
Abstract
Modern commercial software tools have the ability to deceive a viewer who is unable to determine whether the image content is authentic or not. Research on visual traces, image modifications as attacks, and possible misleading forensic analysis in practice, led to reexamining common used formats, like JPEG (Joint Photographic Experts Group) compressed images. This is one of the most popular image and media formats on the Internet that convey information that cannot be easily trusted. Recompression is one of the fundamental aspects to be investigated, where double JPEG (DJPEG) compression is analyzed through spectral and statistical properties. State-of-the-art methods use coefficients to employ characteristics, like periodicity in histogram spectra for various quality factors (QFs). Some of the studies consider only DJPEG estimations when primary QF is less than in a latter case or when the same quantization matrix is applied. In this paper DJPEG and SJPEG (single JPEG) images are considered through large-deviation spectrum method (LDSM) and rounding and truncating (RT) errors, where additional two successive compressions are employed. The proposed methodology gives promising way to address classification between SJPEG and DJPEG. The test results are obtained on publically available image sets and show the effectiveness of the proposed approach with low number of features compared to other available methods.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
JPEG (Joint Photographic Experts Group) compressed images are presented on web pages, sent by e-mails, shared via video-chat applications and social networks. JPEG is a commonly used approach for lossy digital image compression, and it is one of the most convenient media formats for sharing visual information on the Internet due to the well-known property of reducing file size for image storing [34, 51, 55].
Since JPEG compressed images are widespread available on the Internet and supported by digital cameras, they represent important source of visual information. This information can be easily forged due to available commercial software editing tools, and as a result tampered image can be obtained that is difficult to distinguish from the original, source image. Image forensics has become a very active research area, where computer based approaches are developed for dealing with different types of image manipulation. Specific traces that may reveal content modifications or acquisition/source related changes are some of the typical tasks for investigating authenticity and trustworthiness of a digital image [12, 33]. Identification of tampered images which involves double or multiple compressions is one of the major issues in image processing and image forensics [5, 46].
The development of JPEG standard began in the eighties of the last century, and has been adopted as a standard based on preliminary CCITT (International Telegraph and Telephone Consultative Committee; now ITU-T (International Telecommunication Union - Telecommunication)) and JPEG (Joint Photographic Experts Group) research [34, 51]. Primarily it has been developed for still images, but the concept is valuable for motion pictures as well. The division into blocks of 8 × 8 pixels size is one of the main JPEG compression characteristics, where for each block DCT (Discrete Cosine Transform) is calculated. This is followed by quantization. Manipulation can occur in each of the steps during JPEG compression or decompression, which leads to JPEG based forensics analysis [5, 12, 31, 33, 46]. JPEG compression itself leaves traces [11, 15, 30]. Quantization matrix can be estimated for JPEG compressed image by matching with values from a predefined set, or for input uncompressed image format which was previously JPEG compressed [11, 13]. JPEG compression followed by decompression in antiforensics can be used to deceive whether image is compressed or not, or can be even recompressed by another compression method, but JPEG compression traces may provide enough data to estimate quantization matrix and detect the use of the compression. The traces may be in some cases localized or considered as JPEG ghosts [4, 13, 46].
Double JPEG (DJPEG) compression analysis is a very active research area, where a number of different methodologies have been proposed for: DJPEG trace analysis, DJPEG detection, primary quantization matrix or quality factor estimation, forgery detection and similar [3, 4, 8, 9, 11, 13, 17, 28,29,30, 36, 56, 58, 63]. Primary quantization can be estimated and doctored image can be found through detection of different quantization matrices [30]. JPEG block grid may not be aligned in DJPEG, and the JPEG details can be localized [3, 63]. Quantization in the first JPEG and the second JPEG compression can be performed in the same manner. Also, the quantization values may be different, where quality factors can be estimated [3, 8, 9, 17, 18, 21, 23, 27,28,29, 36, 37, 39, 56,57,58, 61, 63]. Double compressed image detection may be valuable for tampering detection or for data hiding. The reason for performing double JPEG compression detection is its relevance in multimedia forensics. The abovementioned examples contribute the overall search for adequate DJPEG traces and characteristics.
State-of-the-art methods perform analysis of statistical and spectral properties of JPEG coefficients with various quality factors (QFs) in order to deal with DJPEG detection. In the literature, methods often focus on particular relation between QF1 and QF2, like QF1 < QF2 or QF1 = QF2, where QF1 and QF2 correspond to quality factors of SJPEG (single JPEG) and DJPEG, respectively [7, 23, 37, 57, 59, 61]. It is well known that for low-quality images DJPEG detection accuracy results decrease. DJPEG periodicity and statistical analysis of difference between JPEG coefficients have been investigated in [3, 7, 59].
In this paper DJPEG and SJPEG compressed images are considered through large-deviation spectrum method (LDSM) and rounding and truncating (RT) errors. The proposed approach uses additional two successive compressions and LDSM based features for binary classification. Large deviation multifractal concept is used here for nonlinear analysis of coefficients dependency and traces related to JPEG compression. The contributions of this paper are following:
-
The obtained results on testing large-deviation spectrum behavior show particular spectral behavior that may be applicable to SJPEG versus DJPEG classification.
-
The proposed approach is based on successive compressions, rounding and truncating (RT) error images, and novel LDSM based features having in mind not only the same quality factors (QF1 = QF2), but also the other relations in mixed double quality compression (QF2 > QF1 and QF1 < QF2), without treating them with significantly different approach as in the literature.
-
It may be applied along with other available methods for the purpose of additional verification, and can be useful for analysis of image patches of different size and quality.
-
The classification model show high accuracy for DJPEG detection tested on publically available image sets, and uses small number of features related to other available methods.
The paper is organized as follows. In Section 2 double JPEG compression is considered, as well as related works on DJPEG detection and rounding and truncation (RT) estimation approaches. The proposed large-deviation spectrum method (LDSM) is explained in Section 3 for DJPEG image detection. The large-deviation characteristics estimation and the spectral analysis of RT errors for different QFs are described. The experimental results using the proposed approach are shown in Section 4 for publically available image sets. In Section 5 final conclusions are given.
2 Double JPEG detection
Research in the area of JPEG compression analysis dates back several decades, as well as methodologies considering JPEG artifact analysis, data hiding and forgery detection which involves JPEG compression steps [12, 34, 51, 55]. Even though, JPEG compression traces remain as one of the main objectives to analyze when image details may reveal made modifications in visual content or image origin [22, 48, 52, 54, 60, 62, 64]. JPEG compression is still one of the most common choices for image format and visual information distribution.
Due to advanced commercial editing software and popularity of digital image trustworthiness and authentification research, DJPEG compressed image analysis and detection has been considered in recent years. DJPEG image is generated when a SJPEG is decompressed and then resaved as another JPEG image with application of quantization matrix. In forensics it is quite common to have DJPEG images where some particular content changes are made (e.g. watermarking, steganography, copy-move, splicing and other tampering) [2, 40, 47]. The content modification in SJPEG is followed by saving the image in JPEG format, producing DJPEG compressed image. This is one of the probable reasons why DJPEG research is particularly of interest. Details due to JPEG traces need to be investigated thoroughly, in order to distinguish them from other manipulations. For example, copy-move or image splicing modifies a part of image by replacing it with another part from the same or different image, leading to changing visual content. Pasted part may show SJPEG traces compared to the rest of the DJPEG image. The content can be also modified by watermarking or steganography (e.g. J-Steg, F5, or similar) where visible or nearly visible results can be produced. Primary quantization matrix estimation can be valuable for data hiding in order to retrieve an adequate message/information.
SJPEG compression is illustrated in Fig. 1(a), where input is an uncompressed image. The block scheme for DJPEG compression is presented in Fig. 1(b).

General block scheme of (a) SJPEG and (b) DJPEG compression
The uncompressed input image is divided into non-overlapping blocks of N × N size (N = 8), and for each pixel b(x, y) within block Bxy the DCT is calculated as:
where \( C(i)=1/\sqrt{2} \) if i = 0, and C(i) = 1, otherwise. The quantization matrix Q (or Q1) is then applied for DCT coefficients:
This is followed by entropy coding of zig-zag arranged quantized coefficients, where compressed data stream is obtained after applying the Huffman encoder. In the decompression phase, for each block, the quantized coefficients \( {D}_{i,j}^q \) are multiplied by quantization matrix \( {D}_{i,j}={D}_{i,j}^q{Q}_{i,j},\kern0.62em i,j=0,\dots, N-1 \). The quantization matrix values are found in a compressed file. Then, after applying IDCT (Inverse DCT), rounding and truncating are performed in order to obtain integer values that fall in range [0, 255]. SJPEG compressed image is a result of this compression process.
The compression process can be repeated with SJPEG as input in order to get DJPEG image. DJPEG can be formed using the same or different quantization matrix as in the process of obtaining SJPEG. When the same quantization matrix is applied, the primary quantization matrix Q1 equals the secondary one, Q2. Different notations for matrices are used intentionally, even though the values may be the same. For the same quantization matrix, three errors can be found: quantization, rounding and truncation error. Note that the quantization error in compression is the difference between actual float value after dividing DCT coefficients and the rounded integer (quantized) JPEG coefficients. The truncation error is found while data reconstruction in spatial domain to belong to range [0, 255] (values lower than 0 are truncated to 0, and values higher than 255 are truncated to 255), and the rounding error in recompression is the difference between the float numbers from range [0, 255] and the corresponding nearest integer values for data reconstruction in spatial domain.
2.1 Overview of DJPEG detection
Methods for DJPEG detection can be categorized in two categories: the methods that deal with different quality factors in SJPEG and DJPEG compression, and the methods that resolve the case of the same quality or quantization.
Fan and de Querioz in [11] considered processing without prior knowledge of whether the compression occurred or not, and developed a module that receives a bitmap image and process it having in mind quantizer estimation and compression detection. They developed method for the maximum likelihood estimation of JPEG quantization steps having in mind block-based approach. In [30] Lukáš and Fridrich analyzed patterns of normalized histograms belonging to coefficients after double compression, and proposed three approaches by distinguishing specific cases based on visual inspection. Namely, characteristic statistical features are noticed for different relations between quantization values, such as missing points (values almost zeroed) or extreme values found in normalized histograms, described as features for primary quantization estimation. In [30] the authors presented visible or hidden double peaks that may be found in histograms. This work belongs to the first category of DJPEG detection methods. When the quantization is the same, a smooth decreasing histogram is found, and it is considered as a special case due to missing visible features, like double peaks. The histograms are compared for primary quantization estimation oriented towards low frequencies, where noise and slight differences due to quantization can be described as high frequency parts. In approaches [4, 11, 13, 29, 30, 36] aligned DJPEG scenario is assumed, while there are methodologies for detection of nonaligned or shifted DJPEG compression [3, 9, 56, 58, 63]. For misalignment the aim is to deal with shifts of JPEG grids and block DCT artifacts, as in Bianchi and Piva [3] and Zhang et al. [63], having in mind that similar content will also appear in shifted compressed images. For example, in [3] the authors propose a method for DJPEG detection which employs integer periodicity map, where QF1 = QF2 case is treated quite differently since the main strategy is oriented towards the QF1 ≠ QF2 case. Different quality factors (QF1 ≠ QF2) for DJPEG are also analyzed in Chouhan and Nigam [8], in order to get proper PSNR (Peak to Signal Noise Ratio) values. Similar is done by Li et al. [28] with muti-branch convolutional neural network and 32 × 32 × 20 tensor, where 20 ac subbands and 32 × 32 DCT coefficients are taken as input. Fu et al. used in [17] the first digits distribution of JPEG coefficients and generalized Benford’s law to describe SJPEG and to differentiate it from DJPEG. The first digit features from selected ac channels are applied in [27] by Li et al. for DJPEG detection. In the QF1 ≠ QF2 case, there are methods that assume only the case when QF1 value is less than QF2 (QF1 < QF2), as in [18, 58, 63].
The same quality factors are considered in [23, 36, 57]. Huang et al. in [23] and Niu et al. in [36] analyzed the QF1 = QF2 case using random and less random perturbation strategies, respectively, in order to enhance the changes found in successive compressions. It is shown that quantization and RT errors are enough to differentiate between single and double compressed images when quantization is the same. The number of modified coefficients per nonzero JPEG coefficients is selected, and the modification is performed in a random manner arbitrarily increasing and decreasing selected coefficients by 1. The authors note that the main challenge is setting the threshold interpreted through the proper ratio after implementing the intrinsic property regarding the number of different JPEG coefficients. The proposed approach use interference process which is repeated several times in to order to get average values to describe the threshold [23, 36]. Low QF presents a particular challenge. Yang et al. in [57] proposed detection model based on the error image and statistical features, like mean and variance in the spatial domain, mean and variance from dequantized coefficients and occurrence ratio forming thirteen features for SVM (support vector machine) classifier input. Yuan et al. in [61] combine perturbation model with the error image approach for low QF cases, where two quite different approaches are bounded to get the results for each quality case. In addition to the DCT coefficients, quantization matrix can be resized and combined into a relatively large feature vector that represents input for classification model as in [39].
The literature in the field of DJPEG detection exploits statistical features, periodicity, histogram spectra and errors during compression and decompression. In this paper, large-deviation multifractal properties are used for SJPEG versus DJPEG differentiation. The same quality in recompression is analyzed as well as other relations between QFs. The motivation is to find a more general approach which does not treat the QF1 = QF2 case as a specific challenging case compared to the case with different values, and uses relatively small number of features for the classification task.
2.2 Rounding and truncation estimation
The compression and decompression processes can be modeled for JPEG coefficients as in (3):
where the coefficients B1 are treated by IDCT and rounding and truncating step (RT), and quantized by Q2 values. By incorporating primary quantization values the relation between the coefficients in the primary and the second JPEG compression can be presented as:
where Q1 corresponds to primary quantization matrix, E2 to error, and × and / are matrix element-wise operators. Furthermore, this relation can be rewritten as:
where residual R2 represents the error. Simplified expression can be written for Q1 = Q2:
Misalignment of DCT grids in DJPEG is illustrated in Fig. 2. DJPEG can be analyzed for aligned and non-aligned compression. Non-aligned one has a grid shift of (r, c), where r corresponds to row-wise and c to column-wise shift. The possible shifts can be in the range [0, 7] for both r and c, where (r, c) = (0, 0) represents the aligned JPEG.

Image patches for: (a) aligned SJPEG, (b) aligned DJPEG and (c) non-aligned DJPEG with grid shift (r,c)
If JPEG compression is applied, the coefficients show periodicity according to quantization values. This can be observed for different bands (r1, c1). The coefficients for band (0, 1) are shown in Fig. 3 for quantization value 6. Generally, the property of periodicity is found useful in JPEG analysis.

(a) Input image, (b) grayscale compressed image with QF1 = 75, (c) quantization matrix with noted value at (0,1) band, and DCT histograms for coefficients at band (0,1): (d) before the first quantization, (e) after the first dequantization, and (f) before the second quantization
JPEG reconstruction gives slight differences that can be considered as RT error. RT errors can be analyzed for three cases of quality factors in SJPEG and DJPEG compression processes: QF1 < QF2, QF1 = QF2 and QF1 > QF2. The RT error is illustrated in Fig. 4, as well as difference values found for three QF relations, where one may notice the residuals in the same quality scenario.

(a) Single compressed image, (b) RT error illustration, (c) double compressed image, and (d) difference values for QF1 = QF2 and lower (QF2 < QF1) and higher QF2 (QF2 > QF1)
In the case of the same quality factors applied in order to obtain DJPEG, a difficult scenario is expected because most of the JPEG coefficients remain the same after the recompression. Nevertheless, relatively small residuals exist. RT errors or error patches in SJPEG and DJPEG class may have different properties from the statistical point of view, and can be even manipulated to enhance the error influence for the differentiation task [23, 57]. There is a tendency of decreasing differences between successive compressions with quantization performed in the same manner. This is shown in Fig. 5 for several QF values. The level of dissimilarity between successive compressions can be viewed through these differences. Similarly, the level of similarity between them can be viewed through measures like the one in [31]:
where E = {(x, y)|JPEG(x, y) = DJPEG(x, y), 0 ≤ x ≤ M − 1, 0 ≤ x ≤ N − 1}.

Decreasing trend for successive compressions and QF1 = QF2 = QF: QF = 95 (left) and QF = 85, 75, 65, 40, 20 (right)
3 The proposed methodology based on large deviation spectral characteristics
In this paper error analysis is performed using LDSM (large-deviation spectrum method). The methodology for DJPEG detection consists of four main phases or steps:
-
reading an input image,
-
application of successive two compressions for construction of triplet of images based on SJPEG or DJPEG, where here the focus is on the aligned case,
-
feature vector extraction, and
-
classification,
for obtaining binary classification result based on large-deviation statistical properties. The four main steps of the methodology/algorithm are presented in Fig.6. Feature extraction includes three LDSM features along with two traditional features for showing the decreasing trend for successive compressions, where for the LDSM approach:
-
two successive compressions are used for construction of a triplet, and this is followed by:
-
estimation of RT error image using reconstructed image I for the triplet,
-
calculation of block-wise DCT coefficients (blocks of 8 × 8 pixels) of grayscale RT error image for the triplet elements,
-
singularity spectra calculation using the DCT coefficients,
-
calculation of singularity spectrum properties and, finally,
-
calculation of LDSM features.

Block scheme of the proposed LDSM based methodology for DJPEG detection
Extraction of LDSM features based on singularity spectrum calculation is also illustrated in Fig. 6. More background on singularity spectral analysis can be found in Section 3.1. In Section 3.2 feature extraction step is described in more detail according to singularity spectrum properties. Moreover, details about the classification approach are given in Section 3.3.
3.1 Large deviation based singularity spectrum
RT error can be estimated after image reconstruction. Large deviation method has been applied in this paper for singularity spectrum calculation based on such errors in DCT domain. Here, a brief description of the concept is explained for better understanding of multifractal calculations. They are popular for statistical analysis of nonstationary signals, like biomedical, seismic signals, data series in finance, meteorology, image segmentation and analysis, and similar applications [1, 16, 19, 24, 32, 41, 43, 49, 50]. Initially, they have been introduced for making turbulent flow velocity measurements [32]. In order to make statistical description two common multifractal spectra can be investigated: Large deviation (LD) and Legendre spectrum [24, 50].
For example, if a box-counting technique is applied for a normalized structure it may be covered by a regular grid of boxes of size ε. The corresponding dimension is described as:
where N(ε) is the number of boxes needed for the structure covering [32]. The Hausdorff dimension Dh can be found for each set of points Sh that have the same exponent value h (Hölder exponent), and Hölder exponent can be assigned to each point of a structure being analyzed for its regularity. Multifractal property can be understood as a wide range of these exponents.
Having in mind the multifractality, for a function g at point x0 a polynomial Pn(x) and constant K can be found such that:
for all x values from the neighborhood of x0. For a set of Hölder exponents found within a range [h, h + Δh], multifractal formalism and singularity spectrum fh can be introduced as:
This enables multifractal spectrum calculation as (h, fh), where τ(q) is a convex function of q such that q-order singularity exponent, h(q), is a monotonically decreasing function of q. Parameter α (alpha) represents an approximation of Hölder exponent, where f(α) represents the corresponding distribution of α values, i.e. the Legendre multifractal spectrum [19, 24]. The coarse Hölder exponent, α, can be estimated to cover the structure with nonoverlapping boxes Bi of size ε, where the structure is approximated as union of Bi and with selected measure μ which corresponds to the strength of analyzed property:
The Hölder exponent α describes the local regularity, while the distribution f(α) represents singularity spectrum, which in the case of Legendre formalism is a smooth concave function of α.
Another popular singularity spectrum is defined through large deviation(s) formalism. Large deviation (LD) spectrum is defined as:
where \( {N}_n^{\varepsilon}\left(\alpha \right)=\#\left\{k:\alpha -\varepsilon \le {\alpha}_n^k\le \alpha +\varepsilon \right\} \), and \( {\alpha}_n^k=-\log \left|{Y}_n^k\right|/\log n \) represents the coarse grained exponent, while \( {Y}_n^k \) represents the oscillation of the structure being analyzed within interval [k/n, (k + 1)/n]. For practical implementations and real discrete samples of function g it is possible to make different choices like:
In this paper discrete samples are analyzed using Fraclab and its LD implementation [16]. The LD singularity spectrum f(α) is generally not concave as Legendre transform based one, but the large deviations formalism can describe structural changes in a more subtle manner compared to the Legendre one [24, 49]. This was the reason why the large deviation singularity approach (12) has been selected. Moreover, the tails of spectrum where function details may be observed are considered more robust for the large deviations, where the left tail of distribution represents small singularity exponents for the large increments or variation whereas small variation and large singularity exponents are found in the right tail [1, 16, 24, 49].
3.2 Feature extraction and three quality factor relations in DJPEG according to singularity spectrum properties
The proposed approach uses additional two compressions besides input JPEG compressed image. Thus, 3JPEG represents compressed DJPEG, while compressed 3JPEG is noted as 4JPEG. LD spectra are calculated for RT errors which correspond for input image and additional two compressions. The successive LD spectra for the same QF are presented in Fig.7 for each compressed image for better understanding. The scenario of the same quality factor results in similar distributions, as expected, Fig. 7(a). Nevertheless, the left tail noted in Fig. 7(a) of each of the distribution curves and small alpha exponents is sensitive enough to show the differences between the calculated errors of successive compressions. The order of compressions (SJPEG, DJPEG, 3-JPEG and 4-JPEG) corresponds to the order of αmin (minimum alpha) of each LD spectrum in the left tail, Fig. 7(b). Each αmin can be described by its height (h) and width (w). Height means the difference between maximum close to one, noted as f(αm), and f(αmin), whereas width is the difference between αm and αmin.

Successive large deviation spectra for the same QF (here QF = 75): (a) spectra with noted left tail and (b) the left tail with minimum alpha described using its height and width
Multifractal properties can be presented in many ways by: maximum of spectra, its corresponding alpha value, minimum and maximum alpha value and its corresponding f(alpha) values, areas calculated on the left and the right side of spectra, distribution of f(alpha) values on the left and the right side [1, 16, 19, 24, 32, 41, 43, 49, 50]. After setting the maxima of each distribution to be the same (distribution maximum is at 0, meaning αm = 0), the width and the height are calculated for triplet, i.e. input and two successive compressions (h1,2,3 and w1,2,3). Then, the corresponding distances r(i) = r1(i) of points (hi, wi) are found using well-known city-block (also referred to as Manhattan distance) metric, and the feature is calculated for the input as:
where adding one in (14) avoids division by zero.
Three possible relations between QFs have analyzed as well. Spectra for successive compressions are presented in Fig. 8(a) for Lena image and QF1 > QF2. It can be noticed that RT spectrum for SJPEG is different from DJPEG, whereas the width in left tail is smaller than the other weights. Similar stands for the SJPEG height. It is assumed here that 3JPEG and 4JPEG have the same quality factor as DJPEG, where adequate order of minimum alpha values still exists. In the last scenario, for QF1 < QF2 the order of αmin values is the same as for the same quality factor case, with noticeable difference between these exponents belonging to each of the compressions, as shown in Fig. 8(b). The difference between SJPEG and DJPEG singularity spectrum is more noticeable when the quality factors are not the same compared to the same quality factors scenario. This only confirms that the QF1 = QF2 case is the most difficult one. Also, similar rules can be set for all three quality factor relations.

Successive large deviation spectra and their left part for: (a) the QF1 > QF2 and (b) the case with QF1 < QF2
Besides these slight differences represented by the mentioned feature, the right tail or part of spectrum can be also informative since it gives information about the details as in [19]. For example, in the case where more details exist in the RT error image more variation can be observed in the right side, even in the case of the same quality factor usage. This is shown for QF = 90 in Fig. 9.

Successive large deviation spectra with noted higher variation for SJPEG on the right side: (a) QF1 = QF2 = 90; (b) QF1 = 90 for SJPEG and QF1 ≠ QF2 for DJPEG (QF2 = 90)
Area of the right side and sum of f(α) from the left and right sides are calculated for each triplet, and the second and the third feature, f2(3), are directly related to the multifractal characterization in order to represent higher SJPEG variation:
where adding one avoids division by zero. One may notice that in (15) that higher variation on the right side is employed and that only first two images from the triplet are applied.
Decreasing tendency of JPEG coefficients and spectral differences are also employed as the fourth and fifth feature for enhancing the differences between successive compressions, as relative changes, expecting the larger difference between the input and the first successive change, and the first and the second successive change, as in Fig. 5. These are the traditional features. LDSM based approach is proposed for the first time to the author’s knowledge compared to the traditional ways to make the differentiation [3, 31, 57, 61]. Multifractal analysis has been performed using Fraclab [16], where the calculation of JPEG compression data and analyzed errors is performed using JPEG Toolbox [25].
3.3 Classification model for DJPEG detection
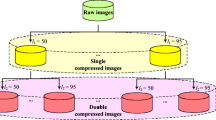
The LDSM based approach has been examined on the standard uncompressed and raw images. The experimental analysis has been performed on test images taken from UCID - Uncompressed Color Image Database, NRCS (Natural Resources Conservation Service) and RAISE (The Raw Images Dataset) datasets [10, 38, 44]. UCID dataset contains uncompressed images of relatively small resolution, 384 × 512 and 512 × 384 pixels in tif(f) (tagged image file format), while NRCS uncompressed tiff images are cropped to fixed common resolution of 512 × 512 pixels. Moreover, images from RAISE dataset are tested as well and cropped to 512 × 512 resolution. Image patches are analyzed for spatial resolution from 1024 × 1024 to 256 × 256 pixels. Camera-native images are found, where in UCID set images are taken with single camera, and three camera models are used for RAISE raw compressed tiff images (Nikon D40, D90, D7000). More than 4500 images are included in the experiment, where both outdoor and indoor acquired images containing different objects are examined (Fig. 10). Thirteen quality factors, from 100 to 20, are tested. Namely, quality factors of 20 to 60 with step of ten, and 60 to 100 with step five are tested. The classification is performed for DJPEG images acquired for both QF1 = QF2 and QF1 ≠ QF2 scenarios, where in the latter scenario the primary factor is selected in a random manner, meaning DJPEG of certain quality factor has been analyzed for different/arbitrary primary quantization.

Column-wise presented image examples from three datasets
Several machine learning methods are used to classify SJPEG and DJPEG images with extracted features: SVM, k-NN, decision tree, and ensemble bagged tree [14, 26, 35]. The SVM (Support Vector Machine) is widely applied for the classification tasks, where separating hyperplane is found in feature based domain to distinguish between different data types. The k-NN is a nonparametric instance based method, where during the training process the nearest neighbors are searched for. The classification of new observations is then applied according to acquired labels and nearest-neighbor distance metric. Decision or classification tree (CT) is found as one of the most popular classification approaches, where the tree architecture is learned according the extracted features. Finally, ensemble tree classifiers (ECT) are commonly used for developing models of high accuracy, where the bagging algorithm is one of the most efficient methods [6].
The classification model analysis is performed similarly to [35], where K-fold cross-validation method is applied. In the five-fold cross-validation, the training includes representatives of each class and quality, while the content of tested images for distinguishing between SJPEG and DJPEG is not included in the training set. Classification model performance is evaluated by the calculation of overall averaged balanced accuracy according to calculated true positive rate (TPR) and true negative rate (TNR):
where TP, TN, FP and FN represent true positives, true negatives, false positives and false negatives for DJPEG detection. The classification is performed on both uncompressed and raw compressed native images with the focus on aligned double compression and low quality factors.
4 Experimental results
Since the research is dealing with DJPEG detection from only one version of an image, it would be useful to show spectra belonging to different images and the effects of multiple compressions and relations between QFs. In Fig. 11 spectra corresponding to different test images with noted left tails for the QF1 > QF2 case are shown. Similarly, in Fig. 12 spectra for three test images with noted left tails for the QF1 < QF2 case are presented. Finally, spectra for the test images from three different datasets are given in Fig. 13 for the QF1 = QF2 case. The famous Lena image is used in Section 3.2 and experiments like [31], but one may assume that it could contain some artifacts that may result in some specific multifractal effect characteristic for this image. Thus, the spectra are visualized for modern-era images from three publicly available datasets. Moreover, Figs. 11, 12 and 13 show similar spectra characteristics due to the approach itself leading to the relevance of the LDSM features.

(a) Test images and (b) corresponding spectra with c noted left tail for the QF1 > QF2 case

(a) Test images and (b) corresponding spectra with c noted left tail for the QF1 < QF2 case

(a) Test images and (b) corresponding spectra with c noted left tail for the QF1 = QF2 case
It is well known that self-similarity properties are found in natural images, as well as in computer generated images and their residuals since computer generated images are relatively locally smoother [42]. Thus, multifractal spectra are calculated for making difference between such variations. Self-similarity behavior exist in DCT coefficients obtained for JPEG images, and it is exploited in many fields like fractal image compression [53], where blocks can show different local variation and fractal characteristics. Nevertheless, fractal image compression is beyond the scope of this paper which deals with SJPEG versus DJPEG discrimination. Here, in the experimental analysis it is shown that it is possible to calculate multifractal spectrum for DCT coefficients of estimated residuals, where large deviation method is found as suitable for JPEG analysis.
The extracted LDSM features are additionally examined in the initial experimental analysis for SJPEG and DJPEG differentiation and the same quantization case (QF1 = QF2). The feature space is analyzed for being able to have adequate clusters belonging to SJPEG and DJPEG. Silhouette method is applied for investigating the separation between clusters [20, 45]. The technique provides graphical representation and the silhouette ranges from −1 to 1. It can easily be observed in Fig. 14 that the separation between the clusters exists where the clusters presented here show relatively high values for city-block metric.

Silhouette separation between clusters for the image samples in the feature space for: (a) UCID, QF1 = 30, (b) NRCS, QF1 = 75, (c) RAISE, QF1 = 90
The spectra may show different behavior when experimenting with various images, but the high accuracy seems to be due to specific effects found using LDSM features. These effects are illustrated in Fig. 15, showing plane or line effect for DJPEG compared to SJPEG. In order to point out the significance of the proposed LDSM features, in Fig. 15 images/points are shown in the three-dimensional space for representation of the specific effects. Namely, two perspectives for NRCS and UCID samples are presented to illustrate the plane effect, while the line effect is shown in the three-dimensional space for RAISE samples cropped to 512 × 512 resolution.

(a-b) Two perspectives of NRCS plane effect for QF = 50, (c-d) two perspectives of UCID plane effect for QF = 75, (b) RAISE line effect for QF = 20
With the focus on the same quantization in DJPEG and the same spatial resolution of 512 × 512 the classification results are found. Namely, balanced accuracy results are calculated for several classification models. The classification based on several classifiers is performed using the selected feature vector that includes LDSM and traditional features described in Section 3.2. Images of high and low quality factors are tested, where the results for factors 30, 50 and 80 are shown in Table 1 which illustrates the best performance for ECT classification model based on bootstrap aggregation or bagging [6]. The ECT classification results for fixed quality and image patches of different resolution are presented in Table 2.
The ECT classification results for both the same and different quantization are shown in Fig. 16. The balanced evaluation is performed for three sets and QF1 = QF2 and QF1 ≠ QF2 scenarios. In the QF1 ≠ QF2 quantization case the selection of primary quality factor is made in a random manner by taking into account not to be the same as the secondary one. The experimental results of the proposed methodology are shown in Table 3.

The classification results for: (a) QF1 = QF2; (b) QF1 ≠ QF2
The proposed methodology has been tested on a large number of images with different quality factors showing the high accuracy performance with the focus on the same quality scenario, without neglecting the other relations between quality factors. The low quality factors have not been analyzed in [23]. Also, the proposed approach uses lower number of features compared to other methodologies, like [61] which apply thirty features to enable efficient discrimination between SJPEG and DJPEG compressed images.
Even though the focus of this investigation has not been the non-aligned case, the tendency of having proper characterization stands even when misalignment occurs. The proposed classification based on large deviation spectral method incorporates characteristics of both tails of spectra in accordance with multifractal concept. The main limitation of the proposed approach can be specific visual content where significant lack of details can be observed, e.g. image patch consisting of clear sky. Higher resolution of images or image patches brings out the advantage of the proposed approach due to a larger amount of details compared to standard 512 × 512 pixels experiments from the literature. This is expected, where relatively high resolution images are becoming more common in everyday life and enable more accurate assessing differences and traces in media.
DJPEG detection method may be dependent on image technology and settings applied during the whole image-processing chain, but in this paper it is shown that a fair classification between SJPEG and DJPEG may be performed for a large number of images of different quality from three different publically available datasets. Thus, machine learning may be considered useful in such tasks.
5 Conclusion
This paper introduces a new LDSM based approach for DJPEG detection. The proposed approach for description of JPEG traces considers all relations between primary and secondary quality factor. The proposed classification methodology enables high accuracy results with relatively small number of features. LDSM features are shown to be highly useful in classification between SJPEG and DJPEG images for various quality factor values. The classification model enabled high accuracy for images from three public datasets even in the case of low quality factors. The specific behavior of selected features has shown to be useful for the classification task.
Since overall differences between JPEG coefficients are difficult to notice and determine, the future work should include the development of efficient model that may overcome the issues in lacking significant amount of details like in uniform regions of computer generated images. Block based local examinations may additionally improve the results since some of the artifacts and residuals may be more detectable in some particular blocks or regions. This may further increase efficiency of the proposed DJPEG detection which can be used as additional tool for DJPEG tracing detection. Further development of the proposed methodology should be oriented towards the localization of DJPEG traces and detection of local changes for multiple compression processes.
Data availability
The datasets analyzed during the current study are/have been available at https://qualinet.github.io/databases/image/uncompressed_colour_image_database_ucid/, https://www.flickr.com/photos/usdagov/collections/72157624326158670/, http://loki.disi.unitn.it/RAISE/, and/or necessary information can be found in ref. [10, 38, 44]. The Lena image can be downloaded from: https://www.imageprocessingplace.com/root_files_V3/image_databases.htm
References
Barral J, Gonçalves P (2011) On the estimation of the large deviations Spectrum. J Stat Phys 144(6):1256–1283. https://doi.org/10.1007/s10955-011-0296-6
Bhartiya G, Jalal AS (2017) Forgery detection using feature-clustering in recompressed JPEG images. Multimed Tools Appl 76(20):20799–20814. https://doi.org/10.1007/s11042-016-3964-3
Bianchi T, Piva A (2011) Detection of nonaligned double JPEG compression based on integer periodicity maps. IEEE Trans Inf Forensics Secur 7(2):842–848. https://doi.org/10.1109/TIFS.2011.2170836
Bianchi T, De Rosa A, Piva A (2011, May) Improved DCT coefficient analysis for forgery localization in JPEG images. In 2011 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp 2444-2447). IEEE. https://doi.org/10.1109/ICASSP.2011.5946978
Birajdar GK, Mankar VH (2013) Digital image forgery detection using passive techniques: a survey. Digit Investig 10(3):226–245. https://doi.org/10.1016/j.diin.2013.04.007
Breiman L (1996) Bagging predictors. Mach Learn 24(2):123–140. https://doi.org/10.1007/BF00058655
Chen YL, Hsu CT (2011) Detecting recompression of JPEG images via periodicity analysis of compression artifacts for tampering detection. IEEE Trans Inf Forensics Secur 6(2):396–406. https://doi.org/10.1109/TIFS.2011.2106121
Chouhan A, Nigam MJ (2016, July) Double compression of JPEG image using DCT with estimated quality factor. In 2016 IEEE 1st international conference on power electronics, intelligent control and energy systems (ICPEICES) (pp 1-3). IEEE. https://doi.org/10.1109/ICPEICES.2016.7853478
Dalmia N, Okade M (2018) Robust first quantization matrix estimation based on filtering of recompression artifacts for non-aligned double compressed JPEG images. Signal Process Image Commun 61:9–20. https://doi.org/10.1016/j.image.2017.10.011
Dang-Nguyen DT, Pasquini C, Conotter V, Boato G (2015, March) Raise: a raw images dataset for digital image forensics. In Proceedings of the 6th ACM multimedia systems conference (pp 219-224). https://doi.org/10.1145/2713168.2713194
Fan Z, De Queiroz RL (2003) Identification of bitmap compression history: JPEG detection and quantizer estimation. IEEE Trans Image Process 12(2):230–235. https://doi.org/10.1109/TIP.2002.807361
Farid H (2009) Image forgery detection. IEEE Signal Process Mag 26(2):16–25. https://doi.org/10.1109/MSP.2008.931079
Farid H (2009) Exposing digital forgeries from JPEG ghosts. IEEE Trans Inf Forensics Secur 4(1):154–160. https://doi.org/10.1109/TIFS.2008.2012215
Fatimah B, Singh P, Singhal A, Pachori RB (2021) Hand movement recognition from sEMG signals using Fourier decomposition method. Biocybern Biomed Eng 41(2):690–703. https://doi.org/10.1016/j.bbe.2021.03.004
Feng X, Doërr G (2010, January) JPEG recompression detection. In Media forensics and security II, vol. 7541 pp 75410J. International Society for Optics and Photonics. https://doi.org/10.1117/12.838888
Fraclab (n.d.) https://project.inria.fr/fraclab/, last accessed (30.08.2021.)
Fu D, Shi YQ, Su W (2007) A generalized Benford’s law for JPEG coefficients and its applications in image forensics. In Security, steganography, and watermarking of multimedia contents IX vol. 6505 pp 65051L. International society for optics and photonics. https://doi.org/10.1117/12.704723
Galvan F, Puglisi G, Bruna AR, Battiato S (2013, September) First quantization coefficient extraction from double compressed JPEG images. In International conference on image analysis and processing (pp 783-792). Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-41181-6_79
Gavrovska A, Zajic G, Reljin I, Reljin B (2013) Classification of prolapsed mitral valve versus healthy heart from phonocardiograms by multifractal analysis. Comput Math Methods Med 2013:1–10. https://doi.org/10.1155/2013/376152
Halim Z (2018) Optimizing the minimum spanning tree-based extracted clusters using evolution strategy. Clust Comput 21(1):377–391. https://doi.org/10.1007/s10586-017-0868-6
He J, Lin Z, Wang L, Tang X (2006, May) Detecting doctored JPEG images via DCT coefficient analysis. In European conference on computer vision (pp 423-435). Springer, Berlin, Heidelberg. https://doi.org/10.1007/11744078_33
Hou W, Ji Z, Jin X, Li X (2013) Double JPEG compression detection based on extended first digit features of DCT coefficients. Int J Inf Educ Technol 3(5):512
Huang F, Huang J, Shi YQ (2010) Detecting double JPEG compression with the same quantization matrix. IEEE Trans Inf Forensics Secur 5(4):848–856. https://doi.org/10.1109/TIFS.2010.2072921
Ihlen EA, Vereijken B (2013) Multifractal formalisms of human behavior. Hum Mov Sci 32(4):633–651. https://doi.org/10.1016/j.humov.2013.01.008
JPEG Toolbox (n.d.) https://digitnet.github.io/jpeg-toolbox/, last accessed (15.07.2021)
Karaca BK, Akşahin MF, Öcal R (2021) Detection of multiple sclerosis from photic stimulation EEG signals. Biomed Signal Process Control 67:102571. https://doi.org/10.1016/j.bspc.2021.102571
Li B, Shi YQ, Huang J (2008, October) Detecting doubly compressed JPEG images by using mode based first digit features. In 2008 IEEE 10th workshop on multimedia signal processing (pp 730-735). IEEE. https://doi.org/10.1109/MMSP.2008.4665171
Li B, Luo H, Zhang H, Tan S, Ji Z (2017) A multi-branch convolutional neural network for detecting double JPEG compression. arXiv preprint arXiv:1710.05477
Lin Z, He J, Tang X, Tang CK (2009) Fast, automatic and fine-grained tampered JPEG image detection via DCT coefficient analysis. Pattern Recogn 42(11):2492–2501. https://doi.org/10.1016/j.patcog.2009.03.019
Lukáš J, Fridrich J (2003, August) Estimation of primary quantization matrix in double compressed JPEG images. In Proc. digital forensic research workshop (pp 5-8)
Luo W, Huang J, Qiu G (2010) JPEG error analysis and its applications to digital image forensics. IEEE Trans Inf Forensics Secur 5(3):480–491. https://doi.org/10.1109/TIFS.2010.2051426
Mandelbrot BB (1982) The fractal geometry of nature, vol 1. WH freeman, New York. https://doi.org/10.1002/esp.3290080415
Meena KB, Tyagi V (2019) Image forgery detection: survey and future directions. In: Data, engineering and applications. Springer, Singapore, pp 163–194. https://doi.org/10.1007/978-981-13-6351-1_14
Mitchell JL, Pennebaker WB (1991) Evolving JPEG color data compression standard. In: Standards for electronic imaging systems: a critical review, vol 10259. International Society for Optics and Photonics, p 1025906. https://doi.org/10.1117/12.48892
Nawayi SH, Vijean V, Salleh AF, Planiappan R, Lim CC, Fook CY, Awang AS (2021, October) Non-invasive detection of Ketum users through objective analysis of EEG signals. J Phys Conf Ser 2071(1):012045). IOP publishing. https://doi.org/10.1088/1742-6596/2071/1/012045
Niu Y, Li X, Zhao Y, Ni R (2019) An enhanced approach for detecting double JPEG compression with the same quantization matrix. Signal Process Image Commun 76:89–96. https://doi.org/10.1016/j.image.2019.04.016
Niu Y, Tondi B, Zhao Y, Barni M (2019) Primary quantization matrix estimation of double compressed JPEG images via CNN. IEEE Signal Process Lett 27:191–195. https://doi.org/10.1109/LSP.2019.2962997
NRCS Photo gallery, (n.d.) https://photogallery.sc.egov.usda.gov/photogallery/#/, last accessed (15.07.2021.)
Park J, Cho D, Ahn W, Lee HK (2018) Double JPEG detection in mixed JPEG quality factors using deep convolutional neural network. In Proceedings of the European conference on computer vision (ECCV) (pp 636-652). https://doi.org/10.1007/978-3-030-01228-1_39
Pasquini C, Schöttle P, Böhme R, Boato G, Perez-Gonzalez F (2016, June) Forensics of high quality and nearly identical jpeg image recompression. In Proceedings of the 4th ACM workshop on information hiding and multimedia security (pp 11-21). https://doi.org/10.1145/2909827.2930787
Pavlović A, Glišović N, Gavrovska A, Reljin I (2019) Copy-move forgery detection based on multifractals. Multimed Tools Appl 78(15):20655–20678. https://doi.org/10.1007/s11042-019-7277-1
Peng F, Zhou DL, Long M, Sun XM (2017) Discrimination of natural images and computer generated graphics based on multi-fractal and regression analysis. AEU-Int J Electron Commun 71:72–81. https://doi.org/10.1016/j.aeue.2016.11.009
Peyrière J (1992) Multifractal measures. In Probabilistic and stochastic methods in analysis, with applications (pp 175–186). Springer, Dordrecht. https://doi.org/10.1007/978-94-011-2791-2_7
Schaefer G, Stich M (2004) UCID - An Uncompressed Colour Image Database, Proc. SPIE, Storage and Retrieval Methods and Applications for Multimedia 2004, pp 472–480, San Jose, USA. https://doi.org/10.1117/12.525375
Shutaywi M, Kachouie NN (2021) Silhouette analysis for performance evaluation in machine learning with applications to clustering. Entropy 23(6):759. https://doi.org/10.3390/e23060759
Stamm MC, Tjoa SK, Lin WS, Liu KR (2010, March) Anti-forensics of JPEG compression. In 2010 IEEE International Conference on Acoustics, Speech and Signal Processing (pp 1694-1697). IEEE. https://doi.org/10.1109/ICASSP.2010.5495491
Tondi B, Costanzo A, Huang D, Li B (2021) Boosting CNN-based primary quantization matrix estimation of double JPEG images via a classification-like architecture. EURASIP J Inf Secur 2021(1):1–14. https://doi.org/10.1186/s13635-021-00119-0
Valenzise G, Tagliasacchi M, Tubaro S (2012) Revealing the traces of JPEG compression anti-forensics. IEEE Trans Inf Forensics Secur 8(2):335–349. https://doi.org/10.1109/TIFS.2012.2234117
Véhel JL, Rams M (2012) Large deviation multifractal analysis of a class of additive processes with correlated nonstationary increments. IEEE/ACM Trans Networking 21(4):1309–1321
Véhel JL, Tricot C (2004) On various multifractal spectra. In Fractal geometry and stochastics III (pp 23–42). Birkhäuser, Basel
Wallace GK (1992) The JPEG still picture compression standard. IEEE Trans Consum Electron 38(1):xviii–xxxiv. https://doi.org/10.1109/30.125072
Wang Q, Zhang R (2016) Double JPEG compression forensics based on a convolutional neural network. EURASIP J Inf Secur 2016:23. https://doi.org/10.1186/s13635-016-0047-y
Wang X, Zhang D, Guo X (2013) Novel hybrid fractal image encoding algorithm using standard deviation and DCT coefficients. Nonlinear Dyn 73(1-2):347–355. https://doi.org/10.1007/s11071-013-0790-2
Wei W, Rang-ding WANG (2012) The analysis and detection of double JPEG2000 compression based on statistical characterization of DWT coefficients. Energy Procedia 17:623–629. https://doi.org/10.1016/j.egypro.2012.02.145
Wiseman Y (2015) The still image lossy compression standard-JPEG. In: Encyclopedia of information science and technology, 3rd edn. IGI global, pp 295–305. https://doi.org/10.4018/978-1-4666-5888-2.ch028
Yang J, Zhu G, Wang J, Shi YQ (2013, October) Detecting non-aligned double JPEG compression based on refined intensity difference and calibration. In International Workshop on Digital Watermarking (pp 169-179). Springer, Berlin, Heidelberg. https://doi.org/10.1145/3464388
Yang J, Xie J, Zhu G, Kwong S, Shi YQ (2014) An effective method for detecting double JPEG compression with the same quantization matrix. IEEE Trans Inf Forensics Secur 9(11):1933–1942. https://doi.org/10.1109/TIFS.2014.2359368
Yao H, Wei H, Qin C, Zhang X (2020) An improved first quantization matrix estimation for nonaligned double compressed JPEG images. Signal Process 170:107430. https://doi.org/10.1016/j.sigpro.2019.107430
Yao H, Wei H, Qiao T, Qin C (2020) JPEG quantization step estimation with coefficient histogram and spectrum analyses. J Vis Commun Image Represent 69:102795. https://doi.org/10.1016/j.jvcir.2020.102795
Ye S, Sun Q, Chang EC (2007, July) Detecting digital image forgeries by measuring inconsistencies of blocking artifact. In 2007 IEEE international conference on multimedia and expo (pp 12-15). IEEE. https://doi.org/10.1109/ICME.2007.4284574
Yuan H, Ou B, Tian H (2019) Detecting double compression for JPEG images of low quality factor. J Electron Imaging 28(3):033011. https://doi.org/10.1117/1.JEI.28.3.033011
Zach F, Riess C, Angelopoulou E (2012, August) Automated image forgery detection through classification of JPEG ghosts. In Joint DAGM (German Association for Pattern Recognition) and OAGM symposium (pp 185-194). Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-32717-9_19
Zhang Y, Song W, Wu F, Han H, Zhang L (2020) Revealing the traces of nonaligned double JPEG compression in digital images. Optik 204:164196. https://doi.org/10.1016/j.ijleo.2020.164196
Zhu N, Shen J, Niu X (2019) Double JPEG compression detection based on noise-free DCT coefficients mixture histogram model. Symmetry 11(9):1119. https://doi.org/10.3390/sym11091119
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interests
The author has no conflict of interest to declare.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Gavrovska, A. Analysis of large-deviation multifractal spectral properties through successive compression for double JPEG detection. Multimed Tools Appl 82, 36255–36277 (2023). https://doi.org/10.1007/s11042-023-15130-5
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-15130-5