ICSA inversion from Pinggirsari SP anomaly. Crosses indicate median of model parameters
5.2 Vilarelho da Raia SP anomaly, Portugal
Data of SP anomaly measured in Vilarelho da Raia, Portugal has been successfully analyzed by several researchers by using inclined sheet approach or simple polarized structures (Biswas and Sharma 2014a; Di Maio et al. 2019; Monteiro Santos 2010; Roy 2019). This anomaly (marked with dots in Fig. 9a) shows that SP data is produced by two or more anomalies. This SP anomaly, caused by the geological structure (fault or fracture) which controls the flow of water in the hot spring (Monteiro Santos et al. 2002; Roy 2019). Consequently, this anomaly is analyzed using the inclined sheet approach (Biswas and Sharma 2014a; Di Maio et al. 2019).

Inversion results of Vilarelho da Raia field SP anomaly using ICSA for structures identification. Measured and calculated of SP data are compared in the upper panel, while the subsurface model estimated by median of PDM in the lower panel
According to Biswas and Sharma (2014a, b), this SP anomaly contains five designated sources of anomalies in which the measurement data is incomplete (particularly the beginning of data set). So, this SP data is analyzed using four sources of anomaly instead of five. For simultaneous inversion, GO is accurate for SP data which contains multiple anomalies instead of using the optimum local approach. The main reason is the optimum local wills not capable of interpreting the multiple anomalies of SP data simultaneously.
Figure 9 shows the inversion result of SP Data for Vilarelho da Raia anomaly using the ICSA algorithm with a population of 150 and 1000 iterations for resulting in the PDM that correlated with the low objective function. Figure 9 upper panel shows that a comparison between synthetic and observed SP data are matched, while Fig. 9 lower panel indicates structure, polarization, the orientation of SP sources anomaly, where both figures derived from PDM with 0.1 as a threshold in the objective function. The interpreted results provide a model parameter and its uncertainty (interquartile) as in Table 3. The table also compares interpretation using ISCA results with results of VFSA (Biswas and Sharma 2014a) and GPA (Di Maio et al. 2019). The central of second and third anomalies are close to previous researchers (Biswas and Sharma 2014a; Di Maio et al. 2019; Monteiro Santos 2010), where the third anomaly is deeper than the second anomaly. Furthermore, for first and the last structures are revealed by ICSA has close central to VFSA result.
5.3 KTB-Borehole anomaly, Germany
SP data, which is called KTB-Borehole anomaly, was measured around the KTB borehole, in NE Bavaria, Germany. The KTB anomaly contains two high negative peak anomalies (Fig. 10a) which are correlated with the position of the subsurface model parameters. It means that the anomaly generally easy in spontaneous analysis and interpretation using a WOA as the inversion method and Eq. (2) for forward modeling (Gobashy et al. 2019). Moreover, the anomaly also separates interpretation using the inversion process individually for the two anomalies using VFSA (Biswas 2017) and Gauss–Newton (GN) (Mehanee 2015).

Subsurface structures in the KTB anomaly, Bavaria, Germany via ICSA inversion. Comparison of calculated and observed of SP data in the upper panel and subsurface model obtained by median of PDM in the lower panel
In this paper, ICSA uses a simultaneous interpretation of the KTB anomaly with 150 populations and 600 iterations. Figure 10 upper panel shows the curve fitting of observed and calculated from median of PDM. The PDM is collected with a threshold of 0.1 for the objective function. The calculated model is a very good agreement with observed SP data.
The inversion results using ICSA are shown in Table 4 and Fig. 10 lower panel. Table 4 shows that ICSA is comparable with VFSA results, especially for electric dipole moment and the position of the top edge of sheet. The distances depth of the top of the sheet for both first and second anomalies is 615 meters, where several authors interpret using different approaches that the distances anomalies around 600 meters (Biswas 2017; Mehanee 2015; Stoll et al. 1995). The condition is slightly different from WOA results, i.e. 518.21 m. Furthermore, several authors have a different interpretation in depth of the top of the sheet for first and second anomalies, for instance, 50 m and 30 m (Stoll et al. 1995), 27 m and 26 m (Mehanee 2015), 22.5 m and 17.2 m (Biswas 2017), − 7.02 m and 18.82 m (Gobashy et al. 2019), correspondingly. In this study, ISCA results for the depth of the top of the sheet model for both anomalies are 22.21 m and 10.80 m. Again, the results are comparable with resulted by inversion of VFSA (Biswas 2017) and GN (Mehanee 2015).
Cross-section determined from several approaches including trial-and-error modeling (Stoll et al. 1995), GN (Mehanee 2015), VFSA (Biswas 2017), and ICSA are shown in Fig. 11. Note that the WOA result does not sketch because the result is not reliable. The figure indicates that the ICSA and GN approaches are good agreement with inclined shear planes (F1 and F2). The F1 and F2 are sheet models for anomaly 1 and anomaly 2, respectively. The anomaly results are confirmed using other geophysical research and drilling, which graphitization has occurred (Fig. 11a).

a The geologic cross-section is around the KTB-HB borehole (Mehanee 2015). Note that the legends for various rock types can be shown from Fig. 6 from Stoll et al. (1995). Subsurface structure determined from the KTB anomaly, Bavaria, Germany for vrioues approaches including, b Stoll et al. (1995), c Mehanee (2015), d Biswas (2017), and e ICSA
WOA inversion using Eq. (2) converted to parameters in Eq. (1). Therefore, the relevance of the geology model must be checked. Model geology is relevant when \( h \ge a { \sin }\left( \varphi \right) \). Thus, the WOA result for the first body is not a relevant model, so the depth of the top edge is negative (Table 4). Consequently, the WOA inversion result does not sketch in Fig. 11.
5.4 Tambakrejo SP anomaly, Indonesia
Tambakrejo Village, Pacitan Regency, East Java is crossed by Grindulu Fault (Samodra et al. 1992). The Grindulu Fault forms left normal oblique strike − slip fault (sinistral) with NE − SW lineaments. SP data is acquired by crossing this fault, as shown in Fig. 12. Measurement length for this anomaly is more than 1 km with porous pot space is configured to 10 meters, so the SP data is clarified by the anomaly and reducing the heterogeneity from the ground itself.

The geological map of SP study in Tambakrejo Village, Pacitan District, East Java, Indonesia (Samodra et al. 1992)
Because the SP data generally noisy sourced by telluric and heterogeneity of resistivity in near-surface, and also affected by drift (Revil and Jardani 2013), the SP data needs to be filtered and detrended. In addition, the separation between local and regional anomaly also needed in SP data (Chengliang et al. 2020). The problems can be done simultaneously using a variant of empirical mode decomposition (Rilling et al. 2005; Sungkono et al. 2014a, 2017). Improved complete ensemble empirical mode decomposition (ICEEMD) (Colominas et al. 2014) is utilized to decompose SP data into several Intrinsic Mode Functions (IMF). The next step is, several IMF is chosen for best-filtered data (Sungkono et al. 2014a). In this selection, only IMF1 is eliminated with several considerations, which are: (1) IMF1 has a short wavelength which caused by ground heterogeneity; (2) Grindulu Fault formed by fault reactivation in the basement (Gultaf et al. 2015), so this fault is presented by SP data that has long wavelength; (3) regional anomaly of SP Data generally has constant value or linear with distance (Li and Yin 2012; Mehanee 2014).
Figure 13 upper panel shows SP data after filtered uses ICEEMD. Qualitatively (based on a different wavelength) and SP anomaly type (Saribudak and Hawkins 2019), this figure shows that the SP formed by several anomalies in the near surfaces and one anomaly in the far surface which is allegedly located at a distance of 700 − 900 meters from the beginning of the measurement point. When Fig. 13 upper panel correlated with Fig. 12 show that the anomaly is caused by Grindulu Fault.

Inversion of filtered SP data via ICSA using a multi inclined sheet model. Comparison between filtered and calculated of SP data in the upper panel, while the subsurface model revealed by median of PDM in the lower panel
Inversion of SP data uses the ICSA method has been done with search space, as shown in Table 5. The inversion process is terminated after 1500 iterations with 200 populations. The inversion is repeated until five times to evaluate consistency result and to provide PDM, where PDM is collected using 0.3 as a threshold in the objective function. The small search space in the third anomaly is caused by the presence of fault that approaches the surface and causing several walls and buildings are cracked (located 400 meters from measurement points). The determination of search space is according to SP Data “characteristic” which used to “decrease” the uncertainty of the model parameter in inversion result. The inversion result shows in Table 5 and Fig. 13. Figure 13 shows that inversion uses nine inclined sheets (lower panel) and resulting in excellent fitting (upper panel) between measured data and the inverted one from ICSA. Furthermore, the inclined sheet that guessed as Grindulu Fault is located in 800 meters of measurement track (as shown in Fig. 12) and the closest surface of fault (minor fault) is located in 400 meters, where in order to validate the results, other geophysical methods are needed. This minor fault is the main reason for the cracked walls and floors of houses in the surrounding area (Fig. 14). Besides those two faults, the inversion data result also produce four other minor faults with different position (Fig. 13 lower panel). Figure 13 and Table 5 reflects how effective the ICSA method in estimating the multiple anomalies of SP parameter and their uncertainty.

The cracked wall and floor of houses located around 400 m from the measurement starting point
6 Conclusion
Both CSA and ICSA algorithms need correct tuning parameters, where ICSA just requires flight length parameters instead of CSA that involves flight length and awareness probability parameters. Both algorithms have tested to estimate PDM for synthetic data of multiple SP anomalies that modeled by inclined sheets. The results indicate that both algorithms are able to provide PDM and their statistically (median and interquartile) to handle non-unique solutions of SP inversion. Based on median and interquartile of PDM, ICSA shows better than CSA for estimating PDM. The ICSA method is also used to analyze several field SP anomalies containing single and multiple anomalies for identifying fault and shear zones from several different areas including Pinggirsari SP anomaly (Indonesia), Vilarelho da Raia SP anomaly (Portugal), KTB SP anomaly (Germany), and Tambakrejo SP anomaly (Indonesia). SP anomaly inversion using ICSA shows good results with different approaches, and the outcome is accurate in geological conditions of the survey area.
Change history
11 January 2021
In subtitle “Tambakrejo SP anomaly, Indonesia”, page 710, for describing Fig. 13 written: “Besides those two faults, the inversion data result also produce four other minor faults with different position (Fig. 13 lower panel)” should be revised as “Besides those two faults, the inversion data result also produce seven other minor faults with different position (Fig. 13 lower panel)”.
References
Abdelazeem M, Gobashy M, Khalil MH, Abdrabou M (2019) A complete model parameter optimization from self-potential data using Whale algorithm. J Appl Geophys 170:103825. https://doi.org/10.1016/j.jappgeo.2019.103825
Agarwal A, Chandra A, Shalivahan S, Singh RK (2018) Grey wolf optimizer: a new strategy to invert geophysical data sets. Geophys Prospect 66:1215–1226. https://doi.org/10.1111/1365-2478.12640
Alzwar M, Akbar N, Bachri S (1992) Peta Geologi Lembar Garut dan Pameungpeuk, Jawa. Pusat Penelitian dan Pengembangan Geologi, Bandung
Arora T, Linde N, Revil A, Castermant (2007) Non-intrusive characterization of the redox potential of landfill leachate plumes from self-potential data. J Contam Hydrol 92:274–292
Askarzadeh A (2016) A novel metaheuristic method for solving constrained engineering optimization problems: Crow search algorithm. Comput Struct 169:1–12. https://doi.org/10.1016/j.compstruc.2016.03.001
Balkaya Ç (2013) An implementation of differential evolution algorithm for inversion of geoelectrical data. J Appl Geophys 98:160–175. https://doi.org/10.1016/j.jappgeo.2013.08.019
Biswas A (2016) A comparative performance of least-square method and very fast simulated annealing global optimization method for interpretation of self-potential anomaly over 2-D inclined sheet type structure. J Geol Soc India 88:493–502. https://doi.org/10.1007/s12594-016-0512-8
Biswas A (2017) A review on modeling, inversion and interpretation of self-potential in mineral exploration and tracing paleo-shear zones. Ore Geol Rev 91:21–56. https://doi.org/10.1016/j.oregeorev.2017.10.024
Biswas A (2018) Inversion of amplitude from the 2-D analytic signal of self-potential anomalies. Minerals. https://doi.org/10.5772/intechopen.79111
Biswas A, Sharma SP (2014a) Optimization of self-potential interpretation of 2-D inclined sheet-type structures based on very fast simulated annealing and analysis of ambiguity. J Appl Geophys 105:235–247. https://doi.org/10.1016/j.jappgeo.2014.03.023
Biswas A, Sharma SP (2014b) Resolution of multiple sheet-type structures in self-potential measurement. J Earth Syst Sci 123:809–825. https://doi.org/10.1007/s12040-014-0432-1
Biswas A, Sharma SP (2015) Interpretation of self-potential anomaly over idealized bodies and analysis of ambiguity using very fast simulated annealing global optimization technique. Near Surface Geophys 13:179–195. https://doi.org/10.3997/1873-0604.2015005
Biswas A, Sharma SP (2016) Integrated geophysical studies to elicit the subsurface structures associated with Uranium mineralization around South Purulia Shear Zone, India: a review. Ore Geol Rev Metallogeny Indian Shield 72:1307–1326. https://doi.org/10.1016/j.oregeorev.2014.12.015
Biswas A, Sharma SP (2017) Interpretation of self-potential anomaly over 2-D inclined thick sheet structures and analysis of uncertainty using very fast simulated annealing global optimization. Acta Geod Geophys 52:439–455. https://doi.org/10.1007/s40328-016-0176-2
Biswas A, Mandal A, Sharma SP, Mohanty WK (2014) Delineation of subsurface structures using self-potential, gravity, and resistivity surveys from South Purulia Shear Zone, India: Implication to uranium mineralization. Interpretation 2:T103–T110. https://doi.org/10.1190/INT-2013-0170.1
Chengliang D, Yixiang C, Yongsheng Z, Bo C (2020) Application of a mathematical method in geophysics: separating anomalies of horizontal gradients of the spontaneous potential field based on first-order difference. J Appl Geophys 176:104009. https://doi.org/10.1016/j.jappgeo.2020.104009
Colominas MA, Schlotthauer G, Torres ME (2014) Improved complete ensemble EMD: a suitable tool for biomedical signal processing. Biomed Signal Process Control 14:19–29
Di Maio R, Piegari E, Rani P, Avella A (2016a) Self-Potential data inversion through the integration of spectral analysis and tomographic approaches. Geophys J Int 206:1204–1220. https://doi.org/10.1093/gji/ggw200
Di Maio R, Rani P, Piegari E, Milano L (2016b) Self-potential data inversion through a Genetic-Price algorithm. Comput Geosci 94:86–95. https://doi.org/10.1016/j.cageo.2016.06.005
Di Maio R, Piegari E, Rani P (2017) Source depth estimation of self-potential anomalies by spectral methods. J Appl Geophys 136:315–325. https://doi.org/10.1016/j.jappgeo.2016.11.011
Di Maio R, Piegari E, Rani P, Carbonari R, Vitagliano E, Milano L (2019) Quantitative interpretation of multiple self-potential anomaly sources by a global optimization approach. J Appl Geophys 162:152–163. https://doi.org/10.1016/j.jappgeo.2019.02.004
Diambama AD, Anggraini A, Nukman M, Lühr B-G, Suryanto W (2019) Velocity structure of the earthquake zone of the M6.3 Yogyakarta earthquake 2006 from a seismic tomography study. Geophys J Int 216:439–452. https://doi.org/10.1093/gji/ggy430
Diaz P, Perez-Cisneros M, Cuevas E, Avalos O, Gálvez J, Hinojosa S, Zaldivar D (2018) An improved crow search algorithm applied to energy problems. Energies. https://doi.org/10.3390/en11030571
Ekinci YL, Balkaya Ç, Göktürkler G (2020) Global optimization of near-surface potential field anomalies through metaheuristics. In: Biswas A, Sharma SP (eds) Advances in modeling and interpretation in near surface geophysics, Springer Geophysics. Springer, Cham, pp 155–188. https://doi.org/10.1007/978-3-030-28909-6_7
Essa KS (2020) Self potential data interpretation utilizing the particle swarm method for the finite 2D inclined dike: mineralized zones delineation. Acta Geod Geophys. https://doi.org/10.1007/s40328-020-00289-2
Fajriani, Srigutomo W, Pratomo PM (2017) Interpretation of Self-Potential anomalies for investigating fault using the Levenberg-Marquardt method: a study case in Pinggirsari, West Java, Indonesia. IOP Conf. Ser.: Earth Environ. Sci. 62, 012004. https://doi.org/10.1088/1755-1315/62/1/012004
Fernández-Martínez JL, García Gonzalo E, Fernández Álvarez JP, Kuzma HA, Menéndez-Pérez CO (2010a) PSO: a powerful algorithm to solve geophysical inverse problems: Application to a 1D-DC resistivity case. J Appl Geophys 71:13–25. https://doi.org/10.1016/j.jappgeo.2010.02.001
Fernández-Martínez JL, García-Gonzalo E, Fernández-Muñiz Z, Mariethoz G, Mukerji T (2010b) Posterior sampling using particle swarm optimizers and model reduction techniques. Int J Appl Evolu Comput 1:27–48. https://doi.org/10.4018/IJAEC
Fernández-Martínez JL, Fernández-Muñiz Z, Pallero JLG, Pedruelo-González LM (2013) From Bayes to Tarantola: new insights to understand uncertainty in inverse problems. J Appl Geophys 98:62–72. https://doi.org/10.1016/j.jappgeo.2013.07.005
Fernández-Muñiz Z, Hassan K, Fernández-Martínez JL (2019) Data kit inversion and uncertainty analysis. J Appl Geophys. https://doi.org/10.1016/j.jappgeo.2018.12.022
Giang NV, Kochanek K, Vu NT, Duan NB (2018) Landfill leachate assessment by hydrological and geophysical data: case study NamSon, Hanoi. Vietnam. J Mater Cycles Waste Manag 20:1648–1662. https://doi.org/10.1007/s10163-018-0732-7
Gobashy M, Abdelazeem M, Abdrabou M, Khalil MH (2019) Estimating model parameters from self-potential anomaly of 2D inclined sheet using whale optimization algorithm: applications to mineral exploration and tracing shear zones. Nat Resour Res. https://doi.org/10.1007/s11053-019-09526-0
Gultaf H, Sapiie B, Syaiful M, Bahtiar A, Fauzan AP (2015) Paleostress analysis of Grindulu Fault in Pacitan and surrounding area its implication to regional tectonic of East Java. In: Proc. 39th Ann. Conv. Indon. Petroleum Assoc. (IPA). Presented at the 39th Ann. Conv. Indon. Petroleum Assoc. (IPA), IPA, Jakarta, pp. IPA15-G-059, 34p
Hardman RFP, Booth JE (1991) The significance of normal faults in the exploration and production of North Sea hydrocarbons. Geol Soc Lond Special Publ 56:1–13. https://doi.org/10.1144/GSL.SP.1991.056.01.01
Hussain K, Salleh MNM, Cheng S, Shi Y (2019) On the exploration and exploitation in popular swarm-based metaheuristic algorithms. Neural Comput Appl 31:7665–7683. https://doi.org/10.1007/s00521-018-3592-0
Ikard SJ, Revil A, Schmutz M, Karaoulis M, Jardani A, Mooney M (2014) Characterization of focused seepage through an earthfill dam using geoelectrical methods. Groundwater 52:952–965. https://doi.org/10.1111/gwat.12151
Laby DA, Sungkono, Santosa BJ, Bahri AS (2016) RR-PSO: fast and robust algorithm to invert Rayleigh waves dispersion. Contemp Eng Sci 9:735–741. https://doi.org/10.12988/ces.2016.6685
Li X, Yin M (2012) Application of differential evolution algorithm on self-potential data. PLoS ONE. https://doi.org/10.1371/journal.pone.0051199
Mauri G, Williams-Jones G, Saracco G (2011) MWTmat—application of multiscale wavelet tomography on potential fields. Comput Geosci Geospatial Cyberinfrastruct Polar ResearchGeospatial Cyberinfrastruct Polar Res 37:1825–1835. https://doi.org/10.1016/j.cageo.2011.04.005
Mehanee SA (2014) An efficient regularized inversion approach for self-potential data interpretation of ore exploration using a mix of logarithmic and non-logarithmic model parameters. Ore Geol Rev 57:87–115. https://doi.org/10.1016/j.oregeorev.2013.09.002
Mehanee SA (2015) Tracing of paleo-shear zones by self-potential data inversion: case studies from the KTB, Rittsteig, and Grossensees graphite-bearing fault planes. Earth Planets Space 67:14. https://doi.org/10.1186/s40623-014-0174-y
Monteiro Santos FA (2010) Inversion of self-potential of idealized bodies’ anomalies using particle swarm optimization. Comput Geosci 36:1185–1190. https://doi.org/10.1016/j.cageo.2010.01.011
Monteiro Santos FA, Almeida EP, Castro R, Nolasco R, Mendes-Victor L (2002) A hydrogeological investigation using EM34 and SP surveys. Earth Planet Sp 54:655–662. https://doi.org/10.1186/BF03353053
Pace B, Visini F, Scotti O, Peruzza L (2018) Preface: linking faults to seismic hazard assessment in Europe. Natural Hazards Earth Syst Sci 18:1349–1350. https://doi.org/10.5194/nhess-18-1349-2018
Ramadhani I, Sungkono S (2019) A new approach to model parameter determination of self-potential data using memory-based hybrid dragonfly algorithm. Int J Adv Sci Eng Inf Technol 9:1772–1782
Revil A, Jardani A (2013) The Self-Potential Method: Theory and Applications in Environmental Geosciences. Cambridge University Press, Cambridge
Rilling G, Flandrin P, Goncalves P (2005) Empirical mode decomposition, fractional Gaussian noise and Hurst exponent estimation. In: IEEE International Conference on Acoustics, Speech, and Signal Processing, 2005. Proceedings. (ICASSP’05). Presented at the IEEE International Conference on Acoustics, Speech, and Signal Processing, 2005. Proceedings. (ICASSP’05), p. iv/489-iv/492 Vol. 4. https://doi.org/10.1109/ICASSP.2005.1416052
Roy IG (2019) On studying flow through a fracture using self-potential anomaly: application to shallow aquifer recharge at Vilarelho da Raia, northern Portugal. Acta Geod Geophys 54:225–242. https://doi.org/10.1007/s40328-019-00256-6
Samodra H, Gafoer S, Tjokrosapoetro S (1992) Peta Geologi lembar Pacitan. Jawa, Pusat Penelitian dan Pengembangan Geologi
Saribudak M, Hawkins A (2019) Hydrogeopysical characterization of the Haby Crossing fault, San Antonio, Texas, USA. J Appl Geophys 162:164–173. https://doi.org/10.1016/j.jappgeo.2019.01.009
Sharma PV (1997) Environmental and engineering geophysics. Cambridge University Press, Cambridge
Sharma SP, Biswas A (2013) Interpretation of self-potential anomaly over a 2D inclined structure using very fast simulated-annealing global optimization—an insight about ambiguity. Geophysics 78:WB3–WB15. https://doi.org/10.1190/geo2012-0233.1
Sree Ranjini KS, Murugan S (2017) Memory based hybrid dragonfly algorithm for numerical optimization problems. Expert Syst Appl 83:63–78. https://doi.org/10.1016/j.eswa.2017.04.033
Stoll J, Bigalke J, Grabner EW (1995) Electrochemical modelling of self-potential anomalies. Surv Geophys 16:107–120. https://doi.org/10.1007/BF00682715
Sundararajan N, Rao PS, Sunitha V (1998) An analytical method to interpret self-potential anomalies caused by 2-D inclined sheets. Geophysics 63:1551–1555. https://doi.org/10.1190/1.1444451
Sungkono (2020a) Robust interpretation of single and multiple self-potential anomalies via flower pollination algorithm. Arab J Geosci. https://doi.org/10.1007/s12517-020-5079-4
Sungkono (2020b) An efficient global optimization method for self-potential data inversion using micro-differential evolution. J Earth Syst Sci 129:178. https://doi.org/10.1007/s12040-020-01430-z
Sungkono, Santosa BJ (2015) Differential evolution adaptive metropolis sampling method to provide model uncertainty and model selection criteria to determine optimal model for rayleigh wave dispersion. Arab J Geosci 8:7003–7023. https://doi.org/10.1007/s12517-014-1726-y
Sungkono, Warnana DD (2018) Black hole algorithm for determining model parameter in self-potential data. J Appl Geophys 148:189–200. https://doi.org/10.1016/j.jappgeo.2017.11.015
Sungkono, Bahri AS, Warnana DD, Monteiro Santos FA, Santosa BJ (2014a) Fast, simultaneous and robust VLF-EM Data Denoising And Reconstruction Via Multivariate Empirical Mode Decomposition. Comput Geosci 67:125–137. https://doi.org/10.1016/j.cageo.2014.03.007
Sungkono, Husein A, Prasetyo H, Bahri AS, Monteiro Santos FA, Santosa BJ (2014b) The VLF-EM imaging of potential collapse on the LUSI Embankment. J Appl Geophys 109:218–232. https://doi.org/10.1016/j.jappgeo.2014.08.004
Sungkono, Santosa BJ, Bahri AS, Monteiro Santos FA, Iswahyudi (2017) Application of multivariate empirical mode decomposition in the VLF-EM data to identify underground river. Adv Data Sci Adapt Anal 9:1650011–1-23. https://doi.org/10.1142/S2424922X1650011X
Sungkono, Feriadi Y, Husein A, Prasetyo H, Charis M, Irawan D, Rochman JPGN, Bahri AS, Santosa BJ (2018) Assessment of Sidoarjo mud flow embankment stability using very low frequency electromagnetic method. Environ Earth Sci. https://doi.org/10.1007/s12665-018-7333-6
Wolpert DH, Macready WG (1997) No Free Lunc Theorems for optimization. IEEE Trans Evol Comput 1:67–82
Yang X-S (2012) Flower pollination algorithm for global optimization. In: Durand-Lose J, Jonoska N (eds) Unconventional computation and natural computation. Lecture Notes in Computer Science. Springer, Berlin, pp 240–249
Zlotnicki J, Nishida Y (2003) Review on morphological insights of self-potential anomalies on volcanoes. Surv Geophys 24:291–338. https://doi.org/10.1023/B:GEOP.0000004188.67923.ac
Acknowledgements
Authors would like to thank students on the Geophysics Laboratory, Department of Physics, Institut Teknologi Sepuluh Nopember (ITS), for their help in the data acquisition. This work is supported by the Institute for Research and Community Services of ITS (Grant No: 1060/PKS/ITS/2019).
Author information
Authors and Affiliations
Corresponding authors
Appendix A: Pseudo-code of ICSA or CSA
Appendix A: Pseudo-code of ICSA or CSA

Rights and permissions
About this article

Cite this article
Haryono, A., Sungkono, Agustin, R. et al. Model parameter estimation and its uncertainty for 2-D inclined sheet structure in self-potential data using crow search algorithm. Acta Geod Geophys 55, 691–715 (2020). https://doi.org/10.1007/s40328-020-00321-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40328-020-00321-5