
Abstract
Objective evaluation of images is one of the most essential and practical aspects of image inpainting. The existing objective evaluation methods of image inpainting are functional only on an individual basis and do not provide an accurate and useful objective evaluation of inpainted images. Currently, there is no objective measure for evaluating inpainted images. In this study, an objective evaluation method was developed for image inpainting. In the proposed method, first, 100 images were inpainted using an exemplar-based algorithm. Then, the saliency map and its complementary region in the original image were obtained and a new objective measure was proposed for the evaluation of inpainted images based on the saliency map features. To make the assessment more realistic and comparable to human judgments, two terms, namely penalty and compensation, were taken into account. To assess the performance of our proposed objective measure, the inpainted images were also evaluated using a subjective test. The experiments demonstrates that the proposed objective measure correlated with the qualitative opinion in a human observer study. Finally, the objective measure was compared against three other measures, and the results showed that our proposed objective measure performed better than the other evaluation measures.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Image inpainting was extensively used in the ancient artwork. However, the term for digital image inpainting was first introduced by Bertalmio in 2000 [6, 7]. Due to its many applications, such as restoring the lost and damaged images, removing objects and noise, etc., the evaluation of inpainted images is one of the topics that has caught the attention of researchers in recent years. As mentioned, one of the uses of image inpainting is the removal of additional and unwanted objects in the image, which has many uses for videos and photos.
One of the applications can be the removal of additional objects in movie pictures and sports, social, cultural, political events, and so on. The use of image inpainting does not require photocopying again, which means saving money. Also, the importance of image inpainting further indicates the fact that most events such as sports events, political events, etc. cannot be repeated, and the presence of an extra object in the picture makes the use of image inpainting inevitable. According to the abovementioned materials, image inpainting is one of the global technologies that has gradually become more important and been more widely used. However, no evaluation measure has been proposed for data. The emergence of numerous algorithms has led to another problem: which one of these algorithms performs better? The most rudimentary way to evaluate these algorithms is to use human observers. Despite the precision, using human observers for evaluation has its problems and limitations, the most notable of which are that they are time consuming and costly. Therefore, it is essential to develop a metric that can objectively and quickly assess the quality of these algorithms. This metric should be able to evaluate the image quality in the same manner that human beings perceive images.
This issue has become very important and hence received significant attention in recent years. However, researchers have failed to develop an efficient measure that can be applied to all methods. Existing methods heavily depend on the reference image, many of which are functional only on an individual basis. Because the reference image is not available in many cases of image inpainting, it is crucial to have a metric that does not rely on the reference image. The characteristics of the human eye can be beneficial in assessing an image. One of these characteristics is the estimated vision density. The human eye can only see a small area of an object at any moment, and ironically, the rest of the object seems blurry and is not seen clearly. Researchers have provided evidence that the human eye only recognizes specific parts of the image at any moment while looking at a picture and ignores the rest of the image. These particular parts are called salience map. They were first presented by Koch and Ullman and later improved by Itti and Koch [10, 16, 17, 21, 44, 56]. Using this property will upgrade the characteristic in a way that the measure operates more similarly to human perception.
2 Objective quality evaluation
In need for the evaluation of image inpainting, researchers proposed measures that operate satisfactorily only in some cases. Ardis et al. presented the ASVS and DN methods in 2010 [2]. In ASVS, the focus is on the part where the pixel is inpainted. Consequently, this measure is applicable only to the inpainted area. However, DN considers the outer part of the inpainted area, indicating how much of the inpainted outer region of the image is under attention. The smallest number obtained for the two methods above in an image shows that the inpainted image is better than the other images. Unfortunately, this method is not efficient and will result only in exceptional cases.
Other methods are \({\text{G}\text{D}}_{\text{o}\text{u}\text{t}}\) and \({ \text{G}\text{D}}_{\text{i}\text{n} }\), which were introduced by Mahalingam [30]. These criteria are based on visual saliency to measure the objective quality of the inpainted image. They show that any change in the saliency is related to the quality of conceptual perception. This method is also weak and not functional in most cases.
Another method is machine learning, which was proposed by Voronin et al. [46, 47]. This approach is also based on the statistical properties of images and not very accurate. The main problem in using Low-level features that have reduced its measurement accuracy The methods, as mentioned earlier, have many weaknesses and are useful only in some cases, which are far from human perception [34]. Although there has not been a proper method for the evaluation of inpainted images, the problem for the assessment of image processing has attracted the attention of scientists in recent years. For example, current methods of assessing segmented images have shown excellent performance [40].
3 Proposed objective measure
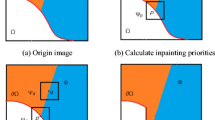
Researchers have proposed numerous image inpainting methods which can be divided into two general categories: partial differential equation (PDE)-based methods [5, 8, 9, 13, 23, 25, 32, 36, 39, 43, 49, 54, 55] and exemplar-based methods [3, 4, 11, 15, 20, 22, 24, 33, 42, 50, 51, 53, 57, 58]. Among the methods mentioned, the exemplar-based approach is more efficient and provides better results than others [52]. To assess an inpainted image, a method which has mid-level features is used so that it can provide results similar to human perception. In this article, mid-level features are orientation, intensity, and color. The symbol I shows the input image in this article, Ω indicates the inpainted area, and \(\phi\) shows its complementary region in the main photo. These areas are shown in Fig. 1 as follows:

Image model input
First, the image is inpainted using the exemplar-based method. Then, the saliency map of the inpainted area and the complementary region of the inpainted area are calculated using the Itti-Koch method [19, 48]. Due to the importance of the method, this method is explained in this paper. Itti et al. used a method for high selective attention based on the prominence point that uses the calculation of the local contrast properties of the prominent positions to reduce the point of prominence. The main reason for using the Itti_Koch method is because of the features that this method uses to get the saliency map. In fact, only the features obtained by the Itti_Koch method are used. Another reason is that these features play an essential role in inpainting based on the exemplar-based method. The better these features are observed, the better the inpainting will be. Basically, exemplar-based inpainting is based on repeating orientation, intensity, and color on the neighborhood.
Considering the importance of Itti et al.’s method, it is also explained in this paper. Itti et al. used a method for bottom-up selective attention based on continuous scanning of a saliency map, which uses the calculation of local contrast features for salient locations to reduce the saliency. The model presented by Itti et al. can be used as an artificial intelligence behavior to replace the diagnosis of normal human feelings.
First, the input image I is sub-sampled into a dyadic Gaussian pyramid. This is done by convolution with a linearly separable Gaussian filter and decimation by a factor of two. This process continues and repeats the pyramid to obtain the next levels of \({\upsigma }\) = [0, …, 8]. The resolution of level \({\upsigma }\) is 1 / \({2}^{{\upsigma }}\) times to the original image resolution. For example, the 4th level has a resolution of \(\frac{1}{16}\) of the input image I and \({\left(\frac{1}{16}\right)}^{2}\)of the total number of pixels.
If r, g, and b are red, green, and blue respectively, then the intensity map is calculated as follows:
This action is repeated for each level of the input pyramid to get a pyramid of intensity with the level \({M}_{I}\left(\sigma \right)\). In addition, each level of the image pyramid is divided into the maps of red-green (RG) and blue-yellow (BY) opponencies:
In the low luminance, the color opponencies values are subject to many fluctuations. In order to avoid this, \({M}_{RG}\) and \({M}_{BY}\) are considered zero at places with a maximum of \(max\left(r,g,b\right)<\frac{1}{10}\), assuming a dynamic range [0, 1].
Applying the steerable filters to the intensity pyramid levels \({M}_{I}\left(\sigma \right)\), local orientation maps \({M}_{\theta }\) are obtained. The lateral inhibition between units with different \(\theta\) can help to detect the faint elongated objects. Another highly salient feature is motion. Center-surround receptive fields are simulated by a cross-scale subtraction \(\ominus\) between two maps at the center (c) and the surround (s) levels in these pyramids, outputting “feature maps”:
With
N (·) is a repetitive and nonlinear normalization operator, simulating local competition between the neighboring salient locations. Each iteration step consists of self-excitation and neighbor-induced inhibition implemented by convolution with a “difference of Gaussians” filter, followed by rectification.
The feature maps are summed over the center-surround combinations using a cross-scale addition \(\oplus\), and the sums are normalized again:
For the general features of color and orientation, the contributions of the sub-features are summed and normalized once more to output the “conspicuity maps”. For intensity, the conspicuity map is the same as \(\stackrel{-}{{F}_{l}}\), which is obtained as follows:
All conspicuity maps are combined into one saliency map:
WTA (winner-take-all) method obtains the locations of the saliency map for each photo. In this method, the locations where the highest values are obtained are considered as the saliency map of the image. For each image, one or more locations may be considered as a saliency map.
The saliency map is the locations of xw and yw, which are obtained using WTA method. Then, the WTA competition generates the second most salient location, which is attended to subsequently and then inhibited, thus allowing the model to simulate a scan path over the image to decrease the saliency of the attended locations.

Architecture of Itti-Koch’s method [19]
The architecture of the Itti-Koch method is shown in Fig. 2. Using the characteristics of the Itti-Koch’s calculations for the saliency map, the similarity between the saliency map of the inpainted area and the complementary region is calculated in terms of intensity, orientation, and colors; the more this similarity, the better the inpainting. This is because the exemplar-based method uses the color and patterns of restructuring to inpaint the damaged images. Thus, the quality of inpainting highly depends on how precise the intensity, color, and orientation are abided by. This method is superior over the method of calculating the similarities between the pixels of the inpainted area and complementary region because it uses Itti-Koch’s method, which in turn uses other features of the image such as orientation, intensity, and color to find the saliency map. In calculating the similarities, repeating the pattern of one part can result in high similarities, while the quality of inpainting is still low. Given this, using the method in this paper increases the accuracy of the assessment of image inpainting.
After obtaining the saliency maps, they are plugged into the Jaccard index [41]. Jaccard index is defined as follows:
It should be noted that in the former methods of image inpainting, only the concept of saliency map is used, and its method of calculation as well as its features are ignored. In the proposed method, however, due to the need for the saliency map features, Itti-Koch’s method is used to find the saliency map. Further, the Jaccard index has never been used in this area (Evaluating of Inpainted Images).
To get a more precise and close-to-human perception measure, one penalty term and one compensation term are added to the above Jaccard index. The penalty expression is calculated as the ratio of the saliency map of the inpainted region to the complementary region and is added to the denominator. The higher this ratio, the greater (lower) the attention to the inpainted region (complementary region), which in turn indicates lower quality inpainting. The penalty term is calculated as follows:
The compensation term is exactly the opposite of the penalty term and is added to the numerator of the Jaccard index. The compensation term is calculated as the ratio of the complementary of the inpainted region to the inpainted region. The higher value of this ratio indicates more considerable attention to the complementary of the inpainted than to the inpainted region. This will help increase the accuracy of the measure and make it closer to human perception. The compensation term is defined as follows:
Finally, the proposed measure, which we call it Objective Inpainting Metric (OIM), is as follows:
This metric is used for the evaluation of inpainted images based on exemplar-based and object removal method. This metric is a quantitative measure and can be a reliable alternative to subjective measurement. This metric is obtained using the features of the saliency map and the Jaccard index. In this metric, a number is obtained for an inpainted image according to formula 11; the closer is this number to zero, the lower is the quality of the image inpainting and the closer is the number obtained to one. This means that the image quality is higher and it is harder to figure out if the image is manipulated. In the next section, the results are examined.
4 Experimental results
In this paper, Ran Shi et al.’s database images are used [41]. The images of this database are from the four well-known public object segmentation databases: Weizmann [1], VOC2012 [14], MSRA [28], and Microsoft Research Cambridge’s grabcut [37] and some Berkeley Segmentation Images [31]. The images include people, objects, animals, images with high structures, simple images, landscapes, etc.
In this section, the images are first inpainted and then the quality of the inpainting is measured by the proposed metric. The point to which these photos and the mask are considered is that the objects removed in the images are in different situations in the picture. This is because the position of the object is deleted and also the quality of inpainting is effective. The size of the objects removed is also different, ranging from the small objects to large objects as well as animals, objects, individuals, and so on. It has been tried to cover all the conditions for inpainting so that evaluation with the obtained criterion can be applied to all the photographs. The images and their masks are inpainted based on the exemplar-based algorithm, and then the saliency map of the inpainted region and its complementary region is extracted using the Itti-Koch’s method. The following photo shows some of the database images and their masks (Fig. 3).

Some examples of the database images with their masks [41]
The results are evaluated using the proposed metric. The Fig. 4 displays the evaluation process. Figure 4, (a) shows the original image and (b) shows the inpainted image, which is inpainted using the exemplar-based method. The saliency maps of the inpainted image and inpainted areas are exhibited in (c) and (d) respectively.

Examples of the inpaint and saliency map of images from the test database
After evaluating the images, the proposed metric reports the quality of each image with a number, which is between zero and one. The closer this number is to zero, the higher is the quality of the image. The Fig. 5 illustrates an example of the evaluation of ten inpainted images. The scores are written below each image using the proposed metric.

Examples of the proposed method rating: image (a) = very good inpainting, image (b) = good inpainting, image (c) = average inpainting, image (d) = bad inpainting, and image (e) = very bad inpainting
5 Evaluation
To assess the proposed evaluation metric, subjective methods were used and inpainted images were evaluated by human observers. After evaluating these images by the proposed criteria, these images were rated by human observers following the ITU(International Telecommunication Union) standard (Table 1) [1]. Respectively, each picture is ranked from 5 to 1; 5 (excellent inpainting), 4 (good inpainting), 3 (average inpainting), 2 (poor inpainting), and 1 (bad inpainting). To do this, 30 inexperienced or low-experienced image-processing human observers were employed. Unrealistic opinions were removed. According to the ITU standard, unrealistic opinions should be deleted in order to prove that observers have understood the meaning of the test or that their comments are not random. 30 participants are used for this article. Each participant evaluated an average of 200 images. The inpainted image and the original image were displayed simultaneously to each participant [18].
The final score for each obtained image is from the average opinion [14] calculated by the following formula:
In the above formula, n represents the number of human observers and represents the score that has been given to each image. All images using Criminisi [12] method were inpainted and then rated by the observers. In this way, the original and inpainted images were shown to the human observers for 5 s, following which they rated them. To avoid a negative impact on the rate, the images were placed randomly [18, 31, 35, 37]. Also according to the ITU standard, subjects should be informed in the test instructions [18] (Fig. 6).

Samples of database [41]
Four general assessment criteria including the Spearman Rank-Order Correlation Coefficients (SROCC), the Linear Correlation Coefficient (LCC), the Root Mean Squared Error (RMSE), and the Outlier Ratio (OR) are used for assessing the objective and subjective results obtained from the assessment[26, 27, 29, 38, 45]. Table 2 shows the results of the assessment for the proposed measure and also three other metrics.
6 Discussion
The coefficients of SROCC and LCC are between zero and one. The closer these numbers to one, the higher the correlation between the proposed metric and the subjective tests, indicating a better performance. This relationship is reversed between RMSE and OR. This means that the lower is the number obtained, the greater is its correlation with the subjective method. In experiments performed on inpainted images to obtain the quality of their inpainting, the proposed method demonstrated that more objects were removed in the inpainted images and other methods could not evaluate the quality of inpainting. This means that if the number of objects to be removed is greater than one, the accuracy of evaluating the quality of other methods will decrease for the image inpainting. The proposed method also works well in these images, and removing an object or several objects does not affect the quality of the inpainted images.
In the images with high complexity, other methods had a very poor performance, but the proposed method performed better, and the quality of inpainted images was better than that of the rest of the methods. In the removal of an object with small dimensions and low complexity, almost all methods could show the quality of inpainted images well. With the removal of large objects, the DN method was weaker than the rest of the methods. As can be seen, the proposed method has the highest correlation (0.88) with the subjective results compared to the other three methods, suggesting that the proposed method is more efficient and accurate than the other three measures.
7 Conclusions
In this paper, a metric was developed based on human visual characteristics to assess the quality of inpainted images. Two terms were added to the metric as penalty and compensation to make the metric more accurate. To assess this metric, the subjective assessment with human observers was used. The results were satisfactory and showed that the metric could provide the quality of human perception. Further, the proposed method was compared against three other methods, whose results confirmed that the proposed method performed better than the other three methods. For future works, we can add terms to human perception to improve the metric. This requires the use of high-level features in the evaluation of images.
References
Alpert S, Galun M, Brandt A, Basri R (2011) Image segmentation by probabilistic bottom-up aggregation and cue integration. IEEE Trans Pattern Anal Mach Intell 34(2):315–327
Ardis P, Singhal A (2009) Visual salience metrics for image inpainting visual salience metrics for image inpainting. Proc. SPIE/IS&T Electron. Imaging, San Jose, CA, USA, vol 7257
Arias P, Caselles V, Facciolo G (2012) Analysis of a variational framework for exemplar-based image inpainting. Multiscale Model Simul 10(2):473–514
Atapour-Abarghouei A, Breckon TP (2018) Extended patch prioritization for depth filling within constrained exemplar-based RGB-D image completion,. In: International Conference Image Analysis and Recognition, pp 306–314
Barbu T, Marinoschi G, Moroșanu C, Munteanu I (2018) Advances in variational and partial differential equation-based models for image processing and computer vision. Math Probl Eng 2018
Bertalmio M, Sapiro G, Caselles, Balleste C (2000) Image inpainting. New Orleans Proc. SIGGRAPH, pp 102–133
Bertalmio M, Vese L, Sapiro G, Osher S (2003) Simultaneous structure and texture image inpainting. IEEE Trans Image Process 12(8):882–889
Bredies K, Lorenz D (2018) Partial differential equations in image processing. In: Mathematical Image Processing. Springer, Berlin, pp 171–250
Brkić AL, Novak A (2018) A nonlocal image inpainting problem using the linear allen–cahn equation. In: Conference on Non-integer Order Calculus and Its Applications, pp 229–239
Bruce N, Tsotsos J (2006) Saliency based on information maximization. Adv Neural Inf Process Syst 18:155
Cao F, Gousseau Y, Masnou S, Pérez P (2011) Geometrically guided exemplar-based inpainting. SIAM J Imaging Sci 4(4):1143–1179
Criminisi A, Pérez P, Toyama K (2004) Region filling and object removal by exemplar-based image inpainting. IEEE Trans image Process 13(9):1200–1212
Demanet L, Song B, Chan T (2003) Image inpainting by correspondence maps: a deterministic approach. Appl Comput Math 1100:217–250
Everingham M, Van Gool L, Williams CKI, Winn J, Zisserman A. The PASCAL visual object classes challenge, 2012 (VOC2012) results. [Online]. Available http://www.pascalnetwork.org/challenges/VOC/voc2012/workshop/index.html2012/workshop/index.html. Accessed May 2013
Fan Q, Zhang L (2018) A novel patch matching algorithm for exemplar-based image inpainting. Multimed Tools Appl 77(9):10807–10821
Harel J, Koch C, Perona P (2006) Graph-based visual saliency. In: NIPS, vol 1, no 2, p 5
Hou X, Zhang L (2007) Saliency detection: A spectral residual approach. In: Computer Vision and Pattern Recognition, 2007. CVPR’07. IEEE Conference on, pp 1–8
ITU (2002) Methodology for the subjective assessment of the quality of television pictures. Itu-R Bt.500 – 11, vol 211, no BT.500 – 11, pp 1–48
Itti L, Koch C, Niebur E (1998) A model of saliency-based visual attention for rapid scene analysis. IEEE Trans Pattern Anal Mach Intell 20(11):1254–1259
Jia J, Tang C-K (2004) Inference of segmented color and texture description by tensor voting. IEEE Trans Pattern Anal Mach Intell 26(6):771–786
Koch C, Ullman S (1987) Shifts in selective visual attention: towards the underlying neural circuitry. In: Matters of intelligence. Springer, Berlin, pp 115–141
Komodakis N, Tziritas G (2007) Image completion using efficient belief propagation via priority scheduling and dynamic pruning. IEEE Trans Image Process 16(11):2649–2661
Kumar BVR, Halim A (2019) A linear fourth-order PDE-based gray-scale image inpainting model. Comput Appl Math 38(1):6
Kumar H, Sharma S, Choudhury T (2018) Improved exemplar-based image inpainting approach. In: Intelligent Computing and Information and Communication. Springer, Berlin, pp 705–717
Levin A, Zomet A, Weiss Y (2003) Learning how to inpaint from global image statistics. In: ICCV, vol 1, pp 305–312
Li S, Mak LC-M, Ngan KN (2011) Visual quality evaluation for images and videos. In: Multimedia Analysis, Processing and Communications, Springer, Berlin, pp 497–544
Li S, Zhang F, Ma L, Ngan KN (2011) Image quality assessment by separately evaluating detail losses and additive impairments. IEEE Trans Multimed 13(5):935–949
Liu T et al (2011) Learning to detect a salient object. IEEE Trans Pattern Anal Mach Intell 33(2):353–367
Ma L, Lin W, Deng C, Ngan KN (2012) Image retargeting quality assessment: A study of subjective scores and objective metrics. IEEE J Sel Top Signal Process 6(6):626–639
Mahalingam VV (2010) Digital inpainting algorithms and evaluation,. PhD thesis, Univ. Kentucky
Martin D, Fowlkes C, Tal D, Malik J (2001) A database of humansegmented naturalimages and its application to evaluating segmentationalgorithms and measuringecological statistics. In: Proc. 8th IEEE Int. Conf. Comput. Vis.(ICCV), vol 2, pp 416–423
Masnou S (2002) Disocclusion: a variational approach using level lines. IEEE Trans Image Process 11(2):68–76
Newson A, Almansa A, Fradet M, Gousseau Y, Pérez P (2013) Towards fast, generic video inpainting. In: Proceedings of the 10th European Conference on Visual Media Production, p 7
Qureshi MA, Deriche M, Beghdadi A, Amin A (2017) A critical survey of state-of-the-art image inpainting quality assessment metrics. J Vis Commun Image Represent 49:177–191
Ribeiro F, Florêncio D, Zhang C, Seltzer M (2011) Crowdmos: An approach for crowdsourcing mean opinion score studies. In: Acoustics, Speech and Signal Processing (ICASSP), (2011) IEEE International Conference on, pp 2416–2419
Roth S, Black MJ (2005) Fields of experts: A framework for learning image priors. In: Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on, vol 2, pp 860–867
Rother C, Kolmogorov V, Blake A (2004) GrabCut’: Interactive foreground extraction using iterated graph cuts. ACM Trans. Graph, vol 23, no 3, pp 309–314
Seshadrinathan K, Soundararajan R, Bovik AC, Cormack LK (2010) Study of subjective and objective quality assessment of video. IEEE Trans Image Process 19(6):1427–1441
Shen J, Chan TF (2002) Mathematical models for local nontexture inpaintings. SIAM J Appl Math 62(3):1019–1043
Shi R, Ngan KN, Li S, Paramesran R, Li H (2015) Visual quality evaluation of image object segmentation: subjective assessment and objective measure. IEEE Trans Image Process 24(12):5033–5045
Shi R, Ngan KN, Li S. Image object segmentation visual quality evaluation database. [Online]. Available: http://www.ee.cuhk.edu.hk/~rshi/. Accessed Jan 2015
Trampert P et al (2018) Exemplar-based inpainting as a solution to the missing wedge problem in electron tomography. Ultramicroscopy 191:1–10
Tschumperle D, Deriche R (2005) Vector-valued image regularization with PDEs: A common framework for different applications. IEEE Trans Pattern Anal Mach Intell 27(4):506–517
Underwood G, Foulsham T, van Loon E, Humphreys L, Bloyce J (2006) Eye movements during scene inspection: A test of the saliency map hypothesis. Eur J Cogn Psychol 18(3):321–342
Van Dijk AM, Martens J-B, Watson AB (1995) Quality asessment of coded images using numerical category scaling. In: Advanced Networks and Services, pp 90–101
Viacheslav V, Vladimir F, Vladimir M, Nikolay G, Roman S, Valentin F (2014) Low-level features for inpainting quality assessment. Int. Conf. Signal Process. Proceedings, ICSP, vol 2015–Janua, no. October, pp 643–647
Voronin V, Marchuk V, Semenishchev E, Maslennikov S, Svirin I (2015) Inpainted image quality assessment based on machine learning
Walther D (2006) Interactions of visual attention and object recognition: computational modeling, algorithms, and psychophysics. Thesis by, PhD thesis, Calif. Inst. Technol. Pasadena, CA
Wei W, Zhou B, Połap D, Woźniak M (2019) A regional adaptive variational PDE model for computed tomography image reconstruction. Pattern Recognit 92:64–81
Wexler Y, Shechtman E, Irani M (2007) Space-time completion of video. IEEE Trans Pattern Anal Mach Intell 29(3):463–476
Xiang S, Deng H, Zhu L, Wu J, Yu L (2019) Exemplar-based depth inpainting with arbitrary-shape patches and cross-modal matching. Signal Process Image Commun 71:56–65
Xiao M, Li G, Xie L, Peng L, Chen Q (2018) Exemplar-based image completion using image depth information. PLoS One 13(9):e0200404
Xu Z, Sun J (2010) Image inpainting by patch propagation using patch sparsity. IEEE Trans Image Process 19(5):1153–1165
Yang X, Guo B, Xiao Z, Liang W (2019) Improved structure tensor for fine-grained texture inpainting. Signal Process Image Commun 73:84–95
Yao F (2018) Damaged region filling by improved criminisi image inpainting algorithm for thangka. Cluster Comput :1–9
Zhang J, Sclaroff S (2013) Saliency detection: A boolean map approach. In: Proceedings of the IEEE International Conference on Computer Vision, pp 153–160
Zhang D, Liang Z, Yang G, Li Q, Li L, Sun X (2018) A robust forgery detection algorithm for object removal by exemplar-based image inpainting. Multimed Tools Appl 77(10):11823–11842
Zhang N, Ji H, Liu L, Wang G (2019) Exemplar-based image inpainting using angle-aware patch matching. EURASIP J Image Video Process, vol 2019, no 1, p 70
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Amirkhani, D., Bastanfard, A. An objective method to evaluate exemplar‐based inpainted images quality using Jaccard index. Multimed Tools Appl 80, 26199–26212 (2021). https://doi.org/10.1007/s11042-021-10883-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-021-10883-3