
Abstract
Air quality forecasting system has acquired high importance in atmospheric pollution due to its negative impacts on the environment and human health. The artificial neural network is one of the most common soft computing methods that can be pragmatic for carving such complex problem. In this paper, we used a multilayer perceptron neural network to forecast the daily averaged concentration of the respirable suspended particulates with aerodynamic diameter of not more than 10 μm (PM10) in Algiers, Algeria. The data for training and testing the network are based on the data sampled from 2002 to 2006 collected by SAMASAFIA network center at El Hamma station. The meteorological data, air temperature, relative humidity, and wind speed, are used as inputs network parameters in the formation of model. The training patterns used correspond to 41 days data. The performance of the developed models was evaluated on the basis index of agreement and other statistical parameters. It was seen that the overall performance of model with 15 neurons is better than the ones with 5 and 10 neurons. The results of multilayer network with as few as one hidden layer and 15 neurons were quite reasonable than the ones with 5 and 10 neurons. Finally, an error around 9 % has been reached.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Algeria is a wonderful country with a diverse, complex geography. However, like every country in the world, it has its own set of environmental issues. This becomes especially apparent in highly industrialized and fast-growing urban areas like Algiers, Oran, and Annaba. Over the past years, the health impact of the particulate matter in the urban area of Algiers has become a very topical subject. Atmospheric pollution created by population growth, traffic density, rapid urbanization, and industrialization has taken alarming dimensions (Kerbachi et al. 2006a), which the authority has to face in the coming years. The main pollutants monitored in the Algiers’s air can be chemical such as ozone (O3), nitrogen oxide (NOx), carbon monoxide (CO), carbon dioxide (CO2), and sulfur dioxide (SO2), or solid such as PM10 (particulate matter with an aerodynamic diameter less than 10 μm). Previous studies have demonstrated that the particulate matter concentration levels frequently exceed the air quality standards in the metropolitan region of Algiers (Yassaa et al. 2001; Kerbachi et al. 2006b). Significant relation was found between health effects and elevated concentrations of particulate air pollution (Pope et al. 2002; Bell et al. 2004).
In recent years, there has been a trend to use more statistical methods instead of traditional semiempirical modeling to predict the atmospheric pollution (Ziomas et al. 1995; Shi and Harrison 1997; Kolehmainen et al. 2000). Nowadays, the application of artificial neural network (ANN) to climatology provides better results than linear approaches (Gardner and Dorling 1999; Grivas and Chaloulakou 2006). The main advantages of an ANN forecasting tool are their ability to ensure regressive estimations of nonlinear functions in high dimensional spaces, something that is absent in traditional statistics (Gardner and Dorling 1999). Methods have been applied in different areas of environmental sciences such as water treatment modeling (Baxter et al. 2002), nonlinear groundwater management remediation (Rogers and Dowla 1994), prediction of ozone concentrations (Ibarra-Berastegi et al. 2008), and vehicular exhaust emission (Alver et al. 2011). Recently, the use of ANNs has been extended also to forecast airborne particulate matter concentrations such as PM2.5 (particulate matter with an aerodynamic diameter less than 2.5 μm) and PM10 (Perez and Reyes 2002; Ordieres et al. 2005). It was concluded that an ANN can be a convenient tool to predict PM concentrations, even though the accuracy reached was lower than that for NO2 (Lu et al. 2002; Kukkonen et al. 2003). Chelani et al. (2002) settled an ANN model to forecast the concentration of ambient respirable particle mater and toxic metals observed in the city of Jaipur, India. The results showed that the ANN was capable to forecast PM10 concentrations and toxic metals quite accurately. Tecer (2007) has developed SO2 and PM forecasting model in Zonguldak Province in the Black Sea region of Turkey by using an ANN. He found that ANN can be a good tool to investigate and forecast air quality. Roy et al. (2011) have established multiple regression and neural network methods for assessment of blasting dust in different seasons at a large open petroleum mines in India. The results showed that ANN can forecast better concentrations than multiple regression methods. In any analysis, missing or incomplete data can pose a serious problem for the quality of the network. Thus, it can overestimate or underestimate the parameters used in the predicted model. Ul-Saufie et al. (2011) have presented a comparison between multiple linear regressions and feed forward back propagation neural network models for forecasting PM10 concentration level based on gaseous and meteorological parameters in the city of Pulau Pinang, Malaysia. Authors used models with missing values for nearly 1 month, evaluated via performance indicators using prediction accuracy (PA), coefficient of determination (R 2), normalized absolute error (NAE), and root mean square error (RMSE). Results indicated that ANN can forecast particulate matter better than multiple regressions, even though there was a gap of 1 month in the testing data.
The aim of this study is to develop a neural network method to forecast the daily average PM10 concentrations in Algiers, Algeria.
Measurements and methods
Study area and data
Algiers is Algeria’s capital city, with an area about 120 km2, and total population of 3 million inhabitants, is one of the major coastal cities around the Mediterranean Sea (Naimi-Ait-Aoudia and Berezowska-Azzag 2014). Algiers’s latitude and longitude are 2° 58′ N and 3° 12′ E, respectively. Numbers of their neighboring clusters of islets have already been turned into a part of the port area. The city has a Mediterranean climate characterized by high variability interannual precipitation: hot and dry in the summer and mild and wet in the winter. The relative humidity varies from 72 % in August to 80 % in January. On average, Algiers receives approximately 683 mm of rain per year. The average annual temperature on the coast is around 19 °C. The topography in Algiers is characterized by the heterogeneity of large natural units. The central part corresponds to a plateau (altitude between 100 and 200 m) crossed by a Thalweg network. Although the eastern part is flat and rich on water situated at altitude between 0 and 100 m, most of the west and south regions are represented by more or less horizontal planes with altitudes ranging between 200 and 300 m. This special topography favors air stagnation and allows the pollutants to accumulate (Khedairia and Khadir 2012). Understanding the interaction between air pollution, topology and climatology can be a valuable tool for urban organizers to decrease the negative effects of pollution (Laiti et al. 2013).
In Algiers, the pollution levels are measured by SAMASAFIA (Arabic term literally means: Clear Sky) monitoring networks, consisted of four stations: Ben Aknoun, EL Hamma, 1er Mai, and Bab El Oued distributed through the city. National Air Pollution Monitoring Network continuously includes the concentrations of SO2, NO2, NOx, NO, CO, O3, and PM10. PM10 mass concentrations (μg/m3) were recorded using automatic beta attenuation monitors.
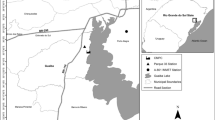
In this research, the available measurements are for more than 5 years and were provided by SAMASAFIA network at El Hamma site on a continuous basis of 24 h (see Fig. 1). Due to the large lack in statistics, mainly caused by power cuts and various failures in different analyses of the measurement stations in Algiers, we focused our study on a period without missing data form 2002 to 2003. Dataset used to predictive PM10 concentration is based also on three meteorological parameters: temperature (Temp), relative humidity (RH), and wind velocity/speed (WS).

Geographic map shows the locations of SAMASAFIA air quality monitoring network at El Hamma in Algiers, Algeria (Google Earth Satellite Imagery)
Implementation of the model
Generally, the multilayer perceptron (MLP) consists of a set of interconnected layers of artificial neurons “nodes,” which are arranged to form three layers: an input, hidden, and an output layers. Each layer of MLP includes one or more neurons directionally linked with the neurons from the previous and the next layer. The input layer has as many nodes as the number of input variables. The role of the hidden nodes is to develop the data and encode the knowledge within the system. Layers between the inputs and the outputs are known as hidden layers (Fontes et al. 2014). Once the net sum at a hidden neuron is determined, an output response is delivered at the neuron using a transfer function (Kim and Gilley 2008). The architecture of multilayer perceptron used in this study is shown in Fig 2.

A three-layer MLP (multilayer perceptions) network architecture
To set up a network of neurons, one must determine the following variables: the number of input neurons, hidden layers, neurons, and the learning samples. One important feature of MLP is its capability to model any smooth functional relationship between one or more predictors and the irrelevant weights. Error-correction learning algorithm is used to train the MLP network, which means that the desired response for the system must be known. In this algorithm, the initial weights of connections are arbitrarily selected. Let’s assume we have N learning specimens with each sample having n inputs and t outputs patterns, the input and the output vector will be then defined as
The input vector X j is incident on the input layer, and an output vector O j = (O 1j ,…, O nj ) is then produced on the basis of the current weights W = (W 1t , …,W nt). By comparing the desired output B j (PM10 measured concentration) and the actual output A j , an error function known as the mean square error (MSE) can be defined by the following expression:
It should be noted that the method essentially consists in minimizing the MSE of the model penalized by number of parameters. However, there are no systematic suggestions to determine this number. The selection of this parameter must be included in the model building process. Using the theory of gradient descent learning: Eq. (2) is back propagated by performing weights based on negative of partial derivative of error function as shown in the equation below:
where 0 < μ < 1 is a parameter controlling the convergence rate (learning rate) of the algorithm, which called the step size. μ is a parameter that defines the size of the weights change during the training process. Small values for the convergence rate cause small weight variations, and large values cause large variations (Attoh-Okine 1999). The difference between the desired and the obtained outputs can be minimized for a large number of samples.
The transfer activation function for the output layer is usually a linear function. In this study, a sigmoid function was selected. Sigmoid transfer function yields to an output that changes incessantly with active level. In order to avoid overestimation of variables with significant quantities, all training and testing data must be normalized. The correlation between calculated (predicted) and observed (experimental) is examined by using linear regression:
where P is the PM10 concentration in μg/m3, and α and β represent the slope of the regression line and the original value of the PM10 concentration, respectively.
For the evaluation of the performance of the developed model, two statistical parameters were selected (Willmott 1982), called the root mean square error (RMSE), and the coefficient of determination (R 2). Predicted and respective observed values of the independent test sets were used for this assessment and are then defined as follows:
where P mean is the mean of observed data. The perfect agreement or the best fit between calculated and observed values should indicate a computed value close to 0 and 1 for RMSE and R 2, respectively.
The subdivision of data sets after pre-processing phase is mandatory for choosing ideal construction and estimating performance of neural networks. Generally, data are segmented into training and testing sets. The largest data are usually used in training set during developing models. However, the testing part must be smaller and used to estimate the performance of ANN model. It should be noted that the ideal proportions use about 80 % and 20 %, for learning and validation, respectively (Zhang et al. 1998).
In this study, the dataset are divided into two main parts: 95 and 5 % for training and validation sets, respectively. This means that each array of rules generated from training is tested on validation data set. For learning data, our analysis will be focused on period from April 26, 2002, to July 29, 2002, while testing data will be concentrated on period between April 26, 2003, and June 5, 2003, with the same climatic parameters. The validity of this model is evaluated based on testing set by using MATLAB 7 neural network toolbox. The software is a powerful computational language for designing and simulating neural networks. This is because of its ability to deal with matrix/arrays and vector variables (Hagan et al. 1996). MATLAB offers various facilities such as simulation, algorithm developments, graphical presentation, normalization, and demoralization approaches (Roy 2012).
Results and discussion
Figure 3 shows the time history of the daily averaged PM10 concentrations at El Hamma station from 2002 to 2006. The regulatory PM10 enforcements are made with 24-h averages, which have a mean concentration of 50 μg/m3. The measurements exhibit a distinct pattern influenced by important car traffic lies in close vicinity. Obviously, the data above the limit value constitute a large part of the overall information. 48 % of the total data exceed the prescribed limit threshold in El Hamma area. The annual average was one of the highest concentrations recorded at the station and may be the most relevant at the national level. This indicates a vital necessity for regular control of air pollutants from anthropogenic sources, especially the particulate pollutants to protect the human population and living system, as well as social assets such as cultural locations in the city.

PM10 daily mean value registered at El Hamma site (2002–2006)
Tables 1 and 2 present the summary of the basic statistics of the PM10 and meteorological parameters sampled and used in the analysis for the years 2002 and 2003.
According to Tables 1 and 2, it seems that the level of PM10 can reach more than four to seven times the limit value of the local air quality standards regulations (≤50 μg/m3). This is considered as highly pollutants environment. In fact, increasing the wind speed will stimulate the dilution, diffusion of particulate matter, and later on decreasing its concentrations in the air (Akpinar et al. 2008). Besides, the relative humidity is usually affected by the amount of rain, which can over wash the atmospheric aerosols, and decreases the concentration of pollutant in the atmosphere (Azmi et al. 2010). On the other hand, there is a correlation between the temperature and PM10 concentrations (Wang et al. 2013). Increase in temperature would cause chemical reactions resulting from the formation of finite particulate matter in the atmosphere, which are obviously part of the PM10 concentration.
In this research work, the model was trained with small data sets due to the incomplete data base available without lack. The neuron number of hidden layer is a vital factor, while the associated number of hidden layer is not so effective. Many epochs are commonly required before the error becomes suitably small. An entire pass through all vectors of the input training set is called an epoch. When such an epoch of the training data has occurred without error, training is then completed.
After repeated experiments, the best prediction on validation data set was attained at 23 epochs with the learning rate of 0.05 for one hidden layer and 15 neurons. Similarly for models with 5 and 10 neurons, the best prediction on validation data was achieved at 11 epochs with the learning rate of 0.05 and 10 epochs with the learning rate of 0.05, respectively. Figure 4 illustrates the performance of the neural network simulations with different number of neurons in the hidden layer.

Evolution of RMSE based on the number of iterations for a network of 5 neurons (a), 10 neurons (b), and 15 neurons (c)
Table 3 gives the summary of the parameters for different numbers of neurons in one hidden layer and the performance statistics on validation data set. Figure 5 indicates the comparison between the observed and the predicted PM10 concentrations for 5, 10, and 15 neurons, respectively.

PM10 concentrations observed and predicted with one hidden layer of 5 neurons (a), 10 neurons (b), and 15 neurons (c)
The PM10 concentration predicted by optimized ANN model for 15 neurons was highly correlated with the measured levels, with R of 0.92 and the index of agreement (IA) of 0.96. Even though the predicted levels for 5 and 10 neurons were less accurate compared to 15 neurons optimization, coefficients show generally a rather good correlation to the measured levels, with R of 0.85/0.78 and IA of 0.91/0.87 for 5 and 10 neurons, respectively. Thus, it can be concluded that the overall performance of model with 15 neurons is better than the ones with 5 and 10 neurons. The developed neural network forecasts satisfactory the PM10 peaks for all cases, which are supported by the mentioned statistical predictors, both for the training and the validation data.
The results obtained in this study are not much different to those found from other methodologies in the literature. In reference (Lal and Tripathy 2012), authors obtained a performance rate of 0.03 for RMSE, while the best prediction obtained in this study was between 0.024 and 0.042. This means that the method is mimicking the variation in the test data set with a reasonable accuracy. Furthermore, the determination coefficient of PM10 concentration in Helsinki (Kukkonen et al. 2003) was approximately from 0.42 to 0.77 in terms of prediction, respectively. Grivas and Chaloulakou (2006) developed NNs for the predictions of hourly levels of PM10 in Athens, Greece, the R values were estimated between 0.70 and 0.82, and the IA values between 0.80 and 0.89, depending on the specific site. Papanastasiou et al. (2007)) developed an NN model for the prediction of daily average PM10 concentrations in the medium-sized city of Volos, Greece, and achieved an R value equal to 0.78, and IA value equal to 0.78. Those are similar to the values of R (0.78, 0.85, and 0.92) and IA (0.91, 0.87, and 0.96) obtained in this work. R 2 value is close to 1, which means that more than 99 % of the prediction obtained is error free. In addition, Kurt et al. (2008) reported an error percentage of 43 % for prediction of SO2 in Istanbul, whereas errors between 9 and 58 % were achieved in this approach. Therefore, the results obtained by the projected technique are in the range with other pollutant predicting methods that have been used around the biosphere.
In the process to predict PM10 concentration, it is clearly proven that the number of neurons has influenced the final model performance. MLP network developed and tested for 41 days showed that the model was able to forecast PM10 concentrations at El Hamma site with an acceptable performance. The multilayer network with as few as one hidden layer is indeed able to provide satisfactory results; however, the differences between the observed and the predicted concentration must be carefully considered. Finally, the performance of PM10 predictions by the Neural Network method can be improved if more input parameter could be tested in large verification period.
Conclusion
The outcome of this research is air quality forecasting model using artificial neural network techniques as tools to resolve the problematic task of the prediction of PM10 hourly concentrations. A multilayer perceptron with one hidden layer was applied to forecast the atmospheric pollutants concentration at El Hamma site in Algiers. It was observed that the combination between the multilayer perceptron model and atmospheric parameters showed a good performance on the test data. An error around 9 % has been reached, which can be considered as a limit success. In addition, the neural model prediction does not vary much from the experimental values.
Though the numbers were trained on a reduced number of input variables, the results were rather satisfactory, for the selected measurement. Thus, it can be stated that the reduced size of the training dataset would result at an improvement of the generalization ability. In fact, if the proposed method is well understood, the neural networks can provide significant services for the local community, such as a tool of preventive policies in public health and urban mobility. In addition, the method is expected to yield better results in the future operation with a wide testing data, including car traffic and new climatological variables. Besides, this investigation can be extended using other computing software in comparison with this research.
References
Akpinar S, Oztop HF, Akpinar EK (2008) Evaluation of relationship between meteorological parameters and air pollutant concentrations during winter season in Elazığ, Turkey. Environ Monit Assess 146:211–224
Alver SU, Cuma B, Osman UN (2011) Application of cellular neural network (CNN) to the prediction of missing air pollutant data. Atmos Res 101:314–326
Attoh-Okine NO (1999) Analysis of learning rate and momentum term in backpropagation neural network algorithm trained to predict pavement performance. Adv Eng Softw 30(4):291–302
Azmi SZ, Latif MT, Ismail AS, Juneng L, Jemain AA (2010) Trend and status of air quality at three different monitoring stations in the Klang Valley, Malaysia. Air Qual Atmos Health 3:53–64
Baxter CW, Stanley SJ, Zhang Q, Smith DW (2002) Developing artificial neural network models of water treatment processes: a guide for utilities. J Environ Eng Sci 1:201–211
Bell ML, McDermott A, Zeger SL, Samet JM, Dominici F (2004) Ozone and short-term mortality in 95 US Urban communities, 1987-2000. JAMA 292(19):2372–2378. doi:10.1001/jama.292.19.2372
Chelani AB, Gajghate DG, Hasan MZ (2002) Prediction of ambient PM10 and toxic metals using artificial neural networks. J Air Waste Manag Assoc 52:805–810
Fontes T, Silva LM, Silva MP, Barros N, Carvalho AC (2014) Can artificial neural networks be used to predict the origin of ozone episodes? Sci Total Environ 488–489:197–207
Gardner MW, Dorling SR (1999) Artificial neural networks (the multi-layer perceptron) a review of applications in the atmospheric sciences. Atmos Environ 32:2627–2636
Grivas G, Chaloulakou A (2006) Artificial neural network models for predictions of PM10 hourly concentrations in greater area of Athens. Atmos Environ 40:1216–1229
Hagan, M.T., Demuth, H.B., Beale, M.H., (1996). Neural NETWORK DESIgn. PWS-Kent Publishing Company, Division of Wadsworth, Inc., 20 Park Plaza, Boston, MA 02116, USA. ISBN 0-534-94332-2.
Ibarra-Berastegi G, Elias A, Barona A, Sáenz J, Ezcurra A, Diaz de Argandoña J (2008) From diagnosis to prognosis for forecasting air pollution using neural networks: air pollution monitoring in Bilbao. Environ Model Softw 23:622–637
Kerbachi R, Boughedaoui M, Bounouna L, Keddam M (2006a) Ambiant air pollution by aromatic hydrocarbons in Algiers. Atmos Environ 40:3995–4003
Kerbachi, R., Boughedaoui, M., Bitouche, M., Joumard, R., (2006b). Etude de la pollution de l’air par les particules fines PM10, PM2,5 et PM1 et évaluation des métaux lourds qu’elles véhiculent en milieu urbain, 15em Colloque international “ Transport et pollution de l’air”, proceedings N°107, Vol. 2, Inrets Ed., Arcueil, France, p. 213-218.
Khedairia S, Khadir MT (2012) Impact of clustered meteorological parameters on air pollutants concentrations in the region of Annaba, Algeria. Atmos Res 113:89–104
Kim M, Gilley JE (2008) Artificial neural network estimation of soil erosion and nutrient concentrations in runoff from land application areas. Comput Electron Agric 64:268–275
Kolehmainen M, Martikainen H, Ruuskanen J (2000) Forecasting air quality parameters using hybrid neural network modelling. Environ Monit Assess 65:277–286
Kukkonen J, Partanen L, Karppinen A, Ruuskanen J, Junninen H, Kolehmainen M, Niska H, Dorling S, Chatterton T, Foxall R, Cawley G (2003) Extensive evaluation of neural network models for the prediction of NO2 and PM10 concentrations, compared with a deterministic modelling system and measurements in central Helsinki. Atmos Environ 37:4539–4550
Kurt A, Gulbagci B, Karaca F, Alagha O (2008) An online air pollution forecasting system using neural networks. Environ Int 34:592–598
Laiti L, Zardi D, de Franceschi M, Rampanelli G (2013) Atmospheric boundary layer structures associated with the Ora del Garda wind in the Alps as revealed from airborne and surface measurements. Atmos Res 132–133:473–489
Lal B, Tripathy SS (2012) Prediction of dust concentration in open cast coal mine using artificial neural network. Atmos Pollut Res 3:211–218
Lu WZ, Fan HY, Leung AYT, Wong JCKE (2002) Analysis of pollutant levels in central Hong Kong applying neural network method with particle swarm optimization. Environ Monit Assess 79:217–230
Naimi-Ait-Aoudia M, Berezowska-Azzag E (2014) Algiers carrying capacity with respect to per capita domestic water use. Sustain Cities Soc 13:1–11
Ordieres JB, Vergara EP, Capuz RS, Salazar RE (2005) Neural network prediction model (PM2.5) for fine particulate matter on the US-Mexico border in E1 Paso (Texas) and Ciudad Juarez (Chihuahua). Environ Model Softw 20:547–559
Papanastasiou DK, Melas D, Kioutsoukis I (2007) Development and assessment of neural network and multiple regression models in order to predict PM10 levels in a medium-sized Mediterranean city. Water Air Soil Pollut 182:325–334
Perez P, Reyes J (2002) Prediction of maximum of 24-h average of PM10 concentrations 30 h in advance in Santiago, Chile. Atmos Environ 36:4555–4561
Pope CA, Burnett RT, Thun MJ, Calle EE, Krewski D, Ito K, Thurston GD (2002) Lung cancer, cardiopulmonary mortality, and long-term exposure to fine particulate air pollution. JAMA 287:1132–41
Rogers LL, Dowla FU (1994) Optimization of groundwater remediation using artificial neural networks with parallel solute transport modeling. Water Resour Res 30:457–481
Roy S, Adhikari GR, Renaldy TA, Jha AK (2011) Development of multiple regression and neural network models for assessment of blasting dust at a large surface coal mine. Environ Sci Technol 4:284–301
Roy S (2012) Prediction of particulate matter concentrations using artificial neural network. Resour Environ 2:30–36
Shi JP, Harrison RM (1997) Rapid NO2 formation in diluted petrol-fuelled engine exhaust-A source of NO2 in winter smog episodes. Atmos Environ 31:3857–3866
Tecer LH (2007) Prediction of SO2 and PM concentrations in a coastal mining area (Zonguldak, Turkey) using an artificial neural network. Pol J Environ Stud 16:633–638
Ul-Saufie AZ, Yahya AS, Ramli NA, Hamid HA (2011) Comparison between multiple linear regression and feed forward back propagation neural network models for predicting PM10 concentration level based on gaseous and meteorological parameters. Int J Appl Sci Technol 1:42–49
Wang F, Fang CS, Zhang Y, Ma Z, Wang J (2013) Study on Relationship between PM10 concentration and temperature condition in Longyan City. Appl Mech Mater 295–298:1556–1559
Willmott CJ (1982) Some comments on the evaluation of model performance. Bull Am Meteorol Soc 63:1309–1369
Yassaa N, Meklati BY, Brancaleoni E, Frattoni M, Ciccioli P (2001) Polar and non-polar volatile organic compounds (VOCs) in urban Algiers and saharian sites of Algeria. Atmos Environ 35:787–801
Zhang G, Patuwo BE, Hu MY (1998) Forecasting with artificial neural networks: the state of the art. Int J Forecast 14:35–62
Ziomas IC, Paliatsos AG, Viras LG, Zerefos CS (1995) A note on smoke concentrations in urban Athens, using data measured by two different methods. Meteorol Atmos Phys 55:215–221
Acknowledgments
The authors would like to thank the Algerian National Observatory of Environment and Sustainable Development (ONEDD) for providing access to the meteorological data used in this study.
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible editor: Gerhard Lammel
Rights and permissions
About this article

Cite this article
Abderrahim, H., Chellali, M.R. & Hamou, A. Forecasting PM10 in Algiers: efficacy of multilayer perceptron networks. Environ Sci Pollut Res 23, 1634–1641 (2016). https://doi.org/10.1007/s11356-015-5406-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11356-015-5406-6