
Abstract
Background
Procedure-specific complications can have devastating consequences. Machine learning–based tools have the potential to outperform traditional statistical modeling in predicting their risk and guiding decision-making. We sought to develop and compare deep neural network (NN) models, a type of machine learning, to logistic regression (LR) for predicting anastomotic leak after colectomy, bile leak after hepatectomy, and pancreatic fistula after pancreaticoduodenectomy (PD).
Methods
The colectomy, hepatectomy, and PD National Surgical Quality Improvement Program (NSQIP) databases were analyzed. Each dataset was split into training, validation, and testing sets in a 60/20/20 ratio, with fivefold cross-validation. Models were created using NN and LR for each outcome. Models were evaluated primarily with area under the receiver operating characteristic curve (AUROC).
Results
A total of 197,488 patients were included for colectomy, 25,403 for hepatectomy, and 23,333 for PD. For anastomotic leak, AUROC for NN was 0.676 (95% 0.666–0.687), compared with 0.633 (95% CI 0.620–0.647) for LR. For bile leak, AUROC for NN was 0.750 (95% CI 0.739–0.761), compared with 0.722 (95% CI 0.698–0.746) for LR. For pancreatic fistula, AUROC for NN was 0.746 (95% CI 0.733–0.760), compared with 0.713 (95% CI 0.703–0.723) for LR. Variables related to intra-operative information, such as surgical approach, biliary reconstruction, and pancreatic gland texture were highly important for model predictions.
Discussion
Machine learning showed a marginal advantage over traditional statistical techniques in predicting procedure-specific outcomes. However, models that included intra-operative information performed better than those that did not, suggesting that NSQIP procedure-targeted datasets may be strengthened by including relevant intra-operative information.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Procedure-specific complications can have devastating consequences. For example, anastomotic leak after colectomy is associated with increased morbidity, length of stay, re-admissions, and mortality, as well as local recurrence and cancer-specific mortality for oncologic surgeries.1–3 Predictive models can be helpful to estimate a patient’s specific risk for post-operative complications, guide peri-operative decision-making such as ostomy placement or early drain removal, and perform risk adjustment for comparing post-operative outcomes.
Prior predictive models, such as the American College of Surgeons (ACS) Surgical Risk Calculator, provide accurate estimates of overall mortality and morbidity.4 However, this model, and others which are based on the National Surgical Quality Improvement Program (NSQIP) dataset, fall short in their ability to predict procedure-specific outcomes.5–7
Machine learning, a branch of artificial intelligence (AI), uses computer algorithms that identify patterns within data without explicit instructions and has the potential to identify subtle, non-linear patterns. Machine learning has been successfully applied to the prediction of post-operative outcomes, but previous projects have focused on broader, rather than procedure-specific, outcomes, such as overall morbidity and mortality.8,9 Our hypothesis is that machine learning could be helpful in the prediction of procedure-specific outcomes. This study seeks to develop machine learning models for predicting three procedure-specific outcomes: anastomotic leak following colectomy, bile leak following hepatectomy, and pancreatic fistula following pancreaticoduodenectomy (PD). We also sought to compare the machine learning models with logistic regression.
Materials and Methods
Data Source
We used the colectomy, hepatectomy, and pancreatectomy procedure–targeted datasets from the ACS National Surgical Quality Improvement Program (NSQIP) database. All available years for colectomy (2012–2019), hepatectomy (2014–2019), and pancreatectomy (2014–2019) were included. Patients missing primary outcome data were excluded. Patients undergoing colectomy who underwent concurrent ostomy placement were also excluded. From the pancreatectomy dataset, patients undergoing procedures other than PD were excluded. This study was determined to be exempt from institutional review board approval.
Outcomes
For each procedure type, we sought to predict a procedure-specific outcome: anastomotic leak for colectomy, bile leak for hepatectomy, and pancreatic fistula for PD. Anastomotic leak included leaks requiring treatment with antibiotics, percutaneous drainage, or reoperation. Bile leak included leaks requiring percutaneous drainage or reoperation. Pancreatic fistula included grade B or C fistulas for 2018–2019 (fistula grading was implemented in NSQIP in 2018). For 2014–2017, clinically relevant pancreatic fistulas were defined according to methods described by Kantor et al.6,10
Predictive Models
Each dataset was split into training, validation, and testing sets in 60%, 20%, and 20% ratios, respectively, using randomly selected data from all years. The training set was used for model development, the validation set was used for model adjustment and to monitor overfitting, and the test set was reserved for evaluation of model performance after completion of development. Cross-validation was used to create 5 different train/test splits to verify model consistency. We selected a deep neural network (NN) as our machine learning approach, as it has been previously demonstrated to have improved performance compared with tree-based methods (such as random forest) in prediction of post-operative outcomes from the NSQIP database.8,9,11 This deep learning approach uses layers of functions, each containing model weights, to transform input data into output data representing predictions.12 Dropout (random removal of functions within layers) and early stopping (stopping training when validation set accuracy decreases) were used to reduce overfitting.13 Logistic regression (LR) models were also created for comparison. LR was implemented with no regularization and no variable elimination techniques to approximate a standard implementation. Models were implemented in Python (version 3.9) with use of the Pandas,14,15 SciKitLearn,16 and Keras17 libraries.
Input data included all available peri-operative variables within the core NSQIP database and procedure-targeted variables that would be known prior to the occurrence of the outcome of interest (Tables 1 and 2 and Supplementary Table 1). Missing variables from the datasets were addressed by imputation techniques, which is standard data pre-processing. Missing categorical values were imputed as “unknown” and missing continuous values as the median.9,13,18 Further details are available in the Supplementary Appendix and code is available at https://github.com/gomezlab/nsqip_procedurespecific.
Evaluation
Models were evaluated primarily with area under the receiver operating characteristic curve (AUROC). The receiver operating characteristic curve plots the true positive rate against the false positive rate and the AUROC summarizes the model’s ability to distinguish positive cases from negative cases. AUROC ranges from 0.5 (random guessing) to 1 (perfect classification). AUROCs were compared between models using the Delong test with significance set at p < 0.05.19 In addition, the area under the precision-recall curve (AUPRC) was also calculated for each model, which assesses a model’s ability to identify all positive cases without identifying false positives. A random classifier will have an AUPRC equal to the rate of the positive class (e.g., rate of anastomotic leak) and a perfect classifier will have an AUPRC of 1.0. The relative importance of input variables was estimated for procedure-specific variables using Shapley additive explanations (SHAP) for NN models and odds ratios for LR models.20
Results
Colectomy
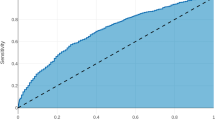
The colectomy dataset included 257,913 patients. After application of exclusion criteria, 197,488 patients remained. A total of 6012 (3.05%) patients experienced an anastomotic leak. After splitting, 118,493 patients were included in the training group, 39,497 patients were included in the validation group, and 39,498 patients were included in the test group. Further input variable characteristics for all groups are described in Table 1. On the test set, NN obtained an AUROC of 0.676 (95% 0.666–0.687) and an AUPRC of 0.104 (95% CI 0.092–0.115). LR obtained an AUROC of 0.633 (95% CI 0.620–0.647) and an AUPRC of 0.056 (95% CI 0.051–0.061) (Table 3). Receiver operating characteristic and precision-recall curves for anastomotic leak are shown in Figs. 1a and 2a. Comparison using the Delong test showed a significant difference between the AUROC of NN and LR with p < 0.001. Of the variables within the procedure-targeted dataset, approach, mechanic bowel prep, and antibiotic bowel prep contributed most to the NN model output, compared with chemotherapy, pre-operative steroid use, and antibiotic bowel prep for the LR model (Table 4).

Receiver operating characteristic curves for procedure-specific outcomes: a Anastomotic leak b Bile leak c Pancreatic fistula. NN—neural network, LR—logistic regression

Precision-recall curves for procedure-specific outcomes: a Anastomotic leak b Bile leak c Pancreatic fistula. NN—neural network, LR—logistic regression
Hepatectomy
The hepatectomy dataset included 25,595 patients. After application of exclusion criteria, 25,403 patients remained. A total of 966 (3.8%) patients experienced a bile leak. After splitting, 15,242 patients were included in the training group, 5,080 patients were included in the validation group, and 5,081 patients were included in the test group. On the test set, NN obtained an AUROC of 0.750 (95% CI 0.739–0.761) and an AUPRC of 0.134 (95% CI 0.115–0.153) (Table 3). LR obtained an AUROC of 0.722 (95% CI 0.698–0.746) and AUPRC of 0.114 (95% CI 0.090–0.139). Receiver operating characteristic and precision-recall curves for anastomotic leak are shown in Figs. 1b and 2b. Comparison using the Delong test showed a significant difference between the AUROC of NN and LR with p = 0.003. Of the variables within the procedure-targeted dataset, placement of drain intra-operatively, biliary reconstruction, surgical approach, biliary stent placement, use of Pringle maneuver, and number of concurrent resections contributed most to the NN model, compared with biliary reconstruction, Pringle maneuver, surgical approach, neoadjuvant chemo-embolization, placement of drain, and neoadjuvant chemo-infusion for the LR model (Table 4).
Pancreaticoduodenectomy
The PD dataset included 23,437 patients. After application of exclusion criteria, 23,233 patients remained. A total of 3,346 (14.4%) patients experienced a pancreatic fistula. After splitting, 13,940 patients were included in the training group, 4,647 patients were included in the validation group, and 4,646 patients were included in the test group. On the test set, NN obtained an AUROC of 0.746 (95% CI 0.733–0.760) and an AUPRC of 0.346 (95% CI 0.327–0.365) (Table 3). LR obtained an AUROC of 0.713 (95% CI 0.703–0.723) and an AUPRC of 0.294 (95% CI 0.281–0.307). Receiver operating characteristic and precision-recall curves for anastomotic leak are shown in Figs. 1c and 2c. Comparison using the Delong test showed a significant difference between the AUROCs of NN and LR with p < 0.001. Of the variables within the procedure-targeted dataset, pancreatic gland texture, indication, drain amylase on post-operative day 1, type of reconstruction, and duct size contributed most to the NN model output, compared with placement of drain intra-operatively, gland texture, pre-operative chemotherapy, type of reconstruction, and indication for the LR model (Table 4).
Discussion
This study developed and compared machine learning and logistic regression models which predict procedure-specific complications after colectomy, hepatectomy, and PD. Overall, the NN showed marginal improvement over LR in terms of predictive accuracy. There was a marked difference between models’ predictive ability for various outcomes, with anastomotic leak after colectomy less accurately predicted compared with bile leak after hepatectomy and pancreatic fistula after PD for both the NN and LR approaches. Evaluation of variable importance using SHAP values and odds ratios showed that both models emphasized intra-operative variables as risk factors. Notably, the colectomy procedure–targeted dataset includes much less intra-operative information compared with hepatectomy and PD.
While machine learning applied to the entire NSQIP dataset predicts general outcomes with high accuracy (AUROC 0.88–0.95) and significantly outperforms the ACS risk calculator,4,8 machine learning to predict procedure-specific complications in the current project does not show as clear of an advantage over LR. For anastomotic leak, previous models developed using LR and the NSQIP dataset obtained AUROCs of 0.65–0.66, similar to our machine learning models, although they significantly outperform the ACS Surgical Risk Calculator (AUROC 0.58).5,21,22 Models developed using LR on single-institution and regional datasets, which also incorporate more intra-operative information, have obtained higher AUROCs 0.73–0.82.7,23 LR models created for bile leak and pancreatic leak from non-NSQIP datasets resulted in AUROC (0.65–0.79), similar to results for our models.24–30 One previous study did apply machine learning methods to predict pancreatic fistula in a smaller, single-institution dataset of 1769 patients with an AUROC 0.74, also similar to our model.31
A particularly interesting finding from this study is that certain outcomes, in particular anastomotic leak after colectomy, are much more difficult to predict from the NSQIP dataset compared with bile leak and pancreatic fistula. This is likely because the NSQIP dataset does not include intra-operative variables for colectomy, in contrast to hepatectomy and pancreatectomy. Tellingly, models for anastomotic leak based on non-NSQIP datasets which include relevant intra-operative information, such as number of staple fires, occurrence of intra-operative adverse events, and need for intra-operative transfusion, have improved accuracy (AUROC 0.73–0.82) that are more similar our results for hepatectomy and PD.7,23 This aligns with a body of literature showing a strong link between intra-operative performance and post-operative outcomes, indicating that the incorporation of intra-operative information is key to predicting procedure-specific outcomes.31,32,33,34
This comparison does have some limitations. First, use of NSQIP as training data introduces selection bias because only hospitals participating in the NSQIP program are included. In addition, predictions are limited to 30-day outcomes. For some variables, data may be missing because of the clinical scenario and for those variables, assumptions made using imputation techniques may not be valid. Missing data for pancreatectomy variables has also improved over time, making earlier years less useful for model training. Second, this study is not an exhaustive analysis of every procedure-specific complication in NSQIP. Rather, it analyzes the abdominal surgical procedures with the most robust procedure-targeted datasets. Finally, while direct comparison of the absolute values of SHAP and odds ratios is not valid, their use for relative importance can provide insights into model decision-making.
Conclusion
In conclusion, our results show that machine learning has a marginal advantage over traditional statistical techniques in predicting procedure-specific outcomes based on the NSQIP dataset. However, models which include intra-operative variables performed better compared with those that did not, suggesting that NSQIP procedure-targeted datasets may be strengthened by the collection of relevant intra-operative information. The application of machine learning to datasets which include multi-modal data, such as real-time electronic health record information and assessments of intra-operative surgeon performance, represents a target of future research.
References
Midura EF, Hanseman D, Davis BR, et al. Risk factors and consequences of anastomotic leak after colectomy: A national analysis. In: Diseases of the Colon and Rectum. Vol 58. Lippincott Williams and Wilkins; 2015:333–338. https://doi.org/10.1097/DCR.0000000000000249
Mirnezami A, Mirnezami R, Chandrakumaran K, Sasapu K, Sagar P, Finan P. Increased local recurrence and reduced survival from colorectal cancer following anastomotic leak: Systematic review and meta-analysis. Ann Surg. 2011;253(5):890-899. https://doi.org/10.1097/SLA.0b013e3182128929
Romagnoni A, Jégou S, Van Steen K, et al. Comparative performances of machine learning methods for classifying Crohn Disease patients using genome-wide genotyping data. Sci Reports 2019 91. 2019;9(1):1–18. https://doi.org/10.1038/s41598-019-46649-z
Bilimoria KY, Liu YL, Paruch JL, Zhou L, et al. Development and evaluation of the universal ACS NSQIP surgical risk calculator: a decision aid and informed consent tool for patients and surgeons. J Am Coll Surg. 2013;217(5). https://doi.org/10.1016/J.JAMCOLLSURG.2013.07.385
McKenna NP, Bews KA, Cima RR, Crowson CS, Habermann EB. Development of a Risk Score to Predict Anastomotic Leak After Left-Sided Colectomy: Which Patients Warrant Diversion? J Gastrointest Surg. 2020;24(1):132-143. https://doi.org/10.1007/s11605-019-04293-y
Kantor O, Talamonti MS, Pitt HA, et al. Using the NSQIP Pancreatic Demonstration Project to Derive a Modified Fistula Risk Score for Preoperative Risk Stratification in Patients Undergoing Pancreaticoduodenectomy. J Am Coll Surg. 2017;224(5):816-825. https://doi.org/10.1016/j.jamcollsurg.2017.01.054
Sammour T, Cohen L, Karunatillake AI, et al. Validation of an online risk calculator for the prediction of anastomotic leak after colon cancer surgery and preliminary exploration of artificial intelligence-based analytics. Tech Coloproctol. 2017;21(11):869–877. https://doi.org/10.1007/S10151-017-1701-1
Bertsimas D, Dunn J, Velmahos GC, Kaafarani HMA. Surgical Risk Is Not Linear: Derivation and Validation of a Novel, User-friendly, and Machine-learning-based Predictive OpTimal Trees in Emergency Surgery Risk (POTTER) Calculator. Ann Surg. 2018;268(4):574-583. https://doi.org/10.1097/SLA.0000000000002956
Varadarajan KM, Muratoglu OK, Malchau H, et al. Assessing the utility of deep neural networks in predicting postoperative surgical complications: a retrospective study. Artic Lancet Digit Heal. 2021;3:471-485. https://doi.org/10.1016/S2589-7500(21)00084-4
Bassi C, Marchegiani G, Dervenis Christos, et al. The 2016 update of the International Study Group (ISGPS) definition and grading of postoperative pancreatic fistula: 11 Years After. Surgery. 2017;161(3):584–591. https://doi.org/10.1016/J.SURG.2016.11.014
Merath K, Hyer JM, Mehta R, et al. Use of Machine Learning for Prediction of Patient Risk of Postoperative Complications After Liver, Pancreatic, and Colorectal Surgery. J Gastrointest Surg 2019 248. 2019;24(8):1843–1851. https://doi.org/10.1007/S11605-019-04338-2
LeCun Y, Bengio Y, Hinton G. Deep learning. Nat 2015 5217553. 2015;521(7553):436–444. https://doi.org/10.1038/nature14539
Géron A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems. O’Reilly Media; 2019.
McKinney W. Data Structures for Statistical Computing in Python. Proc 9th Python Sci Conf. Published online 2010:56–61. https://doi.org/10.25080/MAJORA-92BF1922-00A
pandas development team T. pandas-dev/pandas: Pandas. Published online February 2020. https://doi.org/10.5281/zenodo.3509134
Pedregosa F, Varoquaux G, Gramfort A, et al. Scikit-learn: Machine Learning in Python. J Mach Learn Res. 2011;12:2825-2830.
Chollet F, others. Keras. Published online 2015. https://github.com/fchollet/keras
Nudel J, Bishara AM, de Geus SWL, et al. Development and validation of machine learning models to predict gastrointestinal leak and venous thromboembolism after weight loss surgery: an analysis of the MBSAQIP database. Surg Endosc. Published online 2020.https://doi.org/10.1007/s00464-020-07378-x
DeLong ER, DeLong DM, Clarke-Pearson DL. Comparing the Areas under Two or More Correlated Receiver Operating Characteristic Curves: A Nonparametric Approach. Biometrics. 1988;44(3):837. https://doi.org/10.2307/2531595
Lundberg SM, Allen PG, Lee S-I. A Unified Approach to Interpreting Model Predictions. Accessed October 21, 2021. https://github.com/slundberg/shap
Sammour T, Lewis M, Thomas ML, Lawrence MJ, Hunter A, Moore JW. A simple web-based risk calculator (www.anastomoticleak.com) is superior to the surgeon’s estimate of anastomotic leak after colon cancer resection. Tech Coloproctol. 2017;21(1):35–41. https://doi.org/10.1007/S10151-016-1567-7
Rencuzogullari A, Benlice C, Valente M, Abbas MA, Remzi FH, Gorgun E. Predictors of anastomotic leak in elderly patients after colectomy: nomogram-based assessment from the American College of Surgeons National Surgical Quality Program Procedure-Targeted Cohort. Dis Colon Rectum. 2017;60(5):527-536. https://doi.org/10.1097/DCR.0000000000000789
Rojas-Machado SA, Romero-Simó M, Arroyo A, Rojas-Machado A, López J, Calpena R. Prediction of anastomotic leak in colorectal cancer surgery based on a new prognostic index PROCOLE (prognostic colorectal leakage) developed from the meta-analysis of observational studies of risk factors. Int J Color Dis 2015 312. 2015;31(2):197–210. https://doi.org/10.1007/S00384-015-2422-4
Mohkam K, Fuks D, Vibert E, Nomi T, Cauchy F, Kawaguchi Y, Boleslawski E, Regimbeau J, Gayet B, Mabrut J. External Validation and Optimization of the French Association of Hepatopancreatobiliary Surgery and Transplantation’s Score to Predict Severe Postoperative Biliary Leakage after Open or Laparoscopic Liver Resection. J Am Coll Surg. 2018;226(6):1137–1146. https://doi.org/10.1016/J.JAMCOLLSURG.2018.03.024
Yokoo H, Miyata H, Konno H, et al. Models predicting the risks of six life-threatening morbidities and bile leakage in 14,970 hepatectomy patients registered in the National Clinical Database of Japan. Medicine (Baltimore). 2016;95(49):e5466. https://doi.org/10.1097/{MD}.0000000000005466
Shinde RS, Acharya R, Chaudhari VA, et al. External validation and comparison of the original, alternative and updated-alternative fistula risk scores for the prediction of postoperative pancreatic fistula after pancreatoduodenectomy. Pancreatology. 2020;20(4):751-756. https://doi.org/10.1016/j.pan.2020.04.006
Lao M, Zhang X, Guo C, et al. External validation of alternative fistula risk score (a-{FRS}) for predicting pancreatic fistula after pancreatoduodenectomy. {HPB} Off J Int Hepato Pancreato Biliary Assoc. 2020;22(1):58-66. https://doi.org/10.1016/j.hpb.2019.05.007
Huang X-T, Huang C-S, Liu C, et al. Development and validation of a new nomogram for predicting clinically relevant postoperative pancreatic fistula after pancreatoduodenectomy. World J Surg. 2021;45(1):261-269. https://doi.org/10.1007/s00268-020-05773-y
Mungroop TH, van Rijssen LB, van Klaveren D, et al. Alternative Fistula Risk Score for Pancreatoduodenectomy (a-{FRS}): Design and International External Validation. Ann Surg. 2019;269(5):937-943. https://doi.org/10.1097/{SLA}.0000000000002620
Tabchouri N, Bouquot M, Hermand H, et al. A novel pancreatic fistula risk score including preoperative radiation therapy in pancreatic cancer patients. J Gastrointest Surg. 2021;25(4):991-1000. https://doi.org/10.1007/s11605-020-04600-y
Han IW, Cho K, Ryu Y, et al. Risk prediction platform for pancreatic fistula after pancreatoduodenectomy using artificial intelligence. World J Gastroenterol. 2020;26(30):4453-4464. https://doi.org/10.3748/wjg.v26.i30.4453
Birkmeyer JD, Finks JF, O’Reilly A, et al. Surgical skill and complication rates after bariatric surgery. N Engl J Med. 2013;369(15):1434-1442. https://doi.org/10.1056/NEJMsa1300625
Scally CP, Varban OA, Carlin AM, Birkmeyer JD, Dimick JB. Video Ratings of Surgical Skill and Late Outcomes of Bariatric Surgery. JAMA Surg. 2016;151(6). https://doi.org/10.1001/JAMASURG.2016.0428
Chen AB, Liang S, Nguyen J, Liu Yan, Hung AJ. Machine learning analyses of automated performance metrics during granular sub-stitch phases predict surgeon experience. Surgery. 2021;169(5):1245-1249. https://doi.org/10.1016/J.SURG.2020.09.020
Funding
This work was supported by funding from the National Institutes of Health (Program in Translational Medicine T32-CA244125 to UNC/KAC).
Author information
Authors and Affiliations
Contributions
KAC: study design, model development, manuscript drafting, manuscript editing. MEB: model development, manuscript editing. CSD: study design, manuscript editing. JGG: study design, manuscript editing. JS: study design, manuscript editing. SMG: model development, study design, manuscript editing. MRK: study design, manuscript drafting, manuscript editing.
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Chen, K.A., Berginski, M.E., Desai, C.S. et al. Differential Performance of Machine Learning Models in Prediction of Procedure-Specific Outcomes. J Gastrointest Surg 26, 1732–1742 (2022). https://doi.org/10.1007/s11605-022-05332-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11605-022-05332-x