
Abstract
This paper presents a robust adaptive position and force control scheme for an n-link robot manipulator under unknown environment. The robot manipulator’s model and the stiffness coefficient of contact environment are assumed to be not exactly known. Therefore, the traditional impedance force controller cannot be applied. We herein adopt the fuzzy neural networks (FNNs) to estimate the unknown model matrices of robot manipulator and the adaptive tracking position and force control is developed by the proposed adaptive scheme. Based on the Lyapunov stability theory, the stability of the closed-loop system and convergence of adjustable parameters are guaranteed. The corresponding update laws of FNNs’ parameters and estimated stiffness coefficient of contacting environment can be derived. Finally, simulation results of a two-link robot manipulator with environment constraint are introduced to illustrate the performance and effectiveness of our approach.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Recently, various control strategies for treating the interaction control problem of robot manipulator are proposed, e.g., impedance control and the hybrid force control algorithms [1, 3, 5–13, 15, 16, 28–36, 38, 40]. The impedance control of robot manipulators is to adjust the end-effector position and sense the contact force in response to satisfy the target impedance behavior. Several robust control schemes and adaptive control strategies have been proposed for motion control of robot manipulator [1, 3, 4, 10, 31, 34–36, 38]. In the literature [5, 12, 13, 40], adaptive impedance control schemes using approximation technique for an n-link robot manipulator without regressor are introduced. The modifications of impedance function have been proposed to solve the force tracking problem on unknown environment [16].
As above, the purpose of this paper is to introduce a robust adaptive force and position tracking problem for robot manipulator with model uncertainties and the task environment is unknown. Many approaches are proposed to deal with the adaptive controller design for systems with uncertainties and disturbance. In [17–19], the neural network approach was proposed to treat the system uncertainties in force control problem. In addition, an on-line learning method was introduced to regulate all impedance parameters as well as desired trajectory [39]. Similarly, the fuzzy logic control was developed by human experience to implement nonlinear control algorithms [21–25]. Besides, the recurrent fuzzy neural network is introduced to deal with uncertainties and disturbances [33]. Therefore, the fuzzy neural networks (FNNs) are adopted to treat the tracking control of robot manipulator.
In this paper, a robust FNN-based adaptive force tracking control is proposed for robot manipulator with uncertainties and unknown stiffness coefficient. The dynamic model of the robot manipulator and the stiffness coefficient of contact environment are assumed to be unknown. Therefore, we cannot solve the force tracking control by using the traditional approaches. Thus, the FNN estimators are adopted to approximate the system’s dynamic model and to develop the proposed adaptive tracking control scheme. In addition, the adaptive force control law is established by gradient method. Based on the Lyapunov stability approach, the update laws of FNNs’ parameters and estimated stiffness coefficient are obtained. In addition, the stability of the closed-loop system and convergence of parameters are guaranteed. Finally, simulation results of a two-link robot manipulator with environment constraint are introduced to illustrate the performance and effectiveness of our approach.
The rest of this paper is as follows. Section 2 introduces the problem formulation and the used fuzzy neural network system. The proposed adaptive force control scheme is introduced in Sect. 3. The theoretical analysis is also introduced here. In Sect. 4, simulation results of a two-link robot manipulator are presented. Finally, conclusion is given.
2 Problem formulation
2.1 System description
The dynamic model of an n-link rigid robot manipulator in joint space coordinate is
where \(\mathbf{q}\in \mathfrak {R}^{n}\) denotes the vector of generalized displacement in robot coordinates, \(\varvec{{\uptau } }\in \mathfrak {R}^{n}\) is the vector of joint torque, \(\mathbf{D}(\mathbf{q})\in \mathfrak {R}^{n\times n}\) is the inertia matrix, \(\mathbf{C}(\mathbf{q},\dot{\mathbf{q}})\dot{\mathbf{q}}\in \mathfrak {R}^{n}\) is the vector of centrifugal and Coriolis forces, \(\mathbf{g}(\mathbf{q})\in \mathfrak {R}^{n}\) is the gravity vector. \(\mathbf{J}(\mathbf{q})\in \mathfrak {R}^{n\times n}\) is the Jacobian matrix, which is assumed to be nonsingular, and \(\mathbf{F}_\mathrm{ext} \in \mathfrak {R}^{n}\) is the external force at the end-effector. In the case of \(n>6\), the manipulator is redundant; then, the inverse of Jacobian \((\mathbf{J}^{-1})\) should be replaced by pseudo-inverse \(\mathbf{J}^{+}=\mathbf{J}^{T}(\mathbf{JJ}^{T})^{-1}\). System (1) can be transferred to the Cartesian space as
where \(\mathbf{x}\in \mathfrak {R}^{n}\) is the location vector of the end-effector in Cartesian space and
In most practical cases, the system dynamic model are not exactly known, thus identification or modeling of the robot manipulator model are needed for the controller design. In this paper, the FNN estimators solve this problem, i.e., the FNNs estimate the functions of \(\mathbf{D}_{x},\, \mathbf{C}_{x}\), and \(\mathbf{g}_{x}\).
The purpose of this paper is to provide proper control signals such that the end-effector of robot manipulator follows the desired trajectory for free space and tracks the desired force for contact space even the system with uncertainties and works under unknown environment (stiffness coefficient is unknown).

2.2 Fuzzy neural network system
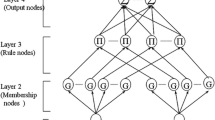
Herein, we introduce the FNN systems briefly as follows [21–23]. The schematic diagram of the used FNN with four layers is shown in Fig. 1, where “G” denotes the Gaussian fuzzy term set. Layer 1 is the input layer that accepts input variables and its nodes represent fuzzy input linguistic variables. The nodes in this layer only transmit input variables to the next layer directly, i.e., \(O_i^{(1)} =x_i \). Layer 2 operates as the fuzzification; each node calculates the corresponding membership grade for input \(x_{i}\)
where \(m_{ij}\) and \(\sigma _{ij}\) are the center and the width of the Gaussian function, respectively. In layer 3 (rule layer), each node represents the fuzzy rule and the t-norm product operation is adopted. Links before layer 3 represent the preconditions of the rules, and the links after layer 3 represent the consequences of the fuzzy rule, the output of Layer 3 is
Layer 4 is the output layer. Each node is for actual output of FNN system that is connected by weighting value \(w_{j}\), the \(p^{\mathrm{th}}\) output is
where \(\mathbf{w}=\left[ {w_1 w_2 ,\,\ldots ,w_R } \right] ^{T}\) is the weighting vector and \(\varvec{{\uppsi } }=\left[ {\varvec{{\uppsi } }^{1}\,\varvec{{\uppsi } }^{2}, \ldots , \varvec{{\uppsi } }^{R}} \right] , \varvec{{\uppsi } }^{j}={O_j^{(3)} }\Big /{\sum \nolimits _j^R {O_j^{(3)}}}\) and R is the chosen rule number. As above, there is R adjustable parameters for a single output FNN with R rules. Herein, the FNN is adopted to estimate the unknown matrices of robot manipulator. In addition, the FNN realizes the fuzzy inference into the network structure. Assume that an FNN system has R rules and n inputs; the \(j\hbox {th}\) rule can be expressed as
where \(x_{j}\) denotes the input linguistic variable, \(A_{1j}\) is the fuzzy set represented by the Gaussian fuzzy term set, and \(\omega _{pj}\) is the consequent part parameter for inference output \(y_{p}\). That is, the FNN provides the linguistic representation for the approximated function. In addition, as the mention of [21], the FNNs have the properties of universal approximator, fast convergence, less adjustable parameters, and parallel distribution scheme. The universal approximation theorem states “if the FNN has a sufficiently large number of fuzzy logical rules (or neurons), then it can approximate any continuous function in \(C(\mathfrak {R}^{n})\) over a compact subset of \(\mathfrak {R}^{n}\).” Therefore, the FNNs have the abilities of estimating the system dynamic matrices.

The proposed adaptive tracking control scheme using FNNs

Force tracking control scheme using FNNs
3 Robust adaptive position and force control scheme under unknown stiffness coefficient
As the results of traditional impedance control [2], the corresponding system parameters are exactly known, and then the closed-loop system satisfies the target impedance
where \(\mathbf{M}_m ,\mathbf{B}_m \), and \(\mathbf{K}_{m}\) are diagonal \(n\times n\) matrices gain, \(\mathbf{x}_\mathrm{d} \in \mathfrak {R}^{n}\) is the reference end-effector trajectory (reference location). However, system dynamic model is not exactly known, the proposed adaptive control utilizes the FNNs to approximate the system model matrices (denote as \(\hat{\mathbf{D}}_\mathbf{x} ,\,\hat{\mathbf{C}}_\mathbf{x}\), and \(\hat{\mathbf{g}}_\mathbf{x} )\) for solving the tracking control problem.
Herein, the control objective is divided into two cases; Case (a) is to design an adaptive controller such that \(\mathbf{x}\) approaches to \(\mathbf{x}_{d}\) asymptotically for free space (\(\mathbf{F}_\mathrm{ext}=0\)); Case (b), we should pay additional effort to design the adaptive force controller such that \(\mathbf{F}_\mathrm{ext}\) is equal to the desired force \(\mathbf{F}_{d}\) for contact space. However, the environment stiffness is not exactly known, then we cannot design the reference trajectory \(\mathbf{x}\) to achieve the desired force directly. In this paper, we solve the problem by using FNN-based adaptive tracking controller firstly, shown in Fig. 2. Based on the Lyapunov stability approach, the stability analysis of the closed-loop system and the update laws of FNNs’ parameters are obtained. After solving the tracking control problem, the adaptive force tracking scheme is introduced for contact environment with unknown stiffness coefficient, shown in Fig. 3. The corresponding parameter estimator and update law are proposed based on the Lyapunov approach that guarantees the convergence. More details are introduced below.
3.1 Adaptive tracking controller design
Herein, we first consider the adaptive tracking control for free space. The system model matrices \(\mathbf{D}_{\mathbf{x}},\, \mathbf{C}_{\mathbf{x}}\), and \(\mathbf{g}_{\mathbf{x}}\) are not exactly known which are estimated by FNNs. Before introducing the proposed approach, we first define \(\mathbf{e}=\mathbf{x}-\mathbf{x}_\mathbf{d} \) and \(\mathbf{s}=\dot{\mathbf{e}}+\Lambda \mathbf{e}\), where \(\Lambda =\hbox {diag}(\lambda _1 ,\lambda _2 ,\ldots ,\lambda _n )\) with \(\lambda _i >0\) for \(i=1,\, {\ldots }, n\). Rewrite system (2) as
where \(\hat{\mathbf{D}}_\mathbf{x} =\hat{{\mathbf{w}}}_D^T \varvec{{\uppsi } }_D\), \(\hat{\mathbf{C}}_\mathbf{x} =\hat{{\mathbf{w}}}_C^T \varvec{{\uppsi } }_C \), and \(\hat{\mathbf{g}}_\mathbf{x} =\hat{{\mathbf{w}}}_g^T \varvec{{\uppsi } }_g \) are the estimations of \(\mathbf{D}_{\mathbf{x}},\, \mathbf{C}_{\mathbf{x}}\), and \(\mathbf{g}_{\mathbf{x}}\), respectively. \(\hat{{\mathbf{w}}}\) denotes the weighting matrix of the FNN, and \(\varvec{{\uppsi }}\) is the normalized firing strength of the corresponding fuzzy rules (it also viewed as basis function matrix). According to the universal approximation property of the FNNs, there exists optimal weighting matrix \(\mathbf{w}^{*}\) such that the unknown functions are represented as follows with approximation error \(\varepsilon \), i.e.,
where \(\mathbf{w}_D^*\in \mathfrak {R}^{n^{2}R}\), \(\mathbf{w}_C^*\in \mathfrak {R}^{n^{2}R}\), and \(\mathbf{w}_g^*\in \mathfrak {R}^{nR}\) and \(\varvec{{\uppsi } }_D \in \mathfrak {R}^{n^{2}R}\), \(\varvec{{\uppsi } }_C \in \mathfrak {R}^{n^{2}R}\), \(\varvec{{\uppsi } }_G \in \mathfrak {R}^{nR}\). R represents the rule number of FNN. Note that \(\hat{\mathbf{D}}_\mathbf{x} \in \mathfrak {R}^{n\times n}\) has \(n\times n\) functions, then we have \(n\times n\times R\) adjustable parameters when each unknown function is approximated by an FNN having R rules.
As above, we have the following theorem to guarantee the stability of the closed-loop systems for tracking control problem.
Theorem 1
Consider the nonlinear system (2) with uncertainties and nonsingular property, i.e., \(\mathbf{D}_{\mathbf{x}},\, \mathbf{C}_{\mathbf{x}}\), and \(\mathbf{g}_{\mathbf{x}}\) are not exactly known, the adaptive controllers are designed as
where \(\varvec{{\uptau } }_\mathrm{robust} \) is the robust controller which plays the role of compensator, \(s_i \), \(i=1,\ldots ,n\) is the ith element of \(\mathbf{s},\, \delta \) is the selected amplitude of robust controller (robust control gain), and \(\mathbf{K}_{d}\) is positive matrix in which is usually chosen as diagonal matrix, i.e., \(\mathbf{K}_{d}= \hbox {diag}(k_{d1},\, k_{d2}, {\ldots },\, k_{dn})\). In addition, the update laws of FNNs are chosen as
where \(\mathbf{Q}_\mathbf{D} \in \mathfrak {R}^{n^{2}R\times n^{2}R}\), \(\mathbf{Q}_\mathbf{C} \in \mathfrak {R}^{n^{2}R\times n^{2}R}\), \(\mathbf{Q}_\mathbf{g} \in \mathfrak {R}^{nR\times nR}\) are positive definite matrices. Then, the asymptotically convergence of tracking error is guaranteed, i.e., the state \(\mathbf{x}\) will follow the desired trajectory \(\mathbf{x}_{\mathbf{d}}\) when t approaches to infinity.
Proof
By the representation of (11) and (12), we have
where \(\tilde{\mathbf{w}}=\hat{{\mathbf{w}}}-\mathbf{w}^{*}\) and \(\varvec{{\upvarepsilon }}_1 =\varvec{{\upvarepsilon }}_1 (\varvec{{\upvarepsilon }}_{{\mathbf{D}_X}} ,\varvec{{\upvarepsilon }}_{{\mathbf{C}_x}} ,\, \varvec{{\upvarepsilon }}_{\mathbf{g}_x} ,\mathbf{s},\ddot{\mathbf{x}})\) denotes the lumped bounded approximation error of \(\mathbf{D}_{\mathbf{x}},\, \mathbf{C}_{\mathbf{x}}\), and \(\mathbf{g}_{\mathbf{x}}\). Define the Lyapunov candidate function
where \(\mathbf{Q}_\mathbf{D} \in \mathfrak {R}^{n^{2}R\times n^{2}R}\), \(\mathbf{Q}_\mathbf{C} \in \mathfrak {R}^{n^{2}R\times n^{2}R}\), \(\mathbf{Q}_\mathbf{g} \in \mathfrak {R}^{nR\times nR}\) are positive definite matrices and Trace(.) is the trace operation. Hence
then
Note that \(\mathbf{s}^{T}[\dot{\mathbf{D}}_x (\mathbf{x})-2\mathbf{C}_x (\mathbf{x},\dot{\mathbf{x}})]\mathbf{s}=0\) for all \(\mathbf{s}\in \mathfrak {R}^{n}\). We choose the FNNs’ update laws (15) and robust controller (14) such that
This concludes that the convergence of \(\mathbf{s}\) is guaranteed if the proper value of \(\delta \) is selected. This completes the proof. \(\square \)
Remark 1
To avoid the highly control gain of robust controller, we have the robust controller with adaptive boundary as follows
where \(\varvec{{\uptau } }_\mathrm{robust} \) is the robust controller (or compensation controller) with adaptive boundary \(\hat{{\delta }}\) and \(\delta ^{*}\) denotes the existed optimal bound of robust controller. Thus, the corresponding Lyapunov function candidate of V is
where \(\tilde{\delta }\equiv \hat{{\delta }}-\delta ^{*}\) denotes the estimated error of approximated error bound. According the above results, we can obtain
Therefore, substitute (23) into (25), we have \(\dot{V}\le 0\) and asymptotic convergence of \(\mathbf{s}\) can be concluded. This guarantees the stability of the closed-loop system.
The remaining work is to develop the adaptive force tracking control for contact space when the environment stiffness is unknown.
3.2 Adaptive force control scheme
As above description, our goal is to achieve \(\mathbf{F}_\mathrm{ext}=\mathbf{F}_{d}\). In contact cases, the end-effector position of robot manipulator \(\mathbf{x}\) satisfies the target impedance equation (10). The inertia and damping parameters only influence the transient response of the end-effector [14, 26]; thus, the steady-state contact force is
Considering for simplicity the environment modeled by a linear spring with stiffness \(\mathbf{K}_\mathrm{e}\), the contact force is given by
where \(\mathbf{K}_\mathrm{e}\) is the stiffness coefficient of contact environment and \(\mathbf{x}_\mathrm{e}\) is the position of environment. This leads to the following steady-state position and contact force [36]
As above description, the desired force \(\mathbf{F}_{d}\) between robot and environment is obtained when \(\mathbf{K}_\mathrm{e}\) is known
where \(\mathbf{x}^*\) is ideal trajectory such that \(\mathbf{F}_\mathrm{ext}=\mathbf{F}_{d}\) which is achieved by designing reference trajectory from (28)
However, the stiffness coefficient \(\mathbf{K}_\mathrm{e} \) is usually unknown; therefore, \(\mathbf{x}^{*}\) cannot be obtained directly. From (26) and (29), the tracking error of force can be represented as
Since the stiffness should be estimated, thus we rewrite (29) as
where \(\hat{{\mathbf{K}}}_\mathrm{e} \) is the estimated stiffness coefficient. In this paper, the update law of \(\hat{{\mathbf{K}}}_\mathrm{e} \) is derived by the gradient method and the convergence is guaranteed by Lyapunov approach. To obtain the adaptation of \(\hat{{\mathbf{K}}}_\mathrm{e} \), we first define the force error and the corresponding objective function to be minimized as
and the Lyapunov candidate function is defined
For simplicity, we consider that the force is applied to only one direction, therefore, \(\mathbf{e}_\mathrm{f} ,\mathbf{F}_\mathrm{d} \), and \(\mathbf{F}_\mathrm{ext}\) are scalar, i.e., \(e_\mathrm{f} =f_\mathrm{d} -f_\mathrm{ext} \) where \(f_{d}\) and \(f_\mathrm{ext}\) denote the desired force and contact force for one direction. Then, let \(\hat{{K}}_\mathrm{e} \) be an element of \(\hat{{\mathbf{K}}}_\mathrm{e} \), thus, \(V_F =\frac{1}{2}e_\mathrm{f}^2 \) and the corresponding gradient of \(V_F \) is

Thus, the update of \(\hat{{K}}_\mathrm{e} \) is chosen as follows by the gradient method
where \(\eta _{K_\mathrm{e}} \) is the learning rate. For the training process, the learning rate plays an important role for this case. A small value of \(\eta _{K_\mathrm{e}}\) leads a slower convergence and a large value may have unstable result. Hence, the selection of \(\eta _{K_\mathrm{e} } \) is important. Herein, the Lyapunov approach is adopted to guarantee the convergence of \(\hat{{K}}_\mathrm{e} \). We then have the convergence theorem.
Theorem 2
Consider the force tracking control problem as above description and let \(\eta _{K_\mathrm{e} } \) be the learning rate of the estimation of stiffness. The force tracking can be achieved if the learning rate \(\eta _{K_\mathrm{e} } \)is selected satisfies
Proof
Rewrite (34) as
where \(e_\mathrm{f} (k)=f_\mathrm{d} (k)-f_\mathrm{ext} (k)\) and k is time-instant for parameter update. Let \(\Delta e_\mathrm{f} (k)=e_\mathrm{f} (k+1)-e_\mathrm{f} (k)\) and then we have
By the gradient result, \(\Delta e_\mathrm{f} (k)\approx \frac{\partial e_\mathrm{f} }{\partial \hat{{K}}_\mathrm{e} }\Delta \hat{{K}}_\mathrm{e} \) and \(\Delta \hat{{K}}_\mathrm{e} =-\eta _{K_\mathrm{e} } (\frac{\partial V_F }{\partial \hat{{K}}_\mathrm{e} })\), we obtain
and
As above, we can obtain the stability condition for selection of learning rate \(\eta _{K_\mathrm{e} } \), condition (37), this implies \(\Delta V(k)<0, \quad \forall k>0\), this means that the force error will approach to zero. In addition, the convergence of stiffness coefficient can be guaranteed, i.e., actual value of \(K_\mathrm{e}\) can be obtained. This completes the proof. \(\square \)
After estimating the coefficient \(\mathbf{K}_\mathrm{e}\), we remain to find the desired trajectory \(\mathbf{x}^*\) such that \(\mathbf{F}_\mathrm{ext}=\mathbf{F}_{d}\). In addition, to accomplish force control, we should design the suitable \(\mathbf{x}\) for contact space. From (28) and estimation of \(\mathbf{K}_\mathrm{e}\), we have the variation of desired position
where \(\Delta \mathbf{x}=\mathbf{x}_{ss} -\mathbf{x}\) and \(\Delta \mathbf{F}=\mathbf{F}_\mathrm{d} -\mathbf{F}_\mathrm{ext} \), then we can design the ideal trajectory to achieve force control as follows iteratively
According equation (30), in considering the steady state, we obtain the new desired trajectory for the contact case

As the results of Theorem 1, the end-effector of robot will follows the desired trajectory, thus, the above discussion guarantees the convergence of force tracking error even the stiffness gain \(K_\mathrm{e} \) is unknown, i.e., \(\mathbf{F}_\mathrm{ext} \) approaches to \(\mathbf{F}_\mathrm{d}\).
4 Simulation results
Herein, the proposed control approach is applied on the impedance force tracking control of a robot manipulator system with two rigid links and two rigid revolute joints. For \(i=1, 2,\, m_{i}\), \(l_{i},\, l_{ci}\), and \(I_{i}\) are mass, length, gravity center length and inertia of link i, respectively. The actual values of quantities are \(m_{1}=2\,\hbox {kg},\, m_{2}=1\,\hbox {kg},\, l_{1}=l_{2}=0.75\,\hbox {m},\, l_{c1}=l_{c2}=0.375\,\hbox {m},\, I_{1}=0.09375\,\hbox {kg}\,\hbox {m}^{2},\, I_{2}=0.046975\,\hbox { kg}\,\hbox {m}^{2}\) [40]. The inertia matrix \(\mathbf{D}(\mathbf{q})\) is defined as
where \(d_{11}=m_1 l_{c1}^2 +m_2 l_1^2 +I_1 +m_2 l_{c2}^2 +I_2 +2m_2 l_1 l_{c2} \cos q_2 , \quad d_{12} =d_{21} =m_2 l_{c2}^2 +I_2 +m_2 l_1 l_{c2} \cos q_2 \), and \(d_{22} =m_2 l_{c2}^2 +I_2 \). \(\mathbf{C}(\mathbf{q},\dot{\mathbf{q}})\) and \(\mathbf{g(q)}\) are defined as
The Jacobian matrix is
The initial condition for the end-effector and reference state are \(\mathbf{x}(0)=[0.75\,0.75\,0\,0]^{T}\) and \(\mathbf{x}_m (0)=[0.8\,0.8\,0\,0]^{T}\). The desired trajectory \(\mathbf{x}_{d}\) is a 0.2 m-radius circle centered at (0.8, 1.0 m) in 10 s as follows
As above discussion, system parameter matrices \(\mathbf{D},\, \mathbf{C}\), and \(\mathbf{g}\) are assumed to be not exactly known and are approximated by the FNNs. Initial weighting vectors of FNN are chosen as to be zero to avoid initial larger control effort and the fuzzy rule number are chosen as seven for \(\hat{\mathbf{D}}_\mathbf{x},\,\hat{\mathbf{C}}_\mathbf{x} ,\) and \(\hat{\mathbf{g}}_\mathbf{x}\). The update laws gain matrices in (15) are chosen with
According to the approximation theorem of FNNS, we assume \(\varvec{{\upvarepsilon }}_1 \) cannot be eliminated and there exists a positive constant \(\delta \) such that \(\left\| {\varvec{{\upvarepsilon }}_1} \right\| \le \delta \) for all \(t\ge 0\). Herein, \(\delta \) is selected to be one. The constraint surface is a flat wall with a triangle crack, and the environment can be modeled as linear spring \(f_\mathrm{ext} =k_w (x-x_w )\). \(f_\mathrm{ext}\) is the force acting on the surface, \(k_w =5000~\hbox {N}/\hbox {m}\) is the environment stiffness, x is the coordinate of the end-effector in the x-direction, and \(x_w =0.95m\) is the position of the surface. Therefore, the external force vector in equation (2) becomes \(\mathbf{F}_\mathrm{ext} =[f_\mathrm{ext} \,0]^{T}\). The controller gains are selected as
Herein, the gain matrices in the target impedance are described in [5]. Several illustrated examples are introduced to demonstrate the performance and effectiveness of the proposed adaptive control approach.

Position tracking performance result at \(t =\) 0–5 s

Force tracking performance with different learning rates
4.1 Adaptive tracking and force control
In this example, the desired force is selected as 3 Nt. Figure 4 shows the trajectory tracking performance in the Cartesian space (solid: robot position; dashed: environment trajectory; dash-dotted: estimated environment trajectory). We can find that the end point of robot contact the constraint surface is a flat wall with a triangle crack and track the reference trajectory in free space. For the force control, herein, we test the different learning rates \(\eta =\)10000, 30000 and 60000 to have the comparison results in Fig. 5. Obviously, the larger value of \(\eta \) performs quickly. Figure 6 shows the estimated stiffness \(\hat{{\mathbf{K}}}_\mathrm{e} \) and environment position. One can observe that the variations of the estimated \(\hat{{\mathbf{K}}}_\mathrm{e} \) and \(x^{*}\) are changed at 1.35 s, 2.1 s, 2.51 s, 2.9 s due to the end-effector touches the wall and triangle crack. From the observation of Fig. 6, we can find that the estimated stiffness coefficient is convergent and the estimated environment position is contained to achieve the adaptive force control. Figure 7 shows the control effort at \(t =\) 1–10 s. We can observe that the impulse control torque is obtained due to the change of environment. In addition, the fast convergence of tracking error and control efforts also shows the performance and effectiveness of our approach.

Stiffness and estimated environment position

Control effort of example 1
4.2 Variation of tracking force
From the observation of Fig. 5, we can find that the estimated stiffness coefficient is convergent and the estimated environment position is obtained to achieve the adaptive force control. Herein, simulation results of variant tracking force example are introduced. Figure 8a introduces the force variation (dashed: desired force; solid: actual force). It can be observed that the contact force follows the desired force even the environment surface is changed. Figure 8b shows the estimated stiffness \(\hat{{K}}_\mathrm{e} \) and environment position. One can find that the adaptive force tracking control is achieved by our proposed approach and the estimated \(x^{*}\) is also obtained such that \(f_\mathrm{ext}\) approaches to \(f_{d}\). From this illustrated examples, we can observe that the proposed adaptive approach performs well (the estimated \(\hat{{K}}_\mathrm{e}\) and \(x^{*}\) can vary at the same time due to the change of environment and desired tracking force).

Simulation results of variant tracking force, a force tracking performance with different force, b estimated stiffness and estimated environment position

The controller performance with uncertainties as mass \(=\) 5 kg of link 2 (dashed desired trajectory; dotted our proposed approach, and dash-dotted ideal controller)
4.3 Robustness illustration
Herein, we introduce the robustness of the proposed adaptive approach and the necessity of the estimation of robot model (\(\mathbf{D}_{\mathbf{x}}\), \(\mathbf{C}_{\mathbf{x}}\), \(\mathbf{g}_{\mathbf{x}}\)) for uncertain systems. In order to illustrate the effectiveness of our approach for system with uncertainties, we assumed the nominal and actual masses of link two are 1 and 5 kg, respectively. The comparison results between our approach and the ideal impedance controller are presented, where the ideal controller is derived by nominal model (\(\mathbf{D}_{\mathbf{x}}\), \(\mathbf{C}_{\mathbf{x}}\), \(\mathbf{g}_{\mathbf{x}}\) are given), i.e., \(\hat{\mathbf{D}}_\mathbf{x} ,\, \hat{\mathbf{C}}_\mathbf{x} ,\, \hat{\mathbf{g}}_\mathbf{x}\) in equation (15) are replaced by \(\mathbf{D}_{\mathbf{x}}\), \(\mathbf{C}_{\mathbf{x}}\), \(\mathbf{g}_{\mathbf{x}}\). Figure 9 shows the tracking trajectories of (x, y) space, dashed: desired trajectory; dotted: our proposed approach, and dash-dotted: ideal controller. From Fig. 9, we can observe that the proposed approach perform well with smaller tracking error than the ideal controller. This illustrates the effectiveness of the proposed approach.
4.4 Discussion of selecting the learning rate \(\eta _{K_\mathrm{e} } \)
As above description, choosing the suitable learning rate is important for force tracking control. A small value of \(\eta _{K_\mathrm{e}}\) results slower convergence and a large one leads higher amplitude of transient response or unstable result. Herein, the discussion of learning rate selection is introduced, in which these selections satisfy the convergent condition (37). Figure 10a, b show the comparison results of force tracking control, the estimated stiffness and desired position, respectively (solid-line: large \(\eta _{K_\mathrm{e} } \); dotted-line: suggested \(\eta _{K_\mathrm{e}}\); dash-dotted: small \(\eta _{K_\mathrm{e} } )\). The adopted large \(\eta _{K_\mathrm{e}}\), suggested \(\eta _{K_\mathrm{e}}\), and small \(\eta _{K_\mathrm{e}}\) are selected such that \(\lambda =0.8;\lambda =0.45\); and \(\lambda =0.001\), respectively, where \(\lambda \equiv \frac{\eta }{2}\left( {\frac{\partial e_\mathrm{f} }{\partial \hat{{K}}_\mathrm{e} }} \right) ^{2}\). That is, the suggested learning rate is \(\eta _{K_\mathrm{e} } =\frac{9}{10\left( {{\partial e_\mathrm{f} }/{\partial \hat{{K}}_\mathrm{e} }} \right) ^{2}}\) as our experience. From Fig. 10, large \(\eta _{K_\mathrm{e} } \) results faster response in force tracking control, but higher transient amplitude of force and \(\hat{{K}}_\mathrm{e} \) are obtained. In addition, this results the larger tracking error when the environment is changed (shown in Fig. 10b). On the other hand, small \(\eta _{K_\mathrm{e} } \) has slow convergence. It can be found that the suggested learning rate \(\eta _{K_\mathrm{e} } =\frac{9}{10\left( {{\partial e_\mathrm{f} }/{\partial \hat{{K}}_\mathrm{e} }} \right) ^{2}}\) preserves the stability and good performance in force tracking and estimation of stiffness and desired position.

Discussion of selecting learning rate, a force tracking performance, b stiffness, estimated environment position
5 Conclusion
In this paper, we have proposed the adaptive tracking force control scheme using FNNs for an n-link robot manipulator under unknown task environment. The unknown system parameter matrices are estimated by the FNNs to develop the tracking control scheme, and the adaptive force control laws are established by gradient method. Based on the Lyapunov stability analysis, we guarantee the stability of the closed-loop system and the convergence of parameters. In addition, the update laws of FNNs and estimation coefficient are designed. Finally, simulation results of a two-link robot manipulator with environment constraint are introduced to illustrate the performance and effectiveness of our approach.
Abbreviations
- \(\mathbf{q}\) :
-
Joint position
- \(\dot{\mathbf{q}}\) :
-
Joint velocity
- \(\ddot{\mathbf{q}}\) :
-
Joint acceleration
- \(\mathbf{x}\) :
-
End-effector position in Cartesian space
- \(\dot{\mathbf{x}}\) :
-
End-effector velocity in Cartesian space
- \(\ddot{\mathbf{x}}\) :
-
End-effector acceleration in Cartesian space
- \(\mathbf{x}_\mathrm{d}\) :
-
Desired end-effector trajectory
- \(\mathbf{D(q)}\) :
-
Robot’s inertial matrix in joint space
- \(\mathbf{C}(\mathbf{q},\dot{\mathbf{q}})\) :
-
Robot’s Coriolis matrix in joint space
- \(\mathbf{g(q)}\) :
-
Robot’s gravitational vector in joint space
- \(\mathbf{D}_{\mathbf{x}}{} \mathbf{(x)}\) :
-
Robot’s inertial matrix in Cartesian space
- \(\mathbf{C}_{\mathbf{x}}(\mathbf{x},\, \dot{\mathbf{x}})\) :
-
Robot’s Coriolis matrix in Cartesian space
- \(\mathbf{g}_{\mathbf{x}}{} \mathbf{(x)}\) :
-
Robot’s gravitational vector in Cartesian space
- \(\varvec{{\uptau }}\) :
-
Joint torque vector
- \(\mathbf{J}\) :
-
Robot’s Jacobian
- \(\mathbf{F}_{\mathbf{ext}}\) :
-
External force at the end-effector
- \(\varvec{{\uptau } }_\mathrm{robust}\) :
-
Robust controller
- \(\hat{\mathbf{D}}_\mathbf{x}\) :
-
FNN’s estimated robot’s inertial matrix in Cartesian space
- \(\hat{\mathbf{C}}_\mathbf{x}\) :
-
FNN’s estimated robot’s Coriolis matrix in Cartesian space
- \(\hat{\mathbf{g}}_\mathbf{x}\) :
-
FNN’s estimated robot’s gravitational vector in Cartesian space
- \(\mathbf{w}\) :
-
Weighting vector of the FNN
- \(\varvec{{\uppsi }}\) :
-
Normalized firing strength of the FNN
- \(\mathbf{K}_\mathrm{e}\) :
-
Stiffness coefficient of contact environment
- \(\hat{\mathbf{K}}_\mathrm{e}\) :
-
Estimated stiffness coefficient of contact environment
- \(\eta _{K_\mathrm{e}}\) :
-
Learning rate for tuning \(\hat{\mathbf{K}}_\mathrm{e}\)
- \(\mathbf{e}_\mathrm{f}\) :
-
Tracking force error
References
Abdallah, A., Dawson, D., Dorato, P., Jamishidi, M.: Survey of robust control for rigid robots. IEEE Control Syst. Mag. 11(2), 24–30 (1991)
Asada, H., Slotine, J.-J.E.: Robot-Analysis and Control. Wiley, New York (1986)
Cai, D., Dai, Y.: A globally convergent robust controller for robot manipulator. In: Proceedings of IEEE international conference on control applications, pp. 328–332, (2001)
Cheah, C.C., Liu, C., Slotine, J.J.E.: Adaptive tracking control for robots with unknown kinematic and dynamic properties. Int. J. Robot. Res. 25(3), 283–296 (2006)
Chien, M.C., Huang, A.C.: Adaptive impedance control of robot manipulator based on function approximation technique. Robotica 22, 395–403 (2004)
Chiu, C.S., Lian, K.Y., Wu, T.C.: Robust adaptive motion/force tracking control design for uncertain constrained robot manipulators. Automatica 40(12), 2111–2119 (2004)
Fanaei, A., Farrokhi, M.: Robust adaptive neuro-fuzzy controller for hybrid position/force control of robot manipulator in contact with unknown environment. J. Intell. Fuzzy Syst. 17(2), 125–144 (2006)
Fateh, M.M., Khorashadizadeh, S.: Robust control of electrically driven robots by adaptive fuzzy estimation of uncertainty. Nonlinear Dyn. 69(3), 1465–1477 (2012)
Fateh, M.M.: Nonlinear control of electrical flexible-joint robots. Nonlinear Dyn. 67(4), 2549–2559 (2012)
Filaretov, V. F., Zuev, A. V.: Adaptive force/position control of robot manipulators. In: 2008 IEEE/ASME international conference on advanced intelligent mechatronics, pp. 96–101, July 2–5, Xi’an, China (2008)
Hogan, N.: Impedance control: an approach to manipulation: part 1—theory, part 2—implementation, part 3—an approach to manipulation. ASME J. Dyn. Syst. Meas. Control 107, 1–24 (1985)
Huang, A.C., Chien, M.C.: Adaptive control of robot manipulators: a unified regressor-free approach. World Scientific Publishing Co., Pte. Ltd, Singapore (2010)
Huang, A.C., Kuo, Y.S.: Sliding control of nonlinear systems containing time varying uncertainties with unknown bound. Int. J. Control 74(3), 252–264 (2001)
Huang, A.C., Chen, Y.C.: Adaptive sliding control for single link flexible-joint robot with mismatched uncertainties. IEEE Trans. Control Syst. Technol. 12(5), 770–775 (2004)
Jafari, A., Monfaredi, R., Rezaei, R., Talebi, M., Ghidary, S. S.: Sliding mode hybrid impedance control of robot manipulators interacting with unknown environments using VSMRC method. In: ASME 2012 international mechanical engineering congress and exposition, pp. 1071–1081, (2012)
Jung, S., Hsia, T.C., Bonitz, R.G.: Force tracking impedance control of robot manipulators under unknown environment. IEEE Trans. Control Syst. Technol. 12(2), 474–483 (2004)
Jung, S., Hsia, T.C.: Neural network impedance force control of robot manipulator. IEEE Trans. Ind. Electron. 45(3), 451–461 (1998)
Jung, S., Yim, S.B., Hsia, T. C.: Experimental studies of neural impedance force control of robot manipulators. In: Proceedings of IEEE conference on robotics and automations, pp. 3453–3458, Seoul, Korea (2001)
Jung, S., Hsia, T. C.: Reference compensation technique of neural force tracking impedance control for robot manipulators. In: World congress on intelligent control and automation, Jinan, China, July 6–9, (2010)
Khatib, O.: A unified approach for motion and force control of robot manipulators: the operational space formulation. IEEE J. Robot. Autom. RA–3(1), 43–53 (1987)
Lee, C.H., Teng, C.C.: Identification and control of dynamic systems using recurrent fuzzy neural network. IEEE Trans. Fuzzy Syst. 8(4), 349–366 (2000)
Lee, C.H., Chung, B.R.: FNN-based disturbance observer controller design for nonlinear uncertain systems. WSEAS Trans. Syst. Control 2(3), 255–260 (2007)
Lee, C.H., Chung, B.R.: Adaptive backstepping controller design for nonlinear uncertain systems using fuzzy neural systems. Int. J. Syst. Sci. 43(10), 1855–1869 (2012)
Lee, C.H., Chang, F.Y., Lin, C.M.: An efficient interval type-2 fuzzy CMAC for chaos time-series prediction and synchronization. IEEE Trans. Cybern. 44(3), 329–341 (2014)
Lee, C.H., Lee, Y.C.: Nonlinear systems design by a novel fuzzy neural system via hybridization of EM and PSO algorithms. Inf. Sci. 186(1), 59–81 (2012)
Lewis, F.L., Dawson, D.M., Abdallah, C.T.: Robot Manipulator Control Theory and Practice, Second Edition, Revised and Expanded. Marcel Dekker, New York (2004)
Li, Y., Ge, S.S., Zhang, Q., Lee, T.H.: Neural networks impedance control of robot interacting with environment. IET Control Theory Appl. 7(11), 1509–1519 (2013)
Li, Z., Ge, S.S., Adams, M., Wijesoma, W.S.: Robust adaptive control of uncertain force/motion constrained nonholonomic mobile manipulators. Automatica 44, 776–784 (2008)
Li, Z., Chen, W.: Adaptive neural-fuzzy control of uncertain constrained multiple coordinated nonholonomic mobile manipulators. Eng. Appl. Artif. Intell. 21(7), 98–1000 (2008)
Li, Z., Chen, W., Luo, J.: Adaptive compliant force-motion control of coordinated non-holonomic mobile manipulators interacting with unknown non-rigid environments. Neurocomputing 71(7–9), 1330–1334 (2008)
Ortega, R., Spong, M.W.: Adaptive motion feedback control of rigid robot: a tutorial. In: Proceedings of 27th conference on decision and control, pp. 1575–1584, (1988)
Raibert, M., Craig, J.J.: Hybrid position/force control of manipulators. ASME J. Dyn. Syst. Meas. Control 102, 126–133 (1981)
Ren, T. J.: A robust impedance control using recurrent fuzzy neural networks. In: The 3rd international conference on innovative computing information and control (ICICIC’08), (2008)
Roy, J., Whitcomb, L.L.: Adaptive force control of position/velocity controlled robots: theory and experiment. IEEE Trans. Robot. Autom. 18(2), 121–137 (2002)
Sedegh, N., Horowitz, R.: Stability and robustness analysis of a class of adaptive controller for robotic manipulators. Int. J. Robot. Res. 9(3), 74–92 (1990)
Singh, S., Popa, D.: An analysis of some fundamental problems in adaptive control of force and impedance behavior: theory and experiments. IEEE Trans. Robot. Autom. 11, 912–921 (1995)
Slotine, J.J.E., Li, W.: Applied Nonlinear Control, Englewood Cliffs. Prentice-Hall, NJ (1991)
Sun, D., Mills, J.K.: Performance improvement of industrial robot trajectory tracking using adaptive-learning scheme. ASME J. Dyn. Syst. Meas. Control 121(2), 285–292 (1999)
Tanaka, Y., Tsuji, T.: On-line learning of robot arm impedance using neural network. In: Proceedings of IEEE international conference on robotic and biomimetics, Shenyang, China, August 22–26, (2004)
Wu, S.C.: Adaptive Controller Design for Robot Manipulators Based on Function Approximation Technique, Master Thesis, National Taiwan University of Science and Technology, Taiwan, July (2002)
Acknowledgments
The authors would like to thank anonymous reviewers for their insightful comments and valuable suggestions. This work was supported in part by the Ministry of Science and Technology, Taiwan, R.O.C., under contracts MOST-102-2221-E-005-061-MY3 and MOST-103-2218-E-005-005-MY2.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Lee, CH., Wang, WC. Robust adaptive position and force controller design of robot manipulator using fuzzy neural networks. Nonlinear Dyn 85, 343–354 (2016). https://doi.org/10.1007/s11071-016-2689-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11071-016-2689-1