
Abstract
A major problem text classification faces is the high dimensional feature space of the text data. Feature selection (FS) algorithms are used for eliminating the irrelevant and redundant terms, thus increasing accuracy and speed of a text classifier. For text classification, FS algorithms have to be designed keeping the highly imbalanced classes of the text data in view. To this end, more recently ensemble algorithms (e.g., improved global feature selection scheme (IGFSS) and variable global feature selection scheme (VGFSS)) were proposed. These algorithms, which combine local and global FS metrics, have shown promising results with VGFSS having better capability of addressing the class imbalance issue. However, both these schemes are highly dependent on the underlying local and global FS metrics. Existing FS metrics get confused while selecting relevant terms of a data with highly imbalanced classes. In this paper, we propose a new FS metric named inherent distinguished feature selector (IDFS), which selects terms having greater relevance to classes and is highly effective for imbalanced data sets. We compare performance of IDFS against five well-known FS metrics as a stand-alone FS algorithm and as a part of the IGFSS and VGFSS frameworks on five benchmark data sets using two classifiers, namely support vector machines and random forests. Our results show that IDFS in both scenarios selects smaller subsets, and achieves higher micro and macro \(F_1\) values, thus outperforming the existing FS metrics.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Advancement in Internet technologies revolutionizes the need for automatic textual data classification [1]. Nowadays, web is a main source of ever increasing unstructured textual data. Approximately 70–80% information of an organization is stored in an unstructured text format [2]. Arranging text documents into predefined different categoriesFootnote 1 is called text document classification [3]. Categorization of documents into known categories helps to find documents related to user queries. Text classification can be performed automatically and efficiently with the help of machine learning algorithms. Text classification is a prevailing application of natural language processing having a wide range of applications, e.g., game industry [4], stock price prediction [5], news agencies and escalating businesses via social media [6].
Broadly, there are three stages for implementing text classification with machine learning: (i) feature extraction or representation (ii) feature selection and (iii) classification [7]. In the feature extraction or data representation stage, each raw text is converted into a vector of numerical values. The most commonly used model for text representation is Bag of Words (BoW) [8]. Assuming a document to be a sequence of independent words, it does not take the structure and order of text into account. To make the BoW representation more compact and effective, various pre-processing steps such as stemming, stop words removal and pruning are applied [9]. In stemming, conversion of wordsFootnote 2 to their root form is performed, e.g., connection becomes connect, and taught is converted into teach. Stop words such as “the,” “an,” “a,” “and,” etc., are too frequently occurring words in documents that do not provide any information about the category of a text and, thus should be removed with the help of a list of stop words [10]. Normally, a corpus of documents consists of a number of rarely occurring terms and a few very frequently occurring terms [11]. Such terms are irrelevant in discriminating among classes and are, thus removed via pruning [10]. In pruning, terms whose occurrence is below a certain lower threshold or above a certain upper threshold value are removed. Finally, a text document is represented as a vector \( \mathbf{d} = \{tw_{1}, tw_{2}, tw_{3}, \ldots , tw_{n} \} \), where \( W= \{w_{1}, w_{2}, w_{3}, \ldots , w_{n}\} \) is a vocabulary of n words and \(tw_{i}\) is the weight of the ith term [12].
In the quest for improving the performance of text classification, researchers have proposed a number of term weighting schemes. For example, terms can be represented by Boolean values indicating whether the term is present or absent. This is more suitable for shorter documents [13]. A term can also be represented by considering the number of times it appears in a document (called term count) or term count that is normalized by the length of a document (called term frequency) [14]. Among the schemes proposed in the literature, the most popular weighting scheme is term frequency-inverse document frequency (tf.idf) [15, 16]. However, researchers have highlighted issues of tf.idf and have suggested alternatives of it. For example, [17] proposed a relevance frequency (rf) to capture the distribution of a term in different categories and showed that better performance for text classification can be obtained with tf.rf as compared to tf.idf. In another work [18], inverse gravity moment (igm) was proposed to capture the class distinguishing power of a term. It considers a term concentrated in one class to be more important than a term having relatively uniform distribution in a number of classes or all classes. Text classification based on tf.igm weighting scheme was found to outperform tf.idf but is computationally slightly more expensive. Similarly, a modified version of term frequency and inverse document frequency was proposed by [19]. The new scheme takes the amount of missing terms into account while calculating the weight of existing terms and has shown to improve text classification results.
Even for a moderate sized text data set, the d vector or vocabulary of words can contain tens of thousands of unique words [20]. Not all these words have the same discriminating power: terms can be relevant, irrelevant and even redundant for discriminating among the categories of the text documents [21]. Also, high dimensionality of the data degrades the classification accuracy and increases the computational complexity of a classifier [22, 23]. Moreover, the processed text data are highly sparse as most of the words are absent and contain no information [24]. Therefore, the data used for text classification require dimensionality reduction or feature selection (FS) [25]. In this stage of text classification, filterFootnote 3 methods are preferred because they are simple and computationally efficient as compared to other feature selection methods [7].
Filter methods can be divided into two groups referred as global and local, which depends on whether the method assigns a unique score or multiple class-based scores to a feature [7]. For a local feature selection method, we define a globalization policy that converts the multiple local scores into a unique global score, while a global method uses the scores directly for ranking the features. Features are then sorted in descending order and the top N features are selected in the final set, where N can be determined empirically [26]. Some well-known examples of the global feature selection methods include information gain (IG) [27], Gini index (GI) [28] and distinguishing feature selector (DFS) [1]. Another criterion with which we can categorize filter methods is whether it uses a one-sided or two-sided feature ranking metric [29]. One-sided metrics select those features that are most indicative of membership of a given category (i.e., positive features), while the two-sided metrics implicitly combine the features most indicative of membership (i.e., positive features) and nonmembership (i.e., negative features) [30]. For example, GI and IG are two-sided FS metrics, while odds ratio and correlation coefficient are examples of one-sided metrics [29].
The final set when populated by a global filter with the addition of top N terms, there can be a number of classes whose terms may not be present in it, thus degrading the text classification performance [7]. To solve this problem, an improved global feature selection scheme (IGFSS) was proposed, which is an ensemble of local and global filter metrics [7]. The classification performance of global methods has shown to be improved by constructing a final set that contains almost equal number of terms from all the classes. In [31], the authors observed that IGFSS does not work well for imbalanced data sets having a large number of classes of varying sizes and addressed this limitation by suggesting a variable global feature selection scheme (VGFSS). This new approach shows better performance as compared to IGFSS and the global filters by selecting a variable number of features from each class depending on the distribution of terms in the classes. Although this approach shows promising results, its performance varies with the selection of different metrics, thus providing a room for improvement.
The major contributions of our research work in this paper are summarized:
-
We discuss and highlight limitations of existing feature ranking metrics with the help of an example data set.
-
We propose a new feature ranking metric named inherent distinguished feature selector (IDFS), which is effective in choosing relevant terms from highly imbalanced data sets.
-
We show the effectiveness of IDFS against five well-known feature ranking metrics as a stand-alone FS algorithm and as a part of the IGFSS and VGFSS frameworks.
-
We carry out experiments on five benchmark data sets using two classifiers, namely support vector machines [32] and random forests [33].
The remainder of this paper is organized in five sections. Section 2 provides a survey of the existing works related to feature selection. In Sect. 3, we illustrate problems with existing feature ranking metrics and also explain the working of our newly proposed IDFS feature ranking metric. Section 4 provides details of our experiments, while Sect. 5 presents the results and discusses them. Finally, we draw conclusions of the work done in this paper in Sect. 6.
2 Related Works
We divide this section into two subsections. In the first subsection, we provide an overview of the works of feature selection (FS) algorithms for text classification, while the second subsection focuses on the well-known filters.
2.1 Overview of Feature Selection Methods
The aim of feature selection is to further improve the performance of classifiers (e.g., text classifiers) while reducing their computational complexity [34]. This can be achieved by searching the feature space for an optimal feature subset whose relevance for the class variable is maximum and redundancy among the features is minimum [35]. In other words, we want to eliminate the irrelevant and redundant features. Feature selection algorithms proposed in the literature can be categorized based on multiple criteria [36]. The most important one is whether an FS algorithm seeks the help of the classifier while searching for the optimal subset [37]. Broadly, there can be three categories: filter, wrapper and embedded methods [38]. Unlike wrapper and embedded methods, filters search for the optimal feature subset without the guidance of the classifier [39]. The filters use a metric to evaluate the usefulness of features and output a ranked list of features according to their relative importance. Wrapper and embedded systems are more complex and computationally more expensive than filter methods due to which the latter methods are preferred for high-dimensional data sets such as text data [40].
Text classification researchers have mostly been focusing on designing filters because they are computationally the least expensive. We discuss some well-known examples in Sect. 2.2. In addition to the proposal of filters, we can find that new feature selection frameworks are being designed to further improve performance of text classification task.
Feature ranking methods ignore the redundancies among the terms. The output is a subset that consists of top ranked features highly relevant for the class but can possibly be redundant [41]. The final subset can miss two or more such features that are individually less relevant but together can better discriminate among the classes [39]. Therefore, designing algorithms for feature selection for high-dimensional data that take term dependencies into account without becoming computationally intractable is a major challenge. Toward this end, researchers have proposed two-stage algorithms. In the first stage, we select a subset of highly relevant terms while the second stage gets rid of redundant terms from the reduced space of features. For example, [42] found that combining IG in the first stage and principal component analysis or a genetic algorithm in the second stage can improve the text classification performance. Similarly, [25] proposed to capture the redundancy among terms selected in the first stage with the help of a Markov blanket in the second stage. The performance of text classification was found to improve significantly.
More recently, FS algorithm designers have focused on the class imbalance problem of the text data, which further aggravates in the one-vs-rest setting. To make feature selection more effective in the class imbalance scenario, [7] proposed an ensemble approach named IGFSS incorporating global and local filters for selecting equal number of features from each class. But [31] found that IGFSS approach does not work well on imbalanced data sets having large number of classes and proposed a new scheme named VGFSS. Unlike IGFSS, VGFSS selects a variable length of features depending on the class size and works well for imbalanced data sets. The downside is that its performance heavily relies on the underlying FS metrics. In case the metrics fail to select useful features, VGFSS also performs poorly.
2.2 Feature Ranking Metrics
Mostly, feature ranking metrics are based on document frequency. For two-class text classification, we present the basic notations in Table 1 and the confusion matrix in Table 2, which will allow us to better understand the feature ranking metrics. The confusion matrix defines true positive (tp), true negative (tn), false positive (fp) and false negative (fn), and their calculations are given in Table 1.
We further need to define term importance. There can be four different types of terms:
-
(a)
Rare or Unique terms: terms present in only one class with higher weight of true positive rate (tpr) or \( p(t_{i}|C_{j}) \) values and absent in other classes, where \( tpr = p(t_{i}|C_{j})= \frac{tp}{tp+fn}\) and false positive rate , \(fpr = p(t_{i}|\overline{C_{j}})=\frac{fp}{fp+tn}\) [43,44,45].
-
(b)
Common terms: terms present either in most of the classes or in all classes.
-
(c)
Negative terms: terms present in all classes but absent in a specific class is negative term for that class.
-
(d)
Sparse terms: rare terms with very low tpr weight.
Accuracy (ACC) is a metric that simply takes the difference between tp and fp [13] and is given in Eq. (1). This metric assigns a higher score to frequent terms in the positive class as compared to the frequent terms in the negative class, thus penalizing latter terms that are highly relevant for the negative class.
Balanced accuracy measure (ACC2) [30] is an improved version of ACC given in Eq. (2). Although ACC2 addresses shortcomings of the ACC metric but can fail in differentiating important terms from redundant terms.
Mutual information (MI) selects features based on their mutual dependence and chooses a higher number of terms of a larger class [46]. Its major weakness is that it is based on marginal probabilities and largely depends on tp values, ignoring class wise importance of terms [27]. The MI local metric is given in Eq. (3). If \(C_T\) denotes the total number of classes, then its global version is given in Eq. (4) [47].
Information gain (IG) is a metric, which gives more weight to negative terms as compared to common terms. Strong common and negative terms are weighted more than rare terms. IG performs poorly for a data set having large number of redundant features [48]. Information gain is given in Eq. (5).
Distinguishing feature selector (DFS) selects most prominent and strong rare features [1] but can neglect negative features. The mathematical expression of DFS is given in Eq. (6).
Bi-normal separation (BNS) is the two threshold criterion between tpr and fpr, calculating normal inverse cumulative distribution function of these values a.k.a z-score [49] and is given in Eq. (7). It gives more importance to rare, weak rare and sparse terms. Also, negative terms are assigned more weight as compared to common terms. The BNS metric locally gives more importance to strong rare features. In case strong rare terms are not present, then more importance is given to sparse terms due to which the BNS metric’s performance deteriorates.
Normalized difference measure (NDM) is an improvement over ACC2 proposed by [50]. It differentiates two terms having the same difference of tpr and fpr, by considering the minimum of tpr and fpr in the denominator. It is given by Eq. (8). NDM assigns correct labels to negative, and rare but for common terms it is biased toward larger classes. However, in large and highly skewed data, highly sparse terms are present in one or both the classes. NDM assigns high scores to sparse terms.
Odds ratio (OR) is another well-known metric and is given in Eq. (9) [51]. Due to the \(\log _2\) function, it is a one-sided local metric assigning scores to features in both positive and negative ranges. It gives more importance to negative and rare terms than common features.
2.3 The Text Categorization Pipeline
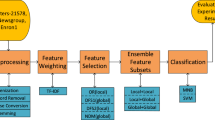
The general steps involved in automatic text categorization are shown in Fig. 1, which has been adopted from [52]. First, the text documents are pre-processed. In the second step, weight of the terms is calculated. The third step applies an FS algorithm. In the fourth and final step, quality of terms selected by the FS algorithm is tested using a classifier.
In Fig. 1, LFSM refers to the local feature selection metric and GFSM means a global feature selection metric. The pipeline remains the same even for global feature selection schemes, including ensemble-based IGFSS [7] and VGFSS [31] approaches that employ both global and local FS metrics.
2.4 The VGFSS Algorithm
Now, we describe the VGFSS approach for selecting terms.

The general pipeline steps for text classification
-
(a)
After applying the pre-processing step on the data set split the word-set into \( D_\mathrm{train} \) and \( D_\mathrm{test} \) sets.
-
(b)
Apply the FS {IG, DFS, BNS, NDM, OR} metrics on vocabulary of \( D_\mathrm{train} \) set to obtain the feature set and arrange the feature set in descending order of their global scores. Global score is obtained by combining local scores of the features.
$$\begin{aligned}&global\_score(t_{i})= G\!F\!S\!S\;(t_{i}, C_{j})&\end{aligned}$$(10) -
(c)
Assign the class label of terms based on the max local policy of GFSS metrics.
$$\begin{aligned} {\text {label}}(t_{i})= C_{n} = \max ({\text {GFSS}}(t_{i}, C_{j})) \end{aligned}$$(11) -
(d)
Count label of each class and total terms (tt) in the vocabulary
$$\begin{aligned} {\text {Count}} (C_{j})&= \sum _{j=1}^{C_T}{\text {count}}\_{\text {if}}({\text {label}}(t_{i}))&\end{aligned}$$(12)$$\begin{aligned} tt&= \sum _{j=1}^{C_T}{\text {Count}}(C_{j})&\end{aligned}$$(13) -
(e)
Let the length of the final feature set is N, then the variable split criterion for each class is:
$$\begin{aligned}&var\_split (C_{j}) = \dfrac{Count(C_{j}) \times N}{tt}&\end{aligned}$$(14) -
(f)
Selecting features from each class according to the \( {\text {var}}\_{\text {split}} \) criterion and total count of the selected features is equal to or less than N number of features.
$$\begin{aligned} \begin{aligned}&{\text {final}}\_{\text {feature}}\_{\text {set}} ({\text {FSS}}) = N\\&{\text {if}}\, ({\text {sizeof}}({\text {FSS}}) > N ) then \\&N_\mathrm{extra} = {\text {sizeof}}({\text {FSS}}) - N \end{aligned} \end{aligned}$$(15) -
(g)
Arrange the features in descending order of their scores and eliminate \( N_\mathrm{extra} \) features from the bottom.
Unlike VGFSS, IGFSS employs the OR metric to assign labels in which case we count negative and positive features of each class and calculate the positive feature ratio (pfr) and negative feature ratio (nfr) and select equal number of features from each class.
The VGFSS algorithm, which selects positive and negative terms from the classes based on their size, has shown promising results to address the text classification class imbalance problem. However, performance of VGFSS is highly dependent on the metric it employs. So, one question that arises is which metric in this VGFSS approach will produce the best results? Different metrics rank the features differently [41]. Hence, different metrics can represent each class with different number of features. If the metric models a class with less number of features, then alternatively the least number of features will be selected by both global FS metric and VGFSS approach for that class. For example, [31] use a synthetic data set that consists of three classes with different sizes {C1 = 2, C2 = 2, C3 = 4 } to investigate the VGFSS approach. When the IG metric was used as part of VGFSS, it represented the three classes with 9, 4 and 3 features, respectively, thus selecting a larger number of features from the smaller class C1 and selecting a smaller number of features from the larger class C3. This is in contradiction of the concept introduced by [31] that the largest class should get the largest number of features in the final set. This behavior varies from metric to metric and motivates us to propose a new metric.
3 Our Proposed Feature Ranking Metric: Inherent Distinguished Feature Selector (IDFS)
In this section, firstly we present a new metric that has a better capability of selecting the most relevant features in imbalanced data sets. Secondly, we illustrate the shortcomings of the existing feature ranking metrics with the help of a synthetic data set and show how our metric addresses those problems.
Researchers while proposing feature ranking metrics have described different important criteria for the selection of most useful terms of text data. For example, according to [1], a term present in some of the categories is important and should be assigned a higher score, i.e., a negative term should be assigned a higher score compared to common terms. Keeping these criteria in mind, we propose a new metric named inherent distinguished feature selector (IDFS) that inherently looks for features which are useful in any sense like rare, negative and common terms. IDFS assigns a higher score to negative terms as compared to common terms. Its mathematical expression is given in Eq. 16. The numerator of IDFS is a product of the precision, \(P(C_{j} | t_{i})\) and the ACC2 metric, where \(P(C_{j} | t_{i})\) is the probability of a class when a term is present. It also dictates global class worth independent of classes, thus giving more weight to strong rare terms. In the denominator, probability of absence of a term when a class is present, and the presence of a term when other classes are present (\(P(\overline{t_{i}} |C_{j}) + P( t_{i} | \overline{C_{j}})\)) is used. This assigns a lower score to the irrelevant terms present in most of the classes. The ACC2 metric is included in the equation so as to select only those features near either fpr or tpr axis according to criterion [13]. An \(\epsilon \), which is of a small value such as 0.0005 is added in the denominator to further discriminate rare terms from the rest of the term categories.
To illustrate the shortcomings of existing well-known metrics and working of our IDFS metric, we refer to an example synthetic data set shown in Table 3. It consists of 10 documents and 12 unique terms. Among the terms, two (“lion, ” “usb”) are rare terms, three (“mouse,” “cat,” “water”) are common terms, six (“dog,” “fridge,” “laptop,” “cow,” “phone,” “apple”) are negative terms, and one (“bulb”) is a sparse term. The three classes are named “house,” “wild,” and “technology” or “tech,” and the size of each of these classes is {C1 = 2, C2 = 3, C3 = 5}, respectively. Table 4 shows the vector space model for this example. For simplicity, we have considered terms with single frequency in the synthetic data set. Furthermore, a feature is assigned that class label having greater tpr value.
Next, we show how the IDFS expression given in Eq. 16 is used to calculate the scores for the 12 features.
Now, we compare IDFS against the five well-known feature ranking metrics on this synthetic data set. Table 5 shows the ranking generated by each of the six metrics along with the label assignment for the 12 features.
First, we discuss the ranks assigned to the terms by feature ranking metrics. This will allow us to understand how good a metric will work as a stand-alone FS algorithm. The “lion” is a rare term (i.e., present in only one class) belonging to the “wild” class. We can see that IDFS, DFS, IG and NDM metrics rank it at the top but is assigned a lower rank by the OR and BNS metrics. The term “dog” is present in all documents of the class “wild” with only one occurrence in the minor class “house,” while “usb” is a rare term of the major class “tech” with 80% presence in that class. We can observe that “dog” is assigned a second rank by IDFS and a third position by DFS, while DFS assigns second place to “usb.” DFS assigns it a greater weight because it is biased toward the major class. On the other hand, IDFS also employs the tpr and fpr values to differentiate the terms, due to which the minor classes also enjoy their share during feature selection in highly skewed data sets. The IG metric assigns a second rank to “dog,” but the NDM, OR and BNS metrics assign a relatively lower score to it. The third important term is “usb” that is placed at the first position by OR, at second position by NDM, BNS and DFS while at third position by IDFS and IG metrics. Although the placement of “usb” at second position is the best for a balanced data set but for a skewed data set, the term “dog” should be placed higher so that rare terms of the minor class can be distinguishable. Next is “cat,” which is a common term with 33% presence in the class “wild” and 20% presence in the major class “tech” while 100% presence in the minor class “house.” IDFS is the only metric that ranks it at the fourth position, while the other FS metrics assign it a lower rank. If a data set is highly unbalanced and rare terms of minor classes are not ranked properly, then such features may be left out in the training procedure. Thus, the incoming test documents would not be classified properly, causing more false negative predictions than false positive ones, which is highly undesirable [53]. Therefore, “cat” should be placed higher than term “laptop” because it is a rare term of the minor class. All metrics except DFS assign a lower score to “laptop” because DFS favors terms with higher probabilities in the major class. The term “apple” is a rare term for the major class with 100% distribution, a rare term for the second class with 67% distribution but a negative term for the minor class “house.” It should be assigned a lower score compared to “laptop” because it is strongly related to the two big classes. However, only IDFS and DFS rank it correctly, while the other metrics are ranking “apple” higher than “laptop.” The term “bulb” has 2/5 distribution in the major class and is a weak rare term of the major class. It should be ranked lower than “cat” because it is a common term and a rare term of the minor class (100% distributed in the class) and a sparse term for the two big classes. If we were to select the top 5 features based on either metric except IDFS for classifying the test documents, then “cat” a rare term of the minor class would have been left out, thus making it difficult for the classifier to predict the appropriate category of the new instances. The remaining five terms (“fridge,” “cow,” “water,” “phone” and “mouse”) are not useful for discriminating the classes and should be positioned in the order as ranked by IDFS and DFS. However, this is not the case. For example, OR and BNS assign “mouse,” which is an irrelevant term a higher rank.
For this data set, the difference between IDFS and DFS seems to be minor. The term “cat,” which is strongly related to the minor class “house,” has obtained more importance by IDFS as compared to “laptop,” which is strongly related to the major class “tech.” Actually, DFS gives more weight to the features of the major class as compared to the rare features of the minor classes. The IDFS metric does not neglect rare features from the minor classes. Due to this reason, IDFS is expected to perform better during feature selection of imbalanced data sets as compared to DFS and other metrics. The time complexity of the IDFS metric is O(n) and is the same as that of DFS.
The shortcomings of existing FS metrics can be summarized as below.
-
The DFS metric ranks features of the major class higher than those of the minor class. Therefore, features of the minor class can be expected to be positioned at the bottom of the ranking in highly skewed data sets such Reuters52.
-
The NDM denominator is \(\min (tpr, fpr)\), but when both tpr and fpr approach zero the irrelevant features are assigned higher scores. The minor class rare features having minor distribution in the major classes can obtain a low score. This can be seen from Table 5, the “cat” feature which is a rare feature of the minor class “house,” but having a minor distribution in other classes is assigned a lower score.
-
For the OR metric, the presence of the conditional probability \(tpr = p(t_{i}|C_{j})\) in the numerator and its inverse in the denominator ranks the terms incorrectly. When a term is present in all classes such as the term “mouse,” which is highly undesirable. Its tpr inverse value, which is negligible makes the denominator very small, thus assigning an overall high score to a common term.
-
As BNS is a difference between inverse distributions of tpr and fpr, a term having a higher tpr in all classes gets a higher weight and rank when its fpr value is also comparable. This is highly undesirable. For example, due to highest values of tpr and fpr of “mouse” (a common term present in all classes) in Table 5, BNS assigns the highest score to it.
-
IG ranks negative terms higher as compared to the common terms. For example, “laptop” is a negative term of the “wild” class and is placed higher than the common term “cat.”
Now, we look at how well the features are assigned class labels, which are crucial for the working of VGFSS and IGFSS frameworks as mentioned toward the end of Sect. 2.
The label assignment performed by different metrics is computed with the same mechanism as used by IDFS, which has been shown above. We can observe that the label assignments of the features by IDFS and DFS metrics are better as compared to the rest of the metrics and are in accordance to our expectations as depicted in Table 4. The IG metric assigns an incorrect label to “bulb” and “mouse,” i.e., “wild” class. Similarly, “cow” is assigned to the “tech” class, which is also wrong. In case of NDM, we can observe that it associates the “apple” term to the incorrect label “house,” which is correctly assigned to the “tech” class by IDFS and DFS metrics. The IG, BNS and OR metrics each incorrectly labels “apple” to the “house” class. The term “laptop,” which is a negative term for class “wild,” should be assigned a label of the major class. But unlike IDFS and DFS, all metrics assign a wrong label to it because these FS metrics mostly assign labels on the basis of the negative classes. We can find that the IG, BNS and OR metrics could not label the correct category to most of the terms, while NDM assigns the correct labels to some of the features. IDFS and DFS have shown the best performance among all the metrics.
Hence, from our above discussion we can conclude that in comparison with the well-known FS metrics IDFS is not only better at ranking the terms but also assigns correct class labels to the them.
4 Empirical Evaluation
This section describes the experimental settings used for the empirical evaluation of the newly proposed IDFS metric.
4.1 Description of the Data Sets
In our experiments, five data sets have been used that are widely used by researchers. Table 6 shows the summary of the data sets. For each data set, we show total number of documents, number of terms, number of classes, sizes of the largest and smallest classes and the class names. All the data sets except for the Classic4 data set have been obtained from the well-known webpage of Ana Cardoso CachopoFootnote 4 and their details are given in [54]. The Classic4 data set was obtained from the webpage of Volkan Tunali.Footnote 5 These data sets have different characteristics. For example, the WebKB data set has four categories and its classes are almost balanced, while R52 consists of 52 classes and its classes are highly imbalanced.
4.2 Data Sets Pre-processing
We stemmed all the data sets used in our experiments and removed the stop words with the help of the Weka APIs [55]. The multi-class text classification data sets were converted into two-class classification tasks using the one-vs-rest strategy, as it is most widely used by text classification researchers [13].
4.3 Feature Ranking Metrics
We compare the performance of five well known feature ranking metrics, namely IG, DFS, BNS, NDM and OR against our newly proposed IDFS metric. These metrics were implemented in the JAVA programming language.
4.4 Classification Algorithms
The quality of terms selected by the feature ranking metrics has been evaluated with the help of two well-known classification algorithms, namely support vector machines (SVM) [32] and random forests (RF) [33]. The implementation of these classifiers in Weka has been used. Weka uses the JAVA programming environment [55]. For RF, we have selected the depth of the tree to be 100, and the number of features, \( n_\mathrm{try} = \sqrt{n} * 2 \), where n is the total number features in the training set.
4.5 Evaluation Measures
The macro averaged \(F_1\) and micro averaged \(F_1\) measures are the most commonly used evaluation measures to estimate the performance of a text classifier [13].
The \(F_1\) measure is defined to be the harmonic mean of precision (p) and recall (r). We can estimate precision by considering the number of correct results out of the results marked correct by the classifier (i.e., p = \(\frac{tp}{tp+fp}\)), while recall is the number of correct results out of actual number of correct results (i.e., r = \(\frac{tp}{tp+fn}\)) [10]. Higher the \(F_1\) value, better is the performance of the classifier. The best value of \(F_1\) is 1, and its worst value is zero.
The micro \(F_1\) is given in Eq. (17), while macro \(F_1\) is given in Eq. (18). The micro \(F_1\) does not take class distribution into account, and it tends to be biased toward large classes, i.e., favoring features of the larger classes. On the other hand, the macro \(F_1\) considers class distributions and locally precision and recall values of individual classes, i.e., if a feature is rare and belongs to the minor class, then that feature might be getting a higher rank [52]. We use \(C_T\) to denote the total number of classes.
where \(precision^{\mu }\) and \(recall^{\mu }\) are estimated as,
where \(p_k\) is the precision and \(r_k\) is the recall for the \(k^{th}\) class.
4.6 Evaluation Procedure
Each data set is randomly split into two sets, namely the training and test sets. The former contains 70% of the documents, while the latter has the remaining 30% documents. The data sets were pre-processed, and then, we applied feature selection algorithms on the training data set and generated a ranked list of terms in the decreasing order of importance. From this ranked list, we construct 4 nested subsets by progressively adding terms of decreasing importance to find an optimal smaller subset of terms. The size of these subsets is 100, 400, 700 and 1500 terms. The quality of each subset is evaluated by training two classifiers (SVM and RF) and measuring the macro \(F_1\) and micro \(F_1\) values on the test set.
To see how good IDFS is as a stand-alone global FS algorithm, we compare it against IG, DFS, BNS, NDM and OR metrics by repeating the above procedure for each of these feature ranking metrics. For each metric, we sum the local class-based scores of the metric to obtain a final global score for a term. In this scenario, IDFS is compared against a metric for \(5_{datasets} \times 4_{subsets} \times 2_{classifiers} = 40\) subsets.
To see which metric performs the best with the IGFSS and VGFSS ensemble frameworks, we also evaluate the working of IDFS, IG, DFS, BNS, NDM and OR metrics as a part of them. In this scenario, IDFS is evaluated and compared against a metric for \(2_{approaches} \times 5_{datasets} \times 4_{subsets} \times 2_{classifiers} = 80\) subsets.
5 Results and Discussion
This section presents the macro and micro \(F_1\) values obtained by the top ranked terms of the six feature ranking (BNS, IDFS, DFS, IG, NDM and OR) metrics in two scenarios: when each metric is used as a stand-alone FS algorithm and when each metric is used as a part of the IGFSS and VGFSS ensemble frameworks. In the tables to follow, for a given subset we mark the maximum \(F_1\) value of a metric(s) bold and underline that bold \(F_1\) of a metric(s) whose value is the highest for a given classifier instance.
5.1 IDFS as a Stand-Alone Global Feature Selection Algorithm
Let us look at the performance of the IDFS metric when it works as a stand-alone FS algorithm. Table 7 shows the macro and micro \(F_1\) values of IDFS and the other five metrics on the five data sets with SVM and RF classifiers.
First, we look at results obtained with the SVM classifier. We can observe that the highest micro and macro \(F_1\) values are 0.770 and 0.798 on the 20NG data set, respectively. These values are attained by the subsets consisting of top 1500 ranked terms of IDFS. On the WebKB data set, the top 700 ranked terms selected by IDFS have resulted in the highest micro \(F_1\) (0.907) and macro \(F_1\) (0.890) values. In the case of the unbalanced Reuters8 data set, the subsets with top 1500 and top 400 ranked terms of IDFS have produced the highest micro \(F_1\) and macro \(F_1\) values, which are 0.980 and 0.941, respectively. Similarly, we can see that on the highly skewed Reuters52 data set, the highest values of micro and macro \(F_1\) values are 0.943 and 0.613, respectively, and that have been achieved by subsets of top 700 ranked terms. Finally, it can be found that a subset with top 1500 ranked terms of IDFS have resulted in the highest micro and macro \(F_1\) values, which are 0.985 and 0.975 on the Classic4 data set, respectively.
In the next half of Table 7, we present the performance shown by the RF classifier on the five data sets after evaluating the terms selected by BNS, IDFS, DFS, IG, NDM and OR metrics. On the 20NG data set, we can see 0.803 and 0.798 are the highest micro and macro \(F_1\) values, respectively, which are achieved by IDFS. The highest classification accuracies on the WebKB data set are 0.901 and 0.889 and are attained by subsets of IDFS. For the Reuters8 data set, RF classifier exhibits the best performance with micro and macro \(F_1\) (0.974 and 0.919) with IDFS subsets. Similarly, subsets of IDFS have obtained the highest micro and macro \(F_1\) values 0.890 and 0.532, respectively, on Reuters52. Finally, the performance (0.975 and 0.969) of IDFS is shown to be the best on Classic4.
From the above results, we can observe that in balanced data sets with few categories the OR and DFS metrics have a comparable performance, while BNS performs better than NDM. Overall, we can conclude that our newly proposed IDFS as a stand-alone FS algorithm has a better capability of selecting the useful terms in comparison with BNS, DFS, IG, NDM and OR metrics on all the data sets with different characteristics.
5.2 IDFS as a Part of the IGFSS and VGFSS Frameworks
Next, we look at how effective IDFS is in comparison with BNS, DFS, IG, NDM and OR metrics when each of these metrics becomes a part of the two well-known ensemble approaches, namely IGFSS and VGFSS. The former was found not to work well for imbalanced data sets having a large number of classes of varying sizes.
First, we compare the performance of the six metrics as part of the IGFSS framework. The first half of the Table 8 shows results using SVM classifier, while the second half consists of results with RF classifier. On all the data sets with balanced and imbalanced classes, we can observe that both the classifiers show the highest micro and macro \(F_1\) values when IDFS is used as a part of the IGFSS framework.
Now, the performance of VGFSS with the six metrics on the five data sets is shown in Table 9. When we analyze the results we find that the highest micro and macro \(F_1\) values in almost all the cases are obtained when VGFSS employs IDFS. There is one instance of the RF classifier when VGFSS and NDM have shown the highest macro \(F_1\) value.
Hence, we can conclude that performance of IGFSS and VGFSS ensemble approaches is improved when the newly proposed IDFS metric is used to select the terms.
5.3 Discussion of the Results
The text classification performance greatly depends on the FS metric being used to select the most useful terms. The presence of strong rare and strong negative terms in the final subset increases the performance of a text classifier. On the other hand, if weak rare and sparse terms are used to train a classifier, then performance of the classifier degrades on the test set. Deterioration in the performances of the SVM and RF classifiers was observed when sparse terms were added in the final feature set.
The BNS metric was found to give more importance to rare, weak rare and sparse terms. Also, negative terms are assigned higher score as compared to common terms. For strong rare terms, it is biased toward the largest class. Furthermore, when used with the ensemble approaches BNS assigns a wrong number of features to each class due to which skewed classes get very few or almost zero features. This causes the useful candidate features for that class to be pushed downward in the ranked list and are unable to get selected in the final feature set. The BNS metric performs better for balanced data sets such as the Classic4 and 20NG data sets, but for unbalanced data sets, its performance is poor. BNS is found to be more compatible with the RF classifier.
We find that the IG metric assigns wrong labels when used with VGFSS algorithm. It performs assignment of labels based on negative terms. IG assigns higher score to the strong negative and strong common terms as compared to the rare terms. Also, IG assigns labels based on size of classes and also ranks the terms in this perspective, i.e., negative terms of major classes are ranked higher. So, a negative term from the major class can be ranked higher than a negative term from a small class. Due to selection of features based on negative term criterion, IG’s performance degrades in R52 data set and worsens for the VGFSS and IGFSS frameworks. For all other data sets, its performance is comparable with DFS metric.
The NDM metric was observed to assign correct labels to negative, rare and sparse terms, but for common terms, it is biased toward larger classes. The main weakness of NDM is that it can assign higher ranks to highly irrelevant sparse terms in large and highly skewed data. Even some strong features having strong recall value are pushed down in the ranked list and the performance degrades. Also, it is not suitable with the VGFSS ensemble approach.
The OR metric prioritizes terms belonging to the larger class during VGFSS process. It gives more importance to negative and rarer terms than common features. The IGFSS algorithm does not do well with the OR metric as the former needs negative features to perform well, but few negative features are provided by OR metric.
The DFS metric neglects most of the negative features. The VGFSS + DFS and IGFSS + DFS shows comparable performance for the SVM classifier. Although features selected by DFS metric are good in order, but too many strong features assigned to different classes are pushed down in the ranking during the selection process because of which these features are refrained from getting selected in the final subset and thus DFS’s performance decreases. But as features from each class are selected by the proportion of class sizes during VGFSS, thus making VGFSS + DFS better.
The newly proposed IDFS metric is designed so that it uplifts the score of only those features, which are rare and having class distribution in fewer classes while absent in other classes as in the case of negative features. From our results, we saw that IDFS and DFS are more suitable with VGFSS and IGFSS ensemble methods as compared to the other metrics. But, both SVM and RF classifiers attain the highest accuracy values when the IDFS metric was used with VGFSS technique on the five data sets. Also, IDFS shows the best results for the highly skewed data sets such as Reuters52. The performance of IDFS was found to exceed that of the other FS metrics in skewed data sets with great margins as it does not ignore rare features of smaller classes. For the balanced data sets with high sparseness such as the 20NG data set, the performance of IDFS is comparable to that of the DFS, IG and OR metrics and in few cases less than them.
6 Conclusions and Future Work
To address the class imbalance problem of text classification, more recently ensemble approaches (e.g., improved global feature selection scheme (IGFSS) and variable global feature selection scheme (VGFSS)) were proposed, but their performance is heavily dependent on the underlying FS metrics. In this paper, we found that existing well-known metrics run into problems while selecting useful terms discriminating the skewed classes, and thus may not take full advantage of these ensemble frameworks. For example, we observed that VGFSS with existing FS metrics leaves out many relevant features from the small classes for highly skewed data sets such as Reuters52. To solve such problems, we proposed a new FS metric named novel inherent distinguished feature selector (IDFS), which is designed to select terms highly useful in discriminating the skewed classes especially from smaller classes. We carry out experiments on five data sets with two classifiers and investigate the effectiveness of IDFS against five well-known FS metrics as a stand-alone FS algorithm and as a part of IDFSS and VGFSS frameworks. The higher micro and macro \(F_1\) values of subsets of top ranked terms of IDFS as a stand-alone FS algorithm and with the ensemble approaches show its superiority over existing FS metrics.
As a part of our future work, we are interested in solving another problem faced by the VGFSS scheme. As VGFSS selects a larger number of features from the larger class, a lot of sparse terms from the larger class can become the part of the final subset, thus degrading the performance of a text classifier. Another interesting area that we intend to explore is how to design effective feature selection algorithms for hierarchical learning tasks [56], where instances are classified at various levels of granularity.
Notes
In text classification, category is the same as the class.
In the paper, “features,” “words” and “terms” are used interchangeably.
We use filters, FS metrics or feature ranking metrics interchangeably.
References
Uysal, A.K.; Gunal, S.: A novel probabilistic feature selection method for text classification. Knowl. Based Syst. 36, 226–235 (2012)
Grimes, S.: Unstructured data and the 80 percent rule. http://breakthroughanalysis.com/2008/08/01/unstructured-data-and-the-80-percent-rule/. Accessed 13 Oct 2019 (2019)
Sebastiani, F.: Machine learning in automated text categorization. ACM Comput. Surv. (CSUR) 34(1), 1–47 (2002)
Marin, A.; Holenstein, R.; Sarikaya, R.; Ostendorf, M.: Learning phrase patterns for text classification using a knowledge graph and unlabeled data. In: 15th Annual Conference of the International Speech Communication Association (2014)
Li, X.; Xie, H.; Chen, L.; Wang, J.; Deng, X.: News impact on stock price return via sentiment analysis. Knowl. Based Syst. 69(1), 14–23 (2014)
Rao, Y.; Xie, H.; Li, J.; Jin, F.; Wang, F.L.; Li, Q.: Social emotion classification of short text via topic-level maximum entropy model. Inf. Manag. 53(8), 978–986 (2016)
Uysal, A.K.: An improved global feature selection scheme for text classification. Expert Syst. Appl. 43, 82–92 (2016)
Mironczuk, M.; Protasiewicz, J.: A recent overview of the state-of-the-art elements of text classification. Expert Syst. Appl. 106, 36–54 (2018)
Joachims, T.: Learning To Classify Text using Support Vector Machines. Kluwer Academic Publishers, Berlin (2002)
Aggarwal, C.C.; Zhai, C.: A survey of text classification algorithms. In: Mining Text Data, pp. 163–222. Springer (2012)
Grimmer, J.; Stewart, B.M.: Text as data: the promise and pitfalls of automatic content analysis methods for political texts. Pol. Anal. 21, 267–297 (2013)
Ko, Y.: A study of term weighting schemes using class information for text classification. In: Proceedings of the 35th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 1029–1030. Citeseer (2012)
Forman, G.: An extensive empirical study of feature selection metrics for text classification. J. Mach. Learn. Res. 3(Mar), 1289–1305 (2003)
Lan, M.; Tan, C.L.; Low, H.B.; Sung, S.Y.: A comprehensive comparative study on term weighting schemes for text categorization with support vector machines. In: Special Interest Tracks and Posters of the 14th International conference on World Wide Web, pp. 1032–1033 (2005)
Zhang, W.; Yoshida, T.; Tang, X.: A comparative study of TF*IDF, LSI and multi-words for text classification. Expert Syst. Appl. 38, 2758–2765 (2011)
Manning, C.D.; Raghavan, P.; Schütze, H.: Introduction to Information Retrieval. Cambridge University Press, Cambridge (2008)
Lan, M.; Tan, C.L.; Su, J.; Lu, Y.: Supervised and traditional term weighting methods for automatic text categorization. IEEE Trans. Pattern Anal. Mach. Intell. 31(4), 721–735 (2008)
Chen, K.; Zhang, Z.; Long, J.; Zhang, H.: Turning from tf-idf to tf-igm for term weighting in text classification. Expert Syst. Appl. 66, 245–260 (2016)
Sabbaha, T.; Selamat, A.; Selamat, M.H.; Al-Anzi, F.S.; Viedmae, E.H.; Krejcar, O.; Fujita, H.: Modified frequency-based term weighting schemes for text classification. Appl. Soft Comput. 58, 193–206 (2017)
Mengle, S.S.; Goharian, N.: Ambiguity measure feature-selection algorithm. J. Am. Soc. Inf. Sci. Technol. 60(5), 1037–1050 (2009)
Maruf, S.; Javed, K.; Babri, H.A.: Improving text classification performance with random forests-based feature selection. Arab. J. Sci. Eng. 41, 951–964 (2016)
Saeed, M.; Javed, K.; Babri, H.A.: Machine learning using bernoulli mixture models: clustering, rule extraction and dimensionality reduction. Neurocomputing 119(7), 366–374 (2013)
Aceto, G.; Ciuonzo, D.; Montieri, A.; Pescapé, A.: Multi-classification approaches for classifying mobile app traffic. J. Netw. Comput. Appl. 103, 131–145 (2018)
Harish, B.; Revanasiddappa, M.: A comprehensive survey on various feature selection methods to categorize text documents. Int. J. Comput. Appl. 164(8), 1–7 (2017)
Javed, K.; Maruf, S.; Babri, H.A.: A two-stage markov blanket based feature selection algorithm for text classification. Neurocomputing 157, 91–104 (2015)
Javed, K.; Babri, H.; Saeed, M.: Feature selection based on class-dependent densities for high-dimensional binary data. IEEE Trans. Knowl. Data Eng. 24(3), 465–477 (2012)
Yang, Y.; Pedersen, J.O.: A comparative study on feature selection in text categorization. ICML 97, 412–420 (1997)
Shang, W.; Huang, H.; Zhu, H.; Lin, Y.: A novel feature selection algorithm for text categorization. Expert Syst. Appl. 33, 1–5 (2007)
Ogura, H.; Amano, H.; Kondo, M.: Comparison of metrics for feature selection in imbalanced text classification. Expert Syst. Appl. 38(5), 4978–4989 (2011)
TaşCı, Ş.; Güngör, T.: Comparison of text feature selection policies and using an adaptive framework. Expert Syst. Appl. 40(12), 4871–4886 (2013)
Agnihotri, D.; Verma, K.; Tripathi, P.: Variable global feature selection scheme for automatic classification of text documents. Expert Syst. Appl. 81, 268–281 (2017)
Cortes, C.; Vapnik, V.: Support vector networks. Mach. Learn. 20(3), 273–297 (1995)
Breiman, L.: Random forests. Mach. Learn. 45(1), 5–32 (2001)
Montieri, A.; Ciuonzo, D.; Aceto, G.; Pescapé, A.: Anonymity services tor, i2p, jondonym: classifying in the dark (web). IEEE Trans. Depend. Sec. Comput. 17(3), 662–675 (2020)
Javed, K.; Babri, H.A.; Saeed, M.: Impact of a metric of association between two variables on performance of filters for binary data. Neurocomputing 143, 248–260 (2014a)
Bolon-Canedo, V.; Sanchez-Marono, N.; Alonso-Betanzos, A.: Feature Selection for High-Dimensional Data. Springer, Basel (2015)
Labani, M.; Moradi, P.; Ahmadizar, F.; Jalili, M.: A novel multivariate filter method for feature selection in text classification problems. Eng. Appl. Artif. Intell. 70, 25–37 (2018)
Guyon, I.; Gunn, S.; Nikravesh, M.; Zadeh, L.: Feature Extraction: Foundations and Applications. Springer, Berlin (2006)
Guyon, I.; Elisseeff, A.: An introduction to variable and feature selection. J. Mach. Learn. Res. 3(Mar), 1157–1182 (2003)
Rehman, A.; Javed, K.; Babri, H.A.; Asim, N.: Selection of the most relevant terms based on a max-min ratio metric for text classification. Expert Syst. Appl. 114, 78–96 (2018)
Javed, K.; Saeed, M.; Babri, H.A.: The correctness problem: evaluating the ordering of binary features in rankings. Knowl. Inf. Syst. 39(3), 543–563 (2014b)
Uğuz, H.: A two-stage feature selection method for text categorization by using information gain, principal component analysis and genetic algorithm. Knowl. Based Syst. 24(7), 1024–1032 (2011)
Srividhya, V.; Anitha, R.: Evaluating preprocessing techniques in text categorization. Int. J. Comput. Sci. Appl. 47(11), 49–51 (2010)
Flach, P.: Machine Learning: The Art and Science of Algorithms that Make Sense of Data. Cambridge University Press, Cambridge (2012)
Forman, G.: Bns feature scaling: an improved representation over TF-IDF for SVM text classification. In: Proceedings of the 17th ACM Conference on Information and Knowledge Management, pp. 263–270. ACM (2008)
Liu, H.; Sun, J.; Liu, L.; Zhang, H.: Feature selection with dynamic mutual information. Pattern Recognit. 42(7), 1330–1339 (2009)
Wang, D.; Zhang, H.; Liu, R.; Lv, W.; Wang, D.: t-test feature selection approach based on term frequency for text categorization. Pattern Recognit. Lett. 45, 1–10 (2014)
Lee, C.; Lee, G.G.: Information gain and divergence-based feature selection for machine learning-based text categorization. Inf. Process. Manag. 42(1), 155–165 (2006)
Pinheiro, R.H.; Cavalcanti, G.D.; Correa, R.F.; Ren, T.I.: A global-ranking local feature selection method for text categorization. Expert Syst. Appl. 39(17), 12851–12857 (2012)
Rehman, A.; Javed, K.; Babri, H.A.: Feature selection based on a normalized difference measure for text classification. Inf. Process. Manag. 53(2), 473–489 (2017)
Chen, J.; Huang, H.; Tian, S.; Qu, Y.: Feature selection for text classification with naïve bayes. Expert Syst. Appl. 36(3), 5432–5435 (2009)
Wang, F.; Li, Ch; Wang Js, XuJ; Li, L.: A two-stage feature selection method for text categorization by using category correlation degree and latent semantic indexing. J. Shanghai Jiaotong Univ. (Sci.) 20(1), 44–50 (2015)
Mladenic, D.; Grobelnik, M.: Feature selection for unbalanced class distribution and naive bayes. In: Proceedings of the 16nth International Conference on Machine Learning, pp. 258–267 (1999)
Cachopo, AMdJC; et al.: Improving Methods for Single-Label Text Categorization. Instituto Superior Técnico, Portugal (2007)
Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H.: The WEKA data mining software: an update. ACM SIGKDD Explor. Newsl. 11(1), 10–18 (2009)
Montieri, A.; Ciuonzo, D.; Bovenzi, G.; Persico, V.; Pescapé, A.: A dive into the dark web: Hierarchical traffic classification of anonymity tools. In: IEEE Transactions on Network Science and Engineering, pp. 1–1 (2019)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Ali, M.S., Javed, K. A Novel Inherent Distinguishing Feature Selector for Highly Skewed Text Document Classification. Arab J Sci Eng 45, 10471–10491 (2020). https://doi.org/10.1007/s13369-020-04763-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13369-020-04763-5