
Abstract
In recent years, image super-resolution (SR) based on deep learning technology has made significant progress. However, most methods are difficult to apply in real life because of their large parameters and heavy computation. Recently, residual learning has been widely applied to the problem of super-resolution. It can make the shallow features extracted from the input image act on each middle layer through long and short connection. Therefore, residual learning can be focused on processing high-frequency feature information, which significantly improves the SR performance of the network. However, with the improvement of network depth, the features that can be effectively utilized are still the shallow ones extracted from the input image. In this paper, we propose the feature separation and fusion network(FSFN). We further enrich the high-frequency feature information by separating and fusing the extracted and unextracted features in the internal shallow layer of each feature separation and fusion module. As the depth of the network increases, the shallow features extracted from the input image can be updated in a direction closer to those extracted from the real high-resolution image. A large number of experimental results show that this method has a strong performance compared with the existing SR algorithm with similar parameters and computation.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Single image super-resolution (SISR) aims to reconstruct a low-resolution image into a high-resolution image, which is a low-level visual recovery task in computer vision [5, 13]. Since the reconstruction of a high-resolution image from a low-resolution image is not just a one-to-one mapping, single image super-resolution (SISR) is a seriously ill-posed problem. Various SISR methods have been proposed and achieved amazing results, among which the most notable ones are some methods based on deep learning [2, 7, 8, 20, 33, 38, 40].
With the development of a convolutional neural network, single image super-resolution has been granted significant attention by researchers, who have achieved state-of-the-art performance on various benchmarks of SR. Dong et al. [7] first applied the convolutional neural network to the super-resolution task.Then, they proposed the FSRCNN [8], which can directly learn the low-resolution inputs and then up-sample the features at the end of the network. In order to improve the performance of the model, Kim et al. proposed the VDSR [15] by increasing the depth of the network model. Inspired by the image classification problem [9], a lot of work has been done to apply residual learning to SR problems. As a result, many models with good performance have relatively large parameters. In order to reduce the parameters of the model, the recursive network model is applied to the SR problem. The recursive model decomposes the complex SR problem into a series of simple and easily solved problems by sharing parameters. Many researchers have taken a recursive network as their basic network architecture, such as DRCN [16], DRRN [28], and MemNet [29]. All of these models guarantee better performance with fewer parameters (Fig. 1).

Trade-off between performance and number of parameters on the Urban100×2 dataset. The orange circle represents the method we proposed, and the blue circle represents the other methods
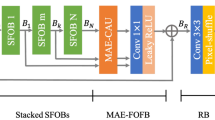
With the improvement of computing performance, many super-resolution networks [20, 33, 38, 40] have large network parameters and large computing overhead. it is difficult to apply this process in real life. Currently, there are many ways to design lightweight SR networks. Recursive networks can achieve better SR performance with fewer model parameters, but they require huge computational overhead. The CARN network [2] adopts the local and global cascading modules, which make full use of the feature information at all levels but can’t avoid information redundancy. Network structure search [6] can give full play to the performance of each module, although the model based on network structure search does not improve the performance of SR very much, as it is limited in terms of search space and search strategy. After learning that the residual network improves the performance of SR [20], we noticed that the residual block promoted the performance of SR by integrating the extracted features with the original features that are not extracted. Because the original features can reach all hierarchical structures of the network through short or long connections, the incremental features extracted from the input image account for a large part of the original features that can be used repeatedly. This also limits the network’s SR performance. In order to make better use of the feature information, we adopt the feature separation technology to separate the extracted features and the unextracted features and then merge them to continuously update the original features information at different levels. Therefore, we propose a feature separation and fusion module, which reduces feature information redundancy. Our network is of great significance in the design of lightweight network models. We can learn from VDSR [15] that increasing the network depth can improve the SR performance of the network, so we adopt the idea of partitioning. As shown in Fig. 2, several feature separation and fusion modules and a convolutional layer constitute our feature residual learning module, and several feature residual learning modules and a convolutional layer constitute a global residual learning module. So our network can integrate and learn features at different levels to increase the richness of the features.

Network architecture of our feature separation and fusion network (FSFN)
In this work, we propose a feature separation and fusion network for SISR. Compared to networks with similar model parameters and multi-adds, our network showed better SR performance. The contributions of this paper can be summarized as follows:
-
We propose a feature separation and fusion module, which separates the original features into extracted features and unextracted features, and then extracts the unextracted features in the next step to increase the diversity of features. Finally, we use a 1x1 convolution to adaptively select fusion features. This makes the fusion feature more representative, which means the image reconstruction quality can be greatly improved. The experimental results show that the proposed feature separation and fusion module improves the performance of SR.
-
We adopt the idea of partitioning, which increases the depth of the network and enables us to better integrate and learn the characteristics of other modules. This approach further improves the SR performance of our network.
-
An extensive experimental evaluation of several publicly available datasets shows that the proposed FSFN model performs better than most existing methods.
2 Related works
In the early stage, in order to solve the problem of image super-resolution, we mostly adopted interpolation technology based on sampling theory [3, 19, 42]. With the development of deep learning technology, the problem of image super-resolution is now mostly solved. Therefore, our main research focus is on the application of deep learning technology in image super-resolution.
2.1 Single image super-resolution
By using a variety of deep learning-based techniques, we have been able to find a solution to the SR problem experienced in the extensive literature on this topic [12, 14, 18, 21, 25, 26, 33,34,35, 41]. Dong et al. proposed SRCNN [7], which was the first successful attempt to use convolution to solve the problem of image super-resolution. Then, they came up with FSRCNN [8], which had better SR performance. In contrast to the shallow network architecture, Simonyan et al. proposed VDSR [15], which has a deeper hierarchical structure. Kim et al. proposed a deep recursive convolutional network named DRCN [16], which, by designing a repeatable convolution unit, enables the model to maintain better SR performance with fewer parameters. Inspired by the success of DenseNet [10] in the image classification architecture, Tong et al. proposed the SR-DenseNet [31], which achieved higher flexibility and richer feature representation through the densely connected CNN layer. Zhang et al. proposed the RDN [40] by introducing local and global residual connections. Then they proposed RCAN [38] by introducing a channel attention mechanism in each local residual block, which improved the performance of SR significantly. Ahn et al. proposed CARN [2], which allows the feature information of each residual block to flow between different levels through a large number of short connections. This model performs well in lightweight networks. Liu et al. proposed a residual feature aggregation network (RFANet) [22] consisting of an RFA framework and a powerful ESA block. The RFA framework groups several residual modules together and directly forwards the features on each local residual branch by adding skip connections. This work also effectively improves the SR performance of the network. Due to the uncertainty of image degradation, Zhang et al. [37] proposed an end-to-end trainable unfolding network which leverages both learning-based the methods and model-based methods. And it can handle the classical degradation model via a single model. This work expands the data processing scope of the network beyond the limitation of bicubic interpolation degradation.
2.2 Residual learning
Residual learning is now widely used in various computer vision tasks. It was originally proposed to avoid gradient disappearance and make it possible to design very deep networks. In the case of SR, residual learning mainly deals with the high-frequency information between the input and the ground truth. The processing of high-frequency features information will be an important factor affecting the SR performance. Lim et al. proposed EDSR [20] by modifying the ResNet architecture for image classification. They greatly improved the SR performance of the model by removing the batch normalization layer. In order to further improve SR performance, we will separate and fuse the high-frequency feature information in the residual block to improve the hierarchical and richness of the high-frequency features. Our network also showed better SR performance.
3 Proposed method
In this section, we describe our proposed feature separation and fusion network (FSFN) in detail.
3.1 Network structure
As shown in Fig. 2, our feature separation and fusion network is mainly composed of three parts: the shallow feature extraction module, the global residual learning module, and the up-sampling reconstruction module. Given an input LR image ILR and its corresponding target HR image IHR. super-resolution image ISR can be obtained by
where FFSFN(⋅) is our FSFN. Like most previous studies, our shallow feature extraction module only uses a convolution layer, described as
where FSFEM(⋅) is represented as our shallow feature extraction module and sf represents the shallow features extracted from the input ILR. Shallow features (sf ) are used as inputs to the global residual learning module to generate more refined features (rf). As such,
where FGRLM(⋅) denotes our proposed global residual learning module. Finally, rf is used as the input of the up-sampling reconstruction module (URM) to generate the super-resolution image ISR. So
where FURM(⋅) denotes our proposed up-sampling reconstruction module, which consists of the upscale module and a convolution layer. As narrative ESPCN [27] institutes, we choose to sub-pixel convolutional as our upscale module. This has been proved to be the most effective option.
Finally, FSFN is optimized using L1 loss function, just like in other networks [2, 20, 41]. Given a training set \(\{{I^{i}_{LR},I^{i}_{HR}}\}^{N}_{i=1}\) that has N LR-HR pairs, the loss function of our FSFN network can be expressed as follows:
where θ represents the updated parameters in the training process of our model and \(\left |\left |\cdot \right |\right |_{1}\) is the l1 norm.
3.2 Global residual learning module(GRLM)
In this section, we will describe the core module of the network in detail, which is the global residual learning module referred to as the GRLM (see Fig. 2). The GRLM consists of N feature residual learning modules (FRLM), a convolutional layer, and a long connection. This was inspired by the EDSR [20], which allows the network to centralize the processing of the high frequency parts of the feature. Similar to the RCAN [38], our FRLM module is divided into M feature residual learning modules, a convolutional layer, and a short connection. This enables the shallow feature (sf) extracted by the shallow feature module to be applied at a deeper level. The GRLM module can be described by the following formula:
In the formula, Fconv(⋅) represents a convolutional layer, rf represents a refined feature, and ffjrepresents the output of the i th feature residual learning module(\( F_{FRLM_{j}}\)), which is defined as the fusion feature. The FRLM can be described as follows:
where fi represents the input features of the (i − 1)th feature fusion module(\(F_{FSFM_{i-1}}\)) and the output features of the i th feature fusion module(\(F_{FSFM_{i}}\)). We will discuss the FSFM in more detail in the next section.
3.3 Feature separation and fusion module (FSFM)
We can learn from the residual block proposed by EDSR [20] that focusing on the processing of high-frequency features will lead to a strong SR performance. As we can see in Fig. 3, the processing of high-frequency characteristics only uses two convolutional layers. In view of the limited feature extraction capability of a single convolution, we propose a feature separation and fusion module. We will retain the feature information extracted by the first convolution and the feature information not yet extracted. Then, we re-extract the unextracted features. We define this module as a local feature extraction module (LFEM) which is shown in Fig. 4. This module can be described as follows:
In the formula, ufi represents unextracted features and eufi represents features of extracted ufi. So, our feature separation module (FSM) can be expressed as
where fi represents the input feature of the i th FSFM. eufi and efi will be combined adaptively by the feature fusion module (FFM). Therefore, our FSFM can be expressed as
where FFSFM(⋅) denotes our proposed feature separation and fusion module. Compared with the residual block proposed by EDSR [20], our FSFM behaves like a residual block which means that the associated path is disconnected assuming that LFEM is not effective. We can understand that the residual block is a special case of FSFM. Since our FSM module uses only a 1×1 convolutional layer, the increase in network volume can be ignored. As shown in Figs. 5 and 6, the number of indistinctive feature maps accounts for more than half among the unextracted feature maps. This fully shows that our network can effectively reduce feature redundancy.

The structure of the residual blocks

Decomposition of feature separation and fusion module (FSFM); (a) represents the feature separation module (FSM), while (b) represents the feature fusion module (FFM)

extracted features in the first feature separation and fusion module

Unextracted features in the first feature separation and fusion module
4 Experiments
4.1 Datasets and metrics
The DIV2K dataset [1] has been widely used for many image restoration tasks. Like these networks [2, 20, 38], we used DIV2K as our FSFN training dataset which contained 800 RGB images. Five commonly used datasets, Set5 [4], Set14 [36], BSD100 [23], Urban100 [11], and Manga109 [24], were used to evaluate network SR performance. To gauge the SR results, we applied two objective image quality assessment criteria: peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) [32], All criteria were calculated on the Y channel of transformed YCbCr space.
4.2 Implementation details
The HR image patch with a size of 192×192 was randomly cropped from the HR image in the DIV2K dataset as the input of our model. The LR image was obtained from the HR image by using the bicubic interpolation according to the scaling factor (2×,3×,4×). And the mini-batch size is set to 16. We set filter size f = 3. The number of filters for FSFN_SP is set to 32 and for FSFN to 48. We train our FSFN with an ADAM optimizer [17] by setting β1 = 0.9, β2 = 0.999 and ε = 10− 8. The learning rate is initialized to 10− 4 and halved at every 2 × 105 minibatch update. We use a PyTorch framework to implement our proposed FSFN network with a Titan Xp GPU.
4.3 Model analysis
In this section, we will delve into the model parameters and calculations, the effectiveness of FSFM, and the superiority of the idea of block processing (BP).
4.3.1 Model parameters and calculations
As we mentioned in Section 3.2, our core module GRLM is composed of N FRLM, and each FRLM is composed of M FSFM which is the smallest indivisible unit of our network. In our proposed FSFN network, we set N to be 3 and M to be 6. In contrast to most networks [2, 20, 39], in our proposed network, the number of feature maps is 48. This greatly reduces the parameters of the model. At the same time, we also proposed a small version of FSFN named FSFN_N2M4. In FSFN_N2M4, we set N to 2 and M to 4. Then, the number of feature maps is 32. In order to further enhance the performance of the small version of FSFN, we proposed FSFN_SP, which changed the number of output feature maps of convolution of LFEM in FSFM to 64. In this way, the SR performance of the model is further improved at the cost of a small parameter increase (Table 1). Table 2 shows the comparison of models under different amounts of FRLM and FSFM. It can be seen that all the models we selected can show better SR performance under the condition of limited number of parameters. In order to enhance the quality of the SR images, we adopt the self-ensemble strategy. This strategy can be summarized as follows. We flip and rotate the input image ILR to generate augmented image \(I_{LR}^{n,i} = T_{i}(I_{LR}^{n})\) for each sample, where Ti represents eight geometric transformations, including indentity. Then, we’ll use augmented images as input to our network to generate super-resolved images \(I_{SR}^{n,1},...,I_{SR}^{n,8}\). We then apply inverse transform to those super-resolved images to get the original geometry \(\tilde {I}_{SR}^{n,i} = T_{i}^{-1}(I_{SR}^{n,i})\). Finally, we average the transformed outputs to get the following self-ensemble results. \(I_{SR}^{n} = \tfrac {1}{8}{\sum }_{i=1}^{n}(\tilde {I}_{SR}^{n,i})\). FSFN_SP+ and FSFN+ are obtained by applying the self-ensemble strategy. As can be seen in Fig. 1, our model performs best against other state-of-the-art algorithms on the parameter scale of 500K and 1000K. We all know that recursive networks greatly increase the number of model parameters by reusing modules, but they also increase the computational complexity of the model. As we can see from Table 1, our FSFN_SP has a significantly reduced computation capacity but better SR performance when compared with DRCN [16], DRRN [28] and MemNet [30].
4.3.2 Block processing (BP) and feature separation and fusion module (FSFM)
As discussed in Section 2.2, residual learning enables our network to focus on high-frequency processing of features. EDSR [20] proposes a network architecture similar to that shown in Fig. 12a, and its smallest modular processing unit is called the residual block (Resblock). We call this structural framework the directly connected structure. The disadvantage of this structure is that, as the network hierarchy deepens, the shallow primitive features that can be utilized effectively will be ignored. To address this, Zhang et al. [39] put forward the Residual in Residual (RIR) module similar to Fig. 12b. We call this structural framework block processing (BP). Through short connection, the M smallest module processing unit is synthesized into a large module, and then N such large modules are synthesized into a larger module. This allows the original shallow features to be utilized effectively at different levels. Therefore, we think that block processing is a better structural framework. As we can see from Table 3. whether the smallest structural unit is Resblock or FSFM, when block processing is adopted, the SR performance of the network is improved. EDSR_S represents the structural framework with a direct connection structure, which contains eight residual blocks. and EDSR_N2M4 represents the structural framework with block processing. We found that EDSR_N2M4 is 0.023dB higher than EDSR_S in PSNR. By comparing EDSR_S and FSFN_S as well as FSFN_N2M4 and EDSR_N2M4, we found that, on the same structural framework, our FSFM improved SR performance more significantly than Resblock. By comparing EDSR_N2M4 with FSFN_S, we find that FSFM improves network performance to a greater degree than block processing and that FSFN_S achieves better performance with fewer parameters. As described in Section 4.3.1, we obtained FSFN_SP through the Extended Local Feature Extraction Module. FSFN_SP performs best on those networks with parameters below 500K. Although the average running time of FSFN_SP on the Urban100 dataset was slightly increased compared to our base network EDSR_S, we chose FSFN_SP as the smaller version of our FSFN network for better SR performance.
4.4 Comparison with the state-of-the-arts
In this section, several state-of-the-art methods will be compared with our proposed FSFN, including SRCNN [7], FSRCNN [8], VDSR [15], DRCN [16], LapSRN [18], DRRN [28], MemNet [30], FALSR [6], and CARN [2]. We will compare our FSFN with the above methods both mathematically and visually. The above methods are divided into two categories according to the number of parameters: those that use about 500K, and those that use about 1000K. As can be seen in Table 1, when the number of parameters of the model is around 500K, the overall SR performance of our proposed FSFN_SP+ network is better than that of all other networks, especially at the scaling factor of ×2. When the number of parameters is around 1000K, our FSFN+ network also performs better than its peer network models. When the comparison criterion is structural similarity (SSIM), the SR performance of our FSFN_SP, FSFN network is superior to all other networks, even without a self-integration strategy.
4.4.1 Visual comparison
Since our proposed FSFN can separate and fuse the shallow features of a single module, we can imagine that the SR images generated by our FSFN network will have better detailed image features. Below we will show the image recovery effects of our network on each dataset. We randomly select an image from the Set14 dataset, named PPT3 as shown in Fig. 7. We can see that our network can show the words in the original image more clearly. Figure 8 shows image 8023 from the BSDS100 dataset. We can see from this image that our FSFN network is able to restore the detail of the bird’s wing with a scaling factor of 4. Figure 9 shows another image from the BSDS100 dataset named img_011. The hardest detail to recover from this image is the vertical line at the left of the locally enlarged image block. We can see that, unlike SR images generated by our FSFN network, SR images generated by other methods experience difficulty in showing the gap between vertical lines. Since the BSDS100 dataset contains a large number of high-resolution images, we have introduced a visual comparison of Figs. 10 and 11, and both images show better SR performance in our network when the scaling factor is 4 and 3. All of the above visual comparisons reflect the superior performance of our FSFN network framework (Fig. 12).

Visual comparison for 4×SR on the Set14

Visual comparison for 4×SR on the BSDS100

Visual comparison for 4×SR on the Urban100

Visual comparison for 4×SR on the Urban100

Visual comparison for 3×SR on the Urban100

Overall network framework selection; (a) represents a directly connected structure, while (b) represents a block processing structure
5 Conclusion
In this paper, we propose a lightweight feature separation and fusion network for single image super-resolution. We adopt the structural framework of block processing so that our network can enrich the features of different levels while making full use of the features of different levels. We also propose a feature separation and fusion module as our smallest module unit, which enhances the ability of our network to extract high-frequency features by separating and fusing the shallow features extracted from the interior of the smallest module unit. In this way, the SR performance of our network is improved significantly, especially in the restoration of texture details of some images. Experiments show that our network model offers better SR performance compared to other lightweight network models.
References
Agustsson E, Timofte R (2017) NTIRE 2017 challenge on single image super-resolution: Dataset and study. In: CVPR, pp 1122–1131
Ahn N, Kang B, Sohn K (2018) Fast, accurate, and lightweight super-resolution with cascading residual network. In: ECCV, pp 256–272
Allebach JP, Wong PW (1996) Edge-directed interpolation. In: Proceedings 1996 International conference on image processing, Lausanne, Switzerland, September 16-19, 1996, pp 707–710
Bevilacqua M, Roumy A, Guillemot C, Alberi-Morel M (2012) Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In: British machine vision conference, BMVC 2012, Surrey, UK, September 3-7, 2012, pp 1–10
Chang H, Yeung D, Xiong Y (2004) Super-resolution through neighbor embedding. In: CVPR, pp 275–282
Chu X, Zhang B, Ma H, Xu R, Li J, Li Q (2019) Fast, accurate and lightweight super-resolution with neural architecture search. arXiv:1901.07261
Dong C, Loy CC, He K, Tang X (2016) Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 38 (2):295–307
Dong C, Loy CC, Tang X (2016) Accelerating the super-resolution convolutional neural network. In: ECCV, pp 391–407
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: CVPR, pp 770–778
Huang G, Liu Z, van der Maaten L, Weinberger KQ (2017) Densely connected convolutional networks. In: CVPR, pp 2261–2269
Huang J, Singh A, Ahuja N (2015) Single image super-resolution from transformed self-exemplars. In: CVPR, pp 5197–5206
Hui Z, Gao X, Yang Y, Wang X (2019) Lightweight image super-resolution with information multi-distillation network. In: Proceedings of the 27th ACM International conference on multimedia, MM 2019, Nice, France, October 21-25, 2019, pp 2024–2032
Irani M, Peleg S (1991) Improving resolution by image registration. CVGIP Graph Model. Image Process. 53(3):231–239
Jin X, Xiong Q, Xiong C, Li Z, Gao Z (2019) Single image super-resolution with multi-level feature fusion recursive network. Neurocomputing 370:166–173
Kim J, Lee JK, Lee KM (2016) Accurate image super-resolution using very deep convolutional networks. In: CVPR, pp 1646–1654
Kim J, Lee JK, Lee KM (2016) Deeply-recursive convolutional network for image super-resolution. In: CVPR, pp 1637–1645
Kingma DP, Ba J (2015) Adam: A method for stochastic optimization. In: 3rd International conference on learning representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings
Lai W, Huang J, Ahuja N, Yang M (2019) Fast and accurate image super-resolution with deep laplacian pyramid networks. IEEE Trans. Pattern Anal. Mach. Intell. 41(11):2599–2613
Li X, Orchard MT (2000) New edge directed interpolation. In: Proceedings of the 2000 international conference on image processing, ICIP 2000, Vancouver, BC, Canada, September 10-13, 2000, pp 311–314
Lim B, Son S, Kim H, Nah S, M Lee K (2017) Enhanced deep residual networks for single image super-resolution. In: CVPR, pp 1132–1140
Liu B, Ait-Boudaoud D (2020) Effective image super resolution via hierarchical convolutional neural network. Neurocomputing 374:109–116
Liu J, Zhang W, Tang Y, Tang J, Wu G (2020) Residual feature aggregation network for image super-resolution. In: CVPR, pp 2356–2365
Martin DR, Fowlkes CC, Tal D, Malik J (2001) A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In: ICCV, pp 416–425
Matsui Y, Ito K, Aramaki Y, Fujimoto A, Ogawa T, Yamasaki T, Aizawa K (2017) Sketch-based manga retrieval using manga109 dataset. Multim. Tools Appl. 76(20):21811–21838
Qiu Y, Wang R, Tao D, Cheng J (2019) Embedded block residual network: A recursive restoration model for single-image super-resolution. In: ICCV, pp 4179–4188
Ren C, He X, Pu Y, Nguyen TQ (2019) Enhanced non-local total variation model and multi-directional feature prediction prior for single image super resolution. IEEE Trans. Image Process. 28(8):3778–3793
Shi W, Caballero J, Huszar F, Totz J, Aitken AP, Bishop R, Rueckert D, Wang Z (2016) Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: CVPR, pp 1874–1883
Tai Y, Yang J, Liu X (2017) Image super-resolution via deep recursive residual network. In: CVPR, pp 2790–2798
Tai Y, Yang J, Liu X, Xu C (2017) Memnet: A persistent memory network for image restoration. In: ICCV, pp 4549–4557
Tai Y, Yang J, Liu X, Xu C (2017) Memnet: A persistent memory network for image restoration. In: ICCV, pp 4549–4557
Tong T, Li G, Liu X, Gao Q (2017) Image super-resolution using dense skip connections. In: ICCV, pp 4809–4817
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13(4):600–612
Wang X, Gu Y, Gao X, Hui Z (2019) Dual residual attention module network for single image super resolution. Neurocomputing 364:269–279
Yang X, Mei H, Zhang J, Xu K, Yin B, Zhang Q, Wei X (2019) DRFN: deep recurrent fusion network for single-image super-resolution with large factors. IEEE Trans. Multimed 21(2):328–337
Yang W, Wang W, Zhang X, Sun S, Liao Q (2019) Lightweight feature fusion network for single image super-resolution. IEEE Signal Process. Lett. 26 (4):538–542
Zeyde R, Elad M, Protter M (2010) On single image scale-up using sparse-representations. In: Curves and surfaces - 7th international conference, Avignon, France, June 24-30, 2010, Revised Selected Papers, pp 711–730
Zhang K, Gool LV, Timofte R (2020) Deep unfolding network for image super-resolution. In: CVPR, pp 3214–3223
Zhang Y, Li K, Li K, Wang L, Zhong B, Fu Y (2018) Image super-resolution using very deep residual channel attention networks. In: ECCV, pp 294–310
Zhang Y, Li K, Li K, Wang L, Zhong B, Fu Y (2018) Image super-resolution using very deep residual channel attention networks. In: ECCV, pp 294–310
Zhang Y, Tian Y, Kong Y, Zhong B, Fu Y (2018) Residual dense network for image super-resolution. In: CVPR, pp 2472–2481
Zhang Z, Wang X, Jung C (2019) DCSR: dilated convolutions for single image super-resolution. IEEE Trans. Image Process. 28(4):1625–1635
Zhang L, Wu X (2006) An edge-guided image interpolation algorithm via directional filtering and data fusion. IEEE Trans. Image Process. 15 (8):2226–2238
Acknowledgment
This work was supported in part by the National Natural Science Foundation of China (61876099), in part by the National Key R&D Program of China (2019YFB1311001), in part by the National Natural Science Foundation of China (U1806202), in part by the National Natural Science Foundation of China (61533011), in part by the Scientific and Technological Development Project of Shandong Province (2019GSF111002), in part by the Shenzhen Science and Technology Research and Development Funds (JCYJ20180305164401921), in part by the Foundation of Ministry of Education Key Laboratory of System Control and Information Processing (Scip201801), and in part by the Foundation of State Key Laboratory of Integrated Services Networks (ISN20-06). Kai Zhu and Zhenxue Chen contributed equally to this work and should be considered as the co-first authors.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Kai Zhu and Zhenxue Chen have contributed equally.
Rights and permissions
About this article

Cite this article
Zhu, K., Chen, Z., Wu, Q.M.J. et al. FSFN: feature separation and fusion network for single image super-resolution. Multimed Tools Appl 80, 31599–31618 (2021). https://doi.org/10.1007/s11042-021-11121-6
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-021-11121-6