
Abstract
We employed functional magnetic resonance imaging (fMRI) and diffuse tensor imaging (DTI) to study neural implications of silent reading of words in mutually comprehensible but visually and orthographically distinct languages for example Hindi and Urdu by independent groups of skilled readers. The fMRI results (conjunction analyses) showed the left inferior frontal gyrus (BA 44/45), bilateral inferior occipital (BA 18/19), bilateral superior parietal (BA 7), left pre-central region (BA 6), and bilateral inferior temporal gyrus (BA 20) as common regions for Hindi and Urdu readers. Some additional regions such as left ventral occipitotemporal, left middle frontal (BA 46), left middle occipital (BA18), and bilateral post-central regions (BA 3) were observed for Urdu readers. DTI results showed significantly higher FA value at the left inferior fronto-occipital fasciculus in Urdu speakers. Overall findings suggest strong engagement of ventral visual pathway in reading Urdu which has a visually complex deep orthography.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Reading is primarily considered as an information processing skill that requires combining and stringing multiple sensory modalities as well as conceptually driven processes. Orthographic depth, grain size, and visual complexity of the script layout influence reading. The aim of present study is to observe the effect of reading in two distinct script (i.e., Hindi (transparent orthography) and Urdu (deep orthography and visually complex script) which are mutually comprehensible but written in mutually incomprehensible scripts) over dorsal and ventral visual pathway.
Studies have suggested that reading involves two distinct neural routes in the left hemisphere for example, a dorsal phonological route and a ventral orthographic route (Sandak, Mencl, Frost, & Pugh, 2004; Schlaggar and McCandliss, 2007). The processing of word in the dorsal route follows the grapheme-to-phoneme mapping (Jobard, Crivello, & Tzourio-Mazoyer, 2003). It actively involves the neural regions such as the left temporoparietal junction (i.e., posterior superior temporal gyrus, the angular gyrus and the supramarginal gyrus) and the part of inferior frontal region. The ventral orthographic route is located in the left occipitotemporal region near the fusiform gyrus. This region accompanied the posterior portion of middle and inferior temporal gyrus and in the inferior frontal gyrus. It helps in establishing the direct lexicosemantic route for reading (Jobard et al, 2003). Evidences from DTI studies suggest that, the arcuate fasciculus (AF) and parts of the superior longitudinal fasciculus (SLF) are the integral regions of the dorsal connection (dorsal phonological route), while the ventral connection (ventral orthographic route) has minimum two bundles for example inferior fronto-occipital fasciculus (IFOF) and uncinate fasciculus (UF) (Brauer, Anwander, Perani, & Friederici, 2013). Apart from ILF (inferior longitudinal fasciculus), the IFOF is the second major fiber bundle connecting the occipital cortex to the frontal brain area. The IFOF runs medially and above the optic pathways and known as a direct pathway, that connects the occipital, posterior temporal, and the orbito-frontal areas (Ashtari, 2012).
Studies (Bolger, Perfetti, & Schneider, 2005; Paulesu et al., 2000) have reported that reading in transparent orthographies actively involves the dorsal pathway, while deep orthographies engage the ventral pathway. Neuroimaging studies have a suggested that both orthographic depth and visual complexity of the script influence cortical network of reading (Seghier, Maurer, & Xue, 2014). Cross-linguistic researchers suggest that scripts with substantial visual spatial complexity induce extensive visual spatial processing demands (Xue et al., 2005; Sun, Yang, Desroches, Liu, & Peng, 2011). Behavioral studies on divergent orthographies such as Arabic-Hebrew, Kanji-Kana, and English-Chinese support this view (Feldman & Turvey, 1980; Ibrahim, Eviatar, & Aharon-Peretz, 2002; Sun et al., 2011).
In the present study, two independent and distinct groups of skilled readers in Hindi and Urdu were recruited. Hindi and Urdu are closely related languages spoken by large communities that cover a huge population of the world. Both Hindi and Urdu have a shared history of evolving in the eleventh century (Kachru & Comrie, 1987). During the course of development, however, Hindi absorbed Sanskrit words freely and adopted ‘Devanagari’ script used by Sanskrit; while Urdu imbibed Arabic and Persian words and adopted Nastaliq script modeled after Arabic-Persian script. Owing to their common origin, Hindi-Urdu presents a unique situation for comparisons. The linguistics differences between the two languages are not significant because Hindi and Urdu share common morphophonology, grammar, and vocabulary for the most part yet have quite distinct orthographies. Devanagari is a transparent abugida script while Nastaliq is an opaque alphabetic system (largely consonantal). Vowels are added to consonants in Hindi following Akshara principle of Brahmi, while Urdu writing is very cursive, graphemically highly complex (with various forms of consonantal segments combined variedly depending upon the initial/mid/end word positions they occur), and the dots or group of dots marked below or above the line play crucial role in differentiating the consonantal forms. Urdu has a lot of foreign influences and loanwords while Hindi has less foreign vocabularies. However, these languages share many common words and lexicons from native, Arabic, Persian, and the English language. The two languages differ widely in the script layout. Hindi is written from left to right while Urdu is written from right to left (like Arabic, Persian, and Hebrew). Behaviour studies support that directional scanning tendencies developed by the directionality of script influence the cognitive process such as verbal memory and perception as well as on a non-linguistics production (Padakannaya, Devi, Zaveria, Chengappa, & Vaid, 2002; Vaid, 1995). Thus, Hindi and Urdu provide a unique condition for examining the orthographic influence on neural network of reading while keeping linguistic differences at a minimum. The fact that there are native speakers of these languages living in the same geographical and socio-cultural settings in India is an added advantage for such studies. So considering all these aspects it is interesting to observe how the neural architecture responds across the two distinct orthographies (Hindi & Urdu). According to our literature search, this is the first study on native Urdu readers where neuroimaging technique (fMRI and DTI) used to advance our understanding towards the processing of complex script. The findings will be an important add on to the existing neuroimaging literature.
The fMRI provides functional information by visualizing cortical activity and it is based on blood oxygen level dependent (BOLD) imaging. It measures fine alterations in signal intensity changes in response to stimuli. Diffusion Tensor Imaging identifies white matter tracts non-invasively using diffusion measurements and provides valuable information regarding white matter pathways. Diffusion Tensor Imaging estimates the random diffusion of water molecules within biological tissue. These diffusion properties within each voxel represented by a systematic diffusion tensor that indicated the 3D orientation of fibre structure. These two methods provide the structural definition of cerebellar connection and the functional aspects of neural network.
Based on the previous findings related to similar studies in different languages we hypothesized that reading in transparent orthographies might exhibit greater inclination towards dorsal pathway (phonologically tuned) while opaque orthographies will show stronger involvement of ventral pathway (lexical semantic). Since Urdu is deep orthography with more visual complexity, we expected to see stronger ventral reading network involvement. Specifically, in left ventral occipitotemporal (vOT), as this region is important in reading across ventral pathway (Oliver, Carreiras, & Paz-Alonso, 2016). This region is actively implicated in aligning visual spatial features with higher-level associations along with bottom up and top down connections (Price & Devlin, 2011). As suggested by Harm and Seidenberg (1999) we also expected the cooperative division of labor between the two pathways. Since arcuate fasciculus and part of superior longitudinal fasciculus form the dorsal pathway and inferior fronto-occipital fasciculus and uncinate fasciculus form the ventral pathway (Brauer et al., 2013), we expected a higher FA value in ventral pathway for deep language. Since Urdu and & Hindi share many common language features there is higher possibilities that it may show some common neural regions.
Methods and materials
Participants
The study followed the protocol approved by the Human Ethics Committee of the Centre of Bio-medical Research and a written informed consent from each participant was obtained before commencing the experiments.
Imaging data were gathered from 36 right-handed male Hindi (18 subjects) and Urdu (18 subjects) speakers (mean age = 19.8 years, SD = 1.9). The Urdu participants were selected from a residential madrasa where teaching and speaking in Urdu is compulsory, while the Hindi participants were recruited from a Government high school situated in a village where teaching and conversation is only in Hindi. All the participants were studying at senior high school level (Grade 12). Both the schools were in similar location. The participants had only nominal exposure to another language (such as English, however, they do not have literacy skills). Since Hindi and Urdu are mutually comprehensible language, both the group understand each other language but they lack proficiency. Each Participant completed a language self-assessment report based on rating of seven-point scale (Meschyan & Hernandez, 2006). Only participants with a score of six and above were recruited in the present study. The self-assessment reports from participants suggested that all those recruited for the study were speaking in their respective languages for the most part of their daily communication (Table 1).
Behavioural reading assessment
Reading fluency was measured in Urdu and Hindi words as reported in similar studies (Das, Padakannaya, Pugh, & Singh, 2011; Kumar, 2014). A written passage of 250 words was presented to each participant individually and time taken to read the passage was measured. The average reading time of Urdu monolinguals was 71.77 (SD = 1. 67) seconds and Hindi monolinguals was 71.64 (SD = 1.59) seconds. It was lower than the mean reading time gathered from a different group of 30 proficient Urdu-Hindi readers for example Urdu 74.26 (SD = 2.17) and Hindi 73.16 (SD = 2.07) seconds. Thus considering the duration of the reading time the present readers were very proficient and skilled readers. The average reading time for Urdu and Hindi speakers as well as in-scanner reaction time (RTs) suggested no significant difference between the groups (Table 1).
Stimuli and task procedure
Stimuli were 180 concrete nouns (90 Hindi and 90 Urdu words (similar words in both the languages) and 90 non-word (Hindi and Urdu i.e., unfamiliar characters in Hindi and Urdu matched in terms of number of characters). Non-word are primarily used to control non-linguistic computations (e.g., motor execution and response selection). The average number of phonemes for both Hindi and Urdu words was 4.11 (SD 1.01). To ensure that the frequency of Hindi and Urdu words did not differ significantly, thirty native readers were asked to rate the words on a five-point scale (1 = very low frequency, 2 = low frequency, 3 = mid frequency, 4 = high frequency and 5 = very high frequency). In the present study we included only high frequency word (rating 4 and above) and no significant differences in Hindi and Urdu word frequency was observed (t (29) = 1.52, p ≤ .14).
The task and stimuli were programmed with E-prime software and presented with an LCD display. The experimental design required participants to read the stimuli silently including the non-word. (An illustration of word stimuli: बादाम (almond), मेमना (lamb) in Hindi;
 (almond),
(almond),
 (lamb) in Urdu). Participants were instructed to read silently the stimulus (words and non-word) and to press the button when they finished reading the word. Silent reading task was chosen against reading aloud with a reason that reading out the words may invoke attributes of spoken words that would be identical across Hindi and Urdu (Vaid, 1985). Common spoken attributes across the languages may obscure orthographic differences. As illustrated in Fig. 1, trials were presented in 18-s blocks consisting of six words each. The experiment included three scanning sessions for each group of participants consisting of five task blocks (18 s and 6 trials in each blocks) for each condition for example Urdu word and Urdu non-word for Urdu participants and Hindi word and Hindi non-word for Hindi participants. The total scan time was 486 s. The entire task block was interspersed with a fixation crosshair (12 s) as a baseline condition. During the fixation condition participants were asked to fixate on a crosshair presented in the middle of the screen. For all task conditions, each trial was presented for 2000 ms with an inter-trial interval (ITI) of 1000 ms (a crosshair).
(lamb) in Urdu). Participants were instructed to read silently the stimulus (words and non-word) and to press the button when they finished reading the word. Silent reading task was chosen against reading aloud with a reason that reading out the words may invoke attributes of spoken words that would be identical across Hindi and Urdu (Vaid, 1985). Common spoken attributes across the languages may obscure orthographic differences. As illustrated in Fig. 1, trials were presented in 18-s blocks consisting of six words each. The experiment included three scanning sessions for each group of participants consisting of five task blocks (18 s and 6 trials in each blocks) for each condition for example Urdu word and Urdu non-word for Urdu participants and Hindi word and Hindi non-word for Hindi participants. The total scan time was 486 s. The entire task block was interspersed with a fixation crosshair (12 s) as a baseline condition. During the fixation condition participants were asked to fixate on a crosshair presented in the middle of the screen. For all task conditions, each trial was presented for 2000 ms with an inter-trial interval (ITI) of 1000 ms (a crosshair).

Experimental design
Data acquisition and analysis
3 T Siemens Magnetom Skyra scanner was used for imaging data collection at the Center of Biomedical Research. Foam padding was used to minimize head motion within the coil. T2*-weighted functional images were acquired using a gradient-echo EPI sequence (TR = 2000 ms, TE = 30 ms, flip angle = 77°, 33 oblique plane slices, FOV = 224 × 224, image matrix = 64 × 64, isotropic 3.5 mm voxels). A three-dimensional T1-weighted image using the magnetization-prepared rapid gradient-echo (MPRAGE) sequence was also collected (TR = 1690 ms, TE = 2. 56 ms, flip angle = 12°, matrix = 224 × 256, 1 mm isotropic voxels, sagittal partitions).
DTI was performed by using a single-shot spin-echo diffusion-weighted echo-planar pulse sequence with 64 sections covering the whole brain at 2.5-mm section thickness (TR/TE = 9500/74 ms; acquisition matrix = 128 × 128). Diffusion MR images were obtained from 32 noncolinear directions with a b-value of 1000 s/mm2 along with a b = 0 image with no diffusion gradients.
fMRI preprocessing and voxelwise analysis
Data was analyzed with Statistical Parametric Mapping software (SPM 8; Wellcome Department of Cognitive Neurology, London, UK). Functional images were spatially realigned to correct for head motion using a least square approach to estimate a six-parameter rigid-body transformation. The functional images were co-registered with the MPRAGE and then normalized to 2 mm isotropic voxels using a standard Montreal Neurological Institute (MNI) T1. Spatial smoothing with a Gaussian kernel of 8 mm FWHM was applied to the normalized images. The first level of analysis was performed using a fixed effect model to construct the General Linear Model using canonical hemodynamic response function (HRF) (Friston et al., 1994). Six regressors were included in the model as nuisance covariates to account for any activity related to head movement. At the individual level there were two contrasts of interest for both the groups for example Hindi > Fixation, Hindi non-word > Fixation and Urdu > Fixation, Urdu non-word > Fixation. The contrast maps from each participant were taken into second-level group analysis.
Within group comparisons
We created maps (using one sample t test) within the group from respective languages in contrast to non-word (i.e., contrast between Hindi word and Hindi matched non-word and Urdu word, and Urdu matched non-word). This analysis was important to know the neural regions activated within each language and further to perform conjunction analysis. The following contrast was adopted to perform the above analysis (Hindi > Fixation) − (Hindi non-word > Fixation) and (Urdu > Fixation) − (Urdu non-word > Fixation).
Conjunction analysis
The group statistical map of word processing in Hindi and Urdu was used to generate conjunction map to determine the common areas of activation underlying Hindi and Urdu. The conjunction analysis tested against the conjunction null (Friston, Penny, & Glaser, 2005) to identify regions that were commonly activated by word reading compared with non-word condition.
Direct comparisons
To assess the distinct regions and to generate the statistical map across the two languages between the groups, we performed direct comparisons (two sample t-tests) between Hindi and Urdu speakers. The following contrast was used to perform the above analysis (Hindi > Hindi non-word) − (Urdu > Urdu non-word) and (Urdu > Urdu non-word) − (Hindi > Hindi non-word).
To achieve accurate correction level as well as to maintain the high sensitivity of data, Monte Carlo correction was performed (Bennett, Wolford, & Miller, 2009; Nichols & Hayasaka, 2003). The Monte Carlo simulations (3dClustSim, 1000 iterations) pointed a significance level p < .001 and cluster threshold 32 voxels in order to reach corrected significance p < .05. This threshold is implicated in all contrasts.
DTI preprocessing and voxelwise statistical analysis of FA
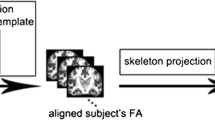
Images were processed by using FSL (FMRIB [The Oxford Centre for Functional Magnetic Resonance Imaging of the Brain] Software Library, http://www.fmrib.ox.ac.uk/fsl), The eddy correct tool in the FMRIB FDT toolbox corrected for gradient coil distortions and participant head motion, by employing an affine registration to a reference volume. Brain extraction was performed on the non-diffusion weighted image using BET (Behrens et al., 2003), to create a mask that excluded non-brain voxels. The next step includes use of DTI Fit to calculate the diffusion tensors, which allows for the computation of the principle diffusion direction, the mean diffusivity, and each voxel’s fractional anisotropy (FA) value (Behrens et al., 2003). Tract Based Spatial Statistics version 1.2 (TBSS) were performed (Smith, 2002; Smith et al., 2006), to place each participant’s FA images into a standard space allowing for voxel-wise statistical analyses of the FA values to be conducted across participants. Each participant’s FA images were aligned to all other FA images to identify target image. The target image was affine-aligned into MNI152 standard space. With the use of nonlinear registration FNIRT all participants’ images were transformed into 1 mm MNI152 space. The mean FA image was then created and thinned to create a mean FA skeleton, which represents the centers of all tracts common to the group. Each subject’s aligned FA data were then projected onto this skeleton and the resulting data were fed into voxelwise cross-subject statistics. A randomization procedure (FSL’s randomize, Monte Carlo permutation test) was used to perform the group analysis statistics. TBSS group maps were generated for the nonparametric 2-sample t test (corrected, p < .05). Anatomic localization was determined using the FSL atlas tool using the available anatomic templates (MNI atlas, Talairach atlas, Harvard–Oxford cortical and subcortical structural atlases, and Johns Hopkins University DTI-based WM atlas). Results were prepared for display using the TBSS_fill script from the FSL package.
We acknowledge that due to fibre crossing (i.e., brain regions that contain two or even more differently oriented fiber bundles within the same voxel) TBSS technique has limitation in measuring FA value. However, tbss_x script was employed to deal with such situations (Jbabdi, Behrens, & Smith, 2010).
Results
Within group comparison
Figure 2a, b shows the rendered map highlighting the activated regions of the Hindi and Urdu speakers contrasted with the non-word condition.

fMRI results of Hindi-Urdu speakers
Common neural regions
The conjunction analysis results presented in Fig. 2c (Table 2(a)) show common neural regions for both groups of speakers, which include the left inferior frontal gyrus (IFG) (BA 44/45), bilateral inferior occipital (BA 18/19), bilateral superior parietal (BA 7), left pre-central region (BA 6), and bilateral inferior temporal gyrus (BA 20).
Direct comparisons
Direct comparisons between the groups are shown in Fig. 3 (Table 2(b)). For Urdu speakers, activations were located in the region of the left ventral occipitotemporal (vOT), left middle frontal (BA 46), left middle occipital (BA18), and bilateral post-central region (BA 3), whereas for Hindi speakers no voxel survived.

Distinct neural regions for Urdu word (Urdu word > Hindi word)
DTI FA value
The DTI finding (Fig. 4) revealed a significantly higher FA value at the left inferior fronto-occipital fasciculus (IFOF) in Urdu speakers.

DTI FA comparison
Discussion
In the present study, we aimed at investigating the neural processing of two distinct scripts (Hindi & Urdu) in two independent groups of native readers using silent word reading task. The findings signify that both alpha-syllabic, shallow Hindi and alphabetic (largely consonantal) deep Urdu engage left hemisphere temporal, occipital and frontal cortices. In line with our hypothesis, the word reading in Urdu shows strong involvement of ventral reading pathways, while we did not observed exclusively the dorsal pathway for Hindi. Within group fMRI activation however, shows some regions (middle frontal and parietal regions) which may justify that both the the languages utilize dorsal pathway and probably, this is the reason why in direct comparison no specific dorsal pathway have been observed for Hindi. The left ventral occipitotemporal (vOT) involvement was observed only for opaque and visually complex deep orthography Urdu. The DTI findings revealed the higher FA value in the IFOF white matter tract in Urdu reader, which further supports the involvement of the ventral reading pathway in visually complex opaque language. Since participants in Hindi and Urdu groups were skilled readers in their respective languages, the differences in cortical activations and FA values of white matter observed may be attributed to the differences in orthographic properties of Hindi and Urdu and these findings support a differential division of labor across distinct orthographies.
The activated regions found in conjunction analysis were widely attributed in various neuroimaging studies suggesting their role in languages with deep or shallow orthography (Turkeltaub, Eden, Jones, & Zeffiro, 2002; Price, 2012). The additional regions observed in Urdu readers included the left ventral occipitotemporal (vOT), left middle frontal (BA 46), left middle occipital (BA18), and bilateral postcentral region (BA 3).
The vOT is precisely located near the border of the posterior fusiform and inferior temporal gyrus. Its role in reading is under debate. Some researchers have suggested that this region is crucial in the processing of orthographic features (Dehaene & Cohen, 2011; Ludersdorfer, Kronbichler, & Wimmer, 2015) as it is implicated in mapping visuo-spatial information to higher level associations such as phonology and semantics (Price & Devlin, 2011). Lesion studies also provided evidence that damage to vOT leads to a deficiency in visual word recognition (Gaillard et al., 2006). A study by Ludersdorfer et al. (2016) using auditory words in an orthographic and a semantic task found that left vOT activation is more linked to orthographic processing than semantic processing. A more recent study by Oliver et al. (2016) observed tight coupling of vOT with the dorsal reading network in transparent orthography while a much better co-activation was reported along with ventral reading pathway in opaque orthography. Duncan et al. (2013) on the processing of multiple Japanese scripts such as morphographic Kanji, syllabographic Hiragana and Katakana reported increased connection strength from right to left vOT only for visually complex Kanji. Similarly, Koyama, Stein, Stoodley, and Hansen (2014) in their study on three distinct scripts syllabic Kana (transparent), logographic Kanji (deep) and alphabetic English (deep) also observed more participation of occipital-temporal region for visually and orthographically complex Kanji. The visual complexity associated with Kanji and Urdu, however, is not identical. In Kanji, the configuration of strokes and radicals in a character is the major contributing factor, while in Urdu, it is the multiple forms of cursive consonants often fused with other consonants (often not so well aligned) and diacritic marks in a word that contributes to the complexity. The results of the present study support the view that left vOT plays a crucial part in visually complex morpho-orthographic processing (Duncan et al., 2013). The less involvement of left vOT in Hindi indicates the existence of a second pathway implicated in reading a shallow orthography as suggested by several earlier studies (Cai, Paulignan, Brysbaert, Ibarrola, & Nazir, 2010; Richardson, Seghier, Leff, Thomas, & Price, 2011; Seghier et al., 2012).
The Nastaliq script is visually more complex as the shape/form of a graphemic symbol varies depending on the position it appears in a word. The presence of the number and position of dots further increases its visual complexity. The involvement of the left middle occipital suggests that reading Urdu requires comprehensive visuospatial processing.
Left middle frontal activation has been observed for Urdu. The role of middle frontal is also not clear. Based on logographic script (i.e., Chinese) processing, a study by Tan et al. (2001a) reported that role of middle frontal is more towards processing of graphic representation (square configuration) of script while some other researcher based on same script reported its involvement in phonological processing (Tan, Feng, Fox, & Gao, 2001b; Wu, Ho, & Chen, 2012). Further studies also suggest its involvement in reading phonologically inconsistent words (Jamal, Piche, Napoliello, Perfetti, & Eden, 2012; Bolger, Hornickel, Cone, Burman, & Booth, 2008). We suggest that in Urdu it may reflect processing of phonologically inconsistent words.
Results of fMRI studies supporting the role of the left IFG in phonological processing are very consistent (Poldrack et al., 1999; Burton, Noll, & Small, 2001; Liakakis, Nickel, & Seitz, 2011). A more recent study by Rueckl et al. (2015) using fMRI supported the notion of common neural network regardless of orthography based on contrasting languages such as Spanish, English, Hebrew and Chinese. Authors suggested “speech-print” as core universal feature of brain organization. In such an event, the additional regions observed for Urdu might correlate more towards the visual complexity of the script rather than orthography depth. However, in the above study many participants were probably bilingual or multilingual.
Largely, the current findings support the division of labor between semantic and phonological processing.
The DTI analysis reveals a significantly higher FA value at the left inferior fronto-occipital fasciculus (IFOF) for Urdu. The IFOF is ventral white matter tract that shows connection with the posterior occipital lobe (extrastriate cortex), posterior part of the fusiform gyrus, temporo-occipital sulcus, and the basal surface of the inferior temporal and prefrontal regions (Martino, Brogna, Robles, Vergani, & Duffau, 2010; Catani & Mesulam, 2008). IFOF has two important subcomponents—a superficial tract (V1) and a deep tract (V2) (Sarubbo, De Benedictis, Maldonado, Basso, & Duffau, 2013). The V1 tract has significant contribution in the language network as it terminates in paras triangularis (BA 45) and paras orbitalis (BA 47), whereas V2 terminates in three crucial regions such as orbitofrontal, middle frontal and dorsolateral prefrontal cortex (Brauer et al., 2013; Martino et al., 2010). In the context of reading, the deep tract has advantages as it connects the visual word form area to semantic regions (Vandermosten, Boets, Wouters, & Ghesquière, 2012a). Vandermosten et al. (2012b) explored the relationship between phonological processing, orthographic processing, and IFOF. They reported a significant positive correlation between orthographic processing and activation of IFOF. This finding suggests that IFOF is involved in ventral orthographic route in reading. The presence of higher FA value in Urdu suggests that mapping of the complex script might initially be processed at the levels of the occipital cortex (posterior occipital lobe) and posterior temporal lobe. The IFOF may constitute a direct efferent pathway from these cortical regions quickly transmitting this visual information to the frontal regions (Catani & Mesulam, 2008; Catani & De Schotten, 2008). Thus, the direct anatomical connection of the IFOF with these areas provides further evidence that languages with deep and visually complex orthography (i.e., Urdu) may rely more on the ventral visual pathway.
In the present study, the embedded features of Urdu orthography viz., opacity and visual complexity could not be separated to bifurcate differential effects of these features. In fact, this confounding effect is common even in earlier studies comparing Kanji and Kana.
In conclusion, this investigation of single-word reading in proficient Hindi and Urdu speakers found that while both languages engage the cortical network previously reported for reading in languages with distinct orthographies, there are language-specific differences. Reading Urdu, which has an opaque and visually complex orthography, shows strong involvement of ventral visual pathway.
References
Ashtari, M. (2012). Anatomy and functional role of the inferior longitudinal fasciculus: A search that has just begun. Developmental Medicine and Child Neurology, 54, 6–7.
Behrens, T. E. J., Woolrich, M. W., Jenkinson, M., Johansen-Berg, H., Nunes, R. G., Clare, S., et al. (2003). Characterization and propagation of uncertainty in diffusion-weighted MR imaging. Magnetic Resonance in Medicine, 50, 1077–1088.
Bennett, C. M., Wolford, G. L., & Miller, M. B. (2009). The principled control of false positives in neuroimaging. Social Cognitive and Affective Neuroscience, 4, 417–422.
Bolger, D. J., Hornickel, J., Cone, N. E., Burman, D. D., & Booth, J. R. (2008). Neural correlates of orthographic and phonological consistency effects in children. Human Brain Mapping, 29, 1416–1429.
Bolger, D. J., Perfetti, C. A., & Schneider, W. (2005). Cross-cultural effect on the brain revisited: Universal structures plus writing system variation. Human Brain Mapping, 25, 92–104.
Brauer, J., Anwander, A., Perani, D., & Friederici, A. D. (2013). Dorsal and ventral pathways in language development. Brain and Language, 127, 289–295.
Burton, M. W., Noll, D. C., & Small, S. L. (2001). The anatomy of auditory word processing: individual variability. Brain and Language, 77, 119–131.
Cai, Q., Paulignan, Y., Brysbaert, M., Ibarrola, D., & Nazir, T. A. (2010). The left ventral occipito-temporal response to words depends on language lateralization but not on visual familiarity. Cerebral Cortex, 20, 1153–1163.
Catani, M., & De Schotten, M. T. (2008). A diffusion tensor imaging tractography atlas for virtual in vivo dissections. Cortex, 44, 1105–1132.
Catani, M., & Mesulam, M. (2008). The arcuate fasciculus and the disconnection theme in language and aphasia: history and current state. Cortex, 44, 953–961.
Das, T., Padakannaya, P., Pugh, K. R., & Singh, N. C. (2011). Neuroimaging reveals dual routes to reading in simultaneous proficient readers of two orthographies. Neuroimage, 54, 1476–1487.
Dehaene, S., & Cohen, L. (2011). The unique role of the visual word form area in reading. Trends in Cognitive Sciences, 15, 254–262.
Duncan, K. J. K., Twomey, T., Jones, Ō. P., Seghier, M. L., Haji, T., Sakai, K., et al. (2013). Inter-and intrahemispheric connectivity differences when reading Japanese Kanji and Hiragana. Cerebral Cortex, 24, 1601–1608.
Feldman, L. B., & Turvey, M. T. (1980). Words written in Kana are named faster than the same words written in Kanji. Language and Speech, 23, 141–147.
Friston, K. J., Holmes, A. P., Worsley, K. J., Poline, J. P., Frith, C. D., & Frackowiak, R. S. (1994). Statistical parametric maps in functional imaging: a general linear approach. Human Brain Mapping, 2, 189–210.
Friston, K. J., Penny, W. D., & Glaser, D. E. (2005). Conjunction revisited. Neuroimage, 25, 661–667.
Gaillard, R., Naccache, L., Pinel, P., Clémenceau, S., Volle, E., Hasboun, D., et al. (2006). Direct intracranial, FMRI, and lesion evidence for the causal role of left inferotemporal cortex in reading. Neuron, 50, 191–204.
Harm, M. W., & Seidenberg, M. S. (1999). Phonology, reading acquisition, and dyslexia: insights from connectionist models. Psychological Review, 106, 491.
Ibrahim, R., Eviatar, Z., & Aharon-Peretz, J. (2002). The characteristics of arabic orthography slow its processing. Neuropsychology, 16, 322.
Jamal, N. I., Piche, A. W., Napoliello, E. M., Perfetti, C. A., & Eden, G. F. (2012). Neural basis of single-word reading in Spanish-English bilinguals. Human Brain Mapping, 33, 235–245.
Jbabdi, S., Behrens, T. E., & Smith, S. M. (2010). Crossing fibres in tract-based spatial statistics. Neuroimage, 49, 249–256.
Jobard, G., Crivello, F., & Tzourio-Mazoyer, N. (2003). Evaluation of the dual route theory of reading: a metanalysis of 35 neuroimaging studies. Neuroimage, 20, 693–712.
Kachru, Y., & Comrie, B. (1987). Hindi-Urdu. The world’s major languages. London: Oxford University Press.
Koyama, M. S., Stein, J. F., Stoodley, C. J., & Hansen, P. C. (2014). A cross-linguistic evaluation of script-specific effects on fMRI lateralization in late second language readers. Frontiers in human neuroscience, 8, 249.
Kumar, U. (2014). Effect of orthography over neural regions in bilinguals: A view from neuroimaging. Neuroscience Letters, 580, 94–99.
Liakakis, G., Nickel, J., & Seitz, R. J. (2011). Diversity of the inferior frontal gyrus—A meta-analysis of neuroimaging studies. Behavioural Brain Research, 225, 341–347.
Ludersdorfer, P., Kronbichler, M., & Wimmer, H. (2015). Accessing orthographic representations from speech: The role of left ventral occipitotemporal cortex in spelling. Human Brain Mapping, 36, 1393–1406.
Ludersdorfer, P., Wimmer, H., Richlan, F., Schurz, M., Hutzler, F., & Kronbichler, M. (2016). Left ventral occipitotemporal activation during orthographic and semantic processing of auditory words. NeuroImage, 124, 834–842.
Martino, J., Brogna, C., Robles, S. G., Vergani, F., & Duffau, H. (2010). Anatomic dissection of the inferior fronto-occipital fasciculus revisited in the lights of brain stimulation data. Cortex, 46, 691–699.
Meschyan, G., & Hernandez, A. E. (2006). Impact of language proficiency and orthographic transparency on bilingual word reading: An fMRI investigation. NeuroImage, 29, 1135–1140.
Nichols, T., & Hayasaka, S. (2003). Controlling the familywise error rate in functional neuroimaging: A comparative review. Statistical Methods in Medical Research, 12, 419–446.
Oliver, M., Carreiras, M., & Paz-Alonso, P. M. (2016). Functional dynamics of dorsal and ventral reading networks in bilinguals. Cerebral Cortex, 27, 5431–5443.
Padakannaya, P., Devi, M. L., Zaveria, B., Chengappa, S. K., & Vaid, J. (2002). Directional scanning effect and strength of reading habit in picture naming and recall. Brain and Cognition, 46, 484490.
Paulesu, E., McCrory, E., Fazio, F., Menoncello, L., Brunswick, N., Cappa, S. F., et al. (2000). A cultural effect on brain function. Nature Neuroscience, 3, 91–96.
Poldrack, R. A., Wagner, A. D., Prull, M. W., Desmond, J. E., Glover, G. H., & Gabrieli, J. D. (1999). Functional specialization for semantic and phonological processing in the left inferior prefrontal cortex. Neuroimage, 10, 15–35.
Price, C. J. (2012). A review and synthesis of the first 20 years of PET and fMRI studies of heard speech, spoken language and reading. Neuroimage, 62, 816–847.
Price, C. J., & Devlin, J. T. (2011). The interactive account of ventral occipitotemporal contributions to reading. Trends in Cognitive Sciences, 15, 246–253.
Richardson, F. M., Seghier, M. L., Leff, A. P., Thomas, M. S., & Price, C. J. (2011). Multiple routes from occipital to temporal cortices during reading. The Journal of Neuroscience, 31, 8239–8247.
Rueckl, J. G., Paz-Alonso, P. M., Molfese, P. J., Kuo, W. J., Bick, A., Frost, S. J., et al. (2015). Universal brain signature of proficient reading: Evidence from four contrasting languages. Proceedings of the National Academy of Sciences, 112, 15510–15515.
Sandak, R., Mencl, W. E., Frost, S. J., & Pugh, K. R. (2004). The neurobiological basis of skilled and impaired reading: Recent findings and new directions. Scientific Studies of Reading, 8, 273–292.
Sarubbo, S., De Benedictis, A., Maldonado, I. L., Basso, G., & Duffau, H. (2013). Frontal terminations for the inferior fronto-occipital fascicle: anatomical dissection, DTI study and functional considerations on a multi-component bundle. Brain Structure and Function, 218, 21–37.
Schlaggar, B. L., & McCandliss, B. D. (2007). Development of neural systems for reading. Annual Review of Neuroscience, 30, 475–503.
Seghier, M. L., Maurer, U., & Xue, G. (2014). What makes written words so special to the brain? Frontiers in Human Neuroscience, 8, 634.
Seghier, M. L., Neufeld, N. H., Zeidman, P., Leff, A. P., Mechelli, A., Nagendran, A., et al. (2012). Reading without the left ventral occipito-temporal cortex. Neuropsychologia, 50, 3621–3635.
Smith, S. M. (2002). Fast robust automated brain extraction. Human Brain Mapping, 17, 143–155.
Smith, S. M., Jenkinson, M., Johansen-Berg, H., Rueckert, D., Nichols, T. E., Mackay, C. E., et al. (2006). Tract-based spatial statistics: voxelwise analysis of multi-subject diffusion data. Neuroimage, 31, 1487–1505.
Sun, Y., Yang, Y., Desroches, A. S., Liu, L., & Peng, D. (2011). The role of the ventral and dorsal pathways in reading Chinese characters and English words. Brain and Language, 119, 80–88.
Tan, L. H., Feng, C. M., Fox, P. T., & Gao, J. H. (2001a). An fMRI study with written Chinese. NeuroReport, 12, 83–88.
Tan, L. H., Liu, H. L., Perfetti, C. A., Spinks, J. A., Fox, P. T., & Gao, J. H. (2001b). The neural system underlying Chinese logograph reading. Neuroimage, 13, 836–846.
Turkeltaub, P. E., Eden, G. F., Jones, K. M., & Zeffiro, T. A. (2002). Meta-analysis of the functional neuroanatomy of single-word reading: method and validation. Neuroimage, 16, 765–780.
Vaid, J. (1985). Memory for script in Hindi-Urdu bilitrates. In Annual meeting of South Asian language analysis roundtable. University of Michigan, Ann Arbor.
Vaid, J. (1995). Script directionality affects nonlinguistic performance: Evidence from Hindi and Urdu. In Scripts and literacy (pp. 295–310). Dordrecht: Springer.
Vandermosten, M., Boets, B., Poelmans, H., Sunaert, S., Wouters, J., & Ghesquière, P. (2012a). A tractography study in dyslexia: neuroanatomic correlates of orthographic, phonological and speech processing. Brain, 135, 935–948.
Vandermosten, M., Boets, B., Wouters, J., & Ghesquière, P. (2012b). A qualitative and quantitative review of diffusion tensor imaging studies in reading and dyslexia. Neuroscience and Biobehavioral Reviews, 36, 1532–1552.
Wu, C. Y., Ho, M. H. R., & Chen, S. H. A. (2012). A meta-analysis of fMRI studies on Chinese orthographic, phonological, and semantic processing. Neuroimage, 63, 381–391.
Xue, G., Dong, Q., Chen, K., Jin, Z., Chen, C., Zeng, Y., et al. (2005). Cerebral asymmetry in children when reading Chinese characters. Cognitive Brain Research, 24, 206–214.
Acknowledgements
We thank Vikram Singh and Dr. Alka Shukla for their support in data collection.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Kumar, U., Padakannaya, P. The effect of written scripts’ dissimilarity over ventral and dorsal reading pathway: combined fMRI & DTI study. Read Writ 32, 2311–2325 (2019). https://doi.org/10.1007/s11145-019-09952-9
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11145-019-09952-9