
Abstract
This paper addresses the time-optimal roto-translational orbital rendezvous maneuver for an inertially asymmetric rigid spacecraft in an all-thrusters configuration. To begin with, the target and chaser relative rotational and translational dynamics are driven. Then, in the presence of torque and force constraints, the simultaneously time-optimal attitude and position control problem is numerically solved using the pseudo-spectral method. The costates are then computed to establish the first-order optimality of the obtained solutions, which is confirmed by satisfying Pontryagin's minimum principle. It is demonstrated via simulation that the obtained control forces and moments are basically “bang-bang,” which is the most natural and convenient form for on–off thrusters.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Time-optimal maneuvers are interesting issues in different fields of aerospace engineering. Especially in space missions, time-optimal reorientation is required in many applications, such as antenna pointing in communication satellites, tracking multiple targets on the Earth in imaging satellites, or observing astronomical objects in space telescopes [1]. In addition, a time-optimal 6DOF maneuver in which attitude and position are simultaneously controlled in an overall minimum time, can be considered for time-critical operations, such as space debris removal, on-orbit spacecraft servicing (like repairing or refueling), and supplying oxygen or food to the International Space Station [2,3,4,5,6].
The time-optimal attitude maneuver has been vastly studied in the literature. Bilimoria and Wie [7] considered the time-optimal rest-to-rest reorientation problem for an inertially symmetric rigid body with three orthogonal control axes and cubical constraints on control torques (i.e., all the control torques are less than a specific magnitude). They showed that the eigen-axis rotation maneuver is not time-optimal, and the optimal control has a "bang-bang" structure in all three control axes. In [8], new results for the time-optimal rest-to-rest reorientation problem have been presented. It has been shown that the time-optimal control structure for a specific attitude maneuver is not unique. Furthermore, it has been demonstrated that by considering a spherical constraint for control torques (i.e., 2-norm of control vector to be less than a specific magnitude), the eigen-axis rotation maneuver will be time-optimal. In [9], the time-optimal reorientation problem for an inertially axisymmetric and under-actuated spacecraft has been discussed. Pager and Rao [10] have studied the time-optimal reorientation of a spin-stabilized axisymmetric rigid spacecraft using three control torques. They have analyzed the optimal control structure of various time-optimal maneuvers.
Furthermore, the time-optimal reorientation problem for an inertially asymmetric body has been solved in many works with different considerations. Hu et al. [11] have investigated the time-optimal smooth attitude maneuver for a flexible spacecraft, considering constraints on the control torques and corresponding derivatives and spacecraft angular velocity. In [12], this problem has been solved for a spacecraft with magnetic actuators. Olivares and Staffetti [13] studied the time-optimal reorientation problem for an under-actuated rigid spacecraft equipped with both reaction wheel and thruster, assuming limitations on the control torques and maximum angular momentum of the reaction wheels. In [14], these authors have solved this time-optimal problem for a multi-target maneuver (pointing toward several targets is performed in minimum time), in which constraints on the control torques and maximum angular momentum of the reaction wheels, and maximum angular velocity of the body are taken into account. Furthermore, in some articles, the time-optimal reorientation problem is solved in the presence of attitude constraints [15,16,17,18,19,20].
In addition, the time-optimal rendezvous maneuver between two spacecraft has been studied in some researches. Miele et al. [21] studied the time-optimal rendezvous problem with max-thrust acceleration constraint in fuel-free and fuel-given cases. Zhang and Ye [25] have investigated the time-optimal problem for short-range rendezvous maneuver using on–off constant thrust. They solved this problem for in-plane and out-of-plane motions. In [23] the time-optimal rendezvous maneuver for any number of space agents using only the relative aerodynamic drag has been discussed. Zhang and Parks [22] have studied time-optimal multiphase orbital rendezvous maneuver. They considered the field-of-view requirements in which the target should never appears out of the chaser’s field of view. Jorgensen and Sharf [26] have worked on the time-optimal rendezvous maneuver between a chaser spacecraft and multiple pieces of space debris. In [24] the planar two-body rendezvous problem with the inclusion of atmospheric drag perturbations has been investigated. These articles [21,22,23,24,25,26] have not considered rotational dynamics for the chaser spacecraft. While in the real applications, the position control actuators are fixed to the spacecraft’s body. Therefore, the attitude and position control are coupled. Ma et al. [2] have studied the time-optimal 3DOF planar rendezvous maneuver for approach to a rotating target spacecraft. They have considered that the chaser spacecraft can move in the plane and rotate about the axis perpendicular to the plane. Although, simultaneously attitude and position control have been considered in this article, but the relative dynamic model has been reduced to the simple 3DOF model in which the relative rotational dynamics (about the other two body axes) and translational dynamics (out-of-plane) have been neglected. Furthermore, the orbital dynamics of chaser and target spacecraft have been ignored. Finding the time-optimal maneuver leads to a time-optimal control problem which is often solved by numerical methods. Generally, numerical methods are divided into two categories, namely direct and indirect methods [27,28,29,30,31,32]. In indirect methods, the continuous first-order optimality conditions are derived by applying the calculus of variations and Pontryagin's minimum principle (PMP) [33] to the continuous-time optimal control problem. These optimality conditions lead to a two-point boundary value problem (TPBVP) that include states and costates differential equations and is solved by the shooting method [28]. The shooting method has been frequently used to solve the time-optimal control problem [7,8,9]. In this method, due to no physical sense of costates variables, it is difficult to find a proper initial guess for unknown initial costates and its convergence radius is small. To overcome this problem, some approaches have been provided to solve the TPBVP [34, 35]. Recently, the homotopic approach has been introduced to solve the TPBVP [36,37,38]. The homotopy scheme is used to continuously deform the problem to approximate the original one and find its solutions. In [39,40,41,42] this approach has been adopted to solve the time-optimal control problem. Nevertheless, for the high-order dynamic systems, the computational burden of this approach is very heavy.
In direct methods, the continuous optimal control problem is transcribed into nonlinear programming (NLP) problem by means of discretization methods [28]. Then, the NLP problem is solved with optimization methods such as gradient-based methods or heuristic algorithms [29]. A subset of direct methods are global collocation methods [29, 31, 43]. In these methods, the states and control trajectories are firstly discretized in collocation points and then approximated using global polynomials. A well-developed class of global collocation methods are pseudo-spectral methods such as Gauss pseudo-spectral method (GPM) [44,45,46,47,48], Lobatto pseudo-spectral method [49, 50] and Radau pseudo-spectral method [51,52,53]. The continuous dynamic constraints are discretized and converted into algebraic constraints using pseudo-spectral approaches. The NLP problem consists of dynamic constraints along with other ones such as path and boundary constraints as well as the cost function. In [19, 54, 55] the pseudo-spectral methods have been used to solve the time-optimal control problem.
The indirect methods have a higher accuracy in comparison with the direct method. However, in direct methods, the costates variables are not involved in optimal control problem formulation. Therefore, the problem is less complicated and there is no need to find a proper initial guess for the costates. Also, the dynamic constraints are satisfied only at the collocation points which causes the computational cost to be relatively lower.
Specifically, the GPM uses a set of non-uniform collocation points and guarantees that the polynomial approximation error monotonically decreases as the number of these points are increased [46]. Therefore, the accuracy of this method is improved, when the number of collocation points increases, and the obtained solution converges to the accurate optimal solution, albeit at the expense of increased computation time [46].
Moreover, using the Gauss pseudo-spectral discretization, the first-order optimality conditions of the NLP [Karush–Kuhn–Tucker (KKT) conditions] are equivalent to the discretized form of the continuous first-order optimality conditions of the continuous-time optimal control problem [44, 45]. Hence, there is a mapping between costates values in collocation points and KKT multipliers that are obtained from solving the NLP problem, and a costate estimation can be performed using KKT multipliers. The estimated costates can be utilized for first-order optimality proof of the obtained solution.
As mentioned before, simultaneously time-optimal rotational and translational control of a spacecraft was not considered in previous works. In the current paper, this time-optimal 6DOF maneuver is investigated. As a case study, the problem is formulated for the rendezvous maneuver of a chaser spacecraft with another target spacecraft and is solved using GPM. Considerations like the inertial asymmetry of spacecraft, applying orbital dynamic to rotational and translational dynamics of spacecraft, and coupled attitude and position control, affect the complexity of this problem. This paper assumes that the attitude and position control actuators are independent and fixed in the body frame. Hence, there is a coupling between attitude and position control. The main contributions of this paper are as follows:
-
The time-optimal 6DOF attitude and position control of an inertially asymmetric spacecraft has been developed.
-
Relative orbital dynamics and coupling between attitude and position control have been applied to the problem.
-
The optimal solution for the mentioned problem which satisfies the first-order optimality conditions has been provided.
-
The obtained control forces and moments are “bang-bang” which systemically can be implemented by simple on–off thrusters.
Generally, for the nonlinear and high-order dynamic systems (\(n\ge 3)\), any closed form solution does not exist for time-optimal control problem, and solving this problem using common methods (indirect and direct) leads to open-loop controls and states trajectories [56]. In real applications, it is necessary to design a closed-loop control law for tracking the calculated optimal states trajectories and compensating for the disturbances and uncertainties. Therefore, the whole problem is broken down into two parts: calculating the optimal open-loop controls and states trajectories and designing the closed-loop control law. This paper concentrates on the first sub-problem, and thus, the uncertainties and disturbances are not considered. Development of the closed-loop control law will be provided in future works.
In the following, the relative dynamic model of a spacecraft (chaser) with respect to another one (target) is introduced. Then the continuous time-optimal control problem is defined and transcribed into an NLP problem using GPM. The optimal states and control trajectories are obtained by solving the NLP problem. Similar to most time-optimal control problems, it is shown that the controls are “bang-bang”, which systemically can be implemented by simple on–off thrusters. On–off thrusters are the most popular thrusters in spacecraft control, used especially when high agility of the control system is required [57]. Also, using KKT multipliers, the costate trajectories are estimated. Finally, the first-order optimality proof of the obtained solution is provided.
The rest of the paper is organized as follows: Sect. 2 details the time-optimal 6DOF maneuver problem, GPM implementation, and costate estimation. Section 3 gives the numerical results, and conclusions are drawn in Sect. 4.
2 Time-optimal 6DOF Maneuver Problem
2.1 Relative Dynamic Model
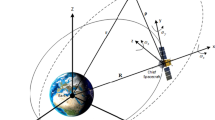
When the distance between two spacecraft is significant, their translational motion is usually described in the Earth-centered inertial (ECI) coordinate system. However, when the distance between two spacecraft is small in comparison to their radial distances from the Earth's center of mass, the relative translational motion is typically described in the target's Local Vertical Local Horizontal (LVLH) coordinate system, in which the z-axis is radially downward to the Earth's center of mass; the y-axis is in the opposite direction of the orbit normal vector, and the x-axis completes the right-hand orthogonal system. The chaser's body, the target's LVLH, and the ECI coordinate systems are presented in Fig. 1. In this paper, the classic and precise notation introduced in [58] is adopted.

Chaser's body, target's LVLH and ECI coordinate systems configuration
The Hill's equations are well-known and widely used equations to express relative translational dynamics, when the target is in a circular or near circular orbit. Because of the first order approximation, in the sense of Taylor, used to derive the Hill's equations, and also the lack of inclusion of orbital perturbations, they are mostly appropriate to describe close range relative motions. Whenever their presumptions are fulfilled, the Hill's equations are the best choice due to their simplicity. Accordingly, they have been used in this work as governing equations of relative translational motion. Relative translational dynamic and kinematic equations of the chaser's body with respect to the target's LVLH are described by the Hill’s formulation, as follows [59]:
where \({\omega }_{n}\) is the orbital mean angular rate of the target, \({m}_{B}\) is the mass of the chaser. The time derivative of a vector \({\varvec{x}}\) with respect to the frame \(Y\) is indicated by \({D}^{Y}{\varvec{x}}\). Hence, \({D}^{L}\) denotes the time derivative with respect to the target's LVLH (\(L\)). Also, \({\left[{{\varvec{v}}}_{B}^{L}\right]}^{L}{=\left[{v}_{x},{v}_{y},{v}_{z}\right]}^{T}\in {\mathbb{R}}^{3}\) and \({\left[{{\varvec{s}}}_{BL}\right]}^{L}{=\left[{s}_{x},{s}_{y},{s}_{z}\right]}^{T}\in {\mathbb{R}}^{3}\) denote the velocity and position vectors of the chaser's body center of mass with respect to the target's LVLH, respectively, and \({\left[{\varvec{f}}\right]}^{L}\in {\mathbb{R}}^{3}\) denotes the vector of control forces expressed in the target's LVLH.
On the other hand, assuming that the target's body coordinate system is aligned with its LVLH coordinate system, the relative rotational dynamic model is commonly derived between the chaser's body and the target's LVLH coordinate systems.
In order to describe the relative rotational dynamic of the chaser's body with respect to the target's LVLH, which is a non-inertial reference frame, Euler's rotational equation is used as follows [58]:
where \({D}^{B}\) denotes the time derivative with respect to the chaser's body coordinate system (\(B\)), \({{\varvec{I}}}_{B}=diag(\left[{I}_{x},{I}_{y},{I}_{z}\right])\in {\mathbb{R}}^{3\times 3}\) is the inertial matrix of the chaser along its principal axes, and it is assumed that the principal axes coincide with the body coordinate system. Also, \({\left[{{\varvec{\omega}}}^{BL}\right]}^{B}={\left[{\omega }_{x},{\omega }_{y},{\omega }_{z}\right]}^{T}\in {\mathbb{R}}^{3}\),\({\left[{{\varvec{\omega}}}^{LI}\right]}^{B}\in {\mathbb{R}}^{3}\) and \({\left[{{\varvec{\omega}}}^{BI}\right]}^{B}\in {\mathbb{R}}^{3}\) denote the angular velocity vector of the chaser's body coordinate system with respect to the target's LVLH, the angular velocity vector of the target's LVLH with respect to the ECI (\(I\)) and the angular velocity vector of the chaser's body coordinate system with respect to the ECI, respectively. All the angular velocity vectors are expressed in the chaser's body coordinate system. Furthermore, \({\left[{\varvec{m}}\right]}^{B}={\left[{m}_{x},{m}_{y},{m}_{z}\right]}^{T}\in {\mathbb{R}}^{3}\) denotes the vector of control torques, expressed in the chaser's body coordinate system. Assuming the target is in the circular orbit, \({{\varvec{\omega}}}^{LI}\) is constant. Hence, the Euler's equation is stated as follows:
In this paper, the rotational kinematic of the chaser's body coordinate system with respect to the target's LVLH is expressed using the modified Rodrigues parameters (MRP), defined as:
where \({[\sigma ]}^{BL}\) is the MRP vector representing transformation from the target's LVLH to the chaser's body coordinate system. Also, \({e}_{x},{e}_{y}\) and \({e}_{z}\) are the components of Euler axis, and \(\Phi\) is the principal rotation angle. The rotational kinematic equation using MRP is derived as follows [60]:
where \({\varvec{B}}({[{\varvec{\sigma}}]}^{BL})\) is defined as:
in which \({\Vert {{\varvec{\sigma}}}^{BL}\Vert }_{2}^{2}={[\overline{{\varvec{\sigma}} }]}^{LB}{[{\varvec{\sigma}}]}^{BL}\) (\({[\overline{{\varvec{\sigma}} }]}^{LB}\) is the transpose of \({[{\varvec{\sigma}}]}^{BL}\)).
Finally, it should be noted that the control force components are basically defined in the chaser's body coordinate system. Hence, to obtain the control force components in the target's LVLH, as appears in Eq. (1), a transformation has to be applied as follows:
where \({\left[{\varvec{f}}\right]}^{B}={\left[{f}_{x},{f}_{y},{f}_{z}\right]}^{T}\in {\mathbb{R}}^{3}\) denotes the vector of control forces and expressed in the chaser's body coordinate system. \({[{\varvec{T}}]}^{LB}\) is the transformation matrix from the chaser's body coordinate system to the target's LVLH and is defined as a function of \({[{\varvec{\sigma}}]}^{BL}\), as follows:
in which \({\left[\overline{{\varvec{T}} }\right]}^{BL}\) is the transpose of \({[{\varvec{T}}]}^{LB}\), and \({[{\varvec{\Sigma}}]}^{BL}\) is the skew-symmetric matrix corresponding to\({[{\varvec{\sigma}}]}^{BL}\).
2.2 Optimal Control Problem Definition
Consider the following general optimal control problem with the cost function in Bolza form:
subject to the following dynamic constraints, boundary conditions, and inequality path constraints, respectively:
where \({\varvec{x}}(t)\in {\mathbb{R}}^{n}\) and \({\varvec{u}}(t)\in {\mathbb{R}}^{m}\) are the state and control input vectors, respectively. Also \({t}_{0}\) and \({t}_{f}\) are the initial and final times, respectively.
As mentioned earlier, in this paper, the problem is to find the states and control trajectories in a 6DOF maneuver, subject to specific constraints, that minimize the maneuver time denoted as \({t}_{f}\). Therefore the optimal control problem is expressed as:
subject to the dynamic constraints:
the boundary conditions:
and the constraints on control torques and forces:
In this problem, the state and control input vectors are defined as:
2.3 Gauss Pseudo-spectral Method
The time-optimal 6DOF maneuver trajectories can be obtained by numerically solving the time-optimal control problem described in the previous section. Pseudo-spectral methods are a class of direct collocation methods that convert the continuous-time optimal control problem to an NLP problem. The basic idea behind these methods is to approximate the states and control trajectories using a basis of global interpolating polynomials, based on a set of discrete points across the interval. This paper uses the GPM to solve the time-optimal control problem. In this method, the states and control trajectories are approximated using the Lagrange polynomials and the base points are the Legendre–Gauss (LG) points. The \(N\) LG points \({\tau }_{1},\dots , {\tau }_{N}\) are defined as the roots of the Nth-degree Legendre polynomial, \({P}_{N}(\tau )\) where [46]
These non-uniform points are located on the interior of the interval [− 1, 1], and are clustered towards the boundaries, as depicted in Fig. 2. In the GPM, the dynamic constraints are forced to be satisfied only at these points (known as the collocation points), which leads to increased computational efficiency.

LG points distribution
As mentioned above, the GPM collocation points are located on the interior of the interval [− 1, 1]. Because of this, the optimal control problem of Eqs. (13–16) must be transformed from the time interval \(t\in [{t}_{0},{t}_{f}]\) to \(\tau \in [-\mathrm{1,1}]\) as:
Under this mapping, the optimal control problem of Eqs. (8–11) can be rewritten as:
subject to the constraints:
In the GPM, the LG collocation points \(-1<{\tau }_{1}<\dots <{\tau }_{N}<1\) and \({\tau }_{0}=-1\) are considered to approximate the state trajectory using a basis of \(N+1\) Lagrange interpolating polynomials [61],
in which \({L}_{i}(\tau )(i=0,\dots ,N)\) are the Lagrange polynomials defined as:
Additionally, by considering the LG collocation points, the control trajectory is approximated using a basis of \(N\) Lagrange interpolating polynomials \({L}_{i}^{*}(\tau )(i=1,\dots , N)\) as
where
It can be shown that the Lagrange polynomials of Eqs. (25) and (27) satisfy the isolation property as:
By differentiating the expression provided in Eq. (24), the derivative of \(x(\tau )\) at the LG points, \({\tau }_{k}\), are obtained as follows:
The derivative of Lagrange polynomials at the LG points, \({\dot{L}}_{i}({\tau }_{k})(k=1,\dots ,N)\) can be expressed as a differential approximation matrix \({\varvec{D}}\in {\mathbb{R}}^{N\times N+1}\), the elements of which are defined as [46]:
where \(i=0,\dots ,N\) and \(k=1,\dots ,N\). The continuous dynamic constraints of Eq. (21) are transcribed into the following set of algebraic dynamic constraints using the differential approximation matrix:
in which \({{\varvec{X}}}_{k}\equiv {\varvec{X}}\left({\tau }_{k}\right)\in {\mathbb{R}}^{n}\) and \({{\varvec{U}}}_{k}\equiv {\varvec{U}}\left({\tau }_{k}\right)\in {\mathbb{R}}^{m }(k=1,\dots , N)\). In the GPM, the dynamic constraints are collocated only at the LG points, and the terminal state is absent in the state approximation. Therefore, \({{\varvec{X}}}_{f}\)(or \({{\varvec{X}}}_{N+1})\) can be constrained via the Gauss quadrature that relates the final state to the initial state as follows [62]:
where \({w}_{k}\) are the Guass weights. Also, the continuous cost function of Eq. (20) can be approximated with a Gauss quadrature as:
Finally, the boundary conditions of Eq. (22) and path constraints of Eq. (20) are expressed as:
The cost function of Eq. (33) and the algebraic constraints of Eqs. (31), (32), (34) and (35) define an NLP. Solving the NLP gives an approximate solution for the continuous-time optimal control problem defined in the former section.
Some optimal control problems have discontinuities in either the states or control trajectories. In these problems, a common procedure to increase the solution accuracy is dividing the trajectories into \(P\)-phases, which involves repeating the structure for the one-phase formulation \(P\) times. Thus, the algebraic dynamic constraints of Eq. (31) are collocated at the LG points within each phase. In addition, the terminal constraints for the first phase, the initial and terminal constraints for the interior phases, and the initial constraints for the \({P}^{th}\) phase are re-characterized as interior point constraints. These interior point constraints include any continuity conditions in the state or time between adjacent phases [44, 46]. A schematic of how phases can be linked is shown in Fig. 3 for a 4-phases trajectory.

Schematic of linkages for a 4-phases trajectory
Accordingly, the boundary constraints of Eq. (34) can be replaced [46]:
where \(P\) is the number of phases and \(r=1,\dots ,P-1\). \({\mathcal{L}}^{\left(1\right)}\), \({\mathcal{L}}^{\left(P\right)}\) and \({\mathcal{L}}_{(r)}^{(r+1)}\) denote the initial constraints for the first phase, the terminal constraints for the last phase (\(P\)), and the continuity constraints for the interior phases, respectively.
2.4 Costate estimation
The transformed continuous-time optimal control problem of Eqs. (20–23), described in Sect. 2.3, can be solved using the calculus of variations and PMP [33] to obtain a set of first-order optimality conditions [56]. The first-order optimality conditions are found by taking the first-order variation of the augmented Hamiltonian, \(H\), defined as:
in which \({\varvec{\lambda}}\left(\tau \right)\in {\mathbb{R}}^{n}\) is the costate and \({\varvec{\mu}}\left(\tau \right)\in {\mathbb{R}}^{c}\) is the Lagrange multiplier associated with the path constraint. The continuous first-order optimality conditions can be expressed as follows:
where \({\varvec{\nu}}\in {\mathbb{R}}^{q}\) is the Lagrange multiplier associated with the boundary condition \(\boldsymbol{\varphi }\).
As mentioned earlier, in the GPM, KKT multipliers obtained from solving the NLP can be used for costate estimation and first-order optimality proof. Using KKT multipliers, a costate estimation for the continuous-time optimal control problem (an estimation for \({\varvec{\lambda}}\left(\tau \right))\), can be obtained at the LG points and the boundary points. Because of brevity, the details are not presented in this paper, and the interested reader is referred to [45]. The Gauss pseudo-spectral costate estimation is stated via the following theorem [45]:
Theorem1 (Gauss pseudo-spectral costate mapping theorem): a costate estimate at the initial time, final time, and the LG points can be found from the KKT multiplier as follows:
where \({\widetilde{\Lambda }}_{0}\) is defined as:
\({\widetilde{{\varvec{\Lambda}}}}_{k}\), \({\widetilde{{\varvec{\Lambda}}}}_{f}\) and \(\widetilde{\upsilon }\) are the KKT multipliers associated with dynamic constraints of Eq. (31), constraints of Eq. (32) and boundary constraints of Eq. (34), respectively. Also, \({{\varvec{\Lambda}}}_{k}\), \({{\varvec{\Lambda}}}_{0}\) and \({{\varvec{\Lambda}}}_{f}\) are the estimated costates in LG points, initial time and final time, respectively.
3 Numerical Simulation
In this section, the time-optimal control problem described in Sect. 2.2 is solved using GPM. The transformed continuous-time optimal control problem is first converted to the NLP, and then the sequential quadratic programming (SQP) iterative algorithm is utilized to solve the NLP and obtain the approximate controls and states trajectories. The GPM optimization and costate estimation pseudo-code are expressed in Table 1. It should be noted that in the time-optimal control problem, the final time is free. Therefore, the NLP variables include states and controls values in LG points, and \({t}_{f}\).
Proximity operations are commonly divided into two stages, namely rendezvous and docking maneuvers. The docking maneuver should be performed at a constant low relative velocity due to safety reasons, and the time-optimality of this maneuver is unnecessary. Therefore, in order to achieve to the target spacecraft in time-critical conditions, the rendezvous maneuver should be designed to be implemented in minimum time. At the end of the rendezvous maneuver, the chaser spacecraft must be in a desired attitude, velocity and position to start the docking maneuver. Without loss of generality, it is assumed that the target's body coordinate system is aligned with its LVLH coordinate system and its docking port is facing up (contrary direction of axis \({{\varvec{z}}}^{L}\)). Also, the chaser spacecraft docking port is in contrary direction of axis \({{\varvec{x}}}^{B}\). Accordingly, in the simulation scenario the chaser spacecraft should be located above the target spacecraft, in the desired attitude, velocity and position, to start the docking maneuver. Assuming that docking will start immediately after rendezvous, the simulation scenario is defined for a rest-to-rest 6DOF rendezvous maneuver.
At the initial time, the chaser spacecraft is located 20 m ahead of the target spacecraft, and the chaser's body coordinate system coincides with the target's LVLH. Also, at the final time, the chaser spacecraft should be located 10 m above the target spacecraft, and the chaser's body coordinate system must have a complete rotation around the \({y}^{B}\) axis. When the chaser spacecraft reaches the final states in the rendezvous maneuver, it starts the docking maneuver and moves toward the target spacecraft at a constant low relative velocity. The docking maneuver is beyond our research and has not be investigated in this section. The schematic of this scenario is shown in Fig. 4. The parameters of the chaser spacecraft are chosen based on the NASA X-ray Timing Explorer (XTE) characteristics [63], as shown in Table 2. Also, the initial and terminal states are given in Table 3. It is assumed that all the chaser's body axes have independent thruster actuators to generate control torques and forces.

Simulation scenario of 6DOF rendezvous maneuver
The number of phases in the GPM discretization and the number of LG points in each phase are considered 20 and 3, respectively. It is assumed that the time interval of the phases is equal. The results of the simulation scenario are shown in Figs. 5, 6, 7, 8, 9, 10, 11, and 12. The rotation sequence for Euler angles trajectories in Fig. 9 is 'YXZ'.

Control torques trajectories

Control forces trajectories

Angular velocities trajectories

MRPs trajectories

Euler angles trajectories

Relative linear velocities trajectories

Relative position trajectories

3D schematic of time-optimal 6DOF maneuver
Some studies have shown that the control structure for a time-optimal reorientation maneuver, considering cubical constraints on control torques magnitude, is "bang-bang" [7,8,9, 13]. Similarly, the results given in Figs. 5 and 6 show that for a time-optimal 6DOF maneuver, considering the cubical constraint on control torques and forces magnitude, the control structure is "bang-bang". It is the most natural and convenient form of control to be implemented via simple on–off thrusters, which are the most popular and widely used thrusters for spacecraft control due to their simplicity and low cost. The time duration of the time-optimal 6DOF maneuver is \({t}_{f}=25.87 \mathrm{s}\). Furthermore, [7] shows that in the spacecraft time-optimal reorientation maneuver with independent three axes control torques, although the net attitude reorientation is just about one body axis, other control torques (about the other body axes) are also engaged in order to achieve the minimum time. Our results given in Figs. 5 and 6 show that this issue can be generalized for the time-optimal 6DOF maneuver.
As shown in Figs. 7 and 10, the relative angular velocity and relative linear velocity vectors meet the rest condition. Also, results in Figs. 8, 9, and 11 show that the attitude and relative position trajectories meet the desired terminal conditions given in Table 3. The 3D schematic of the time-optimal 6DOF maneuver for the mentioned scenario is shown in Fig. 12.
In order to obtain a first-order optimality proof of the obtained solution, the costate estimation is used. Based on Theorem 1, using KKT multipliers obtained from solving the NLP problem, a costate estimation can be achieved at the LG and boundary points. The results of the costate estimation are shown in Figs. 13, 14, 15, and 16.

Angular velocity costates trajectories

MRP costates trajectories

Relative velocity costates trajectories

Relative position costates trajectories
Considering the cost function in Bolza form of Eq. (9), for the assumed time-optimal control problem, the \(\phi \left(x({t}_{0}),{t}_{0},x\left({t}_{f}\right),{t}_{f}\right)\) and \(g\left(x\left(t\right),u\left(t\right),t\right)\) functions are expressed as follows:
Also, in this simulation, the boundary conditions \(\boldsymbol{\varphi }\left(x\left({t}_{0}\right),{t}_{0},x\left({t}_{f}\right),{t}_{f}\right)\) are fixed and are not a function of \({t}_{f}\). Hence, according to Hamiltonian and first-order optimality conditions of Eqs. (37) and (38), respectively:
Regarding the dynamic constraints of Eq. (14), the Hamiltonian, \(H\), does not depend on time:
Therefore, the Hamiltonian must be constant and equal to -1 along the optimal trajectory.
Figure 17 shows that the computed Hamiltonian is approximately equal to -1 and fulfills the first-order optimality conditions.

Hamiltonian trajectory
As mentioned earlier, the costates have no physical interpretation, so their variations do not explicitly represent a tangible phenomenon. The main use of the costate variables is to prove the optimality of the obtained solution (according to Eq. 37). The purpose of providing the corresponding graphs (Figs. 13, 14, 15, 16 in the new version) is thus to provide a basis for the reader to verify the Hamiltonian graph (Fig. 17).
4 Conclusion
The time-optimal 6DOF maneuver problem was studied for an inertially asymmetric rigid spacecraft with independent control actuators for attitude and position control. For example, the time-optimal control problem was formulated for a rendezvous maneuver between two spacecraft. In the relative dynamic modeling of spacecraft, the orbital dynamic and coupling between attitude and position control were applied to rotational and translational dynamics. Then, the GPM was used to discretize the time-optimal control problem, and the SQP algorithm was adopted to solve the resulted problem. Finally, the costates were estimated by using the KKT multiplier.
In the simulation, it was observed that the control structure is "bang-bang" for the assumed time-optimal 6DOF maneuver problem. It is the most natural and convenient control structure which can be implemented by simple on–off thrusters. Although the net attitude reorientation was just about one body axis, and the displacement was along two LVLH axes, other control torques and forces (along the other body axes) were also engaged to achieve the minimum time. This observation can also be attributed to the coupling between attitude and position control stated earlier.
As a verification of the obtained solution, the costate estimation results showed that the solution fulfills the first-order optimality conditions.
Data Availability
Some or all data, models, or code generated or used during the study are available in a repository or online in accordance with funder data retention policies.
Abbreviations
- \({\left[{{\varvec{v}}}_{B}^{L}\right]}^{L}\) :
-
Velocity vector of the chaser's body center of mass (\(B\)) with respect to the target's LVLH frame (\(L\)), expressed in the target's LVLH coordinates (\(L\))
- \({\left[{{\varvec{s}}}_{BL}\right]}^{L}\) :
-
Position vector of the chaser's body center of mass (\(B\)) with respect to the target's LVLH frame origin (\(L\)), expressed in the target's LVLH coordinates (\(L\))
- \({D}^{Y}{\varvec{x}}\) :
-
Time derivative of vector \({\varvec{x}}\) with respect to frame \(Y\)
- \({\left[{\varvec{f}}\right]}^{L}\) :
-
Control force vector, expressed in the target's LVLH coordinate system (\(L\))
- \({\left[{\varvec{f}}\right]}^{B}\) :
-
Control force vector, expressed in the chaser's body coordinate system (\(B\))
- \({m}_{B}\) :
-
Chaser’s mass
- \({\omega }_{n}\) :
-
Orbital mean angular rate of the target
- \({{\varvec{I}}}_{B}\) :
-
Inertial matrix of the chaser's body
- \({\left[{{\varvec{\omega}}}^{\alpha \beta }\right]}^{\gamma }\) :
-
Angular velocity vector of frame \(\alpha\) with respect to frame \(\beta\), expressed in coordinate system \(\gamma\)
- \({\left[{\varvec{m}}\right]}^{B}\) :
-
Control torque vector, expressed in the chaser's body coordinate system (\(B\))
- \({[{\varvec{\sigma}}]}^{BL}\) :
-
MRP vector representing the orientation of the target's LVLH frame w.r.t. the chaser's body frame
- \({e}_{x}\) , \({e}_{y}\) , \({e}_{z}\) :
-
Components of Euler axis
- \(\Phi\) :
-
Principal rotation angle
- \({[{\varvec{T}}]}^{LB}\) :
-
Transformation matrix from the chaser's body coordinates to the target's LVLH coordinates
- \([{{\varvec{\Sigma}}]}^{BL}\) :
-
Skew-symmetric form of \({[{\varvec{\sigma}}]}^{BL}\)
- \(J\) :
-
Cost function
- \(\phi\) :
-
Scalar boundary constraint in cost function
- \(g\) :
-
Integrand function in cost function
- \({\varvec{x}}\) :
-
State vector
- \({\varvec{u}}\) :
-
Control input vector
- \({\varvec{f}}\) :
-
Dynamic constraints
- \(\boldsymbol{\varphi }\) :
-
Boundary conditions
- \({\varvec{C}}\) :
-
Inequality path constraints
- \(t\) :
-
Time
- \(\tau\) :
-
Transformed time
- \({P}_{N}\) :
-
\({N}^{th}\)-Degree Legendre polynomial
- \({\varvec{X}}\) :
-
Approximated state trajectory
- \({\varvec{U}}\) :
-
Approximated control trajectory
- \({L}_{i}\) :
-
Lagrange polynomials \((i=0,\dots ,N)\)
- \({L}_{i}^{*}\) :
-
Lagrange polynomials \((i=1,\dots ,N)\)
- \(w\) :
-
Gauss weights
- \({\varvec{D}}\) :
-
Differential approximation matrix
- \({\mathcal{L}}^{\left(1\right)}\) , \({\mathcal{L}}^{\left({\varvec{P}}\right)}\) , \({\mathcal{L}}_{({\varvec{r}})}^{({\varvec{r}}+1)}\) :
-
Initial constraints for the first phase, terminal constraints for the last phase (\(P\)), and continuity constraints for the interior phases
- \(H\) :
-
Hamiltonian
- \({\varvec{\lambda}}\) :
-
Costate vector
- \({\varvec{\mu}}\) :
-
Lagrange multiplier associated with the path constraint
- \({\varvec{\nu}}\) :
-
Lagrange multiplier associated with the the boundary condition
- \({\varvec{\Lambda}}\) :
-
Estimated costates in LG points
- \(\widetilde{{\varvec{\Lambda}}}\) :
-
KKT multipliers
- \({n}_{I}\) :
-
Number of phases
- \({n}_{LG}\) :
-
Number of LG points in each phase
- \({{\varvec{B}}}_{u}\), \({{\varvec{B}}}_{{\varvec{l}}}\) :
-
Upper and lower bound of states and controls values
- \({{\varvec{S}}}_{0}\) :
-
Initial guess for states and controls values in LG points
- \(x,y,z\) :
-
Components of a vector in arbitrary coordinate system
- \(0\) :
-
Initial time
- \(f\) :
-
Terminal time
References
Karpenko, M., Bhatt, S., Bedrossian, N., Fleming, A., Ross, I.: First flight results on time-optimal spacecraft slews. J. Guid. Control Dyn. 35, 367–376 (2012). https://doi.org/10.2514/1.54937
Ma, Z., Ma, O., Shashikanth, B.N.: Optimal approach to and alignment with a rotating rigid body for capture. J. Astronaut. Sci. 55, 407–419 (2007)
Tournes, C., Shtessel, Y.: Automatic docking using optimal control and second order sliding mode control. In: AIAA Guidance, Navigation and Control Conference and Exhibit (2007)
Chen, X.-Q., Yu, J.: Optimal mission planning of GEO on-orbit refueling in mixed strategy. Acta Astronaut. 133, 63–72 (2017)
Abdollahzadeh, P., Esmailifar, S.M.: Automatic orbital docking with tumbling target using sliding mode control. Adv. Space Res. 67, 1506–1525 (2021). https://doi.org/10.1016/j.asr.2020.12.016
Ma, J., Wen, C., Zhang, C.: Practical optimization of low-thrust minimum-time orbital rendezvous in sun-synchronous orbits. Comput. Model. Eng. Sci. 126, 617–644 (2021)
Bilimoria, K.D., Wie, B.: Time-optimal three-axis reorientation of a rigid spacecraft. J. Guid. Control Dyn. 16, 446–452 (1993). https://doi.org/10.2514/3.21030
Bai, X., Junkins, J.L.: New results for time-optimal three-axis reorientation of a rigid spacecraft. J. Guid. Control Dyn. 32, 1071–1076 (2009). https://doi.org/10.2514/1.43097
Shen, H., Tsiotras, P.: Time-optimal control of axisymmetric rigid spacecraft using two controls. J. Guid. Control Dyn. 22, 682–694 (1999). https://doi.org/10.2514/2.4436
Pager, E.R., Rao, A.V.: Minimum-time reorientation of axisymmetric rigid spacecraft using three controls. J. Spacecr. Rockets 59, 2195–2201 (2022)
Hu, Y., Wu, B., Geng, Y., Wu, Y.: Smooth time-optimal attitude control of spacecraft. Proc. Inst. Mech. Eng. G 233, 2331–2343 (2019). https://doi.org/10.1177/0954410018776531
Jinsong, L., Fullmer, R., Yang Quan, C.: Time-optimal magnetic attitude control for small spacecraft. In: 2004 43rd IEEE Conference on Decision and Control (CDC) (IEEE Cat. No.04CH37601), pp. 255–260 (2004)
Olivares, A., Staffetti, E.: Hybrid switched time-optimal control of underactuated spacecraft. Acta Astronaut. 145, 456–470 (2018). https://doi.org/10.1016/j.actaastro.2018.01.051
Olivares, A., Staffetti, E.: Time-optimal attitude scheduling of a spacecraft equipped with reaction wheels. Int. J. Aerosp. Eng. 2018, 1–14 (2018). https://doi.org/10.1155/2018/5947521
Melton, R.: Numerical analysis of constrained, time-optimal satellite reorientation. Math. Probl. Eng. 2012, 1–19 (2012). https://doi.org/10.1155/2012/769376
Melton, R.G.: Maximum-likelihood estimation optimizer for constrained, time-optimal satellite reorientation. Acta Astronaut. 103, 185–192 (2014). https://doi.org/10.1016/j.actaastro.2014.06.032
Spiller, D., Ansalone, L., Curti, F.: Particle swarm optimization for time-optimal spacecraft reorientation with keep-out cones. J. Guid. Control Dyn. 39, 312–325 (2016). https://doi.org/10.2514/1.G001228
Spiller, D., Melton, R.G., Curti, F.: Inverse dynamics particle swarm optimization applied to constrained minimum-time maneuvers using reaction wheels. Aerosp. Sci. Technol. 75, 1–12 (2018). https://doi.org/10.1016/j.ast.2017.12.038
Yang, J., Stoll, E.: Time-optimal Spacecraft Reorientation with Attitude Constraints Based on A Two-stage Strategy. In: AAS/AIAA Astrodynamics Specialist Conference (2018)
Celani, F., Bruni, R.: Minimum-time spacecraft attitude motion planning using objective alternation in derivative-free optimization. J. Optim. Theory Appl. 191, 776–793 (2021). https://doi.org/10.1007/s10957-021-01834-x
Miele, A., Weeks, M., Ciarcia, M.: Optimal trajectories for spacecraft rendezvous. J. Optim. Theory Appl. 132, 353–376 (2007)
Zhang, J., Parks, G.: Multi-objective optimization for multiphase orbital rendezvous missions. J. Guid. Control Dyn. 36, 622–629 (2013)
Harris, M.W., Açıkmeşe, B.: Minimum time rendezvous of multiple spacecraft using differential drag. J. Guid. Control Dyn. 37, 365–373 (2014)
Kollin, E.M.: Autonomous time-optimal spacecraft rendezvous and proximity operations using stabilized continuation (2016)
Zhang, G., Ye, D.: Optimal short-range rendezvous using on–off constant thrust. Aerosp. Sci. Technol. 69, 209–217 (2017)
Jorgensen, M.K., Sharf, I.: Optimal planning for a multiple space debris removal mission using high-accuracy low-thrust transfers. Acta Astronaut. 172, 56–69 (2020)
Von Stryk, O., Bulirsch, R.: Direct and indirect methods for trajectory optimization. Ann. Oper. Res. 37, 357–373 (1992). https://doi.org/10.1007/BF02071065
Betts, J.T.: Survey of numerical methods for trajectory optimization. J. Guid. Control Dyn. 21, 193–207 (1998). https://doi.org/10.2514/2.4231
Rao, A.V.: A survey of numerical methods for optimal control. Adv. Astronaut. Sci. 135, 497–528 (2009)
Conway, B.A.: A survey of methods available for the numerical optimization of continuous dynamic systems. J. Optim. Theory Appl. 152, 271–306 (2012). https://doi.org/10.1007/s10957-011-9918-z
Ross, I.M., Karpenko, M.: A review of pseudospectral optimal control: from theory to flight. Ann. Rev. Control 36, 182–197 (2012). https://doi.org/10.1016/j.arcontrol.2012.09.002
Dra̧g, P., Styczeń, K., Kwiatkowska, M., Szczurek, A.: A review on the direct and indirect methods for solving optimal control problems with differential-algebraic constraints. In: Recent Advances in Computational Optimization, pp. 91–105. Springer, New York (2016)
Pontryagin, L.S.: Mathematical Theory of Optimal Processes. CRC Press, Boca Raton (1987)
Guibout, V.M., Scheeres, D.J.: Solving relative two-point boundary value problems: spacecraft formulation flight transfers application. J. Guid. Control Dyn. 27, 693–704 (2004)
Park, C., Guibout, V., Scheeres, D.J.: Solving optimal continuous thrust rendezvous problems with generating functions. J. Guid. Control Dyn. 29, 321–331 (2006)
Bertrand, R., Epenoy, R.: New smoothing techniques for solving bang–bang optimal control problems—numerical results and statistical interpretation. Opt. Control Appl. Methods 23, 171–197 (2002)
Thevenet, J.-B., Epenoy, R.: Minimum-fuel deployment for spacecraft formations via optimal control. J. Guid. Control Dyn. 31, 101–113 (2008)
Li, J., Xi, X.-N.: Fuel-optimal low-thrust reconfiguration of formation-flying satellites via homotopic approach. J. Guid. Control Dyn. 35, 1709–1717 (2012)
Li, J., Xi, X.N.: Time-optimal reorientation of the rigid spacecraft using a pseudospectral method integrated homotopic approach. Optim. Control Appl. Methods 36, 889–918 (2015)
Li, J.: Time-optimal three-axis reorientation of asymmetric rigid spacecraft via homotopic approach. Adv. Space Res. 57, 2204–2217 (2016). https://doi.org/10.1016/j.asr.2016.02.016
Lee, D., Song, Y.-J.: Spin-to-spin slew maneuvers under spherically constrained angular acceleration. Adv. Space Res. 64, 1274–1285 (2019). https://doi.org/10.1016/j.asr.2019.06.026
Lan, J., Li, J.: Newton-Kantorovich/Radau pseudospectral solution to rigid spacecraft time-optimal three-axis reorientation. Adv. Space Res. 65, 2662–2673 (2020)
Huntington, G.T., Rao, A.V.: Comparison of global and local collocation methods for optimal control. J. Guid. Control Dyn. 31, 432–436 (2008). https://doi.org/10.2514/1.30915
Benson, D.: A Gauss pseudospectral transcription for optimal control. Ph.D. Thesis, Massachusettes Institute of Technology (2004)
Benson, D.A., Huntington, G.T., Thorvaldsen, T.P., Rao, A.V.: Direct trajectory optimization and costate estimation via an orthogonal collocation method. J. Guid. Control Dyn. 29, 1435–1440 (2006). https://doi.org/10.2514/1.20478
Huntington, G.: Advancement and analysis of a Gauss pseudospectral transcription for optimal control problems. Ph.D. Thesis, Massachusetts Institute of Technology (2007)
Huntington, G.T., Benson, D., Rao, A.V.: Optimal configuration of tetrahedral spacecraft formations. J. Astronaut. Sci. 55, 141–169 (2007). https://doi.org/10.1007/BF03256518
Huntington, G.T., Rao, A.V.: Optimal reconfiguration of spacecraft formations using the Gauss pseudospectral method. J. Guid. Control Dyn. 31, 689–698 (2008). https://doi.org/10.2514/1.31083
Elnagar, G., Kazemi, M.A., Razzaghi, M.: The pseudospectral Legendre method for discretizing optimal control problems. IEEE Trans. Autom. Control 40, 1793–1796 (1995). https://doi.org/10.1109/9.467672
Fahroo, F., Ross, I.M.: Costate estimation by a Legendre pseudospectral method. J. Guid. Control Dyn. 24, 270–277 (2001). https://doi.org/10.2514/2.4709
Darby, C., Garg, D., Rao, A.V.: Costate estimation using multiple-interval pseudospectral methods. J. Spacecr. Rockets 48, 856–866 (2011). https://doi.org/10.2514/1.A32040
Darby, C.L., Hager, W.W., Rao, A.V.: Direct trajectory optimization using a variable low-order adaptive pseudospectral method. J. Spacecr. Rockets 48, 433–445 (2011). https://doi.org/10.2514/1.52136
Garg, D.: Advances in global pseudospectral methods for optimal control. Ph.D. Thesis, University of Florida (2011)
Fleming, A.: Real-time optimal slew maneuver design and control. M.Sc. Thesis, Naval Postgraduate School (2004)
Melton, R.G.: Hybrid methods for determining time-optimal, constrained spacecraft reorientation maneuvers. Acta Astronaut. 94, 294–301 (2014). https://doi.org/10.1016/j.actaastro.2013.05.007
Kirk, D.E.: Optimal Control Theory: An Introduction. Courier Corporation, North Chelmsford (2004)
Bohlouri, V., Jalali-Naini, S.H.: Application of reliability-based robust optimization in spacecraft attitude control with PWPF modulator under uncertainties. J. Braz. Soc. Mech. Sci. Eng. 41, 449 (2019). https://doi.org/10.1007/s40430-019-1955-9
Zipfel, P.H.: Attitude Dynamics. In: Modeling and simulation of aerospace vehicle dynamics, pp. 165–216. American Institute of Aeronautics and Astronautics (AIAA), Reston, Virginia (2007)
Clohessy, W., Wiltshire, R.: Terminal guidance system for satellite rendezvous. J. Aerosp. Sci. 27, 653–658 (1960). https://doi.org/10.2514/8.8704
Schaub, H., Junkins, J.: Rigid Body Kinematics. In: Analytical mechanics of space systems, pp. 79–141. American Institute of Aeronautics and Astronautics (AIAA), Reston, Virginia (2018)
Davis, P.: Interpolation & Approximation. Dover Publications, Mineola (2014)
Davis, P.J., Rabinowitz, P.: Methods of Numerical Integration. Courier Corporation, North Chelmsford (2007)
Betts, J.: Practical Methods for Optimal Control and Estimation Using Nonlinear Programming. Society for Industrial and Applied Mathematics, Philadelphia (2010)
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing Interests
The authors have no competing interests to declare that are relevant to the content of this article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Mousavi, S.M., Esmailifar, S.M. & Chiniforoushan, M. Spacecraft Coupled Roto-translational Time-Optimal Control for Rendezvous Missions. J Astronaut Sci 70, 23 (2023). https://doi.org/10.1007/s40295-023-00390-y
Accepted:
Published:
DOI: https://doi.org/10.1007/s40295-023-00390-y