
Abstract
We present a technique for producing valid dual bounds for nonconvex quadratic optimization problems. The approach leverages an elegant piecewise linear approximation for univariate quadratic functions due to Yarotsky (Neural Netw 94:103–114, 2017), formulating this (simple) approximation using mixed-integer programming (MIP). Notably, the number of constraints, binary variables, and auxiliary continuous variables used in this formulation grows logarithmically in the approximation error. Combining this with a diagonal perturbation technique to convert a nonseparable quadratic function into a separable one, we present a mixed-integer convex quadratic relaxation for nonconvex quadratic optimization problems. We study the strength (or sharpness) of our formulation and the tightness of its approximation. Further, we show that our formulation represents feasible points via a Gray code. We close with computational results on problems with quadratic objectives and/or constraints, showing that our proposed method (i) across the board outperforms existing MIP relaxations from the literature, and (ii) on hard instances produces better bounds than exact solvers within a fixed time budget.
Similar content being viewed by others
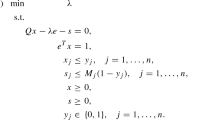


Avoid common mistakes on your manuscript.
1 Introduction
We are interested in methods to solve optimization problems with quadratic objectives and/or constraints. Consider the following generic problem with a quadratic objective:
where \(X \subseteq {\mathbb {R}}^n\) is some nonempty feasible region described by side constraints. When the quadratic objective matrix Q is not positive semidefinite, this is a difficult nonconvex optimization problem. We will focus on techniques to (approximately) reformulate nonconvex quadratic functions like the objective of (1).
Quadratic optimization problems naturally arise in a number of important applications across science and engineering (see [30, 45] and references therein). In the presence of nonconvexity, such problems are in general very difficult to solve from both a practical and theoretical perspective [44]. As a result, there has been a steady stream of research developing new algorithmic techniques to solve quadratic optimization problems, and variants thereof (see [12] for a survey).
Our approach to approximately solving problems of the form (1) will be to reformulate the objective of (1) using mixed-integer programming (MIP). Given some diagonal matrix D, we can equivalently write (1) as
where \(\llbracket n \rrbracket :=\{1,\ldots ,n\}\). If D is chosen such that \(Q + D\) is positive semidefinite, the quadratic objective will be convex, meaning that all the nonconvexity of this problem has been isolated in the univariate quadratic equations \(y_i = x_i^2\). This technique is sometimes called “diagonal perturbation” [22].
In this work, we present a compact, tight MIP formulation for the graph of a univariate quadratic term: \(\{ (x,y) | l \le x \le u, \, y = x^2 \}\). We derive our formulation by adapting an elegant result of Yarotsky [57], who shows that there exists a simple neural network function that approximates \(y = x^2\) exponentially well (in terms of the size of the network) over the unit interval. The resulting neural network can be interpreted as a function \(F_L: {\mathbb {R}}\rightarrow {\mathbb {R}}\) that is built compositionally from a number of simple piecewise linear functions. There is a long and rich strain of research on MIP formulations for piecewise linear functions that serve as approximations for more complex nonlinear functions [18, 19, 36, 39, 40, 43, 51], with recent work focusing particularly on modeling neural networks [3, 4, 11, 48,49,50].
We show that this approximation for univariate quadratic terms leads to a relaxation for optimization problems with quadratic objectives and/or constraints, meaning that it provides valid dual bounds for the true quadratic problem. We will show that our proposed formulation is sharp, meaning that its LP relaxation projects to the convex hull of all feasible points. Further, we show that the formulation is in fact hereditarily sharp, meaning that this sharpness property holds throughout the branch and bound tree. The key to reaching this result is connecting the binary reformulation to the reflected Gray code, a well-studied binary sequence in electrical engineering.
1.1 Literature review
Our approach hews most closely to that of Dong and Luo [23] and Saxena et al. [47]. The diagonal perturbation approach we follow have been applied throughout the years in a number of settings; for example, nonconvex quadratic optimization (with or without integer variables) [8, 9, 25, 31, 55], more general nonlinear [28, 29] optimization with binary variables, and general nonlinear optimization [1, 2, 5].
A string of recent work on optimization methods for nonconvex quadratic problems has focused on methods for relaxing bilinear terms using piecewise McCormick envelopes [13,14,15,16, 41, 42]. These piecewise envelopes can be formulated using mixed-integer programming in multiple ways, typically resulting in either a linear- or logarithmic-sized MIP formulation. Moreover, this piecewise relaxation can be refined dynamically to produce a tighter relaxation in a region of interest without resulting in an unduly large MIP formulation [13, 42]. In a similar vein, a paper of Galli and Letchford [32] presents a binarization heuristic for “box QP” problems, leveraging a structural result of Hansen et al. [35], and compares classical convexification techniques [26, 33, 34] within the heuristic.
An interesting recent paper of Xia et al. [56] reformulates optimization problems with quadratic objectives and linear constraints into MIPs via the KKT conditions. The approach outperforms commercial solvers on certain classes of instances; however, it does not seem to perform favorably on boxQP problems, and in general requires the careful computation of “big-M” coefficients which may lead to loose LP relaxations.
1.2 Outline
In Sect. 2 we describe our MIP approximation for \(y=x^2\). In Sect. 3 we prove some properties of Gray codes that will be useful for proving the results in Sect. 4. In Sect. 4, we show that our formulation is strong (i.e. sharp), and establish the connection between our MIP approximation and the reflected Gray code. In Sect. 5, we show how to derive some facets of the full convex hull of our MIP approximation, with connections to the parity polytope. In Sect. 6, we present a relaxation version of our MIP approximation, derive the total area of the relaxation, and compare against the relaxation of Dong and Luo [23]. Finally, in Sect. 7, we numerically compare our relaxation with other competing methods, including other relaxations such as CDA [23] and NMDT [14], as well as state-of-the-art solvers with quadratic support like Gurobi, CPLEX, and BARON.
2 A piecewise-linear approximation for univariate quadratic terms
In this section, we present our mixed-integer programming relaxation for (1). We start by describing the construction of Yarotsky, which is a piecewise linear neural network approximation for the univariate quadratic function \(F(x) = x^2\). We then formulate the graph of this piecewise-linear function using mixed-integer programming, and use it to build a tight under-approximation for the quadratic optimization problem (1).
For ease of notation, for any integers \(i \le j\), we define \(\llbracket i,j\rrbracket :=\{i, i+1, \dots , j\}\), and for integers \(i \ge 1\) we define \(\llbracket i\rrbracket :=\{1, 2, \dots , i\}\).

Left: The intermediary sawtooth functions \(G_i=2^{2i}(F_{i-1}-F_{i})\). Right: The approximation for \(F(x)=x^2\) of Yarotsky by functions \(F_i\) [57, Fig. 2]
2.1 The construction of Yarotsky
For fixed \(L\in {\mathbb {N}}\), we wish to model the function \(F_L(x)\), defined as the piecewise linear interpolant to \(y=x^2\) on the interval [0, 1] at \(2^L+1\) uniformly spaced breakpoints:
Define the sawtooth functions \(G_i:[0,1] \rightarrow [0,1]\) as \(G_i = 2^i(F_{i-1}-F_i)\). Yarotsky [57] shows that \(G_i\) can be defined recursively as
and, furthermore, that
Yarotsky further shows that F(x) approximates \(x^2\) to a pointwise error of \(|x^2 - F_L(x)| \le 2^{-2L-2}\) [57, Proposition 2].Footnote 1 We include an illustration of \(G_L\) and \(F_L\) for different values of \(L\) in Fig. 1b. Crucially, we will later make use of the fact that \(F_L(x) \ge F(x)\) for each \(0 \le x \le 1\), i.e. \(F_L\) is an overestimator for F.
2.2 A MIP formulation for \(F_L\)
We now turn our attention to constructing a mixed-integer programming formulation for \(F_L\). As (5) tells us that \(F_L\) depends linearly on the sawtooth functions \(G_i\), we turn our attention to formulating the piecewise-linear equations (4) using MIP.
For the remainder of the section we will use \(g_i\) as decision variables in our optimization formulation corresponding to the output of the ith sawtooth function \(G_i\). Therefore, \(g_0 = x\), and for each of the other sawtooth functions \(G_i\) for \(i \in \llbracket L\rrbracket \), we introduce a binary decision variable \(\alpha _i\). Given some input x, these binary variables serve to indicate which piece of the sawtooth the input lies on:
Define the set \(S_i := \{ (g_{i-1},g_i,\alpha _i) \in [0,1] \times [0,1] \times \{0,1\} | (6) \}\) for each \(i\in \llbracket L\rrbracket \). It is not difficult to see that a convex hull formulation for \(S_i\) is given by
Chaining these formulations together for each i, we construct a MIP formulation for \({\mathcal {G}}_L:= \{ (x,y) \in [0,1] \times [0,1] | y = F_L(x) \}\), the graph of the neural network approximation function \(F_L\).
Proposition 1
Fix some \(L\in {\mathbb {N}}\). A MIP formulation for \((x,y) \in {\mathcal {G}}_L\) is
We emphasize that this formulation is extremely compact: it requires only \({\mathcal {O}}(L)\) binary variables, auxiliary continuous variables, and constraints. As noted in Sect. 2.1, \(F_L\) approximates F to within \({\mathcal {O}}(2^{-L})\) pointwise, which implies that the size of our formulation scales logarithmically in the desired accuracy.
It is a straightforward extension of Proposition 1 to consider more general interval domains \(x \in [l,u]\) on the inputs. In particular, introducing two auxiliary variables \({\tilde{x}}, {\tilde{y}} \in [0,1]\), we formulate \({\tilde{y}} = F({\tilde{x}}) = {\tilde{x}}^2\) using (8), and then map them to the (x, y) variables via the linear transformation
2.3 Tying it all together
We are now prepared to construct our mixed-integer programming approximation for (1). For the objective of (1), compute a nonnegative diagonal matrix D such that \(Q + D\) is positive semidefinite.Footnote 2 Then, for a given \(L\), the approximation for (1) is:
Using the formulation (8) for the constraint (9b), this yields a mixed-integer convex quadratic reformulation of the problem (ignoring the potential structure of X). This formulation requires at most nL binary variables and \({\mathcal {O}}(nL)\) auxiliary continuous variables and linear constraints. Furthermore, recall that we may set \(L = {\mathcal {O}}(\log (1/\varepsilon ))\) to attain an approximation of accuracy \(\varepsilon \) for the equations (2b).
Consider any \({\hat{x}} \in X\), along with any \({\hat{y}}\) such that \(({\hat{x}},{\hat{y}})\) satisfies (9b). Since \(F_L\) overestimates F, for each \(i \in \llbracket n \rrbracket \) we have \({\hat{x}}_i^2 \le {\hat{y}}_i\). Therefore, \(h^D({\hat{x}},{\hat{y}}) \le h({\hat{x}})\). Since there always will exist such a \({\hat{y}}\) for any \({\hat{x}} \in X\), (9) offers a valid dual bound on the optimal cost of (1).
Note that this approach can readily be adapted to handle quadratic constraints. In particular, this transformation will offer a relaxation of the quadratically constrained problem. Note that the error bound derived above is with respect to the quadratic constraint that is being relaxed. It may not translate into an error bound on the objective value of the optimization problem, a known phenomena in the global optimization literature [20].
3 Gray codes and binary representation
In this section, we introduce the reflected Gray code, and prove some of its useful properties.
For the remainder of this work, we will work with two notions of expressing integers as vectors in \(\{0,1\}^*\). First, we consider the standard binarization with L bits. That is, for an integer \(i \in \llbracket 0, 2^L-1 \rrbracket \) we define \({\varvec{\beta }}^i \in \{0,1\}^L\) such that
Next, we define the reflected Gray code sequence, which is a sequence of binary representations of integers that is extremely well-studied in electrical engineering and engineering [46]. Notably, each adjacent pair in the sequence differs in exactly one bit. As presented in [27] and references therein, the L-bit reflected Gray code \({\varvec{\alpha }}^i\in \{0,1\}^L\) representing the integer i can be described by the recursion
where we use \(\oplus \) to denote addition modulo 2. By inverting the relation, we obtain the formula
In this way, flipping any \(\alpha _j\) bit implies that we flip all less significant bits \(\beta _k\) for \(k \ge j\). See Fig. 2 for an illustration of how to build the reflected Gray code, which we will henceforth refer to as ‘the Gray code’.

Building the reflected Gray code. The reflected Gray code with \(L+1\) bits is build from the reflected Gray code on L bits by appending 0s in front of it, then reflecting the Gray code sequence, and then appending 1s in front of it
One key property of any Gray code is that successive integer representations differ by only 1 bit, i.e.,
That is, only one bit changes between adjacent binary vectors in the sequence. We show a similar property holds if we restrict the set of integers we work with by fixing some of the bits in the Gray code vector. To help prove this property, we note the following well-known property of the reflected Gray code in this work.
Lemma 1
For each \(i \in \llbracket 0,2^L-1\rrbracket \), let \(\tilde{\varvec{\alpha }}^i\) be the L-bit Gray code for i, and let \({\varvec{\alpha }}^j\) be the \(L+1\)-bit Gray code for some \(i \in \llbracket 0, 2^{L+1}-1\rrbracket \).
-
1.
If \(j \in \llbracket 0,2^L-1\rrbracket \), then \({\varvec{\alpha }}^j = [0,{\tilde{\varvec{\alpha }}}^j].\)
-
2.
If \(j \in \llbracket 2^L,2^{L+1}-1\rrbracket \), then \({\varvec{\alpha }}^j = [1,{\tilde{\varvec{\alpha }}}^{i}]\), where \(i = 2^{L+1}-j-1\).
Proof
First, for each \(i \in \llbracket 0,2^L-1\rrbracket \), let \({\tilde{\varvec{\beta }}}^i\) be the corresponding L-bit binarization. Similarly, for each \(j \in \llbracket 0,2^{L+1}-1\rrbracket \), and let \({\varvec{\beta }}^j\) be the corresponding \(L+1\)-bit binarization. Then, by (11) have that \(\alpha ^j_1 = \beta ^j_1=0\) and \({\varvec{\beta }}^i = [0, {\tilde{\varvec{\beta }}}^i]\). Applying (11) recursively, this yields \({\varvec{\alpha }}^i = [0, {\tilde{\varvec{\alpha }}}^i ]\), as desired.
Now, let \(i \in \llbracket 2^L,2^{L+1}-1\rrbracket \), and let \({\tilde{i}} = 2^{L+1}-i-1\). Since \({\tilde{i}} \in \llbracket 0,2^L-1\rrbracket \) we have as before that \({\varvec{\alpha }}^{{{\tilde{i}}}} = [0, {\tilde{\varvec{\alpha }}}^{{{\tilde{i}}}}].\) We wish to show that \({\varvec{\alpha }}^{i} = [1, {\tilde{\varvec{\alpha }}}^{{{\tilde{i}}}}].\) Now note that
That is, in the binarization for \({\tilde{i}}\), we have \({\varvec{\beta }}^{{{\tilde{i}}}} = {\varvec{\beta }}^i \oplus [1,\dots ,1]\), so that every bit has been flipped. Observing (13), we see that this can be induced by enforcing \(\alpha _1^{{{\tilde{i}}}} = 1-\alpha _1^i\), with all other \(\alpha _j^{{{\tilde{i}}}} = \alpha _j^i\): flipping the first \(\alpha \)-bit induces a flip in all \(\beta \)-bits. Thus, we obtain that \({\varvec{\alpha }}^{i} = [1, {\tilde{\varvec{\alpha }}}^{{{\tilde{i}}}}]\), as desired. \(\square \)
Lemma 2
Let \(J \subseteq \llbracket L\rrbracket \) and \(\overline{{\varvec{\alpha }}} \in \{0,1\}^J\). Let \(X = \{x \in \llbracket 0,2^L-1\rrbracket : {\varvec{\alpha }}^x_J = {\bar{\varvec{\alpha }}}\}\). We will write X as \(X=\{x_1,\dots ,x_t\}\), ordered such that \(x_j < x_{j+1}\). Let \(I = \llbracket L \rrbracket \setminus J\). Then \({\varvec{\alpha }}_I^{x_j}\) is a reflected Gray code for the indices j over X. That is, for any \(j \in 1, \dots , t\), we have
Furthermore, if \(|I| \ge 1\), there exists a \({\varvec{\gamma }} \in \{0,1\}^{|I|}\) such that, for all \(j \in \llbracket 0,t\rrbracket \), we have
That is, the modified Gray code after fixing some bits is the original reflected Gray code on |I| bits, with some bits flipped.
Proof
We will prove this by induction on L. To enable the use of Lemma 1, we will also prove that, if \(|I| \ge 1\), then for all \(j \in \llbracket 0,t\rrbracket \), \(i=t-j\), we have
Base case: \(L=1\)
For \(L=1\), the possibilities are trivial, as there is only one bit. If we do not fix the bit, then we have \(\alpha ^j=[j]\) for each \(j \in \{0,1\}\); this sequence of two vectors is trivially a Gray code sequence. This yields the original reflected Gray code for \(L=1\), and so \({\varvec{\gamma }} = [0]\). Finally, we have \(t=1\), and \(x_j = j\), yielding, for \(i=1-j\), \(x_j = 1-x_i = 2^1 - x^i - 1\), as required.
On the other hand, if we do fix the bit, then there are no pairs of consecutive bits, and (15) holds by default. In this case, we have \(|I|=0\), so that the other results do not apply.
Inductive step:
Let \(L=k\), and suppose the desired properties hold for \(L=k-1\). Let J, \(\overline{{\varvec{\alpha }}}\) be a choice of fixed bits for \(L=k\). First, note that if \(|J| = L\), then all bits are fixed and the (15) holds by default, while the others do not apply, as \(|I|=0\).
Next, suppose \(I = \{1\}\), so that the newly added bit is the first unfixed bit. Then we have \(t=1\), and \({\varvec{\alpha }}^{x_j} = [j, \varvec{{\bar{\alpha }}}]\), with \({\varvec{\alpha }}^{x_j}_I = [j]\). Thus, defining \({\varvec{\gamma }} = [0]\), we have that (15) and (16) hold trivially. Finally, by Lemma 1 and the uniqueness of the L-bit Gray code for j, we have that \(x_0 = 2^L - x_1 - 1\) and \(x_1 = 2^L - x_0 - 1\), as required.
Otherwise, suppose \(|J| \le L-1\), with \(I \ne \{1\}\). Then there are three cases: \(1 \notin J\), or \(1 \in J\) and either \(\bar{\alpha }_1=1\) or \(\bar{\alpha }_1=0\). Regardless of this choice, the corresponding choices \({\tilde{J}}\) and \(\tilde{{\varvec{\alpha }}}\) for \(L=k-1\) can be attained by defining \({\tilde{J}} = J \setminus \{1\}\), and defining \({\tilde{I}}\) and \(\tilde{{\varvec{\alpha }}}\) accordingly. Consider the corresponding sequence \({\tilde{X}}\) for \(L=k-1\). Then, by the inductive hypothesis, the desired results hold for \({\tilde{X}}\), and as \(|{\tilde{I}}| \ge 1\), we can define a corresponding vector \(\tilde{{\varvec{\gamma }}} \in \{0,1\}^{|{\tilde{I}}|}\) so that (16) holds.
Case 1: \(1 \in J\) with \(\bar{\alpha }_1=0\). In this case, define \({\tilde{J}} = J \setminus \{1\}\) and \({\tilde{\alpha }} = {\bar{\alpha }}_{\llbracket 2,L\rrbracket }\), and define \({\tilde{X}}\) and \(\tilde{{\varvec{\gamma }}}\) accordingly, noting that \(|X| = |{\tilde{X}}| = t=2^{k-|J|-1}-1\). Let \(j \in \llbracket t\rrbracket \). Then we have by Lemma 1 that \({{\varvec{\alpha }}}^{x_j} = [0,{\tilde{{\varvec{\alpha }}}}^{{\tilde{x}}_j}]\), so that \({{\varvec{\alpha }}_I}^{x_j} = {\tilde{{\varvec{\alpha }}}_I}^{{\tilde{x}}_j}\). Thus, (15 to (17) hold by the induction hypothesis, with \({\varvec{\gamma }} = \tilde{{\varvec{\gamma }}}\).
Case 2: \(1 \in J\) with \(\overline{\alpha }_1=1\). In this case, define \({\tilde{J}} = J \setminus \{1\}\) and \({\tilde{\alpha }} = {\bar{\alpha }}_{\llbracket 2,L\rrbracket }\), and define \({\tilde{X}}\) accordingly, noting that \(|X| = |{\tilde{X}}| = t\). Let \(j \in \llbracket t\rrbracket \). Then, since \(t-j=2^{k-|J|-1}-j-1\), we have by Lemma 1 that \({{\varvec{\alpha }}}^{x_j} = [1,{\tilde{{\varvec{\alpha }}}}^{{\tilde{x}}_{t-j}}]\), so that \({{\varvec{\alpha }}_I}^{x_j} = {\tilde{{\varvec{\alpha }}}}_I^{{\tilde{x}}_{t-j}}\). That is, the sequence of \({{\varvec{\alpha }}}^{x_j}_I\)’s the sequence of \({\tilde{{\varvec{\alpha }}}}_I^{{\tilde{x}}_{j}}\)’s, but in reversed order. Thus, (15 and (17) hold by the induction hypothesis, as reversing the order of a sequence has no impact on results for consecutive or centrally reflected terms. Furthermore, by Lemma 1 and the induction hypothesis, we have that reversing the order of the sequence corresponds with flipping only the first bit \(\alpha ^{x_j}_1\), so that we can define \({\varvec{\gamma }} = \tilde{{\varvec{\gamma }}} \oplus [1, 0, \dots , 0]\) to obtain (16).
Case 3: \(1 \notin J\), so that the first bit is unfixed. In this case, define \({\tilde{J}} = J\) and \(\tilde{{\varvec{\alpha }}} = \bar{{\varvec{\alpha }}}\), and define \({\tilde{X}}\) accordingly. Then \({\tilde{t}}=|{\tilde{X}}| = 2^{k-|J|-1}\). Let \(j \in \llbracket 0,t\rrbracket \) and let \(i = t-j = 2^{k-|J|} - j - 1\), so that \(j = 2^{k-|J|} - i - 1\) Then, by Lemma 1, we can construct X as follows:
-
1.
If \(j \in \llbracket 0,2^{k-|J|-1}-1\rrbracket \), then \({{\varvec{\alpha }}}^{x_j} = [0,{\tilde{{\varvec{\alpha }}}}^{{\tilde{x}}_j}]\)
-
2.
If \(j \in \llbracket 2^{k-|J|-1},2^{k-|J|}-1\rrbracket \), then \({{\varvec{\alpha }}}^{x_j} = [1,{\tilde{{\varvec{\alpha }}}}^{{\tilde{x}}_{i}}]\).
This yields (17) immediately. Further, define \({\varvec{\gamma }} = [0, \tilde{{\varvec{\gamma }}}]\). Then for \(j \in \llbracket 0,2^{k-|J|-1}-1\rrbracket \), we have
yielding (16). For \(j \in \llbracket 2^{k-|J|-1},2^{k-|J|-1}-1\rrbracket \), defining \(i = t-j = 2^{k-|J|} - j - 1 \in \llbracket {\tilde{t}}+1,t\rrbracket \), we have by Lemma 1 that
again yielding (16).
Now, (15) trivially holds for all \(j \ne 2^{k-|J|-1}-1\) as in cases 1 and 2, since the first bits of \({{\varvec{\alpha }}}^{x_j}\) and \({{\varvec{\alpha }}}^{x_{j+1}}\) match, and exactly one other bit differs by the induction hypothesis. Otherwise, if \(j = 2^{k-|J|-1}-1\), then \(i = 2^{k-|J|}-(2^{k-|J|-1}-1)-1 = 2^{k-|j|} = j+1\), and thus \(x_j\) and \(x_{j+1}\) differ by exactly the first bit \(\alpha _1\) as indicated above. Thus, (15) holds. From these cases, (15 to (17) hold by induction. \(\square \)
Next we show one more property of the code that occurs when extending the Gray code by 1 bit.
Proposition 2
For an integer \(i \in \llbracket 0, 1, \dots , 2^{L} -1\rrbracket \), let \(\varvec{\alpha }^i\) and \(\varvec{\beta }^i\) be the L-bit Gray code and binary representations of i. Let \({\tilde{\varvec{\alpha }}}^{2i}\) and \({\tilde{\varvec{\alpha }}}^{2i+1}\) be the \((L+1)\)-bit Gray codes of the integers 2i and \(2i+1\).
Then
Proof
First, note that
Then
Furthermore, \({\tilde{\beta }}^{2i}_j = \beta ^{2i+1}_j = \beta ^i\) for all \(j= 1, \dots , L\), by definition, we have that \({\tilde{\alpha }}^{2i}_j = {\tilde{\alpha }}^{2i+1}_j = \alpha ^i_j\) for all \(j=1, \dots , L\). \(\square \)
4 Formulation strength
The strength of a MIP formulation is a commonly used metric to assess its potential computational performance. We will work with the three following notions of strength.
Definition 1
Consider a set \(U \subseteq {\mathbb {R}}^n\). For a formulation \(P^{\mathrm{IP}}=\{({\varvec{u}},{\varvec{v}},{\varvec{z}}) \in P^{\mathrm{LP}}: {\varvec{z}} \in \{0,1\}^L\}\), where \(P^{\mathrm{LP}}\subseteq {\mathbb {R}}^{n+d+L}\) is a polyhedron and \({{\,\mathrm{proj}\,}}_{{\varvec{u}}}(P^{\mathrm{IP}}) = U\), we say the the formulation \(P^{\mathrm{LP}}\) is
-
sharp if \({{\,\mathrm{proj}\,}}_{{\varvec{u}}}(P^{\mathrm{LP}}) = {{\,\mathrm{conv}\,}}(U)\).
-
hereditarily sharp if, for all \(I \subseteq \llbracket L\rrbracket \) and \(\varvec{\bar{z}} \in \{0,1\}^{|I|}\), we have
$$\begin{aligned} {{\,\mathrm{proj}\,}}_{{\varvec{u}}}(P^{\mathrm{LP}}|_{\varvec{z}_I = \varvec{\bar{z}}}) = {{\,\mathrm{conv}\,}}(\{{{\varvec{u}}} \in U : ({\varvec{u}},{\varvec{v}},{\varvec{z}}) \in P^{\mathrm{LP}}\}|_{\varvec{z}_I = \varvec{\bar{z}}}). \end{aligned}$$ -
ideal if \({{\,\mathrm{proj}\,}}_{\varvec{z}}({{\,\mathrm{ext}\,}}(P^{\mathrm{LP}})) \subseteq {\mathbb {Z}}^L\).
These definitions closely follow those in [37], except we define hereditary sharpness explicitly in terms of the current branch, and we consider only binary variables instead of general integer variables.
In this section, we explore the strength of our MIP formulation (8). We also draw an interesting connection between how our formulation represents feasible points through a Gray code: in essence, feasible points are represented in the formulation by their L most significant digits in a binary expansion.
For our particular problem, define
and
First, we show that \(Q^{\mathrm{IP}}\) is, unfortunately, not ideal.
Example 1
The formulation \(P^{\mathrm{IP}}\) approximating \(y=x^2\) is not ideal.
Proof
Consider \(L=2\), \(x=0.25\), \({\varvec{\alpha }} = [\tfrac{1}{2}, 1]\), \({\varvec{g}} = [\tfrac{1}{2}, 1]\), and \(y = 0.25 - 2^{-2}(\tfrac{1}{2}) - 2^{-4}(0.25) = \tfrac{11}{64}\). This point is chosen to maximize \(g_2\) along a facet \(g_2 \le 2 \cdot (2_x-\alpha _1)\) of the convex hull. It is an extreme point because it is incident with six facets: \(g_2 \le 1\), \(\alpha _2 \le 1\), \(g_2 \le 2g_1\), \(g_1 \le 2x\), \(\alpha _1-x \le g_2\), and \(y = x - 2^{-2}g_1 + 2^{-4}g_2\). Thus, \(P^{\mathrm{LP}}\) has a fractional extreme point, and so is not ideal.\(\square \)
Next, we will show that \(Q^{\mathrm{IP}}\) is sharp. To assist deriving this result, we define the generic sawtooth function \(G:~{\mathbb {R}}\rightarrow {\mathbb {R}}\) as

Left: The piecewise linear approximation \(Q^{\mathrm{IP}}\) in red and the linear relaxation \(Q^{\mathrm{LP}}\) in yellow filled in. The formulation is sharp because \(Q^{\mathrm{LP}}\) is the convex hull of \(Q^{\mathrm{IP}}\). The vectors \({\varvec{\alpha }} \in \{0,1\}^3\) below are the corresponding binary \(\alpha \) variables for any x value on that interval \((\tfrac{i}{8}, \tfrac{i+1}{8})\). Right: The branch \(Q^{\mathrm{IP}}|_{\alpha _3 = 1}\) in red and the linear relaxation \(Q^{\mathrm{LP}}|_{\alpha _3 = 1}\) in yellow. This demonstrates hereditary sharpness since it holds that \(Q^{\mathrm{LP}}|_{\alpha _3 = 1}\) is the convex hull of \(Q^{\mathrm{IP}}|_{\alpha _3 = 1}\)
Theorem 1
The formulation \(P^{\mathrm{IP}}\) is sharp for \(Q^{\mathrm{IP}}\).
Proof
For sharpness, we wish to show that \(Q^{\mathrm{LP}}={{\,\mathrm{conv}\,}}(Q^{\mathrm{IP}})\). Clearly \(Q^{\mathrm{LP}}\supseteq {{\,\mathrm{conv}\,}}(Q^{\mathrm{IP}})\) from validity of our formulation; therefore, we focus on showing that \(Q^{\mathrm{LP}}\subseteq {{\,\mathrm{conv}\,}}(Q^{\mathrm{IP}})\). We start by fixing some \(\bar{x} \in [0,1]\). The result then follows if we can show that the “slice” of \(Q^{\mathrm{LP}}\) at \(\bar{x}\), \(Q^{\mathrm{LP}}|_{x = {\bar{x}}} :=\{y | (\bar{x},y) \in Q^{\mathrm{LP}}\}\), is contained in \({{\,\mathrm{proj}\,}}_{x}({{\,\mathrm{conv}\,}}(Q^{\mathrm{IP}}))\). Since \(Q^{\mathrm{LP}}|_{x = \bar{x}} \subset [0,1]\) and is convex, it suffices to show that both its maximum value and minimum value are contained in \({{\,\mathrm{conv}\,}}(Q^{\mathrm{IP}})\).
First, let \(y^* = \max \{ y \in Q^{\mathrm{LP}}|_{x = \bar{x}}\}\). From \(Q^{\mathrm{LP}}\), we know that \(y = x - \sum _{i=1}^L 2^{-2i} g_i \le x\) since \(g_i \ge 0\) for all i. Hence, \(y^* \le {\bar{x}}\). Next, we observe that, as \((0,0),(1,1) \in Q^{\mathrm{IP}}\), convexity in turn implies that \((\bar{x},\bar{x}) \in {{\,\mathrm{conv}\,}}(Q^{\mathrm{IP}}) \subseteq Q^{\mathrm{LP}}\). Therefore, \(y^* = \bar{x}\) by maximality, and so \((\bar{x},y^*) \in {{\,\mathrm{conv}\,}}(Q^{\mathrm{IP}})\).
Next, let \(y^* = \min \{ y \in Q^{\mathrm{LP}}|_{x = \bar{x}}\}\). From definition, it follows that there is some \({\varvec{g}}^*\) and \({{\varvec{\alpha }}}^*\) such that \(({\bar{x}}, y^*, \varvec{g}^*, \varvec{\alpha }^*) \in P^{\mathrm{LP}}\). Define G as in (21). If \(g^*_i =G(g^*_{i-1})\) for each \(i \in \llbracket L \rrbracket \), then we immediately conclude that there exists some \(\tilde{{\varvec{\alpha }}} \in \{0,1\}^L\) such that \((\bar{x},y^*,{\varvec{g}}^*, \tilde{{\varvec{\alpha }}}) \in P^I\). This, in turn, implies that \(({\hat{x}},y^*) \in Q^{\mathrm{IP}}\).
Otherwise, take \(i \in \llbracket L \rrbracket \) as the largest index such that \(g^*_i > G(g^*_{i-1})\). Then, recursively define \(\tilde{{\varvec{g}}}\) such that \({\tilde{g}}_j = {\left\{ \begin{array}{ll} g^*_j &{} j < i \\ G({\tilde{g}}_{j-1}) &{} j \ge i \end{array}\right. }\) for each \(j \in \{0,\ldots ,L\}\). Further, take \({\tilde{y}} = \bar{x} - \sum _{i=1}^L 2^{-2i}{\tilde{g}}_i\), with \(\tilde{\alpha }_i = g_{i-1}\) for all i, inducing only lower bounds of 0 on all \(g_j\). Then \(({{\tilde{y}}}, {\bar{x}}, {{\tilde{\varvec{g}}}}, {\tilde{\varvec{\alpha }}}) \in Q^{\mathrm{LP}}\). We now show that \({\tilde{y}} < y^*\), contradicting the minimality of \(y^*\).
Let \(\varepsilon = {\tilde{g}}_i - g^*_i\). Note that \(G:{\mathbb {R}}\rightarrow {\mathbb {R}}\) is Lipschitz continuous with Lipschitz constant 2. That is, for any \(g,g' \in [0,1]\), we have that \(|G(g) - G(g')| \le 2|g - g'|\). Hence, since \(|g^*_i-{\tilde{g}}_i| \le \varepsilon \) we conclude inductively that \(|g^*_{i+k}-{\tilde{g}}_{i+k}| \le 2^k\varepsilon \) for each \(k \in \llbracket L-i \rrbracket \). Thus, we have
Therefore, \({\tilde{y}} < y^*\), contradicting the minimality of \(y^*\). From this, we conclude that no such i exists, completing the proof. \(\square \)
We now show the correspondence between our formulation and the Gray code. It is helpful to note that, in \(P^{\mathrm{IP}}\), we have \(g_i = G(g_{i-1})\), where G is as defined in (21).
Theorem 2
(The MIP formulation follows a Gray code) Take \((x,{\varvec{g}},{\varvec{\alpha }}) \in {{\,\mathrm{proj}\,}}_{x,{\varvec{g}}, {\varvec{\alpha }}}(P^{\mathrm{IP}}|_{g_L \in (0,1)})\) for some fixed value \(g_L \in (0,1)\). Fix some \(j \in \llbracket 0,L-1\rrbracket \), and define \(i_j :=\left\lfloor 2^{L-j} g_j \right\rfloor \). Then \([\alpha _{j+1}, \dots , \alpha _L]\) is the \(L-j\)-bit Gray code \(\varvec{\alpha }^{i_j}\) for \(i_j\), and \(g_j \in (\tfrac{i_j}{2^{L-j}}, \tfrac{i_j+1}{2^{L-j}})\).
Proof
First, we note that, for each \(j \le L+1\), we have
We will proceed by induction in a manner similar to the proof for Lemma 2.
Base Case: \(j=L-1\)
In this case, if \(\alpha _L = 0\), then \(g_{L-1} = \tfrac{1}{2} g_L \in (0,\tfrac{1}{2})\), and so \(i_{L-1} = \left\lfloor 2 g_{L-1} \right\rfloor = 0\), whose 1-bit Gray code is \([0] = [\alpha _L]\), as desired. On the other hand, if \(\alpha _L = 1\), then \(g_{L-1} = 1-\tfrac{1}{2} g_L \in (\tfrac{1}{2},1)\), and so \(i_{L-1} = \left\lfloor 2 g_{L-1} \right\rfloor = 1\), whose 1-bit Gray code is \([1] = [\alpha _L]\), as desired.
Inductive step: Let \(j \in \llbracket 0,L-2\rrbracket \) and suppose the statement holds \(j+1\).
If \(\alpha _{j+1} = 0\), then \(g_j = \tfrac{1}{2} g_{j+1} \in \left( \tfrac{i_{j+1}}{2^{L-j}},\tfrac{i_{j+1}+1}{2^{L-j}}\right) \) and \(2^{L-j}g_j \in (i_{j+1},i_{j+1}+1)\). In this case, we have \(i_j = \left\lfloor 2^{L-j} g_j \right\rfloor = i_{j+1} \in \llbracket 0,2^{L-j-1}-1\rrbracket \). Thus, by Lemma 1, we have that the \(L-j\)-bit Gray code for \(i_j\) is given by \({\varvec{\alpha }}^{i_j} = [0 ~ \tilde{{\varvec{\alpha }}}^{i_{j+1}}]\), where \(\tilde{{\varvec{\alpha }}}^{i_j}\) is the (\(L-j-1\))-bit Gray code for \(i_j\), which is \([\alpha _{j+2} \dots \alpha _L]\) by the induction hypothesis. This yields \({\varvec{\alpha }}^{i_j} = [0 ~ \alpha _{j+2} \dots \alpha _L] = [\alpha _{j+1} \dots \alpha _L]\) as desired. Further, observing the bounds we derived for \(g_j\), we have \(g_j \in (\tfrac{i_j}{2^{L-j}},\tfrac{i_j+1}{2^{L-j}})\).
On the other hand, if \(\alpha _{j+1} = 1\), then \(g_j = 1-\tfrac{1}{2} g_{j+1} \in (1-\tfrac{i_{j+1}+1}{2^{L-j}},1-\tfrac{i_{j+1}}{2^{L-j}})\) and \(2^{L-j}g_j \in (2^{L-j}-i_{j+1}-1,2^{L-j}-i_{j+1})\). Thus, we have that \(i_j = 2^{L-j} - i_{j+1} - 1 \in \llbracket 2^{L-j-1}, 2^{L-j}-1\rrbracket \). Thus, by Lemma 1, computing \({\tilde{i}}_j = 2^{L-j}-1 - i_j = i_{j+1}\), we have that the (\(L-j\))-bit Gray code for \(i_j\) is \({\varvec{\alpha }}^{i_j} = [1 ~ \tilde{{\varvec{\alpha }}}^{{\tilde{i}}_j}]\), where \(\tilde{{\varvec{\alpha }}}^{{\tilde{i}}_j}\) is the (\(L-j-1\))-bit Gray code for \({\tilde{i}}_j\), which by the induction hypothesis is given as \([\alpha _{j+2} \dots \alpha _L]\). This yields \({\varvec{\alpha }}^{i_j} = [1 ~ \alpha _{j+2} \dots \alpha _L] = [\alpha _{j+1} \dots \alpha _L]\) as desired. Further, observing the bounds we derived for \(g_j\), we have \(g_j \in (\tfrac{i_j}{2^{L-j}},\tfrac{i_j+1}{2^{L-j}})\).
Thus, with these cases, the result holds by induction. \(\square \)
Note that, if \(g_L \in \{0,1\}\) (so that \(x \in 2^{-L} {\mathbb {Z}}\cap (0,1)\)), the same Gray codes from Theorem 2 can be used as when \(g_L \in (0,1)\). The primary difference is that there two choices for this Gray code when \(x \in 2^{-L} {\mathbb {Z}}\cap (0,1)\). This dichotomy stems from the fact that we will obtain \(g_j = \tfrac{1}{2}\) from some j, introducing ambiguity in the choice of \(\alpha _j\).
4.1 Hereditary sharpness
In this section, we prove hereditary sharpness of the formulation \(P^{\mathrm{IP}}\).
Let L be a nonnegative integer, and define the sets \(P^{\mathrm{IP}}, P^{\mathrm{LP}}\), \(Q^{\mathrm{IP}}\), and \(Q^{\mathrm{LP}}\) as before. Suppose we fix some subset of the binary variables to \({\varvec{\alpha }}_I = \varvec{{\bar{\alpha }}}_I \in \{0,1\}^{|I|}\) for some set \(I \subseteq L\). Furthermore, define \(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I} :=P^{\mathrm{IP}}|_{{\varvec{\alpha }}_I = \varvec{{\bar{\alpha }}}_I}:=\{(x,y,{\varvec{g}}, {\varvec{\alpha }}) \in P^{\mathrm{IP}}| \alpha _i = {\bar{\alpha }}_i \text { for } i \in I\}\), and similarly for \(Q^{\mathrm{LP}}\), \(Q^{\mathrm{IP}}\), and \(P^{\mathrm{LP}}\). We then wish to show \(Q^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I} = {{\,\mathrm{conv}\,}}(Q^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})\). We will use this notation for the remainder of this section. An example demonstrating the hereditary sharpness of the formulation is shown in Fig. 3
To study this relationship in more detail, we in particular wish to study \(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}\). Let \((x, y, {\varvec{g}}, {\varvec{\alpha }}) \in P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}\). For each \(i \in I\), then \(g_{i-1}\) relates to \(g_i\) via the linear function
Alternatively, for each \(i \in \llbracket L \rrbracket \backslash I\), the relationship can be written as
In this form, simply setting each \(\alpha _i = g_{i-1}\) yields the least restrictive possible lower-bound of 0 on \(g_i\) in terms of \(g_{i-1}\). Thus, making this choice, we find that \({{\,\mathrm{proj}\,}}_{x,y,{\varvec{g}}}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I})\) can be expressed via the constraints
while, after combining the linear constraints with the new constraints (22) fixing variables \(\alpha _i\) for \(i \in I\), \(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}\) can be written as
For convenience, for all \(i \in I\), define
For \(i \in \llbracket L\rrbracket \), define the shorthand \(G_i(g_{i-1}) :=G_i(g_{i-1}, {\bar{\alpha }}_i)\) if \(i \in I\) and \(G_i = G\) otherwise. Then by the construction of \(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}\), we have that \({\varvec{g}} \in {{\,\mathrm{proj}\,}}_{{\varvec{g}}} (P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})\) if and only if for all \(i \in \llbracket L\rrbracket \), we have \(g_i = G_i(g_{i-1})\) and \(g_i \in [0,1]\).
For all \(i \in \llbracket 0,L\rrbracket \), the below proposition explores how to compute the feasible region for \(g_i\), \({{\,\mathrm{proj}\,}}_{g_i}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}) =:[a_i,b_i]\), while establishing that \({{\,\mathrm{proj}\,}}_{g_i}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}) = {{\,\mathrm{conv}\,}}({{\,\mathrm{proj}\,}}_{g_i}(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}))\).
Lemma 3
(Bounds in Projection) For all \(i \in \llbracket 0,L\rrbracket \) and \(I \subseteq \llbracket L \rrbracket \), we have \({{\,\mathrm{proj}\,}}_{g_i}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}) = {{\,\mathrm{conv}\,}}({{\,\mathrm{proj}\,}}_{g_i}(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})) =:[a_i,b_i] \ne \emptyset \). Furthermore, \([a_L,b_L] = [0,1]\), and \([a_{i-1},b_{i-1}]\) can be computed from \([a_i,b_i]\) as
Note that in the last case \(a_i \le \tfrac{1}{2}\) and \(b_i \ge \tfrac{1}{2}\).
Proof
We proceed by induction.
Base Case: \(i=L\)
In this case, Theorem 2 establishes that, even if \({\hat{I}} = \llbracket L\rrbracket \) with some corresponding \(\varvec{\hat{\alpha }}_{{\hat{I}}} \in \{0,1\}^L\), we have \([0,1] = {{\,\mathrm{proj}\,}}_{g_i}(P^{\mathrm{IP}}_{\varvec{\hat{\alpha }}_{{\hat{I}}}})\), yielding
and so \({{\,\mathrm{conv}\,}}({{\,\mathrm{proj}\,}}_{g_L}(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})) = {{\,\mathrm{proj}\,}}_{g_L}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}) = [0,1]\), as required.
Inductive step:
Let \(i \in \llbracket L\rrbracket \), and suppose that \({{\,\mathrm{conv}\,}}({{\,\mathrm{proj}\,}}_{g_i}(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})) = {{\,\mathrm{proj}\,}}_{g_i}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}) = [a_i,b_i]\). Then, observing (23) and (24), we find that there are three cases.
Case 1: If \(i \in I\) and \({\bar{\alpha }}_i = 0\), then in both \(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}\) and \(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}\), we have \(g_{i-1} = \tfrac{1}{2} g_i\), yielding
Furthermore, \(a_i,b_i \in {{\,\mathrm{proj}\,}}_{g_i}(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})\) yields \(\tfrac{1}{2} a_i, \tfrac{1}{2} b_i \in {{\,\mathrm{proj}\,}}_{g_{i-1}}(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})\). This implies \([\tfrac{1}{2} a_i, \tfrac{1}{2}b_i] \subseteq {{\,\mathrm{conv}\,}}({{\,\mathrm{proj}\,}}_{g_{i-1}}(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}))\), yielding
Note that \([a_i,b_i] \ne \emptyset \Rightarrow [\tfrac{1}{2} a_i, \tfrac{1}{2}b_i]\ne \emptyset \), and that \([a_i,b_i] \subseteq [0,1] \Rightarrow [\tfrac{1}{2} a_i, \tfrac{1}{2}b_i] \subseteq [0,1]\).
Case 2: If \(i \in I\) and \({\bar{\alpha }}_i = 1\), then in both \(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}\) and \(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}\), we have \(g_i = 1-\tfrac{1}{2} g_i\), yielding
Furthermore, \(a_i,b_i \in {{\,\mathrm{proj}\,}}_{g_i}(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})\) yields \(1-\tfrac{1}{2} b_i, 1-\tfrac{1}{2} a_i \in {{\,\mathrm{proj}\,}}_{g_{i-1}}(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})\). This implies \([1-\tfrac{1}{2} b_i, 1-\tfrac{1}{2}a_i] \subseteq {{\,\mathrm{conv}\,}}({{\,\mathrm{proj}\,}}_{g_{i-1}}(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}))\), yielding
Note that \([a_i,b_i] \ne \emptyset \Rightarrow [1-\tfrac{1}{2} b_i, 1-\tfrac{1}{2}a_i]\ne \emptyset \), and \([a_i,b_i] \subseteq [0,1] \Rightarrow [1-\tfrac{1}{2} b_i, 1-\tfrac{1}{2}a_i] \subseteq [0,1]\).
Case 3: If \(i \notin I\), then \(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}\) and \(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}\) model different relations between \(g_i\) and \(g_{i-1}\).
In \(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}\), we have
which can be written as
Further, as \(a_i \in {{\,\mathrm{proj}\,}}_{g_i}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I})\), we have that
where \(a_i \in [0,1]\) implies \(\tfrac{1}{2} a_i \in [0,\tfrac{1}{2}]\), so that \([\tfrac{1}{2} a_i,1 - \tfrac{1}{2} a_i] \ne \emptyset \). Thus,
To show \([\tfrac{1}{2} a_i,1 - \tfrac{1}{2} a_i] \subseteq {{\,\mathrm{conv}\,}}({{\,\mathrm{proj}\,}}_{g_{i-1}}(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})\), we have only to show that the endpoints are in \({{\,\mathrm{proj}\,}}_{g_{i-1}}(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})\). To this end, let \(g_i = a_i\). In \(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}\), we can choose either \(\alpha _i = 0\) or \(\alpha _i=1\). If \(\alpha _i = 0\), we have that \(g_{i-1} = \tfrac{1}{2} g_i = \tfrac{1}{2} a_i\), while if \(\alpha _i = 1\), we have \(g_{i-1} = 1-\tfrac{1}{2} g_i = 1-\tfrac{1}{2} a_i\). Thus, we have \([\tfrac{1}{2} a_i,1 - \tfrac{1}{2} a_i] \subseteq {{\,\mathrm{conv}\,}}({{\,\mathrm{proj}\,}}_{g_{i-1}}(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}))\), yielding
as desired. \(\square \)
Note that \({{\,\mathrm{conv}\,}}({{\,\mathrm{proj}\,}}_{x}(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})) = {{\,\mathrm{proj}\,}}_{x}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I})\) is a direct corollary of the above lemma. This fact will be helpful during the proof of hereditary sharpness. Next, to prove hereditary sharpness, we want to show that if we fix some \(g_i\) to either \(a_i\) or \(b_i\), then for each \(j>i\), we have that \(g_j\) has only one feasible solution \(e_j\) in \(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}\), where \(e_j \in \{a_i,b_i\}\).
Lemma 4
(Single solution at endpoints) For all \(i \in \llbracket 0,L\rrbracket \) and \(\hat{g_i} \in \{a_i,b_i\}\), we have for all \(j \ge i\) that \({{\,\mathrm{proj}\,}}_{g_j}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}|_{g_i={\hat{g}}_i}) = \{e_j\}\), where \(e_j \in \{a_j,b_j\}\).
Proof
We will proceed by induction. Let \(\hat{g_i} \in \{a_0,b_0\}\). Fortunately, the base case is trivial, since we have chosen \(g_i \in \{a_i,b_i\}\).
Thus, for an induction, let \(j \in \llbracket i+1,L\rrbracket \), and assume that \({{\,\mathrm{proj}\,}}_{g_{j-1}}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}|_{g_i = {\hat{g}}_i}) = \{e_{j-1}\} \subset \{a_{j-1},b_{j-1}\}\). Then there are three cases.
Case 1: If \(j \in I\) and \(\bar{\alpha }_{j} = 0\), then we have \(g_{j} = 2 g_{j-1}\), so that \({{\,\mathrm{proj}\,}}_{g_j}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}|_{g_i = {\hat{g}}_i}) = \{2 e_{j-1}\} =:\{e_j\}\). Now, by Lemma 3, we have that \(a_{j} = 2 a_{j-1}\) and \(b_{j} = 2 b_{j-1}\), so that \(e_{j-1} \in \{a_{j-1},b_{j-1}\} \Rightarrow e_j \in \{a_j,b_j\}\).
Case 2: If \(j \in I\) and \(\bar{\alpha }_{j} = 1\), then we have \(g_{j} = 2 (1-g_{j-1})\), so that \({{\,\mathrm{proj}\,}}_{g_j}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}|_{g_j = {\hat{g}}_j}) = \{2 (1-e_{j-1})\} =:\{e_j\}\). Now, by Lemma 3, we have that \(a_{j} = 2 (1-b_{j-1})\) and \(b_{j} = 2 (1-a_{j-1})\), so that \(e_{j-1} \in \{a_{j-1},b_{j-1}\} \Rightarrow e_j \in \{a_j,b_j\}\).
Case 3: If \(j \notin I\), then we have by Lemma 3\(a_{j} = 2a_{j-1} = 2(1-b_{j-1})\), with \(a_j \le \tfrac{1}{2}\) and \(b_j \ge \tfrac{1}{2}\). Further, we have in \(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}\) that
Now, if \(e_{j-1} = a_{j-1}\), then \(2 e_{j-1} = 2 a_{j-1} \le 1\), while \(2(1-e_{j-1}) = 2(1-a_{j-1}) \ge 1\). Thus, these bounds consolidate to \(a_j \le g_j \le 2 a_{j-1} = a_j\), which implies \(g_j = a_j\).
On the other hand, if \(e_{j-1} = b_{j-1}\), then \(2 e_{j-1} = 2 b_{j-1} \ge 1\), while \(2(1-e_{j-1}) = 2(1-b_{j-1}) \le 1\). Thus, these bounds consolidate to \(a_j \le g_j \le 2(1-b_{j-1}) = a_j\), which implies \(g_j = a_j\). Thus, in this case, we have \({{\,\mathrm{proj}\,}}_{g_j}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}|_{g_i = {\hat{g}}_i}) = \{a_j\} =:\{e_j\}\). This completes the proof. \(\square \)
Now, computing all \(a_{i}\) and \(b_{i}\) via Lemma 3, we obtain the following form for \({{\,\mathrm{proj}\,}}_{x,y,{\varvec{g}}}\{P^{\mathrm{LP}}|_{I, \varvec{{\bar{\alpha }}}_I}\}\):
Now, note that, for each \(i \in \llbracket L\rrbracket \), \(g_{i}\) has negative coefficient in first equation of (27). Note also that this is the only constraint in (27) involving y. Thus, if we are to minimize over y, then we implicitly maximize \(g_{i}\), and so \(g_{i}\) will tend towards its upper bound. Furthermore, it turns out that, in any y-minimal or y-maximal solution in \(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}\) given some fixed value of x, each \(g_i\) can be explicitly computed from \(g_{i-1}\) using only the constraints from (27) directly connecting \(g_i\) and \(g_{i-1}\). We refer to this as the greedy solution property described in Lemma 5 below, and it holds due to the rapid decay of coefficients of \(g_i\)’s.
For each \(i \in \llbracket L\rrbracket \setminus I\), let \(b_i\) be as in Lemma 3, and define
Lemma 5
Let \(a_i, b_i\) as in Lemma 3, and let \({{\hat{x}}} \in [a_0,b_0]\). Define
Then, for \(i \notin I\), we have
That is, one of the upper bounds is tight for each \(g_i\) when maximizing y, while the domain lower bound is tight for \(g_i\) when minimizing y.
Proof
Let \({\hat{x}} \in [a_0,b_0]\). Then \(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}|_{x={\hat{x}}} \ne \emptyset \) by Lemma 3.
We begin by proving that \(g^*_i = u_i(g^*_{i-1})\) for all \(i \notin I\). Suppose for a contradiction that, for some subset \(j \in J \subseteq \llbracket L\rrbracket \setminus I\) and \(\varepsilon _j>0\), we have \(g_{j}^* = u_{j}(g_{j-1}^*) - \varepsilon _j\). Let i be maximal in J, so that \(g_{j}^*=u_j(g_{j-1}^*)\) for all \(j>i\). Then we have \(i \notin I\), since otherwise we have \(g_{i}^*= 2g_{i-1} (1-{\bar{\alpha }}_i) + 2(1-g_{i-1}) = u_j(g_{j-1}^*)\) from (27).
Let \({\tilde{g}}_{j} = u_{j}(g_{j-1})\) for all \(j \ge i\). for convenience, define
To show that this choice is feasible, i.e., \(\tilde{{\varvec{g}}} \in {{\,\mathrm{proj}\,}}_{{\varvec{g}}}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I})\), we make an inductive observation. First, note that \({\tilde{g}}_{i-1} = g^*_{i-1} \in [a_{i-1},b_{i-1}]\) by Lemma 3, with \(\tilde{{\varvec{g}}}_{\llbracket 0,i-1\rrbracket } \in {{\,\mathrm{proj}\,}}_{{\varvec{g}}_{\llbracket 0,i-1\rrbracket }}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I})\). Furthermore, for any j, \(\tilde{{\varvec{g}}}_{\llbracket 0,j-1\rrbracket } \in {{\,\mathrm{proj}\,}}_{{\varvec{g}}_{\llbracket 0,j-1\rrbracket }}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I})\) implies that there exists some \(g_j \in {{\,\mathrm{proj}\,}}_{g_j}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}|_{{\varvec{g}}_{\llbracket 0,j-1\rrbracket } = \tilde{{\varvec{g}}}_{\llbracket 0,j-1\rrbracket }}) \subseteq [a_j,b_j]\), and \({\tilde{g}}_j\) is the largest such value by construction, yielding \({\tilde{g}}_j \in [a_j,b_j]\) and \(\varvec{\tilde{g}}_{\llbracket 0,j\rrbracket } \in {{\,\mathrm{proj}\,}}_{{\varvec{g}}_{\llbracket 0,j\rrbracket }}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I})\).
Now, we have by definition that \({\tilde{g}}_{i} - g^*_{i} = \varepsilon _i\). Furthermore, observe that for all \(j>i\), \(u_j(g_{j-1})\) is Lipschitz continuous with Lipschitz constant 2, yielding
Applying this recursively yields, for all \(j>i\),
Note that this implies that, for \(j>i\), we have \({\tilde{g}}_{j} - g^*_{j} \ge -2^{j-i} \varepsilon \). Then we have
However, this is a contradiction: it implies \({\tilde{y}}<y^*\), but \(y^*\) was optimal! Thus, all \(g_i\) must take on their upper-bounds given \(g_{i-1}\).
Next, we prove that \(g^\star _i = a_i\) for all \(i \notin I\). The idea behind the proof is identical, with a notable simplifying difference: there is only one (constant) lower-bound \(a_i\) on each \(g_i\) for \(i \notin I\). Thus, when enforcing that each \(g^\star _j = a_i\) for \(j>i\), \(j \notin I\) with \(g_i = a_i + \varepsilon \), the shift from \(g^\star _i\) to \({\tilde{g}}_i\) effects no change in \(g_j\), \(j > i\). That is, if \(i+1 \notin I\), \({\tilde{g}}_{i+1} - g^\star _{i+1} = 0\), yielding \({\tilde{g}}_{j} - g^\star _{j} = 0\) for \(j \ge i+1\), so that (31) simplifies to
implying \({\tilde{y}} > y^\star \), a contradiction. On the other hand, if \(i+1 \in I\), let \(k = \min \{j \in L-I : j \ge i+2\}\). Then, for each \(j \in \llbracket i+1,\dots , k-1\rrbracket \), we have \(|{\tilde{g}}_i - g^\star _i| = 2^{j-i} \varepsilon \). Furthermore, as \(k \notin I\), we have \({\tilde{g}}_{k} = a_k = g^\star _k\), so that \({\tilde{g}}_k = g^\star _k\) for all \(j > k\), yielding
again implying \({\tilde{y}} > y^\star \), a contradiction. \(\square \)
Observation 1
Since each \(u_i\), defined in (28), is a continuous piecewise linear function, Lemma 5 recursively implies that each \(g^*_i\) is continuous in x, and is a function of \(g^*_{i-1}\).
As a corollary to Lemma 4 and Lemma 5, we have that, for the optimal solution to the minimization problem in Lemma 5, we have that \(g_j = b_j < G(g_{j-1})\) for exactly one value of j if \({\hat{x}}\) is not feasible in \(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}\).
Corollary 1
For all \({\hat{x}} \in {{\,\mathrm{proj}\,}}_x(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}) \setminus {{\,\mathrm{proj}\,}}_x(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})\), define \((y^*,{\varvec{g}}^*)\) as in (29a). Then we have for exactly one \(j \in \llbracket L\rrbracket \setminus I\) that \(g^*_j = b_j < G(g^*_{j-1})\).
Furthermore, let \(x^1,x^2 \in {{\,\mathrm{proj}\,}}_x{P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}}\) be such that for all \(\lambda \in (0,1)\), we have \({\hat{x}} :=\lambda x^1 + (1-\lambda ) x^2 \notin {{\,\mathrm{proj}\,}}_x{P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}} = \emptyset \). Then the uniquely determined j discussed above is the same for all \({\hat{x}} \in (x^1,x^2)\) where \((x^1,x^2)\) denotes the open interval between \(x^1\) and \(x^2\).
Proof
Consider the first \(j \in \llbracket L\rrbracket \setminus I\) for which \(g^*_j = b_j\). Such a j exists; otherwise, Lemma 5 would give \(g^*_i = G_i(g_{i-1})\) for all \(i \in \llbracket L\rrbracket \), a contradiction on the choice of \({\hat{x}}\) since there is a corresponding feasible choice of \({\varvec{\alpha }}^* \in \{0,1\}^L\). Then, by Lemma 4, the set \({{\,\mathrm{proj}\,}}_{{\varvec{g}}_{\llbracket j+1,L\rrbracket }}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}|_{g_j = g^*_j})\) consists of only a single point, for which each \(g_i \in \{a_i,b_i\}\) for \(i \ge j+1\). Furthermore, by Lemma 4, this point is also in \({{\,\mathrm{proj}\,}}_{{\varvec{g}}_{\llbracket j+1,L\rrbracket }}(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}|_{g_j = g^*_j})\) so that \(g^*_i = G_i(g^*_{j-1})\) for all \(i \ge j+1\). Further, if \(g^*_j = G(g^*_{j-1}) = b_j\), then we would obtain \({\varvec{g}}^* \in {{\,\mathrm{proj}\,}}_{{\varvec{g}}} P^{\mathrm{IP}}_{x = {\hat{x}}}\), a contradiction on the choice of \({\hat{x}}\). Thus, as \(g^*_j \le G(g^*_{j-1})\) by Lemma 5, we must have that \(g^*_j = b_j < G(g^*_{j-1})\).
Now, let \(x^1,x^2 \in {{\,\mathrm{proj}\,}}_x{P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}}\) be such that \((x^1,x^2) \cap {{\,\mathrm{proj}\,}}_x{P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}} = \emptyset \). Suppose that there is some \({\hat{x}} \in (x^1,x^2)\) such that, for all sufficiently small \(\varepsilon >0\), we have that the value \(j^1\) in for \(x-\varepsilon \) is different from the value \(j^2\) for \(x+\varepsilon \). In this case, since the \(g_j^*\) is continuous in x and \(g^*_{j-1}\), we have at \({\hat{x}}\) that both \(g^*_{j_1} = b_{j_1} = G_{j_1}(g^*_{j_1-1})\) and \(g^*_{j_2} = b_{j_2} = G_{j_2}(g^*_{j_2})\). Furthermore, for all other \(i \in \llbracket L\rrbracket \setminus I\), we have by continuity that \(g^*_i = G_i(g^*_{i-1})\), yielding \(g^*_i = G_i(g^*_{i-1})\) for all i. This yields \({\varvec{g}}^* \in {{\,\mathrm{proj}\,}}_{{\varvec{g}}}{P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}}\), a contradiction on the choice of \({\hat{x}}.\) \(\square \)
With this greedy solution property and the following corollary, we are ready to prove the hereditary sharpness of \(P^{\mathrm{IP}}\) as a formulation for \(Q^{\mathrm{IP}}\). It is helpful to note that, for the minimizer solutions in Lemma 5, \(g^*_i < b_i\) implies \(g^*_i = G_i(g_{i-1})\). Furthermore, if \({\varvec{g}} \in {{\,\mathrm{proj}\,}}_{{\varvec{g}}}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I})\) and \(g^*_i = G_i(g_{i-1})\) for all \(i \in \llbracket L\rrbracket \setminus I\), then we have \({\varvec{g}} \in {{\,\mathrm{proj}\,}}_{{\varvec{g}}}(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})\).
Theorem 3
\(Q^{\mathrm{IP}}\) is hereditarily sharp.
Proof
Let \(a_0, b_0\) as in Lemma 3, so \([a_0, b_0] = {{\,\mathrm{proj}\,}}_x(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}) = {{\,\mathrm{conv}\,}}({{\,\mathrm{proj}\,}}_x(P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}))\).
Let \({{\hat{x}}} \in [a_0, b_0]\). We need to show that \(Q^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I} = {{\,\mathrm{conv}\,}}(Q^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})\). Since both sets are compact convex sets in \({\mathbb {R}}^2\), it suffices to show that \(Q^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}|_{x = {{\hat{x}}}} = {{\,\mathrm{conv}\,}}(Q^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})|_{x = {{\hat{x}}}}\). In this vein, we define the upper and lower bounds in y for each set
We will show that the upper and lower bounds coincide.
Lower bounds We begin by showing that \(y^{\text {IP}}_{l}(x)=y^{\text {LP}}_{l}(x)\). Since \({{\hat{x}}} \in {{\,\mathrm{proj}\,}}_x(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I})\), we have two cases. If \({{\hat{x}}} \in {{\,\mathrm{proj}\,}}_x(Q^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})\), then due to sharpness by Theorem 1, we have
and so the result holds. In order, the four relations hold by: relaxation; relaxation; sharpness; and the fact that \(P^{\mathrm{IP}}|_{x = {{\hat{x}}}}\) consists of a single point for feasible \({\hat{x}}\), so that the restriction does not change the optimal solution.
Otherwise, \({{\hat{x}}} \notin {{\,\mathrm{proj}\,}}_x(Q^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})\). Let
and let \(x^1<{{\hat{x}}}\) and \(x^2>{{\hat{x}}}\) be the closest lower and upper bounds to \({{\hat{x}}}\) in \({{\,\mathrm{proj}\,}}_x(Q^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I})\) (such points exist by Lemma 3). Let \((x^1,y^1,{\varvec{g}}^1, {\varvec{\alpha }}^1), (x^2,y^2,{\varvec{g}}^2, {\varvec{\alpha }}^2) \in P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}\) be chosen such that \({\varvec{\alpha }}^1 \in {{\,\mathrm{proj}\,}}_{{\varvec{\alpha }}}P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}|_{x \in (x^1 - 2^{-L}, x^1)}\) and \({\varvec{\alpha }}^2 \in {{\,\mathrm{proj}\,}}_{{\varvec{\alpha }}}P^{\mathrm{IP}}_{\varvec{{\bar{\alpha }}}_I}|_{x \in (x^2, x^2 + 2^{-L})}\). According to Theorem 2, \({\varvec{\alpha }}^1\) and \({\varvec{\alpha }}^2\) are the Gray codes for some integers \(i_j\) and \(i_{j+1}\). By Lemma 2, we know that there exists exactly one index \(k \in \llbracket L\rrbracket \) such that \(\alpha ^1_i = \alpha ^2_i\) for all \(i \ne k\) and \(\alpha ^1_k = 1 - \alpha ^2_k\).
It follows that \({\varvec{g}}^1\) and \({\varvec{g}}^2\) satisfy the equations
Furthermore, by Lemma 5, for the y-minimal solution at all three x-values, we have that all \(g_i\), \(i \in \llbracket L\rrbracket \setminus I\) take on \(u_i(g_{i-1}) = \min \{2g_{i-1}, 2(1-g_{i-1}), b_i\}\). This function is linear if \(i \in I\); otherwise, it is the minimum of three functions: two linear, and one constant.
Choose \(\lambda \in [0,1]\) such that \({{\hat{x}}} = \lambda x^1 + (1-\lambda ) x^2\) and define \({{\hat{y}}}\) and \(\hat{{\varvec{g}}}\) by \(({{\hat{x}}},{\hat{y}},\hat{{\varvec{g}}}) = \lambda (x^1,y^1,{\varvec{g}}^1) + (1-\lambda ) (x^2,y^2,{\varvec{g}}^2)\). By convexity of \(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}\), the point \(({{\hat{x}}},{\hat{y}},\hat{{\varvec{g}}})\) is in \({{\,\mathrm{proj}\,}}_{x,y,{\varvec{g}}}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I})\). We want to show that \(({{\hat{x}}},{\hat{y}},\hat{{\varvec{g}}})= ({{\hat{x}}},y^*,{\varvec{g}}^*)\). To do so, by Lemma 5, we have only to show that all \({\hat{g}}_{i}=u_{i}({\hat{g}}_{i-1})\).
By convexity, since \({\varvec{g}}^1\) and \({\varvec{g}}^2\) satisfy (33), it follows that \(\hat{{\varvec{g}}}\) satisfies it as well. Hence, \({{\hat{g}}}_i = G_i({{\hat{g}}}_{i-1}, \alpha ^1_i)\) for all \(i \ne k\). Furthermore, we have by induction that \(g_i^* = {\hat{g}}_i\) for all \(i \le k-1\): (base case) \(g_0^*={\hat{g}}_0 = {\hat{x}}\); (inductive case) for \(i \le k-1\), if \(g^*_{i-1} = {\hat{g}}_{i-1}\), then by Lemma 5, we have
so that \({\hat{g}}_i = g^*_i = G_i({\hat{g}}_{i-1}, \alpha ^1_i)\). Similarly, we have \({\hat{g}}_k \le g_k^*\). We will show that \({{\hat{g}}}_k = b_k\).
To do so, we will first show that \(g^*_k = b_k\). If this holds, then since \({\hat{x}}\) was arbitrary, and since \(g_k^*\) is continuous in \({\hat{x}}\) by Observation 1, we have that \(g^1_k = g^2_k = b_k\). Since \({{\hat{g}}}_k\) is a convex combination of \(g^1_k\) and \(g^2_k\), this yields \({{\hat{g}}}_k = b_k\).
To show \(g^*_k = b_k\), we first note that, by Corollary 1, there exists some \(j \in \llbracket L\rrbracket \setminus I\) such that, for all \({\hat{x}} \in (x^1,x^2)\), we have \(g^*_j = b_j < G(g^*_{j-1})\), with \(g^*_i < b_i\) for all \(i<j\). Furthermore, since \(g^*_i = G(g^*_{i-1})\) for \(i \in \llbracket k-1\rrbracket \setminus I\), we must have that \(j \ge k\). To establish that \(j = k\), we will show that \(g^*_k = b_k\) when \(\lambda = \tfrac{1}{2}\), implying that \(j>k\) is impossible, since then we would have \(g^*_k < b_k\).
Now, define \({\tilde{I}} = \llbracket L\rrbracket \setminus \{k\}\), and define \({\tilde{\alpha }}_I\) so that \({\tilde{\alpha }}_i = \alpha ^1_i\) for all \(i \in {\tilde{I}}\). Define \({\tilde{a}}_i\) and \({\tilde{b}}_i\) as in Lemma 3 for \(P^{\mathrm{LP}}_{{\tilde{\alpha }}_{{{\tilde{I}}}}}\). Let
Then by Lemma 5, we have \({\tilde{g}}_k = \min \{{\tilde{b}}_k, G({\tilde{g}}_{k-1})\}\). However, \({\tilde{g}}_k = G({\tilde{g}}_{k-1})\) would yield \(\tilde{\varvec{g}} \in {{\,\mathrm{proj}\,}}_{{\varvec{g}}} (P^{\mathrm{IP}}_{{\tilde{\alpha }}_{{{\tilde{I}}}}})\), a contradiction on the choice of \({\hat{x}}\). Thus, we have \({\tilde{g}}_k = {\tilde{b}}_k\). Since \({\hat{x}}\) was arbitrary and since \({\tilde{g}}_k\) is continuous in \({\hat{x}}\) by Observation 1, this implies that \(g^1_k = g^2_k = {\tilde{b}}_k\). Now, this allows us to compute \(g^1_{k-1}\) and \(g^2_{k-1}\) given \(\alpha ^1_i\), which will allow us to compute \(b^*_k\) for \(\lambda = \tfrac{1}{2}\) via \(g^*_{k-1} = {\hat{g}}_{k-1}\) and \(g^*_k = u_k(g^*_{k-1})\).
To compute \({\hat{g}}_{k-1}\), there are two cases. Either \(\alpha ^1=0\), yielding \(g^1_{k-1} = \tfrac{1}{2} {\tilde{b}}_k\) and \(g^2_{k-1} = 1-\tfrac{1}{2} {\tilde{b}}_k\), or \(\alpha ^1 = 1\), yielding \(g^1_{k-1} = \tfrac{1}{2} (1-{\tilde{b}}_k)\) and \(g^2_{k-1} = \tfrac{1}{2} {\tilde{b}}_k\). In either case, we have \(g^1_{k-1} + g^2_{k-1} = 1\), and so
yielding by Lemma 5 that
as required. Thus, since \({{\hat{g}}}_k = b_k\) and \({\hat{g}}_i\) satisfies (33) for all \(i \ne k\), it follows that \({\hat{g}}_i = u_i({\hat{g}}_{i-1})\) for all \(i \in \llbracket L\rrbracket \). Hence, by Lemma 5, we have \({\varvec{g}}^* = \hat{{\varvec{g}}}\).
Upper bounds For the upper bounds, note that \((x,y) \in Q^{\mathrm{IP}}\) implies \(y = F(x)\), where F is a convex function. Furthermore, by Lemma 4, we have that \(y^{\text {IP}}_{l}(x)=y^{\text {IP}}_{u}(x)=y^{\text {LP}}_{u}(e_0)=y^{\text {LP}}_{l}(x)\) for \(x \in \{a_0,b_0\}\) (as the extended-space solutions are unique in \(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}\) for \(x \in \{a_0,b_0\}\)). Thus, by the convexity of F, we have that \(y^{\text {IP}}_{u}=y^{\text {LP}}_{u}\) if and only if for all \(x \in [a_0,b_0]\), we have for some \(\lambda \in [0,1]\) that \((x, y^{\text {LP}}_{u}(x)) = \lambda (a_0,F(a_0)) + (1-\lambda )(b_0,F(b_0))\). Alternatively, since \(y_{\text {LP}_u}(x) = F(x)\) for \(x \in [a_0,b_0]\), it suffices to show that \(y^{\text {LP}}_{u}(a_0) = F(a_0)\), \(y^{\text {LP}}_{u}(b_0) = F_{b_0}\), and that \(y^{\text {LP}}_{u}\) is a linear function of x.
To this end, consider any \(x \in {{\,\mathrm{proj}\,}}_{x}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I})\), and consider \((y, {\varvec{g}}) = \max _y\{(y, {\varvec{g}}) \in {{\,\mathrm{proj}\,}}_{y, {\varvec{g}}}(P^{\mathrm{LP}}_{\varvec{{\bar{\alpha }}}_I}|_{x})\}\). Then by Lemma 5, we have for all \(i \in \llbracket L\rrbracket \), \(i \notin 1\) that \(g_i = a_i\), which is a constant, while for all \(i \in I\) we have that \(g_i = G(g_{i-1},{\bar{\alpha }}_i)\). Thus, eliminating all \(g_i's\), we find that, \(y^*\) is defined as \(y^* = x - t(x)\), where t(x) is some linear function of x, and thus so is \(y^*(x)\), as required. \(\square \)
4.2 A connection with existing MIP formulations
Interestingly, Gray codes also naturally appear in the “logarithmic” MIP formulations for general continuous univariate piecewise linear functions due to Vielma et al. [52, 53]. Consider applying this existing formulationFootnote 3 to approximate the univariate quadratic term with the same \(2^L+1\) breakpoints as discussed in Sect. 3. The resulting MIP formulation uses L binary variables, which follow the same interpretation as the neural network formulation as discussed in Theorem 2. Moreover, it requires \({\mathcal {O}}(L)\) linear constraints (excluding variable bounds), and is ideal, a stronger property than the sharpness shown in Theorem 3. However, it comes at the price of an additional \(2^L+1\) auxiliary continuous variables, and so is unlikely to be practical without a careful handling through, e.g., column generation. Therefore, our formulation sacrifices strength to reduce this to \({\mathcal {O}}(L)\) auxiliary continuous variables.
5 Convex hull characterization
We explore a facet characterization of the convex hull of our model. Such a characterization could be used to improve the branch & cut scheme when solving MIPs with our model.
Although (7) offers a convex hull formulation for a single “layer” in our construction, the composition over multiple layers (\(L> 1\)) in (8) will in general fail describe the integer hull. We characterize additional valid inequalities for the integer hull of (8) that are derived via a connection with the parity polytope.
We begin by rewriting the relationship between the variables associated with each layer with the quadratic recurrence relation
For convenience, let \(h_i := 2g_i - 1\) and \(a_i := (1-2\alpha _i)\) for each \(i \in \llbracket L \rrbracket \). Then after some simple algebraic manipulation, (34) is equivalent to
Expanding the recurrence relation, we have
Define \(b_i := \prod _{j=1}^i a_j\) for each \(i \in \llbracket L \rrbracket \). As each \(a_j \in \{-1,+1\}\), each \(b_i \in \{-1,+1\}\) as well, and so \(b_i = 1 / b_i\). Hence,
Multiplying both sides of (35) by \(b_L\in \{-1,+1\}\) yields
Combining this with the McCormick inequality \(h_L+ b_L - 1 \le h_Lb_L\) that is valid for the bilinear left-hand side of (36) (recall \(h_L, b_L\in [-1,+1]\)), we derive the following valid inequalities:
which can be readily mapped back to the original space of variables.
Proposition 3
The following inequalities are valid for (8):
If \(L=2\), then (37a) and (37b) are both linear inequalities in g and \(\alpha \).
Based on computational observations, for \(L=2\), these are exactly the nontrivial facet-defining linear inequalities for the integer hull of (8). For \(L> 2\), we can produce a large class of valid inequalities by bounding the product variables \(b_i\). In particular, bounds on these products can be derived from valid inequalities for the parity polytope.
5.1 Parity inequalities
The parity polytope is the convex hull of \(P_n^{\text {even}}\), the set of all \(\alpha \in \{0,1\}^n\) whose components sum to an even number. It has \(2^{n-1}\) facets of the form
Define \(\beta _i \in \{0,1\}\), such that \(b_i = (1-2 \beta _i)\). Then
Hence, for \(\alpha _i \in \{0,1\}\), the sum \(\beta _j + \sum _{i=1}^j \alpha _i\) is even and therefore \((\beta _j, \alpha _1, \dots , \alpha _j) \in P_{j+1}^{\text {even}}\). Therefore, we can apply (39) to derive valid inequalities for feasible solutions to (8) of the form
After recalling the definition \(b_j = (1-2\beta _j)\) and rearranging, we are left with
Hence, combining these upper bounds on \(b_i\) with (37a) and the upper bounds on \(-b_i\) with (37b) produces an exponential family of valid inequalities for feasible solutions to (8). We call these parity inequalities.
Example 2
For \(L= 4\), we compute some of the nontrivial facet-defining inequalities of (8), written in terms of the original variables:
Each of these inequalities is, in fact, a parity inequality, and can be constructed by a suitable combination of either (37a) with inequalities from (42a), or (37b) with inequalities from (42b).
For example, the facet \(g_4 \le 16 g_{0} - 14 \alpha _{1} + 6 \alpha _{2} + 2 \alpha _{3}\) is equivalent to
which can be produced as a conic combination of the inequality
from (37a) with the inequalities
from the family (42a) corresponding to \(I=\{1\}\) for all \(j=1,2,3\), respectively.
5.2 Separation over exponentially many parity inequalities
Since there may be exponentially many parity inequalities, we provide an algorithm to separate over them. In particular, given a point \((g,\alpha ) \subseteq [0,1]^{L+1}\times [0,1]^L\), we can determine if it lies in the intersection of the parity inequalities by computing the inequalities that give smallest upper bounds for \(b_j\) for each \(j \in \llbracket L\rrbracket \). To do so, for each \(b_j\), we need to determine the set \(I_j \subseteq \llbracket j \rrbracket \) that minimizes the right-hand side of equation (42a) or (42b). This can be done, in fact, by optimizing over another parity polytope. That is, set \(I_j := \{i \in \llbracket j \rrbracket : z^*_i = 1\}\), where
Linear functions can be optimized over the parity polytope in polynomial time via a linear size extended formulation [38], or by writing an integer program with a single integer variable [7], or by a simple greedy-like algorithm. An analogous approach can be taken if the sum of \(z_i\) should be odd.
6 Area comparisons
The approximation presented above is an over approximation of \(y = x^2\). This is sufficient for providing dual bounds due how the approximation is applied using the diagonal perturbation. However, our formulation can also be altered slightly to provide an under approximation of \(y=x^2\), and in particular, creates a covering of the curve with a union of polytopes. We describe two relaxations that are comparable to that of Dong and Luo [23]. We then compare these models based on the combined area of the covering to see how these methods converge.
We construct our first relaxation, named NN-R1, from the constraints (7) and
We can form a tighter relaxation NN-R2 by starting with NN-R1, then adding the cut (43b) with \(j=L\):
Tables 2 and 1 compare the volume of our relaxed method with the method of Dong and Luo [23] on the intervals \(x \in [0,1]\) and \(x \in [-2,1]\), respectively. As L increases, the volume of our relaxation consistently shrinks by a factor of 4, which is strictly greater by a fair margin to the improvement rate observed for the method of Dong and Luo. We can formalize our rate of improvement in the following proposition.
Proposition 4
The volume of our approximation decreases by a factor of 4 with each subsequent layer (i.e. as \(L\) increases). Furthermore, the expected error at points x sampled uniformly at random from the input interval domain is proportional to the total volume.
Proposition 4 relies on the characterization of NN-R1 as the piecewise McCormick relaxation of \(y=x^2\) at uniformly-spaced breakpoints. For one piece \([x_1,x_2]\), this relaxation consists of the tangent lines, or outer-approximation cuts, at \(x_1\) and \(x_2\) for the lower bound, and the secant line between \(x_1\) and \(x_2\) for the upper bound. We have already established that the upper bound, the NN approximation, is a piecewise interpolant to \(x^2\) at the chosen breakpoints, yielding the secant line on each interval \([x_1,x_2]\) between interpolation points, and thus the upper-bound of the piecewise McCormick approximation. In Lemma 6 below, we show that the lower bound of the NN-R1 and NN-R2 approximations give the piecewise McCormick lower bounds for \(2^L\) and \(2^{L+1}\) uniformly-spaced breakpoints, respectively.
Lemma 6
Define T as the lower-bounding set in (x, y) for the relaxation NN-R2, \(T = {{\,\mathrm{proj}\,}}_{x,y}\{(x,y,{\varvec{g}}, {\varvec{\alpha }}) \in [0,1] \times {\mathbb {R}}\times [0,1]^L \times \{0,1\}^L :\) (44, (43c, (43d, and (7)}. Then T can be constructed via \(2^{L+1}+1\) uniformly-spaced outer-approximation cuts for \(y \ge x^2\) on the interval [0, 1], based on the tangent lines to \(x^2\) at \(x_i = i \cdot 2^{-(L+1)}\), \(i=0, \dots , 2^{(L+1)}\). That is, letting \(p_{{\hat{x}}}(x)\) be the tangent line to \(y=x^2\) at the point \({\hat{x}}\),
T is equivalent to \(\left\{ (x,y) \in [0,1] \times {\mathbb {R}}: y \ge p_{{\hat{x}}}(x) \quad \forall i \in \{0, \dots , L\},~{\hat{x}} = i\cdot 2^{-(L+1)}\right\} \).
Proof
To begin, we note that, as shown by Yarotsky [57], we have that for each \(l = 0, \dots , L\), \(F_l(x)\) gives a piecewise-linear interpolant in \(y=x^2\) at \(2^l + 1\) uniformly-spaced points on \(x \in [0,1]\). That is, for each \(i \in \{0,1,\dots ,2^l\}\), we have that \(F_l(i \cdot 2^{-l}) = (i \cdot 2^{-l})^2\).
For \(x_1<x_2\), Consider a single linear interpolant to \(y=x^2\) on the interval \([x_1,x_2]\), given as
Since \(h(x)-x^2\) is concave, the deviation \(h(x)-x^2\) is maximized when \(\frac{d}{dx} (h(x)-x^2) = x_1+x_2-2x = 0\), yielding \(x^* = \frac{x_1+x_2}{2}\). At this point, we have
Thus, we have that \((x^*)^2 = h(x^*) - \frac{1}{4} (x_2-x_1)^2\). Since \(x^2\) is a convex function, and since \(h- \frac{1}{4} (x_2-x_1)^2\) is tangent to \(x^2\) at \(x^*\) (as both slopes are \(x_2-x_1\)), this implies that for all \(x \in [0,1]\), we have \((x^*)^2 \ge h(x) - \frac{1}{4} (x_2-x_1)^2\).
Now, since \(F_l(x)\) is a linear interpolant to \(y=x^2\) on each interval \([i \cdot 2^{-l}, (i+1)\cdot 2^{-l}]\), with interval width \(2^{-l}\), we have that the cuts \(y \ge F_l(x) - \frac{1}{4} 2^{-2l} = F_l(x) - 2^{-2l-2}\) are valid for \(y=x^2\), and furthermore are tangent to \(x^2\) at the point \(x=(i+\frac{1}{2}) \cdot 2^{-l}\), the midpoints of all interpolants. Thus, we obtain outer-approximation cuts at \(x=(i+\frac{1}{2}) \cdot 2^{-l}\) for each \(i=0, \dots , 2^l-1\).
We obtain T by applying these cuts for \(l=0, \dots , L\), combined with the outer-approximation cuts \(y \ge 0\) (tangent at \(x=0\)) and \(y \ge 2x-1\) (tangent at \(x=1\)). We now show that this yields \(2^{L+1}+1\) uniformly-spaced outer-approximation cuts to \(y=x^2\). This can be easily seen by expressing the outer-approximation points in binary. The points \(x=(i+\frac{1}{2}) \cdot 2^{-l}\) for each \(i=0, \dots , 2^l-1\) can be characterized as exactly the numbers in (0, 1) such that the \((l+1)\)th binary decimal is a 1, and all later binary decimals are zero. Alternatively, it is the set of points
We then have that the set of outer-approximation points, \(x \in \{0,1\} \cup \bigcup _{l \in \llbracket 0, L\rrbracket } P_l\), is the set of all binary decimals in the interval [0, 1] for which the last 1 occurs no later than the \(L+1\)st decimal place, which has cardinality \(2^{L+1}+1\). This forms the set of uniformly-spaced points \(i \cdot 2^{-(L+1)}\), \(i = 0, \dots , 2^{L+1}\). Thus, we have that the set T consists of a set of \(2^{L+1}+1\) uniformly-spaced outer-approximation cuts to the function \(y=x^2\), as required. \(\square \)
With Lemma 6, we establish that the NN-R1 relaxation is equivalent to the piecewise McCormick relaxation of \(y=x^2\) on the uniformly-spaced breakpoints \(x_i = 2^{-L}i\), \(i \in \llbracket 0,2^L\rrbracket \). We now establish the area of any given piece of the relaxation.
Lemma 7
The area of the McCormick Relaxation of \(y = x^2\) on the interval \([x_1, x_2]\) is \(\tfrac{1}{4}(x_2 - x_1)^3\).
Proof
We wish to obtain a closed-form solution for the area of the resulting triangle region. To do so, we compute the vertices of this triangle, construct vectors between them, then compute the cross-product of these vectors.
The equations of the tangent lines are given by
We thus find that the intersection of these lines is given by the point \((\frac{x_1+x_2}{2},x_1x_2)\). Thus, the three vertices are given as \(v_1 = (x_1,x_1^2)\), \(v_2 = (\frac{x_1+x_2}{2},x_1x_2)\), and \(v_3 = (x_2,x_2^2)\). From these vertices, we obtain two vectors
The area is given by the magnitude of the cross product as
As required. \(\square \)
With Lemma 7, we are now ready to show that the area of NN-R1 is optimal among all piecewise McCormick relaxations with a fixed number of pieces.
Proposition 5
The minimum possible area covering \(y=x^2\) on \(x \in [a,b]\) with a sequence of n McCormick Relaxations is \(\tfrac{1}{4} (b-a)^3/n^2\), and is achieved via uniformly spaced breakpoints.
Proof
Consider a general piecewise McCormick relaxation of \(y=x^2\) on the interval [a, b] with consecutive breakpoints \(a=x_0\le x_1\le \dots \le x_n=b\). For any segment of consecutive breakpoints \(x_i\) and \(x_{i+1}\), the McCormick relaxation between those points is bounded by the secant line between \((x_i,x_i^2)\) and \((x_{i+1},x_{i+1}^2)\), and the tangent lines to \(y=x^2\) at \(x_i\) and \(x_{i+1}\). For simplicity, let \(i=1\) for this discussion.
Thus, letting \(y_i = x_{i} - x_{i-1},~i = 1 \dots n\), the problem of choosing the area-optimal breakpoints \(a \le x_1, \le x_2 \le \dots \le x_{n-1} \le x_n\) reduces to solving
It is then easy to show via the KKT conditions that, due to the convexity of \(\sum _i y_i^3\) on positive support, all \(y_i\) must be equal, yielding the uniformly-spaced solution \(y_i = \frac{b-a}{n}\). Thus, the choice of breakpoints induced by our algorithm is optimal. \(\square \)
The NN-R1 relaxation is exactly a union of McCormick Relaxations \(2^n\) uniformly spaced breakpoints. Hence the total area is \(\tfrac{1}{4} (b-a)^3 2^{-2n}\). We now show that adding the inequality (43b) with \(j=L\) cuts off an extra fourth of the total area.
Proposition 6
The area of the relaxation in (43) is \(\tfrac{3}{16}(b-a)^3 2^{-2n}\).
Proof
We will compute the area removed by the addition of this cut on a general interval \([x_1, x_2]\), where \(x_1 = 2^{-L}i\) for some \(i \in \llbracket 0,2^L-1\rrbracket \). As shown in Lemma 6, the cut (43b) with \(j=L\) intersects the curve at \(x = \frac{x_1+x_2}{2}\). Now, the area removed by the addition of this cut is the area of the triangle formed by the intersections of the tangent lines at \(x_1\), \(x_2\), and the midpoint \(x_3 :=\frac{x_1+x_2}{2}\). These vertices, given as intersection points \(v_{ij}\) for tangent lines for \(x_i\) and \(x_j\), are derived following the process in Lemma 7 as:
From these points, we obtain vectors
Finally, we obtain cut area
The result easily follows. \(\square \)
7 A computational study
We study the efficacy of our MIP relaxation approach on a family of nonconvex quadratic optimization problems. We compare 9 methods:
-
1.
GRB: The native method in Gurobi v9.1.1 for nonconvex quadratic problems.
-
2.
GRB-S: The native method in Gurobi v9.1.1, applied to the diagonalized shift reformulation of (2).
-
3.
BRN: Baron v21.1.13, using CPLEX v12.10 for the MIP/LP solver.
-
4.
BRN-S: Baron v21.1.13, using CPLEX v12.10 for the MIP/LP solver, applied to the diagonalized shift reformulation of (2).
-
5.
CPLEX: The native method in CPLEX v12.10 for nonconvex quadratic objectives.
-
6.
CDA: The algorithm of Dong and Luo [23]. The number of layers L will correspond to the parameter \(\nu \) appearing in their paper.
-
7.
NN: The new formulation (8).
-
8.
NMDT: The “normalized multi-parametric disaggregation technique” (NMDT) of Castro [14]. See Appendix A for a restatement in terms of the number of levels L.
-
9.
T-NMDT: A tightened variant of NMDT also described in Appendix A.
We can cluster these methods into two families: five “native” methods (GRB, GRB-S, BRN, BRN-S, and CPLEX) that pass an exact representation of the quadratic problem to the solver, and four “relaxations” (CDA, NN, NMDT, and T-NMDT) which relax the quadratic problem using a MIP reformulation, which is then passed to an underlying solver. For each of these relaxations, we use Gurobi v9.1.1 as the underlying MIP solver. Note that GRB, BRN, and CPLEX are directly given (50), which is an optimization problem with linear constraints and a nonconvex quadratic objective. In contrast, GRB-S and BRN-S are given the diagonalized reformulation of (50) per (2), which is an optimization problem with a convex quadratic objective and a series of nonconvex quadratic constraints.Footnote 4
Our objective in this computational study is to measure the quality of the dual bound provided by the different methods. To place the methods on an even footing on the primal side, as initialization we run the nonconvex quadratic optimization method in Gurobi v9.1.1 with “feasible solution emphasis” to produce a good starting feasible solution. We then inject this primal objective bound as a “cut-off” for each method.
We will consider 4 metrics, which will be applied with respect to a given family of instances:
-
time: The shifted geometric mean of the solve time in seconds (shift is minimum solve time in the family).
-
gap: The shifted geometric mean of the final relative optimality gap \(\frac{|\texttt {db}-\texttt {bpb}|}{|\texttt {bpb}|}\), where \(\texttt {db}\) is the dual bound provided by the method and \(\texttt {bpb}\) is the best observed primal solution for the instance across all methods. Shift is taken as \(\max \{10^{-4}\), minimum gap observed in the family\(\}\).
-
BB: The number of instances in which the method either produced the best dual bound, or attained Gurobi’s default optimality criteria of \(\texttt {gap} < 10^{-4}\). Note that on a given instance, more than one method can potentially attain the best bound.
-
TO: The number of instances in which the solver times out and terminates due to the time limit.
We note that even if the solver terminates within the time limit (with an “optimal” solver status), the optimality gap for NN or CDA as reported in Table 3 may be nonzero, due to the fact that these two methods serve as relaxations for the original boxQP problem.
We implement each model in the JuMP algebraic modeling language [24]. To compute the shift used by the four relaxations, GRB-S, and BRN-S, we use Mosek v9.2 to solve a semidefinite programming problem to produce the “tightest” diagonal matrix \(D = {\text {diag}}(\delta )\) such that \(Q+D\) is positive semidefinite as in Dong and Luo [23]:
In Sect. 7.4 we study an alternative, simpler method for computing this shift and its computational implications. Note that this time to solve the SDP is not included in the solve time numbers, but is relatively small (on the order of a few seconds for the largest instances) and is computation that is shared by most of the approaches.
Each method is provided a time limit of 10 minutes. Computational experiments are performed on a machine with a 3.8 GHz CPU with 24 cores and 128 GB of RAM. Each solver is restricted to one thread, and all experiments for a given instance are run concurrently. Our code and the corresponding problem instances are publicly available at https://github.com/joehuchette/quadratic-relaxation-experiments.
7.1 Baseline comparison
We start by comparing our nine methods on 99 box constrained quadratic objective (boxQP) optimization problem instances as studied in Chen and Burer [17] and Dong and Luo [23]:
Despite its simple constraint structure, this is a nonconvex optimization problem when Q is not positive semidefinite, and is difficult from both a theoretical and a practical perspective.
For this baseline study, we fix each of the relaxations to use \(L=3\) layers; we will revisit this selection in Sect. 7.3. We leave as future work an implementation that iteratively refines the approximation to guarantee a pre-specified approximation error, as done by Dong and Luo [23].
We split these instances into three families: 63 “solved” instances on which each method terminates at optimality within the time limit, 18 “unsolved” instances on which each method terminates due to the time limit, and 18 “contested” instances on which some methods terminate and some do not. We present the computational results in Table 3, stratified by family. At a high level, we observe that NN attains the “best bound” on 87 of 99 instances. We now survey each family in more detail. Alternatively, we stratify the results based on the size of the instances in Appendix B.
Solved instances On the solved instances, all methods are able to terminate quickly-all in under two seconds, on average. The native methods are able to meet the termination criteria on nearly all instances, while the relaxation methods lag behind. Our new NN method performs the best, attaining the termination gap criteria on roughly half of the instances, while CDA performs the worst, attaining it on only 5 of 63 instances. We stress that, for these experiments, L is set relatively low. In Sect. 7.3 we revisit this decision, and observe that this gap can be closed on these easy instances by increasing L at a nominal computational cost.
Contested instances On the contested instances the native solvers BRN, CPLEX, and GRB perform best, producing the best bound in a clear majority of the 18 instances. Interestingly, the shifted variants BRN-S and GRB-S perform worse, with Gurobi exhibiting a substantial degradation in performance as opposed to without the diagonal shift. In contrast, the relaxations time out on a majority of the instances. Taken together, we conclude that there is a transitional family of instances wherein the native solvers still excel, but which the more complex relaxations succumb to the curse of dimensionality.
Unsolved instances This family of instances tests the scenario where a method is given a fixed time budget and is asked to produce the best possible dual bound. On these 18 instances, NN is the clear winner, producing the best bounds on 15 and the lowest mean gap. The other relaxations come relatively close in terms of termination gap, but do not attain the best bound on any instance. The native GRB performs the worst of all methods in terms of gap closed, but applying the shift as in GRB-S helps tremendously, producing gaps than are much lower than the other native solver methods and close to what the relaxations are able to provide.
7.2 Varying the solver focus
Modern solvers such as Gurobi expose high-level parameters for configuring the search algorithm for different goals. In this subsection, we configure Gurobi to focus on the best objective bound (MIPFocus=3). We summarize our results in Table 4. The story on the “solved” and “contested” instances remains roughly the same as in Sect. 7.1. However, on the “unsolved” instances all methods perform better, with the largest improvement coming from the native Gurobi methods. Nonetheless, the NN method is still attaining the best bound on 10 of 18 instances, with the GRB-S method coming close in terms of gap closed, and is able to produce the best bound on the remaining 8 instances.
7.3 Varying the relaxation resolution
In the previous experiments, we fixed the number of layers for each relaxation at \(L=3\). In this subsection, we study how varying this parameter affects each relaxation, in terms of both solve time and gap closed. In particular, we consider setting \(L \in \{2,4,6,8\}\) for each relaxation method, and experiment with the same set of 99 boxQP instances as before. We summarize the results in Table 5.
On the “solved” instances we observe that, unsurprisingly, increasing L allows us to reach the best bound criteria on far more instances. Moreover, we observe that this results in only a nominal increase in computational cost; all methods terminate with a mean solve time of seconds, even with the finest discretization. We observe that NN performs the best, in terms of mean solve time and “best bound” for each value of L considered. Morever, NN can attain the termination criteria on each instance with \(L=8\), which is not the case for any other method. These results indicate that, on easy instances, increasing the resolution is cheap, and can attain the same dual bound quality as the native solvers in roughly the same time. In contrast, on the “unsolved” instances we observe that increasing L results in higher gaps across the board. This is unsurprising–increasing L results in larger formulations, and on instances where the solver is already struggling this will quickly lead to performance degradation due to the “combinatorial explosion” effect. Moreover, even small values for L offer a nontrivial refinement in a branch-and-bound setting over a tight convex relaxation. This result suggests that, for instances known to be hard, a reasonable strategy would be to set L to a small value by default and then target finer discretizations on individual quadratic terms as-needed, through a dynamic refinement approach or otherwise.
7.4 Varying the diagonal perturbation
We now turn our attention to how the diagonal shift that is used by the relaxations, BRN-S, and GRB-S is computed. As discussed above, we may solve the SDP (49) to compute a valid shift that is “tightest” under some reasonable objective measure. While this approach is reasonable for the boxQP instances studied here, it may not be practical for larger-scale instances due to the scalability of the SDP solver. Therefore, we compare this shift against a simpler “eigenvalue” shift \(D = -\lambda _{{\text {min}}} I\), where \(I \in {\mathbb {R}}^{n \times n}\) is the identity matrix and \(\lambda _{{\text {min}}}\) is the smallest eigenvalue of Q. This minimum eigenvalue can be readily computed, and the resulting shift is conceptually similar to the convexification process used in \(\alpha \)BB [6], for example.
We perform a similar experiment as in Sect. 7.1, focusing on comparing our two shifts head-to-head for each method that utilizes it. We summarize our results in Table 6. We observe that the tighter shift provided by the SDP (49) offers a substantial improvement over the eigenvalue shift across the board. On the “solved” instances, we observe an order of magnitude reduction in solve time for all methods, as well as a significant increase in best bound attainment for the relaxation methods. On the “contested” instances, we observe a similar degradation when using the shift. The difference is perhaps most striking for GRB: on the 22 instances, produces the best bound on 16 of 22 with the SDP shift, but with the eigenvalue shift only attains it on only one, and times out on remaining 21. Finally, for the “unsolved” instances we observe that the SDP shift provides 2-3x smaller gaps than the eigenvalue shift for each method.
7.5 A (simple) problem with quadratic constraints
In this section, we present a unique class of instances on which our model displays suprisingly strong performance compared to Gurobi. In this model, we minimize a 1-norm with respect to box constraints and an additional quadratic constraint stating that the 2-norm is greater than some bound. The specific model considered is
where \(\varepsilon _i = \text {rand}(-1,1) \cdot 10^{-3}\), sorted in ascending order of \(|\varepsilon _i|\). We note that this problem can be solved in closed form.
We compare against GRB, GRB-S, and T-NMDT for various values of n, with \(L=10\). The results are shown in Table 7 below.
The results indicate a strong performance advantage of NN above the competing methods shown. Note that the number of nodes for GRB and GRB-S are consistently close to \(2^{n+1}\), with computational times to match, while T-NMDT is even worse. On the other hand, while \(\texttt {NN}{}\) shows only moderate increases in computational time, with a max of about 1.66s, with a far smaller node count to match.
Upon deeper investigation, we found that the primary computational advantage of the \(\texttt {NN}\) method stems from Gurobi’s Gomory cuts. In fact, turning off presolve, heuristics, and all cuts except for Gomory cuts, the performance significantly improves over the baseline performance. For \(n=22\) the problem solves in 0.09s with only 191 nodes and 39 Gomory cuts. For \(n=250\), over an order of magnitude higher, the problem solves in 10.65s with only 13016 nodes and 378 Gomory cuts.
We expect that Gurobi is performing a spatial branching algorithm. However, the problem was constructed so that the feasible solutions are near corners of a hypercube, while at spatial branching relaxations, optimal solutions to the relaxations are close to the center. Moreover, this property is likely to hold in a spatial branch-and-bound algorithm, meaning that you will likely need to branch on all variables in order to identify the correct corner. This behavior would yield at least \(O(2^n)\) spatial branching nodes, and give poor bounds throughout the branching process, as observed in the computational results. On the other hand, for the NN formulation provides an alternative branching structure that, when combined with Gomory cuts, provide excellent computational performance for this collection of instances.
7.6 More difficult problems with nonconvex quadratic constraints
To conclude our computational section, we study a “best nearest” variant of the boxQP problem that is in the spirit of the problem from Sect. 7.5. In more detail, for some fixed \(\hat{\gamma } \in {\mathbb {R}}\) and \({\hat{x}} \in [0,1]^n\), we solve the problem
Since each boxQP instance considered has negative objective cost, this will constrain the feasible region to those points which are “close” to optimal for the original boxQP instance. We construct 54 instances based on the the basic family of boxQP instances from Chen and Burer [17]. We set \({\hat{x}}\) as the vector of all 0.5s, and set \(\hat{\gamma }\) to be the best primal cost on the underlying boxQP instance that is found by Gurobi after 10 minutes. We summarize the results in Table 8.
On the “solved” instances, we observe that our NN relaxation has the lowest mean solve time of all methods, and is able to prove optimality on 6 of 8 methods. We note that the optimality gaps for CDA and NMDT are nearly two orders of magnitude greater than what was observed on the baseline boxQP instances in Table 3. This is in keeping with the common knowledge in the global optimization (e.g. Dey and Gupte [20]) that tight relaxations for quadratic functions in the constraints do not necessarily lead to tight relaxations in the objective.
Similar to the baseline boxQP instances, we observe that the “contested” instances are a transient class where the native methods are able to terminate within the time limit with greater frequency than the relaxations, leading to significantly smaller mean optimality gaps. On the hardest “unsolved” instances, we again see that our NN method produces the smallest optimality gap across all methods on each of the 6 instances, outperforming all other methods.
8 Conclusion
We present a simple MIP model for relaxing quadratic optimization problems that competes with robust commercial solvers in terms of solve time and bound quality. There are a number of ways that our method could be further improved. For example, we could follow the strategy of Dong and Luo [23] and implement an adaptive strategy that dynamically refines individual quadratic terms as-needed. Additionally, for boxQP instances we can potentially improve performance by leveraging the results of Hansen et al. [35], or applying existing cutting plane procedures [10]. Further, we could apply bound tightening on variables [32] or include a tail-end call to a nonlinear solver to produce an optimal primal feasible solution.
We also have performed preliminary analysis on a variant of this method to model higher-order monomials as opposed to quadratics. Fundamental results of Wei [54] show that our sawtooth functions form a basis for any continuous functions. Unfortunately, we have observed that a comparable approximation for \(x^3\) seem to require a relatively large number of basis functions. We summarize our preliminary results in Appendix C. We believe it would be interesting future work to observe if this seeming obstruction is fundamental, or if compact methods for higher-order monomials can be derived through our approach.
Notes
Furthermore, Yarotsky [57] observes that it is straightforward to represent each of the sawtooth functions as a composition of the standard ReLU activation function \(\sigma (x) = \max \{0,x\}\). For example, \(G_1(x) = 2\sigma (x) - 4 \sigma (x-\frac{1}{2}) + 2 \sigma (x-1)\). In this way, \(F_L\) can be written as a neural network with a very particular choice of architecture and weight values.
This can be accomplished in a number of ways: for example, by computing the minimum eigenvalue of D, or by solving a semidefinite programming problem [23].
In actuality, any Gray code, not just the reflected Gray code studied in this paper, yields a (potentially distinct) logarithmic formulation for a univariate function. Here, we mean the one constructed with the reflected Gray code, which is the most common choice regardless.
CPLEX does not support nonconvex quadratic constraints of this form, so we do not include a corresponding approach with the diagonal shift.
References
Adjiman, C.S., Androulakis, I.P., Floudas, C.A.: A global optimization method, \(\alpha \)bb, for general twice-differentiable constrained NLPs–II. Implementation and computational results. Comput. Chem. Eng. 22(9), 1159–1179 (1998)
Adjiman, C.S., Dallwig, S., Floudas, C.A., Neumaier, A.: A global optimization method, \(\alpha \)BB, for general twice-differentiable constrained NLPs–I. Theoretical advances. Comput. Chem. Eng. 22(9), 1137–1158 (1998)
Anderson, R., Huchette, J., Tjandraatmadja, C., Vielma, J.P.: Strong mixed-integer programming formulations for trained neural networks. In: A. Lodi, V. Nagarajan (eds.) Proceedings of the 20th Conference on Integer Programming and Combinatorial Optimization, pp. 27–42. Springer International Publishing, Cham (2019). arXiv:1811.08359
Anderson, R., Huchette, J., Tjandraatmadja, C., Vielma, J.P.: Strong mixed-integer programming formulations for trained neural networks. In: Lodi, A., Nagarajan, V. (eds.) Integer Programming and Combinatorial Optimization, pp. 27–42. Springer International Publishing, Cham (2019)
Androulakis, I., Maranas, C.D.: \(\alpha \)BB: a global optimization method for general constrained nonconvex problems. J. Glob. Optim. 7(4), 337–363 (1995)
Androulakis, I.P., Maranas, C.D., Floudas, C.A.: \(\alpha \)bb: a global optimization method for general constrained nonconvex problems. J. Glob. Optim. 7(4), 337–363 (1995)
Bader, J., Hildebrand, R., Weismantel, R., Zenklusen, R.: Mixed integer reformulations of integer programs and the affine tu-dimension of a matrix. Math. Program. 169(2), 565–584 (2018)
Billionnet, A., Elloumi, S., Lambert, A.: Extending the QCR method to general mixed-integer programs. Math. Program. 131(1–2), 381–401 (2012). https://doi.org/10.1007/s10107-010-0381-7
Billionnet, A., Elloumi, S., Lambert, A.: Exact quadratic convex reformulations of mixed-integer quadratically constrained problems. Math. Program. 158(1), 235–266 (2016). https://doi.org/10.1007/s10107-015-0921-2
Bonami, P., Günlük, O., Linderoth, J.: Globally solving nonconvex quadratic programming problems with box constraints via integer programming methods. Math. Program. Comput. 10(3), 333–382 (2018). https://doi.org/10.1007/s12532-018-0133-x
Bunel, R., Lu, J., Turkaslan, I., Torr, P.H., Kohli, P., Kumar, M.P.: Branch and bound for piecewise linear neural network verification (2019). arXiv:1909.06588
Burer, S., Saxena, A.: The MILP road to MIQCP. In: Lee, J., Leyffer, S. (eds.) Mixed Integer Nonlinear Programming, pp. 373–405. Springer, New York (2012)
Castillo, P.A.C., Castro, P.M., Mahalec, V.: Global optimization of MIQCPs with dynamic piecewise relaxations. J. Glob. Optim. 71(4), 691–716 (2018). https://doi.org/10.1007/s10898-018-0612-7
Castro, P.M.: Normalized multiparametric disaggregation: an efficient relaxation for mixed-integer bilinear problems. J. Glob. Optim. 64(4), 765–784 (2015)
Castro, P.M.: Tightening piecewise McCormick relaxations for bilinear problems. Comput. Chem. Eng. 72, 300–311 (2015). https://doi.org/10.1016/j.compchemeng.2014.03.025
Castro, P.M., Liao, Q., Liang, Y.: Comparison of mixed-integer relaxations with linear and logarithmic partitioning schemes for quadratically constrained problems. Optim. Eng. (2021). https://doi.org/10.1007/s11081-021-09603-5
Chen, J., Burer, S.: Globally solving nonconvex quadratic programming problems via completely positive programming. Math. Program. Comput. 4(1), 33–52 (2012)
Croxton, K.L., Gendron, B., Magnanti, T.L.: A comparison of mixed-integer programming models for nonconvex piecewise linear cost minimization problems. Manag. Sci. 49(9), 1268–1273 (2003)
Dantzig, G.B.: On the significance of solving linear programming problems with some integer variables. Econometrica J. Econom. Soc. 30–44 (1960)
Dey, S.S., Gupte, A.: Analysis of milp techniques for the pooling problem. Oper. Res. 63(2), 412–427 (2015)
Dey, S.S., Kazachkov, A.M., Lodi, A., Mu, G.: Cutting plane generation through sparse principal component analysis. http://www.optimization-online.org/DB_HTML/2021/02/8259.html
Dong, H.: Relaxing nonconvex quadratic functions by multiple adaptive diagonal perturbations. SIAM J. Optim. 26(3), 1962–1985 (2016)
Dong, H., Luo, Y.: Compact disjunctive approximations to nonconvex quadratically constrained programs (2018)
Dunning, I., Huchette, J., Lubin, M.: JuMP: a modeling language for mathematical optimization. SIAM Rev. 59(2), 295–320 (2017)
Elloumi, S., Lambert, A.: Global solution of non-convex quadratically constrained quadratic programs. Optim. Methods Software 34(1), 98–114 (2019). https://doi.org/10.1080/10556788.2017.1350675
Fortet, R.: L’algebre de boole et ses applications en recherche operationnelle. Trabajos de Estadistica 11(2), 111–118 (1960). https://doi.org/10.1007/bf03006558
Foss, F.A.: The use of a reflected code in digital control systems. Transactions of the I.R.E. Professional Group on Electronic Computers EC-3(4), 1–6 (1954). https://doi.org/10.1109/irepgelc.1954.6499244
Frangioni, A., Gentile, C.: Perspective cuts for a class of convex 0–1 mixed integer programs. Math. Program. Ser. A 106, 225–236 (2006)
Frangioni, A., Gentile, C.: SDP diagonalizations and perspective cuts for a class of nonseparable MIQP. Oper. Res. Lett. 35(2), 181–185 (2007)
Furini, F., Traversi, E., Belotti, P., Frangioni, A., Gleixner, A., Gould, N., Liberti, L., Lodi, A., Misener, R., Mittelmann, H., Sahinidis, N.V., Vigerske, S., Wiegele, A.: QPLIB: a library of quadratic programming instances. Math. Program. Comput. 11(2), 237–265 (2019)
Galli, L., Letchford, A.N.: A compact variant of the qcr method for quadratically constrained quadratic 0–1 programs. Optim. Lett. 8(4), 1213–1224 (2014). https://doi.org/10.1007/s11590-013-0676-8
Galli, L., Letchford, A.N.: A binarisation heuristic for non-convex quadratic programming with box constraints. Oper. Res. Lett. 46(5), 529–533 (2018). https://doi.org/10.1016/j.orl.2018.08.005
Glover, F.: Improved linear integer programming formulations of nonlinear integer problems. Manag. Sci. 22(4), 455–460 (1975). https://doi.org/10.1287/mnsc.22.4.455
Hammer, P., Ruben, A.: Some remarks on quadratic programming with 0–1 variables. Revue Francaise D Automatique Informatique Recherche Operationnelle 4(3), 67–79 (1970)
Hansen, P., Jaumard, B., Ruiz, M., Xiong, J.: Global minimization of indefinite quadratic functions subject to box constraints. Naval Res. Logist. (NRL) 40(3), 373–392 (1993). https://doi.org/10.1002/1520-6750(199304)40:3<373::AID-NAV3220400307>3.0.CO;2-A
Huchette, J., Vielma, J.P.: Nonconvex piecewise linear functions: Advanced formulations and simple modeling tools. Oper. Res. (to appear). arXiv:1708.00050
Huchette, J.A.: Advanced mixed-integer programming formulations : methodology, computation, and application. Ph.D. thesis, Massachusetts Institute of Technology (2018)
Kaibel, V., Pashkovich, K.: Constructing Extended Formulations from Reflection Relations, pp. 77–100. Springer, Berlin (2013)
Lee, J., Wilson, D.: Polyhedral methods for piecewise-linear functions I: the lambda method. Discrete Appl. Math. 108, 269–285 (2001)
Magnanti, T.L., Stratila, D.: Separable concave optimization approximately equals piecewise linear optimization. In: D. Bienstock, G. Nemhauser (eds.) Lecture Notes in Computer Science, vol. 3064, pp. 234–243. Springer (2004)
Misener, R., Floudas, C.A.: Global optimization of mixed-integer quadratically-constrained quadratic programs (MIQCQP) through piecewise-linear and edge-concave relaxations. Math. Program. 136(1), 155–182 (2012). https://doi.org/10.1007/s10107-012-0555-6
Nagarajan, H., Lu, M., Wang, S., Bent, R., Sundar, K.: An adaptive, multivariate partitioning algorithm for global optimization of nonconvex programs. J. Glob. Optim. 74, 639–675 (2019)
Padberg, M.: Approximating separable nonlinear functions via mixed zero-one programs. Oper. Res. Lett. 27, 1–5 (2000)
Pardalos, P., Vavasis, S.: Quadratic programming with one negative eigenvalue is NP-hard. J. Glob. Optim. 1(1), 15–22 (1991)
Phan-huy-Hao, E.: Quadratically constrained quadratic programming: some applications and a method for solution. Zeitschrift für Oper. Res. 26(1), 105–119 (1982)
Savage, C.: A survey of combinatorial gray codes. SIAM Rev. 39(4), 605–629 (1997)
Saxena, A., Bomani, P., Lee, J.: Convex relaxations of non-convex mixed integer quadratically constrained programs: Projected formulations. Math. Program. 130, 359–413 (2011)
Serra, T., Ramalingam, S.: Empirical bounds on linear regions of deep rectifier networks (2018). arXiv:1810.03370
Serra, T., Tjandraatmadja, C., Ramalingam, S.: Bounding and counting linear regions of deep neural networks. In: Thirty-fifth International Conference on Machine Learning (2018)
Tjeng, V., Xiao, K., Tedrake, R.: Verifying neural networks with mixed integer programming. In: International Conference on Learning Representations (2019)
Vielma, J.P., Ahmed, S., Nemhauser, G.: Mixed-integer models for nonseparable piecewise-linear optimization: unifying framework and extensions. Oper. Res. 58(2), 303–315 (2010)
Vielma, J.P., Ahmed, S., Nemhauser, G.: Mixed-integer models for nonseparable piecewise-linear optimization: unifying framework and extensions. Oper. Res. 58(2), 303–315 (2010). https://doi.org/10.1287/opre.1090.0721
Vielma, J.P., Nemhauser, G.L.: Modeling disjunctive constraints with a logarithmic number of binary variables and constraints. Math. Program. 128(1–2), 49–72 (2009). https://doi.org/10.1007/s10107-009-0295-4
Wei, Y.: Triangular function analysis. Comput. Math. Appl. 37(6), 37–56 (1999). https://doi.org/10.1016/s0898-1221(99)00075-9
Wiese, S.: A computational practicability study of MIQCQP reformulations. https://docs.mosek.com/whitepapers/miqcqp.pdf (2021). Accessed 22 Feb 2021
Xia, W., Vera, J.C., Zuluaga, L.F.: Globally solving nonconvex quadratic programs via linear integer programming techniques. INFORMS J. Comput. 32(1), 40–56 (2020). https://doi.org/10.1287/ijoc.2018.0883
Yarotsky, D.: Error bounds for approximations with deep relu networks. Neural Netw. 94, 103–114 (2017)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This work was supported by AFOSR (Grant FA9550-21-0107) and ONR (Grant N00014-20-1-2156). Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the Office of Naval Research or the Air Force Office of Scientific Research.
Appendices
Normalized multi-parametric disaggregation technique
We present a standard approach to descretizing continuous variables for handling bilinear products in nonlinear models. This approach is perhaps the most straightforward way to convert bilinear problems to MILPs and has been referred to as Normalized Multi-Parametric Disaggregation Technique (NMDT) [14]. We adapt the bilinear approach here to a squaring a single variable.
Consider \(x \in [0,1]\), and let L be a positive integer. We then use the representation
where L is the number of binary variables to use.
Multiplying (52a) by x, and substituting the representation into the \(x \varDelta x\) term, we obtain
Now, using the fact that \(x + \varDelta x \in [0, 1+2^{-L}]\), first lift the model by adding variables \(u_i\) and \(\varDelta u\) such that \(u_i = (x + \varDelta x) \beta _i\) and \(\varDelta u = \varDelta x^2\), and then we relax these equations using McCormick Envelopes.
Given bounds \(x \in [ {x}^{\min }, {x}^{\max }]\) and \(\beta \in [0, 1]\), The McCormick envelope \({\mathcal {M}}(x,\beta )\) is defined as the following relaxation of \(u = x \beta \)
To approximate \(u = x^2\) with \(x \in [0, {x}^{\max }]\), this becomes
We present two ways to use this approach. The first is the most direct use of \(\texttt {NMDT}{}\), as used in [14]. This model is
Here, the only error introduced in the relaxation is from \(\varDelta u = x\varDelta x\), yielding a maximum error of \(2^{-L-2}\), again occurring when \(\varDelta x = 2^{-L-1}\).
Alternatively, we consider the expansion of the \(x \varDelta x\) term. We thus obtain the T-NMDT relaxation for \(y=x^2\).
Since \(\beta _i\) is binary, \(u_i = \beta _i (x + \varDelta x)\) is represented exactly. Thus, the only possible error is introduced in the relaxation of \(\varDelta y = \varDelta x^2\), which yields a maximum error of \(2^{-2L-2}\), occurring when \(\varDelta x = 2^{-L-1}\).
Now, the expected error of T-NMDT is the expected error from the relaxation of \(\varDelta y = \varDelta x^2\). Modeling \(\varDelta x\) as a uniform random variable within its bounds \([0,2^{-L}]\), and noting that the only overestimator from (56) is \(y \le 2^{-L} \varDelta x\) we obtain expected overapproximation error
Similarly, the expected underapproximation error can be computed as \(\frac{1}{12} 2^{-2L}\).
Additional baseline computation summaries
In Table 9 we summarize the results of our baseline experiments stratified by the number of decision variables as in, e.g., Table 4 of Dey et al. [21].
General representations with sawtooth bases
The premise of our formulation is that the function \(y=x^2\) can be arbitrarily closely approximated by a series of sawtooth functions. We discuss here if such approximations could conveniently apply to other polynomials.
In [54], the authors present a Fourier series-like method that leverages orthogonal triangular functions to derive a convergent class of \(L_2\)-optimal approximations for general functions on the interval \([-\pi ,\pi ]\). Define the periodic triangular functions
The authors then build their orthogonal basis functions using an orthogonal linear transformation of the basis
However, as with Fourier series approximations, this method has the limitation that all approximating functions are equal at the endpoints of the interval, resulting in a poor approximation for functions at which the endpoints are not equal. Thus, to obtain good approximations for \(x^3\) on \([-\pi ,\pi ]\), we first add the linear function \(-\pi ^2 x\) to enforce equality at the endpoints.
Then, applying this method to \(x^2\) and \(x^3 - \pi ^2 x\) on the interval \(x \in [-\pi ,\pi ]\), we obtain the following numbers for the (\(L_1\)-error). Note that almost all of the Y(nx) functions are relevant for approximating \(x^3 - \pi ^2 x\) (and no X(nx)’s), while only a few X(nx) functions (and no \(Y(nx)'s\)) are relevant for approximating \(x^2\).
To investigate the outlook of sparsely approximating \(x^3\) with triangular functions directly, we solved the following MIP to obtain the \(L_1\)-optimal triangular approximation to \(x^3\) on the interval [0, 1] using re-scaled versions of the basis functions above, and explicitly including a linear shift. We discretely approximate the \(L-1\) error via the error at uniformly-spaced points \(x_1, \dots , x_{N_p} \in [0,1]\), allowing the inclusion of only \(N_f\) triangular functions.
The result, shown in Fig. 4, suggests that it is not possible to use this triangular basis to obtain a similar-quality sparse approximation for \(x^3\) as for \(x^2\): the best achievable error rate for \(x^3\) is roughly \(O(N_f^{-2})\), compared to \(O(2^{-2N_f})\) for the quadratic. See also Table 10 where we compare the convergence of the two approximations.

The \(L_1\)-error of \(x^3\) vs. the number of approximating triangular functions \(N_f\). The equation of the regression line suggests an asymtotic error rate of roughly \(O(N_f^{-2})\), compared to \(O(2^{-2N_f})\) for the quadratic
Rights and permissions
About this article

Cite this article
Beach, B., Hildebrand, R. & Huchette, J. Compact mixed-integer programming formulations in quadratic optimization. J Glob Optim 84, 869–912 (2022). https://doi.org/10.1007/s10898-022-01184-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10898-022-01184-6