
Abstract
Soil liquefaction is one of recognized nonlinear devastating types of ground failures associated with earthquakes. The analyses frameworks for this phenomenon have been addressed using different methods and correlated triggering factors in case histories. In the current paper, a hybrid model using imperialistic competitive metaheuristic algorithm (ICA) incorporated with multi-objective generalized feedforward neural network (MOGFFN) for the purpose of liquefaction potential analysis was assessed. The optimum hybrid ICA-MOGFFN model was applied on a diversified database of 296 compiled case histories comprising nine of the most significant effective parameters on liquefaction. The result of ICA-MOGFFN model demonstrated for 3.01%, 2.09% and 7.46% progress in the success rates for the safety factor, liquefaction occurrence and depth of liquefaction. Accordingly, the conducted precision–recall curves showed 5.08%, 1.73% and 3.92% improvement compared to MOGFFN. Further evaluations using different statistical metrics represented superior progress in performance of hybrid ICA-MOGFFN. The capability of the developed method then was approved from observed agreement with other accepted procedures. The results implied that the developed hybrid model was a flexible and accurate enough tool that can effectively be applied for the liquefaction potential analyses. Using sensitivity analyses, the most and least effective inputs on the predicted liquefaction parameters were identified.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Liquefactions are earthquake-induced ground failure disasters that due to applied stress during excitations, the soil materials behave like liquid. This process has for the first time been defined by Hazen (1919) as a consequence of insufficient time for drainage and the building up water pressure through the soil grains. In such a condition, the seismic disturbance provokes a large drop in stiffness and loss of strength and thus the stability of saturated, unconsolidated or sandy soils (e.g., Kramer 1996). The liquefaction potential analysis (LPA) and corresponding susceptibility of a soil deposit can be evaluated using historical, geological, compositional and state criteria (Kramer 1996; Boulanger and Idriss 2014). Historical criteria provide information on earlier earthquakes, where the previously liquefied soils can be candidates of future events (Cetin et al. 2000; Abbaszadeh Shahri 2016; Green et al. 2014). Such case histories have been reported in several experienced earthquakes (e.g., Nigata 1964; Alaska 1964; San Fernando 1971; Loma preita 1989; Manjil 1990; Kobe 1995; Izmit 1999; Canterbury 2011, etc.). Geological criteria deal with the influence of soil deposits on LPA. This implies that the saturated sediments in rivers and lakes (fluvial or alluvial), debris or eroded material (colluvial), wind deposits (aeolian) and man-made hydraulic filling have shown more proneness for liquefaction (Davis and Berrill 1998). Compositional criteria refer to soil particle sizes, where the analogs provide more susceptibility (Hakam 2016; Sawicki and Mierczynski 2006; Ishibashi 1985). The initial condition of a soil (e.g., density, effective stress) subjected to dynamic loading is expressed in state criteria, where looser soils at higher effective stresses are generally more liquefiable (Kramer and Seed 1988).
The imposed catastrophic damages to structures and human activities imply that studies on identification of LPA, especially in seismic areas, have shown great concern in sustainable land use development to prevent disaster and make disaster prevention plans (Abbaszadeh Shahri et al. 2012a). However, assessment of LPA due to interlinking with diverse geological, mechanical and seismological factors is a complex seismic geotechnical engineering problem. Therefore, finding a fast, but reliable and accurate enough LPA (Boulanger and Idriss 2014; Abbaszadeh Shahri et al. 2013; Cabalar et al. 2012), due to high computational cost of current numerical and analytical methods, is a highly challenging task (Bi et al. 2019).
In recent years, different LPA models through geotechnical in situ tests (standard/cone penetration tests, SPT/CPT) and seismic records have been developed using subcategories of artificial intelligence (AI) and data mining techniques. In literature, artificial neural networks (ANNs)-based models (Tung et al. 1993; Goh et al. 2002; Ramakrishnan et al. 2008; Abbaszadeh Shahri 2016; Xue and Liu 2017; Bi et al. 2019; Njok et al. 2020), support vector machine (Pal 2006; Samui et al. 2011; Xue and Yang 2016), fuzzy (Rahman and Wang 2002), extreme learning machine (Samui et al. 2016), ANFIS (Xue and Yang 2013), decision tree (Ahmad et al. 2019), hybrid models (Rahbarzadeh and Azadi 2019; Hoang and Bui 2018; Xue and Xiao 2016), gene expression programming (Kayadelen 2011), patient-ruled induction method (Kaveh et al. 2018) and stochastic gradient boosting (Zhou et al. 2019) have been utilized successfully for liquefaction susceptibility in different countries. It has also has been shown that incorporating of ANN-based models with metaheuristic algorithm can lead to remarkable progress in predictability level (Hosseini and Al Khaled 2014; Asheghi et al. 2019; Atashpaz Gargari and Lucas 2007). Efficiency, flexibility and model independency are some of the main substantial features of these algorithms (Barbosa and Senne 2017). Flexibility refers to applicability of metaheuristic algorithms on the multi-objective problem with parallel machines and maintenance cost. Although such capability allows the algorithm to find acceptable solutions in a wide range of problems, it demands deep efforts to correctly tune parameters. This implies that tuning the parameters of metaheuristics is an important issue in the context of the design and application (Barbosa and Senne 2017). Efficiency then also refers to the obtained results from the assigned parameters during the optimization. Imperialistic competitive algorithm (ICA) is one of the recently developed metaheuristics inspired by socio-political behaviors (Atashpaz Gargari and Lucas 2007). The optimization process in ICA is motivated by countries that play the role of individual populations. These countries, then using a defined fitness function based on their power, are divided into colonies and imperialists. Accordingly, two operators (assimilation and revolution) and imperialistic competition strategy are applied on the formed empires comprising imperialistic countries and corresponding attracted colonies. Using this algorithm, the empires try to win and take possession of more colonies, even those belonging to other empires. The competition depends on the power of the empire and consequently in each step of the algorithm the chance of weak empires decays until omitted from the competition process. This global search optimization algorithm can provide an evolutionary computation without requiring the gradient of the function. The process iteratively is performed to satisfy a stop condition. Literature reveals that in recent years, ICA has been applied successfully for optimizing the single and multi-objective ANNs model in engineering applications (e.g.,Hosseini and Al Khaled 2014; Pan et al. 2018; Asheghi et al. 2019).
In the current paper, a novel hybridized intelligence model for the purpose of LPA was introduced and discussed. Applying the ICA on multi-objective generalized feedforward neural network (MOGFFN) and forming hybrid ICA-MOGFFN model are the main keys of this paper. The neurons of MOGFFN were simulated using the shunting model (Furman 1965). It has been found that shunting neuron, due to considerable plausibility in receiving two inputs (one excitatory and one inhibitory) and incorporating to the spatial extent of the dendritic tree, can provide much more advantages than percepterons (Koch et al. 1983; Arulampalam and Bouzerdoum 2002; Ghaderi et al. 2019; Abbaszadeh Shahri et al. 2020). Higher computational potencies as well as more flexibility than multilayer percepterons (MLPs) in the same number of neurons (Abbaszadeh Shahri et al. 2015; Arulampalam and Bouzerdoum 2002; Ghaderi et al. 2019) were the reasons why GFFN was selected. The models were evaluated using 296 assembled datasets (Table 1). These discrete datasets including unit weight (γ), SPT value, shear wave velocity (Vs), fine content (FC), cyclic stress ratio (CSR), cyclic resistance ratio (CRR), maximum acceleration at the investigated site (amax) as well as effective vertical stress (σ′v) and stress reduction factor (rd) were retrieved from various depth horizons of different case histories worldwide. The observed improvement in success rates demonstrated that ICA can efficiently be applied to the multi-objective LPA problems. Accordingly, the applicability of hybrid ICA-MOGFFN model as an effective tool then was confirmed using conducted precision–recall curves, statistical accuracy metrics and previous known procedures. Further, the importance of the employed factors on predicted LPA was ranked using the sensitivity technique.
Compiled database
The quality of the acquired data due to effectiveness of the considered output plays key role in organizing the intelligence systems. Previous studies showed that the effective factors on LPA simply can be decomposed into observational records (detected at sites), borelog-based extracted information (e.g. location, soil type, layer thickness), results of in situ geotechnical tests (e.g., SPT, CPT, sieve analysis and FC, γ, pore pressure), earthquake-related parameters (e.g., VS, epicentral distance, CSR, CRR, amax) as well as computed parameters (e.g., σv, σ′v, rd). In this paper, a combination of recommended factors according to literature (e.g.,Youd et al. 2001; Seed and Idriss 1971; Seed et al. 1983; Finn 2002; Cabalar and Cevik 2009; Liao et al. 1988; Tokimatsu and Yoshimi 1983; Cetin et al. 2000, 2018) was managed. Accordingly, a comprehensive database comprising the rd, SPT, FC, γ, VS, CSR, CRR, amax and σ′v was assembled using validated resources (Cetin et al. 2018; Idriss and Boulanger 2014) and then updated with relevant observed or studied case histories of Iran (Yegaian et al. 1995; Abbaszadeh Shahri et al. 2012a, b, 2013; Abbaszadeh Shahri 2016; Kouzegar 2013; Naghizadehrokni et al. 2018). Table 1 shows the characteristics and simple statistical analysis of acquired datasets. The CSR reflects the seismic demand of a soil layer and CRR points out to the capacity of the soil to resist liquefaction. Therefore, liquefaction will occur while CSR > CRR.
MSSD, as non-biased estimation to St.Dev, is a common test to determine the randomness of sequence observations (Von Neumann et al. 1941). Due to involving a successive differentiation process, MSSD is stable and less sensitive to low-frequency drift. The significant difference between the estimated MSSD and the usual variance implies that the process is not random and not in control (Holmes and Mergen 1995). Skewness is a metric that describes the asymmetry of the probability distribution of random variables. In unimodal distributions, negative skew commonly refers to the left side stretched distribution, and positive value reflects that the tail is on the right. Therefore, this descriptive statistic is used in conjunction with the histogram and the normal plot to characterize the data or the deviated direction and relative magnitude of a distribution from the normal sate (Joanes and Gill 1998).
Subsequently, compiled components were then randomized by 55%, 25% and 20% to generate training, testing and validation sets. To improve the learning speed and model stability, the normalizing procedure was applied on datasets to provide dimensionless unified data within the [0, 1] interval.
Applied method to delineate liquefaction potential analysis
Layout of GFFN
The ANNs is a powerful computerized layout of the human brain structure, which can be learned to emulate nonlinear behavioral models. According to Fig. 1a, the output of a jth neuron in hidden layer (yj) is a combined set of weights (W) and biases (b) as:

Structure of perceptron a, applied GSN b and GFFN classifier c in producing the output
where X denotes the input vector. f is the applied activation function on the aggregated signal in the output. Correspondingly, the result of the kth neuron in the output layer (Zk) using yj and the primary input (xi) then are expressed using:

where bj and bk are the bias weights for setting the threshold values. f and g are the applied activation function on the hidden and output layers.
The shunting model (Furman 1965), due to considerable plausibility in receiving two inputs (one excitatory and one inhibitory), has been highlighted in ANNs (Arulampalam and Bouzerdoum 2002; Ghaderi et al. 2019; Asheghi et al. 2019; Abbaszadeh Shahri et al. 2020). This model of neuron then was developed to incorporate the spatial extent of the dendritic tree and the relative positioning of excitatory and shunting inhibition inputs (Koch et al. 1983). The input lines are thought to alter in a postsynaptic neuron in such a way that excitatory input transmits the signals in preferred directions, while in the null direction the response of the excitatory synapse is shunted by the simultaneous activation of the inhibitory synapse (Arulampalam and Bouzerdoum 2002). Therefore, the influence of inhibitory inputs cause shunting on a portion of the excitatory inputs that typically provides significant potentials (Koch et al. 1983; Vida et al. 2006; Arulampalam and Bouzerdoum 2002; Krekelberg 2008; Asheghi et al. 2019; Abbaszadeh Shahri et al. 2020). The two inputs are organized depending on the designed sequences to lead the preferred response to temporally non-overlapping channels. Previous studies (e.g.,Arulampalam and Bouzerdoum 2002; Ghaderi et al. 2019; Asheghi et al. 2019; Abbaszadeh Shahri et al. 2020) have shown that the capability of the neuron can be improved using shunting inhibition (Fig. 1b). Consequently, the GFFN is then configured by replacing the generalized shunting neuron (GSN) (Fig. 1b). The substitution dedicates a subclass of multilayer perceptrons (MLPs) in which the connecting system can jump over one or more layers. This ability (Fig. 1c) allows neurons to operate as adaptive nonlinear filters and provide higher flexibility (Arulampalam and Bouzerdoum 2002; Ghaderi et al. 2019; Asheghi et al. 2019). Therefore, in the same number of neurons, the GFFN due to applied GSN often solves the problem much more efficiently than MLPs (Abbaszadeh Shahri et al. 2015). In such topology, all input is summed and passed through an activation function like a perceptron neuron to produce the output as:
where xj is the output (activity) of the jth neuron; Ij and Ii are inputs to the ith and jth neurons; aj is the passive decay rate of the neuron (positive constant); wji and cji are the connection weight from the ith inputs to the jth neuron; aj and bj are the constant biases; g and f are the activation functions.
The output function of the jth neuron then can be calculated by:
where Oj denotes the output value. The specific error for each sample (Errp) and the corresponding total error (Err) based on a single training sample for the kth output neuron is defined as:
where tk and yk express the actual and output, respectively. To find the optimum weight, the training process changes the weights from neuron i to k (Δwi,j) using adjusted learning rate (η):
Subsequently, this iterative procedure updates the weight for the (n + 1)th pattern using:
Brief description of ICA
The inspired evolutionary methods from natural processes have shown good performance in solving complex optimization problems (Xing and Gao 2013). The ICA, as a robust computational evolutionary algorithm based on imperialist competitive through governmental power and policy systems (Atashpaz Gargari and Lucas 2007), was initially dedicated to the continuous optimization problems. However, this algorithm is currently applied on different complex discrete optimizing issues. Like other evolutionary algorithms, ICA also starts with a random initial ensemble population.
In ICA, the countries (Ncou) play the role of individual populations and, based on cost function, categorized into colonies (Ncol) and imperialists (Nimp), where those with minimum values are selected to be Nimp and the rest fall in colonies Ncol. Subsequently, one empire is formed by imperialist and its corresponding colonies (Fig. 2a). According to Atashpaz and Lucas (2007), an iterative procedure subjected to two operators (assimilation and revolution) and one strategy (imperialistic competition) is configured to eliminate the weakest empires (Fig. 2b–d). The assimilation operator aims to move each colony toward the best solution in the population. Here, imperialistic stands for the best solution and colonies play the role of non-best solution. During assimilation, a sub-population around each imperialist country is formed. Accordingly, the competition processes between imperialists remove the colonies of the weakest sub-population and adds it to another sub-population. In this algorithm, the minimum cost of the initial generated population (Ncou) is selected to be imperialists and the rest play the role of colonies (Ncol). Competition procedure between imperialistic empires causes the colonies to move directly or partially absorbed toward a stronger imperialist to improve their situations. Similar to genetic algorithm (GA) in preventing early convergence to local optima in the search space, ICA uses an embedded revolution process (sudden random changes) to release the trapped colonies. Then, if the new position of the colony possesses a lower cost function than the imperialist, it will be exchanged with the imperialist and vice versa. The more the empire power, the more attracted are the colonies; thus, the weakest empire, because of losing colonies, is gradually collapsed and eliminated (Fig. 2d). Consequently, increasing the empire power approaches to attracting more colonies that implies tending to converge to only one robust empire in the domain of the problem as the desired solution.

Simplified scheme of ICA including a initialized populations to form imperialistic countries and corresponding attracted colonies, b applying assimilation and revolution process when the algorithm get stuck in local optimums and c, d competition scheme between empires to eliminate the weakest
Referring to Atashpaz and Lucas (2007), this algorithm is mathematically configured by a series of parameters (Table 2), which can optimally be adjusted through previous studies (e.g., Asheghi et al. 2019).
The total power of the nth empire (TPn) as summation of the power of imperialist and its attracted colonies is expressed by:
where ξ (Table 2) as a positive value falls within the [0, 1] interval. Small and large values of ξ can affect the TP by the imperialist and the mean power of colonies, respectively. This implies that ξ usually needs to be considered close to 0.
Accordingly, the possession probability of each empire (pn) as result of competition process based on total power is calculated as:
where TCn and NTCn denote the total and normalized cost of the nth empire.
Compared to the genetic algorithm (GA), ICA is a mathematical simulation of human social evolution and can be considered as the social counterpart, while GAs are based on the biological evolution of species (Asheghi et al. 2019). Furthermore, the distribution mechanism of ICA is the probability density function (PDF) which compared to GA requires less computation effort. Referring to these advantages, experimental results using ICA demonstrated to effectively overcome the trapping problem and achieve the global optimum in a low number of iterations. The ease of performing neighborhood movement, less dependency on initial solutions, and having a better convergence rate are the approved advantages of this algorithm. However, ICA suffers for getting stuck in the local optimum area, especially in multimodal and high-dimensional problems (Hosseini and Al Khaled 2014; Asheghi et al. 2019). It also has been indicated that the mechanism for improving the quality of imperialist countries is weak. This implies that the exchanging procedure for improving the power of imperialist countries causes the slow convergence speed. In each generation, only one colony is directly affected by the competition operation, while all colonies are moved by the assimilation operation. This shows that the impact of the competition operation is weaker than the assimilation. Although the quality of each empire during the iteration is improved via the assimilation operator, due to monotonic nature and especially in high-dimensional problems, it cannot be adapted with the search process. Therefore, expedition in finding the location of the globally optimal position in the search space can be achieved through improving the exchanging mechanism. Most of the previous studies on ICA have been focused on improving or replacing the assimilation operator and not on enhancing the interaction among the empires. In low-quality improvement, the weak empires are eliminated quickly and, consequently, population diversity quickly degrades and thus the algorithm is trapped in local optima due to loss of diversity. Therefore, the competition interaction only involves an ill-conditioned solution, i.e., colony from the weakest empire to another and hence this implies poor quality to describe the moving and competition process (Lin et al. 2012; Ji et al. 2016). More insights about the organized formula can be found in Atashpaz Gargari and Lucas (2007), Atashpaz-Gargari et al. (2008), Hosseini and Al Khaled (2014) and Asheghi et al. (2019).
Configuring the optimum hybridized ICA-MOGFFN model
In this paper, numerous MOGFNN-based models subjected to diverse internal characteristics for prediction of liquefaction possibility were developed. Access to an optimum model and avoiding network overfitting and trapping in local minima due to an unaccepted unique method are difficult and important tasks (Ghaderi et al. 2019; Abbaszadeh Shahri 2016). As presented in Fig. 3, the incompetence of these problems was efficiently solved using an iterative procedure integrated with a constructive technique to examine and adjust different sets of internal characteristics (e.g., training algorithm, number and arrangement of neurons, learning rate and activation function). In Fig. 3, the TA, AF and J are referred to the training algorithm, activation function and number of neurons in hidden layers. In this procedure, the models were trained using five learning rules, and thus in the proposed procedure this characteristic was varied between 1 and 5. The quick propagation (QP), conjugate gradient descent (CGD), momentum (MO), Levenberg–Marquardt (LM) and quasi-Newton (QN) are applied to train the models. Subsequently, sigmoid (Sig) and hyperbolic tangent (HyT) were utilized for activation functions. The sum of squares and cross-entropy were managed for output error function. The presented procedure in Fig. 3 was developed using C++ programming environment. To reduce the network complexities, the learning rate (η) of 0.7 with step sizes within [1.0–0.001] interval was managed. Such implementing of training algorithms and activation functions subjected to different step sizes for learning rate can minimize the risk of overfitting and trapping local minima and increase the accuracy of the investigated models. For example, replacing the CGD by MO with step size 0.001 minimizes the chances that it gets stuck in a local minimum. The procedure will break if a two-step termination criterion is met. The priority is to satisfy the minimum target root mean square error (RMSEmin) and, if not achieved, the number of iterations (here set for 1000) will be used. This criterion assists in monitoring those topologies which during the iteration provide lower RMSEmin than the previously examined model. Moreover, the embedded loop in Fig. 3 enables to capture various topologies with similar structure, but different internal characteristics. The most appropriate structure after three runs was subjected to initial randomized datasets and then selected through the observed RMSEmin and maximum network coefficient of determination (R2). The number of neurons (J) as a user-defined characteristic was set to break at 20. As presented in Table 3, the optimum network topology subjected to the determined internal characteristics was found through different arrangements of the number of neurons corresponding to RMSEmin. The performance of the optimum model then should be examined by testing datasets and then assessed by means of validation sets subjected to different accuracy metrics and statistical error indices. The view of executed efforts to distinguish appropriate MOGFFN structure is reflected in Fig. 4.

Schematic employed hybridizing procedure for model optimization

Variation of network RMSE vs. number of neurons using different training algorithm and activation functions (a) and an example of series analyzed MOGFFN structures subjected to MO training algorithm and HyT activation function (b)
To optimize the predictability level and minimize the error of optimum MOGFFN, hybridizing with ICA (Fig. 3) was carried out. An appropriate optimizing process needs to properly select ICA parameters (Table 2), which can be determined using previous studies or parametric investigations (Asheghi et al. 2019). Here, according to previous studies, values of 2, π/4 and 0.02 were assigned to β, θ and ζ (Atashpaz and Lucas 2007; Asheghi et al. 2019; Hosseini and Al Khaled2014). Optimal Ncou, Ndec and Nimp were then assessed using parametric inquiries. To determine the proper Ncou, 12 hybrid models was trained using the developed MOGFFN structure. This process was carried out through the analyzed R2 and RMSEmin (Fig. 5a, c). Nimp also was specified using computed R2 and RMSE of ICA-MOGFFN models (Fig. 5b, d). Following a similar process, the boundary with the lowest variation in RMSE was subjected to different Ncou leads to delineate optimum Ndec (Fig. 5e). Accordingly, the optimum MOGFFN structures (9–5–7–3) were then hybridized by ICA and trained subjected to characterized parameters (Table 4).

Determining the optimum values of the required parameters in ICA using R2 and RMSE a, c Ncou, b, d Nimp and e Ndec
Results of system analysis
The performance of intelligence models for given data can be captured using cost function to quantify the error between predicted and expected values in the form of a single real number. Convergence history then refers to loss reduction per each proceeding epoch on trained datasets. In this study, mean square error (MSE) was considered as the cost function. Comparison of two models (Fig. 6a) shows that MOGFFN after 718 and ICA-MOGFFN after 345 epochs converged to corresponding minimized cost function. More decrease in cost function in the proposed hybrid ICA-MOGFFN than MOGFFN reveals better performance to handle and solve the liquefaction analysis. The efficiency of ICA in the error improvement of the used models also was monitored to control the possible saturation of activation function, overfitting and trapping in local minima (Fig. 6b). This criterion shows the predictability and network performance during the last and or each iteration and consequently can detect the situation when the network does not improve and further training is unavailable. The performance and predictability levels of both MOGFFN and ICA MOGFFN models using randomized training and testing datasets were then figured out and are reflected in Fig. 6(c–g). Liquefaction occurrences are categorical data and, thus for conversion, 0 (Not observed) and 1 (observed) were assigned to be interpretable in mathematical concept. Therefore, the model predicts the liquefaction occurrences in (0, 1) intervals and this is the reason for the scatters produced in Fig. 6e.

Convergence history (a), error improvement (b), and compared predictability of optimum MOGFFN and hybrid ICA-MOGFFN models for SF (c, d), liquefaction occurrence (d) as well as critical depth of liquefaction (f, g) using randomized training and testing datasets
Discussion and validation
Using the confusion matrix, the performance of the system in distinguishing different classes can be quantified and evaluated (Asheghi et al. 2019). The conducted confusion matrix and the calculated model progress in terms of correct classification rate (CCR) and classification error (CE) as reflected in Tables 5 and 6, respectively. Results show that using a hybrid model, the predictability level of SF, liquefaction occurrences and critical depth 3.1%, 2.09% and 7.46% were improved. This implies that applying the ICA on optimum MOGFFN significantly decreased the CE to 16.05%, 8.37% and 39.64%, respectively.
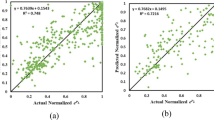
The area under the curve (AUC) is an informative efficient sorting-based algorithm that measures the entire area under the two-dimensional curve from (0, 0) to (1, 1). This scale-invariant metric represents how well predictions are ranked and correspondingly reflects the quality of the predictive model irrespective of what classification threshold is chosen. Using AUC, the true positive rate (the proportion of the individuals with a known positive condition for which the test result is positive) and true negative rate (the proportion of the individuals with a known negative condition for which the test result is negative) can be extracted. Therefore, AUC provides an aggregate measure of performance across all possible classification thresholds. It can also be interpreted as the priority of the model probability in ranking a random positive than negative example. However, in the presence of wide discrepancies, the AUC is not a useful metric to minimize one type of classification error (Fawcett 2006; Hand and Till 2001, 2013). In Fig. 7, the occupied area under curves (AUC) and scatter plots are presented. The AUC of precision–recall as a useful metric reflects the model skill in success of truly predicted results that can directly be compared for different thresholds to get the full picture of evaluation. Here, 3%, 1.4% and 2.1% progress for SF, liquefaction occurrences and critical depth were observed, which demonstrate higher accuracy of the hybrid model.

Comparing the AUC of precision–recall curves (a), predictability level of SF (b, c), depth of liquefaction (d, e) and liquefaction occurrence (f) using ICA-MOGFFN and MOGFFN
Subsequently, the accuracy performance of models was pursued using statistical error indices (Table 7). Here, the mean absolute percentage error (MAPE) for the description of the accuracy and size of the forecasting error, variance account for (VAF) as an intrinsically connected index between the predicted and actual values and the index of agreement (IA) (Willmott 1984) representing the compatibility of the model and observations were implemented. Higher values of VAF, IA and R2 as well as smaller values of MAPE and RMSE exhibit better model performance (Table 7).
The predictability of models was also compared with the procedures proposed by Seed and Idriss (1971), Liao and Whitman (1986) and Youd et al. (2001). According to the results of Table 8, 92.91% correlation of ICA-MOGFFN with observation showed acceptable accuracy.
The contribution of applied factors on predicted outputs (SF, liquefaction occurrence and depth of liquefaction) can be identified using sensitivity analysis techniques (Asheghi et al. 2020). Such analyses provide feedback to prune the input space by removing the insignificant channels to reduce the size of the network and consequently reducing complexity and training times. In this paper, the results of sensitivity analyses using cosine amplitude method (Eq. 11) for network outputs are presented. To represent the importance of each parameter (Fig. 8), all data pairs are expressed in common X-space to provide a data array. The assigned data pairs to a point in m-dimensional space then are described by m-coordinates, where the membership value of each element in m-dimensional space (Rij) in the form of an \(m\times m\) matrix is expressed by a pairwise comparison of two data samples (xi and xj):

Identified effectiveness of applied input factors on predicted network output
It was observed that CRR, Vs and CSR provide significant effect on network output, whereas γ and FC were classified as the factors with least influences.
Concluding remarks
Prediction of the liquefaction potential due to the heterogeneous nature of the soils and participation of a large number of effective factors are complex geotechnical engineering problems. Therefore, refinement of predictive liquefaction models highly depends on the established precedent of case history database. Access to such archived information can effectively improve the interpretation of the analyzed results. In this study, the information of 296 case histories including a wide range of effective parameters was applied on the MOGFFN model to evaluate the liquefaction potential analysis. The model was arranged using rd, SPT, FC, γ, VS, CSR, CRR, amax and σ’v as inputs, while SF, liquefaction occurrence and depth of liquefaction were considered to be desired outputs. Examined models showed that a four-layer MOGFFN with 9–5–7–3 structure can be selected as the optimum topology. According to system analyses, the predictability level of the model was significantly improved by applying ICA and forming a multi-objective hybrid structure. The reduction of RMSE impacted on the effectiveness and efficiency of ICA in the prediction of liquefaction potential problems. For the optimum MOGFFN, 83.8%, 79.7% and 83.1% were achieved as success rates of SF, liquefaction occurrence and depth of liquefaction. These values subjected to hybrid model then were improved to 86.4%, 81.4% and 89.8%, respectively. Moreover, the predicted liquefaction using hybrid ICA-MOGFFN with 93.24% showed higher accuracy than MOGFFN and traditional methods. The evaluated accuracy metrics using different statistical indices and AUC of precision–recall curves indicated more precise results and greater classification accuracy and consequently prior applicability of hybridized model than MOGFFN. Sensitivity analysis showed that the CRR, Vs and CSR can be the categorized as the main effective parameters on predicted liquefaction potential, whereas γ and FC ranked as the least important.
The results confirmed that the hybridized ICA-MOGFFN as a feasible but powerful computational tool can successfully capture the complex relationship between soil and seismic parameters in liquefaction assessment. Due to the approved capability of ICA in multi-objective models, it is anticipated that the current investigation will lead to greater understanding and more developments in liquefaction potential purposes. Thus, this hybridized model can be considered as a novel predictive liquefaction framework worthy of promotion and support.
Abbreviations
- ICA :
-
Imperialistic competitive metaheuristic algorithm
- MOGFFN :
-
Multi-objective generalized feedforward neural network
- LPA :
-
Liquefaction potential analysis
- SPT/CPT :
-
Standard/cone penetration tests
- MLPs :
-
Multilayer percepterons
- γ:
-
Unit weight
- Vs :
-
Shear wave velocity
- FC :
-
Fine content
- CSR :
-
Cyclic stress ratio
- CRR :
-
Cyclic resistance ratio
- a max :
-
Maximum acceleration at investigated site
- σ′ v :
-
Effective vertical stress
- r d :
-
Stress reduction factor
- N cou :
-
Number of countries
- N col :
-
Number of colonies
- N imp :
-
Number of imperialists
- TA/AF/J :
-
Training algorithm/activation function/number of neurons in hidden layers
- RMSE min :
-
Minimum root mean square error
References
Abbaszadeh Shahri A (2016) Assessment and prediction of liquefaction potential using different artificial neural network models - a case study. Geotech Geol Eng 34(3):807–815. https://doi.org/10.1007/s10706-016-0004-z
Abbaszadeh Shahri A, Behzadafshar K, Rajablou R (2013) Verification of a new method for evaluation of liquefaction potential analysis. Arab J Geosci 6(3):881–892. https://doi.org/10.1007/s12517-011-0348-x
Abbaszadeh Shahri A, Rajablou R, Ghaderi A (2012a) An improved method for seismic site characterization with emphasis on liquefaction phenomena. Open J Earthq Res 1(2):13–21. https://doi.org/10.4236/ojer.2012.12002
Abbaszadeh Shahri A, Esfandiyari B, Rajablou R (2012b) A proposed geotechnical-based method for evaluation of liquefaction potential analysis subjected to earthquake provocations (case study: Korzan earth dam, Hamedan province, Iran). Arab J Geosci 5:555–564. https://doi.org/10.1007/s12517-010-0199-x
Abbaszadeh Shahri A, Larsson S, Renkel C (2020) Artificial intelligence models to generate visualized bedrock level: a case study in Sweden. Model Earth Syst Environ 6:1509–1528. https://doi.org/10.1007/s40808-020-00767-0
Abbaszadeh Shahri A, Larsson S, Johansson F (2015) CPT-SPT correlations using artificial neural network approach: a case study in Sweden. Electron J Geotech Eng Vol. 20. Bund 28:13439–13460
Ahmad M, Tang XW, Qiu JN, Ahmad F (2019) Evaluating seismic soil liquefaction potential using Bayesian belief network and C4.5 decision tree approaches. Appl Sci 9(20):4226https://doi.org/10.3390/app9204226
Arulampalam G, Bouzerdoum A (2002) Expanding the structure of shunting inhibitory artificial neural network classifiers. IJCNN, IEEE. https://doi.org/10.1109/IJCNN.2002.1007601
Asheghi R, Abbaszadeh Shahri A, Khorsand Zak M (2019) Prediction of uniaxial compressive strength of different quarried rocks using metaheuristic algorithm. Arabian J Sci Eng. https://doi.org/10.1007/s13369-019-04046-8
Asheghi R, Hosseini SA, Saneie M, Abbaszadeh Shahri A (2020) Updating the neural network sediment load models using different sensitivity analysis methods- a regional application. J Hydroinf 22(3):562–577. https://doi.org/10.2166/hydro.2020.098
Atashpaz-Gargari E, Hashemzadeh F, Rajabioun R, Lucas C (2008) Colonial competitive algorithm, a novel approach for PID controller design in MIMO distillation column process. Int J Intell Comput Cybern 1(3):337–355. https://doi.org/10.1108/17563780810893446
Atashpaz Gargari E, Lucas C (2007) Imperialist competitive algorithm: an algorithm for optimization inspired by imperialistic competition. In: Proceedings of the IEEE Congr Evol Comput, pp 4661–4667.
Barbosa EBM, Senne ELF (2017) Improving the fine-tuning of metaheuristics: an approach combining design of experiments and racing algorithms. J Optim. https://doi.org/10.1155/2017/8042436
Bi C, Fu B, Chen J, Zhao Y, Yang L, Duan Y, Shi Y (2019) Machine learning based fast multi-layer liquefaction disaster assessment. World Wide Web 22:1935–1950. https://doi.org/10.1007/s11280-018-0632-8
Boulanger RW, Idriss IM (2014) CPT and SPT based liquefaction triggering procedures. Report No. UCD/CGM-14/0, Center for Geotechnical Modeling, Department of Civil and Environmental Engineering, University of California, Davis, CA.
Cabalar AF, Cevik A, Gokceoglu C (2012) Some applications of adaptive neuro-fuzzy inference system (ANFIS) in geotechnical engineering. Comput Geotech 40:14–33. https://doi.org/10.1016/j.compgeo.2011.09.008
Cabalar AF, Cevik A (2009) Genetic programming-based attenuation relationship: an application of recent earthquakes in turkey. Comput Geosci 35(9):1884–1896. https://doi.org/10.1016/j.cageo.2008.10.015
Cetin KO, Seed RB, Moss RES, Der Kiureghian AK, Tokimatsu K, Harder LF, Kayen RE (2000) Field performance case histories for SPT-based evaluation of soil liquefaction triggering hazard. Report No. UCB/GT-2000/09, Geotechnical Engineering, Department of Civil Engineering, University of California at Berkeley, CA
Cetin KO, Seed RB, Kayen RE, Moss RES, Bilge HT, Ilgac M, Chowdhury K (2018) Dataset on SPT-based seismic soil liquefaction. Data Brief 20:544–548. https://doi.org/10.1016/j.dib.2018.08.043
Davis RO, Berrill JB (1998) Site specific prediction of liquefaction. Geotechnique 48(2):289–293. https://doi.org/10.1680/geot.1998.48.2.289
Fawcett T (2006) An introduction to ROC analysis. Pattern Recognit Lett 27(8):861–874. https://doi.org/10.1016/j.patrec.2005.10.010
Hand DJ, Till RJ (2001) A simple generalization of the area under the ROC curve for multiple class classification problems. Mach Learn 45:171–186. https://doi.org/10.1023/A:1010920819831
Finn WD (2002) State of the art for the evaluation of seismic liquefaction potential. Comput Geotech 29(5):328–341. https://doi.org/10.1016/S0266-352X(01)00031-3
Furman GG (1965) Comparison of models for subtractive and shunting lateral-inhibition in receptor-neuron fields. Kybernetik 2:257–274. https://doi.org/10.1007/BF00274089
Ghaderi A, Abbaszadeh Shahri A, Larson S (2019) An artificial neural network based model to predict spatial soil type distribution using piezocone penetration test data (CPTu). Bull Eng Geol Env 78(6):4579–4588. https://doi.org/10.1007/s10064-018-1400-9
Goh AT (2002) Probabilistic neural network for evaluating seismic liquefaction potential. Can Geotech J 39(1):219–232. https://doi.org/10.1139/t01-073
Green RA, Cubrinovski M, Cox B, Wood C, Wotherspoon L, Bradley B, Maurer B (2014) Select liquefaction case histories from the 2010–2011 Canterbury earthquake sequence. Earthq Spectra 30(1):131–153. https://doi.org/10.1193/030713EQS066M
Hakam A (2016) Laboratory liquefaction test of sand based on grain size and relative density. J Eng Technol Sci 48(3):334–344. https://doi.org/10.5614/j.eng.technol.sci.2016.48.3.7
Hazen A (1919) Hydraulic-fill dams. Trans ASCE 83(1):1713–1745
Hernandez-Orallo J (2013) ROC curves for regression. Pattern Recogn 46(12):3395–3411. https://doi.org/10.1016/j.patcog.2013.06.014
Hoang ND, Bui DT (2018) Predicting earthquake-induced soil liquefaction based on a hybridization of kernel Fisher discriminant analysis and a least squares support vector machine: a multi-dataset study. Bull Eng Geol Environ 77(1):191–204. https://doi.org/10.1007/s10064-016-0924-0
Holmes DS, Mergen AE (1995) An alternative method to test for randomness of a process. Qual Reliab Eng Int 11(3):171–174. https://doi.org/10.1002/qre.4680110306
Hosseini S, Al Khaled A (2014) A survey on the imperialist competitive clgorithm metaheuristic: implementation in engineering domain and directions for future research. Appl Soft Comput. https://doi.org/10.1016/j.asoc.2014.08.024
Ishibashi I (1985) Effect of grain characteristics on liquefaction potential- In search of standard sand for cyclic strength. Geotech Test J 8(3):137–139. https://doi.org/10.1520/GTJ10525J
Ji X, Gao Q, Yin F, Guo H (2016) An efficient imperialist competitive algorithm for solving the QFD decision problem. Math Probl Eng. https://doi.org/10.1155/2016/2601561
Joanes DN, Gill CA (1998) Comparing measures of sample skewness and kurtosis. J R Stat Soc Ser D 47(1):183–189. https://doi.org/10.1111/1467-9884.00122
Kaveh A, Hamze-Ziabari SM, Bakhshpoori T (2018) Patient rule-induction method for liquefaction potential assessment based on CPT data. Bull Eng Geol Environ 77(2):849–865. https://doi.org/10.1007/s10064-016-0990-3
Kayadelen C (2011) Soil liquefaction modeling by genetic expression programming and neuro-fuzzy. Expert Syst Appl 38(4):4080–4087. https://doi.org/10.1016/j.eswa.2010.09.071
Kramer SL, Seed HB (1988) Initiation of soil liquefaction under static loading conditions. J Geotech Eng 114(4):412–430. https://doi.org/10.1061/(ASCE)0733-9410(1988)114:4(412)
Kramer S (1996) Geotechnical earthquake engineering. Upper Saddle River, Prentice-Hall, NJ
Koch C, Poggio T, Torre V (1983) Nonlinear interactions in a dendritic tree: localization, timing, and role in information processing. Proc Natl Acad Sci USA 80:2799–2802
Kouzegar K (2013) Study of possibility of liquefaction in the body and foundation of embankment dams - case study of Sattarkhan Dam. World Appl Sci J 21(12):1795–1803. https://doi.org/10.5829/idosi.wasj.2013.21.12.2007
Krekelberg B (2008) Motion detection mechanisms. Sens Comprehens Ref 2:133–155. https://doi.org/10.1016/B978-012370880-9.00305-4
Liao SSC, Veneziano D, Whitman RV (1988) Regression models for evaluating liquefaction probability. J Geotech Eng ASCE 114(4):389–411
Liao SSC, Whitman RV (1986) Catalogue of liquefaction and non-liquefaction occurrences during earthquakes. Res. Rep., Dept. of Civ. Engng., Massachusetts Institute of Technology, Cambridge, Mass.
Lin JL, Tsai YH, Yu CY, Li MS (2012) Interaction enhanced imperialist competitive algorithms. Algorithms 5:433–448. https://doi.org/10.3390/a5040433
Naghizadehrokni M, Choobbasti AJ, Naghizadehrokni M (2018) Liquefaction maps in Babol city, Iran through probabilistic and deterministic approaches. Geoenviron Disast 5:2. https://doi.org/10.1186/s40677-017-0094-9
Njok PGA, Shen SL, Zhou A, Lyu HM (2020) Evaluation of soil liquefaction using AI technology incorporating a coupled ENN/ t-SNE model. Soil Dyn Earthq Eng 130:105988. https://doi.org/10.1016/j.soildyn.2019.105988
Pal M (2006) Support vector machines-based modelling of seismic liquefaction potential. Int J Numer Anal Methods Geomech 30:983–996. https://doi.org/10.1002/nag.509
Pan Z, Lei D, Zhang Q (2018) A new imperialist competitive algorithm for multiobjective low carbon parallel machines scheduling. Math Probl Eng. https://doi.org/10.1155/2018/5914360
Rahbarzadeh A, Azadi M (2019) Improving prediction of soil liquefaction using hybrid optimization algorithms and a fuzzy support vector machine. Bull Eng Geol Environ 78(7):4977–4987. https://doi.org/10.1007/s10064-018-01445-3
Rahman MS, Wang J (2002) Fuzzy neural network models for liquefaction prediction. J Soil Dyn Earthquake Eng 22:685–694
Ramakrishnan D, Singh TN, Purwar N, Barde KS, Gulati A, Gupta S (2008) Artificial neural network and liquefaction susceptibility assessment: a case study using the 2001 Bhuj earthquake data, Gujarat. India Comput Geosci 12:491–501. https://doi.org/10.1007/s10596-008-9088-8
Samui P, Kim D, Sitharam TG (2011) Support vector machine for evaluating seismic liquefaction potential using shear wave velocity. J Appl Geophys 73(1):8–15. https://doi.org/10.1016/j.jappgeo.2010.10.005
Samui P, Jagan J, Hariharan R (2016) An alternative method for determination of liquefaction susceptibility of soil. Geotech Geol Eng 34:735–738. https://doi.org/10.1007/s10706-015-9969-2
Sawicki A, Mierczynski J (2006) Developments in modeling liquefaction of granular soils caused by cyclic loads. Appl Mech Rev 59:91–106. https://doi.org/10.1115/1.2130362
Seed HB, Idriss IM (1971) Simplified procedure for evaluating soil liquefaction potential. J Soil Mech Found Div ASCE 97(9):1249–1273
Seed HB, Idriss IM, Arango I (1983) Evaluation of liquefaction potential using field performance data. J Geotech Eng Div ASCE 109(3):458–482. https://doi.org/10.1061/(ASCE)0733-9410(1983)109:3(458)
Tokimatsu K, Yoshimi Y (1983) Empirical correlation of soil liquefaction based on SPT N-value and fines content. Soils Found 23(4):56–74. https://doi.org/10.3208/sandf1972.23.4_56
Tung AT, Wang YY, Wong FS (1993) Assessment of liquefaction potential using neural networks. Soil Dyn Earthq Eng 12(6):325–335. https://doi.org/10.1016/0267-7261(93)90035-P
Vida I, Bartos M, Jonas P (2006) Shunting inhibition improves robustness of gamma oscillations in hippocampal interneuron networks by homogenizing firing rates. Neuron 49:107–117. https://doi.org/10.1016/j.neuron.2005.11.036
Von Neumann J, Bellinson HR, Hart BI (1941) The mean square successive difference. Ann Math Stat 12:153–162
Willmott CJ (1984) On the evaluation of model performance in physical geography. Spatial Stat Models 443–460.
Xing B, Gao WJ (2013) Imperialist competitive algorithm. In: Innovative computational intelligence: a rough guide to 134 clever algorithms. Intelligent systems reference library, 62, 203–209, Springer, Cham, https://doi.org/10.1007/978-3-319-03404-1_15.
Xue X, Yang X (2013) Application of the adaptive neuro-fuzzy inference system for prediction of soil liquefaction. Nat Hazards 67:901–917. https://doi.org/10.1007/s11069-013-0615-0
Xue X, Yang X (2016a) Seismic liquefaction potential assessed by support vector machines approaches. Bull Eng Geol Environ 75:153–162. https://doi.org/10.1007/s10064-015-0741-x
Xue X, Xiao M (2016b) Application of genetic algorithm-based support vector machines for prediction of soil liquefaction. Environ Earth Sci 75:874. https://doi.org/10.1007/s12665-016-5673-7
Xue X, Liu E (2017) Seismic liquefaction potential assessed by neural networks. Environ Earth Sci 76:192. https://doi.org/10.1007/s12665-017-6523-y
Yegaian MK, Ghahraman VG, Nogole-Sadat MAA, Daraei H (1995) Liquefaction during the 1990 Manjil, Iran, Earthquake, I: case history data. Bull Seismol Soc Am 85(1):66–82
Youd TL, Idriss IM, Andrus RD, Arango I, Castro I, Christian JT, Dorby R, Finn WDLL, Harder F, Hynes ME, Ishihara K, Koester JP, Laio SC, Marcuson WF, Martin GR, Mitchell JK, MoriwakiY PMS, Robertson PK, Seed RB, Stokoe KH (2001) Liquefaction resistance of soils: summery report from the 1996 NCEER and 1998 NCEER/NSF workshop on evaluation of liquefaction resistance of soils. J Geotech Geoenviron Eng 127(10):817–833
Zhou J, Li E, Wang M, Chen X, Shi X, Jiang L (2019) Feasibility of stochastic gradient boosting approach for evaluating seismic liquefaction potential based on SPT and CPT case histories. J Perform Constr Facil 33(3):04019024. https://doi.org/10.1061/(ASCE)CF.1943-5509.0001292
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Abbaszadeh Shahri, A., Maghsoudi Moud, F. Liquefaction potential analysis using hybrid multi-objective intelligence model. Environ Earth Sci 79, 441 (2020). https://doi.org/10.1007/s12665-020-09173-2
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12665-020-09173-2