
Abstract
In this paper, we present a polynomial primal-dual interior-point algorithm for linear optimization based on a modified logarithmic barrier kernel function. Iteration bounds for the large-update interior-point method and the small-update interior-point method are derived. It is shown that the large-update interior-point method has the same polynomial complexity as the small-update interior-point method, which is the best known iteration bounds. Our result closes a long-existing gap in the theoretical complexity bounds for large-update interior-point method and small-update interior-point method.
Similar content being viewed by others


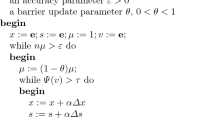
Avoid common mistakes on your manuscript.
1 Introduction
The field of interior-point methods (IPMs) for linear optimization (LO) originated with the Karmarkar’s paper [1] that was proved to have much better polynomial complexity than the Khacian’s ellipsoidal method, the first method with polynomial complexity for LO. Motivated by the success of Karmarkar’s method for LO, many researchers have proposed and analyzed various IPMs for LO [2,3,4,5,6], second-order cone optimization (SOCO) [7], semidefinite optimization (SDO) [8], and linear complementarity problem (LCP) [9,10,11]. Other relevant references are [12,13,14,15,16,17,18]. In this paper, we restrict ourselves to the primal-dual IPMs for the class of LOs.
The primal-dual IPMs use the Newton direction as a search direction, which is derived from the well-known primal-dual logarithmic barrier function. There is a gap between the practical behavior and the theoretical performance results of these algorithm [19], especially for the so-called large-update methods. In practice, large-update methods are much more efficient than the so-called small-update methods [12,13,14,15,16,17,18]. However, small-update methods have better iteration bound in theory than large-update methods.
Several strategies have been proposed to improve the theoretical complexity of large-update IPMs. Hung and Ye [20], Jansen et al. [21] and Monteiro et al. [22] use higher order methods to improve the complexity of large-update IPMs. However, there is a price to pay for the reduced complexity; higher order methods are computationally more expensive per iteration than first order methods, since some additional equation systems need to be solved with the same coefficient matrix at each iteration. Subsequently Peng et al. [2, 3] improved the theoretical complexity for large-update IPMs using a class of self-regular kernel functions to determine the proximity measure and search direction, which are the crucial factors for the analysis of IPMs. Bai et al. [5, 23,24,25,26] consider several specific kernel functions and analyzed complexity of corresponding IPMs. In [6] Bai et al. proposed a new class of kernel functions, called eligible kernel functions that are neither logarithmic nor self-regular, and they presented a unified framework to analyze the complexity of the corresponding IPMs.
Motivated by the above-mentioned papers, in this paper we introduce a new kernel function \(\psi (t)\) as follows:
The new kernel function leads to the best known complexity bound of \(O(\sqrt{n}\log \frac{n}{\epsilon })\) for the large-update primal-dual IPM, which is as good as iteration bound for small-update primal-dual IPM, hence, improving the theoretical complexity of large-update IPMs.
The paper is organized as follows. In Sect. 2, the generic primal-dual IPM based on the kernel function is described. In Sect. 3, we give the properties of the new kernel function which plays a crucial role in the complexity analysis of algorithm. In Sect. 4, the estimation of the step-size is discussed. The iteration bounds of the algorithm with large-updates and small-updates, are derived in Sect. 5. Finally, Sect. 6 contains some concluding remarks.
Some notation used throughout the paper is as follows. First, \(\Re ^n\), \(\Re ^{n}_{+}\) and \(\Re ^{n}_{++}\) denote the set of vectors with n components, the set of nonnegative vectors and the set of positive vectors, respectively. The 2-norm and the infinity norm are denoted by \(\Vert \cdot \Vert \) and \({\Vert \cdot \Vert }_\infty \), respectively. If \(x,s\in \Re ^n\), then xs denotes the componentwise (or Hadamard) product of the vectors x and s. Furthermore, e denotes the all-one vector of length n. If \(z\in \Re ^n_+\) and \(f:\Re _+\rightarrow \Re _+\), then f(z) denotes the vector in \(\Re ^n_+\) whose ith component is \(f(z_i)\), with \(1\le i\le n\). We write \(f(x)=O(g(x))\) if \(f(x)\le cg(x)\) for some positive constant c and \(f(x)=\Theta (g(x))\) if \(c_1g(x)\le f(x)\le c_2g(x)\) for positive constants \(c_1\) and \(c_2\).
2 The generic interior-point algorithm
In this paper, we consider the LO problem, which takes the following standard form
where \(A\in \textbf{R}^{m\times n}\), rank\((A)=m, b\in \textbf{R}^m \), \(c\in \textbf{R}^n\), and its dual problem
Without loss of generality, we assume that both (P) and (D) satisfy the interior point condition (IPC), i.e., there exists \((x^0, s^0, y^0)\) such that
If the IPC holds, finding an optimal solution of (P) and (D) is equivalent to solving the system of optimality conditions
where xs denotes the coordinatewise product of the vectors x and s. The basic idea of primal-dual IPMs is to replace the third equation in (2), the so-called complementarity condition for (P) and (D), by the parameterized equation \(xs = \mu e,\) with \(e = (1,..., 1)^T, \mu >0\). This leads to the following system
If the IPC holds, then for each \(\mu >0\), system (3) has a unique solution \((x(\mu ), y(\mu ), s(\mu ))\), which is called the \(\mu \)-center of the primal-dual pair (P) and (D). The set of all \(\mu \)-center (\(\mu >0\)) is the central path of (P) and (D). The limit of the central path (as \(\mu \) goes to zero) exists, and since the limit point satisfies (2), it naturally yields optimal solutions for both (P) and (D) [12].
Now we describe how classical primal-dual IPMs work. We start with a current iterate (x, y, s) that satisfies the IPC. Without loss of generality (Roos et al. [12]), we may assume this for \(\mu =1\), with \(x(1)=s(1)=e.\) We then decrease parameter \(\mu \) to \(\mu : =(1-\theta )\mu \), for some \(\theta \in (0, 1)\), and we solve the following Newton system
to obtain the search direction. Since matrix A has a full row rank, the Newton system (4) has a unique solution for all \(\mu > 0\). Then we take a step along the search direction with a step size \(\alpha \in (0, 1]\) which is defined by some line search rule. The search direction and line search rule ensure that the new triple \((x+\alpha \Delta x, y+\alpha \Delta y, s+\alpha \Delta s)\) is closer to the \(\mu \)-center \((x(\mu ), y(\mu ), s(\mu ))\). This step is repeated as long as the actual iterate is sufficiently close to the \(\mu \)-center. Then \(\mu \) is reduced again by the factor \((1-\theta )\) and the process is repeated until an approximate solution to the problem is obtained, e.g., until \(n\mu \) is smaller than some prescribed accuracy \(\varepsilon \).
To describe the ideas underlying this paper, we introduce a scaled version of the system (4). Let
Using the above notation, we can rewrite the Newton system (4) as
where \(\bar{A}=\frac{1}{\mu }AV^{-1}X, V=\textrm{diag}\,(v), X=\textrm{diag}\,(x), S=\textrm{diag}\,(s)\).
When analyzing the algorithm, we need to measure the closeness of a primal-dual pair (x, s) to the \(\mu \)-center \((x(\mu ), s(\mu ))\). The most popular tool for measuring this closeness is the so-called primal-dual logarithmic barrier function [12], which is given by
The logarithmic kernel function is defined as
which is a strictly convex function on \(\Re ^n_{++}\) with \( \psi _{c}(1)= \psi '_{c}(t)=0\), and attains its minimal at \(t=1\). Substituting (8) in (7) we obtain
Note that the right side of the third equation in (6) equals the negative gradient of the logarithmic barrier function \(\Psi _c(v)\), i.e.
This shows that the negative gradient of the logarithmic barrier function determines the classical Newton search direction for primal-dual IPMs. Hence, a point on the central path can be characterized by the property of \(v_i=1,\) for any i. In IPMs the iterates usually are not on the central path, but in some neighborhood of it. A natural way to measure the deviation of the i-th coordinate \(v_i\) from 1 is to use the value at \(v_i\) of a smooth strictly convex function \(\psi (t):\Re _{++}\rightarrow \Re _{+}\) that is nonnegative, assumes its minimal value (zero) at 1 and that goes to infinity when the argument goes to zero or infinity. These requirements can be formalized as follows:
As these conditions already include, a proper measure need to be strictly convex and at least twice differentiable. Then a barrier function \(\Psi (v)\), based on the kernel function \(\psi (v_i)\), in the scaled space can be defined as the sum of the componentwise deviations:
Replacing the barrier function \(\Psi _c(v)\) by the above function, we obtain the following modified Newton system
The last equality in system (13) can be expressed as
The generic interior-point algorithm for LO is shown in Fig. 1. It is clear from this description that the closeness of (x, y, s) to \((x(\mu ), y(\mu ), s(\mu ))\) is measured by the value of \(\Psi (v)\), with \(\tau \) as a threshold value: if \(\Psi (v)\le \tau \), then we start a new outer iteration by performing a \(\mu \)-update; otherwise we enter an inner iteration by computing the search directions at the current iterate with respect to the current value of \(\mu \) and apply the update \(x:=x+\alpha \Delta x, y:=y+\alpha \Delta y, s:=s+\alpha \Delta s)\) to get a new iterate.

Generic algorithm
The choice of the step size \(\alpha \) (\(0< \alpha \le 1\)) is a crucial issue in the analysis of the algorithm. It needs to ensure that the resulting iterate is feasible and stays within a certain neighborhood of the current \(\mu \)-center. In the theoretical analysis, the step size \(\alpha \) is usually given a value that depends on the closeness of the current iterates to the \(\mu \)-center.
The choice of the barrier update parameter \(\theta \) plays an important role in both theory and practice of IPM. If \(\theta \) depends on the dimension of the problem, e.g., \(\theta =\frac{1}{\sqrt{n}}\), then we call the algorithm a small-step (or small-update) method. It uses full Newton steps and the iterates stay in a small neighborhood of the central path. If \(\theta \) is the constant independent of the dimension n of the problem, e.g., \(\theta =\frac{1}{2}\), then we call the algorithm a large-step (or large-update) method. In large-update method the iterates are allowed to move in a wide neighborhood of the central path.
3 Properties of the new kernel and barrier functions
In this section, we discuss some properties of the new kernel function \(\psi (t)\) defined in (1) and the corresponding barrier function that will be used in the complexity analysis of the algorithm. According to (1), the scaled barrier function \(\Psi (v)\) is given by
where \(v\in R^n_{++}\). In the analysis of the algorithm, we also use the norm-based proximity measure \(\delta (v)\) defined by
Since \(\Psi (v)\) is strictly convex and attains its minimum value of zero at \(v = e\), we have
Obviously, the new kernel function (1) satisfies the properties
We write down the first three derivatives of \(\psi (t)\) as follows
Obviously, \(\psi ''(t)\) is monotonically decreasing for all \(t>0,\) and
In [6], the authors introduced a class of eligible kernel function, satisfied the following conditions
In order to analyze the new algorithm, we would give the proof that the new kernel function is eligible in the following Lemma.
Lemma 3.1
The new kernel function (1) is eligible kernel function that satisfies conditions (19).
Proof
For any \(t>0\), according to (17), we have
and
the right-hand side of the above equality is positive for \(0<t<1\), which proves (19-d). It was shown in [6] that condition (e) is implied by (b) and (c). This completes the proof. \(\square \)
Lemma 3.2
For \(\psi (t)\) we have
Proof
Proof of (20): using (17) and (18), we have
and
\(\square \)
Proof of (21):
since \(\psi (1)=\psi '(1)=0, \psi '''(t)<0, \psi ''(1)=\frac{5}{2},\) and by using Taylor’s Theorem at the right neighborhood of \(t=1\), we have
for some \(\xi , 1\le \xi \le t.\) This completes the proof. \(\square \)
Lemma 3.3
Let \(\varrho :[0,+\infty )\rightarrow [1,+\infty )\) be the inverse function of \(\psi (t)\) for \(t\ge 1\) and \(\rho :[0,+\infty )\rightarrow (0,1]\) be the inverse function of \(-\frac{1}{2}\psi '(t)\) for all \(t\in (0,1].\) Then we have
Proof
Proof of (22): let \(s=\psi (t), t\ge 1,\) i.e. \(\varrho (s)=t, t\ge 1.\) By the definition of \(\psi (t)\), we have
Because \(-2\ln (1+\frac{1}{t})+2\ln 2 \) is monotonically increasing with respect to \(t\ge 1,\) we have
which implies that
By (20), we have \(s=\psi (t)\ge \frac{1}{2}(t-1)^2\), so
\(\square \)
Proof of (23):
let \(z=-\frac{1}{2}\psi '(t), t\in (0,1].\) Using the definition of \(\rho :\rho (z)=t, t\in (0,1]\), we have
On one hand, for \(t\in (0,1],\) we have
On the other hand, for any number \(t_0\in (0,1]\), there exists a real number \(\lambda =1+\frac{1}{t_0}\), such that
The above two inequations imply that
This completes the proof. \(\square \)
The lemma below provides a bound for \(\delta (v)\) in terms of \(\Psi (v)\) which will play an important role in the analysis of the algorithm.
Lemma 3.4
Let \(\delta (v)\) be as defined in (16). Then we have
Proof
Using (20), we have
so
This completes the proof. \(\square \)
Remark 3.5
Throughout the paper we assume that \(\tau \ge 1.\) Using Lemma 3.4 and the assumption \(\Psi (v)\ge \tau ,\) we have
4 Analysis of the algorithm
4.1 Growth behavior of the barrier function at the start of outer iteration
The following theorem yields an upper bound for \(\Psi (v)\) after the \(\mu \)-update in terms of the inverse function of \(\psi (t)\) for \(t>0\).
From Theorem 3.2 in [6], we have the following Lemma 4.1.
Lemma 4.1
Let \(\varrho :[0,+\infty )\rightarrow [1,+\infty )\) be defined as in Lemma 3.3. Then we have
Lemma 4.2
Let \(0\le \theta <1,\) \(v_+=\frac{v}{\sqrt{1-\theta }}\). If \(\Psi (v)\le \tau \). Then we have
Proof
Since \(\frac{1}{\sqrt{1-\theta }}\ge 1\) and \(\varrho (\frac{\Psi (v)}{n})\ge 1\), we have \(\frac{\varrho (\frac{\Psi (v)}{n})}{\sqrt{1-\theta }}\ge 1.\) Using Lemma 4.1 with \(\beta =\frac{1}{\sqrt{1-\theta }}\), (21), (22), and \(\Psi (v)\le \tau \), we have
where the last inequality holds from \(1-\sqrt{1-\theta }=\frac{\theta }{1+\sqrt{1-\theta }}\le \theta , 0\le \theta <1.\) This completes the proof. \(\square \)
Denote
then \(\Psi _0\) is an upper bound for \(\Psi (v)\) during the process of the algorithm.
Remark 4.3
For large-update method we take \(\tau =O(n), \theta =\Theta (1), {\Psi }_0=O(n)\). For small-update method we take \(\tau =O(1), \theta =\Theta (\frac{1}{\sqrt{n}}), {\Psi }_0=O(1)\).
4.2 Determining the stepsize
In this section, we determine a default stepsize which not only keeps the iterations feasible but also gives rise to a sufficiently large decrease of \(\Psi (t)\), as defined in (15), in each inner iteration. In each inner iteration we first compute the search direction \((\Delta x, \Delta y, \Delta s)\) from the system (14). After a stepsize \(\alpha \), we have the new iterates
Using (5), we have
So we have
For \(\alpha > 0,\) we define
Then \(f(\alpha )\) is the difference of proximities between a new iterate and a current iterate for fixed \(\mu .\) By (25), we have
Therefore we have \(f(\alpha )\le f_1(\alpha )\), where
Obviously \(f(0)=f_1(0)=0.\) Taking the first two derivative of \(f_1(\alpha )\) with respect to \(\alpha \) we have
From Lemmas 4.1\(-\)4.3 in [6], we have the following Lemmas 4.4–4.6.
Lemma 4.4
Let \(f_1(\alpha )\) be as defined in (25) and \(\delta (v)\) be as defined in (16). Then we have
Lemma 4.5
If the step size \(\alpha \) satisfies the inequality
we have
Lemma 4.6
Let \(\rho :[0,+\infty )\rightarrow (0,1]\) be defined as in Lemma 3.3. Then the largest step size \(\bar{\alpha }\) satisfying (28) is given by
Lemma 4.7
Let \(\rho \) be defined as in Lemma 3.3 and \(\bar{\alpha }\) be defined as in Lemma 4.6. If \(\Psi (v)\ge \tau \ge 1,\) then we have
Proof
By the definition of \(\rho \), we have
Taking the derivative with respective to \(\delta \), we find
which gives
Since \(\rho \) is monotonically decreasing, (29) can be written as
Due to (17), \(\psi ''\) is monotonically decreasing. So \(\psi ''(\rho (\sigma ))\) is maximal for \(\sigma \in [\delta , 2\delta ]\) when \(\rho (\sigma )\) is minimal. Since \(\rho \) is monotonically decreasing, this occurs when \(\sigma =2\delta \). Therefore
Since \( t\in (0,1],\) we have \(\frac{1}{t+1}<1\) and
Using the above two inequalities, Remark 2.5 and (23), we have
This completes the proof. \(\square \)
If we denote
then \(\tilde{\alpha }\) is the default step size and \(\bar{\alpha }\ge \tilde{\alpha }.\)
4.3 Decrease of the barrier function during an inner iteration
Lemma 4.8
Let \(\tilde{\alpha }\) be the default step size as defined in (30) and \(\Psi (v)\ge 1\). Then
Proof
Let the univariate function h satisfy
Due to Lemma 3.4, \(f_1''(\alpha )\le h''(\alpha )\). As a consequence, \(f_1'(\alpha )\le h'(\alpha )\) and \(f_1(\alpha )\le h(\alpha )\). Taking \(\alpha \le \bar{\alpha }\), with \(\bar{\alpha }\) as defined in Lemma 3.6, we have
Since \(h''(\alpha )\) is increasing with respect to \(\alpha \), using Lemma 3.12 in [2], we have
So, for \(\bar{\alpha }\ge \tilde{\alpha }\), we have
This completes the proof. \(\square \)
5 Complexity of the algorithm
In this section we estimate the complexity of our new IPM. We first estimate the complexity of the inner process, i.e., how many inner iterations are required to bring the iterates back to the specified neighborhood of the current \(\mu \)-center. We denote the value of \(\Psi (v)\) after the \(\mu \)-update as \(\Psi _0\), the subsequent values in the same outer iteration are denoted as \(\Psi _k, k = 1,2,\ldots .\) If K denotes the total number of inner iterations in the outer iteration, we have
by equation (24), and the decrease in each inner iteration is given
by inequality (31). We assume that
for some positive constants \(\kappa \) and \(\gamma \), with \(\gamma \in (0,1]\). We can find the appropriate values
such that
Lemma 5.1
Let K be the total number of inner iterations in the outer iteration. Then we have
Proof
Proof. By Lemma 1.3.2 in [3], we have
This completes the proof. \(\square \)
Theorem 5.2
Consider LO problem with assumptions stated in Sect. 2. Then the upper bound on the number of iterations of the IPM in Fig. 1 with the new kernel function (1) to obtain \(\varepsilon \)-approximate solution of LO problem is
Proof
The number of outer iterations is bounded above by \(\frac{1}{\theta }\log \frac{n}{\epsilon }\) (see [12] ). Multiplying the number of outer iterations by the number of inner iterations stated in Lemma 5.1 we get an upper bound for the total number of iterations, namely,
This completes the proof. \(\square \)
Corollary 5.3
. Considering the case of a large-update method, taking \(\tau =O(n)\) and \(\theta =\Theta (1),\) then we have
So the iterations complexity for large-update method is
In case of a small-update method, taking \(\tau =O(1), \theta =\Theta (\frac{1}{\sqrt{n}}),\) then we have
Therefore, the iterations complexity for small-update method is
which as same as the iterations complexity for large-update IPM.
6 Conclusions
In this paper we introduced a new modified logarithmic barrier function (1) and studied its properties in Sect. 3. We used this kernel function to design and analyze IPM stated in Fig. 1. We show that iteration bound for the small-update version of the method matches the best known iteration bound for small-update IPM, namely \(O(\sqrt{n}\log \frac{n}{\epsilon })\). We show that the iteration bound for large-update version of the method is the same, as for the small-update method. This is the best known upper bound for large-update method effectively closing the gap between iterations bounds of small- and large-update IPMs.
Data availability
The data are available from the corresponding author on reasonable request.
References
Karmarkar, N.K.: A new polynomial-time algorithm for linear programming. In: Proceedings of the 16th Annual ACM Symposium on Theory of Computing, 4, pp. 373–395 (1984)
Peng, J., Roos, C., Terlaky, T.: Self-regular functions and new search directions for linear and semidefinite optimization. Math. Program. 93, 129–171 (2002)
Peng, J., Roos, C., Terlaky, T.: Self-Regularity: A New Paradigm for Qrimal-Dual Interior-Point Algorithms. Princeton University Press, Princeton, NJ (2002)
Bai, Y.Q., Xie, W., Zhang, J.: New parameterized kernel functions for linear optimization. J. Global Optim. 54, 353–366 (2012)
Bai, Y.Q., Ghami, M.E., Roos, C.: A new efficient large-update primal-dual interior-point method based on a finite barrier. SIAM J. Optim. 13(3), 766–782 (2003)
Bai, Y.Q., Ghami, M.E., Roos, C.: A comparative study of kernel functions for primal-dual interior-point algorithms in linear optimization. SIAM J. Optim. 15(1), 101–128 (2004)
Alzalg, B.: Decomposition-based interior point methods for stochastic quadratic second-order cone programming. Appl. Math. Comput. 249, 1–18 (2014)
Choi, B.K., Lee, G.M.: On complexity analysis of the primal dual interior-point method for semidefinite optimization problem based on a new proximity function, Nonlinear. Analysis 71, 2628–2640 (2009)
Lee, Y.H., Cho, Y.Y., Cho, G.M.: Interior-point algorithms for \(P_\ast (k)\)-LCP based on a new class of kernel functions. J. Global Optim. 58, 137–149 (2014)
Potra, F.A., Sheng, R.: A path following method for LCP with superlinearly convergent iteration sequence. Ann. Oper. Res. 81, 97–114 (1998)
Wang, G.Q., Yu, C.J., Teo, K.L.: A full-Newton step feasible interior-point algorithm for \(P_\ast (k)\)- linear complementarity problems. J. Global Optim. 59, 81–99 (2014)
Roos, C., Terlaky, T., Vial, J.P.: Theory and Algorithms for Linear Optimization. An Interior-Point Approach. John Wiley & Sons, Chichester (1997)
Potra, F.A., Wright, S.J.: Interior-point methods. J. Comput. Appl. Math. 124(1–2), 281–302 (2000)
Wright, S.J.: Primal-Dual Interior-Point Methods. SIAM, Philadelphia (1997)
Potra, F.A.: Q-superlinear convergence of the iterates in primal-dual interior-point methods. Math. Programm. Ser. A 91, 99–115 (2001)
Ye, Y.: Interior Point Algorithms, Theory and Analysis. John Wiley & Sons, Chichester (1997)
Potra, F.A.: A quadratically convergent predictor-corrector method for solving linear programs from infeasible starting points. Math. Program. 67, 383–406 (1994)
Potra, F.A.: An infeasible-interior-point predictor-corrector algorithm for linear programming. SIAM J. Optim. 6, 19–32 (1996)
Andersen, E.D., Gondzio, J., Meszaros, C., Xu, X.: Implementation of interior point methods for large scale linear programming. In: Terlaky, T. (ed.) Kluwer Academic Publishers, Dordrecht, pp. 189–252 (1996)
Hung, P., Ye, Y.: An asymptotically O(x/ L)-iteration path-following linear programming algorithm that uses long steps. SIAM J. Optim. 6, 570–586 (1996)
Jansen, B., Roos, C., Terlaky, T., Ye, Y.: Improved complexity using higher order correctors for primal-Dual Dikin Affine scaling. Math. Programm. Ser. B 76, 11–130 (1997)
Monteiro, R.D.C., Adler, I., Resende, M.G.C.: A polynomial-time primal-dual affine scaling algorithm for linear and convex quadratic programming and its power series extensions. Math. Oper. Res. 15, 191–214 (1990)
Bai, Y.Q., Roos, C.: A primal-dual interior point method based on a new kernel function with linear growth rate. In: Proceedings of the 9th Australian Optimization Day, Perth, Australia (2002)
Bai, Y.Q., Roos, C.: A polynomial-time algorithm for linear optimization based on a new simple kernel function. Optim. Methods Softw. 18, 631–646 (2003)
Bai, Y.Q., Lesaja, G., Roos, C., Wang, G.Q., El Ghami, M.: A class of large-update and small-update primal-dual interior-point algorithms for linear optimization. J. Optim. Theory Appl. 138, 341–359 (2008)
Bai, Y.Q., Guo, J., Roos, C.: A new kernel function yielding the best known iteration bounds for primal-dual interior-point algorithms. Acta Mathematica Sinica, English Series 49, 259–270 (2007)
Acknowledgements
We are sincerely grateful to the editors and the anonymous referees for the careful reading and useful suggestions, which have improved the manuscript of the present version. This research was funded by Natural Science Foundation of Shandong Province (Grand No.ZR2020MA026).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
About this article

Cite this article
Liu, L., Hua, T. A polynomial interior-point algorithm with improved iteration bounds for linear optimization. Japan J. Indust. Appl. Math. 41, 739–756 (2024). https://doi.org/10.1007/s13160-023-00630-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13160-023-00630-6