
Abstract
Radar sea clutter is the backscattering radar echo of rough sea surface, the research of radar sea clutter is of great significance to national defense construction and national economic development. Sea clutter prediction is also an important point in radar signal processing field. The traditional sea clutter prediction method has lower precision when predicting long-distance sea clutter data, and when the amount of data is large, the time is also lengthened, thereby reducing the efficiency of prediction. In this paper, a new method based on long short-term memory (LSTM) for predicting sea clutter at longer distances in the atmospheric duct environment using near-distance observations is proposed, the principle of LSTM network is introduced, and the factors affecting prediction accuracy are analyzed. The high precision prediction of radar sea clutter by LSTM network is realized. It provide the basis for further work on inversion problem of atmospheric ducts. It also has very important application value for studying the clutter suppression of the radar model and improving the target detection performance of the radar.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Radar sea clutter (Wang et al. 2007) is the backscattering radar echo of rough sea surface. Sea clutter is the most difficult and challenging problem of marine radar, sea clutter prediction is also an important point in radar signal processing field (Wang et al. 2009). The accurate modeling of radar sea clutter and the realization of prediction techniques are of great significance to national defense construction and national economic development. For example, a commonly used atmospheric duct inversion technique called refractivity from clutter (RFC) (Krolik and Tabrikian 1998) is implemented based on radar sea clutter. In addition, the analysis and prediction of sea clutter have very important application value for studying the clutter suppression of radar models and improving the target detection performance of radars.
In 2000, Haykin et al. (2002) proposed chaotic characteristics of sea clutter based on a large number of IPIX radar data, the results that sea clutter is chaotic dynamic rather than purely random. The chaotic phenomenon (Haykin and Puthusserypady 1997; Lin et al. 2004) is between the certain relationship and the random relationship, it is a generalization of the existing determination mode and an important form of objective existence in the natural world. Chaos contains order, which is different from random motion that cannot be controlled, but has obvious nonlinear relationship, it can usually be determined by nonlinear dynamic equations and is locally predictable (Bian-zhang 2004; Xie 2009). Because sea clutter has such chaotic characteristics, the sequence of sea clutter can be predicted, which has important theoretical and practical significance for the study of sea clutter and subsequent target detection.
For a stable data sequence, using the traditional statistical model can get the good prediction results, but for the sea clutter sequence with chaotic characteristics, even if the model matches the data well, sometimes it is impossible to make an accurate prediction (Xie 2009). So far, many methods for modeling and predicting sea clutter have been developed. For example, the similarity point method (Xi 2005) is to find the closest or most similar point to the current time point in the history record, and replace the current time point with the similar point to predict the future evolution of the current state point. This method is simple, but not very accurate. In 2004, a local-region multi-steps forecasting model based on phase-space reconstruction is presented for chaotic time series prediction (Cai et al. 2004), simulation results from several typical chaotic time series demonstrate that the models are effective for multi-steps prediction of chaotic time series. In addition to this, there is a regression method, Xiaohong et al. (2010) used the traditional nonlinear regression model to predict sea clutter, they get the better prediction effect, but the method is easy to eliminate the chaotic characteristics and nonlinear characteristics of sea clutter, resulting in the nature of sea clutter changes being concealed. Since Lapedes and Farber (1987) first applied neural networks for prediction in 1987, the method of using neural networks for sequence prediction has received much attention. In 2006, a sea clutter prediction method based on radial basis function (RBF) and K-means clustering has been proposed (Chen et al. 2007; Xiaohong and Jidong 2006) Besides, Bin et al. (2007) also used the least squares-support vector machine (LS-SVM) algorithm to achieve sea clutter prediction. Xie (2009) compared error back propagation method (BP) with RBF method, and verified the effectiveness of above prediction method using sea clutter data. Ting (2015) proposed a chaotic time series prediction method based on genetic wavelet neural network (GA-WNN), and obtained good prediction results.
However, previous neural networks for sea clutter prediction has short-term predictable and long-term unpredictable defects. Their accuracy is lower at the long distances. Besides, as the amount of data increases, the training model takes longer time, which reduces the efficiency of predict the sea clutter power. This paper proposes a new method of radar sea clutter prediction using long short-term memory (LSTM), compared with the previous method, LSTM has higher prediction accuracy and it takes less than one second to make predictions using the trained LSTM deep learning network, which is very efficient.
This paper discusses the principle of the LSTM network model, and builds the sea clutter prediction model, and analyzes the factors affecting the prediction accuracy. The final prediction results show that the prediction of sea clutter using LSTM neural network can obtain higher precision results, and it also has better accuracy for predictions at farther distance.
2 Radar sea clutter power calculation
In order to apply the radar sea clutter to solve the inversion problem of atmospheric refractivity estimation, it is first necessary to model and calculate the radar sea clutter in the atmospheric duct environment (Guo et al. 2018), different duct environments and radar parameters will affect sea clutter power value. According to the basic radar theory (Gerstoft et al. 2003) and calculation theory of sea clutter power (Karimian et al. 2016), M is used to represent the atmospheric duct profile structure in a maritime environment, the sea clutter power received by the radar can be expressed as follows:
where r is the distance between the radar receiving antenna and the sea surface scattering unit, Pt and Gt represents transmit power and transmit antenna gain, respectively. λ represents the known wave length,\( \sigma_{ 0} \) is the radar scattering coefficient. Ac is the area of the radar unit, it has a linear relationship with the distance r as shown below:
\( \theta_{\text{az}} \) is the azimuth beam width of the antenna, \( \theta \) is the incident angle and the product of \( c\tau \) is the distance resolution of the radar, these are all the radar system parameter. The propagation factor F(r, M) and propagation loss L(r, M) have the following relationship:
Substituting (2) and (3) into (1), the equation for calculating the sea clutter power can be obtained:
Then, the Eq. (4) can be expressed in logarithmic form as follows:
The propagation loss LdB(r, M) Equation in logarithmic form is shown in (6), C is a constant related to radar parameters such as transmit power and gain, after simplification, it can be expressed as Eq. (7):
The propagation factor F(r, M) can be solved by the parabolic equation model (Liu et al. 2011) and the \( \sigma_{0} \) can be obtained by the NRL empirical model (Levis et al. 2010). Several groups of sea clutter power that varied with distance are shown in Fig. 1.

Sea clutter power
3 LSTM network model principle
LSTM is a special type of recurrent neural networks (RNN). It was first proposed by Hochreiter and Schmidhuber (1997) and improved by Kawakami (2008). It solves the problem of RNN echelon disappearance and explosion, it also compensates for the inability of RNN to predict distant sequences. LSTM is a popular part of the current deep learning field, it is mainly used to solve the timing prediction problem. It can predict the state of the next moment based on the state of the data at the previous moment.
Neural network consists of one input unit, one output unit and many intermediate units which are called hidden units. The output of the input unit forms the input of the unit of the first hidden layer, and the output of each hidden layer forms the input of each subsequent hidden layer (Tax et al. 2017). One or more hidden layers make up the hidden unit, compared with the ordinary neural network, the biggest difference of RNN is that hidden unit will self-loop. RNN can be seen as multiple copies of the same neural network, and each neural network module will pass the information to the next one. For easy understanding, RNN can be unfolded as shown in Fig. 2.

Unfolding of single RNN network
For the sea clutter prediction problem to be solved in this paper, the input data is a set of sea clutter power sequence. As the sequence progresses, the hidden unit of the previous distance will affect the hidden unit of the latter distance point, this feature is of great help to the sea clutter power that has a certain nonlinear relationship between the previous data and the latter data. So the network can predict the sea clutter power value at the next distance based on the values at the previous few distance points. The state of the hidden unit at each distance point in the Fig. 2 is related to the previous point, where Xt is the clutter power value at the distance t, ht is the predicted value at the distance.
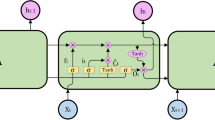
But RNN has such a problem (Zhang et al. 2017): for the standard RNN architecture, the influence of the “features” at a farther moment on the output is either attenuated to a small extent or exponentially exploding. This problem is often referred to as the “gradient demise and explosion problem”. The cleverest thing about the LSTM network is that the weight of the self-loop is changed by adding the input gate, the forget gate and the output gate into the hidden unit. In this way, when the model parameters are fixed, the integral scale at different times can be dynamically changed, avoiding the “gradient demise and explosion problem”.
The LSTM unit structure (Kawakami 2008) is shown in Fig. 3. One or more cells exist in one LSTM unit to describe the current state of the LSTM unit. There are three control gates in Fig. 3 that control the input, output of the network and the status of the cell unit. After getting the output h1 at the initial time, as long as the Input Gate is kept off (equivalent to a multiplication coefficient of 0) and the Forget Gate is open (equivalent to a multiplication coefficient of 1), the output of the network will continues to be affected by h1. Therefore, using LSTM to establish a sea clutter prediction model, it is possible to obtain a highly accurate prediction result at farther distance.

Structure of LSTM unit
4 Establishment of radar sea clutter prediction model
The specific process of establishing and training the LSTM network model is shown in Fig. 4 for the sea clutter prediction problem in the atmospheric duct environment. It can be seen that the LSTM can continuously circulate the sea clutter information, pass it from the current step to the next step, and predict the next state according to the previous state, thus realizing the prediction of the horizontal distance sea clutter.

Flow chart for establishing LSTM sea clutter prediction model
When establishing the LSTM prediction model, the input data is a set of radar sea clutter power values calculated by formula (6). We select a sea clutter power value every 100 m from the horizontal distance range of 3–200 km, finally a total of 1970 data constitutes the input data set. The radar system parameters used for the calculation are listed in Table 1.
As shown in Fig. 5, it is a set of sea clutter power values for training. It can be seen that as the distance increases, the sea clutter power has a certain attenuation characteristic, and there is some periodic change. Therefore, it is feasible to use the LSTM neural network model to fit this nonlinear relationship.

Radar sea clutter
In order to evaluate the accuracy and generalization ability of the established model, it is necessary to select the first 80% as the training set from the input sea clutter data, the last 20% as the test set. And select the root mean square error function (RMSE) as the evaluation function to evaluate the prediction results:
where predicted represents the sea clutter prediction value, and real represents the supposed sample value.
The quality of the model can be judged by calculating the result of the RMSE on the test set. The smaller the result of RMSE, the higher accuracy of the prediction model established. In order to select the optimal parameters to train the LSTM radar sea clutter prediction model, the following factors which easily affect the accuracy of the prediction results are analyzed.
-
1)
The influence of epochs on prediction accuracy
When the input sea clutter data set passes through the LSTM network once and returns once, the process is called an epoch (Lecun et al. 2015). As shown in Fig. 6, as the epoch increases, the RMSE value on the test set and training set both decreases, it shows that there is no overfitting problem in the process of establishing the LSTM model. Eventually, the RMSE converges after about 100 epochs, because every time an epoch is passed, the LSTM network model updates its weight parameters based on the results, making the predictions closer to the true value. At the same time, the more epoch, the longer the training time, so you need to choose an appropriate epoch number based on the number of input sea clutter sample data set.

RMSE varies with the number of epochs
-
2)
The influence of batchsize on prediction accuracy
The input data set has nearly 2000 values, if the complete data set is used in each training process, the gradient cannot be corrected, and the network cannot converge to the global optimum. Therefore, when training the LSTM prediction network, need to choose a suitable batchsize (Lecun et al. 2015) value. Batchsize represents the number of sea clutter power samples that are input to the network each time. The data set is divided into multiple batches according to the value of batchsize. These batches are input into the network for training in stages. Choosing the right batchsize not only improves memory utilization, but also reduces the time required for training.
Within a reasonable range, different batchsize values were selected to train the LSTM sea clutter prediction model. As shown in Fig. 7, when the value of batchsize is 16, the RMSE on the test set is the smallest, that is, when batchsize is selected 16, the optimal prediction result can be obtained.

RMSE varies with the number of batchsize
-
3)
The influence of neurons on prediction accuracy
Figure 8 shows the change curve of RMSE with epochs under different number of neurons. As shown in Fig. 8, the number of neurons increases, the RMSE of the sea clutter prediction model on the test set decreases, which means that the prediction accuracy is increasing. This is because increasing the number of neurons allows the LSTM neural network model to learn more training data features, thereby more accurately fitting the nonlinear relationship between sea clutter powers, and the prediction results will be more accurate. However, it can be seen from the figure, when the number of neurons reaches 256 and 512, the accuracy on the test set decreases, which indicates that the number of neurons is not the more the better. Too many neurons sometimes lead to over-fitting, because too many neurons will learn too many features between training data, resulting in poor generalization of the network model, the accuracy on the test set will decrease. In addition, the more neurons, the longer the training time, reducing the efficiency. So the number of neurons is not the more the better.

RMSE varies with the number of neurons and epochs
Through the above analysis of the data, when the number of neurons = 128, epoch = 100, the optimal results can be achieved, and the training time will not be too long. SO this paper selects epochs as 100, batching as 16 and neuron as 128, then training LSTM sea clutter prediction model based on tensorflow (Hope et al. 2017) framework in Python language environment. After training, the obtained model can be saved, and the model can be directly used to predict when needed without repeated training process, it is very flexible to use, and greatly improves the efficiency of sea clutter prediction.
5 Prediction results and analysis
According to the analysis results in the previous section, four sets of the sea clutter power data in the different atmospheric duct environments are selected to train the LSTM prediction model. Then, the trained prediction model is used to predict the sea clutter power data of each group from 160 to 200 km, in order to reflect the prediction accuracy of the LSTM network model at a long distance. In addition, we also use the traditional BP neural network to predict the sea clutter power. Figure 9 shows the comparison of the predicted results of the two methods and their relative error curves.

The sea clutter prediction result and the relative error curve
It can be seen from the Fig. 9 that the relative error of sea clutter prediction using LSTM network is much lower than that of BP neural network, which fully proves the validity of the LSTM model. And the relative error curve shows that although the relative error varies with distance, the relative error generated by the four sets of data all does not exceed 0.5%, and some even far below 0.5%, which proves that the LSTM network model still has high prediction accuracy even at a long distance. In addition, it takes less than 1 ms to call the trained LSTM for prediction, while it takes longer to use BP neural network, which fully proves the efficiency of sea clutter prediction using LSTM.
6 Conclusion
In this paper, a new method for predicting radar sea clutter power over horizontal distance is proposed. Firstly, based on the theoretical basis of radar sea clutter calculation in the atmospheric duct environment, a large amount of sea clutter power values are generated to form the training data set. Then, the factors affecting the accuracy of the prediction result are analyzed in many aspects. According to the analysis result, the optimal parameters are selected to train the LSTM network, and finally an optimal prediction model is obtained, which is applied to the prediction problem of sea clutter at in horizontal distance. According to the final prediction results, compared with the previous method (like BP neural network), the prediction of radar sea clutter using LSTM has the advantages of high precision and high efficiency, and accurate prediction results can be obtained even at a long distance. The new method proposed in this paper lays the foundation for the next step of using sea clutter to invert the atmospheric ducts. At the same time, because of the high-precision prediction ability of LSTM for radar sea clutter, we can try to apply LSTM to the subsequent target signal detection in the background of sea clutter, which has certain significance for the research of ocean radar clutter.
References
Bian-zhang XHMY (2004) Detecting weak signal in chaotic sea clutter using RBF neural network predictor. Mod Rad 2004:9
Bin J, HongQiang W, YaoWen F, Xiang L, Rong GG (2007) Prediction of Chaotic Sea clutter based on LS-SVM. Prog Nat Sci 17:415–420
Cai M, Cai F, Shi A, Zhou B, Zhang Y (2004) Chaotic time series prediction based on local-region multi-steps forecasting model. International symposium on neural networks. Springer, Berlin, pp 418–423
Chen XN, Xiao-Ke XU, Suo JD (2007) Forecasting method of chaotic time series based on RBF. J Dalian Marit Univ 33(1):115–118
Gerstoft P, Rogers LT, Krolik JL, Hodgkiss WS (2003) Inversion for refractivity parameters from radar sea clutter. Radio Sci 38:3
Guo X, Wu J, Zhang J, Han J (2018) Deep learning for solving inversion problem of atmospheric refractivity estimation. Sustain Cities Soc 43:524–531
Haykin S, Puthusserypady S (1997) Chaotic dynamics of sea clutter Chaos. Interdiscip J Nonlinear Sci 7:777–802
Haykin S, Bakker R, Currie BW (2002) Uncovering nonlinear dynamics—the case study of sea clutter. Proc IEEE 90:860–881
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9:1735–1780
Hope T, Resheff YS, Lieder I (2017) Learning tensorflow: a guide to building deep learning systems. O’Reilly Media, Inc., Newton
Karimian A, Yardim C, Gerstoft P, Hodgkiss WS, Barrios AE (2016) Refractivity estimation from sea clutter: an invited review. Radio Sci 46:1
Kawakami K (2008) Supervised sequence labelling with recurrent neural networks. Ph D thesis
Krolik J, Tabrikian J (1998) Tropospheric refractivity estimation using radar clutter from the sea surface. In: Proceedings of the 1997 Battlespace atmospherics conference, SPAWAR Sys. Command Tech. Rep, pp 635–642
Lapedes A, Farber R (1987) How neural nets work. In: Proceedings of the 1987 international conference on neural information processing systems. MIT Press, pp 442–456
Lecun Y, Bengio Y, Hinton G (2015) Deep learning. Nature 521:436
Levis CA, Johnson JT, Teixeira FL (2010) Radiowave propagation: physics and applications
Lin SH, Zhu H, Zhao YG (2004) Study of sea clutter chaotic dynamics. Syst Eng Electron 26(2):178–181
Liu Y, Zhou XL, Jin HQ (2011) Forecasting technique of radio propagation characteristics based on parabolic equation model. Mod Electron Tech 34(18):74–76
Tax N, Verenich I, La Rosa M, Dumas M (2017) Predictive business process monitoring with LSTM neural networks. In: Dubois E, Pohl K (eds) Advanced information systems engineering. CAiSE 2017. Lecture notes in computer science, vol 10253. Springer, Cham, pp 477–492
Ting XU (2015) Prediction of sea clutter based on GA-WNN. Electron Des Eng 23(18):34–37
Wang FY, Yuan GN, Zhi-Zhong LU, Hao YL (2007) Research on real-time wave height measurement using Xband navigation radar. Ocean Eng 25(4):84–87
Wang F-Y, Yuan G-N, Xie Y-J, Qiao X-W (2009) Nonlinear prediction of short-time sea clutter. Radar Sci Technol 1
Xi JH (2005) Research on long-term prediction method of chaotic time series. PhD thesis, Dalian University of Technology
Xiaohong S, Jidong S (2006) Prediction of sea clutter based on chaos theory with RBF and K-mean clustering. In: 2006 CIE international conference on radar. IEEE, Shanghai, China, pp 1–4
Xiaohong SU, Suo J, Liu X, Wang Y (2010) Sea clutter prediction based on linear and non-linear models. J Dalian Marit Univ 36:100–102 + 106
Xie L (2009) Research on clutter simulation and sea clutter prediction of broadband radar. University of Electronic Science and Technology of China
Zhang YH, Qiu CM, Xing HE, Ling ZN, Shi X (2017) A short-term load forecasting based on LSTM neural network. Electr Power Inf Commun Technol 15(9):19–25
Acknowledgements
The authors gratefully acknowledge the financial supports by the National Natural Science Foundation of China under Grant numbers 61775175 and 61801446.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Zhao, J., Wu, J., Guo, X. et al. Prediction of radar sea clutter based on LSTM. J Ambient Intell Human Comput 14, 15419–15426 (2023). https://doi.org/10.1007/s12652-019-01438-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12652-019-01438-4