
Abstract
A smooth simultaneous confidence band (SCB) is obtained for heteroscedastic variance function in nonparametric regression by applying spline regression to the conditional mean function followed by Nadaraya–Waston estimation using the squared residuals. The variance estimator is uniformly oracally efficient, that is, it is as efficient as, up to order less than \(n^{-1/2}\), the infeasible kernel estimator when the conditional mean function is known, uniformly over the data range. Simulation experiments provide strong evidence that confirms the asymptotic theory while the computing is extremely fast. The proposed SCB has been applied to test for heteroscedasticity in the well-known motorcycle data and Old Faithful geyser data with different conclusions.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Conditional variance function is an important ingredient in regression analysis, as many statistical applications require knowledge of the variance function, such as weighted least squares estimation of the mean function and construction of confidence intervals/bands for the mean function. Compared to mean function estimation, the literature on the estimation of variance function is rather sparse. Fan and Yao (1998) proved efficiency of the residual-based kernel variance estimator, Müller and Stadtmüller (1987) and more recently, Levine (2006) and Brown and Levine (2007) proposed difference-based kernel estimator and obtained its asymptotic normality, while Wang et al. (2008) derived the minimax rate of convergence for variance function estimation and constructed minimax rate optimal kernel estimators. For applications of variance estimation in the analysis of assay and microarray data, see Davidian et al. (1988) and Cai and Wang (2008).
Existing literature had mostly overlooked one crucial aspect of the problem, that is, simultaneous confidence band (SCB) for the variance function, which is an extremely powerful tool for inference on the global shape of curves, see for instance, Bickel and Rosenblatt (1973), Hall and Titterington (1988), Härdle (1989), Xia (1998), Claeskens and Van Keilegom (2003), Ma et al. (2012), Wang et al. (2014), Zheng et al. (2014) for theoretical works on SCB. This paper provides a spline–kernel two-step estimator of the variance function that is oracally efficient and comes equipped with a smooth SCB that substantially improves over the spline SCB of Song and Yang (2009), both theoretically and computationally.
To describe the problem, let observations \(\left\{ \left( X_{i},Y_{i}\right) \right\} _{i=1}^{n}\) and unobserved errors \(\left\{ \varepsilon _{i}\right\} _{i=1}^{n}\) be i.i.d copies of \(\left( X,Y,\varepsilon \right) \) satisfying the regression model
where \(\mathsf {E}\left( \varepsilon \mid X\right) =0,\mathsf {E}\left( \varepsilon ^{2}\mid X\right) =\sigma ^{2}\left( X\right) \), and the conditional mean function \(m\left( x\right) \) and variance function \( \sigma ^{2}\left( x\right) \), defined on a compact interval \(\left[ a,b\right] ,\) are unknown. Note that with squared errors \(Z_{i}=\varepsilon _{i}^{2},1\le i\le n,\mathsf {E}\left( Z_{i}\mid X_{i}\right) =\sigma ^{2}\left( X_{i}\right) \), hence the variance function \(\sigma ^{2}(x)\) is in fact the conditional mean function of \(Z_{i}\) on \(X_{i}\). If \(\sigma ^{2}(\cdot )\) is constant, the model is homoscedastic, otherwise heteroscedastic, see Dette and Munk (1998) for testing of heteroscedasticity, Carroll and Ruppert (1988), Akritas and Van Keilegom (2001), Cai and Wang (2008) for regression methods in the presence of heteroscedastic errors, and Hall and Marron (1990) for rate-optimal estimator of homoscedastic variance.
Suppose for the sake of discussion that the mean function \(m\left( x\right) \) were known by “oracle”, one could obtain a new data set \(\left\{ \left( X_{i},Z_{i}\right) \right\} _{i=1}^{n}\), in which \(Z_{i}=\left\{ Y_{i}-m\left( X_{i}\right) \right\} ^{2},1\le i\le n\) , and estimate the function \(\sigma ^{2}(x)\) by a regressor \(\tilde{\sigma } ^{2}(x)\) of the \(Z_{i}\)’s on the \(X_{i}\)’s, a would-be estimator called “infeasible estimator” as it is based on unavailable knowledge, serves as a useful benchmark against which feasible ones can be compared to. Fan and Yao (1998) had obtained two-step estimator \(\hat{\sigma }^{2}\left( x\right) \) of \(\sigma ^{2}\left( x\right) \) by local linear regression of \(\hat{Z} _{i}=\{ Y_{i}-\hat{m}\left( X_{i}\right) \} ^{2}\) on \(X_{i}\), in which \(\hat{m}\left( x\right) \) is a first-step local linear estimator of \( m\left( x\right) \), and shown that for any fixed \(x\in \left( a,b\right) \), \( \hat{\sigma }^{2}\left( x\right) \) was asymptotically as efficient as the “infeasible local linear estimator” \( \tilde{\sigma }^{2}(x)\). Since this efficiency was merely pointwise, it allowed only the construction of confidence interval for \(\sigma ^{2}\left( x\right) \) at a single point \(x\), not at every point \(x\in \left[ a,b\right] \) with simultaneous coverage, see also Hall and Carroll (1989) for the negligible effect of mean on the estimation of variance function.
Song and Yang (2009) had formulated a two-step estimator \(\hat{\sigma } ^{2}\left( x\right) \) of \(\sigma ^{2}\left( x\right) \) by spline regression of \(\hat{Z}_{i}=\{ Y_{i}-\hat{m}\left( X_{i}\right) \} ^{2}\) on \( X_{i}\), in which \(\hat{m}\left( x\right) \) is a first step spline estimator of \(m\left( x\right) \), and established asymptotic efficiency of \(\hat{\sigma }^{2}\left( x\right) \) relative to an “infeasible spline estimator” \(\tilde{\sigma }^{2}(x)\) over the data range \( [a,b]\), and as a result an SCB was obtained for the whole variance curve as formulated in Wang and Yang (2009). There are some serious theoretical shortcomings, however with the shortcomings, however, with the spline SCB of Wang and Yang (2009) and hence also of Song and Yang (2009): the constant spline SCB is too wide and inaccurate; the linear spline SCB is narrow but its coverage probability is higher than the nominal level.
We propose a two-step estimator of \(\sigma ^{2}(x)\) by spline estimator \( \hat{m}\left( x\right) \) of \(m\left( x\right) \) in step one and kernel estimator \(\hat{\sigma }^{2}\left( x\right) \) of \(\sigma ^{2}\left( x\right) \) in step two, which is uniformly as efficient as the infeasible kernel estimator, and hence oracally efficient. It is smooth as it comes from kernel smoothing, and enjoys excellent convergence rate of kernel smoother as well as coverage probability quickly approaching the nominal value. As an illustration, consider the motorcycle data, with Fig. 4 depicting the spline–kernel SCB of its variance function, at confidence levels 99.991 and 98.698 %, overlaid with a constant variance estimate which is either a consistent estimate \(n^{-1}\sum \nolimits _{i=1}^{n}\hat{ \varepsilon }_{i,p}^{2}\) or the maximum of lower confidence line, the constant variance hypothesis is rejected in both scenarios, with \(p\) value \(=0.00009\) or \(0.01302\). While the proposed SCB is superior to the SCB of Song and Yang (2009), the spline–kernel estimator is computationally much faster than the kernel–kernel estimator of Fan and Yao (1998), due to using spline instead of kernel in step one, which cuts computing burden substantially, see Xue and Yang (2006) and Wang and Yang (2007) for speed comparison of spline and kernel smoothing. The new spline–kernel estimator is shown in Theorem to be globally as efficient as the “infeasible kernel estimator” while the kernel–kernel estimator of Fan and Yao (1998) is as efficient as the “infeasible kernel estimator” only at a fixed point, see also Equation (3.2) of Hall and Carroll (1989) for pointwise oracle efficiency. Furthermore, oracle efficiency in Theorem 1 is of order smaller than \(n^{-1/2} \), which had not existed in previous works.
The paper is organized as follows. Section 2 presents main theoretical results and Sect. 3 provides insights of proofs, Sect. 4 gives concrete steps to implement the SCB, while Sects. 5 and 6 report simulation results and analysis of the motorcycle data and Old Faithful geyser data. Section 7 concludes, and technical proofs are in the “Appendix”.
2 Main result
Without loss of generality, we take \(\left[ a,b\right] =\left[ 0,1\right] \). An asymptotic \(100\left( 1-\alpha \right) \%\) simultaneous confidence band (SCB) for the unknown variance function \(\sigma ^{2}\left( x\right) \) over a sequence of subintervals \(\left[ a_{n},b_{n}\right] \subseteq \left[ 0,1\right] \) where \(a_{n}\rightarrow 0,b_{n}\rightarrow 1\) as \(n\rightarrow \infty \), consists of an estimator \(\hat{\sigma }^{2}\left( x\right) \) of \(\sigma ^{2}\left( x\right) \), lower and upper confidence limit \(\hat{\sigma }^{2}\left( x\right) -l_{n,L}\left( x\right) ,\) \(\hat{ \sigma }^{2}\left( x\right) +l_{n,U}\left( x\right) \) at every \(x\in \left[ a_{n},b_{n}\right] \) such that
\(\underset{n\rightarrow \infty }{\lim }P\left\{ \sigma ^{2}\left( x\right) \in \left[ \hat{\sigma }^{2}\left( x\right) -l_{n,L}\left( x\right) ,\hat{ \sigma }^{2}\left( x\right) +l_{n,U}\left( x\right) \right] ,\quad \forall x\in \left[ a_{n},b_{n}\right] \right\} =1-\alpha .\)
Our goal is to construct error bound function \(l_{n,L}(x)\), \(l_{n,U}(x)\) based on data \(\left\{ \left( X_{i},Y_{i}\right) \right\} _{i=1}^{n}\) drawn from model (1). We describe briefly below the ideas of oracally efficient estimation, which will be shown later to yield the SCB.
If the mean function \(m\left( x\right) \) were known by “oracle ”, one could compute the errors \(\varepsilon _{i}=Y_{i}-m\left( X_{i}\right) \) and the squared errors \(Z_{i}=\varepsilon _{i}^{2},1\le i\le n\), and then smooth the data \(\left\{ \left( X_{i},Z_{i}\right) \right\} _{i=1}^{n}\), taking advantage of the fact that \( \mathsf {E}\left( Z_{i}\mid X_{i}\right) \equiv \sigma ^{2}\left( X_{i}\right) \). Specifically, denote by \(K\) a kernel function, \(h=h_{n}\) a sequence of smoothing parameters called bandwidth, and \(K_{h}\left( u\right) =K\left( u/h\right) /h\), an “infeasible kernel estimator” of the variance function is
To mimic this would-be kernel estimator \(\tilde{\sigma }_{\text {K}}^{2}\left( x\right) \) of \(\sigma ^{2}\left( x\right) \), a spline–kernel oracally efficient estimator \(\hat{\sigma }_{\text {SK}}^{2}\left( x\right) \) of \( \sigma ^{2}\left( x\right) \) is
where \(\hat{Z}_{i}=\hat{\varepsilon }_{i,p}^{2}\) are the square of residuals \( \hat{\varepsilon }_{i,p}\) obtained from spline regression,
the spline estimator \(\hat{m}_{p}\left( x\right) \) is defined as follows, for some positive integer \(p\),
in which \(G_{N}^{\left( p-2\right) }\) is the space of functions that are piecewise polynomials of degree \(\left( p-1\right) \) on interval \(\left[ 0,1 \right] \), defined below.
The interval \(\left[ 0,1\right] \) is divided into \(\left( N+1\right) \) subintervals \(J_{j}=[ t_{j},t_{j+1}) ,j=0,\ldots ,N-1,J_{N}=[ t_{N},1] \) by a sequence of equally spaced points \(\{ t_{j}\} _{j=1}^{N}\), called interior knots, given as
in which \(H=1/\left( N+1\right) \) is the distance between neighboring knots. We denote by \(G_{N}^{\left( p-2\right) }=G_{N}^{\left( p-2\right) }\left[ 0,1\right] \) the space of functions that are polynomials of degree \(\left( p-1\right) \) on each \(J_{j}\) and have continuous \(\left( p-2\right) \)th derivative. In particular, \(G_{N}^{\left( 0\right) }\) denotes the space of functions that are linear on each \(J_{j}\) and continuous on \(\left[ 0,1\right] \), with linear B-spline basis \(\{ b_{j,2}( x) \} _{j=-1}^{N}\) being
Alternatively, one can estimate \(\sigma ^{2}\left( x\right) \) by spline local linear estimator \(\hat{\sigma }_{\text {SLL}}^{2}\left( x\right) \) based on \(\{ X_{i},\hat{Z}_{i}\} _{i=1}^{n}\), which mimics the would-be local linear estimator \(\tilde{\sigma }_{\text {LL}}^{2}\left( x\right) \) based on \(\left\{ X_{i},Z_{i}\right\} _{i=1}^{n}\),
in which the oracle and pseudo-response vectors are
with the same weight and design matrices
The idea of synthesizing spline and kernel smoothing in one estimator appeared first in Wang and Yang (2007), Wang and Yang (2009) for additive model and later extended to generalized additive model in Liu et al. (2013).
To formulate the necessary technical assumptions, for sequences of real numbers \(c_{n} \) and \(d_{n}\), one writes \(c_{n}\ll d_{n}\) to mean \( c_{n}/d_{n}\rightarrow 0\), as \(n\rightarrow \infty \).
-
(A1)
The function \(m\left( \cdot \right) \in C^{p}\left[ 0,1 \right] \), \(p>1\).
-
(A2)
The joint distribution of \((X,\varepsilon ) \) is bivariate continuous with \(\mathsf {E}(\varepsilon \mid X) =0\), \(\mathsf {E}(\varepsilon ^{2}\mid X) =\sigma ^{2}(X) \), and for some \(\eta >1/2\),\( \sup _{x\in [ 0,1] }\mathsf {E}(\vert \varepsilon \vert ^{4+2\eta }\mid X=x) =M_{\eta }<+\infty \).
-
(A3)
The density function \(f( x) \in C[ 0,1 ] \), the variance function \(\sigma ^{2}( x) \in C^{2}[ 0,1] \), and \(0<c_{f}\le f( x) \le C_{f}<+\infty ,0<c_{\sigma }\le \sigma ( x) \le C_{\sigma }<+\infty \) for \(x\in [ 0,1] \).
-
(A4)
The kernel function \(K\in C^{( 1) }( \mathbb {R}) \) is a symmetric probability density function supported on \( [ -1,1] \).
-
(A5)
The bandwidth \(h\) satisfies \(n^{2\alpha -1}(\log n) ^{4}\ll h\ll n^{-1/5}(\log n) ^{-1/5}\), for some \(\alpha \) such that \(\alpha <2/5\), \(\alpha (2+\eta ) >1\), \(\alpha (1+\eta ) >2/5\).
-
(A6)
The number of interior knots \(N=N_{n}\) satisfies
$$\begin{aligned} \max \left\{ \! \left( \frac{n}{h^{2}}\right) ^{1/4p}\!,\left( \frac{\log n}{h} \right) ^{1/2\left( p-1\right) }\!\right\} \!\ll \! N\!\ll \! \min \left\{ n^{1/2}h,\left( \frac{nh}{\log n}\!\right) ^{\!1/3}\!,\left( \frac{n}{h}\right) ^{1/5}\!\right\} . \end{aligned}$$
Assumptions (A1)–(A3) are adapted from Song and Yang (2009), Assumption (A4) is standard for kernel regression, and Assumptions (A5) and (A6) are general conditions on the choice of number of knots \(N\) and bandwidth \(h\) to ensure oracle efficient and the extreme distribution result in (6) below. In particular, one may take the mean squared error optimal order \(N\) \( \sim n^{1/\left( 2p+1\right) }\) and an undersmoothing \(h=n^{-1/5}\left( \log n\right) ^{-1/5-\delta }\) for any \(\delta >0\), which satisfy all the requirements in Assumptions (A5) and (A6). As an example, data-driven implementation of \(N\) and \(h\) is given in Sect. 4, aided by explicit formulae (13) for BIC and (15) for rule-of-thumb bandwidth.
It follows from Assumption (A2) that the conditional variance of \( Z=\varepsilon ^{2}\) is \(v_{Z}^{2}\left( x\right) \equiv \text {var}\left( Z\mid X=x\right) \equiv \mu _{4}\left( x\right) -\sigma ^{4}\left( x\right) \) in which \(\mu _{4}\left( x\right) \equiv \mathsf {E}(\varepsilon ^{4}\mid X=x) \). In addition
Consequently, under Assumptions (A2)–(A5), by applying classic SCB theory to the unobservable sample \(\left\{ \left( X_{i},Z_{i}\right) \right\} _{i=1}^{n}\), one has
where

From (6) one obtains an asymptotic \(100\left( 1-\alpha \right) \%\) oracle SCB for \(\sigma ^{2}\left( x\right) \) over \(\left[ h,1-h\right] \) ,
where
In stating our main theoretical results in the next two Theorems, and throughout this paper, we denote by \(\left\| \cdot \right\| _{\infty }\), the supremum norm of a function \(r\) on \(\left[ 0,1\right] \), i.e., \( \left\| r\right\| _{\infty }=\sup _{_{x\in \left[ 0,1\right] }}\left| r\left( x\right) \right| \).
Theorem 1
Under Assumptions (A1)–(A6), as \(n\rightarrow \infty \) , the estimator \(\hat{\sigma }_{\text {SK}}^{2}\left( x\right) \) is asymptotically as efficient as the “infeasible estimator”, \(\tilde{\sigma }_{ \text {K}}^{2}\left( x\right) \) i.e.,
As commented in the introduction, the oracle efficiency stated in Theorem 1 is of the unprecedented small order \(o_{p}\left( n^{-1/2}\right) \), and the next result follows immediately.
Theorem 2
Under Assumptions (A1)–(A6), an asymptotic \(100\left( 1-\alpha \right) \%\) oracally efficient SCB for \(\sigma ^{2}\left( x\right) \) over \(\left[ h,1-h\right] \) is
with \(V_{n}\) and \(Q_{n}\left( \alpha \right) \) given in (7) and (9) respectively. In other words,
The proofs of Theorems 1 and 2 depend on Propositions 1, 2 and 3 given in Sect. 3. The proofs of these Propositions are based on Lemmas 1, 4 and 2. All of them are provided in the “Appendix”. Both Theorems 1 and 2 remain true with spline–kernel estimator \(\hat{\sigma }_{\text {SK} }^{2}\left( x\right) \) replaced by spline-local linear estimator \(\hat{\sigma }_{\text {SLL}}^{2}\left( x\right) \), but detailed proofs for local linear estimator are omitted as in Wang and Yang (2007, 2009).
3 Error decomposition
To break the estimation error \(\hat{\sigma }_{\text {SK}}^{2}\left( x\right) - \tilde{\sigma }_{\text {K}}^{2}\left( x\right) \) into simpler parts, we begin by discussing the spline space \(G^{(p-2)}_{N}\) and the representation of the spline estimator of \(\hat{m}_{p}(x)\) in Eq. (5).
Denote by \(\left\| \phi \right\| _{2}\) the theoretical \(L^{2}\) norm of a function \(\phi \) on \(\left[ 0,1\right] \) , i.e., \(\left\| \phi \right\| _{2}^{2}=\mathsf {E}\{ \phi ^{2}( X) \} =\int _{0}^{1}\phi ^{2}\left( x\right) f\left( x\right) dx\), the empirical \(L^{2}\) norm as \(\left\| \phi \right\| _{2,n}^{2}=n^{-1}\small {\sum _{i=1}^{n}}\phi ^{2}\left( X_{i}\right) \), and then define the rescaled B-spline basis \(\{ B_{j,p}( x) \} _{j=1-p}^{N}\) for \(G_{N}^{\left( p-2\right) } \), each with theoretical norm equal to \(1\)
The estimator \(\hat{m}_{p}\left( x\right) \) in Eq. (5) can then be expressed as
where the vector \(\{ \hat{\lambda }_{1-p,p},\ldots ,\hat{\lambda } _{N,p}\} ^{\scriptstyle {T}}\) solves the following least-squares problem
We write \(\mathbf {Y}\) as the sum of a signal vector \(\mathbf {m}\) and a noise vector \(\mathbf {E}\),
Projecting this relationship into the space \(G_{n}^{\left( p-2\right) }\), one obtains
Correspondingly, in the space \(G_{N}^{\left( p-2\right) }\), one has \(\hat{m} _{p}\left( x\right) =\tilde{m}_{p}\left( x\right) +\tilde{\varepsilon } _{p}\left( x\right) ,\) where
with the vectors \(\left\{ \tilde{\lambda }_{1-p,p},\ldots ,\tilde{ \lambda }_{N,p}\right\} ^{\scriptstyle {T}}\) and \(\left\{ \tilde{a} _{1-p,p},\ldots ,\tilde{a}_{N,p}\right\} ^{\scriptstyle {T}}\) being solutions to (11) with \(Y_{i}\) replaced by \(m(X_{i})\) and \(\varepsilon _{i}\) respectively.
Regarding variance estimator in (2) and (3)
in which \(\hat{f}\left( x\right) =n^{-1}\sum _{i=1}^{n}K_{h}\left( X_{i}-x\right) \),
By Assumption (A3), \(\hat{f}\left( x\right) =f\left( x\right) +u_{p}\left( 1\right) \ge c_{f}+u_{p}\left( 1\right) \), hence Theorem 1 follows from the next three Propositions on I, II, III.
Proposition 1
Under Assumptions (A1)–(A6), as \(n\rightarrow \infty ,\)
Proposition 2
Under Assumptions (A1)–(A6), as \(n\rightarrow \infty \),
Proposition 3
Under Assumptions (A1)–(A6), as \(n\rightarrow \infty \),
4 Implementation
We describe in this section one concrete procedure that implements the oracally efficient SCB in Theorem 2, and is used throughout Sects. 5 and 6 for both simulated and real data examples. Given any sample \(\left\{ \left( X_{i},Y_{i}\right) \right\} _{i=1}^{n}\) from model (1), let \(a=\min \left( X_{1},\ldots ,X_{n}\right) ,b =\max \left( X_{1},\ldots ,X_{n}\right) \) and transform the data range from \( \left[ a,b\right] \) into \(\left[ 0,1\right] \) by the linear transformation \( x\rightarrow \) \((x-a)/(b-a)\). If this linear operation fails to make design variable \(X\) conform to Assumption (A3), one applies the quantile transformation \(x\rightarrow \) \(F_{n}=n^{-1}\sum \nolimits _{i=1}^{n}\mathrm{I}\left( X_{i}\le x\right) \).
To select the number of interior knots \(N\), let \(\hat{N}^{\text {opt}}\) be the minimizer of BIC defined below, over integers from \(\left[ 0.5N_{r},\min \left( 5N_{r},Tb\right) \right] \), with \(N_{r}=n^{-1/\left( 2p+1\right) }\) and \(Tb=n/4-1\), which ensures that \(\hat{N}^{\text {opt} }\) is order of \(n^{-1/\left( 2p+1\right) }\) and the number of parameters in the least-squares estimation is less than \(n/4\). The chosen \( \hat{N}^{\text {opt}}\) obviously satisfies Assumption (A6), but other choices of \(N\) remain open possibility. For any candidate integer \(N\in \left[ 0.5N_{r},\min \left( 5N_{r},Tb\right) \right] \), denote the predictor for the \(i\)-th response \(Y_{i}\) by \(\hat{Y} _{i}=\hat{m}_{p}(X_{i})\), and let \(q_{n}=\left( 1+N_{n}\right) \) be the number of parameters in (11), the BIC value corresponding to \(N\) is,
Algebra shows that the least-squares problem in Eq. (11) can be also solved via the truncated power basis \(\left\{ 1,x,\ldots ,x^{p-1}\!,\left( x-t_{j}\right) _{+}^{p-1}\!,j=1,2,\ldots N\right\} \), see de Boor (2001), which is regularly used in implementation. In other words,
where the coefficients \(\left( \hat{r}_{0},\ldots ,\hat{r}_{p-1},\hat{r} _{1,p},\ldots ,\hat{r}_{N,p}\right) ^{\scriptstyle {T}}\) are solutions to the least squares problem
\(\left( \hat{r}_{0},\dots ,\hat{r}_{N,p}\right) ^{\scriptstyle {T}}\!=\!\mathop {\text {argmin}}\limits _{\left( r_{0},\dots ,r_{N,p}\right) \in \mathbb {R}^{N+P}}\sum \limits _{ i=1}^{n}\left\{ \! Y_{i}\!-\!\sum \limits _{k=0}^{p-1} r_{k}X_{i}^{k}\!-\!\sum \limits _{j=1}^{N}r_{j,p}\left( X_{i}-t_{j}\right) _{+}^{k}\right\} ^{2}\!.\)
To choose an appropriate bandwidth \(h=h_{n}\) for computing \(\hat{\sigma }_{ \text {SK}}^{2}\left( x\right) \), one adopts the following rule-of-thumb (ROT) bandwidth of Fan and Gijbels (1996), Equation (4.3):
in which \(\left( \widehat{a}_{k}\right) _{k=0}^{4}=\text {argmin}_{\left( a_{k}\right) _{k=0}^{4}\in \mathbb {R}^{5}}\sum \nolimits _{i=1}^{n}\left( \hat{ Z}_{i}-\sum \nolimits _{k=0}^{4}a_{k}X_{i}^{k}\right) ^{2}\). One then sets \( h=h_{n}=h_{\text {rot}}(\log n)^{-1/2} \sim n^{-1/5}\left( \log n\right) ^{-1/2}\), which clearly satisfies Assumption (A5), especially the undersmoothing condition \(h\ll n^{-1/5}\left( \log n\right) ^{-1/5}\).
For constructing the SCB, the unknown functions \(v_{Z}^{2}\left( x\right) \) and \(f\left( x\right) \) are evaluated and then plugged in, the same approach taken in Hall and Titterington (1988), Härdle (1989), Xia (1998), Wang and Yang (2009), Song and Yang (2009). Let \(\tilde{K}\left( u\right) \) \( =15\left( 1-u^{2}\right) ^{2}\mathrm{I}\left\{ \left| u\right| \le 1\right\} /16\) be the quadratic kernel and \(s_{n}\) be the sample standard deviation of \(\left\{ X_{i}\right\} _{i=1}^{n}\) and
where \(h_{\text {rot},f}\) is the rule-of-thumb bandwidth in Silverman (1986). Define \(\mathbf {\nabla }^{\scriptstyle {T}}=\{ \nabla _{i},1\le i\le n\} \), \(\nabla _{i}=\{ \hat{Z}_{i}-\hat{\sigma }_{\text {SK} }^{2}\left( X_{i}) \right\} ^{2}\), and
where \(h_{\text {rot},\sigma }\) is the ROT bandwidth of Fan and Gijbels (1996) Equation (4.3), as \(h_{\text {rot}}\) in (15), but with the \(\hat{Z}_{i}\)’s replaced by \(\nabla _{i}\)’s, and define the following estimator of \(v_{Z}^{2}\left( x\right) \)
The following results follow from Bickel and Rosenblatt (1973) and Fan and Gijbels (1996)
The function \(V_{n}\) is approximated by the following, with \(\hat{f}\left( x\right) \) and \(\hat{v}_{Z}^{2}\left( x\right) \) defined in Eqs. (16) and (17)
Then Eq. (18) and Theorem 2 imply that as \(n\rightarrow \infty \), the SCB below is asymptotically \(100\left( 1-\alpha \right) \%\)
The construction described above of SCB according to Theorem 2, is over an interior portion of the data range \(\left[ 0,1\right] \), namely \( \left[ a_{n},b_{n}\right] =\left[ h_{n},1-h_{n}\right] \subseteq \left( 0,1\right) \), as seen in the SCB plots of Figs. 3, 2, 4 and 5. It should be emphasized, however, that the interval sequence \(\left[ h_{n},1-h_{n}\right] \) covers the entire interior \(\left( 0,1\right) \) as sample size \(n\rightarrow \infty \) and \(h_{n}\rightarrow 0\), which reflects, for instance, the widening range in Fig. 3 of SCB in (c) and (d) over (a) and (b).
Although any spline order \(p>1\) can be employed, we have used only linear splines \(\left( \text {with }p=2\right) \) for simplicity. It is well-known that the choice of kernel function is of less importance, according to Assumptions (A4) and (A5), the kernel function \(K\) is chosen to be the quadratic kernel. Simulation comparison will be made in Sect. 5 of the above oracally efficient SCB with the infeasible SCB, which is computed from (8) with \(v_{Z}^{2}(x)\) and \(f(x)\) replaced by \(\tilde{v} _{Z}^{2}(x)\) and \(\hat{f}(x)\) in (16), respectively, where \( \tilde{v}_{Z}^{2}(x)\) is the right side of (17) with \(\mathbf {\nabla }\) substituted by \(\tilde{\mathbf {\nabla }}\), where \( \tilde{\mathbf {\nabla }}^{\scriptstyle {T}}=\{ \tilde{\nabla }_{i},1\le i\le n\} \), \(\tilde{\nabla }_{i}=\{ {Z}_{i}-\tilde{\sigma }_{\text { K}}^{2}\left( X_{i}\right) \} ^{2}\).
5 Simulation
In this section, simulation results are presented to illustrate the finite-sample behavior of the oracally efficient SCB, on data sets generated from model (1), with \(X\sim U[-1/2,1/2]\), and
We choose \(c=1,c=0.5\), which have included variance functions \(\sigma ^{2}\left( x\right) \) that are strongly heteroscedastic \( \left( c=1\right) \) and nearly homoscedastic \(\left( c=0.5\right) \), while sample sizes are taken to be \(n=100,200,500\) and the confidence levels are \( 1-\alpha =0.99,0.95\). Table 1 contains the coverage frequency of the true curve \(\sigma ^{2}\left( x\right) \) at all data points \(\left\{ X_{i}\right\} _{i=1}^{n}\) by the oracally efficient SCB whose construction details are in Sect. 4 over \(500\) replications of sample size \(n\). Coverage frequency over the same data sets of the infeasible SCB in (8) is also listed in the table. In all cases, the coverage improves with increasing sample size, which confirms to Theorem 2, and the two SCBs are quite close to each other in terms of coverage frequency, showing positive confirmation of Theorem 1. For both cases \(c=1\) and \(c=0.5\), the oracally efficient SCB has coverage frequency approaching the nominal level for sample size as low as \(n=200\).
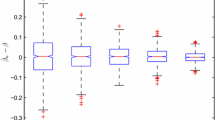
Figure 1 depicts the boxplots over \(500\) replications of \( \Delta _{n}=\sqrt{n}\max \) \(\big \vert \tilde{\sigma }_{\text {K}}^{2}\left( x_{j}\right) -\hat{\sigma }_{ \text {SK}}^{2}\left( x_{j}\right) \big \vert \), where {\(x_{j},j=1,2,\ldots n_{\text {grid}}\)} points on \(\left[ -0.5+h,0.5-h\right] \) with \(n_{\text { grid}}=401\), \(h\) being the chosen bandwidth of estimator (3 ). it can be seen that the boxplot of \(\Delta _{n}\) becomes narrower as \(n\) increases, implying that difference between the spline–kernel variance estimator and the infeasible estimator with known mean function is asymptotically of smaller order than \(n^{-1/2}\), which confirms Theorem 1. For visual impression of the SCB, Figs. 3 and 2 are created based on sample sizes \(n=100,500\), and \(c=1,0.5\), respectively, each with symbols: center thick line (true curve), center solid line (the estimated curve), upper- and lower-dashed line (SCB). In all figures, the SCB becomes narrower and fit better for \(n=500\) than for \(n=100\).

Boxplots of \(\Delta _{n}\) with a \(c=1\); b \(c=0.5\)

Plots of SCB for variance function (dashed) which is computed according to (19), the estimator \(\hat{\sigma }_{\text {SK}}^{2}\left( x\right) \) (solid), the true function \(\sigma ^{2}\left( x\right) \) with \(c=0.5\) (thick). a \(n=100\), 95 % SCB; b \(n=100\), 99 % SCB; c \(n=500\), 95 % SCB; d \(n=500\), 99 % SCB

Plots of SCB for variance function (dashed) which is computed according to (19), the estimator \(\hat{\sigma }_{\text {SK}}^{2}\left( x\right) \) (solid), the true function \(\sigma ^{2}\left( x\right) \) with \(c=1\) (thick). a \(n=100, 95\%\) SCB; b \( n=100, 99\%\) SCB; c \(n=500\), 95 % SCB; d \(n=500\), 99 % SCB
6 Empirical examples
In this section, we test the null hypothesis of homoscedasticity \( H_{0}:\sigma ^{2}(x)=\sigma _{0}^{2}>0\) for two well-known data sets. The first is the motorcycle data with \(n=133\) observations, with \(X= \) time (in milliseconds) after a simulated impact on motorcycles, \(Y=\) the head acceleration of a PTMO (post mortem human test object). The data can be called in R by the command “data(motorcycledata)”, see http://www.inside-r.org/node/52453. In Fig. 4, the center thick lines are the spline–kernel estimator \(\hat{\sigma }_{\text {SK}}^{2}(x)\) for \(\sigma ^{2}(x)\), the upper/lower solid lines represent the SCB for the variance function. Since the \(100(1-0.00009)\%\) SCB in (a) does not contain the consistent estimate of \(\sigma _{0}^{2}\) under the null hypothesis, which equals \(n^{-1}\sum \nolimits _{i=1}^{n}\hat{\varepsilon } _{i,p}^{2}\), one rejects the null hypothesis of homoscedasticity with \(p\) value \(<0.00009\).

For the motorcycle data, plots of SCB (solid) computed according to the (19), the spline–kernel estimator \(\hat{\sigma }_{\text {SK}}^{2}(x)\) (thick), the scatterplot of \(\hat{Z}_{i}=\hat{ \varepsilon }_{i,p}^{2}\) a \(99.991\% \) SCB, a constant variance fit which equals \(n^{-1}\sum \nolimits _{i=1}^{n}\hat{\varepsilon } _{i,p}^{2}\), \(\alpha =0.00009\); b 98.698 % SCB, a constant variance fit which equals the maximum of upper SCB, \(\alpha =0.01302\)
Song and Yang (2009) had obtained a \(p\) value of \(0.008\) with spline SCB, as minimum of the upper confidence line equals the maximum of the lower confidence line for the spline SCB of confidence level \(99.2~\%=1-0.008\). The \(99.2~\%\) spline SCB therefore contains completely a horizontal line, even though its height is not equal to \(n^{-1}\sum \nolimits _{i=1}^{n}\hat{\varepsilon }_{i,p}^{2}\). For comparison, we have computed the confidence level at which the upper and lower lines of the spline–kernel SCB coincide, which turns out to be \(98.698~\%\), thus one rejects the null hypothesis of homoscedasticity with \(p\) value \(\le 0.01302\). Figure 4b depicts the \( 98.698~\%\) spline–kernel SCB and the horizontal line that completely fits inside the SCB. We have also constructed ad hoc local linear SCBs by substituting \(\hat{ \sigma }_{\text {SK}}^{2}\left( x\right) \) in (19) with the two-step local linear estimator of \(\sigma ^{2}\left( x\right) \) in Fan and Yao (1998), and with minimum of upper line and maximum of lower line equal, the confidence level is \(99.999865~\%\), thus the \(p\) value is \(0.00000135\) for rejecting the null hypothesis of homoscedasticity. To sum up, for the motorcycle data, homoscedasticity is rejected by all four approaches, with \( p \) values ranging from \(0.00000135\) to \(0.01302\).
The second data set is the Old Faithful geyser data, which can be downloaded from http://www.stat.cmu.edu/~larry/all-of-statistics/=data/faithful.dat. Geysers are a special kind of hot springs that erupt a mixture of hot water, steam and other gases, and by studying geysers scientists obtain useful information about the structure and the dynamics of earth’s crust. The data consists of \(n=272\) observations for the Old Faithful geyser in Yellowstone National Park, Wyoming, USA: \(X=\) eruption time in mins, \(Y=\) the waiting time to next eruption. Figure 5 shows that for the geyser data one can not reject the null hypothesis of homoscedasticity with a \(p\) value \(0.12\).

For the Old Faithful geyser data, plots of SCB (solid) computed according to the (19), the spline–kernel estimator \( \hat{\sigma }_{\text {SK}}^{2}(x)\) (thick), a constant variance fit which equals \(n^{-1} \sum \nolimits _{i=1}^{n}\hat{\varepsilon } _{i,p}^{2}\), the scatterplot of \(\hat{Z}_{i}=\hat{\varepsilon } _{i,p}^{2}\) a 95 % SCB, \(\alpha =0.05\), b 88 % SCB, \( \alpha =0.12\)
7 Conclusions
A spline–kernel estimator is proposed for the conditional variance function in nonparametric regression model, which is shown to be oracally efficient, that is, it uniformly approximates an infeasible kernel variance estimator at the rate of \(o_{p}\left( n^{-1/2}\right) \). A powerful technical Lemma 4 is used in the proofs of Propositions 2 and 3, both indispensable in establishing oracle efficiency. A data-driven procedure implements the kernel SCB centered around the oracally efficient two-step estimator, with limiting coverage probability equal to that of the infeasible kernel SCB. As illustrated by both the motorcycle and the Old Faithful geyser data, the theoretically justified kernel SCB is also a useful tool for testing hypotheses on the conditional variance function, and is expected to find wide applications in many scientific disciplines.
References
Akritas MG, Van Keilegom I (2001) ANCOVA methods for heteroscedastic nonparametric regression models. J Am Stat Assoc 96:220–232
Bickel PJ, Rosenblatt M (1973) On some global measures of deviations of density function estimates. Ann Stat 31:1852–1884
Brown DL, Levine M (2007) variance estimation in nonparametric regression via the difference sequence method. Ann Stat 35:2219–2232
Cai T, Wang L (2008) Adaptive variance function estimation in heteroscedastic nonparametric regression. Ann Stat 36:2025–2054
Carroll RJ, Wang Y (2008) Nonparametric variance estimation in the analysis of microarray data: a measurement error approach. Biometrika 95:437–449
Carroll RJ, Ruppert D (1988) Transformations and weighting in regression. Champman and Hall, London
Claeskens G, Van Keilegom I (2003) Bootstrap confidence bands for regression curves and their derivatives. Ann Stat 31:1852–1884
Davidian M, Carroll RJ, Smith W (1988) Variance functions and the minimum detectable concentration in assays. Biometrika 75:549–556
De Boor C (2001) A practical guide to splines. Springer, New York
Dette H, Munk A (1998) Testing heteroscedasticity in nonparametric regression. J R Stat Soc Ser B 60:693–708
Fan J, Gijbels T (1996) Local polynomial modelling and its applications. Champman and Hall, London
Fan J, Yao Q (1998) Efficient estimation of conditional variance functions in stochastic regression. Biometrika 85:645–660
Hall P, Titterington MD (1988) On confidence bands in nonparametric density estimation and regression. J Multivar Anal 27:228–254
Hall P, Carroll RJ (1989) Variance function estimation in regression: the effect of estimating the mean. J R Stat Soc Ser B 51:3–14
Hall P, Marron JS (1990) On variance estimation in nonparametric regression. Biometrika 77:415–419
Härdle W (1989) Asmptotic maximal deviation of M-smoothers. J Multivar Anal 29:163–179
Härdle W (1992) Applied nonparametric regression. Cambridge University Press, Cambridge
Levine M (2006) Bandwidth selection for a class of difference-based variance estimators in the nonparametric regression: a possible approach. Comput Stat Data Anal 50:3405–3431
Liu R, Yang L, Härdle W (2013) Oracally efficient two-step estimation of generalized additive model. J Am Stat Assoc 108:619–631
Ma S, Yang L, Carroll RJ (2012) A simultaneous confidence band for sparse longitudinal regression. Stat Sin 22:95–122
Müller HG, Stadtmüller U (1987) Estimation of heteroscedasticity in regression analysis. Ann Stat 15:610–625
Silverman WB (1986) Density estimation for statistics and data analysis. Chapman and Hall, London
Song Q, Yang L (2009) Spline confidence bands for variance functions. J Nonparametr Stat 5:589–609
Tusnády G (1977) A remark on the approximation of the sample df in the multidimensional case. Periodica Mathematica Hungarica 8:53–55
Wang L, Brown LD, Cai T, Levine M (2008) Effect of mean on variance function estimation in nonparametric regression. Ann Stat 36:646–664
Wang J, Liu R, Cheng F, Yang L (2014) Oracally efficient estimation of autoregressive error distribution with simultaneous confidence band. Ann Stat 42:654–668
Wang L, Yang L (2007) Spline-backfitted kernel smoothing of nonlinear additive autoregression model. Ann Stat 35:2474–2503
Wang J, Yang L (2009a) Polynomial spline confidence bands for regression curves. Stat Sin 19:325–342
Wang L, Yang L (2009b) Spline estimation of single-index models. Stat Sin 19:765–783
Wang J, Yang L (2009c) Efficient and fast spline-backfitted kernel smoothing of additive models. Ann Inst Stat Math 61:663–690
Xia Y (1998) Bias-corrected confidence bands in nonparametric regression. J R Stat Soc Ser B 60:797–811
Xue L, Yang L (2006) Additive coefficient modeling via polynomial spline. Stat Sin 16:1423–1446
Zheng S, Yang L, Härdle W (2014) A smooth simultaneous confidence corridor for the mean of sparse functional data. J Am Stat Assoc 109:661–673
Acknowledgments
This work has been supported by NSF award DMS 1007594, Jiangsu Specially-Appointed Professor Program SR10700111, Jiangsu Key-Discipline Program ZY107992, National Natural Science Foundation of China award 11371272, and Research Fund for the Doctoral Program of Higher Education of China award 20133201110002. The authors thank the Editor and two Reviewers for helpful comments.
Author information
Authors and Affiliations
Corresponding author
Appendix A
Appendix A
Throughout this Appendix, we denote by \(\left\| \xi \right\| \) the Euclidean norm and \(\left| \xi \right| \) means the largest absolute value of the elements of any vector \(\xi \). We use \(c\), \(C\) to denote any positive constants in the generic sense. We denote for any given constant \( C>0\), a class of Lipschitz continuous functions by \(\text {Lip}\left( \left[ 0,1\right] ,C\right) =\left\{ \varphi \left| \left| \varphi \left( x\right) -\varphi \left( x^{\prime }\right) \right| \le C\left| x-x^{\prime }\right| \text {, }\forall x,x^{\prime }\in \left[ 0,1\right] \right. \right\} \).
1.1 A.1 Preliminaries
The Lemmas of this Subsection are needed for the proof of Propositions 1, 2 and 3. These Propositions clearly establish Theorems 1 and 2.
Lemma 1
Under Assumptions (A1)–(A5), there exists a constant \(C_{p}>0\), \(p>1\), such that for any \(m\in C^{p}\left[ 0,1\right] \) there is a spline function \(g_{p}\in G_{N}^{\left( p-2\right) }\) satisfying \(\left\| m-g_{p}\right\| _{\infty }\) \(\le CH^{p}\) and \(m-g_{p}\in \text {Lip}\left( \left[ 0,1\right] ,CH^{p-1}\right) \). The function \(\tilde{m}_{p}\left( x\right) \) given in Equation (12)
Moreover, for the function \(\tilde{\varepsilon }_{p}\left( x\right) \) given in Equation (12)
See Lemma A.1 of Song and Yang (2009), and also Wang and Yang (2009) for detailed proof.
Lemma 2
Under Assumption (A6), as \(n\rightarrow \infty \),
See Lemma A.4 of Song and Yang (2009) for detailed proof.
The strong approximation result of Tusnády (1977) is also needed.
Lemma 3
Let \(U_{1},\ldots ,U_{n}\) be i.i.d. r.v.’s on the \(2\) -dimensional unit square with \(P\left( U_{i}<\mathbf {t}\right) =\lambda \left( \mathbf {t}\right) ,\mathbf {0\le t\le 1,}\) where \(\mathbf {t=(} t_{1,}t_{2}\mathbf {)}\) and \(\mathbf {1=(}1,1\mathbf {)}\) are \(2\)-dimensional vectors, \(\lambda \left( \mathbf {t}\right) =t_{1}t_{2}.\) The empirical distribution function \(F_{n}^{u}\left( \mathbf {t}\right) \) based on sample \( \left( U_{1},\ldots ,U_{n}\right) \) is defined as \(F_{n}^{u}\left( \mathbf {t} \right) =n^{-1}\sum _{i=1}^{n}\mathrm{I}_{\left\{ U_{i}<\mathbf {t}\right\} }\) for \( \mathbf {0}\le \mathbf {t\le 1.}\) The \(2\)-dimensional Brownian bridge \( B\left( \mathbf {t}\right) \) is defined by \(B\left( \mathbf {t}\right) =W\left( \mathbf {t}\right) -\lambda \left( \mathbf {t}\right) W\left( \mathbf { 1}\right) \) for \(\mathbf {0}\le \mathbf {t\le 1}\), where \(W\left( \mathbf {t} \right) \) is a \(2\)-dimensional Wiener process. Then there is a version \( B_{n}\left( \mathbf {t}\right) \) of \(B\left( \mathbf {t}\right) \) such that
holds for all \(x\), where \(C,K,\) \(\lambda \) are positive constants.
Denote the well-known Rosenblatt transformation for bivariate continuous \( \left( X,\varepsilon \right) \) as
so that \(\left( X^{\prime },\varepsilon ^{\prime }\right) \) has uniform distribution on \(\left[ 0,1\right] ^{2}\), therefore
with \(F_{n}\left( x,\varepsilon \right) \) denoting the empirical distribution of \(\left( X,\varepsilon \right) \). Lemma 3 implies that there exists a version \(B_{n}\) of \(2\)-dimensional Brownian bridge such that
Lemma 4
Under Assumptions (A2)-(A5), as \(n\rightarrow \infty \), for any sequence of functions \(r_{n}\) \(\in \text {Lip}\left( \left[ 0,1\right] ,l_{n}\right) ,l_{n}>0\) with \({\left\| r_{n}\right\| _{\infty }=\rho }_{n}\ge 0\)
Proof
Step 1. We first discretize the problem by letting \( 0=x_{0}<x_{1}\,<\cdots <x_{M_{n}}=1,M_{n}=n^{4}\) by equally spaced points, the smoothness of kernel \(K\) in Assumption (A4) imples that
and the moment conditions on error \(\varepsilon \) in Assumption (A2), the rate of \(h\) in Assumption (A5) imply next that
Step 2. To truncate the error, we denote \(D_{n}=n^{\alpha }\) with \(\alpha \) as in Assumption (A5). Assumption (A5) implies that \(D_{n}n^{-1/2}h^{-1/2} \log ^{2}n\rightarrow 0,\) \(n^{1/2}h^{1/2}D_{n}^{-\left( 1+\eta \right) }\rightarrow 0\), \(\sum _{n=1}^{\infty }D_{n}^{-\left( 2+\eta \right) }<\infty \). Write \(\varepsilon _{i}=\varepsilon _{i,1}^{D_{n}}+\varepsilon _{i,2}^{D_{n}}\), where \(\varepsilon _{i,1}^{D_{n}}=\varepsilon _{i}\mathrm{I}\left\{ \left| \varepsilon _{i}\right| >D_{n}\right\} ,\varepsilon _{i,2}^{D_{n}}=\varepsilon _{i}\mathrm{I}\left\{ \left| \varepsilon _{i}\right| \le D_{n}\right\} \), and denote \(\mu ^{D_{n}}\left( x\right) =\mathsf {E}\left\{ \varepsilon _{i}\mathrm{I}\left\{ \left| \varepsilon _{i}\right| \le D_{n}\right\} \mid X_{i}=x\right\} \). One immediately obtains that
Next, since \(P\left( \left| \varepsilon _{i}\right| >D_{n}\right) \le \mathsf {E}\left| \varepsilon \right| ^{2+\eta }D_{n}^{-(2+\eta )}\), \(\sum \nolimits _{n=1}^{\infty }P\left( \left| \varepsilon _{n}\right| >D_{n}\right) \le \) \(\mathsf {E}\left| \varepsilon \right| ^{2+\eta }\sum \nolimits _{n=1}^{\infty }D_{n}^{-\left( 2+\eta \right) }<+\infty \), Borel–Cantelli Lemma then implies that
So one has for any \(k>0\)
Step 3. The truncated sum \(n^{-1}\sum _{i=1}^{n}K_{h}\left( X_{i}\!-\!x\right) r_{n}\left( X_{i}\right) \varepsilon _{i,2}^{D_{n}}\) equals \(\int _{\left| \varepsilon \right| \le D_{n}}K_{h}\left( u\!-\!x\right) r_{n}\left( u\right) \varepsilon dF_{n}\left( u,\varepsilon \right) \), while
according to (27). The above two Equations imply that
Step 4. The term \(n^{-1/2}\int _{\left| \varepsilon \right| \le D_{n}}K_{h}\left( u-x\right) r_{n}\left( u\right) \varepsilon dZ_{n}\left( u,\varepsilon \right) \) equals
Note that
by the growth constraint on \(D_{n}=n^{\alpha }\). Note also that
in which
Meanwhile
so the \(M_{n}\) Gaussian variables \(n^{-1/2}\int _{\left| \varepsilon \right| \le D_{n}}K_{h}\left( u-x_{j}\right) r_{n}\left( u\right) \varepsilon dW_{n}\left\{ M\left( u,\varepsilon \right) \right\} ,0\le j<M_{n}\) each has variance less than \(n^{-1}h^{-1}{\rho }_{n}^{2}C_{\sigma }^{2}C_{f}\), hence
Finally, putting together Eqs. (26), (28 ), (29), (30), (31 ) and (32) proves the Lemma.
1.2 A.2 Proof of Propositions
Proof of Proposition
1 It is obvious that \( \left| \mathrm{I}_{i,p}\right| \le 2\left\{ \tilde{m}_{p}\left( X_{i}\right) -m\left( X_{i}\right) \right\} ^{2}+2\tilde{\varepsilon }_{p}^{2}\left( X_{i}\right) .\) Meanwhile applied Lemma 1, \( \left\| m-\tilde{m}_{p}\right\| _{2,n}^{2}\le \left\| m-\tilde{m} _{p}\right\| _{\infty }^{2}=\mathcal {O}_{p}\left( H^{2p}\right) \), \( \left| \mathrm{I}\right| \) is bounded by
Proof of Proposition
2 By (12), \(\tilde{\varepsilon }_{p}( X_{i}) =\sum _{J=1-p}^{N}\tilde{a}_{J,p}B_{J,p}( X_{i}) \), Lemma 1 and Wang and Yang (2009) entail that \((\sum _{J=1-p}^{N}\tilde{a}_{J,p}^{2}) ^{1/2}=\mathcal {O}_{p}(\Vert \tilde{\varepsilon }_{p}(x) \Vert _{2,n}) =\mathcal {O}_{p}(n^{-1/2}N^{1/2}) \). Set \(r_{n}\left( x\right) =B_{J,p}\left( x\right) \), then Lemma 2 entails that \(\rho _{n}=\mathcal {O}\left( H^{-1/2}\right) \) and it is easy to verify that \( l_{n}=\mathcal {O}\left( H^{-3/2}\right) \). Applying Lemma 4, one obtains that
and hence
the lemma is proved.
Proof of Proposition
in which the spline function \(g_{p}\in G_{N}^{\left( p-2\right) }\) satisfies \(\left\| m-g_{p}\right\| _{\infty }\) \(\le CH^{p},m-g_{p}\in \text {Lip }\left( \left[ 0,1\right] ,CH^{p-1}\right) \) as in Lemma 1. Set \(r_{n}\left( x\right) =m\left( x\right) -g_{p}\left( x\right) \), then \(\rho _{n}=\mathcal {O}\left( H^{p}\right) ,l_{n}=\mathcal {O} \left( H^{p-1}\right) \), so applying Lemma 4 yields
Denoting \(g_{p}\left( x\right) -\tilde{m}_{p}\left( x\right) =\sum _{J=1-p}^{N}\gamma _{J,p}B_{J,p}\left( x\right) \) and applying Lemma 1, one has
which, together with (33) imply that
which, together with (34), prove the lemma.
Rights and permissions
About this article

Cite this article
Cai, L., Yang, L. A smooth simultaneous confidence band for conditional variance function. TEST 24, 632–655 (2015). https://doi.org/10.1007/s11749-015-0427-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11749-015-0427-5
Keywords
- B spline
- Confidence band
- Heteroscedasticity
- Infeasible estimator
- Knots
- Nadaraya–Waston estimator
- Variance function