
Abstract
In situ glacier discharge and sediment observations are uncommon in the Himalayan region because of the complex terrain and bad weather conditions. This research is the first study of the glaciers investigated to collect and forecast in situ glacier melt SSC (suspended sediment concentration) data from streams associated with the Pindari and Kafni glaciers in the central Himalayan region valley (Pindar basin) during three consecutive years (2017–2019). Stream discharge and sedimentation play a crucial role in hydroelectric power projects located in the Himalayan mountain regions. The problem is severe in the flood season due to excessive sediment concentration. In the Pindari and Kafni glacier stream dynamics, discharge, precipitation, and temperature were identified as major regulating components of variations in sediment concentration. Multiple linear regression (MLR) and artificial neural network (ANN) models were used. A bivariate correlation test was carried out, with a significant p-value of less than 0.05. The analytical measurement used daily values calculated between 2017 and 2018. MLR analysis revealed that the precipitation and SSC are not proportional since precipitation has a negative beta coefficient. The normalized importance of precipitation concerning discharge was determined to range between 11.54 and 76.1%. Statistical indices evaluated the performance of the used models, specifically residual sum of squares error (RSS), relative error (RE), and mean squared error (MSE). When predicting future SSCs for Pindari and Kafni streams, the ANN model outperforms the MLR model. The results clearly show that extreme events such as floodings and landslides cannot be predictable considering the research area based on the collected in situ hydro-meteorological data. In light of the results, it is thought that there are other factors, such as solar radiation, that affect discharge values and thus sediment transport. Sustained multi-year observations using machine learning applications could improve regional water resources assessment and management and regulate the policy to develop multi-purpose hydroelectric projects in the region.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
The scarcity of data generation in the Himalayan region is the most debatable issue, and it is caused due to tough terrain and bad weather conditions. Worldwide, all emerging and industrial economies have effects from global climate change. Governments and nongovernmental organizations have conducted various studies to understand, evaluate, forecast, and address the anticipated global climate change mechanisms and propose mitigation policies in recent years. Extreme weather events such as excessive rainfall, cloudburst, flash floods, and mountain-based avalanches endanger human life and state and economic economies. There are scarcer, rarely available well-distributed hydro-meteorological records in the Indian Himalayan region, which helps understand the processes that lead to severe weather events. However, over the last three decades, the capacity to observe, calculate, and quantify regional precipitation has dramatically improved. The topography of the Indian Himalayan region gives a favorable environment to a cloud burst that often leads to flash floods and slopes that kill thousands of people annually. There is still a vague understanding of the exact mechanism of the cloud driving processes, such as orographic elevation, rainfall distribution, precipitation thresholds, and their source or origin. As the frequency and intensity of cloud bursts are growing, they will probably escalate soon.
This study predicted suspended sediment concentration (SSC) for streams connected to the Pindari and Kafni glaciers in the central Himalayan region valleys (Pindar basin) during three consecutive (2017–2019) years as a pioneering work. Excessive rainfall, cloudbursts, flash floods, and mountain-based avalanches imperil human lives and commercial economies. In the Indian Himalayan area, there are fewer and more sparsely dispersed hydro-meteorological records. The Himalayas are a geodynamically active terrain with significant erosion and sedimentation rates. The Himalayan region has the majority of India’s hydroelectric potential. Reservoir storage capacity in these areas is rapidly depleted owing to sediment deposition. A nonlinear modeling technique is required to predict and forecast the sediment yield process in watershed basins (Anand et al. 2021; Kaur et al. 2003). Artificial neural networks (ANNs) can identify complicated temporal fluctuations (Kisi 2005). ANNs are a new branch of soft computing with many potentials (Khan et al. 2019). This research aims to see if artificial neural networks (ANNs) can simulate sediment concentrations in the Himalayas. In the Pindari and Kafni glacier stream dynamics, discharge, precipitation, and temperature were identified as major regulating components of variations in sediment concentration. The Himalayan glacier stream rivers Pindari and Kafni employed ANN to predict sediment concentrations in the glacier environment.
With its data-driven, practical, and easy-to-use approach, ANN is ideal for applications with minor data requirements (Jothiprakash and Garg 2009). Understanding the hydrological process is required for effective usage of ANN, which leads to the optimal selection of network inputs, design, and other modeling characteristics (Cigizoglu 2004; Talebizadeh et al. 2010). Daily data generated between 2017 and 2019 were utilized in the analysis. In both MLR and ANN studies, eight feedings and one outlet out of nine rivers were employed. A bivariate correlation test with a significant p-value of less than 0.05 was performed.
A neural network (ANN) is a complex regression model with a different equation for each hidden neuron (Mustafa et al. 2011). The size of these connections is determined by the network’s design. Since the precipitation has a negative beta coefficient in the Pinadri and Kafni glacier streams, the results show that precipitation and SSC are not proportionate. Nonlinear network parameters are used in multi-layer perceptron (MLP), whereas linear network parameters are used in radial basis function (RBF). The activation function was the hyperbolic tangent function (tanh), while the output layer was the identity function. The gradient descent algorithm was used as the optimization process to find the global minimum value. Each data stream shifts the number of neurons in the ANN design, which comprises one hidden layer. The most common training approach is backpropagation.
Training decreases the discrepancy between the network output and the observed data goal in time series forecasting. Internal computational architecture differs depending on the application. The SPSS application was used to analyze the artificial neural network models built. When predicting future SSCs for Pindari and Kafni streams, the ANN model outperforms the MLR model. For both daily simulations, the MLP technique outperformed RBF for all rivers. The first part of the hydrologically active season, generally between June and August, was characterized by many snowmelt-induced high discharge occurrences.
Results indicate that the rainfall intensity has a minor effect on sediment transport. Extreme events such as floods and landslides cannot be predicted using meteorological data, and natural climate change may have had a considerably lower role in these catastrophic disasters than previously thought. Because of the random separation of time series, data were not subjected to any prior qualitative interpretation. The discharge size affects SSC since the degree and spectrum of SSC are related to the discharge.
Literature review
The Himalayan rivers supply vital resources for almost half of the world’s population (Bookhagen 2012). Discharge of the high Himalayan rivers is controlled by the comprehensive presence of the valley forest ecosystem, glacial melt runoff, and precipitation from both summer and winter monsoons. Besides being a geo-dynamically active region, the Himalayas are characterized by high sedimentation and erosion rates (Valdiya 1999). According to studies, the storage capacity of reservoirs across the globe declines by around 1% every year owing to sediment deposition. According to the country’s data, Chinese storage capacity loss is more than 2% on average (Broomhead and Lowe 1988; Chang and Chen 2001). The average sediment loss rate for reservoir sediments in India is 0.78% per year (Chen et al. 1991; Chibanga et al. 2003). A large portion of India’s hydropower potential is located in the Himalayan area, where rivers carry enormous amounts of sediment during the monsoon season owing to the region’s rough and fragile geology and high slope. As a result, sediment deposition significantly reduces reservoir storage capacity in these areas (Isaac and Eldho 2017). The sediment rating curve is the most practical way for assessing sediment concentration and forecasting (Asselman 2000; Walling 1988). Several different mathematical techniques have been used to solve nonlinear regression issues using linear regression equations (Crowder et al. 2007; Holtschlag 2001).
Because of the geographical variability of basin parameters and temporal climatic trends, the dynamics of suspended sediments include intrinsic nonlinearity and complexity (Mustafa et al. 2011). The traditional sediment rating curve (SRC) and other empirical approaches fail to forecast the outcome accurately. Artificial neural networks (ANNs) have risen to prominence in recent decades as one of the most sophisticated modeling tools for resolving the inherent nonlinearity in hydrological systems (Cigizoglu and Kisi 2006). Nonlinear modeling techniques like artificial neural networks (ANNs) are needed to predict and forecast the sediment yield process in watershed basins because of the complicated temporal fluctuations in time-series data (Singh et al. 2012). The ANNs are an emerging field and powerful soft computing technique and are widely used in many different water resource management and environmental sciences (Eslamian et al. 2008). Several studies were carried out concerning the potential advantage of ANNs in sediment modeling and prediction analysis (Abrahart and White 2001). Thus, accessing ongoing changes in the fluxes and fate of river-derived materials is critically needed to understand current impacts and future trend prediction (Himanshu et al. 2017). A valid policy must be designed for sediment management and future forecast for favorable hydroelectric power projects (Isaac and Eldho 2017). The feed-forward backpropagation (FFBP) approach of ANNs was used to forecast this study’s discharge-suspended sediment interaction. In addition to the ANN analysis, this research also used multiple linear regression (MLR). The input dependence for suspended sediment concentration (SSC) in two adjacent glacier valleys of the central Himalaya was investigated using MLR, multi-layer perceptron (MLP), and radial basis function (RBF) neural networks.
Materials and methods
This study looks at the possibilities of simulating the concentration of sediments in the Himalayans with artificial neural networks (ANNs). Discharge, precipitation, and temperature were recognized as critical governing elements of changes in sediment concentration in the Pindari and Kafni glacier stream dynamics. Backpropagation algorithms were used to establish, train, and validate neural feed systems for predicting sediment concentration.
Suspended sediment processes contain intrinsic nonlinearity and complexity, given that the basin features and temporal climate patterns are both spatially variable (Ahmed et al. 2018). Therefore, this complexity leads to a poor forecast using the standard sediment rating curve and other empirical processes. Artificial neural networks (ANNs) have become a sophisticated modeling tool to tackle the hydrological processes’ intrinsic nonlinearity over several decades (Khan et al. 2019). In this work, ANN feed-forward backpropagation (FFBP) algorithms for melt flush discharged from the Pindari and Kafni Glaciers in the Himalayas were used to model the SSC for the ablation period (May–October).
Predicting sediment concentration in complicated river systems is critical for earth scientists, hydrologists, civil engineers, and even social scientists because it is essential for understanding river hydraulic systems, geomorphology, irrigation, generation of hydro-energy, and designing and managing water resource projects (Kerich 2020; Yadav et al. 2018). In addition to the scientific significance, geo-hydrological modeling is politically, socially, and economically relevant (Van Engelenburg et al. 2018). One of the main processes governing fluvial bank stability, soil formation, crustal development, and many other processes connected to the earth is sediment transportation from the continent to the sea. However, a broad range of aquatic sediment systems has been utilized to evaluate, predict, build, and manage hydrodynamic models because of the geographical variety of different physical and geomorphological qualities. The artificial neural networks (ANNs) computational efficiency produced several promising achievements in hydrology and modeling of water resources. ANN provides the benefit of a data-driven, practical, and easy-to-use methodology for rapid, minimal data requirements and high model precision simulations, developing technology for nonlinear mapping of inputs and outputs. For several water resource applications, ANNs have been employed. Numerical models may bridge the gap in sediment measurements and predict or analyze future and historical trends that will allow terrestrial responses to human and environmental changes to be investigated.
ANN was being used to estimate the concentration of sediments in the glacier environment of the Himalayan glacier stream rivers Pindari and Kafni. This study’s primary goal is to develop ANN models that forecast high-precision suspended sediment concentrations (SSC) of Pindari and Kafni Rivers. The field of research offers an excellent setting in which the most freight of water and sediment is carried out in the period between March and October because of the high weather rates with a minimum impact on human activities.
Description of the study area
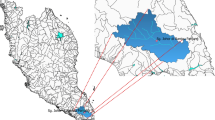
Geographically, the Pindar basin is bounded (29°50′4″–30°20′4″ N; 79°34′30″–80°8′35″ E) and covers a significant part of the Kumaun Himalaya and is located in the southern side of the Greater Himalaya in Uttarakhand, India (Fig. 1). The Pindar basin (~ 1945 km2) constitutes about 20% of the Alaknanda basin (10,880 km2), the largest basin of the river Ganga (Joshi et al. 2018). The Pindar River significantly contributes to and confluences the Alaknanda River at Karnaprayag (Uttarakhand). The study comprises two adjacent glacier valleys (Pindari and Kafni streams). Glacier stream discharge and sediment quantification were carried out at these adjacent streams’ confluence (2500 m asl) at Diwali (Fig. 1).

Location of the study area, satellite imagery shows the streams connected to the glaciers, meteorological, and discharge sites
The Pindari formation of the Vaikrita Group, which comprises the higher Himalayan crystalline rocks, dominates the basin’s lithology (Valdiya 1999). The basin is dominated by crystalline lithoclast (gneisses, schist, and calc-silicate rocks). The region’s climate is broadly subtropical, influenced by the Indian summer monsoon (ISM) during summer, while westerlies have a considerable influence during winter (November–March) (Shekhar et al. 2010; Singh et al. 2012).
Meteorological data generation
The stated parameters utilized in this study consist of meteorological observations obtained from the meteorological station installed in Diwali at 2600 MSL (middle of the valleys) and the site where the confluence of the Pindari and Kafni glaciers stream. The meteorological observatory at Diwali station was established in 2017. It consisted of the following sensors with an automatic data logging system that logs data every 5 min (averaged at sub-hourly scale): (1) air temperature-relative humidity probe with a shielded and aspirated sensor (AT-RH/TH-P-S/VEC, Roorkee, India), (2) barometer (SEN-Baro1, VEC, Roorkee, India), and (3) rain gauge of tipping bucket type (DREL-R, VEC, Roorkee, India).
Hydrological dataset
For quantification of discharge (Q) in the Pindari (30°10′43″ N, 79°59′43″E) and Kafni (30°10′34″ N, 79°59′44″E) streams, we established two gauging sites at the Dwali station. For manual observations of water levels, graduated staff gauges were installed at each glacier stream. Due to rugged terrain, velocity-measuring instruments are not recommended in the Himalayan region. Therefore, we applied the velocity-area method (Eq. 1) to compute the flow velocity with the help of wooden floats (Ramanathan 2011; Chauhan et al. 2017). Stream channels were divided into five segments to measure velocity. The mean velocity was calculated by multiplying the surface velocity by a factor of 0.90 since the surface velocity is greater (Singh and Ramasastri 1999). A sounding rod was used to determine the cross-sectional area of the stream channels. As Himalayan valley streams are highly turbulent, having steep gradients, the stage-discharge curve relationship serves as the reliability of our discharge data (Kumar et al. 2018).
Here, Q is discharged (m3 s−1); k is the correction factor (0.9) for calculating the mean channel velocity. A is the cross-sectional area of the water channel (m2), and V is the velocity of streamflow (m s−1).
It is acknowledged that flow measurements, particularly during the monsoon season (July–September), could have an error margin of 5–10% when the discharge is high, which is usual for measurements associated with turbulent streams having steep gradients (Singh et al. 2012).
Water samples from both streams were collected twice a day (08:00 h and 16:00 h) during the study period (2017–2019) to estimate SSC. Samples were filtered at the study site and analyzed at the sedimentological laboratory (Wadia Institute of Himalayan Geology, Dehradun) using standard procedures (Chauhan et al. 2017; Kumar et al. 2018). Moreover, SSC measurements were complemented and frequently validated with an automatic suspended solid analyzer (Model: 3150, VEC, Roorkee, India).
Artificial neural networks (ANNs)
ANN consists of artificial neurons stacked into layers, which can learn from the surroundings and extract connections between process inputs and outputs. A very often in-depth discussion about the internal structure and work of ANN was carried out, and the literature might be accessed for this (Rahman and Chakrabarty 2020; Ebtehaj et al. 2021). The inputs to the neuron are weighed by a factor that reflects the strength of the synaptic weight in simple forward networks. These signals’ total input and weight are called neuronal activity or activation.
ANN learning is an approach to weight determination, and error backpropagation (BP) is the most used learning principle. The error, or difference between observation and prediction, is transmitted back into the network, and all neurons’ weights are modified. This technique is repeated until a defined number of iterations or error tolerance is reached. A well-understood hydrological process is required to effectively use ANN, which leads to a suitable selection of network inputs, architecture, and other modeling elements (Buyukyildiz and Kumcu 2017).
MLR and ANN models were used to estimate SSC for streams connected to the Pindari and Kafni glaciers. There is no single definition of artificial neural networks, but it is generally an information processing system that replicates how the human brain learns (Kriegeskorte 2015). As a result of the interaction of hundreds of thousands of nerve cells with each other, there will be an infinite number of synaptic unions. It is calculated that a computer that will perform this number of synaptic combinations will occupy a larger volume than the world. The complexity of the human brain, which is 1.5 kg on average, can be expressed in its simplicity with this example (Yang and Wang 2020).
The analytical measurement used daily values calculated between 2017 and 2019. The total data sample (n) size is 552. Samples (n = 368) were used for training and (n = 184) for testing in each glacier stream. Data from 2019 was used to verify the study results. Eight feedings and one outlet out of nine rivers have been used in MLR and ANN analyses. A bivariate correlation test was carried out, with a significant p-value of less than 0.05. A conventional statistical approach was used to construct the MLR model. Finally, IBM SPSS Statistics for Windows, Version 21.0, was used to build an ANN model. The automated architecture selection choice in the program allows for an infinite number of iterations. The investigation will go on until the right network architecture is discovered.
In the SPSS neural network module, there are two widely used ANN methods. The first and second are the MLP and RBF artificial neural network models. Although neural network models have more than one name, they all consist of dense connections of simple computational tools inspired by the biological nervous system and aimed at high performance. Since performance is not needed in simple operations, the target is to be used in models that require intensive calculations, such as face recognition, handwriting recognition, churn analysis, and meteorological forecast, to achieve high performance in applications (Yang et al. 2020).
Multiple linear regressions
The MLR approach was used to evaluate the performance of the ANN model against that of an alternative time series and data-driven model. In addition, time-series analyses for the daily time steps were carried out using similar datasets to those used in the ANN simulations, and performance statistics were used to compare the results.
ANN may be viewed as a sophisticated regression model with a different equation for every hidden neuron (Sarangi and Bhattacharya 2005). The inputs are processed using the resulting synaptic weight between the input, hidden, and output neurons, adding to the activation function. The extent of these links relies entirely on the architecture of the network. Likewise, the number of such connections relies directly on the architecture of the network. The more complicated a network is, the more synaptic weights it needs to compute. Therefore, the relevance of the factors based on raw weight values is frequently hard to determine. MLR analysis predictions for SSC are shown in Fig. 2. It shows that the predicted SSC from the Pindari glacier stream achieved a better correlation with a value of (R2 = 0.9009) than the SSC from the Kafni glacier stream (R2 = 0.8731). Detail statistical description is presented in Tables 1 and 2. If the collection of independent variables consists of more than one variable coupled with one continuous dependent variable, MLR is the right approach to apply. If the nature of the dependent variable measurement is at least at the interval level, MLR might be applied. To investigate the link between a group of independent factors and one continuous dependent variable, Tables 1 and 2 exhibit the SPSS software MLR analysis outcomes for the Pindari and Kafni glacier streams, respectively. The essential measure revealing the dependence of SSC on temperature, precipitation, and discharge parameters is the standardized coefficients used for comparing the impacts of independent variables (beta coefficient). Results revealed that the precipitation and SSC are not proportional since precipitation has a negative beta coefficient in Pinadri and Kafni glacier streams.

Correlation of predicted and observed values (a) from Pindari glacier stream and (b) Kafni glacier stream
Multilayer perceptron
MLP employs nonlinear network parameters, while RBF uses linear parameters, and both methods can be applied to the same problem. The MLP network performed better in this study and provided results for all datasets. The activation function was the hyperbolic tangent function (Eq. 2) (tanh), and the output layer used the identity function. The data is converted to a value between − 1 and 1 by the hyperbolic tangent equation, and the identity function does not alter the vector.
As a mode of preparation, the batch learning method was chosen. It is an excellent method for dealing with small amounts of data. Batch learning is a popular approach for minimizing error since synaptic weights are changed after the entire data collection. Gradient descent was chosen as an optimization algorithm to arrive at the global minimum value, beginning with random variables. The best form of ANN architecture was calculated based on the training error. The ANN architecture has one hidden layer, and neuron numbers shift with each data stream (see Fig. 3).

The general architecture of multi-layer perceptron
Figure 3 shows the computational elements of n layers, which perform similar functions to biological nerve cells in each layer and can be in different numbers, consisting of dense connections between these computing elements throughout the layers. The computational features used in various ANN models are called artificial neurons, nodes, units, or processing elements (Hamedi and Jahromi 2021).
Radial basis function (RBF)
The multi-layer perceptron (MLP) and radial basis function (RBF) are often utilized in the same form, although the internal computational structures vary from one application to another. The most popular architecture of the neural network MLP was developed to capture nonlinear processes effectively. One or more hidden layers can be found between the input and output layers (Fig. 4). Weights are typically defined by training the system and linking the input and hidden layers. The hidden layer adds the weighted inputs to generate the resulting value using the transfer function. The transfer function connects the activation function, which is the inner activity of the neuron, to the outputs. A distinctive transfer feature is a sigmoid function, ranging from 0 to 1. These features are present in many processes and so qualify for sigmoid functions. Monitored training is used when the ANN is trained to reduce the disparity between the network output and the observed data objective in time series forecasting. As a result, the training adjusts the weights to reach the desired result with fewer residual squares. In the ANN literature, backpropagation is the most often utilized training strategy.

The general architecture of radial basis function
The logarithmic and hyperbolic tangent functions are the essential nonlinear activation functions in MLP. The command is pureline for linear activation. The multi-layer nonlinear function of activation allows the network to develop nonlinear interactions between input and output vectors.
The RBF system has several advantages, including a simple three-layered architecture, good generalization, and high tolerance for input noise, as well as online learning. Because RBF networks are generic, they may react successfully to patterns that have not been used for training (Elbisy and Elbisy 2021). The RBF activation function is located within the network neuron’s hidden layer. RBFs work as local approximation networks, with hidden units that calculate outputs in specified local receptive fields. MLP networks, on the other hand, run at a global level, with all neurons determining the network outputs (Sadeghi et al. 2020).
The MLP and RBF models were used in this research because they have three inputs and one output, and they have been used to investigate the connection of sediment concentration with discharge, rainfall, and temperature.
Development of models
Forecasting is a process that is uncertain about what will happen in the future. This study aims to estimate the SSC concentration in light of the available data. For this purpose, artificial neural network models were created, and the SPSS program was used for analysis. There are two commonly used ANN methods in the SPSS neural network module. The first is multi-layer perceptron (MLP), and the second is radial basis function (RBF) artificial neural network models. MLP uses nonlinear network parameters, RBF works with linear parameters, and both methods can be used in the same application areas. Case processing summary of MLP and RBF neural network is shown in Table 3. First of all, the dataset was divided into training, testing, and validation parts.
The reason for this is to use the separated part to verify the established model later. We randomly concluded this process according to the Bernoulli distribution. In the case processing summary for RBF and MLP models, samples were used in the same numbers. The results show that the models have used samples for training and testing (N = 265, N = 103) for the Pindari glacier stream, whereas the Kafni glacier stream indicates that the samples for training and testing (N = 205, N = 118) respectively used out of the total inputs for the development. In percent for the Pindari glacier stream, 72% and 28% were used for training and testing, respectively, as 68% and 32% samples were adopted by the models for the Kafni glacier stream. Valid, excluded, and total numbers of samples were the same for both model and stream. Summary of MLP and RBF model of neural networks is shown in Table 3.
The performance of the used models was weighed by statistical indices, i.e., residual sum of squares error (RSS) and relative error (RE). The summary of the residuals for training and testing the MLP and RBF models to evaluate the Pindari and Kafni glaciers shows that MLP has achieved good performance with fewer residuals than the RBF neural network model. The details of the MLP and RBF for both streams are shown in Tables 4 and 5.
The topology resulting from the connection of neurons, the addition and transfer functions used by the processor elements, the learning method, and the learning rule and algorithm should be determined to create a neural network model. The model is designed according to the data at hand and the shape of the application to be made in the network. The success of the established model is closely related to the correct creation of the model’s shape. The ANN designer needs to make decisions regarding the structure and operation of the network. Selection of the network architecture and determination of its structural features, determining the characteristics of the functions used by the processor elements such as the number of layers and the number of processor elements in the layer, determining the learning algorithm and parameters, creating the training and test set are essential steps towards this purpose. Selected architectures for MLP and RBF in Pindari and Kafni glacier streams are shown in Figs. 5 and 6, respectively, showing the excellent representation of each node and weighing of the input, hidden, and output layers.

MLP architecture shows the processing summary of the input, hidden, and out layers with adopted synaptic weights (> 0) and (< 0) for both glacier streams. Left panel Pinadri and right panel of the Kafni glacier

RBF architecture shows the processing summary of the input, hidden, and out layers with adopted synaptic weights (> 0) and (< 0) for both glacier streams. Left panel for Pinadri and right panel for Kafni glacier
The importance of an independent variable refers to how much the ANN model’s projected value varies as the independent variable’s value changes. The detailed summary (Table 6 and Supplementary Figures S-7 and 8) of the inputs from independent parameters such as temperature, precipitation, and discharge shows that rainfall has found minimal importance. In contrast, the discharge has fully developed the SSC generation for the Pindari and Kafni glacier streams.
Results and discussion
The model’s estimated sediment concentration levels were compared to the values obtained using scatter plots. The criteria used in the research to assess model performance are comparisons of R2 values with MSE. The determination coefficient (R2) quantifies the degree of correlation between the observed and estimated output variable models, and R2 indicates a high value, while a low MSE value indicates a favorable model output. The residual difference is assessed by the mean square error (MSE) (Malika and Sonawane 2021; Asanjarani et al. 2020). As a result, MSE was employed to assess models where the optimal value is null. The correlation coefficient, also known as the R-value, is often used to verify the fit of hydrological variables and is obtained using linear regression between the ANN data and the target data (Alam et al. 2019). R equal to 1 denotes a perfect relationship between the goal and the predicted values, while R equivalent to 0 denotes no correlation between them (Hosseinzadeh et al. 2020). The model characteristics and performance parameters are shown in Table 1.
Multiple linear regression analysis determines the relationship between a dependent variable and a collection of independent factors. In multiple linear regression, each independent variable has a changing effect on the dependent variable, and the variable does not correlate with the dependent variable in its null hypothesis. The P-value indicates significance, and the maximum permissible P-value for rejecting the null hypothesis is 0.05. If the P-value is between 0.01 and 0.05, the difference is statistically significant (Derosa et al. 2018). When examining Table 6, it is clear that the independent variable discharge provides the most precise SSC estimate of the independent variables.
On the other hand, temperature and precipitation have smaller normalized importance. The data were analyzed for significance, and the bivariate (Pearson) correlation test yielded two-tailed P-values (see Table 7). The maximum degree of significance is 0.05. This model is statistically significant because the results are reported within a 95% confidence range.
The comparison of MLR and ANN models depends on the determination coefficient (R2) and the mean squared error (MSE), which are the two main criteria for assessing the data-based success of the statistical models. \(\overline{{SSC}_{pre.}}\) is the mean value for the SSC prediction, \(\overline{{SSC}_{M}}\) is the mean value for the SSC measurement, and \(N\) stands for the total number of observations presented in Eqs. 3 and 4.
Some of the total input data were utilized for training, and the rest were used for model testing (see Table 9). The determination coefficient (R2) and the mean squared error (MSE), the two significant metrics for measuring the data-based effectiveness of statistical models, are used to compare MLR and ANN models. The findings indicate that the ANN model is the best dependable model compared to the MLR model to forecast future SSCs for Pindari and Kafni streams (see Tables 8 and 9).
The details of the observed and predicted SSC from the Pindari and Kafni glacier streams are presented in ST-1), which shows day-wise fluctuation in the observed and predicted values. Both models’ (RBF and MLP) day-wise accuracy for the applied models to predict the SSC can also be seen in ST-1. This measure is needed because SSC is an essential measure to assess the total amount of alluvial material and indicate the contamination level of incoming water. Thus, the conclusion has been drawn that a model for SSC in surface water may be developed using an artificial neural network (ANN), and future sediment transport concerns are predicted.
There is a near-exponential decline in discharge as the ending of the melt season approaches. Glacier ablation and climatic variables such as average air temperature and rainfall are linked to seasonal discharge fluctuations. Snowmelt-induced high discharge occurrences, on the other hand, were more likely in the first part of the hydrologically active season, between June and August, on average. Shifts in meltwater development rates, governed by meteorological variables, dictate the SSC’s seasonal and interannual trajectory. The ablation rate is related to the diurnal intensity of the suspended sediment concentration and is influenced by air temperature and incoming solar radiation. Results indicate that the rainfall intensity has a minor effect on sediment transport, and this is a new outcome considering the previous studies, which mainly underlines the impact of the rainfall on sediment transport (Halecki et al. 2018; Alizadeh et al. 2017). Recent experiments have shown that air temperature controls sediment flow rather than rainfall activity. However, the average air temperature has a minor impact on SSC, according to the findings of this study. The results clearly show that extreme events such as floodings and landslides cannot be predictable considering the research area based on meteorological data. In light of the results, it is thought that there are other factors, such as solar radiation, that affect discharge values and thus sediment transport.
Implications
The current research analyzes and systematically summarizes the evidence and impacts of cloudburst occurrences in the Indian Himalayan Region by compiling hydro-meteorological reports and analyzing available data. The findings suggest that natural climate change played a much smaller part in driving these catastrophic events than previously assumed. These results differ from streams feeding temperate glaciers, where there is frequently no seasonal pattern in diurnal hysteresis, and sediment supply is drained throughout the melt season. The data were not subjected to any previous qualitative interpretation due to the random separation of the time series. The hydrographs are mainly unaffected by rainfall. The degree and spectrum of SSC are proportional to the discharge, implying that the discharge magnitude controls SSC and suspended-sediment transport fluctuates seasonally. The estimation and predictions of long-term in situ discharge and sediment would be valuable for installing sustainable small hydroelectric power plants in the region. The prediction of the amount of the SSC was in terms of a milligram per liter in a day, month, and season. The unpredicted and unmeasurable sediment trend can stop or make irregularity to generate electricity due to the excessive transportation of the sediment.
Sediment yield estimation
The results suggest that MLP is exceptionally relevant to SSC simulation when viewed as a regressive model. The intriguing conclusion here is to overestimate SSC values in all models. Furthermore, nearly no outliers exist for MLPs, while RBFs often make such mistakes, demonstrating that MLPs are better fitted to the hydrological conditions encountered. There is a significant association between mean daily SCS and discharge (R2 = 0.9). However, the lesser correlation for day-to-day data shows that the rainfall and temperature of both variables are associated poorly at the diurnal level. The supplementary figures from S-1 to S-6 demonstrated the relationship between SSC vs. discharge, SSC vs. temperature, and SSC vs. precipitation in Pindari and Kafni glacier streams. Figures show the representation of the observed and ANN predicted SSC.
The actual and expected SSC values based on ANN analysis are shown in Figs. 7 and 8. The SSC observed from 2017 and 2018 and predicted in the part of the testing dataset from Pindari and Kafni glacier streams are shown in supplementary figures (S-11 and S-12). When contrasted with Figs. 9 and 10, it is evident that the MLP model provides better and more precise forecasts for the observed findings.

a Relationship between predicted and observed SSC, b show day-wise the graphical presentation of observed and precited SSC in 2019 from Pindari glacier stream

a Relationship between predicted and observed SSC, b show day-wise the graphical presentation of observed and precited SSC in 2019 from Kafni glacier stream

MLP and RBF developed model accuracy in percent with the day-wise presentation of Pindari and Kafni glacier streams

Day-wise combined presentation between observed and predicted SSC in 2019 from MLP and RBF neural network models of Pindari and Kafni glacier streams
Accuracy and comparison of models
Percent model output accuracy is shown in Figs. 9 and 10, and individuals with employed models (MLP and RBF) in this study for each stream of predicted and observed presentation with model accuracy can also see the individual glacier streams in supplementary figures from S-13 to S-16 and the graphical representation of the residual of the dependent SSC and predicted values can be seen in supplementary figures (S-11 and S-12). Each day predicted and observed values in 2019 from both models, and glacier streams with percent accuracy are presented in supplementary tables (ST-1 and ST-2).
Many recent pieces of research have suggested the potential benefit of ANN, notably for forecasting. Geohydrological time-series data may also be accurately predicted using ANN modeling. Precipitation is not usually directly proportionate to sediment transport, and it was essential to identify the most influential parameter governing sediment transport to avoid natural disasters at the study site. Contrary to popular belief, this study discovered that the most critical metric is discharge rather than precipitation. The normalized importance of the precipitation compared to the discharge was calculated to vary between 11.54 and 76.1%. As a result of this conclusion, which has received little attention in the literature, our study produced remarkably novel findings.
Conclusions
The Himalayas are geodynamically active terrain with significant rates of erosion and sedimentation. India’s hydropower potential is concentrated mainly in the Himalayan region. Due to sediment deposition, reservoir storage capacity in these places is rapidly exhausted. The Pindar basin is located in Uttarakhand, India, on the southern slope of the Greater Himalaya. It includes two nearby glacier valleys (Pindari and Kafni streams). The Dwali station meteorological observatory was established in 2017. Daily data generated between 2017 and 2019 were utilized in the analysis. Glacier melt-induced high discharge events were usual during the first half of the hydrologically active season.
Extreme events such as floods and landslides can only be predicted using meteorological data. An asymptotic discharge drop during the end of the melting period draws to a close. Fluctuations in seasonal flow are linked to glacier ablation and climatic variables, including mean air temperature, rainfall, and other vital parameters. On the other hand, glacier melt-induced large flow spikes were more likely in the first part of the hydrologically active season, usually between June and August. Shifts in meltwater development rates driven by meteorological conditions affect the SSC’s seasonal and interannual course. The ablation rate is related to the diurnal intensity of the suspended sediment concentration, which is governed by air temperature and incoming solar radiation.
Discharge, rainfall, and temperature data have been utilized to forecast the sediment load from the glacier melt discharge of Pindari and Kafni Rivers as inputs in the BP algorithm of the ANN model. The analysis of the data structure is based on statistical coefficients. The correlation coefficient (R) determines and picks ANN inputs to indicate the correlation level of hydro-climatological inputs to sediment load. A comparison between the ANN and MLR techniques found that ANN is the best methodology to simulate the actual status of the sediment transport with minimum error. Moreover, in ANN analysis, multi-layer perceptron (MLP) technique was superior to radial basis function (RBF) for all rivers for both daily simulations. When several input configurations were compared, it became clear that precipitation was not a significant factor. Precipitation was not a familiar figure due to the vast regions of the watershed, and rainfall intensity is more closely linked to soil detachment than rainfall volume. Precipitation and SSC are not proportionate, according to MLR analysis, since precipitation has a negative beta coefficient. Based on the findings, other possible natural effects, such as solar radiation, are expected to alter discharge levels and sediment movement. The work will also open up new research directions to increase the use of various ANN algorithms and soft hybrid calculation methodologies for short-term meltwater discharge prediction of SSC. Modeling the glacier sediment delivery mechanism and predicting the amount of SSC delivered by Himalayan rivers from glacierized basins are two potential applications of the findings. This research would be precious in managing the establishment of sustainable hydropower plants and irrigation projects, and other water resources in the Himalayan region, upstream and downstream of the Himalayas. The continued data generation in the Himalayan glacier region is a challenging task due to complex hilly terrain and bad weather conditions; therefore, the machine learning approach could be very beneficial to understand the overall hydrological cycle and pattern of sediment flux in the region.
Data availability
Data needed to evaluate the conclusions are published and presented in the paper and the Supplementary Material. Any additional data/code related to this paper may be requested from the authors.
References
Abrahart RJ, White SM (2001) Modelling sediment transfer in Malawi: comparing backpropagation neural network solutions against a multiple linear regression benchmark using small data sets. Phys Chem Earth Part B 26(1):19–24
Ahmed F, Hassan M, Hashmi HN (2018) Developing nonlinear models for sediment load estimation in an irrigation canal. Acta Geophys 66(6):1485–1494
Alam MT, Arif S, Ansari AH, Alam MN (2019) Optimization of wear behaviour using Taguchi and ANN of fabricated aluminium matrix nanocomposites by two-step stir casting. Materials Research Express 6(6): 065002.
Alizadeh MJ, Nodoushan EJ, Kalarestaghi N, Chau KW (2017) Toward multi-day-ahead forecasting of suspended sediment concentration using ensemble models. Environ Sci Pollut Res 24(36):28017–28025
Anand A, Beg M, Kumar N (2021) Experimental studies and analysis on mobilization of the cohesionless sediments through alluvial channel: a review. Civil Engineering Journal 7(5):915–936
Asanjarani N, Bagtash M, Zolgharnein J (2020) A comparison between Box–Behnken design and artificial neural network: modeling of removal of Phenol Red from water solutions by nanocobalt hydroxide. Journal of Chemometrics 34(9): e3283.
Asselman NEM (2000) Fitting and interpretation of sediment rating curves. J Hydrol 234(3–4):228–248
Bookhagen B (2012) Himalayan groundwater. Nat Geosci 5(2):97–98
Broomhead D, Lowe D (1988) Multivariable functional interpolation and adaptive networks. Complex Syst 2:321–355
Buyukyildiz M, Kumcu SY (2017) An estimation of the suspended sediment load using adaptive network-based fuzzy inference system, support vector machine, and artificial neural network models. Water Resour Manage 31(4):1343–1359
Chang FJ, Chen YC (2001) A counterpropagation fuzzy neural network modeling approach to real-time streamflow prediction. J Hydrol 245:153–164
Chauhan P, Singh N, Chauniyal DD, Ahluwalia RS, Singhal M (2017) Differential behaviour of a Lesser Himalayan watershed in extreme rainfall regimes. Journal of Earth System Science 126(2):1–13
Chen S, Cowan CFN, Grant PM (1991) Orthogonal least squares learning algorithm for radial basis function networks. IEEE Trans Neural Networks 2(2):302–309
Chibanga R, Berlamont J, Vandewalle J (2003) Modelling and forecasting of hydrological variables using artificial neural networks: the Kafue River subbasin. Hydrol Sci J 48(3):363–379
Cigizoglu HK (2004) Estimation and forecasting of daily suspended sediment data by multi-layer perceptrons. Adv Water Resour 27(2):185–195
Cigizoglu HK, Kisi Ö (2006) Methods to improve the neural network performance in suspended sediment estimation. J Hydrol 317(3–4):221–238
Crowder DW, Demissie M, Markus M (2007) The accuracy of sediment loads when log transformation produces nonlinear sediment load–discharge relationships. J Hydrol 336(3–4):250–268
Derosa L, Hellmann MD, Spaziano M, Halpenny D, Fidelle M, Rizvi H, Routy B (2018) Negative association of antibiotics on clinical activity of immune checkpoint inhibitors in patients with advanced renal cell and non-small-cell lung cancer. Ann Oncol 29(6):1437–1444
Ebtehaj I, Bonakdari H, Zaji AH, Gharabaghi B (2021) Evolutionary optimization of neural network to predict sediment transport without sedimentation. Complex & Intelligent Systems 7(1):401–416
Elbisy MS, Elbisy AM (2021) Prediction of significant wave height by artificial neural networks and multiple additive regression trees. Ocean Engineering 230: 109077.
Eslamian SS, Gohari SA, Biabanaki M, Malekian R (2008) Estimation of monthly pan evaporation using artificial neural networks and support vector machines. J Appl Sci 8(19):3497–3502
Halecki W, Kruk E, Ryczek M (2018) Estimations of nitrate nitrogen, total phosphorus flux and suspended sediment concentration (SSC) as indicators of surface-erosion processes using an ANN (Artificial Neural Network) based on geomorphological parameters in mountainous catchments. Ecol Ind 91:461–469
Hamedi S, Jahromi HD (2021) Performance analysis of all-optical logical gate using artificial neural network. Expert Systems with Applications 178: 115029.
Himanshu SK, Pandey A, Yadav B (2017) Assessing the applicability of TMPA-3B42V7 precipitation dataset in wavelet support vector machine approach for suspended sediment load prediction. J Hydrol 550:103–117
Holtschlag DJ (2001) Optimal estimation of suspended-sediment concentrations in streams. Hydrol Process 15(7):1133–1155
Hosseinzadeh A, Baziar M, Alidadi H, Zhou JL, Altaee A, Najafpoor AA, Jafarpour S (2020) Application of artificial neural network and multiple linear regression in modeling nutrient recovery in vermicompost under different conditions. Bioresource technology 303: 122926.
Isaac N, Eldho TI (2017) Sediment management of run-of-river hydroelectric power project in the Himalayan region using hydraulic model studies. Sādhanā 42(7):1193–1201
Joshi KD, Das, SCS, Pathak RK, Khan A, Sarkar UK, Roy K (2018) Pattern of reproductive biology of the endangered golden mahseer Tor putitora (Hamilton 1822) with special reference to regional climate change implications on breeding phenology from lesser Himalayan region, India. Journal of Applied Animal Research 46(1):1289–1295
Jothiprakash V, Garg V (2009) Reservoir sedimentation estimation using artificial neural network. J Hydrol Eng 14(9):1035–1040
Kaur R, Srinivasan R, Mishra K, Dutta D, Prasad D, Bansal G (2003) Assessment of a SWAT model for soil and water management in India. Land Use and Water Resources Research 3:41–47
Kerich EC (2020) Households drinking water sources and treatment methods options in a regional irrigation scheme. Journal of Human Earth and Future 1(1):10–19
Khan MYA, Tian F, Hasan F, Chakrapani GJ (2019) Artificial neural network simulation for prediction of suspended sediment concentration in the River Ramganga Ganges Basin. India Int J Sediment Res 34(2):95–107
Kisi O (2005) Suspended sediment estimation using neuro-fuzzy and neural network approaches/Estimation des matières en suspension par des approaches neuro floueset à base de réseau de neurones. Hydrol Sci J 50(4):683–696
Kriegeskorte N (2015) Deep neural networks: a new framework for modeling biological vision and brain information processing. Annu Rev Vis Sci 1:417–446
Kumar A, Verma A, Gokhale AA, Bhambri R, Misra A, Sundriyal S, Dobhal DP, Kishore N (2018) Hydrometeorological assessments and suspended sediment delivery from a central Himalayan glacier in the upper Ganga basin. International Journal of Sediment Research 33(4):493–509
Malika M, Sonawane SS (2021) Application of RSM and ANN for the prediction and optimization of thermal conductivity ratio of water based Fe2O3 coated SiC hybrid nanofluid. International Communications in Heat and Mass Transfer 126: 105354.
Mustafa MR, Isa MH, Rezaur RB, (2011) A comparison of artificial neural networks for prediction of suspended sediment discharge in river-a case study in Malaysia. World Academy of Science, Engineering, and Technology (WASET) 81: 372–376.
Rahman SA, Chakrabarty D (2020) Sediment transport modelling in an alluvial river with artificial neural network. Journal of Hydrology 588: 125056.
Ramanathan AL (2011) Status report on Chhota Shigri Glacier (Himachal Pradesh), Department of science and technology, ministry of science and technology, New Delhi. Himal Glaciol Tech Rep 1:88
Sadeghi A, Younes Sinaki R, Young WA, Weckman GR (2020) An intelligent model to predict energy performances of residential buildings based on deep neural networks. Energies 13(3):571
Sarangi A, Bhattacharya AK (2005) Comparison of artificial neural network and regression models for sediment loss prediction from Banha watershed in India. Agric Water Manag 78(3):195–208
Shekhar MS, Chand H, Kumar S, Srinivasan K, Ganju A (2010) Climate-change studies in the western Himalaya. Annals of Glaciology 51(54):105–112
Singh A, Imtiyaz M, Isaac RK, Denis DM (2012) Comparison of soil and water assessment tool (SWAT) and multi-layer perceptron (MLP) artificial neural network for predicting sediment yield in the Nagwa agricultural watershed in Jharkhand, India. Agric Water Manag 104:113–120
Singh P, Ramasastri KS (1999) Project report on Dokriani glacier. National Institute of Hydrology, Roorkee, India.
Talebizadeh M, Morid S, Ayyoubzadeh SA, Ghasemzadeh M (2010) Uncertainty analysis in sediment load modeling using ANN and SWAT model. Water Resour Manage 24(9):1747–1761
Valdiya KS (1999) Lithological subdivisions and tectonics of the Central Crystalline Zone of Kumaon Himalaya. In: Proceedings of the seminar on geodynamics of Himalayan Region, National Geophysical Research Institute, Hyderabad, pp 204–205.
Van Engelenburg J, Hueting R, Rijpkema S, Teuling AJ, Uijlenhoet R, Ludwig F (2018) Impact of changes in groundwater extractions and climate change on groundwater-dependent ecosystems in a complex hydrogeological setting. Water Resour Manage 32(1):259–272
Walling DE (1988) The reliability of rating curve estimates of suspended sediment yield: some further comments. In Symposium on Sediment Budgets, Porto Alegre, Brazil.
Yadav B, Mathur S, Ch S, Yadav BK (2018) Data-based modelling approach for variable density flow and solute transport simulation in a coastal aquifer. Hydrol Sci J 63(2):210–226
Yang GR, Wang XJ (2020) Artificial neural networks for neuroscientists: a primer. Neuron 107(6):1048–1070
Yang JQ, Wang R, Ren Y, Mao JY, Wang ZP, Zhou Y, Han ST (2020) Neuromorphic engineering: from biological to spike-based hardware nervous systems. Adv Mater 32(52):2003610
Acknowledgements
Authors appreciate to independent reviewers and the editor for their contribution to this paper.
Funding
The first author thankfully acknowledged SERB (Science and Engineering Research Board)/DST for the financial support for this research project (File No. EEQ/2016/000292). The authors are thankful to the Director, Wadia Institute of Himalayan Geology (WIHG), for all logistical support.
Author information
Authors and Affiliations
Contributions
PC and MEA analyzed the dataset and wrote drafts of the manuscript. All authors contributed equally to the interpretation, discussion, and editing of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Responsible Editor: Amjad Kallel
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Chauhan, P., Akıner, M.E., Sain, K. et al. Forecasting of suspended sediment concentration in the Pindari-Kafni glacier valley in Central Himalayan region considering the impact of precipitation: using soft computing approach. Arab J Geosci 15, 683 (2022). https://doi.org/10.1007/s12517-022-09773-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12517-022-09773-1