
Abstract
The presented study aims to design a computer-aided detection and diagnosis system for breast dynamic contrast enhanced magnetic resonance imaging. In the proposed system, the segmentation task is performed in two stages. The first stage is called breast region segmentation in which adaptive noise filtering, local adaptive thresholding, connected component analysis, integral of horizontal projection, and breast region of interest detection algorithms are applied to the breast images consecutively. The second stage of segmentation is breast lesion detection that consists of 32-class Otsu thresholding and Markov random field techniques. Histogram, gray level co-occurrence matrix and neighboring gray tone difference matrix based feature extraction, Fisher score based feature selection and, tenfold and leave-one-out cross-validation steps are carried out after segmentation to increase the reliability of the designed system while decreasing the computational time. Finally, support vector machines, k- nearest neighbor, and artificial neural network classifiers are performed to separate the breast lesions as benign and malignant. The average accuracy, sensitivity, specificity, and positive predictive values of each classifier are calculated and the best results are compared with the existing similar studies. According to the achieved results, the proposed decision support system for breast lesion segmentation distinguishes the breast lesions with 86%, 100%, 67%, and 85% accuracy, sensitivity, specificity, and positive predictive values, respectively. These results show that the proposed system can be used to support the radiologists during a breast cancer diagnosis.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Breast cancer is a commonly seen cancer that affects over two million women each year and has the highest percentage among the cancer-related deaths [1, 2]. According to the statistical data presented by the American Institute for Cancer Research, in 2018, the top three countries for breast cancer occurrence are Belgium, Luxembourg, and the Netherlands. Breast cancer ratios of these countries are 113.2, 109.3, and 105.9 per 100,000 people, respectively [3]. This ratio for Turkey is 43.0 and continues to increase each year. The ages of women that are subject to breast cancer change in a wide interval. However, 44.5% and 40.4% of women diagnosed as breast cancer are 50–69 and 25–49 years old, respectively [4].
There are three modalities; ultrasound, mammography, and magnetic resonance imaging (MRI) mainly used for breast cancer diagnosis. Among them, MRI attracts attention from the radiologists and also from the researchers in other disciplines, in recent years. MRI is preferable for scanning women who may have asymptomatic breast cancer. Also, the anomalies detected by using mammography can be studied in detail with MRI. The interpretations of the radiologists are crucial for breast cancer diagnosis via MRI. So, Breast Imaging and Reporting Data System (BI-RADS) is developed by the American College of Radiology to provide standardized breast imaging findings terminology in breast imaging treatments. BI-RADS defines the evaluation criteria and future treatments for lesions detected by MRI. However, it is known that inter-observer variability in lesion classification is still high and BI-RADS descriptors are not sufficient to distinguish benign and malignant lesions [6, 7].
Recently, computer-aided diagnosis (CAD) systems are developed to help the detection of cancerous lesions and evaluate the success of the complete diagnosis. These systems analyze the data (i.e. MR images, mammography images, and ultrasound scans) through improved deterministic algorithms. Through CAD systems, inter- and intra-observer variability that causes different diagnosis and treatment approaches for the same lesions can be minimized. The studies about breast cancer diagnosis can roughly be divided into two groups. CAD systems also have this subdivision. In the first group, researchers aim to determine the region of the lesions in the breast. This group can be named as the segmentation group. The goal of the second group, which is called the lesion analysis group, is to distinguish the lesions as benign and malignant. In the proposed study, breast lesions are detected by utilizing segmentation methods and classified as benign and malignant by applying signal processing, data mining, and machine learning techniques. To demonstrate the contribution of the study a detailed literature analysis is made. The related works are summarized as given in Table 1.
Literature review
The aim of supporting radiologists for breast lesion detection and diagnosis can be reached in a pattern recognition framework by choosing straight segmentation, feature extraction, and classification techniques. Thus, the literature is analyzed from this perspective. The related studies are given from present to past.
Segmentation
Segmentation is the primary step of breast lesion detection and diagnosis systems. It can be applied to a medical image after a preprocessing step including motion artifact compensation, noise reduction, and no-interest tissue elimination. In Table 1, segmentation is divided into three categories as manual, semi-automatic, and automatic, if it exists. In a few studies, segmentation is performed manually by an expert. Semi-automatic segmentation techniques need a seed point to start lesion detection. These techniques include an operator-dependent phase (i.e. seed point initialization) in the CAD workflow. In the fully automatic segmentation, there is no interference with the system. The seed point or region initialization is directly carried out by automatically extracted rough segmentation. Segmentation techniques for lesion detection or maybe for lesion classification can be given briefly. The simplest way to identify the lesion region is thresholding. Otsu method is one of the adaptive thresholding-based methods that give good results in medical image segmentation. Some of the studies perform segmentation by determining the ROI that includes the breast area. Chest Wall Line (CWL) and Most Suspect Region (MSR) methods aim to find a breast lesion region based on ROI detection, automatically. Template Matching (TM) is another way of segmenting breast with the help of a specialist who constructs the breast templates before the segmentation starts. Constructing the templates is a time-consuming task, so template matching based segmentation techniques are uncommon. The techniques utilizing the geometric based iterative algorithms are Region Growing (RG), Graph Cuts (GC), Watershed (WS), Gradient Vector Flow (GVF) snake, and Magnetostatic snake model (M-snake). Other techniques can be referred to as supervised and unsupervised methods. Unsupervised techniques are k-means, Vector Quantization (VQ), Fuzzy C-means (FCM), and mean shift. On the other hand, supervised methods, that can be grouped into regression and classification methods, are Logistic Regression Analysis (LRA), Linear Discriminant Analysis (LDA), Artificial, Cellular, Backpropagation, Pulse-Coupled and Multilayer Perceptron Neural Networks (ANN, CNN, BNN, PCNN, MLPNN), Decision Tree (DT), Probabilistic Boosting Tree (PBT), k-NN, Least-Squares Support Vector Machines (LS-SVM) and Markov random field (MRF). Optimization-based segmentation studies also exist in the literature. Ant and swarm bee colony optimization techniques can be given as examples. Furthermore, in recent years deep learning-based approaches attract attention from researches in various disciplines. But deep learning-based methods require a large database that is impossible or difficult to construct for a vast majority of the studies.
Feature extraction
The second main step of the mentioned system is feature extraction whereby breast lesions are represented by their inherent properties. Dynamic features (DYN) represent the temporal kinetics of the time-intensity curve which plots the signal intensity values versus time after contrast agent uptake. Textural features (TXT) can be used to segment an image and classify its segments. These features are spatial properties that measure the relative uniformity in a bounded region. Geometrical features (GEO), sometimes referred to as morphological or shape features are other commonly used features to diagnose the lesion. Pharmacokinetic features (PKF) model the contrast agent uptake of the tissue in an ROI. The physiological parameters of pharmacokinetic models are mainly related to tissue perfusion, vascular permeability, and extracellular volume fraction.
Feature selection
The target of feature selection is to improve the decision performance of the classifier while reducing the computational complexity. Hence, some of the studies given in Table 1 use feature selection methods to reduce the dimension of the feature vector by eliminating the irrelevant features from the feature vector. Among these techniques, LDA and LRA can also be used for classification. Some of the most popular feature selection methods are Correlation-Based Feature Subset Selection (CBFS), Fisher Linear Discriminant (FLD), Average Correlation Coefficient (ACC), Genetic Algorithm (GA), T-Test, Ranking Based (RB) and, Mutual Information (MI) based techniques. Besides, the Probability of Classification Error (PCE) method, considers the feedback mechanism between classifier and feature selection process, can be used for the same purpose. In a few studies, a hybrid feature selection step is applied to the feature vector.
Classification
The final stage of the given framework is to distinguish the detected lesions according to their inherent properties represented by the extracted features. Most of the classification techniques are given in segmentation and feature extraction parts. Except for them, Random Forest (RF), Quadratic Discriminant Analysis (QDA), Naïve Bayes (NB), Principal Component Analysis (PCA), and Three Well-Chosen Time Point (3TP) techniques are also applied for classification. In addition to these techniques, a ROCKIT software package is used by the researchers.
Materials and methods
The dynamic contrast enhanced magnetic resonance imaging (DCE-MRI) database of the system on which all the tests were performed is constructed from “Sakarya University Education and Research Hospital, Radiology Department” with ethical permission. The database includes 10 benign and 40 malignant histopathologically proven breast lesions analyzed from 49 patients. The histopathologically proven malignancy of each lesion is reported in Table 2. The total number of the analyzed lesions is 50. In the left breast of one of 49 patients, there are two lesions. The remaining patients have one lesion in their right or left breast. The patients were female and their ages change between 30–72. MRI scans are performed in patients participating in a protocol for women who underwent breast MRI examination after detecting anomalies by using mammography or ultrasound. DCE-MRI of the breast was performed on prone patients (feed first prone) in the 1.5 T MRI system (GE Healthcare-Signa Voyager). For each patient, MRI examination takes about 20 min. Before contrast agent administration one scan and after injection of gadolinium (0.1 mmol/kg dose and 1.5 mL/s flow rate) five scans are utilized at a temporal resolution 26.1 s. The most proper slices that provide useful information to determine the region of the lesion were chosen by the radiologist. The dynamic T1series’ parameters are TR 7.2 ms, TE per scan 2.0 ms, flip angle (FA) 11, slice thickness 1.4, FOV frequency 35.0, FOV phase 1.0, maximum slices 1618, pixel size 0.9 × 1.2, the number of excitation (NEX) 1.0 and matrix size 192 × 300. These parameter values can vary in a range from patient to patient according to the structural features of the patient.
The reported ACR BI-RADS categories of background parenchymal enhancement (BPE) are minimal, mild, and moderate. More than half of the BPE is evaluated as minimal for our database. However, in the proposed study, the degree of BPE is not considered. As discussed in reference [79], BPE represents breast activity and depends on several factors. So, the effect of BPE degree must be investigated alone. This investigation is out of the scope of the paper.
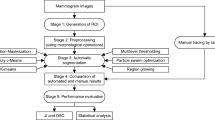
The target of the proposed study is to design a decision support system for detecting and then classifying the breast lesions in DCE-MRI. The designed system is named as Decision Support System for Breast Lesions (DSSBL). The block diagram of the DSSBL is given in Fig. 1. The details of the applied steps are introduced in the following sections.

The main steps of proposed system
Breast region segmentation
In this step, the goal is to take out breasts from the MR image including pectoral muscle, air, and breast region. For this purpose, several operations given in Fig. 2 are applied to the MR images. These operations are carried out in sequence. At the end of the breast region segmentation process, breast region that probably includes breast lesion is obtained. At first, an adaptive noise reduction filtering is performed to eliminate the motion artifact and other noise components. Then the local adaptive thresholding process is applied to the images to dominate the intensity inhomogeneity raised from the bias field and low contrast intensity on the gyrate region between breast and pectoral muscle. Although there exist a few thresholding methods, Niblack’s technique is preferred in this study according to the performed several trials on the database [76]. The denoised and thresholded image is shown in Fig. 3b. The connected component labeling process follows the local adaptive thresholding to eliminate the undesired extra regions, such as arms and thorax area. After connected component labeling, the region including the breast area and the fat tissue over the backbone remains in the binary image (Fig. 3c). As can be seen from the figure, the horizontal projection that is calculated by summing the pixel intensities over each row indicates the location of the virtual cutting line (green line in Fig. 3c). The location of this line corresponds to a row of the binary image and can be calculated as follows.

Breast region segmentation process

Breast region segmentation: a original MR image, b local adaptive thresholding method’s result, c binary image after connected component labeling, d obtained breast region, e left breast region, f right breast region, g, h original left and right breast regions, respectively
where cl is the location of cutting line, f is the first nonzero element of horizontal projection vector and indicates the end of breast body point, g is the last nonzero element of horizontal projection vector representing the nipple points. The breast area and gyrate region are separated by the cutting line, as illustrated in Fig. 3d. Finally, left and right breasts are disconnected by determining the sternum midpoint. The left and right breast masks, the original left and right breast regions are given in Fig. 3e–h, respectively. As discussed before, the study aims to detect lesions and classify them as benign and malignant. So, the left and right breasts are separated from each other to determine if they contain lesion. Then, the breasts that are containing lesions are analyzed. This process also decreases the computational load of the system.
Breast lesion segmentation
After determining the left and right breast areas of each subject, the lesion region for the breast must be obtained, if it exists. For this purpose, at first, we attained the original left and right breast regions by using the locations obtained in the breast region segmentation stage (Fig. 3g, h). Then, two segmentation methods are applied to the breast regions. The first method is the Otsu thresholding method which is an adaptive method that determines a different threshold value for each class. The number of classes is specified by the user. The main idea behind the Otsu method is to maximize the inter-class variance while minimizing the intra-class variance. In our study, the 32-class Otsu method is performed as a pre-segmentation process. Before performing this method, the color MR image is converted to the gray level image. For the sake of simplicity, the main steps of the two-class Otsu method are summarized as follows:
-
i.
In the first step, normalized histogram values of an image, that has L different intensity levels, are calculated with Eq. (2),
$${P}_{i}=\frac{{n}_{i}}{M.N}, i=1, 2,\ldots , L-1$$(2)where \(MxN\) is the dimension of the image and \({n}_{i}\) denotes the number of pixels in the i.th intensity level. In Eq. (2), \(\sum_{i=0}^{L-1}{P}_{i}=1, {P}_{i}\ge 0\) condition must be satisfied.
-
ii.
The image is separated into two classes by using a threshold value \(T\left(k\right)=k, 0<k<L-1\). The pixels in [0, k] intensity interval are assigned to class \({C}_{1}\) and the remaining pixels belong to class \({C}_{2}\).
-
iii
In this step, the global mean value of the image (\({m}_{G}\)) is calculated with the equation given below.
$${m}_{G}={P}_{1}\cdot {m}_{1}+{P}_{2}\cdot {m}_{2}$$(3)As can be seen from Eq. (3), we need to obtain mean intensity values of the pixels (\({m}_{1}, {m}_{2}\)) assigned to \({C}_{1}\) and \({C}_{2}\) classes. For this purpose, Eqs. (4) and (5) are used.
$${m}_{1}\left(k\right)=\frac{1}{{P}_{1}(k)}\sum_{i=1}^{k}i.{P}_{i}$$(4)$${m}_{2}\left(k\right)=\frac{1}{{P}_{2}(k)}\sum_{i=1}^{k}i.{P}_{i}$$(5)where, \({P}_{1}=\sum_{i=0}^{k}{P}_{i}\) and \({P}_{2}=\sum_{i=k+1}^{L-1}{P}_{i}\).
-
iv.
Now, a criterion must be used to evaluate the accuracy of the specified threshold values. This criterion is referred to as a separation criterion and can be calculated as follows:
$${\eta }_{k}=\frac{{Q}_{B}^{2}}{{Q}_{G}^{2}}$$(6)In Eq. (6), inter-class variance \({Q}_{B}^{2}\) and global variance \({Q}_{G}^{2}\) are expressed with Eqs. (7) and (8)
$${Q}_{B}^{2}=\frac{{({m}_{G}{P}_{1}\left(k\right)-m\left(k\right))}^{2}}{{P}_{1}\left(k\right).{P}_{2}(k)}, \quad m\left(k\right)=\sum_{i=0}^{k}i.{P}_{i}$$(7)$${Q}_{G}^{2}=\sum_{i=0}^{L-1}{(i-{m}_{G})}^{2}\cdot {P}_{i}$$(8)Note that, to reach the maximum separation criterion value, \({Q}_{B}^{2}\) must be increased since \({Q}_{G}^{2}\) is constant.
-
v.
The goal of the final step is to find optimum \({k}^{*}\) value which maximizes the inter-class variance. This problem can be expressed as follows:
$${Q}_{B}^{2}\left({k}^{*}\right)=max{Q}_{B}^{2}\left(k\right), \quad 0<k<L-1$$(9)Once the \({k}^{*}\) value is specified, thresholding process is applied to the input image \(f(x,y)\) as given below:
$$g\left(x,y\right)=\left\{\begin{array}{ll}1, & \quad if f\left(x,y\right)>{k}^{*}\\ 0, & \quad if f(x,y)\le {k}^{*}\end{array}\right.$$(10)
In Eq. (10), \(g(x,y)\) is the final image. In the description given above, the Otsu method is used to separate the input image into two classes. In the proposed study, the 32-class Otsu thresholding method is applied. For this extension, some modifications must be done in the equations. For example, in 32-class thresholding, the threshold values are, \(1\le {k}_{1}<{k}_{2}<\ldots <{k}_{31}<L\). By applying these values to the image, classes as \({C}_{1}\) for [1, 2, …, \({k}_{1}\)], \({C}_{2}\) for \({[k}_{1}+1,\ldots ,{k}_{2}]\), …, \({C}_{32}\) for \({[k}_{31}+1,\ldots , L]\) are obtained. In this case, the criterion measure \({{Q}_{B}}^{2}\) is the function of \({k}_{1}, {k}_{2},\ldots , {k}_{31}\) variables, and an optimal set of threshold values \({{k}_{1}}^{*}, {{k}_{2}}^{*},\ldots , {{k}_{31}}^{*}\) is specified by maximizing \({{Q}_{B}}^{2}\). Finally, the image can be partitioned into desired intensity levels by using optimal threshold values. The details of the Otsu method can be found in [77].
It is shown that the MRF method improves the performance of the pre-applied segmentation algorithm. So, the MRF method is used in the post-segmentation process to improve the segmentation attainment of the Otsu thresholding method. MRF is a stochastic process to model the joint probability distribution of an image in terms of local characteristics of it The main idea behind the MRF technique is based on Bayes rule. According to this rule,
where F and Y are the random variables represent the feature set and segmentation results of the image, respectively. Hence, f and y are the values of these random variables. As known from the probability theory, p(Y = y|F = f) denotes the conditional probability of event Y = y given F = f and a priori probability p(F = f|Y = y) is the conditional probability of F = f conditioned on Y = y. To simplify the MRF approach, two assumptions are made. The first one is the conditional independence of F = f instances each other concerning Y = y. Because of using one feature (class of the pixel obtained by pre-segmentation), this assumption doesn’t influence our algorithm. The second assumption is to assume distribution feature data is a Gaussian function with mean \({\mu }_{\lambda }\) and standard deviation \({\sigma }_{\lambda }\) where λ is the class of feature.
As F = f is known, p(F = f) can be thought of as a constant value. So, when maximizing P (Y = y | F = f), \(p\left(F=f|Y=y\right)P\left(Y=y\right)\) must be considered. The steps of the MRF-based segmentation algorithm applied in the proposed study are summarized as follows:
-
i.
n-level segmentation is performed by using the Otsu method (n ≥ 32).
-
ii.
A training region \({S}_{\lambda }\) is created for each class (λ = 1,2, 3, …n). S is the two-dimensional image lattice (S = {(i, j) | 1 ≤ i ≤ H, 1 ≤ j ≤ W, i, j, H, W ∈ I} where I is an image with dimensional H×W).
-
iii.
A mean value (\({\mu }_{\lambda }\)) is calculated for each class.
$${\mu }_{\lambda }=\frac{1}{{S}_{\lambda }}.\sum_{s \in {S}_{\lambda } }{f}_{s}$$(12) -
iv.
A variance value (\({\sigma }_{\lambda }\)) is calculated for each class.
$${\sigma }_{\lambda }=\frac{1}{{S}_{\lambda }}.\sum_{s \in {S}_{\lambda } }{(f}_{s}-{\mu }_{\lambda })$$(13) -
v.
First, energy regarding image regions (ER) is calculated.
$${E}_{R}=\sum_{s,r}\beta .\delta \left({w}_{s}, {w}_{r}\right), \left\{\begin{array}{c}{\delta \left({w}_{s}, {w}_{r}\right)=-1, if w}_{s}={w}_{r} \\ \delta \left({w}_{s}, {w}_{r}\right)=+1, if {w}_{s}\ne {w}_{r}\end{array}\right.$$(14) -
vi.
Second, the energy form of feature modeling component (EF) given in Eq. (11) is calculated.
$${E}_{F}=\sum_{s}\left[log\left(\sqrt{2\pi {\sigma }_{ws}}\right)+ \frac{{\left({f}_{s}-{\mu }_{ws}\right)}^{2}}{2{{\sigma }^{2}}_{ws}}\right]$$(15) -
vii.
After the ER and EF values are obtained, the objective function is minimized.
$$\begin{array}{c}argmin\\ w \in \Omega \end{array} E={E}_{R}+{\alpha E}_{F}$$(16)where \(\alpha\) is a constant parameter that must be adjusted according to the image database [68].
Repeat the above five steps until all combinations considered to find the segmentation result which provides the minimum energy. The implementation algorithm of MRF can be found in reference [68].
At the end of the breast lesion segmentation step, the target of determining the boundaries of the lesion is reached, as perfect as possible. The accuracy of determining the lesion regions affects the success of other processes, directly. Note that, all techniques that are applied in the segmentation stage of the proposed system don’t need any intervention during their processes.
Feature extraction
Feature extraction is a method that represents the visual content of an object determined in an image. The main idea behind feature extraction is to express the determined object with fewer parameters to reduce the storage and computational load. This process can be performed in the time domain and /or frequency domain. In this study, time-domain features based on the histogram, GLCM, and NGTDM are extracted for each breast lesion. In general, the histogram provides more information from the first-order statistics of the original image than the simple averaging of the image intensity values. In the proposed study, six histogram features are derived from the gray level breast MR images. These histogram features are mean, variance, standard deviation, skewness, kurtosis, and absolute deviation. GLCM and NGTDM features are explained in the following subsections.
Gray level co-occurrence matrix (GLCM)
The texture is an important distinctive used to identify and recognize the regions or objects in an image. GLCM is a popular statistical method used to extract textural features of an image. Haralick defines fourteen textural features given in Table 3, which are calculated from the gray level co-occurrence probability matrix [69]. Before calculating the textural features, 32-level segmentation is applied to the breast lesion images. So, in the following equations, the number of distinct gray levels denoted with Ng is 32. The offsets for GLCM define relationships of varying direction and distance. In our study, four directions (\({0}^{\circ }, {45}^{\circ }, {90}^{\circ }, {135}^{\circ })\) and one distance (d = 1) is used. So, the input image represented by four GLCMs. To calculate the statistics from these GLCMs, the mean and range values are calculated [69]. P(i,j) is the (i,j).th entry of the matrix. p (i, j) is the normalized value of P (i,j) and calculated with Eq. (17).
In Table 3, the px and py are the marginal-probability matrices obtained by summing the rows and columns of p(i,j), respectively. These matrices are calculated with Eq. (18) given below.
\({\mu }_{x}\), \({\mu }_{Y}\) and \({\sigma }_{x}\), \({\sigma }_{Y}\) are the mean values and standard deviations of px and py probability distributions. The px+y(k) and px−y(k) values can be expressed as follows.
Features (12) and (13) measure the information of correlation. HXY1, HXY2, and HXY values are given in Eqs. (21), (22), and (23).
In f12, HX and HY are the entropies of X and Y random variables having px and py distributions, respectively. In the equations comprising log (.) operator, to not encounter the log (0), it is recommended to use \(\log\left(p\left(i,j\right)+\varepsilon \right)\) instead of \(\log\left(p\left(i,j\right)\right)\) where ε is an arbitrarily small positive constant. Finally, Q used in the feature denoted with f14 can be expressed as follows.
Correlation measures calculated with features 12, 13 and 14 consider some desirable properties which are not exposed in the third feature. At the end of the GLCM process, 14 features are attained for each direction. Instead of using all features (\(14\times 4=56\)), the mean and range values of each of these 14 features are used as an input of the classifier. So, the number of GLCM features is 28.
Neighboring gray tone difference matrix features (NGTDM)
Neighboring gray tone difference matrix features (NGTDM) is a method used to represent the spatial changes on pixel intensity. As an example, the labeling values of the 5-level segmented image with size 4 × 4 and its NGTDM parameters are shown in Fig. 4. In this figure, ni is the number of label i, and pi is the ratio of ni to the size of the image the matrix. The calculation of si is given with Eq. (25).
where \({\stackrel{-}{A}}_{i}\) is the ratio of the neighbor sum to the number of the neighbor of i. th label. An example of calculating si is explained below.

NGTDM calculations: a 5-level segmented image matrix, b NGTDM parameters
Once the NGTDM parameters are obtained, the five features extracted easily. These features introduced below are named as coarseness, contrast, busyness, complexity, and texture strength.
-
i.
Coarseness (COA): It is the most fundamental feature of image texture and measures the average difference between the center pixel and its neighborhood. The higher coarseness is the lower spatial change and a locally more uniform texture. The formula for the coarseness is as follows
$$COA=\frac{1}{\sum_{i=1}^{{N}_{g}}{p}_{i}{s}_{i}+\varepsilon }$$(26)where \({N}_{g}\) is the number of labels in the segmented image. If the image is completely homogenous \(\sum_{i=1}^{{N}_{g}}{p}_{i}{s}_{i}\) will be zero. To overcome the infinity problem of coarseness value, a small number of ε is added to the denominator of COA.
-
ii.
Contrast (CNT): This feature is a spatial intensity change measure and also dependent on the overall gray level dynamic range. If the regions with different intensity levels are visible, the contrast of the image is high. The mathematical equation of contrast is given in Eq. (27)
$$CNT=\left(\frac{1}{{N}_{g,p}({N}_{g,p}-1)}\sum_{i=1}^{{N}_{g}}\sum_{i=1}^{{N}_{g}}{p}_{i}{p}_{j}{(i-j)}^{2}\right)\left(\frac{1}{{N}_{v,p}}\sum_{i=1}^{{N}_{g}}{s}_{i}\right), {p}_{i }\,and\,{p}_{j}\ne 0.$$(27)where, \({N}_{g,p}\) is the number of gray levels for \({p}_{i}\ne 0\) and \({N}_{v,p}\) is the total number of pixels in the region.
-
iii.
Busyness (BSY): In a busy texture image, there exist rapid changes of intensity from one pixel to its neighbor. In this case, the spatial frequency of intensity variations is very high. This computational measure can be expressed as
$$BSY= \frac{\left(\sum_{i=1}^{{N}_{g}}{p}_{i}{s}_{i}\right)}{\left(\sum_{i=1}^{{N}_{g}}\sum_{i=1}^{Ng}\left|i.{p}_{i}-j.{p}_{j}\right|\right)}, {p}_{i }\,and\,{p}_{j}\ne 0.$$(28) -
iv.
Complexity (CMP): This measure represents the information content of an image. If it is high, it is said that the image contains many patches or primitives in its texture. Complexity is expressed as follows
$$CMP=\frac{1}{{N}_{v,p}}\sum_{i=1}^{{N}_{p}}\sum_{i=1}^{{N}_{p}}\left|i-j\right|\frac{{p}_{i}{s}_{i}+{p}_{j}{s}_{j}}{{p}_{i}+{p}_{j}}, {p}_{i }\,and\,{p}_{j}\ne 0.$$(29) -
v.
Strength (STR): Texture strength can be thought in a correlation with coarseness and contrast. It takes small values for coarse textures and high values for busy textures. The strength measure can be calculated as given below
$$STR=\left(\sum_{i=1}^{{N}_{g}}\sum_{i=1}^{{N}_{g}}({p}_{i}+{p}_{j}){(i-j)}^{2}\right)/\sum_{i=1}^{{N}_{g}}{s}_{i}, {p}_{i }\,and\, {p}_{j}\ne 0.$$(30)
At the end of the feature extraction step, 39 features are derived from each breast lesion image. Time-domain features based on the histogram (mean, variance, standard deviation, skewness, kurtosis, and absolute deviation), GLCM (28 features), and NGTDM (5 features) are extracted for each lesion.
Feature selection
In medical imaging systems, noise affects the quality of images and so the performance of the decision-support system. To remove the noise, filtering techniques are applied to the MR images in the breast segmentation phase of the proposed study. Besides, feature extraction and feature selection are the dimensionality reduction techniques that are popular to remove noisy and redundant features. In this study, histogram, GLCM, and NGTDM-based feature extraction approach is offered to construct a feature space with lower dimensionality. On the other hand, feature selection approaches aim to select a small feature subset that eliminates the irrelevant features and maximizes relevance to the target such as class labels in classification. At the feature selection step of the presented system, the Fisher Score (FS) method is utilized to determine the most effective features. The feature extraction and selection steps provide learning performance improvement, computational complexity reduction, better generalizable models, and storage decrease.
FS is one of the most representative algorithms of supervised feature selection. FS is referred to as a filter model that evaluates the features without utilizing any classification algorithm. In the first step of the method, features are ranked based on a certain criterion and in the second step, the features with the highest ranks are selected to induce classification models. According to the FS, if the score of feature is higher than the determined threshold value changing between 0 and 1, this feature is more selective and so it survives. The features having a score lower than the threshold value are removed from the feature vector. FS can be used to measure the discrimination of two sets of real numbers (i.e. positive and negative data sets) and expressed with the following equation
where \({m}_{i}\), \({m}_{i}^{(p)}\), and \({m}_{i}^{(n)}\) are the mean of the ith feature of the whole, positive and negative data sets, respectively. The np and nn are the numbers of positive and negative instances in the given training vector. \({f}_{k,i}^{p}\) and \({f}_{k,i}^{n}\) are the values of i.th feature of the k.th positive and negative instances, respectively [70, 72].
In Fig. 5, F-score values of the extracted features, that are sorted smallest to largest, are demonstrated. After calculating the FS of each feature, three different threshold values are specified experimentally. The number of the surviving features changes depending on the specified threshold value. By evaluating the performance of the classifiers the most appropriate threshold value is determined for the proposed system.

F-Score values of the extracted features
Cross-validation
In many applications, the amount of training and testing data is not enough to build stable and good models. We need to use as much of the available data as possible for training in order to build reliable models. But, if the size of the validation set is small, a relatively noisy estimate of predictive performance will be obtained. Cross-validation is one of the solutions to this dilemma and it is illustrated in Fig. 6. This method allows a proportion \((S-1)/S\) of the available data to be used for training while making use of all the data to assess performance [71].

S-fold cross-validation scheme
According to the figure, available data is partitioned into S groups of equal size. Then, S-1 of the groups is applied to the classifier as the training set and the remaining group is used to evaluate the performance of the classifier. This process is repeated for all S possible choices. The final performance is calculated by averaging the scores of S runs. If the size of data particularly small, the S = N case, where N is the number of data, will be more appropriate. This case is known as the Leave-One-Out (LOO) technique. The major drawback of the cross-validation techniques is the increase in the computational complexity of the system. In the proposed study, ten-fold and LOO cross-validation techniques are utilized to improve the performance of the classifiers.
Classification
The proposed study aims to distinguish benign and malignant breast lesions with maximum accuracy. This is a pattern classification process and depicted in Fig. 7. Many techniques are applied to the breast MR images as discussed in the previous sections to perform the given task. In this section, k-nearest neighbor (k-NN), support vector machines (SVM), and artificial neural network (ANN) techniques are utilized to classify lesions.

Pattern classification model
The Nearest Neighbor technique is a simple technique for classification which involved assigning to each test vector the same label as the closest example from the training set. k-NN can be referred to as a two-stage example-based classification technique of which the first stage is determining the neighbors and the second stage is to assign a class for new data points by using the classes of neighbors. During the experiments, the k value is changed between 1 and 9 to determine the most appropriate k value for the given task. The best accuracy values are obtained when k = 7 and Euclidean metric is used to calculate the distances between the required data points [71].
SVM are another category of feedforward networks that have some highly elegant properties about binary learning. The main idea behind the SVM technique can be explained as follows: when a training sample is given, the machine uses an optimization technique to construct a hyperplane as the decision surface. The distance between positive and negative samples is maximized. In most cases, patterns can be separated linearly. However, in some difficult cases, nonlinearly separable patterns can be encountered. The details of SVM can be found in reference [73, 74]. In the proposed study, after performing several computer simulations, Gaussian kernel SVM is preferred to attain the best performance for the given classification problem.
ANN is a machine imitating the human brain that is a highly complex information-processing system. Neural Networks (NN) employ a massive interconnection of simple computing cells known as “neurons” or “processing units”. NN performs two main tasks similar to the brain: (1) through a learning process, knowledge is attained from the network’s environment, (2) to store the attained knowledge, synaptic weights which connect to the neurons are utilized. During the learning process, synaptic weights of the network are updated adaptively to perform the given task. The details about NN architecture can be found in references [72, 73]. In this study, a Multilayer Feed-Forward Backpropagation Network (MLFBNN) is used to classify breast lesions. The number of the hidden layers is chosen as 5 according to the experimental results. The transfer function of each layer is tangent sigmoid. The backpropagation network training function is “trainlm” that updates the weight and bias values according to Levenberg–Marquardt optimization and learning function is gradient descent with momentum weight and bias function. The performance of the NN is measured according to the mean square error approach.
Results
The results of the performed steps, shown in Fig. 1, are given in this section. As discussed before, the performance of each block directly affects the performance of the whole system. So, at first, the output of breast lesion segmentation and lesion detection steps is taken into account. For this purpose, Figs. 8, 9, and 10 are illustrated.

The result of two-stage segmentation process: a an original breast MR image, b segmented image

Visualization of breast lesion detection output: a, c color overlays of a benign and a malignant lesion, respectively, b, d original MR images (lesions are indicated with arrows)

Visualization of breast lesion detection output for a different case: a color overlay of a malignant lesion with increased breast skin thickness, b original breast MR image (white and red arrows show malignant lesion and abnormal breast skin, respectively)
In Fig. 8, the two-stage segmentation process is shown for an MR image including both benign and malignant breast lesions. Figure 8a shows the output of breast region segmentation and Fig. 8b gives the result of breast lesion segmentation in which Otsu and MRF methods are applied to the breast region. As can be seen from the figure, the proposed segmentation process makes the breast lesions more explicit. Figures 9 and 10 are demonstrated to compare the manually selected lesion region with an automatically determined lesion region. For this comparison, in Fig. 9, automatically determined lesion regions are indicated by color overlay and manually selected lesion regions are marked with arrows by an expert radiologist. Figure 9a, c shows the color visualization of breast lesion detector output for a benign and malignant lesion, respectively. Figure 9b, d illustrates the lesion regions selected by an expert radiologist. According to the comparison performed by the radiologist, breast segmentation and lesion detection blocks perform the given task successfully. In the figures, the regions having reddishness are more suspicious about malignancy. The more “reddish” the color of a pixel is; the higher chance it is in a cancerous region. So, breast segmentation and lesion detection provide some information about the malignancy of the breast lesions. Besides, in Fig. 10, a different case is considered. As far as we know this case is not investigated in the earlier studies. Figure 10a visualize the color overlay of a malignant lesion with increased skin thickness. As can be seen from the overlay, there exists a reddish region on the breast skin. It means that the breast mass lesion carcinoma affects the breast skin. This case is also detected by the proposed segmentation process. However, the breast skin is not included in the ROI. Including affected skin regions variates the features of lesions and may cause false classification results. Thus, we take into account only the lesions that are inside the breast region.
The 2D-ROI selection is performed for feature extraction. After obtaining the lesion area, the feature extraction step is applied to represent breast lesions with their specific properties. Histogram, GLCM, and NGTDM features of breast lesions are calculated to constitute the feature vector. The obtained feature vector with size 39 × 1 is the input of the feature selection block. The feature selection is carried out by the FS method. However, classification results are also given for case 1 to show the effectiveness of the feature selection process on the system’s decision performance. FS gives scores changing between 0 and 1 to each feature. FS value for the most relevant feature is 1. In this study, two FS threshold value is selected experimentally to eliminate the irrelevant features. The first threshold value is the mean of all features’ scores and the second one is 0.1. The number of surviving features are 15 and 25 for FS (mean) and FS (0,1) cases, respectively. Then cross-validation algorithms are utilized to augment the success of the proposed system. Tenfold and LOO cross-validation scenarios, which are the most preferred scenarios for small databases, are taken into account. The contributions of these scenarios are also investigated during the experiments. To examine the effectiveness of feature vector on distinguishing benign lesions from malignant lesions, SVM, KNN, and ANN classifiers are utilized. The performance of the applied classifiers is given in Table 4 for six different scenarios. The performance metrics used in the tables are accuracy, sensitivity, specificity, and positive predictive value.
Accuracy (ACC) is the ratio of the number of true predictions (TP + TN) to the number of all predictions (TP + TN + FP + FN). Sensitivity (SEN) can be defined as the proportion of correctly identified positive instances (TP\TP + FN). If the sensitivity value is close to one, it means the number of FN predictions are close to zero. Specificity (SPE) is the proportion of correctly identified negative instances (TN\TN + FP). When the value of FP is close to zero, the specificity of the classifier approaches to its best value 1. Finally, positive predictive value (PPV) is the ratio of the number of TP to the sum of the number of TP and FP. It is a measure telling what the proportion of patients that are diagnosed as having a malignant lesion, actually had a malignant lesion. In the above discussions, TP, TN, FP, and FN are true positive, true negative, false positive, and false negative, respectively. Except for the first case, ACC, SEN, and PPV values given in Table 4 are calculated by averaging the testing results of each fold.
As can be seen from the table, SVM provides the highest ACC, SEN, and PPV values under cases 2 and 6. Among the classifiers, SVM performs the given task with the better ACC, SEN, and PPV values almost for all cases. According to the results, the proposed DSSBL system distinguishes the breast lesions with 85.89%, 100%, 66.67%, 85.00% accuracy, sensitivity, specificity and positive predictive values, respectively. These results ensure that the DSSBL system can be used to support the radiologists during the breast cancer diagnosis.
In the presented study the database includes 10 benign and 40 malignant histopathologically proven breast lesions analyzed from 49 patients. After the segmentation process 39 features are extracted for each lesion. To overcome the overfitting problem, some precautions that are offered in the literature are taken. Cross-validation is a powerful preventative measure against overfitting. So, at first, ten-fold and leave-one-out cross-validation techniques are applied. Then Fisher score based feature extraction step is used. Finally, accuracy percentages of the training and test dataset are controlled to verify the overfitting problem has not occurred.
Finally, Table 5 compares the achievements of DSSBL with the existing studies. In the table, applied methods are also given. ACC and SEN values of the proposed system are the highest values among the studies given in Table 5. SPE value of the system is not the highest one but at an acceptable level.
Discussion
In this section, the performance of the proposed DSSBL is discussed. The main contributions of the system are evaluated in comparison with the published studies. The success of each block affects the performance of the other one. So, at first, the results of breast segmentation and lesion detection steps are considered. The target of these blocks is to determine the boundaries of breast lesions as correct as possible. To ensure whether this target is achieved or not, the original breast images are compared with the segmented images. The results of the performed breast region and breast lesion segmentation processes are shown to an expert radiologist. The radiologist analyzes the determined regions by comparing manual segmentation results with automatic segmentation results whether to understand the lesion region is correctly detected or not. Thus, the success of the proposed two-stage segmentation process is verified. According to the comparison performed by the radiologist, breast segmentation and lesion detection blocks perform the given task successfully. In the figures, the regions having reddishness are more suspicious about malignancy. So, breast segmentation and lesion detection provide some information about the malignancy of the breast lesions. The color visualization of breast lesions can be very useful for MRI-guided biopsy. This procedure uses computer technology to guide a needle to an abnormality seen on MRI. A radiologist locates and identifies the specific area of the breast tissue to be biopsied. So, color visualization will provide valuable information to the radiologist to identify the area on which biopsy is acquired. Besides, a different case in which the thickness of the breast skin increases because of breast mass lesion carcinoma is considered. As far as we know, this case is not investigated in earlier studies. In the color overlay of this breast, a reddish region on the breast skin is observed. This region is not inside the lesion region but must be considered in terms of interpreting lesion characterization. The proposed segmentation process has the ability to detect this case.
After determining the breast lesion area, feature extraction is applied for each breast lesion. In the presented study, histogram, GLCM, and NGTDM features of the lesions are calculated to construct the feature vector. Then, the feature selection step is carried out by the FS method. Finally, classification results are achieved for six different scenarios. Tenfold and LOO cross-validation scenarios, which are the common scenarios used for small databases, are utilized to see whether they provide a performance augmentation for classifiers or not. The proposed study provides an exhaustive breast lesion detection and classification system in which lesion segmentation, feature extraction, feature selection, cross-validation, and classification are investigated for DCE-MRI examinations. In this study, the lesions are considered as benign or malignant. The subgroups given in Table 2 are not classified separately. So, there are two groups in the decision step. Group 1 consists of malignant lesions and Group 2 includes benign lesions. The three most popular classifiers k-NN, SVM, and ANN are utilized to characterize the breast lesions as malignant or benign according to their inherent properties represented by the derived features. The achieved ACC, SEN, SPE, and PRE values show that the DSSBL successfully performs the given task. This success has resulted from (i) determining the boundaries of the lesions accurately, (ii) representing the lesions by considering their histogram and favorable texture (GLCM and NGTDM) properties, (iii) eliminating the irrelevant features from the feature vector, and (iv) applying three different classifiers. The achieved ACC value shows that 86% of the breast lesions are correctly classified. The SEN value is 100% which means that the number of FN is zero. In other words, no malignant lesion is diagnosed as benign. This result is very important because if the system decides the type of lesion as benign the specialist can miss this patient. The SPE is defined as \(TN/(TN+FP)\). If this proportion approaches one, the number of lesions that are predicted as malignant but are actually benign goes to zero. The maximum SPE achieved in the proposed study is 67.00%. The SPE value of the classifier is equal to that of the study given in reference [75] and higher than the percentage obtained in reference [32]. The FP (identifying a benign lesion as malignant) error is not extremely important in terms of health but sometimes cause despondency of the patient. In the presented study, feature extraction and classification are applied for the whole lesion region. This process decreases the computational complexity of the system. To increase the SPE, pixel-based feature extraction and classification approach can be performed. However, pixel-based approaches will increase the computational complexity of the system, as expected.
Background parenchymal enhancement (BPE), is the normal breast tissue enhancement that occurs after contrast agent uptake of breast tissues. In the proposed study, the degree of BPE is not considered. However, in reference [79], the goal is to develop a model that detects the lesions independently from the presence of the BPE. According to the discussions given in [79], BPE represents breast activity and depends on several factors. So, the effect of BPE must be investigated in another study of the authors. Also, in [79], the gradient of the image and the entropy are calculated to extract useful information from the dynamic MRI acquisitions. After a preprocessing step, the gradient is used to find directional change and the entropy measures the statistical randomness of the image. The authors perform temporal sequence selection and slice selection automatically. In the proposed study, the most proper slices that include useful information to reach the aim of the study are specified by an expert radiologist who is one of the authors of the paper
In addition to investigating the BPE effect and performing the slice selection process automatically, in our future studies, we aim to consider the following aspects: (i) At first, the number of subjects should be increased by taking MR images from the available medical centers. An increased number of breast images makes the system more reliable and augments the performance of the system. (ii) In addition to the extracted features, new features such as geometrical features and transform domain features can be derived. (iii) Instead of the traditional techniques, deep learning techniques, which consist of successive layers performing feature extraction and classification tasks, can be utilized to improve the performance of the system. According to the literature review, deep learning-based approaches are commonly used in brain DCE-MRI. So, adopting these techniques to the proposed DSSBL can be a new research target. iv. Finally, after classifying the lesions as benign and malignant, breast lesions can be divided into sub-categories as given in Table 2.
Conclusions
The goal of this study is to introduce a CAD system for breast DCE-MRI. In the proposed system segmentation task is performed in two stages. The first stage is named as breast segmentation in which adaptive noise filtering, Niblack’s formula-based local adaptive thresholding, connected component analysis, integral of horizontal projection, and breast RIO detection algorithms are applied to the breast images, consecutively. The second stage of segmentation is breast lesion detection in which 32-class Otsu and MRF techniques are used for the pre-segmentation and post-segmentation processes, respectively. In the segmentation step of the study, different cases are considered. In the first case, a breast MR image including both benign and malignant lesions is taken into account. It is shown that the designed segmentation process is able to determine the region of benign and malignant lesions even if they exist on the same breast. In another case, a malignant lesion with increased skin thickness is considered. The proposed segmentation methods could successfully detect breast lesions and affected breast skin.
After two-stage segmentation, histogram, GLCM, and NGTDM based feature extraction, FS based feature selection, and tenfold and LOO cross-validation steps are utilized to increase the reliability of the designed system. Finally, SVM, k-NN, and ANN methods are performed to classify the breast lesions as benign and malignant. The average accuracy, sensitivity, specificity, and positive prediction values of each classifier are calculated and the achieved the best result is compared with the existing similar studies. According to the results, the proposed DSSBL distinguishes the breast lesions with 86%, 100%, 67%, 85% accuracy, sensitivity, specificity and positive prediction values, respectively. These results ensure that the DSSBL can be used to support the radiologists during the breast cancer diagnosis.
References
Lee CI, Lehman CD, Bassett LW (2018) Breast imaging. Oxford University Press, Oxford
World Health Organization (2019) https://www.who.int/cancer/prevention/diagnosis-screening/breast-cancer/en/. Accessed 5 Mar 2019
American Institute for Cancer Research Breast Cancer Statistics (2014) https://www.wcrf.org/dietandcancer/cancer-trends/breast-cancer-statistics. Accessed 5 Mar 2019
T. C. Ministry of Health Public Health Agency of Turkey, Turkey Cancer Statistics (2019) https://hsgm.saglik.gov.tr/depo/birimler/kanser-db/istatistik/2014-RAPOR._uzun.pdf. Accessed 5 Mar 2019
Losurdo L, Fanizzi A, Basile TM, Bellotti R, Bottigli U, Dentamaro R, et al. (2018) A combined approach of multiscale texture analysis and interest point/corner detectors for microcalcifications diagnosis. In: International conference on bioinformatics and biomedical engineering. Springer, Cham, pp 302–313. https://doi.org/10.1007/978-3-319-78723-7_26
Pandey D, Yin X, Wang H, Su MY, Chen JH, Wu J, Zhang Y (2018) Automatic and fast segmentation of breast region-of-interest (ROI) and density in MRIs. Heliyon 4:1–30. https://doi.org/10.1016/j.heliyon.2018.e01042
Illan IA, Ramirez J, Gorriz JM (2018) Automated detection and segmentation of nonmass-enhancing breast tumors with dynamic contrast-enhanced magnetic resonance imaging. Contrast Media Mol Imaging. https://doi.org/10.1155/2018/5308517
Shokouhi SB, Fooladivanda A, Ahmadinejad N (2017) Computer-aided detection of breast lesions in DCE-MRI using region growing based on fuzzy C-means clustering and vesselness filter. Eurasip J Adv Sig Process. https://doi.org/10.1186/s13634-017-0476-x
Marrone S, Piantadosi G, Fusco R, Petrillo A, Sansone M, Sansone C (2016) Breast segmentation using Fuzzy C-Means and anatomical priors in DCE-MRI. In: Proceedings of the international conference on pattern recognition, pp 1472–1477. https://doi.org/10.1109/ICPR.2016.7899845
Waugh SA, Purdie CA, Jordan LB, Vinnicombe S, Lerski RA (2016) Magnetic resonance imaging texture analysis classification of primary breast cancer. Eur Radiol 26:322–330. https://doi.org/10.1007/s00330-015-3845-6
Tzalavra A, Dalakleidi K, Zacharaki EI, Tsiaparos N (2016) Comparison of multi-resolution analysis patterns for texture classification of breast tumors based on DCE-MRI. In: 7th international workshop on machine learning in medical imaging (MICCAI), pp 296–304. https://doi.org/10.1007/978-3-319-47157-0_36
Honda E, Nakayama R, Koyama H, Yamashita A (2016) Computer-aided diagnosis scheme for distinguishing between benign and malignant masses in breast DCE-MRI. J Digit Imaging 29:388–393. https://doi.org/10.1007/s10278-015-9856-7
Antropova N, Huynh B, Giger M (2016) Predicting breast cancer malignancy on DCE-MRI data using pre-trained convolutional neural networks. Med Phys 43:3349–3350. https://doi.org/10.1118/1.4955674
Mahrooghy M, Ashraf AB (2015) Pharmacokinetic tumor heterogeneity as a prognostic biomarker for classifying breast cancer recurrence risk. IEEE Trans Biomed Eng 62:1585–1594. https://doi.org/10.1109/TBME.2015.2395812
Commons C, License A (2015) Automatic segmentation in breast cancer using watershed algorithm. Int J Biomed Eng Sci 2:1–6
Yang Q, Li L, Zheng B (2015) A new quantitative image analysis method for improving breast cancer diagnosis using DCE-MRI examinations. Med Phys 42:103–109. https://doi.org/10.1118/1.4903280
Navaei-Lavasani S, Fathi-Kazerooni A, Saligheh-Rad H, Gity M (2015) Discrimination of benign and malignant suspicious breast tumors based on semi-quantitative DCE-MRI parameters employing support vector machine. Front Biomed Technol 2:87–92
Chaudhurya B, Zhou M, Goldgof DB, Hall LO (2015) Identifying metastatic breast tumors using textural kinetic features of a contrast based habitat in DCE-MRI. Med Imaging. https://doi.org/10.1117/12.2081386
Hassanien AE, Moftah H, Azar AT, Shoman M (2014) MRI breast cancer diagnosis hybrid approach using adaptive ant-based segmentation and multilayer perceptron neural networks classifier. Appl Soft Comput J 14:62–71. https://doi.org/10.1016/j.asoc.2013.08.011
Song H, Zhang Q, Sun F, Wang J (2014) Breast tissue segmentation on MR images using KFCM with spatial constraints. In: Proceedings of the 2014 IEEE international conference on granular computing GrC, pp 254–258. https://doi.org/10.1109/GRC.2014.6982845
Al-faris AQ, Ngah UK, Ashidi N, Isa M, Shuaib IL (2014) Breast MRI tumour segmentation using modified automatic seeded region growing based on particle swarm optimization image clustering. Soft Comput Ind Appl 223:49–60
Wang TC, Huang YH, Huang CS, Chen JH (2014) Computer-aided diagnosis of breast DCE-MRI using pharmacokinetic model and 3-D morphology analysis. Magn Reson Imaging 32:197–205. https://doi.org/10.1016/j.mri.2013.12.002
Jayender J, Chikarmane S, Jolesz FA, Gombos E (2014) Automatic segmentation of invasive breast carcinomas from dynamic contrast-enhanced MRI using time series analysis. J Magn Reson Imaging 40:467–475. https://doi.org/10.1002/jmri.24394
Cai H, Peng Y, Ou C, Chen M, Li L (2014) Diagnosis of breast masses from dynamic contrast-enhanced and diffusion-weighted MR: a machine learning approach. PLoS ONE 9:873–887. https://doi.org/10.1371/journal.pone.0087387
Chen JH, Chen S, Chan S, Lin M, Su MY, Wang X (2013) Template-based automatic breast segmentation on MRI by excluding the chest region. Med Phys 40:22301. https://doi.org/10.1118/1.4828837
Yang Q, Li L, Zhang J, Shao G, Zhang C, Zheng B (2013) Computer-aided diagnosis of breast DCE-MRI images using bilateral asymmetry of contrast enhancement between two breasts. J Digit Imaging 27:152–160. https://doi.org/10.1007/s10278-013-9617-4
Wu S, Weinstein SP, Conant EF, Schnall MD, Kontos D (2013) Automated chest wall line detection for whole-breast segmentation in sagittal breast MR images. Med Phys 40:042301. https://doi.org/10.1118/1.4793255
Wang Y, Morrell G, Heibrun ME, Payne A, Parker DL (2013) 3D multi-parametric breast MRI segmentation using hierarchical support vector machine with coil sensitivity correction. Acad Radiol 20:137–147. https://doi.org/10.1016/j.acra.2012.08.016
Sathya DJ, Geetha K (2013) Experimental investigation of classification algorithms for predicting lesion type on breast DCE-MR images. Int J Comput Appl 82:1–8. https://doi.org/10.5120/14101-2125
Sathya DJ, Geetha K (2013) Mass classification in breast DCE-MR images using an artificial neural network trained via a bee colony optimization algorithm. Sci Asia 39:294–305. https://doi.org/10.2306/scienceasia1513-1874.2013.39.294
Nagarajan MB, Huber MB, Schlossbauer T, Leinsinger G, Krol A, Wismüller A (2013) Classification of small lesions in dynamic breast MRI: eliminating the need for precise lesion segmentation through spatio-temporal analysis of contrast enhancement. Mach Vis Appl 24:1371–1381. https://doi.org/10.1007/s00138-012-0456-y
McClymont D, Trakic A, Mehnert A, Crozier S, Kennedy D (2013) Fully automatic lesion segmentation in breast MRI using mean-shift and graph-cuts on a region adjacency graph. J Magn Reson Imaging 39:795–804. https://doi.org/10.1002/jmri.24229
Glaßer S, Niemann U, Preim B, Spiliopoulou M (2013) Can we distinguish between benign and malignant breast tumors in DCE-MRI by studying a tumor’s most suspect region only? In: Proceedings of 26th IEEE international symposium of computing medical system, pp 77–82. https://doi.org/10.1109/CBMS.2013.6627768
Wang L, Platel B, Ivanovskaya T, Harz M, Hahn HK (2012) Fully automatic breast segmentation in 3D breast MRI. In: Proceedings of international symposium of biomedical imaging, pp 1024–1027. https://doi.org/10.1109/ISBI.2012.6235732
Nagarajan MB, Huber MB, Schlossbauer T, Leinsinger G, Krol A, Wismüller A (2012) Classification of small lesions in breast MRI: evaluating the role of dynamically extracted texture features through feature selection. J Med Biol Eng 33:59–68. https://doi.org/10.5405/jmbe.1183
Hassanien AE, Kim TH (2012) Breast cancer MRI diagnosis approach using support vector machine and pulse coupled neural networks. J Appl Log 10:277–284. https://doi.org/10.1016/j.jal.2012.07.003
Fusco R, Sansone M, Petrillo A, Sansone C (2012) A multiple classifier system for classification of breast lesions using dynamic and morphological features in DCE-MRI. Lect Notes Comput Sci 7626:684–692
Vignati A, Giannini V, De Luca M, Voral L (2011) Performance of a fully automatic lesion detection system for breast DCE-MRI. J Magn Reson Imaging 34:1341–1351. https://doi.org/10.1002/jmri.22680
Kannan SR, Ramathilagam S, Devi R, Sathya A (2011) Robust kernel FCM in segmentation of breast medical images. Expert Syst Appl 38:4382–4389. https://doi.org/10.1016/j.eswa.2010.09.107
Agner SC, Soman S, Libfeld E, McDonald M (2011) Textural kinetics: a novel dynamic contrast-enhanced (DCE)-MRI feature for breast lesion classification. J Digit Imaging 24:446–463. https://doi.org/10.1007/s10278-010-9298-1
Giannini V, Vignati A, Morra L, Persano D (2010) A fully automatic algorithm for segmentation of the breasts in DCE-MR images. In: Annual international conferences of the IEEE engineering in medicine and biology society in EMBC, pp 3146–3149. https://doi.org/10.1109/IEMBS.2010.5627191
Lee SH, Kim JH, Cho N, Yang Z (2010) Multilevel analysis of spatiotemporal association features for differentiation of tumor enhancement patterns in breast DCE-MRI. Med Phys 37:3940–3956. https://doi.org/10.1118/1.3446799
Dyck DV, Backer SD, Juntu J, Sijbers J, Rajan J (2010) Machine learning study of several classifiers trained with texture analysis features to differentiate benign from malignant soft-tissue tumors in T1-MRI images. J Magn Reson Imaging 31:680–689. https://doi.org/10.1002/jmri.22095
Newstead GM, Lan L, Giger ML, Li H, Jansen SA, Bhooshan N (2010) Cancerous breast lesions on dynamic contrast-enhanced MR images: computerized characterization for image-based prognostic markers. Radiology 254:680–690. https://doi.org/10.1148/radiol.09090838
Manuscript A, Levman J, Leung T, Causer P, Martel AL (2010) Resonance breast lesions by support vector machines. IEEE Trans Med Imaging 27:688–696. https://doi.org/10.1109/TMI.2008.916959
Zheng Y, Englander S (2009) STEP: Spatiotemporal enhancement pattern for MR-based breast tumor diagnosis. Med Phys 36:3192–3204. https://doi.org/10.1118/1.3151811
Newell D, Nie K, Chen JH, Hsu CC (2009) Selection of diagnostic features on breast MRI to differentiate between malignant and benign lesions using computer-aided diagnosis: differences in lesions presenting as mass and non-mass-like enhancement. Eur Radiol 20:771–781. https://doi.org/10.1007/s00330-009-1616-y
McLaren CE, Chen WP, Nie K, Su MY (2009) Prediction of malignant breast lesions from MRI features: a comparison of artificial neural network. Acad Radiol 16:842–851. https://doi.org/10.1016/j.acra.2009.01.029
Lee SH, Kim JH, Park JS, Jung YS, Moon WK (2009) Characterizing time-intensity curves for spectral morphometric analysis of intratumoral enhancement patterns in breast DCE-MRI: comparison between differentiation performance of temporal model parameters based on DFT AND SVD. In: IEEE international symposium on biomedical imaging: from nano to macro, ISBI 2009, pp 65–68. https://doi.org/10.1109/ISBI.2009.5192984
Furman-Haran E, Eyal E, Kirshenbaum KJ, Kelcz F, Degani H, Badikhi D (2009) Principal component analysis of breast DCE-MRI adjusted with a model-based method. J Magn Reson Imaging 30:989–998. https://doi.org/10.1002/jmri.21950
Agner SC, Xu J, Fatakdavala H, Ganesan S (2009) Segmentation and classification of triple negative breast cancers using DCE-MRI. In: Proceedings of 2009 IEEE international symposium on biomedical imaging: from nano to macro, ISBI 2009, pp 1227–1230. https://doi.org/10.1109/ISBI.2009.5193283
Twellmann T, Romeny BT (2008) Computer-aided classification of lesions by means of their kinetic signatures in dynamic contrast-enhanced MR images. Proc SPIE. https://doi.org/10.1117/12.769651
Mayerhoefer ME, Breitenseher M, Amann G, Dominkus M (2008) Are signal intensity and homogeneity useful parameters for distinguishing between benign and malignant soft tissue masses on MR images. Magn Reson Imaging 26:1316–1322. https://doi.org/10.1016/j.mri.2008.02.013
Lee SH, Kim JH, Park JS, Chang CM (2008) Computerized segmentation and classification of breast lesions using perfusion volume fractions in dynamic contrast-enhanced MRI. Biomed Eng Inform New Dev Futur 2:58–62. https://doi.org/10.1109/BMEI.2008.215
Ertaş G, Gülçür HÖ, Osman O, Uçan ON, Tunaci M, Dursun M (2008) Breast MR segmentation and lesion detection with cellular neural networks and 3D template matching. Comput Biol Med 38:116–126. https://doi.org/10.1016/j.compbiomed.2007.08.001
Woods BJ, Clymer BD, Kurc T, Heverhagen JT (2007) Malignant-lesion segmentation using 4D co-occurrence texture analysis applied to dynamic contrast-enhanced magnetic resonance breast image data. J Magn Reson Imaging 25:495–501. https://doi.org/10.1002/jmri.20837
Meinel LA, Stolpen AH, Berbaum KS, Fajardo LL, Reinhardt JM (2007) Breast MRI lesion classification: improved performance of human readers with a backpropagation neural network computer-aided diagnosis (CAD) system. J Magn Reson Imaging 25:89–95. https://doi.org/10.1002/jmri.20794
Khazen M, Leach MO, Hawkes DJ, Tanner C, Kessar P (2006) Does registration improve the performance of a computer aided diagnosis system for dynamic contrast-enhanced MR mammography? In: 3rd IEEE international symposium biomedical imaging nano to macro, pp 466–469. https://doi.org/10.1109/ISBI.2006.1624954
Leinsinger G, Schlossbauer T, Scherr M, Lange O, Reiser M, Wismüller A (2006) Cluster analysis of signal-intensity time course in dynamic breast MRI: does unsupervised vector quantization help to evaluate small mammographic lesions? Eur Radiol 16:1138–1146. https://doi.org/10.1007/s00330-005-0053-9
Chen W, Giger ML, Bick U, Newstead GM (2006) Automatic identification and classification of characteristic kinetic curves of breast lesions on DCE-MRI. Med Phys 33:2878–2887. https://doi.org/10.1118/1.2210568
Xiaohua C, Brady M, Lo JJ (2005) Simultaneous segmentation and registration of contrast-enhanced breast MRI. Inf Process Med Imaging 3565:31–59
Arbach L, Stolpen A, Reinhardt JM (2004) Classification of breast MRI lesions using a backpropagation neural network (BNN). In: IEEE international symposium on biomedical imaging nano to macro (IEEE cat no. 04EX821), pp 253–256. https://doi.org/10.1109/ISBI.2004.1398522
Vomweg TW, Buscema M, Kauczor HU, Teifke A (2003) Improved artificial neural networks in prediction of malignancy of lesions in contrast-enhanced MR-mammography. Med Phys 30:2350–2359. https://doi.org/10.1118/1.1600871
Tzacheva AA, Najarian K, Brockway JP (2003) Breast cancer detection in gadolinium-enhanced MR images by static region descriptors and neural networks. J Magn Reson Imaging 17:337–342. https://doi.org/10.1002/jmri.10259
Lucht R, Delorme S, Brix G (2002) Neural network-based segmentation of dynamic MR mammographic images. Magn Res Imaging 20:147–154. https://doi.org/10.1016/S0730-725X(02)00464-2
Abdolmaleki P, Buadu LD, Naderimansh H (2001) Feature extraction and classification of breast cancer on dynamic magnetic resonance imaging using artificial neural network. Cancer Lett 171:183–191. https://doi.org/10.1016/s0304-3835(01)00508-0
Vergnaghi D, Monti A, Setti E, Musumeci R (2001) A use of a neural network to evaluate contrast enhancement curves in breast magnetic resonance images. J Digit Imaging 14:58–59. https://doi.org/10.1007/bf03190297
Deng H, Clausi DA (2004) Unsupervised image segmentation using a simple MRF model with a new implementation scheme. Pattern Recogn 37:2323–2335. https://doi.org/10.1016/j.patcog.2004.04.015
Haralick RM, Shanmugam K, Dinstein I (1973) Textural features for image classification. IEEE Trans Syst Man Cybern 3:610–621. https://doi.org/10.1109/TSMC.1973.4309314
Bishop CM (1995) Neural networks for pattern recognition. Oxford University Press, Oxford
Bishop CM (2006) Pattern recognition and machine learning. BMEI, New York
Duda RO, Hart PE, Stark DG (2001) Pattern classification, 2nd edn. Wiley, New York
Haykin S (2009) Neural networks and learning machines. Prentice Hall, Upper Saddle River
Evgeniou T, Pentil M (2001) Support vector machines: theory and applications machine learning and its applications advanced lectures. Mach Learn Its Appl. https://doi.org/10.1007/3-540-44673-7_12
Piantadosi G, Marrone S, Fusco R, Sansone M, Sansone C (2018) Comprehensive computer-aided diagnosis for breast T1-weighted DCE-MRI through quantitative dynamical features and spatio-temporal local binary patterns. IET Comput Vis 12:1007–1017
Fooladivanda A, Shokouki BS, Ahmedinejad N, Mosaui MR (2015) Automatic segmentation of breast and fibroglandular tissue in MRI using local adaptive thresholding. ICMBE 2015:195–200. https://doi.org/10.1049/iet-cvi.2018.5273
Gül S, Çetinel G (2017) Detection of lesion boundaries in breast magnetic resonance imaging with OTSU thresholding and fuzzy C-means. ICAT 2017:1–5
Marrone S, Pantodosi G, Fusco R, Sansone M, Sansone C (2017) An investigation of deep learning for lesions malignancy classification in breast DCE-MRI. In: International conference on image analysis and processing, pp 479–489. https://doi.org/10.1007/978-3-319-68548-9_44
Losurdo L, Basile TMA, Fanizzi A, Bellotti R, Bottigli U, Carbonara R et al (2018) A gradient-based approach for breast DCE-MRI analysis. Biomed Res Int. https://doi.org/10.1155/2018/9032408
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
Authors Dr. Gökçen Çetinel is the coordinator, Dr. Fuldem Mutlu is the researcher and Sevda Gül is the scholarship student in the project that is supported by The Scientific and Technical Research Council of Turkey (TUBITAK) through The Research Support Programs Directorate (ARDEB) with Project Number of 118E201.
Ethical approval
The study was approved by the Ethical Committee of Sakarya University Medical Sciences Faculty. All procedures in studies involving human participants were in accordance with the ethical standards of the institutional and/or national search committee.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Çetinel, G., Mutlu, F. & Gül, S. Decision support system for breast lesions via dynamic contrast enhanced magnetic resonance imaging. Phys Eng Sci Med 43, 1029–1048 (2020). https://doi.org/10.1007/s13246-020-00902-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13246-020-00902-2