
Abstract
Accurate and consistent annual runoff prediction in a region is a hot topic in management, optimization, and monitoring of water resources. A novel prediction model (ESMD-SE-WPD-LSTM) is presented in this study. Firstly, extreme-point symmetric mode decomposition (ESMD) is used to produce several intrinsic mode functions (IMF) and a residual (Res) by decomposing the original runoff series. Secondly, sample entropy (SE) method is employed to measure the complexity of each IMF. Thirdly, wavelet packet decomposition (WPD) is adopted to further decompose the IMF with the maximum SE into several appropriate components. Then long short-term memory (LSTM) model, a deep learning algorithm based recurrent approach, is employed to predict all components. Finally, forecasting results of all components are aggregated to generate the final prediction. The proposed model, which is applied to seven annual series from different areas in China, is evaluated based on four evaluation indexes (R, MAE, MAPE and RMSE). Results indicate that ESMD-SE-WPD-LSTM outperforms other benchmark models in terms of four evaluation indexes. Hence the proposed model can provide higher accuracy and consistency for annual runoff prediction, rendering it an efficient instrument for scientific management and planning of water resources.
Similar content being viewed by others
Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Long-term runoff forecasting is essential for optimal management of hydro-resources (Reddy et al. 2021), ecological restoration (Feng et al. 2020a), flood mitigation (He et al. 2020), power generation (Feng et al. 2020b), irrigation scheduling (Poul et al. 2019), etc. The problem has received extensive attention globally (Xiang et al. 2020). Numerous models have been applied to the prediction accuracy of annual hydrologic time series (Al-Juboori 2021), which can be divided into two types (Chau et al. 2005): physical-based and data-driven models. Physical-based models require detailed multi-source information and powerful computational tools, while data-driven models are an efficient alternative by building direct relationships between input and output data, without involving the complex internal physical mechanisms. Recently, many data-driven models (such as LSTM, ANFIS (Adaptive Network-based Fuzzy Inference System), ANN (Artificial Neural Network), etc.) have been adopted in the field (Parisouj et al. 2020; Sahoo et al. 2019). Hence, this paper focuses on developing an appropriate data-driven model for annual runoff prediction.
In the last few decades, deep learning algorithm has been gradually employed for hydrological field with fruitful research results (Tao et al. 2017; Yen et al. 2019). Recurrent neural network (RNN) is capable of modeling complex temporal dynamics. Numerous improvement methods have been undertaken to overcome problems of vanishing gradients and gradient explosion of RNN. As a representative of them, LSTM has been used in signal recognition and forecast. LSTM model was employed to predict monthly water table depth in agricultural field (Zhang et al. 2018). Kratzert et al. (2018) investigated the potential of LSTM for daily streamflow prediction. Akbari Asanjan et al. (2018) developed a rainfall prediction method by extrapolating cloud-top brightness temperature utilizing LSTM. Yuan et al. (2018) examined the accuracy of a hybrid method for monthly runoff forecasting by integrating LSTM and ant lion optimizer algorithm. Saeed et al. (2020) proposed a method for wind speed prediction by using a bidirectional LSTM model and automatic encoder. Bai et al. (2021) proposed a two-level cascade LSTM (C-LSTM) model for daily runoff forecasting, and the C-LSTM yielded better performance than single LSTM. These studies proved the competitiveness of LSTM hydrological time series prediction.
Recently, many hybrid forecasting models for hydrological time series prediction have been developed, which include forecast modeling and data preprocessing. A decomposition algorithm can enhance the forecasting ability of a model by decomposing the raw hydrological series into more clean sub-series. The emergence of multi-resolution decomposition tools, namely singular spectrum analysis (SSA), ESMD, ensemble empirical mode decomposition (EEMD), CEEMDAN (complete EEMD with adaptive noise), WPD, wavelet transform (WT), and variational mode decomposition (VMD), have further stimulated researchers to make in-depth research on data preprocessing. Meng et al. (2021) proposed a hybrid VMD-SVM (support vector machine) coupling innovative input selection framework and stepwise decomposition sampling strategy for practical hydrological prediction. Bojang et al. (2020) examined the reliability of combining SSA with random forest (RF) and least-squares support vector regression (LS-SVR) for monthly precipitation prediction. However, SSA involved certain subjective factors in the process of noise reduction and was subject to the restriction of r matrix perturbation. Yuan et al. (2021) coupled two methods, namely group by month (GM) and EEMD, with LSTM to enhance the forecasting accuracy of daily runoff. Discrete wavelet transform (DWT) was capable of helping forecasting models to extract useful information (Tayyab et al. 2019), yet it might suffer from signal loss. Zuo et al. (2020) proposed a single-model forecasting (SF) framework, termed SF-VMD-LSTM, to forecast daily streamflow. However, the drawback of VMD is that the optimal parameter combination needs to be artificially set in advance. EEMD lacks accurate mathematical theory. To overcome their weaknesses, termed ESMD proposed by Wang and Li (2013), was adopted to attain more linear signal. The main idea of ESMD is to identify large-scale cycle and nonlinear trend of the data using internal extreme-point symmetry interpolation according to the characteristics of data itself. ESMD method replaces traditional integral transformation with direct interpolation, and the residual is optimized by a least square approach. Therefore, ESMD is capable of reflecting time-varying characteristics of frequency and amplitude of each component. ESMD has been successfully used in broad fields(Zhou et al. 2019), few attempts have tended to the latest advance of ESMD for hydrological prediction. Therefore, this paper is to explore the efficiency of ESMD in capturing hydrological time series characteristics.
WPD is another data decomposition technology that has gained numerous attentions. WPD, an improvement of DWT, decomposes the approximation value same as details of signals in each level of decomposition. Whilst DWT only decomposes the approximation coefficient, WPD has the capability of splitting both detail coefficient and approximation coefficient simultaneously; thereby WPD provides more possibilities for hydrological time series. Seo et al. (2016) combined three models, including SVM, ANFIS, and ANN, with WPD for daily river stage prediction. Sun et al. (2020) coupled WPD and FS (feature selection) with ELM (extreme learning machine) to predict multi-step wind speed. Although WPD has achieved fruitful results in many fields, it is of great significance to fill the research gap in mid- and long-term runoff forecasting.
Despite the above fruitful results, it should be noted out that single decomposition method might be hard to fully mitigate signal nonlinearity. To attain more linear series and higher forecasting accuracy, Liu et al. (2018) proposed a wind speed multistep prediction model by combining VMD, SSA, LSTM, and ELM. Sun and Huang (2020) combined secondary decomposition (SD) with sequence reconstruction to predict air pollutant concentration, and the model had excellent prediction performance. In summary, SD method can provide more linear signal and solve the limitation of single decomposition method to a certain extent. Therefore, this paper uses a secondary decomposition framework (ESMD-SE-WPD) to attain more linear series. Then, LSTM model is adopted for annual runoff forecasting. Finally, forecasted results of all sub-series are summed to generate the final prediction. The performance of the developed model is then compared with several benchmarking prediction models (LSTM, ANFIS, ANN, ESMD-LSTM, ESMD-SE-SSA-LSTM, ESMD-SE-CEEMDAN-LSTM).
The contribution of this paper includes three parts. First, an ESMD-SE-WPD-LSTM hybrid model, which can provide reasonable forecasting accuracy for annual runoff forecasting practice, is proposed. Second, an data preprocessing method based on secondary decomposition technology, which can provide more linear sub-series than single decomposition method, is proposed. Finally, three machine learning models are investigated with applications on seven basins, and LSTM model is combined with four preprocessing methods for examining the performance of data preprocessing technologies.
The remainder of the paper is arranged as follows: Sect. 2 is literature review. Section 3 depicts data source and evaluation indexes. Section 4 introduces the empirical forecasting experiments and discussion. Finally, Sect. 5 summarizes the paper.
2 Methodology
2.1 ESMD
ESMD, proposed by Wang and Li (2013), is a new adaptive data processing method and can be applied to analyze non-stationary and nonlinear signal. ESMD uses internal extreme-point symmetry interpolation, instead of external envelope interpolation, and optimizes the residual mode using least square approach, which overcomes shortcomings of modal aliasing and screening termination in EMD. Detailed steps of ESMD are shown in (Sun et al. 2018).
2.2 Sample Entropy
Sample entropy (SE), proposed by Alcaraz and Rieta (2010), is a novel approach to describe the complexity of series. The computation steps are as follows:
(1) Recombine \({{X}}=({{x}}{(1), }{{x}}{(2),}\ldots{,}{{x}}\text{(n))}\) into a matrix:
(2) The distance between vector \(x(j)\) and \(x(i)\) can be defined as \({\text{d}}[x(i), \, x(j)]\):
where \(l = 0,1,2, \cdots m - 1\);
(3) For \({\text{x}}(i)\), r denotes the threshold. Compute their number meeting the threshold \({\text{d}}[x(i), \, x(j)] \le {\text{r}}\) as \(B_{{\text{i}}}\). Then, compute ratio \(B_{i}^{m} (r)\):
(4) Compute the average value \(B^{m} (r)\) of \(B_{i}^{m} (r)\):
(5) Increase m by 1 and repeat steps 1 to 3, then compute \(B^{m + 1} (r)\):
(6) SE is defined as follows:
2.3 WPD
WPD is identical to wavelet decomposition, except that the former extends the abilities of the latter (Alickovic et al. 2018). The three-layer binary trees of WPD are illustrated in Fig. 1. WPD splits the signal into approximation coefficients and detail coefficients by a mother wavelet function. The decomposition levels and mother wavelet function have a deep influence on the performance of WPD. WPD includes DWT and CWT (continuous wavelet transform). CWT is as follows:
where \(x(t)\) is input, ∗ complex conjugate, b translation parameter, a scale parameter, and \(\psi (t)\) mother wavelet function. \({\text{a}}\) and \({\text{b}}\) in DWT are:
where \({\text{i}}\) and \({\text{j}}\) denotes the scale and translation parameters, respectively.

Sketch map of WPD method
2.4 LSTM
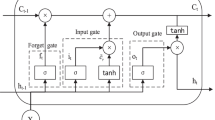
LSTM model is capable of solving the dependency problems of short-term and long-term time series. The memory cell of LSTM is a critical parameter, which contributes to memorize the temporal state. Each memory cell encompasses three gates, namely input, output, and forget gates. These gates perform as filters in playing different roles, solving exploding and vanishing gradient problems of RNN. The framework of LSTM is shown in Fig. 2.

The basic LSTM architecture
The implementation of cell state update and computation of LSTM output are:
where \(x(t)\) is input, \(y(t)\) output, \(f_{t}\) forget gate, \({\text{o}}_{t}\) output gate, \(i_{t}\) input gate, \(c_{t}\) cell state at time t, W weight matrix, b bias vector, \(\sigma (x)\) nonlinear activation function, and \(h_{t}\) activation vectors for each memory block.
2.5 Model Construction
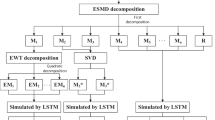
The basic framework of the runoff forecasting system proposed in this paper is shown in Fig. 3. The modeling processes are as follows:

Framework of the proposed model
Step 1: ESMD. ESMD is adopted to split the observed runoff series into several IMFs and a Res.
Step 2: Sample entropy. Compute SE of each subsequence obtained in the previous step.
Step 3: Two-phase decomposition. ESMD-SE-WPD is adopted to attain more linear subseries.
Step 4: Normalize all data between [0, 1] by:
Step 5: Select input variables. PACF (partial autocorrelation function) and precipitation knowledge are used to screen the number of input variables.
Step 6: Training and prediction. All model components are input to LSTM for training and prediction.
3 Data Description and Evaluation Indicators
The reliability of data is an important factor affecting the accuracy of mid- and long-term runoff prediction. The data in this paper are from seven areas in China, namely Mopanshan reservoir, Dahuofang reservoir, Biliuhe reservoir, Changshui hydrological station, Hongjiadu reservoir, Jiayuguan station and Yingluoxia station. Mopanshan Reservoir is located in Heilongjiang Province, Northeast China. The water source area of the reservoir is 1151 \({\text{km}}^{2}\), the average annual precipitation is about 750 mm, and the average annual runoff is 5.60 billion \({\text{m}}^{3}\). Dahuofang reservoir is located in Fushun City, Northeast China, with a watershed area of 5437 \({\text{km}}^{2}\), annual average discharge of 52.3 \({\text{m}}^{3}\text{/}{\text{s}}\) and annual average precipitation of 812 mm. Biliuhe reservoir is located in Liaoning Province of China. The drainage area is 2085 \({\text{km}}^{2}\), and the average annual precipitation is 742.8 mm. Hongjiadu hydropower is located on the main stream of Wujiang River in northwest of Guizhou Province, China, with a drainage area of 9900 \({\text{km}}^{2}\) and an average annual runoff of 4.89 billion \({\text{m}}^{3}\). Changshui hydrological station is located in Henan Province, China. It is a national basic hydrological station with a drainage area of 874 \({\text{km}}^{2}\), annual average rainfall of 530 mm and annual average runoff of 8.17 billion \({\text{m}}^{3}\). TaoLai River is a tributary of Heihe River system in China’s inland river basin. Jiayuguan hydrological station is a national first-class streamflow control station for monitoring changes in TaoLai river regime, with a catchment area of 7095 km2 and average runoff of 6.36 billion m3. Yingluoxia hydrological station is a control station and boundary section between upper and middle reaches of Heihe River, with a catchment area of 10,009 km2 and average annual discharge of 51.5 m3/s. The observed annual data for seven stations are shown in Fig. 4. Their statistical descriptions are listed in Table 1, where data for Mopanshan hydropower, Dahuofang hydropower, Biliuhe hydropower Changshui station, Hongjiadu hydropower, Jiayuguan station and Yingluoxia station, run from 1952–2004, 1953–2008, 1951–2007, 1961–2016, 1951–2005, 1956–2009 and 1956–2009, respectively. These data variations of seven stations are quite different, implying the high modeling difficulty of these regions. For these seven stations, approximately 90% of the data are used for training and the remainder are used for testing.

Original runoff series
Results of the models are evaluated based on four evaluation indicators. These indexes include coefficient of correlation (R), mean absolute percentage error (MAPE), mean absolute error (MAE), and root mean square errors (RMSE). Their equations are as follows:
where \({y}_{e}(i)\), \({y}_{o}(i)\), \(\overline{{y }_{e}}\) and \(\overline{{y }_{o}}\) are estimated, observed, mean estimated, and mean observed precipitation values, respectively.
4 Case Studies
4.1 Series Decomposition
The first stage of the runoff prediction framework is to decompose the observed data using ESMD. Before decomposing the runoff series, the best screening number should be determined by repeating tests and comparisons. In this paper, the number of iterations is 100, and the numbers of remaining extreme points of the seven runoff datasets are 5, 6, 7, 5, 7, 5 and 5, respectively. The results at Site 1 after the decomposition are shown in Figs. 5, 6 and 7, whilst the decomposition results of other sites are not presented here. In Fig. 7, A1 and F1denote the amplitude and frequency of IMF1, A2 and F2 the amplitude and frequency of IMF2, and A3 and F3 the amplitude and frequency of IMF3, respectively. It can be seen from Fig. 5 that each IMF split by ESMD is independent, the fluctuation of sub-series from IMF1 to Res decreases steadily and the stability becomes stronger gradually. Therefore, IMFs are steadier than original data and more conducive to capture signal features and predict non-linear sequences.

Decomposition at Mopanshan hydropower by ESMD

Frequency distribution of each IMF at Site 1

Amplitude of each IMF at Site 1
4.2 Sample Entropy Computation and Two-Phase Decomposition
SE of each subsequence obtained in the previous step is computed. Three decomposition methods are then adopted to further decompose IMF with the maximum SE. As shown in Fig. 8, SE of all sub-series present a similar trend, and it can be noted that SE of IMF1 in each dataset is higher than that of other subseries, which means that it is more difficult to predict IMF1. To mitigate the complexity of IMF1, three decomposition algorithms, namely WPD, CEEMDAN and SSA, are used to decompose IMF1.

SE of each sequence decomposed by ESMD
The selection of an appropriate wavelet basis function is very important to WPD. Symlet wavelet is an improved approximate symmetric wavelet function based on Daubechies wavelet, which can avoid signal distortion during decomposition and reconstruction(Yin et al. 2019). Therefore, a three-scale and fourth order Symlet wavelet is adopted as the wavelet basis function of WPD.
SSA is a traditional and powerful non-parametric decomposition algorithm for signal identification and analysis, which can capture noise component, trend and periodic from input signal(Dong et al. 2017). SSA can decompose a time series into some decipherable and simpler components, and contains two steps, namely decomposition and reconstruction. Decomposition incorporates singular value decomposition (SVD) and embedding whilst reconstruction comprises diagonal averaging and grouping. In SSA, window size (L) and eigenvalue grouping (EVG) are key parameters. Before decomposing IMF1, the best L and EVG value should be determined by repeating tests and comparisons. In this paper, L and EVG are set to 12 and 6, respectively.
CEEMDAN proposed by Colominas et al. (2012), is an enhancement on EEMD and can attain better separation and accurately reconstruct the raw signal. CEEMDAN obtains the modes by adding white Gaussian noise and computing a unique residue to reduce EEMD deficiency. The method overcomes the mode mixing problem since the procedure of CEEMDAN in decomposition and reconstruction are complete. In CEEMDAN application, too many modes may cause extra computational costs and complex training process. Hence, five IMFs and a residual are reconstructed in this paper.
All IMF1 are then split by WPD, SSA and CEEMDAN. The re-decomposition results of IMF1 at Site 1 are shown in Fig. 9, where y is the reconstructed series by SSA, whilst results at other sites are not presented here, and IMF1 with the maximum SE is decomposed into 16 subsequences with more regular fluctuation by three methods.

Decomposition results of IMF1 at Site 1
4.3 Number of Input Variables
The determination of input variables is an important procedure for prediction results. In this paper, two methods are utilized to select input combinations: (a) trial-and-error method; (b) PACF statistical approach. We conduct twelve ANN models with different input combinations. Table 2 lists input variables for Site 1 with respect to PACF and trial-and-error method, while input variables and PACF value for other sites are not shown here.
4.4 Model Development
To verify the proposed model, seven models, namely LSTM, ANN, ANFIS, ESMD-LSTM, ESMD-SE-WPD-LSTM, ESMD-SE-SSA-LSTM, ESMD-SE-CEEMDAN-LSTM, are employed as benchmark for comparison. Detailed information relating to these models are presented in the following section.
-
(1)
ANN
A standard three-layer feed forward ANN is adopted for annual runoff prediction. The numbers of input and output layer nodes are equal to that of input variables and one, respectively. Levenberg–Marquardt (LM) method, sigmoid function and purelin formula are adopted as the training, transfer and output functions, respectively. The best number of hidden nodes is determined as eight by trial-and-error method, and the training epochs are 500.
-
(2)
ANFIS
Three methods, namely genfis1, genfis2 and genfis3, are available to initialize the data structure of ANFIS. Of three methods, genfis3 provides the most robust results in terms of generalization and stability in runoff modeling, and hence is employed throughout the processes. The specific parameter settings are shown in Table 3.
-
(3)
LSTM
The selection of hyper-parameters is a difficult task for LSTM model construction. Adaptive moment estimation is to optimize the parameters. The model structure of LSTM, i.e., hyper-parameters and the number of hidden units are determined by trial-and-error method. The number of hidden units is 200. The maximum number of epochs is 2000. The mini-batch size in each training iteration is 100. The initial learning rate is set to 0.01. Other parameters are determined to default values used by adaptive moment estimation. RMSE is adopted as the loss function.
-
(4)
ESMD-LSTM model
For ESMD-LSTM model, the runoff datasets are first decomposed into a certain number of sub-series by ESMD. Each component is then modeled using LSTM, and the input variables for each composition are shown in Table 2.
-
(5)
Two-phase decomposition methods combined with LSTM
For ESMD-SE-WPD-LSTM, ESMD-SE-SSA-LSTM and ESMD-SE-CEEMDAN-LSTM, ESMD is adopted to decompose the raw data into several IMFs and a Res. Then SE method is employed to measure the complexity of each composition. Three decomposition algorithms, namely WPD, SSA and CEEMDAN, are adopted to further decompose the IMF with the maximum SE. Then, LSTM model is employed to predict each subseries obtained in the previous step.
4.5 Results and Discussion
Forecasting results of different methods for seven runoff datasets are presented in this section. Tables 4, 5, 6, 7, 8, 9 and 10 show error estimation results of different methods for seven runoff time series. Table 11 presents forecasting results of ESMD-LSTM of different sites. Figures 10, 11, 12, 13, 14, 15 and 16 present forecasting results of seven stations. The following should be noted before analyzing the results. The forecasting results of the testing phase play a greater role than those of the training phase. It is because the training period is utilized to train the model, and its performance is measured by data related to modeling. Since the testing dataset does not participate in modeling, its performance can truly reflect the model application efficiency.

Forecasting results of Mopanshan Hydropower

Forecasting results of Dahuofang Hydropower

Forecasting results of Biliuhe Hydropower

Forecasting results of Changshui station

Forecasting results of Hongjiadu Hydropower

Forecasting results of Yingluoxia station

Forecasting results of Jiayuguan station
4.5.1 Experiment 1: Comparison of Several Single Prediction Models
In this section, we analyze prediction results of three single models at seven sites. As seen from Tables 4, 5, 6, 7, 8, 9 and 10, in the testing period, LSTM obtain the best average R in seven sites, the lowest average MAE, RMSE, MAPE in Hongjiadu station and Yingluoxia station, and similar MAE, RMSE, and MAPE with ANN in Biliuhe and Changshui station. Meanwhile, the differences between the best and worst value of four evaluation indicators of ANN and ANFIS are significantly higher than those of LSTM model. Besides, results of LSTM and ANFIS in the training period are clearly better than those in the testing period. ANN is in the lower level during the training period but can provide middle level result during the testing period.
Overall, LSTM model can provide optimal results for seven datasets in terms of four evaluation indexes. This analysis also demonstrates that there is still room to improve the forecasting accuracy of LSTM.
4.5.2 Experiment 2: Comparison of LSTM and ESMD-LSTM
This section compared the performance between single LSTM model and ESMD-LSTM hybrid model. Taking Site 1 as an example, ESMD-LSTM significantly improves the forecasting accuracy of LSTM model. In the testing period, ESMD-LSTM model improves LSTM model with 50.02%, 53.31% and 48.58% reduction in average MAE, RMSE and MAPE, respectively, and the improvement of prediction accuracy regarding average R is 21.24%. According to results in Tables 5, 6, 7, 8, 9 and 10, ESMD-LSTM model is able to provide better results than LSTM model with substantial improvement in terms of four evaluation indexes. Table 11 lists the prediction results of different subseries obtained by ESMD-LSTM for seven datasets, the forecasting results of IMF1 are inferior to those of the other subseries. For IMF1, in the testing phase, the average R value of Sites 1–7 are 0.841, 0.654, 0.795, 0.573, 0.841, and 0.828, respectively, with an average of 0.735. However, in the testing period, the average R value of IMF2, IMF3 and Res are 0.904, 0.972 and 0.996, respectively. These results demonstrate that there is still room for improvement in the prediction performance of IMF1.
In general, this analysis illustrates that ESMD is suitable to decompose the annual runoff series and can improve forecasting accuracy. In addition, it can be confirmed from Table 11 that results of IMF1 are inferior to those of other subsequences. These analyses also illustrate that single decomposition method may have difficulty in fully capturing the frequency characteristics of the original data. The secondary decomposition method is then attempted to attain more linear sub-series and overcome the limitation of the single decomposition method to a certain extent.
4.5.3 Experiment 3: Comparison of Several Re-decomposition Hybrid Models
In this section, composite methods including ESMD-LSTM, ESMD-SE-WPD-LSTM, ESMD-SE-SSA-LSTM, ESMD-SE-CEEMDAN-LSTM, and ESMD-LSTM are treated as the benchmark methods. Tables 4, 5, 6, 7, 8, 9 and 10 list the composite results for Sites 1–7. When forecasting annual runoff in seven stations, ESMD-SE-WPD-LSTM model exhibits the best results in terms of all evaluation indexes. Table 5 lists the forecasting results of Dahuofang reservoir in the testing period and average R values of ESMD-LSTM, ESMD-SE-SSA-LSTM, ESMD-SE-CEEMDAN-LSTM, and ESMD-SE-WPD-LSTM are 0.620, 0.838, 0.821, and 0.954, respectively. For Dahuofang reservoir in the testing period, compared with average R value of ESMD-LSTM model, ESMD-SE-SSA-LSTM, ESMD-SE-CEEMDAN-LSTM and ESMD-SE-WPD-LSTM yield improvements of 32.25%, 32.48% and 93.55%, respectively. Compared with average RMSE value of ESMD-LSTM, the three two-phase decomposition prediction methods yield reductions of 8.48%, 35.61% and 48.90% in the testing period, respectively. Compared to ESMD-LSTM, the three two-phase decomposition prediction methods exhibit average MAE value reductions of 14.02%, 27.86% and 41.42% in the testing period, respectively. Compared to ESMD-LSTM, the three two-phase decomposition prediction methods exhibit average MAPE value reductions of 16.41%, 37.03% and 50.52% in the testing period, respectively. To verify the performance of the presented model, seven datasets are used to test the model. The forecasting results of remainder stations reaffirm the superior performance of ESMD-SE-WPD-LSTM model for annual runoff forecasting. It can be seen from Tables 4, 5, 6, 7, 8, 9 and 10 that forecasting performances of seven prediction methods (except ANN) have little difference. The running time of the LSTM-based models is significantly longer than those of ANN and ANFIS models. In addition, in the testing period, compared to three two-phase decomposition prediction methods, the deviation between the best and worst value of four indexes of ESMD-LSTM is clearer. Therefore, the following conclusions can be drawn:
-
(1)
IMF1 is highly nonlinear and difficult to forecast, which can affect the overall prediction accuracy of models.
-
(2)
The two-phase decomposition can capture important features better than the conventional single decomposition method. Besides, when comparing ESMD-SE-WPD-LSTM model with ESMD-SE-SSA-LSTM, and ESMD-SE-CEEMDAN-LSTM, the proposed model exhibits the best performance for all forecasting sites because the results in testing period are better. From Tables 4, 5, 6, 7, 8, 9 and 10 indicate that the prediction performance of ESMD-SE-SSA-LSTM is not stable, and the forecasting accuracy of ESMD-SE-CEEMDAN-LSTM is slightly inferior to the proposed model. Therefore, compared with SSA and CEEMDAN methods, WPD is more suitable to extract the significant features of IMF1. Overall, ESMD-SE-WPD-LSTM model outperforms all other methods. The reason may be that the model can make full use of the time–frequency positioning ability of WPD, the auto-adapted feature extraction properties of ESMD and the long-term memory function of LSTM.
4.5.4 Comparison of All Investigated Models
The performances of all investigated models developed in this study are shown in Figs. 10, 11, 12, 13, 14, 15 and 16, which imply that forecasting performances of six models (except ANN) in the training phase are slightly overestimated. Meanwhile, in the testing phase, the forecasting accuracy of all sites can be significantly improved, and performances of different models are uneven. The proposed hybrid prediction model with the secondary decomposition provides the best performance as the trend line is very close to observed data line, and the method can capture abrupt changes in annual runoff series.
4.6 Discussion of Results
Experimental results demonstrate these differences between LSTM, ANFIS and ANN, indicating the importance of choosing an appropriate forecasting method. ANFIS is greatly affected by the clustering parameters, which limits the performance of the model. The gradient-based training strategy of the traditional ANN may suffer from dimensionality and overfitting issues. LSTM discards or retains information to the cell state using unique gate structure. If information at a certain time is more important, the forget gate can keep the information transmission, which is one of the reasons why LSTM can process long sequences. The gate structure of LSTM overcomes the weaknesses of ANFIS and ANN to some extent and attains relatively better prediction results. However, runoff contains different frequency components due to influencing climate, underlying surface characteristic of river basin, human activities, etc. Therefore, it is difficult for a single prediction model to fully reflect the formation mechanism of runoff since only one resolution component is used to construct the forecasting model. In this paper, data preprocessing technologies are utilized to identify the resolution subcomponents. The characteristics of each component can be separated, which reduces the difficulty of modeling. Therefore, the modified LSTM models can provide better performance than standard LSTM model.
The followings are an analysis of possible reasons why the proposed hybrid model (ESMD-SE-WPD-LSTM) can improve the forecasting accuracy. Firstly, ESMD-SE-WPD decomposes the original data into several more linear sub-series, facilitating comprehensive identification of frequency features in original data. Secondly, LSTM is employed to model complex relationships of input–output variables in each subseries. Through specially designed model architecture, LSTM overcomes the shortcoming of RNN and provides an avenue for deeply exploring internal features of runoff time series. Finally, ESMD-SE-WPD-LSTM hybrid model overcomes shortcomings of a single LSTM method by generating synergistic effect in the prediction. Overall, the incorporation of data preprocessing and sample entropy into LSTM model can provide more accurate and reliable results for long-term runoff prediction.
5 Conclusion
Long-term runoff forecasting plays a critical role in the management and monitoring of water resources. To attain more accurate prediction of annual runoff, this paper presents a hybrid model for long-term runoff prediction, which couples two-phase decomposition and LSTM (ESMD-SE-WPD-LSTM). Firstly, ESMD is used to decompose the original time series, and SE (sample entropy) of all sub-series is computed. Secondly, the sub-series with the maximum SE is adopted for secondary decomposition using WPD method, which can provide more linear subseries. Next, LSTM model is employed to train and forecast the data. Finally, the forecasting accuracy of the proposed model is compared with ANN, ANFIS, ESMD-LSTM, ESMD-SE-SSA-LSTM, and ESMD-SE-CEEMDAN-LSTM. The forecasting errors of all investigated models are evaluated based on four evaluation indexes. According to the results, the following conclusions can be drawn:
Firstly, the proposed hybrid model with secondary decomposition provides the most robust performance and excellent forecasting accuracy among all investigated models. This demonstrates that the proposed model can significantly improve the prediction accuracy of long-term runoff time series.
Secondly, the forecasting accuracies of hybrid methods (ESMD-LSTM, ESMD-SE-SSA-LSTM, ESMD-SE-CEEMDAN-LSTM, and ESMD-SE-WPD-LSTM) preprocessed by decomposition method are superior to those of ANN, ANFIS, and LSTM models, demonstrating high efficiency of data preprocessing technology in reducing non-linearity of runoff series.
Thirdly, EMSD and WPD, as two signal processing methods with high efficiency, can complement each other. After screening by sample entropy, the original single time series is re-decomposed by two-phase decomposition mode to attain a more linear annual time series, which reduces the complexity of forecasting, and mitigate the limitation of conventional single-phase decomposition method.
The hybrid model presented in this paper combines data preprocessing technology, sample entropy, and forecasting model to develop runoff forecasting model, which is more conducive to be a useful and efficient soft computing model to forecast runoff time series.
Availability of Data and Materials
All authors made sure that all data and materials support our published claims and comply with field standards.
References
Akbari Asanjan A, Yang T, Hsu K, Sorooshian S, Lin J, Peng Q (2018) Short-term precipitation forecast based on the PERSIANN system and LSTM recurrent neural networks. J Geophys Res Atmos 123:12543–12563. https://doi.org/10.1029/2018JD028375
Al-Juboori AM (2021) A hybrid model to predict monthly streamflow using neighboring rivers. Annu Flows Water Resour Manag 35:729–743. https://doi.org/10.1007/s11269-020-02757-4
Alcaraz R, Rieta JJ (2010) A review on sample entropy applications for the non-invasive analysis of atrial fibrillation electrocardiograms. Biomed Signal Process Control 5:1–14. https://doi.org/10.1016/j.bspc.2009.11.001
Alickovic E, Kevric J, Subasi A (2018) Performance evaluation of empirical mode decomposition, discrete wavelet transform, and wavelet packed decomposition for automated epileptic seizure detection and prediction. Biomed Signal Process Control 39:94–102. https://doi.org/10.1016/j.bspc.2017.07.022
Bai Y, Bezak N, Zeng B, Li C, Sapac K, Zhang J (2021) Daily runoff forecasting using a cascade long short-term memory model that considers different variables. Water Resour Manag 35:1167–1181. https://doi.org/10.1007/s11269-020-02759-2
Bojang PO, Yang TC, Pham QB, Yu PS (2020) Linking singular spectrum analysis and machine learning for monthly rainfall forecasting. Appl Sci. https://doi.org/10.3390/app10093224
Chau KW, Wu CL, Li YS (2005) Comparison of several flood forecasting models in Yangtze River. J Hydrol Eng 10:485–491. https://doi.org/10.1061/(ASCE)1084-0699(2005)10:6(485)
Colominas MA, Schlotthauer G, Torres ME, Flandrin P (2012) Noise-assisted EMD methods in action. Adv Adapt Data Anal 04:1250025. https://doi.org/10.1142/S1793536912500252
Dong Q, Sun Y, Li P (2017) A novel forecasting model based on a hybrid processing strategy and an optimized local linear fuzzy neural network to make wind power forecasting: a case study of wind farms in China. Renew Energy 102:241–257. https://doi.org/10.1016/j.renene.2016.10.030
Feng Z, Liu S, Niu W, Li S, Wu H, Wang J (2020a) Ecological operation of cascade hydropower reservoirs by elite-guide gravitational search algorithm with Lévy flight local search and mutation. J Hydrol 581:124425. https://doi.org/10.1016/j.jhydrol.2019.124425
Feng Z, Niu W, Cheng X, Wang J, Wang S, Song Z (2020b) An effective three-stage hybrid optimization method for source-network-load power generation of cascade hydropower reservoirs serving multiple interconnected power grids. J Clean Prod. https://doi.org/10.1016/j.jclepro.2019.119035
He XX, Luo JG, Li P, Zuo GG, Xie JC (2020) A hybrid model based on variational mode decomposition and gradient boosting regression tree for monthly runoff forecasting. Water Resour Manag 34:865–884. https://doi.org/10.1007/s11269-020-02483-x
Kratzert F, Klotz D, Brenner C, Schulz K, Herrnegger M (2018) Rainfall-runoff modelling using Long Short-Term Memory (LSTM) networks. Hydrol Earth Syst Sci 22:6005–6022. https://doi.org/10.5194/hess-22-6005-2018
Liu H, Mi X, Li Y (2018) Smart multi-step deep learning model for wind speed forecasting based on variational mode decomposition, singular spectrum analysis, LSTM network and ELM. Energy Convers Manag 159:54–64. https://doi.org/10.1016/j.enconman.2018.01.010
Meng ER et al (2021) A hybrid VMD-SVM model for practical streamflow prediction using an innovative input selection framework. Water Resour Manag 35:1321–1337. https://doi.org/10.1007/s11269-021-02786-7
Parisouj P, Mohebzadeh H, Lee T (2020) Employing machine learning algorithms for streamflow prediction: a case study of four river basins with different climatic zones in the United States. Water Resour Manag 34:4113–4131. https://doi.org/10.1007/s11269-020-02659-5
Poul AK, Shourian M, Ebrahimi H (2019) A comparative study of MLR, KNN, ANN and ANFIS models with Wavelet transform in monthly stream flow prediction. Water Resour Manag 33:2907–2923. https://doi.org/10.1007/s11269-019-02273-0
Reddy BSN, Pramada SK, Roshni T (2021) Monthly surface runoff prediction using artificial intelligence: a study from a tropical climate river basin. J Earth Syst Sci. https://doi.org/10.1007/s12040-020-01508-8
Saeed A, Li C, Danish M, Rubaiee S, Tang G, Gan Z, Ahmed A (2020) Hybrid bidirectional LSTM model for short-term wind speed interval prediction. IEEE Access 8:182283–182294. https://doi.org/10.1109/access.2020.3027977
Sahoo BB, Jha R, Singh A, Kumar D (2019) Long short-term memory (LSTM) recurrent neural network for low-flow hydrological time series forecasting. Acta Geophys 67:1471–1481. https://doi.org/10.1007/s11600-019-00330-1
Seo Y, Kim S, Kisi O, Singh VP, Parasuraman K (2016) River stage forecasting using wavelet packet decomposition and machine learning models. Water Resour Manag 30:4011–4035. https://doi.org/10.1007/s11269-016-1409-4
Sun D, Zhang H, Guo Z (2018) Complexity Analysis of precipitation and runoff series based on approximate entropy and extreme-point symmetric mode. Decomposition 10:1388
Sun SZ, Fu JQ, Zhu F, Du DJ (2020) A hybrid structure of an extreme learning machine combined with feature selection, signal decomposition and parameter optimization for short-term wind speed forecasting. Trans Inst Meas Control 42:3–21. https://doi.org/10.1177/0142331218771141
Sun W, Huang C (2020) A hybrid air pollutant concentration prediction model combining secondary decomposition and sequence reconstruction. Environ Pollut. https://doi.org/10.1016/j.envpol.2020.115216
Tao YM, Gao XG, Ihler A, Sorooshian S, Hsu KL (2017) Precipitation identification with bispectral satellite information using deep learning approaches. J Hydrometeorol 18:1271–1283. https://doi.org/10.1175/jhm-d-16-0176.1
Tayyab M, Zhou JZ, Dong XH, Ahmad I, Sun N (2019) Rainfall-runoff modeling at Jinsha River basin by integrated neural network with discrete wavelet transform. Meteorol Atmos Phys 131:115–125. https://doi.org/10.1007/s00703-017-0546-5
Wang J-L, Li Z-J (2013) Extreme-point symmetric mode decomposition method for data analysis. Adv Adapt Data Anal 05:1350015. https://doi.org/10.1142/S1793536913500155
Xiang ZR, Yan J, Demir I (2020) A rainfall-runoff model with LSTM-based sequence-to-sequence learning. Water Resour Res. https://doi.org/10.1029/2019wr025326
Yen MH, Liu DW, Hsin YC, Lin CE, Chen CC (2019) Application of the deep learning for the prediction of rainfall in Southern Taiwan. Sci Rep. https://doi.org/10.1038/s41598-019-49242-6
Yin Y, Bai Y, Ge F, Yu H, Liu Y (2019) Long-term robust identification potential of a wavelet packet decomposition based recursive drift correction of E-nose data for Chinese spirits. Measurement 139:284–292. https://doi.org/10.1016/j.measurement.2019.03.011
Yuan RF et al (2021) Daily runoff forecasting using ensemble empirical mode decomposition and long short-term memory. Front Earth Sci. https://doi.org/10.3389/feart.2021.621780
Yuan XH, Chen C, Lei XH, Yuan YB, Adnan RM (2018) Monthly runoff forecasting based on LSTM-ALO model. Stoch Env Res Risk Assess 32:2199–2212. https://doi.org/10.1007/s00477-018-1560-y
Zhang JF, Zhu Y, Zhang XP, Ye M, Yang JZ (2018) Developing a Long Short-Term Memory (LSTM) based model for predicting water table depth in agricultural areas. J Hydrol 561:918–929. https://doi.org/10.1016/j.jhydrol.2018.04.065
Zhou J, Xu X, Huo X, Li Y (2019) Forecasting Models for wind power using extreme-point symmetric mode decomposition and artificial neural networks. Sustainability. https://doi.org/10.3390/su11030650
Zuo G, Luo J, Wang N, Lian Y, He X (2020) Decomposition ensemble model based on variational mode decomposition and long short-term memory for streamflow forecasting. J Hydrol. https://doi.org/10.1016/j.jhydrol.2020.124776
Funding
Project of key science and technology of the Henan province (No: 202102310259; No: 202102310588), Henan province university scientific and technological innovation team (No: 18IRTSTHN009).
Author information
Authors and Affiliations
Contributions
WW: Conceptualization, Methodology, Writing-original draft. YD: Methodology, data curation, Writing—original draft preparation. KC: Writing and editing-original draft. DX: Formal analysis and data collection. CL: Formal analysis. QM: Investigation.
Corresponding author
Ethics declarations
Ethics Approval
All authors kept the ‘Ethical Responsibilities of Authors’.
Consent to Participate
All authors gave explicit consent to participate in this work.
Consent to Publish
All authors gave explicit consent to publish this manuscript.
Competing of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Wang, Wc., Du, Yj., Chau, Kw. et al. An Ensemble Hybrid Forecasting Model for Annual Runoff Based on Sample Entropy, Secondary Decomposition, and Long Short-Term Memory Neural Network. Water Resour Manage 35, 4695–4726 (2021). https://doi.org/10.1007/s11269-021-02920-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-021-02920-5