
Abstract
In this paper, we propose a steganalysis method based on the principle of additive operator, which chooses non-zero AC coefficients as carriers, with secret information independent of the carrier information flow. In the proposed method, AC coefficient statistical and energy features are initially extracted and used to construct a 3D feature vector. By employing the principle of Fisher linear discriminate analysis, a flexible discriminate classifier suitable for the extracted features is designed to improve detection performance. We infer and confirm theory of change in the statistical and energetic characteristics of the AC coefficient before and after additive steganography. The effectiveness of the proposed method is proven by the experiments. Moreover, the proposed method consistently outperforms related methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
With the rapid development in Internet technology, communication has become convenient and efficient. Meanwhile, the quantity of data transmitted through networks is increasing substantially [18]. Under such conditions, network information security is becoming increasingly important. To address this critical problem, steganography and steganalysis have recently become key research areas. Compared with the temporal/spatial domain steganographic algorithm, steganography in the DCT domain distributes its energy into the local pixels of an image, thus realizing invisibility. More importantly, this method does not only combine certain characteristics of the human perception system with steganographic algorithm, but also complies with international data compression standards to realize steganographic encoding in the compression domain. Therefore, steganography in the DCT domain is one of the most popular approaches among steganographers.
Numerous steganalytic methods have been proposed in the literature. Li et al. [16] proposed a steganalysis method called yet another steganography scheme (YASS). The success of YASS suggests that a properly selected SO-domain is beneficial for steganalysis. Liu et al. [21] proposed an improved approach for the steganalysis of JPEG images. They extracted a 3950-D feature vector and applied support vector machine to detect covert images. The method has exhibited good detection performance on several JPEG-based steganographic systems. However, the performance of this approach depends on the number of features, and a large number of features decrease detection efficiency. Chen et al., [4] proposed an Improved Kernel Linear Discriminate Analysis algorithm to analyze the distribution differences between cover images and stego-images in the reduced dimensional space. They observed that the hidden information, the information hidden in the cover images, of stego-images are clustered in a plane while all other information of cover images are scattered more evenly in the whole space and have no other clusters. Awrangjeb and Lu [1] proposed micro and macro calibration methods that detect hidden information by calibrating the local and global distribution of the DCT coefficients of the image. All these methods employ high-dimensional feature vectors to describe the difference between cover and covert images, thus significantly affecting their performance in engineering applications. Based on the DCT coefficient generalized Gaussian distribution (GGD) statistical model, Natarajan and Anitha [22] put forward Universal Steganalysis Using Contourlet Transform. Pevny and Fridrich [24] proposed a JPEG image steganalysis that combines the features of Markov and DCT. Shi et al. [25] designed a Markov process-based approach to apply JPEG steganography effectively.
This study analyses the basic principle of steganography. For additive steganography that employs non-zero AC coefficients as carriers and a secret information stream independent of the carrier information stream, we extract the statistical and energetic features of the AC coefficients as the steganalytic features, according to the change in these characteristics before and after steganography. Then, by conducting Fisher linear discriminate (FLD) analysis, we design a flexible discriminate classifier suitable for the extracted features to improve detection performance. After experimenting on various cover and covert images using different embedding rates with two typical kinds of steganography, our proposed detection method has been exhibited to be effective.
2 Basic principles of steganography in the DCT domain
Steganographic technology can achieve covert communication [6, 14]. Research has been widely conducted on carrier positions relative to the suitability for embedding information. The research results show that in certain areas or bands of an image, embedded information is effective against several conventional signal processing and geometric attacks. However, embedding information in such areas or frequency bands can result in poor visual quality of the carrier. This finding shows the contradiction between robustness and imperceptibility.
According to References [5, 13, 14, 19, 20, 29, 32, 33], steganography in the DCT domain is often described by the following formulas:
where X refers to the DCT coefficients that carry secret information. This term is also called the actual carrier data set, such as AC coefficients, except for zero or zero and one; α refers to the intensity factor used to control embedding intensity and S refers to the covert image DCT coefficient. Formulas (1) and (2) are actually equal, and α in Formula (1) is equivalent to αX in Formula (2). Considering that ln S = ln X + αW is obtained after taking the logarithm of Formula (3), we can conclude that Formula (3) is equivalent to Formula (1) in the logarithm coordinate.
A common steganography process in the DCT domain is shown in Fig. 1. The DCT coefficients of the cover image often adopt quantized DCT coefficients because unchastised DCT coefficients result in the quantization and elimination of secret information during the quantizing encoding process. In Fig. 1, the key selecting model is mainly employed to choose the DCT coefficient as the information carrier and to take down the position of the coefficient to prepare to extract information. After obtaining the covert DCT coefficient, such coefficient is encoded according to JPEG standards, and then, the covert image is saved.

Common steganography process in the DCT domain
3 Histogram model of still image DCT coefficients
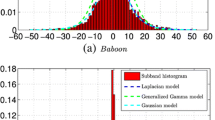
In the field of steganalysis, numerous researchers have investigated the statistical distribution model of image DCT coefficients and have proposed a number of statistical models. For example, Reference [10] developed DCT coefficients for JPEG images following the Gaussian distribution model. Lie and Lin [17] proposed DCT coefficients following the Laplacian distribution model. Yang and Kot [30] and Fridrich [7] devised DCT coefficients following the GGD statistical model.
The characteristics of the GGD model are determined by parameter c, sample mean value μ and standard deviation σ. The probability distribution function (PDF) is defined as
where
Γ(•) is a gamma function; and \( \varGamma (1)=1,\varGamma \left(1/2\right)=\sqrt{\pi } \). When c = 1, the GGD model becomes a Laplacian distribution model, whereas when c = 2, it becomes a Gaussian distribution model. Parameter c in GGD is flexible and changes with the actual data model.
A sample image with 256 × 256 pixels is shown in Fig. 2. An image for the DCT coefficient probability density (excluding DC coefficients in the DCT domain) is shown in Fig. 3. From this figure, we see that the distribution of DCT coefficients follows GGD.

A sample image

The AC coefficient histogram of the sample image
4 Changes in the statistical characteristics of DCT coefficients after steganography and steganalysis feature selection
4.1 Related steganographic methods in the DCT domain
As shown in Section 1, steganography in the DCT domain has numerous advantages over steganography in the spatial domain. Thus, numerous existing steganographic algorithms are usually based on the DCT domain. A common characteristic of these steganographic algorithms is that the carrier coefficient set is composed of AC coefficients, except for zero [8, 9, 11, 12, 23]. Actual embedding methods are often according to Formulas (1), (2) and (3), among which Formula (1) is the simplest, most convenient and most useful. Therefore, Formula (1) is used in many steganographic algorithms, such as least significant bit (LSB) and perturbed quantization (PQ) steganography. The embedding process can be described as follows.
-
1)
Addition: Suppose that the secret information bit stream {0,1} is converted into a set W = {w| − 1, 1}. Embedding according to Formula (1) is called additive frequency band steganography in this paper. The PDF of the secret information bit stream is as follows:
$$ p(w)=\left\{\begin{array}{c}\hfill 1/2,w=-1\hfill \\ {}\hfill 1/2,w=1.\hfill \end{array}\right. $$(6) -
2)
Substitution: Suppose that the secret information bit stream {0,1} is converted into a set W = {w| − 1, 0, 1}. Embedding according to Formula (1) is called a substituting operator in this paper. Similar to LSB steganography, the PDF of the secret information bit stream is as follows:
$$ p(w)=\left\{\begin{array}{c}\hfill 1/4,w=-1\hfill \\ {}\hfill 1/2,w=0\hfill \\ {}\hfill 1/4,w=1.\hfill \end{array}\right. $$(7)
These two steganographic methods are referred to as additive embedding operations in the present work.
4.2 Changes in histogram characteristics after image additive steganography
In this section, we introduce the definition of the embedding rate of the steganography operation and account for the changes in characteristics after image steganography.
Definition1. Suppose that the secret information flow is W and its length is length (W). The actual carrier data set X is composed of the AC coefficients of JPEG images, except zero, and its length is length (X). The bits per non-zero AC coefficient (bpc) of the embedding rate R is then defined as
Suppose that a covert JPEG image I s is obtained after the secret information is embedded into a cover image I c, then the following changes happen to the statistical characteristics of the covert image.
THEOREM1. Suppose that the frequency of the AC coefficients of the cover image being zero is f c0 , and that the frequency of the AC coefficients of the covert image being zero after additive embedding operation is f s0 . When the mean value of f s0 is larger than that of f c0 , the following formula can be obtained:
PROOF. Suppose that the frequencies of the AC coefficients of a cover image being 1 and −1 are f c1 and f c− 1 , respectively. Given that the secret information flow W is −1,1 or −1,0,1, according to additive steganographic principles, then AC coefficients with a value of 1 may changed its value to 0 or 2 and those with a value of −1 may changed its value to 0 or −2. From Formulas (6) and (7), a value of p(−1) = p(1) = 1/2 or 1/4 can be obtained. Suppose that the embedding rate is R, then we have:
THEOREM2. Suppose that the frequency of the AC coefficient absolute value of a cover image being 1 is f c|η| = 1 , and that of the AC coefficient absolute value of a covert image being 1 after additive embedding operation is f s|η| = 1 . Then, the following formula can be obtained:
PROOF. Given that f s|η| = 1 = f s1 + f s− 1 and f c|η| = 1 = f c1 + f c− 1 , then p(−1) = p(1) can be derived from Formulas (6) and (7). Suppose that the embedding rate is R, then:
Adding these values yields:
From Section 3, we can see that the AC coefficients follow zero-mean GGD. Then, E(f c|1| ) > E(f c|2| ) and Formula (10) are derived.
THEOREM3. Let the maximum AC coefficient be max(AC) and the minimum AC coefficient be min(AC). To determine their minimum absolute value, γ = min(abs(max(AC)), abs(min(AC))) should be obtained. Suppose η ∈ X and γ > |η| > 1, then:
PROOF. Given that zero-mean GGD is symmetrical, E(f s η ) > E(f c η ) is obtained when γ > η > 1. Then, Formula (10) is also obtained. Suppose the embedding rate is R, then:
Taking the mean value, then:
Suppose that Δ 1 = f c η − 1 − f c η and Δ 2 = f c η − f c η + 1 . Given that η < γ, η + 1 ≤ γ, then we have:
The two sides of the GGD model show an exponential decline (Fig. 4). Thus, we obtain Δ 1 > Δ 2. (E(Δ 1) − E(Δ 2))p(1)R > 0 can also be obtained, and the preceding formula can be converted into E(f s η ) > E(f c η ). Given that the zero-mean GGD model is symmetrical, then Formula (11) is derived.

The GGD model (Δ 1 > Δ 2)
Formula (11) shows that the frequency of AC coefficients increases if they have a value of more than 2 after the additive embedding operation, which is called the ‘heavy tail’ phenomenon [3]. The frequency of the AC coefficients after being embedded with the additive method at an embedding rate of 0.2 bpc in the sample image (Fig. 2) is shown in Fig. 4. Compared with the frequency of the AC coefficients of the cover sample (Fig. 3), the frequency of the AC coefficients is zero, as shown in Fig. 5, which is higher than that in Fig. 3. Although other changes are not evident, the tail is heavy after careful observation.

Sample image of the distribution frequency of AC coefficients after additive embedding operation at an embedding rate of 0.2 bpc
4.3 AC coefficient energy changes after image additive steganography
Definition2. Suppose that the AC coefficient flow of an image is A = {η i |i = 1, 2, ⋯, length(A)}. The AC coefficient energy can be defined as:
Where length(A) refers to the length of the AC coefficients and E(•) refers to the mean operator. The carrier data set X is a subset of AC coefficient set A, that is, X ⊂ A. According to References [3, 12, 27, 30, 31], the carrier information is an original signal, whereas the secret information is a noise signal, and these two kinds of signals are independent of each other.
THEOREM 4. Suppose that En c is the AC coefficient energy of a cover image, and En s is that of a covert image after additive embedding operation, then:
PROOF. Suppose that the secret information flow is W. The AC coefficient energy of the covert image after additive embedding operation can be written as
Given that the carrier information and the secret information are independent of each other, the following equation can be derived:
The secret information flow consists of −1,1 or −1,0,1. By combining Formulas (6) and (7), E(W) = 0 can be obtained, E(W 2) is the mean energy value of the secret information flow. Evidently, E(W 2) > 0, and the preceding formula can be transformed into:
THEOREM5. Suppose that the AC coefficient energies of a cover image and a corresponding covert image with absolute values of 0 and 1 are En c|η| ≤ 1 and En s|η| ≤ 1 , respectively. Then, we have:
PROOF. Suppose that the probability of the AC coefficient value of a cover image being a is f c η , and that of a covert image is f s η , then:
Formula (14) can be obtained according to Theorem 2.
The AC coefficient energy of the covert image after additive embedding operation is larger than that of the cover image. However, the situation is reversed when the coefficient value is −1, 0, or 1. Therefore, the following conclusion can be inferred.
Inference: When the absolute value of the AC coefficient is greater than 1, the energy of the AC coefficient of a cover image is less than that of a covert image, which is:
PROOF. Suppose that the energy of the AC coefficient absolute value of a cover image is greater than 1, that is, En c|η| >1 , and the AC coefficient absolute value of a covert image is also greater than 1, that is, En s|η| >1 , then:
Formula (15) can be easily obtained according to Theorems 4 and 5.
Table 1 shows the AC coefficient energy of a sample image (Fig. 2), i.e., the AC coefficient energy with different embedding rates (bpc) after additive embedding operation. The AC coefficient energy increases when the general energy and absolute value are greater than 1 along with the increasing embedding rate. By contrast, when the absolute value is less than or equal to 1, the AC coefficient energy decreases along with the increasing embedding rate. This finding complies with our previous conclusion.
4.4 Feature selection of steganalysis
From the preceding discussion, we learn that AC coefficient characteristics change after additive embedding operation in the DCT domain. Some characteristic values increase, such as zero frequency, frequency with absolute value greater than 1 and AC coefficient energy. By contrast, other characteristic values are reduced, such as 1 and −1 frequencies and energy with an absolute value smaller than 1. Thus, the question is which characteristics should be selected and constructed as the steganalysis feature. This important issue will be addressed in the succeeding paragraphs.
The classifier of steganalysis is, in nature, a binary classifier that distinguishes between cover and covert images. According to the pattern recognition principle [2], if we aim to distinguish between two samples clearly, then the inner area of similar samples should be concentrated as much as possible. That is, the intra degree of scatter should be as small as possible, whereas the inter degree of scatter should be as large as possible. Based on this principle and on several other theorems obtained previously, we construct the following characteristics as our steganalysis features:
According to Theorems 1, 2, 3 and 5, and based on inference, the feature value of the covert image is larger than that of the cover image. That is:
Thus, 500 covert images can be obtained from 500 cover images after additive spread spectrum operation at an embedding rate of 0.2 bpc. We select the 3D features of Formulas (16), (17) and (18), as shown in Fig. 6, where ‘.’ and ‘*’ refer to the feature points of the cover and covert images, respectively. The feature value of the covert image is evidently larger than that of the cover image.

Comparison between the feature values of 500 cover images and those of 500 covert images
5 Design of the classifier
Selecting a feature is an essential step to detect information. A classifier suitable for features with good discrimination performance is required. After the features are selected, distinguishing whether such features include secret information is a problem of the binary classifier.
FLD analysis is a typical method employed in this type of work. We combine the single characteristic values of F(1), F(2) and F(3) into a 3D feature vector x to obtain:
According to FLD analysis [3], the best projection direction w should be:
where m s and m c in Formula (21) refer to the feature mean vector of the cover and covert images, respectively. S − 1 w refers to the inverse matrix of the intra matrix of scatter S w :
Thus, according to Formula (24), any unknown sample x can be distinguished as a cover or covert image. y 0 in Formula (24) is the discrimination threshold.
6 Simulation experiment
6.1 Experimental setup
The experiment design is critical to evaluate a steganalysis method. A good experiment design should have the following key properties.
-
1)
Generalization. The proposed image features and associated classifiers should be capable of identifying the presence of hidden data, which are possibly generated by various kinds of embedding methods, regardless of steganography.
-
2)
Good performance. The classifier should, on one hand, have a detection rate of hidden data that is as high as possible and, on the other hand, keep false alarms as low as possible for cover images.
-
3)
Robustness. The classifier should be capable of differentiating ordinary image-processing operations (such as smoothing, sharpening, recompression, rotation and cropping) from data embedding.
Starting from the aforementioned considerations, we choose four steganographic methods, PQ [9], Jsteg [15], and EBS [28] with representative steganography for the experimental evaluation of our additive embedding operation. PQ, Jsteg, and EBS are representative methods for adding and substituting embedding operators, respectively.
PQ: Fridrich [9] designed a method called PQ, which uses the wet paper code to develop a steganographic methodology for digital media. PQ embeds a secret message while downgrading the cover object by using information-reducing operations that involve quantization. PQ uses the knowledge of the unprocessed object and embeds data into elements with the most uncertain values after processing.
Jsteg: Jsteg [15] can use the LSB of the quantized DCT coefficients as redundant bits in which to embed the hidden message. The modification of a single DCT coefficient affects all 64 image pixels. The steganographic systems that modify LSBs of these image formats are often susceptible to visual attacks. The modifications are in the frequency domain instead of in the spatial domain, such that no visual attack occurs against JPEG image format.
EBS: Wang [28] presents an efficient JPEG steganography scheme based on the block entropy of OCT coefficients and syndrome trellis coding (STC). The proposed cost function explores both the block complexity and distortion effects due to flipping and rounding errors. The STC provides multiple solutions to embed messages to a block of coefficients.
When more information is embedded into an image, such image is easy to detect. By contrast, when less information is embedded, the image is difficult to distinguish from the cover image. Therefore, embedding rate is also an important factor that affects correct discrimination.
Our experimental data consist of two parts: JPEG cover images and covert images. We have 2000 cover images, including classic images widely used in the existing literature, such as Lena and Cameraman, digital camera images, and images downloaded from an online image library (http://sipi.usc.edu/database/database.cgi?volume=textures). All images are transformed into 256 × 256 JPEG grey images. These images are called cover images in this paper, and half of the images (i.e., 1000) are used for training and the other half are used for testing. Moreover, PQ and Jsteg are employed. The covert image library is obtained after additive embedding operations at different embedding rates are conducted. We adopt five processing operations: 3 × 3 smoothing (averaging) spatial filter, 3 × 3 Laplacian sharpening spatial filter, recompression with 75, 65, and 50 quality factors, rotation of 25° anticlockwise and cropping to 1/4 of the original image to obtain 100 processed images (shown in Table 2).
6.2 Experimental results
In the present experiment, the DCT coefficients of the cover and covert images in the training library are chosen, and their feature values comprise the 3D cover and covert feature vector library according to Formulas (16), (17) and (18). These coefficients will be used as training data in FLD analysis to determine the projection direction w = (θ 1, θ 2, θ 3)T and discrimination threshold y 0. FLD analysis is designed. The process of distinguishing an image is shown in Fig. 7.

The detection process
When determining the projection direction, we input the feature vector set of the training images into the Fisher discriminate, that is, Formulas (21), (22) and (23), to obtain θ 1 = 31.3024, θ 2 = 0.1335 and θ 3 = 3.3993. We identify the threshold for determination. As we randomly select images, the feature values y follow GGD according to the central limit theorem in probability and statistics. For two class samples, suppose y of the cover and covert images follows GGD with a mean value of μ i and a standard deviation of σ i, i = c or i = s. As shown in Fig. 8, the selection of the discrimination threshold y 0 is important for excellent detection effects. In general, false positive and false negative probability contradicts each other. When y 0 changes from large to small, the false negative probability decreases, whereas the false positive probability increases. When y 0 changes from small to large, the false positive probability decreases, whereas the false negative probability increases. Given that steganalysis is concerned with information security, we aim for a small false negative probability. Therefore, we design a flexible method for threshold selection, that is:
where μ s and σs in Formula (25) refer to the mean value and standard deviation of the projection feature value y 0 of the covert image, respectively. λ is the regulatory factor called the false negative probability controlling factor. The mean value and standard deviation of the training sample projection feature in this paper are: μ c = 347.341, μ s = 459.1301, σ c = 45.6131 and σ s = 64.2332. Table 3 shows the testing results with varying regulatory factors λ. When the projection feature probability of the cover image is the same as that of the covert image, that is, when p(y c) = p(y s), the false positive and false negative probability attain balance, i.e., y 0 = 395.4431 and λ = 0.9915.

FLD analysis
Table 3 indicates that a high embedding rate makes an image easy to detect. Moreover, detection and false positive probability increase simultaneously with increasing regulatory factor λ. We should control the regulatory factor according to practice requirements. To detect processed images, the images produced after sharpening the spatial filter exhibit the best results because non-zero AC coefficients are increased, which is contrary to that of the proposed method wherein zero AC coefficients increase. Although the detection results after smoothing the spatial filter or recompression are not as good as the original results, these two kinds of processed images increase the number of zero AC coefficients. However, the detection results of geometric attacks, such as rotation and cropping, is the same as that in the original images, thus indicating that the number of non-zero AC coefficients slightly change under a fixed image quality factor.
The experimental results show that higher compression quality factor leads to lower false positive probability while lower quality factor results in higher false positive probability. This is mainly due to when the quality factor is lowed, the compression rate will become higher, and at this time more zero coefficients will appear, which could easily lead to incorrect judgment.
6.3 Detection performance analysis
There are two approaches [2, 26] to measure the performance of detecting steganography: the first one is the ROC curve while the other one is the minimal total detection error [28]. The ROC curve is a relation curve that describes false positive and positive detection probability. The minimal total detection error is calculated as follows:
where \( {\mathrm{P}}_{\mathrm{FP}} \) and \( {\mathrm{P}}_{\mathrm{MD}} \) denote the probability of false positive and false negative misdetection, respectively. The false negative is also called misdetection. Several ROC curvesare needed to show the detection performance while one figure is enough by using minimal error. So, we use minimal total detection error to show the performance of detecting steganography.
The FLD method of the threshold is demonstrated and shown in Fig. 7. As shown in Fig. 8, this study analyses the detection system. Different \( {\mathrm{P}}_{\mathrm{FP}} \) and \( {\mathrm{P}}_{\mathrm{MD}} \) are obtained by changing the regulatory factor λ. In our work, we change λ from −4 to 4 with a step of 0.001. Therefore, a sequence of \( {\mathrm{P}}_{\mathrm{FP}} \) and \( {\mathrm{P}}_{\mathrm{MD}} \) are obtained. Thus, the minimal total detection error is calculated based on Eq. (26), as shown in Fig. 9.

The minimal total detection error of our system
We calculate minimal detection error of the PQ(0.1, 0.2,and 0.3), Jsteg(0.1, 0.2, and 0.3), NUIWARD(0.2), EBS(0.2), as well as the value of the regulatory factor λ when the detection error minimum. This figure clearly shows that our minimal detection error is lower than 18 %, thus our proposed method has good detection performance for additive steganography.
Table 4 shows the results of the comparison of our detection method with a previous related work. The advantages of our detection method are summarized as follows.
(1) In terms of feature extraction, existing methods employed high dimensional features (the number of features range from 36 dimensional features [12] to 3950 dimensional features [21]) while our method use only 3 features. Therefore, our method of feature extraction is significantly simpler than existing methods.
(2) Although the PD in the reference [10] is slightly higher than that of our method, our approach achieves a significantly lower FP. Further, our minimal total detection error has much better performance, specifically, 10 % lower than the results reported in [10].
(3) Our system design is more reasonable compared with earlier work. This is due to we use the regulatory factor λ to control the false positive and false negative probability, while exiting methods do not use the regulatory factor at all.
(4) We infer and prove the feature changes of images before and after the embedding operation. Compared with previous work, in our paper we give a detailed theoretical derivation, which could help the readers to understand our work.
7 Conclusions
Additive embedding operation has been widely applied to information hiding during the last decade. For example, technologies such as PQ, Jsteg, and EBS are all based on additive embedding operation in the DCT domain. This study proposes a special steganalysis method by choosing several addition steganography or substitution steganography with non-zero AC coefficients as carrier and secret information, which are independent of carrier information flow. The statistical characteristics of AC coefficients change after steganography. We first select the statistical and energy characteristics of AC coefficients to construct a 3D feature vector. Then, by conducting FLD analysis, we design a flexible classifier with matching particular features, thus significantly improving detection performance. After evaluating cover and covert images with different embedding rates by using two typical kinds of steganography, the proposed method is found to be effective.
References
Awrangjeb M, Lu G (2008) A robust content-based watermarking technique. MMSP 2008,MMSP 2008, Cairns, Queensland, Australia, pp. 713–718
Bian ZQ, Zhang XG (2005) Pattern recognition. Tsinghua University Press, BeiJing, pp 87–90
Briassouli A, Tsakslides P, Stouraitis A (2007) Hidden messages in heavy-tails: DCT-domain watermark detection using alpha-stable models. IEEE Trans Multimedia 7(3):700–715
Chen GM, Chen Q, Zhang D, Zhou DN (2014) Steganalysis based on distribution characters of stego-images in reduced dimension space. Multimedia Tools Appl 71(2):497–515
Cheng Q, Huang TS, Leighton T, Shamoon T (2001) An additive approach to transform-domain information hiding and optimum detection structure. IEEE Trans Multimedia 3(3):273–284
Dai ZH and Qi X (2012) Research on the large scale image steganalysis technology based on cloud computing and BP neutral network. 2012 Eighth International Conference on Intelligent Information Hiding and Multimedia Signal Processing, pp. 415–419
Fridrich J (2004) Feature-based steganalysis for JPEG images and its implications for future design of steganographic schemes. Proc.of the 6th Information Hiding Workshop, Springer-Verlag Berlin Heidelberg, pp. 67–81
Fridrich J, Goljan M, Hogea D (2002) Setganalysis of JPEG image: breaking the F5 algorithm. Information Hiding 5th International Workshop, Netherlands, pp. 310–323
Fridrich J, Goljan M, Soukal D (2005) Perturbed quantization steganography. Multimedia System. Proc. of the 6th Information Hiding Workshop 11(2):98–107.
Giannlual A, Boulgouris NV, Hatzinakos D, Platanitis KN (2006) Watermark detection for noisy interpolated images. IEEE Trans Circuits Syst 53(5):359–403
Hernadez JR, Amado M, Gonzalez FP (2000) DCT-domain watermarking techniques for still images: detector performance analysis and a new structure. IEEE Trans Image Process 9(1):55–68
Hou XD, Tao Z, Xiong G (2014) A novel steganalysis framework of heterogeneous images based on GMM clustering. Signal Process Image Commun 29(3):143–154
Jafari R, Ziou D, Rashidi MM (2013) Increasing image compression rate using steganography. Expert Syst Appl 40(17)
Kazem Q, Reza S (2014) A new steganography method which preserves histogram: generalization of LSB++. Inf Sci 277:90–101
Lee YK, Hwang SY, Ou ZH (2006) A novel quantity based on clipping statistics for Jsteg steganalysis. 8th IASTED Int. Con. On Signal & Image Processing (SIP 2006), Honolulu, Hawaii, USA, pp. 14–16
Li B, Shi Y, Huang JW (2009) Steganalysis of YASS. IEEE Trans Inf Forensics Secur 4(3):369–382
Lie WN, Lin GS (2005) A Feature-based classification technique for blind image steganalysis. IEEE Trans Multimedia 7(6):1077–1020
LiFang Y, Yao Z, RongRong N (2014) A channel selection rule for YASS. Sci Chin Inf Sci 87(8):1–10
Lingyun X, Xingming S, Gang L (2014) Linguistic steganalysis using the features derived from synonym frequency. Multimedia Tools Appl 71(3)
Liu QZ, Cooper PA, Chen L (2013) Detection of JPEG double compression and identification of smartphone image source and post-capture manipulation. Appl Intell 39(4):705–726
Liu Q, Sung A, Qiao M, Chen Z, Ribeiro B (2010) An improved approach to steganalysis of JPEG images. Inf Sci 180(9):1643–1655
Natarajan V, Anitha R (2012) Universal steganalysis using contourlet transform. Adv Comput Sci Eng Appl AISC 167:727–735
Ogihara T, Nakamura D, Yokoya N (1996) Data embedding into pictorial with less distortion using discrete cosine transform. In Proc.ICPR’96, Vienna, Austria 1996, pp. 675–679
Pevny T, Fridrich J (2007) Merging Markov and DCT features for mutli-class JPEG Steganalysis. Proceedings of SPIE Electronimc Imaging, Secruity, Steganography, and Watermarking of Multimedia Contents IX. San Jose, CA, USA, 6505, pp. 650503-1–650503-13
Shi YQ, Chen C, Chen W (2006) A Markov process based approach to effective attacking JPEG steganography. Information Hiding 8th international workshop, Berlin, Germany: Springer Berlin, 4437, pp. 249–264
Swaminathan A, Wu MK, Liu JR (2008) Digital image forensics via intrinsic fingerprints. IEEE Trans Inf Forensics Secur 3(1):101–117
Wang Y, Moulin P (2007) Optimized feature extraction for learning-based image steganalysis. IEEE Trans Inf Forensics Secur 2(1):31–45
Wang C, Ni J (2012) An efficient JPEG steganographic scheme based on the blook entropy of DCT coefficients. Proceeding of IEEE ICASSP 2012, Kyoto, Japan, pp. 1785–1788
Wu M, Yu H, Lui B (2003) Data hiding in image and video: pat-designs and applications. IEEE Trans Image Process 12(6):696–705
Yang HJ, Kot A (2007) Pattern-based data hiding for binary image authenticationby connectivity-preserving. IEEE Trans Multimedia 9(3):475–486
Yang CH, Weng CY, Wang SJ, Sun HM (2008) Adative data hiding in edge of images with spatial LSB domain systems. IEEE Trans Inf Forensics Secur 3(3):488–497
Yih-Kai L (2014) A data hiding scheme based upon DCT coefficient modification. Comput Stand Interfaces 36(5):855–862
Zhan-He O, Ling-Hwei C (2014) A steganographic method based on tetris games. Inf Sci 276:343–353
Acknowledgments
The authors thank Jiangqun Ni research team in Sun Yat-sen University, China, they provide EBS steganography tool software. This work is supported by the National Natural Science Foundation of China (No. 61170271, 61272310, 61203288) and the ZheJiang province Natural Science Foundation of China (No. LY15F020032,LY12F02031).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Jia-Fa, M., Xin-Xin, N., Gang, X. et al. A steganalysis method in the DCT domain. Multimed Tools Appl 75, 5999–6019 (2016). https://doi.org/10.1007/s11042-015-2708-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-015-2708-0