
Abstract
Enhancing the network lifetime of wireless sensor networks is an essential task. It involves sensor deployment, cluster formation, routing, and effective utilization of battery units. Clustering and routing are important techniques for adequate enhancement of the network lifetime. Since the existing clustering and routing approaches have high message overhead due to forwarding collected data to sinks or the base station, it creates premature death of sensors and hot-spot issues. The objective of this study is to design a dynamic clustering and optimal routing mechanism for data collection in order to enhance the network lifetime. A new dynamic clustering approach is proposed to prevent premature sensor death and avoid the hot spot problem. In addition, an Ant Colony Optimization (ACO) technique is adopted for effective path selection of mobile sinks. The proposed algorithm is compared with existing routing methodologies, such as LEACH, GA, and PSO. The simulation results show that the proposed cluster head selection algorithm with ACO-based MDC enhances the sensor network lifetime significantly.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
A sensor is a small electronic device that combines microelectronics and computers with advanced digital communication technologies. In general, sensors are low-power and low-energy devices that involve low operating costs. They have attracted considerable attention in recent decades owing to their useful functionalities, such as sensing environmental conditions, processing the sensed information, and providing effective wireless communication between the source and the destination [1, 2]. Wireless Sensor Networks (WSNs) consist of a number of sensors deployed in a particular region to monitor the environment. If any change occurs in the environment, the sensors automatically sense the change, process the data, and send the collected information to the destination. Once deployed, the sensors operate independently by using their own energy. Placement, routing, and energy scheduling of the sensors are the most crucial tasks for enhancing the network lifetime. WSNs have many medical, scientific, and military applications, including environmental monitoring, agricultural monitoring, wildlife tracking, smart home automation, security, transport, and vehicular networking [3,4,5,6,7,8,9].
Sensor deployment can be broadly classified into two types: statistical and random [10,11,12]. In general, the type of deployment depends on the environment to be monitored and the sensor application. The sensed information is passed through neighboring nodes, cluster heads, sinks, and the base station, and it finally reaches the server for further processing. This approach is inefficient when a large region is to be monitored or when the sensors are randomly deployed. The nodes close to sinks often consume more energy than other nodes because of their high data forwarding activities [13, 14]. However, most battery units can neither be recharged nor be replaced after sensor deployment in the environment. As a result, the energy hole problem or the premature death of sensors may occur in WSNs. Hence the acquired data cannot be transmitted to the base station, which ends in data loss. Thus, clustering, data collection, and routing are major issues in WSNs, and it is necessary to improve them to enhance the network lifetime [15,16,17].
The data collection and routing process mainly involves the cluster heads or gateways and sinks [16, 17]. All these components are also operated by batteries; hence, they consume more energy than other sensor nodes. Another important issue in WSNs is the selection of a proper routing protocol. Existing routing mechanisms pass information through multiple hops to the base station. Thus, the general data forwarding approach creates hot spot problems during the network communication [18, 19].
Low-Energy Adaptive Clustering Hierarchy (LEACH) is a well-known routing protocol for WSNs. Several modified or updated versions of this protocol have been developed [20]. Since the data collection and routing process mainly involve the cluster heads or gateways and sinks, they consume more energy than other sensor nodes. Moreover, a fixed sink also consumes more energy with or without any load-balancing mechanism. In addition, it causes high latency during data collection and communication. In many situations, the data flow in a fixed sink and its nearby cluster heads is very high. Thus, hot spot problems occur during routing [18]. Therefore, it is necessary to modify the LEACH protocol.
To overcome the aforementioned issues, a number of clustering and routing algorithms have been proposed to improve the network lifetime; we refer [19, 21,22,23,24] and the references therein. These techniques achieve efficient clustering in the first phase, followed by a routing approach. However, gateway-based routing results in the hot spot problem, and gateway nodes consume more energy than normal nodes during each transmission. Thus, the data-forwarding mechanisms are replaced by introducing Mobile Sinks (MS) or Mobile Data Collectors (MDC). MS are responsible for collecting and forwarding data to the Base Station (BS) [15] and they avoid the hot spot problem and enhances the network lifetime by preventing fast battery drainage.
1.1 Motivations
The existing approaches have apparent limitations, which are discussed here. (i) Most of the existing cluster head (CH) selection methods concentrate only on the residual energy and not on other parameters such as the degree of CH, and the distances between CH and other cluster members. Therefore, other sensor members should be joined to CH by using these parameters. (ii) In general, CHs near the sink need to forward most of the data. As a result, these CHs drain their energy faster than other CHs which are far away from the sink and so it causes the energy hole problem [18]. However, the data forwarding mechanism can be improved to prolong the network lifetime [25]. (iii) Almost all the existing WSN algorithms are based on multi-path routing and data aggregation where CH acts as a relay node. But in the literature, mobile data collector with optimal route traversing for data collection is not explored thoroughly [26]. Consequently, the operation scope of data collection methods for WSNs needs to be expanded.
In recent years, data collection using mobile robots in WSNs attracts much attention. When the mobile device is in the proximity of a cluster head, it transmits the collected data to the mobile device directly. Thus, the data transfer can be direct. In this scenario, the mobile device visits all the cluster heads to collect the buffered data and returns to the base station to upload the information for further processing [27]. The advantages of this approach are as follows; data forwarding to longer distance can be avoided and CH can save the energy. Hence it avoids the energy hole problem. Furthermore, the mobile device increases the security in WSNs by direct data transferring, for example, in military applications.
1.2 Contributions
The approach proposed in this paper involves two steps. First, the cluster head is selected for each sub-region using the proposed algorithm. Next, mobile sinks are implemented for efficient data collection with the shortest routing mechanism for all the cluster heads. Thus, the proposed method can prevent premature sensor death and mitigate the hot spot problem significantly by performing routing through mobile sinks. The main contributions of this paper can be summarized as follows:
-
A new cluster head selection algorithm is proposed for effective routing.
-
The proposed cluster head selection method enhances the sensor network lifetime through a dynamic load-balancing approach.
-
The Ant Colony Optimization (ACO) technique is integrated with mobile sinks to enhance the network lifetime of WSNs.
-
Numerical simulation demonstrates the superiority of the proposed algorithm over existing optimization techniques.
The remainder of this paper is organized as follows. Section 2 reviews the literature. Section 3 explains the system model, including the preliminaries, definitions, and energy model. Section 4 describes the proposed algorithm. Section 5 presents the simulation results. Finally, Sect. 6 concludes the paper.
2 Literature review
In the literature, various types of WSN clustering algorithms have been proposed and implemented. Here, studies related to the proposed approach are briefly discussed. Sara et al. [28] proposed an efficient clustering mechanism by developing a hybrid multi-path routing algorithm. A node having a good communication range, high residual energy, and low mobility is selected as a cluster head. Two different schemes, namely energy-aware selection and maximal nodal surplus energy determination, are used to manage the energy consumption during routing. These techniques include a clustering and routing protocol that can perform well in low-energy network conditions as well as in highly dynamic environments.
Karim and Nasser [29] designed the Location-aware and Fault-tolerant Clustering Protocol for Mobile Wireless Sensor Network (LFCP-MWSN). During cluster formation and node movement between clusters, a range-free mechanism is implemented and the nodes are localized by LFCP-MWSN. Compared to conventional protocols, such as LEACH-Mobile and LEACH-Mobile-Enhanced, LFCP-MWSN consumes 30% less energy. Furthermore, it minimizes the end-to-end transmission delay. In [30], a mobile data collector for heterogeneous networks was discussed and a data collector that gathers data from sensors was employed. The data collection starts from the base station, proceeds throughout the region, and ends at the base station to perform data transfer. In the case of larger networks, the authors suggested the divide-and-conquer method with multiple data collectors. Thus, the computation time of this method is longer than that of methods involving a single data collector.
In [31], the authors proposed a biased adaptive sink mobility scheme that is adjustable to local network conditions, such as the number of past visits in each network region, surrounding density, and remaining energy. To cover the network area faster and to adaptively remain in network regions for a longer time, the sink moves probabilistically by favoring less visited areas that tend to produce more data. The mobility scheme was implemented and evaluated in diverse network settings, and the results showed that the scheme can reduce latency, especially in networks with non-uniform sensor distribution. Moreover, its energy consumption is lower than that of blind random non-adaptive schemes. However, although its success rate is high, random walks with no stop involve high energy consumption.
Arshad et al. [32] proposed an MDC-based LEACH routing protocol that involves a multi-hop routing strategy for deploying self-organized sensor nodes with distributed cluster formation techniques for environmental applications. To balance the energy consumption equally among the sensor nodes and finally forward the data to the base station with the support of MDC, this technique selects the cluster heads randomly. The results showed that this technique reduces the energy consumption of the sensor nodes and enhances the network lifetime. In addition, data collection at the base station is performed more efficiently compared to the LEACH protocol. However, during data transmission, the delay, which can significantly degrade the performance, is longer.
The Intelligent Agent-based Routing (IAR) protocol was proposed to provide efficient data delivery to mobile sinks [33]. The performance of the IAR protocol was mathematically analyzed, and the results showed that this scheme effectively supports sink mobility with low overhead while mitigating the triangular routing problem. However, if a collision occurs, then retransmission will occur four times, and this scheme fails. Consequently, the network overhead increases. In addition, this scheme may cause overuse of resources. Moreover, owing to the link failure between the sink and its immediate relay, packet loss may occur.
Gupta and Prasanta [34] implemented Genetic Algorithm (GA)-based approaches for clustering and routing in WSNs. The proposed clustering algorithm balances the gateway energy usage and marginally reduces the energy consumption of the sensors. This approach produces better results than conventional genetic algorithms because it periodically runs a genetic algorithm for clustering and route generation. Even though it performs all the GA computations, including selection, crossover, and mutation, for clustering and routing, the gateway with the routing mechanism reduces the overall network lifetime of the sensors. Therefore, this method might fall into local optima. In addition, the authors did not consider sensor nodes or gateway failures during the operation time, nor did they consider a dynamic clustering approach.
Srinivasa Rao et al. [35] discussed an energy-efficient cluster head selection algorithm for clustering based on Particle Swarm Optimization (PSO). Using PSO in each iteration, the algorithm selects new cluster heads. The results were compared with those of existing algorithms, such as LEACH and its variants. Because the authors did not consider the routing algorithm, efficient routing or Quality of Service (QoS) cannot be guaranteed. Moreover, the sensor battery drains quickly owing to the computations in each iteration.
In [24], clustering and routing were formulated as optimization problems using linear and non-linear programming. The routing algorithm was developed on the basis of the number of hops and transmission distance in order to enhance the network lifetime. The cluster heads are used as next-hop relay nodes as well as for data forwarding. Thus, the computation is heavy and gateway-based WSNs require more energy in the data forwarding or routing phase.
In order to increase the network lifetime, we propose a clustering algorithm for head selection and sensor joining. In addition, an ACO-based algorithm is adapted to guide MDC to move optimally in the sensor region for efficient data collection. Experimental results demonstrate that the proposed algorithm can extend the network lifetime.
3 System model
We adopt the following common assumptions in [36,37,38] to implement the sensor network:
-
Sensor nodes are homogeneous.
-
Initially, all sensor nodes have the same residual energy.
-
All sensors are homogeneous and have the same operational capabilities, including data collection, processing, and communication.
-
The communication links between sensor nodes are bi-directional and symmetric.
-
The mobile sink node has unlimited energy and it is capable of traveling anywhere in the given region R.
-
There are no obstacles between the sensor nodes.
The sensors are randomly deployed in the region, and the entire region is subdivided into multiple clusters. Based on the energy level of the sensors, the cluster head for the region is selected. In general, the sensor having the highest residual energy is selected as the cluster head. Then, the other members send the data to the cluster head. The cluster head is responsible for sending data to the mobile sink.
3.1 Energy model
In the proposed approach, we consider the mobile sink as a vehicle or a robot with unlimited energy for performing the routing process. The basic energy utilization of the sensor nodes is due to environment sensing and information exchange, which involves transmission and reception of data.
Figure 1 shows the radio energy dissipation model of the transmitter and receiver of a sensor unit. Energy is consumed by the transmitter and receiver units on the basis of the sensor activity. During transmission, energy is consumed by the transmitter unit to run the radio electronics and power amplifier. Similarly, the receiver unit consumes energy to run the radio electronics. The rate of energy consumption by a sensor unit depends on the transmission distance and data size.

Energy model for radio
Based on the model presented in [39], the energy required to transmit an l-bit message with distance d is given by
where \(E_{elec}\) denotes the energy required by the electronics, and \(\epsilon _{fs}\) and \(\epsilon _{mp}\) denote the energy required by the amplifier in free space and multi-path operation, respectively. The energy dissipated by the reception of l bit is denoted by \(E_{rx} (l)\) and given by
The energy dissipation is experimentally calculated using the two above-mentioned formulae.
3.2 Network model
In this paper, the general WSN model is used. It has the following properties and features. Sensor nodes are deployed randomly in the sensing region, and each node has the capability to calculate the distance from its neighbor nodes [15, 40]. Once the random deployment is completed, all the sensor nodes become stationary and are involved in the cluster selection process. In the sensing field, each sensor can operate either as a normal node or as a cluster head depending on its properties, including the distance between sensors, the distance between clusters, and remaining residual energy. Each cluster member senses the environment and sends the data to its corresponding cluster head. The network always maintains the number of cluster heads to be less than the number of sensors in the region. In general, each sensor operates at different sensing and power levels. The communication medium is wireless, and communication can be established between the cluster members and the cluster heads when they are within the communication radius.
4 Proposed algorithm
Cluster head selection is a crucial step in WSNs. Most of the above-mentioned algorithms assign a high-energy node as a cluster head without considering any other parameters, such as distance from a sensor to the cluster head or residual energy. In general, the network lifetime enhancement of WSNs is not a single process; based on it, there are multiple granularities in the sensory environment.
The sensors are deployed randomly in the region R, which is subdivided into multiple regions called the clusters or sub-regions \(r_1, r_2, r_3,\ldots ,r_n\). Cluster heads are selected for each sub-region on the basis of the threshold value calculated using three different parameters. BS provides the cluster head information including the locations to all the members in R. After cluster formation, the cluster members send the sensed data to the cluster head. The cluster head receives and processes the data for further operations. The ACO algorithm is adopted to find the shortest route to reach all the cluster heads for data collection. Then, the traversing path information is provided to MDC. Based on the route calculated by ACO, MDC starts traversing to all the cluster heads to collect the data without forming a loop. The process is repeated, and in every iteration, a new cluster head is selected in each region to prevent premature death due to over-burdening of a particular node. The clustering and ACO-based traversing techniques with MDC for efficient data collection are described in detail herein.
4.1 Terminologies
In the proposed approach, we use the following terminologies to elucidate sensor deployment, clustering, and routing:
-
1.
R: region to monitor.
-
2.
S: set of sensor nodes deployed in R where \(S=\{s_1,s_2,s_3,\ldots ,s_n\}\).
-
3.
C: set of cluster head nodes \(C=\{c_1,c_2,c_3,\ldots ,c_m\}\), \(m \le n\).
-
4.
\(dis(s_i, c_j)\): distance between sensor node \(s_i\) and cluster head \(c_j\).
-
5.
X: weight factor or constraint value for sensor node \(s_i\) to be selected as a cluster head.
-
6.
\(E_{res}\): residual energy of sensor node \(s_i\).
-
7.
\(E_i\): initial energy of sensor node \(s_i\).
-
8.
\(CR_i\): maximum communication range of \(s_i\).
-
9.
\(T_h\): threshold value for \(s_i\) to be selected as a cluster head.
-
10.
\(D_{c_{j}}\): degree of \(c_{j}\), i.e., number of cluster members connected with \(c_j\). Initially, for all the cluster heads, \(D_{c_{j}}\) is 0.
The network lifetime is an important metric for the performance evaluation of WSNs. Various definitions of the lifetime are available in the literature [41], e.g., the time until the first node dies, the time until the last node dies, and the time until the first gateway dies. The network lifetime depends on the application of the sensor network. This study considers the longest network lifetime, i.e., the time until the last node dies, because the mobile sinks or MDCs can traverse the entire region R to collect the data from the cluster heads.
4.2 Clustering
To enhance the network lifetime, an efficient cluster head selection method should deal with various aspects, such as minimum energy usage of the nodes, the distance between the cluster members and the cluster head, and the communication range. Furthermore, the mobile sink should traverse the region R to cover all the cluster heads effectively. Therefore, based on the proposed approach, the best cluster head for the cluster is selected and the best route for MDC is calculated.
We denote the membership of the sensor nodes to the cluster heads by the Boolean value \(x_{ij}\):
for \(1 \le i \le n\), \(1 \le j \le m\). The entire network is partitioned into several clusters. A node from each cluster serves as a cluster head and the remaining nodes act as cluster members. The cluster head for a cluster is selected as follows: First, calculate the total residual energy of the network:
Then, calculate the threshold value \(T_h\) by finding the average residual energy of the sensors:
For a sensor \(s_i\) to be selected as a cluster head, the residual energy of \(s_i\) should be higher than the threshold value, and it should be the highest compared to that of the other sensors. In addition, the total distance between \(s_i\) and other sensors in that sub-region should be minimum. The distance between sensors \(s_i\)\((x_1,y_1)\) and \(s_j\)\((x_2,y_2)\) within the sub-region \(r_k\) is given by
where \((x_1,y_1)\) are the coordinates of the sensor \(s_i\) and \((x_2,y_2)\) are the coordinates of the sensor \(s_j\). The cluster head \(c_j\) is selected by the above-mentioned constraints, and its information is broadcasted to the entire cluster members.
The broadcast message is received by \(s_i\) only if the distance between \(s_i\) and \(c_j\) is less than the communication range \(CR_i\). If \(s_i\) is to join \(c_j\), then it should satisfy the following constraints: (i) the residual energy of \(c_j\) should be maximum, (ii) the minimum distance between \(s_i\) and \(c_j\), i.e., \(dis(s_i,c_j\)), should be less, and (iii) the degree of \(c_j\), i.e., \(D_{c_{j}}\), should be minimum. Based on the above constraints, the weight factor \(X_{ic_{j}}\) for \(s_i\) to join \(c_j\) is calculated as follows:
-
Residual energy of \(c_j\): Sensor \(s_i\) compares the residual energies of all the cluster heads within its communication range, and it is likely to join the cluster head with the highest residual energy. The constraint equation for the residual energy of \(c_j\) is given by
$$\begin{aligned} X_{ic_{j}} \propto E_{res(c_j)}, \end{aligned}$$(7)where \(X_{ic_{j}}\) is the constraint value and \(E_{res(c_j)}\) is the residual energy of \(c_j\).
-
Distance between \(s_i\) and \(c_j\): The distance between \(s_i\) and \(c_j\) should be minimum, and the communication range \(CR_i\) of \(s_i\) should allow communication with \(c_j\). The energy consumed for transferring data between \(s_i\) and \(c_j\) increases with the distance between \(s_i\) and \(c_j\). The constraint equation for the distance between \(s_i\) and \(c_j\) is given by
$$\begin{aligned} \begin{aligned} X_{ic_{j}}&\propto \frac{1}{dis(s_i,c_j)}, \\ \end{aligned} \end{aligned}$$(8)i.e., the weight factor increases as the distance between the sensor and the cluster head decreases. Hence, if the distance is less, then it is more likely that \(s_i\) will join \(c_j\)
-
Degree of the cluster head \(D_{c_{j}}\): The degree of the cluster head should be minimum compared to the neighboring cluster heads. Note that \(s_i\) is more likely to join \(c_j\) if the degree of \(c_j\) is low, and the weight factor is given by
$$\begin{aligned} \begin{aligned} X_{ic_{j}}&\propto \frac{1}{D_{c_{j}}}. \end{aligned} \end{aligned}$$(9)By combining all the above-mentioned constraints, we can obtain the value of \(X_{ic_{j}}\) in the form
$$\begin{aligned} \begin{aligned} X_{ic_{j}} = W \cdot \frac{E_{res(c_j)}}{ dis(s_i, c_j) \cdot D_{c_{j}} },\\ \end{aligned} \end{aligned}$$(10)where W is a constant that is set to 1 in order to maintain the performance of the algorithm. If \(s_i\) has the maximum \(X_{ic_{j}}\) with \(c_j\) in Eq. (10), then \(s_i\) will join with the corresponding \(c_j\).
The cluster head sends the TDMA broadcast message with the scheduling information to its sensor nodes. Then, the sensed data is sent to \(c_j\) from \(s_i\). The base station collects all the cluster head position information and executes the ACO algorithm to find the shortest traversing path. MDC traverses the path fed by the base station and collects the data from all the cluster heads. In general, if the distance between the nodes, gateway, and base station increases, then the network lifetime decreases proportionately. In this study, the concept of mobile sink is adopted and the gateways are removed from the model. The gateway removal enhances the network lifetime because most of the energy is dissipated during the routing phase, especially while forwarding the data from one gateway to another. Hence, cluster head selection and data collection with the mobile sink achieves a fast and efficient data collection. Furthermore, to increase the efficiency, the clustering parameters are considered to have joined the sensors in their cluster heads.

4.3 Illustration example
In this sub-section, we consider a small WSN to illustrate how the proposed cluster head selection and sensor joining work. We consider a WSN with 25 sensors, randomly deployed in a region, as given in Fig. 2. We set \(E_{res}\) and \(E_{init}\) by the same value \(0.5\,\hbox {J}\). Initially, the region is split into 4 sub-regions and the cluster head is randomly selected in each sub-region, for instance, \(CH={3, 9, 15, 21}\) and we set \(D_{c_{j}} = 1\) for those CHs.
For clustering, all other sensors \(s_i\) calculate the weight value \(X_{ic_{j}}\) for each cluster head \(c_{j}\) and join CH of the largest \(X_{ic_{j}}\). For example, the sensor 5 is 3m and 7m away from CH3 and CH9, respectively, and all other CHs are farther than those. In this case, \(X_{5c_{3}} = 0.166\) and \(X_{5c_{9}}=0.07\). Hence the sensor 5 joins CH3 and we set \(D_{c_{3}} = 2\). Similarly, the sensor 8 is 2m and 5m away from CH9 and CH3, respectively, and thus, \(X_{8c_{9}} = 0.25\) and \(X_{8c_{3}} = 0.1\). So, the sensor 8 joins CH9 and \(D_{c_{9}}\) is updated as 2. The process is repeated until all the sensors join proper CHs. After clustering, a directed graph is formed, where the sensor members are connected to their cluster head. The graph is also given in Fig. 2. The members send their sensed information to their corresponding CH in a single hop and CHs do to the mobile collector in a single hop.

Illustration example round 1
At each round, new cluster heads are selected to balance the energy. Contrary to the first round, CHs are selected by the threshold value \(T_h\), which is the average residual energy. The sensors of which residual energy is less than \(T_h\) are not selected for CH. For example, after the first round, if \(T_h\) is 0.49 J and the residual energy of the sensor 3 is 0.489 J, then CH3 is needed to be replaced by a sensor among 4, 5, 6, 1 and 7. We assume that the residual energy of the sensor 1 is more than 0.49 J and so, it is selected as CH. Similarly, we let CH9, CH15 and CH21 be replaced by the sensors 12, 13, and 23, respectively.
A new round of clustering is illustrated in Fig. 3. The same process is repeated until all other sensors are assigned to proper CHs. For example, if the sensor 2 is 2m away from CH1 and \(D_{c_{1}} = 5\), then \(X_{2c_{1}}\) is 0.499. Similarly, if the sensor 2 is 5m away from CH12 and \(D_{c_{12}} = 3\), then \(X_{5c_{12}}\) is 0.33. Hence the sensor 2 joins CH1. The same cluster head selection and sensor joining processes are repeated at each round.

Illustration example round 2
4.4 ACO-based traveling with MDC
To maximize the network lifetime and to avoid the hot spot problem in WSNs, MDC or MS is deployed, i.e., a moving object is introduced to collect data from the cluster head effectively. The location of the cluster head is well known to the base station, and it has unlimited energy with computation capabilities. Once the cluster heads are determined by the proposed algorithm, MDC finds the shortest routing path to collect the data from the cluster heads. Therefore, the cluster members consume less energy for data transmission as well as data reception because routing via gateways and fixed sinks consumes more energy, which is a concerning real-time issue. To maintain the energy consumption balance between the sensors, cluster head selection is performed in each iteration. Furthermore, MDC is a device with unlimited energy capacity, and it can travel anywhere in region R. In each iteration, BS supplies the cluster head information to MDC with the execution of the ACO algorithm. Thus, the load balance of the cluster is maintained and the hot spot problem is avoided owing to dynamic selection of the cluster heads.

In this approach, MDC traverses the entire region in the network and reaches the initial point again after transmitting the data to BS. Hence, the routing approach is typically a traveling salesman problem. MDC acts as a salesperson who visits all the cities and returns to his/her hometown. Therefore, in each iteration, cluster head points are passed to the ACO routing section in order to enhance the network lifetime. In the ACO approach, N represents the cities to be visited (destination or food source) and M denotes MDC (salesperson or ant) that covers all the cluster heads. The probability of MDC choosing the next destination is directly proportional to the cost metric, which is denoted as the intensity of the pheromone value; furthermore, it is inversely proportional to the present cluster head and next cluster head. Here, the ants are artificial ants that are capable of storing the visited cities in memory to avoid revisiting the same city. However, the cost details of neighboring cities are well known to the artificial ants, and among these cities, the city to be visited is based on its cost details. Therefore, the probability of visiting the next cluster head from the current cluster head, i.e., the cluster head i to the cluster head j, using the \(k^{th}\) ant is given by
where \(P_{ij}\) denotes the probability of the food source being found by an ant, \(\tau _{ij}\) is the pheromone initialization matrix value, i.e., intensity of the route pheromone between the cluster head i and cluster head j, \(allowed_k\) denotes the set of destinations to be visited, \(\eta _{ij}\) is the distance between the cluster head i and cluster head j, which can be calculated as \(\eta _{ij} = 1/d_{ij}\), i.e., \((d_{ij})\) the Euclidean distance, \(\alpha \) and \(\beta \) are the constant parameters to regulate the influence of the pheromone that supports decision making by the ant. In each visit, MDC decides the next cluster head to be visited according to the probability \(P^{k}_{ij}\) given by Eq. (11), and in each iteration, the ants ignore cities at longer distances while leaving a larger pheromone value along shorter distances. Thus, in each iteration, the pheromone value \(\tau _{ij}\) can be updated, and it can be expressed as
where \(\rho \) is the pheromone evaporation rate, and on successful completion of the ants journey, the pheromone field is updated. Furthermore, t is the iteration counter, \(\rho \in [0, 1]\) is the parameter that regulates the reduction of \(\tau _{ij}\), and \(\delta \tau _{ij}\) denotes the sum of the pheromones deposited by all the ants, expressed as
The trail levels are updated on a journey, and the pheromone quantity left by each ant k is given by
where \(Q/d_{ij}\) denotes the pheromone quantity of each ant, Q is a constant, and \(d_{ij}\) is the length of the journey. Once the iteration conditions are satisfied, the process will be terminated and an optimal solution will be obtained.
5 Experimental results
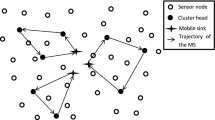
In this section, the performance of the proposed approach is compared with that of LEACH, GA, and PSO on the different number of sensor nodes. The simulation test was conducted in a MATLAB environment. The simulation parameters are displayed in Table 1. Figure 4 shows the basic sensor nodes deployment and sink position. Each experiment was performed more than 10 times, and the average result was obtained on the basis of the simulation environment with the following scenarios:

Placement of nodes
5.1 Scenario #1
Figures 5 and 6 compare the network lifetimes of existing algorithms and the proposed algorithm when the first node dies and the last node dies, respectively. In Scenario 1, the conventional TSP approach is implemented with the proposed algorithm for MDC traversal. Initially, the algorithm is evaluated in terms of the network lifetime with the dead conditions for the first and last nodes. For this evaluation, the number of sensor nodes is varied from 100 to 500.

First node dead

Last node dead
From Figs. 5 and 6, it can be inferred that the proposed approach achieves a longer network lifetime than the other heuristic and meta-heuristic algorithms. Furthermore, the proposed algorithm ensures an efficient selection and gateway avoidance. In each iteration, the proposed algorithm selects the cluster head on the basis of the threshold value of the node. Thus, through this approach, dynamic clustering with load balancing is achieved and premature sensor death is prevented.
Figure 7 shows the dead nodes obtained as a result of implementing the proposed algorithm. In each iteration, the number of dead members in the clusters of the proposed method is smaller than that of the existing approaches. Furthermore, from Fig. 7, it can be inferred that the sensor network lifetime is maximum when the number of dead nodes is minimum.

Number of dead nodes
Table 2 shows the energy consumption Scenario 1 when the first node dies. Here, the energy consumptions of existing algorithms are compared with the energy consumption of the proposed algorithm. The number of sensors is varied from 100 to 500. Table 2 indicates that the proposed algorithm consumes lower energy than the existing approaches.
5.2 Scenario #2
Here, WSN with ACO-based MDC is introduced to collect the information from the cluster heads. It differs from the previous scenario in terms of routing and produces better results. Furthermore, it is important to note that the network lifetime is significantly longer in the case of the ACO-based MDC implementation. The reason is that the ACO-based MDC traversal method is more efficient than the conventional traversals. In addition, the proposed algorithm achieves cluster head selection and data collection with high efficiency. The obtained initial and last node dead conditions with respect to the network lifetime in each iteration are shown in Figs. 8 and 9, respectively. It is evident that the proposed ACO-based MDC approach enhances the network lifetime under the both conditions. Compared to Scenario 1, Scenario 2 enhances the network lifetime owing to an optimal selection of the route and dynamic selection of the cluster heads.

First node dead

Last node dead
Figure 10 compares the proposed algorithm with the other algorithms in terms of the number of dead nodes in each round. The proposed algorithm shows better results than the other algorithms because of its efficient use of ACO-based MDC during the traversal. Thus, it significantly reduces the number of dead nodes in each round and enhances the network lifetime.

Number of dead nodes
Table 3 clearly shows that the energy consumption values in Scenario 2 are lower than those in Scenario 1. For example, if the number of sensors is 100 in Scenario 1 and Scenario 2, the proposed approach with ACO-based MDC reduces the average energy consumption from 11.98 to 11.07 J. Similar results are observed for the remaining values in Table 3.
6 Conclusion
In this paper, an efficient path selection routing algorithm for mobile sinks was proposed on the basis of ACO. The proposed approach involves two steps: an energy-efficient load-balanced clustering and effective data collection through mobile sinks using ACO. The results show that the proposed clustering algorithm balances the energy by cluster head selection in each round and reduces the energy consumption of the cluster members during data transmission. The cluster head selection algorithm is implemented using an efficient load-balancing technique because of its dynamic cluster head selection behavior in each round. From the results, we infer that periodically running ACO for routing with mobile sinks enhances the overall sensor network lifetime while ensuring a maximum operability. Furthermore, the experimental results show that the performance of the proposed cluster head selection algorithm with the ACO mobile sink routing is better than that of existing algorithms, such as LEACH, GA, and PSO. In the future, MDC should be implemented with other optimization algorithms on the basis of the requirements of an application using the self-healing approach.
References
Zhao, M., Yang, Y., & Wang, C. (2015). Mobile data gathering with load balanced clustering and dual data uploading in wireless sensor networks. IEEE Transactions on Mobile Computing, 14(4), 770–785.
Ji, L., Yang, Y., & Wang, W. (2015). Mobility assisted data gathering with solar irradiance awareness in heterogeneous energy replenishable wireless sensor networks. Computer Communications, 69, 88–97.
Dong, M., Liu, X., Qian, Z., Liu, A., & Wang, T. (2015). QoE-ensured price competition model for emerging mobile networks. IEEE Wireless Communications, 22(4), 50–57.
Cayirpunar, O., Kadioglu-Urtis, E., & Tavli, B. (2015). Optimal base station mobility patterns for wireless sensor network lifetime maximization. IEEE Sensors Journal, 15(11), 6592–6603.
Fadel, E., Gungor, V. C., Nassef, L., Akkari, N., Abbas Malik, M. G., Almasri, S., et al. (2015). A survey on wireless sensor networks for smart grid. Computer Communications, 71, 22–33.
Rashid, B., & Rehmani, M. H. (2016). Applications of wireless sensor networks for urban areas: A survey. Journal of Network & Computer Applications, 60(6), 192–219.
Liu, Y., Xiong, N., Zhao, Y., Vasilakos, A. V., Gao, J., & Jia, Y. (2010). Multi-layer clustering routing algorithm for wireless vehicular sensor networks. IET Communications, 4(7), 810–816.
Sharmin, S., Nur, F. N., Razzaque, M. A., Rahman, M. M., Almogren, A., & Hassan, M. M. (2017). Tradeoff between sensing quality and network lifetime for heterogeneous target coverage using directional sensor nodes. IEEE Access, 5, 15490–15504.
Ullah, R., Faheem, Y., & Kim, B. S. (2017). Energy and congestion-aware routing metric for smart grid AMI networks in smart city. IEEE Access, 5, 13799–13810.
Deif, D. S., & Gadallah, Y. (2014). Classification of wireless sensor networks deployment techniques. IEEE Communications Surveys & Tutorials, 16(2), 834–855.
Krishnan, M., Rajagopal, V., & Rathinasamy, S. (2016). Performance evaluation of sensor deployment using optimization techniques and scheduling approach for K-coverage in WSNs. Wireless Networks. https://doi.org/10.1007/s11276-016-1361-5.
Almobaideen, W., Hushaidan, K., Sleit, A., & Qatawneh, M. (2011). A cluster based approach for supporting qos in mobile adhoc networks. International Journal of Digital Content Technology and its Applications, 5(1), 1–9.
Patil, P., & Kulkarni, U. (2013). Analysis of data aggregation techniques in wireless sensor networks. International Journal of Computational Engineering & Management, 16(1), 22–27.
Kallapur, P. V., & Geetha, V. (2011). Research challenges in using mobile agents for data aggregation in wireless sensor networks with dynamic deadlines. International Journal of Computer Applications, 30(5), 34–38.
Xu, J., Liu, W., Lang, F., Zhang, Y., & Wang, C. (2010). Distance measurement model based on RSSI in WSN. Wireless Sensor Networks, 2(8), 606–611.
Maraiya, K., Kant, K., & Gupta, N. (2011). Architectural based data aggregation techniques in wireless sensor network: A comparative study. International Journal on Computer Science & Engineering, 3(3), 6599–6605.
Wang, F., & Liu, J. (2011). Networked wireless sensor data collection: Issues, challenges, and approaches. IEEE Communications Surveys & Tutorials, 13(4), 673–687.
Chilamkurti, N., Zeadally, S., Vasilakos, A., & Sharma, V. (2009). Cross-layer support for energy efficient routing in wireless sensor networks. Journal of Sensors, 2009, 1–9.
Azharuddin, M., & Jana, P. K. (2016). A PSO based fault tolerant routing algorithm for wireless sensor networks. Wireless Networks, 22(8), 2637–2647.
Han, G., Qian, A., Jiang, J., Sun, N., & Liu, L. (2016). A grid-based joint routing and charging algorithm for industrial wireless rechargeable sensor networks. Computer Networks, 101, 19–28.
Song, Y., Liu, L., Ma, H., & Vasilakos, A. V. (2014). A Biology-based algorithm to minimal exposure problem of wireless sensor networks. IEEE Transactions on Network & Service Management, 11(3), 417–430.
Wang, Y. C., Wu, F. J., & Tseng, Y. C. (2012). Mobility management algorithms and applications for mobile sensor networks. Wireless Communications & Mobile Computing, 12(1), 7–21.
Cobo, L., Quintero, A., & Pierre, S. (2010). Ant-based routing for wireless multimedia sensor networks using multiple QoS. Computer Networks, 54(17), 2991–3010.
Kuila, P., & Jana, P. K. (2014). Energy efficient clustering and routing algorithms for wireless sensor networks: Particle swarm optimization approach. Engineering Applications of Artificial Intelligence, 33, 127–140.
Hamida, E. B., & Chelius, G. (2008). Strategies for data dissemination to mobile sinks in wireless sensor networks. IEEE Wireless Communications, 15(6), 31–37.
Yun, Y., & Xia, Y. (2010). Maximizing the lifetime of wireless sensor networks with mobile sink in delay-tolerant applications. IEEE Transactions on Mobile Computing, 9(9), 1308–1318.
Di Francesco, M., Das, S. K., & Anastasi, G. (2011). Data collection in wireless sensor networks with mobile elements: A survey. ACM Transactions on Sensor Networks (TOSN), 8(11), 7. https://doi.org/10.1145/1993042.1993049.
Sara, G., Kalaiarasi, R., Pari, N., & Sridharan, D. (2010). Energy efficient clustering and routing in mobile wireless sensor network. International Journal of Wireless and Mobile Networks, 2(4), 106–114.
Karim, L., & Nasser, N. (2012). Reliable location-aware routing protocol for mobile wireless sensor network. IET Communications, 6(14), 2149–2158.
Ma, M., Yang, Y., & Zaho, M. (2013). Tour planning for mobile data-gathering mechanisms in wireless sensor networks. IEEE transactions on Vehicular Technology, 62(4), 1472–1482.
Kinalis, A., Nikoletseas, S., Patroumpa, D., & Rolim, J. (2014). Biased sink mobility with adaptive stop times for low latency data collection in sensor networks. Information Fusion, 15, 56–63.
Arshadlis, M., Kamel, N., Armi, N., & Saad, N. M. (2011). Mobile data collector based routing protocol for wireless sensor networks. Scientific Research and Essays, 6(29), 6162–6175.
Kim, J. W., In, J. S., Hur, K., Kim, J. W., & Eom, D. S. (2010). An intelligent agent-based routing structure for mobile sinks in WSNs. IEEE Transactions on Consumer Electronics, 56(4), 2310–2316.
Gupta, S. K., & Prasantam, K. J. (2015). Energy efficient clustering and routing algorithms for wireless sensor networks: GA based approach. Wireless Personal Communications, 83(3), 2403–2423.
Srinivasa Rao, P. C., Prasanta, K. Jana, & Banka, Haider. (2016). A particle swarm optimization based energy efficient cluster head selection algorithm for wireless sensor networks. Wireless Networks, 23(7), 2005–2020.
Chen, T. S., Tsai, H. W., Chang, Y. H., & Chen, C. T. (2013). Geographic convergecast using mobile sink in wireless sensor networks. Computer communications, 36(4), 445–458.
Ghosh, N., & Banerjee, I. (2015). An energy-efficient path determination strategy for mobile data collectors in wireless sensor network. Computers & Electrical Engineering, 48, 417–435.
Wang, J., Cao, J., Li, B., Lee, S., & Sherratt, R. S. (2015). Bio-inspired ant colony optimization based clustering algorithm with mobile sinks for applications in consumer home automation networks. IEEE Transaction on Consumer Electronics, 61(4), 438–444.
Heinzelman, W. R., Chandrakasan. A., & Balakishnan, H. (2002). Energy efficient communication protocol for wireless microsensor networks. In Proceedings of the 33rd Annual Hawaii International Conference on System Sciences, pp. 8020–8024.
Tyagi, S., & Kumar, N. (2013). A systematic review on clustering and routing techniques based upon LEACH protocol for wireless sensor networks. Journal of Network and Computer Applications, 36(2), 623–645.
Dietrich, I., & Dressler, F. (2009). On the lifetime of wireless sensor networks. ACM Transactions on Sensor Networks, 5(1), 1–38.
Acknowledgements
This work was supported by the National Research Foundation of Korea NRF-2016R1A5A1008055. The corresponding author was supported by NRF-2016R1D1A1B03931337. The second author was supported by NRF-2016R1D1A1B03934371.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Krishnan, M., Yun, S. & Jung, Y.M. Dynamic clustering approach with ACO-based mobile sink for data collection in WSNs. Wireless Netw 25, 4859–4871 (2019). https://doi.org/10.1007/s11276-018-1762-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11276-018-1762-8