
Abstract
Multimedia streaming of three-dimensional (3D) stereoscopic videos over last-generation networks subject to bandwidth limitations is an open problem. The development and spread of communication networks and devices that accept 3D videos is not supported by proper scheduling strategies. Namely the high variability of streams should be considered to reduce effects of network delays, packet losses, shortage of bandwidth resources, and shared use by multiple clients. Then, it is important to improve the characterization of 3D videos for more effective streaming. To this aim, this paper proposes a fractional exponential reduction moments approach based on the statistics of the so-called fractional moments. Each random sequence of frames in 3D videos can be analyzed and reduced to a finite set of parameters, that allow fitting to the sequence by exponential functions and then a characterization and classification of the video by a sort of fingerprint. The method does not depend on the format and the encoding technique of the video. Finally, the approach will allow comparing real streams and numerical data output from fractional dynamical models by means of the reduced parameters. Statistical proximity between time series and a fractional model or between different models simplifies formalization and classification of fractional models.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Research on multimedia streaming over wired/wireless last-generation mobile networks is motivated by complex problems posed by technology advances. Namely developments are fast, multimedia services on advanced mobile terminals continuously grow, and structure and operation of networks become complex [8]. Moreover, multimedia reproduction requires high Quality of Service (QoS) performance indices and a reduced impact of the permanent problems in a classical client–server architecture (delays, packet losses, shortage of bandwidth resources, contemporaneous use by multiple users, etc.).
These problems are emphasized by three-dimensional (3D) stereoscopic videos that are very important for entertainment, medicine and surgery, industrial processes, etc. Effective streaming on fixed (TV sets) or mobile (smartphones, tablets) terminals requires to properly process the available information and to choose an adequate scheduling algorithm. Namely the amount of data for 3D video frames is higher than for two-dimensional (2D) ones. In addition, more bandwidth is required from resources on the network links, and video compression and formats generate highly Variable Bit Rate (VBR) streams [18, 28]. VBR and bandwidth limitations were considered [9], but few works focused on the specific topic regarding 3D videos [5, 6].
To develop simple theoretical models and to properly assign bandwidth resources so that an efficient VBR 3D video streaming achieves a high QoS, a statistical characterization of the 3D frames sequence can be of great help [2]. Moreover, it is helpful for reducing complexity of the schedulers that control data transmission. However, few works analyze the statistical properties of 3D data flows. Long memory properties or Long Range Dependence of compressed 3D flows were characterized by estimating the Hurst parameter. The drawback is that the empirical computation methods assume asymptotic convergence of the sample size and, hence, a stationary process [26]. There exist also several methods that analyze long time series when there is no mathematical model of the process generating the data. For example, computation of Lyapunov exponents from time series [31]. But some limiting assumptions are often required. In other cases, algorithms extract useful hidden information and parameters from biological signals [22], signals related to delivery of drugs [23], and signals for other biomedical applications [24].
Moreover, the state-of-the-art literature proposes the detrended fluctuation analysis (DFA) [25, 26] for reducing long time series. DFA was applied to different kinds of data [1, 4, 11, 12, 16, 27] and can be considered as an extension of the Hurst analysis in [26], then it suffers from the same drawbacks of the Hurst parameter computation. Moreover, it is suitable to catch only the correlation properties on large time scales, i.e., if the trends of the time series are slowly varying. However, this is a specific property of a time series. So, it substantially differs from the goal herein to capture all the statistical trends of the considered 3D videos. Then, the idea behind this work is to develop a totally new approach that is free from the drawbacks and limitations of DFA.
A novel method is developed by exploiting the idea underlying the statistics of the fractional moments [19] to provide a more reliable fitting and a robust set of the reduced parameters. The purpose is twofold. Firstly, the analysis should help to identify a fractional behavior in absence of a process model. Secondly, the aim is to reduce each sequence of 3D video frames to a finite and stable set of parameters that encapsulate the statistical properties of the 3D video. Then, the method is named Fractional Exponential Reduction Moments Approach (FERMA). It is straightforward and robust and aims at generating a “fingerprint” for each 3D video. A small number of parameters represent the statistical properties, whichever are the video and the length of the time series associated with the sequence of frames. This result is very important because:
-
a.
the fingerprint allows to identify the main features of the stream, depending on the compression degree, the format, and the type of represented scenes;
-
b.
different kinds of streams can be identified according to the ranges of variation of the fingerprint parameters, then a classification of streams is possible;
-
c.
scheduling of 3D video streams and bitrate control can benefit from fingerprint identification and classification, i.e., a feedback system can regulate the transmission bitrate to obtain the same statistical properties at receiver’s side as those that characterize the video at transmission side. Then, a fingerprint-based strategy can increase the user QoS.
It is also remarkable the relationship between the FERMA approach and fractional dynamics models that can describe some phenomenon under analysis. Namely assume to obtain numerical data from a known model, say a fractional model, and to compare them with other data available from real experiments (or from a different model). Assume also that the dynamic equations of the fractional model for the second set of data are unknown. Then, the generality of FERMA provides the unique possibility to compare one set of data (generated from the known fractional equations) with another set. The comparison between large sets of data is possible because the final set of the reduced parameters is relatively small. If the parameters obtained for the two sets are close to each other, then one can conclude about the closeness of the analyzed data/models, then the second set has the same fractional behavior as in the first set. In the opposite case, data are not similar and can be rejected. Here, the flexibility of the new approach is also stressed. If some set of stable parameters are not sufficient for model identification of the compared data, then the cumulative data obtained by integration or differentiation of initial data can be used to receive an additional set of parameters. The advantages of these options are illustrated below in the paper. It can be concluded that this paper sets the basis of a methodology, even if well formalized fractional order models of 3D video streaming are not available yet, as far as the authors are aware. However, it is intuitive to conjecture about the fractional nature of the process if one considers several studies and results [3, 10].
The rest of the paper is organized as follows. Sections 2.1 and 2.2 describe the reduction procedure to identify the set of fingerprint parameters and the classification method to group similar data sequences, respectively. Section 2.3 shows how to obtain further statistically different sequences. Section 3 shows simulation results with different compression techniques and formats of 3D videos. Remarks are also made on relevant points for future developments related to the streaming control. Finally, Sect. 4 concludes the paper.
2 Reduction and classification of random 3D video streams
In this section, the reduction of a random 3D video sequence of frames to a finite set of stable parameters is synthesized by an effective procedure and used to classify videos by a clusterization method. The reduction must face the fact that modern technologies and terminals allow receiving and reproducing long sequences of data (video frames) that constitute a long time series which is available for statistical analysis. On the other hand, the existing statistical methods are not capable of easily managing large amounts of data. Typically, random sequences of \(10^5-10^6\) data points and more must be processed to extract the useful information. Therefore, new approaches are required to reduce the data to a finite reduced and stable set of few fitting parameters (say, 10–20 parameters), that allow us to establish properties of the stream. In this way, different streams can be compared to find the “qualitative” presence of an external factor that affects some streams (maybe the altered ones with respect to the original video frame sequence) and to quantitatively express this factor by means of the identified parameters. Moreover, after reduction, a problem of clusterization originates. Namely if distinct identified sets of reduced parameters are strongly correlated one with another, then it is necessary to form clusters between these sets and hence further reduce the complexity of the representation of distinct streams.
2.1 The reduction procedure
The proposed method is based on the statistics of the fractional moments, based on the idea originally presented in [19]. Consider a sequence of \(N\) data points with or without a clearly expressed trend. The matter is to find \(k\) points in the sequence, so that the \(k\) moments taken from this new set of points coincide with the \(k\) moments derived from the \(N\) initial points. This occurs if the following condition holds true [19]:
The set \(\{Y_s, s = 1, \, 2, \ldots , \, k\}\) represents the reduced set of \(k < N\) unknown points, while \(\{y_j, j = 1, \, 2, \ldots , \, N\}\) is the set of points in the initial sequence. Obviously, for the simplest case \(k = 2\), it follows:
that easily leads to \(\varDelta _N^{(2)} - \left( \varDelta _N^{(1)}\right) ^2 = (Y_1-Y_2)^2/4\). Since \(Y_{1,2} = (Y_1+Y_2)/2 \pm (Y_1-Y_2)/2\), the analytical solution is:
Instead, the analytical solution of (1) for \(k > 2\) is not always possible. For \(k = 3, 4\), the Cardano and Ferrari formulas can be used. For \(k > 4\), only numerical solutions can be provided. If \(k\) is sufficiently large \((k > 10)\), any procedure for calculating the roots of a \(k\)th order polynomial represents an ill-posed problem and therefore is numerically unstable [15]. However, the numerical solution to system (1) can be determined by a different formulation of the problem. Namely restate (1) more generally as:
with \(\lambda _s = \ln (\tilde{Y}_s)\) and \(\displaystyle \sum \nolimits _{s=1}^{k} w_s = 1\), where \(w_s\) are normalized statistical weights and \(\lambda _s\) are exponents, for \(s = 1, 2, \ldots , k\). In this way, (4) establishes the problem of determining a reduced set of \(2 k\) unknown parameters \((w_s, \lambda _s)\), for \(s = 1, 2,\ldots , k\), by using the normalized initial sequence of values \(\left( y_j/y_{max} \right) \), for \(j = 1, 2,\ldots , N\), that define \(\varDelta _N(x)\) and the moments \(x\), with \(0 \le x \le k\). Note that system (4) provides an approximate solution by employing the total set of the moments \(x\) from \([0, k]\), including the fractional ones.
The main benefit of the proposed algorithm is that the unknown exponents can be easily computed in a linear way. Namely it is possible to redefine (4) as follows:
where the \(s\)th weight and exponent are separated from the other ones. Given that \(f_s(x) = w_s \, e^{\lambda _s x}\), it follows \(\frac{d f_s(x)}{dx} = \lambda _s \, f_s(x)\) so that one integration gives \(f_s(x) = f_s(0) + \lambda _s \int _0^x f_s(u) du\) and expression (5) gives:
with \(B_{q,s} = w_q \, \left( 1 - \frac{\lambda _s}{\lambda _q} \right) \) and \(\displaystyle C_s = f_s(0) + \sum \nolimits _{q = 1, q \ne s}^{k} w_q \frac{\lambda _s}{\lambda _q} = 1 - \sum \nolimits _{q = 1, q \ne s}^{k} B_{q,s}\), for \(s = 1, 2, \ldots , k\).
The previous formulas can then be used to iteratively compute the unknown fitting parameters \(\{\lambda _s, s = 1, 2, \ldots , k\}\) by applying the linear least square method (LLSM). Namely (6) can be explicitly written as:
that is solved by LLSM to find the exponents \(\{\lambda _s, s = 1, 2, \ldots , k \}\) and the coefficients \(B_{q,k} \, (q = 1, 2, \ldots ,\) \( k-1)\). Moreover, to correct the computed values and further adjust the approximate values of the exponents, the normalized statistical weights can be considered, and the LLSM is again applied by using the following expression:
The unknown value of \(k\) can be found by considering all positive statistical weights and by minimizing the percentage relative fitting error:
To synthesize, the reduction procedure is defined by (7)–(9) and solves (4) to determine the reduced set of parameters \(\{ (w_s, \lambda _s), s = 1, 2, \ldots , k \}\), \(k \ll N\).
2.2 The clusterization method
The similar time series of 3D video frames can be grouped together by using a complete correlation factor, based on an accurate selection that takes into account internal correlation between sequences. To this aim, the generalized Pearson correlation function (GPCF) is used [20, 21] based on generalized mean value (GMV) functions:
where the GMV function of \(K\)th order is
that employs normalized sequences \(nrm_j(y)\), with \(0 < nrm_j(y) < 1\), and the current value of the moment, i.e., \(mom_p\). More specifically, for \(j = 1, 2, \ldots , N\), it holds:
where \(y_j\) denotes the initial random sequence that can contain a trend or that is to be compared with another trendless sequence. The initial sequences are chosen like follows. The minimum of the GMV function is zero, while the maximum coincides with the maximum of the normalized sequence. Moreover, the set of moments is computed as follows:
so that \(L_{n_p}\) takes values between \((mn)\) and \((mx)\) that define the limits of the moments in the uniform logarithmic scale. Usually, \(mn = -15\), \(mx = 15\), and \(50 \le P \le 100\). This choice is because the transition region of the random sequences that are expressed in the form of GMV-functions is usually concentrated in the interval \([-10,10]\). The extension to \([-15,15]\) is considered for the accurate calculation of the limit values of the functions in the space of fractional moments. Finally, note that \(GPCF_p\) determined by (10)–(11) coincides with the conventional definition of the Pearson correlation coefficient at \(mom_p = 1\).
If the limits \((mn)\) and \((mx)\) have the opposite signs and take sufficiently large values, then the GPCF has two plateaus (with \(GPCF_{mn} = 1\) for small values of \(mn\)) and another limiting value \(GPCF_{mx}\) that depends on the degree of internal correlation between the two compared random sequences. This right-hand limit, say \(Lm\), satisfies the following condition:
The appearance of two plateaus implies that all information about possible correlations is complete and a further increase of \((mn)\) and \((mx)\) is useless. Several tests showed that the highest degree of correlation between two random sequences is achieved when \(Lm = 1\), while the lowest when \(Lm = M\). This remark holds for all random sequences and allows us to introduce a new correlation parameter \(CC\), the so-called complete correlation factor:
Note that \(CC\) is determined by using the total set of the fractional moments in \([e^{mn}, e^{mx}]\). Putting \((mn) = -15\) and \((mx) = 15\), \(CC\) tends to \(M\) for high correlation, and to 0 for the lowest (remnant) degree of correlations. Moreover, \(CC\) does not depend on the amplitudes of two compared random sequences. Since \(0 \le |y_j| \le 1\) must hold for both sequences, (15) gives indication of the internal correlation between sequences that is based on the similarity of probability distribution functions of the sequences, even if the last are usually not known.
Recently, the statistics of the fractional moments was applied with promising results [21], that gave the idea to use the \(CC\) factor for clusterization of the significant parameters. Namely for a set of significant parameters referring to one qualitative factor, it holds:
where \(cf_{min}\) is determined by the sampling volume and the practical conditions of random sequences, that should be almost the same when comparing two different sequences, e.g., the first affected by a qualitative factor, the second by another factor like a control action.
Then, the clusterization method is based on comparing the values of the \(CC\) factor, by making a sort of extension of the conventional method based on the Pearson correlation coefficient (PCC) that is instead not proper for the purpose of this paper.
To synthesize, the clusterization of \(S\) different sequences by their correlation follows a step procedure:
-
i.
For each sequence \(r\), determine the set of the \(2k\) reduced parameters \(P_{r_q} = \{ w_q, l_q \}_r\), for \(q = 1, 2,\ldots , k\), and for \(r = 1, 2,\ldots , S\). Moreover, compute the fitting error (9) and other parameters that are important for the structuring.
-
ii.
Obtain the normalized sequences according to (12) by the set of reduced parameters \(P_{r_q}\).
-
iii.
Compute \(GPCF_p(s_1, s_2)\) for each pair \((s_1, s_2)\), with \(s_1\) and \(s_2 = 1, 2, \ldots , S\), find the limits, and apply (15) to get the symmetrical matrix \(CC(s_1, s_2)\) of size \(S \times S\).
-
iv.
Realize the clusterization by taking into account (16) and defining the whole correlation interval \([cf_{min}, 1.0]\) on subset of other intervals.
The previously defined clusterization procedure has a relative character because it depends on the number of correlation subintervals that are defined in \([cf_{min}, 1.0]\). Then, an absolute clusterization cannot be realized.
2.3 Integration and differentiation pre-processing
To stress the power of the proposed approach, a further processing of the originally available data is added. Namely an integration and a differentiation is applied to the sequence of frames, so that two additional and different random sequences of frames are obtained that are characterized by totally different statistical properties. By processing data in this way, it is expected that differentiation creates high-frequency fluctuations. On the contrary, integration is particularly suitable for restoring the long-term trend of video sequences and analyzing their fluctuations on longer time scales. This is a very important consideration, since it is known by literature that the low-frequency part of the spectrum of compressed VBR video data are utilized for managing bandwidth and QoS [7, 17, 32]. The very simple numerical integration by the trapezoidal rule filters the high-frequency components of the video data.
More specifically, integration is performed on the initial video sequence of frames by the following numerical approximation [29]:
where \(Jy_j\) is the integrated sample, \(Dy_j\) is the original sample \(y_j\), but translated in its value with respect to the mean \(<\!y\!>\). By this operation, a low-pass filtering is performed, that cuts off the high-frequency components. The low complexity of this filter is guaranteed by the trapezoidal rule, which is a particularization of the Simpson’s rule method for numerical integration [29].
Nevertheless, the 3D video statistical characterization in the high-frequency domain can still be useful. It is known, in fact, that high-frequency components in compressed VBR videos allow to study the amount of buffering needed to reduce frame losses in video transmission [13, 17]. To this aim, data are also differentiated by a discrete approximation of the derivative:
Both the integrated and differentiated sequences are treated and represented by the same FERMA approach. Then, the same reduction procedure and the clusterization method are applied to the integrated and differentiated curves. This helps to find and recognize common features of random sequences without a specific trend (i.e., the sequences obtained by differentiation), besides those that are proper of sequences that may be characterized by a certain weakly expressed trend (i.e., the original sequences).
3 Simulation results
The reduction and clusterization method is tested on data taken from real 3D stereoscopic videos. The formats are: side by side (SBS) and frame-sequential (FS). SBS combines left and right views into standard 2D format so that the resolution of a given 3D frame is the same as a regular 2D frame. The left and right frames are subsampled along the horizontal axis and put side by side. FS creates a single frame sequence by temporally interlacing left and right images. Each image preserves its original resolution, but the transmission rate is doubled with respect to SBS.
All videos last about 35 min at the constant rate of 24 frames per second, with resolution of \(1920 \times 1080\) pixels. The well-known H.264/MPEG-4 Advanced Video Coding standard [14] is used to encode them. The compressed streams are defined by Group of Pictures (GoP) [30], i.e., a periodic sequence of three types of frames: Intracoded (I), Predictive-encoded (P) and Bidirectionally-encoded (B). I-frames are coded independently from other frames, whereas the P-frames take into account the dependencies with I-frames and B-frames the dependencies with both I- and P-frames. The GoP sequence is defined by the total number of frames and by the number of B-frames between successive I- and P-frames. Moreover, each trace is characterized by a Quantization Parameter (QP) that indicates the degree of compression of video frames [30]: a high QP corresponds to a coarse resolution.
To test the proposed reduction and clusterization algorithm, three 3D movies are considered with different dynamic characteristics: Alice in Wonderland, a mix of animations and real characters (Mov1); Monsters vs Aliens, a computer-graphics animation (Mov2); IMAX Space Station, a documentary (Mov3). All videos have left and right views, each composed by 51200 3D frames (pictures), and are encoded with three different values (24, 28 and 34) of QP (each value is used for all I-, P-, and B-frames) and two different types of GoP, called B1 and B7 (one or seven B-frames between successive I- and P-frames). Tests are made for the formats FS and SBS. All data points in the sequences are positive, then the normalization follows the second case in (12).
Finally, to further analyze the statistical properties of the 3D video sequences, the initial data sets are integrated and differentiated, so that two more random sequences are obtained from the original one but with completely different statistical properties. Then, the reduced set of parameters is computed both for the original video data (O) and for the sequences that are obtained from integration (I) and differentiation (D). Tables 1 and 2 summarize the results for FS (GoP = 32) and SBS (GoP = 16) videos, respectively.
As an illustration example, Mov1 is considered in SBS format with GoP = B7 and QP = 34 (see column “Mov1 O” of Table 2). Similar results are obtained in other cases. An initial monotone curve of the normalized fractional moments in (4) is obtained by linear combination of exponential functions with \(\lambda _1 = -2.4526, \lambda _2 = -0.2546\). An exponential fit is obtained, and the reduced parameters provide the fingerprint. The exponentially decaying curve in Fig. 1 shows the normalized function of the moments \(\varDelta _N(x)\).

Fitting of the function \(\varDelta _N(x)\): initial curve \((\lambda _1 = -2.4526, \lambda _2 = -0.2546)\) and exponential separated curve \((\lambda _{sep1} = -1.5546, \lambda _{sep2} = 0.6434)\)
Then, the separation procedure improves the exponents \(\lambda _1 = -2.4526, \lambda _2 = -0.2546\) fitting the initial function. The function is preliminarily multiplied by \(e^{\alpha _{sep} x}\), with \(\alpha _{sep} > 0\), in order to increase artificially the contribution of small exponents (see Fig. 1). To this aim, \(\alpha _{sep}\) is set by the condition that the limiting heights of the separated curve should coincide one with another. Then, the separated curve is fitted by linear combination of two exponential functions with \(\lambda _{sep1} = -1.5546, \lambda _{sep2} = 0.6434\).
However, this fit is not sufficient. The requirements on the weighting constants \(w_s\) and the iteration formula (7) show that only three exponents are enough. A higher number of exponents is avoided because it leads to negative values of weighting factors. The final fit of the initial function \(\varDelta _N(x)\) with three exponents is shown in Fig. 2. Three exponents allow to reduce the relative fitting error with respect to Fig. 1, which showed the fit of the initial function and of the separated function by two exponential functions only.

The final fit of the initial function \(\varDelta _N(x)\) with 8 fingerprint significant parameters
For the final comparison, eight reduced parameters are obtained, including the modulus of the exponents \((|\lambda _s|, s = 1, 2, 3)\), their weights \((w_s, s = 1, 2, 3)\), the value of the separation exponent \((\alpha _{sep})\), and the value of the percentage relative error \((e_r \%)\). Note that the values specified in Tables 1 and 2 are slightly different because the final comparison is based on 50 moments instead of 10, as used in Figs. 1 and 2 for clarity of illustration. All the other files, also for the other movies, are processed in the same way. The resulting reduced parameters are collected in Tables 1 and 2. The clusterization procedure applied to these reduced parameters shows that they are statistically close to each other. The minimal value of the correlation matrix lies between \(0.95\) and \(0.97\).
The previous results lead to two very interesting conclusions. The first is that, since these parameters verify the condition of statistical stability, it is possible to reduce the statistical properties of each of the different considered 3D video movies to a subset of parameters, whichever is the 3D video format (FS or SBS) and whichever is the encoding technique as defined by the specific grouping of frames, according to the GoP parameter, and by the quantization parameter QP. The identified reduced parameters constitute the stream fingerprint that can be fruitfully adopted to mark the stream sequence and possibly regulate the streaming process. Moreover, this kind of result occurs even when the reduction method is applied to completely new and statistically different sequences that are determined by integration and differentiation that completely change the original sequence. Then, this remarkable fact is observed for the first time here and can be exploited in future investigations.
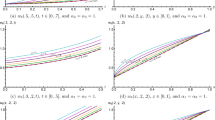
Finally, Figs. 3, 4, 5 show the average values and the confidence intervals for the reduced parameters, for each analyzed movie, format, and data type (original, differentiated, and integrated data). All the values of the reduced set of parameters have been averaged on both the quantization parameter (24, 28, and 34) and the GoP structure (G16B1 and G16B7 for SBS, and G32B1 and G32B7 for FS). More in details, the results provided in Figs. 3 and 4 are very interesting. For each considered movie, the original and differentiated data show very small variations of all the parameters around the mean. This means that the reduced set of parameters can be fruitfully exploited to accurately characterize an original, or differentiated, 3D flow regardless its compression degree (the QP) and GoP structure, providing in this way an effective “fingerprint” of the 3D flow.

Mean values and confidence intervals of the parameters for the original data of the three considered videos, with SBS format (left) and FS format (right)

Mean values and confidence intervals of the parameters for the differentiated data of the three considered videos, with SBS format (left) and FS format (right)

Mean values and confidence intervals of the parameters for the integrated data of the three considered videos, with SBS format (left) and FS format (right)
Regarding the analysis of integral data provided in Fig. 5, the streams characterization is a bit less accurate. This is testified by two different aspects: an increased number of parameters that constitute the set (ten in total, against the eight of the two previous cases), and a larger variation around the mean of some parameters. For this reason, the integral data are less suitable for providing a 3D video fingerprint independent of the encoding properties. Nevertheless, the previously illustrated general procedure keeps its validity.
Finally, it is worthy to note that the proposed method can be developed and used to evaluate the statistical effect the communication network has onto the reduced and stable set of parameters that characterize the streamed video sequence of frames. Since the video fingerprint in general does not depend on the encoding and compression properties, the existence and influence of external factors from the network can be detected and expressed quantitatively. This could be of great help for updating the streaming process and changing the transmission bitrate in order to obtain a better quality of video reproduction on the client’s terminal.
4 Concluding remarks
This paper proposed and described a novel approach to analyze and characterize a random sequence that is associated with the streaming of 3D stereoscopic videos. The statistics approach is based on the reduction of the available data points to a reduced set of parameters, so that each sequence can be characterized in the space of few fractional moments. Typically, 6–8 parameters are sufficient to characterize each video random sequence and consequently to define a sort of fingerprint that is specific to the considered video. The powerful effectiveness of the approach is demonstrated by considering also a perturbation of the original sequence that is obtained by differentiating or integrating the initial sequence. It is remarkable that the derivative and integral sequences have totally different statistical properties, but the proposed approach is capable to identify the stream fingerprint. Then, it is stressed that the method is rather general and can be applied to sequences with or without trend. It can differentiate the statistical peculiarities for integrated (with trend) and differentiated (when possible trend is removed) sequences, without any knowledge of the probability distribution function (PDF), which is not known in many cases. Then, the PDF can be replaced by the parameters in the space of the fractional moments. As far as the authors’ are aware, this is a novel result obtained for the first time in the literature.
Moreover, the efficiency of the approach is shown by applying the methodology to videos that differ by the format or the encoding parameters. Finally, it is remarked that the approach may detect the influence of external factors that affect the fingerprint of the streamed video sequences (communication delays, errors, specific actions, etc.) and that can not be quantitatively measured by other methods. Therefore, the statistics of fractional moments and FERMA can be an opportunity to find new effective solutions in communication and control problems in which the complexity of the networks, the multiple users, and the shortages of bandwidth resources represent a major issue.
Finally, the novel FERMA approach enables to compare different data extracted from fractional models having different dynamics. If the fractional dynamics of one set of data is unknown, the comparison by the reduced parameters computed in the frame of FERMA helps to evaluate the statistical proximity of two compared models and judge upon the fractional nature of the unknown model. This “language” is very common and helps to classify different fractional models in one unified scheme.
References
Bashan, A., Bartsch, R., Kantelhardt, J.W., Havlin, S.: Comparison of detrending methods for fluctuation analysis. Phys. A Stat. Mech. Appl. 387(21), 5080–5090 (2008)
Beran, J.: Statistics for long-memory processes, vol. 61. Chapman & Hall, London (1994)
Buche, R.T., Ghosh, A., Pipiras, V., Zhang, J.X.: Heavy traffic methods in wireless systems: towards modeling heavy tails and long range dependence. Wirel. Commun. IMA Vol. Math. Appl. 143, 53–74 (2007)
Burr, R.L., Kirkness, C.J., Mitchell, P.H.: Detrended fluctuation analysis of the ICP predicts outcome following traumatic brain injury. IEEE Trans. Biomed. Eng. 55(11), 2509–2518 (2008)
Ceglie, C., Maione, G., Striccoli, D.: Periodic feedback control for streaming 3D videos in last-generation cellular networks. In: Giri, F., Van Assche, V. (eds.), 5th IFAC Int. Workshop on Periodic Control Systems (PSYCO 2013), Vol. 5, Part 1, pp. 23–28, Caen, France, July 3–5 (2013)
Ceglie, C., Maione, G., Striccoli, D.: Statistical analysis of long-range dependence in three-dimensional video traffic. In Proceedings of International Conference on Mathematical Methods in Engineering (MME 2013), Porto, Portugal, July 22–26 (2013)
Chong, S., Li, S.-Q., Ghosh, J.: Predictive dynamic bandwidth allocation for efficient transport of real-time vbr video over atm. IEEE J. Sel. Areas Commun. 13(1), 12–23 (1995)
Dahlman, E., Parkvall, S., Skold, S.: New Imaging Frontiers: 3D and Mixed Reality. Elsevier, Amsterdam (2011)
Feng, W.C., Rexford, J.: Performance evaluation of smoothing algorithms for transmitting prerecorded variable-bit-rate video. IEEE Trans. Multimed. 1(3), 302–313 (1999)
Garrett, M.W., Willinger, W.: Analysis, modeling and generation of self-similar VBR video traffic. In: Proceedings of ACM SIGCOMM ’94, pp. 269–280, London, UK, Aug. 31–Sept. 2 (1994)
Hausdorff, J.M., Peng, C.-K., Ladin, Z., Wei, J.Y., Goldberger, A.L.: Is walking a random walk? Evidence for long-range correlations in the stride interval of human gait. J. Appl. Physiol. 78, 349–358 (1995)
Hausdorff, J.M., Purdon, P., Peng, C.-K., Ladin, Z., Wei, J.Y., Goldberger, A.L.: Fractal dynamics of human gait: stability of long-range correlations in stride interval fluctuations. J. Appl. Physiol. 80, 1448–1457 (1996)
Hwang, C.-L., Li, S.-Q.: On input state space reduction and buffer noneffective region. In: Proceedings of IEEE INFOCOM, pp. 1018–1028 (1994)
ITU-T and ISO/IEC JTC 1: Advanced video coding for generic audiovisual services. In: ITU-T Recommendation H.264 and ISO/IEC 14496–10 (MPEG-4 AVC) (2010)
Jenkins, M.A., Traub, J.F.: Algorithm 419: zeros of a complex polynomial. Commun. ACM 15, 97–99 (1972)
Jospin, M., Caminal, P., Jensen, E.W., Litvan, H., Vallverdu, M., Struys, M.R., Vereecke, H.E.M., Kaplan, D.T.: Detrended fluctuation analysis of EEG as a measure of depth of anesthesia. IEEE Trans. Biomed. Eng. 54(5), 840–846 (2007)
Li, S.-Q., Chong, S., Hwang, C.-L.: Link capacity allocation and network control by filtered input rate in high-speed networks. IEEE/ACM Trans. Netw. 3(1), 10–25 (1995)
Maione, G., Striccoli, D.: Transmission control of variable-bit-rate video streaming in UMTS networks. Control Eng. Pract. 20(12), 1366–1373 (2012)
Nigmatullin, R.R.: The statistics of the fractional moments: is there any chance to read “quantitatively” any randomness? J. Signal Process. 86, 2529–2547 (2006)
Nigmatullin, R.R.: Universal distribution function for the strongly-correlated fluctuations: general way for description of random sequences. Commun. Nonlinear Sci. Numer. Simul. 15, 637–647 (2010)
Nigmatullin, R.R., Ionescu, C., Baleanu, D.: NIMRAD: novel technique for respiratory data treatment. J. Signal Image Video Process 15, 637–647 (2012)
Nigmatullin, R.R., Ionescu, C.M., Osokin, S.I., Baleanu, D., Toboev, V.A.: Non-invasive methods applied for complex signals. Rom. Rep. Phys. 64(4), 1032–1045 (2012)
Nigmatullin, R.R., Baleanu, D., Al-Zhrani, A.A., Alhamed, Y.A., Zahid, A.H., Youssef, T.E.: Spectral analysis of HIV drugs for acquired immunodeficiency syndrome within modified non-invasive methods. Rev. Chim. 64(9), 987–993 (2013)
Nigmatullin, R.R., Baleanu, D., Povarova, D., Salah, N., Habib, S.S., Memic, A.: Raman spectra of nanodiamonds: new treatment procedure directed for improved Raman signal marker detection. Math. Probl. Eng. 847076 (2013)
Ossadnik, S.M., Buldyrev, S.V., Goldberger, A.L., Havlin, S., Mantegna, R.N., Peng, C.-K., Simons, M., Stanley, H.E.: Correlation approach to identify coding regions in DNA sequences. Biophys. J. 67, 64–70 (1994)
Peng, C.-K., Havlin, S., Stanley, H.E., Goldberger, A.L.: Quantification of scaling exponents and crossover phenomena in nonstationary heartbeat time series. Chaos 5, 82–87 (1995)
Penzel, T., Kantelhardt, J.W., Grote, L., Peter, J.-H., Bunder, A.: Comparison of detrended fluctuation analysis and spectral analysis for heart rate variability in sleep and sleep apnea. IEEE Trans. Biomed. Eng. 50(10), 1143–1151 (2003)
Pulipaka, A., Seeling, P., Reisslein, M., Karam, L.J.: Traffic and statistical multiplexing characterization of 3D video representation formats. IEEE Trans. Broadcast. 59(2), 382–389 (2013)
Scott, L.: Numerical Analysis. Princeton University Press, Princeton (2011)
Seeling, P., Reisslein, M.: Video transport evaluation with H.264 video traces. IEEE Commun. Surv. Tutor. 14(4), 1142–1165 (2012)
Wolf, A., Swift, B., Swinney, H., Vastano, J.: Determining Lyapunov exponents from a time series. Phys. D 16, 285–317 (1985)
Zhang, Z.-L., Kurose, J., Salehi, J., Towsley, D.: Smoothing, statistical multiplexing, and call admission control for stored video. IEEE J. Sel. Areas Commun. 15(6), 1148–1166 (1997)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Nigmatullin, R.R., Ceglie, C., Maione, G. et al. Reduced fractional modeling of 3D video streams: the FERMA approach. Nonlinear Dyn 80, 1869–1882 (2015). https://doi.org/10.1007/s11071-014-1792-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11071-014-1792-4