
Abstract
Image segmentation is an important part of image processing, which directly affects the quality of image processing results. Threshold segmentation is the simplest and most widely used segmentation method. However, the best method to determine the threshold has always been a NP-hard problem. Therefore, this paper proposes Kapur’s entropy image segmentation based on multi-strategy manta ray foraging optimization, which has a good effect in CEC 2017 test function and image segmentation. Manta ray foraging optimization (MRFO) is a new intelligent optimization algorithm, which has good searchability, but the local development ability is insufficient, so it can not effectively find a reliable point. To solve this defect, this paper proposes a multi-strategy learning manta ray foraging optimization algorithm, referred to as MSMRFO, which uses saltation learning to speed up the communication within the population and improve the convergence speed, and then puts forward a behavior selection strategy to judge the current situation of the population, Tent disturbance and Gaussian mutation are used to avoid the algorithm falling into local optimization and improve the convergence speed of the algorithm. In the complete CEC 2017 test set, MSMRFO is compared with 8 algorithms, including FA_CL and ASBSO are variants of new algorithms proposed in recent years. The results show that MSMRFO has good optimization ability and universality. In nine underwater image data sets, MSMRFO has better segmentation quality than the other eight algorithms, and the segmentation indicators under high threshold processing has better advantages.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
With the rapid development of computer technology, computer vision has gradually refined and formed its scientific system, in which image segmentation, as an important branch of the field of image processing, plays an increasingly important role. Image segmentation refers to the division of images into disjoint, meaningful sub-regions, the pixels in the same area have a certain correlation, and the pixels in different areas have certain differences, that is, the process of assigning the same label to pixels with the same nature in the picture [18]. Threshold segmentation is one of the classical segmentation techniques, and it is also the simplest, most practical, and efficient method [42]. The target of threshold segmentation is to select one or more specific thresholds to divide the image into several different regions. The main purpose of the threshold segmentation method is to obtain the most appropriate and effective thresholds for image segmentation. Common segmentation methods are the maximum class method, minimum error method, maximum entropy method, and so on. Kapur’s entropy is also a popular segmentation method in recent years and has been applied to many fields by many researchers. This method is an image segmentation technique based on the entropy threshold transformation, which combines the probability distribution of image histogram in the process of use. When the threshold value is selected accurately, the entropy will get the maximum value. Therefore, how to find the best threshold quickly and accurately is the focus of threshold segmentation. When threshold segmentation is performed by a common exhaustive search, the computation time is long and the limitations are large.
With the rise and development of swarm intelligence optimization algorithms, it has been widely used in image segmentation because of its strong global optimization ability and fast convergence speed, which has played a role in reducing the segmentation time and improving the accuracy of the segmentation. Akay et al. [3] applied classical particle swarm algorithm and artificial bee swarm algorithm to multi-threshold image segmentation. Kapur’s entropy and Otsu were selected as fitness functions to search for thresholds to obtain the best segmentation results. Mohamed Abd El Aziz [1] uses WOA and Moth-Flame Optimization (MFO) to solve the multi-threshold image segmentation problem. The results show that the two algorithms have better segmentation quality than other algorithms. Fayad et al. [15] proposed an image segmentation algorithm based on ACO. Upadhyay [46] proposed the Crow search algorithm to handle the multi-threshold segmentation problem, which has a good segmentation effect. Xing [29] applies TLBO to image segmentation. Zhou Y et al. [58] proposed a moth swarm algorithm for image segmentation. At the same time, to further obtain the optimal segmentation effect, scholars improved some algorithms and better handle the threshold segmentation problem. For example, Wachs-Lopes G et al. [13] proposed an improved Firefly algorithm to deal with the threshold search problem. It uses Gaussian mutation and neighborhood strategy to improve search efficiency and global searchability. Wang [47] introduced Levy flight into the salp swarm algorithm, which showed better pioneering ability and searchability, and made the segmentation quality better. Yang Z et al. [54] proposed a non-revisiting quantum-behaved PSO (NRQPSO) algorithm for image segmentation. Xin Lv et al. [49] proposed a multi threshold segmentation method based on improved sparrow search algorithm (ISSA). ISSA adopts the idea of bird swarm algorithm to improve the search and development ability of the algorithm and can find the best threshold quickly and accurately. Bao x et al. [7] proposed a method to solve the multi-threshold segmentation problem based on differential Harris Hawks Optimization. The results show that HHO-DE is an effective color image segmentation tool. Jia et al. [28] proposed a mutation strategy, Harris Hawks Optimization, to handle the multi-threshold segmentation problem, and achieved good results in the quality of the segmentation. Zhao D et al. [56] proposed the horizontal and vertical search ACO, which effectively reduces the probability of the algorithm falling into the local optimal, has better searchability, and makes the segmentation result better. Ismail S G et al. [44] proposed a chaotic optimal foraging algorithm for leukocyte segmentation in microscopic images. Pare S et al. [36] proposed CS and egg-laying radius-cuckoo search optimizer to solve multilevel threshold problems for color images using different parametric analysis methods. However, the global optimization capabilities of the above algorithms are still inadequate and can fall into local states in complex datasets. Before optimization, a large number of experiments are needed to select appropriate algorithm parameters, which makes the workload and efficiency of these algorithms significantly unbalanced.
Manta ray foraging optimization (MRFO) is a new swarm intelligence optimization algorithm proposed in 2020. It is stronger than Particle Swarm Optimization (PSO) [31], Genetic Algorithm (GA) [48], Differential Evolution (DE) [9], Cuckoo Search (CS) [53], Gravitational Search Algorithm (GSA) [40], and Artificial Bee Colony (ABC) [30] in function optimization. It has the advantages of few parameters, easy to understand, and strong global optimization [57]. So far, it has been successfully applied to solar energy [14, 23], ECG [24], generator [6, 21], power system [20], cogeneration energy system [45], geophysical inversion problem [8], directional overcurrent relay [4], feature selection [17], hybrid energy system [5], and sewage treatment [12]. MRFO has flexible searchability and strong global searchability, but it lacks local development ability. For example, the ordered search between individuals will cause greater dependence and lack of initiative, resulting in a better overall search range, but poor local search performance.
Inspired by the above literature, this paper presents a multi-strategy learning manta ray foraging optimization (MSMRFO) algorithm. It introduces saltation learning, which enables individuals to communicate closely and obtain important information in different locations. Then, a behavior selection strategy is presented, which introduces Tent disturbance and Gauss mutation to prevent the convergence shortage and local optimum in the later stage. This strategy makes an important judgment on the current situation and effectively improves the global optimization ability of the algorithm. The specific workload and contributions of this article are as follows:
-
(1)
Firstly, Saltation learning is introduced to speed up the information exchange of the population and improve the search efficiency of the algorithm.
-
(2)
A behavioral selection strategy is designed, which uses Tent disturbance and Gauss mutation to improve Manta ray convergence and trap into local optimum.
-
(3)
In the CEC 2017 test set, MSMRFO is compared with 8 algorithms, among which the firefly algorithm with courtship learning (FA_CL) [37] and ASBSO [55] proposed in recent years are also compared. The results verify that the algorithm has good searching ability and universality.
-
(4)
MSMRFO is used to optimize the threshold segmentation. It is also the first time that MRFO performs threshold segmentation in the underwater image. Nine underwater image datasets are used to validate the optimal segmentation from different thresholds. The result shows that MSMRFO has better segmentation quality than other algorithms.
The main part of the paper is structured as follows: Section 2 mainly introduces the background knowledge, including Kapur’s entropy and basic MRFO. Section 3 introduces and analyses the content and process of MSMRFO. Section 4 is to test and analyze the algorithms in CEC 2017. Section 5 describes the process of Kapur’s entropy threshold segmentation based on MSMRFO. Section 6 introduces and analyses the threshold segmentation experiments of each algorithm. The seventh section summarizes the full text, and the last section discusses the future work.
2 Background
2.1 Multi-threshold segmentation based on Kapur entropy
Kapur’s entropy is one of the early methods applied to single-threshold image segmentation, and it has been applied to the field of multi-threshold segmentation by many scholars. This segmentation method is a more effective image segmentation technique based on the entropy threshold transformation method, which combines the probability distribution of the image histogram. When the optimal threshold value is correctly selected and allocated, the maximum entropy will go. The ultimate goal of this method is to search for the optimal threshold value, which is the maximum direct value.
Assume that K is the gray level of 0-K-1 for a given picture, N is the total number of pixels, and f(i) is the frequency of the i-th intensity level.
The probability of the i-th strength level can be expressed as:
Assume there are G thresholds: {th1, th2, ⋯, thG}, where 1 ≤ G ≤ K − 1. Use these thresholds to divide a given picture into G + 1 classes, each represented by the following symbols:
The combination entropy is obtained by calculating the sum of each type of entropy. Entropy-based methods are calculated as follows:
Where Ei represents the entropy of class i. The final current function is as follows:
For the best threshold, the higher the F(th) value, the better.
2.2 Manta ray foraging optimization
Inspired by the foraging behavior of manta rays, the algorithm is divided into three stages: chain foraging, spiral foraging, and somersault foraging.
2.2.1 Chain foraging
When manta rays are foraging, the higher the food concentration at a certain location, the better the location. Although the specific location of the best food source is not known, assuming that the location with the highest known food concentration is the best food source, manta rays will observe and swim to the best food source first. During swimming, the first manta ray moves to the best food source, while other manta rays move to the best food source and the manta ray in front of it at the same time, forming a foraging chain from head to tail. That is, in each iteration, each manta ray updates its position according to the best food source position found so far and the manta ray in front of it. The mathematical model of the chain foraging process can be expressed as follows:
In eq. (6), \( {x}_i^d(t) \) represents the d-dimensional information of the location of the i-th manta ray in the t-generation, and r is a random number subject to [0,1] uniform distribution. \( \alpha =2\cdot r\cdot \sqrt{\mid \log\ (r)\mid } \) is the weight coefficient, \( {x}_{best}^d(t) \) is the d-dimensional information of the best location found at present. The manta ray in position i depends on the manta ray in position i-1 and the best food location currently found. The update of the first manta ray depends on the optimal location.
2.2.2 Cyclone foraging
When a manta ray finds a high-quality food source in a certain space, each manta ray in the manta ray population will connect the head to the tail and spiral to the food source. During the aggregation process, the movement mode of the manta ray population changed from simple chain movement to spiral movement around the optimal food source. The cyclone foraging process can be represented by the following mathematical model:
Among them, \( \beta =2{e}^{\frac{r_1\left(T-t+1\right)}{T}}\cdotp \sin \left(2\pi {r}_1\right) \) represents the weight coefficient of helical motion, t is the maximum number of iterations, r1 is the rotation factor and obeys the uniform random number of [0,1]. In addition, to improve the efficiency of group foraging, MRFO randomly generates a new location in the optimization process and then performs a spiral search at that location. Its mathematical model is:
\( {x}_{rand}^d(t) \) represents a new position in space.
2.2.3 Somersault foraging
When a manta ray finds a food source, it regards the food source as a fulcrum, rotates around the fulcrum, and somersaults to a new position to attract the attention of other manta rays. For the manta ray population, somersault foraging is a random, local and frequent action, which can improve the foraging efficiency of the manta ray population. The mathematical model is as follows:
S is the somersault factor, which determines the flip distance. r2 and r3 are two random numbers that are uniformly distributed [0,1]. As S values vary, individual bats somersault to locations in search space that are symmetrical to the optimal solution at their current location.
3 Manta ray foraging optimization based on fusion mutation and learning
3.1 Algorithm analysis
From these equations, it can be seen that more communication between individuals and orderly work can improve the searchability of the algorithm and perform a wide search. However, the lack of initiative among individuals in the population limits their ability to develop. On the other hand, updates within the population are related to the best location. When encountering high-bit complex problems, the change of the optimal position is similar, which results in less change in the two updates before and after the algorithm, and limits the algorithm’s optimization ability. Therefore, a flexible change strategy is needed to improve the development ability and local convergence effect of the algorithm.
3.2 Related work
At present, Scholars are also constantly exploring new technologies to make MRFO play a better optimization ability. For example, Mohamed Abd Elaziz [2] will combine fractional calculus with MRFO to provide the direction of manta ray movement. CEC 2017 has verified the feasibility of the algorithm and applied it to image segmentation with good results. Mohamed H. Hassan [19] combines a gradient optimizer with MRFO to reduce the probability that the algorithm will fall into a local optimum and has been successfully applied in single- and multi-objective economic emission scheduling. Haitao Xu [51] uses adaptive weighting and chaos to improve MRFO to efficiently handle thermodynamic problems. Essam H. Houssein [25] uses reverse learning to initialize the population, enhances the diversity of the population, and applies it to threshold image segmentation problems with good segmentation quality. Bibekananda Jena [27] adds an attack capability to MRFO, which allows it to jump out of local optimization and find a globally optimal solution. It is then applied to the image segmentation problem of 3D Tsallis. Mihailo Micev [33] fuses SA with MRFO and applies it to the PID controller, which is better than other algorithms. In addition, Serdar Ekinci [11] uses a reverse learning and fusion simulated annealing algorithm to improve the convergence speed of the algorithm. It has good control performance when applied to the FOPID controller.
Although the above work has achieved some results, there are still some problems: Firstly, simple fusion can not show good results in different optimization environments. Secondly, adaptive strategy and reverse learning still have drawbacks in the face of high-dimensional complex problems, and can not jump out of local optimum later.
3.3 Proposed algorithm
3.3.1 Saltation learning (SL)
In the process of searching for the MRFO, the individuals are connected and the location update is only related to the optimal location, which results in a lack of learning ability and monotonous searching methods. Therefore, an individual learning behavior needs to be enhanced to improve the searchability of the algorithm in different environments.
Saltation learning is a new learning strategy proposed by Penghu et al. [38]. It can learn in different dimensions. It calculates candidate solutions through the best location, the worst location, and the randomly selected location, which increases the population diversity and has good searchability. This reduces the chance of falling into a local optimum. SL is described as follows:
In eq. (10), \( {x}_{best}^t \) and \( {x}_{worst}^t \) represents the best and worst position of the t iterations, k, l, n are three different integers selected from [1, D]. D is the dimension, r is the random number of [−1,1], exploring positions in different directions by changing the sign. a is a random integer of [1,P], and P is the population number. As shown in Fig. 1, assuming a dimension of 3, individuals from three different dimensions guide the selection of the next location, which accelerates information exchange within the population and improves search efficiency.

SL Diagram
3.3.2 Gaussian mutation (GM)
A search chain is formed between individuals of the algorithm, which can perform a good search, but it is small on local development problems. Individuals are lazy and cannot search freely. Gauss mutation can solve this problem well and perform a good local search.
The Gauss variance comes from the Gauss distribution. Specifically, in the process of performing the variance, the original parameter value is replaced by a random number that fits the normal distribution of the mean μ and variance σ2 [16, 22]. The variance equation is:
In the eq. (11), x is the original parameter value, and N (0,1) indicates the expected value is 0. A random number with a standard deviation of 1; mutaion(x) represents the value after the Gaussian mutation.
From the characteristics of normal distribution, it can be seen that the Gaussian distribution focuses on the local scope of the individual, carries out an efficient search, and improves the local search ability of the algorithm. For function problems with many local extremum points, it helps the algorithm to find global minimum points efficiently and accurately. it also improves the robustness of the algorithm.
3.3.3 Tent disturbance (TD)
Later individual manta rays are prone to fall into the local optimum, so chaotic disturbance is needed to make the algorithm jump out of the local optimum and improve the global searchability and optimization accuracy of the algorithm.
Chaos represents a nonlinear phenomenon in nature, so chaotic variables have the characteristics of randomness, ergodicity, and regularity, which can effectively improve the search efficiency of the algorithm. At present, the sequence generated by Tent mapping is more uniform than that generated by Logistic mapping. Therefore, using Tent mapping can effectively enable individuals to find quality positions [50]. The mathematical expression of Tent mapping is as follows:
The Tent mapping is expressed as follows after Bernoulli shift transformation:
Therefore, the steps of introducing Tent disturbance are as follows:
-
Step 1, generate chaotic variable x according to xn + 1;
-
Step 2, apply chaotic variables to the solution of the problem to be solved:
mind and maxd are the minimum and maximum values of the d-th dimension x, respectively.
-
Step 3, make a chaotic disturbance to the individual according to the following equation:
In the equation, X, represents the individual requiring chaotic perturbation, newX is the chaotic variable generated, and newX, is the individual after chaotic perturbation.
3.3.4 Selection of mutation and disturbance
First, to minimize the objective function, assume that Fave is the average fitness value within the population. If the fitness value of an individual is less than Fave, then clustering occurs. Gauss mutation makes these individuals slightly dispersed and improves the local search ability of the algorithm. Conversely, this means that individuals diverge, their current position is unreliable and disturbances are needed to improve their quality. Individuals after mutation and disturbance will change their position if they are better than those before, otherwise, the position will not change. The specific behavior selection (BC) equation is as follows:
\( {x}_i^d(t) \) represents the updated individual, Fi represents the fitness value of the i-th individual.
3.3.5 Fusion multi-strategy learning manta ray foraging optimization
To improve the local development and learning ability of the manta ray foraging optimization, this paper proposes a multi-strategy learning manta ray foraging optimization algorithm. The algorithm uses saltation learning to speed up the internal communication of the population and improve the learning ability of the algorithm to adapt to different environments. Then a behavior selection strategy is presented, which uses Tent disturbance and Gauss mutation to balance the global search and local development capabilities of the algorithm by comparing the current and average fitness values, thus improving the quality of each optimal solution. The algorithm flow is as follows:

Algorithm: The framework of the MSMRFO.
3.3.6 Time complexity analysis
Time complexity is an important index to measure an algorithm, so it is necessary to balance the optimization ability and time complexity of the algorithm in order to improve it effectively. The basic MRFO consists of only three stages: chain foraging, spiral foraging, and somersault foraging, in which chain foraging and spiral foraging are in the same cycle. Set the population number to N, the maximum number of iterations to T, and the dimension to D, so the time complexity of MRFO can be summarized as follows:
MSMRFO can be summarized as:
Therefore, it can be seen that the time complexity of MSMRFO has not changed radically.
3.3.7 Strategy effectiveness test
In order to test whether MSMRFO can really improve the optimization mechanism of the original algorithm, this paper takes sphere function as an example, and tests on MRFO and MSMRFO respectively. The population number is 50, the maximum number of iterations is 5, the theoretical optimal value of sphere function is 0, and the location is x∗ = (0, …, 0). The final individual distribution of the two algorithms is given as shown in Fig. 2.

Algorithmic Personal Distribution Map (a)MRFO (b)MSMRFO
As shown in Fig. 2, it is clear that MRFO does not find an optimal value and is in a dispersed state, while MSMRFO has been clustered near the theoretical optimal value. Therefore, MSMRFO has a very fast convergence rate and a high accuracy. It can be seen that the introduction of multiple strategies significantly improves the optimization methods of the MRFO algorithm, speeds up the population exchange speed, and improves the quality of each solution obtained.
4 Performance testing
To verify the optimization capability of the MSMRFO algorithm, this paper tests each algorithm on the CEC 2017 test set, and compares eight algorithms with MSMRFO. The population number is 100, the number of assessments is 100 × D, and D is the dimension. To better reflect the effectiveness of the MSMRFO algorithm, this paper compares it with PSO, whale optimization algorithm (WOA) [34], sparrow search algorithm (SSA) [52], naked mole-rat algorithm (NMRA) [43], MRFO, Grey Wolf Optimizer (GWO) [35], and compares the two algorithms proposed in recent years, FACL and ASBSO, which have a good performance on the test set of CEC. PSO, GWO, and WOA are classical algorithms. SSA, MRFO, and NMRA are new swarm intelligence algorithms proposed in recent years. Because the parameters of some algorithms do not need special declaration and internal parameters do not need to be set, the parameters of some algorithms are shown in Table 1 In this paper, the Wilcoxon rank test is used to show whether there is a significant difference between each algorithm, which is tested at 5% significant level. “+” means that MSMRFO has more optimization capabilities than other algorithms, “-” conversely, “=“means that the optimization performance between the two algorithms is equal, and “N/A” means that the values of the two algorithms are the same and cannot be compared. Specific test results are shown in Tables 2 and 3 in the Appendix.
The results of 30 operations of each algorithm are counted, and the five indexes of each algorithm, namely, optimal value, worst value, median, average value, and standard deviation, are calculated. In addition, the rank of each algorithm in each function is calculated, and the average rank is calculated to measure the universality of the algorithm. In order to clearly see the stability and optimization interval of each algorithm, a box diagram of 30 times the results of these functions in F3–6, F11–14, and F22–25 is given as shown in Fig. 3. These functions represent different types.


Statistical chart of algorithm operation results (a)F3 (b)F4 (c)F5 (d)F6 (e)F11 (f)F12 (g)F13 (h)F14 (i)F22 (j)F23 (k)F24 (l)F25
From Tables 2 and 3 and Fig. 3, we can see that MSMRFO has a great advantage in searchability and stability, especially in functions that show better searchability. Although some functions do not show better performance indicators, most of them have shown better search performance. Based on the fact that there is no free lunch theorem in the world, it is impossible to find an algorithm that performs well on any optimization problem, so MSMRFO is generally applicable. From the test results and average ranking, the average ranking of MSMRFO in the two tables is 1.34 and 1.7241 respectively. NMRA, PSO, and MRFO are second only to MSMRFO. And are the lowest ranking. MSMRFO has better advantages and is more perfect than the algorithm proposed in recent years. From the box diagram, the optimization effect of MSMRFO in each function is relatively stable, and the accuracy of the solution is also high. Generally speaking, the saltation learning and behavior selection strategy introduced by MSMRFO effectively avoids the phenomenon that the algorithm falls into local optimum and greatly improves the searchability of the algorithm.
5 Threshold segmentation process based on MSMRFO
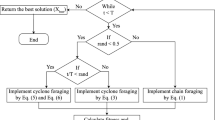
Assuming a k-dimensional threshold segmentation of the image, the solution vector is T = [t1, t2, ⋯, tk], which takes a positive integer and satisfies 0 < t1 < t2 < ⋯ < tn < L. Multi-threshold segmentation is the process of finding a set of thresholds [t1, t2, ⋯, tk] (K > 0) in the image f(x, y) to be segmented according to a certain criterion and dividing it into K + 1 parts. In this paper, Kapur’s entropy is used as the segmentation criterion, MSMRFO is used to optimize the selection among L gray levels in solution space, and the maximization of eq. (1) is used as the objective function to solve. The multi-threshold segmentation process based on MSMRFO is shown in Fig. 4, and the detailed process is as follows:
-
Step1, Read the image to be split (grayscale image);
-
Step2, Get gray histogram of read-in image;
-
Step3, Initialization of MSMRFO parameters and setting of segmentation threshold K;
-
Step4, Initialization of the manta ray population. The individual position of a manta ray represents a threshold vector for image segmentation, and the component value of each vector ranges from [0,255] to an integer;
-
Step5, Perform MSMRFO;
-
Step6, if the algorithm reaches the preset end condition, the algorithm finishes the optimization and returns the best fitness of the bat location information. That is, the optimal threshold segmentation, otherwise jump to step 5.
-
Step7, Segment gray-scale images by the optimal threshold vector obtained, and output it.

MSMRFO-based threshold segmentation flowchart
6 Threshold segmentation experiment
6.1 Evaluating indicator
It is impossible to see the difference between each algorithm in image segmentation by human eyes. Therefore, three commonly used image segmentation indicators, PSNR, SSIM, and FSIM, are selected to measure the quality of each algorithm.
PSNR is mainly used to measure the difference between the segmented image and the original image. The equation is as follows:
In the equation, RMSE represents the root mean square error of the pixel; M × Q represents the size of the image; I(i, j) represents the pixel gray value of the original image; Seg(i, j) represents the pixel gray value of the segmented image. The larger the PSNR value, the better the image segmentation quality.
SSIM is used to measure the similarity between the original image and the segmented image. The larger the SSIM, the better the segmentation results. SSIM is defined as:
In the equation, μI and μseg represent the average value of the original image and the segmented image. σI and σseg represent the standard deviation between the original image and the segmented image; σI, seg represents the covariance between the original image and the segmented image; c1, c2 are constants used to ensure stability.
FSIM is a measure of feature similarity between the original image and the segmentation quality, used to evaluate local structure and provide contrast information. The value range of FSIM is [0,1], and the closer the value is to 1, the better the result is. FSIM is defined as follows:
In the above equation, Ω is all the pixel areas of the original image; SL(X) is the similarity score; PCm(X) is a measure of phase consistency; T1 and T2 are constant; G is a gradient descent; E(X) is the size of the response vector at position X and the scale is n; ε is a very small number; An(X) is the local size at scale n.
6.2 Experiment and analysis
To verify the effectiveness and feasibility of the MSMRFO algorithm, nine underwater image test sets [26] are selected in this paper. The underwater environment is complex and has a lot of debris, so the optimum performance of an algorithm can be tested most. At the same time, in order to prove that MSMRFO is competitive, it is compared with ten algorithms: MRFO, PSO, WOA, Teaching Learning Based Optimization (TLBO) [39], SSA, ISSA, GWO, BSA [32], CPSOGSA [41], HHO-DE. These ten algorithms have been applied to threshold image segmentation by researchers, so they are very persuasive. Each algorithm has experimented with 4 thresholds from 2 to 5. Each algorithm has a population of 30 and a maximum number of iterations of 100. A stop parameter of 10 is set in the experiment. If the solution found 10 times is the same in the optimization, it is assumed that the convergence has been completed. The significance of this is to reflect the value of the algorithm and find an algorithm with higher search efficiency. The experimental environment is Window10 64bit, the software is matlab2019b, the memory is 16GB, and the processor is Intel(R) Core(TM) i5-10200H CPU @ 2.40GHz. The MSMRFO algorithm segmentation image is shown in Fig. 5. The results of each algorithm are shown in Tables 4, 5, 6 and 7 in the Appendix. If MSMRFO has the best performance Indicators, the font will be bold. Among them, Table 4 shows the average fitness value (F(th)) of each algorithm to verify the optimization ability of the algorithm, and Tables 5, 6 and 7 show the PSNR, SSIM and FSIM performance indicators of each algorithm to verify the segmentation quality of the algorithm, respectively.

Threshold segmentation image based on MSMRFO
From Table 4, it can be seen that the number of optimal indicators of MSMRFO is higher relative to other algorithms, which shows the stronger optimization ability of MSMRFO, on the other hand, the indicators are not optimal in the case that its values are close to other optimal indicators want. Taken together, MSMRFO is effective in optimizing Kapur’s Entropy and has sufficient generalizability.
It can see from Fig. 5, the image after MSMRFO segmentation becomes clearer with the increase of the threshold value, so MSMRFO has a good application value in threshold segmentation. From Table 5, 6 and 7, we can see that there are more optimal indicators for MSMRFO. In Test 05, the PSNR of each threshold segmentation is better than other algorithms. In Test 08, the SSIM indicators of each threshold segmentation is the best. In the individual images in Table 7, the FSIM indicators is optimal for MSMRFO with a threshold of 3 or more categories. Other algorithms have optimal criteria, but they are small in number and have better segmentation quality only at a certain threshold. Overall, MSMRFO has better segmentation quality at high thresholds and generally worse at low thresholds.
In order to better show the quality of MSMRFO segmentation under each threshold, the Friedman test [10] is applied to three performance indicators of each threshold, the ranking of each algorithm under different thresholds is calculated, and the final average rank is calculated to evaluate the segmentation effect of an algorithm. The test results are shown in Tables 8 and 9 in the Appendix. Table 8 shows the ranking results of MSMRFO and classical algorithms, and Table 9 shows the ranking of MSMRFO and the new algorithms and variant algorithms proposed in recent years. Similarly, if MSMRFO ranks best, its value will be bolded.
It can be seen from Tables 8 and 9 that MSMRFO has a large number of optimal values, indicating that MSMRFO has a better optimization effect than the classical algorithm or compared with the algorithm proposed in recent years. At the same time, it also shows that MSMRFO has good universality in threshold segmentation and can show good application value in underwater images.
7 Conclusion
To better determine the optimal threshold in threshold segmentation, a Kapur’s entropy image segmentation based on multi-strategy manta ray foraging optimization is presented. At the same time, a multi-strategy learning manta ray foraging optimization algorithm is proposed to improve the local development capability of the original algorithm and the probability of falling into the local optimum. The algorithm uses saltation learning to communicate among individuals, which accelerates the convergence speed of the algorithm. A new selection behavior strategy is proposed to make a better judgment on the current optimization stage, to prevent the algorithm from falling into local optimization and insufficient convergence, and to improve the global search ability of the algorithm. Tests on CEC 2017 show that the algorithm has good optimization ability and strong universality. Finally, nine underwater image data sets are segmented by MSMRFO. According to the segmented indicators, MSMRFO has better advantages and better quality in high threshold segmentation. From the Friedman test, MSMRFO ranked the highest, indicating that MSMRFO is generally good at segmentation in nine datasets.
8 Future work
Firstly, saltation learning has some randomness, so the final result is not maintained at a good level. Secondly, in some functions, no theoretical optimal value is found. At the same time, the fitness value does not yet achieve a certain advantage when optimizing the threshold. Thirdly, in many image data collections, it is not guaranteed that the three evaluation indicators in the same segmented image are optimal. For example, in Test 08, PSNR is not optimal with a threshold of 3, but the values of the other two indicators are the best. Finally, poor segmentation quality is common in low threshold processing. For example, in Test 02, none of the three MSMRFO indicators with a threshold of 3 was optimal. Therefore, The next step is to balance the optimization ability of the algorithm at high and low thresholds. In the aspect of image segmentation, we need to balance the quality of one image to ensure that the three indicators of image quality obtained at each time are excellent.
Data availability
The data used to support the findings of this study are available from the corresponding author upon request.
References
Abd El Aziz M, Ewees AA, Hassanien AE (2017) Whale optimization algorithm and moth-flame optimization for multilevel thresholding image segmentation. Expert Syst Appl 83:242–256. https://doi.org/10.1016/j.eswa.2017.04.023
Abd Elaziz M, Yousri D, Al-qaness MA, AbdelAty AM, Radwan AG, Ewees AA (2021) A Grunwald–Letnikov based Manta ray foraging optimizer for global optimization and image segmentation. Eng Appl Artif Intell 98:104105. https://doi.org/10.1016/j.engappai.2020.104105
Akay B (2013) A study on particle swarm optimization and artificial bee colony algorithms for multilevel thresholding. Appl Soft Comput 13(6):3066–3091. https://doi.org/10.5555/2467341.2467507
Akdag O, Yeroglu C (2021) Optimal directional overcurrent relay coordination using MRFO algorithm: A case study of adaptive protection of the distribution network of the Hatay province of Turkey. Electr Power Syst Res 192:106998. https://doi.org/10.1016/j.epsr.2020.106998
Alturki FA, Farh MH, Al-Shamma’a AA, AlSharabi K (2020) Techno-economic optimization of small-scale hybrid energy systems using manta ray foraging optimizer. Electronics 9(12):2045. https://doi.org/10.3390/electronics9122045
Aly M, Rezk H (2021) A MPPT based on optimized FLC using manta ray foraging optimization algorithm for thermo-electric generation systems. Int J Energy Res 45(9):13897–13910. https://doi.org/10.1002/er.6728
Bao X, Jia H, Lang C (2019) A novel hybrid Harris hawks optimization for color image multilevel thresholding segmentation. IEEE Access 7:76529–76546. https://doi.org/10.1109/ACCESS.2019.2921545
Ben UC, Akpan AE, Mbonu CC, Ebong ED (2021) Novel methodology for interpretation of magnetic anomalies due to two-dimensional dipping dikes using the Manta ray foraging optimization. J Appl Geophys 192:104405. https://doi.org/10.1016/j.jappgeo.2021.104405
Das S, Suganthan PN (2010) Differential evolution: A survey of the state-of-the-art. IEEE Trans Evol Comput 15(1):4–31. https://doi.org/10.1109/TEVC.2010.2059031
Demšar J (2006) Statistical comparisons of classifiers over multiple data sets. J Mach Learn Res 7:1–30. https://doi.org/10.5555/1248547.1248548
Ekinci S, Izci D, Hekimoğlu B (2021) Optimal FOPID speed control of DC motor via opposition-based hybrid manta ray foraging optimization and simulated annealing algorithm. Arab J Sci Eng 46(2):1395–1409. https://doi.org/10.1007/s13369-020-05050-z
Elmaadawy K, Abd Elaziz M, Elsheikh AH, Moawad A, Liu B, Lu S (2021) Utilization of random vector functional link integrated with manta ray foraging optimization for effluent prediction of wastewater treatment plant. J Environ Manag 298:113520. https://doi.org/10.1016/j.jenvman.2021.113520
Erdmann H, Wachs-Lopes G, Gallao C, Ribeiro MP, Rodrigues PS (2015) A study of a firefly meta-heuristics for multithreshold image segmentation. In Developments in medical image processing and computational vision. Springer, Cham. pp. 279–295 https://doi.org/10.1007/978-3-319-13407-9_17
Fathy A, Rezk H, Yousri D (2020) A robust global MPPT to mitigate partial shading of triple-junction solar cell-based system using manta ray foraging optimization algorithm[J]. Sol Energy 207:305–316. https://doi.org/10.1016/j.solener.2020.06.108
Fayad H, Hatt M, Visvikis D (2015) PET functional volume delineation using an Ant colony segmentation approach. (2015):1745–1745. https://jnm.snmjournals.org/content/56/supplement_3/1745.short
Fogel DB, Atmar JW (1990) Comparing genetic operators with Gaussian mutations in simulated evolutionary processes using linear systems. Biol Cybern 63(2):111–114. https://doi.org/10.1007/BF00203032
Ghosh KK, Guha R, Bera SK, Kumar N, Sarkar R (2021) S-shaped versus V-shaped transfer functions for binary Manta ray foraging optimization in feature selection problem. Neural Comput & Applic 33(17):11027–11041. https://doi.org/10.1007/s00521-020-05560-9
Haralick RM, Shapiro LG (1985) Image segmentation techniques. Comput Vis Graph Image Process 29(1):100–132. https://doi.org/10.1016/S0734-189X(85)90153-7
Hassan MH, Houssein EH, Mahdy MA, Kamel S (2021) An improved manta ray foraging optimizer for cost-effective emission dispatch problems. Eng Appl Artif Intell 100:104155. https://doi.org/10.1016/j.engappai.2021.104155
Hemeida MG, Alkhalaf S, Mohamed AAA, Ibrahim AA, Senjyu T (2020) Distributed generators optimization based on multi-objective functions using manta rays foraging optimization algorithm (MRFO). Energies 13(15):3847. https://doi.org/10.3390/en13153847
Hemeida MG, Ibrahim AA, Mohamed AAA, Alkhalaf S, El-Dine AMB (2021) Optimal allocation of distributed generators DG based Manta ray foraging optimization algorithm (MRFO). Ain Shams Eng J 12(1):609–619. https://doi.org/10.1016/j.asej.2020.07.009
Higashi N, Iba H (2003, April) Particle swarm optimization with Gaussian mutation. In: Proceedings of the 2003 IEEE swarm intelligence symposium. SIS'03 (cat. No. 03EX706). IEEE. pp. 72-79 https://doi.org/10.1109/SIS.2003.1202250
Houssein EH, Zaki GN, Diab AAZ, Younis EM (2021) An efficient Manta ray foraging optimization algorithm for parameter extraction of three-diode photovoltaic model. Comput Electr Eng 94:107304. https://doi.org/10.1016/j.compeleceng.2021.107304
Houssein EH, Ibrahim IE, Neggaz N, Hassaballah M, Wazery YM (2021) An efficient ECG arrhythmia classification method based on Manta ray foraging optimization. Expert Syst Appl 181:115131. https://doi.org/10.1016/j.eswa.2021.115131
Houssein EH, Emam MM, Ali AA (2021) Improved manta ray foraging optimization for multi-level thresholding using COVID-19 CT images. Neural Comput & Applic 33(24):16899–16919. https://doi.org/10.1007/s00521-021-06273-3
Islam MJ, Luo P, Sattar J (2020) Simultaneous enhancement and super-resolution of underwater imagery for improved visual perception. arXiv preprint arXiv:2002.01155. https://doi.org/10.48550/arXiv.2002.01155
Jena B, Naik MK, Panda R, Abraham A (2021) Maximum 3D Tsallis entropy based multilevel thresholding of brain MR image using attacking Manta ray foraging optimization. Eng Appl Artif Intell 103:104293. https://doi.org/10.1016/j.engappai.2021.104293
Jia H, Lang C, Oliva D, Song W, Peng X (2019) Dynamic Harris hawks optimization with mutation mechanism for satellite image segmentation. Remote Sens 11(12):1421. https://doi.org/10.3390/rs11121421
Jin H, Li Y, Xing B, Wang L (2016) A geometric image segmentation method based on a bi-convex, fuzzy, variational principle with teaching-learning optimization. J Intell Fuzzy Syst 31(6):3075–3081. https://doi.org/10.3233/JIFS-169193
Karaboga D, Basturk B (2008) On the performance of artificial bee colony (ABC) algorithm. Appl Soft Comput 8(1):687–697. https://doi.org/10.1016/j.asoc.2007.05.007
Kennedy J, Eberhart RC (1997, October) A discrete binary version of the particle swarm algorithm. In: 1997 IEEE international conference on systems, man, and cybernetics. Computational cybernetics and simulation. IEEE. (Vol. 5, pp. 4104-4108) https://doi.org/10.1109/ICSMC.1997.637339
Meng XB, Gao XZ, Lu L, Liu Y, Zhang H (2016) A new bio-inspired optimisation algorithm: bird swarm algorithm. J Exp Theor Artif Intell 28(4):673–687. https://doi.org/10.1080/0952813X.2015.1042530
Micev M, Ćalasan M, Ali ZM, Hasanien HM, Aleem SHA (2021) Optimal design of automatic voltage regulation controller using hybrid simulated annealing–Manta ray foraging optimization algorithm. Ain Shams Eng J 12(1):641–657. https://doi.org/10.1016/j.asej.2020.07.010
Mirjalili S, Lewis A (2016) The whale optimization algorithm. Adv Eng Softw 95:51–67. https://doi.org/10.1016/j.advengsoft.2016.01.008
Mirjalili S, Mirjalili SM, Lewis A (2014) Grey wolf optimizer. Adv Eng Softw 69:46–61. https://doi.org/10.1016/j.advengsoft.2013.12.007
Pare S, Kumar A, Bajaj V, Singh GK (2016) A multilevel color image segmentation technique based on cuckoo search algorithm and energy curve. Appl Soft Comput 47:76–102. https://doi.org/10.1016/j.asoc.2016.05.040
Peng H, Zhu W, Deng C, Wu Z (2021) Enhancing firefly algorithm with courtship learning. Inf Sci 543:18–42. https://doi.org/10.1016/j.ins.2020.05.111
Peng H, Zeng Z, Deng C, Wu Z (2021) Multi-strategy serial cuckoo search algorithm for global optimization. Knowl-Based Syst 214:106729. https://doi.org/10.1016/j.knosys.2020.106729
Rao RV, Savsani VJ, Vakharia DP (2011) Teaching–learning-based optimization: a novel method for constrained mechanical design optimization problems. Comput Aided Des 43(3):303–315. https://doi.org/10.1016/j.cad.2010.12.015
Rashedi E, Nezamabadi-Pour H, Saryazdi S (2009) GSA: a gravitational search algorithm. Inf Sci 179(13):2232–2248. https://doi.org/10.1016/j.ins.2009.03.004
Rather SA, Bala PS (2021) Constriction coefficient based particle swarm optimization and gravitational search algorithm for multilevel image thresholding. Expert Syst 38(7):e12717. https://doi.org/10.1111/exsy.12717
Saleh S, Kalyankar NV, Khamitkar SD (2010) Image segmentation by using threshold techniques. J Comput 2:2151–9617. https://arxiv.53yu.com/abs/1005.4020
Salgotra R, Singh U (2019) The naked mole-rat algorithm. Neural Comput & Applic 31(12):8837–8857. https://doi.org/10.1007/s00521-019-04464-7
Sayed GI, Solyman M, Hassanien AE (2019) A novel chaotic optimal foraging algorithm for unconstrained and constrained problems and its application in white blood cell segmentation. Neural Comput & Applic 31(11):7633–7664. https://doi.org/10.1007/s00521-018-3597-8
Shaheen AM, Ginidi AR, El-Sehiemy RA, Ghoneim SS (2020) Economic power and heat dispatch in cogeneration energy systems using manta ray foraging optimizer. IEEE Access 8:208281–208295. https://doi.org/10.1109/ACCESS.2020.3038740
Upadhyay P, Chhabra JK (2020) Kapur’s entropy based optimal multilevel image segmentation using crow search algorithm. Appl Soft Comput 97:105522. https://doi.org/10.1016/j.asoc.2019.105522
Wang S, Jia H, Peng X (2020) Modified salp swarm algorithm based multilevel thresholding for color image segmentation. Math Biosci Eng 17(1):700–724. https://doi.org/10.3934/mbe.2020036
Whitley D (1994) Genetic algorithm tutorial. Stat Comput 4(2):65–85. https://doi.org/10.1007/BF00175354
Xin Lv, Xiaodong M, Jun Z (2021) Multi-threshold image segmentation based on improved sparrow search algorithm. Syst Eng Electron Technol 43(2):10. https://doi.org/10.12305/j.issn.1001-506X.2021.02.05
Xin LV, Xiaodong M, Jun Z, Zhen W (2021) Chaotic sparrow search optimization algorithm. J Beijing Univ Aeronaut Astronaut 47(8):1712–1720. https://doi.org/10.13700/j.bh.1001-5965.2020.0298
Xu H, Song H, Xu C, Wu X, Yousefi N (2020) Exergy analysis and optimization of a HT-PEMFC using developed Manta ray foraging optimization algorithm. Int J Hydrog Energy 45(55):30932–30941. https://doi.org/10.1016/j.ijhydene.2020.08.053
Xue J, Shen B (2020) A novel swarm intelligence optimization approach: sparrow search algorithm. Syst Sci Control Eng 8(1):22–34. https://doi.org/10.1080/21642583.2019.1708830
Yang XS, Deb S (2009, December) Cuckoo search via Lévy flights. In: 2009 world congress on nature & biologically inspired computing (NaBIC). IEEE. pp. 210-214 https://doi.org/10.1109/NABIC.2009.5393690
Yang Z, Wu A (2020) A non-revisiting quantum-behaved particle swarm optimization based multilevel thresholding for image segmentation. Neural Comput & Applic 32(16):12011–12031. https://doi.org/10.1007/s00521-019-04210-z
Yu Y, Gao S, Wang Y, Cheng J, Todo Y (2018) ASBSO: an improved brain storm optimization with flexible search length and memory-based selection. IEEE Access 6:36977–36994. https://doi.org/10.1109/ACCESS.2018.2852640
Zhao D, Liu L, Yu F, Heidari AA, Chen H (2020) Ant colony optimization with horizontal and vertical crossover search: fundamental visions for multi-threshold image segmentation. Expert Syst Appl, http://aliasgharheidari.com:114122. https://doi.org/10.1016/j.eswa.2020.114122
Zhao W, Zhang Z, Wang L (2020) Manta ray foraging optimization: an effective bio-inspired optimizer for engineering applications. Eng Appl Artif Intell 87:103300. https://doi.org/10.1016/j.engappai.2019.103300
Zhou Y, Yang X, Ling Y, Zhang J (2018) Meta-heuristic moth swarm algorithm for multilevel thresholding image segmentation. Multimed Tools Appl 77(18):23699–23727. https://doi.org/10.1007/s11042-018-5637-x
Acknowledgements
This work is supported by the National Natural Science Foundation of China (Nos.62002046,62006106),The Project Supported by Zhejiang Provincial Natural Science Foundation of China(No.LQ21F020005), Basic public welfare research program of Zhejiang Province(No.LGG18E050011).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhu, D., Zhou, C., Qiu, Y. et al. Kapur’s entropy underwater image segmentation based on multi-strategy Manta ray foraging optimization. Multimed Tools Appl 82, 21825–21863 (2023). https://doi.org/10.1007/s11042-022-14024-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-022-14024-2