
Abstract
In this paper, we discuss PD-type learning control law for linear differential equations of fractional order \(\alpha \in (1,2)\). We derive convergence results for open-loop and closed-loop iterative learning schemes with zero initial error and random but bounded initial error in the sense of \(\lambda \)-norm by utilizing properties of Mittag–Leffler functions. Numerical examples are presented to demonstrate the validity of the design methods.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
It is well known that fractional differential equations are gaining more and more attention in different research areas, such as physics, engineering and control (see [1–11]). In recent years, there are many important quality analysis and control results for various fractional differential equations (see for example, [12–18]).
On the other hand, iterative learning control is a useful control method in terms of basic theory and experimental applications by adjusting the past control experience again and again to improve the current tracking performance. Recently, there are many contribution on P-type and D-type iterative learning control for integer order ordinary differential equations [19–29], linearization theorem of fenner and pinto [30] and varieties of local integrability [31] and few work on iterative learning control of fractional order differential equations [32–36]. In particular, the authors obtain the robust convergence of the tracking errors with respect to initial positioning errors under P-type iterative learning control scheme for fractional order nonlinear differential equations [34] and noninstantaneous impulsive fractional order differential equations [36]. Meanwhile, the authors discuss D-type iterative learning control to fractional order linear time-delay equations [35]. We remark that the above convergence results are valid for fractional order \(\alpha \in (0,1)\).
In this paper, we consider the following linear differential equations of fractional order:
where k denotes the iterative times, T denotes pre-fixed iteration domain length, and the symbol \(^c_0 D^\alpha _t x_k(t)\) is the Caputo derivative with lower limit zero of order \(\alpha \) to the function \(x_k\) at the point t (see Definition 2.1, [37, p. 91]), \(x_k, y_k, u_k\in \mathbb {R}\) and \(a\in \mathbb {R}^+\), \(b,c,d\in \mathbb {R}\).
Consider the boot time of the machine, \(x_k(t)\) may not change immediately on a very small finite time interval \([0,\delta ]\). Letting \(\delta \rightarrow 0\), we obtain the condition \(\dot{x}_k(0)=0\) in (1). Then the solution of (1) can be formulated by (see [37, p. 140–141, (3.1.32)–(3.1.34)]):
where the Mittag–Leffler functions \({\mathbb {E}}_{\alpha }(z)\) and \({\mathbb {E}}_{\alpha ,\beta }(z)\) are described as:
\(z\in \mathbb {R}\) and \(\alpha ,~\beta \) are positive real numbers.
Let
be a desired trajectory where \(x_d(t)\), \(u_d(t)\) are the desired state trajectory and the desired control, respectively. As usual, we denote \(e_k(t):=y_d(t)-y_k(t)\) be a tracking error and \(\delta u_k(t):=u_d(t)-u_k(t)\).
The main objective of this paper is to design open-loop and closed-loop iterative learning schemes with zero initial error and random but bounded initial error in the sense of \(\lambda \)-norm. We adopt the PD-type iterative learning law.
The paper is organized as follows. In Sect. 2, we present integral and derivative properties of Mittag–Leffler functions. In Sects. 3 and 4, we give main results, open-loop and closed-loop iterative learning schemes with zero initial error and random but bounded initial error in the sense of \(\lambda \)-norm respectively. Examples are presented in Sect. 5 to demonstrate the validity of the design methods.
2 Preliminaries
Let \(C\left( [0,T],\mathbb {R}\right) \) be the space of \(\mathbb {R}\)-valued continuous functions on [0, T]. We consider three possible norms: \(\lambda \)-norm: \( \Vert x\Vert _\lambda =\max _{t\in [0,T]} e^{-\lambda t}|x(t)|\) and C-norm: \( \Vert x\Vert _C=\max _{t\in [0,T]}|x(t)|\) and \(L^2\)-norm: \( \Vert x\Vert _{L^2}=\left( \int _0^T |x(s)|^2 ds\right) ^{\frac{1}{2}}. \) Obviously, \(\Vert x\Vert _\lambda \le \Vert x\Vert _C\) for any \(x\in C\left( [0,T],\mathbb {R}\right) \).
Definition 2.1
(see [37, p. 91]) The Caputo derivative of order \(\gamma \) for a function \(f:[a,\infty )\rightarrow \mathbb {R}\) can be written as
where
The following properties of Mittag–Leffler functions will be used in the sequel.
Lemma 2.2
(see [38, (4.3.1)] ) Let \(\alpha >0\), \(\beta \in \mathbb {R}\),
Lemma 2.3
(see [39, (7.1)] or [38, (4.9.3)]) Let \(\lambda , \alpha , \beta \in \mathbb {R}^+\), and \(|a\lambda ^{-\alpha }|<1\),
Lemma 2.4
(see [40, p. 1861]) Let \(z\in \mathbb {R}\), \(\alpha >0\),
Lemma 2.5
(see [41]) Let \(\bar{\alpha } \in (0,2)\) and \(\bar{\beta }\in {\mathbb {R}}\) be arbitrary. Then for \(\bar{p}=[\frac{\bar{\beta }}{\bar{\alpha }}]\), the following asymptotic expansion hold:
By inserting \(\bar{\alpha }=\alpha \), \(\bar{\beta }=\alpha \) and \(z=at^{\alpha }\), we give asymptotic expansions for Mittag–Leffler functions \(E_{\alpha ,\alpha }\).
Lemma 2.6
For any \(a>0\), \(\alpha \in (0,2)\), it holds
It is clearly that \(t^{\alpha -1}E_{\alpha ,\alpha }(a t^{\alpha })\) is an increasing function for any \(t\in [0,T]\) since \(a>0\).
To end this section, we recall the following convergence theorem.
Lemma 2.7
(see [42, Lemma 3]) Let \(\{a_k\}\), \(k\in \mathbb {N}\) be a real sequence defined as
where \(d_k\) is a specified real sequence. If \(p<1\), then
implies that
3 Convergence analysis of open-loop law
In this section, we investigate (1) with the following PD-type learning control law:
Now we are ready to give the first results for zero initial error.
Theorem 3.1
Assume that the ILC scheme (3) is applied to (1) and the initial condition at each iteration remains the desired, i.e., \(x_k(0)=x_d(0)\), \(k=0,1,2,\ldots .\) If \(|1-k_d d|<1\), then \(\lim _{k\rightarrow \infty }y_k(t)=y_d(t)\) uniformly on \(t\in [0,T]\).
Proof
It follows from (2), we have
Taking the derivative on both side of (4), we have
where we set \(z=a^\frac{1}{\alpha }(t-s)\) and use Lemma 2.2 to derive
By using (3), (4) and (5), we have
Taking the absolute value on both side of (6) and multiplying both side by \(e^{-\lambda t}\), we obtain
By using Lemma 2.3, we have
Repeating the similar computation in (8) and using Lemma 2.3 again, one has
Substituting (8) and (9) into (7), and taking \(\lambda \)-norm, we obtian
where
Note that the condition \(0\le |1-k_d d|<1\), it is possible to make
for some \(\lambda \) large enough. Thus, (10) derives that
By using (4), (8) and (11), we have
This implies that
uniformly on \(t\in [0,T]\). \(\square \)
In general, the initial condition may be varying with the change of iterative times but in a small range. That is, the initial condition is always in the neighborhood of \(x_d(0)\) at each iteration such that
The expression (12) implies that the initial output error is also bounded.
Next, we are ready to give the Robustness results for random but bounded initial error.
Theorem 3.2
Assume that the ILC scheme (3) is applied to (1) and the initial condition at each iteration conform to (12). If \(|1-k_dd|<1\), then the error between \(y_d(t)\) and \(y_k(t)\) is bounded and its bound depends on \(\bar{\Delta }\), \(|k_p|\) and \(|k_d|\).
Proof
Similar to the proof of Theorem 3.1, we obtain
Taking the derivative on both side of the above equality, we obtain
where we use Lemma 2.4 to derive
By learning law (3), we have
Taking \(\lambda \)-norm, we have
Keeping in mind of \({\mathbb {E}}_{\alpha }(at^\alpha )\) and \(t^{\alpha -1}{\mathbb {E}}_{\alpha ,\alpha }(at^\alpha )\), \(\alpha \in (1,2)\) are increasing functions (see Lemma 2.6) for \(t\ge 0\) and the relationship between \(\lambda \)-norm and C-norm, we have
and
Thus, (14) becomes
Using Lemma 2.7, we have
It follows (13) that we have
Let iterative time \(k\rightarrow \infty \), we have
The proof is completed. \(\square \)
Remark 3.3
For some pre-fixed iteration domain length T. Linking the formula (16), one can make the tracking error decreasing by applying two possible methods: (i) Adjusting the learning law, i.e., making \(|k_p|\) decrease, (ii) Improving the system initial state tracking accuracy, i.e., making \(\bar{\Delta }\) decreasing. But we can’t see that \(|k_d|\) increase or decrease will effect on the tracking error by (16). In fact, \(\frac{1}{1-\rho }\) would increase if \(|k_d|\) decrease.
Remark 3.4
Suppose that the initial error satisfy \(x_d(0)\ne x_0\) and \(|x_k(0)-x_0|\le \Delta ^*\). Denote \(|x_d(0)- x_0|=\Delta ^{**}\). Then (12) becomes to \(|\delta x_k(0)|\le \Delta ^*+\Delta ^{**}:=\bar{\Delta }\). One can obtain similar results in Theorem 3.2.
4 Convergence analysis of close-loop law
In this section, we investigate the following PD-type learning control law:
In this law, proportional closed-loop learning algorithm can provide faster convergence speed. We assume that \(\dot{e}_k(t)=\lim _{\tau \rightarrow t^-}\frac{e_k(\tau )-e_k(t)}{\tau -t}\) without violate the law of causality.
Below is the first result in this section.
Theorem 4.1
Assume that the ILC scheme (17) is applied to (1) and the initial condition at each iteration remains the desired, i.e., \(x_k(0)=x_d(0)\), \(k=0,1,2,\ldots .\) If \(|1+k_d d|>1\), then \(\lim _{k\rightarrow \infty }y_k(t)=y_d(t)\) uniformly on \(t\in [0,T]\).
Proof
By repeating the same argument as Theorem 3.1, it can be proved easily that
and
From above, we obtain
Owning to \(|1+k_dd|>1\), there exists a sufficiently large \(\lambda \) such that:
Now the rest of proof is similar to that of Theorem 3.1, so we omit it here. \(\square \)
We also give the Robustness results for random but bounded initial error.
Theorem 4.2
Assume that the ILC scheme (17) is applied to (1) and the initial condition at each iteration conform to (12). If \(|1+k_dd|>1\), then the error between \(y_d(t)\) and \(y_k(t)\) is bounded and its bound depends on \(\bar{\Delta }\), \(|k_p|\) and \(|k_d|\).
Proof
From the learning law (17) that
Substituting (8), (9) into (18), we obtain
Since \(|1+k_dd|>1\), it is possible to choose \(\lambda \) sufficiently large that \(\bar{\rho }>1\). By using Lemma 2.7, we have
By using (15), we obtain
The proof is completed. \(\square \)
To end this section, we give two remarks as the extension of Sects. 3 and 4.
Remark 4.3
When \(\alpha =1\), the Eq. (1) become an one-order ordinary differential equation as follows:
It is well known that the solution of (19) is given as
By repeating some elementary computation, we obtain the error formula:
Taking the derivative, we have
Similar to the contents of Sects. 3 and 4, one can give the convergence analysis of open-loop and closed-loop law immediately.
Remark 4.4
For learning law (3) and (17), the main results of Sects. 3 and 4 can be extended to the following the fractional relaxation semilinear differential equations
when \(f: [0,T]\times \mathbb {R} \times \mathbb {R}\) is a Lipschitz type continuous function with respect to the second and third variables. We will give more details in our forthcoming paper.
5 Simulation examples
In this section, numerical examples are presented to demonstrate the validity of the design methods.
In order to describe the stability of the system which is associated with the increase of iterations, we denote the total energy in kth iteration as \( E_k=\Vert u_k\Vert _{L^2}. \)
Example 5.1
Consider the following fractional order differential system:
The learning law in the system is set as (3), where \(k_p=1\), \(k_d=1.2\). The initial state and the 1st control are proposed as \(x_k(0)=0\), \(~k=1.2,\ldots ,\) and \(u_1(t)=1\), \(t\in [0,1]\), respectively.
Next, we set the desired trajectory as \(y_d(t)=12t(1-t)\), \(t\in [0,1]\). Obviously, all the conditions of Theorem 3.1 are satisfied.
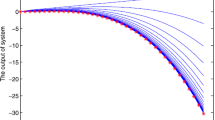
The upper figure of Fig. 1 shows the system (21) output \(y_k\) of the first 25 iterations and the referenced trajectory \(y_d\). The middle figure shows the \(L^2\)-norm of the tracking error in each iteration. The tracking error at the 25th iteration is 0.0378, which is very small. The lower figure shows the total energy in each iteration. We can see the total energy become stable gradually with increase of iterations.

The system output, the \(L^2\)-norm of the tracking errors, and the total energy in each iteration
Example 5.2
Consider the following one-order differential system:
The learning law in the system, the initial state, the 1st control and the desired trajectory are proposed as Example 5.1, respectively.
The upper figure of Fig. 2 shows the system (22) output \(y_k\) of the first 25 iterations and the referenced trajectory \(y_d\). The middle figure shows the \(L^2\)-norm of the tracking error in each iteration. The tracking error at the 25th iteration is 0.0042, which is very small. The lower figure shows the total energy in each iteration. We can see the total energy become stable gradually with increase of iterations.

The system output, the \(L^2\)-norm of the tracking errors, and the total energy in each iteration
Between Examples 5.1 and 5.2, we need to more input energy in order to offset the memory of the fractional order system.
Example 5.3
Consider the system, initial control and the desired trajectory in Example 5.1. In this example, the initial errors are assumed to be random but bounded. We set the initial condition \(x_k(0)\) is a random number which is uniformly distributed in \([-0.1,0.1]\).
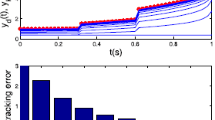
Next we analysis the tracking error to by the different parameters of learning law. Due to the initial state of random, we take the average tracking error of the 20th to 200th iterations as the evaluation criteria of tracking error (Fig. 3; Table 1).

The tracking error by the different paramenters of learning law
By figures (a), (b) and (c), the \(|k_d|\) decrease will result in \(\Vert e_k\Vert _{L^2}\) increased. By (b) and (d), the \(|k_p|\) decrease will lead to \(\Vert e_k\Vert _{L^2}\) decrease.
References
Baleanu, D., Machado, J.A.T., Luo, A.C.J.: Fractional Dynamics and Control. Springer, New York (2012)
Diethelm, K., Ford, N.J.: The Analysis of Fractional Differential Equations. Lecture Notes in Mathematics. Springer, Berlin (2010)
Kilbas, A.A., Srivastava, H.M., Trujillo, J.J.: Theory and Applications of Fractional Differential Equations. Elsevier Science B.V., Amsterdam (2006)
Lakshmikantham, V., Leela, S., Devi, J.V.: Theory of Fractional Dynamic Systems. Cambridge Scientific Publishers, Cambridge (2009)
Miller, K.S., Ross, B.: An Introduction to the Fractional Calculus and Differential Equations. Wiley, New York (1993)
Podlubny, I.: Fractional Differential Equations. Academic Press, San Diego (1999)
Tarasov, V.E.: Fractional Dynamics: Application of Fractional Calculus to Dynamics of Particles, Fields and Media. Springer, HEP, New York (2011)
Zhou, Y.: Basic Theory of Fractional Differential Equations. World Scientific, Singapore (2014)
Kaczorek, T., Rogowski, K.: Fractional Linear Systems and Electrical Circuits, Studies in Systems, Decision and Control. Springer, London (2015)
Hilfer, R.: Experimental evidence for fractional time evolution in glass forming materials. Chem. Phys. 284, 339–408 (2002)
Hilfer, R.: Application of Fractional Calculus in Physics. World Scientific Publishing Company, Singapore (2000)
Debbouche, A., Baleanu, D.: Controllability of fractional evolution nonlocal impulsive quasilinear delay integro-differential systems. Comput. Math. Appl. 62, 1442–1450 (2011)
Ahmad, B., Ntouyas, S.K.: On Hadamard fractional integrodifferential boundary value problems. J. Appl. Math. Comput. 47, 119–131 (2015)
Abbas, S., Benchohra, M., Rivero, M., Trujillo, J.J.: Existence and stability results for nonlinear fractional order Riemann–Liouville Volterra–Stieltjes quadratic integral equations. Appl. Math. Comput. 247, 319–328 (2014)
Wang, Q., Lu, D., Fang, Y.: Stability analysis of impulsive fractional differential systems with delay. Appl. Math. Lett. 40, 1–6 (2015)
Stamova, I., Stamov, G.: Stability analysis of impulsive functional systems of fractional order. Commun. Nonlinear Sci. Numer. Simulat. 19, 702–709 (2014)
Ma, Q., Wang, J., Wang, R., Ke, X.: Study on some qualitative properties for solutions of a certain two-dimensional fractional differential system with Hadamard derivative. Appl. Math. Lett. 36, 7–13 (2014)
Han, Z., Li, Y., Sui, M.: Existence results for boundary value problems of fractional functional differential equations with delay. J. Appl. Math. Comput. (2015). doi:10.1007/s12190-015-0910-x
Bien, Z., Xu, J.X.: Iterative Learning Control Analysis: Design, Integration and Applications. Springer, Berlin (1998)
Chen, Y.Q., Wen, C.: Iterative Learning control: Convergence, Robustness and Applications. Springer, London (1999)
Norrlof, M.: Iterative Learning Control: Analysis, Design, and Experiments, Linkoping Studies in Science and Technology, Dissertations, No. 653, Sweden, (2000)
Ahn, H.S., Chen, Y.Q., Moore, K.L.: Iterative Learning Control. Springer, New York (2007)
Xu, J.X., Panda, S.K., Lee, T.H.: Real-Time Iterative Learning Control: Design and Applications, Advances in Industrial Control. Springer, Berlin (2009)
Hou, Z., Xu, J., Yan, J.: An iterative learning approach for density control of freeway traffic flow via ramp metering. Transp. Res. C Emerg. Technol. 16, 71–97 (2008)
de Wijdeven, J.V., Donkers, T., Bosgra, O.: Iterative learning control for uncertain systems: robust monotonic convergence analysis. Automatica 45, 2383–2391 (2009)
Sun, M., Wang, D., Wang, Y.: Varying-order iterative learning control against perturbed initial conditions. J. Frankl. Inst. 347, 1526–1549 (2014)
Xu, J.X.: A survey on iterative learning control for nonlinear systems. Int. J. Control 84, 1275–1294 (2011)
Liu, X., Kong, X.: Nonlinear fuzzy model predictive iterative learning control for drum-type boiler-turbine system. J. Process Control 23, 1023–1040 (2013)
Zhang, C., Li, J.: Adaptive iterative learning control for nonlinear pure-feedback systems with initial state error based on fuzzy approximation. J. Frankl. Inst. 351, 1483–1500 (2014)
Xia, Y.H., Chen, X., Romanovski, V.G.: On the linearization theorem of fenner and pinto. J. Math. Anal. Appl. 400, 439–451 (2013)
Romanovski, V., Xia, Y.H., Zhang, X.: Varieties of local integrability of analytic differential systems. J. Differ. Equ. 257, 3079–3101 (2014)
Li, Y., Chen, Y.Q., Ahn, H.S.: Fractional-order iterative learning control for fractional-order linear systems. Asian J. Control 13, 1–10 (2011)
Li, Y., Chen, Y.Q., Ahn, H.S., Tian, G.: A survey on fractional-order iterative learning control. J. Optim. Theory Appl. 156, 127–140 (2013)
Lan, Y.H., Zhou, Y.: Iterative learning control with initial state learning for fractional order nonlinear systems. Comput. Math. Appl. 64, 3210–3216 (2012)
Lan, Y.H., Zhou, Y.: \(D\)-type iterative learning control for fractional order linear time-delay systems, Asian. J. Control. 15, 669–677 (2013)
Liu, S., Wang, J., Wei, W.: Iterative learning control based on noninstantaneous impulsive fractional order system, J. Vib. Control, (2014), http://jvc.sagepub.com/content/early/2014/08/18/1077546314545638
Kilbas, A.A., Srivastava, H.M., Trujillo, J.J.: Theory and Applications of Fractional Differential Equations. Elsevier, Amsterdam (2006)
Gorenflo, R., Kilbas, A.A., Mainardi, F., Rogosin, S.V.: Mittag–Leffler Functions, Related Topics and Applications. Springer, New York (2014)
Haubold, H.J., Mathai, A.M., Saxena, R.K.: Mittag–Leffler functions and their applications. J. Appl. Math. 2011, 1–51 (2011)
Wang, J., Fec̆kan, M., Zhou, Y.: Presentation of solutions of impulsive fractional Langevin equations and existence results. Eur. Phys. J. Special Top. 222, 1857–1874 (2013)
Gorenflo, R., Loutchko, J., Luchko, Y.: Computation of the Mittag–Leffler function \(E_{\alpha ,\beta }(z)\) and its derivative. Fract. Calc. Appl. Anal. 5, 491–518 (2002). Correction: Fract. Calc. Appl. Anal. 6, 111–112 (2003)
Ruan, X., Bien, Z.: Pulse compensation for \(\mathit{PD}\)-type iterative learning control against initial state shift. Int. J. Syst. Sci. 43, 2172–2184 (2012)
Acknowledgments
The authors are grateful to the referees for their careful reading of the manuscript and valuable comments. The authors thank the help from the editor too. This work is partially supported by NSFC (No.11201091;11261011) and Outstanding Scientific and Technological Innovation Talent Award of Education Department of Guizhou Province ([2014]240).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Liu, S., Wang, J. & Wei, W. Analysis of iterative learning control for a class of fractional differential equations. J. Appl. Math. Comput. 53, 17–31 (2017). https://doi.org/10.1007/s12190-015-0955-x
Received:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12190-015-0955-x