
Abstract
Cold chain logistics requires low-temperature transportation, which consumes more energy and has higher distribution costs than ordinary logistics. Moreover, as the scale of cities continues to expand, traffic congestion is becoming more frequent. Therefore, it is particularly important to plan the distribution route reasonably. In this paper, we study the problem of cold chain logistics vehicle path planning based on travel time prediction. First of all, multiple connected routes with real-time changes in traffic conditions between customers in the road network were considered to describe the distribution scene. Second, a genetic algorithm-optimized backpropagation algorithm fused travel time predictions for road segments based on fixed detector technology and floating car technology to improve the accuracy of road segment travel time prediction. Then, based on the prediction of road segment travel time, a method for predicting the travel time of the route is proposed, and the actual road network is transformed into a travel time network for each customer. Finally, the vehicle routing problem in cold chain logistics was investigated using predicted travel time as input. This problem is formulated as a bi-objective model aimed at minimizing costs and carbon emissions. To address this problem, the Non-dominated Sorting Genetic Algorithm-II (NSGA-II) was proposed. The study provides support for cold chain logistics distribution companies to develop distribution strategies based on local environmental policies and their own operational conditions.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In recent years, there has been a significant enhancement in people’s living standards, leading to a rapid surge in the demand for fresh products. However, fresh products, being perishable and delicate, necessitate heightened consumption of fuel to sustain a low-temperature environment during the distribution process. Consequently, this imposes stringent requirements on cold chain logistics and distribution, resulting in elevated energy consumption and costs. Therefore, how to reasonably plan the distribution route to ensure customer demand while reducing costs and environmental pollution has become a key issue in cold chain logistics and distribution.
With the continuous expansion of urban areas, the demand for transportation has surged, leading to escalating road traffic loads. Consequently, urban traffic congestion and traffic accidents have become more frequent, exacerbating environmental pollution. In 2020, the global transportation sector emitted 8.258 billion tons of carbon dioxide, accounting for 24% of total global emissions and ranking second in the world (Guo et al. 2023). Compared to conventional logistics, cold chain operations necessitate increased fuel consumption to maintain low-temperature environments, resulting in approximately 30% higher exhaust emissions from refrigerated trucks (Kim et al. 2016). Consequently, mitigating the carbon footprint of cold chain logistics and distribution is imperative, with a shift towards low-carbon strategies becoming an inevitable necessity for its sustainable development (Guo et al. 2017; Chen et al. 2021).
Due to the perishable and delicate nature of cold chain products, the distribution process incurs additional costs and carbon emissions. Strategic planning of distribution routes has the potential to enhance distribution efficiency, leading to cost savings and reduced carbon emissions. However, the rapid growth of the cold chain industry has resulted in limited research on Vehicle Routing Problems (VRP) in cold chain logistics that take carbon emissions into account. Consequently, addressing the low-carbon VRP in cold chain logistics and minimizing costs and carbon emissions have emerged as central challenges in cold chain logistics distribution.
However, most existing studies on low-carbon vehicle routing problems in cold chain logistics have overlooked the impacts of road network complexity and time-varying traffic conditions (Zheng et al. 2021; Li and Li 2022; Stellingwerf et al. 2021). The complexity of the road network is evident in the presence of multiple interconnected paths between customers in the actual road network. The constantly changing traffic conditions are manifested in the real-time fluctuations in the traffic situation along each path connecting customers. Essentially, current studies typically formulate a Vehicle Routing Problem (VRP) model for cold chain logistics with objective functions including vehicle operating costs, transportation costs, product freshness costs, quality loss costs, penalty costs, and carbon emission costs, without accounting for the influence of road network complexity and dynamic traffic conditions on route planning. Instead, they often assume that there is only one connection route with Euclidean distance between each customer point, with constant traffic conditions along the route. It is crucial to recognize that, apart from vehicle operating costs, all these identified costs are either directly or indirectly linked to travel time. Hence, developing a low-carbon VRP model for cold chain logistics based on travel time prediction holds significant importance. It not only enables cold chain logistics companies to circumvent heavily congested road segments and enhance delivery efficiency but also facilitates cost reduction and carbon emission mitigation.
The main contributions of this paper are summarized as follows:
-
(1)
A bi-objective mixed integer programming model considering the complexity of the road network and the time-varying traffic conditions is proposed for the cold chain logistics vehicle routing problem.
-
(2)
Based on fixed detector data and floating vehicle data, a data fusion prediction model for travel time prediction is proposed to quantify time-varying travel time in complex road networks, laying the foundation for research on cold chain logistics vehicle routing problems.
-
(3)
The GA-BP algorithm is developed to solve the data fusion model for travel time prediction.
-
(4)
The NSGA-II algorithm is used to solve the bi-objective mixed integer programming model on the vehicle routing problem.
The remainder of this paper is as follows. Section 2 presents relevant literature. In Sect. 3, we studied the travel time prediction first. And then build a cold chain logistics vehicle routing planning model based on the travel time prediction. The solution method is proposed in Sect. 4. Section 5 is based on a simulation case to solve the model and analyze the results. In Sect. 6, the work of this article is summarized and the future research direction is pointed out.
2 Literature review
This section respectively reviews the existing research on travel time prediction and Cold Chain Logistics VRP.
2.1 Investigation VRP for cold chain logistics
Cold chain logistics distribution, as the circulation method of fresh products, has increasingly become a research hotspot for many scholars and experts (Lim et al. 2022; Al Theeb et al. 2020; Diabat et al. 2019). This section mainly introduces the research status of VRP considering carbon emissions for cold chain logistics, and VRP considering traffic conditions for cold chain logistics.
The VRP for cold chain logistics, also known as the cold chain logistics distribution problem (Zhang et al. 2018), aims to deliver fresh produce from distribution centers to customers with minimal cost, maximizing customer satisfaction or other objectives. Cold chain logistics is more sensitive to temperature and time. Compared with other delivery issues, cold chain VRP generates higher costs, including quality loss costs, refrigeration costs, and penalty costs, in addition to transportation costs and vehicle operating costs (Li et al. 2019; Bai et al. 2022). Ma et al. (2016), Akkerman et al. (2010), and Diabat et al. (2019) proposed a mathematical model with the objective of minimizing the total cost to optimize the vehicle routes for distributing fresh products. Song and Ko (2016) proposed a model that defines customer satisfaction in terms of freshness, aiming to enable planned vehicle routes to maximize the quality of perishable products. Amorim and Almada-Lobo (2014) proposed a bi-objective model to examine the relation between cost and freshness with the objective of minimizing cost and maximizing freshness.
With environmental problems becoming more and more severe today, more and more scholars in the field of cold chain logistics have focused their attention on the research of low-carbon VRP for cold chain logistics that reduce energy consumption and pollution emissions (Li et al. 2019; Chen et al. 2021; Kim et al. 2019). A VRP model with carbon emission constraints is proposed by Tang et al. (2021), and an improved ant colony system algorithm is proposed to solve it. Kang et al. (2019) comprehensively considered the various costs in the cold chain logistics and distribution process, constructed a vehicle routing optimization model for fresh agricultural products that considered carbon emissions, and used an improved genetic algorithm to solve examples to verify the effectiveness of the model and algorithm.
The above research makes the distribution scene of cold chain logistics description in terms of the goal of minimizing distribution costs gradually closer to reality, but the above research does not consider the traffic situation in the distribution process. However, traffic conditions will affect the speed and duration of refrigerated truck delivery, which in turn will affect various costs in the delivery. Therefore, researchers in the field of cold chain logistics have produced numerous research results taking traffic conditions into consideration (Zhu and Hu 2019; Xiao and Konak 2016; Liu et al. 2020). Xiao and Konak (2016) proposed a low-carbon VRP model with a time window that uses time division to reflect the impact of traffic on distribution. Experiments show that this model can reduce carbon emissions by 8%. A model is proposed by Wu and Ma (2017) for time-dependent production-delivery problems with time windows for perishable foods and verified that the time-dependent characteristics of road networks have a significant impact on routing decisions. Zhao et al. (2020) and Liu et al. (2020) considered the impact of traffic congestion on delivery costs, and divided the delivery time into congestion and non-congestion periods, thereby integrating road congestion factors into the VRP model for cold chain logistics, the improved ant colony algorithm, genetic algorithm and two-stage optimization algorithm are used to solve the problem.
In summary, the research on VRP for cold chain logistics has produced more research results, but there are also some limitations: (1) The current research on the VRP for cold chain logistics mainly discusses economics, and there is little involvement in vehicle energy saving, emission reduction and environmental protection. (2) Most of the existing research results of VRP for cold chain logistics assume constant traffic conditions. Although there are a few research that considered traffic conditions, most of them divide the delivery time into multiple periods and assume the traffic situation is constant in each time period, which is far from the actual situation.
2.2 Investigation of travel time prediction
Currently, there has been extensive research on predicting travel times for road segments. These studies can be categorized into three major types: parametric methods, nonparametric methods, and hybrid integration methods.
The parametric method refers to learning a predetermined functional form that is used to reveal the mathematical relationship between travel time and contributing variables (Lin et al. 2022). The parametric methods mainly include exponential smoothing methods (Gao et al. 2004; Kumar et al. 2017), time series models(Kumar et al. 2017), and linear regressive models (Rice and Van Zwet 2004). These models are relatively simple and only use average travel time data to identify rule changes or statistical patterns. However, when the data volume is large, parameter estimation is complex, or traffic conditions change drastically, it is difficult to guarantee prediction accuracy.
Different from parametric methods, non-parametric methods involve learning a function form that changes with the circumstances (dataset), and the number of parameters increases with the growth of data. Examples include artificial neural networks (Tang and Hu 2020), support vector machines, etc (Zheng et al. 2019). These methods use high-dimensional kernel functions to process complex nonlinear traffic data and can better reflect the traffic characteristics of the real world.
The hybrid integration method is a method that combines parametric methods with non-parametric methods. For example, Zhang et al. (2017) presented back propagation (BP) neural network algorithm and time series analysis to predict travel time.
However, most existing studies that use these three methods to predict travel time are mostly based on a single data source, either fixed detector data or floating car data (Zhang et al. 2017; Tang and Hu 2020). Prediction studies based on a single data source suffer from the drawback that prediction accuracy is affected by the precision of the collecting instruments and the sample size, thus limiting the accuracy of the prediction results. Therefore, some studies combine data from both sources. For example, Xing and Liu (2021) considered the complementary and comprehensive advantages of integrating data and constructed a data fusion powered bi-directional long short-term memory model for individual lan and aggregate traffic flow, and through case analysis proves that the accuracy of traffic flow prediction results of multi-source traffic data fusion is higher than that of a single data source.
In conclusion, numerous scholars and experts have conducted extensive research on the prediction of road segment travel time, yielding a significant body of results. However, existing research in this field predominantly relies on either fixed detector data or floating car data, with limited exploration into the fusion of these two data sources for prediction.
Addressing the shortcomings of previous studies, this paper incorporates the intricacies of the road network and dynamic traffic conditions. Firstly, a data fusion model centered on predicting road segment travel time is developed to enhance prediction accuracy. Secondly, a routine travel time weighted on the current time segment travel and historical road segment travel time prediction model is established. Lastly, a vehicle routing model is constructed for low-carbon cold chain logistics using the predicted road segment travel time and routing travel time models. This aims to assist logistics companies in formulating superior distribution strategies, enhancing distribution efficiency, lowering distribution costs, reducing carbon emissions, boosting customer satisfaction, and offering robust support for the distribution activities of cold chain logistics firms.
3 Problem description and model formulation
Most previous studies on vehicle routing problems (VRP) in cold chain logistics have overlooked the complexity of the road network and have oversimplified the consideration of time-varying traffic conditions. Consequently, accurate distribution costs and carbon emissions have been difficult to obtain, rendering the planned distribution routes meaningless. Recognizing the limitations of prior research, this paper addresses the complexity of actual road networks and the dynamic nature of traffic conditions. Initially, the study focuses on predicting travel times and converting the real road network into a travel time network. Subsequently, the analysis incorporates both economic and environmental costs to minimize the total distribution cost and carbon emissions. Furthermore, a vehicle routing planning model for cold chain logistics is developed.
3.1 Problem description and hypothesis
There is a cold chain distribution center. Z refrigerated trucks are responsible for distributing goods to N customers. The maximum load of the vehicle, customer demand, and soft time window are known. Each refrigerated truck returns to the distribution center after completing the distribution task.
For the convenience of research, refer to Wang et al. (2018), and make the following assumptions:
-
(1)
There is only one type of refrigerated truck.
-
(2)
The demand of each customer must be met and can only be visited once.
-
(3)
The total customer demand on each distribution route cannot exceed the maximum load of the refrigerated truck.
-
(4)
The demand of a single customer is less than the maximum load of the refrigerated truck. that is, the refrigerated truck can deliver to multiple customers.
The symbols used in this paper are shown below
Sets | Description |
|---|---|
N | Set of demand points |
Z | Set of refrigerated truck |
B | Set of route between two demand points |
Parameters | Description |
|---|---|
\({t_1}\) | Road segment travel time predicted based on fixed detector technology |
\({t_d}\) | Normal travel time through the road segment |
\({t_l}\) | Delay time due to signal lights |
L | Length of the road segment |
\({\bar{v}}\) | Average speed of a vehicle passing a fixed detector |
c | Traffic signal cycle |
\(\lambda\) | Effective green light time ratio |
q | traffic flow |
\(\mu\) | Probability of delay due to the signal light |
x | Lane saturation |
C | Practical saturated capacity of the entrance road |
\({t_2}\) | Road segment travel time predicted based on the floating car technology |
\({v_f}\) | Average speed of the floating car |
\({C_o}\) | Vehicle operating cost |
\({P_1}\) | The fixed cost of the vehicle |
\({C_f}\) | Product freshness cost |
\({C_{f1}}\) | Transportation product freshness cost |
\({C_{f2}}\) | Unloading product freshness cost |
\({C_r}\) | Product freshness cost per unit time during the transportation |
\({C_d}\) | Unloading freshness cost per unit time during the transportation |
\(t_{i,s}^z\) | Service time of vehicle z at customer i |
\({C_l}\) | Quality loss cost |
\({C_{l1}}\) | Transportation quality loss cost |
\({C_{l2}}\) | Unloading quality loss cost |
\({P_2}\) | The unit price of the goods |
\({q_i}\) | Demand of the customer i |
\({\gamma _1}\) | The rate of decrease in the freshness of the goods during transportation |
\({\gamma _2}\) | The rate of decrease in the freshness of the goods during unloading |
\(t_0^z\) | The moment vehicle z leaves the distribution center |
\({c_{ew}}\) | The penalty cost per unit of time for vehicles arriving early |
\({c_{lw}}\) | The penalty cost per unit of time for vehicles arriving late |
\(W\left( {Q_{ij}^{b,z}} \right)\) | Fuel consumption per unit time of the vehicle z on the \(b{{ - }}th\) route between customer |
points i and j with a load of Q. | |
\({W_0}\) | Fuel consumption per unit time when vehicle z is unloaded |
\({W_1}\) | Fuel consumption per unit time when vehicle z is fully loaded |
\({Q^ * }\) | Maximum load of vehicle z |
\({P_3}\) | Unit price of fuel |
\(t_{ij}^b\) | Predicted travel time of the \(b{{ - }}th\) route from the customer i to j. |
\({C_c}\) | Carbon emission cost |
\({C_{c1}}\) | Transportation carbon emission cost |
\({C_{c2}}\) | Refrigeration carbon emission cost |
\({e_{c{o_2}}}\) | Emission coefficient of \(c{o_2}\) |
\(\omega\) | Carbon emission produced by refrigeration equipment per unit weight of goods per unit time |
Decision variables | Description |
|---|---|
\({a_z}\) | 1 if vehicle z is used, 0 otherwise |
\(y_{ij}^{b,z}\) | 1 if vehicle z passes through the \(b{{ - }}th\) route of customer points i and j, 0 otherwise |
\(t_i^z\) | The moment the vehicle z arrives at customer point i |
3.2 Travel time prediction
This section uses data fusion methods to study travel time prediction. The specific details are as follows: Firstly, the road travel time prediction model is established based on fixed detector technology and floating car technology, respectively. Secondly, the GA-BP algorithm is used to fuse the two results to improve prediction accuracy. Finally, on the basis of road segment travel time prediction, a route travel time prediction model weighted based on current time data and historical data is proposed, which lays a foundation for the subsequent study of VRP for cold chain logistics.
3.2.1 Road segment travel time prediction based on fixed detector technology
At present, the study of travel time prediction based on fixed detector technology has been very much and very mature. Most scholars and researchers have accepted and adopted the method proposed by Cheu et al. (2001) to obtain the travel time of the road segment. That is, the road travel time \({t_1}\) can be divided into two parts: the time \({t_d}\) of the vehicle normally passing the road segment and the delay time \({t_l}\) caused by the signal light (Fig. 1). The details are as follows:

The diagram of the road segment
among them,
Detailed derivation of the above equation, which is based on deterministic queuing theory, can be found in Cheu et al. (2002)
3.2.2 Road segment travel time prediction based on floating car technology
The driving speed of the floating car can be obtained directly, so most scholars and experts use the method of calculating the average speed when conducting research on the road segment travel time prediction based on the floating car technology.
There are many types of vehicles in the actual road network, and all types of vehicles should be considered for the calculation of travel time. According to Robinson (2005), the vehicles in the road network can be divided into the following four types:
-
(1)
Vehicles that stop during driving (for example, taxis, buses, etc. stop to let passengers get on and off the bus).
-
(2)
Vehicles that can not comply with standard traffic rules due to the particularity of the vehicle (such as emergency vehicles, etc.).
-
(3)
Vehicles that drive irrationally (for example, a sightseeing vehicle that deliberately idles).
-
(4)
Vehicles that drive rationally, that is, vehicles that have been excluded from the above three types.
Therefore, when calculating the travel time of the road segment based on the floating car technology, taking these four types of vehicles into account, we can get:
among them,
where \({v_1}\), \({v_2}\), \({v_3}\), and \({v_4}\) are the average speeds of the four types of vehicles, respectively.
3.2.3 Road segment travel time prediction based on GA-BP
GA-BP algorithm can automatically learn the previous experience from the massive historical data in the past and automatically approach the characteristics of the function that best reflects the historical law. So it has a great advantage when dealing with function problems with unknown prior relations, especially complex nonlinear problems. Therefore, this section uses the GA-BP algorithm to fuse the road segment travel time prediction results based on the fixed detector technology and the floating car technology to improve the accuracy of the road segment travel time prediction results. Here we only show the BP network structure (Fig. 2). The remaining can be seen in Sect. 4.

Topology map of road segment travel time prediction model based on neural network
Let sample \(t = \left[ {{t_1},{t_2}} \right]\) be the travel time of the road segment predicted based on the fixed detector technology and the floating car technology. The input layer neuron is \(I = \left[ {{t_1},{t_2}} \right]\). The hidden layer neuron is \(H = [{h_1},{h_2}, \ldots ,{h_j}]\). The weight between the input layer neuron and the hidden layer neuron is \({\omega _{ij}}\). The weight between hidden layer neurons and output layer neurons is \({\omega _{jk}}\), the threshold value of hidden layer neurons is \({b_j}\), and the threshold value of output layer neurons is \({c_k}\). \(f( \cdot )\) is the transfer function of the hidden layer. In this paper, the S-tangent function is used as the transfer function of the hidden layer neuron, that is \(f(x) = \frac{2}{{1 + {e^{ - 2x}}}} - 1\). \(g( \cdot )\) is the transfer function of the output layer, and the sigmoid logarithmic function is used as the transfer function of the neurons in the output layer, that is \(g(x) = \frac{1}{{1 + {e^{ - x}}}}\). \({N_1}\), \({N_2}\), \({N_3}\) are the number of neurons in the input layer, hidden layer, and output layer, respectively.
The number of neurons in the hidden layer is based on the empirical formula:
Then, the input layer I is:
The hidden layer H is:
The output layer Q is:
3.2.4 Routing travel time prediction
In actual distribution activities, due to the difference in customer demand and the limited loading capacity of refrigerated trucks, it is necessary to determine which customer’s goods are loaded on the refrigerated truck before the refrigerated truck departs, and then plan the optimal delivery route, which makes the delivery cost and the smallest carbon emissions.
The method for predicting the travel time of a particular road segment has been studied previously. Due to the time-varying characteristics of the road network, the traffic flow parameters collected at the time of departure are unable to accurately describe the traffic conditions of downstream road segments after the refrigerated truck has driven several road segments along the planned route. However, when the future traffic condition is unknown, the greatest indicator of the traffic condition’s changing trend is the corresponding period’s historical traffic flow data. Therefore, this section proposes a road segment travel time prediction model weighted based on the current time predicted road segment travel time and the historical average road segment travel time. The model is constructed as follows:
Suppose the vehicle departs from customer A to customer B at time t, and there are n road segments between customer A and B. The traffic data is collected at a certain time interval \(\tau\), and the travel time of the road section is also obtained at this time interval, so the time is divided into time intervals based on this time interval, and the vehicle travel time is \(t \in ((k - 1)\tau ,k\tau ],k = 1,2, \ldots ,\frac{{1440}}{\tau }\). Therefore, the routing travel time prediction model is:
Among them,
where \({T_{AB}}(t)\) is the predicted travel time of the vehicle through the route AB at time t. \({T_i}(t)\) is the predicted travel time of the vehicle through road segment i at time t. \({\Delta _{i - 1}}\) is the time spent by the vehicle before the \(i-1\) th road segment. \(T_i^ * (k)\) is the predicted value of the travel time of the road segment obtained based on the traffic flow data of the starting period. \(T_i^H(k + {\Delta _{i - 1}})\) is the historical average travel time required by the vehicle on the road segment i in the \(k + {\Delta _{i - 1}}\) period. \(\alpha ({\Delta _{i - 1}})\) is the weight coefficient that varies with the elapsed period of time \({\Delta _{i - 1}}\), the larger the \({\Delta _{i - 1}}\), the smaller the \(\alpha ({\Delta _{i - 1}})\). [] is a rounding symbol.
According to the actual situation, with the passage of time, in the above road network travel time prediction model, the weight of the current traffic data in the road segment travel time prediction will gradually decrease, and the weight of historical data will gradually increase. Reference the research of Wu (2015), using the Gaussian function to assign a value to \(\alpha\).
Then, the method of obtaining \(\alpha ({\Delta _{i - 1}})\) is as follows:
where \(T_i^ * (k + {\Delta _{i - 1}})\) is the road segment travel time predicted based on the actual traffic flow data in the \(k + {\Delta _{i - 1}}\) period.
3.3 Vehicle routing planning model for cold chain logistics
Based on the estimated travel time obtained in Sect. 3.2, we calculate the costs and carbon emissions as follows:
Vehicle operating cost. The operating cost \({C_o}\) is related to fixed costs \({p_1}\) such as driver wages and vehicle maintenance.
Product freshness cost. In the transportation process, a constant low temperature must be maintained to ensure the freshness of the goods, so energy will be consumed and transportation refrigeration costs will be generated. During the unloading process, due to frequent opening and closing of the compartment doors, in order to maintain a constant low temperature in the compartment, energy will also be consumed, and unloading refrigeration costs will be generated.
Therefore, the product freshness cost \({C_f}\) is
Quality loss cost. The goods distributed by cold chain logistics are susceptible to corruption and deterioration due to environmental temperature, oxygen, water activity of microorganisms in food, product PH value, and other factors, resulting in loss, that is, the quality loss cost. The quality loss cost \({C_l}\) exists in two aspects: during the transportation process, as time accumulates, the freshness of fresh products will decrease, resulting in transportation quality loss cost \({C_{l1}}\). During the unloading process, the door of the refrigerated truck has been opened and closed many times to cause hot air to enter, which will affect the temperature in the compartment to a certain extent. This will also cause the freshness of the fresh products to decrease, which in turn will cause the unloading quality loss cost \({C_{l2}}\).
Therefore, the total cargo damage cost \({C_l}\) is
Penalty cost. Due to the perishable nature of fresh products, customers typically request that the fresh products be delivered within the time window \([{T_1},{T_2}]\). If it is violated, a corresponding penalty cost \({C_p}\) will be incurred.
Transportation cost. Vehicles consume fuel during transportation, and the weight of the refrigerated vehicle is different, and the fuel consumption per unit of time is also different. Therefore, the transportation cost \({C_t}\) is:
Carbon emission. The carbon emissions in the cold chain distribution process mainly include two aspects: carbon emissions from transportation and refrigeration. For the carbon emissions generated during transportation, this paper uses this formula: \(Carbon emission = {e_{c{o_2}}} \times fuel consumption\) (Ottmar 2014). The carbon emissions produced by refrigeration are related to the length of delivery time and the amount of loading.
Therefore, the carbon emissions \({C_c}\) is
Aiming at the VRP for cold chain logistics, considering the complexity of the actual road network and the time variability of traffic conditions, the model is constructed through a comprehensive analysis of vehicle operating cost, product freshness cost, quality loss cost, penalty cost, transportation cost, and carbon emissions.
s.t
The load of vehicle z on the \(b-th\) route between customer points i and j is \(Q_{ij}^{b,z} = \left\{ \begin{array}{c} \sum \nolimits _{i = 0}^{N - 1} {\sum \nolimits _{j = 1}^N {\sum \nolimits _b^B {{q_j}y_{ij}^{b,z}} } } - {q_i} - \\ \sum \nolimits _{h = 0}^N {\left( {{q_h}\max \left( {\frac{{t_i^z - t_h^z}}{{\left| {t_i^z - t_h^z} \right| }},0} \right) } \right) } \end{array} \right\}\). Constraints (32) indicate that there are N customers to be delivered. Constraints (33) indicate that the sum of the customers on each delivery route is less than or equal to the maximum load of the refrigerated truck. Constraints (34) indicate that each customer is delivered by only one refrigerated vehicle, and the distribution center has Z vehicles. Constraints (35) indicate that the load when the vehicle leaves the previous customer is the sum of the demand for the next customer and the load when it leaves the next customer. Constraints (36) show that the distribution process of each refrigerated truck is continuous.
4 Algorithm design
In this section, we proposed GA-BP and NSGA-II algorithms to solve the model. First, we use the GA-BP algorithm to fuse the travel time of the road segment based on the floating car technology and the fixed detector technology to improve the prediction accuracy. Second, on the basis of the travel time prediction, the NSGA-II algorithm is used to solve the vehicle routing planning model. In the following content, we will introduce the GA-BP algorithm and the NSGA-II algorithm in detail. The flowchart is shown in Fig. 3.

Algorithm flow chart
4.1 GA-BP algorithm
The GA-BP algorithm consists of three parts: determining the structure of the BP neural network, GA optimizing the initial weights and thresholds of the neural, BP neural network training and predicting. We have introduced the determination of the structure of the BP neural network before, and then we will introduce the remaining two parts in detail.
4.1.1 GA optimizing the initial weights and thresholds
The elements of GA to optimize the BP neural network include population initialization, fitness function, selection, crossover, and mutation operations.
Population initialization.Each chromosome is composed of the connection weight \({\omega _{ij}}\) between the input layer and the hidden layer neuron, the connection weight \({\omega _{jk}}\) between the hidden layer and the output layer neuron, the threshold value of the hidden layer neuron and the output layer neuron, so its length is \({N_1} \times {N_2} + {N_2} + {N_2} \times {N_3} + {N_3}\). The chromosomes are coded by real numbers, and the value of each gene is in the range of \([-1,1]\).
Fitness function. The reciprocal of the absolute error between the predicted output obtained through the BP neural network and the expected output is used as the fitness function F.
Selection. The selection operation in this section adopts the roulette method, which is based on the fitness ratio. The probability \({p_i}\) that individual i is selected is:
where \({F_i}\) is the fitness value of individual i, m is the number of individuals in the population, and k is the coefficient.
Crossover. The crossover operation in this section uses a partial crossover method. The crossover operation method of the \(l{{ - }}th\) chromosome \({a_l}\) and the \(q{{ - }}th\) chromosome \({a_q}\) at the \(j{{ - }}th\) genes is as follows:
where b is a random number with a value in the range of [0,1].
Mutation. The mutation operation in this section adopts a single-point mutation method. For example, the \(j{{ - }}th\) gene \({a_{ij}}\) of the \(i{{ - }}th\) individual is mutated, as follows:
where \(f(g) = {r_2}(1 - g/{G_{\max }})\). \({r_2}\) is a random number. g is the current iteration number. \({G_{\max }}\) is the maximum evolution number. \({a_{\max }}\) and \({a_{\min }}\) is the upper and lower bound of gene \({a_{ij}}\). r is a random number within the range of [0, 1].
4.1.2 BP neural network training and predicting
The algorithm uses the gradient descent method to minimize the mean square error of the error between the actual output value of the network and the expected result, which is composed of two processes: the forward propagation of the signal and the backpropagation of the error. The forward propagation process, that is, the input signal is nonlinearly transformed through the hidden layer to produce the output signal, which acts on the neurons in the output layer. When the actual output does not match the expected output, the output error is fed back layer by layer from the output layer to the input layer through the hidden layer, which is the backpropagation process. Disperse the error to all neurons in each layer through the backpropagation process, and use the error signal obtained from each layer as the basis for adjusting the weight of each network. Adjust the weights between the input layer neurons and hidden layer neurons, as well as between the hidden layer neurons and output layer neurons, the threshold value of hidden layer neurons, and the threshold value of output layer neurons through the process of forward propagation and backpropagation. Then the error decreases in the direction of the largest decrease (gradient direction). After going through these two processes repeatedly, determine the weight between each neuron and the threshold of each neuron corresponding to the smallest error.
The error between the actual and expected outputs is:
When \(E > \varepsilon\) (the upper limit of error), adjust the weights between neurons in each layer:
Among them,
where \({\eta _1}\) and \({\eta _2}\) are the learning efficiency of the hidden layer and the output layer, respectively, and n is the number of iterative learning. It should be noted that if \(E(n + 1) < E(n)\), the learning efficiency is increased, or otherwise reduced.
4.2 NSGA-II algorithm
The model we built has two goals: the minimum total cost and the least carbon emissions, which belong to the category of multi-objective optimization problems. There are many optimization algorithms for solving multi-objective problems. NSGA-II algorithm is used as a benchmark to verify its performance by other multi-objective optimization algorithms because of its fast solution speed, good solution convergence, robustness and excellent characteristics. Therefore, the NSGA-II algorithm is widely used in similar research(Kuo et al. 2023; Menares et al. 2023). We use the NSGA-II algorithm to solve the model in this paper. The details are as follows:
Coding and population initialization. We construct L chromosomes of length N. The chromosome code in this article uses natural number coding. Each gene represents a customer, as shown in Fig. 4 (assuming there are 10 customers):

Coding diagram
Fitness function. The fitness function is used to evaluate the pros and cons of chromosomes. The higher the fitness value of the chromosome, the greater the probability it will enter the next generation. so good genes will be inherited. Otherwise, the easier it will be to be eliminated. For the bi-objective model established in this paper, set the total cost target as object1, the carbon emission target as object2, and the fitness function as the reciprocal of the two objective functions.
where \({F_1}\) is the fitness function of the total cost target, and \({F_2}\) is the fitness function of the carbon emission target.
Crossover. We adopt the partial mapping cross strategy as the method of cross operation. The crossover probability is pc. Whether the crossover is performed is determined by generating a random number in the range of [0,1]. When the generated random number is less than the crossover probability, crossover is performed, otherwise it is not performed. When performing crossover, the details are shown in Fig. 5 (Suppose the crossover occurs at positions 4 and 7).

Schematic diagram of a cross operation
Because there are duplicate customer point numbers in the same individual after the crossover, the non-duplicate customer point numbers are retained, and the conflicting customer numbers (with * positions) are eliminated by partial mapping, that is to use the corresponding relationship of the middle segment for mapping.
Mutation. In this section, the mutation strategy adopts the method of randomly selecting two points and swapping them. The probability of mutation is pm. Whether the mutation is performed is determined by generating a random number in the range of [0,1]. When the generated random number is less than the mutation probability, mutation is performed. Otherwise, it is not performed. When performing mutation, the details are shown in Fig. 6 (Suppose the mutation occurs at positions 4 and 7).

Schematic diagram of mutation operation
Select. The selection operation exists in two processes. The first selection operation is when the algorithm is just started. The competition selection method is used to select individuals from the parents for cross-mutation to generate offspring. The second selection operation is through crowding and non-dominated sorting. Use the roulette method to select the number to enter the next generation population.
5 Numerical example
In this section, we first validate the effectiveness of the data fusion model to predict travel times using the VISSIM traffic simulation software. Then the importance and necessity of considering the complexity of the road network is verified based on a case with one distribution center and 16 customers.
5.1 Comparison of prediction results of various models
Due to practical reasons, we are unable to obtain the traffic parameters in the actual road network. This article uses VISSIM traffic simulation software to simulate the operation of urban road traffic. The obtained traffic parameter data is respectively based on the fixed detector technology and the floating car technology to predict the travel time of the road section. Then the results obtained by the two methods are fused by the GA-BP. Finally, the prediction results obtained by various methods are compared and analyzed with the actual value (the travel time of the road segment obtained by the VISSIM software), as shown in Table 4.
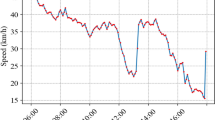
The road segment parameters are shown in Table 1. The traffic light settings are shown in Table 2. The vehicle types and their speed distributions are shown in Table 3. According to experience, input the traffic flow from 06:00 to 21:00, the sampling period is 5min, and take a total of 180 sets of data, the result is shown in Fig. 7. Among them, in the road segment travel time prediction model based on GA-BP, 150 sets of data (06:00–18:30) are used to train the network, and 30 sets of data (18:30–21:00) are used to detect model accuracy.

Prediction graph of data fusion model based on genetic algorithm to optimize BP neural network

Percentage error graph of the prediction results of the three methods
Figure 8 is a graph of percentage error based on the comparison between the prediction results of the three methods and the actual value. It can be seen from the figure that the results of the data fusion model are more accurate than those based on the fixed detector or floating car (Table 4).
After training, the result of the fusion model has a connection weight matrix \({\omega _{ij}}\) between each neuron in the hidden layer and each neuron in the input layer, a threshold matrix\({b_j}\)of each neuron in the hidden layer, and a difference between each neuron in the hidden layer and each neuron in the output layer, the connection weight matrix \({\omega _{jk}}\) and the threshold matrix \({b_k}\) of each neuron in the output layer are shown in Table 5.
It can be seen from Table 4, the travel time of the road segment predicted based on the fixed detector technology is quite different from the real value, and the absolute percentage error is as high as 14–22%. The accuracy of the road segment travel time predicted based on the floating car technology is improved compared with the predicted value based on the fixed detector. However, in the 30 sets of data, only 9 sets differ from the actual value within 5%. The 21 sets of data below all have a large gap with the actual value. The largest is as high as 19%. The accuracy of the road segment travel time predicted by the data fusion model based on GA-BP is greatly improved compared with the road segment predicted travel time based on the fixed detector technology and the floating car technology. The absolute percentage error with the largest difference from the actual value is about 5%. Therefore, it can be seen that the road segment travel prediction model based on GA-BP can overcome the defect of the large prediction error of a single data source.
5.2 Routing planning case
5.2.1 Traffic data source
The demand and service time window of the cold chain distribution center and each customer are shown in Table 6. The parameters of the refrigerated truck are shown in Table 7. The values of the relevant parameters of the model are shown in Table 8.
Due to some restrictions, we cannot obtain traffic flow data in the real road network. Therefore, we simulated the actual road network by creating a square grid with 64 intersections and 112 two-way road sections in the VISSIM traffic simulation software. The traffic flow data of each road segment at the initial time of the delivery day is obtained through VISSIM software simulation, and the historical travel time data of each road segment are assumed to be available in advance.
Create a road network in the VISSIM traffic simulation software as shown in Fig. 9. The road segment numbering rules are: first number by column, add 1 from left to right, and 10 from top to bottom; then number by row, from top Add 1 to the bottom and 10 from left to right. Assuming the refrigerated trucks start delivery at 07:00, we collect traffic flow data of each road segment at 07:00 on the day of delivery firstly, and then predict the travel time of each road segment based on fixed detector technology and floating car technology, and finally, the GA-BP neural network algorithm is used to fuse the two prediction results to get Table 9. The historical transit time data of each road segment is shown in Table 10.

Customer point distribution map
Since the connecting route between the intersections are two-way, and the traffic conditions on the two-way roads are different, so there are two results after the fusion. The first column is the forward travel time of the road segment, and the second column is the reverse travel time. Due to the excessive data in the average travel timetable of the historical period of each road segment, only part of the data is given here. For details, see Online Appendix Table 1.
In the vehicle routing planning model for cold chain logistics that does not consider the complexity of the road network and the time-varying traffic conditions, there is one and only one connected route with the length of the Euclidean distance between the customers, and the traffic situation is constant. The Euclidean distance matrix between customer points measured in the VISSIM software is shown in Online Appendix Table 2. And the default speed of the refrigerated truck is 50 Km/H.
5.2.2 Comparative results
This paper used MATLAB 2018b as a simulation experiment tool, a computer with a CPU of 1.60 GHZ and a memory of 16 G as the running tool. Figure 10 shows the results. Figure 10a show the model’s results built in this paper. Figure 10b show the model result without considering the road network’s complexity and the time-varying traffic conditions. In Fig. 10, the ordinate represents carbon emissions, the abscissa represents costs, the curve represents the Pareto frontier, and each point on the curve represents a solution. Through the Pareto curve, it can be seen that all solutions in the Pareto solution set cannot be better than the other points on both objectives. To a certain extent, a small increase in distribution costs can substantially reduce carbon emissions. However, after exceeding a certain limit, simply chasing the reduction of carbon emissions will significantly increase the distribution cost. In real life, cold chain logistics distribution enterprises can choose the appropriate solution in the Pareto set according to their own situation, the relevant policies of the local government on carbon emissions and the environmental protection situation.

The Pareto front of four instances
Comparing the model built in this paper with the model that does not consider the complexity of the road network and the time-varying traffic conditions, it can be seen that the model that does not consider the complexity of the road network and the time-varying traffic conditions results in a smaller total distribution cost and carbon emissions than the model built in this paper. The reason is that costs and carbon emissions other than the cost of vehicle use are related to travel time. When the complexity of the road network and the time-varying traffic conditions are not considered, the travel time is simply treated as the quotient of the Euclidean distance between customers and the fixed speed of the refrigerated truck. Therefore, the travel time is smaller than the model built in this article, resulting in the total cost of distribution and carbon emissions being small. In real life, there are multiple connected routes between customers, and the length of each connected route often differs greatly from the spatial Euclidean distance. Traffic conditions are constantly changing due to uncertain factors such as weather conditions, traffic accidents, traffic flow, and road construction, which leads to continuous changes in the speed of vehicles during driving. Therefore, regardless of the complexity and time-varying of the road network, the actual delivery scene will be inaccurate. However, the precise description of the distribution scene is the basic premise of cold chain logistics distribution routing planning. Once this premise is lost, it cannot get close to the true distribution cost and cannot plan the optimal distribution route.
Table 11 lists the three representative solutions of the model built in this article, as well as the distribution route, total distribution cost, and carbon emissions corresponding to each solution. Cold chain logistics companies can choose suitable solutions based on their own operating conditions.
5.2.3 The balance between cost and carbon emissions
Based on Fig. 10a, it can be observed that within a certain range, a slight increase in cost can significantly reduce carbon emissions. However, beyond a certain limit, solely reducing carbon emissions will significantly increase costs. For instance, transitioning from solution a to b involves a slight increase in carbon emissions, resulting in a substantial cost reduction. Similarly, transitioning from solution 2 to 3 incurs only a slight increase in distribution costs but leads to a significant decrease in carbon emissions. This finding is beneficial for both cold chain logistics enterprises and governments.
For cold chain logistics enterprises, when devising distribution routes, they can opt for schemes that involve a slight increase in carbon emissions while significantly reducing costs, provided they comply with relevant environmental protection policies and laws, thus addressing intense market competition.
For governments, in formulating carbon taxes, they can aim to align enterprise strategic choices as much as possible with the lower right portion of the curve. Coupled with relevant social responsibility education, this approach can guide cold chain logistics enterprises towards strategies that entail a slight increase in distribution costs while markedly reducing carbon emissions, thereby achieving sustainable development.
This article can support the distribution activities of cold chain logistics companies and the government to formulate carbon tax policies for environmental protection. For cold chain logistics companies, when planning distribution routes, they must be based on actual distribution scenarios, that is, taking into account the complexity of the road network and time-varying traffic conditions, because such routing planning is meaningful.
For government agencies, this research can provide a reference for the formulation of carbon tax policies. That is to say. When the government formulates a carbon tax, it can enable companies to choose as much as possible the areas on the curve that increase distribution costs and greatly reduce carbon emissions, and cooperate with relevant social responsibility education to guide cold chain logistics companies to choose their own strategies.
6 Conclusion
With the substantial improvement of people’s quality of life, the demand for fresh products has also increased unprecedentedly. However, because cold chain products are fragile and perishable, more fuel will be consumed during the distribution process to maintain a low-temperature environment to ensure the freshness of the goods. Therefore, cold chain logistics and distribution have high energy consumption and high costs. Based on previous research, this paper considers the complexity of the road network and the time-varying nature of actual traffic conditions. Complexity means that there are multiple connected paths between customers; time-varying means that the traffic conditions on each connected path between customers change in real time. Therefore, this article considers the “space-time effect” in path planning. That is, the “shortest path” between customers is not the “shortest spatial distance”, but the “shortest travel time”. Based on the above considerations, this article first researches travel time prediction, and then conducts research on cold chain logistics vehicle path planning based on travel time prediction.
On the basis of this article, related extended research will be carried out in the future. A distribution center with a single type of distribution vehicle was assumed in this paper. In future research, the low-carbon cold chain logistics vehicle path optimization problem with multiple distribution centers and multiple types of vehicles will be focused on.
References
Akkerman R, Farahani P, Grunow M (2010) Quality, safety and sustainability in food distribution: a review of quantitative operations management approaches and challenges. OR Spectr 32:863–904
Al Theeb N, Smadi HJ, Al-Hawari TH, Aljarrah MH (2020) Optimization of vehicle routing with inventory allocation problems in cold supply chain logistics. Comput Ind Eng 142:106341
Amorim P, Almada-Lobo B (2014) The impact of food perishability issues in the vehicle routing problem. Comput Ind Eng 67:223–233
Bai Q, Yin X, Lim MK, Dong C (2022) Low-carbon vrp for cold chain logistics considering real-time traffic conditions in the road network. Ind Manag Data Syst 122:521–543
Chen J, Liao W, Yu C (2021) Route optimization for cold chain logistics of front warehouses based on traffic congestion and carbon emission. Comput Ind Eng 161:107663
Cheu RL, Lee DH, Xie C (2001) An arterial speed estimation model fusing data from stationary and mobile sensors, In: ITSC 2001, 2001 IEEE intelligent transportation systems, proceedings (Cat. No. 01TH8585). IEEE, pp 573–578
Cheu RL, Lee DH, Xie C (2002) An arterial speed estimation model fusing data from stationary and mobile sensors. In: Intelligent transportation systems, IEEE
Diabat A, Jabbarzadeh A, Khosrojerdi A (2019) A perishable product supply chain network design problem with reliability and disruption considerations. Int J Prod Econ 212:125–138
Gao Z, Zhu J, Huang C, Dong D (2004) A method of travel time survey and prediction. J Transp Inf Saf. https://doi.org/10.3963/j.issn.1674-4861.2004.04.011
Guo J, Wang X, Fan S, Gen M (2017) Forward and reverse logistics network and route planning under the environment of low-carbon emissions: A case study of shanghai fresh food e-commerce enterprises. Comput Ind Eng 106:351–360
Guo X, He J, Yu H, Liu M (2023) Carbon peak simulation and peak pathway analysis for hub-and-spoke container intermodal network. Transp Res Part E Logist Transp Rev 180:103332
Kang K, Han J, Pu W, Ma Y (2019) Optimization research on cold chain distribution routes considering carbon emissions for fresh agricultural products. Comput Eng Appl 55:259–265
Kim HW, Joo GH, Lee DH (2019) Multi-period heterogeneous vehicle routing considering carbon emission trading. Int J Sustain Transp 13:340–349
Kim K, Kim H, Kim SK, Jung JY (2016) i-rm: an intelligent risk management framework for context-aware ubiquitous cold chain logistics. Expert Syst Appl 46:463–473
Kumar BA, Vanajakshi L, Subramanian SC (2017) Bus travel time prediction using a time-space discretization approach. Transp Res Part C Emerg Technol 79:308–332
Kumar SV, Chaitanya Dogiparthi K, Vanajakshi L, Subramanian SC (2017) Integration of exponential smoothing with state space formulation for bus travel time and arrival time prediction. Transport 32:358–367
Kuo R, Edbert E, Zulvia FE, Lu SH (2023) Applying NSGA-ii to vehicle routing problem with drones considering makespan and carbon emission. Expert Syst Appl 221:119777
Li N, Li G (2022) Hybrid partheno-genetic algorithm for multi-depot perishable food delivery problem with mixed time windows. Annals of Operations Research , 1–32
Li Y, Lim MK, Tseng ML (2019) A green vehicle routing model based on modified particle swarm optimization for cold chain logistics. Ind Manag Data Syst 119:473–494
Lim MK, Li Y, Wang C, Tseng ML (2022) Prediction of cold chain logistics temperature using a novel hybrid model based on the mayfly algorithm and extreme learning machine. Ind Manag Data Syst 122:819–840
Lin W, Wei H, Nian D (2022) Integrated Ann-Bayes-based travel time prediction modeling for signalized corridors with probe data acquisition paradigm. Expert Syst Appl 209:118319
Liu C, Kou G, Zhou X, Peng Y, Sheng H, Alsaadi FE (2020) Time-dependent vehicle routing problem with time windows of city logistics with a congestion avoidance approach. Knowl-Based Syst 188:104813
Ma X, Liu T, Yang P, Jiang R (2016) Vehicle routing optimization model of cold chain logistics based on stochastic demand. J Syst Simul 28:1824
Menares F, Montero E, Paredes-Belmar G, Bronfman A (2023) A bi-objective time-dependent vehicle routing problem with delivery failure probabilities. Comput Ind Eng 185:109601
Ottmar RD (2014) Wildland fire emissions, carbon, and climate: modeling fuel consumption. For Ecol Manag 317:41–50
Rice J, Van Zwet E (2004) A simple and effective method for predicting travel times on freeways. IEEE Trans Intell Transp Syst 5:200–207
Robinson S (2005) The development and application of an urban link travel time model using data derived from inductive loop detectors. Department of Civil and Environmental Engineering, Imperial College London
Song BD, Ko YD (2016) A vehicle routing problem of both refrigerated-and general-type vehicles for perishable food products delivery. J Food Eng 169:61–71
Stellingwerf HM, Groeneveld LH, Laporte G, Kanellopoulos A, Bloemhof JM, Behdani B (2021) The quality-driven vehicle routing problem: Model and application to a case of cooperative logistics. Int J Prod Econ 231:107849
Tang H, Tang H, Zhu X (2021) Research on low-carbon vehicle routing problem based on modified ant colony algorithm. Chin J Manag Sci 29:118–27
Tang Q, Hu X (2020) Modeling individual travel time with back propagation neural network approach for advanced traveler information systems. J Transp Eng Part A Syst 146:04020039
Wang S, Tao F, Shi Y (2018) Optimization of location-routing problem for cold chain logistics considering carbon footprint. Int J Environ Res Public Health 15:86
Wu Q (2015) Travel time estimation and prediction for urban road networks. Zhejiang University, Zhejiang
Wu Y, Ma Z (2017) Time-dependent production-delivery problem with time windows for perishable foods. Syst Eng Theory Pract 37:172–181
Xiao Y, Konak A (2016) The heterogeneous green vehicle routing and scheduling problem with time-varying traffic congestion. Transp Res Part E Logist Transp Rev 88:146–166
Xing L, Liu W (2021) A data fusion powered bi-directional long short term memory model for predicting multi-lane short term traffic flow. IEEE Trans Intell Transp Syst 23:16810–16819
Zhang S, Gajpal Y, Appadoo S (2018) A meta-heuristic for capacitated green vehicle routing problem. Ann Oper Res 269:753–771
Zhang Z, Wang Y, Chen P, He Z, Yu G (2017) Probe data-driven travel time forecasting for urban expressways by matching similar spatiotemporal traffic patterns. Transp Res Part C Emerg Technol 85:476–493
Zhao Z, Li X, Zhou X, Liu C (2020) Research on green vehicle routing problem of cold chain distribution: considering traffic congestion. Comput Eng Appl 56:224–231
Zheng F, Pang Y, Xu Y, Liu M (2021) Heuristic algorithms for truck scheduling of cross-docking operations in cold-chain logistics. Int J Prod Res 59:6579–6600
Zheng Y, Xie M, Wang X (2019) Research on passenger flow forecast of hangzhou metro based on lstm-svr, In: 2019 international conference on artificial intelligence and advanced manufacturing (AIAM), IEEE. pp 273–276
Zhu L, Hu D (2019) Study on the vehicle routing problem considering congestion and emission factors. Int J Prod Res 57:6115–6129
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflict of interest to declare that are relevant to the content of this article. They did not receive support from any organization for the submitted work.
Ethical approval
The authors declare that this study does not involve human or animal participants.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Bai, Q., Yuan, Y., Fu, X. et al. Vehicle routing Problem for cold chain logistics based on data fusion technology to predict travel time. Oper Res Int J 24, 55 (2024). https://doi.org/10.1007/s12351-024-00851-8
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12351-024-00851-8