
Abstract
Resource-constrained project scheduling problem is to make a schedule for minimization of the makespan subject to precedence and resource constraints. In this paper, we consider an uncertain resource-constrained project scheduling problem (URCPSP) in which the activity durations, with no historical data generally, are estimated by experts. In order to deal with these estimations, an uncertainty-theory-based project scheduling model is proposed. Furthermore, a genetic algorithm integrating a 99-method based uncertain simulation is designed to search the quasi-optimal schedule. Numerical examples are also provided to illustrate the effectiveness of the model and the algorithm.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The resource-constrained project scheduling problem (RCPSP) has been a widely studied optimization problem since it was initiated. The problem considers the minimization of the makespan while schedules the project subject to precedence and resource constraints [1]. As a job-shop generalization, RCPSP is NP-hard which was proved by Blazewicz et al. [2]. Most literature about RCPSP has based on the deterministic assumption that complete information of resource usage and deterministic activity duration are given in advance in which a feasible baseline schedule, i.e., a list of activity starting times and a definite makespan, can be determined as a result. During project execution, however, this simplification may lead to poor performance since project activities are usually subject to considerable disruptions such as unavailable resources, delayed delivery of materials, absent workers etc. [3]. Stochastic resource-constrained project scheduling problem (SRCPSP) has been developed to deal with the variability in activity durations [4–10]. In these researches, the execution of a project is viewed as a dynamic decision process in which activity durations are represented as random variables. Aiming at the minimization of the expected makespan, different scheduling policies are proposed to schedule the activities with random durations; these policies define which activities to start at each decision point (the start of project and the completion times of activities).
Considering the uniqueness of each project in real world, it is not uncommon that its activities are seldom or even never have been executed before. As a result, the activity durations cannot be depicted by probability distributions for the lack of historical data. In this case, belief degrees given by experienced project managers or experts can be employed to estimate distributions of the durations. Surveys have shown that these human beings’ estimations generally possessed much wider range of values than the real ones [11]. Therefore, these indeterminacies cannot be treated as fuzziness [12, 13], probability [14, 15], roughness [16], ambiguity [17] or entropy [18]. Instead, uncertainty theory, initiated by Liu [19, 20], can be a useful tool to deal with these belief degrees. So far, the new theory has been successfully applied in various problems: option pricing problem [21, 22], production control problem [23], inventory problem [24], assignment problem [25], supply chain pricing problem [26] etc. In project scheduling field, Zhang and Chen [27] built an uncertain model to minimize the expected project makespan under chance constraint of the total cost. Ji and Yao [28] considered an uncertain project scheduling problem to make a schedule for allocating the loans so that the total cost and the completion time of project are balanced. Ding and Zhu [29] considered two types of models for uncertain project scheduling problems to satisfy different management requirements. Based on genetic algorithm, Ke [30] proposed a hybrid approach to solve a project time-cost trade-off problem with uncertain measure, and also further studied this trade-off problem in uncertainty and randomness coexisting environment [23, 31].
However, no research deal with the RCPSP with uncertain durations and renewable resource constraints, this paper will fill the gap and explore this uncertain resource-constrained project scheduling problem. Specially, the activity durations whose distributions are estimated by professional managers or experts are characterized as uncertain variables. Furthermore, an uncertain serial project generation scheme (US-SGS) is introduced to produce a schedule from an activity list. An uncertain simulation based on 99-method is employed to approximate the uncertain functions, since the calculated makespan based on the expected value or medium number of each activity duration is usually less than the real one [6]. Afterwards, we design a GA-based algorithm to search for the quasi-optimal schedule.
The reminder of this paper organized as follows: In Sect. 2, formulations of the URCPSP are detailed. An uncertain expected value model is established and transformed into a crisp form in some special cases in Sect. 3. Furthermore, Sect. 4 proposes a hybrid algorithm integrating 99-method and genetic algorithm. Section 5 presents numerical examples to illustrate the effectiveness of the model and the algorithm. Relevant conclusions and some prospective extensions are discussed in Sect. 6. Specially, some basic concepts in uncertainty theory are introduced in appendix.
2 Problem description
The URCPSP considered in this paper is described as an activity-on-the-node network G(N, A), where N is the set of activities and A is the set of pairs of activities between which a zero-lag finish-start precedence relationship exists. Dummy activities \(i =1\) and \(i=N+2\) respectively mark the beginning and the end of the project. The duration of each activity \(\tilde{d}_{i}\) is assumed to be an uncertain variable whose distribution is given by experts’ or managers’ belief degrees, and the resource requirement of resource k is indicated by \(r_{ik}\). For renewable resource k, the availability \(R_{k}\) is a constant, which is constrained throughout the project. Each activity is executed in exclusive one mode and preemption is not allowed in this paper.
The execution of a project in uncertain context can be regarded as a dynamic decision process. At each decision time (the start of the project and the completion times of activities), the manager makes decisions about which activities to start subject to the precedences and resource constraints. Therefore, the solution of URCPSP is an activity order list which depicts the priority of each activity. Due to the uncertainty, the actual activity duration can only be attained after its entire processes completed, and meanwhile, the decision maker can merely apply partial information which is available before or at the time he makes the decision. So the schedule generation scheme (SGS) used in deterministic condition may not always be feasible. In this paper, we develop a new procedure denoted as US-SGS to decode the activity list \(\lambda\), which works as the Serial SGS, but adds the side constraint
where \(\lambda ^{i}\) is the position of activity i in activity list \(\lambda\) and \(s_{i}\) is the starting time of activity i.
The US-SGS works as follows:
0: Given a network G(N, A). \(\lambda\):= activity list; \(\lambda _{i}\):=activity in position i; \({\varvec{d}}\):= duration; A:= underway activity set; U:= unexecuted activity set; S:= starting time; F:= finish time; T:= Time point; num: number of the activities; K:=the number of renewable resources; \(r_{ik}\): demand of activity i for resource type k; \(R_{k}\):= available amount of resource i.
1: \(A=\varnothing , \ U=[1,2,\ldots ,num], \ F=[inf, inf,\ldots ,inf],\ S=[0, 0,\ldots ,0]\)
2: \(im=1\), \(T=0\)
3: While is empty \((U)=0\)
4: \(S_{\lambda _{im}}=\max \limits _{i<im} S_{\lambda _{i}}\vee \max \limits _{(j,\lambda _{im})\in A}F_{j}\)
5: if \(\sum \limits _{i\in A}(r_{ik})+r_{imk}\le R_{k},\ k=1,2\ldots \,K \&\,S_{\lambda _{im}}\le T\)
6: \(F(\lambda _{im})=T+d(\lambda _{im})\)
7: Put \(\lambda _{im}\) into A
8: \(im=im+1\)
9: else
10: \(T=\min \limits _{i\in A} (F(i))\)
11: Take out i from A and U if: \(F(i)_{i\in A}\le T\)
12: end
13: end
14: Return S and F
3 The expected value model
The URCPSP aims at minimizing the expected total project duration (makespan), equivalent to the start time of activity \(N+2\), denoted as \(s_{n+2}\), since it is a dummy end. Therefore the makespan \(F_{t}\) is:
The mathematical model of the URCPSP can be established as follows:
In the above model, the objective function is to minimize expected makespan. The first constraint ensures that the earliest start time of activity j is forbidden to be smaller than the finish time of its predecessor activity i. The second constraint guarantees, for each time point t and resource type k, the resource demand should be below the resource limitation. Note that \(P_{t}\) represents the set of underway activities at time t, \(r_{ik}\) is the demand of activity i for resource type k, and \(R_{k}\) is the given available amount of resource k.
Because of the uncertain durations, the finish time of each activity is changeable and the makespan is an uncertain variable as well. Given the activity list \(\lambda\), the finish time of each activity can be attained as follows:
The critical problem is to determine the starting time of activity i. If resource constraint is eliminated, the \(s_{i}\), which is an uncertain variable as well, can be computed by
where \(\lambda\) is an activity list depicting the priority of each activity.
When resource constraint is considered, however, this formula is no longer valid. Since activity may be feasible in terms of precedence relation when all of its predecessors have been finished, while simultaneously infeasible for the lack of resource. In other words, one activity has predecessors in both precedence relation logic and resource logic. Besides, a side constraint is added to decode the activity list. To address this problem, similar with Artigues and Roubellat [32], we define an extended precedence relation set as \(G(N, A^{*})\) by adding extra resource flow network into the original activity-on-the-node network G(N, A). The resource flow network exists if there is a resource flow between two activities without precedence relations. Then the starting time of activity i, the function of activity list \(\lambda\) and uncertain durations, can be attained by
where \(\lambda ^{i}\) is the position of activity i in activity list \(\lambda\).
Given an activity list \(\lambda\), one can attain that \(s_{i}(\lambda )\)is monotone increasing function of \(\widetilde{d_{j}}\) where \(\lambda ^{j}<\lambda ^{i}\) or \((j,i)\in A^*\). Therefore, referring to Lemma 3, we have
Theorem 1
Suppose that the duration of activity i has regular distribution \(\Phi _{i}\) and inverse uncertainty distribution \(\Phi ^{-1}_{i}(\alpha )\). Given the activity list \(\lambda\), \(s_{i}(\lambda )\) has an inverse uncertainty distribution \(\Psi _{i}^{-1}(\lambda ,\alpha )\) \(\alpha \in (0,1]\), we can get
With Theorem 1, we can attain that the \(\alpha\)-value of the makespan can be calculated by \(\varvec{d} = (\Phi _{d_{1}}^{-1}(\alpha ), \Phi _{d_{2}}^{-1}(\alpha ), \ldots , \Phi _{d_{n+2}}^{-1}(\alpha ))\). Therefore, referring to Lemma 4, we have
Theorem 2
The expected makespan, depicting by the starting time of dummy end activity, can be attained as follows:
The equivalent form of the uncertain model can be transformed as follows:
With the crisp-form of the expected model, 99-method can be applied to make approximation of the expected makespan.
4 GA-based algorithms
In RCPSP with uncertain durations, the expected duration or medium number is usually employed to replace the random or uncertain numbers and then the deterministic model is applied. However, the optimal solution attained from the deterministic model may perform very poor in real context. Meanwhile, the expected value of calculated makespan, based on the expected value of each activity duration, is often less than the real one. Stork [6] presented that the expected makespan is more than 4 % larger than the deterministic makespan with instances containing 20 activities. Moreover, coherently, Ballestin [7] revealed that this variation may extend to more than 10 % when the number of activities increases to 120.
Even just for precedence constrained jobs without any resource restrictions, the computation of the expected length of a critical path is NP-complete, if each activity processing time distribution has two (discrete) values. Similar to the researches in stochastic cases, uncertain simulation is essential for approximation of the expected makespan.
In order to solve URCPSP, a heuristic algorithm integrated by 99-method and GA is introduced in this section. The chromosome is denoted by the activity list \(\lambda\) in which activities are arranged in different orders on the premise that the precedence relationship is satisfied. Then, with a specific schedule generation scheme, a feasible solution can be gained. Besides, the most essential part of the algorithm is the process of decoding in accordance with different schedule generation schemes, which will be highlighted in this part.
The structure of the hybrid algorithm is as follows:
Step 1: Initialization
The first step is to randomly generate initial population with size Popsize as parent population. Individual creations rely on a list of chromosome representation: an activity order list (\(\lambda\)) in which activities are arranged randomly on the premise that the precedence relationship is satisfied.
Step 2: Crossover
Crossover is the main operation to produce the new chromosomes, simultaneously expanding the population. In this paper, we implement one point crossover. The crossover points are randomly generated as well as the randomly chosen mother and father chromosomes. Taking the position denoted by crossover point as divide, the left positions inherit exactly the same activity order from the mother. Subsequently, the remaining right positions are filled according to the father by left-to-right scan on the premise that the precedence relationship is satisfied, skipping the activities already taken from the mother.
Step 3: Mutation
Mutation is significant for the purpose of population diversity. For the activity order list, mutation begins with randomly selecting the activity which will be mutated. Mutation applied to the activity order list is built to keep list precedence feasible. It determines the predecessor and successor of the selected activity first, taking their positions as bound, and then randomly chooses and inserts in a position in the range to generate a feasible child chromosome.
Step 4: Decoding
In this step, we employ the US-SGS to decode the activity list \(\lambda\) and approximate the fitness of each chromosome by uncertain simulation based on 99-method, initiated by [20] and successfully applied in project scheduling by [27].
The uncertain simulation based on 99-method for \(E[F_{t}]\) is presented in Algorithm 1.
Algorithm 1 (Uncertain simulation for \(E[F_{t}]\))
1: Given an activity list \(\lambda\);
2: Generate \(d_{1}^m, d_{2}^m, \ldots , d_{n}^m\) according to the inverse uncertainty distributions of activities’ durations \(\Phi _{d_{1}}^{-1}, \Phi _{d_{2}}^{-1}, \ldots , \Phi _{d_{n}}^{-1} ,\) and denote \(\varvec{d^m} = (\Phi _{d_{1}}^{-1}(m/100), \Phi _{d_{2}}^{-1}(m/100), \ldots , \Phi _{d_{n}}^{-1}(m/100))\), \(m = 1,2,\ldots ,99\), respectively;
3: Decode the activity list \(\lambda\) by using US-GSG for each \(\varvec{d^m}\), \(m = 1,2,\ldots ,99\). Then the start time \(\varvec{s^{m}}\) and finish time \(\varvec{f^{m}}\) can be attained;
4: \(f_{t}^{m}=s_{n}^{m}\), \(m = 1,2,\ldots ,99\);
5: \(E[F_{t}]\)=\(\sum \limits _{m = 1}^{99}f_{t}^{m}/99.\)
Step 5: Selection
With the purpose of keeping the population size consistent, new parent population requires to be selected from the combined population. This paper employs the genetic roulette wheel selection, in which individuals with better fitness value are awarded with larger probability to be selected in the roulette wheel. Additionally, the top-5 best-to-now chromosomes are specifically preserved in the population. As a consequence, selection process guarantees the high quality of population, and meanwhile avoids the local optimum.
The framework of the algorithm is presented in Fig. 1.

Outline of the hybrid GA algorithm
5 Numerical examples
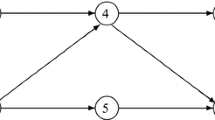
In this section, we consider a project scheduling problem containing 30 activities (J30) and 4 renewable resources. Specially, the durations are estimated by experts and characterized as uncertain variables. Interested readers can consult [11] for more details about how to use experts’ belief degrees to estimate uncertain distributions. Information of the numerical instance including durations, resource utilizations and successor activities is presented in Table 1, and correspondingly, the structure of the project is provided in Fig. 2.

The activity-on-the-node network of the project
To minimize the expected makespan, the following model can be applied.
The algorithm is coded by MATLAB and runs on a PC with core i3 with 2.3GHz clock speed and 2G RAM. The quasi-optimal schedules attained from experiments are presented in Table 2, resulting from 10 times’ run of the hybrid intelligent algorithm with 1000 cycles for the expected models under different parameter settings.
Similar to [33, 34], the quality of solution can be obtained via the deviation of the worst solution from the optimal solution attained in the 10 times’ run and the results are presented in Table 3. The results reveal that the deviation denoted by percent error does not exceed \(5~\%\), which implies the effectiveness of the algorithm integrating uncertain simulations.
Additionally, some other computational experiments are presented. Our test instances are all come from the benchmark library PSPLIB http://www.om-db.wi.tum.de/psplib/data.html initiated by [35] in which different characteristics of the deterministic RCPSP are presented. Since the uncertain simulation is the time-consuming task, this paper only considers four instances with 30, 60, 90 and 120 activities under 4 renewable resource constraints. The uncertain distributions of the activity processing times are generated by \(\fancyscript{Z}(d_{i}-\sqrt{d_{i}},d_{i}, d_{i}+\sqrt{d_{i}})\) with the deterministic \(d_{i}\) as expectation. After running each instance 10 times, the results are presented in Table 4. Referring to Table 4, we can find that the deviation denoted by percent error does not exceed \(10~\%\).
6 Conclusion
In this paper, an uncertain model was proposed to deal with uncertain resource constrained project scheduling problem (URCPSP), in which the durations, with no historical data generally, were described as uncertain variables. Furthermore, an uncertain serial schedule generation scheme (US-SGS) was introduced to process the activities with uncertain durations. Besides, a GA-based hybrid algorithm integrating uncertain simulation was designed to search the quasi-optimal schedule. Numerical examples were provided to illustrate the effectiveness of model and the algorithm as well.
Meanwhile, there are some limitations in this paper. First of all, this paper involves merely one type of indeterminacy, while the real world project might be complicated that randomness (activity duration estimated by historical data) and uncertainty (activity duration estimated by experts’ experienced data) might co-exist. Future research can extend the RCPSP to twofold indeterminacy and correspondingly uncertain random variable can be applied. Secondly, this paper assumed that each activity was executed with one mode, multi-mode RCPSP in uncertain environment can be taken into consideration in further development.
References
Herroelen W, De Reyck B, Demeulemeester E (1998) Resource-constrained project scheduling: a survey of recent developments. Comput Oper Res 25(4):279–302
Blazewicz J, Lenstra JK, Kan A (1983) Scheduling subject to resource constraints: classification and complexity. Discret Appl Math 5(1):11–24
Herroelen W, Leus R (2005) Project scheduling under uncertainty: survey and research potentials. Eur J Oper Res 165(2):289–306
Igelmund G, Radermacher FJ (1983) Preselective strategies for the optimization of stochastic project networks under resource constraints. Networks 13(1):1–28
Tsai YW , Gemmill DD (1998) Using tabu search to schedule activities of stochastic resource-constrained projects. Eur J Oper Res 111(1):129–141
Stork F (2000) Branch-and-bound algorithms for stochastic resource-constrained project scheduling. Technical Rep 702–2000
Ballestín F (2007) When it is worthwhile to work with the stochastic rcpsp? J Sched 10(3):153–166
Ballestin F, Leus R (2009) Resource-constrained project scheduling for timely project completion with stochastic activity durations. Prod Oper Manag 18(4):459–474
Ashtiani B, Leus R, Aryanezhad MB (2011) New competitive results for the stochastic resource-constrained project scheduling problem: exploring the benefits of pre-processing. J Sched 14(2):157–171
Creemers S (2015) Minimizing the expected makespan of a project with stochastic activity durations under resource constraints. J Sched 1–11
Liu B (2015) Uncertainty theory. Springer-Verlag, Berlin
Ke H, Liu B (2010) Fuzzy project scheduling problem and its hybrid intelligent algorithm. Appl Math Model 34(2):301–308
Wang X, Xing H, Li Y, Hua Q, Dong C, Pedrycz W (2015) A study on relationship between generalization abilities and fuzziness of base classifiers in ensemble learning. Fuzzy Syst IEEE Trans 23(5):1638–1654. doi:10.1109/TFUZZ.2014.2371479
Ke H, Liu B (2005) Project scheduling problem with stochastic activity duration times. Appl Math Comput 168(1):342–353
Wang XZ, He YL, Wang DD (2014) Non-naive bayesian classifiers for classification problems with continuous attributes. Cybern IEEE Trans 44(1):21–39
Sun B, Ma W (2015) Rough approximation of a preference relation by multi-decision dominance for a multi-agent conflict analysis problem. Inf Sci 315:39–53
Wang XZ, Dong LC, Yan JH (2012) Maximum ambiguity-based sample selection in fuzzy decision tree induction. Knowl Data Eng IEEE Trans 24(8):1491–1505
Wang XZ, Dong CR (2009) Improving generalization of fuzzy if-then rules by maximizing fuzzy entropy. Fuzzy Syst IEEE Trans 17(3):556–567
Liu B (2007) Uncertainty Theory. Springer-Verlag, Berlin
Liu B (2010) Uncertainty Theory. Springer-Verlag, Berlin
Chen X (2011) American option pricing formula for uncertain financial market. Int J Oper Res 8(2):32–37
Chen X (2012) Variation analysis of uncertain stationary independent increment processes. Eur J Oper Res 222(2):312–316
Ke H., Su T., Ni Y (2014) Uncertain random multilevel programming with application to production control problem. Soft Comput 1–8. doi:10.1007/s00500-014-1361-2
Qin Z, Kar S (2013) Single-period inventory problem under uncertain environment. Appl Math Comput 219(18):9630–9638
Zhang B, Peng J (2013) Uncertain programming model for uncertain optimal assignment problem. Appl Math Model 37(9):6458–6468
Huang H, Ke H (2014) Pricing decision problem for substitutable products based on uncertainty theory. J Intell Manuf. doi:10.1007/s10845-014-0991-7
Zhang X, Chen X (2012) A new uncertain programming model for project scheduling problem. Inf Int Interdiscip J 15(10): 3901–3910
Ji X, Yao K (2014) Uncertain project scheduling problem with resource constraints. J Intell Manuf 1–6. doi:10.1007/s10845-014-0980-x
Ding C, Zhu Y (2014) Two empirical uncertain models for project scheduling problem. J Oper Res Soc. doi:10.1057/jors.2014.115
Ke H (2014) A genetic algorithm-based optimizing approach for project time-cost trade-off with uncertain measure. J Uncertain Anal Appl 2(8)
Ke H, Liu H, Tian G (2015) An uncertain random programming model for project scheduling problem. Int J Intell Syst 30(1):66–79
Artigues C, Roubellat F (2000) A polynomial activity insertion algorithm in a multi-resource schedule with cumulative constraints and multiple modes. Eur J Oper Res 127(2):297–316
Ke H, Liu B (2007) Project scheduling problem with mixed uncertainty of randomness and fuzziness. Eur J Oper Res 183(1):135–147
Zhu J, Li X, Shen W (2011) Effective genetic algorithm for resource-constrained project scheduling with limited preemptions. Int J Mach Learn Cybern 2(2):55–65
Kolisch R, Sprecher A (1997) Psplib-a project scheduling problem library: Or software-orsep operations research software exchange program. Eur J Oper Res 96(1):205–216
Liu Y, Ha M (2010) Expected value of function of uncertain variables. J Uncert Syst 4(3):181–186
Acknowledgments
This work was supported by National Natural Science Foundation of China (No.71371141, 71071113, 71001080), a Ph. D. Programs Foundation of Ministry of Education of China (No. 2010007211011), Shanghai Philosophical and Social Science Program (No. 2010BZH003), and the Fundamental Research Funds for the Central Universities.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
In this section, some concepts and theorems of uncertainty theory are introduced to lay the foundation for the URCPSP modeling. Uncertainty theory is a branch of axiomatic mathematics for subjective uncertainty modeling, which has been well developed and applied in a wide variety of real problems.
Let \(\Gamma\) be a nonempty set, \(\fancyscript{ L }\) a \(\sigma\)-algebra over \(\Gamma\), and each element \(\Lambda\) in \(\fancyscript{L}\) is called an event. Uncertain measure is defined as a function from \(\fancyscript{L}\) to [0, 1]. In detail, the concept of uncertain measure is pioneered by [19] and redefined by [20]. Uncertain measure \(\fancyscript{M}\) is a set function defined over the following four axioms.
Axiom 1
(Normality Axiom) \(\fancyscript{M}\{\Gamma \}=1\).
Axiom 2
(Duality Axiom) \(\fancyscript{M}\{\Lambda \}+\fancyscript{M}\{\Lambda ^{c}\}=1\) for any event \(\Lambda\).
Axiom 3
(Subadditivity Axiom) For every countable sequence of events \(\{\Lambda _{i}\}\), we have:
Axiom 4
(Product Measure Axiom) Let \((\Gamma _k, \fancyscript{L}_{k}, \fancyscript{M}_{k})\) be uncertainty spaces for \(k=1,2,\ldots\), the product uncertain measure \(\fancyscript{M}\) is an uncertain measure satisfying
where \(A_{k}\) are arbitrarily chosen events from \(\fancyscript{ L }_{k}\) for \(k=1,2,\ldots\), respectively.
Definition 1
[19] An uncertain variable is a measurable function \(\xi\) from an uncertainty space \((\Gamma , \fancyscript{ L }, \fancyscript{M})\) to the set of real numbers, i.e., for any Borel set B of real numbers, the set
is an event.
The uncertainty distribution is indispensable to establish the practical uncertain optimization problems model.
Definition 2
[19] The uncertainty distribution \(\Phi\) of an uncertain variable \(\xi\) is defined by
for any real number x.
An uncertainty distribution \(\Phi\) is confirmed to be regular if its inverse function \(\Phi ^{-1}(\alpha )\) exists uniquely for each \(\alpha \in [0,1]\).
Definition 3
[19] Let \(\xi\) be an uncertain variable. The expected value of \(\xi\) is defined by
provided that at least one of the above two integrals is finite.
Lemma 1
[20] Let \(\xi\) be an uncertain variable with uncertainty distribution \(\Phi\). If the expected value exists, then
Lemma 2
([20]) Let \(\xi\) be an uncertain variable with regular uncertainty distribution \(\Phi\). If the expected value exists, then
Example 1
The expected value of the zigzag uncertain variable \(\xi =\fancyscript{ Z }(a,b,c)\) is:
Lemma 3
[20] Let \(\xi _{1}, \xi _{2}, \ldots ,\xi _{n}\) be independent uncertain variables with regular uncertainty distributions \(\Phi _{1},\Phi _{2},\ldots ,\Phi _{n}\), respectively. A function \(f(x_{1},x_{2},\ldots ,x_{n})\) which is strictly increasing with respect to \(x_{1},x_{2},\ldots ,x_{m}\) and strictly decreasing with respect to \(x_{m+1},x_{m+2},\ldots ,x_{n}\). Then the \(\xi =f(\xi _{1},\xi _{2},\ldots , \xi _{n})\) is an uncertain variable with inverse uncertainty distribution
Lemma 4
[36] Let \(\xi _{i}(i = 1, 2, . . . , n)\) be independent uncertain variables with regular uncertainty distributions \(\Phi _{1},\Phi _{2},\ldots ,\Phi _{n}\) respectively. If a function \(f(x_{1},x_{2},\ldots ,x_{n})\) is strictly increasing with respect to \(x_{1},x_{2},\ldots ,x_{m}\) and strictly decreasing with respect to \(x_{m+1},x_{m+2},\ldots ,x_{n}\) , respectively, then the expected value of uncertain variables \(\xi =f(\xi _{1},\xi _{2},\ldots , \xi _{n})\) has an expected value as follows:
provided that the expected value \(E[\xi ]\) exists.
Rights and permissions
About this article

Cite this article
Ma, W., Che, Y., Huang, H. et al. Resource-constrained project scheduling problem with uncertain durations and renewable resources. Int. J. Mach. Learn. & Cyber. 7, 613–621 (2016). https://doi.org/10.1007/s13042-015-0444-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13042-015-0444-4