
Abstract
In this paper we extend the denominator rule for ratios given in different units of measurement and we explain how to derive the relevant aggregation shares, which are given in terms of the denominator variable and the constants converting the relevant variables into the same unit of measurement.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
This paper was motivated by a stimulating question raised by W.E. Diewert about the applicability of the denominator rule for ratios given in different units of measurement. As initially stated by Fӓre and Karagiannis (2017), the denominator rule, namely that aggregation of ratio-type variables should be based on weights given in terms of the denominator variable of the relevant quotient, is related to the theoretically consistent aggregation of ratios given in the same unit of measurement across decision-making units (DMUs). In this paper we undertake the task of extending the denominator rule for ratios given in different units of measurement.
In many empirical studies we are not only interested in individual performance but also on how well a group of DMUs performs. Consider, for example, the case of public hospitals: hospital managers are more interested on their specific units while health authority staff are more interested on the overall picture. Notice however that the vast majority of previous efficiency studies in health care delivery, with the exception of Pilayavsky and Staat (2008), Nguyen and Zelenyuk (2021) and Färe and Karagiannis (2022), analyzed the overall picture by means of a simple arithmetic average of individual efficiency scores. As it is explained in Karagiannis (2015a), this accurately reflects aggregate achievements only when performance and size are uncorrelated. Otherwise, a weighted average should be used and in this case, the choice of aggregation weights become crucial in order to ensure theoretical consistency, in the sense that the individual and the aggregate scores have the same form and the same intuitive interpretation.
Fӓre and Karagiannis (2017) have recently provided such an aggregation rule, i.e., the denominator rule, for ratios given in the same unit of measurement and explained how it can be used to aggregate, for example, individual (radial) technical, allocative and scale efficiency scores, measures of input congestion, and capacity utilization. It is important to note however that the applicability of the denominator rule is not limited to the above cases presupposing DMU’s optimizing behavior, where the denominator rule may be viewed as the practical counterpart of Koopmans (1957) theorem and its cost and revenue corollaries, but it may also be used to aggregate partial and total productivity indicesFootnote 1 as well as other ratio-type measures of performance given in the same unit of measurement. The latter may include programmatic efficiency scores or metafrontier technology gap ratios (Karagiannis 2015b; Walheer 2018a), DEA-based composite indicators (Karagiannis 2017; Rogge 2018), cost efficiency scores with private and public inputs (Walheer 2019), and markup or Lerner market power indices (Basu 2019; deLoecker et al. 2020; Shaffer and Spierdijk 2020).
In this paper we extend the denominator rule for ratios given in different units of measurement and we explain how to derive the relevant aggregation shares. In this case, the aggregation weights are given in terms of the denominator variable and the constants that are used to convert the relevant variables into the same unit of measurement. This enlarges considerably the applicability of the denominator rule to include cases of aggregating (across DMUs) performance measures given in different units of measurement as well as cases of aggregating across commodities, inputs or outputs. In this direction, we provide a number of applications illustrating how the denominator rule with unit ratio difference can be used for (i) aggregating Fӓre efficiency indices, enhanced Russell efficiency indices, and Lerner’s indices of market power across DMUs and (ii) deriving a weighted Russell efficiency index, a weighted potential improvement efficiency index as well as the weighted average form of the Laspeyres, Paasche and Lowe price and quantity indices.
The rest of this paper unfolds as follows: in the next section we present the theoretical part and the main results. In the third section, we provide a number of applications of the denominator rule with unit ratio difference. Concluding remarks follow in the last section.
2 Problem setting and main results
Consider that our objective is to aggregate two ratios z1/ξ1 and z2/ξ2, given in different units of measurement, by means of an aggregator function \(L:R_ + ^2 \to R_ +\) describing the type of aggregation, namely, arithmetic, harmonic, geometric, etc., in such a way to preserve theoretical consistency in the sense that z1/ξ1, z2/ξ2 and the resulting aggregate measure have the same (ratio) form and the same intuitive interpretation. The main result is stated as:Footnote 2
2.1 Denominator rule with unit ratio difference
Let z=(z1, z2)>0, ξ=(ξ1, ξ2)>0 and c1, c2>0 are constants converting c1z1, c1ξ1, c2z2, and c2ξ2 into the same unit of measurement. Then, for arithmetic aggregation we have
where \(\theta _1 = \frac{{c_1\xi _1}}{{c_1\xi _1 + c_2\xi _2}} \ge 0\), \(\theta _2 = \frac{{c_2\xi _2}}{{c_1\xi _1 + c_2\xi _2}} \ge 0\) and θ1 + θ2 = 1.
If the ratios are given in the same unit of measurement c1 = c2 = 1 and the conventional denominator rule applies (see Fӓre and Karagiannis 2017). If, in addition to c1 = c2 = 1, we have ξ1 = ξ2 = ξ then
in which case, the average reflects accurately the aggregate. Two are the implications of this result: first, (2) provides one of the alternative ways to derive the simple (equally-weighted) arithmetic average form of the translation function–based Luenberger productivity indicator, introduced in Chambers (2002); for the other two see Fӓre and Zelenyuk (2019). Second, (2) provides the theoretically consistent way for aggregating (across DMUs) composite indicators by means of the Benefit-of-the-Doubt (BoD) model (see Karagiannis 2017), which essentially is an input-oriented DEA model with a single constant (unitary) input.
On the other hand, an alternative way to obtain the same aggregate value, namely c1z1+c2z2/(c1ξ1+c2ξ2), is to use harmonic aggregation and define the aggregation weights in terms of the numerator (instead of the denominator) of the relevant ratio–this is called the numerator rule by Fӓre and Karagiannis (2017):
where \(\delta _1 = c_1z_1/\left( {c_1z_1 + c_2z_2} \right) \ge 0\), \(\delta _2 = c_2z_2/\left( {c_1z_1 + c_2z_2} \right) \ge 0\) and δ1+δ2 = 1.
Next let us consider the relationship between the denominator rule with unit ratio difference and Aczél’s (1987, p. 150) geometric aggregation rule, namely:
where g1≥0, g2≥0 and g1+g2 = 1. In particular, we look for the values of g1 and g2 that make the aggregate value in (1) equal to the aggregate value in (4). For this purpose, we use Reinsdorf et al. (2002) result for the additive decomposition of geometric means, namely that
where \(\pi _1 = g_1/m\left( {z_1,\xi _1L} \right)\), \(\pi _2 = g_2/m\left( {z_2,\xi _2L} \right)\) and m(.) denotes the logarithmic mean, i.e., \(m\left( {z_1,\xi _1L} \right) = \left( {z_1 - \xi _1L} \right)/\left[ {\ln \left( {z_1} \right) - {{{\mathrm{ln}}}}\left( {\xi _1L} \right)} \right]\) and \(m\left( {z_2,\xi _2L} \right) = \left( {z_2 - \xi _2L} \right)/\left[ {\ln \left( {z_2} \right) - {{{\mathrm{ln}}}}\left( {\xi _2L} \right)} \right]\).Footnote 3 Then, from (1) and (5), we have \(\theta _1 = \pi _1\xi _1/\left( {\pi _1\xi _1 + \pi _2\xi _2} \right)\) and \(\theta _2 = \pi _2\xi _2/\left( {\pi _1\xi _1 + \pi _2\xi _2} \right)\). By substituting π1 and π2 into these and rearranging terms yields:
But from (1) we know that \(\theta _1 = c_1\xi _1/\left( {c_1\xi _1 + c_2\xi _2} \right)\) and \(\theta _2 = c_2\xi _2/\left( {c_1\xi _1 + c_2\xi _2} \right)\). Combining these with (6) and given that g1+g2 = 1, we obtain the values of g1 and g2 for which \(L\,=\,{\underline{L}}\) as:
An alternative proof of (7), following Balk (2008, pp. 141-42), is:Footnote 4 rewrite (1) as:
and use the logarithmic mean to get:
After few manipulations and rearrangement of terms, (9) results in:
where
By substituting \(\theta _1 = c_1\xi _1/\left( {c_1\xi _1 + c_2\xi _2} \right)\) and \(\theta _2 = c_2\xi _2/\left( {c_1\xi _1 + c_2\xi _2} \right)\) into (11) we can verify that η1 = g1 and η2 = g2.
If the ratios are given in the same units of measurement, then c1 = c2= 1 and the aggregation weights in (7) are simplified as follows:
This should be compared to the approximate solutions provided by Fӓre and Zelenyuk (2005) and Fӓre and Karagiannis (2020) for the arithmetic aggregation to result in the same aggregate value as the geometric aggregation. Here, thanks to the denominator rule with unit ratio difference, we are able to provide an exact solution to this problem.
As suggested by a referee, g1 and g2 in (7) may also be obtained by relating (3) and (4). In this case, a relation analogous to (5) is given as:
where \(\pi _1^\prime = g_1/m\left( {\xi _1,z_1L^{ - 1}} \right)\), \(\pi _2^\prime = g_2/m\left( {\xi _2,z_2L^{ - 1}} \right)\), \(m\left( {\xi _1,z_1L^{ - 1}} \right) = \left( {\xi _1 - z_1L^{ - 1}} \right)/\left[ {\ln \left( {\xi _1} \right) - {{{\mathrm{ln}}}}\left( {z_1L^{ - 1}} \right)} \right]\) and \(m\left( {\xi _2,z_2L^{ - 1}} \right) = \left( {\xi _2 - z_2L^{ - 1}} \right)/\left[ {\ln \left( {\xi _2} \right) - {{{\mathrm{ln}}}}\left( {z_2L^{ - 1}} \right)} \right]\). Then, following the same steps as above, one can verify that
We have thus shown that there are four alternative ways to obtain the same aggregate value of \(\left( {c_1z_1 + c_2z_2} \right)/\left( {c_1\xi _1 + c_2\xi _2} \right)\) by using either (1), (3), (4) with (7) or (4) with (14). The last two alternatives are less attractive than the first two, as the aggregate and the individual ratios (or their inverse) occur in the aggregation weights in (7) and (14). On the other hand, as aggregate data is published in the form of totals, aggregate performance ratios are better understood as arithmetic rather than geometric aggregates of the individual performance ratios (Färe and Karagiannis 2020). In addition, by comparing the first two alternatives, the denominator rule is intuitively more appealing and simpler than the numerator rule.
Notice that (1) and (4) with (7) rely on denominator-based weights while (3) and (4) with (14) on numerator-based weights. One may think that advantages would result by combining the two types of weights to obtain the aggregate ratio. This can be done, for example, by taking the geometric means of either (1) and (3) or (4) with (7) and (4) with (14). In such cases, however, the resulting relations are less useful for analytical purposes (e.g., for ascertaining the impact of individual ratios on the aggregate ratio) compared to those using either the denominator- or the numerator-based weights. Alternatively, one may follow a procedure analogous to that used for obtaining Montgomery and Sato-Vartia type of indices (see Balk 2008, pp. 85–87). In the former case, one can verify that the resulting aggregation weights do no add-up to 1 and this is a serious shortcoming when considering share weighted averages while in the latter the aggregation weights are given as:
which add-up to one but they are far less intuitively appealing compared to those of the denominator rule with unit ratio difference. In particular, the aggregation weights in (15) may be interpreted as the normalized logarithmic mean of the “value” shares of the numerator and denominator variables while the aggregation weights in (1) are simply the “value” shares of the denominator variable. For c1= c2 = 1, i.e., when the ratios are given in the same unit of measurement, (15) have been used by Balk (2021, ch. 9) for aggregating labor and total factor productivity indices across DMUs.
3 Some applications
In this section, we present several applications where the denominator rule with unit ratio difference may be used:
3.1 Price and quantity indices
We start by explaining how the denominator rule with unit ratio difference can be used to obtain the weighted average form of several well-known price and quantity indices.Footnote 5First, consider the case where \(c_1 = y_1^0\), \(c_2 = y_2^0\), \(z_1 = p_1^1\), \(\xi _1 = p_1^0\), \(z_2 = p_2^1\), and \(\xi _2 = p_2^0\), with pi and yi being respectively the price and the quantity of the ith commodity (subscripts are used to index commodities and superscripts to index time periods). Then, the application of the denominator rule with unit ratio difference results in the Laspeyres price index:
Similarly, if \(c_1 = y_1^1\), \(c_2 = y_2^1\), \(z_1 = p_1^1\), \(\xi _1 = p_1^0\), \(z_2 = p_2^1\), and \(\xi _2 = p_2^0\), then the application of the denominator rule with unit ratio difference results in the Paasche price index:
In addition, if \(c_1 = y_1^b\), \(c_2 = y_2^b\), \(z_1 = p_1^1\), \(\xi _1 = p_1^0\), \(z_2 = p_2^1\), and \(\xi _2 = p_2^0\), then the application of the denominator rule with unit ratio difference results in the Lowe price index:
where b refers to some third period.
Second, by interchanging the role of prices and quantities one can obtain the corresponding quantity indices: that is, (i) if \(c_1 = p_1^0\), \(c_2 = p_2^0\), \(z_1 = y_1^1\), \(\xi _1 = y_1^0\), \(z_2 = y_2^1\), and \(\xi _2 = y_2^0\), the application of the denominator rule with unit ratio difference results in the Laspeyres quantity index, (ii) if \(c_1 = p_1^1\), \(c_2 = p_2^1\), \(z_1 = y_1^1\), \(\xi _1 = y_1^0\), \(z_2 = y_2^1\), and \(\xi _2 = y_2^0\), one can obtain the Paasche quantity index, and (iii) if \(c_1 = p_1^b\), \(c_2 = p_2^b\), \(z_1 = y_1^1\), \(\xi _1 = y_1^0\), \(z_2 = y_2^1\), and \(\xi _2 = y_2^0\), we get the Lowe quantity index. These results clearly support Caves et al. (1982, p. 73) assertion that “numerous index number formulas can be explicitly derived from particular aggregator functions”. In the cases of the Laspeyres, Paasche and Lowe price and quantity indices, we have shown that this is given by the denominator rule with unit ratio difference.
3.2 Efficiency indices
Consider first the Fӓre (1975) input-oriented non-radial efficiency measure, which is defined as:
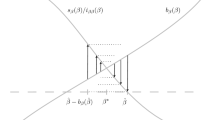
where xi refers to input quantities, L(y) = {x:(x,y)∈T} is the input requirement set and T is the production possibility set. The input requirement set is assumed to be closed and non-empty for finite y, to satisfy strong (input and output) disposability, input convexity, continuity, and 0I∉L(y) for y ≥ 0J but 0I∈L(0J).Footnote 6Ek (xk, yk) seeks the shortest, uni-dimensional distance to the frontier by scaling down each input in turn, holding output and other inputs fixed, and then takes the minimum over all these scalings. Let us assume that there are only two inputs and that we want to aggregate the efficiency scores of two firms or DMUs A and B (see Fig. 1). Then, according to the Fӓre (1975) efficiency measure, the score of firm A is determined by means of the first input while that of firm B by means of the second input; that is \(E^A = 1/\lambda _1^A = x_1^A/\widetilde x_1^A\) and \(E^B = 1/\lambda _2^B = x_2^B/\widetilde x_2^B\), where a tilde over a variable denotes its potential or technically efficient quantity. Applying the denominator rule with unit ratio difference to the optimal solution of (19) and let \(z_1 = x_1^A\), \(\xi _1 = \widetilde x_1^A = \lambda _1^Ax_1^A\), \(z_2 = x_2^B\), and \(\xi _2 = \widetilde x_2^B = \lambda _2^Bx_2^B\), we obtain:
with input prices being potential candidates for c1 and c2.

Fӓre input-oriented efficiency measure for a technology with two inputs and a single output
Second, consider the most widely used non-radial efficiency metric, namely the Russell measure, the input-oriented form of which is defined by Fӓre and Lovell (1978) as:
where \(\lambda _i^k = \widetilde x_i^k/x_i^k\). \(R^k\left( {x^k,y^k} \right)\) reduces all non-zero inputs by a set of individual factors that minimize the arithmetic mean of the reductions in such a way to ensure that the resulting input vector belongs to the efficient subset. The Russell measure has been often criticized (see e.g., Ruggiero and Bretschneider 1998) for implicitly assuming that all inputs equally affect the level of potential production, regardless of their importance in total cost as well as the extent of their input-specific inefficiency, i.e., the magnitude of the λi’s. To overcome this shortcoming, Zhu (1996) and Ruggiero and Bretschneider (1998) proposed a weighted Russell measure defined as:
In the literature, there are several different alternatives for determining the weights ϕ’s, ranging from expert opinion (Zhu 1996), to regression analysis (Ruggiero and Bretschneider 1998) and to Shannon entropy (Hsiao et al. 2011).
We may also use the denominator rule with unit ratio difference for determining the ϕ’s as the \(\lambda _i^k = \widetilde x_i^k/x_i^k\) are in different units of measurement. By substituting \(z_1 = \widetilde x_1^k\), \(z_2 = \widetilde x_2^k\), \(\xi _1 = x_1^k\) and \(\xi _2 = x_2^k\), we have for the two-inputs case:
where \(\theta _1^k = c_1^kx_1^k/\left( {c_1^kx_1^k + c_2^kx_2^k} \right)\) and \(\theta _2^k = c_2^kx_2^k/\left( {c_1^kx_1^k + c_2^kx_2^k} \right)\). There are several candidates for \(c_1^k\) and \(c_2^k\) but here we focus only on two that have been previously used in the literature. If we use input prices for \(c_1^k\) and \(c_2^k\), i.e., \(c_1^k = w_1\) and \(c_2^k = w_2\) where w refers to inputs prices, then (23) becomes what Fӓre et al. (1985, p. 148) referred to as the Russell input cost measure of technical efficiency. Alternatively, one may use output elasticities obtained from a production function regression model for \(c_1^k\) and \(c_2^k\), as Ruggiero and Bretschneider (1998) suggested, but this choice is less intuitively appealing.
Notice that if θ1= θ2 in (23) then we are back to the conventional Russell measure with \(c_1^kx_1^k = c_2^kx_2^k\) or alternatively, \(c_1^k/c_2^k = x_2^k/x_1^k\), which determines the slope of the implicit isocost line. The latter is essentially related to de Borger et al. (1998) interpretation of the conventional Russell measure’s projection point: for DMU A in Fig. 2, the projection point A1 reflects the cost minimizing input choice when the relative factor price equals the (negative) ratio of actual input quantities, i.e., \(- x_2^A/x_1^A\).Footnote 7 Given that cost at point A1 is equal to that at point A3, i.e., the point of intersection between the implicit isocost line and the ray through DMU A’s actual input bundle, the ratio OA3/OA renders to the conventional Russell measure of technical efficiency a (shadow) cost-saving interpretation (see Dervaux et al. 1998).Footnote 8 On the other hand, as actual cost at point A1 equals that at point A2, i.e., the point of intersection between the market isocost line and the ray through DMU A’s actual input bundle, the ratio OA2/OA renders to the Russell input cost measure of technical efficiency a clear cost saving interpretation.

Russell input-oriented efficiency measure for a technology with two inputs and a single output
Third, a similar issue, namely that input excesses are considered as equally important, arises in the case of the potential improvement inefficiency index, which in its input-oriented form is given as (see Bogetoft and Hougaard 1998):
where \(\widehat x_i^k\) is the ith coordinate of the ideal reference point corresponding to the largest possible reduction in the ith input such that \(\widehat x_i^k = min\left\{ {x_i^k:\left( {x_1^k, \ldots ,\widehat x_i^k, \ldots ,x_I^k} \right) \in L\left( y \right)} \right\}\), and \(\beta ^k = \left( {x_i^k - \widetilde x_i^k} \right)/\left( {x_i^k - \widehat x_i^k} \right)\) is constant for all inputs.Footnote 9 For the two-inputs case depicted in Fig. 3, the projection point of PA (xA, yA) is A1 and its coordinates are given by a “weighted” average of actual and ideal reference point coordinates, i.e., \(\widetilde x_i^k = \left( {1 - \beta ^k} \right)x_i^k + \beta ^k\widehat x_i^k\) for i = 1, 2. Both the potential improvement inefficiency index in (24), which is equal to the sum of the (normalized) input-specific potential improvement indices, and that of Wang et al. (2013), which is equal to the simple average of the (normalized) input-specific potential improvement indices, weight the excess of each input equally even if their prices or their cost shares differ significantly. Based on the denominator rule with unit ratio difference and by substituting \(z_1^k = x_1^k - \widehat x_1^k\), \(z_2^k = x_2^k - \widehat x_2^k\), \(\xi _1^k = x_1^k\) and \(\xi _2^k = x_2^k\) we can obtain a weighted potential improvement inefficiency index \(P_w^k\left( {x^k,y^k} \right)\), which overcomes the above criticism:
where \(\theta _1^k = c_1^kx_1^k/\left( {c_1^kx_1^k + c_2^kx_2^k} \right)\) and \(\theta _2^k = c_2^kx_2^k/\left( {c_1^kx_1^k + c_2^kx_2^k} \right)\). If \(c_1^k\) and \(c_2^k\) are set equal to input prices then \(P_w^k\left( {x^k,y^k} \right)\) has a nice cost-saving interpretation: let the slope of the iso-cost line passing through point A in Fig. 3 reflect the actual relative input prices, then \(P_w^A\left( {x^A,y^A} \right)\) = (cost at point A – cost at point A1)/cost at point A.

Potential improvement inefficiency measure for a technology with two inputs and a single output
Fourth, consider the enhanced Russell efficiency measure and its aggregation across DMUs. The enhanced Russell measure is defined as (Pastor et al. 1999):Footnote 10
Cooper et al. (2007), using essentially the conventional denominator rule suitable for ratios given in the same unit of measurement, derived a “system” efficiency measure for each input and output as:
where \(x_i^T = \mathop {\sum}\nolimits_{k = 1}^K {x_i^k}\) and \(y_j^T = \mathop {\sum}\nolimits_{k = 1}^K {y_j^k}\). Then, in an attempt to obtain an overall “system” efficiency measure they used the following relationship:Footnote 11
which however implicitly assumes that every input (output) has the same effect on cost-saving (revenue-enhancing). A more intuitively appealing overall “system” efficiency measure can be obtained by relying on the denominator rule with unit ratio difference. By setting \(z_i = \widetilde x_i^T\) and \(\xi _i = x_i^T\) for inputs and \(z_j = \tilde y_j^T\) and \(\xi _j = y_j^T\) for outputs we get:
with the most obvious candidates for ci and cj being the input and output prices.
3.3 Market Power Index
If we set c1 = y1, z1= p1−MC1, ξ1= p1, c2= y2, z2= p2−MC2, and ξ2= p2 then we can use the denominator rule with unit ratio difference to aggregate price-cost margins or Lerner (1934) indices of market power:
where MC refers to marginal cost. That is, the aggregate Lerner index is obtained by aggregating the individual measures with revenue shares as weights. Without any formal reasoning or any further explanation, Dickson (1979) used these weights to relate the aggregate Lerner index of market power with the Herfindahl index, the conjectural variation, and the industry demand elasticity.
4 Concluding remarks
In this paper we have provided a rule for consistent (arithmetic) aggregation of ratio-type variables with different units of measurement. This consists an extension of the denominator rule and the implied aggregation shares are given in terms of the denominator variable of the relevant ratio and the constants converting the relevant variables into the same unit of measurement. The denominator rule with unit ratio difference is a necessary and sufficient condition for consistent aggregation of ratio-type variables with different units of measurement. Its main advantage is that it can be used to aggregate ratio-type variables not only across DMUs but also across commodities, outputs or inputs.
The applicability of the conventional denominator rule is mainly limited to aggregation across DMUs and it is thus particular helpful for working with ratio-type performance measures, including a quite large number of efficiency and productivity indices. For some other performance measures though such as the non-radial technical efficiency indices, e.g., Fӓre efficiency measure and the enhanced Russell efficiency measure, and the Lerner index of market power that we considered in this paper, the denominator rule with unit ratio difference should be used to obtain a theoretically consistent aggregate (across DMUs) measure. By doing so, we have shown that (23) provides an alternative set of weights for aggregate Russell efficiency measure compared to that of Zhu (1996) based on expert opinion, and that of Hsiao et al. (2011) based on Shannon entropy. In addition, the denominator rule with unit ratio difference provides a justification for the weights used by Dickson (1979) to obtain the aggregate Lerner index of market power.
However, the applicability of the denominator rule with unit ratio difference goes beyond aggregation across DMUs as it can be used to aggregate price and/or quantities across commodities, outputs or inputs. As an illustration in Section 3, we have shown how Laspayres, Paasche and Lowe price and quantity indices can be obtained by applying the denominator rule with unit ratio difference. In addition, we have used it to derive a weighted Russell efficiency index and a weighted potential improvement efficiency index. In particular, (24) provides an alternative set of weights for the weighted potential improvement inefficiency index compared to equal weights used by Wang et al. (2013) while (29) provides an alternative set of weights for the enhanced Russell efficiency measure compared to those of Cooper et al. (2007) and Lozano (2009). The denominator rule with unit ratio difference could also be found useful in several other aggregation problems in economics, management and operation research.
Notes
The following result can easily be extended to the case of more than two variables.
See Balk (2004) for an alternative derivation of (5).
This was suggested by one of the reviewers.
But this does not, for example, apply to Palgrave price and quantity indices, which use comparison period value shares to aggregate price and quantity relatives.
0I and 0J are I- and J-dimensional zero vectors, respectively.
Bogetoft and Hougaard (1998) suggested that the projection point is determined by minimizing a linear function with gradient \(\left( {\frac{1}{{x_1^A}},\frac{1}{{x_2^A}}} \right)\).
Dervaux et al. (1998) also provided such a cost reinterpretation for the Fӓre efficiency index.
There is no general rule that applies for the normalization in (24) (Asmild et al. 2003). Here we follow Hougaard et al. (2004) and use \(x_i^k\), i.e., the actual input quantity. There is no need for any normalization when all input variables are measured on the same scale, e.g., in monetary terms.
The enhanced Russell measure is essentially a reformulation of the Fӓre et al. (1985, pp. 160-61) graph Russell measure of technical efficiency.
References
Aczél J (1987) A Short Course on Functional Equations. D. Reidel Publ. Co., Dordecht
Asmild M, Hougaard JL, Kronborg D, Kvist HK (2003) Measuring inefficiency via potential improvements. J Prod Anal. 19:59–76
Balk BM (2004) Decompositions of Fisher Indexes. Econ Lett. 82:107–13
Balk BM (2016) Various approaches to the aggregation of economic productivity indices. Pac Econ Rev. 21:445–63
Balk BM (2021) Productivity: concepts, measurement, aggregation and decomposition. Springer Nature, Switzerland AG
Balk BM (2008) Price and quantity index numbers: models for measuring aggregate change and difference, Cambridge University Press, Cambridge
Basu S (2019) Are price-cost markups rising in the United States? A discussion of the evidence. J Econ Perspect.33:3–22
Bogetoft P, Hougaard JL (1998) Efficiency evaluations based on potential (non-proportional) improvements. J Product Anal. 12:233–47
Caves DW, Christensen LR, Diewert WE (1982) Multilateral comparison of output, input and productivity using superlative index numbers. Econ J. 92:73–86
Chambers RG (2002) Exact nonradial input, output and productivity measurement. Econ Theory 20:751–65
Cooper WW, Huang Z, Li SX, Parker BR, Pastor JT (2007) Efficiency aggregation with enhanced Russell measures in data envelopment analysis. Soc-Econ Plan Sci. 41:1–21
de Borger B, Ferrier GD, Kerstens K (1998) The choice of a technical efficiency measure on the free disposal hull reference technology: a comparison using US banking data. Eur J Oper Res. 105:427–46
deLoecker J, Eeckhout J, Unger G (2020) The rise of market power and the macroeconomic implications. Q J Econ. 135:561–644
Dervaux B, Kerstens K, van den Eeckaut P (1998) Radial and nonradial static efficiency decompositions: a focus on congestion measurement. Transp Res Part B 32:299–312
Dickson VA (1979) The Lerner index and measures of concentration. Econ Lett. 3:275–79
Fӓre R (1975) Efficiency and the production function. J Econ. 35:317–24
Fӓre R, Lovell CAK (1978) Measuring the technical efficiency of production. J Econ Theory 19:150–62
Fӓre R, Zelenyuk V (2005) On Farrell’s decomposition and aggregation. Int J Bus Econ. 4:167–71
Fӓre R, Karagiannis G (2017) The denominator rule for share-weighting aggregation. Eur J Oper Res. 260:1175–80
Fӓre R, Zelenyuk V (2019) On Luenberger input, output and productivity indicators. Econ Lett 179:72–74
Fӓre R, Karagiannis G (2020) On the denominator rule and a theorem by Janos Aczel. Eur J Oper Res. 282:398–400
Fӓre R, Karagiannis G (2022) Aggregating Farrell efficiencies without value data: the case of hospitals. Soc-Econ Plan Sci. 84:101393
Fӓre R, Grosskopf S, Lovell CAK (1985) The Measurement of Efficiency of Production, Kluwer Publ., Dordrecht
Hougaard JL, Kronborg D, Overgӓrd C (2004) Improvement potential in Danish elderly care. Health Care Manag Sci 7:225–35
Hsiao B, Chern CC, Chiu CR (2011) Performance evaluation with entropy-based weighted Russell measure in data envelopment analysis. Expert Syst Appl. 38:9965–72
Karagiannis G (2015a) On structural and average technical efficiency. J Prod Anal. 43:259–67
Karagiannis G (2017) On aggregate composite indicators. J Oper Res Soc. 68:741–746
Karagiannis G (2015b) On Aggregating Programmatic Efficiency, 5th Workshop on Efficiency and Productivity Analysis, Porto, Portugal
Koopmans TC (1957) Three Essays on the State of Economic Science. McGraw Hill, N.Y
Lerner AP (1934) The concept of monopoly and the measurement of monopoly power. Rev Econ Stud. 1:157–75
Lozano S (2009) A note on efficiency aggregation with enhanced Russell measures in data envelopment analysis. Soc-Econ Plan Sci. 43:217–18
Nguyen BH, Zelenyuk V (2021) Aggregate efficiency of industry and its groups: the case of Queensland public hospitals. Empir Econ. 60:2795–2836
Pastor JT, Ruiz JL, Sirvent I (1999) An enhanced Russell graph efficiency measure. Eur J Oper Res. 115:596–607
Pilayavsky A, Staat M (2008) Efficiency and productivity change in Ukrainian health case. J Prod Anal. 29:143–54
Reinsdorf MB, Diewert WE, Ehemann C (2002) Additive decompositions for Fisher, Tornqvist and geometric mean indexes. J Econ Soc Measurement 28:51–61
Rogge N (2018) On aggregating Benefit of the Doubt composite indicators. Eur J Oper Res. 264:364–369
Ruggiero J, Bretschneider S (1998) The weighted Russell measure of technical efficiency. Eur J Oper Res. 108:438–51
Shaffer S, Spierdijk L (2020) Measuring multi-product banks’ market power using the Lerner index. J Bank and Finance 117:105859
Walheer B (2018b) Cost Malmquist productivity index: an output-specific approach to group comparison. J Product Anal. 49:79–94
Walheer B (2018a) Aggregation of metafrontier technology gap ratios: the case of European sector in 1995-2015. Eur J Oper Res. 269:1013–26
Walheer B (2019) Aggregating Farrell efficiencies with private and public inputs. Eur J Oper Res. 276:1170–77
Wang K, Wei YM, Zhang X (2013) Energy and emissions efficiency patterns in Chinese regions: a multi-directional efficiency analysis. Appl Energy 104:105–16
Zhu J (1996) Data envelopment analysis with preferences structure. J Oper Res Soc. 47:136–50
Acknowledgements
We would like to thank three anonymous Reviewers, an Associate Editor, and an Editor (Victor Podinovski) for useful comments and suggestions.
Funding
Open access funding provided by HEAL-Link Greece.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Färe, R., Karagiannis, G. The denominator rule with unit ratio difference. J Prod Anal 61, 183–190 (2024). https://doi.org/10.1007/s11123-023-00698-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11123-023-00698-9