
Abstract
Measuring blood pressure from photoplethysmograph (PPG) signals is gaining popularity as the PPG devices are inexpensive, convenient to use and much portable. The advent of wearable PPG devices, machine learning and signal processing has motivated in the development of cuffless blood pressure calculation from PPG signals captured from fingertip. The conventional pulse transit time-based method of measuring blood pressure from PPG is inconvenient as it requires electrocardiogram signals and PPG signals or PPG signals captured simultaneously from two different sites of the body. The proposed system uses the PPG signals alone to estimate blood pressure (BP). A signal analysis method called wavelet scattering transform is applied on the preprocessed PPG signals to extract features. Predictor model that estimates BP are derived by training the support vector regression model and long short term memory prediction model. The derived models are evaluated with testing dataset and the results are compared with ground truth values. The results show that the accuracy of the proposed method achieves grade B for the estimation of the diastolic blood pressure and grade C for the mean arterial pressure under the standard British Hypertension Society protocol. On comparing the results of the proposed system with the benchmark machine learning algorithms, it is observed that the proposed model outperforms others by a considerable margin. A comparative analysis with prior studies shows that the results obtained from proposed work are comparable with existing works in the literature.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
According to World Health Organization, presently, 1.13 billion people in the world have high BP and among them less than 1 in 5 people have taken remedial measures to keep BP under control. Hypertension is one of the biggest causes of life threatening cardiovascular diseases such as stroke and heart attack. Cardiovascular disease caused 17.9 million (31%) deaths worldwide in the year 2016. Hence blood pressure needs to be checked regularly, and if found high, remedial measures such as medications, healthy diet and physical activity need to be taken to keep the blood pressure under control [1].
Hypertension, also known as high blood pressure is a condition in which the blood vessels have constricted due to deposit of fats and free radicals and the individual has persistently ‘raised’ blood pressure. Blood is carried from the heart to all parts of the body through the blood vessels. Each time the heart beats, it pumps blood into the vessels. Blood pressure is created due to the force exerted by blood, which pushes against the blood vessel walls and the arteries, when it is pumped by the heart. The unit for measuring blood pressure is millimetres of mercury (“mmHg”). Blood pressure is recorded with the systolic reading followed by the diastolic reading. Systolic blood pressure (SBP) is the pressure created when the heart pumps out blood. Diastolic blood pressure (DBP) is created while the heart muscle is resting between beats and is being refilled with blood. Mean arterial pressure (MAP) refers to the average of SBP and DBP values for one cardiac cycle.
The sphygmomanometer is the gold standard for measuring blood pressure. This is not convenient for the continuous monitoring of blood pressure and also it requires trained medical practitioners to assess the measurement. Recently, measuring blood pressure using the technique of photoplethysmography is gaining more popularity, due to the convenience it offers in continuous monitoring of blood pressure without the need for any special training. There have been several methods proposed to estimate blood pressure based on photoplethysmography [2,3,4,5,6,7,8,9]. The most well-known method is estimation of systolic blood pressure (SBP) and diastolic blood pressure (DBP) from pulse transit time (PTT), which requires the measurement from two different spots of the human body, and special training to assess the readings. Hence, it is inconvenient and is difficult to measure regularly, even for a trained person. This process is quiet complicated, as it involves synchronizing two different signals being captured simultaneously.
In this paper, a novel approach is presented that exploits the features extracted using wavelet scattering and deep learning algorithm to estimate blood pressure accurately. This BP estimation technique uses only photoplethysmograph signals in which measurement is taken from a single site, fingertip. This BP estimation technique consists of four steps. The first step involves preprocessing of PPG signals. The second step involves extraction of wavelet scattering features from the preprocessed signals. The third step involves training the regression model. In this work, support vector regression model and long short-term memory network regression model are used. The fourth step involves evaluation of the learning model’s performance using hold out dataset. Wavelet scattering transform is a good feature extraction technique that exhibits some typical properties: It computes a time shift invariant image representation. It remains stable to time warping deformation. It also retains vital information such as frequency content. Using wavelet scattering transform, a new representation of the original PPG signal is generated that contains time and local frequency [10]. The rest of this paper is organized as follows, Sect. 2 presents an overview of photoplethysmography and explores the related research in this area. Section 3 provides an overview of the database used, elaborates the wavelet scattering-based feature extraction technique and derivation of BP estimation model. Section 4 elucidates the experimental results. Section 5 gives the conclusion of the paper.
2 Underlying technology and related research
2.1 Principle of photoplethysmography
Photoplethysmography is a technique in which blood pressure is calculated based on the blood volume changes that are observed over the surface of the skin, especially in areas where the skin is sensitive (nerve endings) and its color changes based on the amount of blood flow. Measuring blood pressure using PPG is a noninvasive technique and user friendly model; hence it can be seamlessly integrated into any portable devices such as smart phones, smart watches and smart bracelets [2, 9, 11]. In photoplethysmography, low intensity infrared light is used to measure blood volume changes in peripheral blood circulation. When light passes through the skin, it is absorbed by the tissues, blood, bones and skin pigments. Blood naturally absorbs more light than the surrounding tissues; hence it is quiet easy to detect the changes in blood flow using this technique. Thus by measuring the blood volume changes, blood pressure can be assessed. Accuracy of results depends on various factors influencing the environment of measurement, such as intensity of the surrounding light and ability of the subject to hold still. The most commonly used measuring areas are the fingertips, earlobes and forehead as the blood flow can be easily measured in these light sensitive areas, the light source illuminates the skin and the photodetector captures the intensity of light variations from a specified area [3]. These light variations in conjunction with the time differences from the signals are used to calculate the blood pressure.
2.2 Related research
For the past few years, there have been lot of research works carried out in estimating blood pressure from PPG signals. The common method typically consists of three steps, namely (1) PPG signal is analysed and features are extracted, (2) machine learning algorithms are used to study how far the extracted features correlate with the actual blood pressure values obtained using standard medical devices, (3) a prediction model to evaluate blood pressure is derived using correlated features. The widely acceptable feature used to estimate blood pressure is pulse transit time (PTT). PTT is the time duration for the pulse wave to travel from heart to the extremity of the body. Pulse wave velocity (PWV) is found to have relationship with blood pressure which in turn is inversely proportional to pulse transit time (PTT). This method requires two sources to calculate the time interval. In most of the studies ECG signals and PPG signals are used to calculate PTT [8, 12,13,14,15]. In some other studies two PPG signals captured at two different peripheral sites are used [16]. It was observed that BP and PTT are negatively correlated with each other. Hence, using linear regression, the correlation between PTT and blood pressure is determined and regression equations are obtained. The drawback here is, it is difficult to synchronize the ECG signal data and PPG to calculate PTT [11]. Positioning the PPG sensor wrongly in wrist may lead to distortion in PPG signals and this affects the accuracy.
Blood pressure has also been estimated from vascular transit time (VTT) which is measured from heart sound and finger pulse [17, 18]. VTT is defined as the time it takes for the blood to propagate from the heart to body peripherals for one cardiac cycle. Two mobile phones are used to record heart sound and finger pulse. The clocks in both mobile phones should be synchronized which is a challengeable task. Another challenge is finding the best spot to record heart sound.
There are many research works done in estimating blood pressure using only PPG signals [4, 5, 7, 19,20,21,22]. The shape of the PPG signal is analyzed and features are extracted. Such features include peak width, peak height, peak area, distance between consecutive peak and valley. But, achieving accuracy equivalent to that of accuracy provided by standard medical device is challengeable.
The proposed BP estimator uses the PPG signals for BP estimation. PPG features are extracted using wavelet scattering transform, using which the learning model is trained to derive a BP estimator.
3 Proposed method
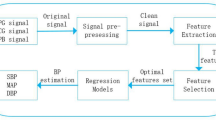
In this paper, a system is proposed, that computes blood pressure noninvasively from PPG signals captured from the fingertip of a person. The proposed system is developed in various phases viz., (1) dataset collection, (2) data preprocessing, (3) feature extraction, (4) training the machine learning model, (5) model evaluation. These phases are depicted in Fig. 1.

Block diagram depicting the phases of BP estimation using wavelet scattering and regression model
3.1 Dataset collection
The dataset required for the design of PPG-based BP estimation system was collected from Multi-parameter Intelligent Monitoring in Intensive care (MIMIC) II online database provided by PhysioNet organization [6]. The database contains preprocessed and cleaned waveform signals. Ten thousand records were extracted from this database. Each record consists of three rows, in which first row corresponds to PPG signal extracted from fingertip, second row corresponds to invasive arterial blood pressure (ABP) (in mmHg) signal and the third row corresponds to electrocardiogram (ECG) signal. The sampling frequency of each signal is 125 Hz. PPG signals and ABP signals were collected from database and used for this work. Target systolic and diastolic values were derived from ABP signals and were used in the training of machine learning model, and for comparing the estimated BP values from proposed system and thereby evaluating the accuracy of the proposed system.
3.2 Data selection
Analyzing the dataset collected from the database, few PPG signals were found to have insufficient record duration which were not suitable for BP estimation. Those signals were detected from the collected records by analyzing the pulse onsets in the ABP waveform and then eliminated. Pulse onset indicates the arrival of ABP pulse at the site of recording. Pulse onsets were detected by applying the following three steps on ABP signal [23] viz., (1) suppression of high frequency noise that might affect the ABP onset detection using a low pass filter. (2) Conversion of filtered ABP signal into slope sum function signal in which the upslope of the ABP pulse is enhanced and the remaining pressure waveform is suppressed. (3) Detection of pulse onset from the slope sum function signal by applying adaptive thresholding and local search strategy.
The number of ABP pulse onsets in the ABP signal in each record was counted. The records with pulse onsets less than or equal to 30 were detected and eliminated because those records contain signals with insufficient length that were not suitable for analysis and estimation of BP. After elimination, the resultant dataset contains 8271 records. Later irrelevant signals with BP values outside the scope i.e., very high or very low BP values were eliminated. As a result of eliminating such invalid signals, the final dataset contained 4314 records. The distribution of values for systolic blood pressure (SBP) and diastolic blood pressure (DBP) in the final dataset is depicted in Fig. 2
3.3 Data preprocessing
The signals from MIMIC database are found to have certain blocks deteriorated due to different distortions and artifacts [24], which when processed for BP estimation may lead to incorrect results. To remove the noise and other artifacts, wavelet denoising technique used in [24] was adapted in this work. Preprocessing involves resampling signals at a fixed frequency of 1000 Hz, wavelet decomposition, Zeroing \(0\tilde{0}.25\) Hz, Zeroing \(250\tilde{5}00\) Hz, wavelet reconstruction, threshold selection and wavelet thresholding. The original signal and the denoised signal are shown in Fig. 3. The resultant preprocessed signals were used for feature extraction and training the learning model.

The distribution of values for SBP and DBP in the final dataset. a SBP values and b DBP values

Original PPG signal and the preprocessed signal is shown
3.4 Feature extraction
In this proposed work, a signal analysis approach called wavelet scattering transform [10] is applied to extract features from the PPG signal. In order to extract features wave like oscillations called wavelets are used which can be scaled and shifted to best fit the signal. By creating a linear combination of wavelets, a new signal representation is created. Wavelet is operated on the signal in order to generate a set of coefficients which displays the similarity within a wavelet and the signal. These coefficients create a new representation of the original signal containing time and local frequency. This process is referred to as wavelet transform and it is the foundation of the wavelet scattering transform.
A wavelet scattering builds translation invariant representations which are stable to deformation by applying convolution, nonlinearity and scaling functions. Scattering transform delocalizes signal data, y into scattering decomposition paths. Let the original signal be segmented into equal sized timing windows. If p is a wavelet scattering path \(\left( p=\lambda 1,\lambda 2,\ldots ,\lambda m\right) \) of length m, w is the timing window position and window size \(2^{k}\), then the scattering coefficient of order m at the scale \(2^{k}\) denoted by \(S_{k}\left[ p\right] y\left( w\right) \) is computed as in Eq. (1) [10].
where \(\psi \left( w\right) \) is the morlet wavelet that forms the building block of wavelet scattering and is given by Eq. (2)
where \(\nu \) is the frequency, \(\sigma \) is the measure of spread, c1, c2 are constants that are adjusted so that Eqs. (3) and (4) are satisfied
Scaling function \(\phi _{2^{k}}\left( w\right) \) is given by Eq. (5)
Original PPG signal, Y is segmented into equal sized time windows say \(Y=y1,y2,y3,\ldots ,yn \). Vector of scattering coefficients are computed from each time window as follows. First the segmented slice of signal, y1 is filtered with \(\phi _{2^{k}}\), the scaling function which yields an averaging of the signal. The averaged signal is represented by \(y1*\phi _{2^{k}}\) and provides invariance to local time shifting. The averaging of the signal removes high frequencies and hence loses information. The original signal is once again filtered with a high pass filter \(\psi _{\lambda 1}\), the wavelet that yields new representation of the signal and is given by \(y1*\psi _{\lambda 1}\). High pass filtering retains detailed information about the signal. Also, it recovers the information lost during low pass filtering. The modulus of the high pass filtered output is taken that results in \(\left| y1*\psi _{\lambda 1}\right| \). The modulus computes the low frequency envelope. Now the high pass filtered output from the previous layer is selected and is filtered with low pass filter giving \(\left| y1*\psi _{\lambda 1}\right| *\phi _{2^{k}}\) and high pass filters giving \(\left| y1*\psi _{\lambda 1}\right| *\psi _{\lambda 2}\) and modulus of high pass filtered output is taken. This process is continued for the desired number of layers. The output of low pass filtering yields a scattering coefficients that represent the signal at every layer. The next time window is selected and the process is repeated. This process is depicted in Fig. 4. This operation helps in extracting the wavelet scattering features. This operation of extraction of wavelet scattering features was implemented in MATLAB by executing the following steps: (i) Construction of wavelet time scattering decomposition framework with default filterbanks, adjusted invariance scale and sampling frequency set to 125. (ii) Extraction of scattering coefficients from PPG signal.

Process of extracting wavelet scattering features from a time window i.e. slice yi of original signal Y

Wavelet scattering coefficients for first 50 consecutive time windows of layer 1, layer 2 and layer 3 extracted from three PPG signals are shown
Wavelet scattering features were extracted from the preprocessed PPG signals of all the 4314 records one by one. This extraction operation yields a set of robust features in two-dimensional matrix of size \(157\times N\). Hence, for each PPG signal, scattering coefficients were obtained across M scattering paths. N represents the number of time windows whose value depends on the length of the PPG signal. The coefficients at layers 0, 1 and 2 contain most of the energy [25]. Figure 5 shows the wavelet scattering coefficients computed for first 50 consecutive time windows for three PPG signals. Hence, scattering coefficients derived at layers 0, 1 and 2 were selected for training the learning model in this work. Wavelet scattering coefficients (SC) obtained at layers 0,1, and 2 are represented using Eq. (6).

Error Histogram from SVR. a Histogram of relative error in calculated SBP. b Histogram of relative error in calculated DBP. c Histogram of relative error in calculated MAP

Error Histogram from LSTM. a Histogram of relative error in calculated SBP. b Histogram of relative error in calculated DBP. c Histogram of relative error in calculated MAP
3.5 Support vector regression model
The dataset consisting of 4314 records were partitioned into training set with 3883 records and testing set with 431 records. Training set and testing set were selected using hold out technique. There is no overlapping between training set and the testing set. The features obtained using wavelet scattering transform is given as input to support vector regression model. SVR model is a supervised machine learning technique that relies on kernel function and can predict data accurately [26]. It has good generalization capability. It handles both linear and nonlinear data efficiently. It is highly noise tolerant. Predictor model was constructed by training the support vector regression model with features set, systolic and diastolic values obtained from ABP signal. Derived predictor model was evaluated using the testing dataset.
3.6 Long short-term memory (LSTM) network model
LSTM network [27] is the recurrent neural network used in several time series forecasting tasks and has shown remarkable results. Learned LSTM networks performs the prediction task in a quick manner [28]. Predictive model using LSTM network was developed using the Keras deep learning package. Table 1 shows the architecture of the LSTM. The dataset was partitioned into training set with 3883 records and testing set with 431 records. The extracted wavelet scattering features was fed into the LSTM network for learning. The learned model was evaluated using testing set and have obtained the RMSE value of 10.95 for diastolic BP estimation and 19.36 for systolic BP estimation.
4 Results and discussion
4.1 Analysis of error distribution
Error histogram for estimated SBP, DBP and MAP for SVM regression model and LSTM regression model are shown in Figs. 6 and 7 respectively. Results of DBP and MAP are comparatively good in both the models since the models have a good relationship between wavelet scattering features and the BP values. Training the models with large samples enabled the machine learning algorithms to build a accurate model. Error rate is found to be high in SBP targets.
4.2 Comparison with the grading criteria used by the British society of hypertension
Table 2 shows an evaluation of our predicted models using support vector machine and long short term memory network by the British Hypertension Society (BHS) standard. BHS standard is designed to evaluate the accuracy of proposed BP monitor devices based on the cumulative percentage of error readings (i.e., absolute difference between BP values estimated by standard device and proposed one) under three threshold values 5 mmHg, 10 mmHg and 15 mmHg [31]. It is observed from Table 2 that both the learned models, SVM regression and LSTM regression model achieve grade B for diastolic blood pressure and grade C for mean arterial pressure according to BHS protocol.

Bland Altman plot for the difference between the actual values and the values obtained from proposed method for 431 observation pairs. a SBP predicted using SVR model, b DBP predicted using SVR model, c MAP predicted using SVR model, d SBP predicted using LSTM model, e DBP predicted using LSTM model and f MAP predicted using LSTM model
Figure 8 presents Bland Altman plots for SBP, DBP and MAP (Mean Arterial Pressure) targets. Bland Altman plot finds out how far the values obtained using proposed model agrees with one measured from standard device [32]. In the Bland Altman plot, the mean of BP values obtained using standard device and proposed model is plotted against the x axis, difference between the two values is plotted against the y axis. The number of observation pairs for which the SBP, DBP and MAP targets are plotted is 431. The results are found to be satisfactory for DBP and MAP as most of the plots are tightly scattered about the bias line and the limits of agreement are appreciably low. It can be observed from the plot that the samples of BP with very high or very low values produced poor results. This is because, the training set contains only a limited number of samples with very high or very low values. It can be deduced from these results that both the regression algorithms produced poor results for infrequent samples. This is the limitation of both the regression algorithms.
4.3 Comparison with existing work
The results of the proposed work are compared with the results of prior studies and are reported in Table 3. The metrics used for evaluation are mean absolute error (MAE) and standard deviation (SD). Table presents input signals used, number of subjects or samples used for BP measurement, features extracted from input signals, techniques used for analysis and learning, \(\mathrm{MAE}\pm \mathrm{SD}\) for SBP, DBP and MAP targets for each of the work. In the proposed work, only PPG signals captured from single site, of 4314 samples collected from MIMIC II database are used and the results achieved are comparable to existing works in the literature.
4.4 Comparison of BP prediction accuracy of proposed model with that of various benchmark regression algorithms
The results of proposed method are compared with three benchmark prediction algorithms. The regression algorithms used for comparison are artificial neural network (ANN), random forest regression (RFR) and K-nearest neighbour (K-NN) regression. The algorithms have been implemented using Scikit-learn python library. Their performance are compared with that of proposed system and the results are produced in Table 4. MAE, SD, mean squared error (MSE), relative absolute error (RAE) and root relative squared error (RRSE) are the metrics used for comparison. From the table, it is evident that, in the calculation of systolic blood pressure SVR outperforms other methods marginally and in the calculation of diastolic blood pressure LSTM and Random Forest outperforms other methods by a margin. But on the whole, these algorithms produced an acceptable accuracy for systolic blood pressure estimation, but produced appreciable accuracy in the estimation of diastolic blood pressure.
The error observed in the prediction of Diastolic blood pressure by SVM and LSTM are 9.8% and 10% respectively and that of mean arterial blood pressure is 9.5% and 9.0% respectively. The formula used for the calculation of error is given in Eq. (7).
5 Conclusion
This paper describes blood pressure estimation from photoplethysmograph signals, captured from fingertip. A new signal analysis method for extracting novel features from PPG signals has been introduced. Derivation of predictor model using machine learning and the model evaluation using testing set was described. The testing results were compared using BHS standard and it is shown that proposed model achieved B grade for DBP and C grade for MAP. A comparative analysis of results produced by proposed models and various benchmark regression models were performed. The results showed a marginal improvement in the accuracy of proposed model. Also results were compared with existing works in the literature and it is found that the results of proposed method are comparable with existing works. MIMIC II database used for this study contains signal parts that are weakened due to noise. Hence improving the preprocessing step for noise removal would improve the results. This work differentiates itself from the existing works as it involves wavelet scattering techniques.
References
Allen, J.: Photoplethysmography and its application in clinical physiological measurement. Physiol. Meas. 28(3), R1 (2007)
Hassan, M.A., Malik, A.S., Fofi, D., Saad, N., Karasfi, B., Ali, Y.S., Meriaudeau, F.: Heart rate estimation using facial video: a review. Biomed. Signal Process. Control 38, 346–360 (2017)
Liu, M., Po, L.M., Fu, H.: Cuffless blood pressure estimation based on photoplethysmography signal and its second derivative. Int. J. Comput. Theory Eng. 9(3), 202 (2017)
Xing, X., Sun, M.: Optical blood pressure estimation with photoplethysmography and FFT-based neural networks. Biomed. Opt. Express 7(8), 3007–3020 (2016)
Kachuee, M., Kiani, M.M., Mohammadzade, H., Shabany, M.: Cuff-less high accuracy calibration free blood pressure estimation using pulse transit time. In: IEEE International Symposium on Circuits and Systems (ISCAS), pp. 1006–1009 (2015)
Teng, X. F., Zhang, Y.T.: Continuous and noninvasive estimation of arterial blood pressure using a photoplethysmographic approach. In: Proceedings of the 25th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (IEEE Cat. No. 03CH37439), Vol. 4, pp. 3153–3156 (2003)
Atef, M., Xiyan, L., Wang, G., Lian, Y.: PTT based continuous time non-invasive blood pressure system. In: IEEE 59th International Midwest Symposium on Circuits and Systems (MWSCAS), pp. 1–4 (2016)
Castaneda, D., Esparza, A., Ghamari, M., Soltanpur, C., Nazeran, H.: A review on wearable photoplethysmography sensors and their potential future applications in health care. Int. J. Biosensors Bioelectron. 4(4), 195 (2018)
Bruna, J., Mallat, S.: Invariant scattering convolution networks. IEEE Trans. Pattern Anal. Mach. Intell. 35(8), 1872–1886 (2013)
Elgendi, M., Fletcher, R., Liang, Y., Howard, N., Lovell, N.H., Abbott, D., Lim, K., Ward, R.: The use of photoplethysmography for assessing hypertension. NPJ Digit. Med. 2(1), 1–11 (2019)
Hassan, M.K.B.A., Mashor, M.Y., Nasir, N.M., Mohamed, S.: Measuring blood pressure using a photoplethysmography approach. In: 4th Kuala Lumpur International Conference on Biomedical Engineering. Springer, Berlin, Heidelberg, pp. 591–594 (2008)
Hosseini, H.G., Baig, M.M., Mirza, F., Luo, D.: Smartphone-based continuous blood pressure monitoring application-robust security and privacy framework. In: IEEE Region 10 Conference (TENCON), pp. 2939–2942 (2016)
Wagner, D.R., Roesch, N., Harpes, P., Kortke, H., Plumer, P., Saberin, A., Gilson, G.: Relationship between pulse transit time and blood pressure is impaired in patients with chronic heart failure. Clin. Res. Cardiol. 99(10), 657–664 (2010)
Lin, H., Wenyao, X., Nan, G., Dong, J., Yangjie, W., Wang, Y.: Noninvasive and continuous blood pressure monitoring using wearable body sensor networks. IEEE Intell. Syst. 30(6), 38–48 (2015)
Myint, C.Z., Lim, K.H., Wong, K.I., Gopalai, A.A., Oo, M.Z.: Blood pressure measurement from photo-plethysmography to pulse transit time. In: IEEE Conference on Biomedical Engineering and Science (IECBES), pp. 496–501 (2014)
Chandrasekaran, V., Dantu, R., Jonnada, S., Thiyagaraja, S., Subbu, K.P.: Cuffless differential blood pressure estimation using smartphones. IEEE Trans. Biomed. Eng. 60(4), 1080–1089 (2012)
Foo, J.Y.A., Lim, C.S., Wang, P.: Evaluation of blood pressure changes using vascular transit time. Physiol. Meas. 27(8), 685 (2006)
Gaurav, A., Maheedhar, M., Tiwari, V.N., Narayanan, R.: Cuffless PPG based continuous blood pressure monitoring—a smartphone based approach. In: 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), pp. 607–610 (2016)
Samria, R., Jain, R., Jha, A., Saini, S., Chowdhury, S.R.: Noninvasive cuffless estimation of blood pressure using Photoplethysmography without electrocardiograph measurement. In: IEEE Region 10 Symposium, pp. 254–257 (2014)
Yan, Y.S., Zhang, Y.T.: Noninvasive estimation of blood pressure using photoplethysmographic signals in the period domain. In: IEEE Engineering in Medicine and Biology 27th Annual Conference, pp. 3583–3584 (2005)
Kurylyak, Y., Lamonaca, F., Grimaldi, D.: A Neural Network based method for continuous blood pressure estimation from a PPG signal. In: IEEE International Instrumentation and Measurement Technology Conference(I2MTC), pp. 280–283 (2013)
Zong, W., Heldt, T., Moody, G.B., Mark, R.G.: An open source algorithm to detect onset of arterial blood pressure pulses. In: Computers in Cardiology, pp. 259–262 (2003)
kachuee, M., Kiani, M.M., Mohammadzade, H., Shabany, M.: Cuffless blood pressure estimation algorithms for continuous health-care monitoring. IEEE Trans. Biomed. Eng. 64(4), 859-869 (2016)
Soro, B., Chaewoo, L.: A wavelet scattering feature extraction approach for deep neural network based indoor fingerprinting localization. Sensors 19(8), 1790 (2019)
Smola, A.J., Schölkopf, B.: A tutorial on support vector regression. Stat. Comput. 14(3), 199–222 (2004)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Qing, X., Yugang, N.: Hourly day ahead solar irradiance prediction using weather forecasts by LSTM. Energy 148, 461–468 (2018)
Simjanoska, M., Gjoreski, M., Gams, M., Madevska, B.A.: Non-invasive blood pressure estimation from ECG using machine learning techniques. Sensors 18(4), 1160 (2018)
Gao, S.C., Wittel, P., Zhao, L., Jiang, W.J.: Data-driven estimation of blood pressure using photoplethysmographic signals. In: 38th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), pp. 766–769 (2016)
O’brien, E., Waeber, B., Parati, G., Staessen, J., Myers, MG.: Blood pressure measuring devices: recommendations of the European Society of Hypertension. BMJ 322(7285), 531–536 (2001)
Bland, J.M., Altman, D.G.: Statistical methods for assessing agreement between two methods of clinical measurement. Int. J. Nurs. Stud. 47(8), 931–936 (2010)
Acknowledgements
The first author would like to thank Manonmaniam Sundaranar University Constituent College of Arts and Science, Kadayanallur and the second author would like to thank Bharathiar University, Coimbatore for providing the necessary support to carry out the research work.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Jean Effil, N., Rajeswari, R. Wavelet scattering transform and long short-term memory network-based noninvasive blood pressure estimation from photoplethysmograph signals. SIViP 16, 1–9 (2022). https://doi.org/10.1007/s11760-021-01952-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-021-01952-z