
Abstract
A number of recent works have emphasized the prominent role played by the Kurdyka-Łojasiewicz inequality for proving the convergence of iterative algorithms solving possibly nonsmooth/nonconvex optimization problems. In this work, we consider the minimization of an objective function satisfying this property, which is a sum of two terms: (i) a differentiable, but not necessarily convex, function and (ii) a function that is not necessarily convex, nor necessarily differentiable. The latter function is expressed as a separable sum of functions of blocks of variables. Such an optimization problem can be addressed with the Forward–Backward algorithm which can be accelerated thanks to the use of variable metrics derived from the Majorize–Minimize principle. We propose to combine the latter acceleration technique with an alternating minimization strategy which relies upon a flexible update rule. We give conditions under which the sequence generated by the resulting Block Coordinate Variable Metric Forward–Backward algorithm converges to a critical point of the objective function. An application example to a nonconvex phase retrieval problem encountered in signal/image processing shows the efficiency of the proposed optimization method.
Similar content being viewed by others

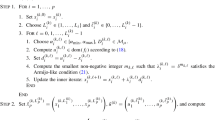

Avoid common mistakes on your manuscript.
1 Introduction
In this work, we are interested in the following optimization problem:
where \(G: {\mathbb {R}} ^N \rightarrow (-\infty ,+ \infty ]\) is a coercive function (i.e. \(\lim _{\Vert {\varvec{x}} \Vert \rightarrow +\infty } G({\varvec{x}}) = +\infty \)), \(F\) is a differentiable function, \(R\) is a proper lower semicontinuous function which is additively block separable, and \(\underset{\begin{array}{c} {} \end{array}}{\mathrm {Argmin}}\;G \ne {\varnothing }\) denotes the set of minimizers of G. More precisely, let \((\mathbb {J}_j)_{1 \le j \le J}\) be a partition of \(\{1,\ldots ,N\}\) into \(J\ge 2 \) subsets, and for every \(j\in \{1,\ldots ,J\}\), let \(N_j\ne 0\) be the cardinality of \(\mathbb {J}_j\). Any vector \({\varvec{x}} \in {\mathbb {R}} ^N\) with elements \((x^{(n)})_{1\le n \le N}\) is block-decomposed into \(\left( \varvec{x}^{(j)}\right) _{1 \le j \le J} \in {\mathbb {R}} ^{N_1} \times \ldots \times {\mathbb {R}} ^{N_J}\), where, for every \(j \in \{1, \ldots , J\}\), \(\varvec{x}^{(j)}= \left( x^{(n)}\right) _{n \in \mathbb {J}_j} \in {\mathbb {R}} ^{N_j}\). With this notation, we assume that
where for every \(j \in \{ 1, \ldots , J \}\), \(R_j:{\mathbb {R}} ^{N_j} \rightarrow (-\infty , +\infty ]\).
A standard approach for solving (1) in this context consists of using a Block Coordinate Descent (BCD) algorithm, where, at each iteration \(\ell \in {\mathbb {N}} \), \(G\) is minimized with respect to the \(j_\ell \) block coordinates with \(j_\ell \in \{1, \ldots ,J\}\), while the others remain fixed, leading to the following iterations:
In the above algorithm, for every \(j \in \{1, \ldots , J\}\), \(\overline{\jmath }\) denotes the complementary set of j on \( \{1, \ldots , J\}\), i.e. \(\overline{\jmath } := \{1,\ldots ,J\}{\setminus } \{j\}\), and for every \({\varvec{x}} \in {\mathbb {R}} ^N\), \({\varvec{x}} ^{(\overline{\jmath })} := \left( {\varvec{x}} ^{(1)}, \ldots , {\varvec{x}} ^{(j - 1)}, {\varvec{x}} ^{(j + 1)}, \ldots , {\varvec{x}} ^{(J)} \right) \). Moreover, for a given \({\varvec{x}} ^{(\overline{\jmath })} \in \times _{i \in \overline{\jmath }} {\mathbb {R}} ^{N_i}\), function \(F_{j}( \cdot , \varvec{x}^{(\overline{\jmath })}) :{\mathbb {R}} ^{N_j} \rightarrow {\mathbb {R}} \) is the partial function defined as
The BCD method (3) is described in various reference books [9, 35, 43, 62] assuming a cyclic rule, i.e.
In this case, since Algorithm (3) can be viewed as a generalization of the Gauss-Seidel strategy for solving linear systems [29], it is sometimes also referred to as a nonlinear Gauss-Seidel method ([9, Chap.2], [43, Chap.7]). Up to the best of our knowledge, one of the most general convergence results for the BCD algorithm (3) has been established in [58] under the assumptions that (i) G is quasi-convex and hemivariate regular in each block, (ii) \((j_\ell )_{\ell \in {\mathbb {N}}}\) follows an essentially cyclic rule (i.e. blocks can be updated in an arbitrary manner as far as each of them is updated at least once within a given number of iterations) and (iii) either G is pseudoconvex in every pair of blocks or has at most one minimizer with respect to each block. As pointed out in [58], the last assumption is sharp in the sense that the algorithm may not converge if we only assume that G is convex w.r.t. each block (see an illustration in [45]). The proximal version of the BCD algorithm, introduced in [5], allows this limitation to be overcome. It is defined as follows:
where for every \(\ell \in {\mathbb {N}} \), \(\gamma _\ell \in (0,+\infty )\) and \({\varvec{A}} _{j_\ell }(\varvec{x}_\ell )\in {\mathbb {R}} ^{N_{j_\ell } \times N_{j_\ell }}\) is a symmetric positive definite matrix. Hereabove, \({\text {prox}}_{\psi }^{{\varvec{U}}}\) denotes the so-called proximity operator of a proper lower semicontinuous function \(\psi :{\mathbb {R}} ^{M} \rightarrow {\mathbb {R}} \) relative to the metric induced by a symmetric positive definite matrix \({\varvec{U}} \in {\mathbb {R}} ^{M\times M}\) (see Sect. 2.1). Note that Algorithm (6) has been extended in [8] for Bregman projection operators, in the case when \(J = 2\), \(F\) is a Bregman distance and \(R_1\), \(R_2\) are convex functions. Note also that, when \(F\equiv 0\) and, for every \(j \in \{1, \ldots ,J\}\), \(R_j\) is the indicator function of a convex set, Algorithm (6) allows us to recover the celebrated POCS (Projection Onto Convex Sets) algorithm [14].
The convergence of the sequence \(\left( \varvec{x}_\ell \right) _{\ell \in {\mathbb {N}}}\) generated by Algorithm (6) to a solution to (1) has been established in [5] for a convex Lipschitz differentiable function F and proper lower semicontinous convex functions \((R_j)_{1\le j \le J}\), in the case when \((j_\ell )_{\ell \in {\mathbb {N}}}\) follows a cyclic rule, and \(({\varvec{A}} _{j_\ell }(\varvec{x}_\ell ))_{\ell \in {\mathbb {N}}}\) are identity matrices. Recently, the convergence of the proximal BCD iterates to a critical point of G in the case of nonconvex functions F and \((R_j)_{1\le j \le J}\), has been proved in [3] when \(({\varvec{A}} _{j_\ell }(\varvec{x}_\ell ))_{\ell \in {\mathbb {N}}}\) are identity matrices, and then generalized in [4] for general symmetric positive definite matrices \(({\varvec{A}} _{j_\ell }(\varvec{x}_\ell ))_{\ell \in {\mathbb {N}}}\), again assuming a cyclic rule. The convergence studies in [3, 4] mainly rely on the assumption that the objective function G satisfies the Kurdyka-Łojasiewicz (KL) inequality [34]. The interesting point is that this inequality holds for a wide class of functions such as real analytic functions, semi-algebraic functions and many others [10, 11, 33, 34]. Since the proximal step in (6) is not explicit in general, an inexact version of the proximal BCD method is also considered in [4], with similar convergence guarantees.
Another strategy to circumvent the difficulty of solving the block subproblems in (6) is to replace, at each iteration, the proximal step by a Forward–Backward step, thus leading to the so-called Block Coordinate Variable Metric Forward–Backward (BC-VMFB) algorithm:
where for every \({\varvec{x}} \in {\mathbb {R}} ^N\) and \(j \in \{1,\ldots ,J\}\), \(\nabla _{j}F({\varvec{x}}) \in {\mathbb {R}} ^{N_j} \) is the partial gradient of \(F\) with respect to \(\varvec{x}^{(j)}\) computed at \({\varvec{x}} \). Algorithm (7) was firstly introduced in [16] for the minimization of the Burg entropy function under linear constraints, and then extended to the more general case of a smooth function F [36, 37]. Recently, the convergence of this algorithm has been studied in the case of an arbitrary nonsmooth function R under the assumptions that G satisfies the KL inequality and F is Lipschitz differentiable [13, 27, 60]. The convergence of the sequence \(\left( \varvec{x}_\ell \right) _{\ell \in {\mathbb {N}}} \) generated by (7) to a critical point of (1) has been proved in [60] in the case when F and R are respectively convex and convex w.r.t. each block variable, and generalized in [13] when neither F nor R is necessarily convex. Note that the aforementioned works considered actually a simplified version of Algorithm (7) where \(({\varvec{A}} _{j_\ell }(\varvec{x}_\ell ))_{\ell \in {\mathbb {N}}}\) are identity matrices and the sequence \((j_\ell )_{\ell \in {\mathbb {N}}}\) follows a cyclic rule. The BC-VMFB algorithm is then referred to as the Proximal Alternating Linearized Minimization (PALM) algorithm [13]. A variant of PALM algorithm with similar convergence guarantees has been recently proposed in [30], alternating between Forward–Backward and proximal steps. Another related work is [61], where the convergence properties of PALM in the case of an essentially cyclic rule are studied.
An exact (resp. inexact) version of Algorithm (7) with general symmetric positive definite matrices \(({\varvec{A}} _{j_\ell }(\varvec{x}_\ell ))_{\ell \in {\mathbb {N}}}\) is studied in [51] (resp. [57]), in the context of a random rule, i.e., for every \(\ell \in {\mathbb {N}} \), \(j_\ell \) is a realization of a uniform random variable. Assuming that F and \(R_j\) are convex, the authors establish the convergence of the sequence \(\left( G( \varvec{x}_\ell )\right) _{\ell \in {\mathbb {N}}}\) in the sense that, for all \(\delta \ge 0\) and \(\epsilon \ge 0\), there exists \(\ell _0 \in {\mathbb {N}} \) such that the probability of having \(G(\varvec{x}_{\ell _0}) - G(\widehat{{\varvec{x}}}) \le \epsilon \) is greater than \(1 - \delta \) (see also [20] for almost sure convergence results). Finally, let us emphasize that, as already noticed in [47], for carefully chosen matrices \(({\varvec{A}} _{j_\ell }(\varvec{x}_\ell ))_{\ell \in {\mathbb {N}}}\), the BC-VMFB algorithm can be viewed as a particular form of the block alternating majorize–minimize (MM) approach proposed in [25, 53, 56] in the context of image reconstruction. Therefore, some convergence properties of Algorithm (7) can be deduced from those derived in [32] in the case when \(R_j\) are indicator functions of closed convex subsets of \({\mathbb {R}} ^{N_j}\), and in [47] for arbitrary nonsmooth convex functions \(R_j\). However, it should be noticed that the convergence of \(\left( \varvec{x}_\ell \right) _{\ell \in {\mathbb {N}}}\) to a solution to (1) is only proved in [32, 47] under specific assumptions, in particular the uniqueness of solutions to each block subproblem and to the initial problem (1) is required.
In this paper, we consider an inexact version of (7) where the preconditioning matrices \(({\varvec{A}} _{j_\ell }(\varvec{x}_\ell ))_{\ell \in {\mathbb {N}}}\) are chosen according to MM arguments. The convergence of the proposed algorithm is established for blocks following an essentially cyclic rule, under weak assumptions on the involved functions (G is mainly assumed to satisfy the KL inequality similarly to [4]). Note that this convergence study generalizes our previous work [18] (see also [42] for a related approach, and [22] for the case when the functions are convex) which was restricted to an inexact Variable Metric Forward–Backward algorithm without block alternation (i.e. \(J = 1\) and \(N_1 = N\)).
In a recent work [27], other authors have independently and concurrently established the convergence of the iterates generated by a version of Algorithm (7) for a class of nonconvex problems that encompasses the one we consider here. The main difference with respect to our work is that their approach is restricted to the use of a cyclic updating rule for the sequence \((j_\ell )_{\ell \in {\mathbb {N}}}\). By contrast, our analysis allows more flexibility in the choice of the blocks, since the essentially cyclic rule assumption we adopt makes it possible to update some of the target variables more frequently than others. Such a strategy appears to be of major interest in terms of numerical performance in some applications (see, for instance, [48]). Due to this fact, our convergence study significantly differs from the one conducted in [27]. The application to phase reconstruction provided in Sect. 4, which deals with an important problem in signal processing, is also completely novel. Table 1 hereafter summarizes the differences/similarities between our work and existing works, by precising whether convergence results are available for the sequence of iterates, or only for the sequence of objective function values.
The rest of the paper is organized as follows: Sect. 2 introduces the assumptions made in the paper and presents the proposed inexact BC-VMFB strategy. Section 3 investigates the convergence properties. In particular, the convergence rate of the proposed algorithm is studied. Finally, Sect. 4 provides some numerical results and a discussion of the algorithm performance by means of experiments concerning a large-size image reconstruction problem.
2 Proposed optimization method
2.1 Analysis background
Let us first recall some definitions and the notation that will be used throughout the paper. We define the weighted norm:
where \(\left\langle \cdot , \cdot \right\rangle \) is the standard scalar product of \({\mathbb {R}} ^N\) and \({\varvec{U}} \in {\mathbb {R}} ^{N \times N}\) is some symmetric positive definite matrix. Moreover, for every \({\varvec{U}} _1 \in {\mathbb {R}} ^{N \times N}\) and \({\varvec{U}} _2 \in {\mathbb {R}} ^{N \times N}\), we define the Loewner partial order on \({\mathbb {R}} ^{N \times N}\) as
Definition 2.1
Let \(\psi \) be a function from \({\mathbb {R}} ^N\) to \((-\infty ,+\infty ]\). The domain of \(\psi \) is \({\text {dom}}\,\psi := \{{\varvec{x}} \in {\mathbb {R}} ^N : \psi ({\varvec{x}}) < + \infty \}\). Function \(\psi \) is proper iff \({\text {dom}}\,\psi \) is nonempty. The level set of \(\psi \) at height \(\delta \in {\mathbb {R}} \) is \({\text {lev}}_{\le \delta }\psi := \{ {\varvec{x}} \in {\mathbb {R}} ^N : \psi ({\varvec{x}}) \le \delta \}\).
Definition 2.2
[52, Def. 8.3],[39, Sec.1.3] Let \(\psi :{\mathbb {R}} ^N \rightarrow (-\infty ,+\infty ]\) be a proper function and let \({\varvec{x}} \in {\text {dom}}\,\psi \). The Fréchet sub-differential of \(\psi \) at \({\varvec{x}} \) is the following set:
If \({\varvec{x}} \not \in {\text {dom}}\,\psi \), then \(\widehat{\partial }\psi ({\varvec{x}}) = {\varnothing }\).
The sub-differential of \(\psi \) at \({\varvec{x}} \) is defined as
Remark 2.1
-
(i)
A necessary condition for \({\varvec{x}} \in {\mathbb {R}} ^N\) to be a minimizer of \(\psi \) is that \({\varvec{x}} \) is a critical point of \(\psi \), i.e. \({\mathbf {0}} \in \partial \psi ({\varvec{x}})\). Moreover, if \(\psi \) is convex, this condition is also sufficient.
-
(ii)
Definition 2.2 implies that \(\partial \psi \) is closed [4], that is: Let \( ({\varvec{y}} _k, {\varvec{t}} _k)_{k \in {\mathbb {N}}} \) be a sequence of \({\text {Graph}}\,\partial \psi := \left\{ ({\varvec{x}},{\varvec{t}}) \in {\mathbb {R}} ^N \times {\mathbb {R}} ^N : {\varvec{t}} \in \partial \psi ({\varvec{x}}) \right\} \). If \(\left( {\varvec{y}} _k, {\varvec{t}} _k \right) \) converges to \( \left( {\varvec{x}}, {\varvec{t}} \right) \) and \( \psi ( {\varvec{y}} _k ) \) converges to \( \psi ( {\varvec{x}}) \), then \(( {\varvec{x}}, {\varvec{t}}) \in {\text {Graph}}\,\partial \psi \).
The proximity operator ([31, Sec. XV.4], [21] and [4]) is defined as follows:
Definition 2.3
Let \(\psi :{\mathbb {R}} ^N \rightarrow (-\infty ,+\infty ]\) be a proper, lower semicontinuous function, let \({\varvec{U}} \in {\mathbb {R}} ^{N \times N}\) be a symmetric positive definite matrix, and let \({\varvec{x}} \in {\mathbb {R}} ^N\). The proximity operator of \(\psi \) at \({\varvec{x}} \) relative to the metric induced by \({\varvec{U}} \) is defined as
Remark 2.2
-
(i)
In the above definition, since \(\Vert \cdot \Vert _{\varvec{U}} ^2\) is coercice and \(\psi \) is proper and lower semicontinuous, if \(\psi \) is bounded from below by an affine function, then \({\text {prox}}_{\psi }^{{\varvec{U}}}\) is a nonempty set.
-
(ii)
If \({\varvec{U}} \) is equal to \({\mathbf {I}}_N\), the identity matrix of \({\mathbb {R}} ^{N \times N}\), then \({\text {prox}}_\psi \equiv {\text {prox}}_{\psi }^{{\mathbf {I}}_N}\) is the proximity operator employed in [4]. In addition, if \(\psi \) is a convex function, then the minimizer of \( \psi + \frac{1}{2} \Vert \cdot - {\varvec{x}} \Vert ^2_{\varvec{U}} \) is unique and \({\text {prox}}_\psi \equiv {\text {prox}}_{\psi }^{{\mathbf {I}}_N}\) is the proximity operator originally defined in [40].
2.2 Assumptions
In the remainder of this paper, we will focus on functions \(F\) and \(R\) satisfying the following assumptions:
Assumption 2.1
-
(i)
For every \(j \in \{ 1, \ldots , J\}\), \(R_j:{\mathbb {R}} ^{N_j}\rightarrow (-\infty ,+\infty ]\) is proper, lower semicontinuous, bounded from below by an affine function and its restriction to its domain is continuous.
-
(ii)
\(F:{\mathbb {R}} ^N \rightarrow {\mathbb {R}} \) is differentiable. Moreover, \(F\) has an L-Lipschitzian gradient on \({\text {dom}}\,R\) where \(L > 0\), i.e.,
$$\begin{aligned} \left( \forall ({\varvec{x}}, {\varvec{y}}) \in ({\text {dom}}\,R)^2 \right) \quad \Vert \nabla F({\varvec{x}}) - \nabla F({\varvec{y}}) \Vert \le L \Vert {\varvec{x}}- {\varvec{y}} \Vert . \end{aligned}$$ -
(iii)
\(G\) is coercive.
Some comments on these assumptions which will be useful in the rest of the paper are made below.
Remark 2.3
-
(i)
Assumption 2.1(ii) is weaker than the assumption of Lipschitz differentiability of \(F\) usually adopted to prove the convergence of the FB algorithm [4, 23]. In particular, if \({\text {dom}}\,R\) is compact and \(F\) is twice continuously differentiable, Assumption 2.1(ii) holds.
-
(ii)
According to Assumption 2.1(ii), \({\text {dom}}\,R\subset {\text {dom}}\,F= {\mathbb {R}} ^N \). Thus, as a consequence of Assumption 2.1(i), \({\text {dom}}\,G= {\text {dom}}\,R\) is nonempty.
-
(iii)
Under Assumption 2.1, \(G\) is proper and lower semicontinuous, and its restriction to its domain is continuous. In particular, due to the coercivity of \(G\), for every \({\varvec{x}} \in {\text {dom}}\,R\), \({\text {lev}}_{\le G({\varvec{x}})}G\) is a compact set. Moreover, the set of minimizers of \(G\) is nonempty and compact.
-
(iv)
If, for every \(j \in \{1, \ldots , J\}\), \(R_j\) is proper, lower semicontinuous and convex, then \(R_j\) is bounded from below by an affine function.
Assumption 2.2
Function \(G\) satisfies the Kurdyka-Łojasiewicz (KL) inequality i.e., for every \(\xi \in {\mathbb {R}} \), and, for every bounded subset E of \({\mathbb {R}} ^N\), there exist three constants \(\kappa \in (0,+\infty )\), \(\zeta \in (0,+\infty )\) and \(\theta \in [0,1)\) such that
for every \({\varvec{x}} \in E\) such that \(|G({\varvec{x}})-\xi | \le \zeta \) (with the convention \(0^0 = 0\)).
Remark 2.4
Note that a more general local version of Assumption 2.2 can be found in the literature [11, 12]. Nonetheless, as emphasized in [2], Assumption 2.2 is satisfied for a very wide class of functions, such as, in particular, real analytic and semi-algebraic functions.
Some matrices serving to define some appropriate variable metric will play a central role in the algorithm proposed in this work. More specifically, let \(j_{\ell } \in \{1, \ldots , J\}\) be the index of the block selected at iteration \(\ell \in {\mathbb {N}} \) of Algorithm (7), let \(\varvec{x}_\ell \in {\text {dom}}\,R\) be the associated iterate and let \({\varvec{A}} _{j_\ell }(\varvec{x}_\ell )\in {\mathbb {R}} ^{N_{j_{\ell }} \times N_{j_{\ell }}}\) be a symmetric positive definite matrix that fulfills the following so-called majorization condition:
Assumption 2.3
-
(i)
The quadratic function defined as
$$\begin{aligned} (\forall \varvec{y}\in {\mathbb {R}} ^{N_{j_\ell }})\quad Q_{j_\ell }(\varvec{y} \left| \right. \varvec{x}_\ell ):= & {} F(\varvec{x}_\ell ) + \left\langle \varvec{y}- \varvec{x}^{(j_\ell )}_\ell , \nabla _{j_\ell }F(\varvec{x}_\ell ) \right\rangle \\&+ \frac{1}{2} \left\langle \varvec{y}-\varvec{x}^{(j_\ell )}_\ell , {\varvec{A}} _{j_\ell }(\varvec{x}_\ell )(\varvec{y}-\varvec{x}^{(j_\ell )}_\ell )\right\rangle , \end{aligned}$$is a majorant function of \(F_{j_\ell }( \cdot , \varvec{x}_\ell ^{(\overline{\jmath }_\ell )})\) at \(\varvec{x}^{(j_\ell )}_\ell \) on \({\text {dom}}\,R_{j_\ell } \), i.e.,
$$\begin{aligned} (\forall \varvec{y}\in {\text {dom}}\,R_{j_\ell }) \quad F_{j_\ell }( \varvec{y} , \varvec{x}_\ell ^{(\overline{\jmath }_\ell )}) \le Q_{j_\ell }(\varvec{y} \left| \right. \varvec{x}_\ell ). \end{aligned}$$ -
(ii)
There exists \((\underline{\nu },\overline{\nu })\in (0, +\infty )^2\) such that
$$\begin{aligned} (\forall \ell \in {\mathbb {N}}) \quad \underline{\nu } \mathbf {I}_{N_{j_\ell }} \preceq {\varvec{A}} _{j_\ell }(\varvec{x}_\ell )\preceq \overline{\nu } \mathbf {I}_{N_{j_\ell }}. \end{aligned}$$
Remark 2.5
-
(i)
Note that it is not necessary to build a quadratic majorant of \(F_{j}( \cdot , \varvec{x}^{(\overline{\jmath })})\) on \({\text {dom}}\,R_j\), for every \(j \in \{1, \ldots , J\}\) and for every \(\varvec{x}^{(\overline{\jmath })}\in \times _{i \in \overline{\jmath }} {\text {dom}}\,R_i\).
-
(ii)
Suppose that, for every \({\varvec{x}} '\in {\text {dom}}\,R\), a quadratic majorant function of \(F\) on \({\text {dom}}\,R\) is given by
$$\begin{aligned} (\forall {\varvec{x}} \in {\mathbb {R}} ^N)\quad Q({\varvec{x}} \left| \right. \varvec{x}') : = F({\varvec{x}} ') + \left\langle {\varvec{x}}- {\varvec{x}} ' , \nabla F({\varvec{x}} ') \right\rangle + \frac{1}{2} \left\langle {\varvec{x}}- {\varvec{x}} ', {\varvec{B}} (\varvec{x}')({\varvec{x}}- {\varvec{x}} ') \right\rangle ,\nonumber \\ \end{aligned}$$(11)where \({\varvec{B}} (\varvec{x}')\in {\mathbb {R}} ^{N \times N}\) is a symmetric positive definite matrix. Then, Assumption 2.3(i) is satisfied for \({\varvec{A}} _{j_\ell }(\varvec{x}_\ell )= ( B(\varvec{x}_\ell )^{(n,n')} )_{ (n,n') \in \mathbb {J}_{j_\ell }^2}\), where, for every \((n,n')\in \{1, \ldots , N\}^2\), \(B(\varvec{x}_\ell )^{(n,n')}\) denotes the \((n,n')\) element of matrix \({\varvec{B}} (\varvec{x}_\ell )\). Moreover, if there exists \((\underline{\nu }, \overline{\nu }) \in (0,+\infty )^2\) such that, for every \({\varvec{x}} ' \in {\text {dom}}\,R\), \(\underline{\nu } \mathbf {I}_N \preceq {\varvec{B}} (\varvec{x}')\preceq \overline{\nu } \mathbf {I}_N\), then Assumption 2.3(ii) is also satisfied.
-
(iii)
If \({\text {dom}}\,R\) is convex, the existence of the majorant function (11) is ensured when \(F\) satisfies Assumption 2.1(ii) (see [18, Lem. 3.1]).
Moreover, in order to ensure that each block is updated an infinite number of times, we make the following assumption, which is equivalent to the essentially cyclic rule from [58]:
Assumption 2.4
Let \((j_\ell )_{\ell \in {\mathbb {N}}}\) be the sequence of updated block indices. There exists a constant \(K \ge J\) such that, for every \(\ell \in {\mathbb {N}} \), \( \{1, \ldots , J\} \subset \{j_{\ell }, \ldots , j_{\ell +K-1} \} \).
Note that the blocks do not need to be updated in any specific order.
Finally, we suppose that, for every \(\ell \in {\mathbb {N}} \), the stepsize \(\gamma _{\ell }\) involved in Algorithm (7) satisfies the following assumption:
Assumption 2.5
There exists \((\underline{\gamma },\overline{\gamma }) \in (0,+\infty )^2 \) such that, for every \(\ell \in {\mathbb {N}} \), one of the following statements holds:
-
(i)
\(\underline{\gamma }\le \gamma _{\ell } \le 1 - \overline{\gamma }\),
-
(ii)
\(R_{j_\ell }\) is a convex function and \(\underline{\gamma }\le \gamma _{\ell } \le 2 (1- \overline{\gamma })\).
Remark 2.6
Assumption 2.5 can be interpreted as the fact that, for every \(j\in \{1,\ldots ,J\}\), larger stepsizes can be used when \(R_j\) is convex. More precisely, if \(R_j\) is nonconvex, the stepsize is restricted to (0, 1), whereas it can belong to (0, 2) if \(R_j\) is convex.
2.3 Inexact BC-VMFB algorithm
In general, the proximity operator relative to an arbitrary metric does not have a closed form expression. To circumvent this difficulty, we propose to solve Problem (1) by introducing the following inexact version of Algorithm (7):

Remark 2.7
As already mentioned, under our working assumptions, Algorithm (12) can be viewed as an inexact version of Algorithm (7). To see this, let us consider sequences \((\varvec{x}_\ell )_{\ell \in {\mathbb {N}}}\) and \((j_\ell )_{\ell \in {\mathbb {N}}}\) generated by Algorithm (7). Let \(\ell \in {\mathbb {N}} \).
-
(i)
Suppose that Assumption 2.5(i) holds. Due to the definition of the proximity operator, we have,
$$\begin{aligned} R_{j_\ell }\big (\varvec{x}^{(j_\ell )}_{\ell +1}\big )+\left\langle \varvec{x}^{(j_\ell )}_{\ell +1}- \varvec{x}^{(j_\ell )}_\ell , \nabla _{j_\ell }F(\varvec{x}_\ell )\right\rangle +\frac{\gamma _\ell ^{-1}}{2} \left\| \varvec{x}^{(j_\ell )}_{\ell +1}-\varvec{x}^{(j_\ell )}_\ell \right\| _{{\varvec{A}} _{j_\ell }(\varvec{x}_\ell )}^2\le R_{j_\ell }\big (\varvec{x}^{(j_\ell )}_\ell \big ), \end{aligned}$$so that the sufficient-decrease condition (12a) holds with \( \alpha = (1 - \overline{\gamma })^{-1}/2 \) (as \(\gamma _\ell ^{-1} \ge (1-\overline{\gamma })^{-1} > 1\)).
-
(ii)
Suppose now that Assumption 2.5(ii) holds. Due to the variational characterization of the proximity operator and the convexity of \(R_{j_\ell }\), there exists \(\varvec{r}^{(j_\ell )}_{\ell +1}\in \partial R_{j_\ell }(\varvec{x}^{(j_\ell )}_{\ell +1})\) such that
$$\begin{aligned} \left\{ \begin{array}{l} \varvec{r}^{(j_\ell )}_{\ell +1}= - \nabla _{j_\ell }F(\varvec{x}_\ell ) + \gamma _\ell ^{-1} {\varvec{A}} _{j_\ell }(\varvec{x}_\ell )(\varvec{x}^{(j_\ell )}_\ell - \varvec{x}^{(j_\ell )}_{\ell +1}) \\ \left\langle \varvec{x}^{(j_\ell )}_{\ell +1}- \varvec{x}^{(j_\ell )}_\ell , \varvec{r}^{(j_\ell )}_{\ell +1}\right\rangle \ge R_{j_\ell }(\varvec{x}^{(j_\ell )}_{\ell +1}) - R_{j_\ell }(\varvec{x}^{(j_\ell )}_\ell ), \end{array} \right. \end{aligned}$$which yields
$$\begin{aligned} R_{j_\ell }(\varvec{x}^{(j_\ell )}_{\ell +1}) + \left\langle \varvec{x}^{(j_\ell )}_{\ell +1}- \varvec{x}^{(j_\ell )}_\ell , \nabla _{j_\ell }F(\varvec{x}_\ell ) \right\rangle + \gamma _\ell ^{-1} \left\| \varvec{x}^{(j_\ell )}_{\ell +1}-\varvec{x}^{(j_\ell )}_\ell \right\| _{{\varvec{A}} _{j_\ell }(\varvec{x}_\ell )}^2 \le R_{j_\ell }(\varvec{x}^{(j_\ell )}_\ell ), \end{aligned}$$so that the sufficient-decrease condition (12a) holds with the same value of \(\alpha \) as in case (i) (since \(\gamma _\ell ^{-1} \ge (2-2\overline{\gamma })^{-1} > 1/2\)).
Secondly, according to the variational characterization of the proximity operator, there exists \(\varvec{r}^{(j_\ell )}_{\ell +1}\in \partial R_{j_\ell }(\varvec{x}^{(j_\ell )}_{\ell +1})\) such that
Using Assumptions 2.3(ii) and 2.5, we obtain
which is the inexact optimality condition (12b) with \(\beta = \underline{\gamma }^{-1}\sqrt{\overline{\nu }}\).
3 Convergence analysis
3.1 Descent properties
In this section, we provide some technical results concerning the behavior of the sequence \(\big (G(\varvec{x}_\ell )\big )_{\ell \in {\mathbb {N}}}\) generated by Algorithm (12), which will be useful in proving the convergence of the proposed algorithm.
Lemma 3.1
Let \((\varvec{x}_\ell )_{\ell \in {\mathbb {N}}}\) be a sequence generated by Algorithm (12). Under Assumptions 2.1 and 2.3, there exists \(\mu \in (0, +\infty )\) such that, for every \(\ell \in {\mathbb {N}} \),
Proof
Let \(\ell \in {\mathbb {N}} \). We have
On the one hand, according to Assumption 2.3(i),
On the other hand, using (12c),
Then, using (12a), we obtain
Therefore, combining (14) and (15) yields
Finally, (13) is deduced from Assumption 2.3(ii) and the fact that \(\alpha \in (1/2, +\infty )\), by setting \(\mu = \underline{\nu } (2 \alpha -1)\), and using (12c). \(\square \)
Let the sequence \(({\varvec{\chi }} _\ell )_{\ell \in {\mathbb {N}}}\) be defined as
where \((\varvec{x}_\ell )_{\ell \in {\mathbb {N}}}\) is a sequence generated by Algorithm (12) and K is the integer constant from Assumption 2.4. Then,
and the following property holds.
Lemma 3.2
Let \((\varvec{x}_\ell )_{\ell \in {\mathbb {N}}}\) be a sequence generated by Algorithm (12). Under Assumptions 2.1, 2.3 and 2.4, for every \(\ell \in {\mathbb {N}} \),
where \(\mu \in (0, +\infty )\) is the same constant as in Lemma 3.1.
Proof
Let \(\ell \in {\mathbb {N}} \). According to Lemma 3.1, we have
\(\square \)
3.2 Convergence theorem
We first state the following two lemmas which will be useful to handle the essentially cyclic rule:
Lemma 3.3
Let \((\varvec{x}_\ell )_{\ell \in {\mathbb {N}}}\) be a sequence of iterates generated by Algorithm (12). Let \(\ell _0 \in {\mathbb {N}} \) and let \(\mathcal {J}_{\ell _0}\) be a subset of \(\{1, \ldots , J\}\) containing \(j_{\ell _0}\). Then, under Assumptions 2.1 and 2.3, we have
where \(\varvec{r}^{(j_{\ell _0})}_{\ell _0+1}\) is defined by Algorithm (12) and, for every \(j \in \mathcal {J}_{\ell _0}{\setminus } \{j_{\ell _0}\}\), \(\varvec{r}^{(j)}_{\ell _0+1} \in \partial R_j(\varvec{x}_{\ell _0+1}^{(j)})\) and \(\varvec{r}^{(j)}_{\ell _0} \in \partial R_j(\varvec{x}_{\ell _0}^{(j)})\).
Proof
Let \(\ell _0 \in {\mathbb {N}} \). According to Jensen’s inequality,
On the one hand, since \( \sum \limits _{j=1}^J \Vert \nabla _{j}F(\varvec{x}_{\ell _0+1}) - \nabla _{j}F(\varvec{x}_{\ell _0}) \Vert ^2 = \Vert \nabla F(\varvec{x}_{\ell _0+1}) - \nabla F(\varvec{x}_{\ell _0}) \Vert ^2 \), Assumption 2.1(ii) leads to
On the other hand, since \(j_{\ell _0} \in \mathcal {J}_{\ell _0}\)
Moreover, using (12b) and Assumption 2.3(ii), and since, for every \(j \in \mathcal {J}_{\ell _0} {\setminus } \{j_{\ell _0}\}\), \(\varvec{x}_{\ell _0+1}^{(j)} = \varvec{x}_{\ell _0}^{(j)}\),
Finally, (18) results from (19), (20) and (21). \(\square \)
Lemma 3.4
Let \((\varvec{x}_\ell )_{\ell \in {\mathbb {N}}}\) be a sequence of iterates generated by Algorithm (12). Let \((\ell _0, \ell _0') \in {\mathbb {N}} ^2\) be such that \(\ell _0 \le \ell _0' \) and let \(\mathcal {J}_{\ell _0, \ell _0'} \subset \{1, \ldots , J\}\) be such that, for every \(\ell \in \{\ell _0, \ldots , \ell _0'\}\), \( j_{\ell } \in \mathcal {J}_{\ell _0, \ell _0'}\). Then, under Assumptions 2.1 and 2.3, we have
where \(\varvec{r}^{(j_{\ell _0'})}_{\ell _0'+1}\) is defined by Algorithm (12), for every \(j \in \mathcal {J}_{\ell _0, \ell _0'} {\setminus } \{j_{\ell _0'}\}\), \(\varvec{r}_{\ell _0'+1}^{(j)} \in \partial R_j({\varvec{x}} _{\ell _0'+1}^{(j)})\) and, for every \(j \in \mathcal {J}_{\ell _0, \ell _0'} {\setminus } \{j_{\ell _0}\}\), \(\varvec{r}^{(j)}_{\ell _0} \in \partial R_j(\varvec{x}_{\ell _0}^{(j)})\).
Proof
Let \((\ell _0, \ell _0') \in {\mathbb {N}} ^2\) be such that \(\ell _0 \le \ell _0' \). Under the considered assumptions, by applying successively Lemma 3.3 for \(\ell _0', \ell _0'-1, \ldots , \ell _0\), we have
\(\square \)
Some notation will be needed in the remainder. Let \(j \in \{1, \ldots , J\}\), let \(\ell \in {\mathbb {N}} \), and let \(K>0\) be defined by Assumption 2.4. We denote by
the first time the j-th block is updated after the \(\ell \)-th iteration of Algorithm (12). Moreover, we define the permutation \(\sigma _\ell :\{1,\ldots ,J\} \rightarrow \{1,\ldots ,J\}\) ensuring that \( ( k_{\ell , \sigma _\ell (i)} )_{1 \le i \le J} \) is increasing.
Our main result concerning the asymptotic behavior of Algorithm (12) is given below:
Theorem 3.1
Let \( (\varvec{x}_\ell )_{\ell \in {\mathbb {N}}} \) be defined by (12). Under Assumptions 2.1–2.4, the following hold.
-
(i)
The sequence \( (\varvec{x}_\ell )_{\ell \in {\mathbb {N}}} \) converges to a critical point \(\widehat{{\varvec{x}}}\) of \( G\).
-
(ii)
This sequence has a finite length in the sense that
$$\begin{aligned} \sum \limits _{\ell =0}^{+\infty } \Vert \varvec{x}_{\ell +1}- \varvec{x}_\ell \Vert < + \infty . \end{aligned}$$ -
(iii)
\(\big (G(\varvec{x}_\ell )\big )_{\ell \in {\mathbb {N}}}\) is a nonincreasing sequence converging to \(G(\widehat{{\varvec{x}}})\).
Proof
According to Lemma 3.1, we have
thus, \((G(\varvec{x}_\ell ))_{\ell \in {\mathbb {N}}}\) is a nonincreasing sequence. In addition, since \({\varvec{x}} _0 \in {\text {dom}}\,R\), by Remark 2.3(iii), the sequence \( \big ( \varvec{x}_\ell \big )_{\ell \in {\mathbb {N}}} \) belongs to the compact subset \( E = {\text {lev}}_{\le G({\varvec{x}} _0)}G\subset {\text {dom}}\,R\) and \(G\) is lower bounded. Thus, \(\big ( G(\varvec{x}_\ell ) \big )_{\ell \in {\mathbb {N}}} \) converges to a real \( \xi \), and \( \big ( G(\varvec{x}_\ell )-\xi \big )_{\ell \in {\mathbb {N}}} \) is a nonnegative sequence converging to 0 .
Moreover, by invoking Lemma 3.2, we have
where \(K>0\) is defined in Assumption 2.4. Let us apply to the convex function \( \psi :[0, +\infty ) \rightarrow [0, +\infty ) :u \mapsto u^{ \frac{1}{1-\theta } } \), with \( \theta \in [0,1) \), the gradient inequality
which, after a change of variables, can be rewritten as
Using the latter inequality with \( u = G(\varvec{x}_\ell )-\xi \) and \( v =G(\varvec{x}_{\ell + K})-\xi \) leads to
where
Thus, combining the above inequality with (23) yields
Let us define
where for every \(j \in \{1, \ldots , J \}\), \(\varvec{r}^{(j)}_{\ell } \in \partial R_j(\varvec{x}^{(j)}_\ell ) \). Using the differentiation rule for separable functions, we have \(\varvec{r}_{\ell } = \big ( \varvec{r}^{(j)}_{\ell } \big )_{1 \le j \le J} \in \partial R(\varvec{x}_\ell )\). Thus, for every \(\ell \in {\mathbb {N}} \),
Since E is bounded and Assumption 2.2 holds, there exist constants \( \kappa >0 \), \( \zeta >0 \) and \( \theta \in [0,1) \) such that (10) holds for every \( {\varvec{x}} \in E \) for which the inequality \( | G( {\varvec{x}}) - \xi | \le \zeta \) is satisfied. Since \( \big ( G(\varvec{x}_\ell ) \big )_{\ell \in {\mathbb {N}}} \) converges to \( \xi \), there exists \( \ell ^* \in {\mathbb {N}} \), such that, for every \( \ell \ge \ell ^* \), \( | G(\varvec{x}_\ell ) - \xi | < \zeta \). Hence, we have
Let K be defined by Assumption 2.4. For every \(\ell \in {\mathbb {N}} \),
For every \(k \in \{\ell + k_{\ell , \sigma _{\ell }(J)}, \ldots , \ell + K-1\}\), let \(\varvec{r}_{k+1}^{(j_k)} \in \partial R_{j_k}(\varvec{x}_{k+1}^{(j_k)})\) be defined as in Algorithm (12). Thus, Lemma 3.4 with \(\ell _0 = \ell + k_{\ell , \sigma _{\ell }(J)}\), \(\ell _0' = \ell + K-1\) and \(\mathcal {J}_{\ell _0,\ell _0'} = \{1, \ldots ,J\}\) leads to
Using again Lemma 3.4 on \( \sum \limits _{\underset{j \ne \sigma _\ell (J)}{j=1}}^J \Vert \nabla _{j}F(\varvec{x}_{\ell + k_{\ell , \sigma _\ell (J)}}) + \varvec{r}^{(j)}_{\ell + k_{\ell , \sigma _\ell (J)}} \Vert ^2 \) with \(\ell _0 = \ell + k_{\ell , \sigma _{\ell }(J-1)}\), \(\ell _0'= \ell + k_{\ell , \sigma _{\ell }(J)}-1\) and \(\mathcal {J}_{\ell _0,\ell _0'} = \{1, \ldots ,J\}{\setminus } \{\sigma _\ell (J)\}\), we obtain
Proceeding similarly for \(i \in \{1, \ldots , J-2\}\), we get
where we have used the fact that \( \{1,\ldots ,J\} {\setminus } \{\sigma _\ell (1), \ldots , \sigma _\ell (J)\} = \varnothing \), thus
Since \(k_{\ell , \sigma _\ell (1)}=0\) and, for every \(k\in \{\ell , \ldots , \ell + K-1\}\), \(2^{\ell +K-k} \le 2^K\), it follows from (17) and (27) that
Combining (24), (26) and (28) yields
By using the fact that
and by setting \(u= \Vert {\varvec{\chi }} _{\ell -K} \Vert \) and \( v = 2 \mu ^{-1} (1-\theta )^{-1} \kappa ^{-1} 2^{K/2} ( L^2 + \beta ^2 \overline{\nu } )^{1/2} \varDelta _\ell \), we obtain
Furthermore, it can be noticed that
which shows that \( ( \varDelta _\ell )_{\ell \in {\mathbb {N}}} \) is a summable sequence. As \( (\Vert {\varvec{\chi }} _\ell \Vert )_{\ell \ge \max \{\ell ^*, K\}} \) satisfies inequality (29), \( (\Vert {\varvec{\chi }} _\ell \Vert )_{\ell \in {\mathbb {N}}} \) is also a summable sequence. According to (17),
and \( (\Vert \varvec{x}_{\ell +1}- \varvec{x}_\ell \Vert )_{\ell \in {\mathbb {N}}} \) is a summable sequence.
Hence, the sequence \( (\varvec{x}_\ell )_{\ell \in {\mathbb {N}}} \) satisfies the finite length property. In addition, since this latter condition implies that \( (\varvec{x}_\ell )_{\ell \in {\mathbb {N}}} \) is a Cauchy sequence, it converges towards a point \( \widehat{{\varvec{x}}} \).
It remains us to show that the limit \(\widehat{{\varvec{x}}}\) is a critical point of \(G\). According to (25), we have, for every \(\ell \in {\mathbb {N}} \),
In addition, since the sequence \( \left( \Vert {\varvec{\chi }} _\ell \Vert \right) _{\ell \in {\mathbb {N}}} \) is summable, it converges to 0. Moreover, according to (28), we have
hence \( \left( \varvec{x}_\ell , \varvec{t}_{\ell } \right) _{\ell \in {\mathbb {N}}} \) converges to \((\widehat{{\varvec{x}}},{\mathbf {0}})\). Furthermore, according to Remark 2.3(iii), the restriction of \(G\) to its domain is continuous. Thus, as, for every \( \ell \in {\mathbb {N}} \), \( \varvec{x}_\ell \in {\text {dom}}\,G\), the sequence \( \left( G(\varvec{x}_\ell ) \right) _{\ell \in {\mathbb {N}}} \) converges to \( G(\widehat{{\varvec{x}}}) \). Finally, according to the closedness property of \(\partial G\) (see Remark 2.1), \((\widehat{{\varvec{x}}},{\mathbf {0}})\in {\text {Graph}}\,\partial G\) i.e., \(\widehat{{\varvec{x}}} \) is a critical point of \(G\). \(\square \)
Remark 3.1
In the case when the blocks are updated according to a cyclic rule and the proximity operator is computed exactly, one can obtain similar convergence results without assuming the continuity of functions \((R_j)_{1\le j \le J}\), by using similar arguments to those in the proof of [13, Lem. 5 (i)].
As a consequence of the previous theorem, the proposed algorithm can be shown to locally converge to a global minimizer of \(G\):
Corollary 3.1
Suppose that \((\varvec{x}_\ell )_{\ell \in {\mathbb {N}}}\) is a sequence generated by Algorithm (12), and suppose that Assumptions 2.1–2.4 hold. There exists \(\upsilon \in (0,+\infty )\) such that, if
then \((\varvec{x}_\ell )_{\ell \in {\mathbb {N}}}\) converges to a solution to Problem (1).
Proof
Same proof as in [18, Cor. 3.2]. \(\square \)
3.3 Convergence rate
According to Theorem 3.1, the limit \(\widehat{{\varvec{x}}}\) of a sequence \((\varvec{x}_\ell )_{\ell \in {\mathbb {N}}}\) generated by Algorithm (12) is a critical point of \(G\), under Assumptions 2.1–2.4. Thus, proceeding similarly to the derivation of (26), there exists \(\zeta \in (0,+\infty )\) such that for every \({\varvec{x}} \in {\mathbb {R}} ^N\) with \(G({\varvec{x}}) \le G(\widehat{{\varvec{x}}})+\zeta \), (10) is satisfied for some \(\kappa \in (0,+\infty )\) and \(\theta \in [0,1)\). The number \(\theta \) is then called a Łojasiewicz exponent of G at \(\widehat{{\varvec{x}}}\). Similarly to other algorithms based on Kurdyka-Łojasiewicz inequality [2, 3], the local convergence rate of the BC-VMFB algorithm depends on this exponent.
The following lemma, which can be deduced from [2, Thm. 2], is instrumental to establish the convergence rate:
Lemma 3.5
Let \((\varLambda _m)_{m\in {\mathbb {N}}}\) be a nonnegative sequence of reals decreasing to 0. Assume that there exist \(m^* \in {\mathbb {N}} {\setminus } \left\{ 0\right\} \) and \(C\in (0,+\infty )\) such that, for every \(m\ge m^*\),
where \(\theta \in (0,1)\).
If \(\theta \in \left( \frac{1}{2}, 1\right) \), then there exists \(\lambda \in (0,+\infty )\) such that
If \(\theta \in \big (0, \frac{1}{2}\big ]\), then there exist \(\lambda \in (0,+\infty )\) and \(\tau \in [0,1)\) such that
Theorem 3.2
Let \((\varvec{x}_\ell )_{\ell \in {\mathbb {N}}}\) be a sequence generated by Algorithm (12) and suppose that Assumptions 2.1–2.4 hold. Let \(\theta \) be a Łojasiewicz exponent of G at the limit point \(\widehat{{\varvec{x}}}\) of \((\varvec{x}_\ell )_{\ell \in {\mathbb {N}}}\). The following properties hold:
-
(i)
If \(\theta \in (\frac{1}{2}, 1)\), then there exists \((\lambda ',\lambda '') \in (0,+\infty )^2\) such that
$$\begin{aligned} (\forall \ell > K)\qquad&\Vert \varvec{x}_\ell - \widehat{{\varvec{x}}} \Vert \le \lambda ' \Big (\frac{\ell }{K}-1\Big )^{- \frac{1-\theta }{2 \theta - 1}}, \end{aligned}$$(31)$$\begin{aligned} (\forall \ell > 2K)\qquad&G(\varvec{x}_\ell ) - G(\widehat{{\varvec{x}}}) \le \lambda '' \Big (\frac{\ell }{K}-2\Big )^{- \frac{1-\theta }{\theta (2 \theta - 1)}}. \end{aligned}$$(32) -
(ii)
If \(\theta \in (0, \frac{1}{2}]\), then there exist \((\lambda ',\lambda '')\in (0,+\infty )^2\) and \(\tau ' \in [0,1)\) such that
$$\begin{aligned} (\forall \ell \in {\mathbb {N}})\qquad&\Vert \varvec{x}_\ell - \widehat{{\varvec{x}}} \Vert \le \lambda ' (\tau ')^{\ell }, \end{aligned}$$(33)$$\begin{aligned}&G(\varvec{x}_\ell ) - G(\widehat{{\varvec{x}}}) \le \lambda '' (\tau ')^{\frac{\ell }{\theta }}. \end{aligned}$$(34) -
(iii)
If \(\theta = 0\), then the sequence \((\varvec{x}_\ell )_{\ell \in {\mathbb {N}}}\) converges in a finite number of steps.
Proof
We use the same notation as in the proof of Theorem 3.1. Let K be given by Assumption 2.4. For every \(\ell \in {\mathbb {N}} \), there exist \(m \in {\mathbb {N}} \) and \(k \in \{0, \ldots , K-1\}\) such that \(\ell = mK + k\). Then, according to the triangle inequality,
Moreover, using again the triangle inequality, we have
and according to Jensen’s inequality and (17),
For every \(m'\in {\mathbb {N}} \), let \( \varLambda _{m'} = \sum \limits _{p=m'}^{+\infty } \Vert {\varvec{\chi }} _{pK} \Vert \) which is finite by Theorem 3.1. Hence, the last two inequalities yield
Involving again Jensen’s inequality, we have
Altogether, (35), (38), and (39) lead to
Using (29), we have, for every \(m\ge \max \{\ell ^*/K,1\}\),
where \(\varDelta _{m K} = \big ( G({\varvec{x}} _{m K}) - G(\widehat{{\varvec{x}}}) \big )^{1-\theta } - \big (G({\varvec{x}} _{(m+1)K}) - G(\widehat{{\varvec{x}}})\big )^{1-\theta }\). Thus, since \(\big (G(\varvec{x}_\ell ) - G(\widehat{{\varvec{x}}})\big )_{\ell \in {\mathbb {N}}}\) is a nonnegative sequence converging to 0, we obtain
Let us now assume that \(\theta \ne 0\). According to (26) and (28), we have
so that
Thus, by defining
we get, for every \(m\ge \max \{\ell ^*/K,1\}\),
and (30) is satisfied.
Thus, according to Lemma 3.5 and (40), if \(\theta \in \left( \frac{1}{2}, 1\right) \), there exists \(\lambda \in \left( 0,+\infty \right) \) such that
where m is the lower integer part of \(\ell /K\). Inequality (31) is thus obtained by setting \(\lambda ' = 2 \sqrt{K} \lambda \). Similarly, if \(\theta \in (0, \frac{1}{2}]\), then there exist \(\lambda \in (0,+\infty )\) and \(\tau \in [0,1)\) such that
Hence, if \(\tau \ne 0\), (33) is satisfied by setting \(\lambda ' = 2 \sqrt{K} \lambda /\tau \) and \(\tau ' = \tau ^{1/K}\), while (33) also holds trivially when \(\tau = 0\).
In addition, since \(\big (G(\varvec{x}_\ell ) - G(\widehat{{\varvec{x}}})\big )_{\ell \in {\mathbb {N}}}\) is a decreasing sequence, for every \(\ell \in {\mathbb {N}} \),
where m still denotes the lower integer part of \(\ell /K\). Using (41), if \(m\ge \max \{\ell ^*/K,1\}\), then
So, if \(\theta \in (\frac{1}{2}, 1)\), using again Lemma 3.5, there exists \(\lambda \in (0,+\infty )\) such that, when \(m > 2\),
Hence, one can find \(\lambda '' \in (0,+\infty )\) such that (32) holds for every \(\ell > 2K\). If \(\theta \in (0, \frac{1}{2}]\), there exist \(\lambda \in (0,+\infty )\) and \(\tau \in [0,1)\) such that
Therefore, one can find \(\lambda '' \in (0,+\infty )\) such that (34) holds for every \(\ell \in {\mathbb {N}} \).
Let us now prove Property (iii) by assuming that \(\theta = 0\). Set \( \mathcal {L} = \{ \ell \in {\mathbb {N}}: \varvec{x}_\ell \ne \widehat{{\varvec{x}}}\}\), and let \(\ell \ge \max \{\ell ^*,K\}\) be in \(\mathcal {L}\). According to Lemmas 3.1 and 3.2,
Using (28), we obtain
where \(\mu '\in (0,+\infty )\). Combined with (26), and since \(\theta =0\), this yields
that is,
Since \(\lim \limits _{\ell \rightarrow +\infty } G(\varvec{x}_\ell ) = G(\widehat{{\varvec{x}}})\), the above inequality implies that \(\mathcal {L}\) is finite, and (iii) follows. \(\square \)
Remark 3.2
-
(i)
Note that, when G is strongly convex, the Łojasiewicz exponent \(\theta \) of G is equal to 1 / 2. In this case, \(\widehat{{\varvec{x}}}\) is a global minimizer of \(G\) and sequences \(\left( \Vert \varvec{x}_\ell - \widehat{{\varvec{x}}} \Vert \right) _{\ell \in {\mathbb {N}}}\) and \(\left( G(\varvec{x}_\ell ) - G(\widehat{{\varvec{x}}})\right) _{\ell \in {\mathbb {N}}}\) converge linearly.
-
(ii)
Note that, if \(\theta \in (0,1/2]\), then, for m large enough, (30) yields
$$\begin{aligned} \varLambda _m \le (1+C) (\varLambda _{m-1} - \varLambda _m), \end{aligned}$$so that the constant \(\tau '\) in (33)–(34) can be chosen equal to \(\left( (1+C)/(2+C)\right) ^{1/K}\) where C is given by (42).
4 Application
4.1 Optimization problem
In this section, we consider a phase retrieval inverse problem which consists of estimating the phase of a complex-valued signal from measurements of its modulus and additional a priori information.
Let \({\varvec{z}} =\big (z^{(s)}\big )_{1 \le s \le S}\in [0,+\infty )^S\) be a degraded signal related to an original unknown signal \(\overline{\varvec{v}} \in {\mathbb {R}} ^M\) through the model
where \({\varvec{H}} \in {\mathbb {C}} ^{S \times M}\) is an observation matrix with complex elements, \(|\cdot |\) denotes the componentwise modulus operator, and \({\varvec{w}} \in [0,+\infty )^S\) is a realization of an additive noise. The objective is then to find an estimate \(\widehat{\varvec{v}} \in {\mathbb {R}} ^M\) of the target image \(\overline{\varvec{v}}\) from the observed data \({\varvec{z}} \) and the observation operator \({\varvec{H}} \).
Such a problem is of paramount importance in numerous areas of applied physics and engineering [7, 15, 24, 54, 59]. Note that unlike many existing works [6, 15, 26, 28], it is not assumed that \({\varvec{H}} \) is a Fourier transform matrix.
Set \(\widehat{\varvec{v}} = {\varvec{W}} \widehat{{\varvec{x}}}\) where \({\varvec{W}} \in {\mathbb {R}} ^{M \times N}\), \(N \ge M\), is a given frame synthesis operator (e.g. a possibly redundant wavelet synthesis operator) [38]. Then, following a synthesis approach, the frame coefficient vector \(\widehat{{\varvec{x}}}\) can be estimated by solving Problem (1) where F is the so-called data fidelity term of the form:
Hereabove, for every \(s \in \{1, \ldots , S\}\), \(\varphi ^{(s)} :[0,+\infty ) \rightarrow {\mathbb {R}} \), and \([{\varvec{H}} {\varvec{W}} {\varvec{x}} ]^{(s)}\) is the s-th component of \({\varvec{H}} {\varvec{W}} {\varvec{x}} \in {\mathbb {C}} ^{S}\). Moreover, in (1), a penalty function \(R\) is employed serving to incorporate a priori information on the frame coefficients.
We propose to choose, for every \(s \in \{1, \ldots , S\}\), \(\varphi ^{(s)} := \varphi _1^{(s)} + \varphi _2^{(s)}\), where
with \(\delta >0\) and \(z^{(s)}\), the s-th component of \({\varvec{z}} \). Thus, the data fidelity term (43) is split as \(F = F_1 + F_2\) where
For every \(s\in \{1,\ldots ,S\}\), the first and second order derivatives of \(\varphi _1^{(s)}\) and \(\varphi _2^{(s)}\) with respect to \(\omega \) are, respectively,Footnote 1
and
Thus, \(\varphi _2^{(s)}\) is concave on \([0,+\infty )\), while \(\varphi ^{(s)}\) is nonconvex. Moreover, \(\varphi ^{(s)}\) is Lipschitz differentiable, and Assumption 2.1(ii) is satisfied. Note that, in the limit case when \(\delta =0\), the usual nonconvex nonsmooth least squares data fidelity term [26] is recovered (i.e. \(F= \frac{1}{2}\Vert |{\varvec{H}} {\varvec{W}} \cdot |-{\varvec{z}} \Vert ^2\)), which shows that the proposed function can be viewed as a smoothed version of it.
In addition, following [17, 46], the following penalization term is employed on the wavelet coefficients:
where, for every \(n \in \{1, \ldots , N\}\),
and, for every \(n\in \{1, \ldots , N\}\), \(\vartheta _n \in (0,+\infty )\), \(\pi _n \in {\mathbb {N}} {\setminus } \left\{ 0\right\} \), \(\underline{\eta }_n \in [-\infty , +\infty )\), \(\overline{\eta }_n \in [\underline{\eta }_n,+\infty ]\), and \(\overline{\omega }_n \in {\mathbb {R}} \). Assumption 2.1 is thus satisfied. Moreover, since for every \(n \in \{1, \ldots ,N\}\), \(\rho ^{(n)}\) is a semi-algebraic function, \(F\) is also a semi-algebraic function, and Assumption 2.2 holds.
In the following, in order to simplify the notation, we introduce the linear operator \({\varvec{T}}:= {\varvec{H}} {\varvec{W}} = ( T^{(s,n)} )_{1 \le s \le S,1 \le n \le N} \in {\mathbb {C}} ^{S \times N}\).
4.2 Construction of the preconditioning matrices
The numerical efficiency of the proposed method relies on the use of quadratic majorants providing good approximations of \(F_{j_\ell }( \cdot , \varvec{x}_\ell ^{(\overline{\jmath }_\ell )})\) at iteration \(\ell \in {\mathbb {N}} \), and whose curvature matrices \(({\varvec{A}} _{j_\ell }(\varvec{x}_\ell ))_{\ell \in {\mathbb {N}}}\) are simple to compute.
Similarly to (4), let us define, for every \(\ell \in {\mathbb {N}} \), functions \(F_{1,j_\ell }( \cdot , \varvec{x}_\ell ^{\overline{\jmath }_\ell })\) and \(F_{2,j_\ell }( \cdot , \varvec{x}_\ell ^{\overline{\jmath }_\ell })\) associated with \(F_1\) and \(F_2\), respectively. It has already been noticed that, for every \(s \in \{1, \ldots , S\}\), \(\varphi _2^{(s)}\) is concave. Hence, for every \(\ell \in {\mathbb {N}} \), \(F_{2,j_\ell }( \cdot , \varvec{x}_\ell ^{\overline{\jmath }_\ell })\) is majorized by
Thus, there remains to find a family of symmetric positive definite matrices \(({\varvec{A}} _{j_\ell }(\varvec{x}_\ell ))_{\ell \in {\mathbb {N}}}\) such that, for every \(\ell \in {\mathbb {N}} \),
is a majorant function of \(F_{1,j_\ell }( \cdot , \varvec{x}_\ell ^{\overline{\jmath }_\ell })\). The following proposition allows us to propose a symmetric positive definite matrix \({\varvec{B}} \in {\mathbb {R}} ^{N \times N}\) for building majorizing approximations of \(F_1\) at \({\varvec{x}} _\ell \) for every \(\ell \in {\mathbb {N}} \). Hereafter, \(\mathrm {Re}\{\cdot \}\) (resp. \(\mathrm {Im}\{\cdot \}\)) designates the real (resp. imaginary) part of its argument.
Proposition 4.1
Let \(\varvec{u}\in {\mathbb {R}} ^N\). A quadratic majorant of \( F_1\) at \(\varvec{u}\) is
where \({\varvec{B}}:= {\text {Diag}}\,\left( {\varvec{\varOmega }} ^\top \mathbf {1}_{S} \right) + \varepsilon \mathbf {I}_N\), where \(\mathbf {1}_{S}\) is the unit vector on \({\mathbb {R}} ^{S}\), \(\varepsilon \ge 0\), and \({\varvec{\varOmega }} = \left( \varOmega ^{(s,n)} \right) _{1 \le s \le S, 1 \le n \le N} \in {\mathbb {R}} ^{S \times N}\) is given by
Proof
Let \(\varvec{u}\in {\mathbb {R}} ^N\). For every \(s \in \{1, \ldots , S\}\), we have, for every \({\varvec{x}} \in {\mathbb {R}} ^N\),
where \({\varvec{T}} ^{(s)}\) denotes row s of matrix \({\varvec{T}} \) and \((\cdot )^*\) is the matrix trans-conjugate operation. Then, summing over \(s \in \{1,\ldots ,S\}\), we obtain
where \(|||\cdot |||\) is the Hermitian norm of \({\mathbb {C}} ^S\).
Let \((V^{(s,n)}_{\mathcal {R}})_{1 \le s \le S, 1 \le n \le N} \in [0, + \infty )^{S \times N}\) and \((V^{(s,n)}_{\mathcal {I}})_{1 \le s \le S, 1 \le n \le N} \in [0, + \infty )^{S \times N}\) be such that, for every \(s\in \{1,\ldots ,S\}\), \(\sum _{n \in \mathcal {S}_\mathcal {R}^{(s)}} V^{(s,n)}_{\mathcal {R}} \le 1 \), \(\sum _{n \in \mathcal {S}_\mathcal {I}^{(s)}} V^{(s,n)}_{\mathcal {I}} \le 1\) where
Jensen’s inequality yields, for every \(s\in \{1,\ldots ,S\}\),
Let us now choose
It follows from (58) that, for every \(s\in \{1,\ldots ,S\}\),
It can be deduced that
where \({\varvec{\varOmega }} \) is defined by (56). Altogether, (57) and (59) lead to the desired majorization. \(\square \)
Combining the above lemma with Remark 2.5(ii) leads to the construction, for every \(\ell \in {\mathbb {N}} \), of a quadratic majorant of \(F_{1,j_\ell }( \cdot , \varvec{x}_\ell ^{\overline{\jmath }_\ell })\) at \(\varvec{x}_\ell \) of the form (54) with
where \({\varvec{\varOmega }} _{j_\ell } \in {\mathbb {R}} ^{S \times N_{j_\ell }}\) is the matrix obtained by extracting the columns with indices in \(\mathbb {J}_{j_\ell }\) from the matrix \({\varvec{\varOmega }} \) given by (56). Note that Assumption 2.3(ii) is satisfied for matrices (60) with
If each column of \({\varvec{T}} \) is nonzero, then one can choose \(\varepsilon = 0\) in (61). Otherwise, we must choose \(\varepsilon >0\).
4.3 Implementation of the proximity operator of \(R\)
Let \(\ell \in {\mathbb {N}} \), let \(\varvec{x}_\ell \) be the \(\ell \)-th iterate in Algorithm (12) and let \(j_\ell \in \{1, \ldots , J\}\) be the block selected at iteration \(\ell \). Since \(R_{j_\ell }\) is an additive separable function, and \({\varvec{A}} _{j_\ell }(\varvec{x}_\ell )\) reads \({\text {Diag}}\,(a_{j_\ell }^{(1)}, \ldots , a_{j_\ell }^{(N_{j_\ell })})\), we have
For every \(n \in \mathbb {J}_{j_\ell }\), let \(\varsigma _{j_\ell }^{(n)} := \gamma _\ell \vartheta _n \left( a_{j_\ell }^{(n)}\right) ^{-1}>0\). According to (52), we have then
Hence, provided that the proximity operator \({\text {prox}}_{ \varsigma _{j_\ell }^{(n)} |\cdot |^{\pi _n} }\) has an explicit form, the exact version (7) of Algorithm (12) can be used.

Original image \(\overline{\varvec{v}}\) (a), example of frame coefficient \(\overline{{\varvec{x}}}\) with approximation coefficients in top-left (b), and index set \(\mathbb {E}\) in black (c)
4.4 Simulation results
We now demonstrate the practical performance of our algorithm on an image reconstruction problem. In our experiments, \({\varvec{W}} \) is an overcomplete Haar synthesis operator performed on a single resolution level. Thus, \(N = 4M\), and, for every \({\varvec{x}} =(x^{(n)})_{1 \le n \le N} \in {\mathbb {R}} ^N\), \((x^{(n)})_{1 \le n \le M}\) correspond to the approximation frame coefficients, whereas \((x^{(n)})_{pM+1 \le n \le (p+1)M}\) with \(p\in \{1,2,3\}\) correspond to the horizontal, vertical and diagonal detail coefficients, respectively. We take, for every \(n \in \{1, \ldots , M\}\), \((\pi _n,\vartheta _n) = (2,\vartheta ^\text {a})\) and, for every \(n \in \{M+1, \ldots , N\}\), \((\pi _n,\vartheta _n) = (1,\vartheta ^\text {d})\), with \((\vartheta ^\text {a},\vartheta ^\text {d}) \in (0,+\infty )^{2}\). Note that, for these choices of \((\pi _n)_{1 \le n \le N}\) and \((\vartheta _n)_{1 \le n \le N}\), the proximity operator (63) has an explicit form [19]. The original image \(\overline{\varvec{v}}\), with size \(M = 256 \times 256\), is shown in Fig. 1a. Although the Haar coefficient vector \(\overline{{\varvec{x}}}\) is not uniquely defined, an example is displayed in Fig. 1b. The observation matrix is here \({\varvec{H}} = {\varvec{H}} _{{\mathcal {R}}} + \text {i} {\varvec{H}} _{{\mathcal {I}}}\) where \([{\varvec{H}} _{{\mathcal {R}}}^\top ,{\varvec{H}} _{{\mathcal {I}}}^\top ]^\top \in {\mathbb {R}} ^{2S \times M} \) models \(2S = 92160\) distinct projections from 256 parallel acquisition lines and 360 angles. The magnitude measurement vector \(\left| {\varvec{H}} \overline{\varvec{v}}\right| \) is then corrupted with an additive real-valued white zero-mean Gaussian noise with variance equals to 0.1 which is truncated so as to guarantee the nonnegativity of the observed data. For every \(n \in \{1, \ldots , N\}\), \((\underline{\eta }_n , \overline{\eta }_n, \overline{\omega }_n )\) are minimal, maximal and mean values, imposed on the sought frame coefficients. In order to set to zero the coefficients located in a subset \({\mathbb {E}} \subset \{1, \ldots , N\}\) corresponding to the object background, we choose, for every \(n \in {\mathbb {E}} \), \(\underline{\eta }_n = \overline{\eta }_n =0\), as illustrated in Fig. 1c, and for coefficient indices \(n \in \{1,\ldots ,N\} {\setminus } \mathbb {E}\), we do not introduce specific range assumption by setting \(\underline{\eta }_n = -\infty \) and \(\overline{\eta }_n = +\infty \). Moreover, we take \(\overline{\omega }_n=0.8\), for every \(n \in \{1, \ldots , M\} {\setminus } {\mathbb {E}} \), \(\overline{\omega }_n=0\) otherwise. Parameters \(\vartheta ^\text {a}\), \(\vartheta ^\text {d}\) and \(\delta \) are adjusted so as to maximize the signal-to-noise ratio (SNR) between the original image \(\overline{\varvec{v}}\) and the reconstructed one \(\widehat{\varvec{v}}\), expressed as
We adopt the essentially cyclic rule described in Assumption 2.4 to update the \((K=J)\) blocks. Let \(\ell \in {\mathbb {N}} \) be an iterate of the BC-VMFB algorithm, and \((m,j') \in {\mathbb {N}} \times \{1, \ldots , J\}\) be such that \(\ell = mJ + j'-1\). Then the block index \(j_\ell \) is defined as \(j_\ell = \sigma _m(j')\), where \(\sigma _m\) is a random permutation from \(\{1, \ldots ,J\}\) to \(\{1, \ldots ,J\}\), and
with \((J,P)\in ({\mathbb {N}} {\setminus } \left\{ 0\right\} )^2\) such that \(M = JP\). Thus, at each iteration \(\ell \in {\mathbb {N}} \), the updated \( j_{\ell }\) block is of constant size \(N_{j_\ell } = 4 P\). Figure 2 illustrates two examples of a resulting block index set \(\mathbb {J}_{j'}\) for two different values of P.

An example of index set \(\mathbb {J}_{j'}\) (black), for \(P = 4096\) (left) and \(P = 64\) (right), the frame coefficients being structured as depicted in Fig. 1b
Figure 3 (left) shows the reconstructed image with Algorithm (7), using the majorant curvature (60) where \(\varepsilon = 0\), \(P = 64\) and \(\gamma _\ell \equiv 1.9\). We also present in Fig. 3 (right) the variations of the reconstruction time with respect to the block-size parameter P, when performing tests on an Intel(R) Core(TM) i7-3520M @ 2.9GHz using a Matlab 7 implementation. The reconstruction time corresponds to the computation time necessary to fulfill the following condition:

Reconstructed image \(\widehat{\varvec{v}} = {\varvec{W}} \widehat{{\varvec{x}}}\) with SNR \(= 27.64\) dB (left) and reconstruction time for different block-sizes (right)

Convergence profile of BC-VMFB algorithm (solid line), PALM algorithm (dashed line) and BC-FB algorithm (dotted line)
where \(\widehat{{\varvec{x}}}\) is precomputed by running the algorithm, for each block size, until full stabilization of the iterates (up to the machine precision). The image \(\widehat{{\varvec{x}}}\) is a critical point of the criterion, since the convergence of the iterates of BC-VMFB to such a point is guaranteed, so that (65) aims at evaluating the computation time necessary to allow an iterate to be close enough to this limit point. Note that (65) is not led to be a practical stopping criterion for the method, since it requires two runs of the algorithm. A practical termination test could consist of controling the relative difference in norms between two consecutive iterates. One can observe on Fig. 3 (right) that the best compromise in terms of convergence speed is obtained for an intermediate block-size, namely \(P = 64\). Moreover, even if different values of P may result in different limit points \(\widehat{{\varvec{x}}}\) for the algorithm, we did not observe any significant variation in terms of reconstruction quality between these vectors. Figure 4 illustrates the variations of \(\big (G({\varvec{x}} _\ell )-\widehat{G}\big )_\ell \) and \(\big (\Vert {\varvec{x}} _\ell - \widehat{{\varvec{x}}}\Vert / \Vert \widehat{{\varvec{x}}}\Vert \big )_\ell \) with respect to the computation time, using either the proposed BC-VMFB algorithm, BC-FB algorithm or PALM algorithm for the previous optimal block-size. Hereabove, \(\widehat{G}\) denotes the minimum of the (possibly) different values \(G(\widehat{{\varvec{x}}})\) resulting from each simulation. Note that BC-FB (resp. PALM) algorithm can be viewed as a special instance of Algorithm (7) where the cyclic rule (5) is adopted and the preconditioning matrix is proportional to identity matrices, i.e.
where L is a Lipschitz modulus of \(\nabla F\) (resp., for every \(j \in \{1, \ldots , J\}\), \(L_j\) a Lipschitz modulus of \(\nabla _j F({\varvec{x}} ^{(1)}, \ldots , {\varvec{x}} ^{(j-1)}, \cdot , {\varvec{x}} ^{(j+1)}, \ldots , {\varvec{x}} ^{(J)})\) [13]). All the algorithms lead asymptotically to solutions of similar quality in terms of SNR. Furthermore, one can observe on Fig. 4 that BC-VMFB algorithm requires less time than BC-FB and PALM algorithms to reach small values of \(\big (G({\varvec{x}} _\ell )-\widehat{G}\big )_\ell \), and \(\big (\Vert {\varvec{x}} _\ell - \widehat{{\varvec{x}}}\Vert / \Vert \widehat{{\varvec{x}}}\Vert \big )_\ell \). This illustrates the fact that the metric strategy given by (60) leads to a significant acceleration in terms of decay of both the objective function and the error on the iterates. Note that the benefits of BC-VMFB over its non preconditioned versions have also been observed in the context of blind video deconvolution [1], spectral unmixing [49] and gene regulatory network inference [44].
Although the phase retrieval reconstruction problem has led to a large amount of works in the litterature [6, 7, 15, 28, 41, 55, 59], comparisons with the competing techniques were difficult to perform. Actually, the aforementioned methods tend to be sensitive to noise and/or to be less effective in the under-determined case and/or to be difficult to apply in a large scale non-Fourier context. On the one hand, when applied to our problem, the alternating projection algorithm from [28] and the regularized version [41] were extremely demanding in computational time and available memory. Moreover, they led to unsatisfactory results in terms of image quality. On the other hand, due to the large size of the data, and the complicated structure of \({\varvec{T}} \), it appeared impossible to run the semidefinite programming phase retrieval technique from [59] or the greedy sparse technique from [55]. Similar conclusions were drawn when applying our method to a phase retrieval problem involving complex-valued images [50]. Finally, we would like to emphasize that, while this paper was under revision, we have been made aware of [15] where a nonconvex variational approach for phase reconstruction was developed in an independent manner. The advantage of our approach is to easily deal with a constraint or a regularization term so as to model prior knowledge on the sought solution, which is of major importance when the inverse problem is under-determined, as it is the case here.
Notes
We consider right derivatives at \(\omega =0\).
References
Abboud, F., Chouzenoux, E., Pesquet, J.-C., Chenot, J.H., Laborelli, L.: A hybrid alternating proximal method for blind video restoration. In: Proceedings of European Signal Processing Conference (EUSIPCO 2014), pp. 1811–1815. Lisboa, Portugal (2014)
Attouch, H., Bolte, J.: On the convergence of the proximal algorithm for nonsmooth functions involving analytic features. Math. Program. 116, 5–16 (2009)
Attouch, H., Bolte, J., Redont, P., Soubeyran, A.: Proximal alternating minimization and projection methods for nonconvex problems. An approach based on the Kurdyka-Łojasiewicz inequality. Math. Oper. Res. 35(2), 438–457 (2010)
Attouch, H., Bolte, J., Svaiter, B.F.: Convergence of descent methods for semi-algebraic and tame problems: proximal algorithms, forward-backward splitting, and regularized Gauss-Seidel methods. Math. Program. 137, 91–129 (2011)
Auslender, A.: Asymptotic properties of the Fenchel dual functional and applications to decomposition problems. J. Optim. Theory Appl. 73(3), 427–449 (1992)
Bauschke, H.H., Combettes, P.L., Luke, D.R.: Phase retrieval, error reduction algorithm, and Fienup variants: a view from convex optimization. J. Opt. Soc. Am. A 19(7), 1334–1345 (2002)
Bauschke, H.H., Combettes, P.L., Luke, D.R.: A new generation of iterative transform algorithms for phase contrast tomography. In: Proceedings of IEEE International Conference Acoust., Speech Signal Process. (ICASSP 2005), vol. 4, pp. 89–92. Philadelphia, PA (2005)
Bauschke, H.H., Combettes, P.L., Noll, D.: Joint minimization with alternating Bregman proximity operators. Pac. J. Optim. 2(3), 401–424 (2006)
Bertsekas, D.P.: Nonlinear Programming, 2nd edn. Athena Scientific, Belmont, MA (1999)
Bolte, J., Daniilidis, A., Lewis, A.: The Łojasiewicz inequality for nonsmooth subanalytic functions with applications to subgradient dynamical systems. SIAM J. Optim. 17, 1205–1223 (2006)
Bolte, J., Daniilidis, A., Lewis, A., Shiota, M.: Clarke subgradients of stratifiable functions. SIAM J. Optim. 18(2), 556–572 (2007)
Bolte, J., Daniilidis, A., Ley, O., Mazet, L.: Characterizations of Łojasiewicz inequalities: subgradient flows, talweg, convexity. Trans. Am. Math. Soc. 362(6), 3319–3363 (2010)
Bolte, J., Sabach, S., Teboulle, M.: Proximal alternating linearized minimization for nonconvex and nonsmooth problems. Math. Program. 146(1), 459–494 (2014)
Brègman, L.M.: The method of successive projection for finding a common point of convex sets. Soviet Math. Dokl. 6, 688–692 (1965)
Candès, E., Eldar, Y., Strohmer, T., Voroninski, V.: Phase retrieval via matrix completion. SIAM J. Imaging Sci. 6(1), 199–225 (2013)
Censor, Y., Lent, A.: Optimization of \(\log x\) entropy over linear equality constraints. SIAM J. Control Optim. 25(4), 921–933 (1987)
Chaux, C., Combettes, P.L., Pesquet, J.-C., Wajs, V.R.: A variational formulation for frame based inverse problems. Inverse Probl. 23(4), 1495–1518 (2007)
Chouzenoux, E., Pesquet, J.-C., Repetti, A.: Variable metric forward-backward algorithm for minimizing the sum of a differentiable function and a convex function. J. Optim. Theory Appl. 162(1), 107–132 (2014)
Combettes, P.L., Pesquet, J.-C.: Proximal splitting methods in signal processing. In: Bauschke, H.H., Burachik, R., Combettes, P.L., Elser, V., Luke, D.R., Wolkowicz, H. (eds.) Fixed-Point Algorithms for Inverse Problems in Science and Engineering, pp. 185–212. Springer, New York (2010)
Combettes, P.L., Pesquet, J.-C.: Stochastic quasi-Fejér block-coordinate fixed point iterations with random sweeping. SIAM J. Optim. 25, 1221–1248 (2015)
Combettes, P.L., Vũ, B.C.: Variable metric quasi-Fejér monotonicity. Nonlinear Anal. 78, 17–31 (2013)
Combettes, P.L., Vũ, B.C.: Variable metric forward-backward splitting with applications to monotone inclusions in duality. Optimization 63(9), 1289–1318 (2014)
Combettes, P.L., Wajs, V.R.: Signal recovery by proximal forward-backward splitting. Multiscale Model. Simul. 4(4), 1168–1200 (2005)
Dainty, J.C., Fienup, J.R.: Phase retrieval and image reconstruction for astronomy. In: Stark, H. (ed.) Image Recovery: Theory and Application, pp. 231–275. Academic Press, Orlando, FL (1987)
Fessler, J.A.: Grouped coordinate ascent algorithms for penalized-likelihood transmission image reconstruction. IEEE Trans. Med. Imag. 16(2), 166–175 (1997)
Fienup, J.R.: Phase retrieval algorithms: a comparison. Appl. Opt. 21(15), 2758–2769 (1982)
Frankel, P., Garrigos, G., Peypouquet, J.: Splitting methods with variable metric for Kurdyka-Łojasiewicz functions and general convergence rates. J. Optim. Theory Appl. 165(3), 874–900 (2015)
Gerchberg, R.W., Saxton, W.O.: A practical algorithm for the determination of phase from image and diffraction plane pictures. Optik 35, 237–246 (1972)
Golub, G.H., Van Loan, C.F.: Matrix Computations, 3rd edn. Johns Hopkins University Press, Baltimore (1996)
Hesse, R., Luke, D.R., Sabach, S., Tam, M.K.: Proximal heterogeneous block input-output method and application to blind ptychographic diffraction imaging. Tech. rep. (2014). arXiv:1408.1887
Hiriart-Urruty, J.B., Lemaréchal, C.: Convex Analysis and Minimization Algorithms. Springer, New York (1993)
Jacobson, M.W., Fessler, J.A.: An expanded theoretical treatment of iteration-dependent majorize-minimize algorithms. IEEE Trans. Image Process. 16(10), 2411–2422 (2007)
Kurdyka, K., Parusinski, A.: \(w_f\)-stratification of subanalytic functions and the Łojasiewicz inequality. Comptes rendus de l’Académie des sciences. Série 1, Mathématique 318(2), 129–133 (1994)
Łojasiewicz, S.: Une propriété topologique des sous-ensembles analytiques réels. Editions du centre National de la Recherche Scientifique, pp. 87–89 (1963)
Luenberger, D.G.: Linear and Nonlinear Programming. Addison-Wesley, Reading (1973)
Luo, Z.Q., Tseng, P.: On the convergence of the coordinate descent method for convex differentiable minimization. J. Optim. Theory Appl. 72(1), 7–35 (1992)
Luo, Z.Q., Tseng, P.: On the linear convergence of descent methods for convex essentially smooth minimization. SIAM J. Control Optim. 30(2), 408–425 (1992)
Mallat, S.: A Wavelet Tour of Signal Processing, 3rd edn. Academic Press, Burlington (2009)
Mordukhovich, B.S.: Variational Analysis and Generalized Differentiation. Vol. I: Basic theory, Series of Comprehensive Studies in Mathematics, vol. 330. Springer, Berlin (2006)
Moreau, J.J.: Proximité et dualité dans un espace hilbertien. Bull. Soc. Math. France 93, 273–299 (1965)
Mukherjee, S., Seelamantula, C.S.: An iterative algorithm for phase retrieval with sparsity constraints: application to frequency domain optical coherence tomography. In: Proceedings of IEEE Internationl Conference Acoust., Speech and Signal Process. (ICASSP 2012), pp. 553–556. Kyoto, Japan (2012)
Ochs, P., Chen, Y., Brox, T., Pock, T.: iPiano: inertial proximal algorithm for non-convex optimization. SIAM J. Imaging Sci. 7(2), 1388–1419 (2014)
Ortega, J.M., Rheinboldt, W.C.: Iterative Solution of Nonlinear Equations in Several Variables. Academic Press, New York (1970)
Pirayre, A., Couprie, C., Duval, L., Pesquet, J.-C.: Fast convex optimization for connectivity enforcement in gene regulatory network inference. In: Proceedings of IEEE International Conference Acoust., Speech Signal Process. (ICASSP 2015), pp. 1002–1006. Brisbane, Australia (2015)
Powell, M.J.D.: On search directions for minimization algorithms. Math. Program. 4, 193–201 (1973)
Pustelnik, N., Benazza-Benhayia, A., Zheng, Y., Pesquet, J.-C.: Wavelet-based image deconvolution and reconstruction. To appear in Wiley Encyclopedia of Electrical and Electronics Engineering (2016). https://hal.archives-ouvertes.fr/hal-01164833v1
Razaviyayn, M., Hong, M., Luo, Z.: A unified convergence analysis of block successive minimization methods for nonsmooth optimization. SIAM J. Optim. 23(2), 1126–1153 (2013)
Repetti, A., Pham, M.Q., Duval, L., Chouzenoux, E., Pesquet, J.-C.: Euclid in a taxicab: Sparse blind deconvolution with smoothed \(\ell _1/\ell _2\) regularization. IEEE Signal Process. Lett. 22(5), 539–543 (2015)
Repetti, A., Chouzenoux, E., Pesquet, J.-C.: A preconditioned forward-backward approach with application to large-scale nonconvex spectral unmixing problems. In: Proceedings of IEEE International Conference Acoust., Speech Signal Process. (ICASSP 2014), pp. 1498–1502. Firenze, Italy (2014)
Repetti, A., Chouzenoux, E., Pesquet, J.-C.: A nonconvex regularized approach for phase retrieval. In: Proceedings of IEEE International Conference Image Process. (ICIP 2014), pp. 1753–1757. Paris, France (2014)
Richtárik, P., Talác, M.: Iteration complexity of randomized block-coordinate descent methods for minimizing a composite function. Math. Program. 144(1), 1–38 (2014)
Rockafellar, R.T., Wets, R.J.B.: Variational Analysis, 1st edn. Springer, Berlin (1997)
Saquib, S., Zheng, J., Bouman, C.A., Sauer, K.D.: Parallel computation of sequential pixel updates in statistical tomographic reconstruction. In: Proceedings of IEEE International Conference Image Process. (ICIP 1995), vol. 2, 93–96. Washington, DC (1995)
Saxton, W.O.: Computer Techniques for Image Processing in Electron Microscopy. Academic Press, New York (1978)
Shechtman, Y., Beck, A., Eldar, Y.: GESPAR: efficient phase retrieval of sparse signals. IEEE Trans. Signal Process. 4(62), 928–938 (2014)
Sotthivirat, S., Fessler, J.A.: Image recovery using partitioned-separable paraboloidal surrogate coordinate ascent algorithms. IEEE Trans. Signal Process. 11(3), 306–317 (2002)
Tappenden, R., Richtárik, P., Gondzio, J.: Inexact coordinate descent: complexity and preconditioning. J. Optim. Theory Appl. (to appear). arXiv:1304.5530v2
Tseng, P.: Convergence of a block coordinate descent method for nondifferentiable minimization. J. Optim. Theory Appl. 109(3), 475–494 (2001)
Waldspurger, I., d’Aspremont, A., Mallat, S.: Phase recovery, maxcut and complex semidefinite programming. Math. Program. 149(1), 47–81 (2015)
Xu, Y., Yin, W.: A block coordinate descent method for regularized multiconvex optimization with applications to nonnegative tensor factorization and completion. SIAM J. Imaging Sci. 6(3), 1758–1789 (2013)
Xu, Y., Yin, W.: A globally convergent algorithm for nonconvex optimization based on block coordinate update. Tech. rep. (2014). arXiv:1410.1386
Zangwill, W.I.: Nonlinear Programming. Prentice-Hall, Englewood Cliffs (1969)
Author information
Authors and Affiliations
Corresponding author
Additional information
This work was supported by the CNRS MASTODONS project under grant 2013MesureHD and by the CNRS Imag’in Project under Grant 2015OPTIMISME.
Rights and permissions
About this article

Cite this article
Chouzenoux, E., Pesquet, JC. & Repetti, A. A block coordinate variable metric forward–backward algorithm. J Glob Optim 66, 457–485 (2016). https://doi.org/10.1007/s10898-016-0405-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10898-016-0405-9
Keywords
- Nonconvex optimization
- Nonsmooth optimization
- Proximity operator
- Majorize–Minimize algorithm
- Block coordinate descent
- Alternating minimization
- Phase retrieval
- Inverse problems