
Abstract
A computer system’s hardware and software work together to ensure that it runs smoothly. This article may be used to calculate the performance and profit of a computer system that includes hardware maintenance and software upgrades. Weibull distribution, regeneration point technique, and semi-Markov approach are used to create a stable cold standby redundant system. The scale parameter and standard shape parameter of the Weibull distribution are distinct. Hardware or software problems has caused the system to fail. The Weibull distribution governs all forms of failure, repair, and upgrade rates. To get out of this condition, all types of failures must be solved by a single repairman. The significance of the study is demonstrated by numerical estimates for mean time to system breakdown, availability, and profit function.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Industry, aeroplanes, satellite systems, engineering activities, medical science, and all academic divisions that use computer technology all have a role in science and technology. Because the performance of a system is determined by its hardware and software, high-quality software and hardware are necessary for better outcomes. When a computer system's hardware and software operate in a logical and consistent manner, it operates at maximum capacity. As the utilisation of a computer system grows, so does the likelihood of the system failing. The system can occasionally fail owing to hardware or software problems. Economic loss is the result of system breakdowns. Hardware maintenance and software upgrades can only be performed on a single server. Redundancy provides a parallel unit that comes into existence and functioning after the failure of the operative unit. Generally, redundancy is three types such as cold standby, hot standby, and warm standby. It is considered that in cold standby mode, the chance of failure of the unit is zero. Thus, scientists and engineers always suggest a reliable computer system by considering cold standby redundancy.
Many scientists and researchers have examined reliability and standard measures of a cold-standby redundant system with a single sever for its repairing purpose under the assumption that failure and repair rates of the units are generally distributed. Srinivasan and Gopalan (1973) analysed reliability and standard measures of a cold-standby redundant system with a single sever for its repairing purpose under the assumption that failure and repair rates of the units are generally distributed. Birolini (1974) used stochastic processes and regenerating points to investigate the reliability of a warm standby system. Subramanian (1978) emphasised a different units system based on the premise that the operative unit is undergoing preventative maintenance and the backup unit is operational. Gopalan and Nagarwalla (1985) described the benefit of a redundant age replacement cold standby system with a single server to repair the failed unit. Chander (2007) discussed on economic aspects of an electric transformer subjected to inspection to perform online repair and replacement activity. Malik and Pawar (2010) evaluated a stochastic system having a single server inspect the failed unit before online repair and under an abnormal atmosphere, no repair activity was performed. Pawar and Malik (2011) threw light on a single unit system with a single server that inspected the failed unit in distinct modes working in an abnormal condition. Kadyan (2012) analyzed reliability measures of a single unit system with a single server for inspection and repair at different stages of failure under an abnormal climate.
Malik and Deswal (2012) described a repairable stochastic system of distinct units having seniority for operation and repair under normal and abnormal atmosphere. Gupta et al. (2013) evaluated a two distinct unit system having a cold standby unit with Weibull failure and repair activity with a switching device. Kumar et al. (2014) discussed the single unit system under preventive maintenance and having a repair facility subject to maximum operation. Kumar and Sirohi (2015) analyzed the profit of a two-unit cold standby system with delayed repair of partially failed unit for better utilization of unit. Kumar et al. (2015) threw light on a cold standby redundant stochastic system with preventive maintenance, seniority, and maximum repair. Yadav and Barak (2016) threw light on the semi-Markov system having identical cold standby units under the provision of a single server. Barak et al. (2016) described reliability measures under preventive maintenance of a redundant system subjected to inspection before repairing the failed unit and single server facility. Kumar et al. (2016a, b) analyzed two distinct unit redundant systems with Weibull distribution having distinct scale parameters and standard shape parameters for failure and repair activity. Kumar et al. (2016a, b) discussed the performance and economic aspect of two distinct unit redundant systems using Weibull distribution and semi Markov process for failure and repair. Barak et al. (2017) scrutinized the stochastic system having one spare unit under the conditional inability of the server. Kumar et al. (2017) described the performance of redundant systems using the regenerative point technique with Weibull failure and repair activity.
Barak et al. (2018) analyzed the two-unit redundant stochastic system having one spare unit in cold standby mode subjected to inspection with one server and its application in the water supply system. Barak et al. (2018) threw light on the two-unit cold standby system working fully under abnormal environmental conditions. Kumar and Saini (2018) threw light on comparing reliability measures of single-unit repairable systems with degradation and unconventional environment. Kumar et al. (2018) analyzed the economic aspects of a distinct warm standby system having a single server where the operative unit fails directly from normal mode, and the standby unit fails due to being unused for a long time. Singh and Poonia (2019) assessment the probability of two units parallel system with correlated lifetime under inspection using regenerative point technique. Kumar et al. (2020) analyzed reliability measures of the soft water treatment plant and its supply using the goodness of fit test. Kadyan and Barak (2020) discussed the distinct units repairable system on a seniority basis for operation and continued functioning of cold standby units. Gupta et al. (2020) discussed on benefits and availability aspects of generators in steam turbine power plants. Raghav et al. (2021) predicaiton of reliability of distribution system with homogeneity in software and server subject to different repair policies using joint probability disribution via Copula approach and a complex repairable system with n-identical units under (k-out-of-n: G) scheme and copula linguistic repair approach has been assessed by Singh et al.(2021). Saini et al. (2021) examined the behavior of two distinct redundant systems with seniority in repair and preventive maintenance with a single server facility.
2 System assumptions
-
(a)
The system has two units- one operative, and the second cold standby unit
-
(b)
The system has one cold standby unit that comes into existence and functioning after the failure of the operative unit.
-
(c)
The system is failed due to hardware failure or software failure.
-
(d)
A single repairman is required to solve the failure situations.
-
(e)
When the system fails due to hardware failure, the repairman comes and repairs it.
-
(f)
When the system fails due to software failure, the repairman comes and up-grades it.
-
(g)
Hardware/software failure and repair/up-gradation rates follow the Weibull distribution.
3 System notations
- \(R\):
-
Group of regenerative states (S0, S1, S2, S3, S4)
- \(O/\,Cs\):
-
Operative unit/cold standby unit
- \(HFur/\,HFUR\):
-
Failure of hardware under repair/continuously from the previous stage
- \(WHf/\,WHF\):
-
Failure of hardware waiting for repair/continuously waiting for repair from the previous state
- \(Sup/\,SUP\):
-
Software up-gradation/continuously from the previous state
- \(WSup\,/\,WSUP\):
-
Software up-gradation waiting for repair/continuously waiting for repair from the previous state
- \(\mu_{i}\):
-
Mean sojourn time to the system failure \(\mu_{i} = \int\limits_{0}^{\infty } {p(T > t)dt}\), T represents the system failure time in the state Si.
- \(q_{ij} (t)/Q_{ij} (t)\):
-
Probability density function/ cumulative density function of direct transition time from \(S_{i} \in R\) to \(S_{j} \in R\) without transit to any other regenerative state
- \(q_{ij.\,k} (t)/Q_{ij.\,k} (t)\):
-
Probability density function/cumulative density function of first passage time from \(S_{i}\) to \(S_{j} \in R\) or a failed state \(S_{j}\) with visiting state \(S_{k}\) once in (0,t]
- \(\begin{gathered} q_{ij.k(r,s)} (t)/ \hfill \\ Q_{ij.k(r,s)} (t) \hfill \\ \end{gathered}\):
-
Probability density function/ cumulative density function of first passage time from \(S_{i} \in R\) to \(S_{j} \in R\) or to a failed state \(S_{j}\) with visiting states \(S_{k}\), \(S_{r}\), \(S_{s}\) once in (0,t]
- \(M_{i} (t)\):
-
Represents the probability that the system is in working state \(S_{i} \in R\) up to the time (t) without passing via any other regenerative state \(S_{i} \in R\)
- \(W_{i} (t)\):
-
The probability that server is busy in his job at the state \(S_{i}\) up to time (t) and state transition to any other state \(S_{i} \in R\) are not allowed or transit to the same state via one or more non-regenerative states.
- \(\oplus / \otimes\):
-
Notation for Laplace convolution/Laplace stieltjes convolution.
- \(* / * * /^{\prime }\):
-
Notations for Laplace transform (LT)/Laplace stieltjes transform (LST)/derivative of the function.
 :
:-
Up state/failed state/regenerative state
 :
:\(f_{1} (t) = \alpha \eta t^{\eta - 1} e^{{ - \alpha t^{\eta } }}\), \(f_{2} (t) = \beta \eta t^{\eta - 1} e^{{ - \beta t^{\eta } }}\), \(g_{1} (t) = k\eta t^{\eta - 1} e^{{ - kt^{\eta } }}\), \(g_{2} (t) = l\eta t^{\eta - 1} e^{{ - lt^{\eta } }}\) and \(w(t) = h\eta t^{\eta - 1} e^{{ - ht^{\eta } }}\) are hardware failure, software failure, hardware repair, software upgradation and rate of waiting time for server arrival respectively.
4 Model description
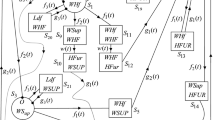
This paper is convenient for calculating the performance and profit of a computer system with hardware repair and software up-gradation facilities in which hardware and software working simultaneously. It is assumed that out of two identical unit one unit is sufficient to opearte the system and another unit kept as cold standby as shown in the state S0, there are some probabilility to transite one stage to another stage as explain in the second and third Sections “ 2. System assumtions, and 3. Notations”. Keeping these assumtions and notations in mind construct the state transition diagram Fig. 1 which is itself expalinatory in nature.

State transition diagram
5 Transition probabilities
The following are the probable transition probabilities:
It is simply confirmed that
6 Mean time of sojourn
Allow system breakdown duration is represented by the letter T, in the state Si, the average sojourn time is:
7 Mean time to system failure (MTSF)
Let \(\phi_{i} (t)\) is the density function of the first passage time from \(S_{i} \in R\) to a failed state. And, treating the failed states as trapping states, then upcoming recursive interface for \(\phi_{i} (t)\) is:
Now taking LST of the above Eq. (4) and solving for \(\phi_{0}^{**} (s)\), we have
Now, the system model reliability is obtained by using inverse LT of Eq. (5). We have
8 Steady state availability
Let \(A_{i} (t)\) is the probability that the system is in up-state at the moment ‘t’ specified that the system arrives at the regenerative-state \(S_{i}\) at t = 0. And then upcoming recursive relation for \(A_{i} (t)\) is:
where, \(M_{0} (t) = e^{{ - (\alpha + \beta )t^{n} }}\), \(M_{1} (t) = e^{{ - (\alpha + \beta + h)t^{n} }}\), \(M_{2} (t) = \,e^{{ - (\alpha + \beta + k)t^{n} }}\), \(M_{3} (t) = e^{{ - (\alpha + \beta + h)t^{n} }}\), \(M_{4} (t) = e^{{ - (\alpha + \beta + l)t^{n} }}\).
Now taking LT of above Eq. (7) and solving for \(A_{0}^{*} (s)\), the steady-state availability is given by
where, \(N_{A} = \left[ \begin{gathered} (\mu_{0} + p_{01} \mu_{1} + p_{03} \mu_{3}^{\prime } )[p_{20} (p_{40} + p_{47} ) + p_{2,\,14} p_{40} ] \hfill \\ + \mu_{2}^{\prime } [p_{47} + p_{01} \{ p_{40} (1 - p_{19} )\} + p_{03} p_{35} p_{40} \hfill \\ + \mu_{4}^{\prime } [p_{2,\,14} + p_{01} p_{20} p_{19} + p_{03} \{ p_{20} (1 - p_{35} )\} ] \hfill \\ \end{gathered} \right]\)
9 Busy period of the server due to repair of the failed unit
Let \(B_{i} (t)\) is the probability that the repairman is busy due to repair of the failed unit at the moment ‘t’ specified that the system arrives at the regenerative state \(S_{i}\) at t = 0. Then the upcoming recursive interface for \(B_{i} (t)\) is:
where, \(W_{1} (t) = e^{{ - (\alpha + \beta + h)t^{n} }}\), \(W_{2} (t) = \,e^{{ - (\alpha + \beta + k)t^{n} }}\), \(W_{3} (t) = e^{{ - (\alpha + \beta + h)t^{n} }}\), \(W_{4} (t) = e^{{ - (\alpha + \beta + l)t^{n} }}\).
Now taking LT of above Eq. (10) solving for \(B_{0}^{R*} (s)\), the time for which server is busy due to repair is given by
and \(D^{\prime }\) is earlier defined by Eq. (9).
10 Expected number of visit by the server
Let \(V_{i} (t)\) is the estimated no. of visits by the repairman for repair in (0, t] specified the arrival at the regenerative state \(S_{i}\) at t = 0. The upcoming recursive interface for \(V_{i} (t)\) is:
We are now taking LST of the above Eq. (13) and solving for \(V_{0}^{**} (s)\). The expected no. of visits of the server can be obtained as:
and \(D^{\prime }\) is earlier defined by Eq. (9).
11 Particular cases
and Z1, Z2, Z3 are defined earlier.
and Z1, Z2, Z3 are defined earlier.
12 Profit analysis
The profit analysis of the system can be done by using the profit function;
where, \(E_{0} =\) 5000 (Revenue per unit uptime of the system is available), \(E_{1} =\) 500 (Charge per unit time for which server is busy due to repair), \(E_{2} =\) 200 (Charge per unit visit by the server)
13 Discussion
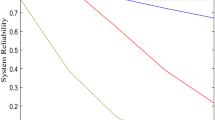
From the given Tables 1, 2, 3, it is clear that the values of MTSF, availability, and profit function having an increasing trend when software up-gradation rate (l) enhance but having decreasing trends when shape parameter (η) enhance where other parameters α = 0.003, β = 0.002, k = 1.5, h = 0.002, are hardware failure rate, software failure rate, hardware repair rate, and server waiting rate taken as constant for simplicity. When the hardware repair rate (k) changes from 1.5 to 2.5, then MTSF, availability, and profit function enhance.
14 Conclusion
The table represents the numerically behavior of reliability measures which observe very small changes in the comparison of graphical behavior. It is clear that the MTSF, availability, and profit function of the computer system having two identical unit in which one unit is sufficent to operate the system and another unit kept as cold standby as an alternate unit, increases when software up-gradation rate (l) increased and the other parameters are kept as constant. But the values of reliability measures decreases when shape parameter (η) increased. Also, when the hardware repair rate increases (k), then the system’s MTSF, availability, and profit function values increases in the comparison of software upgradation by keeping other parameters has fixed constant values. Thus, system performance is improved by using timely up-gradation of the software and hardware repair of computer system.
15 Future scope
Because hardware repairs are expensive and time-consuming, it is sometimes feasible to increase the capacity of a computer system by employing a cold standby computer system and software upgrades rather than hardware repairs. Hardware repairs need a specialist, but software upgrades may be performed easily by anybody following the instructions provided.
References
Barak MS, Barak SK (2018) Profit analysis of a two-unit cold standby system model operating under different weather conditions. Life Cycle Reliab Saf Eng 7(3):173–183
Barak SK, Barak MS, Malik SC (2016) Cost-benefit analysis of a cold standby system with preventive maintenance and repair subject to inspection. J Math Stat Sci 2016:274–285
Barak MS, Yadav D, Barak SK (2017) Stochastic analysis of a cold standby system with conditional failure of server. Int J Stat Reliab Eng 4(1):65–69
Barak MS, Yadav D, Kumari S (2018) Stochastic analysis of a two-unit system with standby and server failure subject to inspection. Life Cycle Reliab Saf Eng 7(1):23–32
Birolini A (1974) Some applications of regenerative stochastic processes to reliability theory-part one: tutorial introduction. IEEE Trans Reliab 23(3):186–194
Chander S (2007) MTSF and profit evaluation of an electric transformer with inspection for on-line repair and replacement. J Indian Soc Stat Opers Res 28(1–4):33–43
Gopalan MN, Nagarwalla HE (1985) Cost-benefit analysis of a one-server two-unit cold standby system with repair and age replacement. Microelectron Reliab 25(5):977–990
Gupta R, Kumar P, Gupta A (2013) Cost benefit analysis of a two dissimilar unit cold standby system with Weibull failure and repair laws. Int J Syst Assur Eng Manage 4(4):327–334
Gupta N, Saini M, Kumar A (2020) Operational availability analysis of generators in steam turbine power plants. SN Appl Sci 2(4):1–11
Kadyan S, Barak MS (2020) Stochastic analysis of a non-identical repairable system of three units with priority for operation and simultaneous working of cold standby units. Int J Stat Reliab Eng 7(2):269–274
Kadyan MS (2012) Reliability and cost-benefit analysis of a single unit system with degradation and inspection at different stages of failure subject to weather conditions. Int J Comput Appl 55(6)
Kumar A, Saini M (2018) Comparison of reliability characteristics of two semi-Markov repairable systems under degradation and abnormal environment. Life Cycle Reliab Saf Eng 7(4):257–268
Kumar P, Sirohi A (2015) Profit analysis of a two-unit cold standby system with delayed repair of partially failed unit and better utilization of units. Int J Comput Appl 117(1):41–46
Kumar A, Baweja S, Barak M (2015) Stochastic behavior of a cold standby system with maximum repair time. Decis Sci Lett 4(4):569–578
Kumar A, Saini M, Devi K (2016a) Analysis of a redundant system with priority and Weibull distribution for failure and repair. Cogent Math 3(1):1135721
Kumar A, Barak MS, Devi K (2016b) Performance analysis of a redundant system with Weibull failure and repair laws. Investig Oper 37(3):247–257
Kumar I, Kumar A, Saini M, Devi K (2017) Probabilistic analysis of performance measures of redundant systems under Weibull failure and repair laws. Computing and network sustainability. Springer, Singapore, pp 11–18
Kumar A, Malik SC, Pawar D (2018) Profit analysis of a warm standby non-identical units system with single server subject to priority. Int J Future Revolut Comput Sci Commun Eng 4(10):108–112
Kumar A, Singh R, Saini M, Dahiya O (2020) Reliability, availability and maintainability analysis to improve the operational performance of soft water treatment and supply plant. J Eng Sci Technol Rev 13(5)
Kumara A, Sainia M, Malikb SC (2014) A single unit system with preventive maintenance and repair subject to maximum operation and repair times. Int J Appl Math Comput 6:1
Malik SC, Deswal S (2012) Stochastic analysis of a repairable system of non-identical units with priority for operation and repair subject to weather conditions. Int J Comput Appl 49(14)
Malik SC, Pawar D (2010) Reliability and economic measures of a system with inspection for on-line repair and no repair activity in abnormal weather. Bull Pure Appl Sci 29(2):355–368
Pawar D, Malik SC (2011) Performance measures of a single-unit system subject to different failure modes with operation in abnormal weather. Int J Eng Sci Technol 3(5):4084–4089
Raghav D, Rawal DK, Ibrahim Y, Kankarofi RH, Singh VV (2021) Reliability prediction of distributed system with homogeneity in software and server using joint probability distribution via copula approach. Reliab Theory Appl 16(61):217–230
Saini M, Devi K, Kumar A (2021) Stochastic modeling of a non-identical redundant system with priority in repair activities. Thail Stat 19(1):155–162
Singh VV, Poonia PK (2019) Probabilistic assessment of two units parallel system with correlated lifetime under inspection using regenerative point technique. Int J Reliab Risk Saf Theory Appl 2(1):5–14
Singh VV, Mohhammad AI, Ibrahim KH, Yusuf I (2021) Performance assessment of the complex repairable system with n-identical units under (k-out-of-n: G) scheme and copula linguistic repair approach. Int J Qual Reliab Manage 39(2):367–386
Srinivasan SK, Gopalan MN (1973) Probabilistic analysis of a 2-unit cold-standby system with a single repair facility. IEEE Trans Reliab 22(5):250–254
Subramanian R (1978) Availability of 2-unit system with preventive maintenance and one repair facility. IEEE Trans Reliab 27(2):171–172
Yadav D, Barak MS (2016) Stochastic analysis of a cold standby system with server failure. Int J Math Stat Invention 4(6):18–22
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All the authors contributed equally to this manuscript and there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Kumar, A., Garg, R. & Barak, M.S. Performance of computer system with three types of failure using weibull distribution subject to hardware repair and software up-gradation. Int J Syst Assur Eng Manag 14 (Suppl 1), 483–491 (2023). https://doi.org/10.1007/s13198-023-01879-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13198-023-01879-3